RePlug:检索增强的黑盒语言模型
摘要
我们引入了RePlug,这是一种检索增强的语言建模框架,它将语言模型(LM)视为黑匣子,并通过可调整的检索模型对其进行增强。 与之前的检索增强 LM 不同,之前的检索增强 LM 使用特殊的交叉注意机制来训练语言模型来对检索到的文本进行编码,而 RePlug 只是将检索到的文档添加到冻结黑盒 LM 的输入中。 这种简单的设计可以轻松应用于任何现有的检索和语言模型。 此外,我们表明 LM 可以用来监督检索模型,然后检索模型可以找到帮助 LM 做出更好预测的文档。 我们的实验表明,使用经过调整的检索器的 RePlug 将 GPT-3 (175B) 在语言建模上的性能显着提高了 6.3%,将 Codex 在五次 MMLU 上的性能提高了 5.1%。
1简介
GPT-3 (Brown 等人, 2020a) 和 Codex (Chen 等人, 2021a) 等大型语言模型(大语言模型)在广泛的语言任务。 这些模型通常在非常大的数据集上进行训练,并在其参数中隐式存储大量的世界或领域知识。 然而,它们也容易产生幻觉,无法代表训练语料库中完整的长尾知识。 相比之下,检索增强语言模型(Khandelwal 等人, 2020; Borgeaud 等人, 2022; Izacard 等人, 2022b; Yasunaga 等人, 2022) 可以在需要时从外部数据存储中检索知识,有可能减少幻觉并增加覆盖范围。 以前的检索增强语言模型方法需要访问内部 LM 表示(例如,训练模型 (Borgeaud 等人, 2022; Izacard 等人, 2022b) 或索引数据存储 (Khandelwal 等人, 2020)),因此很难应用于非常大的语言模型。 此外,许多一流的大语言模型只能通过API访问。 此类模型的内部表示不会公开,也不支持微调。
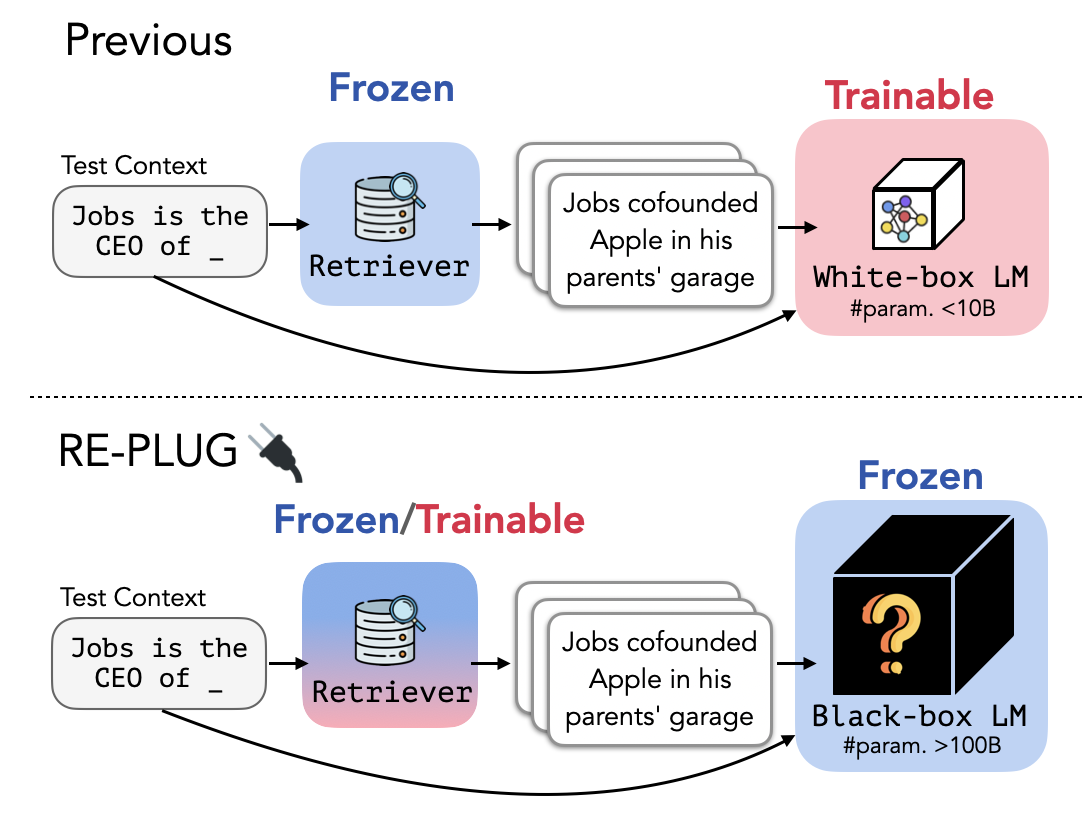
在这项工作中,我们引入了 RePlug(Retrieve 和 Plug),这是一种新的检索增强型 LM 框架,其中语言模型被视为黑匣子和检索组件被添加为可调节的即插即用模块。 给定输入上下文,RePlug 首先使用现成检索模型从外部语料库检索相关文档。 检索到的文档被添加到输入上下文中,并输入到黑盒 LM 中以进行最终预测。 由于 LM 上下文长度限制了可以前置的文档数量,因此我们还引入了一种新的集成方案,该方案与相同的黑盒 LM 并行地对检索到的文档进行编码,使我们能够轻松地以计算换取准确性。 如 Figure 1 所示,RePlug 非常灵活,可与任何现有的黑盒 LM 和检索模型配合使用。
我们还引入了RePlug LSR(RePlug与LM-S监督Retrieval ),一种训练方案,可以使用来自黑盒语言模型的监督信号进一步改进 RePlug 中的初始检索模型。 关键思想是让检索器适应语言模型,这与之前的工作(Borgeaud等人,2022)形成鲜明对比,该工作使语言模型适应检索器。 我们使用的训练目标更喜欢检索能够改善语言模型复杂性的文档,同时将 LM 视为冻结的黑盒评分函数。
我们的实验表明,RePlug 可以提高多种黑盒 LM 在语言建模和下游任务上的性能,包括 MMLU (Hendrycks 等人,2021) 和开放域QA (Kwiatkowski 等人,2019;Joshi 等人,2017)。 例如,RePlug 可以将 MMLU 上的 Codex (175B) 性能提高 4.5%,达到与 540B、指令微调 Flan-PaLM 相当的结果。 此外,使用我们的训练方案(即 RePlug LSR)调整检索器会带来额外的改进,包括 GPT-3 175B 语言建模高达 6.3% 的提升。 据我们所知,我们的工作首次展示了对大型 LM(>100B 模型参数)进行检索的好处,既可以减少 LM 的困惑,又可以提高上下文中的学习性能。 我们的贡献总结如下:
2 背景及相关工作

黑盒语言模型
大型语言模型(即 >100B),例如 GPT-3 (Brown 等人, 2020a)、Codex (Chen 等人, 2021a) 和 Yuan 1.0 (Wu 等人, 2021),出于商业考虑,并未开源,仅作为黑盒 API 提供,用户可以通过该 API 发送查询并接收响应。 另一方面,即使是 OPT-175B (Zhang 等人,2022a) 和 BLOOM-176B (Scao 等人,2022) 等开源语言模型也需要大量计算在本地运行和微调的资源。 例如,微调 BLOOM-176B 需要 72 个 A100 GPU(80GB 内存,每个 1.5 万美元(Younes Belkda,2022)),这使得资源有限的研究人员和开发人员无法使用它们。 传统上,检索增强模型框架(Khandelwal 等人, 2020; Borgeaud 等人, 2022; Yu, 2022; Izacard 等人, 2022b; Goyal 等人, 2022) 专注于白盒设置,其中语言模型被微调以合并检索到的文档。 然而,大型语言模型的规模不断扩大和黑盒性质使得这种方法不可行。 为了解决大型语言模型带来的挑战,我们研究了黑盒设置中的检索增强,其中用户只能访问模型预测,而无法访问或修改其参数。
检索增强模型
使用从各种知识存储中检索到的相关信息来增强语言模型已被证明可以有效提高各种 NLP 任务的性能,包括语言建模(Min 等人,2022;Borgeaud 等人,2022;Khandelwal 等人,2020) 和开放域问答(Lewis 等人,2020;Izacard 等人,2022b;Hu 等人,2022)。 具体来说,使用输入作为查询,(1) 检索器首先从语料库中检索一组文档(即标记序列),然后 (2) 语言模型将检索到的文档合并为附加信息以进行最终预测。 这种检索方式可以添加到编码器-解码器(Yu, 2022; Izacard等人, 2022b)和仅解码器模型(Khandelwal 等人, 2020; Borgeaud 等人, 2022; Shi 等人, 2022; Rubin 等人, 2022)。 例如,Atlas (Izacard 等人, 2022b) 通过将文档建模为潜在变量,与检索器联合微调 encoder-decoder 模型,而 RETRO (Borgeaud 等人,2022) 更改了仅解码器架构,以合并检索到的文本并从头开始预训练语言模型。 这两种方法都需要通过梯度下降来更新模型参数,这不能应用于黑盒 LM。 另一行检索增强型语言模型,例如 kNN-LM (Khandelwal 等人, 2020; Zhu 等人, 2022) 检索一组标记,并在 LM 的下一个词符分布和计算出的 kNN 分布之间进行插值从推理时检索到的标记。 尽管 kNN-LM 不需要额外的训练,但它需要访问内部 LM 表示来计算 kNN 分布,这对于 GPT-3 等大型 LM 并不总是可用。 在这项工作中,我们研究了通过检索改进大型黑盒语言模型的方法。 而并行工作(Mallen 等人,2022;Si 等人,2023;Yu 等人,2023;Khattab 等人,2022) 已经证明,使用冻结检索器可以提高 GPT-3 在开放环境下的性能-领域问答,我们在更一般的环境中处理问题,包括语言建模和理解任务。 我们还提出了一种整合更多文档的集成方法和一种训练方案,以进一步使检索器适应大型语言模型。
3 重新插拔
我们引入了RePlug(Retrieve和Plug),这是一种新的检索增强型LM范式,其中语言模型被视为黑盒,检索组件被添加为潜在的可调整模块。
3.1文档检索
给定输入上下文 ,检索器旨在从语料库 中检索与 相关的一小组文档。 继之前的工作(Qu等人,2021;Izacard & Grave,2021b;Ni等人,2021)之后,我们使用基于双编码器架构的密集检索器,其中编码器用于对两者进行编码输入上下文 和文档 。具体来说,编码器通过对 中标记的最后一个隐藏表示进行平均池化,将每个文档 映射到嵌入 。在查询时,相同的编码器应用于输入上下文 以获得查询嵌入 。 查询嵌入和文档嵌入之间的相似度是通过它们的余弦相似度计算的:
| (1) |
在此步骤中检索与输入 相比具有最高相似度分数的 top- 文档。 为了高效检索,我们预先计算每个文档 的嵌入,并在这些嵌入上构建 FAISS 索引 (Johnson 等人, 2019)。
3.2 输入重构
检索到的 top- 文档提供了有关原始输入上下文 的丰富信息,并且可以帮助 LM 做出更好的预测。 将检索到的文档合并为 LM 输入的一部分的一种简单方法是在 前面添加所有 文档。 然而,考虑到语言模型的上下文窗口大小,这个简单的方案从根本上受到我们可以包含的文档数量(即 )的限制。 为了解决这个限制,我们采用如下所述的集成策略。 根据等式 1 中的评分函数,假设 由 与 最相关的文档组成。 (1)。 我们将每个文档 前置到 之前,将此串联单独传递给 LM,然后将所有 传递的输出概率集成在一起。 形式上,给定输入上下文及其顶部相关文档,下一个词符的输出概率为计算为加权平均系综:
其中 表示两个序列的串联,权重 基于文档 和输入上下文 之间的相似度得分>:
尽管我们的集成方法需要运行 LM 次,但交叉注意力是在每个检索到的文档和输入上下文之间执行的。 因此,与预先考虑所有检索到的文档的方法相比,我们的集成方法不会产生额外的计算成本开销。
4 RePlug LSR:训练密集猎犬
我们不只依赖现有的神经密集检索模型(Karpukhin 等人,2020a;Izacard 等人,2022a;Su 等人,2022),我们进一步提出RePlug LSR( RePlug with LM-Supervised Retrieval),它通过使用 LM 本身提供有关应检索哪些文档的监督来适应 RePlug 中的检索器。
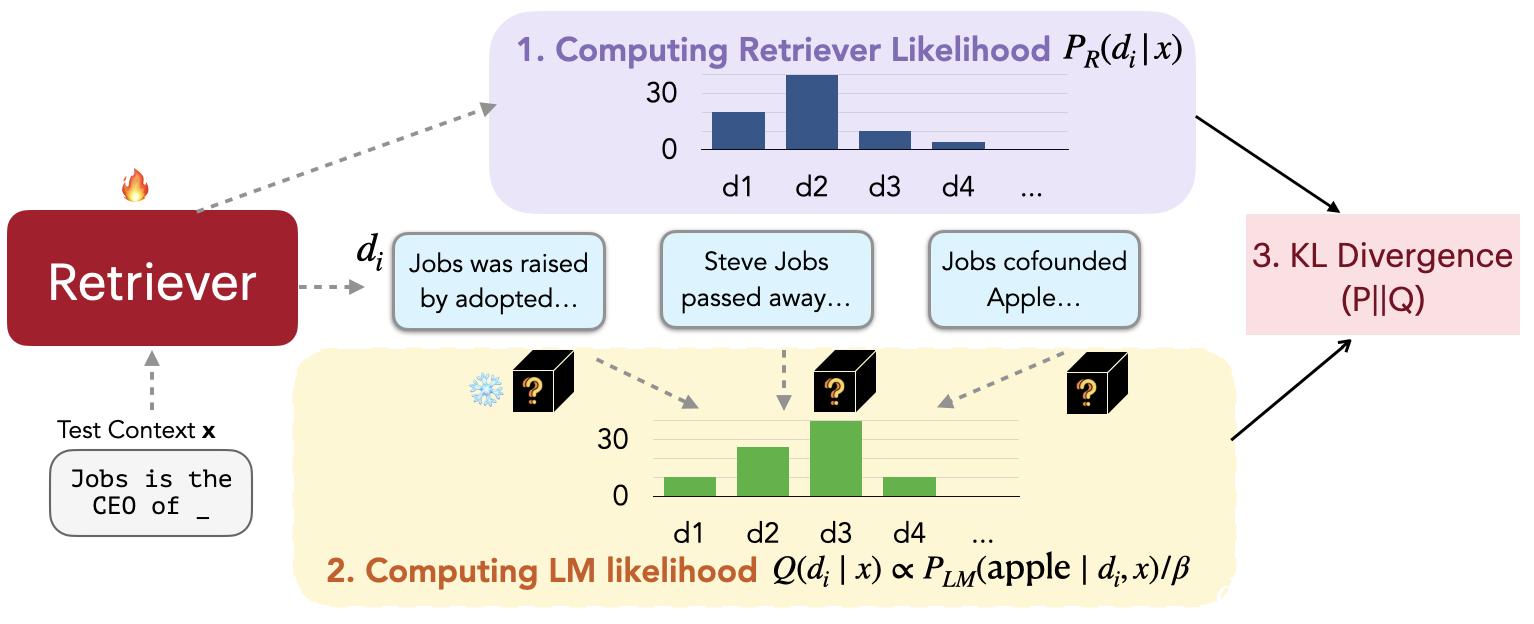
受 Sachan 等人 (2022) 的启发,我们的方法可以看作是调整检索到的文档的概率以匹配语言模型的输出序列困惑的概率。 换句话说,我们希望检索器找到导致较低困惑度分数的文档。 如图3所示,我们的训练算法由四个步骤组成:(1)检索文档并计算检索可能性(§4.1),(2)对检索到的内容进行评分(§4.2),(3) 通过最小化检索可能性和 LM 分数分布之间的 KL 散度来更新检索模型参数 (§4.3) ,以及 (4) 数据存储索引的异步更新 (§4.4)。
4.1 计算检索可能性
我们从给定输入上下文 的语料库 中检索具有最高相似度分数的 文档 ,如 §3.1。 然后我们计算每个检索到的文档 的检索可能性:
其中是控制softmax温度的超参数。 理想情况下,检索可能性是通过边缘化语料库 中的所有文档来计算的,这在实践中很难处理。 因此,我们通过仅边缘化检索到的文档来近似检索可能性。
4.2计算LM似然
我们使用 LM 作为评分函数来衡量每个文档可以在多大程度上改善 LM 困惑度。 具体来说,我们首先计算 ,即给定输入上下文 和文档 的真实输出 的 LM 概率。概率越高,文档在改善LM的困惑度方面就越好。 然后我们计算每个文档 的 LM 可能性,如下所示:
其中 是另一个超参数。
4.3损失函数
给定输入上下文和相应的地面真实延续,我们计算检索可能性和语言模型可能性。 密集检索器是通过最小化这两个分布之间的 KL 散度来训练的:
其中 是一组输入上下文。 在最小化损失的情况下,我们只能更新检索模型参数。 由于我们的黑盒假设,LM 参数是固定的。
4.4 数据存储索引异步更新
由于检索器中的参数在训练过程中更新,因此之前计算的文档嵌入不再是最新的。 因此,按照Guu等人(2020),我们重新计算文档嵌入,并在每个训练步骤中使用新的嵌入重建有效的搜索索引。 然后我们使用新的文档嵌入和索引进行检索,并重复该过程。
5训练设置
5.1 重新插拔
理论上,任何类型的检索器,无论是密集(Karpukhin等人,2020b;Ni等人,2021)还是稀疏(Robertson等人,2009),都可以使用对于重新插入。 继之前的工作(Izacard 等人, 2022b)之后,我们使用Contriever (Izacard 等人, 2022a)作为RePlug的检索模型,因为它已经表现出了强大的性能。
5.2 重新插入 LSR
对于RePlug LSR,我们使用Contriever模型(Izacard等人,2022a)初始化检索器。 我们使用 GPT-3 Curie (Brown 等人, 2020b) 作为监督 LM 来计算 LM 似然。
训练数据
我们使用从 Pile 训练数据 (Gao 等人, 2020) 中采样的 800K 个序列,每个序列包含 256 个标记,作为我们的训练查询。 每个查询分为两部分:前 128 个标记用作输入上下文 ,最后 128 个标记用作基本事实延续 。 对于外部语料库 ,我们从 Pile 训练数据中采样了 128 个 token 的 36M 个文档。 为了避免琐碎的检索,我们确保外部语料库文档不与训练查询采样的文档重叠。
训练详情
为了使训练过程更加高效,我们预先计算外部语料库 的文档嵌入,并创建 FAISS 索引 (Johnson 等人, 2019) 以进行快速相似性搜索。 给定查询 ,我们从 FAISS 索引中检索前 20 个文档,并计算检索似然度和温度为 0.1 时的 LM 似然度。 我们使用 Adam 优化器 (Kingma & Ba,2015) 训练检索器,学习率为 2e-5,批量大小为 64,预热比率为 0.1。 我们每 3k 步重新计算文档嵌入,并对检索器进行总共 25k 步的计算。
| Model | # Parameters | Original | + RePlug | Gain % | + RePlug LSR | Gain % | |
| GPT-2 | Small | 117M | 1.33 | 1.26 | 5.3 | 1.21 | 9.0 |
| Medium | 345M | 1.20 | 1.14 | 5.0 | 1.11 | 7.5 | |
| Large | 774M | 1.19 | 1.15 | 3.4 | 1.09 | 8.4 | |
| XL | 1.5B | 1.16 | 1.09 | 6.0 | 1.07 | 7.8 | |
| GPT-3 | Ada | 350M | 1.05 | 0.98 | 6.7 | 0.96 | 8.6 |
| (black-box) | Babbage | 1.3B | 0.95 | 0.90 | 5.3 | 0.88 | 7.4 |
| Curie | 6.7B | 0.88 | 0.85 | 3.4 | 0.82 | 6.8 | |
| Davinci | 175B | 0.80 | 0.77 | 3.8 | 0.75 | 6.3 |
6实验
我们对语言建模 (§6.1) 和下游任务(例如 MMLU (§6.2) 和开放域 QA (§6.3))进行评估)。 在所有设置中,RePlug 提高了各种黑盒语言模型的性能,显示了我们方法的有效性和通用性。
6.1 语言建模
数据集
Pile (Gao 等人,2020)是一种语言建模基准,由来自不同领域的文本源(例如网页、代码和学术论文)组成。 根据之前的工作,我们将每个 UTF-8 编码字节 (BPB) 的位数报告为每个子集域的度量。
基线
我们以 GPT-3 和 GPT-2 家庭语言模型为基线。 GPT-3 的四个模型(Davinci、Curie、Baddage 和 Ada)是黑盒模型,只能通过 API 访问
我们的模型
我们将 RePlug 和 RePlug LSR 添加到基线中。 我们对 Pile 训练数据(128 个标记的 367M 文档)进行随机二次采样,并将它们用作所有模型的检索语料库。 由于 Pile 数据集已努力在训练、验证和测试拆分中消除重复文档(Gao 等人,2020),因此我们没有进行额外的过滤。 对于RePlug和RePlug LSR,我们使用长度为128-token的上下文进行检索并采用集成方法(第3.2节)在推理过程中纳入前 10 个检索到的文档。
结果
表1报告了原始基线、使用RePlug增强的基线以及使用RePlug LSR增强的基线的结果。 我们观察到 RePlug 和 RePlug LSR 均显着优于基线。 这表明,简单地向冻结的语言模型(即黑盒设置)添加检索模块可以有效地提高不同大小的语言模型在语言建模任务上的性能。 此外,RePlug LSR 的性能始终比 RePlug 好很多。 具体而言,RePlug LSR 的结果比基线提高了 7.7%,而 RePlug 的 8 个模型平均提高了 4.7%。 这表明进一步使检索器适应目标 LM 是有益的。
6.2MMLU
| Model | # Parameters | Humanities | Social. | STEM | Other | All |
| Codex | 175B | 74.2 | 76.9 | 57.8 | 70.1 | 68.3 |
| PaLM | 540B | 77.0 | 81.0 | 55.6 | 69.6 | 69.3 |
| Flan-PaLM | 540B | - | - | - | - | 72.2 |
| Atlas | 11B | 46.1 | 54.6 | 38.8 | 52.8 | 47.9 |
| Codex + RePlug | 175B | 76.0 | 79.7 | 58.8 | 72.1 | 71.4 |
| Codex + RePlug LSR | 175B | 76.5 | 79.9 | 58.9 | 73.2 | 71.8 |
数据集
Massive Multi-task Language Understanding(MMLU (Hendrycks 等人, 2021))是一个多项选择的 QA 数据集,涵盖数学、计算机科学、法律、美国历史等 57 个任务的考试题。 57 项任务分为 4 类:人文、STEM、社会科学和其他。 继 Chung 等人 (2022a) 之后,我们在 5-shot 上下文学习设置中评估 RePlug。
基线
我们考虑两组强大的先前模型作为比较的基线。 第一组基线是最先进的大语言模型,包括 Codex111Code-Davinci-002 (Chen 等人, 2021b)、PaLM (Chowdhery 等人, 2022) 和 Flan-PaLM (钟等人,2022b)。 根据 Chung 等人 (2022b) 的数据,这三个模型在 MMLU 排行榜中排名前三。 第二组基线由检索增强语言模型组成。 我们仅将 Atlas (Izacard 等人, 2022b) 纳入该组中,因为尚未在 MMLU 数据集上评估其他检索增强的 LM。 Atlas 训练检索器和语言模型,我们将其视为白盒检索 LM 设置。
我们的模型
我们仅将 RePlug 和 RePlug LSR 添加到 Codex,因为 PaLM 和 Flan-PaLM 等其他模型无法向公众开放。 我们使用测试问题作为查询,从维基百科(2018 年 12 月)检索 10 个相关文档,并将每个检索到的文档添加到测试问题之前,从而产生 10 个单独的输入。 然后,这些输入被分别输入到语言模型中,并且输出概率被集成在一起。
结果
表 2 显示了 MMLU 数据集上的基线、RePlug 和 RePlug LSR 的结果。 我们观察到 RePlug 和 RePlug LSR 分别将原始 Codex 模型提高了 4.5% 和 5.1%。 此外,RePlug LSR在很大程度上优于之前的检索增强语言模型Atlas,证明了我们黑盒检索语言模型设置的有效性。 尽管我们的模型表现略低于 Flan-PaLM,但这仍然是一个很好的结果,因为 Flan-PaLM 的参数多了三倍。 如果我们能够访问该模型,我们预计 RePlug LSR 可以进一步改进 Flan-PaLM。
另一个有趣的观察结果是,即使在 STEM 类别中,RePlug LSR 的性能也比原始模型高出 1.9%。 这表明检索可以提高语言模型解决问题的能力。
6.3 开放域质量检查
最后,我们对两个开放域 QA 数据集进行评估:Natural Questions (NQ) (Kwiatkowski 等人, 2019) 和 TriviaQA (Joshi 等人, 2017)。
| NQ | TQA | |||
| Model | Few-shot | Full | Few-shot | Full |
| Chinchilla | 35.5 | - | 64.6 | - |
| PaLM | 39.6 | - | - | - |
| Codex | 40.6 | - | 73.6 | - |
| RETRO† | - | 45.5 | - | - |
| R2-D2† | - | 55.9 | - | 69.9 |
| Atlas† | 42.4 | 60.4 | 74.5 | 79.8 |
| Codex + Contrievercc222Si et al. (2022) augment Codex with concatenation of 10 documents retrieved by contriever. | 44.2 | - | 76.0 | - |
| Codex + RePlug | 44.7 | - | 76.8 | - |
| Codex + RePlug LSR | 45.5 | - | 77.3 | - |
数据集
NQ 和 TriviaQA 是两个开放域 QA 数据集,由从维基百科和网络收集的问题、答案组成。 继之前的工作(Izacard & Grave,2021a;Si 等人,2022)之后,我们报告了 TriviaQA 过滤集的结果。 为了进行评估,我们考虑少样本设置,其中模型仅给出几个训练示例,而模型则给出所有训练示例的完整数据。
基线
我们将我们的模型与几个最先进的训练基线进行比较,无论是在少样本设置中还是在完整数据中。 第一组模型由功能强大的大语言模型组成,包括 Chinchilla (Hoffmann 等人, 2022)、PaLM (Chowdhery 等人, 2022) 和 Codex。 这些模型均在少样本设置下使用上下文学习进行评估,Chinchilla 和 PaLM 使用 64 个镜头进行评估,Codex 使用 16 个镜头进行评估。 第二组用于比较的模型包括检索增强语言模型,例如 RETRO (Borgeaud 等人, 2021)、R2-D2 (Fajcik 等人, 2021) 和Atlas (Izacard 等人, 2022b)。 所有这些检索增强模型都在训练数据上进行了微调,无论是在少样本设置中还是在完整的训练数据中。 具体来说,Atlas 在少样本设置中对 64 个示例进行了微调。
我们的模型
我们将 RePlug 和 RePlug LSR 添加到 Codex with Wikipedia(2018 年 12 月)作为检索语料库,以在上下文学习中以 16 个镜头评估模型。 与语言建模和 MMLU 中的设置类似,我们使用我们提出的集成方法合并前 10 个检索到的文档。
结果
如表3所示,RePlug LSR在NQ上显着提高了原始Codex的性能12.0%,在TQA上显着提高了5.0%。 它优于之前的最佳模型 Atlas,后者通过 64 个训练示例进行了微调,在少样本设置中达到了新的最先进水平。 然而,这个结果仍然落后于在完整数据上微调的检索训练增强语言模型的性能。 这可能是由于训练集中存在近乎重复的测试问题(例如,Lewis 等人 (2021) 发现 32.5% 的测试问题与 NQ 中的训练集重叠)。
7分析
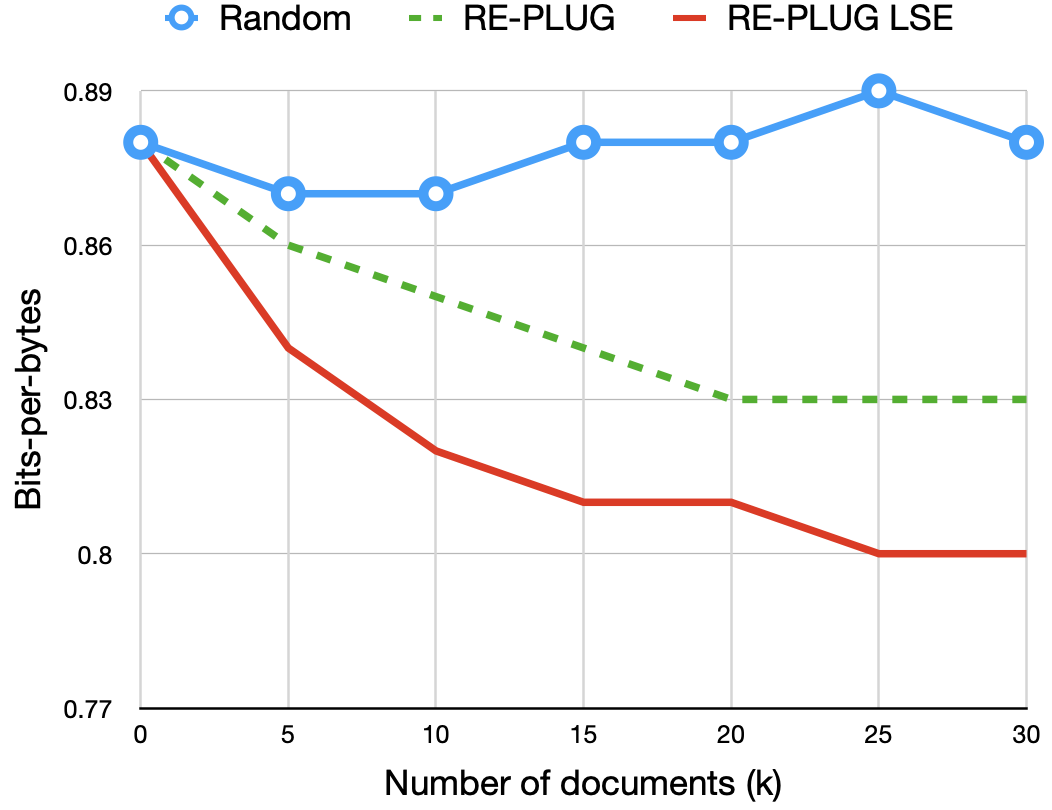
7.1 RePlug性能增益不仅仅来自集成效应
我们方法设计的核心是使用集成方法,该方法结合了不同通道的输出概率,其中每个检索到的文档都单独添加到输入之前并输入到语言模型中。 为了研究收益是否仅来自集成方法,我们将我们的方法与集成随机文档进行比较。 为此,我们随机采样多个文档,将每个随机文档与输入连接起来,并将不同运行的输出进行集成(称为“随机”)。 如 Figure 6 所示,我们评估了 GPT-3 Curie 在 Pile 上使用随机文档、通过 RePlug 检索的文档和通过 RePlug LSR 检索的文档时的性能。 我们观察到,集成随机文档会导致性能较差,这表明 RePlug 的性能提升不仅仅来自集成效应。 相反,整合相关文档对于RePlug的成功至关重要。 此外,随着更多文档的集成,RePlug 和 RePlug LSR 的性能单调提高。 然而,少量文档(例如 10 个)就足以实现较大的性能提升。
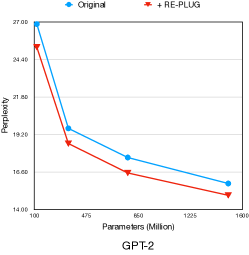
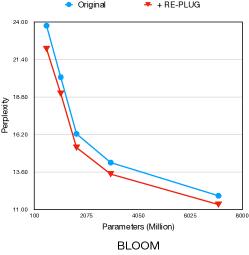
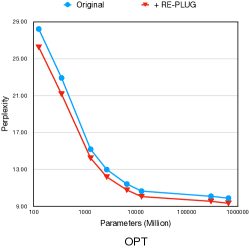
7.2 RePlug适用于多种语言模型
在这里,我们进一步研究RePlug是否可以增强使用不同数据和方法预训练的多样化语言模型系列。 具体来说,我们关注三组不同大小的语言模型:GPT-2(117M,345M,774M,1.5B参数)(Brown等人,2020a),OPT(125M,350M,1.3) B, 2.7B, 6.7B, 13B, 30B, 66B) (张 等人, 2022b) 及 BLOOM (560M, 1.1B, 1.7B, 3B 及 7B) (Scao 等人,2022)。 我们在 Wikitext-103 (Stephen 等人, 2017) 测试数据上评估每个模型并报告其困惑度。 为了进行比较,我们使用 RePlug 增强每个模型,该模型采用集成方法来合并前 10 个检索到的文档。 继之前的工作(Khandelwal 等人, 2020)之后,我们使用 Wikitext-103 训练数据作为检索语料库。
Figure 5 显示了使用和不使用 RePlug 的不同大小的语言模型的性能。 我们观察到 RePlug 带来的性能增益与模型大小保持一致。 例如,具有125M参数的OPT实现了6.9%的困惑度改善,而具有66B参数的OPT实现了5.6%的困惑度改善。 此外,RePlug 改善了所有模型系列的复杂性。 这表明RePlug适用于不同大小的多种语言模型。
7.3 定性分析:稀有实体受益于检索
为了理解为什么RePlug提高了语言建模性能,我们对RePlug导致困惑度降低的示例进行了手动分析。 我们发现当文本包含稀有实体时,RePlug 更有帮助。 Figure 6 显示了 Wikitext-103 测试集的测试上下文及其延续。 对于 RePlug,我们使用测试上下文作为查询来从 Wikitext-103 训练数据中检索相关文档。 然后,我们使用原始 GPT-2 1.5B 及其 RePlug 增强版本来计算延续的困惑度。 合并检索到的文档后,延续的困惑度提高了 11%。 在延续中的所有标记中,我们发现RePlug对于稀有实体名称“Li Bai”最有帮助。 这可能是因为原始 LM 没有关于这个罕见实体名称的足够信息。 然而,通过合并检索到的文档,RePlug 能够将名称与检索到的文档中的相关信息相匹配,从而获得更好的性能。

8结论
我们引入了RePlug,这是一种检索增强的语言建模范例,它将语言模型视为黑匣子,并使用可调整的检索模型对其进行增强。 我们的评估表明,RePlug 可以与任何现有语言模型集成,以提高其在语言建模或下游任务上的性能。 这项工作为将检索集成到大规模黑盒语言模型中开辟了新的可能性,并证明即使是最先进的大规模语言模型也可以从检索中受益。 然而,RePlug 缺乏可解释性,因为不清楚模型何时依赖于检索知识或参数知识。 未来的研究可以集中于开发更具可解释性的检索增强语言模型。
参考
- Borgeaud et al. (2021) Borgeaud, S., Mensch, A., Hoffmann, J., Cai, T., Rutherford, E., Millican, K., Driessche, G. v. d., Lespiau, J.-B., Damoc, B., Clark, A., et al. Improving language models by retrieving from trillions of tokens. arXiv preprint arXiv:2112.04426, 2021.
- Borgeaud et al. (2022) Borgeaud, S., Mensch, A., Hoffmann, J., Cai, T., Rutherford, E., Millican, K., Van Den Driessche, G. B., Lespiau, J.-B., Damoc, B., Clark, A., et al. Improving language models by retrieving from trillions of tokens. In International Conference on Machine Learning, pp. 2206–2240. PMLR, 2022.
- Brown et al. (2020a) Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., and Amodei, D. Language models are few-shot learners. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp. 1877–1901. Curran Associates, Inc., 2020a. URL https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf.
- Brown et al. (2020b) Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., and Amodei, D. Language models are few-shot learners. In Proc. of NeurIPS, 2020b. URL https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf.
- Chen et al. (2021a) Chen, M., Tworek, J., Jun, H., Yuan, Q., de Oliveira Pinto, H. P., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., Ryder, N., Pavlov, M., Power, A., Kaiser, L., Bavarian, M., Winter, C., Tillet, P., Such, F. P., Cummings, D., Plappert, M., Chantzis, F., Barnes, E., Herbert-Voss, A., Guss, W. H., Nichol, A., Paino, A., Tezak, N., Tang, J., Babuschkin, I., Balaji, S., Jain, S., Saunders, W., Hesse, C., Carr, A. N., Leike, J., Achiam, J., Misra, V., Morikawa, E., Radford, A., Knight, M., Brundage, M., Murati, M., Mayer, K., Welinder, P., McGrew, B., Amodei, D., McCandlish, S., Sutskever, I., and Zaremba, W. Evaluating large language models trained on code. CoRR, abs/2107.03374, 2021a. URL https://arxiv.org/abs/2107.03374.
- Chen et al. (2021b) Chen, M., Tworek, J., Jun, H., Yuan, Q., de Oliveira Pinto, H. P., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., Ryder, N., Pavlov, M., Power, A., Kaiser, L., Bavarian, M., Winter, C., Tillet, P., Such, F. P., Cummings, D., Plappert, M., Chantzis, F., Barnes, E., Herbert-Voss, A., Guss, W. H., Nichol, A., Paino, A., Tezak, N., Tang, J., Babuschkin, I., Balaji, S., Jain, S., Saunders, W., Hesse, C., Carr, A. N., Leike, J., Achiam, J., Misra, V., Morikawa, E., Radford, A., Knight, M., Brundage, M., Murati, M., Mayer, K., Welinder, P., McGrew, B., Amodei, D., McCandlish, S., Sutskever, I., and Zaremba, W. Evaluating large language models trained on code. CoRR, abs/2107.03374, 2021b. URL https://arxiv.org/abs/2107.03374.
- Chowdhery et al. (2022) Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H. W., Sutton, C., Gehrmann, S., et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- Chung et al. (2022a) Chung, H. W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, E., Wang, X., Dehghani, M., Brahma, S., et al. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022a.
- Chung et al. (2022b) Chung, H. W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, E., Wang, X., Dehghani, M., Brahma, S., et al. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022b.
- Fajcik et al. (2021) Fajcik, M., Docekal, M., Ondrej, K., and Smrz, P. R2-D2: A modular baseline for open-domain question answering. In Findings of the Association for Computational Linguistics: EMNLP 2021, pp. 854–870, Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.findings-emnlp.73. URL https://aclanthology.org/2021.findings-emnlp.73.
- Gao et al. (2020) Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., Presser, S., and Leahy, C. The Pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020.
- Goyal et al. (2022) Goyal, A., Friesen, A., Banino, A., Weber, T., Ke, N. R., Badia, A. P., Guez, A., Mirza, M., Humphreys, P. C., Konyushova, K., et al. Retrieval-augmented reinforcement learning. In International Conference on Machine Learning, pp. 7740–7765. PMLR, 2022.
- Guu et al. (2020) Guu, K., Lee, K., Tung, Z., Pasupat, P., and Chang, M. Retrieval augmented language model pre-training. In International Conference on Machine Learning, pp. 3929–3938. PMLR, 2020.
- Hendrycks et al. (2021) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=d7KBjmI3GmQ.
- Hoffmann et al. (2022) Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. d. L., Hendricks, L. A., Welbl, J., Clark, A., et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- Hu et al. (2022) Hu, Y., Hua, H., Yang, Z., Shi, W., Smith, N. A., and Luo, J. Promptcap: Prompt-guided task-aware image captioning. arXiv preprint arXiv:2211.09699, 2022.
- Izacard & Grave (2021a) Izacard, G. and Grave, E. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pp. 874–880, Online, April 2021a. Association for Computational Linguistics. doi: 10.18653/v1/2021.eacl-main.74. URL https://aclanthology.org/2021.eacl-main.74.
- Izacard & Grave (2021b) Izacard, G. and Grave, E. Leveraging passage retrieval with generative models for open domain question answering. In Proc. of EACL, 2021b. URL https://arxiv.org/abs/2007.01282.
- Izacard et al. (2022a) Izacard, G., Caron, M., Hosseini, L., Riedel, S., Bojanowski, P., Joulin, A., and Grave, E. Unsupervised dense information retrieval with contrastive learning. Transactions on Machine Learning Research, 2022a. URL https://openreview.net/forum?id=jKN1pXi7b0.
- Izacard et al. (2022b) Izacard, G., Lewis, P., Lomeli, M., Hosseini, L., Petroni, F., Schick, T., Dwivedi-Yu, J., Joulin, A., Riedel, S., and Grave, E. Few-shot learning with retrieval augmented language models. arXiv preprint arXiv:2208.03299, 2022b.
- Johnson et al. (2019) Johnson, J., Douze, M., and Jégou, H. Billion-scale similarity search with gpus. IEEE Transactions on Big Data, 7(3):535–547, 2019.
- Joshi et al. (2017) Joshi, M., Choi, E., Weld, D., and Zettlemoyer, L. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1601–1611, Vancouver, Canada, July 2017. Association for Computational Linguistics. doi: 10.18653/v1/P17-1147. URL https://aclanthology.org/P17-1147.
- Karpukhin et al. (2020a) Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., and Yih, W.-t. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 6769–6781, Online, November 2020a. Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.550. URL https://aclanthology.org/2020.emnlp-main.550.
- Karpukhin et al. (2020b) Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., and Yih, W.-t. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 6769–6781, 2020b.
- Khandelwal et al. (2020) Khandelwal, U., Levy, O., Jurafsky, D., Zettlemoyer, L., and Lewis, M. Generalization through memorization: Nearest neighbor language models. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=HklBjCEKvH.
- Khattab et al. (2022) Khattab, O., Santhanam, K., Li, X. L., Hall, D., Liang, P., Potts, C., and Zaharia, M. Demonstrate-search-predict: Composing retrieval and language models for knowledge-intensive nlp. arXiv preprint arXiv:2212.14024, 2022.
- Kingma & Ba (2015) Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. In ICLR (Poster), 2015.
- Kwiatkowski et al. (2019) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., Toutanova, K., Jones, L., Kelcey, M., Chang, M.-W., Dai, A. M., Uszkoreit, J., Le, Q., and Petrov, S. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:452–466, 2019. doi: 10.1162/tacl_a_00276. URL https://aclanthology.org/Q19-1026.
- Lewis et al. (2020) Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.-t., Rocktäschel, T., Riedel, S., and Kiela, D. Retrieval-augmented generation for knowledge-intensive nlp tasks, 2020. URL https://arxiv.org/abs/2005.11401.
- Lewis et al. (2021) Lewis, P., Stenetorp, P., and Riedel, S. Question and answer test-train overlap in open-domain question answering datasets. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pp. 1000–1008, 2021.
- Mallen et al. (2022) Mallen, A., Asai, A., Zhong, V., Das, R., Hajishirzi, H., and Khashabi, D. When not to trust language models: Investigating effectiveness and limitations of parametric and non-parametric memories. arXiv preprint arXiv:2212.10511, 2022.
- Min et al. (2022) Min, S., Shi, W., Lewis, M., Chen, X., Yih, W.-t., Hajishirzi, H., and Zettlemoyer, L. Nonparametric masked language modeling. arXiv preprint arXiv:2212.01349, 2022.
- Ni et al. (2021) Ni, J., Qu, C., Lu, J., Dai, Z., Ábrego, G. H., Ma, J., Zhao, V. Y., Luan, Y., Hall, K. B., Chang, M., and Yang, Y. Large dual encoders are generalizable retrievers, 2021. URL https://arxiv.org/abs/2112.07899.
- Qu et al. (2021) Qu, Y., Ding, Y., Liu, J., Liu, K., Ren, R., Zhao, W. X., Dong, D., Wu, H., and Wang, H. RocketQA: An optimized training approach to dense passage retrieval for open-domain question answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 5835–5847, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main.466. URL https://aclanthology.org/2021.naacl-main.466.
- Robertson et al. (2009) Robertson, S., Zaragoza, H., et al. The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends® in Information Retrieval, 3(4):333–389, 2009.
- Rubin et al. (2022) Rubin, O., Herzig, J., and Berant, J. Learning to retrieve prompts for in-context learning. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 2655–2671, 2022.
- Sachan et al. (2022) Sachan, D. S., Lewis, M., Yogatama, D., Zettlemoyer, L., Pineau, J., and Zaheer, M. Questions are all you need to train a dense passage retriever. arXiv preprint arXiv:2206.10658, 2022.
- Scao et al. (2022) Scao, T. L., Fan, A., Akiki, C., Pavlick, E., Ilić, S., Hesslow, D., Castagné, R., Luccioni, A. S., Yvon, F., Gallé, M., et al. Bloom: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100, 2022.
- Shi et al. (2022) Shi, W., Michael, J., Gururangan, S., and Zettlemoyer, L. Nearest neighbor zero-shot inference. 2022.
- Si et al. (2022) Si, C., Gan, Z., Yang, Z., Wang, S., Wang, J., Boyd-Graber, J., and Wang, L. Prompting gpt-3 to be reliable. arXiv preprint arXiv:2210.09150, 2022.
- Si et al. (2023) Si, C., Gan, Z., Yang, Z., Wang, S., Wang, J., Boyd-Graber, J., and Wang, L. Prompting gpt-3 to be reliable. In Proc. of ICLR, 2023. URL https://openreview.net/forum?id=98p5x51L5af.
- Stephen et al. (2017) Stephen, M., Caiming, X., James, B., and Socher, R. Pointer sentinel mixture models. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings, 2017.
- Su et al. (2022) Su, H., Kasai, J., Wang, Y., Hu, Y., Ostendorf, M., Yih, W.-t., Smith, N. A., Zettlemoyer, L., Yu, T., et al. One embedder, any task: Instruction-finetuned text embeddings. arXiv preprint arXiv:2212.09741, 2022.
- Wu et al. (2021) Wu, S., Zhao, X., Yu, T., Zhang, R., Shen, C., Liu, H., Li, F., Zhu, H., Luo, J., Xu, L., et al. Yuan 1.0: Large-scale pre-trained language model in zero-shot and few-shot learning. arXiv preprint arXiv:2110.04725, 2021.
- Yasunaga et al. (2022) Yasunaga, M., Aghajanyan, A., Shi, W., James, R., Leskovec, J., Liang, P., Lewis, M., Zettlemoyer, L., and Yih, W.-t. Retrieval-augmented multimodal language modeling. arXiv preprint arXiv:2211.12561, 2022.
- Younes Belkda (2022) Younes Belkda, T. D. A gentle introduction to 8-bit matrix multiplication, 2022. URL https://huggingface.co/blog/hf-bitsandbytes-integration.
- Yu (2022) Yu, W. Retrieval-augmented generation across heterogeneous knowledge. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Student Research Workshop, pp. 52–58, Hybrid: Seattle, Washington + Online, July 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.naacl-srw.7. URL https://aclanthology.org/2022.naacl-srw.7.
- Yu et al. (2023) Yu, W., Iter, D., Wang, S., Xu, Y., Ju, M., Sanyal, S., Zhu, C., Zeng, M., and Jiang, M. Generate rather than retrieve: Large language models are strong context generators. 2023.
- Zhang et al. (2022a) Zhang, S., Diab, M., and Zettlemoyer, L. Democratizing access to large-scale language models with opt-175b. Meta AI, 2022a.
- Zhang et al. (2022b) Zhang, S., Roller, S., Goyal, N., Artetxe, M., Chen, M., Chen, S., Dewan, C., Diab, M., Li, X., Lin, X. V., et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022b.
- Zhong et al. (2022) Zhong, Z., Lei, T., and Chen, D. Training language models with memory augmentation. In Empirical Methods in Natural Language Processing (EMNLP), 2022.
| Knowledge: Arctic Ocean. Although over half of Europe’s original forests disappeared through the centuries of deforestation, Europe still has over one quarter of its land area as forest, such as the broadleaf and mixed forests, taiga of Scandinavia and Russia, mixed rainforests of the Caucasus and the Cork oak forests in the western Mediterranean. During recent times, deforestation has been slowed and many trees have been planted. However, in many cases monoculture plantations of conifers have replaced the original mixed natural forest, because these grow quicker. The plantations now cover vast areas of land, but offer poorer habitats for many European |
| Question: As of 2015, since 1990 forests have in Europe and have in Africa and the Americas. |
| A. "increased, increased" B. "increased, decreased" C. "decreased, increased" D. "decreased, decreased" |
| Answer: B |
| Knowledge: Over the past decades, the political outlook of Americans has become more progressive, with those below the age of thirty being considerably more liberal than the overall population. According to recent polls, 56% of those age 18 to 29 favor gay marriage, 68% state environmental protection to be as important as job creation, 52% "think immigrants śtrengthen the country with their hard work and talents,"́ 62% favor a "tax financed, government-administrated universal health care" program and 74% "say ṕeopleś willśhould have more influence on U.S. laws than the Bible, compared to 37%, 49%, 38%, 47% and 58% among the |
| Question: As of 2019, about what percentage of Americans agree that the state is run for the benefit of all the people? |
| A. 31% B. 46% C. 61% D. 76% |
| Answer: B |
| … |
| Knowledge: last week at a United Nations climate meeting in Germany, China and India should easily exceed the targets they set for themselves in the 2015 Paris Agreement… India is now expected to obtain 40 percent of its electricity from non-fossil fuel sources by 2022, eight years ahead of schedule." Solar power in Japan has been expanding since the late 1990s. By the end of 2017, cumulative installed PV capacity reached over 50 GW with nearly 8 GW installed in the year 2017. The country is a leading manufacturer of solar panels and is in the top 4 ranking for countries |
| Question: Which of the following countries generated the most total energy from solar sources in 2019? |
| A. China B. United States C. Germany D. Japan |
| Knowledge: received 122,000 buys (excluding WWE Network views), down from the previous yearś 199,000 buys. The event is named after the Money In The Bank ladder match, in which multiple wrestlers use ladders to retrieve a briefcase hanging above the ring. The winner is guaranteed a match for the WWE World Heavyweight Championship at a time of their choosing within the next year. On the June 2 episode of "Raw", Alberto Del Rio qualified for the match by defeating Dolph Ziggler. The following week, following Daniel Bryan being stripped of his WWE World Championship due to injury, Stephanie McMahon changed the |
| Question: Who won the mens money in the bank match? |
| Answer: Braun Strowman |
| Knowledge: in 3D on March 17, 2017. The first official presentation of the film took place at Disneyś three-day D23 Expo in August 2015. The world premiere of "Beauty and the Beast" took place at Spencer House in London, England on February 23, 2017; and the film later premiered at the El Capitan Theatre in Hollywood, California, on March 2, 2017. The stream was broadcast onto YouTube. A sing along version of the film released in over 1,200 US theaters nationwide on April 7, 2017. The United Kingdom received the same version on April 21, 2017. The film was re-released in |
| Question: When does beaty and the beast take place |
| Answer: Rococo-era |
| … |
| Knowledge: Love Yourself "Love Yourself" is a song recorded by Canadian singer Justin Bieber for his fourth studio album "Purpose" (2015). The song was released first as a promotional single on November 8, 2015, and later was released as the albumś third single. It was written by Ed Sheeran, Benny Blanco and Bieber, and produced by Blanco. An acoustic pop song, "Love Yourself" features an electric guitar and a brief flurry of trumpets as its main instrumentation. During the song, Bieber uses a husky tone in the lower registers. Lyrically, the song is a kiss-off to a narcissistic ex-lover who did |
| Question: love yourself by justin bieber is about who |