Uni3D:多数据集 3D 对象检测的统一基线
摘要
当前的 3D 对象检测模型遵循单一数据集特定的训练和测试范例,当直接部署在另一个数据集中时,通常会面临严重的检测精度下降。 在本文中,我们研究了从多个数据集训练统一 3D 检测器的任务。 我们观察到这似乎是一项具有挑战性的任务,这主要是因为这些数据集呈现出由不同激光雷达类型和数据采集标准引起的巨大数据级别差异和分类级别变化。 受这种观察的启发,我们提出了一种 Uni3D,它利用简单的数据级校正操作和设计的语义级耦合和重新耦合模块来分别减轻不可避免的数据级和分类级差异。 我们的方法简单且易于与许多 3D 对象检测基线(例如 PV-RCNN 和 Voxel-RCNN)相结合,使它们能够有效地从多个现成的 3D 数据集中学习,以获得更具区分性和通用性的表示。 在许多数据集整合设置上进行了实验,包括 Waymo-nuScenes、nuScenes-KITTI、Waymo-KITTI 和 Waymo-nuScenes-KITTI 整合。 他们的结果表明,Uni3D 超越了在单个数据集上训练的一系列单独检测器,其参数比选定的基线检测器增加了 1.04 倍。 我们预计这项工作将激发 3D 泛化的研究,因为它将突破感知性能的极限。 我们的代码位于:https://github.com/PJLab-ADG/3DTrans。
1简介
基于 LiDAR 的 3D 对象检测[5, 25, 17, 18, 37, 4, 2, 10, 32]旨在使用 LiDAR 传感器识别和定位给定帧中的实例对象,该传感器最近已由于 Waymo [22]、nuScenes [1] 和 KITTI [5 等大规模注释 3D LiDAR 数据集的快速发展,取得了巨大进展]。
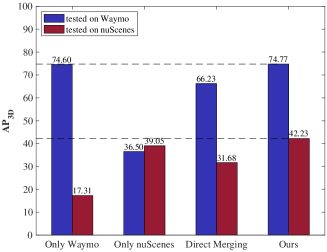
不幸的是,现有的有监督 3D 目标检测模型是按照典型的单数据集训练和测试范式设计的,当这些检测模型时,不可避免地会遇到严重的精度下降问题[29, 30]直接部署到具有不同数据分布的另一个数据集。 例如,图 1 表明在 Waymo [22] 上训练的基线检测器出现了严重的检测精度下降(从 到 )当它在另一个不同的数据集 nuScenes [1] 上进行评估时。 因此,这种单数据集训练和测试范式无法在不同数据集上表现良好,进一步损害了当前 3D 感知模型的数据集级泛化能力。
为了减少不同 3D 数据集之间的差异,一些研究人员[11,29,30,25,26]尝试利用无监督域适应(UDA)技术,该技术旨在传输预先训练的模型源域检测器到新域(或数据集)。 尽管这些基于UDA的3D物体检测工作在新的目标域上取得了良好的检测精度增益,但它们仍然是源到目标的单向模型适应过程,而不是多数据集双向泛化过程。
因此,为了设计一个能够充分学习不同目标数据集的统一的 3D 物体检测框架,我们首先直接合并多个数据集,并在合并的数据集上重新训练基线检测器,并发现通过这种方法实现的多数据集检测精度简单的方法并不令人满意,如图1中直接合并的结果所示。 这主要是因为与2D图像域相比,3D点云数据呈现出更严重的跨数据集差异,其原因包括传感器类型差异、交通场景变化、数据采集变化等多种复杂原因等,这被称为数据集干扰问题。 此外,随着自动驾驶数据集的不断增加,如何从如此多样化的3D数据集中训练统一的检测器成为一个非常重要的课题。
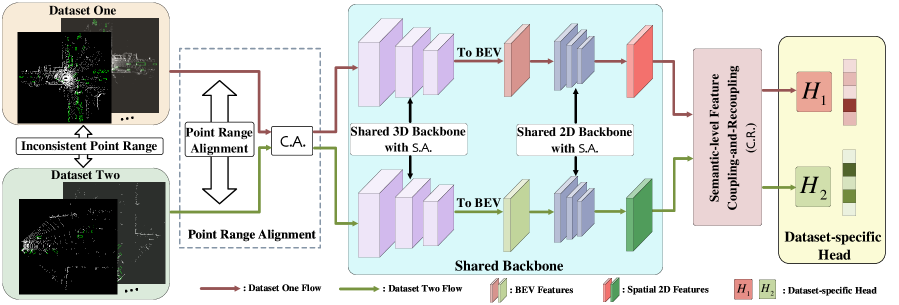
在本文中,我们提出了一个统一 3D 对象检测框架(Uni3D)来解决数据集干扰问题。 与现有的 3D 对象检测研究工作[17,4,10,19,27]正交,重点是开发在单个数据集中验证的有效框架,Uni3D 旨在提出一种简单而通用的方法使现有的3D物体检测模型具有从许多多样化的3D数据集中学习的能力。 为了实现这一目标,我们设计了一个简单的数据级校正操作,可以使用数据集特定的通道均值和方差来规范化每个骨干层的特征。 此外,语义级耦合和重新耦合模块旨在通过计算空间注意力图和数据集级注意力掩模来将学习到的高级特征约束为数据集,从而增强跨不同3D数据集的特征可重用性-不可知论者。
在 Waymo [22]、nuScenes [1] 和 KITTI [5] 三个公共 3D 自动驾驶数据集上进行了大量实验,调查 3D 数据集干扰问题的原因。 此外,本文提供了许多基础知识研究,探索在合并数据集下训练 3D 对象检测模型的可能性。 实验结果表明,Uni3D具有很强的数据集级泛化能力,提高了对未见过场景的零样本学习能力,甚至超越了在单个数据集上训练的基线方法。
2相关作品
2.1 基于LiDAR的通用3D物体检测
最近基于 LiDAR 的 3D 物体检测工作[2, 4, 10, 13, 19, 20, 17, 27, 28, 31, 37]可以大致分为基于体素的方法,点-基于方法和点体素融合方法。 基于体素的方法[21,27,37]在骨干特征提取之前将不规则的LiDAR点转换为有序体素。 SECOND [27]是一项利用稀疏卷积作为3D主干的先前工作,大大提高了检测效率。 Voxel-RCNN[4]分析了体素特征的优势,探索了检测精度和推理速度之间的良好权衡。 与基于体素的方法不同,基于点的方法[33, 19]直接从原始点云生成特征图。 受 PointNet [14] 和 PointNet++ [15] 的启发,Point-RCNN [19] 是研究如何生成边界框的先驱点云数据。 为了降低基于点的方法的高内存和计算成本,IA-SSD[33]提出了一种单阶段方法,采用基于学习的实例感知下采样策略。 此外,一些作品尝试结合基于点和基于体素的表示的优点。 其中,PV-RCNN[17]设计了点体素特征集抽象,将点特征和体素特征充分结合起来。 然而,上述检测器是在单个 3D 数据集中进行训练和评估的,它们在不同数据集上会遇到严重的检测精度下降问题。 此外,由于更严重的数据集级别差距,在 3D 场景中学习不同数据集之间的泛化表示更具挑战性。
2.2 多个数据集联合训练
对于传统的2D感知任务,例如目标检测[38, 16]和语义分割[35],从不同数据集训练统一模型会导致识别精度较低,因为不同的数据集通常呈现不一致的类定义和标注粒度。 受此启发,一些研究人员开始研究如何实现多数据集感知任务[24,36,9,34,3,6]。 早期作品[9, 34]专注于将分类信息和模型合并到统一的标签空间上。 Mseg [9]对齐了七个数据集的像素级注释,显着提高了模型的泛化能力。 赵等人。[34]建议训练一个特定于数据集的检测器来生成伪标签,该标签提供来自另一个数据集的附加标注信息,最终网络使用伪标签和真实数据在特定数据集上进行训练。 为了减轻统一标签空间的标注成本,最近的工作[24, 36]尝试使用特定于数据集的监督。 Wang 等人。 [24]采用设计的域适应层和注意机制来减轻数据集级别的差异。 Zhou 等人. [36]引入了一种新颖的自动方法来合并分类空间,表明在多个数据集上训练的统一检测器可以优于每个检测器都在特定数据集上进行训练。 尽管最近在 2D 感知任务中联合训练统一检测器已得到研究,但其在 3D 感知任务(例如 3D 物体检测)上的进一步探索仍然不足。
3建议的方法
整体框架如图3所示。 我们首先描述我们的问题设置和多数据集评估方法。 接下来,我们分析当前基线检测器在多数据集检测中的局限性,然后介绍一个简单的解决方案,即Uni3D。
3.1初步
问题设置。 假设域由 上的联合概率分布 定义,其中 和 是输入点云和标签空间,分别。 在多域融合(MDF)范围内,表示可用于模型训练的域的数量,其中每个单独的域 与特定数据分布 相关联。 MDF的目的是从多个标记域训练一个统一的模型,以获得更通用的表示,这将在多个不同域上具有最小的预测误差t2>。
3D 多数据集训练和评估。 假设在实际应用中,我们可以同时访问多个基于标记的 3D 点云域或数据集(例如 Waymo [22] 和 nuScenes [1]),但这些标记数据集通常具有不同的标签空间,例如仅出现在nuScenes中的Barrier类别[1]。 我们的研究主要针对自动驾驶场景下的MDF,针对与自动驾驶场景相关的感兴趣类别:车辆、行人、骑行者进行模型训练和评估。 需要注意的是,这种选择常见类别(例如车辆、行人、骑行者类别)来进行预备知识研究的设置在许多跨数据集的 3D 检测工作中非常常见,例如 ST3D [29]、ST3D++ [30]。
3.2 当单数据集3D探测器遇到多个数据集时
单数据集 3D 物体检测。 目前,最先进的 3D 对象检测模型 [20, 27, 17, 18, 4, 10] 在单个公共基准 [22, 1] 内进行训练和评估,可以视为所谓的单数据集训练范式。 在这里,为了更好地说明我们的 MDF 任务,我们首先将当前 3D 目标检测模型的优化目标总结如下:
| (1) |
其中用于生成预设提案的准确定位预测,有助于细化提案以获得最终的3D边界框结果。 此外,一些 3D 基线检测器,例如 PV-RCNN [17] 和 PV-RCNN++ [18],使用关键点预测损失 可以识别重要的前景点并实现关键点到网格的RoI特征提取过程。
基于 MDF 的 3D 对象检测的限制。 在多个数据集上进行训练的一种自然方法是将所有源数据集简单地组合成一个合并但更大的数据集。 不幸的是,我们对这种自然数据集组合方式的初步尝试表明,与每个特定子数据集上的训练性能相比,在合并数据集上训练的检测器的性能显着下降。
如第 2 节的表 3 所示。 4.3,我们观察到,通过比较Single-dataset和Direct Merging基线,对于3D场景级数据集,直接执行数据集级合并无助于提高检测器的跨数据集检测精度。 相反,由于不同数据集之间的显着差异,检测器可能会受到特征学习干扰。 例如,Voxel-RCNN [4] 仅在 Waymo 上训练时可以获得相对较高的检测精度(Waymo 验证集上的 AP 为 75.08)[ 22]数据集。 但当 Voxel-RCNN 在 Waymo 和 nuScenes 的组合数据集上联合训练时,它面临着严重的性能下降(在 Waymo 验证集上只有 66.67 AP)。
在这里,通过大量的实验,我们给出了上述性能下降问题的两个主要原因。
| Datasets | Beam | VFOV | Point Range | Collection Location |
|---|---|---|---|---|
| Waymo [22] | 64 | [, ] | L=[-75.2, 75.2]m | USA |
| W=[-75.2, 75.2]m | ||||
| H=[-2.0, 4.0]m | ||||
| KITTI [5] | 64 | [, ] | L=[0.0, 70.4]m | Germany |
| W=[-40.0, 40.0]m | ||||
| H=[-3.0, 1.0]m | ||||
| nuScenes [1] | 32 | [, ] | L=[-51.2, 51.2]m | USA/Singapore |
| W=[-51.2, 51.2]m | ||||
| H=[-5.0, 3.0]m |
1)数据级别差异:与由具有一致值范围[0, 255]的像素组成的2D自然图像相比,3D点云通常是使用具有不同点云的不同传感器类型来收集的范围,这导致数据集之间的分布差异。 三个广泛使用的数据集的主要区别如表1所示。 实际上,我们从表2中发现,传感器导出的点范围差异是干扰从多个数据集学习共同特征的主要因素,这是由于相同物体的感受野大小差异很大当点云范围不一致的数据被输入 3D 检测器时。 因此,点云范围对齐是实现多数据集 3D 物体检测的必要预处理步骤。
| Methods | Waymo Range | KITTI Range | tested on Waymo | tested on KITTI |
| / | / | |||
| Not Align. | L=[-75.2, 75.2]m | L=[0.0, 70.4]m | 26.93 / 26.56 | 89.56 / 83.14 |
| W=[-75.2, 75.2]m | W=[-40.0, 40.0]m | |||
| H=[-2.0, 4.0]m | H=[-3.0, 1.0]m | |||
| Align. (w/ ours) | L=[-75.2, 75.2]m | L=[-75.2, 75.2]m | 74.83 / 74.33 | 90.03 / 82.39 |
| W=[-75.2, 75.2]m | W=[-75.2, 75.2]m | |||
| H=[-2.0, 4.0]m | H=[-2.0, 4.0]m | |||
| Methods | nuScenes Range | KITTI Range | tested on nuScenes | tested on KITTI |
| / | / | |||
| Not Align. | L=[-51.2, 51.2]m | L=[0.0, 70.4]m | 21.32 / 15.35 | 89.35 / 81.66 |
| W=[-51.2, 51.2]m | W=[-40.0, 40.0]m | |||
| H=[-5.0, 3.0]m | H=[-3.0, 1.0]m | |||
| Align. (w/ ours) | L=[-75.2, 75.2]m | L=[-75.2, 75.2]m | 59.25 / 41.51 | 90.09 / 83.10 |
| W=[-75.2, 75.2]m | W=[-75.2, 75.2]m | |||
| H=[-2.0, 4.0]m | H=[-2.0, 4.0]m |
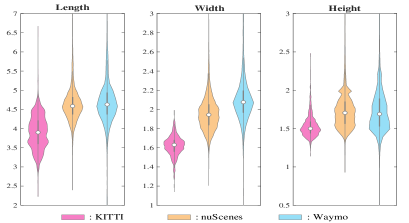
此外,如图2所示,由于3D数据集是在不同城市和国家收集的,其实例大小差异很大,因此不同数据集的点云呈现出更加多样化的数据分布。
2)分类级别差异:考虑到不同自动驾驶制造商采用的类别定义和标注粒度不一致。 例如,对于 Waymo [22],所有在道路上行驶的车辆,包括汽车和卡车,都被注释为一个统一的类别,即“车辆”。 而对于 nuScenes [1],不同的车辆使用不同粒度的不同分类法进行注释,例如“Car”、“Truck”和“Van”。 因此,MDF 任务需要考虑如何在不一致的分类标签空间下训练 3D 检测器,并有效地重用可以在不同数据集之间共享的与领域无关的知识。
3.3 Uni3D:统一的 3D 多数据集对象检测基线
为了解决上一节中描述的数据和分类级别差异问题,我们的目标是开发简单的模块,使现有的 3D 检测器[17, 4]能够从不同的数据集中学习可概括的表示。
数据级校正操作。 首先,为了完成数据级校正操作,我们引入了统计级对齐(S.A.),它可以减轻常见2D或3D主干提取的特征的统计级差异。 该方法可以与任何 3D 检测器结合使用,包括 PV-RCNN [17] 和 Voxel-RCNN [4]。
具体来说,假设 和 表示第 网络层中每个通道的均值和方差。 通常,使用基本的均值和方差统计来对每一层的特征进行归一化,使得每一层的输入数据符合零均值和单方差,例如 BN [8] 。 然而,这种统计数据共享的归一化方式可能会损害 MDF 训练中的模型可迁移性,因为一个批量大小内的数据可能来自具有较大均值和方差差异的不同数据集。 为此,在 MDF 设置下,我们首先从第 数据集获取数据集特定的通道均值 和 方差。 然后,每个数据集的样本通过当前数据集特定的均值/方差进行正则化,如下所示:
| (2) |
其中表示第数据集中各网络层的输入特征,添加是为了保证数值稳定性。 此外,与BN [8]类似,采用变换步骤来恢复表示能力,如下所示:
| (3) |
我们使用数据集共享的 gamma 和 beta ,因为在将来自不同数据集的特征标准化为零均值和单方差之后,第一个/中的数据集间差异二阶是对齐的,此外,对于不同的数据集使用相同的 gamma 和 beta 是合理的。
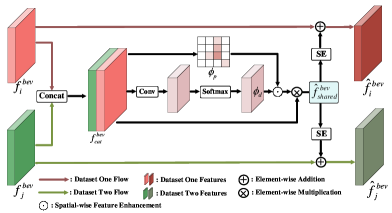
语义级特征耦合和重新耦合模块。 在这一部分中,我们介绍了一个简单的语义级耦合和重新耦合模块(C.R.),该模块也可以轻松插入到许多单数据集 3D 检测器中,以利用来自两个数据集的可重用功能。方面:1)特征耦合和2)特征重新耦合。
1)特征耦合:假设表示2D骨干网络提取的鸟瞰图(BEV)特征,其中表示通道数、 和 分别是特征的高度和宽度。 来自不同数据集的 BEV 特征 沿着通道维度耦合在一起,以使用前景感知和数据集级注意掩模来学习与数据集无关的表示,如下所示:
| (4) |
其中是沿通道维度的串联操作,和表示来自和-th 数据集,分别。 ,其中表示前景感知空间注意操作,这是通过计算BEV特征的通道最大值来实现的。 此外,表示由多层感知器(MLP)后跟-cls softmax操作实现的数据集级注意力掩模,其中表示要合并的数据集的数量。 这样的数据集级注意力掩码意味着 可以预测重新缩放分数以重新组合来自不同数据集的 BEV 特征,以便组合后的 BEV 特征与数据集无关。
2)特征重新耦合:由于共享特征主要关注多个数据集的共同知识,因此我们期望将此类共享特征与之前的融合使用逐通道重新缩放操作的数据集相关 BEV 特征 或 :
| (5) |
其中是挤压和激励网络[7],其网络架构在附录中描述。 所设计的耦合与重耦合模块的整体网络结构如图4所示。 然而,跨数据集探索这种特征关系会导致模型多数据集训练和单数据集测试之间的不一致,这主要是由于共享特征依赖于多个输入。 为了解决这个问题,我们简单地使用BEV特征复制方法,这意味着在单数据集推理阶段,来自单个数据集的BEV特征将同时复制到并,获取共享特征。 因此,BEV 特征复制方法使我们能够在单个数据集上执行推理,并且 Uni3D 在推理过程中不依赖于来自另一个域的某个给定帧。 附录中描述了不同训练和测试方法(包括BEV特征复制和BEV特征掩码)的消融研究。
数据集特定的检测头。 为了进一步解决数据集之间的分类级别差异,我们假设 3D 数据源的先验知识是已知的,并建议使用不同的检测头,然后是特定于数据集的检测损失 对不同数据集执行实例级预测。 MDF训练损失函数可以写成如下:
| (6) |
其中 是第 数据集的数据集特定损失。
在推理阶段,我们使用数据级校正操作来解决传感器引起的或数据分布引起的差异,并使用参数共享的 3D 和 2D 主干来提取点和体素特征。 同时,分配给相应数据集的检测头用于产生最终的预测结果。
| Trained on | Baseline Detectors | Tested on Waymo | Tested on nuScenes | ||||
|---|---|---|---|---|---|---|---|
| Vehicle | Pedestrian | Cyclist | Car | Pedestrian | Cyclist | ||
| only Waymo | Voxel-RCNN [4] (w/o P.T.) | 75.08 / 74.60 | 75.17 / 68.76 | 65.28 / 64.33 | 34.10 / 17.31 | 2.99 / 1.69 | 0.05 / 0.01 |
| Voxel-RCNN [4] (w/ P.T. on nuScenes) | 75.46 / 74.99 | 74.58 / 68.06 | 65.92 / 64.98 | 34.34 / 21.95 | 2.84 / 1.57 | 0.09 / 0.02 | |
| only nuScenes | Voxel-RCNN [4] (w/o P.T.) | 36.77 / 36.50 | 4.64 / 3.18 | 2.49 / 2.45 | 53.63 / 39.05 | 22.47 / 17.85 | 10.86 / 9.70 |
| Voxel-RCNN [4] (w/ P.T. on Waymo) | 6.11 / 5.90 | 0.77 / 0.56 | 0.01 / 0.01 | 55.23 / 39.14 | 23.65 / 16.47 | 8.51 / 5.80 | |
| Waymo+nuScenes | Voxel-RCNN [4] (w/ D.M.) | 66.67 / 66.23 | 60.36 / 54.08 | 52.03 / 51.25 | 51.40 / 31.68 | 15.04 / 9.99 | 5.40 / 3.87 |
| Voxel-RCNN [4] (w/ C.A.) | 69.40 / 68.86 | 63.43 / 56.49 | 52.83 / 51.93 | 51.39 / 29.04 | 16.24 / 10.96 | 4.55 / 3.13 | |
| Voxel-RCNN [4] (w/ C.A.+S.A.) | 75.16 / 74.67 | 74.83 / 68.07 | 64.68 / 63.73 | 58.41 / 40.84 | 26.52 / 20.98 | 9.19 / 7.65 | |
| Voxel-RCNN [4] (w/ C.A.+C.R.) | 74.56 / 74.05 | 74.29 / 67.04 | 63.14 / 62.21 | 59.10 / 42.25 | 29.86 / 23.76 | 14.46 / 12.73 | |
| Voxel-RCNN [4] (w/ C.A.+S.A.+C.R.) | 75.26 / 74.77 | 75.46 / 68.75 | 65.02 / 63.12 | 60.18 / 42.23 | 30.08 / 24.37 | 14.60 / 12.32 | |
| only Waymo | PV-RCNN [17] (w/o P.T.) | 74.97 / 74.46 | 73.41 / 66.57 | 64.58 / 63.49 | 32.99 / 17.55 | 3.34 / 1.94 | 0.02 / 0.01 |
| PV-RCNN [17] (w/ P.T. on nuScenes) | 74.77 / 74.26 | 73.32 / 66.31 | 64.06 / 63.05 | 33.86 / 17.47 | 2.88 / 1.53 | 0.04 / 0.01 | |
| only nuScenes | PV-RCNN [17] (w/o P.T.) | 41.01 / 40.58 | 4.57 / 2.96 | 0.98 / 0.95 | 57.78 / 41.10 | 24.52 / 18.56 | 10.24 / 8.25 |
| PV-RCNN [17] (w/ P.T. on Waymo) | 44.59 / 44.24 | 7.67 / 6.33 | 8.77 / 8.58 | 57.92 / 41.53 | 24.32 / 17.31 | 11.52 / 9.19 | |
| Waymo+nuScenes | PV-RCNN [17] (w/ D.M.) | 66.22 / 65.75 | 55.41 / 49.29 | 56.50 / 55.48 | 48.67 / 30.43 | 12.66 / 8.12 | 1.67 / 1.04 |
| PV-RCNN [17] (w/ C.A.) | 66.90 / 65.61 | 56.41 / 51.06 | 56.00 / 55.00 | 48.93 / 31.21 | 14.47 / 10.31 | 1.70 / 1.07 | |
| PV-RCNN [17] (w/ C.A.+S.A) | 74.24 / 73.71 | 67.38 / 60.79 | 60.20 / 59.16 | 59.49 / 42.05 | 27.44 / 20.94 | 12.69 / 10.34 | |
| PV-RCNN [17] (w/ C.A.+C.R.) | 74.88 / 74.36 | 73.39 / 66.02 | 62.84 / 61.79 | 59.01 / 41.16 | 26.59 / 20.49 | 9.86 / 7.60 | |
| PV-RCNN [17] (w/ C.A.+S.A.+C.R.) | 75.54 / 74.90 | 74.12 / 66.90 | 63.28 / 62.12 | 60.77 / 42.66 | 27.44 / 21.85 | 13.50 / 11.87 | |
| Trained on | Baseline Detectors | Tested on KITTI | Tested on nuScenes | ||||
|---|---|---|---|---|---|---|---|
| Car | Pedestrian | Cyclist | Car | Pedestrian | Cyclist | ||
| only KITTI | Voxel-RCNN [4] (w/o P.T.) | 89.34 / 80.91 | 59.67 / 56.88 | 61.10 / 60.49 | 11.37 / 4.64 | 0.15 / 0.11 | 0.01 / 0.00 |
| Voxel-RCNN [4] (w/ P.T. on nuScenes) | 89.90 / 81.25 | 59.49 / 56.17 | 54.55 / 54.15 | 12.89 / 5.52 | 0.24 / 0.18 | 0.05 / 0.03 | |
| only nuScenes | Voxel-RCNN [4] (w/o P.T.) | 69.41 / 33.48 | 28.06 / 19.20 | 0.44 / 0.43 | 53.63 / 39.05 | 22.47 / 17.85 | 10.86 / 9.70 |
| Voxel-RCNN [4] (w/ P.T. on KITTI) | 71.61 / 40.64 | 39.67 / 29.99 | 7.29 / 6.88 | 53.57 / 39.65 | 24.93 / 21.17 | 11.42 / 9.95 | |
| KITTI+nuScenes | Voxel-RCNN [4] (w/ D.M.) | 89.24 / 73.72 | 61.03 / 54.55 | 62.71 / 59.92 | 41.88 / 20.48 | 12.58 / 8.32 | 1.77 / 0.97 |
| Voxel-RCNN [4] (w/ C.A.) | 89.35 / 76.77 | 59.01 / 53.67 | 43.45 / 42.41 | 49.95 / 28.43 | 16.63 / 11.93 | 3.84 / 3.12 | |
| Voxel-RCNN [4] (w/ S.A.) | 89.21 / 82.68 | 62.32 / 57.99 | 63.10 / 61.67 | 57.87 / 40.23 | 27.21 / 21.44 | 13.65 / 12.24 | |
| Voxel-RCNN [4] (w/ C.R.) | 89.13 / 82.50 | 61.45 / 56.65 | 61.72 / 58.66 | 58.13 / 40.26 | 27.27 / 21.50 | 13.81 / 12.18 | |
| Voxel-RCNN [4] (w/ S.A.+C.R.) | 90.09 / 83.10 | 62.99 / 58.30 | 70.20 / 68.10 | 59.25 / 41.51 | 29.12 / 23.18 | 15.16 / 13.16 | |
| only KITTI | PV-RCNN [17] (w/o P.T.) | 89.41 / 83.15 | 59.09 / 54.73 | 62.25 / 61.71 | 6.58 / 2.54 | 0.22 / 0.16 | 0.03 / 0.01 |
| PV-RCNN [17] (w/ P.T. on nuScenes) | 89.26 / 83.14 | 60.56 / 55.90 | 63.60 / 62.88 | 13.43 / 5.61 | 0.69 / 0.27 | 0.04 / 0.00 | |
| only nuScenes | PV-RCNN [17] (w/o P.T.) | 74.37 / 36.54 | 39.30 / 29.07 | 0.58 / 0.55 | 57.78 / 41.10 | 24.52 / 18.56 | 10.24 / 8.25 |
| PV-RCNN [17] (w/ P.T on KITTI) | 69.40 / 38.25 | 33.24 / 24.88 | 1.68 / 1.61 | 53.24 / 36.72 | 20.65 / 17.09 | 8.95 / 7.58 | |
| KITTI+nuScenes | PV-RCNN [17] (w/ D.M.) | 87.79 / 77.95 | 55.52 / 48.29 | 59.15 / 55.10 | 41.29 / 21.57 | 10.21 / 7.08 | 1.23 / 1.15 |
| PV-RCNN [17] (w/ C.A.) | 88.53 / 77.20 | 47.13 / 39.53 | 44.22 / 41.64 | 46.34 / 25.28 | 12.70 / 9.64 | 2.18 / 1.34 | |
| PV-RCNN [17] (w/ S.A.) | 87.51 / 78.13 | 56.13 / 49.21 | 61.22 / 58.49 | 56.93 / 40.11 | 20.15 / 15.33 | 10.19 / 8.73 | |
| PV-RCNN [17] (w/ C.R.) | 90.93 / 83.56 | 58.96 / 55.78 | 60.92 / 58.13 | 57.76 / 41.31 | 24.65 / 18.96 | 12.19 / 10.13 | |
| PV-RCNN [17] (w/ S.A.+C.R.) | 89.77 / 85.49 | 60.03 / 55.58 | 69.03 / 66.10 | 59.08 / 41.67 | 25.27 / 19.26 | 12.26 / 10.83 | |
4实验
4.1实验设置。
数据集。 我们在 Waymo [22]、nuScenes [1] 和 KITTI [5] 三个常用的自动驾驶数据集上进行了实验。 这些数据集呈现出:1)不同激光雷达类型和数据采集地理位置造成的数据级别分布差异; 2) 由不同类别的标注定义引起的分类水平变化。 在我们的实验中,我们首先考虑合并两个不同数据集的任务设置,然后进行合并所有上述数据集的研究。
实施细节。 所有实验均使用 OpenPCDet [23] 实现。 特别是,由于我们观察到点云范围差异极大地降低了跨数据集检测精度,如表 2 所示,因此我们将所有上述数据集的点云范围对齐到 对于 和 轴, 对于 轴。 对于所有实验设置,遵循 PV-RCNN [17] 和 Voxel-RCNN [4] 采用的常见优化,Adam 优化器的初始学习率为 被使用,学习率衰减时间表利用了众所周知的 OneCycle 策略。 我们在 8 个 NVIDIA Tesla A100 GPU 上使用批量大小 32、动量 0.9 来训练网络,总训练周期等于 30。 此外,对于Waymo-KITTI和nuScenes-KITTI合并的实验,权重衰减设置为,对于其余实验,权重衰减设置为。 对于 Waymo 数据集,我们仅使用均匀采样的 帧(约 32k 帧)进行模型训练。
| Trained on | Baseline Detectors | Tested on KITTI | Tested on Waymo | ||||
|---|---|---|---|---|---|---|---|
| Car | Pedestrian | Cyclist | Vehicle | Pedestrian | Cyclist | ||
| only KITTI | Voxel-RCNN [4] (w/o P.T.) | 89.34 / 80.91 | 59.67 / 56.88 | 61.10 / 60.49 | 6.81 / 6.75 | 16.52 / 13.65 | 14.74 / 14.00 |
| Voxel-RCNN [4] (w/ P.T. on Waymo) | 89.51 / 81.41 | 60.30 / 57.10 | 55.53 / 51.34 | 8.70 / 8.62 | 19.14 / 16.01 | 21.87 / 20.83 | |
| only Waymo | Voxel-RCNN [4] (w/o P.T.) | 67.07 / 19.80 | 65.44 / 61.92 | 59.48 / 54.10 | 75.08 / 74.60 | 75.17 / 68.76 | 65.28 / 64.33 |
| Voxel-RCNN [4] (w/ P.T. on KITTI) | 64.84 / 19.99 | 62.58 / 59.01 | 56.44 / 49.43 | 72.76 / 72.26 | 72.42 / 64.94 | 63.27 / 62.23 | |
| KITTI+Waymo | Voxel-RCNN [4] (w/ D.M.) | 74.53 / 32.11 | 60.11 / 54.85 | 59.69 / 55.94 | 74.35 / 73.85 | 74.80 / 68.39 | 64.87 / 63.95 |
| Voxel-RCNN [4] (w/ S.A.+C.R.) | 90.03 / 82.39 | 62.51 / 57.01 | 69.52 / 66.30 | 74.83 / 74.33 | 74.79 / 68.24 | 66.83 / 65.82 | |
| only KITTI | PV-RCNN [17] (w/o P.T.) | 89.41 / 83.15 | 59.09 / 54.73 | 62.25 / 61.71 | 2.98 / 2.94 | 7.99 / 6.56 | 5.84 / 5.54 |
| PV-RCNN [17] (w/ P.T. on Waymo) | 89.40 / 83.42 | 62.69 / 58.86 | 59.96 / 59.43 | 8.75 / 8.64 | 12.12 / 9.90 | 9.20 / 8.76 | |
| only Waymo | PV-RCNN [17] (w/o P.T.) | 56.20 / 54.81 | 60.04 / 57.06 | 54.29 / 50.05 | 74.97 / 74.46 | 73.41 / 66.57 | 64.58 / 63.49 |
| PV-RCNN [17] (w/ P.T. on KITTI) | 69.25 / 25.91 | 59.16 / 55.92 | 56.09 / 50.50 | 71.08 / 70.54 | 70.12 / 62.91 | 62.37 / 61.40 | |
| KITTI+Waymo | PV-RCNN [17] (w/ D.M.) | 87.49 / 68.35 | 62.84 / 60.06 | 68.09 / 65.75 | 50.68 / 50.31 | 58.76 / 52.59 | 55.14 / 54.17 |
| PV-RCNN [17] (w/ S.A.+C.R.) | 89.42 / 83.15 | 60.85 / 57.49 | 71.61 / 65.88 | 75.07 / 74.54 | 72.95 / 66.08 | 63.80 / 62.92 | |
| Trained on | Tested on K | Tested on N | Tested on W | Avg. on KNW |
|---|---|---|---|---|
| K | 89.34 / 80.91 | 11.37 / 4.64 | 6.81 / 6.75 | 35.84 / 30.77 |
| N | 69.41 / 33.48 | 53.63 / 39.05 | 36.77 / 36.50 | 53.27 / 36.34 |
| W | 67.07 / 19.80 | 34.10 / 17.31 | 75.08 / 74.60 | 58.75 / 37.23 |
| K+N+W (Uni3D) | 89.65 / 83.41 | 60.42 / 42.30 | 75.47 / 74.97 | 75.18 / 66.89 |
| Trained on | Baseline Detectors | #nuScenes | Tested on KITTI | Tested on nuScenes | ||||
|---|---|---|---|---|---|---|---|---|
| Car | Pedestrian | Cyclist | Car | Pedestrian | Cyclist | |||
| only nuScenes | Voxel-RCNN [4] | - | - | - | 53.63 / 39.05 | 22.47 / 17.85 | 10.86 / 9.70 | |
| only nuScenes | Voxel-RCNN [4] | - | - | - | 45.42 / 31.09 | 10.39 / 7.16 | 1.55 / 0.89 | |
| only nuScenes | Voxel-RCNN [4] | - | - | - | 30.01 / 16.15 | 4.70 / 2.56 | 0.06 / 0.05 | |
| only nuScenes | Voxel-RCNN [4] | - | - | - | 0.00 / 0.00 | 0.00 / 0.00 | 0.00 / 0.00 | |
| KITTI+nuScenes | Voxel-RCNN [4] (ours) | 90.09 / 83.10 | 62.99 / 58.30 | 70.20 / 68.10 | 59.25 / 41.51 | 29.12 / 23.18 | 15.16 / 13.16 | |
| Voxel-RCNN [4] (ours) | 88.81 / 81.75 | 60.09 / 56.61 | 70.03 / 68.54 | 52.08 / 34.40 | 20.40 / 15.60 | 8.42 / 7.40 | ||
| Voxel-RCNN [4] (ours) | 89.10 / 81.86 | 59.17 / 54.42 | 73.30 / 70.25 | 51.81 / 34.43 | 19.82 / 14.94 | 5.52/ 4.58 | ||
| Voxel-RCNN [4] (ours) | 89.06 / 81.55 | 56.74 / 52.28 | 71.11 / 69.06 | 44.74 / 28.28 | 15.94 / 11.11 | 1.28 / 0.99 | ||
| only nuScenes | PV-RCNN [17] | - | - | - | 57.78 / 41.10 | 24.52 / 18.56 | 10.24 / 8.25 | |
| only nuScenes | PV-RCNN [17] | - | - | - | 50.39 / 31.68 | 13.64 / 8.75 | 0.85 / 0.51 | |
| only nuScenes | PV-RCNN [17] | - | - | - | 35.87 / 19.76 | 5.89 / 3.15 | 0.00 / 0.00 | |
| only nuScenes | PV-RCNN [17] | - | - | - | 0.08 / 0.01 | 0.02 / 0.01 | 0.00 / 0.00 | |
| KITTI+nuScenes | PV-RCNN [17] (ours) | 89.77 / 85.49 | 60.03 / 55.58 | 69.03 / 66.10 | 59.08 / 41.67 | 25.27 / 19.26 | 12.26 / 10.83 | |
| PV-RCNN [17] (ours) | 88.99 / 83.12 | 57.06 / 52.48 | 71.14 / 70.60 | 51.75 / 33.85 | 15.60 / 10.78 | 3.33 / 2.09 | ||
| PV-RCNN [17] (ours) | 88.95 / 82.83 | 56.62 / 53.25 | 71.99 / 69.86 | 50.32 / 34.35 | 16.11 / 11.20 | 2.59 / 2.00 | ||
| PV-RCNN [17] (ours) | 88.92 / 82.81 | 55.22 / 51.84 | 71.12 / 69.73 | 41.09 / 25.38 | 11.27 / 7.00 | 0.60 / 0.33 | ||
4.2比较基线的设计
1)w/o P.T.(单数据集):我们采用现成的 3D 检测器,例如、Voxel-RCNN [4] 和 PV-RCNN [17] 作为基线检测模型,从头开始训练并在单个数据集中进行评估。
2)P.T.(预训练):由于MDF设置允许检测器访问两个数据集中的带注释数据,因此我们首先在另一个数据集上预训练基线检测器,然后在另一个数据集上预训练检测器当前数据集。
3)D.M.(直接合并):通过简单地将多个3D数据集组合成合并数据集,单数据集基线检测器能够使用公共检测损失从合并数据集中进行训练,这可以被视为作为验证现有 3D 模型是否可以在直接合并数据集下进行改进的直接方法。 请注意对于这样的基线,我们对齐点云范围并合并每个数据集的标签空间以进行多数据集训练。
4) C.A.:坐标原点 对齐基线旨在缓解传感器安装位置差异。 如前所述,为了从具有不一致点云范围的多个 3D 数据集训练检测器,我们必须对齐所有数据集的点云范围。 但这种点范围级别的对齐操作会导致对象的坐标原点和中心点的分布变化。 为此,继之前的3D跨数据集研究[29,30,25]之后,需要将不同数据集的坐标原点转移到地平面。 对于KITTI和nuScenes数据集,沿高度方向的坐标偏移设置为m和m。 我们使用C.A. 基线来检查现有原点对齐方法在多数据集 3D 对象检测上的有效性。
5) S.A.:如第 2 节中所述。 3.3,统计级对齐基线旨在减少学习的统计分布(例如、和)差异数据集之间的特征。
6) C.R.:耦合和重新耦合基线尝试跨多个数据集挖掘可重用的与数据集无关的表示,并输出特定于数据集的语义表示,以提高单数据集检测的准确性。
评估指标。 我们采用官方发布的评估工具来评估我们的所有基线,其中对于 KITTI 和 nuScenes 数据集,报告了超过 40 个召回位置的鸟瞰图 (BEV) 和 3D 中的 AP,对于 Waymo 数据集,我们采用平均精度(AP) 和平均精度按每个类别的标题 (APH) 重新加权,以进行模型评估。 我们报告了 KITTI 数据集的中等案例结果,以及 Waymo 数据集上的 LEVEL_1 指标,请参阅附录以了解使用 LEVEL_2 指标的结果。 AP 在汽车类别(Waymo 上的车辆)的 IoU 阈值 0.7 和行人和骑行者类别的 IoU 阈值 0.5 下进行评估。 在本文中,所有实验结果均在官方验证集上报告。
4.3 多数据集3D物体检测结果
Waymo-nuScenes、nuScenes-KITTI、Waymo-KITTI 合并的结果。 为了研究从多个公共数据集训练 3D 基线检测器的可行性,我们从三个广泛使用的自动驾驶数据集中选择两个代表性 3D 数据集进行实验:Waymo [22]、KITTI [5 ] 和 nuScenes [1]。 根据表3至5的结果,我们可以观察到以下五个重要发现:
1)3D 数据集之间的巨大差距:我们首先仅在单个数据集(例如、Waymo 或 nuScenes)上训练基线检测器,并在两个数据集上评估这个训练有素的基线不同的数据集(例如、Waymo 和 nuScenes)。 从表 3 中可以看出,基线仅在其原始训练数据集上表现良好(例如、车辆 AP)。 当基线检测器部署到nuScenes数据集时,其检测精度严重下降(仅 AP for Car)。 这主要是因为单数据集检测模型对其训练数据集过度拟合,但未能考虑源到目标数据集的变化。 在另一个基线检测器(例如 PV-RCNN [17])上也可以观察到相同的精度下降问题。
2)预训练模型在MDF设置下无法很好地工作:另一种同时提高Waymo和nuScenes基线检测器检测精度的方法是全监督预训练。 这种方式意味着我们首先在完全标记的 nuScenes(或 Waymo)上预训练基线,并在 Waymo(或 nuScenes)上调整训练有素的模型。 通过比较 P.T 和无 P.T. 基线,我们从表3观察到,虽然模型已经在nuScenes上进行了预训练,但是nuScenes的检测精度仍然不理想,这是由于模型已经针对Waymo进行了微调,忘记从之前的预训练数据集中学到的知识。
3)3D单数据集训练范式在MDF设置下不能很好地工作:通过比较w/o P.T. 和D.M基线从表3中可以看出,典型的3D检测器(例如,Voxel-RCNN [4] 和 PV-RCNN [17])在合并数据集上训练无法在两个数据集上实现高检测精度。
4)坐标原点对齐提高MDF精度:通过比较C.A. 和D.M. 可以看出,坐标原点平移方案可以减少点云范围对齐操作带来的负面影响。 此外,应该注意的是,对于 KITTI-nuScenes 合并设置,对原始点云应用坐标原点移位操作会导致 KITTI 数据集中的行人和骑行者类的检测精度严重下降。 这可能是由于预设的坐标原点偏移参数在不同类别之间共享,这对于校正样本样本少的类别(例如行人和骑车人)的分布很敏感。 因此,类之间共享相同的坐标原点偏移参数对某些场景是有害的,需要在未来的工作中进一步研究。
5)每个设计模块的有效性和通用性:如表3、4和5所示, Uni3D 实现的平均检测结果超过了所有设计的基线,验证了 Uni3D 在多个 3D 数据集学习方面的有效性。 此外,我们还通过选择 PV-RCNN [17] 作为另一个基线检测器进行实验,并重复上述实验,观察到一致的检测精度增益。
Waymo-KITTI-nuScenes 整合结果。 表 6 显示了 Waymo、nuScenes 和 KITTI 联合训练 Voxel-RCNN [4] 的结果。 此外,Uni3D 在多个数据集上同时实现了较高的检测结果。
4.4进一步分析
Uni3D:降低数据采集成本。 考虑一个现实场景:由于昂贵的数据获取成本,我们可能无法为新场景收集大量激光雷达数据。 Uni3D 提供了解决这种困境的另一种选择,即在新场景的少样本数据与先前构建良好的数据集的完整数据之间的组合集上进行训练。 从表7可以看出,我们的Uni3D在nuScenes数据集上实现的检测精度优于仅使用少样本nuScenes本身的检测精度。 这种改进主要来自于Uni3D能够学习更多的泛化特征,在少样本样本下不太容易出现过拟合,进一步验证了我们的Uni3D在减少数据依赖性方面的优越性。
Uni3D:加强零样本和领域适应能力。 Uni3D 的另一个优点是,它可以通过从多个数据集中学习可概括的特征,很大程度上提高基线检测器的零样本学习能力。 如表8所示,利用Uni3D提供的预训练模型(包括3D和2D主干),零样本推理精度显着提高(从到)。 这种改进的一个可能原因是 Uni3D 通过在 Waymo 和 nuScenes 上联合训练来了解潜在的数据集间变化,并且 Waymo 到 nuScenes 数据集变化有利于识别不可预见的领域。 此外,我们的 Uni3D 生成的预训练参数还可以进一步增强现有 UDA 模型(例如 ST3D [29])的领域适应性。
| Methods | Baseline Models | Pre-trained on | Tested on KITTI |
| / | |||
| Source-only | PV-RCNN | Waymo | 61.18 / 22.01 |
| Source-only | PV-RCNN | nuScenes | 68.15 / 37.17 |
| Source-only | PV-RCNN (ours) | Waymo+nuScenes | 73.51 / 39.71 |
| ST3D [29] (w/ SN) | PV-RCNN | Waymo | 86.65 / 76.86 |
| ST3D [29] (w/ SN) | PV-RCNN | nuScenes | 84.29 / 72.94 |
| ST3D [29] (w/ SN) | PV-RCNN (ours) | Waymo+nuScenes | 88.25 / 77.01 |
5结论
在这项工作中,我们首次研究如何使用现成的公共 3D 基准训练统一的 3D 检测模型,并提出了一个统一的 3D 检测框架(Uni3D),该框架由数据级校正操作和语义级特征耦合和重新耦合模块,可以轻松与现有的3D检测器结合。 我们在许多公共基准上进行了广泛的实验,结果表明 Uni3D 在获取数据集级可推广特征方面的有效性。
致谢
该工作得到了上海市科学技术委员会的资助(批准号: 22DZ1100102)。
参考
- [1] Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020.
- [2] Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, and Tian Xia. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 1907–1915, 2017.
- [3] Xiyang Dai, Yinpeng Chen, Bin Xiao, Dongdong Chen, Mengchen Liu, Lu Yuan, and Lei Zhang. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7373–7382, 2021.
- [4] Jiajun Deng, Shaoshuai Shi, Peiwei Li, Wengang Zhou, Yanyong Zhang, and Houqiang Li. Voxel r-cnn: Towards high performance voxel-based 3d object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 1201–1209, 2021.
- [5] Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In 2012 IEEE conference on computer vision and pattern recognition, pages 3354–3361. IEEE, 2012.
- [6] Rui Gong, Dengxin Dai, Yuhua Chen, Wen Li, and Luc Van Gool. mdalu: Multi-source domain adaptation and label unification with partial datasets. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8876–8885, 2021.
- [7] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7132–7141, 2018.
- [8] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, pages 448–456. PMLR, 2015.
- [9] John Lambert, Zhuang Liu, Ozan Sener, James Hays, and Vladlen Koltun. Mseg: A composite dataset for multi-domain semantic segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2879–2888, 2020.
- [10] Alex H Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12697–12705, 2019.
- [11] Zhipeng Luo, Zhongang Cai, Changqing Zhou, Gongjie Zhang, Haiyu Zhao, Shuai Yi, Shijian Lu, Hongsheng Li, Shanghang Zhang, and Ziwei Liu. Unsupervised domain adaptive 3d detection with multi-level consistency. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8866–8875, 2021.
- [12] Jiageng Mao, Yujing Xue, Minzhe Niu, Haoyue Bai, Jiashi Feng, Xiaodan Liang, Hang Xu, and Chunjing Xu. Voxel transformer for 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3164–3173, 2021.
- [13] Charles R Qi, Wei Liu, Chenxia Wu, Hao Su, and Leonidas J Guibas. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 918–927, 2018.
- [14] Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660, 2017.
- [15] Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Advances in neural information processing systems, 30, 2017.
- [16] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 28, 2015.
- [17] Shaoshuai Shi, Chaoxu Guo, Li Jiang, Zhe Wang, Jianping Shi, Xiaogang Wang, and Hongsheng Li. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10529–10538, 2020.
- [18] Shaoshuai Shi, Li Jiang, Jiajun Deng, Zhe Wang, Chaoxu Guo, Jianping Shi, Xiaogang Wang, and Hongsheng Li. Pv-rcnn++: Point-voxel feature set abstraction with local vector representation for 3d object detection. arXiv preprint arXiv:2102.00463, 2021.
- [19] Shaoshuai Shi, Xiaogang Wang, and Hongsheng Li. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 770–779, 2019.
- [20] Shaoshuai Shi, Zhe Wang, Jianping Shi, Xiaogang Wang, and Hongsheng Li. From points to parts: 3d object detection from point cloud with part-aware and part-aggregation network. IEEE transactions on pattern analysis and machine intelligence, 43(8):2647–2664, 2020.
- [21] Vishwanath A Sindagi, Yin Zhou, and Oncel Tuzel. Mvx-net: Multimodal voxelnet for 3d object detection. In 2019 International Conference on Robotics and Automation (ICRA), pages 7276–7282. IEEE, 2019.
- [22] Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020.
- [23] OpenPCDet Development Team. Openpcdet: An open-source toolbox for 3d object detection from point clouds. https://github.com/open-mmlab/OpenPCDet, 2020.
- [24] Xudong Wang, Zhaowei Cai, Dashan Gao, and Nuno Vasconcelos. Towards universal object detection by domain attention. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7289–7298, 2019.
- [25] Yi Wei, Zibu Wei, Yongming Rao, Jiaxin Li, Jie Zhou, and Jiwen Lu. Lidar distillation: Bridging the beam-induced domain gap for 3d object detection. arXiv preprint arXiv:2203.14956, 2022.
- [26] Qiangeng Xu, Yin Zhou, Weiyue Wang, Charles R Qi, and Dragomir Anguelov. Spg: Unsupervised domain adaptation for 3d object detection via semantic point generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15446–15456, 2021.
- [27] Yan Yan, Yuxing Mao, and Bo Li. Second: Sparsely embedded convolutional detection. Sensors, 18(10):3337, 2018.
- [28] Bin Yang, Wenjie Luo, and Raquel Urtasun. Pixor: Real-time 3d object detection from point clouds. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 7652–7660, 2018.
- [29] Jihan Yang, Shaoshuai Shi, Zhe Wang, Hongsheng Li, and Xiaojuan Qi. St3d: Self-training for unsupervised domain adaptation on 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10368–10378, 2021.
- [30] Jihan Yang, Shaoshuai Shi, Zhe Wang, Hongsheng Li, and Xiaojuan Qi. St3d++: Denoised self-training for unsupervised domain adaptation on 3d object detection. IEEE Transactions on Pattern Analysis & Machine Intelligence, (01):1–17, 2022.
- [31] Zetong Yang, Yanan Sun, Shu Liu, Xiaoyong Shen, and Jiaya Jia. Std: Sparse-to-dense 3d object detector for point cloud. In Proceedings of the IEEE/CVF international conference on computer vision, pages 1951–1960, 2019.
- [32] Tianwei Yin, Xingyi Zhou, and Philipp Krahenbuhl. Center-based 3d object detection and tracking. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11784–11793, 2021.
- [33] Yifan Zhang, Qingyong Hu, Guoquan Xu, Yanxin Ma, Jianwei Wan, and Yulan Guo. Not all points are equal: Learning highly efficient point-based detectors for 3d lidar point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18953–18962, 2022.
- [34] Xiangyun Zhao, Samuel Schulter, Gaurav Sharma, Yi-Hsuan Tsai, Manmohan Chandraker, and Ying Wu. Object detection with a unified label space from multiple datasets. In European Conference on Computer Vision, pages 178–193. Springer, 2020.
- [35] Sixiao Zheng, Jiachen Lu, Hengshuang Zhao, Xiatian Zhu, Zekun Luo, Yabiao Wang, Yanwei Fu, Jianfeng Feng, Tao Xiang, Philip HS Torr, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6881–6890, 2021.
- [36] Xingyi Zhou, Vladlen Koltun, and Philipp Krähenbühl. Simple multi-dataset detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7571–7580, 2022.
- [37] Yin Zhou and Oncel Tuzel. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4490–4499, 2018.
- [38] Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159, 2020.
附录A附录
A.1Uni3D 实现
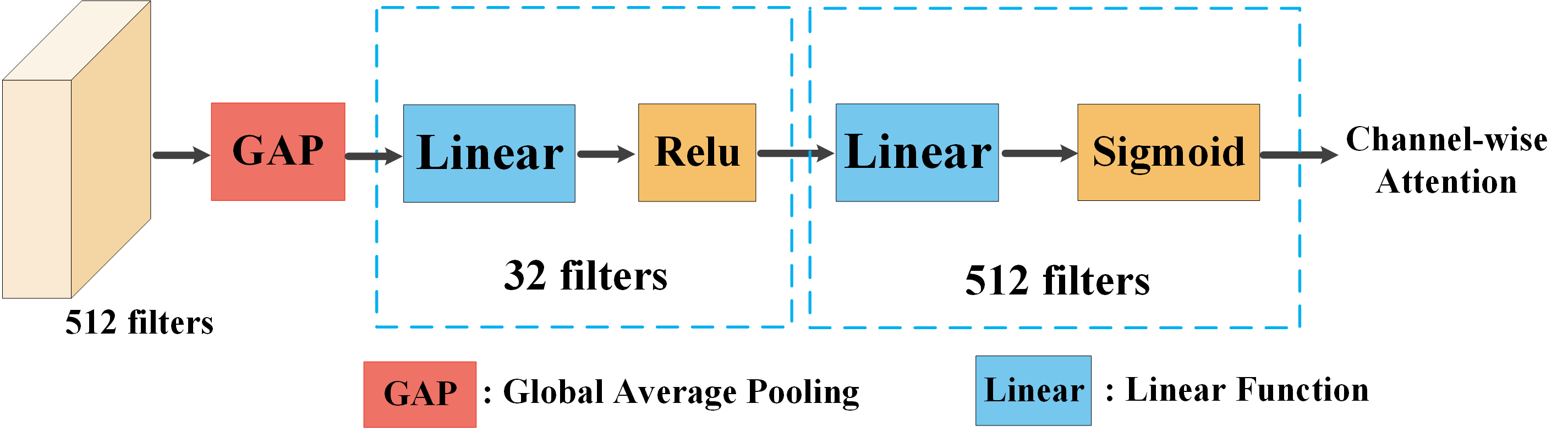
设计的SE模块的详细结构。 正如第 2 节中提到的。 3.3 在我们的正文中,利用挤压和激励(SE)网络来获取重新缩放的数据集特定特征。 设计的SE网络可视化网络如图5所示。

| Methods | Waymo Range | KITTI Range | Tested on Waymo | Tested on KITTI | ||
|---|---|---|---|---|---|---|
| Pedestrian | Cyclist | Pedestrian | Cyclist | |||
| Not Align. | L=[-75.2, 75.2]m | L=[0.0, 70.4]m | 26.61 / 23.37 | 26.47 / 25.87 | 59.17 / 57.16 | 62.16 / 61.25 |
| W=[-75.2, 75.2]m | W=[-40.0, 40.0]m | |||||
| H=[-2.0, 4.0]m | H=[-3.0, 1.0]m | |||||
| Align. (w/ ours) | L=[-75.2, 75.2]m | L=[-75.2, 75.2]m | 74.79 / 68.24 | 66.83 / 65.82 | 62.51 / 57.01 | 69.52 / 66.30 |
| W=[-75.2, 75.2]m | W=[-75.2, 75.2]m | |||||
| H=[-2.0, 4.0]m | H=[-2.0, 4.0]m | |||||
| Methods | nuScenes Range | KITTI Range | tested on nuScenes | tested on KITTI | ||
| Pedestrian | Cyclist | Pedestrian | Cyclist | |||
| Not Align. | L=[-51.2, 51.2]m | L=[0.0, 70.4]m | 11.34 / 9.08 | 8.67 / 6.37 | 60.05 / 54.43 | 63.98 / 63.06 |
| W=[-51.2, 51.2]m | W=[-40.0, 40.0]m | |||||
| H=[-5.0, 3.0]m | H=[-3.0, 1.0]m | |||||
| Align. (w/ ours) | L=[-75.2, 75.2]m | L=[-75.2, 75.2]m | 29.12 / 23.18 | 15.16 / 13.16 | 62.99 / 58.30 | 70.20 / 68.10 |
| W=[-75.2, 75.2]m | W=[-75.2, 75.2]m | |||||
| H=[-2.0, 4.0]m | H=[-2.0, 4.0]m | |||||
| Model | Option | Tested on Waymo | Tested on nuScenes | ||||
| Vehicle | Pedestrian | Cyclist | Car | Pedestrian | Cyclist | ||
| Voxel-RCNN (Direct Merging) | - | 66.67 / 66.23 | 60.36 / 54.08 | 52.03 / 51.25 | 51.40 / 31.68 | 15.04 / 9.99 | 5.40 / 3.87 |
| Voxel-RCNN (w/ C.A.+S.A.+C.R.) | BEV feature copy | 75.26 / 74.77 | 75.46 / 68.75 | 65.02 / 63.12 | 60.18 / 42.23 | 30.08 / 24.37 | 14.60 / 12.32 |
| Voxel-RCNN (w/ C.A.+S.A.+C.R.) | BEV feature mask | 73.78 / 73.29 | 72.67 / 66.32 | 64.20 / 62.81 | 60.37 / 40.66 | 29.57 / 23.51 | 14.13 / 12.42 |
| Model | Ensemble? | Vehicle | Pedestrian | Cyclist |
| Voxel-RCNN (w/ C.A.+S.A.) | No | 75.16 / 74.67 | 74.83 / 68.07 | 64.68 / 63.73 |
| Voxel-RCNN (w/ C.A.+S.A.+E.N.) | Yes | 70.59 / 70.07 | 73.56 / 66.86 | 62.75 / 61.82 |
| Voxel-RCNN (w/ C.A.+S.A.+C.R.) | No | 75.26 / 74.77 | 75.46 / 68.75 | 65.02 / 63.12 |
数据集简介。 Waymo 开放数据集 [22] 涵盖 1000 个完整注释的序列,这些序列是在美国使用 64 束 LiDAR 收集的。 Waymo 数据集分为包含 798 个序列(158081 个样本)的训练集和包含 202 个序列(39987 个样本)的验证集。 对于所有 Waymo 相关的数据集整合实验,我们仅使用所有训练样本的 帧(大约 32k 帧)来节省模型训练时间。
nuScenes [1]数据集使用32束激光雷达构建,所有数据均来自不同国家和地区,例如新加坡和美国波士顿。 nuScenes 包括 28130 个训练帧和 6019 个验证帧。 在我们的实验中,我们使用 28130 个训练帧作为模型,并在 6019 个验证帧上评估我们的所有模型。
KITTI数据集[5]是自动驾驶社区中最流行的数据集之一,由7481个训练帧组成,我们将7481个训练帧分为一个训练集(包括3712个样本)和一个验证集集(包括3769个样本)。 这种数据分割方法与之前的作品[29,30,25]一致。 与 Waymo 数据集类似,KITTI 数据集中的点云是使用 64 束激光雷达收集的。 请注意,由于 KITTI 仅提供来自前置摄像头视野 (FOV) 的注释,因此我们在模型评估阶段删除了 FOV 之外的点云和预测结果。
A.2 合并数据集的挑战
随着自动驾驶数据集的快速增加,我们的研究重点是如何从不断增加的 3D 数据集中训练统一的 3D 检测器。
| Model | Module | Vehicle | Pedestrian | Cyclist |
|---|---|---|---|---|
| Voxel-RCNN | C.A.+S.A.+C.R. w/o AT | 75.06 / 74.56 | 74.90 / 68.34 | 64.31 / 63.36 |
| Voxel-RCNN | C.A.+S.A.+C.R. w/o SE | 74.37 / 73.85 | 74.42 / 67.77 | 64.47 / 63.50 |
| Voxel-RCNN | C.A.+S.A.+C.R. | 75.26 / 74.77 | 75.46 / 68.75 | 65.02 / 63.12 |
| PV-RCNN | C.A.+S.A.+C.R. w/o AT | 74.25 / 73.71 | 70.85 / 63.89 | 62.03 / 60.95 |
| PV-RCNN | C.A.+S.A.+C.R. w/o SE | 74.79 / 74.24 | 73.69 / 66.65 | 62.68 / 61.04 |
| PV-RCNN | C.A.+S.A.+C.R. | 75.54 / 74.90 | 74.12 / 66.90 | 63.28 / 62.12 |
| Trained on | Baseline Detectors | Avg. on Waymo+nuScenes | ||
|---|---|---|---|---|
| Vehicle&Car | Pedestrian | Cyclist | ||
| only Waymo | Voxel-RCNN [4] (w/o P.T.) | 46.20 | 38.43 | 32.64 |
| Voxel-RCNN [4] (w/ P.T. on nuScenes) | 48.71 | 38.08 | 32.97 | |
| only nuScenes | Voxel-RCNN [4] (w/o P.T.) | 37.91 | 11.25 | 6.10 |
| Voxel-RCNN [4] (w/ P.T. on Waymo) | 22.63 | 8.62 | 2.91 | |
| Waymo+nuScenes | Voxel-RCNN [4] (w/ D.M.) | 49.18 | 35.18 | 27.95 |
| Voxel-RCNN [4] (w/ C.A.) | 49.22 | 37.20 | 27.98 | |
| Voxel-RCNN [4] (w/ C.A.+S.A.) | 58.00 | 47.91 | 36.17 | |
| Voxel-RCNN [4] (w/ C.A.+C.R.) | 58.41 | 49.03 | 37.94 | |
| Voxel-RCNN [4] (w/ C.A.+S.A.+C.R.) | 58.75 | 49.92 | 38.67 | |
| only Waymo | PV-RCNN [17] (w/o P.T.) | 46.26 | 37.68 | 32.30 |
| PV-RCNN [17] (w/ P.T. on nuScenes) | 46.12 | 37.43 | 32.04 | |
| only nuScenes | PV-RCNN [17] (w/o P.T.) | 41.06 | 11.57 | 4.62 |
| PV-RCNN [17] (w/ P.T. on Waymo) | 43.06 | 12.49 | 8.98 | |
| Waymo+nuScenes | PV-RCNN [17] (w/ D.M.) | 48.33 | 31.77 | 28.77 |
| PV-RCNN [17] (w/ C.A.) | 49.06 | 33.36 | 28.54 | |
| PV-RCNN [17] (w/ C.A.+S.A) | 58.15 | 44.16 | 35.27 | |
| PV-RCNN [17] (w/ C.A.+C.R.) | 58.02 | 46.94 | 35.22 | |
| PV-RCNN [17] (w/ C.A.+S.A.+C.R.) | 59.10 | 47.99 | 37.58 | |
| Trained on | Baseline Detectors | Avg. on KITTI+nuScenes | ||
|---|---|---|---|---|
| Car | Pedestrian | Cyclist | ||
| only KITTI | Voxel-RCNN [4] (w/o P.T.) | 42.78 | 28.50 | 30.25 |
| Voxel-RCNN [4] (w/ P.T. on nuScenes) | 43.39 | 28.18 | 27.09 | |
| only nuScenes | Voxel-RCNN [4] (w/o P.T.) | 36.27 | 18.53 | 5.07 |
| Voxel-RCNN [4] (w/ P.T. on KITTI) | 40.15 | 25.58 | 8.42 | |
| KITTI+nuScenes | Voxel-RCNN [4] (w/ D.M.) | 47.1 | 31.44 | 30.45 |
| Voxel-RCNN [4] (w/ C.A.) | 52.60 | 32.80 | 22.77 | |
| Voxel-RCNN [4] (w/ S.A.) | 61.46 | 39.72 | 36.96 | |
| Voxel-RCNN [4] (w/ C.R.) | 61.38 | 39.08 | 35.42 | |
| Voxel-RCNN [4] (w/ S.A.+C.R.) | 62.31 | 40.74 | 40.63 | |
| only KITTI | PV-RCNN [17] (w/o P.T.) | 42.85 | 27.45 | 30.86 |
| PV-RCNN [17] (w/ P.T. on nuScenes) | 44.38 | 28.09 | 31.44 | |
| only nuScenes | PV-RCNN [17] (w/o P.T.) | 38.82 | 23.82 | 4.40 |
| PV-RCNN [17] (w/ P.T on KITTI) | 37.49 | 20.99 | 4.59 | |
| KITTI+nuScenes | PV-RCNN [17] (w/ D.M.) | 49.76 | 27.69 | 28.13 |
| PV-RCNN [17] (w/ C.A.) | 51.24 | 24.59 | 21.49 | |
| PV-RCNN [17] (w/ S.A.) | 59.12 | 32.27 | 33.61 | |
| PV-RCNN [17] (w/ C.R.) | 62.44 | 37.37 | 34.13 | |
| PV-RCNN [17] (w/ S.A.+C.R.) | 63.58 | 37.42 | 38.47 | |
| Trained on | Baseline Detectors | Avg. on KITTI+Waymo | ||
|---|---|---|---|---|
| Car&Vehicle | Pedestrian | Cyclist | ||
| only KITTI | Voxel-RCNN [4] (w/o P.T.) | 43.86 | 36.70 | 37.62 |
| Voxel-RCNN [4] (w/ P.T. on Waymo) | 45.06 | 38.12 | 36.61 | |
| only Waymo | Voxel-RCNN [4] (w/o P.T.) | 47.44 | 68.55 | 59.69 |
| Voxel-RCNN [4] (w/ P.T. on KITTI) | 46.38 | 65.72 | 56.35 | |
| KITTI+Waymo | Voxel-RCNN [4] (w/ D.M.) | 53.22 | 64.83 | 60.41 |
| Voxel-RCNN [4] (w/ S.A.) | 78.82 | 65.65 | 65.92 | |
| Voxel-RCNN [4] (w/ C.R.) | 78.14 | 63.06 | 65.27 | |
| Voxel-RCNN [4] (w/ S.A.+C.R.) | 78.61 | 65.90 | 66.56 | |
| only KITTI | PV-RCNN [17] (w/o P.T.) | 43.07 | 31.36 | 33.78 |
| PV-RCNN [17] (w/ P.T. on Waymo) | 46.09 | 35.49 | 34.32 | |
| only Waymo | PV-RCNN [17] (w/o P.T.) | 64.89 | 65.24 | 57.32 |
| PV-RCNN [17] (w/ P.T. on KITTI) | 48.50 | 63.02 | 56.44 | |
| KITTI+Waymo | PV-RCNN [17] (w/ D.M.) | 59.52 | 59.41 | 60.45 |
| PV-RCNN [17] (w/ S.A.) | 78.69 | 61.77 | 64.71 | |
| PV-RCNN [17] (w/ C.R.) | 78.75 | 61.22 | 64.08 | |
| PV-RCNN [17] (w/ S.A.+C.R.) | 79.11 | 65.22 | 64.84 | |
| Trained on | Baseline Detectors | Tested on Waymo | Tested on nuScenes | ||||
|---|---|---|---|---|---|---|---|
| Vehicle | Pedestrian | Cyclist | Car | Pedestrian | Cyclist | ||
| Waymo+nuScenes | Voxel-RCNN [4] (w/ D.M.) | 58.26 / 57.87 | 52.72 / 47.11 | 50.26 / 49.50 | 51.40 / 31.68 | 15.04 / 9.99 | 5.40 / 3.87 |
| Voxel-RCNN [4] (w/ C.A.+S.A.+C.R.) | 66.94 / 66.37 | 67.04 / 60.57 | 62.21 / 61.32 | 60.18 / 42.23 | 30.08 / 24.37 | 14.60 / 12.32 | |
| Trained on | Baseline Detectors | Tested on Waymo | Tested on KITTI | ||||
| Vehicle | Pedestrian | Cyclist | Car | Pedestrian | Cyclist | ||
| Waymo+KITTI | Voxel-RCNN [4] (w/ D.M.) | 66.31 / 65.85 | 65.39 / 59.47 | 62.69 / 61.80 | 74.53 / 32.11 | 60.11 / 54.85 | 59.69 / 55.94 |
| Voxel-RCNN [4] (w/ S.A.+C.R.) | 66.73 / 66.26 | 66.39 / 60.36 | 64.52 / 63.55 | 90.03 / 82.39 | 62.51 / 57.01 | 69.52 / 66.30 | |


最初,我们做了很多尝试,通过直接合并现有的 3D 数据集(例如合并 Waymo [22] 和 nuScenes [1])来从多个数据集训练基线检测器>。 然而,我们发现常用的3D基线检测模型如PV-RCNN [17]和Voxel-RCNN [12]存在严重的检测性能下降问题,当他们在多个 3D 检测数据集上联合训练时。 同样,之前的2D研究工作[36, 24]也指出,多个数据集下的单个2D检测器仍然面临着巨大的挑战。 但与 2D 图像域数据集级整合相比,在 3D 点云场景中实现此类多数据集检测更具挑战性,这主要是由于: 1)数据级别差异:不同的数据集通常由不同的传感器类型收集和构建,以及2)分类差异:由多个制造商构建的不同数据集通常呈现不一致的类别标签定义。
A.3 Uni3D 推理用法
使用 Uni3D 进行单数据集推理的消融研究。 在这一部分中,我们尝试深入研究C.R. Uni3D中的模块从以下两个方面进行:
1) C.R. 的推理用法 模块:如正文中所述,C.R. 的目的 模块的目的是在模型训练阶段利用可重用功能。 然而,跨数据集探索这种特征关系会导致模型多数据集训练和单数据集测试之间的不一致,这主要是由于共享特征依赖于多个输入。 在这一部分中,我们提供了Uni3D在推理使用过程中的许多选项,并展示了实验比较结果。 对于选项一,BEV特征复制方法表示在推理阶段,单个数据集中的BEV特征将同时复制到和,为了获得共享特征。 然后,可以使用数据集特定的 SE 模块获得特定于数据集的 BEV 特征,该模块使用 作为输入。 对于选项二,BEV特征掩码意味着我们将另一个数据集的输入BEV张量(特征)设置为零,并生成共享特征。
相应的实验结果如表10所示。 我们观察到,在进行单数据集模型推理时,BEV 特征复制方法取得了更好的检测精度。 这主要是因为Uni3D在多数据集训练过程中引入了跨不同数据集的BEV特征交互。 然而,BEV特征掩码方法将掩码来自两个分支之一的BEV特征,显着增加执行推理时BEV特征的分布差异(零张量v.s. 来自点云数据的 BEV 特征)。 实际上,虽然BEV特征复制方法可以保证Uni3D训练和测试的一致性,但这种方法并不是解决融合不同数据集的BEV特征时多数据集训练和单数据集推理不一致问题的最佳解决方案在模型训练阶段,这将是我们未来工作中可能的研究课题。
2) 与模型集成的比较:此外,为了验证在模型训练阶段融合不同数据集的 BEV 特征的有效性,我们将 Uni3D 与模型集成方法进行比较。 具体来说,为了避免数据级校正操作的影响,我们首先使用具有点范围对齐和统计级对齐的基线模型(i.e. Voxel-RCNN (w/ C.A.+ S.A.)基线),然后仅在 Waymo 数据集或 nuScenes 数据集上调节检测头,而不使用 C.R. 模块,其中微调的目的是使模型能够使用经过训练的数据集特定检测头在不同数据集上执行检测任务。 最后,我们使用在不同数据集上训练的两个特定于数据集的检测头来执行测试时间集成。 测试时间集成的实验结果如表11所示。 我们观察到这种数据集级集成方法所实现的检测精度并不令人满意。 这是因为,两个集成头之一(检测头)仅使用 nuScenes 进行训练,并且在 Waymo 上测试时具有很强的预测偏差(例如,仅 和 AP(车辆和行人)。
A.4 C.R.的消融研究 模块
在这一部分中,我们进行了去除C.R.中的注意力组件和SE组件的实验 使用两个不同基线检测器的模块。 从表12可以看出,每个新添加的组件(注意力和SE)都可以在Waymo数据集上带来准确性的提升。
A.5更多实验结果
不同数据集的平均检测结果。 按照正文中的实验设置,我们展示了平均检测结果,以便更好地展示所提出的 Uni3D 的优势。 需要强调的是,对于不同的数据集,我们采用不同的评估指标,例如 Waymo 上的 3D-AP/3D-APH 和 nuScenes 上的 BEV-AP/3D-AP。 因此,为了计算跨数据集的平均检测精度,我们简单地将Waymo数据集上的3D-AP结果和KITTI或nuScenes数据集上的3D-AP结果进行平均,这有利于与正文中报告的结果保持一致。