BiomedCLIP:从1500万对科学图像-文本对中预训练的多模态生物医学基础模型
摘要
生物医学数据本质上是多模态的,包括物理测量和自然语言叙述。 一般的生物医学人工智能模型需要同时处理不同模态的数据,包括文本和图像。 因此,训练有效的通用生物医学模型需要高质量的多模态数据,例如平行图像-文本对。 在这里,我们介绍了PMC-15M,这是一个新的数据集,其规模比现有的生物医学多模态数据集(如MIMIC-CXR)大两个数量级,涵盖了各种生物医学图像类型。 PMC-15M 包含从 440 万篇科学文章中收集的 1500 万对生物医学图像-文本对。 基于 PMC-15M,我们预训练了 BiomedCLIP,一个多模态基础模型,并对其进行了针对生物医学视觉-语言处理的领域特定适应。 我们对从检索到分类到视觉问答 (VQA) 的标准生物医学成像任务进行了广泛的实验和消融研究。 BiomedCLIP 在各种标准数据集上取得了新的最先进的结果,大大优于先前的方法。 令人感兴趣的是,通过在各种生物医学图像类型上进行大规模预训练,BiomedCLIP 甚至在放射学特定任务(例如 RSNA 肺炎检测)上超越了 BioViL 等最先进的放射学特定模型。 总之,BiomedCLIP 是一个完全开放访问的基础模型,它在各种生物医学任务上实现了最先进的性能,为变革性的多模态生物医学发现和应用铺平了道路。 我们在 aka.ms/biomedclip 发布了我们的模型,以促进未来多模态生物医学人工智能的研究。
导言
生物医学数据本质上是多模态的,包含物理测量和自然语言叙述 [1, 2]。 但是,只有少量这样的数据以结构化的形式被解释并提供,因为人工整理成本高且难以扩展。 多模态学习可以通过利用跨模态对应关系中的自监督来缓解整理瓶颈。 它还有助于通过多模态融合揭示可能在独立模态中保持潜在的预测信号。 因此,已经开发了生物医学视觉语言基础模型 [3, 4, 5, 6] 来共同建模生物医学图像(例如,数字病理学和放射学图像)和生物医学文本(例如,科学论文和临床笔记)。 生物医学视觉语言基础模型有两个主要优势。 首先,通过使用自监督学习对大规模数据进行预训练,这些模型在低资源环境中表现出色,在各种下游应用程序中,只有少量微调数据可访问,从而大大降低了与数据标注相关的成本。 其次,通过对高质量的并行图像文本数据进行预训练,这些模型可以解决需要全面理解图像和文本数据的任务,例如图像描述生成和视觉问答。
由于这两种优势都依赖于高质量的生物医学图像文本数据,因此获取此类数据对于构建准确且可泛化的模型至关重要。 与通用领域视觉语言模型 [7, 8, 9] 使用的预训练数据相比,现有的生物医学视觉语言模型使用的预训练数据存在三个主要局限性。 首先,许多预训练数据是私有数据,导致许多生物医学基础模型无法访问。 其次,现有的生物医学领域并行图像文本数据集相对较小,从 7k 到 377k 对不等(例如,MIMIC-CXR [10] 为 377,110 对,CheXpert [11] 为 224,316 对,ARCH [12] 为 7,562 对,ROCO [13] 为 87,952 对)。 最后,现有数据集普遍缺乏多样性,其中大多数集中在胸部 X 光片上,从而限制了它们对其他生物医学图像类型的泛化能力。 一般领域中的先前研究已经证明了在多样化、扩展数据集上进行预训练的优势 [7],并且越来越多的努力集中在挖掘网络图像和标题 [14, 15, 16, 17] 上,但此类网络资源中的生物医学图像文本对相对稀缺,并且质量差异很大。
在本文中,我们开发了 PMC-15M,这是一个大型生物医学数据集,其中包含从 PubMed Central (PMC) 111https://www.ncbi.nlm.nih.gov/pmc/ 中的科学出版物中提取的高质量并行图像-文本对。 PMC-15M 包含 1500 万个生物医学图像-文本对,旨在解决先前生物医学视觉语言模型中的三个局限性。 首先,PMC-15M 是从科学论文中收集的公共数据集,没有隐私问题。 因此,在 PMC-15M 上训练的基础模型是公开可访问的。 其次,PMC-15M 比先前的 MIMIC-CXR 等大型数据集大两个数量级。 最后,PMC-15M 涵盖了生物医学研究感兴趣的几乎所有类别,跨越 30 种主要的生物医学图像类型,为生物医学研究和临床实践提供了一个多样化且具有代表性的数据集。
基于 PMC-15M,我们已经预训练了 BiomedCLIP,这是一种最先进的生物医学视觉语言基础模型,在跨模态检索、零样本图像分类和医疗视觉问答等广泛的下游应用中表现出色。 BiomedCLIP 在所有方面都大大优于通用领域的 CLIP 模型 [7],证实了探索生物医学领域特定模型的重要性。 通过在更大、更多样化的数据上进行预训练,BiomedCLIP 也大大优于先前的最先进的生物医学视觉语言模型,例如 PubMedCLIP 和 MedCLIP,特别是在资源匮乏的环境中。 令人惊讶的是,BiomedCLIP 在放射学特定任务(如 RSNA 肺炎检测 [19])中甚至优于放射学特定最先进模型,如 BioViL [18],这突出了从不同图像类别进行预训练的正向迁移的潜力。 为了促进未来的生物医学多模态研究,我们将在发表后在 aka.ms/biomedclip 中发布我们的 BiomedCLIP 模型和脚本,以重现 PMC-15M。
结果
数据集、模型和基准概述
数据集
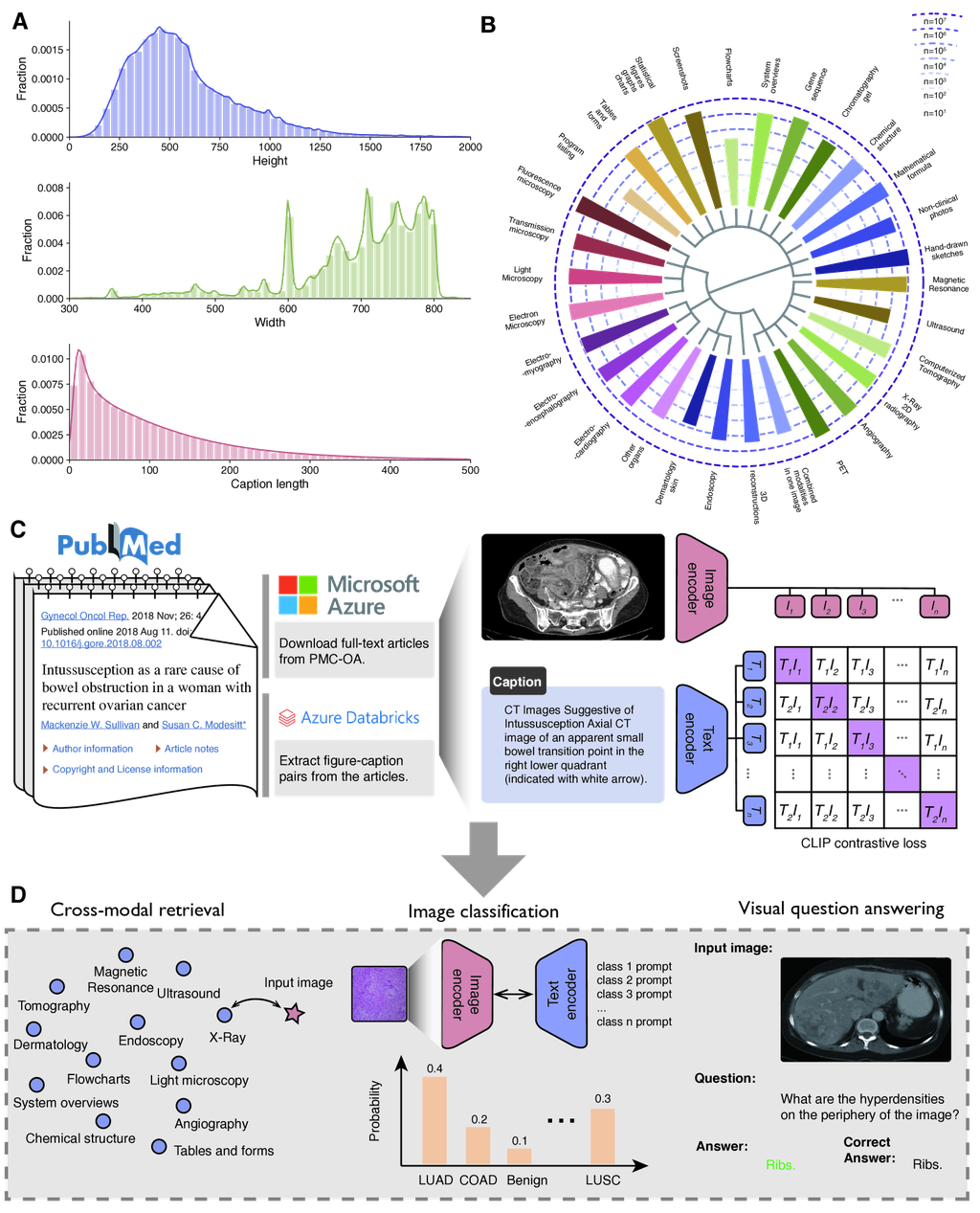
我们创建了 PMC-15M,这是一个大型并行图像-文本数据集,来自从 PubMed Central (PMC) 收集的科学论文。 请参见 图 1A, B。PMC 是一个全面的生物医学研究论文库。 我们之前使用 PubMed 论文对最先进的生物医学大型语言模型(例如,PubMedBERT [20]、BioGPT [21])进行预训练。 在这里,我们建议进一步利用 PMC 全文文章中丰富的图文对进行视觉-语言预训练。 PMC 包含 440 万篇公开可用的全文文章(截至 2022 年 6 月 15 日)。 我们下载并提取了包含完整文章包的压缩目录。 每篇文章都表示为 XML、PDF、媒体和补充材料的包。 我们提取了图形文件和匹配的标题,以及来源文章的 PMID 和 PMCID。 这产生了包含 15,282,336 个图像-标题对的数据集。 我们使用 Azure Databricks 来处理数据,因为它提供了一个可扩展且可靠的平台,该平台设计用于使用 Apache Spark (图 1C) 并行处理大型数据集和复杂工作流。
我们在 图 1A 中展示了 PMC-15M 的汇总统计信息。 我们发现,生物医学图像通常比一般领域中的标准图像大小 () 要大得多,并且生物医学图像标题比标准 CLIP 方法 [7] 使用的默认最大长度 (77) 要长得多。 这需要探索新的模型配置来预训练生物医学图像和文本。 为了探究 PMC-15M 中图像类别的多样性和覆盖范围,我们通过将每个科学图形拆分为单个面板图像来创建 PMC-Fine-Grained-46M(参见 方法)。 然后,我们使用一个经过精心策划的分类法 [22],其中包含手动分配的图像类型关键字,通过将每个图像分配给 BiomedCLIP 学习的嵌入空间中最接近的关键字来估计每种图像类型的频率。 这些数字很可能高估了真实的类别频率,但对于粗略估计来说已经足够接近了。 图 1B 显示了 PMC-Fine-Grained-46M 中排名前 30 的图像类型。 PMC 中的图像种类繁多,从通用的生物医学插图(例如,统计数字、图表、表格和表单)到放射学(例如,磁共振成像、计算机断层扫描和 X 射线)到数字病理学和显微镜(例如,光学显微镜和电子显微镜)等。 PMC-15M 的庞大规模和多样性让我们相信它可以用于训练最先进的生物医学视觉语言处理基础模型。
模型
BiomedCLIP 是 CLIP (对比语言-图像预训练) 模型 [7] 的一种先进改编,专门针对生物医学领域。 CLIP 训练图像和文本编码器,将 图像、文本 对嵌入到一个共享空间中,通过 InfoNCE 损失 [23] 优化正样本对之间的较高余弦相似度和负样本对之间的较低相似度。 与从互联网来源的图像文本对从头开始训练的原始 CLIP 不同,BiomedCLIP 调整了这种方法,使其更适合生物医学图像和文本的独特特征。 这种调整包括使用特定领域的语言模型 PubMedBERT [20] 来代替通用领域的 GPT-2 [24] 作为文本编码器,并调整标记器和上下文大小以适应通常较长的生物医学文献。 这与 PubMedCLIP [25] 和 MedCLIP [26] 形成对比,其中 PubMedCLIP 只是在 PubMed Central 的有限数据集上对原始 CLIP 进行微调,而 MedCLIP 将医学知识融入学习过程,但仍受原始 CLIP 架构的约束。 BiomedCLIP 还对图像处理引入了特定领域的改编,利用更大的 Vision Transformer 模型 [27] 和更高的图像分辨率,以更好地捕捉生物医学理解所需的详细视觉信息。 此外,它还实施了补丁 dropout 策略 [28] 以保持预训练效率,同时提高模型性能。 BiomedCLIP 的定制批量大小优化进一步强调了其针对生物医学领域的自定义适应性。
基准测试
BiomedCLIP 能够实现准确的跨模态检索
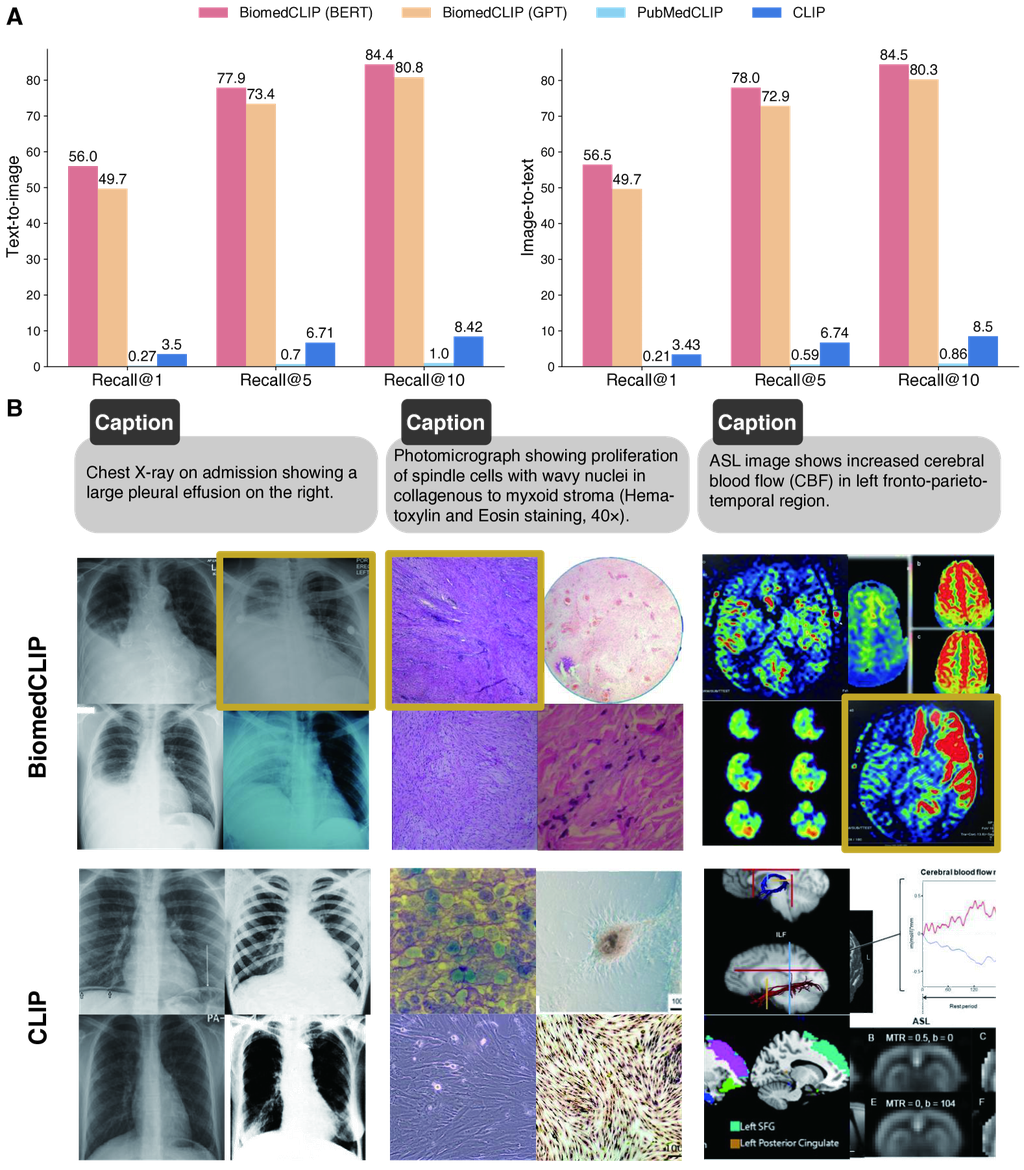
我们首先评估跨模态检索的任务,该任务旨在从标题中检索相应的图像(文本到图像检索)或反之亦然(图像到文本检索)。 检索任务反映了现实世界应用中各种图像搜索和文本生成,并且可以在保留的图像-文本对中自动评估。 我们使用来自 PMC-15M 的保留测试集,包含 725,739 个 PMC 图像-标题对。 结果总结在 图 2A 中。 我们首先注意到,通用领域的 CLIP 模型在生物医学领域表现不佳,因此需要开发特定于领域的视觉语言模型。 相反,BiomedCLIP 取得了非常高的检索准确率:在超过 70 万个候选者中,BiomedCLIP 的前 5 个结果中有超过 77% 包含正确的结果,其前 1 个结果中有超过 56% 是正确的。 令我们惊讶的是,PubMedCLIP [25] 即使经过生物医学适应,其性能仍然比 CLIP 差。 我们将其归因于 PubMedCLIP 使用的训练数据。 尽管以 PubMed 命名,PubMedCLIP 只使用了一小部分放射影像-文本对,这些对在 CLIP 的持续预训练中被使用,占生物医学文献中图像的一小部分。 此外,在没有额外关注的情况下(例如,使用预训练目标进行增强)对小型数据集进行持续预训练可能会容易导致灾难性遗忘 [31]。 相反,BiomedCLIP 通过在来自 PMC-15M 的大规模数据上进行预训练而表现出色,这进一步表明利用多样化和大型数据集对于特定领域的视觉语言模型的重要性。
为了了解 BiomedCLIP 如何在生物医学跨模态检索方面胜过通用领域 CLIP,我们在 图 2B 中展示了三个随机示例。 在每个示例中,我们展示了给定文本提示的前 4 个图像检索结果,正确答案显示在金色方框中。 通用 CLIP 可以找到匹配“胸部 X 光”等通用关键字的图像,但难以区分“胸腔积液”、“纺锤形细胞”等细微语义,甚至难以区分“ASL”(动脉自旋标记)等重要的生物医学图像类别。 相反,BiomedCLIP 不仅识别高层类别,还识别“右侧大量胸腔积液”等细节。 例如,根据标题,BiomedCLIP 在第一个示例中检索到的图像完全正确,除了右下角的图像,它仍然与其他图像非常相似。 在第二个示例中,BiomedCLIP 能够找到正确的答案以及具有纺锤形细胞的额外 H&E 图像,如提示中所述,这与通用 CLIP 不同。 我们将 BiomedCLIP 能够捕捉到粗粒度和细粒度语义的能力归功于我们多样化且庞大的预训练数据集 PMC-15M。
BiomedCLIP 能够实现准确的生物医学图像分类。
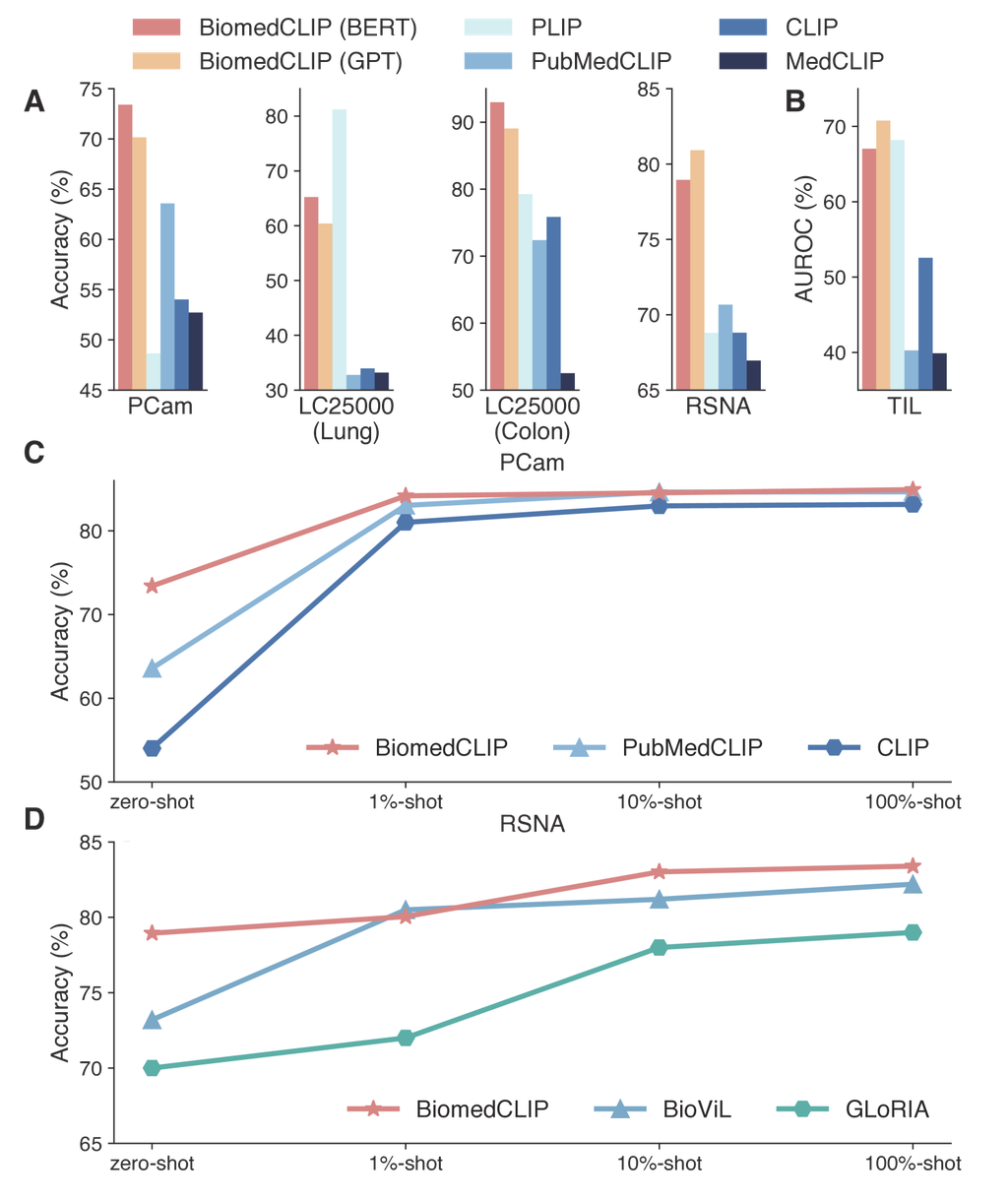
接下来,我们评估 BiomedCLIP 在五个数据集上的生物医学图像分类性能(见 方法)。 我们研究了 BiomedCLIP 模型的零样本性能,其中使用描述类别的简短文本提示来辅助分类(Supplementary Table 10)。 BiomedCLIP 在零样本分类方面表现出优越的性能,在所有数据集上实现了最高的整体准确率(分数的平均值)(图 3A,B)。 PubMedCLIP 使用放射学数据进行持续预训练,因此在 RSNA 基准测试中优于通用域 CLIP,但在数字病理学基准测试(如 LC25000 和 TCGA-TIL)中普遍表现出较差的性能。 PLIP [6] 使用来自社交媒体的数字病理学数据进行预训练,因此在一些病理学基准测试中表现良好,但在 RSNA 上表现出明显较差的性能。 令人惊讶的是,PLIP 在病理学基准测试 PCam 上的表现也相当差。 我们怀疑 PCam 中的病理图像(淋巴结转移肿瘤)在 PLIP 预训练的社交媒体数据中可能代表性不足。 相反,BiomedCLIP 在所有来自不同图像来源的数据集中都取得了良好的结果,再次表明在多样化的大规模数据集上进行预训练对于构建基础视觉语言模型的重要性。
我们还通过分别使用 1%、10% 和 100% 的训练数据对模型进行线性探测,评估了 PCam 和 RSNA 上的少样本和全样本性能(图 3C,D)。 值得注意的是,通过在所有生物医学图像类别中对多样化数据进行预训练,BiomedCLIP 甚至在标准放射学基准测试 RSNA 上超越了最先进的特定于放射学的 BioViL 模型 [18]。 此外,BiomedCLIP 仅使用 10% 的标记数据就已优于完全监督的 BioViL。 如(图 1B)所示,BiomedCLIP 预训练中使用的放射学相关图像不超过 BioViL 预训练中使用的 MIMIC-CXR,图像文本对可能更加嘈杂。 这排除了 BiomedCLIP 在 RSNA 上的优异性能是由于更专业的放射学预训练造成的可能性。 相反,在大型且多样的 PMC-15M 上进行的整体预训练,包括非放射学图像类型,帮助预训练了一个更强大的图像编码器,再次表明使用 PMC-15M 开发多模态基础模型的优越性。
BiomedCLIP 改善了医学视觉问答
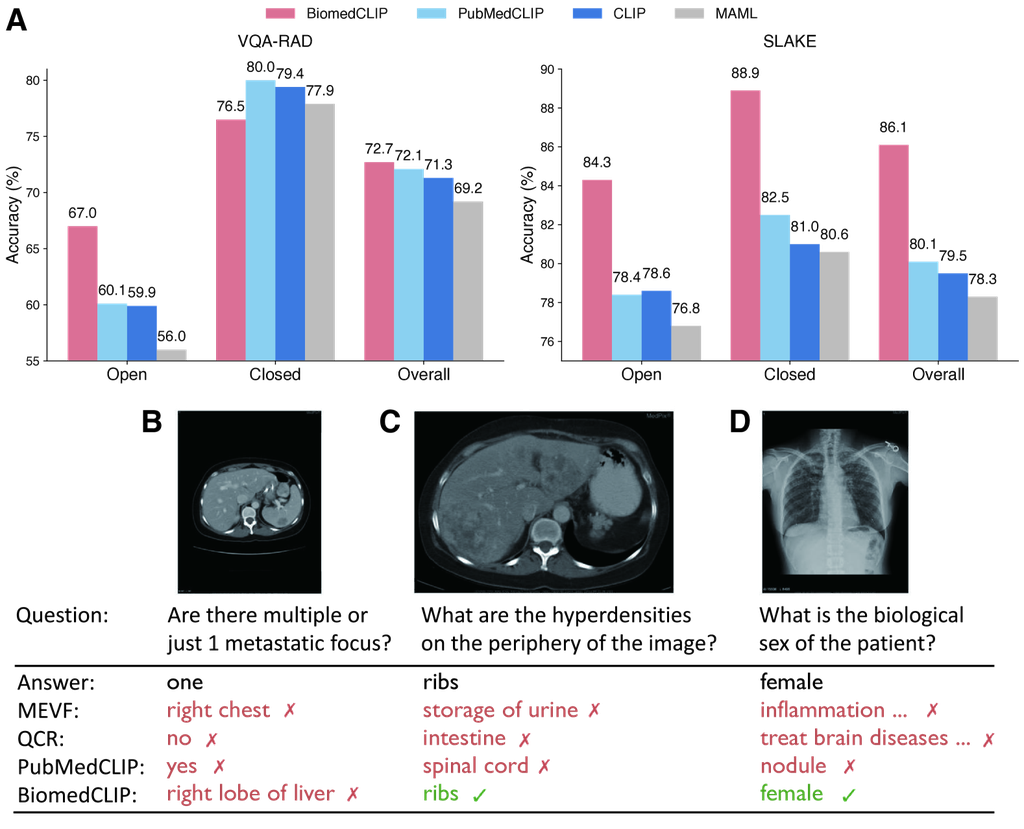
最后,我们评估了 BiomedCLIP 在医学视觉问答 (VQA) 上的性能。 遵循先前工作中的标准方法,我们将 VQA 制定为使用 METER [32] 框架的分类任务(参见 方法)。 我们在两个标准数据集上评估模型:VQ-RAD 和 SLAKE (图 4A)。 我们报告了总体准确率以及开放式问题和封闭式问题的各自准确率。 同样,BiomedCLIP 在两个放射学基准测试中都表现出优于放射学特定最先进的 PubMedCLIP 的性能,总体准确率分别提高了约一个点和六个点。 BiomedCLIP 的优势在 VQA-RAD 的开放式问题和 SLAKE 的所有问题类型中尤为明显。
为了进一步检查 BiomedCLIP 提供的答案,我们评估了 BiomedCLIP 在 PubMedCLIP 论文 [25] 中突出显示的一些最具挑战性的示例,其中所有先前最先进的模型,包括 PubMedCLIP,都无法正确回答 (图 4B-D)。 在第二个示例 (图 4C) 中,先前的模型无法返回正确的答案,而在第三个示例 (图 4D) 中,它们的答案表明它们甚至无法理解问题的含义。 BiomedCLIP 完美地回答了这两个问题。 在第一个示例中,这是最具挑战性的示例 (图 4B),MEVF 误将图像中显示的部位识别为身体部位,而 QCR 和 PubMedCLIP 将问题误解为二元问题(是/否)。 虽然 BiomedCLIP 也未能得到正确答案,但它正确地识别出了图像中呈现的相关器官。 由于医学视觉问答需要强大的文本理解和图像理解能力,我们将 BiomedCLIP 的优异结果归因于 PMC-15M 中大量并行的图像-标题对。
讨论
我们根据我们的知识,提出了迄今为止最大的生物医学视觉语言预训练研究,使用从 PubMed Central 全文文章中提取的 1500 万个图像-标题对。 我们的预训练数据量至少比之前的 datasets 大两个数量级,涵盖了极其广泛的生物医学图像。 我们对生物医学领域的特定领域适应性进行了系统研究,并提出了 BiomedCLIP 用于生物医学视觉语言处理。 在对八个标准生物医学数据集进行的大量实验中,BiomedCLIP 在跨模态检索、图像分类和视觉问答等标准应用中取得了新的最佳性能。 我们方法的良好结果表明 BiomedCLIP 在各种生物医学图像任务中的有效性,并验证了在大规模预训练中使用极其多样化数据的优势。
我们的工作与生物医学多模态表示学习最为相关。 大多数现有的视觉语言预训练工作都集中在胸部 X 光片 (CXR) 上,但训练数据量有限。 ConVIRT [30] 率先使用自然发生的医学图像-文本对进行自监督,并展示了对比学习在视觉语言预训练中的潜力。 他们的图像编码器有利于下游 CXR 分类和检索任务。 他们的文本编码器继承了通用领域的词汇,这导致在处理医学文本时经常遇到词汇外词。 虽然词片标记缓解了这个问题,但常见的生物医学术语经常被分割成碎片,导致性能不佳 [20]。 GLoRIA [33] 使用相同的通用领域词汇,并扩展了 ConVIRT,通过将医学图像的多模态全局和局部表示进行联合学习,对比注意加权图像区域与配对报告中的词语。 LoVT [34] 提出了一种类似的预训练方法,该方法将图像区域和报告句子的局部表示进行对齐。 [35] 通过最大化医学图像和文本的局部特征之间的互信息来学习多模态表示。 PubMedCLIP [25] 在来自 ROCO 数据集 [13] 的 8 万个放射学图像-标题对上对原始 CLIP 进行了微调,该数据集从 PubMed Central [36] 收集,与 PMC-15M 相比,这是一个很小的子集。 [37] 提出了一种基于 Transformer 的混合图像-文本预训练框架,该框架使用掩蔽视觉/语言建模用于仅图像或仅文本数据,并使用二元交叉熵用于配对图像-文本数据。 他们展示了在三种 CXR 应用中采用预训练模型的好处,即分类、检索和图像再生。 MedCLIP [26] 同样扩展了对比学习,以涵盖仅图像和仅文本数据。 他们还引入了医学知识以减轻假阴性。 MedAug [38] 利用患者元数据来选择超出同一图像增强范围的正图像对。 BioViL [18] 通过针对 CXR 图像和报告量身定制的放射学特定语义建模,改进了自监督视觉语言处理中的对比学习。 它在放射学自然语言推理和一系列 CXR 基准测试中取得了最先进的成果。 [39] 表明,在 CXR 数据上进行的自监督多模态预训练始终优于 ImageNet 预训练模型,用于 CXR 解释。
在未来,我们希望进一步探索预训练和微调、多模态生成以及图像搜索、数字病理学和多模态融合等现实世界应用,以实现精准健康。 虽然 BiomedCLIP 显示了大规模领域特定预训练在生物医学视觉语言处理中的明显优势,但我们的当前方法存在一些局限性: 首先,除了标题外,内联参考文献(即论文中的引文)也可以提取并与相应的图形配对以创建额外的训练信号。 PMC-15M 目前不包含此类数据。 其次,PMC-15M 中一半的图像是复合图形。 将这些复合图形拆分为子图形可以实现更细粒度的建模,并可能导致更好的视觉语言表示和接地。 PMC-Fine-Grained-46M 通过内联参考文献和细粒度图像文本对进行了增强。 虽然我们目前对 PMC-Fine-Grained-46M 的使用仅限于统计细粒度图像分布,但我们计划在未来的工作中探索利用 PMC-Fine-Grained-46M 来增强 BiomedCLIP 预训练。 第三,由于计算限制,我们探索过的最大视觉编码器是 ViT-B,它与 ViT-L、ViT-H 和 ViT-G 相比相对较小。 同样,我们一直在使用 336 的相对较低图像分辨率。 虽然这对于一般领域网页图像来说已经足够了,但生物医学图像往往具有更高的分辨率。 例如,PMC-15M 中超过 75% 的图像大小超过 336,如 图 1 所示。 我们计划在未来的工作中探索更大的模型和更高的分辨率。 最后,将我们的方法应用于图像以外的其他生物医学模式将很有趣,其中类似的自然共现数据比比皆是,例如基因表达和序列数据以及文本描述。
方法
创建 PMC-15M 的详细信息
PubMed Central 开放获取子集 (PMC-OA) [40] 包含 440 万篇公开可用的全文文章(截至 2022 年 6 月 15 日)。 我们从 ncbi.nlm.nih.gov/pmc/tools/ftp/#indart 下载 PMC-OA,并提取包含 XML、PDF、媒体和补充材料的文章的完整包。 我们使用 PubMed 解析器 [41] 解析 XML 文件并提取标题和相应的图引用,以及来源文章的 PMID 和 PMCID。 此处理会生成以 JSONL 格式存储的 JSON 对象,其中每行代表一篇文章,便于后期处理。 没有图引用或 XML 文件格式错误、语法错误或信息缺失错误的文章将被忽略。 在此清理之后,我们从超过 300 万篇不同的文章中收集了 1500 万个图-标题对(PMC-15M)。
创建 PMC-Fine-Grained-46M 的详细信息
PMC-Fine-Grained-46M 是使用一种新颖的数据整理管道创建的,该管道从 PMC-15M 中提取和细化图像-文本对。 该管道旨在通过将复合图分解为子图和标题来处理复合图,并且它还将文章中的内联文本引用作为图像-文本对的附加数据源纳入。 该过程从数据摄取器开始,数据摄取器下载并处理文章文件。 然后,Citance Extractor 解析文章文本以查找图形引用,Caption Splitter 使用正则表达式和规则将图形标题分成带有单独标签的子标题。 接下来,Citance Splitter 将 citances 块分配给每个标签,光学字符识别 (OCR) 检测图形中的文本,Label-To-Box Matcher 将标签与 OCR 检测到的文本匹配。 最后,Figure Splitter 将复合图像分割成面板(子图形),Label-to-Panel Matcher 将标签分配给正确的面板。 该流程克服了各种挑战,例如不一致的标签样式、OCR 错误以及标签相对于子图形的模糊定位。 采用了先进的技术和启发式方法,例如用于 OCR 文本的字符串匹配、用于纠正 OCR 错误的布局分析以及用于将标签与面板匹配的基于区域的启发式方法。 通过这个复杂的过程,PMC-Fine-Grained-46M 数据集(包含 4600 万个图像-文本对)被精心构建,以促进生物医学领域中视觉-语言表示的发展。
跨模态检索
为了评估检索性能,我们遵循先前的工作 [17] 预先计算图像和文本嵌入并执行近似最近邻搜索。 具体来说,我们使用 CLIP 模型的预训练视觉编码器和文本编码器分别预先计算图形和标题的嵌入。 给定一个图形嵌入,我们计算它与测试集中所有标题的余弦相似度,并检索 个最相似的标题。 我们的评估指标衡量图形的原始标题是否在 个检索到的标题中,即 top- 的召回率或 R@。 类似地,我们评估文本到图像跨模态检索的 Recall@。
我们将几个 CLIP 模型作为基线:OpenAI CLIP [7],它在从互联网收集的 4 亿个通用领域(图像,文本)对上进行预训练;PubMedCLIP [42],它在 8 万个放射学图像-标题对上对 OpenAI CLIP 进行微调。 我们还与 BiomedCLIP 的一个变体(即 BiomedCLIP ViT-B/16-224-GPT/77)进行比较,该变体继续在 PMC-15M 上对 OpenAI CLIP 进行预训练。
生物医学图像分类
我们使用评估工具包 ELEVATER [29] 来促进我们对图像分类的实验。 ELEVATER 是一款易于使用的工具包,可以有效地适应预训练的视觉-语言模型,并自动调整超参数。 它支持零样本、少样本和全样本评估,对于后两种设置,可以使用线性探测和完整模型微调。 它还包含从各个领域收集的 20 个图像分类数据集,包括一个生物医学数据集 PatchCamelyon,我们在实验中使用它。 此外,我们在三个标准生物医学成像基准 LC25000、TCGA-TIL 和 RSNA 上进行评估。
数据集概述见表 1。 PatchCamelyon (PCam) [43] 包含 彩色图像 (9696px),这些图像取自淋巴结切片组织病理学扫描。 这些图像被分配了一个二进制标签,指示它们是否包含转移组织。 LC25000 [44] 包含 组织病理学图像 (768768px)。 这些图像通过从 HIPAA 合规的经过验证的来源进行增强而生成,这些来源最初包含 750 张肺组织图像(250 张良性,250 张腺癌和 250 张鳞状细胞癌)和 500 张结肠组织图像(250 张良性和 250 张腺癌)。 该数据集分为五个类别:肺良性组织、肺腺癌、肺鳞状细胞癌、结肠腺癌和结肠良性组织,每个类别包含 5,000 张图像。 TCGA-TIL [45, 46] 包含 图像块 (500500px),这些图像块从癌症基因组图谱 (TCGA) [47] 肺腺癌 (LUAD) 病例的 H&E 全幻灯片图像中分区(5.9% 的块被标记为 LUAD)。 RSNA 肺炎 [19] 包含大约 张从美国国立卫生研究院的胸部 X 光公共数据库收集的正面视图胸部 X 光片。 它包含将肺炎分类为正常病例的二进制标签。
我们将我们的方法与四种竞争方法 CLIP、MedCLIP 和 PubMedCLIP 进行比较。 MedCLIP [26] 通过对比学习将预训练扩展到包括大型未配对图像和文本。 它使用预训练的 BioClinicalBERT 和 Swin Transformer [48] 作为主干文本编码器和视觉编码器,并在 MIMIC-CXR 和 CheXpert 数据集上进行微调。 PubMedCLIP [25] 在放射学对象上下文 (ROCO) 数据集 [13] 上对 CLIP 进行微调,该数据集包含 80,000 个从 PubMed 文章中提取的放射学图像文本对。 所有模型都被改编为 ELEVATER 进行评估。
医学视觉问答
我们利用 METER [32] 框架来促进我们在视觉问答 (VQA) 上的实验。 它将 VQA 任务表述为分类任务。 METER 的核心模块是一个基于 Transformer 的 共同注意 多模态融合模块,它生成跨模态表示,并将图像和文本编码馈送到分类器以预测最终答案。 我们将 BiomedCLIP 与通用域 CLIP、仅在视觉数据上预训练的 MAML (模型无关元学习) 网络以及最先进的 PubMedCLIP 进行比较。 所有三个模型都使用 QCR (通过条件推理进行问答) 框架 [49] 对 VQA 任务进行了微调,该框架交替使用基于 MLP 的注意网络,并使用条件推理作为融合模块。 MAML、CLIP 和 PubMedCLIP 的结果来自 [25]。
我们在 VQA-RAD [50] 上评估了我们的方法和竞争方法。 VQA-RAD 由 放射学图像和 由临床医生手动构建的问答对组成。 测试集中的图像也出现在训练集中,但问答对不重叠。 SLAKE (仅限英语) [51] 包含 放射学图像和超过 个由经验丰富的医生标注的问答对。 它涵盖的人体部位比 VQA-RAD 多,并且训练集和测试集之间没有共同的图像。 详细信息请参见 Supplementary Table 1。
数据可用性
本文发表后,我们将提供脚本以从 PubMed Central 开放获取数据 (PMC-OA) 重现 PMC-15M 和 PMC-Fine-Grained-46M。 这些脚本将在 https://aka.ms/biomedclip 上提供。 (目前,此 URL 指向 Hugging Face 上的预备模型版本。)
代码可用性
BiomedCLIP 将在 https://aka.ms/biomedclip 上完全公开,包括模型权重以及用于预训练、微调和推理的相关源代码。 我们还将提供详细的方法和实现步骤,以促进独立复制。
参考文献
- [1] Moor, M. et al. Foundation models for generalist medical artificial intelligence. Nature 616, 259–265 (2023).
- [2] Tu, T. et al. Towards generalist biomedical ai. arXiv preprint arXiv:2307.14334 (2023).
- [3] Heiliger, L., Sekuboyina, A., Menze, B., Egger, J. & Kleesiek, J. Beyond medical imaging-a review of multimodal deep learning in radiology (2022).
- [4] Huang, S.-C., Pareek, A., Seyyedi, S., Banerjee, I. & Lungren, M. P. Fusion of medical imaging and electronic health records using deep learning: a systematic review and implementation guidelines. NPJ digital medicine 3, 1–9 (2020).
- [5] Ikezogwo, W. O. et al. Quilt-1m: One million image-text pairs for histopathology. arXiv preprint arXiv:2306.11207 (2023).
- [6] Huang, Z., Bianchi, F., Yuksekgonul, M., Montine, T. J. & Zou, J. A visual–language foundation model for pathology image analysis using medical twitter. Nature medicine 29, 2307–2316 (2023).
- [7] Radford, A. et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, 8748–8763 (PMLR, 2021).
- [8] Ramesh, A. et al. Zero-shot text-to-image generation. In International Conference on Machine Learning, 8821–8831 (PMLR, 2021).
- [9] Rombach, R., Blattmann, A., Lorenz, D., Esser, P. & Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10684–10695 (2022).
- [10] Johnson, A. E. et al. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports. Scientific data 6, 1–8 (2019).
- [11] Irvin, J. et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI conference on artificial intelligence, vol. 33, 590–597 (2019).
- [12] Gamper, J. & Rajpoot, N. Multiple instance captioning: Learning representations from histopathology textbooks and articles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 16549–16559 (2021).
- [13] Pelka, O., Koitka, S., Rückert, J., Nensa, F. & Friedrich, C. M. Radiology objects in context (roco): a multimodal image dataset. In Intravascular Imaging and Computer Assisted Stenting and Large-Scale Annotation of Biomedical Data and Expert Label Synthesis, 180–189 (Springer, 2018).
- [14] Sharma, P., Ding, N., Goodman, S. & Soricut, R. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2556–2565 (Association for Computational Linguistics, Melbourne, Australia, 2018). URL https://aclanthology.org/P18-1238.
- [15] Changpinyo, S., Sharma, P., Ding, N. & Soricut, R. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3558–3568 (2021).
- [16] Srinivasan, K., Raman, K., Chen, J., Bendersky, M. & Najork, M. Wit: Wikipedia-based image text dataset for multimodal multilingual machine learning. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2443–2449 (2021).
- [17] Schuhmann, C. et al. Laion-5b: An open large-scale dataset for training next generation image-text models. arXiv preprint arXiv:2210.08402 (2022).
- [18] Boecking, B. et al. Making the most of text semantics to improve biomedical vision–language processing. In European Conference on Computer Vision (ECCV), 1–21 (Springer, 2022).
- [19] Shih, G. et al. Augmenting the national institutes of health chest radiograph dataset with expert annotations of possible pneumonia. Radiology. Artificial intelligence 1 (2019).
- [20] Gu, Y. et al. Domain-specific language model pretraining for biomedical natural language processing. ACM Transactions on Computing for Healthcare (HEALTH) 3, 1–23 (2021).
- [21] Luo, R. et al. Biogpt: generative pre-trained transformer for biomedical text generation and mining. Briefings in Bioinformatics 23 (2022).
- [22] García Seco de Herrera, A., Müller, H. & Bromuri, S. Overview of the ImageCLEF 2015 medical classification task. In Working Notes of CLEF 2015 (Cross Language Evaluation Forum) (2015).
- [23] Oord, A. v. d., Li, Y. & Vinyals, O. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748 (2018).
- [24] Radford, A. et al. Language models are unsupervised multitask learners. OpenAI blog 1, 9 (2019).
- [25] Eslami, S., de Melo, G. & Meinel, C. Does clip benefit visual question answering in the medical domain as much as it does in the general domain? arXiv preprint arXiv:2112.13906 (2021).
- [26] Wang, Z., Wu, Z., Agarwal, D. & Sun, J. Medclip: Contrastive learning from unpaired medical images and text. arXiv preprint arXiv:2210.10163 (2022).
- [27] Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
- [28] Li, Y., Fan, H., Hu, R., Feichtenhofer, C. & He, K. Scaling language-image pre-training via masking. arXiv preprint arXiv:2212.00794 (2022).
- [29] Li, C. et al. Elevater: A benchmark and toolkit for evaluating language-augmented visual models. Neural Information Processing Systems (2022).
- [30] Zhang, Y., Jiang, H., Miura, Y., Manning, C. D. & Langlotz, C. P. Contrastive learning of medical visual representations from paired images and text. arXiv preprint arXiv:2010.00747 (2020).
- [31] McCloskey, M. & Cohen, N. J. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of learning and motivation, vol. 24, 109–165 (Elsevier, 1989).
- [32] Dou, Z.-Y. et al. An empirical study of training end-to-end vision-and-language transformers. In Conference on Computer Vision and Pattern Recognition (CVPR) (2022). URL https://arxiv.org/abs/2111.02387.
- [33] Huang, S.-C., Shen, L., Lungren, M. P. & Yeung, S. GLoRIA: A multimodal global-local representation learning framework for label-efficient medical image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 3942–3951 (2021).
- [34] Müller, P., Kaissis, G., Zou, C. & Rueckert, D. Joint learning of localized representations from medical images and reports. In European Conference on Computer Vision, 685–701 (Springer, 2022).
- [35] Liao, R. et al. Multimodal representation learning via maximization of local mutual information. In International Conference on Medical Image Computing and Computer-Assisted Intervention, 273–283 (Springer, 2021).
- [36] Roberts, R. J. Pubmed central: The genbank of the published literature (2001).
- [37] Wang, X., Xu, Z., Tam, L., Yang, D. & Xu, D. Self-supervised image-text pre-training with mixed data in chest x-rays. arXiv preprint arXiv:2103.16022 (2021).
- [38] Vu, Y. N. T. et al. Medaug: Contrastive learning leveraging patient metadata improves representations for chest x-ray interpretation. In Jung, K., Yeung, S., Sendak, M., Sjoding, M. & Ranganath, R. (eds.) Proceedings of the 6th Machine Learning for Healthcare Conference, vol. 149 of Proceedings of Machine Learning Research, 755–769 (PMLR, 2021). URL https://proceedings.mlr.press/v149/vu21a.html.
- [39] Iyer, N. S. et al. Self-supervised pretraining enables high-performance chest x-ray interpretation across clinical distributions. medRxiv (2022). URL https://www.medrxiv.org/content/early/2022/11/25/2022.11.19.22282519. https://www.medrxiv.org/content/early/2022/11/25/2022.11.19.22282519.full.pdf.
- [40] Pmc open access subset. [Internet] (2003). URL https://www.ncbi.nlm.nih.gov/pmc/tools/openftlist/.
- [41] Achakulvisut, T., Acuna, D. & Kording, K. Pubmed parser: A python parser for pubmed open-access xml subset and medline xml dataset xml dataset. Journal of Open Source Software 5, 1979 (2020). URL https://doi.org/10.21105/joss.01979.
- [42] Eslami, S., de Melo, G. & Meinel, C. Does CLIP benefit visual question answering in the medical domain as much as it does in the general domain? arXiv e-prints (2021). 2112.13906.
- [43] Veeling, B. S., Linmans, J., Winkens, J., Cohen, T. & Welling, M. Rotation equivariant CNNs for digital pathology (2018). 1806.03962.
- [44] Borkowski, A. A. et al. Lung and colon cancer histopathological image dataset (lc25000). arXiv preprint arXiv:1912.12142 (2019).
- [45] Saltz, J., Gupta, R., Hou, L. et al. Tumor-infiltrating lymphocytes maps from tcga h&e whole slide pathology images. Cancer Imaging Arch (2018).
- [46] Saltz, J. et al. Spatial organization and molecular correlation of tumor-infiltrating lymphocytes using deep learning on pathology images. Cell reports 23, 181–193 (2018).
- [47] Clark, K. et al. The cancer imaging archive (tcia): maintaining and operating a public information repository. Journal of digital imaging 26, 1045–1057 (2013).
- [48] Liu, Z. et al. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2021).
- [49] Zhan, L.-M., Liu, B., Fan, L., Chen, J. & Wu, X.-M. Medical visual question answering via conditional reasoning. In Proceedings of the 28th ACM International Conference on Multimedia, 2345–2354 (2020).
- [50] Lau, J. J., Gayen, S., Ben Abacha, A. & Demner-Fushman, D. A dataset of clinically generated visual questions and answers about radiology images. Scientific data 5, 1–10 (2018).
- [51] Liu, B. et al. Slake: A semantically-labeled knowledge-enhanced dataset for medical visual question answering. In 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), 1650–1654 (IEEE, 2021).
- [52] He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778 (2016).
- [53] Vaswani, A. et al. Attention is all you need. Advances in neural information processing systems 30 (2017).
- [54] Sennrich, R., Haddow, B. & Birch, A. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1715–1725 (Association for Computational Linguistics, Berlin, Germany, 2016). URL https://aclanthology.org/P16-1162.
- [55] Kudo, T. & Richardson, J. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 66–71 (Association for Computational Linguistics, Brussels, Belgium, 2018). URL https://aclanthology.org/D18-2012.
- [56] Cherti, M. et al. Reproducible scaling laws for contrastive language-image learning. arXiv preprint arXiv:2212.07143 (2022).
- [57] Loshchilov, I. & Hutter, F. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017).
- [58] Ilharco, G. et al. Openclip (2021). URL https://doi.org/10.5281/zenodo.5143773.
- [59] Li, S. et al. Pytorch distributed: Experiences on accelerating data parallel training. arXiv preprint arXiv:2006.15704 (2020).
- [60] Paszke, A. et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems 32 (2019).
| Task | Dataset | Metric | Description | Data size | ||
| Train | Dev | Test | ||||
|
Cross-Modal Retrieval |
PMC-15M |
Recall@k |
Given textual description (caption), retrieve the corresponding image, or vice versa. (Image size: see Fig. 1A) |
13.9M | 13.6k | 726k |
|
PCam |
Accuracy |
Binary classification on whether a histopathology image of lymph node contains metastatic tumor tissue. (Image size: 9696) |
262,144 | 32,769 | 32,769 | |
|
LC25000 (Lung) |
Accuracy |
Ternary classification (benign, adenocarcinoma, squamous cell carcinoma) on histopathology images of lung tissue. (Image size: 768768) |
- | - | 15,000 | |
|
Image Classification |
LC25000 (Colon) |
Accuracy |
Binary classification (benign, adenocarcinoma) on histopathology images of colon tissue. (Image size: 768768) |
- | - | 10,000 |
|
TCGA-TIL |
AUROC |
Binary classification on whether lung H&E whole-slide image patches show adenocarcinoma. (Image size: 512512) |
- | - | 2,480 | |
|
RSNA |
Accuracy |
Binary classification on whether chest X-rays show pneumonia. (Image size: 500500) |
18,678 | 4,003 | 9,069 | |
|
VQA |
VQA-RAD |
Accuracy |
Answer clinician questions about radiology images. |
3,064 | - | 451 |
|
SLAKE |
Accuracy |
Answer clinician questions about radiology images (X-rays, and single slices of CTs and MRIs). |
9,849 | 2,109 | 2,070 | |
附加说明
BiomedCLIP 架构和消融研究的细节
CLIP 的回顾
我们首先简要回顾一下 CLIP 预训练方法[7]。 给定一批 对,CLIP 通过联合训练图像编码器和文本编码器来学习多模态嵌入空间,以最大化批次中 对的图像和文本嵌入之间的余弦相似度,同时最小化其他 的嵌入之间的余弦相似度。 具体来说,CLIP 最小化了 InfoNCE 损失 [23],即这些相似度得分上的对称交叉熵损失:
| (1) |
其中 是一个可学习的温度参数,在训练期间直接优化为对数参数化的乘法标量; 和 是第 个图像和文本的嵌入,由图像编码器和文本编码器顶部的线性投影层生成。 CLIP 并没有使用预训练权重进行初始化,而是从头开始训练图像编码器和文本编码器。 对于图像编码器,CLIP 考虑了两种不同的架构,ResNet-50 [52] 和 Vision Transformer [ViT; 27]。 文本编码器实际上是基于 Transformer [53] 的 GPT-2 [24]。
将 CLIP 调整为 BiomedCLIP
生物医学文本和图像与 CLIP 预训练中使用的网络数据有很大不同。 我们发现,标准 CLIP 设置对于生物医学视觉语言预训练来说不是最佳的。 因此,我们对潜在的调整进行了系统研究,并确定了一系列针对生物医学领域的特定领域调整。 我们使用验证集上的优化损失和跨模态检索结果来指导我们最初的探索,并进行了详细的消融研究。
在文本方面,我们用更适合生物医学的预训练语言模型替换了空白 GPT-2。 具体来说,我们用 PubMedBERT 初始化,PubMedBERT 在特定领域预训练方面显示出显著的增益 [20]。 相应地,对于标记器,我们用 WordPiece [55] 替换了 Byte-Pair Encoding [BPE; 54],WordPiece 使用基于单字的似然,而不是将所有单词分解为字符,并根据频率贪婪地形成更大的标记。 原始 CLIP 使用 77 个标记的上下文,但生物医学文本通常更长,如 图 1A 所示。 因此,我们将上下文大小增加到 256,它覆盖了 90% 的 PMC 标题。 Supplementary Table 1 显示,这两种修改在验证集上都比原始 CLIP 模型带来了显著的改进。
| img2txt (%) | txt2img (%) | ||||
| text encoder | vocab | context length | loss () | R@1() | R@1() |
| GPT | 50k general domain | 77 | 0.6626 | 64.53 | 63.56 |
| PubMedBERT | 30k domain specific | 77 | 0.5776 | 69.03 | 67.41 |
| PubMedBERT | 30k domain specific | 256 | 0.4807 | 73.50 | 72.26 |
在图像方面, 我们首先评估了 Vision Transformer (ViT) 在不同尺度上的表现,范围从 ViT-Small、ViT-Medium 到 ViT-Base。 ViT 模型名称中的后缀“/16”指的是 1616 像素的补丁大小,即输入图像被划分为这种大小的补丁,并通过 Transformer 块进行处理。 如 Supplementary Table 2 所示,我们发现更大的 ViT 会带来更好的性能,证实了模型可扩展性在我们的新数据集 PMC-15M 上的重要性。 在随后的所有实验中,我们都使用了最大的 ViT-B/16。
| img2txt (%) | txt2img (%) | ||||
| vision encoder | trainable params | hidden dim | loss () | R@1() | R@1() |
| ViT-S/16 | 22M | 384 | 0.5342 | 69.45 | 68.02 |
| ViT-M/16 | 39M | 512 | 0.5063 | 71.85 | 70.22 |
| ViT-B/16 | 86M | 768 | 0.4807 | 73.50 | 72.26 |
| img2txt (%) | txt2img (%) | |||
| vision encoder | initialization | loss () | R@1() | R@1() |
| ViT-B/16 | random initialization | 0.3814 | 83.15 | 81.75 |
| ViT-B/16 | pretrained on ImageNet | 0.3819 | 82.90 | 81.86 |
接下来,我们比较了两种不同的视觉编码器初始化方法。 Supplementary Table 3 表明,在 ImageNet [27] 上预训练的视觉编码器没有比随机初始化更优。 然而,在我们的下游任务中,ImageNet 预训练权重提供了更稳定的性能。 因此,我们选择用 ImageNet 预训练权重初始化 ViT-B/16。 最后,生物医学图像理解通常需要细粒度的视觉特征 [30]。 在 Supplementary Table 4 中,我们比较了两种输入图像分辨率的选择:224224 和 384384。 通过增加图像分辨率,我们在验证结果中观察到显著的收益。 但这也导致预训练时间翻倍。 此外,增加图像分辨率并不总是能提高下游任务的性能。 如表 Supplementary Table 5 所示,BiomedCLIP 在使用 384 的更大图像尺寸时,在所有五个数据集的零样本分类中表现出较差的性能,而使用 224 时的性能则更好。 这种差异在 PCam 中尤为显著,其中原始图像分辨率(9696)远小于模型的输入图像尺寸。 此处对图像进行上采样可能会引入噪声,这可能是导致观察到的性能下降的原因。 因此,我们在后续实验中选择 224 的图像尺寸。
| img2txt (%) | txt2img (%) | |||
| image size | training time | loss () | R@1() | R@1() |
| 224px | 1.00x | 0.3819 | 82.90 | 81.86 |
| 384px | 1.92x | 0.3406 | 84.63 | 83.56 |
| LC25000 | LC25000 | TCGA- | ||||
| image size | PCam | (Lung) | (Colon) | TIL | RSNA | mean |
| 224px | 73.41 | 65.23 | 92.98 | 67.04 | 78.95 | 75.52 |
| 384px | 67.15 | 61.80 | 87.42 | 57.00 | 78.49 | 70.37 |
| image-to-text retrieval (%) | text-to-image retrieval (%) | |
| batch size | R@1() | R@1() |
| 2k | 79.69 | 78.43 |
| 4k | 82.90 | 81.86 |
| img2txt (%) | txt2img (%) | |
| batch size | R@1() | R@1() |
| 4k 4k | 83.98 | 82.71 |
| 4k 64k | 87.32 | 86.66 |
最后,我们研究了批次大小的影响。 在 Supplementary Table 6 中,我们展示了更大的批次大小通常具有更好的验证性能。 在 Supplementary Table 7 中,我们研究了将批次大小增加到 64k,以匹配 [7, 56] 的选择。 虽然验证性能进一步提高,但我们发现,在达到 4k 的批次大小后,这种提升并没有转化为下游评估 (Supplementary Table 6)。 这种现象的潜在解释可能是,极大的批次大小需要更多训练数据和更长的 epoch。 CLIP [7] 使用 4 亿个图像-文本对,而 PMC-15M 有 1500 万对。 我们选择 4k 批次大小来训练我们的 BiomedCLIP。
将所有内容整合在一起
我们使用上面提到的最佳批次计划在 PMC-15M 上预训练了一系列 BiomedCLIP 模型,并将它们与通用领域 CLIP 模型进行了比较 [7]。 如 Supplementary Table 8 所示,在 PMC-15M 上进行大规模预训练或持续预训练总是有帮助的,并且通常使用生物医学预训练语言模型 (PubMedBERT)、更大的视觉 Transformer 和更高的图像分辨率可以获得最佳验证性能。 所有超参数都在 Supplementary Table 9 中总结。
| img2txt (%) | txt2img (%) | |||
| model | config | data | R@1() | R@1() |
| OpenAI CLIP | ResNet-50-224-GPT/77 | WIT-400M | 10.31 | 10.38 |
| OpenAI CLIP | ViT-B/16-224-GPT/77 | WIT-400M | 11.82 | 11.65 |
| BiomedCLIP | ResNet-50-224-GPT/77 | WIT-400M PMC-15M | 81.17 | 80.17 |
| BiomedCLIP | ViT-B/16-224-GPT/77 | WIT-400M PMC-15M | 81.57 | 80.89 |
| BiomedCLIP | ViT-B/16-224-BERT/256 | ImageNet/PubMed PMC-15M | 82.90 | 81.86 |
| Hyperparameters | Value |
| optimizer | AdamW [57] |
| peak learning rate | 5.0e-4 |
| weight decay | 0.2 |
| optimizer momentum | , = 0.9, 0.98 |
| eps | 1.0e-6 |
| learning rate schedule | cosine decay |
| epochs | 32 |
| warmup (in steps) | 2000 |
| random seed | 0 |
| image mean | (0.48145466, 0.4578275, 0.40821073) |
| image std | (0.26862954, 0.26130258, 0.27577711) |
| augmentation | RandomResizedCrop |
| validation frequency | every epoch |
实现
我们的实现基于 OpenCLIP [58],这是一种开源软件,适用于使用对比图像-文本监督进行大规模分布式训练。 预训练实验使用多达 16 个 NVIDIA A100 GPU 或 16 个 NVIDIA V100 GPU 进行,通过 PyTorch DDP [59, 60]。 为了减少内存消耗,我们启用梯度检查点和自动混合精度 (AMP),数据类型为 bfloat16(只要硬件支持)。 此外,我们使用了一种分片对比损失 [56],该损失与 InfoNCE [23] 的梯度相同,并通过消除冗余计算并仅计算每个 GPU 上局部相关特征的相似性来减少内存使用。
| BiomedCLIP | ||
| dataset | classes | templates |
| PCam | normal lymph node | this is an image of {}; |
| lymph node metastasis | {} presented in image | |
| LC25000 (Lung) | lung adenocarcinomas | this is an image of {}; |
| normal lung tissue | {} presented in image | |
| lung squamous cell carcinomas | ||
| LC25000 (Colon) | colon adenocarcinomas | a photo of {}; |
| normal colonic tissue | {} presented in image | |
| TCGA-TIL | none | a photo of {}; |
| tumor infiltrating lymphocytes | {} presented in image | |
| RSNA | normal lung | a photo of {}; |
| pneumonia | {} presented in image | |