Wise-IoU:带有动态聚焦机制的边界框回归损失
摘要
边界框回归(BBR)的损失函数对于目标检测至关重要。 其良好的定义将为模型带来显着的性能提升。 大多数现有工作假设训练数据中的示例是高质量的,并侧重于加强 BBR 损失的拟合能力。 如果我们盲目地在低质量的例子上加强BBR,将会损害本地化性能。 Focal-EIoU v1就是为了解决这个问题而提出的,但由于其静态聚焦机制(FM),非单调FM的潜力没有得到充分发挥。 基于这个想法,我们提出了一种基于 IoU 的损失,具有动态非单调 FM,称为 Wise-IoU (WIoU)。 当 WIoU 应用于最先进的实时检测器 YOLOv7 时,MS-COCO 数据集上的 从 53.03% 提高到 54.50%。
索引术语:
物体检测、边界框回归、动态非单调聚焦机制、泛化性能我简介
YOLO系列的实时检测器自问世以来就得到了大多数研究人员的认可,并应用于许多场景[1,2,3,4,5,6]。 如YOLOv1[7],构造了一个由BBR损失、分类损失、客观性损失加权的损失函数。 到目前为止,这种构造仍然是目标检测任务中最有效的损失函数范式[7,8,9,10,11,12,13,14],其中BBR损失直接决定了定位模型的性能。 为了进一步提高模型的定位性能,精心设计的BBR损失至关重要。
I-A 正常损失
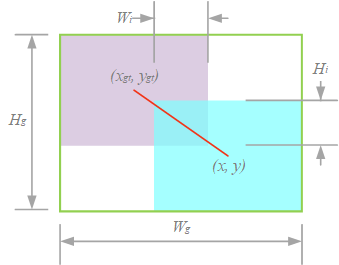
对于锚框,其中的值对应于边界框的中心坐标和大小。 类似地,描述了目标框的属性。
YOLOv1 [7]和YOLOv2 [8]在BBR损失的定义上非常相似。 YOLOv2将BBR损失定义为:
| (1) |
然而这种形式的损失函数无法屏蔽边界框尺寸的干扰,使得YOLOv2[8]对于小物体的定位性能较差。 虽然YOLOv3 [9]构造试图减少模型对大物体的注意力,但这种BBR损失给模型带来的定位性能仍然非常有限。
I-B 联合上的交集
Intersection over Union [19](IoU)用于衡量物体检测任务中锚框和目标框之间的重叠程度。 它以比例的形式有效屏蔽了边界框尺寸的干扰,使得模型在(方程2)时能够很好地平衡大物体和小物体的学习被用作BBR损失。
| (2) |
现有的工作[15,16,17,18]考虑了许多与边界框相关的几何因素,并构造了惩罚项来解决这个问题。 现有的 BBR 损失遵循以下范式:
| (4) |






I-C 调焦机构
图2显示了数据中一些低质量的训练示例。 性能良好的模型在为低质量示例生成高质量锚框时会生成较大的 。 如果单调 FM 为这些锚框分配较大的梯度增益,则模型的学习将受到损害。
在[17]中,张一凡等人提出了使用非单调FM的Focal-EIoU v1。 Focal-EIoU v1的FM 是静态的,它指定了anchor box的边界值,使得等于边界值的anchor box具有最高的梯度增益。 Focal-EIoU v1没有注意到anchor box的质量评价是体现在相互比较中的。 它没有充分发挥非单调调频的潜力。
我们通过估计锚框的离群度为来定义动态FM。 我们的 FM 通过将小梯度增益分配给具有小 的高质量锚框,使 BBR 能够专注于普通质量的锚框。 同时,该机制将较小的梯度增益分配给较大的低质量锚框,有效削弱了低质量示例对BBR的危害。
我们将这种明智的 FM 与基于 IoU 的损失相结合,并将其称为 Wise-IoU (WIoU)。 为了评估我们提出的方法,我们将 WIoU 纳入最先进的实时检测器 YOLOv7 [11] 中。 本文的主要贡献总结如下:
-
•
我们为 BBR 提出了基于注意力的损失 WIoU v1,它在模拟实验中实现了比最先进的 SIoU [18] 更低的回归误差。
-
•
我们设计了具有单调 FM 的 WIoU v2,以及具有动态非单调 FM 的 WIoU v3。 受益于动态非单调调频的明智梯度增益分配策略,WIoU v3 实现了优越的性能。
-
•
我们对低质量示例的影响进行了一系列详细研究,证明了动态非单调 FM 的有效性和效率。
二相关工作
II-A BBR 的损失函数
为了补偿-范数损失的尺度敏感性,YOLOv1 [7]通过对边界框的大小进行平方根变换来削弱大边界框的影响。 YOLOv3[9]提出构造一个惩罚项来降低大盒子的竞争力。 然而,-norm损失忽略了边界框属性之间的相关性,使得这种类型的BBR损失效果较差。
为了解决IoU损失的梯度消失问题,GIoU [15]使用由最小包围盒构造的惩罚项。 DIoU [16]使用距离度量构造的惩罚项,CIoU [16]是在DIoU的基础上加上长宽比度量得到的。 Zhora Gevorgyan 利用角度成本、距离成本和形状成本构建了 SIoU [18],具有更快的收敛速度和更好的性能。
II-B FM 损失函数
交叉熵损失广泛应用于二元分类任务。 然而,这个损失函数的一个显着特性是,即使是简单的例子也会产生很大的损失值,与困难的例子竞争。 Tsungyi Lin 等人提出了单调FM的焦点损失[20],有效降低了简单示例的竞争力。
在[17]中,张一凡等人提出了非单调FM的Focal-EIoU v1和单调FM的Focal-EIoU。 在他们的实验中,单调 FM 被证明是比非单调 FM 更好的选择。
Focal-EIoU v1的FM是静态的,它规定了锚框的质量划分标准。 当锚框的 IoU 损失等于边界值时,它为锚框提供最高的梯度增益。 没有注意到锚框的质量评估反映在比较中,因此它没有充分发挥非单调FM的潜力。
三方法
III-A 模拟实验
为了初步比较BBR的各个损失函数,我们使用郑朝晖等人[16]提出的模拟实验进行评估。 我们在 (0.5, 0.5) 处生成了具有 7 个长宽比(即 1:4、1:3、1:2、1:1、2:1、3:1、4)的目标框(全部面积为 1/32) :1)。 在以(0.5,0.5)为中心、半径为的圆形区域内,均匀生成个锚点。 同时,49个锚框具有7种尺度(即1/32、1/24、3/64、1/16、1/12、3/32、1/8)和7种长宽比(即1:4、 1:3、1:2、1:1、2:1、3:1、4:1)为每个锚点放置。 每个锚框需要拟合每个目标框,有6860000个回归案例。 为了比较不同时期的收敛速度,我们设置了以下实验环境:
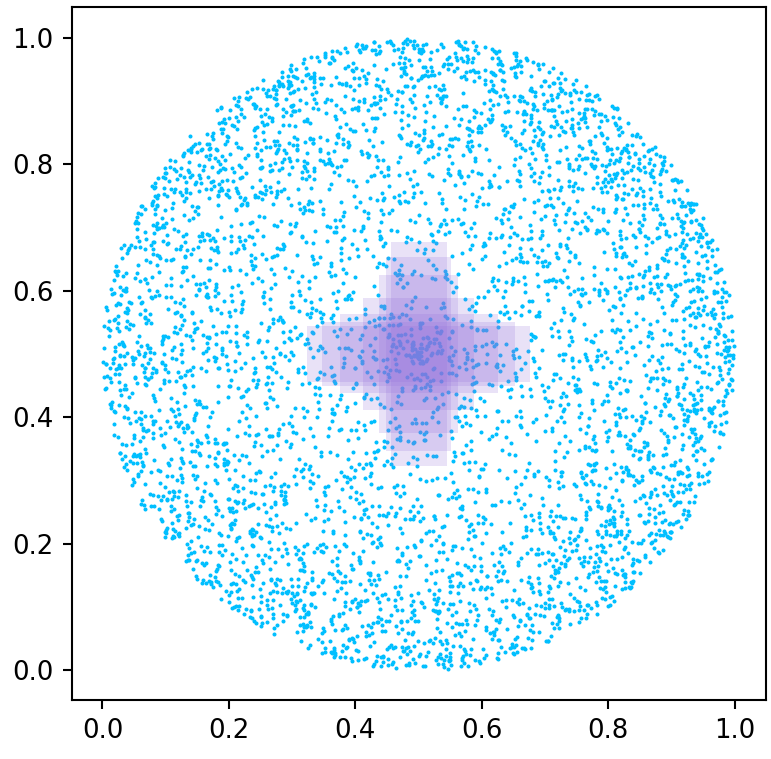
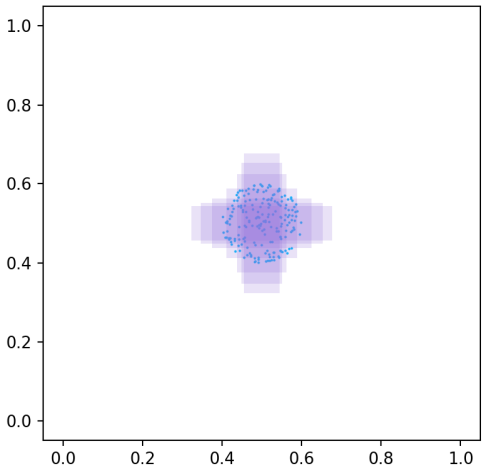
我们还将损失值定义为总体回归案例,并使用学习率为0.01的梯度下降算法对其进行优化。
III-B 梯度消失问题的解决方法
现有的 BBR 损失[15,16,17,18]是基于加法的,并遵循式(1)所示的范式。 4。
距离IoU:郑朝晖等人将 [16]定义为两个边界中心点之间的归一化距离盒子:
| (5) |
这项不仅解决了的梯度消失问题,而且还充当了几何因子。 让DIoU在面对具有相同的锚框时可以做出更直观的选择。
| (6) |
同时,为最小包围盒的大小提供了负梯度,这将使和增加并阻碍锚框和锚框之间的重叠。目标框。 但不可否认的是,距离度量确实是一个极其有效的解决方案,并成为 BBR [17, 18] 的必要度量。 在此基础上,张一凡等人增加了距离度量的惩罚,提出了EIoU[17]:
| (7) |
完整的IoU:郑朝晖等人在的基础上增加了长宽比的考虑,提出了 [16]:
| (8) |
其中描述了纵横比的一致性:
| (9) |
| (10) |
张一凡等[17]认为CIoU的非理性在于,这意味着无法提供锚框的宽度 和高度 具有相同符号的渐变。 在前面对DIoU的分析中,可以看出会产生负梯度(方程6)。 当这个负梯度恰好抵消了锚框上生成的梯度时,锚框将不会被优化。 CIoU对长宽比的考虑将打破这一僵局(图3b)。
Scylla IoU:Zhora Gevorgyan [18]证明了中心对齐的anchor box会有更快的收敛速度,并从角度成本、距离成本和形状成本。
角度成本描述了中心点连接(图1)与x-y轴之间的最小角度:
| (11) |
当中心点在 x 轴或 y 轴上对齐时,。 当中心点与x轴成45°时,。 这一项可以引导anchor box漂移到距离目标box最近的轴,减少BBR的总自由度数。
距离成本描述了中心点之间的距离,其惩罚与角度成本正相关。 距离成本定义为:
| (12) |
| (13) |
形状成本描述了边界框之间的尺寸差异。 当边界框大小不一致时,。 它被定义为:
| (14) |
| (15) |
与类似,它们都由距离成本和形状成本组成:
| (16) |
由于对距离度量的惩罚随着形状成本的增加而增加,因此SIoU训练的模型具有更快的收敛速度和更低的回归误差。
III-C 提议的方法
由于训练数据不可避免地包含低质量示例,距离和长宽比等几何因素会加剧对低质量示例的惩罚,从而降低模型的泛化性能。 一个好的损失函数应该在锚框与目标框重合良好时削弱几何训练因素的惩罚,并且较少的干预将使模型获得更好的泛化能力。 在此基础上,我们构造距离注意力(Eq.17)并得到具有两层注意力机制的WIoU v1:
-
•
,这将显着放大普通质量锚框的。
-
•
,这会显着降低高质量锚框的,并且当锚框与目标框重合良好时,其对中心点之间距离的关注。
| (17) |
其中是最小包围盒的尺寸(图1)。 为了防止产生阻碍收敛的梯度,将从计算图中分离出来(上标表示此操作)。 因为它有效地消除了阻碍收敛的因素,所以我们没有引入宽高比等新的指标。



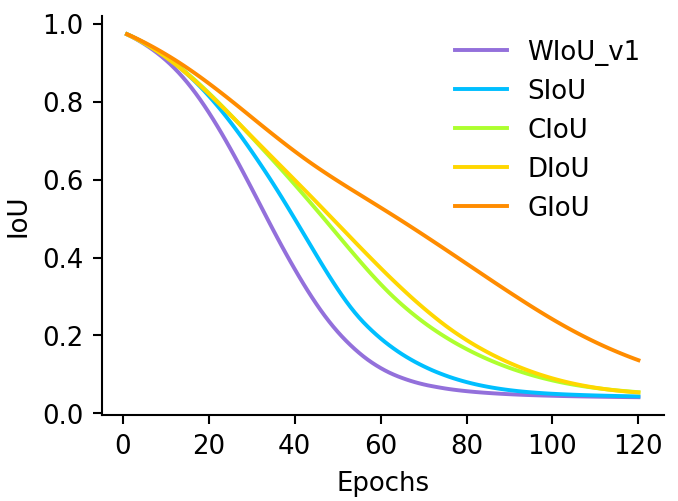
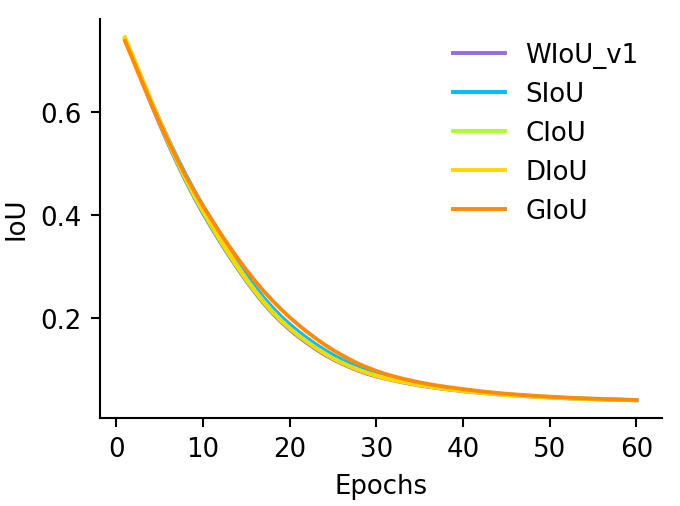
-
1.
在现有作品中提到的一系列BBR损失中,SIoU [18]具有最快的收敛速度。
-
2.
对于 BBR 中的主要情况,所有 BBR 损失都具有极其相似的收敛速度。 由此可见,收敛速度的差异主要来自于不重叠的边界框。 我们提出的基于注意力的 WIoU v1 在这部分效果最好。
从焦点损失中学习:焦点损失[20]设计了交叉熵的单调FM,有效降低了简单示例对损失值的贡献。 因此,模型可以专注于困难示例并获得分类性能的提升。 类似地,我们为构造单调聚焦系数。
| (18) |
由于聚焦系数的加入,WIoU v2反向传播的梯度也发生了变化:
| (19) |
请注意,梯度增益为。 模型训练过程中,梯度增益随着的减小而减小,导致训练后期收敛速度较慢。 因此,引入的均值作为归一化因子:
| (20) |
其中 是动量 的运行平均值。动态更新归一化因子,使梯度增益总体保持在较高水平,解决了训练后期收敛速度慢的问题。
动态非单调FM:anchor box的离群程度用与的比值来表征:
| (21) |
离群值小意味着锚框是高质量的。 我们为其分配一个小的梯度增益,以便将 BBR 集中在普通质量的锚框上。 此外,为异常值较大的锚框分配较小的梯度增益将有效防止低质量示例产生较大的有害梯度。 我们使用 构造一个非单调聚焦系数并将其应用于 WIoU v1:
| (22) |
其中 在 时生成 。 如图8所示,当锚框的离群度满足(为常数值)时,锚框将享有最高的梯度增益。 由于是动态的,因此锚框的质量划分标准也是动态的,这使得WIoU v3能够在每一个时刻做出最符合当前情况的梯度增益分配策略。






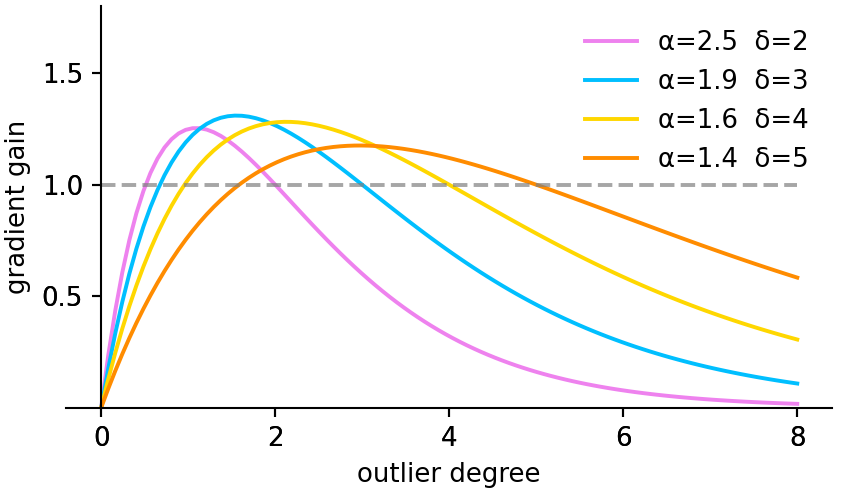
为了防止训练初期留下低质量的锚框,我们初始化,使的锚框享有最高的梯度增益。 为了在训练初期维持这样的策略,需要设置一个小的动量来延迟接近真实值的时间。 对于数据批次数的训练,我们建议将动量设置为:
| (23) |
此设置使 在 训练周期之后。
在训练的中后期,WIoU v3将较小的梯度增益分配给低质量的锚框,以减少有害梯度。 同时,还重点关注普通质量的anchor box,以提高模型的定位性能。
IV 实验
IV-A 实验装置
为了公平比较,我们所有的实验都是在 PyTorch 框架[21]上进行的。 对于数据集,我们在MS-COCO数据集中选择了20个类别[22],并选择28474张图像作为训练数据,1219张图像作为验证数据。 对于模型,我们选择 YOLOv7-w6 [11] 进行训练,层通道倍数为 0.75。 这些模型接受了 120 个具有不同 BBR 损失的 epoch 训练。
YOLOv7的检测头产生的锚框主要包含两部分:来自引导头的锚框(ABLH)和来自辅助头的锚框(ABAH)。 ABLH 往往具有更好的拟合结果和更少的信息,而 ABAH 则相反。 如果只计算ABLH的均值,会导致ABAH的梯度增益逐渐消失,使得FM忽略了ABAH丰富的信息量。 因此,我们的平均统计数据包括 ABLH 和 ABAH。
| CIoU [16] | 53.03 | 63.14 | 45.20 |
|---|---|---|---|
| CIoU v2 () | 53.47 (+0.44) | 63.41 (+0.27) | 45.12 |
| CIoU v3 () | 53.25 (+0.22) | 63.34 (+0.20) | 44.76 |
| CIoU v3 () | 53.68 (+0.65) | 63.34 (+0.20) | 45.10 |
| CIoU v3 () | 53.04 | 62.92 | 44.91 |
| SIoU [18] | 53.15 | 63.46 | 45.21 |
| SIoU v2 () | 53.07 | 63.12 | 44.66 |
| SIoU v3 () | 53.27 (+0.12) | 64.13 (+0.67) | 45.15 |
| SIoU v3 () | 53.21 | 63.48 | 44.89 |
| SIoU v3 () | 53.42 (+0.27) | 63.28 | 45.03 |
| EIoU [17] | 53.55 | 63.17 | 45.39 |
| Focal-EIoU [17] | 52.88 | 63.37 (+0.20) | 44.75 |
| WIoU v1 | 52.82 | 63.15 | 44.87 |
| WIoU v2 () | 53.67 (+0.85) | 64.15 (+1.00) | 45.56 (+0.68) |
| WIoU v3 () | 53.75 (+1.07) | 64.05 (+0.90) | 45.15 (+0.28) |
| WIoU v3 () | 53.91 (+1.09) | 64.16 (+1.01) | 45.44 (+0.57) |
| WIoU v3 () | 54.50 (+1.68) | 64.20 (+1.05) | 45.68 (+0.81) |
| airplane | train | truck | traffic light | stop sign | parking meter | bench | elephant | |
|---|---|---|---|---|---|---|---|---|
| SIoU | 74.74 | 78.85 | 51.37 | 54.96 | 58.33 | 58.18 | 40.27 | 86.32 |
| Focal-EIoU | 72.92 | 84.26 | 53.37 | 51.95 | 55.10 | 54.55 | 38.13 | 85.17 |
| WIoU v3 | 71.58 | 81.82 | 55.94 | 55.45 | 64.58 | 62.26 | 36.81 | 87.83 |
IV-B 消融研究
我们将 FM 应用于 BBR 损失,以研究 FM 对基于加法的损失的影响。 这些 BBR 损失的版本 2 使用 设置,以与 Focal-EIoU [17] 的单调 FM 保持一致。 他们的版本 3 使用本文提出的动态非单调 FM。
通过比较 BBR 损失的版本 2 和原始版本(表 I),可以知道单调调频对 SIoU [18] 和 EIoU [17] 的性能都有负面影响。 由于这两者对距离度量的惩罚更强烈,因此在单调FM的作用下合成了更大的有害梯度。 CIoU [16] 和 WIoU v1 对于距离度量的惩罚较小,这使得它们能够有效削弱单调 FM 对有害梯度的放大。
通过比较BBR损失的版本3和原始版本(表I),我们可以知道非单调FM可以有效提高BBR损失的性能。 对于每个 BBR 损失,都有一组独特的参数可以最大限度地提高性能增益。
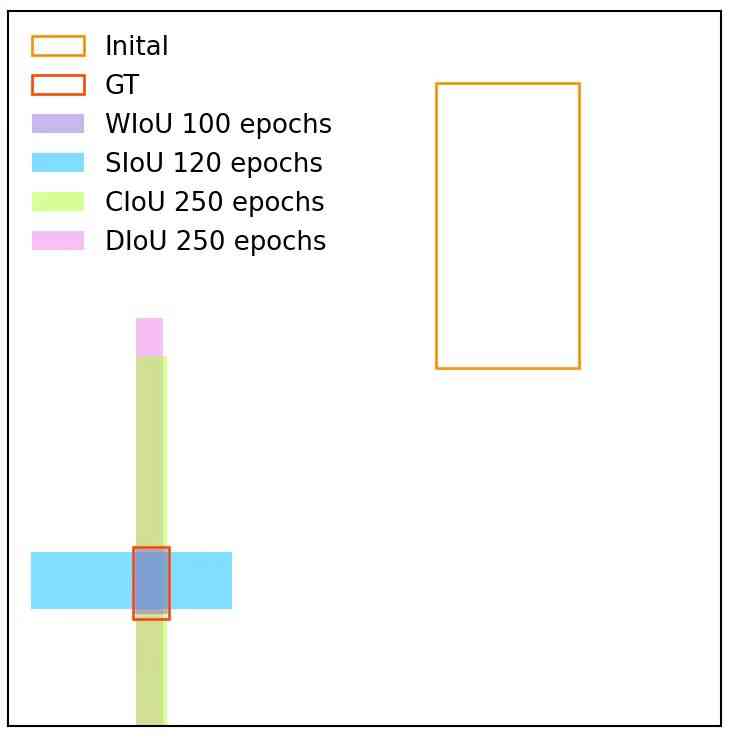
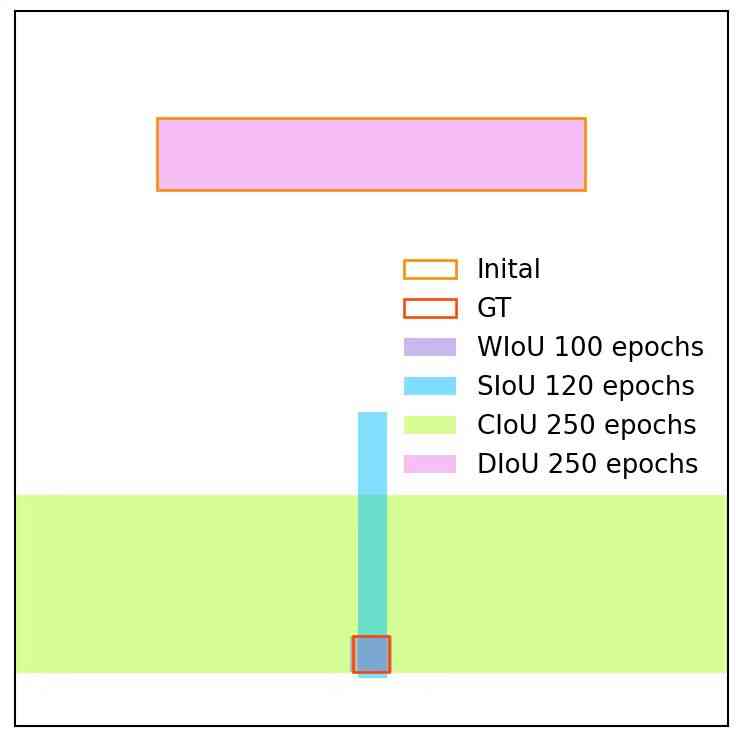
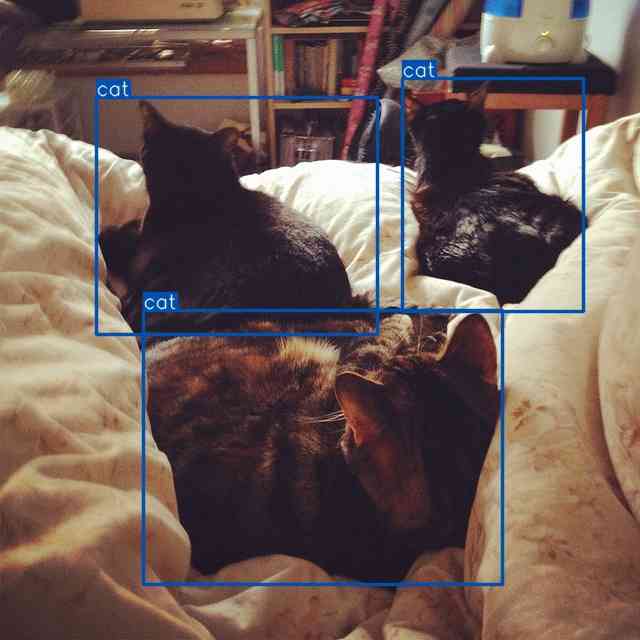
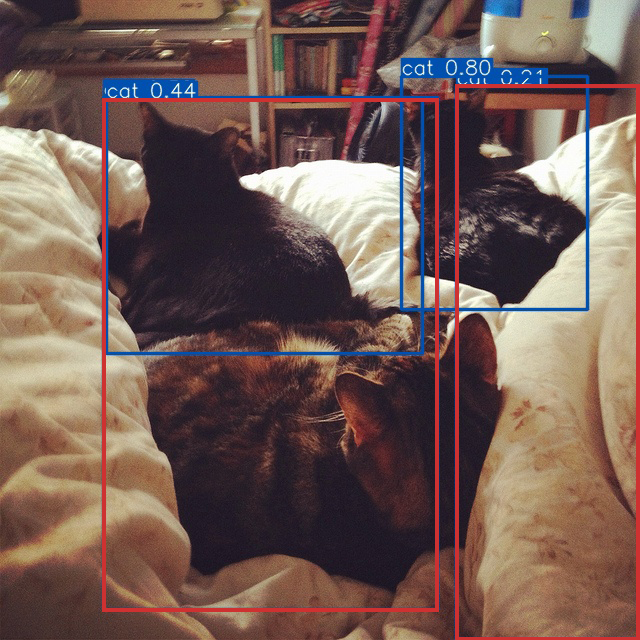
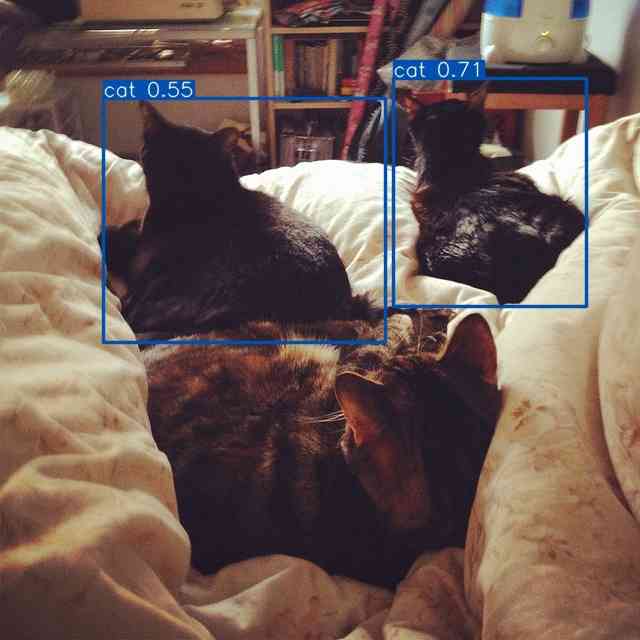
此外,我们还比较了锚框的回归结果(图5)。 具有单调 FM 的 WIoU v2 受到低质量示例的影响,导致预测结果不佳。 我们的WIoU v3受益于动态非单调FM,有效屏蔽了低质量示例的影响,实现了理想的预测。
IV-C 比较研究
在表I中,BBR损失原始版本的性能排名为:EIoU SIoU CIoU WIoU v1。 这样的命令也与他们对距离度量的惩罚强度一致。 然而,当应用 FM 时,BBR 损失的性能增益是相反的。 在我们进行的实验中,WIoU v3 训练的模型取得了最佳性能。
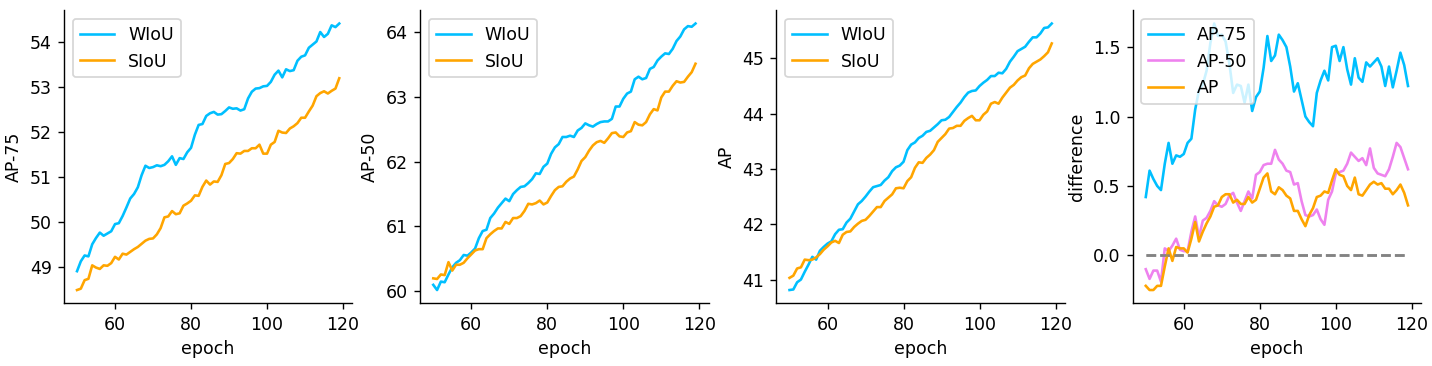
我们在训练过程中监测YOLOv7精度的变化(图9)。 由于动态非单调FM训练,我们提出的WIoU v3有效屏蔽了FM训练过程中的许多负面影响,因此模型的精度可以更快地提高。
我们将 WIoU v3 与最先进的 BBR 损失进行比较,得到了几个精度差异较大的类别(表 II)。 受益于识别低质量示例的能力,WIoU v3 训练的模型对于某些类别的精度有了很大的提高。 与此同时,飞机和长凳模型的精度有所下降。
我们注意到,部分飞机的标签存在争议(图7),部分入选飞机缺乏机身等突出特征。 这些例子和低质量的例子一样难学,这部分难的例子被WIoU v3的FM丢弃了。 此外,凳子的标签存在大量错误,也有大量凳子没有标签。 这对于泛化良好并检测更多工作台的模型来说是不公平的。
用有限的参数学习适当的知识是实时检测器成功的关键。 WIoU v3 通过权衡低质量示例和高质量示例的学习来提高模型的整体性能。
V 结论
在本文中,我们观察到训练数据中的低质量示例将阻碍目标检测模型的泛化。 大多数现有工作仅限于静态调频,没有充分发挥非单调调频的潜力。 他们提倡的单调FM虽然可以提高定位性能,但并不能解决这个问题。 我们提出了一种动态非单调 FM,可以降低高质量锚框的竞争力并掩盖低质量示例的影响。 当具有这种机制的WIoU应用于最先进的实时检测器YOLOv7时,模型的泛化能力得到了有效的提高。
参考
- [1] Jing Nie, Yanwei Pang, Shengjie Zhao, Jungong Han, and Xuelong Li, “Efficient selective context network for accurate object detection,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 9, pp. 3456–3468, 2020.
- [2] Song Peng, Zhenfeng Shao, Xiao Huang, Yi Zhu, Ruiqian Zhang, and Junwei Zha, “Bicsnet: A bidirectional cross-scale backbone for recognition and localization,” IEEE Transactions on Circuits and Systems for Video Technology, 2021.
- [3] Jung Uk Kim, Jungsu Kwon, Hak Gu Kim, and Yong Man Ro, “Bbc net: Bounding-box critic network for occlusion-robust object detection,” IEEE transactions on circuits and systems for video technology, vol. 30, no. 4, pp. 1037–1050, 2019.
- [4] Meng Cheng, Hanli Wang, and Yu Long, “Meta-learning-based incremental few-shot object detection,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 4, pp. 2158–2169, 2021.
- [5] Kaiyou Song, Hua Yang, and Zhouping Yin, “Multi-scale attention deep neural network for fast accurate object detection,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 29, no. 10, pp. 2972–2985, 2018.
- [6] Shifeng Zhang, Longyin Wen, Zhen Lei, and Stan Z Li, “Refinedet++: Single-shot refinement neural network for object detection,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 2, pp. 674–687, 2020.
- [7] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi, “You only look once: Unified, real-time object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 779–788.
- [8] Joseph Redmon and Ali Farhadi, “Yolo9000: better, faster, stronger,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 7263–7271.
- [9] Joseph Redmon and Ali Farhadi, “Yolov3: An incremental improvement,” arXiv preprint arXiv:1804.02767, 2018.
- [10] Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao, “Yolov4: Optimal speed and accuracy of object detection,” arXiv preprint arXiv:2004.10934, 2020.
- [11] Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao, “Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors,” arXiv preprint arXiv:2207.02696, 2022.
- [12] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He, “Fcos: Fully convolutional one-stage object detection,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9627–9636.
- [13] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He, “Fcos: A simple and strong anchor-free object detector,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [14] Xiang Long, Kaipeng Deng, Guanzhong Wang, Yang Zhang, Qingqing Dang, Yuan Gao, Hui Shen, Jianguo Ren, Shumin Han, Errui Ding, et al., “Pp-yolo: An effective and efficient implementation of object detector,” arXiv preprint arXiv:2007.12099, 2020.
- [15] Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese, “Generalized intersection over union: A metric and a loss for bounding box regression,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 658–666.
- [16] Zhaohui Zheng, Ping Wang, Wei Liu, Jinze Li, Rongguang Ye, and Dongwei Ren, “Distance-iou loss: Faster and better learning for bounding box regression,” in Proceedings of the AAAI conference on artificial intelligence, 2020, vol. 34, pp. 12993–13000.
- [17] Yi-Fan Zhang, Weiqiang Ren, Zhang Zhang, Zhen Jia, Liang Wang, and Tieniu Tan, “Focal and efficient iou loss for accurate bounding box regression,” Neurocomputing, vol. 506, pp. 146–157, 2022.
- [18] Zhora Gevorgyan, “Siou loss: More powerful learning for bounding box regression,” arXiv preprint arXiv:2205.12740, 2022.
- [19] Jiahui Yu, Yuning Jiang, Zhangyang Wang, Zhimin Cao, and Thomas Huang, “Unitbox: An advanced object detection network,” in Proceedings of the 24th ACM international conference on Multimedia, 2016, pp. 516–520.
- [20] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár, “Focal loss for dense object detection,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2980–2988.
- [21] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer, “Automatic differentiation in pytorch,” 2017.
- [22] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick, “Microsoft coco: Common objects in context,” in European conference on computer vision. Springer, 2014, pp. 740–755.