RAMM:具有多模态预训练的检索增强生物医学视觉问答
摘要
视觉和语言多模态预训练和微调在视觉问答(VQA)方面取得了巨大成功。 与一般领域 VQA 相比,生物医学 VQA 的性能受到数据有限的影响。 在本文中,我们提出了一种用于生物医学 VQA 的检索增强预训练和微调范例,名为 RAMM,以克服数据限制问题。 具体来说,我们收集了一个名为 PMCPM 的新生物医学数据集,它提供基于患者的图像文本对,其中包含来自 PubMed 的不同患者情况。 然后,我们预训练生物医学多模态模型,以学习图像文本对的视觉和文本表示,并将这些表示与图像文本对比目标(ITC)对齐。 最后,我们提出了一种检索增强方法来更好地利用有限的数据。 我们建议基于 ITC 从预训练数据集中检索相似的图像文本对,并引入一种新颖的检索注意力模块,将图像和问题的表示与检索到的图像和文本融合在一起。 实验表明,我们的检索增强预训练和微调范例在 Med-VQA2019、Med-VQA2021、VQARAD 和 SLAKE 数据集上获得了最先进的性能。 进一步分析表明,与以前的资源和方法相比,所提出的 RAMM 和 PMCPM 可以提高生物医学 VQA 性能。 我们将开源我们的数据集、代码和预训练模型。
1简介
生物医学视觉问答(VQA)旨在通过提供的图像回答生物医学相关问题。 生物医学VQA中的图像通常是放射学图像(例如CT、MRI和X射线),问题通常涉及相应图像中的模态、身体部位、平面和异常部位。 回答这些问题需要丰富的临床和医学成像知识[17],这对于自动化方法来说是一个挑战。
随着通用领域 VQA [27,10,26] 的成功,一些工作遵循预训练和微调范式来尝试生物医学 VQA 的特定领域视觉和语言建模 [20, 4]。 然而,与一般领域足够的标记VQA对进行微调不同,生物医学领域的微调数据仍然有限,这使得模型容易过度拟合,并阻碍模型学习全面的领域知识来回答复杂问题的能力。
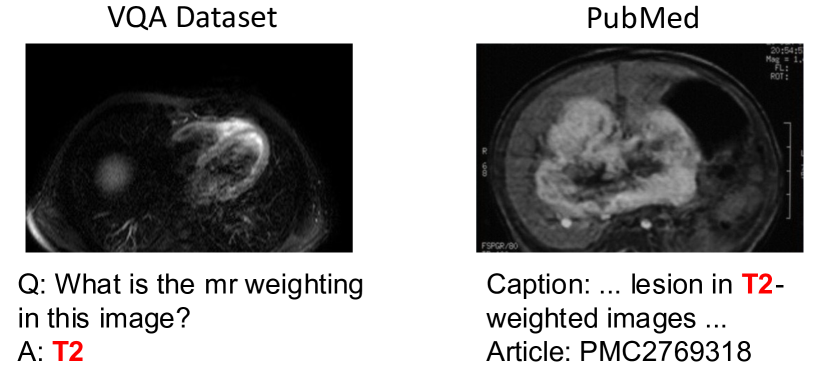
与生物医学 VQA 数据集中的有限数据相比,生物医学文献包含丰富且高质量的图像文本对。 这些文本通常描述图像的各个方面,包括形态、身体部位、平面和异常,这些都是生物医学VQA感兴趣的信息。 图1显示了来自PubMed111https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2769318/ 有助于回答 VQA 数据集中的问题。 基于这一观察,我们认为检索是生物医学 VQA 的一个可行选择。 此过程模拟医生如何解决复杂的患者病例:医生搜索与所提供的病例相似的病例,并根据以前的经验提出解决方案。 因此,我们可以从文献中检索相似的图像文本对来帮助回答问题。 要从生物医学文献中检索相关的图像文本对,需要回答三个关键问题:在哪里检索? 如何检索? 以及如何利用检索到的图像-文本对?
为此,我们提出了一种用于生物医学 VQA 的检索增强生物医学多模态预训练和微调范例 (RAMM)。 首先,现有的生物医学图文对包括ROCO [36]和MIMIC-CXR [18]可用于检索。 然而,ROCO 受到数量限制,MIMIC-CXR 只专注于胸部 X 光检查。 为了更好的检索,需要海量、多样化、高质量的数据集。 因此,我们提出 PMC-Patients-Multi-modal (PMCPM),这是一个从 PubMed Central 过滤的基于患者的图像文本数据集,它比 ROCO 和 MIMIC-CXR 更大,具有各种模式和条件图片。 其次,由于生物医学 VQA 中的问题是同质的,我们建议使用图像进行检索。 我们结合 PMCPM 数据集和之前广泛使用的 ROCO 和 MIMIC-CXR 数据集,预训练了包含三个任务的生物医学多模态模型:掩蔽语言建模、图像文本对比学习和图像文本匹配。 由于预训练阶段的图像文本对比目标旨在在同一嵌入空间[37, 27]中对齐视觉和文本表示,因此图像文本对比相似度可用于检索相似对。 最后,以上述数据集为资源,我们建议检索给定图像的相关图像文本对。 为了利用检索到的对,我们提出了一种检索增强微调方法,在多模态编码器层中使用新颖的检索注意模块,并应用融合表示来预测最终答案。
我们在四个生物医学 VQA 数据集上进行了实验。 我们的 RAMM 在 VQA-Med 2019 [2]、VQA-Med 2021 [16] 上取得了最先进的结果,分别为 82.13、39.20、78.27 和 86.05 分>、VQARAD [22] 和 SLAKE(英文版)[30]。 我们还进行了消融研究,以验证我们收集的 PMCPM 数据集和检索增强微调方法的有效性。 案例研究表明检索到的图像文本对有助于回答问题。
我们的贡献总结如下:
-
•
我们从 PubMed 收集 PMCPM,这是一个基于患者的图像文本数据集,可用于生物医学多模式预训练和检索。
-
•
我们提出了 RAMM,一种用于生物医学 VQA 的检索增强多模态预训练和微调范例,具有新颖的检索注意模块。
-
•
实验表明,所提出的带有附加 PMCPM 数据集的 RAMM 在 VQA-Med 2019、VQA-Med 2021、VQARAD 和 SLAKE 数据集上优于之前的 VQA 方法。
2相关工作
生物医学多模式预训练
在一般领域,多模态预训练模型在各种与图像文本相关的下游任务中显示出有效性[27,10,26,41]。 在生物医学 NLP 界,前期研究表明,在域内语料库中进一步继续训练可以增强预训练语言模型的性能[1, 23, 14, 45, 44]。 结合上述两点,可以直接考虑预训练生物医学VQA的生物医学域内多模态模型。 之前的生物医学预训练多模态模型[11,20,34,4,5]主要利用ROCO[36]和MIMIC-CXR[18] 作为预训练数据集。 这些模型预测屏蔽标记 [4, 5] 或图像补丁 [4] 并进行图像文本对齐 [11] 作为预训练任务。 与以前的模型相比,我们的 RAMM 使用我们额外提出的 PMCPM 数据集进行了预训练,该数据集包含来自不同患者状况的图像。 对于预训练任务,我们的模型采用掩码语言建模、图文对比学习和图文匹配。 RAMM 中使用图像-文本对比相似度进行检索。
生物医学视觉问答
VQA 需要回答与图像相关的问题。 与一般领域VQA[27,10,26]不同,生物医学VQA的训练样本要少得多。 为了克服生物医学 VQA 中的数据限制,元学习可快速拟合 VQA 问题[35, 9]。 随着预训练和微调范例的成功,预训练具有大规模无监督数据集的多模态模型可以学习更好的视觉和文本表示,从而减轻数据限制的影响并显着提高生物医学 VQA 性能[3, 11, 4]。 在本文中,我们还使用基于患者的图像文本对 PMCPM 预训练了生物医学多模态模型 RAMM。 在微调 VQA 数据集时,RAMM 检索相似的图像-文本对,并尝试利用这些图像和文本中的有用信息。
检索增强
已成功应用于 NLP [24, 25, 15] 和 CV [32, 39] 知识密集型任务。 在本文中,我们决定使用检索增强来解决知识密集型和标记不足的生物医学 VQA 任务。 检索器可以像 BM-25 [38, 24] 一样稀疏,也可以使用预训练编码器 [15, 39] 进行密集。 对于我们的任务,由图像文本对比(ITC)任务预训练的模型可以自然地用作多模态检索器。 因此,我们通过 ITC 预训练了一个生物医学多模态模型,用于检索增强。 我们还提出了一个检索注意模块来融合这些检索到的样本。 据我们所知,这是第一个在生物医学 VQA 中利用检索增强的工作。
3方法
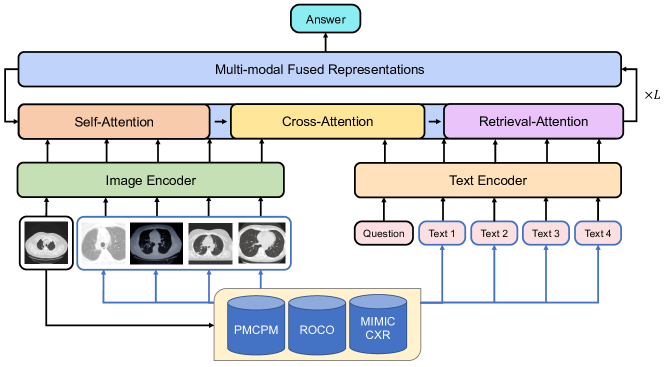
在本节中,我们首先介绍如何构建 PMCPM 数据集。 然后我们描述模型架构和预训练任务。 最后,我们介绍 RAMM 如何从预训练数据集中检索图像文本对,以及如何在生物医学 VQA 微调期间组合检索到的样本。 我们的整体工作流程如图2所示。
3.1 PMCPM数据集
为了获得高质量和大规模的特定领域图像文本对,我们首先考虑使用 PubMed Central (PMC OA) 的开放获取子集222https://www.ncbi.nlm.nih.gov/pmc/tools/openftlist/,免费的生物医学超过 M 种出版物的文献档案,其中包含全文(包括图片标题)和这些文章中的图片,可通过官方 FTP 服务公开获取333https://www.ncbi.nlm.nih.gov/pmc/tools/ftp/ 。 然而,PMC OA全套中的图形可能相当嘈杂:除了临床图像之外,一篇研究文章中还出现了多种图形,包括流程图、直方图和散点图,这些图形为多模态预训练提供的信息很少。 Pelka 等人。 [36] 使用在人类注释数据集上训练的神经网络来自动过滤复合、多窗格和非放射图像,收集包含 81k 个图像文本对的干净数据集。 为了进一步探索和利用 PMC 中的图形资源,我们转而采用受赵等人启发的“基于患者”的收集管道。 [47]. “病例报告”是一种特定类型的医学文献,一般描述患者入院的整个过程。 跟随Zhao 等人. [47],我们使用正则表达式来识别包含患者注释的部分,提取相应的文本,并应用各种过滤器消除噪音,从而收集了 167,000 份高质量且多样化条件的患者笔记。 这些患者笔记所附的图表与患者的临床状况密切相关,并且比单纯的放射学图像包含更丰富的信息。 因此,我们收集这些带有相应标题的数字来构建我们的 PMCPM 数据集。 图 3 显示了我们的 PMCPM (PMCID: 509249) 的两个示例以及图像及其相应的标题。 图3A显示了一张显微照片,描述了腺样囊性癌的存在,具有筛状图案和神经周围浸润。 图3B显示放射学图像,双叶散布多个转移病灶。 这些例子表明,我们基于患者的收集方法可以通过更多的图像模态和详细的文本描述来定位临床相关的图形。

3.2模型架构
给定图像-文本对,RAMM首先独立获得单模态特征,然后将它们融合以获得多模态表示。 融合表示用于 VQA 分类。 RAMM 由文本编码器、图像编码器和用于融合两种不同模态表示的多模态编码器组成。 文本 被标记为子词 并由文本编码器转换为隐藏表示 。 图像被图像编码器分成块并表示为。 多模态编码器是一种共同关注风格的双流 Transformer。
多模态融合层
我们将共同注意风格的多模态融合层 [10] 应用于文本特征 和视觉特征 ,层数 。具体来说,共同注意融合层由双流 Transformer 层组成,其中一个流对应一个模态。 每个 Transformer 层都结合了一个自注意力模块和一个交叉注意力模块444为了符号简洁,省略了前馈网络。. 对于层,我们将文本隐藏表示表示为,将图像隐藏表示表示为。 Transformer 中的注意力模块定义为:
| (1) |
使用这种表示法,自注意力被定义为:
| (2) |
| (3) |
| (4) |
| (5) |
我们重用了 的表示法,将 替换为 ,将 替换为 ,并进行交叉注意力定义为:
| (6) |
| (7) |
文本和图像的融合表示表示为和。
3.3 预训练任务
对于预训练 RAMM,我们采用了三个预训练任务,包括图像文本对比学习 (ITC) [27]、图像文本匹配 (ITM) [27] 和掩码语言建模 (MLM) [8]。 RAMM 的预训练目标函数由这三个任务的总和定义。 ITC 在同一嵌入空间中对齐单模态视觉和文本表示 和 ,其中 和 是两个线性投影与 标准化。 ITM 根据融合表示 和 预测一张图像和一个文本是否相互匹配。 MLM 基于融合文本表示 预测文本 中的屏蔽词符。 由于ITC的目标是通过余弦相似度来对齐图像和文本,因此检索相关图像和文本就成为自然的选择。
3.4 检索增强微调
我们使用图像-文本对比相似性来检索相关的图像-文本对,并在微调中将它们与检索注意模块融合。
检索相关图像文本对
让 表示所有图像文本对的集合,其中 是索引集。 对于来自 VQA 数据集的图像-问题对 ,我们基于单模态图像表示 从 检索 增强样本。 这里我们不使用问题 中的表示来检索,因为 VQA 数据集中的问题是同质的且非信息性的。 对于不同的图像,问题可能类似于 这张图片有什么异常? 或者 这张图有什么异常吗? 对于具有单模态表示 和 的图像文本对 ,我们使用 ITC 相似度分数计算图像 之间的相似度:
| (8) |
| (9) |
ITC 在预训练时优化了,这导致和接近。 因此我们使用和中的最大值来定义与之间的相似度:
| (10) |
我们在计算 时冻结单模态编码器。 第一个原因是ITC分数在微调时可能会发生巨大变化。 第二个原因是可以预先计算预训练数据集的表示,并且可以通过 Faiss [19] 快速进行相似度计算。
我们首先使用 Faiss 计算 中的 top- ,以及 中的 top- 。 包含 图像文本对。 训练时,我们从中随机选择图像文本对。 每个图像-文本对的概率对于相似度 是有理数的。 推理时,我们根据从中选择top-相似的图像文本对。 我们将检索到的 图像文本对表示为 。
多模态编码器中的检索融合
为了融合检索样本的知识,我们在多模态融合层中提出了检索注意模块。 在每个多模态融合层中的自注意力和交叉注意力之后应用检索注意力模块。 图4显示了应用于文本模态的检索注意力模型架构。 具体来说,我们使用单模态编码器将检索到的图像文本对 编码为 。 我们用 表示符号统一。 对于多模态融合层,文本隐藏表示的输入是,图像隐藏表示的输入是。 通过应用3.2节中定义的自注意力和交叉注意力,我们获得文本表示和图像表示。 检索注意力独立地应用于每个模态。 以文本表示为例,retrieval-attention使用的表示作为注意力查询,使用的表示作为注意力键和值。 检索注意力的输出仅添加到原始表示,但不添加到检索表示。
| (11) |
| (12) |
| (13) |
| (14) |
类似地计算图像模态的检索注意力。
| (15) |
| (16) |
| (17) |
| (18) |
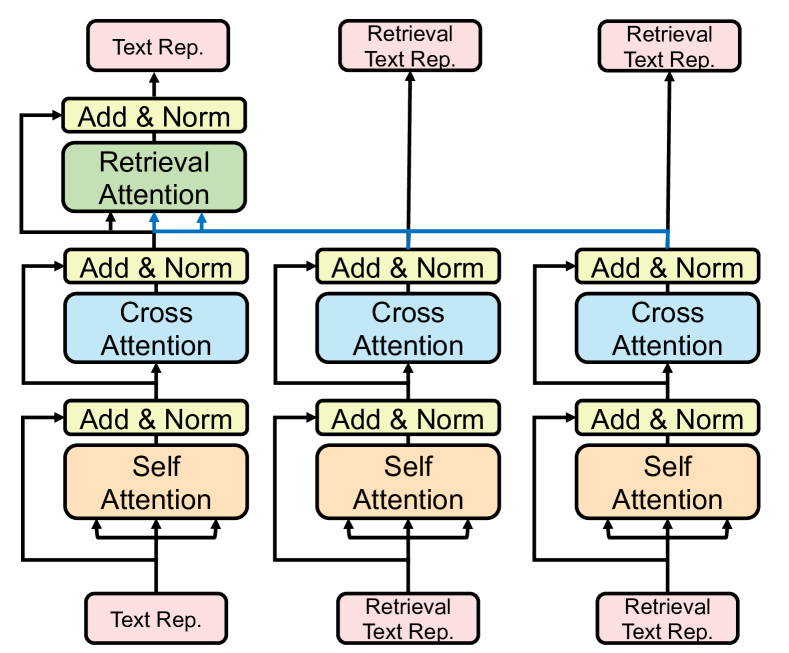
我们对原始表示 或 执行检索注意,以融合来自 或 的附加信息。 我们不会将其应用于检索到的样本,因为我们不需要在它们之间交换信息。 我们使用原始样本表示的最后一层进行VQA分类。
4实验
4.1数据集
我们在四个生物医学 VQA 数据集 VQA-Med 2019 [2]、VQA-Med 2021 [16]、VQARAD [22] 上进行实验、SLAKE(英文版)[30]。 为了与之前的工作进行公平比较,我们遵循与 Chen et al 相同的数据分割。VQA-Med 2019、VQARAD、 [4]和 SLAKE,以及Gong 等人。 [13] VQA-Med 2021。 我们使用准确性来衡量模型性能。 这些数据集的详细统计数据列于附录 A。
4.2基线
我们将 RAMM 与生物医学 VQA 中的非预训练方法[43,42,21,13,7]和预训练方法[3,29,46]进行比较。 由于与我们关系比较密切,我们介绍以下方法:
PubmedCLIP [11] 使用 ROCO 微调 CLIP 以获得生物医学图像和文本表示。
MMBert [20] 使用掩码标记提供图像的 CNN 特征,以应用掩码语言模型预训练。
MTPT [12]提出了一种包含图像理解任务和问题图像兼容性任务的多任务预训练。
M3AE [4] 通过重建屏蔽标记和图像来预训练生物医学多模态模型。
4.3实现细节
预训练数据
如3.1节所述,我们从PMC OA收集了398k个出版物质量和各种类型的生物医学图文对作为PMCPM。 然后,我们将 PMCPM 与两个广泛使用的生物医学预训练数据集 ROCO [36] 和 MIMIC-CXR [18] 相结合进行模型预训练。 继之前的工作之后,我们仅使用它们的训练分割作为预训练数据集,并且仅使用 MIMIC-CXR 的正面视图中的图像。 训练数据统计如表1所示。
| Dataset | Count | Sources |
|---|---|---|
| ROCO | 70,306 | PubMed |
| MIMIC-CXR | 225,829 | BIDMC |
| PMCPM | 398,109 | Case Report |
预训练设置
对于单模态编码器,我们通过 PubmedBert [14] 初始化文本编码器,通过 Swin-Base [31] 初始化图像编码器。 对于多模态编码器,我们应用一个 6 层 Transformer [40],其隐藏维度 和随机初始化的头数 。 使用 RandAugment [6] 将图像转换为分辨率 。 我们应用动量蒸馏[27],动量参数为0.995。 该模型训练了 30 个 epoch,批量大小为 512。 我们使用 AdamW [33] 通过线性学习率衰减来优化我们的模型。 详细预训练超参数请参见附录B。
微调设置
继之前的工作之后,我们将生物医学 VQA 视为一个分类问题,并通过交叉熵损失来优化模型。 对于所有数据集,我们对预训练模型进行了 100 轮训练。 我们使用 RAMM 的冻结单模态编码器来检索图像文本对,如 3.4 节中所述。 我们从 ROCO、MIMIC-CXR 和 PMCPM 的组合中检索每个实例的 对。 图像在微调时转换为分辨率。 在 VQA-Med 2019、VQARAD 和 SLAKE 中,我们以裁剪图像为中心,而在 VQA-Med 2021 中我们使用 RandAugment [6]。 微调时还使用指数移动平均线和R-Drop[28]。 我们在附录 C 中列出了详细的超参数。
| Model | VQAMed2019 | VQARAD | SLAKE |
|---|---|---|---|
| No Pretraining | |||
| MFB [43] | - | 50.60 | 73.30 |
| SAN [42] | - | 54.30 | 76.00 |
| BAN [21] | - | 58.30 | 76.30 |
| With Pretraining | |||
| MEVF-BAN [3] | 77.86 | 66.10 | 78.60 |
| CPRD-BAN [29] | - | 67.80 | 81.10 |
| COND-RE [46] | - | 71.60 | - |
| PubmedCLIP [11] | - | 72.10 | 80.10 |
| MMBert [20] | 77.90 | 72.00 | - |
| MTPT [12] | - | 73.20 | - |
| M3AE [4] | 79.87 | 77.01 | 83.25 |
| RAMM | 82.13 | 78.27 | 86.05 |
| w/o retrieval | 80.27 | 76.72 | 85.58 |
| Model | VQA-Med 2021 |
|---|---|
| VilMedic * [7] | 37.80 |
| SYSU-HCP * [13] | 38.20 |
| RAMM | 39.20 |
4.4 主要结果
我们将我们的方法与四个数据集中的基线方法进行比较。 如表2所示,预训练模型的方法大大优于非预训练模型。 我们提出的 RAMM 在 VQA-Med 2019、VQARAD 和 SLAKE 上分别达到 82.13、78.27 和 86.05,分别超出之前的最佳结果 1.86、1.26 和 2.80。 表 4 显示了 VQA-Med 2021 数据集的结果。 我们的 RAMM 在准确性方面达到了 39.20,甚至超过了 VQA-Med 2021 挑战赛中最先进的集成方法(1.00)。
我们还报告了 RAMM 的结果,而无需在 VQA-Med 2019、VQARAD 和 SLAKE 数据集上检索额外的图像文本对。 如表2所示,在VQA-Med 2019、VQARAD和SLAKE上分别达到80.27、76.72和85.58。 在没有检索增强的情况下,RAMM 在 VQA-Med 2019 上的表现仍然优于之前最先进的方法 M3AE(0.4)以及 SLAKE(2.33),并且在 VQARAD 上的表现不相上下(76.72 vs. 77.01)。 这表明带有附加 PMCPM 数据集的预训练可以为生物医学 VQA 任务学习更好的视觉和文本表示。 与没有检索增强的模型相比,我们观察到我们的 RAMM 在 VQA-Med 2019、VQARAD 和 SLAKE 上分别实现了 1.90、1.55、0.47 的一致改进,这表明我们提出的检索增强可以提高生物医学 VQA 性能。
| Pre-training | Retrieval | VQA Datasets | |||||
| PMCPM | ROCO+CXR | PMCPM | ROCO+CXR | VQAMed19 | VQARAD | SLAKE | |
| (a) | ✗ | ✗ | ✗ | ✗ | 77.60 | 74.06 | 81.43 |
| (b) | ✓ | ✗ | ✗ | ✗ | 78.40 | 74.94 | 83.60 |
| (c) | ✗ | ✓ | ✗ | ✗ | 79.73 | 75.17 | 82.94 |
| (d) | ✓ | ✓ | ✗ | ✗ | 80.27 | 76.72 | 85.58 |
| (e) | ✗ | ✓ | ✗ | ✓ | 80.00 | 76.72 | 85.20 |
| (f) | ✓ | ✓ | ✗ | ✓ | 81.07 | 77.16 | 85.67 |
| (g) | ✓ | ✓ | ✓ | ✓ | 82.13 | 78.27 | 86.05 |
| Task | VQAMed19 | VQARAD | SLAKE | |||
|---|---|---|---|---|---|---|
| Dataset | Retrieve% | Have Ans% | Retrieve% | Have Ans% | Retrieve% | Have Ans% |
| PMCPM + ROCO + MIMIC-CXR | 100.0% | 29.6% | 100.0% | 28.4% | 100.0% | 38.7% |
| PMCPM | 52.2% | 20.8% | 51.9% | 21.3% | 54.9% | 30.5% |
| ROCO + MIMIC-CXR | 47.8% | 21.1% | 48.1% | 20.0% | 45.1% | 26.9% |
4.5消融研究
为了进一步分析收集的PMCPM数据集和检索策略的影响,我们进行了详细的消融研究,如表4所示。
首先,我们分析在预训练阶段使用不同数据的影响。 ROCO 和 MIMIC-CXR 是常用的生物医学多模态预训练数据集。 ROCO 包含相对少量的标记放射学图像。 MIMIC-CXR 的量很大,但仅包含胸部 X 射线图像-文本对。 PMCPM的集合来自于患者丰富多样的情况,并且PMCPM比ROCO和MIMIC-CXR要大得多。 借助 PMCPM 中的大量多样的图像文本对,该模型有可能获得更好的视觉和文本表示。 比较 (a) 和 (b),我们展示了预训练在我们收集的 PMCPM 数据集上的有效性。 (b)和(c)的结果表明PMCPM和之前的ROCO加MIMIC-CXR的数据可以互补。 ROCO 加 MIMIC-CXR 在 VQA-Med-2019 和 VQARAD 数据集上显示出更好的结果,而 PMCPM 在 SLAKE 数据集上表现更好。 通过将两种设置与三种资源相结合,设置(d)仅使用其中任何一种即可获得较大裕度的最佳性能。 上述结果表明PMCPM可以增强生物医学VQA任务中的模型预训练。
其次,上述数据集在本工作中也被视为检索资源。 因此,我们还分析了微调阶段使用不同数据的影响。 设置(e)仅使用之前的ROCO和MIMIC-CXR数据集进行检索。 通过与设置(c)进行比较,我们表明所提出的检索策略在以前广泛使用的资源中是有效的。 然后,我们进一步证明了我们收集的 PMCPM 数据的有用性。 与设置 (f) 和 (g) 相比,我们观察到检索额外的 PMCPM 数据分别产生 1.06、1.11 和 0.38 的增益。 此外,设置(g)和(d)的结果反映了我们提出的检索方法带来的巨大改进。 上述消融研究表明,我们收集的 PMCPM 数据集和我们提出的检索方法可以使生物医学 VQA 任务中的预训练和检索受益。
4.6分析与讨论
4.6.1检索
检索分布
为了了解 RAMM 如何从不同资源中检索以及检索到的文本如何帮助我们的生物医学 VQA 任务模型,我们计算检索到的样本的来源以及有多少检索到的文本包含答案。 统计数据列于表5中。 在 VQA-Med 2019、VQARAD 和 SLAKE 的检索文本中分别可以找到 29.6%、28.4% 和 38.7% 的答案,数量相当可观。 这些检索到的文本可以帮助 RAMM 直接回答问题。 我们观察到,在这些任务中,RAMM 从 PMCPM 检索图像文本对超过一半,这表明 PMCPM 与生物医学 VQA 图像的相关性比 ROCO 和 MIMIC-CXR 更相关。 在 VQA-Med 2019 和 VQARAD 中,PMCPM 和 out of PMCPM 检索到的包含答案的文本的百分比几乎相同。 在 SLAKE 中,PMCPM 贡献了更多包含答案的文本。 总而言之,PMCPM 在检索过程中非常重要,它提供包含答案的附加文本。
| # Retrieval | VQARAD | SLAKE |
|---|---|---|
| 0 | 76.72 | 85.58 |
| 1 | 77.38 | 86.33 |
| 2 | 78.05 | 86.33 |
| 4 | 78.27 | 86.05 |
| 8 | 76.50 | 84.54 |
| Model | VQARAD | SLAKE | ||
|---|---|---|---|---|
| Open | Closed | Open | Closed | |
| MEVF-BAN | 49.20 | 77.20 | 77.80 | 79.80 |
| CPRD-BAN | 52.50 | 77.90 | 79.50 | 83.40 |
| M3AE | 67.23 | 83.46 | 80.31 | 87.82 |
| RAMM | 67.60 | 85.29 | 82.48 | 91.59 |
图文对检索次数
为了探索图像-文本对检索计数如何影响生物医学 VQA 微调,我们在 中搜索检索图像的数量。 VQARAD 和 SLAKE 的结果如表6所示。 与普通微调(即检索计数 0)相比,检索 图像文本对可以提高性能。 我们凭经验发现检索 2 或 4 个图像文本对效果很好。 此外,使用 8 个图像-文本对会降低模型性能,这表明检索太多图像-文本对可能会引入带有噪声知识的不相关图像-文本对。
4.6.2 问题类型
在生物医学VQA中,问题可以分为封闭式问题和开放式问题。 封闭式问题的答案仅限于是或否等多种选择,而开放式问题的答案则不受限制。 由于形式的原因,封闭式问题比开放式问题更容易。 表7列出了不同方法在开放式和封闭式问题上的比较。 RAMM 在封闭式和开放式问题上的表现均优于 M3AE。 RAMM 在封闭式问题上比开放式问题对 M3AE 的改进更多。 原因是封闭式问题的答案选择有限,并且更容易被检索到的文本覆盖。
4.6.3与ROCO比较
ROCO 和 PMCPM 都是 PubMed 的子集。 ROCO 使用训练有素的神经网络来过滤放射图像,而 PMCPM 通过 PubMed 的“病例报告”查找图像。 我们计算ROCO和PMCPM训练拆分中涉及的文章数。 ROCO 使用了 PubMed 中的 40,857 篇文章,PMCPM 使用了 PubMed 中的 127,455 篇文章。 两个数据集中均出现了 17,189 篇文章。 尽管ROCO和PMCPM使用不同的方法过滤图像文本对,但ROCO中近一半的图像文本对也是由PMCPM收集的。 考虑到ROCO是手动校正的数据集,它可以从侧面反映较大数据集PMCPM的质量。
4.6.4案例研究
我们在图 5 中显示了检索到的 RAMM 图像文本对。 检索到的样本均来自PMCPM。 检索到的图像与原始图像具有相同的模态和相同的器官。 这些案例表明,检索到的图像包含对回答问题有用的信息。 尽管第二个示例的检索文本中未涵盖答案(即 Yes/No),但检索文本对于回答仍然有用。 第二个和第三个例子进一步表明,RAMM 可以通过检索增强正确回答,而朴素微调会失败。

5结论
在本文中,我们提出了一种用于生物医学 VQA 的检索增强预训练和微调范式 RAMM,其中包括高质量图像文本对 PMCPM、预训练多模态模型和用于精细检索的新型检索增强注意力模块。调整。 RAMM 使用 ITC 来检索相关的图像文本对,并将检索到的信息与检索注意力融合。 实验表明,我们的方法在各种生物医学 VQA 数据集中优于最先进的方法。 消融研究表明了所提出的 RAMM 和 PMCPM 对于预训练和检索的有效性。
参考
- [1] Iz Beltagy, Kyle Lo, and Arman Cohan. SciBERT: A pretrained language model for scientific text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3615–3620, Hong Kong, China, Nov. 2019. Association for Computational Linguistics.
- [2] Asma Ben Abacha, Sadid A Hasan, Vivek V Datla, Dina Demner-Fushman, and Henning Müller. Vqa-med: Overview of the medical visual question answering task at imageclef 2019. In Proceedings of CLEF (Conference and Labs of the Evaluation Forum) 2019 Working Notes. 9-12 September 2019, 2019.
- [3] D. Nguyen Binh, Do Thanh-Toan, X. Nguyen Binh, Do Tuong, Tjiputra Erman, and D. Tran Quang. Overcoming data limitation in medical visual question answering. In MICCAI, 2019.
- [4] Zhihong Chen, Yuhao Du, Jinpeng Hu, Yang Liu, Guanbin Li, Xiang Wan, and Tsung-Hui Chang. Multi-modal masked autoencoders for medical vision-and-language pre-training. In International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2022.
- [5] Zhihong Chen, Guanbin Li, and Xiang Wan. Align, reason and learn: Enhancing medical vision-and-language pre-training with knowledge. In Proceedings of the 30th ACM International Conference on Multimedia, pages 5152–5161, 2022.
- [6] Ekin Dogus Cubuk, Barret Zoph, Jon Shlens, and Quoc Le. Randaugment: Practical automated data augmentation with a reduced search space. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 18613–18624. Curran Associates, Inc., 2020.
- [7] Jean-benoit Delbrouck, Khaled Saab, Maya Varma, Sabri Eyuboglu, Pierre Chambon, Jared Dunnmon, Juan Zambrano, Akshay Chaudhari, and Curtis Langlotz. ViLMedic: a framework for research at the intersection of vision and language in medical AI. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 23–34, Dublin, Ireland, May 2022. Association for Computational Linguistics.
- [8] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics.
- [9] Tuong Do, Binh X. Nguyen, Erman Tjiputra, Minh Tran, Quang D. Tran, and Anh Nguyen. Multiple meta-model quantifying for medical visual question answering. In MICCAI, 2021.
- [10] Zi-Yi Dou, Yichong Xu, Zhe Gan, Jianfeng Wang, Shuohang Wang, Lijuan Wang, Chenguang Zhu, Pengchuan Zhang, Lu Yuan, Nanyun Peng, Zicheng Liu, and Michael Zeng. An empirical study of training end-to-end vision-and-language transformers. In Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
- [11] Sedigheh Eslami, Gerard de Melo, and Christoph Meinel. Does CLIP benefit visual question answering in the medical domain as much as it does in the general domain? arXiv e-prints, Dec. 2021.
- [12] Haifan Gong, Guanqi Chen, Sishuo Liu, Yizhou Yu, and Guanbin Li. Cross-modal self-attention with multi-task pre-training for medical visual question answering. In ICMR ’21: International Conference on Multimedia Retrieval, Taipei, Taiwan, August 21-24, 2021, pages 456–460. ACM, 2021.
- [13] Haifan Gong, Ricong Huang, Guanqi Chen, and Guanbin Li. Sysu-hcp at vqa-med 2021: A data-centric model with efficient training methodology for medical visual question answering. In CLEF 2021 – Conference and Labs of the Evaluation Forum, September 21–24, 2021, Bucharest, Romania, CEUR Workshop Proceedings, 2021.
- [14] Yuxian Gu, Robert Tinn, Hao Cheng, Michael R. Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. Domain-specific language model pretraining for biomedical natural language processing. ACM Transactions on Computing for Healthcare (HEALTH), 3:1 – 23, 2022.
- [15] Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. Retrieval augmented language model pre-training. In International Conference on Machine Learning, pages 3929–3938. PMLR, 2020.
- [16] Bogdan Ionescu, Henning Müller, Renaud Péteri, Asma Ben Abacha, Mourad Sarrouti, Dina Demner-Fushman, Sadid A Hasan, Serge Kozlovski, Vitali Liauchuk, Yashin Dicente Cid, et al. Overview of the imageclef 2021: Multimedia retrieval in medical, nature, internet and social media applications. In International Conference of the Cross-Language Evaluation Forum for European Languages, pages 345–370. Springer, 2021.
- [17] Qiao Jin, Zheng Yuan, Guangzhi Xiong, Qianlan Yu, Huaiyuan Ying, Chuanqi Tan, Mosha Chen, Songfang Huang, Xiaozhong Liu, and Sheng Yu. Biomedical question answering: A survey of approaches and challenges. ACM Comput. Surv., 55(2), jan 2022.
- [18] Alistair E. W. Johnson, Tom J. Pollard, Seth J. Berkowitz, Nathaniel R. Greenbaum, Matthew P. Lungren, Chih ying Deng, Roger G. Mark, and Steven Horng. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports. Scientific Data, 6, 2019.
- [19] Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 7(3):535–547, 2019.
- [20] Yash Khare, Viraj Bagal, Minesh Mathew, Adithi Devi, U Deva Priyakumar, and CV Jawahar. Mmbert: multimodal bert pretraining for improved medical vqa. In 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), pages 1033–1036. IEEE, 2021.
- [21] Jin-Hwa Kim, Jaehyun Jun, and Byoung-Tak Zhang. Bilinear Attention Networks. In Advances in Neural Information Processing Systems 31, pages 1571–1581, 2018.
- [22] Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images. Scientific data, 5(1):1–10, 2018.
- [23] Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240, 2020.
- [24] Kenton Lee, Ming-Wei Chang, and Kristina Toutanova. Latent retrieval for weakly supervised open domain question answering. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 6086–6096, Florence, Italy, July 2019. Association for Computational Linguistics.
- [25] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- [26] Chenliang Li, Haiyang Xu, Junfeng Tian, Wei Wang, Ming Yan, Bin Bi, Jiabo Ye, Hehong Chen, Guohai Xu, Zheng Cao, et al. mplug: Effective and efficient vision-language learning by cross-modal skip-connections. arXiv preprint arXiv:2205.12005, 2022.
- [27] Junnan Li, Ramprasaath R. Selvaraju, Akhilesh Deepak Gotmare, Shafiq Joty, Caiming Xiong, and Steven Hoi. Align before fuse: Vision and language representation learning with momentum distillation. In NeurIPS, 2021.
- [28] Xiaobo Liang, Lijun Wu, Juntao Li, Yue Wang, Qi Meng, Tao Qin, Wei Chen, Min Zhang, and Tie-Yan Liu. R-drop: Regularized dropout for neural networks. In NeurIPS, 2021.
- [29] Bo Liu, Li-Ming Zhan, and Xiao-Ming Wu. Contrastive pre-training and representation distillation for medical visual question answering based on radiology images. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 210–220. Springer, 2021.
- [30] Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu. Slake: a semantically-labeled knowledge-enhanced dataset for medical visual question answering. In 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), pages 1650–1654. IEEE, 2021.
- [31] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012–10022, 2021.
- [32] Alexander Long, Wei Yin, Thalaiyasingam Ajanthan, Vu Nguyen, Pulak Purkait, Ravi Garg, Alan Blair, Chunhua Shen, and Anton van den Hengel. Retrieval augmented classification for long-tail visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6959–6969, 2022.
- [33] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019, 2019.
- [34] Jong Hak Moon, Hyungyung Lee, Woncheol Shin, Young-Hak Kim, and Edward Choi. Multi-modal understanding and generation for medical images and text via vision-language pre-training. IEEE Journal of Biomedical and Health Informatics, 2022.
- [35] Binh D Nguyen, Thanh-Toan Do, Binh X Nguyen, Tuong Do, Erman Tjiputra, and Quang D Tran. Overcoming data limitation in medical visual question answering. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 522–530. Springer, 2019.
- [36] Obioma Pelka, Sven Koitka, Johannes Rückert, Felix Nensa, and Christoph M Friedrich. Radiology objects in context (roco): a multimodal image dataset. In Intravascular Imaging and Computer Assisted Stenting and Large-Scale Annotation of Biomedical Data and Expert Label Synthesis, pages 180–189. Springer, 2018.
- [37] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
- [38] Stephen E. Robertson and Hugo Zaragoza. The probabilistic relevance framework: Bm25 and beyond. Found. Trends Inf. Retr., 3:333–389, 2009.
- [39] Sara Sarto, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. Retrieval-augmented transformer for image captioning. In International Conference on Content-based Multimedia Indexing, pages 1–7, 2022.
- [40] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [41] Wenhui Wang, Hangbo Bao, Li Dong, Johan Bjorck, Zhiliang Peng, Qiang Liu, Kriti Aggarwal, Owais Khan Mohammed, Saksham Singhal, Subhojit Som, et al. Image as a foreign language: Beit pretraining for all vision and vision-language tasks. arXiv preprint arXiv:2208.10442, 2022.
- [42] Zichao Yang, Xiaodong He, Jianfeng Gao, Li Deng, and Alex Smola. Stacked attention networks for image question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 21–29, 2016.
- [43] Zhou Yu, Jun Yu, Jianping Fan, and Dacheng Tao. Multi-modal factorized bilinear pooling with co-attention learning for visual question answering. IEEE International Conference on Computer Vision (ICCV), pages 1839–1848, 2017.
- [44] Hongyi Yuan, Zheng Yuan, Ruyi Gan, Jiaxing Zhang, Yutao Xie, and Sheng Yu. BioBART: Pretraining and evaluation of a biomedical generative language model. In Proceedings of the 21st Workshop on Biomedical Language Processing, pages 97–109, Dublin, Ireland, May 2022. Association for Computational Linguistics.
- [45] Zheng Yuan, Yijia Liu, Chuanqi Tan, Songfang Huang, and Fei Huang. Improving biomedical pretrained language models with knowledge. In Proceedings of the 20th Workshop on Biomedical Language Processing, pages 180–190, Online, June 2021. Association for Computational Linguistics.
- [46] Li-Ming Zhan, Bo Liu, Lu Fan, Jiaxin Chen, and Xiao-Ming Wu. Medical visual question answering via conditional reasoning. In Proceedings of the 28th ACM International Conference on Multimedia, pages 2345–2354, 2020.
- [47] Zhengyun Zhao, Qiao Jin, and Sheng Yu. Pmc-patients: A large-scale dataset of patient notes and relations extracted from case reports in pubmed central. arXiv preprint arXiv:2202.13876, 2022.