BakedSDF:网格化神经 SDF 以进行实时视图合成
摘要。
我们提出了一种重建大型无界现实世界场景的高质量网格的方法,适用于逼真的新颖视图合成。 我们首先优化混合神经体积-表面场景表示,设计为具有与场景中的表面相对应的表现良好的水平集。 然后,我们将这种表示烘焙成高质量的三角形网格,并为其配备基于球形高斯的简单且快速的依赖于视图的外观模型。 最后,我们优化此烘焙表示以最好地再现捕获的视点,从而产生一个可以利用加速多边形光栅化管道在商用硬件上进行实时视图合成的模型。 我们的方法在准确性、速度和功耗方面优于以前的实时渲染场景表示,并生成高质量的网格,支持外观编辑和物理模拟等应用。





1. 介绍
当前用于新颖视图合成的最佳方法(使用捕获的图像来恢复可以从未观察到的视点渲染的 3D 表示的任务)主要基于神经辐射场(NeRF)(Mildenhall 等人,2020). 通过将场景表示为由多层感知器 (MLP) 参数化的连续体积函数,NeRF 能够生成逼真的渲染,展示详细的几何形状和依赖于视图的效果。 由于 NeRF 底层的 MLP 评估成本很高,而且必须对每个像素进行数百次查询,因此从 NeRF 呈现高分辨率图像的速度通常很慢。
最近的工作通过将计算量大的 MLP 换成离散体积表示(例如体素网格),提高了 NeRF 渲染性能。 然而,这些方法需要大量的 GPU 内存和自定义体积光线行进代码,并且不适合在商用硬件上进行实时渲染,因为现代图形硬件和软件面向渲染多边形表面而不是体积场。
虽然当前类似 NeRF 的方法能够恢复具有简单几何形状的单个对象的高质量实时可渲染网格(Boss 等人,2022),但可以从捕获的事实证明,现实世界的无界场景(例如Barron等人(2022)的“360度捕捉”)更加困难。 最近,MobileNeRF (Chen 等人, 2022a) 通过训练一个 NeRF 来解决这个问题,该 NeRF 的体积内容被限制在多边形网格的面上,然后将该 NeRF 烘焙成纹理贴图。 虽然这种方法产生了合理的图像质量,但 MobileNeRF 将场景几何体初始化为轴对齐图块的集合,优化后变成带纹理的多边形“汤”。 生成的几何体不太适合常见的图形应用程序,例如纹理编辑、重新照明和物理模拟。
在这项工作中,我们演示了如何从类似 NeRF 的神经体积表示中提取高质量的网格。 我们的系统(我们称之为 BakedSDF)扩展了 VolSDF (Yariv 等人,2021) 的混合体积表面神经表示,以表示无界的现实世界场景。 该表示被设计为具有与场景中的表面相对应的表现良好的零水平集,这使我们能够使用行进立方体提取高分辨率三角形网格。
我们的核心思想是在收缩坐标空间(Barron等人, 2022)中定义SDF,因为它具有以下优点:它更强烈地正则化远处的内容,并且允许我们还可以在收缩空间中提取网格,从而更好地分配三角形预算(中心较多,外围较少)。
然后,我们为该网格配备基于球面高斯的快速高效的依赖于视图的外观模型,该模型经过微调以再现场景的输入图像。 我们系统的输出可以在商用设备上以实时帧速率渲染,并且我们表明我们的实时渲染系统在真实性、速度和功耗方面优于之前的工作。 此外,我们还表明(与之前的同类工作不同)我们的模型生成的网格是准确且详细的,支持标准图形应用程序,例如外观编辑和物理模拟。
总而言之,我们的主要贡献是:
-
(1)
无界现实世界场景的高质量神经表面重建,
-
(2)
在浏览器中实时渲染这些场景的框架,以及
-
(3)
我们证明球面高斯是视图合成的视图相关外观的实际表示。
2. 相关工作
视图合成,即给定一组捕获的图像渲染场景的新视图的任务,是计算机视觉和图形领域中长期存在的问题。 在观察到的视点被密集采样的场景中,可以通过光场渲染来合成新的视图——直接插值到观察到的光线集合中(Gortler等人,1996;Levoy和Hanrahan,1996)。 然而,在实际环境中,观察到的视点捕获得更加稀疏,重建场景的 3D 表示对于渲染令人信服的新颖视图至关重要。 大多数经典的视图合成方法都使用三角形网格(通常使用由多视图立体 组成的管道进行重建(Furukawa 和 Hernández,2015;Schönberger 等人,2016)、泊松曲面重建 (Kazhdan等人,2006;Kazhdan 和 Hoppe,2013) 和行进立方体 (Lorensen 和 Cline,1987))作为底层 3D 场景表示,并通过将观察到的图像重新投影到并使用启发式定义的(Debevec等人,1996;Buehler等人,2001;Wood等人,2000)或学习的(Hedman等人,2018;Buehler等人,2001;Wood等人,2000)将它们融合在一起。 Riegler 和 Koltun,2020、2021) 混合权重。 尽管基于网格的表示非常适合使用加速图形管道进行实时渲染,但这些方法生成的网格在具有精细细节或复杂材质的区域中往往具有不准确的几何形状,这会导致渲染的新颖视图中出现错误。 另外,基于点的表示(Rückert等人,2022;Kopanas等人,2021)更适合对薄几何体进行建模,但在相机移动时无法有效渲染,而不会出现明显的裂纹或不稳定的结果。
最近的视图合成方法通过使用几何和外观的体积表示(例如体素网格)来回避高质量网格重建的困难(Szeliski 和 Golland,1999;Vogiatzis 等人,2007;Penner 和Zhang,2017; Lombardi 等人, 2019)或多平面图像(Srinivasan 等人, 2019; Zhou 等人, 2018; Wizadwongsa 等人, 2021)。 这些表示非常适合基于梯度的渲染损失优化,因此可以有效地优化它们以重建输入图像中看到的详细几何形状。 这些体积方法中最成功的是神经辐射场(NeRF)(Mildenhall 等人,2020),它构成了许多最先进的视图合成方法的基础(参见 Tewari 等人 (2022) 进行审查)。 NeRF 将场景表示为发射和吸收光的连续体积物质场,并使用体积光线追踪渲染图像。 NeRF 使用 MLP 从空间坐标映射到体积密度和发射的辐射亮度,并且必须在沿光线的一组采样坐标处评估 MLP,以产生最终颜色。
随后的工作建议修改 NeRF 的场景几何和外观表示,以提高质量和可编辑性。 Ref-NeRF (Verbin 等人, 2022) 重新参数化 NeRF 的视图相关外观,以实现外观编辑并改进镜面材质的重建和渲染。 其他作品(Boss 等人,2021;Kuang 等人,2022;Srinivasan 等人,2021;Zhang 等人,2021a, b)尝试将场景依赖于视图的外观分解为材质和光照属性。 除了修改 NeRF 的外观表示之外,论文还包括 UNISURF (Oechsle 等人, 2021)、VolSDF (Yariv 等人, 2021)、NeuS (Wang 等人, 2021)、MetaNLR++ (bergman2021metanlr) 和 NeuMesh (neumesh) 使用混合体积-表面模型增强 NeRF 的全体积表示,但不针对实时渲染并仅显示对象和有界场景的结果。
用于表示场景的 MLP NeRF 通常很大且评估成本昂贵,这意味着 NeRF 的训练速度很慢(每个场景需要数小时或数天),渲染速度也很慢(每百万像素需要数秒或数分钟)。 虽然可以通过采样网络来加速渲染,从而减少每条光线的 MLP 查询(Neff 等人,2021),但最近的方法通过用体素网格替换大型 MLP 来改善渲染时间和性能(Neff 等人,2021) t1>(Karnewar 等人, 2022; Sun 等人, 2022),小型 MLP 网格(Reiser 等人, 2021),低秩 (Chen 等人) , 2022b) 或稀疏 (Yu 等人, 2022) 网格表示,或具有小型 MLP 的多尺度哈希编码 (Müller 等人, 2022)。
虽然这些表示减少了训练和渲染所需的计算(以增加存储为代价),但可以通过预计算和存储(即“烘焙”)将经过训练的 NeRF 转换为更有效的表示来进一步加速渲染。 SNeRG (Hedman 等人, 2021)、FastNeRF (Garbin 等人, 2021)、Plenoctrees (Yu 等人, 2021) 和 Scalable神经室内场景渲染(Wu等人,2022)都将经过训练的NeRF烘焙成稀疏体积结构,并使用依赖于视图的外观的简化模型,以避免沿着每条射线评估每个样本的MLP。 这些方法可以在高端硬件上实现 NeRF 的实时渲染,但它们对体积光线行进的使用妨碍了在商用硬件上的实时性能。 在我们工作的同时,reiser2023merf 开发了内存高效辐射场 (MERF),这是一种用于无界场景的压缩表示体积,有助于在商用硬件上快速渲染。 与我们的网格相比,这种体积表示实现了更高的质量分数,但需要更多内存,需要复杂的渲染器,并且不能直接用于物理模拟等下游图形应用程序。 请参阅 MERF 论文与我们的方法进行直接比较。
3. 初步知识
在本节中,我们将描述 NeRF (Mildenhall 等人, 2020) 用于视图合成的神经体积表示以及 mip-NeRF 360 (Barron 等人, 2022) 引入的改进 用于表示无限的“360 度”场景。
NeRF 是一种 3D 场景表示,由学习函数组成,该函数将位置 和出射光线方向 映射到体积密度 和颜色 。 要呈现目标相机视图中单个像素的颜色,我们首先要计算该像素对应的射线 ,然后在射线沿线的一系列点 上评估 NeRF。 每个点的结果输出 被合成为单个输出颜色值 :
| (1) |
的定义是体积渲染方程 (Max,1995) 的基于正交的近似。
NeRF 使用 MLP 参数化该学习函数,其权重经过优化以隐式编码场景的几何形状和颜色:一组训练输入图像及其相机姿势被转换为一组(光线,颜色)对,梯度下降为用于优化 MLP 权重,使每条光线的渲染类似于其相应的输入颜色。 形式上,NeRF 最小化了地面真实颜色 和方程 1 中产生的颜色 之间的损失,对所有训练光线进行平均:
| (2) |
如果输入图像提供了足够的场景覆盖(就多视图 3D 约束而言),这个简单的过程会产生一组 MLP 权重,可以准确描述场景的 3D 体积密度和外观。
Mip-NeRF 360 (Barron 等人,2022) 扩展了基本的 NeRF 公式,以重建和渲染现实世界的“360 度”场景,其中摄像机可以在各个方向观察无限的场景内容。 mip-NeRF 360 中引入的两项改进是使用收缩函数和提议 MLP。 收缩函数将 中的无界场景点映射到有界域:
| (3) |
它产生非常适合作为 MLP 输入进行位置编码的收缩坐标。 此外,mip-NeRF 360 表明,具有详细几何形状的大型无界场景需要非常大的 MLP 以及每条光线上更多的样本,而这在原始 NeRF 框架中是无法处理的。 因此,Mip-NeRF 360 引入了一个建议 MLP:一个更小的 MLP,经过训练以限制实际 NeRF MLP 的密度。 该建议 MLP 用于分层采样过程,该过程有效地为 NeRF MLP 生成一组输入样本,这些样本紧密关注场景中的非空内容。
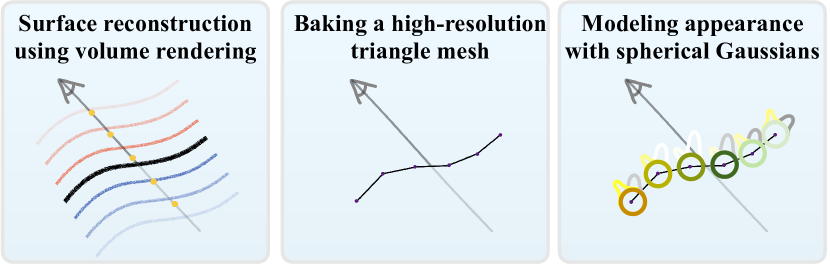
4. 方法
我们的方法由三个阶段组成,如图2所示。 首先,我们使用类似 NeRF 的体积渲染来优化基于表面的几何形状和外观的表示。 然后,我们将该几何体“烘焙”成网格,我们证明该网格足够精确,可以支持令人信服的外观编辑和物理模拟。 最后,我们训练一个新的外观模型,该模型使用嵌入网格每个顶点的球形高斯(SG),取代了第一步中昂贵的类似 NeRF 的外观模型。 这种方法产生的 3D 表示可以在商用设备上实时渲染,因为渲染只需要光栅化网格并查询少量球形高斯。
 |
 |
 |
 |
| Mesh | Diffuse color | Specular | Full appearance |
4.1. 使用 SDF 建模密度
我们的表示结合了 mip-NeRF 360 表示无界场景的优点与 VolSDF 混合体积-表面表示的良好表面特性(Yariv 等人,2021)。 VolSDF 将场景的体积密度建模为 MLP 参数化符号距离函数 (SDF) 的参数函数,该函数返回距每个点 的符号距离 > 到表面。 因为我们的重点是重建无界的现实世界场景,所以我们在收缩空间(方程3)而不是世界空间中参数化。 场景的底层表面是 的零级集,即距表面零距离的点集:
| (4) |
根据 VolSDF,我们将体积密度 定义为:
| (5) |
其中 是具有尺度参数 的零均值拉普拉斯分布的累积分布函数。 请注意,当 接近 时,体积密度接近在任何对象内返回 并在自由空间中返回 的函数。 为了鼓励 近似有效的带符号距离函数(即 返回所有 的 水平集的带符号欧氏距离),我们对 与满足 Eikonal 公式 (Gropp 等人,2020) 的偏差进行惩罚:
| (6) |
请注意,由于 是在收缩空间中定义的,因此此约束也适用于收缩空间。
最近,Ref-NeRF (Verbin 等人, 2022) 通过将其参数化为关于表面法线反射的视图方向的函数,改进了视图相关的外观。 我们使用 SDF 参数化密度可以轻松采用,因为 SDF 具有明确定义的表面法线:。 因此,当训练我们模型的这个阶段时,我们采用 Ref-NeRF 的外观模型,并使用单独的漫反射和镜面反射分量计算颜色,其中镜面反射分量通过关于法线方向反射的视图方向的串联来参数化,即法向和视图方向,以及参数化 的 MLP 输出的 元素瓶颈向量。
我们使用 mip-NeRF 训练 360 的变体作为我们的模型(有关具体细节,请参阅补充材料中的附录 A)。 与 VolSDF (Yariv 等人, 2021) 类似,我们将密度比例因子参数化为方程 5 中的 。 然而,我们发现调度 而不是将其保留为免费的可优化参数会导致更稳定的训练。 因此,我们根据 对 进行退火,其中 在训练期间从 到 ,和对于三个分层采样阶段分别是、和。 由于密度 SDF 参数化所需的 Eikonal 正则化已经消除了漂浮物并产生了表现良好的法线,因此我们认为没有必要使用来自 Ref-NeRF 的方向损失或预测法线,或来自 mip-NeRF 360 的畸变损失。
4.2. 烘焙高分辨率网格
优化神经体积表示后,我们通过在常规 3D 网格上查询恢复的 MLP 参数化 SDF,然后运行 Marching Cubes (Lorensen 和 Cline,1987),从恢复的 MLP 参数化 SDF 创建三角形网格。 请注意,VolSDF 使用密度衰减对边界进行建模,该衰减超出了 SDF 零交叉(由 参数化)。 我们在提取网格时考虑了这种扩展,并选择 作为表面交叉点的 iso 值,否则我们会发现场景几何形状被轻微侵蚀。
可见性和自由空间剔除
运行 Marching Cubes 时,MLP 参数化的 SDF 可能在从观察到的视点被遮挡的区域以及提案 MLP 标记为“自由空间”的区域中包含虚假表面交叉。 SDF MLP 在这两种类型区域中的值在训练期间不受监督,因此我们必须剔除在重建网格中显示为虚假内容的任何表面交叉点。 为了解决这个问题,我们检查了训练数据中沿光线采集的 3D 样本。 我们计算每个样本的体积渲染权重,即它对训练像素颜色的贡献有多大。 然后,我们将具有足够大渲染权重 () 的任何样本放入 3D 网格中,并将相应的单元标记为表面提取的候选单元。
 bicycle
bicycle
|
|
||||||||||||
|
treehill
|
|
||||||||||||
|
flowerbed
|
|








网格提取
我们在收缩空间中均匀间隔的坐标处对 SDF 网格进行采样,这会在世界空间中产生间隔不均匀的非轴对齐坐标。 这具有为靠近原点的前景内容创建较小的三角形(在世界空间中)和为远处的内容创建较大的三角形的理想属性。 实际上,我们利用收缩算子作为细节级别策略:由于我们所需的渲染视图接近场景原点,并且由于收缩的形状旨在消除透视投影的影响,因此所有三角形将具有大约投影到图像平面上时面积相等。
地区增长
提取三角形网格后,我们使用区域生长过程来填充可能存在于输入视点未观察到的区域或在烘焙过程中建议 MLP 错过的区域中可能存在的小孔。 我们迭代地标记当前网格周围邻域中的体素,并提取这些新活动体素中存在的任何表面交叉点。 这种区域增长策略有效地解决了 SDF MLP 中存在表面但由于训练视图覆盖不足或建议 MLP 中的错误而未被行进立方体提取的情况。 然后,我们将网格转换为世界空间,以便准备好通过在欧几里得空间中运行的传统渲染引擎进行光栅化。
执行
我们使用 网格来实现可见性以及自由空间剔除和行进立方体。 最初,我们仅在未剔除的体素(即可见且非空)上运行行进立方体。 然后,我们通过 32 次区域增长迭代来完成网格,其中我们在当前网格顶点周围的 体素邻域中重新运行行进立方体。 最后,我们使用顶点顺序优化(Sander等人,2007)对网格进行后处理,这通过允许顶点着色器输出在相邻三角形之间缓存和重用来加速现代硬件上的渲染性能。 在附录 B 中,我们详细介绍了网格提取的其他步骤,这些步骤并不严格提高重建精度,但可以实现更令人愉悦的交互式观看体验。
4.3. 建模依赖于视图的外观
上述烘焙过程从我们基于 MLP 的场景表示中提取高质量的三角形网格几何形状。 为了对场景的外观进行建模,包括依赖于视图的效果(例如镜面反射),我们为每个网格顶点配备漫反射颜色 和一组球形高斯波瓣。 由于只能从一组有限的视图方向观察远处区域,因此我们不需要在场景中的任何地方以相同的保真度对视图依赖性进行建模。 在我们的实验中,我们在中心区域 () 使用三个球形高斯波瓣,在外围使用一个波瓣。 图 3 演示了我们的外观分解。
这种外观表示满足我们的计算和内存效率目标,因此可以实时渲染。 每个球形高斯波瓣都有七个参数:代表波瓣平均值的 3D 单位向量 、代表波瓣颜色的 3D 向量 以及代表波瓣颜色的标量 波瓣的宽度。 这些波瓣由视图方向向量 参数化,因此与任何给定顶点相交的光线的渲染颜色 可以计算为:
| (7) |
| Outdoor Scenes | Indoor Scenes | ||||||
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | ||
| offline | NeRF (Mildenhall et al., 2020) | 21.46 | 0.458 | 0.515 | 26.84 | 0.790 | 0.370 |
| NeRF++ (Zhang et al., 2020) | 22.76 | 0.548 | 0.427 | 28.05 | 0.836 | 0.309 | |
| Stable View Synthesis (Riegler and Koltun, 2021) | 23.01 | 0.662 | 0.253 | 28.22 | 0.907 | 0.160 | |
| Mip-NeRF 360 (Barron et al., 2022) | 24.47 | 0.691 | 0.283 | 31.72 | 0.917 | 0.180 | |
| Instant-NGP (Müller et al., 2022) | 22.90 | 0.566 | 0.371 | 29.15 | 0.880 | 0.216 | |
| Ours (offline) | 23.40 | 0.619 | 0.379 | 30.21 | 0.888 | 0.243 | |
| real-time | Deep Blending (Hedman et al., 2018) | 21.54 | 0.524 | 0.364 | 26.40 | 0.844 | 0.261 |
| Mobile-NeRF (Chen et al., 2022a) | 21.95 | 0.470 | 0.470 | ||||
| Ours (real-time) | 22.47 | 0.585 | 0.349 | 27.06 | 0.836 | 0.258 | |
为了优化这种表示,我们首先将网格栅格化到所有训练视图中,并存储与每个像素关联的顶点索引和重心坐标。 经过此预处理后,我们可以通过将重心插值应用于学习的每个顶点参数,然后运行我们的依赖于视图的外观模型(模拟片段着色器的操作)来轻松渲染像素。 因此,我们可以通过最小化每像素颜色损失来优化每顶点参数,如方程 2 所示。 如附录 B 中详述,我们还优化了背景清晰颜色,以便为交互式查看器提供更愉快的体验。 为了防止优化受到网格几何形状未很好建模的像素(例如软对象边界和半透明对象处的像素)的影响,我们使用鲁棒损失 在训练期间使用超参数 、,这使得优化对异常值更加稳健(Barron,2019)。 我们还使用直通估计器(Bengio等人,2013)对量化进行建模,确保与视图相关的外观的优化值能够通过8位精度很好地表示。
我们发现直接优化这种逐顶点表示会使 GPU 内存饱和,从而阻止我们扩展到高分辨率网格。 相反,我们优化基于 Instant NGP 的压缩神经哈希网格模型(Müller 等人,2022)(请参阅补充材料中的附录 A)。 在优化过程中,我们在训练批次中的每个 3D 顶点位置查询该模型,以生成漫反射颜色和球形高斯参数。
优化完成后,我们通过在每个顶点位置查询 NGP 模型中的外观相关参数来烘焙哈希网格中包含的压缩场景表示。 最后,我们使用 gLTF 格式 (ISO/IEC 12113:2022, 2022) 导出生成的网格和每个顶点的外观参数,并使用 gzip(一种 Web 协议本身支持的格式)对其进行压缩。
5. 实验
我们根据输出渲染的准确性以及速度、能量和内存要求来评估我们方法的性能。 为了保证准确性,我们测试了两个版本的模型:第 4.1 节中描述的中间体积渲染结果,我们称之为 "离线 "模型;第 4.2 节和第 4.3 节中描述的烘焙实时模型,我们称之为 "实时 "模型。 作为基线,我们使用之前为保真度而设计的离线模型(Mildenhall等人,2020;Zhang等人,2020;Riegler和Koltun,2021;Barron等人,2022;Müller等人,2022),如下以及之前为性能而设计的实时方法(Hedman等人,2018;Chen等人,2022a)。 我们还将我们的方法恢复的网格与 COLMAP (Schönberger 等人,2016)、mip-NeRF 360 (Barron 等人,2022) 和 MobileNeRF (陈等人,2022a)。 所有 FPS(每秒帧数)测量均以 分辨率进行渲染。
5.1. 无界场景实时渲染
我们在 mip-NeRF 360 (Barron 等人,2022) 的真实世界场景数据集上评估我们的方法,其中包含从所有视角捕获的复杂室内和室外场景。 在表 1 中,我们根据基线对模型的离线和实时版本进行了定量评估。 尽管我们的离线模型优于一些先前的工作(正如我们所期望的,因为我们的重点是性能),但我们的实时方法优于我们在所有三个错误上再次评估的两个最新的实时基线该基准测试使用的指标。 在图4中,我们展示了我们的模型渲染与这两个最先进的实时基线的定性比较,我们观察到我们的方法比以前的工作表现出更多的细节和更少的伪影。
在表2中,我们通过与 Instant-NGP(我们评估的最快“离线”模型)和 MobileNeRF(在我们自己的模型之后产生最高质量渲染的实时模型)进行比较来评估我们方法的渲染性能。 )。 我们在 处测量所有方法的性能。 MobileNeRF 和我们的方法都在配备 Radeon 5500M GPU 的 16 英寸 Macbook Pro 上的浏览器中运行,而 Instant NGP 在配备强大 NVIDIA RTX 3090 GPU 的工作站上运行。 尽管我们的方法比 MobileNeRF () 和 Instant NGP () 需要更多的磁盘存储,但我们发现我们的模型比这两个基线都显着更高效 - 我们的模型产生 FPS除了产生更高质量的渲染之外,/瓦特指标还分别更高和。
| W | FPS | FPS/W | MB (disk) | |
| Instant-NGP (Müller et al., 2022) | 350 | 3.78 | 0.011 | 106.8 |
| Mobile-NeRF (Chen et al., 2022a) | 85 | 50.06 | 0.589 | 341.9 |
| Ours | 85 | 72.21 | 0.850 | 434.5 |
乍一看,我们相对于 MobileNeRF 显着提高的性能可能看起来很不寻常,因为我们的方法和 MobileNeRF 都产生了可以轻松快速光栅化的优化网格。 这种差异可能是由于 MobileNeRF 对 alpha 掩蔽的依赖(这会导致大量的计算密集型透支)以及 MobileNeRF 使用 MLP 来对视图相关的辐射率进行建模(这比我们的球形高斯方法需要更多的计算来评估)。
与深度混合(Hedman等人,2018)相比,我们从表1中看到我们的方法实现了更高的质量。 不过,值得注意的是,我们的表现形式也更加简单:我们的网格可以在浏览器中渲染,而深度混合则依赖于经过精心调整的 CUDA 渲染,并且必须为场景中的所有训练图像存储颜色和几何图形。 因此,户外场景中深度混合的总存储成本比我们相应的网格要高(平均 1154.78 MB)。
| COLMAP | MobileNeRF | Mip-NeRF360 | Ours |
 |
 |
 |
 |
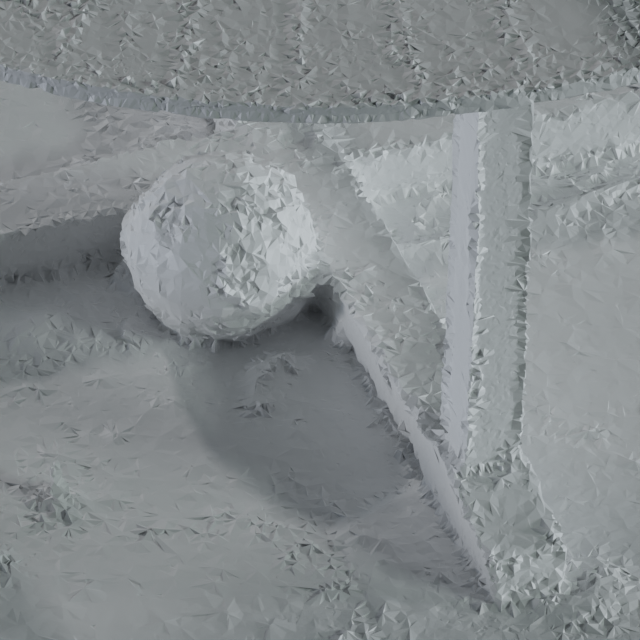 |
 |
 |
 |
5.2. 网格提取
在图 5 中,我们对我们的网格与使用 COLMAP (Schönberger 等人, 2016)、MobileNeRF (Chen 等人, 2022a)< 获得的网格进行了定性比较/t3> 和 Mip-NeRF 360 的等值面(Barron 等人,2022)。 我们针对 COLMAP 进行评估,不仅因为它代表了成熟的运动结构软件包,还因为 COLMAP 生成的几何图形被用作稳定视图合成和深度混合的输入。 COLMAP 在场景的四面体化上使用体积图切割(Labatut 等人,2007;Jancosek 和 Pajdla,2011) 来获得场景的二元分割,然后形成三角形网格作为这些分割之间的表面地区。 由于这种二元分割不允许对表面进行任何平均,因此初始重建中的小噪声往往会导致重建网格的噪声,从而导致“凹凸不平”的外观。 MobileNeRF 将场景表示为断开连接的三角形集合,因为它的唯一焦点是视图合成。 因此,其经过优化和修剪的“三角汤”噪声很大,可能不适合外观编辑等下游任务。
5.3. 外观模型消融
在表 3 中,我们展示了球形高斯外观模型的消融研究结果。 我们看到,将 SG 数量减少到 2、1 和 0(即扩散模型)会导致准确性单调下降。 然而,当在外围使用 3 个 SG 时,我们的模型往往会过度拟合训练视图,与我们提出的仅使用单个外围 SG 的模型相比,导致质量略有下降。 此外,与各处 3 个 SG 相比,在外围使用单个 SG 将平均大小顶点减少了 (从 到 字节),这显着减少内存带宽消耗(渲染的主要性能瓶颈)。 也许令人惊讶的是,用 SNeRG (Hedman 等人,2021) 和 MobileNeRF (Chen 等人,2022a) 使用的小型依赖于视图的 MLP 替换我们的 SG 外观模型显着降低渲染质量并产生与“1 球面高斯”消融大致相当的误差指标。 考虑到与单个球形高斯(每像素 FLOPS)相比,评估小型 MLP(每像素 FLOPS)的成本高昂,这一点尤其违反直觉。 此外,我们用简单的 L2 损失消除了用于训练外观表示的鲁棒损失,这毫不奇怪地提高了 PSNR(与 MSE 成反比),但牺牲了其他指标。
| PSNR | SSIM | LPIPS | MB (GPU) | |
| Diffuse (0 Spherical Gaussians) | 22.32 | 0.636 | 0.352 | 436.1 |
| 1 Spherical Gaussian | 24.02 | 0.680 | 0.322 | 549.1 |
| 2 Spherical Gaussian | 24.39 | 0.693 | 0.312 | 662.2 |
| 3 SGs in the periphery | 24.34 | 0.688 | 0.317 | 775.3 |
| View-dependent MLP (2021) | 24.30 | 0.687 | 0.318 | 516.8 |
| L2 loss | 24.52 | 0.690 | 0.316 | 572.6 |
| Ours | 24.51 | 0.697 | 0.309 | 572.6 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Ground truth | Our rendering | Our mesh |
5.4. 局限性
尽管我们的模型对于无界场景实时渲染的既定任务实现了最先进的速度和准确性,但仍存在一些限制,这些限制代表了未来改进的机会:我们使用完全不透明的网格表示来表示场景,并且因此,我们的模型可能很难表示半透明内容(玻璃、雾等)。 正如基于网格的方法所常见的那样,我们的模型有时无法准确表示具有小或详细几何形状(茂密的树叶、薄结构等)的区域。 图6描述了额外的提取网格可视化,它演示了我们的表面重建限制及其对渲染重建的影响。 这些问题也许可以通过增加网格的不透明度值来解决,但允许连续不透明度将需要复杂的多边形排序过程,而该过程很难集成到实时光栅化管道中。 我们技术的另一个限制是模型的输出网格占用大量磁盘空间(每个场景 兆字节),这对于某些应用程序来说可能难以存储或流式传输。 这可以通过网格简化和 UV 图集来改善。 然而,我们发现现有的简化和图集工具主要是为艺术家制作的 3D 资源而设计的,对于我们通过行进立方体提取的网格效果不佳。
6. 结论
我们提出了一个系统,可以生成高质量的网格,用于实时渲染大型无界现实世界场景。 我们的技术首先优化场景的混合神经体积表面表示,该表示是为精确的表面重建而设计的。 从这种混合表示中,我们提取一个三角形网格,其顶点包含依赖于视图的外观的有效表示,然后优化该网格表示以最好地再现捕获的输入图像。 这使得网格能够在速度和准确性方面产生最先进的实时视图合成结果,并且具有足够高的质量以支持下游应用程序。
致谢。
我们要感谢 Forrester Cole 和 Srinivas Kaza 实施了 JAX 光栅器,感谢 Simon Rodriguez 作为实时图形编程的宝贵知识来源,感谢 Marcos Seefelder 对实时渲染器进行了集思广益。 我们还感谢 Thomas Müller 在针对 Mip-NeRF 360 数据集调整 Instant-NGP 方面提供的宝贵建议,并感谢 Zhuqin Chen 慷慨地与我们分享 MobileNeRF 评估。 最后,我们感谢 Keunhong Park 对我们的手稿进行了深思熟虑的审阅。参考
- (1)
- Barron (2019) Jonathan T. Barron. 2019. A General and Adaptive Robust Loss Function. CVPR (2019).
- Barron et al. (2022) Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. 2022. Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields. CVPR (2022).
- Bengio et al. (2013) Yoshua Bengio, Nicholas Léonard, and Aaron Courville. 2013. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432 (2013).
- Boss et al. (2021) Mark Boss, Raphael Braun, Varun Jampani, Jonathan T. Barron, Ce Liu, and Hendrik P. A. Lensch. 2021. NeRD: Neural Reflectance Decomposition from Image Collections. ICCV (2021).
- Boss et al. (2022) Mark Boss, Andreas Engelhardt, Abhishek Kar, Yuanzhen Li, Deqing Sun, Jonathan T. Barron, Hendrik P.A. Lensch, and Varun Jampani. 2022. SAMURAI: Shape And Material from Unconstrained Real-world Arbitrary Image collections. NeurIPS (2022).
- Buehler et al. (2001) Chris Buehler, Michael Bosse, Leonard McMillan, Steven Gortler, and Michael Cohen. 2001. Unstructured Lumigraph Rendering. SIGGRAPH (2001).
- Chen et al. (2022b) Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. 2022b. TensoRF: Tensorial Radiance Fields. ECCV (2022).
- Chen et al. (2022a) Zhiqin Chen, Thomas Funkhouser, Peter Hedman, and Andrea Tagliasacchi. 2022a. MobileNeRF: Exploiting the polygon rasterization pipeline for efficient neural field rendering on mobile architectures. arXiv:2208.00277 (2022).
- Debevec et al. (1996) Paul E. Debevec, Camillo J. Taylor, and Jitendra Malik. 1996. Modeling and Rendering Architecture from Photographs: A hybrid geometry- and image-based approach. SIGGRAPH (1996).
- Furukawa and Hernández (2015) Yasutaka Furukawa and Carlos Hernández. 2015. Multi-View Stereo: A Tutorial. Foundations and Trends in Computer Graphics and Vision (2015).
- Garbin et al. (2021) Stephan J. Garbin, Marek Kowalski, Matthew Johnson, Jamie Shotton, and Julien Valentin. 2021. FastNeRF: High-Fidelity Neural Rendering at 200FPS. ICCV (2021).
- Gortler et al. (1996) Steven J. Gortler, Radek Grzeszczuk, Richard Szeliski, and Michael F. Cohen. 1996. The lumigraph. SIGGRAPH (1996).
- Gropp et al. (2020) Amos Gropp, Lior Yariv, Niv Haim, Matan Atzmon, and Yaron Lipman. 2020. Implicit Geometric Regularization for Learning Shapes. Proceedings of Machine Learning and Systems (2020).
- Hedman et al. (2018) Peter Hedman, Julien Philip, True Price, Jan-Michael Frahm, George Drettakis, and Gabriel Brostow. 2018. Deep blending for free-viewpoint image-based rendering. SIGGRAPH Asia (2018).
- Hedman et al. (2021) Peter Hedman, Pratul P. Srinivasan, Ben Mildenhall, Jonathan T. Barron, and Paul Debevec. 2021. Baking Neural Radiance Fields for Real-Time View Synthesis. ICCV (2021).
- Hendrycks and Gimpel (2016) Dan Hendrycks and Kevin Gimpel. 2016. Gaussian Error Linear Units (GELUs). arXiv:1606.08415 (2016).
- ISO/IEC 12113:2022 (2022) ISO/IEC 12113:2022 2022. Information technology — Runtime 3D asset delivery format — Khronos glTF 2.0. Standard. International Organization for Standardization.
- Jancosek and Pajdla (2011) Michal Jancosek and Tomás Pajdla. 2011. Multi-view reconstruction preserving weakly-supported surfaces. (2011).
- Karnewar et al. (2022) Animesh Karnewar, Tobias Ritschel, Oliver Wang, and Niloy Mitra. 2022. ReLU fields: The little non-linearity that could. SIGGRAPH (2022).
- Kazhdan et al. (2006) Michael Kazhdan, Matthew Bolitho, and Hugues Hoppe. 2006. Poisson Surface Reconstruction. Symposium on Geometry Processing (2006).
- Kazhdan and Hoppe (2013) Michael Kazhdan and Hugues Hoppe. 2013. Screened Poisson Surface Reconstruction. ACM TOG (2013).
- Kingma and Ba (2015) Diederik P. Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. ICLR (2015).
- Kopanas et al. (2021) Georgios Kopanas, Julien Philip, Thomas Leimkühler, and George Drettakis. 2021. Point-Based Neural Rendering with Per-View Optimization. Computer Graphics Forum (2021).
- Kuang et al. (2022) Zhengfei Kuang, Kyle Olszewski, Menglei Chai, Zeng Huang, Panos Achlioptas, and Sergey Tulyakov. 2022. NeROIC: Neural Rendering of Objects from Online Image Collections. SIGGRAPH (2022).
- Labatut et al. (2007) Patrick Labatut, Jean-Philippe Pons, and Renaud Keriven. 2007. Efficient multi-view reconstruction of large-scale scenes using interest points, Delaunay triangulation and graph cuts. ICCV (2007).
- Levoy and Hanrahan (1996) Marc Levoy and Pat Hanrahan. 1996. Light field rendering. SIGGRAPH (1996).
- Lombardi et al. (2019) Stephen Lombardi, Tomas Simon, Jason Saragih, Gabriel Schwartz, Andreas Lehrmann, and Yaser Sheikh. 2019. Neural Volumes: Learning Dynamic Renderable Volumes from Images. SIGGRAPH (2019).
- Lorensen and Cline (1987) W. E. Lorensen and H. E. Cline. 1987. Marching cubes: A high resolution 3D surface construction algorithm. SIGGRAPH (1987).
- Max (1995) Nelson Max. 1995. Optical models for direct volume rendering. IEEE TVCG (1995).
- Mildenhall et al. (2020) Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. 2020. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. ECCV (2020).
- Müller et al. (2022) Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. 2022. Instant neural graphics primitives with a multiresolution hash encoding. SIGGRAPH (2022).
- Neff et al. (2021) Thomas Neff, Pascal Stadlbauer, Mathias Parger, Andreas Kurz, Joerg H. Mueller, Chakravarty R. Alla Chaitanya, Anton Kaplanyan, and Markus Steinberger. 2021. DONeRF: Towards Real-Time Rendering of Compact Neural Radiance Fields using Depth Oracle Networks. Computer Graphics Forum (2021).
- Oechsle et al. (2021) Michael Oechsle, Songyou Peng, and Andreas Geiger. 2021. UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction. ICCV (2021).
- Penner and Zhang (2017) Eric Penner and Li Zhang. 2017. Soft 3D Reconstruction for View Synthesis. SIGGRAPH Asia (2017).
- Reiser et al. (2021) Christian Reiser, Songyou Peng, Yiyi Liao, and Andreas Geiger. 2021. KiloNeRF: Speeding up neural radiance fields with thousands of tiny MLPs. ICCV (2021).
- Riegler and Koltun (2020) Gernot Riegler and Vladlen Koltun. 2020. Free View Synthesis. ECCV (2020).
- Riegler and Koltun (2021) Gernot Riegler and Vladlen Koltun. 2021. Stable view synthesis. CVPR (2021).
- Rückert et al. (2022) Darius Rückert, Linus Franke, and Marc Stamminger. 2022. ADOP: Approximate differentiable one-pixel point rendering. SIGGRAPH (2022).
- Sander et al. (2007) Pedro V. Sander, Diego Nehab, and Joshua Barczak. 2007. Fast Triangle Reordering for Vertex Locality and Reduced Overdraw. SIGGRAPH (2007).
- Schönberger et al. (2016) Johannes Lutz Schönberger, Enliang Zheng, Marc Pollefeys, and Jan-Michael Frahm. 2016. Pixelwise View Selection for Unstructured Multi-View Stereo. ECCV (2016).
- Srinivasan et al. (2021) Pratul P. Srinivasan, Boyang Deng, Xiuming Zhang, Matthew Tancik, Ben Mildenhall, and Jonathan T. Barron. 2021. NeRV: Neural reflectance and visibility fields for relighting and view synthesis. CVPR (2021).
- Srinivasan et al. (2019) Pratul P. Srinivasan, Richard Tucker Joand nathan T. Barron, Ravi Ramamoorthi, Ren Ng, and Noah Snavely. 2019. Pushing the Boundaries of View Extrapolation with Multiplane Images. CVPR (2019).
- Sun et al. (2022) Cheng Sun, Min Sun, and Hwann-Tzong Chen. 2022. Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction. CVPR (2022).
- Szeliski and Golland (1999) Richard Szeliski and Polina Golland. 1999. Stereo Matching with Transparency and Matting. IJCV (1999).
- Tewari et al. (2022) Ayush Tewari, Justus Thies, Ben Mildenhall, Pratul Srinivasan, Edgar Tretschk, W Yifan, Christoph Lassner, Vincent Sitzmann, Ricardo Martin-Brualla, Stephen Lombardi, et al. 2022. Advances in neural rendering. Computer Graphics Forum (2022).
- Verbin et al. (2022) Dor Verbin, Peter Hedman, Ben Mildenhall, Todd Zickler, Jonathan T Barron, and Pratul P Srinivasan. 2022. Ref-NeRF: Structured view-dependent appearance for neural radiance fields. CVPR (2022).
- Vogiatzis et al. (2007) G. Vogiatzis, C. Hernández, P. Torr, and R. Cipolla. 2007. Multi-View Stereo via Volumetric Graph-Cuts and Occlusion Robust Photo-Consistency. IEEE TPAMI (2007).
- Wang et al. (2021) Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. 2021. NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction. NeurIPS (2021).
- Wizadwongsa et al. (2021) Suttisak Wizadwongsa, Pakkapon Phongthawee, Jiraphon Yenphraphai, and Supasorn Suwajanakorn. 2021. NeX: Real-time View Synthesis with Neural Basis Expansion. CVPR (2021).
- Wood et al. (2000) Daniel N. Wood, Daniel I. Azuma, Ken Aldinger, Brian Curless, Tom Duchamp, David H. Salesin, and Werner Stuetzle. 2000. Surface Light Fields for 3D Photography. SIGGRAPH (2000).
- Wu et al. (2022) Xiuchao Wu, Jiamin Xu, Zihan Zhu, Hujun Bao, Qixing Huang, James Tompkin, and Weiwei Xu. 2022. Scalable Neural Indoor Scene Rendering. ACM TOG (2022).
- Yariv et al. (2021) Lior Yariv, Jiatao Gu, Yoni Kasten, and Yaron Lipman. 2021. Volume rendering of neural implicit surfaces. NeurIPS (2021).
- Yu et al. (2022) Alex Yu, Sara Fridovich-Keil, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. 2022. Plenoxels: Radiance fields without neural networks. CVPR (2022).
- Yu et al. (2021) Alex Yu, Ruilong Li, Matthew Tancik, Hao Li, Ren Ng, and Angjoo Kanazawa. 2021. PlenOctrees for real-time rendering of neural radiance fields. ICCV (2021).
- Zhang et al. (2021a) Kai Zhang, Fujun Luan, Qianqian Wang, Kavita Bala, and Noah Snavely. 2021a. PhySG: Inverse Rendering with Spherical Gaussians for Physics-based Material Editing and Relighting. CVPR (2021).
- Zhang et al. (2020) Kai Zhang, Gernot Riegler, Noah Snavely, and Vladlen Koltun. 2020. NeRF++: Analyzing and Improving Neural Radiance Fields. arXiv:2010.07492 (2020).
- Zhang et al. (2021b) Xiuming Zhang, Pratul P. Srinivasan, Boyang Deng, Paul Debevec, William T. Freeman, and Jonathan T. Barron. 2021b. NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination. SIGGRAPH Asia (2021).
- Zhou et al. (2018) Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. 2018. Stereo Magnification: Learning View Synthesis Using Multiplane Images. SIGGRAPH (2018).
附录A训练和优化细节
SDF模型定义和优化。
如第 4.1 节所述,我们使用 mip-NeRF 360 的变体对 SDF 进行建模。 我们使用与 mip-NeRF 360 相同的优化设置来训练模型(Adam (Kingma 和 Ba,2015) 进行 25 万次迭代,批量大小为 ,学习率为热启动,然后从 到 进行对数线性插值,其中 、、)和类似的 MLP 架构(具有 4 层和 256 个隐藏单元的建议 MLP,以及具有 8 层和 1024 个隐藏单元的 NeRF MLP,均使用 swish/SiLU 整流器(Hendrycks 和 Gimpel,2016)和 8 个位置编码尺度)。 遵循 mip-NeRF 360 的分层采样程序,我们使用使用建议 MLP 评估的 64 个样本执行两个重采样阶段,然后使用 NeRF MLP 的 32 个样本执行一个评估阶段。 提案 MLP 通过最小化 进行优化,其中 是 (Barron 等人, 2022) 中描述的提案损失,旨在限制权重输出NeRF MLP 密度。
通过压缩哈希网格优化每个顶点属性。
如第 4.3 节所述,在优化过程中,我们使用 Instant NGP (Müller 等人,2022) 作为顶点属性的底层表示。 我们使用以下超参数:、 和 。 我们从 NGP 模型中删除了视图方向输入,稍后我们将其合并到公式 7 中。 我们对哈希网格而不是 MLP 使用 的权重衰减,使用 Adam (Kingma 和 Ba,2015) 进行优化,进行 150k 次迭代,批量大小为 和初始学习率 ,每 50k 次迭代我们就会降低 。
附录 B为了吸引观众而进行的调整
在这里,我们详细介绍了对管道的一些调整,这些调整并不会严格提高重建精度,而是带来更引人注目的观看体验。 考虑到这一点,我们发现减轻重建场景内容和背景颜色之间的不和谐过渡非常重要。 为此,我们还在第 4.3 节中优化的外观参数中包含了全局透明颜色。 也就是说,我们将此颜色分配给训练数据中没有有效三角形索引的任何像素。
为了进一步掩盖几何体和背景之间的过渡,我们在第 4.2 节中提取网格之前将 SDF 与边界几何体包围起来。 我们计算一个凸包,该凸包计算为 随机定向平面的交集,其中每个平面的位置已设置为已标记为表面提取候选体素的边界 。 然后,我们通过将其稍微膨胀 来进一步使该船体变得保守。 然而,由于提取的网格需要转换到世界空间中进行渲染,因此我们必须注意避免在光栅化过程中使用无界顶点坐标可能引起的数值精度问题。 我们通过用一个半径为 世界空间单位的遥远球体来限制场景来解决这个问题。 通过将每个网格单元中的 SDF 值设置为 MLP 参数化 SDF 和定义边界几何体的 SDF 的逐点最小值,可以轻松实现这两个操作。
附录 C基线详细信息
MobileNeRF 查看器配置
请注意,默认情况下,MobileNeRF 查看器在各种设备上以降低的分辨率运行以实现高帧速率。 为了进行比较,我们对其进行修改以在不同的分辨率下运行。 当我们计算图像质量指标时,我们选择测试集图像的分辨率。 此外,当我们测量运行时性能时,我们使用 ,这是代表大多数现代显示器的分辨率。
即时NGP
表 1 报告了 Instant NGP (Müller 等人,2022) 方法的质量结果,我们仔细调整它以使其适用于无界大场景。 我们向 Instant NGP 的作者寻求帮助来调整他们的方法,并进行了以下更改:
-
•
我们使用官方代码发布时提供的 big.json 配置文件,
-
•
我们将批量大小增加了 至 ,并且
-
•
我们将场景比例从 增加到 。
请注意,这些更改均不会对 Instant NGP 的渲染时间产生重大影响。
默认情况下,Instant NGP 查看器配备动态放大实现,它以较低分辨率渲染图像,然后应用智能放大。 为了公平比较,我们在测量性能时关闭此功能,因为这些动态升级器可以应用于任何渲染器。 更重要的是,我们希望性能数字与测试集质量指标相对应,并且没有使用升级来计算测试集图像。