大型语言模型是多功能的分解器:为基于表格的推理分解证据和问题
摘要
基于表格的推理在各种基于表格的任务中取得了显著进展。 这是一项具有挑战性的任务,需要对非结构化的自然语言 (NL) 问题和(半)结构化的表格数据进行推理。 然而,以前的基于表格的推理解决方案在“巨大”证据(表格)上通常会遇到明显的性能下降。 此外,大多数现有方法难以对复杂问题进行推理,因为必要信息分散在不同的地方。 为了缓解上述挑战,我们利用大型语言模型 (LLM) 作为分解器,以实现有效的基于表格的推理,该模型 (i) 将庞大的证据(庞大的表格)分解为子证据(小型表格),以减轻无用信息对表格推理的干扰,以及 (ii) 将复杂的问题分解为更简单的子问题,以进行文本推理。 首先,我们使用强大的 LLM 将当前问题中涉及的证据分解为保留相关信息并排除“巨大”证据中其余无关信息的子证据。 其次,我们提出了一种新颖的“解析-执行-填充”策略,通过生成中间 SQL 查询作为桥梁,利用强大的 LLM 生成数值和逻辑子问题,从而将复杂问题分解为更简单的逐步子问题。 最后,我们利用分解后的子证据和子问题,通过几个上下文提示示例来获得最终答案。 在三个基准数据集(TabFact、WikiTableQuestion 和 FetaQA)上的大量实验表明,我们的方法在基于表格的推理方面取得了比竞争基线显著更好的结果。 值得注意的是,我们的方法首次在 TabFact 数据集上超过了人类的表现。 除了令人印象深刻的整体性能之外,我们的方法还具有可解释性的优势,其中返回的结果在一定程度上可以通过生成的子证据和子问题进行跟踪。
1 引言
表格数据可以作为文本数据的宝贵补充,它在我们日常生活中提供信息并无处不在。 关于表格和文本信息推理是自然语言理解 (NLU) 和信息检索 (IR) (Wang 等人,2021) 中的一个基本问题。 它可以使各种下游应用受益,例如基于表格的事实验证 (FV) (Chen 等人,2020; Aly 等人,2021; Gupta 等人,2020) 和基于表格的问答 (QA) (Pasupat 和 Liang,2015; Zhong 等人,2017; Nan 等人,2022; Cho 等人,2019)。 如图 1 所示,基于表格的推理具有挑战性,因为它涉及跨非结构化文本和(半)结构化表格进行复杂的文本、数值和逻辑推理。 为了解决上述挑战,基于表格的推理通常通过合成可执行语言(例如 SQL 和 SPARQL)来与表格交互 (Date,1989; Abdelaziz 等人,2017; Hui 等人,2021, 2022)。 然而,这些方法忽略了表格内文本块的语义,难以有效地建模具有非规范化自由格式文本的网页表格。
最近,基于表格的预训练模型 (Herzig 等人,2020; Liu 等人,2021; Jiang 等人,2022; Gu 等人,2022; Cai 等人,2022) 已被证明在增强文本和表格数据的推理能力方面非常有效,这得益于从大规模爬取或合成的表格和文本数据中学习到的丰富知识。 例如,TaPas (Herzig 等人,2020) 通过恢复表格中被屏蔽的单元格信息来增强对表格数据的理解。 然而,这些模型通常需要在大量特定任务的下游数据集上进行微调,在处理具有未见推理类型的新数据集时难以取得优异的性能。 此外,在特定任务上微调预训练模型通常会破坏其上下文能力 (Wang 等人,2022c)。 为了替代微调预训练模型,大语言模型 (LLM) 中的上下文学习 (Brown 等人,2020; Wei 等人,2022; Kojima 等人,2022; Min 等人,2022) 近年来引起了人们的关注,以探索 LLM 的推理能力,其中提供了一些输入-输出示例用于提示。 例如,人们发现 思维链 提示 (Wei 等人,2022) 可以使 LLM 通过生成中间推理步骤来执行复杂的推理。
先前的研究 (Wei 等人,2022; Kojima 等人,2022) 表明,LLM 可以在许多文本推理任务上取得令人印象深刻的性能,而无需特定任务的模型设计和训练数据。 然而,LLM 在基于表格的推理任务上的能力仍有待探索。 利用 LLM 进行基于表格的推理存在几个技术挑战,其中涉及大型表格和复杂问题。 首先, 由于一个表格可能包含大量的行和列, 直接通过预训练模型对所有表格内容进行编码在计算上可能是难以处理的, 并且会干扰大量的无关信息. 正如 (Chen, 2022) 中所指出的, 由于符元限制, 大语言模型无法泛化到具有 30 多行的“巨大”表格. 尽管之前的一些研究已经利用了一些方法 (Yin et al., 2020; Chen et al., 2020), 例如文本匹配来检索子证据, 但这些方法通常需要大量的领域特定数据进行训练, 因为子证据检索过程需要对问题和表格进行深入理解和推理. 其次, 将一个复杂问题分解成更简单的子问题可以有效地促进大型模型的多步推理 (Huang et al., 2022; Dua et al., 2022; Chen et al., 2022). 但是, 直接利用思维链提示 (Wei et al., 2022) 对复杂问题进行分解很容易陷入幻觉困境 (Ji et al., 2022), 其中模型可能会生成包含与证据不一致的信息的误导性子问题. Chen 等人 (Chen, 2022) 表明, 大语言模型在执行符号运算时有时会犯简单的错误. 这会影响后续推理的过程, 因此我们需要一种更可靠的基于表格的复杂问题分解方法.
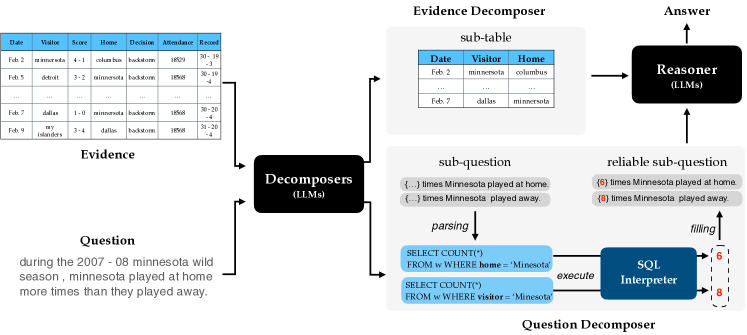
为了缓解上述挑战, 在本文中, 我们探索了大语言模型中的上下文学习, 以便 Decompose evidence And questions for effective Table-basEd Reasoning (Dater). 首先, 我们利用一个强大的大语言模型将当前问题中涉及的(半)结构化证据(一个巨大的表格)分解成相关的子证据(一个小的表格). 我们通过预测行和列的索引来实现子证据提取, 借助于一个强大的大语言模型和一些提示. 通过这种方式, 我们可以保留相关证据, 并排除其余无关证据对决策的干扰. 此外, 我们的方法具有可解释性的优点, 其中返回的基于表格的结果是可处理的. 其次, 我们提出了一种“解析-执行-填充”策略, 该策略探索了编程语言 SQL, 将复杂的非结构化自然语言(NL)问题分解成逻辑和数值计算. 具体而言, 我们通过掩盖数值范围来生成一个抽象的逻辑子问题, 然后将抽象逻辑转换为 SQL 查询语言, 该语言在证据上执行, 以获得可靠的子问题. 最后, 我们利用分解后的子证据和子问题, 在一些上下文提示示例的帮助下获得最终答案.
本文的贡献主要列举如下:
-
•
我们通过一个强大的 LLM 和一些提示示例,预测证据中行和列的相关索引,将“巨大”证据(一个巨大的表格)简化为“较小”子证据(一个较小的表格)。 我们的证据分解方法使推理器能够关注与给定问题相关的基本子证据。
-
•
我们提出了一种新颖的“解析-执行-填充”策略,通过生成一个中间 SQL 作为桥梁,借助强大的 LLM 和一些提示示例,将复杂问题分解为更简单的逐步子问题,从而产生数值和逻辑子问题。 我们的问题分解方法已被证明在基于表格的推理中是有效的,不需要大量的标注训练数据。
-
•
我们在三个属于基于表格的事实验证和基于表格的问答任务的基准数据集上进行了广泛的实验。 实验结果表明,我们的 Dater 方法在基于表格的推理方面取得了显著优于竞争基线的成果。 特别是,Dater 首次在 TabFact 数据集上超越了人类的表现。
-
•
除了令人印象深刻的整体性能外,我们的 Dater 还具有可解释性的优势,其中返回的结果在一定程度上可以通过生成的子证据和子问题来追踪。
2 相关工作
2.1 基于表格的推理
基于表格的推理需要对自由形式的自然语言 (NL) 问题和(半)结构化表格进行推理。 传统方法生成可执行语言(例如,SQL 和 SPARQL)来访问表格数据 (Date, 1989; Abdelaziz et al., 2017)。 但是,这些方法无法捕获表格内文本块的语义,并且无法对表格单元格中包含自由文本的网络表格进行建模。 最近,已经提出了一些基于表格的推理基准,例如 TabFact (Chen et al., 2020),WikiTableQuestion (Pasupat and Liang, 2015) 和 FetaQA (Nan et al., 2022),以帮助学习不同类型的基于表格的任务。 大规模训练数据的可用性极大地提高了基于表格的推理的性能,借助深度学习技术 (Neeraja et al., 2021; Aly et al., 2021)。
与此同时,已经提出了表格预训练来对表格和文本进行编码,这进一步提高了基于表格的推理性能。 受掩码语言建模(MLM)成功的启发,TaPas (Herzig 等人,2020) 通过恢复表格中掩盖的单元格信息来增强对表格数据的理解。 TAPEX (Liu 等人,2021) 利用 BART 模型在预训练阶段模拟 SQL 执行器,以便 TAPEX 可以获得更好的表格推理能力。 ReasTAP (Zhao 等人,2022) 基于表格任务的推理技能设计了预训练任务,通过预训练注入推理技能。 TaBERT (Yin 等人,2020) 提出了内容快照,以对与输入话语最相关的表格内容子集进行编码。 PASTA (Gu 等人,2022) 引入了一种表格操作感知的事实验证方法,该方法通过从 WikiTables 合成的句子-表格完形填空问题,对 LMs 进行预训练,使其了解常见的基于表格的操作。 随后,(Chen,2022; Cheng 等人,2022) 探讨了 LLMs 在基于表格任务中的能力。
2.2 大型语言模型的推理
大型语言模型 (LLMs) 已被证明具有多种推理能力,例如算术 (Lewkowycz 等人,2022)、常识 (Liu 等人,2022) 和符号推理 (Zhou 等人,2022a),因为模型参数正在扩大 (Brown 等人,2020)。 值得注意的是,思维链 (CoT) (Wei 等人,2022) 利用一系列中间推理步骤,在复杂任务上取得了更好的推理性能。 基于 CoT,已经提出了许多先进的改进,包括集成过程 (Wang 等人,2022b)、迭代优化 (Zelikman 等人,2022) 和示例选择 (Creswell 等人,2022)。 值得注意的是,ZeroCoT (Kojima 等人,2022) 通过在每个答案之前简单地添加“让我们一步一步地思考”来提高推理性能。 Fu 等人 (Fu 等人,2022) 提出基于复杂性的提示可以为链生成更多推理步骤,并实现显着更好的性能。 Zhang 等人 (Zhang 等人,2022) 通过聚类自动选择上下文中的示例,无需人工编写。 尽管 LLMs 在文本推理方面表现出色,但它们在表格任务上的推理能力仍然有限。 与本文最相关的两项工作是 (Cheng 等人,2022) 和 (Chen,2022),但它们都没有关注强大 LLM 分解证据(表格)的能力,以及推理步骤的可靠性。
2.3 问题分解
问题分解对于理解复杂问题至关重要。 早期的工作 (Kalyanpur 等人,2012) 利用了一套基于词汇句法特征的问题分解分解规则。 基于规则的方法的缺点是它们需要专家手动设计规则,这使得将规则扩展到新的任务或领域变得困难。 近年来,神经模型 (Talmor 和 Berant,2018; Zhang 等人,2019) 被提议以端到端的方式进行问题分解。 Zhang 等人 (Zhang 等人,2019) 提出了一种基于序列到序列模型的层次语义解析方法,该方法结合了问题分解器和信息提取器。 然而,这些监督方法依赖于大量的标注训练数据,而这些数据需要大量的人工来获得。 与此同时,无监督分解被提议在没有强监督的情况下产生子问题。 例如,Perez 等人 (Perez 等人,2020) 自动为每个复杂问题生成了一个嘈杂的“伪分解”,它使用无监督序列到序列学习在爬取的数据上训练了分解模型。 与之前的分解方法不同,我们探索了 LLM 作为通用的分解器,它在强大 LLM 和一些提示示例的帮助下,为基于表格的推理分解了大量的证据和复杂问题。
3 问题公式和符号
基于表格的推理中的每个实例都包含一个表格 、一个自然语言问题 和一个答案 。 尤其,每个表格 包含 行和 列,其中 表示 单元格中的内容。 一个问题 包含 个符元。 在本文中,我们关注两个基于表格的推理任务,包括基于表格的事实验证 (FV) 和基于表格的问答 (QA)。 对于基于表格的 FV,最终答案 是一个布尔值,用于确定输入语句的真假。 对于基于表格的 QA,答案是一个自然语言序列 ,它回答由输入语句描述的问题。
4 方法
4.1 上下文学习
给定一些包含有关详细特定任务的说明的示例,大型语言模型 (LLM) 可以执行无需训练的上下文学习,它从类比中学习。 这种强大的能力已在自然语言任务中得到广泛验证,包括文本分类、语义解析、数学推理等。 受 LLM 进展的启发,我们旨在探索 LLM 是否能够解决结构化证据 (即表格数据) 上的推理任务。 正式地,最终答案 可以通过使用证据表格 和问题 预测 来获得。 这里, 是一组小的来自手动编写的上下文提示,其中每个示例 。 我们提供了详细的上下文提示作为提示 4.1。
![[Uncaptioned image]](x3.png)
![[Uncaptioned image]](x4.png)
根据经验观察,通过上述提示 4.1 直接执行上下文学习无法达到最佳性能。 基于表格的推理是一项复杂且艰巨的任务,需要类人的思维和细粒度的理解过程。 最近,思维链 (Wei 等人,2022) 提出了一个问题分解方法,它诱导 LLM 执行逐步思考,从而实现更好的推理。 然而,他们没有分解证据,导致性能不佳。 具体来说,直接处理庞大的表格通常效率低下,并且容易受到大量无关信息的干扰。 为此,我们引入了证据和问题分解,以帮助大型模型对证据(表格)和问题进行细粒度推理。
4.2 证据分解器
人类通过观察与当前问题相关的子证据来完成他们的判断,从而处理基于表格的推理任务。 在本文中,我们希望使用证据分解来模仿这个过程。 尽管之前的一些研究已经利用了一些方法 (Yin 等人,2020;Chen 等人,2020),例如文本匹配来检索子证据,但经验结果表明,这些方法往往不完美,需要大量的特定领域数据进行训练,因为子证据检索过程依赖于强大的常识以及领域知识,并且需要对问题和表格进行联合理解和推理。 为此,我们使用一个强大的 LLM 来分解当前问题中涉及的证据(表格),保留相关证据,并排除剩余的无关证据对决策的干扰。 具体来说,我们通过借助一个强大的 LLM 和一些提示来预测行索引和列索引,从而实现子证据提取。 正式地说,在上下文中学习阶段,可以通过预测 来获得子证据表 的行索引 和列索引 ,其中 是完整的证据, 是相应的问题。 是一个包含上下文的小型示例集,其中每个 是示例实例 。 一些详细的提示在提示 4.2 中进行了说明。
4.3 问题分解器
将复杂问题分解为一步一步的子问题可以有效地促进大型模型的推理过程,这已被证明在数值和常识推理中是有效的 (Huang 等人,2022;Dua 等人,2022;Chen 等人,2022)。 然而,我们观察到,直接利用思维链过程分解复杂问题很容易陷入幻觉困境,即 LLM 可能无法忠实地生成与给定证据(表格)一致的内容,尤其是在涉及数值时。 这将影响后续推理的过程,因此我们需要一种可靠的子问题生成方法。
4.3.1 可靠的子问题
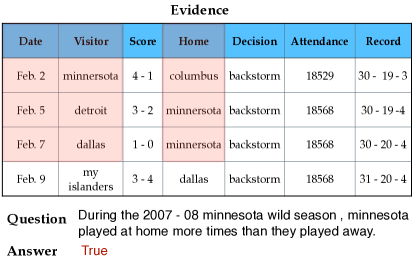
为了有效地将复杂问题分解为逐步的子问题,我们提出了一种“解析-执行-填充”策略,通过探索SQL编程语言来划分逻辑步骤和数值计算,从而扩展了基本的思维链方法。 具体来说,我们首先生成一个抽象的逻辑子问题,其中我们使用完形填空的方式掩盖数值范围,然后将抽象逻辑转换为SQL查询,类似于文本到SQL解析(Qin et al., 2022; Wang et al., 2022a)。 之后,我们在证据上执行SQL语言,以获取最终结果进行回填,从而产生一个可靠的子问题。 例如,如图2底部所示,给定一个问题 “ 在2007-08赛季的明尼苏达野人队中,明尼苏达队主场比赛次数超过客场比赛次数。 ” ,我们首先在提示示例中掩盖涉及数值的跨度,剩余部分可以视为逻辑问题。 这里,逻辑子问题是 “q1: {…} 明尼苏达队主场比赛次数。 ” 和 “q2: {…} 明尼苏达队客场比赛次数。” 正式来说,子问题可以通过预测,并结合完整证据和完整问题来获得。 是一组小的上下文提示示例,其中每个都是一个示例实例。 详细提示如提示4.3所示。
![[Uncaptioned image]](x5.png)
![[Uncaptioned image]](x6.png)
然后将逻辑语句解析为SQL查询“SELECT COUNT(*) FROM w WHERE home = ’minnesota’”和 “SELECT COUNT(*) FROM w WHERE visitor = ’minnesota’”, 这些查询在证据上进一步执行,产生可靠的跨度“6”和“8”,以回填到子问题占位符中。 通过这种方式,我们可以获得可靠的子问题 “q1: {6} 明尼苏达队主场比赛次数。 ”和“q2:{8} 明尼苏达队客场比赛次数。 ”。
从形式上看,SQL 查询 可以通过预测 来获得,这得益于完整证据 和子问题 的帮助。 这里, 是一组小的上下文示例,其中每个 都是一个示例实例 。 详细的提示如提示 4.4 所示。
4.4 联合推理
在执行上述证据和问题分解之后,推理器利用子证据 和可靠子问题 来获得最终答案 ,通过预测 ,其中 是一组小的新的上下文提示示例。 这里,每个提示示例都表示为 。 详细的提示如提示 4.5 所示。
![[Uncaptioned image]](x7.png)
5 实验设置
5.1 数据集
我们在三个基于表格的推理数据集上评估了我们提出的方法 Dater,包括 TabFact (Chen et al., 2020),WikiTableQuestion (Pasupat and Liang, 2015) 和 FetaQA (Nan et al., 2022)。 鉴于 LLM 的请求和成本限制,我们只在这些语料库的测试集上评估我们的 Dater,而没有在训练集上进行微调。 值得注意的是,LLM 主要在网络爬取和代码数据上进行训练。 由于 LLM 的预训练数据不包含表格数据,因此不存在测试数据泄露的风险。 这三个数据集的详细信息如下所示。
-
•
TabFact 是一個基於表格的事實驗證基準,其中包含由群眾工作者根據維基百科表格編寫的陳述。 例如,一個 陳述:“工業和商業小組比文化和教育小組多四名成員。” 需要根據給定的表格判斷它是 “真” 還是 “假”。 我們報告了包含 2,024 個陳述和 298 個表格的 test-small 集上的準確性。
-
•
WikiTableQuestion 包含由群眾工作者根據維基百科表格標記的複雜問題。 群眾工作者被要求寫出涉及多個複雜操作的問題,例如比較、聚合和算術運算,這些操作需要對給定表格中的一系列條目進行組合推理。 我們分別使用標準驗證集和測試集,其中包含 2,381 個和 4,344 個樣本。
-
•
FetaQA 包含需要深度推理和理解的自由格式表格問題。 FetaQA 中的大多數問題都基於表格中不連續塊的信息。 我們在包含 2,003 個樣本的測試集上評估 Dater。
5.2 評估指標
TabFact 用於評估基於表格的事實驗證,其目的是檢查陳述是否根據表格為真。 我們採用二元分類準確性作為 TabFact 資料集的評估指標。 對於 WikiTableQuestion,我們使用指稱準確性作為我們的評估指標,它驗證預測的答案是否等於黃金答案。 與生成短語答案的 TabFact 和 WikiTableQuestion 資料集不同,FetaQA 的目標是生成完整的長格式答案。 因此,對於 FetaQA,我們利用 BLEU (Papineni 等人,2002)、ROUGE-1、ROUGE-2、ROUGE-L (Lin,2004) 作為評估指標。
5.3 實施細節
在实验中,我们使用 GPT-3 Codex (code-davinci-002) 作为我们的大型语言模型。 对于最终的推理上下文学习步骤,我们分别为 TabFact、WikiTableQuestion 和 FetaQA 标注了 4、2 和 6 个提示示例。 为了获得一致的结果,我们使用了一种自一致性解码策略 (Wang et al., 2022b)。
| Model | Test |
| Fine-tuning based Methods | |
| Table-BERT | 68.1 |
| LogicFactChecker | 74.3 |
| SAT | 75.5 |
| TaPas | 83.9 |
| TAPEX | 85.9 |
| SaMoE | 86.7 |
| PASTA | 90.8 |
| w/ Dater | 93.0 ( 2.2) |
| Human | 92.1 |
| LLM based Methods | |
| Binder | 85.1 |
| Codex | 72.6 |
| w/ Dater | 85.6 ( 13.0) |
| Model | Dev | Test |
| Fine-tuning based Models | ||
| MAPO | 42.7 | 43.8 |
| MeRL | 43.2 | 44.1 |
| LatentAlignment | 43.7 | 44.5 |
| IterativeSearch | 43.1 | 44.7 |
| T5-3B | - | 49.3 |
| TaPas | 49.9 | 50.4 |
| TableFormer | 51.3 | 52.6 |
| TAPEX | 58.0 | 57.2 |
| ReasTAP | 58.3 | 58.6 |
| TaCube | 60.9 | 60.8 |
| OmniTab | 61.3 | 61.2 |
| w/ Dater | 62.5 ( 1.2) | 62.5 ( 1.3) |
| LLM based Methods | ||
| Binder | 62.6 | 61.9 |
| Codex | 49.3 | 47.6 |
| w/ Dater | 64.8( 15.5) | 65.9 ( 18.3) |
5.4 基线
我们将提出的 Dater 与一系列强大的基线方法进行比较,这些方法可以分为两类:需要在特定任务数据上进行训练的微调方法和不需要微调的基于 LLM 的上下文学习方法。
基于微调的方法
对于基于微调的方法,我们比较了以下方法: Table-BERT (Chen et al., 2020) 采用基于规则的方法将表格线性化为自然语言 (NL) 句子。 然后使用 BERT 模型直接对线性化表格和语句进行编码。 LogicFactChecker (Zhong et al., 2020) 采用序列到动作语义解析器生成一个程序,该程序表示为一个包含多个操作的树。 然后利用图神经网络对语句、表格和生成的程序进行编码。 TaPas (Herzig et al., 2020) 通过结合将表格编码为输入的能力来增强 BERT 架构。 它是在从维基百科收集的文本片段和表格的联合数据集上预训练的,这使得模型能够更好地处理表格数据,并提高了各种下游任务的整体性能。 SAT (Zhang 等人,2020) 通过引入一个结构感知掩码矩阵,提高了模型对表格中相关信息的关注能力。 特别是,它侧重于在低层捕获低级词汇信息,在高层捕获语义信息。 TAPEX (Liu 等人,2021) 被设计为使 BART 模型模仿 SQL 执行器,这使得模型能够获得更好的表格理解能力。 预训练的 SQL 查询模板语料库是从 SQUALL 数据集中提取的。 SaMoE (Zhou 等人,2022c) 将混合专家 (MoE) (Masoudnia 和 Ebrahimpour,2014) 引入表格事实验证领域,旨在使不同的专家专注于不同类型的推理任务。 ReasTAP (Zhao 等人,2022) 定义了七种关于半结构化数据的推理技能,包括联合、时间比较、日期差异等等。 它通过在合成数据集上预训练模型来注入表格推理能力。 PASTA (Gu 等人,2022) 设计了六种类型的句子-表格完形填空任务,这些任务是在从 WikiTables 合成的 120 万个项目的语料库上预训练的。 “用选择然后排序进行微调”策略用于调整输入长度以适应模型,这使得模型能够有效地处理长输入序列。 TableFormer (Yang 等人,2022) 提出了一种对表格行和列中的扰动具有鲁棒性的方法,从而通过使用位置编码来提高模型对表格的理解。 TaCube (Zhou 等人,2022b) 是一种基于预计算的方法,旨在提高 PLM 在数值推理方面的能力。 此方法预先计算表格的聚合/算术结果,使其在解决问答问题时可供 PLM 方便使用。 OmniTab (Jiang 等人,2022) 提出了一种杂食性预训练方法,它同时使用自然数据和合成数据来增强模型,使其具有两种类型数据的处理能力。
基于 LLM 的方法
对于基于 LLM 的具有上下文学习的方法,我们比较了以下方法: Codex (Chen 等人,2021) 通过在提示 4.1 中所示的上下文学习来直接生成最终答案。 Binder (Cheng et al., 2022) 生成编程语言程序,并扩展了编程语言解决常识问题的能力。
| Model | BLEU | ROUGE-1 | ROUGE-2 | ROUGE-L |
| Fine-tuning based Methods | ||||
| T5-small | 21.60 | 0.55 | 0.33 | 0.47 |
| T5-base | 28.14 | 0.61 | 0.39 | 0.51 |
| T5-large | 30.54 | 0.63 | 0.41 | 0.53 |
| LLM based Methods | ||||
| Codex | 27.96 | 0.62 | 0.40 | 0.52 |
| w/ Dater | 30.92 | 0.66 | 0.45 | 0.56 |
5.5 主要结果
我们在 TabFact、WikiTableQuesion 和 FetaQA 上进行了大量实验。 TabFact 上的实验结果总结在表 2 中。 从结果来看,我们发现我们的 Dater 模型在与其他方法的比较中取得了实质性的改进。 如果我们使用 LLM (Codex) 作为推理器,我们的 Dater 达到了 85.6% 的准确率,比没有证据和问题分解阶段的 Codex 预测结果高出 13.0%。 另一方面,当我们在 Dater 框架中使用微调后的模型作为推理器时,即,将 Dater 生成的中间分解注入到 PASTA 中,准确率比 PASTA 提高了 2.2% (93.0% 对比 90.8%)。 值得注意的是,Dater 首次在 TabFact 数据集上超越了人类的表现。
表格 2 提供了 WikiTableQuestion 数据集的实验结果。 Dater 在测试集上取得了 65.9% 的新的最先进的准确率,超过了最佳基线方法 (即 Binder) 4.0%。 当将 Dater 生成的中间分解注入到 OmniTab 中时,我们仍然可以在测试集上获得 1.3% 的提升。 此外,与基于表格的 QA 的原始 Codex 相比,Dater 有 18.3% 的绝对提升。 这种显著的改进可能是由于 WikiTableQuestion 具有相对较大的表格和复杂的问题,而我们的表格和问题分解方法可以有效地解决这些问题。 表格 3 展示了 FetaQA 数据集上的实验结果。 我们观察到,我们的 Dater 方法比 T5 和 Codex 等比较方法取得了更好的结果,进一步验证了 Dater 的有效性。
| Model | TabFact | WikiTableQuestion | FeTaQA | ||||
| All | Simple | Complex | All | Simple | Complex | BLEU | |
| Dater | 85.6 | 91.2 | 80.0 | 65.9 | 68.2 | 63.5 | 30.92 |
| w/o Evidence Decomposition | 81.8 ( 3.8) | 86.9 ( 4.3) | 76.8 ( 3.2) | 63.9 ( 2.0) | 65.5 ( 2.7) | 62.2 ( 1.3) | 28.46 ( 2.46) |
| w/o Question Decomposition | 81.9 ( 3.7) | 90.0 ( 1.2) | 74.1 ( 5.9) | 61.4 ( 4.5) | 63.6 ( 4.6) | 59.1 ( 4.4) | 30.73 ( 0.19) |
5.6 消融实验
为了分析两种分解对 Dater 的影响,我们进行了一项消融实验,通过在 TabFact、WikiTableQuestion 和 FetaQA 上丢弃证据分解模块(表示为 w/o 证据分解)和问题分解模块(表示为 w/o 问题分解)。 TabFact 和 WikiTableQuestion 数据集中的问题可以根据问题的难度进一步分为两个级别:简单 和 复杂,这可以用来更好地评估模型在不同问题上的表现。 具体来说,TabFact 是根据官方提供的题目难度标签进行划分的,而 WikiTableQuestion 是根据题目的长度进行分类的。 虽然 FetaQA 的问题在长度上比较相似,而且很难区分,所以我们没有对它们进行划分。 消融测试结果如表 4 所示。 毫无疑问,结合证据和问题组合在所有实验设置中都取得了最佳性能。 对于 FabFact,证据分解和问题分解对 Dater 的性能都有很大的影响。 在没有证据/问题分解的情况下,Dater 的准确率在 FabFact 的 所有 测试集中下降了 3.8%/3.7%。 对于 WikiTableQuestion,问题分解对 Dater 的性能影响远大于证据分解。 这是因为 WikiTableQuestion 包含更多涉及比较、聚合和算术运算的复杂问题。 这验证了我们提出的问题分解方法在处理复杂问题方面的有效性。 对于 FetaQA,问题比较简单,涉及的数值推理较少,因此性能瓶颈主要在于表格内容理解。 当丢弃证据分解时,Dater 的性能会显著下降。 由于 FetaQA 主要侧重于数据到文本的生成,因此我们预计从问题分解中不会获得显著收益。
| Semantic Understanding | ||
| Question | on august 25 , remlinger (6 - 6) took the win against the rockies. | |
| Rule-based method | date, loss | ✗ |
| Dater | date, loss, score, opponent | ✓ |
| Ground Truth: | date, loss, score, opponent | |
| Commonsense Knowledge | ||
| Question | the top scorer (matias suarez) has 5 fewer goals than bart goor , who has 11 goals. | |
| Rule-based method | player, league | ✗ |
| Dater | player, total | ✓ |
| Ground Truth: | player, total | |
| Question | denver did not lose more than one game in a row during november. | |
| Rule-based method | date | ✗ |
| Dater | team, date, score | ✓ |
| Ground Truth | team, date, score |
| WikiTableQuestion | |
| Question 1 | what is the number of listings from barrington, farmington, and rochester combined? |
| Codex CoT | there are totally 1+1+1=3 listings from barrington, farmington, and rochester combined. |
| Codex Prediction | “3” ✗ |
| Dater Sub-question | the number of listings from barrington is {…}. the number of listings from farmington is {…}. the number of listings from rochester is {…}. |
| Dater Parsing | SELECT COUNT(*) FROM w WHERE city or town = ’barrington’ SELECT COUNT(*) FROM w WHERE city or town = ’farmington’ SELECT COUNT(*) FROM w WHERE city or town = ’rochester’ |
| Dater CoT | the number of listings from barrington is {1}. the number of listings from farmington is {1}. the number of listings from rochester is {3}. |
| Dater Prediction | “5” ✓ |
| Gold Answer | “5” |
| Question 2 | does the team have more 5th or 7th place finishes during the regular season? |
| Codex CoT | the team have 1 5th place finishes and 2 7th place finish during the regular season. |
| Codex Prediction | “7th” ✗ |
| Dater Sub-question | the team have {…} 5th place finishes during the regular season. the team have {…} 7th place finishes during the regular season. |
| Dater Parsing | SELECT COUNT(*) FROM w WHERE reg.season LIKE ’%5th%’ SELECT COUNT(*) FROM w WHERE reg.season LIKE ’%7th%’ |
| Dater CoT | the team have {3} 5th place finishes during the regular season. the team have {2} 7th place finishes during the regular season. |
| Dater Prediction | “5th” ✓ |
| Gold Answer | “5th” |
| TabFact | |
| Question 1 | pádraig harrington and graeme mcdowell are both fron northern ireland. |
| Codex CoT | pádraig harrington is fron northern ireland.graeme mcdowell is fron northern ireland. |
| Codex Prediction | True ✗ |
| Dater Sub-question | pádraig harrington is {…} fron northern ireland. graeme mcdowell is {…} fron northern ireland. |
| Dater Parsing | SELECT COUNT(*) FROM w WHERE player = ’pádraig harrington’ AND country = ’northern ireland’ SELECT COUNT(*) FROM w WHERE player = ’graeme mcdowell’ AND country = ’northern ireland’ |
| Dater CoT | pádraig harrington is {0} fron northern ireland. graeme mcdowell is {1} fron northern ireland. |
| Dater Prediction | False ✓ |
| Gold Answer | False |
| Question 2 | atlético ciudad played 28 matches with an average of less than 0.61 |
| Codex CoT | atlético ciudad played 28 matches. the average of atlético ciudad is 0.61. |
| Codex Predict | True ✗ |
| Dater Sub-question | atlético ciudad played {…} matches. atlético ciudad played {…} matches with an average of less than 0.61. |
| Dater Parsing | SELECT SUM(matches) FROM w WHERE team = ’atlético ciudad’ SELECT COUNT(*) FROM w WHERE team = ’atlético ciudad’ AND average < 0.61 |
| Dater CoT | atlético ciudad played {28} matches. atlético ciudad played {0} matches with an average of less than 0.61. |
| Dater Prediction | False ✓ |
| Gold Answer | False |
5.7 案例研究
证据分解的案例研究
为了更好地理解证据分解如何帮助我们的模型捕获相关的子证据,我们展示了从 TabFact 中选出的三个关于体育的示例案例。 由于空间限制,我们只提供表格列选择结果。 从表 5 中我们可以观察到,基于规则的方法无法精确地对齐问题和证据,因为它无法捕获问题和证据的深层语义信息。 以第一个案例为例,基于规则的方法无法将短语“against the rockies”和列名“opponent”联系起来。 此外,基于规则的方法通常缺乏常识知识,无法有效地理解复杂的问题。 例如,如第三个案例所示,基于规则的方法无法识别“denver”作为一个球队名称,也无法发现“score”列可以用来确定比赛结果。 相反,我们的 Dater 方法可以解决先前方法在证据分解方面的局限性,并通过从强大的 LLM 中获取丰富的语义和常识知识,准确地从表格中选择相关列。
问题分解案例研究
我们使用从 WikiTableQuestion 和 TabFact 数据集中选择的四个示例案例,以定性验证我们问题分解的有效性。 表 6 显示了 Codex 和我们的 Dater 方法生成的“思维链”,其中前两个案例来自 WikiTableQuestion,后两个案例来自 TabFact。 从这些案例中,我们可以观察到 Dater 可以将复杂的问题分解为更简单的子问题,这些问题可以通过利用“解析-执行-填充”策略轻松解决。 特别是,Dater 可以生成高质量的 SQL 查询,以从证据中检索正确的信息。 检索到的信息对于预测最终答案至关重要。 相反,如果没有问题组合,Codex 无法理解和理解复杂问题,因此它只是从给定问题中获取信息。 例如,Codex 倾向于生成一个与证据不一致的“思维链”(一系列中间推理步骤)。
5.8 子证据分析
正如 (Chen, 2022) 所揭示的那样,基于表格的推理模型无法推广到包含 30 多行的“庞大”表格,这是主要错误来源。 为了解决这个问题,提出了证据分解,通过从“庞大”证据中过滤掉无关信息来获取子证据。 为了说明证据分解在缩小无关证据范围方面的有效性,在图 3 中,我们报告了三个数据集上证据分解前后表格单元格的平均数量。 从结果中,我们可以观察到子证据大约是原始证据的三分之一,同时获得了更好的性能。 尤其是在 WikiTableQuestion 上,我们可以将平均表格单元格数量从 164 减少到 56,极大地减轻了 LLM 处理“巨大”表格的负担。 在 TabFact 和 FetaQA 数据集上也可以观察到类似的趋势。
6 结论
在本文中,我们探讨了 LLM 中的上下文学习,以分解结构化证据和非结构化 NL 问题,以实现有效的基于表格的推理。 首先,我们利用强大的 LLM 将当前问题中涉及的证据分解为相关的子证据。 子证据提取可以识别相关子证据并排除其余无关证据,方法是借助 LLM 和一些提示预测行和列的索引。 其次,我们引入了一种“解析-执行-填充”策略,该策略探索了编程语言 SQL,将复杂问题分解为逻辑和数值计算。 最后,我们利用分解后的子证据和子问题,借助一些上下文提示示例,有效地获得最终答案。 在三个基准数据集上的实验结果表明,我们的 Dater 在基于表格的推理方面,与之前的竞争基线(基于微调的方法和基于 LLM 的上下文学习方法)相比,取得了明显更好的结果。 特别是,Dater 首次在 TabFact 数据集上超越了人类的表现。 除了令人印象深刻的整体性能外,Dater 还具有可解释性的优势,其中返回的结果在一定程度上可以通过生成的子证据和子问题进行追踪。
我们的证据分解方法通过强大的 LLM 提取行和列的索引作为整体,而不考虑给定问题的“思维链”特征。 在未来,我们计划通过对表格进行逐步推理来学习表格和问题之间的细粒度对齐。
参考文献
- Abdelaziz et al. (2017) Ibrahim Abdelaziz, Razen Harbi, Zuhair Khayyat, and Panos Kalnis. 2017. A survey and experimental comparison of distributed sparql engines for very large rdf data. Proceedings of the VLDB Endowment, 10(13):2049–2060.
- Aly et al. (2021) Rami Aly, Zhijiang Guo, Michael Schlichtkrull, James Thorne, Andreas Vlachos, Christos Christodoulopoulos, Oana Cocarascu, and Arpit Mittal. 2021. Feverous: Fact extraction and verification over unstructured and structured information. ArXiv preprint, abs/2106.05707.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Cai et al. (2022) Zefeng Cai, Xiangyu Li, Binyuan Hui, Min Yang, Bowen Li, Binhua Li, Zhen Cao, Weijie Li, Fei Huang, Luo Si, and Yongbin Li. 2022. Star: Sql guided pre-training for context-dependent text-to-sql parsing. In EMNLP.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. ArXiv preprint, abs/2107.03374.
- Chen (2022) Wenhu Chen. 2022. Large language models are few (1)-shot table reasoners. ArXiv preprint, abs/2210.06710.
- Chen et al. (2022) Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W Cohen. 2022. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. ArXiv preprint, abs/2211.12588.
- Chen et al. (2020) Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. 2020. Tabfact: A large-scale dataset for table-based fact verification. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net.
- Cheng et al. (2022) Zhoujun Cheng, Tianbao Xie, Peng Shi, Chengzu Li, Rahul Nadkarni, Yushi Hu, Caiming Xiong, Dragomir Radev, Mari Ostendorf, Luke Zettlemoyer, et al. 2022. Binding language models in symbolic languages. ArXiv preprint, abs/2210.02875.
- Cho et al. (2019) Minseok Cho, Gyeongbok Lee, and Seung-won Hwang. 2019. Explanatory and actionable debugging for machine learning: A tableqa demonstration. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2019, Paris, France, July 21-25, 2019, pages 1333–1336. ACM.
- Creswell et al. (2022) Antonia Creswell, Murray Shanahan, and Irina Higgins. 2022. Selection-inference: Exploiting large language models for interpretable logical reasoning. ArXiv preprint, abs/2205.09712.
- Date (1989) Chris J Date. 1989. A Guide to the SQL Standard. Addison-Wesley Longman Publishing Co., Inc.
- Dua et al. (2022) Dheeru Dua, Shivanshu Gupta, Sameer Singh, and Matt Gardner. 2022. Successive prompting for decomposing complex questions. ArXiv preprint, abs/2212.04092.
- Fu et al. (2022) Yao Fu, Hao Peng, Ashish Sabharwal, Peter Clark, and Tushar Khot. 2022. Complexity-based prompting for multi-step reasoning. ArXiv preprint, abs/2210.00720.
- Gu et al. (2022) Zihui Gu, Ju Fan, Nan Tang, Preslav Nakov, Xiaoman Zhao, and Xiaoyong Du. 2022. Pasta: Table-operations aware fact verification via sentence-table cloze pre-training. ArXiv preprint, abs/2211.02816.
- Gupta et al. (2020) Vivek Gupta, Maitrey Mehta, Pegah Nokhiz, and Vivek Srikumar. 2020. INFOTABS: Inference on tables as semi-structured data. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2309–2324, Online. Association for Computational Linguistics.
- Herzig et al. (2020) Jonathan Herzig, Pawel Krzysztof Nowak, Thomas Müller, Francesco Piccinno, and Julian Eisenschlos. 2020. TaPas: Weakly supervised table parsing via pre-training. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4320–4333, Online. Association for Computational Linguistics.
- Huang et al. (2022) Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. 2022. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. In International Conference on Machine Learning, pages 9118–9147. PMLR.
- Hui et al. (2021) Binyuan Hui, Ruiying Geng, Qiyu Ren, Binhua Li, Yongbin Li, Jian Sun, Fei Huang, Luo Si, Pengfei Zhu, and Xiaodan Zhu. 2021. Dynamic hybrid relation exploration network for cross-domain context-dependent semantic parsing. In AAAI Conference on Artificial Intelligence.
- Hui et al. (2022) Binyuan Hui, Ruiying Geng, Lihan Wang, Bowen Qin, Yanyang Li, Bowen Li, Jian Sun, and Yongbin Li. 2022. S2SQL: Injecting syntax to question-schema interaction graph encoder for text-to-SQL parsers. In Findings of the Association for Computational Linguistics: ACL 2022, pages 1254–1262, Dublin, Ireland. Association for Computational Linguistics.
- Ji et al. (2022) Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Andrea Madotto, and Pascale Fung. 2022. Survey of hallucination in natural language generation. ACM Computing Surveys.
- Jiang et al. (2022) Zhengbao Jiang, Yi Mao, Pengcheng He, Graham Neubig, and Weizhu Chen. 2022. OmniTab: Pretraining with natural and synthetic data for few-shot table-based question answering. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 932–942, Seattle, United States. Association for Computational Linguistics.
- Kalyanpur et al. (2012) Aditya Kalyanpur, Siddharth Patwardhan, BK Boguraev, Adam Lally, and Jennifer Chu-Carroll. 2012. Fact-based question decomposition in deepqa. IBM Journal of Research and Development, 56:13–1.
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. ArXiv preprint, abs/2205.11916.
- Lewkowycz et al. (2022) Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. 2022. Solving quantitative reasoning problems with language models. ArXiv preprint, abs/2206.14858.
- Lin (2004) Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
- Liu et al. (2022) Jiacheng Liu, Skyler Hallinan, Ximing Lu, Pengfei He, Sean Welleck, Hannaneh Hajishirzi, and Yejin Choi. 2022. Rainier: Reinforced knowledge introspector for commonsense question answering. ArXiv preprint, abs/2210.03078.
- Liu et al. (2021) Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, and Jian-Guang Lou. 2021. Tapex: Table pre-training via learning a neural sql executor. ArXiv preprint, abs/2107.07653.
- Masoudnia and Ebrahimpour (2014) Saeed Masoudnia and Reza Ebrahimpour. 2014. Mixture of experts: a literature survey. The Artificial Intelligence Review, 42(2):275.
- Min et al. (2022) Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2022. Rethinking the role of demonstrations: What makes in-context learning work? ArXiv preprint, abs/2202.12837.
- Nan et al. (2022) Linyong Nan, Chiachun Hsieh, Ziming Mao, Xi Victoria Lin, Neha Verma, Rui Zhang, Wojciech Kryściński, Hailey Schoelkopf, Riley Kong, Xiangru Tang, Mutethia Mutuma, Ben Rosand, Isabel Trindade, Renusree Bandaru, Jacob Cunningham, Caiming Xiong, Dragomir Radev, and Dragomir Radev. 2022. FeTaQA: Free-form table question answering. Transactions of the Association for Computational Linguistics, 10:35–49.
- Neeraja et al. (2021) J. Neeraja, Vivek Gupta, and Vivek Srikumar. 2021. Incorporating external knowledge to enhance tabular reasoning. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2799–2809, Online. Association for Computational Linguistics.
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics.
- Pasupat and Liang (2015) Panupong Pasupat and Percy Liang. 2015. Compositional semantic parsing on semi-structured tables. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1470–1480, Beijing, China. Association for Computational Linguistics.
- Perez et al. (2020) Ethan Perez, Patrick Lewis, Wen-tau Yih, Kyunghyun Cho, and Douwe Kiela. 2020. Unsupervised question decomposition for question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8864–8880, Online. Association for Computational Linguistics.
- Qin et al. (2022) Bowen Qin, Binyuan Hui, Lihan Wang, Min Yang, Jinyang Li, Binhua Li, Ruiying Geng, Rongyu Cao, Jian Sun, Luo Si, Fei Huang, and Yongbin Li. 2022. A survey on text-to-sql parsing: Concepts, methods, and future directions. ArXiv, abs/2208.13629.
- Talmor and Berant (2018) Alon Talmor and Jonathan Berant. 2018. The web as a knowledge-base for answering complex questions. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 641–651, New Orleans, Louisiana. Association for Computational Linguistics.
- Wang et al. (2021) Fei Wang, Kexuan Sun, Muhao Chen, Jay Pujara, and Pedro Szekely. 2021. Retrieving complex tables with multi-granular graph representation learning. ArXiv preprint, abs/2105.01736.
- Wang et al. (2022a) Lihan Wang, Bowen Qin, Binyuan Hui, Bowen Li, Min Yang, Bailin Wang, Binhua Li, Fei Huang, Luo Si, and Yongbin Li. 2022a. Proton: Probing schema linking information from pre-trained language models for text-to-sql parsing. Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining.
- Wang et al. (2022b) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022b. Self-consistency improves chain of thought reasoning in language models.
- Wang et al. (2022c) Yihan Wang, Si Si, Daliang Li, Michal Lukasik, Felix Yu, Cho-Jui Hsieh, Inderjit S Dhillon, and Sanjiv Kumar. 2022c. Preserving in-context learning ability in large language model fine-tuning. ArXiv preprint, abs/2211.00635.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. ArXiv preprint, abs/2201.11903.
- Yang et al. (2022) Jingfeng Yang, Aditya Gupta, Shyam Upadhyay, Luheng He, Rahul Goel, and Shachi Paul. 2022. TableFormer: Robust transformer modeling for table-text encoding. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 528–537, Dublin, Ireland. Association for Computational Linguistics.
- Yin et al. (2020) Pengcheng Yin, Graham Neubig, Wen-tau Yih, and Sebastian Riedel. 2020. TaBERT: Pretraining for joint understanding of textual and tabular data. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8413–8426, Online. Association for Computational Linguistics.
- Zelikman et al. (2022) Eric Zelikman, Yuhuai Wu, and Noah D Goodman. 2022. Star: Bootstrapping reasoning with reasoning. ArXiv preprint, abs/2203.14465.
- Zhang et al. (2019) Haoyu Zhang, Jingjing Cai, Jianjun Xu, and Ji Wang. 2019. Complex question decomposition for semantic parsing. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4477–4486, Florence, Italy. Association for Computational Linguistics.
- Zhang et al. (2020) Hongzhi Zhang, Yingyao Wang, Sirui Wang, Xuezhi Cao, Fuzheng Zhang, and Zhongyuan Wang. 2020. Table fact verification with structure-aware transformer. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1624–1629, Online. Association for Computational Linguistics.
- Zhang et al. (2022) Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. 2022. Automatic chain of thought prompting in large language models. ArXiv preprint, abs/2210.03493.
- Zhao et al. (2022) Yilun Zhao, Linyong Nan, Zhenting Qi, Rui Zhang, and Dragomir Radev. 2022. Reastap: Injecting table reasoning skills during pre-training via synthetic reasoning examples. ArXiv preprint, abs/2210.12374.
- Zhong et al. (2017) Victor Zhong, Caiming Xiong, and Richard Socher. 2017. Seq2sql: Generating structured queries from natural language using reinforcement learning. CoRR, abs/1709.00103.
- Zhong et al. (2020) Wanjun Zhong, Duyu Tang, Zhangyin Feng, Nan Duan, Ming Zhou, Ming Gong, Linjun Shou, Daxin Jiang, Jiahai Wang, and Jian Yin. 2020. LogicalFactChecker: Leveraging logical operations for fact checking with graph module network. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6053–6065, Online. Association for Computational Linguistics.
- Zhou et al. (2022a) Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Olivier Bousquet, Quoc Le, and Ed Chi. 2022a. Least-to-most prompting enables complex reasoning in large language models. ArXiv preprint, abs/2205.10625.
- Zhou et al. (2022b) Fan Zhou, Mengkang Hu, Haoyu Dong, Zhoujun Cheng, Shi Han, and Dongmei Zhang. 2022b. Tacube: Pre-computing data cubes for answering numerical-reasoning questions over tabular data. ArXiv preprint, abs/2205.12682.
- Zhou et al. (2022c) Yuxuan Zhou, Xien Liu, Kaiyin Zhou, and Ji Wu. 2022c. Table-based fact verification with self-adaptive mixture of experts. In Findings of the Association for Computational Linguistics: ACL 2022, pages 139–149, Dublin, Ireland. Association for Computational Linguistics.