跑步,不要走路:追求更高的 FLOPS 以实现更快的神经网络
摘要
为了设计快速神经网络,许多工作一直致力于减少浮点运算(FLOP)的数量。 然而,我们观察到,FLOP 的减少并不一定会导致延迟的类似程度的减少。 这主要源于每秒浮点运算 (FLOPS) 效率低下。 为了实现更快的网络,我们重新审视流行的算子,并证明如此低的 FLOPS 主要是由于算子的频繁内存访问,尤其是深度卷积。 因此,我们提出了一种新颖的部分卷积法(PConv),通过同时减少冗余计算和内存访问,更高效地提取空间特征。 在我们的 PConv 的基础上,我们进一步提出了 FasterNet,这是一个新的神经网络系列,它在各种设备上比其他网络获得更高的运行速度,而不会影响各种视觉任务的准确性。 例如,在 ImageNet-1k 上,我们的小型 FasterNet-T0 在 GPU、CPU 和 ARM 上比 MobileViT-XXS 快 、 和 处理器分别提高了 2.9% 的准确度。 我们的大型 FasterNet-L 实现了令人印象深刻的 83.5% top-1 准确率,与新兴的 Swin-B 相当,同时 GPU 上的推理吞吐量提高了 36%,并节省了 37% 的 CPU 计算时间。 代码可在 https://github.com/JierunChen/FasterNet 获取。
1简介
神经网络在图像分类、检测和分割等各种计算机视觉任务中经历了快速发展。 虽然它们令人印象深刻的性能为许多应用程序提供了动力,但一个蓬勃的趋势是追求低延迟和高吞吐量的快速神经网络,以实现出色的用户体验、即时响应、安全原因等。
怎样才能快呢? 研究人员和从业者不要求更昂贵的计算设备,而是更愿意设计具有成本效益的快速神经网络,降低计算复杂性,主要以浮点op的数量来衡量>迭代s(FLOPs)111我们遵循广泛采用的 FLOP 定义,即乘加次数 [84, 42]。. MobileNets [25, 54, 24]、ShuffleNets [84, 46] 和 GhostNet [17] 等利用深度卷积( DWConv) [55] 和/或组卷积 (GConv) [31] 来提取空间特征。 然而,在努力减少 FLOP 的过程中,操作员经常会遭受内存访问增加的副作用。 MicroNet [33]进一步分解和稀疏网络,将其FLOPs推至极低的水平。 尽管它在 FLOP 方面有所改进,但这种方法的碎片计算效率较低。 此外,上述网络通常伴随着额外的数据操作,例如串联、洗牌和池化,其运行时间对于小型模型来说往往很重要。
除了上述纯卷积神经网络(CNN)之外,人们对制作视觉变换器(ViT)[12]和多层感知器(MLP)架构[64]也产生了新的兴趣> 更小、更快。 例如,MobileViTs [48, 49, 70] 和 MobileFormer [6] 通过将 DWConv 与改进的注意力机制相结合来降低计算复杂度。 然而,他们仍然受到上述 DWConv 问题的困扰,并且还需要专用硬件支持修改后的注意力机制。 使用先进但耗时的标准化和激活层也可能会限制它们在设备上的速度。
所有这些问题共同引出了以下问题:这些“快速”神经网络真的很快吗? 为了回答这个问题,我们研究了延迟和 FLOP 之间的关系,该关系由
| (1) |
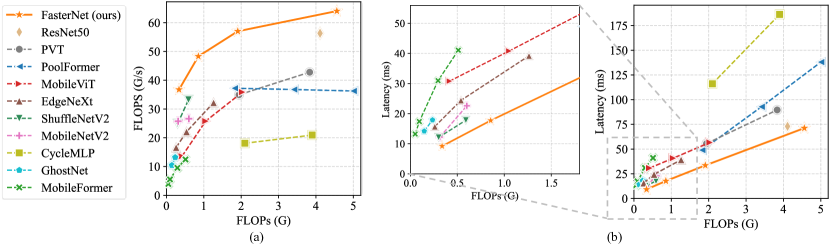
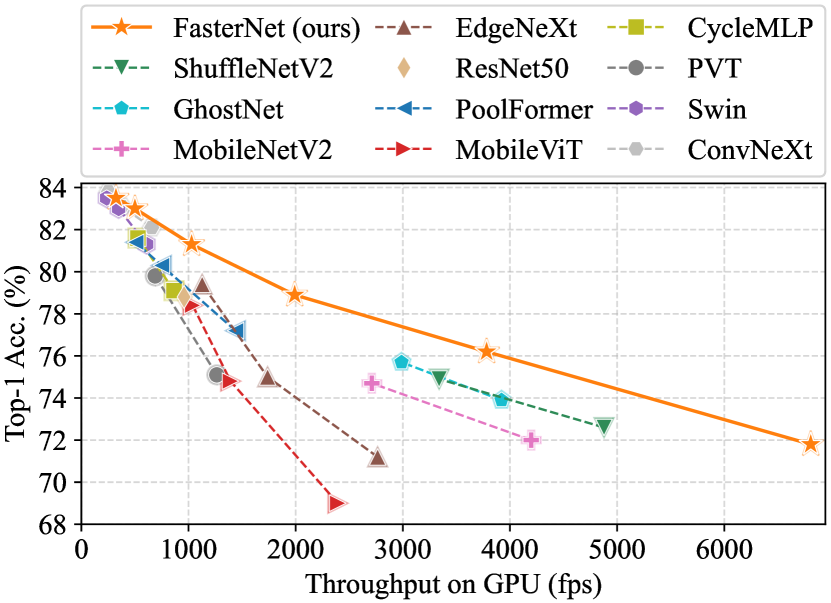
其中 FLOPS 是每秒浮点操作的缩写,作为有效计算速度的度量。 虽然有很多减少 FLOP 的尝试,但很少考虑同时优化 FLOPS 以实现真正的低延迟。 为了更好地了解情况,我们比较了英特尔 CPU 上典型神经网络的 FLOPS。 图2的结果表明,许多现有的神经网络存在FLOPS较低的问题,其FLOPS普遍低于流行的ResNet50。 由于 FLOPS 如此之低,这些“快速”神经网络实际上还不够快。 它们对 FLOP 的减少不能转化为确切的延迟减少量。 在某些情况下,没有任何改善,甚至导致更严重的延迟。 例如,CycleMLP-B1 [5] 的 FLOP 是 ResNet50 [20] 的一半,但运行速度更慢(即。,CycleMLP-B1 vs。 ResNet50:116.1ms vs。 73.0ms)。 请注意,之前的工作 [46, 48] 中也注意到了 FLOP 和延迟之间的这种差异,但部分仍未得到解决,因为它们采用了 DWConv/GConv 和各种低 FLOPS 的数据操作。 认为没有更好的替代方案可用。
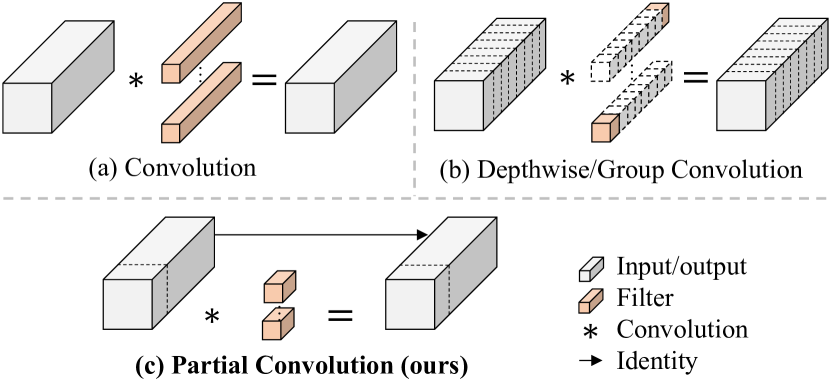
本文旨在通过开发一种简单而快速且有效的算子来消除这种差异,该算子可以在减少 FLOPS 的同时保持较高的 FLOPS。 具体来说,我们在计算速度(FLOPS)方面重新检查现有算子,特别是 DWConv。 我们发现导致低 FLOPS 问题的主要原因是频繁的内存访问。 然后,我们提出了一种新颖的部分卷积(PConv)作为一种有竞争力的替代方案,可以减少计算冗余以及内存访问次数。 图 1说明了我们的 PConv 的设计。 它利用特征图中的冗余,并仅在部分输入通道上系统地应用常规卷积(Conv),而其余通道保持不变。 从本质上讲,PConv 的 FLOPS 比常规 Conv 低,而比 DWConv/GConv 的 FLOPS 更高。 换句话说,PConv 更好地利用了设备上的计算能力。 PConv 在提取空间特征方面也很有效,正如本文后面的经验验证。
我们进一步介绍 FasterNet,它主要构建在我们的 PConv 之上,作为一个新的网络系列,可以在各种设备上高速运行。 特别是,我们的 FasterNet 在分类、检测和分割任务方面实现了最先进的性能,同时具有更低的延迟和更高的吞吐量。 例如,我们的小型 FasterNet-T0 在 GPU 上比 MobileViT-XXS [48] 快 、 和 、CPU 和 ARM 处理器,同时在 ImageNet-1k 上准确率提高 2.9%。 我们的大型 FasterNet-L 实现了 83.5% 的 top-1 准确率,与新兴的 Swin-B [41] 相当,同时 GPU 吞吐量提高了 36%,CPU 计算时间节省了 37%。 总而言之,我们的贡献如下:
-
•
我们指出了实现更高 FLOPS 的重要性,而不仅仅是减少 FLOPS 以实现更快的神经网络。
-
•
我们引入了一种简单而快速且有效的运算符,称为 PConv,它很有可能取代现有的首选 DWConv。
-
•
我们介绍 FasterNet,它在 GPU、CPU 和 ARM 处理器等各种设备上运行良好且普遍快速。
-
•
我们对各种任务进行了广泛的实验,并验证了 PConv 和 FasterNet 的高速性和有效性。
2相关工作
我们简要回顾了先前关于快速高效神经网络的工作,并将这项工作与它们区分开来。
CNN。 CNN 是计算机视觉领域的主流架构,尤其是在实践中部署时,快速与准确同样重要。 尽管已经有大量研究[55,56,7,8,83,33,21,86]来实现更高的效率,但它们背后的基本原理或多或少是为了执行低秩近似。 具体来说,组卷积[31]和深度可分离卷积[55](由深度卷积和点卷积组成)可能是最流行的。 它们已广泛应用于面向移动/边缘的网络,例如 MobileNets [25, 54, 24]、ShuffleNets [84, 46]、GhostNet [ 17]、EfficientNets [61, 62]、TinyNet [18]、Xception [8]、CondenseNet [ 27, 78]、TVConv [4]、MnasNet[60] 和 FBNet [74]。 虽然它们利用滤波器中的冗余来减少参数和 FLOP 的数量,但在增加网络宽度以补偿精度下降时,它们会受到内存访问量增加的影响。 相比之下,我们考虑了特征图中的冗余,并提出了部分卷积来减少 FLOP 和内存访问同时。
ViT、MLP 及其变体。 自从Dosovitskiy 等人开始,人们对ViT的研究越来越感兴趣。 [12]扩大了 Transformer 的应用范围[69] 从机器翻译[69]或预测[73]到计算机视觉领域。 许多后续工作都尝试在训练设置[65,66,58]和模型设计[41,40,72,15,85]方面改进ViT 。 一个值得注意的趋势是通过降低注意力算子 [1, 68, 29, 45, 63] 的复杂性,将卷积合并到 ViTs [10 中,以追求更好的准确性与延迟权衡。 , 6, 57],或同时执行 [3, 34, 52, 49]。 此外,其他研究[64,35,5]提出用简单的基于MLP的算子取代注意力。 然而,它们通常演变成类似 CNN 的[39]。 在本文中,我们重点分析卷积运算,特别是 DWConv,原因如下:首先,注意力相对于卷积的优势尚不明确或存在争议[71, 42]。 其次,基于注意力的机制通常比卷积机制运行得慢,因此不太受当前行业的青睐[48, 26]。 最后,DWConv 仍然是许多混合模型中的流行选择,因此值得仔细研究。
3PConv和FasterNet的设计
在本节中,我们首先重新审视 DWConv 并分析其频繁内存访问的问题。 然后我们引入 PConv 作为有竞争力的替代运营商来解决该问题。 之后,我们介绍 FasterNet 并解释其细节,包括设计注意事项。
3.1初步
DWConv 是 Conv 的一个流行变体,已被广泛采用作为许多神经网络的关键构建块。 对于输入 ,DWConv 应用 过滤器 来计算输出 。 如图图1(b)所示,每个滤波器在一个输入通道上进行空间滑动,并对一个输出通道做出贡献。 与具有 的常规 Conv 相比,这种深度计算使得 DWConv 的 FLOP 低至 。 虽然可以有效减少 FLOP,但 DWConv(通常后面跟着一个点卷积或 PWConv)不能简单地用来替换常规 Conv,因为它会导致准确度严重下降。 因此,在实践中,DWConv 的通道数 (或网络宽度)增加到 以补偿精度下降,例如。 ,反转残差块[54]中的DWConv宽度扩大了六倍。 然而,这会导致更高的内存访问量,从而导致不可忽略的延迟并减慢整体计算速度,特别是对于 I/O 密集型设备。 特别是,内存访问的数量现在升级为
| (2) |
高于常规转化率,即。,
| (3) |
请注意,内存访问花费在I/O操作上,这被认为已经是最小成本并且难以进一步优化。

3.2 部分卷积作为基本算子
下面我们证明,可以通过利用特征图的冗余来进一步优化成本。 如图图 3所示,不同通道之间的特征图具有高度相似性。 许多其他著作[17, 82]也涵盖了这种冗余,但很少有人以简单而有效的方式充分利用它。
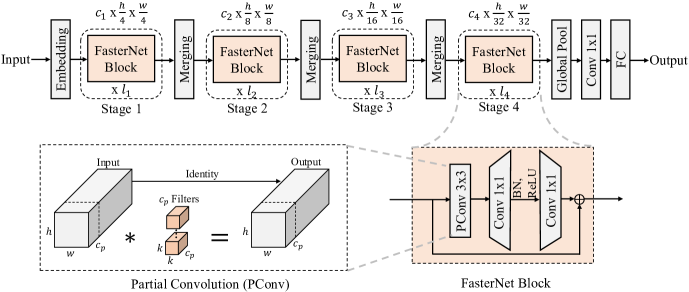
具体来说,我们提出了一个简单的 PConv 来同时减少计算冗余和内存访问。 图 4中的左下角说明了我们的 PConv 的工作原理。 它只是在部分输入通道上应用常规 Conv 以进行空间特征提取,而其余通道保持不变。 对于连续或常规的内存访问,我们将第一个或最后一个连续的 通道视为整个特征图的代表进行计算。 不失一般性,我们认为输入和输出特征图具有相同数量的通道。 因此,PConv 的 FLOP 仅为
| (4) |
使用典型的部分比率 时,PConv 的 FLOP 仅为常规 Conv 的 。 此外,PConv 的内存访问量较小,即。,
| (5) |
这只是 常规 Conv 的 。
由于只有个通道用于空间特征提取,有人可能会问我们是否可以简单地删除剩余的通道? 如果是这样,PConv 将降级为通道较少的常规 Conv,这偏离了我们减少冗余的目标。 请注意,我们保持剩余通道不变,而不是将它们从特征图中删除。 这是因为它们对于后续的 PWConv 层非常有用,该层允许特征信息流经所有通道。
3.3 PConv 随后是 PWConv
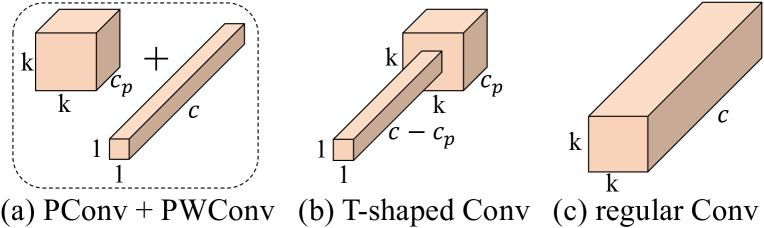
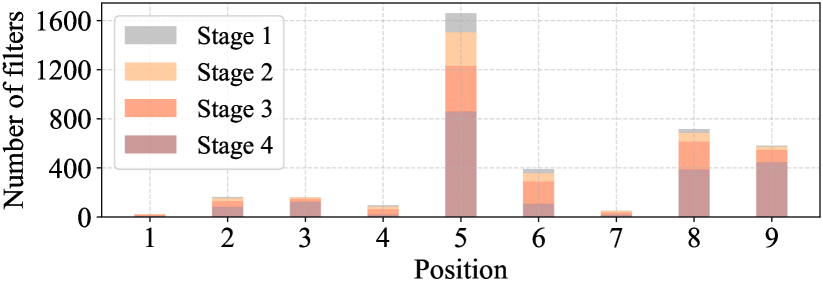
为了充分有效地利用来自所有通道的信息,我们进一步向 PConv 附加了点卷积 (PWConv)。 它们在输入特征图上的有效感受野一起看起来像一个T形Conv,与统一处理补丁的常规Conv相比,它更关注中心位置,如图图所示5。 为了证明这个 T 形感受野的合理性,我们首先通过计算位置方面的 Frobenius 范数来评估每个位置的重要性。 我们假设,如果某个位置的弗罗贝尼乌斯范数大于其他位置,则该位置往往更重要。 对于常规Conv过滤器,位置处的Frobenius范数由计算。 我们认为显着位置是具有最大弗罗贝尼乌斯范数的位置。 然后,我们共同检查预训练的 ResNet18 中的每个滤波器,找出它们的显着位置,并绘制显着位置的直方图。 图6中的结果表明,中心位置是滤波器中最常见的显着位置。 换句话说,中心位置的权重大于其周围邻居的权重。 这与集中于中心位置的T型计算是一致的。
虽然T形Conv可以直接用于高效计算,但我们表明最好将T形Conv分解为PConv和PWConv,因为分解利用了滤波器间的冗余并进一步节省了FLOP。 对于相同的输入和输出,T形Conv的FLOPs可以计算为
| (6) |
它高于 PConv 和 PWConv 的 FLOP,即。,
| (7) |
其中例如。当和时 此外,我们可以轻松地利用常规 Conv 来进行两步实施。
3.4 FasterNet作为通用骨干网
鉴于我们新颖的 PConv 和现成的 PWConv 作为主要构建算子,我们进一步提出了 FasterNet,这是一个新的神经网络系列,运行速度非常快,并且对于许多视觉任务非常有效。 我们的目标是使架构尽可能简单,没有花里胡哨的东西,使其总体上对硬件友好。
我们在图4中展示了整体架构。 它有四个分层阶段,每个阶段之前都有一个嵌入层(步幅为 4 的常规 Conv )或合并层(步幅为 2 的常规 Conv )空间下采样和通道数扩展。 每个阶段都有一堆 FasterNet 块。 我们观察到最后两个阶段的块消耗更少的内存访问并且往往具有更高的 FLOPS,正如在 选项卡。 1. 因此,我们放置了更多的 FasterNet 块,并相应地为最后两个阶段分配了更多的计算量。 每个 FasterNet 块都有一个 PConv 层,后面跟着两个 PWConv(或 Conv )层。 它们一起显示为反向残差块,其中中间层具有扩展数量的通道,并且放置快捷连接以重用输入特征。
除了上述算子之外,归一化层和激活层对于高性能神经网络也是不可或缺的。 然而,许多先前的工作[20,54,17]在整个网络中过度使用这些层,这可能会限制特征多样性,从而损害性能。 它还会减慢整体计算速度。 相比之下,我们仅将它们放在每个中间 PWConv 之后,以保留特征多样性并实现更低的延迟。 此外,我们使用批量归一化(BN)[30]而不是其他替代方法[2,67,75]。 BN 的好处是它可以合并到相邻的 Conv 层中,以实现更快的推理,同时与其他层一样有效。 至于激活层,考虑到运行时间和有效性,我们根据经验为较小的 FasterNet 变体选择 GELU [22],为较大的 FasterNet 变体选择 ReLU [51]。 最后三层,即即。全局平均池化、Conv和全连接层一起用于特征转换和分类。
为了在不同的计算预算下服务于广泛的应用程序,我们提供了 FasterNet 的微型、小型、中型和大型变体,称为 FasterNet-T0/1/2、FasterNet-S、FasterNet-M 和 FasterNet-L,分别。 它们具有相似的架构,但深度和宽度有所不同。 附录中提供了详细的架构规范。
4实验结果
我们首先检查 PConv 的计算速度及其与 PWConv 结合使用时的有效性。 然后,我们全面评估 FasterNet 在分类、检测和分割任务方面的性能。 最后,我们进行了简短的消融研究。
为了对延迟和吞吐量进行基准测试,我们选择了以下三种典型的处理器,它们涵盖了广泛的计算能力:GPU(2080Ti)、CPU(Intel i9-9900X,使用单线程)和ARM(Cortex-A72,使用单线程)。 我们报告批量大小为 1 的输入的延迟和批量大小为 32 的输入的吞吐量。 在推理过程中,BN 层会在适用的情况下合并到其相邻层。
4.1 PConv 速度快,FLOPS 高
| Operator | Feature map size | FLOPs (M), 10 layers | GPU | CPU | ARM | |||
|---|---|---|---|---|---|---|---|---|
| Throughput (fps) | FLOPS (G/s) | Latency (ms) | FLOPS (G/s) | Latency (ms) | FLOPS (G/s) | |||
| Conv 33 | 965656 | 2601 | 3010 | 7824 | 35.67 | 72.90 | 779.57 | 3.33 |
| 1922828 | 2601 | 4893 | 12717 | 28.41 | 91.53 | 619.64 | 4.19 | |
| 3841414 | 2601 | 4558 | 11854 | 31.85 | 81.66 | 595.09 | 4.37 | |
| 76877 | 2601 | 3159 | 8212 | 62.71 | 41.47 | 662.17 | 3.92 | |
| Average | - | 10151 | - | 71.89 | - | 3.95 | ||
| GConv 33 (16 groups) | 965656 | 162 | 2888 | 469 | 21.90 | 7.42 | 166.30 | 0.97 |
| 1922828 | 162 | 10811 | 1754 | 7.58 | 21.44 | 96.22 | 1.68 | |
| 3841414 | 162 | 15534 | 2514 | 4.40 | 36.88 | 63.57 | 2.55 | |
| 76877 | 162 | 16000 | 2598 | 4.28 | 37.97 | 65.20 | 2.49 | |
| Average | - | 1833 | - | 25.93 | - | 1.92 | ||
| DWConv 33 | 965656 | 27.09 | 11940 | 323 | 3.59 | 7.52 | 108.70 | 0.24 |
| 1922828 | 13.54 | 23358 | 315 | 1.97 | 6.86 | 82.01 | 0.16 | |
| 3841414 | 6.77 | 46377 | 313 | 1.06 | 6.35 | 94.89 | 0.07 | |
| 76877 | 3.38 | 88889 | 302 | 0.68 | 4.93 | 150.89 | 0.02 | |
| Average | - | 313 | - | 6.42 | - | 0.12 | ||
| PConv 33 (ours, with ) | 965656 | 162 | 9215 | 1493 | 5.46 | 29.67 | 85.30 | 1.90 |
| 1922828 | 162 | 14360 | 2326 | 3.09 | 52.43 | 66.46 | 2.44 | |
| 3841414 | 162 | 24408 | 3954 | 3.58 | 45.25 | 49.98 | 3.24 | |
| 76877 | 162 | 32866 | 5324 | 5.02 | 32.27 | 48.30 | 3.35 | |
| Average | - | 3274 | - | 39.91 | - | 2.73 | ||
下面我们展示了我们的 PConv 速度很快,并且更好地利用了设备上的计算能力。 具体来说,我们堆叠 10 层纯 PConv 并以典型维度的特征图作为输入。 然后,我们测量 GPU、CPU 和 ARM 处理器上的 FLOPS 和延迟/吞吐量,这也使我们能够进一步计算 FLOPS。 我们对其他卷积变体重复相同的过程并进行比较。
结果是 选项卡。 1 结果表明,对于高 FLOPS 和减少 FLOP 而言,PConv 总体而言是一个有吸引力的选择。 它仅具有常规 Conv 的 FLOPs,并且在 GPU、CPU 上比 DWConv 实现更高的 、 和 FLOPS 、 和 ARM 分别。 我们毫不惊讶地看到常规 Conv 具有最高的 FLOPS,因为它多年来一直在不断优化。 然而,它的总 FLOP 和延迟/吞吐量是无法承受的。 GConv 和 DWConv 尽管显着减少了 FLOPS,但 FLOPS 却急剧下降。 此外,他们倾向于增加通道数量来补偿性能下降,但这会增加延迟。
4.2 PConv 与 PWConv 配合使用有效
接下来我们将展示,PConv 后跟 PWConv 可以有效地逼近常规 Conv 来转换特征图。 为此,我们首先通过将 ImageNet-1k val 分割图像输入到预训练的 ResNet50 中来构建四个数据集,并在四个阶段的每个阶段中提取第一个 Conv 之前和之后的特征图。 每个特征图数据集进一步分为训练(70%)、验证(10%)和测试(20%)子集。 然后,我们构建一个由 PConv 和 PWConv 组成的简单网络,并在具有均方误差损失的特征图数据集上对其进行训练。 为了进行比较,我们还在相同设置下构建和训练 DWConv + PWConv 和 GConv + PWConv 网络。
选项卡。 2 显示 PConv + PWConv 实现了最低的测试损失,这意味着它们在特征转换中更好地逼近常规 Conv。 结果还表明,仅从部分特征图中捕获空间特征是足够且有效的。 PConv 显示出成为设计快速有效的神经网络的新首选的巨大潜力。
| Stage | DWConv+PWConv |
|
|
||||
|---|---|---|---|---|---|---|---|
| 1 | 0.0089 | 0.0065 | 0.0069 | ||||
| 2 | 0.0158 | 0.0137 | 0.0136 | ||||
| 3 | 0.0214 | 0.0202 | 0.0172 | ||||
| 4 | 0.0130 | 0.0128 | 0.0115 | ||||
| Average | 0.0148 | 0.0133 | 0.0123 |
4.3 ImageNet-1k 分类上的 FasterNet
| Network |
|
|
|
|
|
|
|||||||||||||||
| ShuffleNetV2 1.5 [46] | 3.5 | 0.30 | 4878 | 12.1 | 266 | 72.6 | |||||||||||||||
| MobileNetV2 [54] | 3.5 | 0.31 | 4198 | 12.2 | 442 | 72.0 | |||||||||||||||
| MobileViT-XXS [48] | 1.3 | 0.42 | 2393 | 30.8 | 348 | 69.0 | |||||||||||||||
| EdgeNeXt-XXS [47] | 1.3 | 0.26 | 2765 | 15.7 | 239 | 71.2 | |||||||||||||||
| FasterNet-T0 | 3.9 | 0.34 | 6807 | 9.2 | 143 | 71.9 | |||||||||||||||
| GhostNet 1.3 [17] | 7.4 | 0.24 | 2988 | 17.9 | 481 | 75.7 | |||||||||||||||
| ShuffleNetV2 2 [46] | 7.4 | 0.59 | 3339 | 17.8 | 403 | 74.9 | |||||||||||||||
| MobileNetV2 1.4 [54] | 6.1 | 0.60 | 2711 | 22.6 | 650 | 74.7 | |||||||||||||||
| MobileViT-XS [48] | 2.3 | 1.05 | 1392 | 40.8 | 648 | 74.8 | |||||||||||||||
| EdgeNeXt-XS [47] | 2.3 | 0.54 | 1738 | 24.4 | 434 | 75.0 | |||||||||||||||
| PVT-Tiny [72] | 13.2 | 1.94 | 1266 | 55.6 | 708 | 75.1 | |||||||||||||||
| FasterNet-T1 | 7.6 | 0.85 | 3782 | 17.7 | 285 | 76.2 | |||||||||||||||
| CycleMLP-B1 [5] | 15.2 | 2.10 | 865 | 116.1 | 892 | 79.1 | |||||||||||||||
| PoolFormer-S12 [79] | 11.9 | 1.82 | 1439 | 49.0 | 665 | 77.2 | |||||||||||||||
| MobileViT-S [48] | 5.6 | 2.03 | 1039 | 56.7 | 941 | 78.4 | |||||||||||||||
| EdgeNeXt-S [47] | 5.6 | 1.26 | 1128 | 39.2 | 743 | 79.4 | |||||||||||||||
| ResNet50 [20, 42] | 25.6 | 4.11 | 959 | 73.0 | 1131 | 78.8 | |||||||||||||||
| FasterNet-T2 | 15.0 | 1.91 | 1991 | 33.5 | 497 | 78.9 | |||||||||||||||
| CycleMLP-B2 [5] | 26.8 | 3.90 | 528 | 186.3 | 1502 | 81.6 | |||||||||||||||
| PoolFormer-S24 [79] | 21.4 | 3.41 | 748 | 92.8 | 1261 | 80.3 | |||||||||||||||
| PoolFormer-S36 [79] | 30.9 | 5.00 | 507 | 138.0 | 1860 | 81.4 | |||||||||||||||
| ConvNeXt-T [42] | 28.6 | 4.47 | 657 | 86.3 | 1889 | 82.1 | |||||||||||||||
| Swin-T [41] | 28.3 | 4.51 | 609 | 122.2 | 1424 | 81.3 | |||||||||||||||
| PVT-Small [72] | 24.5 | 3.83 | 689 | 89.6 | 1345 | 79.8 | |||||||||||||||
| PVT-Medium [72] | 44.2 | 6.69 | 438 | 143.6 | 2142 | 81.2 | |||||||||||||||
| FasterNet-S | 31.1 | 4.56 | 1029 | 71.2 | 1103 | 81.3 | |||||||||||||||
| PoolFormer-M36 [79] | 56.2 | 8.80 | 320 | 215.0 | 2979 | 82.1 | |||||||||||||||
| ConvNeXt-S [42] | 50.2 | 8.71 | 377 | 153.2 | 3484 | 83.1 | |||||||||||||||
| Swin-S [41] | 49.6 | 8.77 | 348 | 224.2 | 2613 | 83.0 | |||||||||||||||
| PVT-Large [72] | 61.4 | 9.85 | 306 | 203.4 | 3101 | 81.7 | |||||||||||||||
| FasterNet-M | 53.5 | 8.74 | 500 | 129.5 | 2092 | 83.0 | |||||||||||||||
| PoolFormer-M48 [79] | 73.5 | 11.59 | 242 | 281.8 | OOM | 82.5 | |||||||||||||||
| ConvNeXt-B [42] | 88.6 | 15.38 | 253 | 257.1 | OOM | 83.8 | |||||||||||||||
| Swin-B [41] | 87.8 | 15.47 | 237 | 349.2 | OOM | 83.5 | |||||||||||||||
| FasterNet-L | 93.5 | 15.52 | 323 | 219.5 | OOM | 83.5 |
| Backbone |
|
|
|
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet50 [20] | 44.2 | 253 | 54.9 | 38.0 | 58.6 | 41.4 | 34.4 | 55.1 | 36.7 | ||||||
| PoolFormer-S24 [79] | 41.0 | 233 | 111.0 | 40.1 | 62.2 | 43.4 | 37.0 | 59.1 | 39.6 | ||||||
| PVT-Small [72] | 44.1 | 238 | 89.5 | 40.4 | 62.9 | 43.8 | 37.8 | 60.1 | 40.3 | ||||||
| FasterNet-S | 49.0 | 258 | 54.3 | 39.9 | 61.2 | 43.6 | 36.9 | 58.1 | 39.7 | ||||||
| ResNet101 [20] | 63.2 | 329 | 68.9 | 40.4 | 61.1 | 44.2 | 36.4 | 57.7 | 38.8 | ||||||
| ResNeXt101-324d [77] | 62.8 | 333 | 80.5 | 41.9 | 62.5 | 45.9 | 37.5 | 59.4 | 40.2 | ||||||
| PoolFormer-S36 [79] | 50.5 | 266 | 146.9 | 41.0 | 63.1 | 44.8 | 37.7 | 60.1 | 40.0 | ||||||
| PVT-Medium [72] | 63.9 | 295 | 117.3 | 42.0 | 64.4 | 45.6 | 39.0 | 61.6 | 42.1 | ||||||
| FasterNet-M | 71.2 | 344 | 71.4 | 43.0 | 64.4 | 47.4 | 39.1 | 61.5 | 42.3 | ||||||
| ResNeXt101-644d [77] | 101.9 | 487 | 112.9 | 42.8 | 63.8 | 47.3 | 38.4 | 60.6 | 41.3 | ||||||
| PVT-Large [72] | 81.0 | 358 | 152.2 | 42.9 | 65.0 | 46.6 | 39.5 | 61.9 | 42.5 | ||||||
| FasterNet-L | 110.9 | 484 | 93.8 | 44.0 | 65.6 | 48.2 | 39.9 | 62.3 | 43.0 |
| Ablation | Variant |
|
|
|
|
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Partial ratio | w/ | 6626 | 9.6 | 145 | 71.7 | |||||||||||
| T0 w/ | 6807 | 9.2 | 143 | 71.9 | ||||||||||||
| w/ | 6204 | 8.9 | 140 | 71.3 | ||||||||||||
| Normalization | T0 w/ BN | 6807 | 9.2 | 143 | 71.9 | |||||||||||
| T0 w/ LN | 5515 | 10.7 | 159 | 71.9 | ||||||||||||
| Activation | T0 w/ ReLU | 6929 | 8.2 | 114 | 71.3 | |||||||||||
| w/ ReLU | 5866 | 9.3 | 143 | 71.7 | ||||||||||||
| T0 w/ GELU | 6807 | 9.2 | 143 | 71.9 | ||||||||||||
| T2 w/ ReLU | 1991 | 33.5 | 497 | 78.9 | ||||||||||||
| T2 w/ GELU | 1985 | 35.4 | 557 | 78.7 |
为了验证 FasterNet 的有效性和效率,我们首先在大规模 ImageNet-1k 分类数据集[53]上进行实验。 它涵盖了 1k 个常见对象类别,并包含约 130 万个用于训练的标记图像和 50k 个用于验证的标记图像。 我们使用 AdamW 优化器 [44] 对模型进行 300 轮训练。 我们将 FasterNet-M/L 的批量大小设置为 2048,将其他变体的批量大小设置为 4096。 我们使用余弦学习率调度器 [43] ,峰值为 和 20 epoch 线性预热。 我们应用常用的正则化和增强技术,包括权重衰减[32]、随机深度[28]、标签平滑[59]、 Mixup [81]、Cutmix [80] 和 Rand Augment [9],不同的 FasterNet 变体具有不同的幅度。 为了减少训练时间,我们对前 280 个训练周期使用 分辨率,对剩余 20 个训练周期使用 分辨率。 为了公平比较,我们不使用知识蒸馏[23]和神经架构搜索[87]。 我们报告了验证集的 top-1 准确度,中心裁剪分辨率为 ,裁剪比例为 0.9。 附录中提供了详细的训练和验证设置。
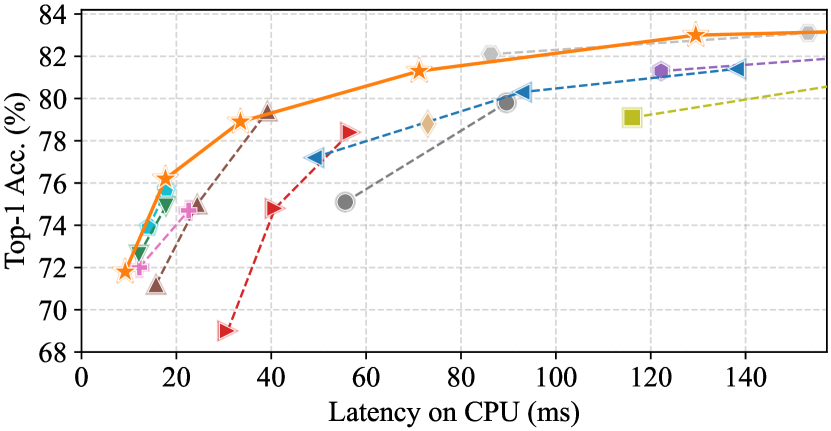
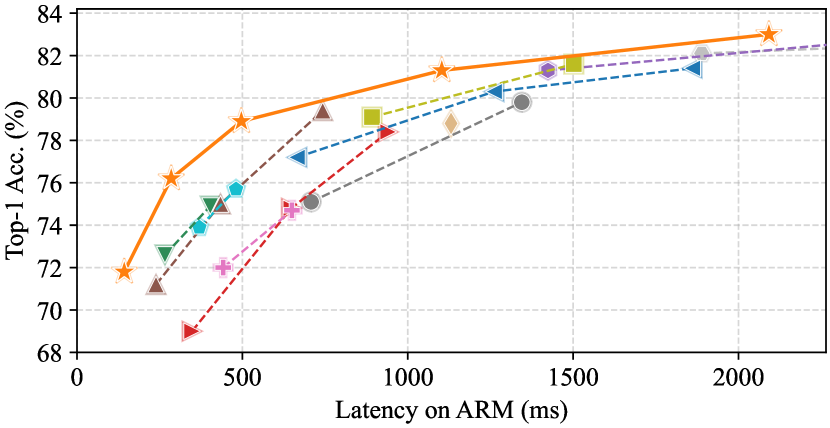
图7和 选项卡。 3 展示我们的 FasterNet 相对于最先进的分类模型的优越性。 图7中的权衡曲线清楚地表明FasterNet在平衡准确性和延迟方面设定了新的最先进水平/所有被检查网络的吞吐量。 从另一个角度来看,当具有类似的 top-1 精度时,FasterNet 在各种设备上比各种 CNN、ViT 和 MLP 模型运行得更快。 如定量所示 选项卡。 3在 GPU、CPU 和 ARM 处理器上,FasterNet-T0 的速度分别比 MobileViT-XXS [48] 、 和 更快,而精确度则高出 2.9%。 我们的大型 FasterNet-L 实现了 83.5% 的 top-1 准确率,与新兴的 Swin-B [41] 和 ConvNeXt-B [42] 相当,同时具有 36% 和 28 GPU 上的推理吞吐量提高了 %,并且 CPU 上的计算时间节省了 37% 和 15%。 鉴于如此有希望的结果,我们强调我们的 FasterNet 在架构设计方面比许多其他模型简单得多,这展示了设计简单但强大的神经网络的可行性。
4.4 下游任务上的 FasterNet
为了进一步评估 FasterNet 的泛化能力,我们在具有挑战性的 COCO 数据集 [36] 上进行了实验,用于对象检测和实例分割。 作为一种常见的做法,我们采用 ImageNet 预训练的 FasterNet 作为主干,并为其配备流行的 Mask R-CNN 检测器[19]。 为了突出骨干网本身的有效性,我们简单地遵循 PoolFormer [79] 并采用 AdamW 优化器、 训练计划(12 epoch)、批量大小为 16,和其他训练设置,无需进一步的超参数调整。
选项卡。 4 显示了 FasterNet 和代表性模型之间的比较结果。 FasterNet 具有更高的平均精度 (AP) 和相似的延迟,因此始终优于 ResNet 和 ResNext。 具体来说,与标准基线 ResNet50 相比,FasterNet-S 产生 更高的 box AP 和 更高的 mask AP。 FasterNet 还可以与 ViT 变体竞争。 在相似的 FLOP 下,FasterNet-L 将 PVT-Large 的延迟降低了 38%,即。,在 GPU 上从 152.2 ms 降低到 93.8 ms,并达到 更高的框 AP 和 更高的掩模 AP。
4.5消融研究
我们对部分比率的值以及激活层和归一化层的选择进行了简短的消融研究。 我们在 ImageNet top-1 准确度和设备上延迟/吞吐量方面比较了不同的变体。 结果总结为 选项卡。 5. 对于部分比率 ,我们默认将所有 FasterNet 变体的其设置为 ,这样可以在相似的复杂度下实现更高的精度、更高的吞吐量和更低的延迟。 太大的部分比率 会使 PConv 降级为常规 Conv,而太小的值会使 PConv 在捕获空间特征方面效果较差。 对于归一化层,我们选择 BatchNorm 而不是 LayerNorm,因为 BatchNorm 可以合并到其相邻的卷积层中以实现更快的推理,同时它在我们的实验中与 LayerNorm 一样有效。 对于激活函数,有趣的是,我们凭经验发现 GELU 比 ReLU 更有效地拟合 FasterNet-T0/T1 模型。 然而,FasterNet-T2/S/M/L 的情况则相反。 这里我们只展示两个例子 选项卡。 5 由于空间限制。 我们推测 GELU 通过具有更高的非线性来增强 FasterNet-T0/T1,而对于较大的 FasterNet 变体,其优势会逐渐消失。
5结论
在本文中,我们研究了许多已建立的神经网络每秒浮点运算次数 (FLOPS) 较低的常见且尚未解决的问题。 我们重新审视了瓶颈算子 DWConv,并分析了其速度下降的主要原因——频繁的内存访问。 为了克服这个问题并实现更快的神经网络,我们提出了一种简单而快速且有效的算子 PConv,它可以轻松插入到许多现有网络中。 我们进一步介绍了基于 PConv 构建的通用 FasterNet,它在各种设备和视觉任务上实现了最先进的速度和准确性权衡。 我们希望我们的 PConv 和 FasterNet 能够激发更多关于简单而有效的神经网络的研究,超越学术界,直接影响行业和社区。
致谢 这项工作得到了香港普通研究基金的部分支持,资助号为 16200120。 C.-H的工作。 Lee 得到了 NSF 授予的 IIS-2209921 的部分支持。
附录
在本附录中,我们提供了有关实验设置、完整比较图、架构配置、PConv 实现、与相关工作的比较、局限性和未来工作的更多详细信息。
附录AImageNet-1k实验设置
我们提供 ImageNet-1k 训练和评估设置 选项卡。 6. 它们可用于重现我们的主要结果 选项卡。 3 和图7。 不同的 FasterNet 变体在正则化和增强技术的程度上有所不同。 随着模型变大,幅度也会增加,以减轻过度拟合并提高准确性。 请注意,大多数比较的作品都在 选项卡。 3 和图 7,例如。、MobileViT、EdgeNext、PVT、CycleMLP 、ConvNeXt、Swin等,也采用了此类高级训练技术(ADT)。 有些甚至严重依赖超参数搜索。 对于其他没有 ADT 的,i.e.、ShuffleNetV2、MobileNetV2 和 GhostNet,虽然比较并不完全公平,但我们将它们包含在内以供参考。
附录B下游任务实验设置
对于 COCO2017 数据集上的对象检测和实例分割,我们为 FasterNet 主干配备了流行的 Mask R-CNN 检测器。 我们使用 ImageNet-1k 预训练权重来初始化主干网,并使用 Xavier 来初始化附加层。 详细设置总结于 选项卡。 7.
附录 CImageNet-1k 上的完整比较图
图 8显示了ImageNet-1k上的完整比较图,它是图的扩展> 主论文中的7具有较大的延迟范围。 图 8 显示了一致的结果,即 FasterNet 在平衡 GPU、CPU 和 ARM 上的准确性和延迟/吞吐量方面比其他模型取得了更好的权衡处理器。
附录D详细架构配置
我们在中介绍了详细的架构配置 选项卡。 8. 虽然不同的 FasterNet 变体共享统一的架构,但它们在网络宽度(通道数量)和网络深度(每个阶段的 FasterNet 块数量)方面有所不同。 架构末尾的分类器用于分类任务,但在其他下游任务中被删除。
| Variants | T0 | T1 | T2 | S | M | L |
|---|---|---|---|---|---|---|
| Train Res | 192 for epoch 1280, 224 for epoch 281300 | |||||
| Test Res | 224 | |||||
| Epochs | 300 | |||||
| # of forward pass | 188k | |||||
| Batch size | 4096 | 4096 | 4096 | 4096 | 2048 | 2048 |
| Optimizer | AdamW | |||||
| Momentum | 0.9/0.999 | |||||
| LR | 0.004 | 0.004 | 0.004 | 0.004 | 0.002 | 0.002 |
| LR decay | cosine | |||||
| Weight decay | 0.005 | 0.01 | 0.02 | 0.03 | 0.05 | 0.05 |
| Warmup epochs | 20 | |||||
| Warmup schedule | linear | |||||
| Label smoothing | 0.1 | |||||
| Dropout | ✗ | |||||
| Stoch. Depth | ✗ | 0.02 | 0.05 | 0.1 | 0.2 | 0.3 |
| Repeated Aug | ✗ | |||||
| Gradient Clip. | ✗ | ✗ | ✗ | ✗ | 1 | 0.01 |
| H. flip | ✓ | |||||
| RRC | ✓ | |||||
| Rand Augment | ✗ | 3/0.5 | 5/0.5 | 7/0.5 | 7/0.5 | 7/0.5 |
| Auto Augment | ✗ | |||||
| Mixup alpha | 0.05 | 0.1 | 0.1 | 0.3 | 0.5 | 0.7 |
| Cutmix alpha | 1.0 | |||||
| Erasing prob. | ✗ | |||||
| Color Jitter | ✗ | |||||
| PCA lighting | ✗ | |||||
| SWA | ✗ | |||||
| EMA | ✗ | |||||
| Layer scale | ✗ | |||||
| CE loss | ✓ | |||||
| BCE loss | ✗ | |||||
| Mixed precision | ✓ | |||||
| Test crop ratio | 0.9 | |||||
| Top-1 acc. (%) | 71.9 | 76.2 | 78.9 | 81.3 | 83.0 | 83.5 |
| Variants | S | M | L |
|---|---|---|---|
| Train and test Res | shorter side 800, longer side 1333 | ||
| Batch size | 16 (2 on each GPU) | ||
| Optimizer | AdamW | ||
| Train schedule | 1 schedule (12 epochs) | ||
| Weight decay | 0.0001 | ||
| Warmup schedule | linear | ||
| Warmup iterations | 500 | ||
| LR decay | StepLR at epoch 8 and 11 with decay rate 0.1 | ||
| LR | 0.0002 | 0.0001 | 0.0001 |
| Stoch. Depth | 0.15 | 0.2 | 0.3 |
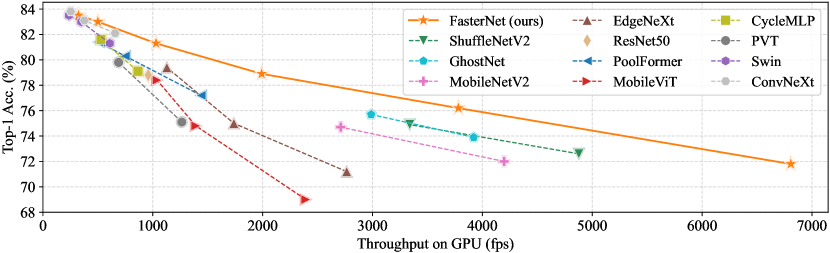
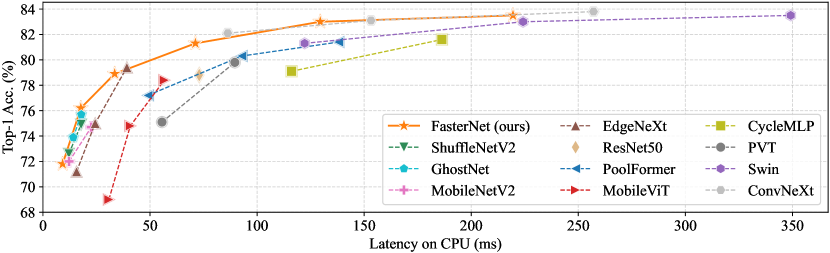
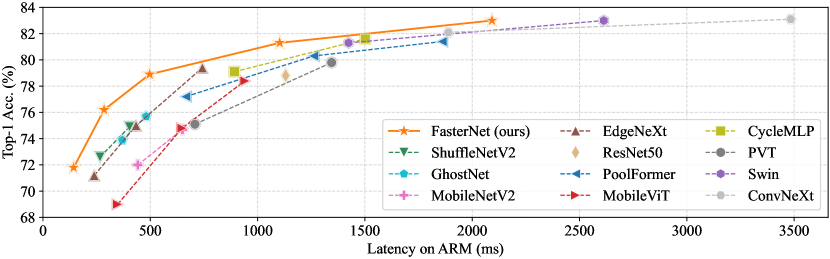
附录E与相关工作的更多比较
提高浮点运算次数。 还有一些其他作品 [11, 76] 也在研究 FLOPS 问题并尝试改进它。 他们通常遵循现有的算子并尝试找到合适的配置,例如。,RepLKNet [11]只是增加内核大小,而TRT-ViT [76] 对架构中的不同块重新排序。 相比之下,本文通过提出一种新颖且高效的 PConv 来推进该领域的发展,为 FLOPS 改进开辟了新的方向和潜在的更大空间。
| Name | Output size | Layer specification | T0 | T1 | T2 | S | M | L | |||||
| Embedding |
|
# Channels | 40 | 64 | 96 | 128 | 144 | 192 | |||||
| Stage 1 | # Blocks | 1 | 1 | 1 | 1 | 3 | 3 | ||||||
| Merging |
|
# Channels | 80 | 128 | 192 | 256 | 288 | 384 | |||||
| Stage 2 | # Blocks | 2 | 2 | 2 | 2 | 4 | 4 | ||||||
| Merging |
|
# Channels | 160 | 256 | 384 | 512 | 576 | 768 | |||||
| Stage 3 | # Blocks | 8 | 8 | 8 | 13 | 18 | 18 | ||||||
| Merging |
|
# Channels | 320 | 512 | 768 | 1024 | 1152 | 1536 | |||||
| Stage 4 | # Blocks | 2 | 2 | 2 | 2 | 3 | 3 | ||||||
| Classifier |
|
Acti | GELU | GELU | ReLU | ReLU | ReLU | ReLU | |||||
| FLOPs (G) | 0.34 | 0.85 | 1.90 | 4.55 | 8.72 | 15.49 | |||||||
| Params (M) | 3.9 | 7.6 | 15.0 | 31.1 | 53.5 | 93.4 | |||||||
PConv 与 GConv。 PConv 在原理上等同于修改后的 GConv [31],它在单个组上运行,而其他组保持不变。 虽然简单,但这种修改以前尚未探索过。 从某种意义上说,它也很重要,因为它可以防止操作员过度访问内存,并且计算效率更高。 从低秩近似的角度来看,PConv 通过进一步减少滤波器间冗余[16]之外的滤波器内冗余来改进 GConv。
FasterNet 与 ConvNeXt。 用我们的 PConv 替换 DWConv 后,我们的 FasterNet 看起来与 ConvNeXt [42] 类似。 然而,他们的动机不同。 虽然 ConvNeXt 通过反复试验寻找更好的结构,但我们在 PConv 之后附加 PWConv,以更好地聚合来自所有通道的信息。 此外,ConvNeXt 遵循 ViT 使用更少的激活函数,而我们有意将它们从 PConv 和 PWConv 中间删除,以最小化它们在逼近常规 Conv 时的误差。
其他有效推理的范例。 我们的工作重点是高效的网络设计,与其他范例正交,例如。、神经架构搜索(NAS)[13]、网络剪枝[50],以及知识蒸馏[23]。 它们可以在本文中应用以获得更好的性能。 然而,我们选择不这样做,以保持我们的核心理念为中心,并使绩效收益清晰和公平。
其他部分/屏蔽卷积工作。 有几个作品[38,14,37]与我们的 PConv 共享相似的名称。 然而,它们在目标和方法上有很大不同。 例如,他们对部分像素应用过滤器以排除无效补丁[38],启用自我监督学习[14],或合成新颖的图像[37] ,而我们的目标是通道维度以进行有效的推理。
附录F局限性和未来的工作
我们已经证明 PConv 和 FasterNet 快速有效,与现有运营商和网络具有竞争力。 然而本文存在一些小的技术限制。 一方面,PConv 的设计目的是仅对部分输入通道应用常规卷积,而其余通道保持不变。 因此,部分卷积的步幅应始终为 1,以便使卷积输出的空间分辨率与未触及通道的空间分辨率保持一致。 请注意,对空间分辨率进行下采样仍然是可行的,因为架构中可以有额外的下采样层。 另一方面,我们的 FasterNet 只是建立在具有可能有限的感受野的卷积算子之上。 未来可以努力扩大其感受野并与其他算子结合以追求更高的精度。
参考
- [1] Alaaeldin Ali, Hugo Touvron, Mathilde Caron, Piotr Bojanowski, Matthijs Douze, Armand Joulin, Ivan Laptev, Natalia Neverova, Gabriel Synnaeve, Jakob Verbeek, et al. Xcit: Cross-covariance image transformers. Advances in neural information processing systems, 34:20014–20027, 2021.
- [2] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- [3] Han Cai, Chuang Gan, and Song Han. Efficientvit: Enhanced linear attention for high-resolution low-computation visual recognition. arXiv preprint arXiv:2205.14756, 2022.
- [4] Jierun Chen, Tianlang He, Weipeng Zhuo, Li Ma, Sangtae Ha, and S-H Gary Chan. Tvconv: Efficient translation variant convolution for layout-aware visual processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12548–12558, 2022.
- [5] Shoufa Chen, Enze Xie, Chongjian Ge, Ding Liang, and Ping Luo. Cyclemlp: A mlp-like architecture for dense prediction. arXiv preprint arXiv:2107.10224, 2021.
- [6] Yinpeng Chen, Xiyang Dai, Dongdong Chen, Mengchen Liu, Xiaoyi Dong, Lu Yuan, and Zicheng Liu. Mobile-former: Bridging mobilenet and transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5270–5279, 2022.
- [7] Yunpeng Chen, Haoqi Fan, Bing Xu, Zhicheng Yan, Yannis Kalantidis, Marcus Rohrbach, Shuicheng Yan, and Jiashi Feng. Drop an octave: Reducing spatial redundancy in convolutional neural networks with octave convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3435–3444, 2019.
- [8] François Chollet. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1251–1258, 2017.
- [9] Ekin D Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V Le. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 702–703, 2020.
- [10] Zihang Dai, Hanxiao Liu, Quoc V Le, and Mingxing Tan. Coatnet: Marrying convolution and attention for all data sizes. Advances in Neural Information Processing Systems, 34:3965–3977, 2021.
- [11] Xiaohan Ding et al. Scaling up your kernels to 31x31: Revisiting large kernel design in cnns. In CVPR, 2022.
- [12] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- [13] Thomas Elsken, Jan Hendrik Metzen, and Frank Hutter. Neural architecture search: A survey. The Journal of Machine Learning Research, 20(1):1997–2017, 2019.
- [14] Peng Gao, Teli Ma, Hongsheng Li, Jifeng Dai, and Yu Qiao. Convmae: Masked convolution meets masked autoencoders. arXiv preprint arXiv:2205.03892, 2022.
- [15] Benjamin Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, and Matthijs Douze. Levit: a vision transformer in convnet’s clothing for faster inference. In Proceedings of the IEEE/CVF international conference on computer vision, pages 12259–12269, 2021.
- [16] Daniel Haase et al. Rethinking depthwise separable convolutions: How intra-kernel correlations lead to improved mobilenets. In CVPR, 2020.
- [17] Kai Han, Yunhe Wang, Qi Tian, Jianyuan Guo, Chunjing Xu, and Chang Xu. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1580–1589, 2020.
- [18] Kai Han, Yunhe Wang, Qiulin Zhang, Wei Zhang, Chunjing Xu, and Tong Zhang. Model rubik’s cube: Twisting resolution, depth and width for tinynets. Advances in Neural Information Processing Systems, 33:19353–19364, 2020.
- [19] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017.
- [20] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [21] Tianlang He, Jiajie Tan, Weipeng Zhuo, Maximilian Printz, and S-H Gary Chan. Tackling multipath and biased training data for imu-assisted ble proximity detection. In IEEE INFOCOM 2022-IEEE Conference on Computer Communications, pages 1259–1268. IEEE, 2022.
- [22] Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.
- [23] Geoffrey Hinton, Oriol Vinyals, Jeff Dean, et al. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2(7), 2015.
- [24] Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF international conference on computer vision, pages 1314–1324, 2019.
- [25] Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017.
- [26] Han Hu, Zheng Zhang, Zhenda Xie, and Stephen Lin. Local relation networks for image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3464–3473, 2019.
- [27] Gao Huang, Shichen Liu, Laurens Van der Maaten, and Kilian Q Weinberger. Condensenet: An efficient densenet using learned group convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2752–2761, 2018.
- [28] Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian Q Weinberger. Deep networks with stochastic depth. In European conference on computer vision, pages 646–661. Springer, 2016.
- [29] Tao Huang, Lang Huang, Shan You, Fei Wang, Chen Qian, and Chang Xu. Lightvit: Towards light-weight convolution-free vision transformers. arXiv preprint arXiv:2207.05557, 2022.
- [30] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, pages 448–456. PMLR, 2015.
- [31] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25, 2012.
- [32] Anders Krogh and John Hertz. A simple weight decay can improve generalization. Advances in neural information processing systems, 4, 1991.
- [33] Yunsheng Li, Yinpeng Chen, Xiyang Dai, Dongdong Chen, Mengchen Liu, Lu Yuan, Zicheng Liu, Lei Zhang, and Nuno Vasconcelos. Micronet: Improving image recognition with extremely low flops. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 468–477, 2021.
- [34] Yanyu Li, Geng Yuan, Yang Wen, Eric Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, and Jian Ren. Efficientformer: Vision transformers at mobilenet speed. arXiv preprint arXiv:2206.01191, 2022.
- [35] Dongze Lian, Zehao Yu, Xing Sun, and Shenghua Gao. As-mlp: An axial shifted mlp architecture for vision. arXiv preprint arXiv:2107.08391, 2021.
- [36] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014.
- [37] Guilin Liu, Aysegul Dundar, Kevin J Shih, Ting-Chun Wang, Fitsum A Reda, Karan Sapra, Zhiding Yu, Xiaodong Yang, Andrew Tao, and Bryan Catanzaro. Partial convolution for padding, inpainting, and image synthesis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
- [38] Guilin Liu, Fitsum A Reda, Kevin J Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro. Image inpainting for irregular holes using partial convolutions. In Proceedings of the European conference on computer vision (ECCV), pages 85–100, 2018.
- [39] Ruiyang Liu, Yinghui Li, Linmi Tao, Dun Liang, and Hai-Tao Zheng. Are we ready for a new paradigm shift? a survey on visual deep mlp. Patterns, 3(7):100520, 2022.
- [40] Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12009–12019, 2022.
- [41] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012–10022, 2021.
- [42] Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11976–11986, 2022.
- [43] Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016.
- [44] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- [45] Jiachen Lu, Jinghan Yao, Junge Zhang, Xiatian Zhu, Hang Xu, Weiguo Gao, Chunjing Xu, Tao Xiang, and Li Zhang. Soft: softmax-free transformer with linear complexity. Advances in Neural Information Processing Systems, 34:21297–21309, 2021.
- [46] Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, and Jian Sun. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European conference on computer vision (ECCV), pages 116–131, 2018.
- [47] Muhammad Maaz, Abdelrahman Shaker, Hisham Cholakkal, Salman Khan, Syed Waqas Zamir, Rao Muhammad Anwer, and Fahad Shahbaz Khan. Edgenext: efficiently amalgamated cnn-transformer architecture for mobile vision applications. arXiv preprint arXiv:2206.10589, 2022.
- [48] Sachin Mehta and Mohammad Rastegari. Mobilevit: light-weight, general-purpose, and mobile-friendly vision transformer. arXiv preprint arXiv:2110.02178, 2021.
- [49] Sachin Mehta and Mohammad Rastegari. Separable self-attention for mobile vision transformers. arXiv preprint arXiv:2206.02680, 2022.
- [50] Pavlo Molchanov, Stephen Tyree, Tero Karras, Timo Aila, and Jan Kautz. Pruning convolutional neural networks for resource efficient inference. arXiv preprint arXiv:1611.06440, 2016.
- [51] Vinod Nair and Geoffrey E Hinton. Rectified linear units improve restricted boltzmann machines. In Icml, 2010.
- [52] Junting Pan, Adrian Bulat, Fuwen Tan, Xiatian Zhu, Lukasz Dudziak, Hongsheng Li, Georgios Tzimiropoulos, and Brais Martinez. Edgevits: Competing light-weight cnns on mobile devices with vision transformers. arXiv preprint arXiv:2205.03436, pages 1–6, 2022.
- [53] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3):211–252, 2015.
- [54] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4510–4520, 2018.
- [55] Laurent Sifre and Stéphane Mallat. Rigid-motion scattering for texture classification. arXiv preprint arXiv:1403.1687, 2014.
- [56] Pravendra Singh, Vinay Kumar Verma, Piyush Rai, and Vinay P Namboodiri. Hetconv: Heterogeneous kernel-based convolutions for deep cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4835–4844, 2019.
- [57] Aravind Srinivas, Tsung-Yi Lin, Niki Parmar, Jonathon Shlens, Pieter Abbeel, and Ashish Vaswani. Bottleneck transformers for visual recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16519–16529, 2021.
- [58] Andreas Steiner, Alexander Kolesnikov, Xiaohua Zhai, Ross Wightman, Jakob Uszkoreit, and Lucas Beyer. How to train your vit? data, augmentation, and regularization in vision transformers. arXiv preprint arXiv:2106.10270, 2021.
- [59] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016.
- [60] Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, and Quoc V Le. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2820–2828, 2019.
- [61] Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning, pages 6105–6114. PMLR, 2019.
- [62] Mingxing Tan and Quoc Le. Efficientnetv2: Smaller models and faster training. In International Conference on Machine Learning, pages 10096–10106. PMLR, 2021.
- [63] Shitao Tang, Jiahui Zhang, Siyu Zhu, and Ping Tan. Quadtree attention for vision transformers. arXiv preprint arXiv:2201.02767, 2022.
- [64] Ilya O Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, et al. Mlp-mixer: An all-mlp architecture for vision. Advances in Neural Information Processing Systems, 34:24261–24272, 2021.
- [65] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning, pages 10347–10357. PMLR, 2021.
- [66] Hugo Touvron, Matthieu Cord, and Hervé Jégou. Deit iii: Revenge of the vit. arXiv preprint arXiv:2204.07118, 2022.
- [67] Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky. Instance normalization: The missing ingredient for fast stylization. arXiv preprint arXiv:1607.08022, 2016.
- [68] Ashish Vaswani, Prajit Ramachandran, Aravind Srinivas, Niki Parmar, Blake Hechtman, and Jonathon Shlens. Scaling local self-attention for parameter efficient visual backbones. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12894–12904, 2021.
- [69] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [70] Shakti N Wadekar and Abhishek Chaurasia. Mobilevitv3: Mobile-friendly vision transformer with simple and effective fusion of local, global and input features. arXiv preprint arXiv:2209.15159, 2022.
- [71] Guangting Wang, Yucheng Zhao, Chuanxin Tang, Chong Luo, and Wenjun Zeng. When shift operation meets vision transformer: An extremely simple alternative to attention mechanism. arXiv preprint arXiv:2201.10801, 2022.
- [72] Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 568–578, 2021.
- [73] Song Wen, Hao Wang, and Dimitris Metaxas. Social ode: Multi-agent trajectory forecasting with neural ordinary differential equations. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXII, pages 217–233. Springer, 2022.
- [74] Bichen Wu, Xiaoliang Dai, Peizhao Zhang, Yanghan Wang, Fei Sun, Yiming Wu, Yuandong Tian, Peter Vajda, Yangqing Jia, and Kurt Keutzer. Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10734–10742, 2019.
- [75] Yuxin Wu and Kaiming He. Group normalization. In Proceedings of the European conference on computer vision (ECCV), pages 3–19, 2018.
- [76] Xin Xia et al. Trt-vit: Tensorrt-oriented vision transformer. arXiv preprint, 2022.
- [77] Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, and Kaiming He. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1492–1500, 2017.
- [78] Le Yang, Haojun Jiang, Ruojin Cai, Yulin Wang, Shiji Song, Gao Huang, and Qi Tian. Condensenet v2: Sparse feature reactivation for deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3569–3578, 2021.
- [79] Weihao Yu, Mi Luo, Pan Zhou, Chenyang Si, Yichen Zhou, Xinchao Wang, Jiashi Feng, and Shuicheng Yan. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10819–10829, 2022.
- [80] Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6023–6032, 2019.
- [81] Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412, 2017.
- [82] Qiulin Zhang, Zhuqing Jiang, Qishuo Lu, Jia’nan Han, Zhengxin Zeng, Shang-Hua Gao, and Aidong Men. Split to be slim: An overlooked redundancy in vanilla convolution. arXiv preprint arXiv:2006.12085, 2020.
- [83] Ting Zhang, Guo-Jun Qi, Bin Xiao, and Jingdong Wang. Interleaved group convolutions. In Proceedings of the IEEE international conference on computer vision, pages 4373–4382, 2017.
- [84] Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, and Jian Sun. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6848–6856, 2018.
- [85] Shuhan Zhong, Sizhe Song, Guanyao Li, and S-H Gary Chan. A tree-based structure-aware transformer decoder for image-to-markup generation. In Proceedings of the 30th ACM International Conference on Multimedia, pages 5751–5760, 2022.
- [86] Weipeng Zhuo, Ka Ho Chiu, Jierun Chen, Jiajie Tan, Edmund Sumpena, S-H Gary Chan, Sangtae Ha, and Chul-Ho Lee. Semi-supervised learning with network embedding on ambient rf signals for geofencing services. arXiv preprint arXiv:2210.07889, 2022.
- [87] Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. arXiv preprint arXiv:1611.01578, 2016.