基于互信息的时间差分学习
视频中人体姿态估计
摘要
时间建模对于多帧人体姿势估计至关重要。 大多数现有方法直接采用光流或可变形卷积来预测全谱运动场,这可能会产生许多不相关的线索,例如附近的人或背景。 如果不进一步努力挖掘有意义的运动先验,它们的结果就不是最优的,特别是在复杂的时空相互作用中。 另一方面,时间差异能够对代表性运动信息进行编码,这对于姿态估计可能有价值,但尚未得到充分利用。 在本文中,我们提出了一种新颖的多帧人体姿势估计框架,该框架利用帧之间的时间差异来建模动态上下文,并客观地利用相互信息来促进有用的运动信息解开。 具体来说,我们设计了一个多级时间差分编码器,它以多级特征差异序列为条件执行增量级联学习,以获得信息丰富的运动表示。 我们进一步从互信息的角度提出了表示解缠模块,它可以通过明确定义原始运动特征的有用和噪声成分并最小化它们的互信息来掌握判别性的任务相关运动信号。 这些使我们在基准数据集 HiEve 上的复杂事件挑战人群姿势估计中排名第一,并在三个基准 PoseTrack2017、PoseTrack2018 和 PoseTrack21 上实现了最先进的性能。
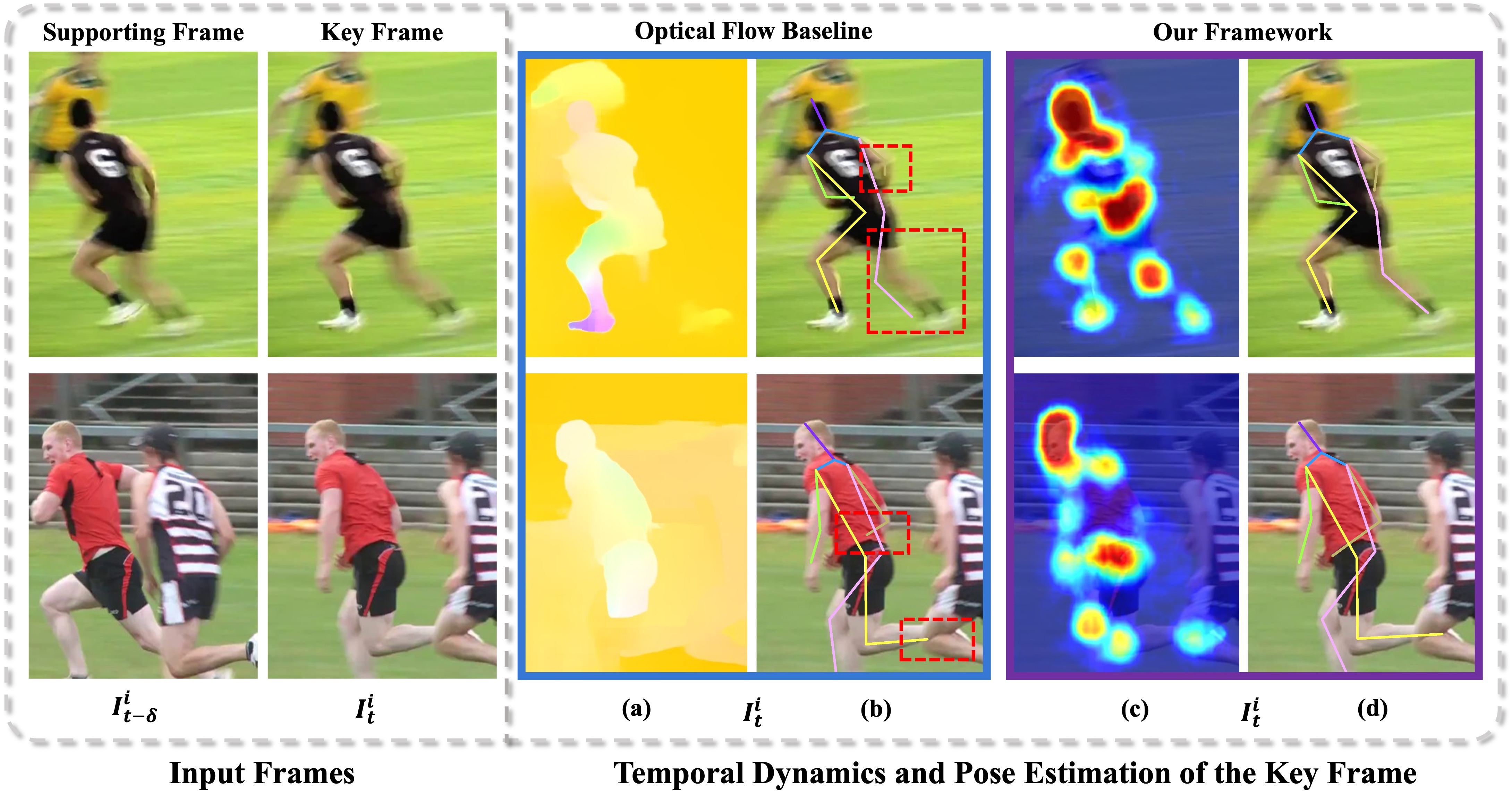
1简介
人体姿势估计长期以来一直是计算机视觉领域的一个重要且基本的问题。 目标是从图像或视频中定位人体的解剖关键点(例如鼻子、脚踝等)。 如今,随着越来越多的视频被无休止地录制,基于视频的人体姿态估计在直播、增强现实、监控和运动跟踪等众多应用中得到了极大的需求[22,42,33] 。
大量文献侧重于估计静态图像中的人体姿势,从早期使用图像结构模型的方法[53,49,67,41]到最近利用深度学习的尝试卷积神经网络[47,54,56,33]或视觉 Transformer [30,63,59]。 尽管在静态图像中的性能令人印象深刻,但由于视频中额外的时间维度[55, 32],将此类方法扩展到基于视频的人体姿势估计仍然具有挑战性。 从本质上讲,视频呈现了独特且有价值的动态上下文(即,视觉内容的时间演变)[69]。 因此,能够有效地利用时间动态(运动信息)对于视频中准确的姿态估计至关重要[33]。
其中一项工作[33,52,35]尝试通过隐式运动补偿导出统一的时空表示。 [52] 提出了一个 3DHRNet,它利用 3D 卷积提取视频轨迹的时空特征来估计姿势序列。 [33]采用可变形卷积来对齐多帧特征并聚合对齐的特征图来预测人体姿势。 另一方面,[43,38,65]显式使用光流对运动上下文进行建模。 [43, 38] 建议计算每两帧之间的密集光流,并利用流特征在多个帧上临时细化姿态热图。
在研究之前的方法[32,33,38,43]后,我们凭经验观察到,通过隐式或显式施加运动先验来提高姿态估计性能。 然而,在这些范例中通常会关注任何视觉证据的移动,从而导致混乱的运动特征,其中包含大量不相关的信息(例如,附近的人,背景),如图1. 直接利用这种普通的运动特征会产生较差的结果,特别是在相互遮挡和快速运动的复杂场景中。 更具体地说,并非所有像素运动在基于视频的人体姿势估计中都同等重要[64]。 例如,由图像质量下降(例如、模糊和遮挡)引起的背景变化和像素变化通常是无用且分散注意力的,而由人体运动驱动的显着像素运动在理解中发挥着更重要的作用。运动模式[19]。 因此,发现有意义的运动动力学对于在视频中完全恢复人体姿势至关重要。 另一方面,研究视频帧之间的时间差异可以发现代表性的运动线索[50,57,23]。 尽管它已经在各种视频相关任务(动作识别[50]、视频超分辨率[22])中取得了成功,但它在基于视频的人体姿势上的应用估计仍有待探索。
在本文中,我们提出了一种新颖的框架,名为基于M互I信息的T时D差异学习(TDMI)用于人体姿势估计。 我们的 TDMI 由两个关键组件组成:(i) 多级时间差分编码器 (TDE) 旨在对以视频帧之间的多级特征差异为条件的运动上下文进行建模。 具体来说,我们首先利用时间差分算子计算跨多个阶段的特征差异序列。 然后,我们通过阶段内和阶段间特征集成来执行增量级联学习,以导出运动表示。 (ii) 我们从互信息的角度进一步引入了表示解缠模块(RDM),该模块提取与任务相关的运动特征以增强姿势估计的帧表示。 特别是,我们首先通过激活相应的特征通道来解开普通运动表示的有用成分和噪声成分。 然后,我们从理论上分析有用运动特征和噪声运动特征之间的统计依赖性,并得出信息论损失。 最小化这种互信息目标会鼓励有用的运动组件更具辨别力和任务相关性。 我们的方法在四个基准数据集上比当前最先进的方法实现了显着且一致的性能改进。 进行了广泛的消融研究,以验证所提出的方法中每个组件的功效。
这项工作的主要贡献可以总结如下:(1)我们提出了一种新颖的框架,利用时间差异来模拟基于视频的人体姿势估计的动态上下文。 (2)我们提出了一种解开的表示学习策略,通过信息论目标来掌握与任务相关的判别性运动信号。 (3) 我们证明我们的方法在四个基准数据集(PoseTrack2017、PoseTrack2018、PoseTrack21 和 HiEve)上取得了最新的结果。
2相关工作
基于图像的人体姿势估计。 随着深度学习架构[16, 48]的最新进展以及大规模数据集[21,1,11,31]的可用性,各种深度学习方法[2,10,44,56,30,63,59]被提出用于基于图像的人体姿态估计。 这些方法大致分为两种范式:自下而上和自上而下。 自下而上方法[7,27,28]检测各个身体部位并将它们与整个人联系起来。 [28]提出了一种复合框架,该框架采用部位强度场来定位人体部位,并使用部位关联场将检测到的身体部位相互关联。 相反,自上而下方法[56,54,44,13,30]首先检测人的边界框并预测每个边界框区域内的人体姿势。 [44]提出了一种高分辨率卷积架构,在所有阶段都保留了高分辨率特征,展示了人体姿态估计的卓越性能。
基于视频的人体姿势估计。 现有的基于图像的方法不能很好地推广到视频流,因为它们本质上难以捕获跨帧的时间动态。 一种直接的方法是利用光流来施加运动先验[43, 38]。 这些方法通常计算帧之间的密集光流,并利用此类运动线索来细化预测的姿势热图。 然而,光流估计计算量大,并且在遇到严重的图像质量下降时往往很脆弱。 另一种方法[33,5,32,52]考虑使用可变形卷积或3DCNN进行隐式运动补偿。 [5, 32]提出基于热图残差对多粒度关节运动进行建模,并通过可变形卷积执行姿势重采样或姿势扭曲。 由于上述情况通常考虑来自所有像素位置的运动细节,因此它们的结果表示对于准确的姿势估计来说不是最佳的。
时间差异建模。 时间差异操作,即、RGB差异(图像级)[51, 69, 36, 50]和特征差异(特征级)[34, 23, 29],通常用于运动提取,在许多视频相关任务中表现出出色的性能和高效率,例如动作识别[50, 29]和视频超分辨率[22]。 [69,36,50]利用 RGB 差异作为光流的有效替代方式来表示运动。 [22] 建议对 LR 和 HR 空间中的时间差异进行显式建模。 然而,额外的 RGB 差异分支通常会复制特征提取主干,这会增加模型的复杂性。 另一方面,[34,23,29]采用特征差异运算进行网络设计,我们的工作更接近这个范围。 与之前简单计算特征差异的方法相比,我们寻求解开用于姿势估计的判别性任务相关时间差异表示。
3 我们的方法
基础知识。 我们的工作遵循自上而下的范例,从对象检测器开始获取视频帧 中个人的边界框。 然后,将每个边界框放大,以裁剪连续帧序列中的同一个体,其中是预定义的时间跨度。 这样,我们就获得了人物的裁剪视频片段。
问题表述。 给定以关键帧 为中心的裁剪视频片段 ,我们有兴趣估计 中的姿势。 我们的目标是通过有原则的时间差异学习和有用信息解开来更好地利用帧序列,从而解决现有方法未能充分挖掘运动动力学的常见缺点。
方法概述。 所提出的 TDMI 的总体流程如图2所示。 我们的框架由两个关键组件组成:多级时间差分编码器(TDE)(第 3.1 节)和表示解缠模块(RDM)(第 3.2 节) 。 具体来说,我们首先提取输入序列的视觉特征并将其输入 TDE,TDE 计算特征差异并执行信息集成以获得运动特征 。 然后,RDM将运动特征作为输入并挖掘其有用成分以产生。 最后,运动特征和关键帧的视觉特征被聚合以产生增强表示。 被传递给输出姿态估计 的检测头。 下面,我们将深入解释这两个关键组件。
3.1多级时间差分编码器
由于多阶段特征集成使网络能够保留从细到粗的不同语义信息[24,37,64],我们建议同时聚合浅层特征差异(早期阶段)来压缩详细的运动线索深度特征差异(后期)编码全局语义运动,以得出信息丰富且细粒度的运动表示。 在多个阶段融合特征的一种简单方法是将它们输入卷积网络[26, 9]。 然而,这种简单的融合解决方案有两个缺点:(i)可能会过分强调冗余特征,(ii)无法完全保留每个阶段的细粒度线索。 受这些观察和见解的启发,我们提出了一种具有增量级联学习架构的多级时间差分编码器(TDE),通过两种设计解决上述问题:空间调制机制,自适应地关注重要的每个阶段的信息,以及一个渐进积累机制来保留所有阶段的细粒度上下文。
具体来说,给定图像序列,我们提出的TDE首先构造多级特征差异序列,并执行级内和级间特征融合以产生编码的运动表示。 为了简单起见,我们在下面取。
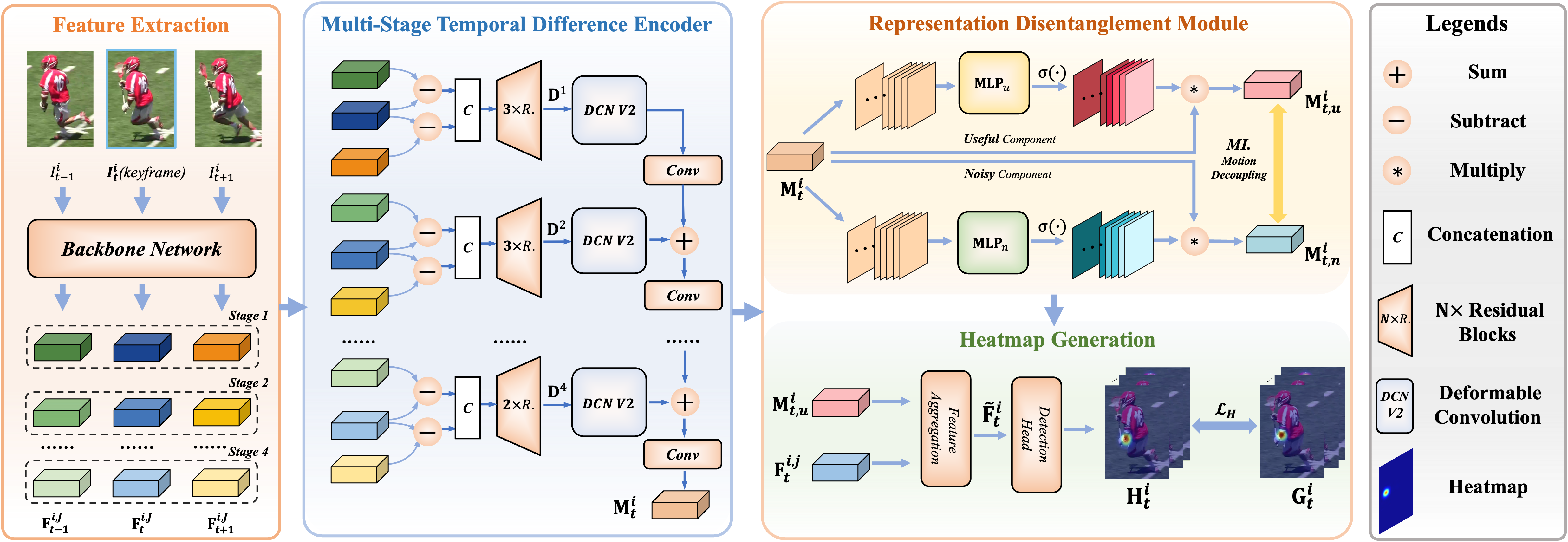
特征差异序列生成。 我们在 HRNet-W48 [44] 网络上构建 TDE,该网络包括四个卷积阶段来提取输入序列 的特征图。 上标指的是网络阶段。 随后,我们计算四个阶段的连续特征差异序列,如下所示:
| (1) |
阶段内特征融合。 给定特征差异序列,利用几个残差块[16]分别聚合每个阶段内的特征元素,以生成阶段特定的运动表示。 该计算可以表示为:
| (2) |
其中是连接操作,是卷积块的函数。 在实践中,我们使用内核大小为的残差块分别聚合相应阶段的特征。
阶段间特征融合。 在获得每个阶段的运动特征后,我们通过建议的空间调制和渐进累积进行跨阶段特征整合,以获得融合运动表示。 (1) 我们首先采用可变形卷积(DCN V2 [70])来自适应调制每个阶段特征的空间响应。 具体来说,给定,我们独立估计内核采样偏移和调制标量:
| (3) | ||||
自适应学习的偏移量揭示了像素运动关联场,而调制标量反映了每个像素位置中运动信息的幅度。 然后,我们应用可变形卷积,将运动特征 、内核偏移 和调制标量 作为输入,并输出空间校准的运动每个阶段的特点:
| (4) |
(2) 如图2所示,空间调制后,TDE将前一阶段的运动特征添加到调制后的特征中,后面跟着几个 卷积。 这样的处理逐步执行,直到所有阶段的特征都收敛到。 上述计算公式为:
| (5) |
通过选择性地、全面地聚合多阶段特征,我们的 TDE 能够编码信息丰富且细粒度的运动表示 。
3.2 表示解开模块
直接利用编码的运动特征进行后续姿势估计很容易不可避免地出现与任务无关的像素移动(例如、背景、遮挡)。 为了缓解这一限制,人们可以通过热图损失来端到端训练视觉注意力模块,以进一步提取有意义的运动线索。 虽然很简单,但这种方法中学习到的特征往往是平淡无奇的,这导致性能提升有限(见表7)。 在手动检查提取的用于姿态估计的时间动态特征之后,研究对有意义的信息蒸馏引入监督是否会促进该任务将是富有成果的。
理想情况下,将运动信息注释合并为特征约束将简化这个问题。 不幸的是,在大多数情况下,视频中通常不存在此类运动标签。 鉴于上述观察,我们建议通过相互信息的观点来解决这个问题。 具体来说,我们明确定义了普通运动特征 的有用组合 和噪声组合 ,其中使用 用于后续任务,而 作为对比标志。 通过引入互信息监督来减少和之间的统计依赖性,我们可以掌握有区别的任务相关运动信号。 耦合这些网络目标,设计了表示解缠模块(RDM)。
表示因式分解。 给定普通运动表示 ,我们通过激活相应的特征通道将其分解为有用的运动分量 和噪声分量 。 具体来说,我们首先通过全局平均池(GAP)层将全局空间信息压缩到通道描述符中。 然后,使用多层感知器 (MLP) 捕获通道间的交互,然后使用 sigmoid 函数输出注意掩模。 最后利用这个通道注意矩阵将输入特征 分别重新缩放为输出 和 。 上述因式分解过程可表述为:
| (6) | |||
符号表示sigmoid函数,表示通道乘法。 和的网络参数是独立学习的。
热图生成。 我们通过几个残差块整合有用的运动特征和关键帧的视觉特征,以获得增强表示。 被馈送到检测头以生成估计的姿态热图 。 我们使用 卷积层实现检测头。
互信息目标。 互信息 (MI) 衡量一个变量揭示的关于另一个变量的信息量[33, 18]。 形式上,两个随机变量 和 之间的 MI 定义为:
| (7) |
其中是和之间的联合概率分布,而和是它们的边缘。 在此框架内,我们学习有效时间差异的主要目标表述为:
| (8) |
术语严格量化了有用运动特征和噪声特征之间共享的信息量。 回想一下, 用于后续的姿态估计任务。 直观地,在模型训练开始时,在互信息最小化的约束下,有意义的和嘈杂的运动线索将同时编码为和。 随着训练的进行,和编码的特征逐渐系统化为与任务相关的运动信息和不相关的运动线索。 在的这种对比设置下,有用的运动特征将更具辨别力并且有利于姿态估计任务,如图1所示( C)。
此外,引入了两个正则化函数来促进模型优化。 (i) 我们建议提高多级时间差分编码器(TDE)感知有意义信息的能力:
| (9) |
其中 测量在普通运动特征 中压缩的有用运动信息。 最大化该术语可以鼓励在我们的 TDE 中编码更丰富、更有效的运动线索。
(ii) 我们建议减少 功能增强期间的信息丢失:
| (10) |
其中 指的是标签,而术语 和 分别量化了 和 中消失的任务相关信息,当它们聚合成增强特征 时。 最小化这两个正则化项可以促进信息的无损传播。 鉴于条件 MI 计算 [17, 46] 众所周知的困难,我们采用 [33, 68] 中所做的简化版本。 我们将第一项 近似为:
3.3损失函数
总的来说,我们的损失函数由两部分组成。 (1) 我们采用标准姿态热图损失来监督最终的姿态估计:
| (14) |
其中 和 分别表示预测和地面真实姿势热图。 (2)我们还利用提出的互信息目标来监督运动特征的学习。 我们的总损失由下式给出:
| (15) |
其中是一个超参数,用于平衡不同损失项的比率。
4实验
| Method | Head | Shoulder | Elbow | Wrist | Hip | Knee | Ankle | Mean |
|---|---|---|---|---|---|---|---|---|
| PoseTracker [14] | ||||||||
| PoseFlow [58] | ||||||||
| JointFlow [12] | - | - | - | - | - | - | - | |
| FastPose [66] | ||||||||
| TML++ [20] | - | - | - | - | - | - | - | |
| Simple (R-50) [56] | ||||||||
| Simple (R-152) [56] | ||||||||
| STEmbedding [25] | ||||||||
| HRNet [44] | ||||||||
| MDPN [15] | ||||||||
| CorrTrack [40] | ||||||||
| Dynamic-GNN [60] | ||||||||
| PoseWarper [5] | ||||||||
| DCPose [32] | ||||||||
| DetTrack [52] | ||||||||
| FAMI-Pose [33] | ||||||||
| TDMI (Ours) | ||||||||
| TDMI-ST (Ours) |
| Method | Head | Shoulder | Elbow | Wrist | Hip | Knee | Ankle | Mean |
|---|---|---|---|---|---|---|---|---|
| STAF [39] | - | - | - | - | - | |||
| AlphaPose [13] | ||||||||
| TML++ [20] | - | - | - | - | - | - | - | |
| MDPN [15] | ||||||||
| PGPT [3] | - | - | - | - | - | |||
| Dynamic-GNN [60] | ||||||||
| PoseWarper [5] | ||||||||
| PT-CPN++ [61] | ||||||||
| DCPose [32] | ||||||||
| DetTrack [52] | ||||||||
| FAMI-Pose [33] | ||||||||
| TDMI (Ours) | ||||||||
| TDMI-ST (Ours) |
| Method | Head | Shoulder | Elbow | Wrist | Hip | Knee | Ankle | Mean |
|---|---|---|---|---|---|---|---|---|
| Tracktor++ w. poses [4, 11] | - | - | - | - | - | - | - | |
| CorrTrack [40, 11] | - | - | - | - | - | - | - | |
| CorrTrack w. ReID [40, 11] | - | - | - | - | - | - | - | |
| Tracktor++ w. corr. [4, 11] | - | - | - | - | - | - | - | |
| DCPose [32] | ||||||||
| FAMI-Pose [33] | ||||||||
| TDMI (Ours) | ||||||||
| TDMI-ST (Ours) |
4.1实验设置
数据集。 PoseTrack 是用于基于视频的人体姿势估计的大规模基准数据集。 具体来说,PoseTrack2017包含个用于训练的视频序列和个用于验证的视频序列(遵循官方协议),总共 姿势注释。 PoseTrack2018 大大增加了视频数量,并包括用于训练的 和用于验证的 (带有 姿势注释)。 两个数据集都用 关键点进行注释,并带有用于联合可见性的附加标志。 PoseTrack21进一步扩展了PoseTrack2018数据集的姿势注释,特别是对于特定的小人和人群中的人,包括姿势注释。 PoseTrack21 中重新定义了关节可见性标志,以便可以利用遮挡信息。 HiEve [31] 是一个非常具有挑战性的基准数据集,用于在各种现实的拥挤和复杂事件(例如、地震、 -off 训练和自行车碰撞),包含 视频剪辑,其中 用于训练, 用于测试。 该数据集拥有更大的数据规模,并包含当前最大数量的姿势注释()。
| Method | w_AP@avg | w_AP@50 | w_AP@75 | w_AP@90 | AP@avg | AP@50 | AP@75 | AP@90 |
|---|---|---|---|---|---|---|---|---|
| RSN18 [6] | ||||||||
| DHRN FT [44] | ||||||||
| ADAM+PRM [31] | ||||||||
| DH_IBA [62] | ||||||||
| TryNet [32] | ||||||||
| ccc [8] | ||||||||
| TDMI-ST (Ours) |
评估指标。 我们采用标准姿态估计指标,即平均精度(AP)来评估我们的模型。 我们首先计算每个关节的 AP,然后通过对所有关节进行平均来获得最终性能 (mAP)。
实施细节。 我们的 TDMI 框架是使用 PyTorch 实现的。 对于视觉特征提取,我们利用在 COCO 数据集上预训练的 HRNet-W48 [44] 模型。 我们结合了[44,5,56]中采用的几种数据增强策略,包括随机旋转、随机缩放、截断(半体)和翻转。 时间跨度设置为、即、先前帧和未来帧。 我们使用亚当优化器,其初始学习率为(在、和历时分别衰减为、和)。 我们使用 TITAN RTX GPU 训练模型。 训练过程在 epoch 内终止。 方程中的重量差异损失。 15,我们凭经验发现是最有效的。 在的特征增强过程中,采用最终阶段特征作为视觉特征。

4.2与最先进方法的比较
PoseTrack2017 数据集上的结果。 我们首先在 PoseTrack2017 数据集上评估我们的方法。 总共比较了 种方法,它们在验证集上的性能如表 1 所示。 我们的 TDMI 模型始终优于现有的最先进方法,达到 的 mAP。 为了充分利用时间线索,我们将 TDMI 扩展到 TDMI-ST,其中我们用输入序列的时空特征替换关键帧视觉特征,以产生最终表示 。 所提出的 TDMI-ST 进一步推进了性能边界并实现了 的 mAP。 值得注意的是,我们的 TDMI-ST 比采用的骨干网络 HRNet-W48 [44] 将 mAP 提高了 个点。 与之前性能最佳的方法 FAMI-Pose [33] 相比,我们的 TDMI-ST 还提供了 mAP 增益。 对于具有挑战性的关节(即、手腕、脚踝)的性能提升也令人鼓舞:我们获得了手腕的 mAP () 和 mAP脚踝的 ()。 这种一致且显着的性能改进表明明确接受有意义的运动信息的重要性。 此外,我们在图3中显示了具有复杂时空相互作用(例如、遮挡、模糊)的场景的可视化结果,这证明了所提出方法的鲁棒性。 PoseTrack2018 数据集上的结果。 我们在 PoseTrack2018 数据集上进一步对我们的模型进行基准测试。 验证集的经验比较列于表2中。 如此表所示,我们的基本模型 TDMI 超越了所有其他方法并实现了 的 mAP。 另一方面,我们的 TDMI-ST 模型在所有关节上获得了新的最先进结果,并获得了 mAP 的最终性能,其中 mAP 为 、 和 分别表示肘部、手腕和脚踝。
PoseTrack21 数据集上的结果。 表 3 报告了我们的方法以及 PoseTrack21 数据集上其他最先进方法的结果。 前四个基线[4,40,11]的定量结果由数据集[11]正式提供。 我们根据 GitHub 上发布的实现进一步重现了之前几种令人印象深刻的方法(即、DCPose [32] 和 FAMI-Pose [33]) ,并评估他们在此数据集中的表现。 从表3中,我们观察到FAMI-Pose [33]取得了良好的姿态估计结果,mAP为。 相反,我们的TDMI和TDMI-ST能够分别获得 mAP和 mAP。 另一个观察是,PoseTrack21主要为PoseTrack2018增加了小个子和人群中的人的姿势注释。 有趣的是,所提出的 TDMI-ST 在 PoseTrack21 上相对于 PoseTrack2018 ( mAP) 获得了更好的性能,这可能是证明我们的方法的有效性和鲁棒性的证据,特别是对于具有挑战性的场景。
HiEve 数据集上的结果。 此外,我们在最大 HiEve 基准数据集上评估我们的模型。 测试集的详细结果如表4所示。 我们将模型的预测结果上传到 HiEve 测试服务器111http://humaninevents.org/oltp.html?title=3 获取结果。 我们的 TDMI-ST 在 HiEve 排行榜上取得了 的最高得分权重平均 AP (w_AP@avg)。 值得注意的是,与使用额外数据来训练模型的 ccc [8] 相比,我们仍然通过 w_AP 和
| Method | TDE | RDM | Mean |
|---|---|---|---|
| HRNet [44] | |||
| Op-Flow | |||
| (a) | ✓ | ||
| (b) | ✓ | ✓ |
| Method | Multi-stage | Spatial modulation | Progressive fusion | Mean |
| (a) | ||||
| (b) | ✓ | |||
| (c) | ✓ | ✓ | ||
| (d) | ✓ | ✓ | ✓ |
| Method | Factorization | MI objective | Mean |
|---|---|---|---|
| TDMI, w/o RDM | |||
| (a) | ✓ | ||
| (b) | ✓ | ✓ | |
| (c) | ✓ | ✓ |
视觉结果比较。 除了定量分析之外,我们还定性地检查我们的方法处理遮挡和模糊等复杂情况的能力。 我们在图 4 中描述了 a) 我们的 TDMI 与最先进方法 b) HRNet [44] 和 c) 的并排比较FAMI-姿势[33]。 据观察,我们的方法始终为各种具有挑战性的场景提供更准确和稳健的姿势检测。 HRNet 专为静态图像而设计,不包含时间动态,从而导致帧质量下降,结果不理想。 相比之下,FAMI-Pose 执行隐式运动补偿,但缺乏有效的信息蒸馏。 通过 TDE 和 RDM 的时差建模和有用信息解缠的原理设计,我们的 TDMI 更擅长处理遮挡和模糊等具有挑战性的场景。
4.3消融研究
我们进行消融研究,重点检查 TDMI 框架中每个组件的贡献,包括多级时间差分编码器 (TDE) 和表示解缠模块 (RDM)。 我们还研究了每个组件内各种微观设计的有效性。 所有实验均在 PoseTrack2017 验证集上进行。

TDMI的组成部分研究。 我们根据经验评估了所提出的 TDMI 中每个组件的功效,并在表 7 中报告了定量结果。 Op-Flow 是一个基线,我们使用 RAFT [45] 预测的光流作为运动表示。 (a) 对于第一个设置,我们将 TDE 引入 HRNet-W48 [44] 基线以捕获运动上下文。 值得注意的是,TDE 编码的运动线索已经比基线提高了 mAP 的大幅提升。 这证明了我们的 TDE 在引入运动信息以促进基于视频的人体姿势估计方面的有效性。 另一方面,我们的 TDE 还比基准 Op-Flow 提供了 mAP 的性能增益。 与复杂的光流相比,这凸显了时间差异在表示运动方面的巨大潜力。 (b) 对于下一个设置,我们进一步结合 RDM 来发现有意义的动作。 mAP 结果增加到 ,增加了 。 在成熟的 TDE 之上,这种显着的性能改进证实了挖掘有意义的时间动态在指导准确的姿态估计方面的重要性。
多级时间差分编码器的研究。 我们用各种设计修改 TDE,以研究它们对最终性能的影响。 如表7所示,进行了四个实验:(a)仅融合最后阶段的特征、(b) 通过简单的串联和卷积直接聚合多阶段特征,(c)逐步集成多阶段特征,以及(d)我们具有空间调制的完整TDE和渐进融合。 从该表中,我们观察到多阶段特征融合确实优于仅使用单阶段特征,但简单的融合方案(b)产生了轻微的性能提升( mAP )。 通过逐步聚合多阶段特征(c),保留每个阶段的详细信息,从而提供点的mAP增益。 我们完整的TDE (d)进一步结合了空间调制机制来自适应地选择每个阶段的重要信息,从而实现最佳性能。
表征解缠模块的研究。 此外,我们还研究了 RDM 在不同设置下的效果,并将结果显示在表7中。 我们首先进行一个简单的基线(a),其中删除了 MI 目标。 该方法部分提取了有用的运动信息,并将 mAP 略微提高了 ()。 然后,我们合并 MI 目标,它对应于我们完整的 RDM (b)。 mAP 的显着性能增强提供了经验证据,表明我们提出的 MI 目标作为额外的监督是有效的,以促进区分性任务相关运动线索的学习。 我们还尝试通过分割通道 (c) 和 mAP 下降 来执行特征分解,这表明通道分割方案可能不适用到我们的 TDMI 框架。
5 结论和未来的工作
在本文中,我们从通过时间差异学习和有用信息解开有效利用动态上下文的角度研究了基于视频的人体姿势估计任务。 我们提出了一种多级时间差分编码器(TDE)来捕获以显式特征差异表示为条件的运动线索。 理论上,我们在互信息之上进一步构建表示解缠模块(RDM)来掌握任务相关信息。 大量实验表明,所提出的方法在四个基准数据集上的性能优于最先进的方法,包括 PoseTrack2017、PoseTrack2018、PoseTrack21 和 HiEve。 未来的工作包括应用于其他视频相关任务,例如 3D 人体姿势估计和动作识别。 时间差异特征还可以集成到现有的姿势跟踪管道中,以评估人体运动的相似性以进行数据关联。
6致谢
这项工作得到了国家自然科学基金项目的部分支持,批准号为: 62203184. 这项工作还得到了韩国 MSIT 的部分支持,根据 ITRC 计划 (IITP-2022-2020-0-01789) 和 IITP 监督的高潜力个人全球培训计划 (RS-2022-00155054)。
参考
- [1] Mykhaylo Andriluka, Umar Iqbal, Eldar Insafutdinov, Leonid Pishchulin, Anton Milan, Juergen Gall, and Bernt Schiele. Posetrack: A benchmark for human pose estimation and tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- [2] Bruno Artacho and Andreas Savakis. Unipose: Unified human pose estimation in single images and videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7035–7044, 2020.
- [3] Qian Bao, Wu Liu, Yuhao Cheng, Boyan Zhou, and Tao Mei. Pose-guided tracking-by-detection: Robust multi-person pose tracking. IEEE Transactions on Multimedia, 23:161–175, 2020.
- [4] Philipp Bergmann, Tim Meinhardt, and Laura Leal-Taixe. Tracking without bells and whistles. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 941–951, 2019.
- [5] Gedas Bertasius, Christoph Feichtenhofer, Du Tran, Jianbo Shi, and Lorenzo Torresani. Learning temporal pose estimation from sparsely-labeled videos. In Advances in Neural Information Processing Systems, pages 3027–3038, 2019.
- [6] Yuanhao Cai, Zhicheng Wang, Zhengxiong Luo, Binyi Yin, Angang Du, Haoqian Wang, Xinyu Zhou, Erjin Zhou, Xiangyu Zhang, and Jian Sun. Learning delicate local representations for multi-person pose estimation. arXiv preprint arXiv:2003.04030, 2020.
- [7] Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- [8] Shuning Chang, Li Yuan, Xuecheng Nie, Ziyuan Huang, Yichen Zhou, Yupeng Chen, Jiashi Feng, and Shuicheng Yan. Towards accurate human pose estimation in videos of crowded scenes. In Proceedings of the 28th ACM International Conference on Multimedia, pages 4630–4634, 2020.
- [9] Yilun Chen, Zhicheng Wang, Yuxiang Peng, Zhiqiang Zhang, Gang Yu, and Jian Sun. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7103–7112, 2018.
- [10] Bowen Cheng, Bin Xiao, Jingdong Wang, Honghui Shi, Thomas S Huang, and Lei Zhang. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5386–5395, 2020.
- [11] Andreas Doering, Di Chen, Shanshan Zhang, Bernt Schiele, and Juergen Gall. Posetrack21: A dataset for person search, multi-object tracking and multi-person pose tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20963–20972, 2022.
- [12] Andreas Doering, Umar Iqbal, and Juergen Gall. Joint flow: Temporal flow fields for multi person tracking. arXiv preprint arXiv:1805.04596, 2018.
- [13] Hao-Shu Fang, Shuqin Xie, Yu-Wing Tai, and Cewu Lu. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, pages 2334–2343, 2017.
- [14] Rohit Girdhar, Georgia Gkioxari, Lorenzo Torresani, Manohar Paluri, and Du Tran. Detect-and-track: Efficient pose estimation in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 350–359, 2018.
- [15] Hengkai Guo, Tang Tang, Guozhong Luo, Riwei Chen, Yongchen Lu, and Linfu Wen. Multi-domain pose network for multi-person pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), pages 0–0, 2018.
- [16] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [17] R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, and Yoshua Bengio. Learning deep representations by mutual information estimation and maximization. In International Conference on Learning Representations, 2018.
- [18] Xuege Hou, Yali Li, and Shengjin Wang. Disentangled representation for age-invariant face recognition: A mutual information minimization perspective. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3692–3701, 2021.
- [19] Ziyuan Huang, Shiwei Zhang, Jianwen Jiang, Mingqian Tang, Rong Jin, and Marcelo H Ang. Self-supervised motion learning from static images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1276–1285, 2021.
- [20] Jihye Hwang, Jieun Lee, Sungheon Park, and Nojun Kwak. Pose estimator and tracker using temporal flow maps for limbs. In 2019 International Joint Conference on Neural Networks (IJCNN), pages 1–8. IEEE, 2019.
- [21] Umar Iqbal, Anton Milan, and Juergen Gall. Posetrack: Joint multi-person pose estimation and tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- [22] Takashi Isobe, Xu Jia, Xin Tao, Changlin Li, Ruihuang Li, Yongjie Shi, Jing Mu, Huchuan Lu, and Yu-Wing Tai. Look back and forth: Video super-resolution with explicit temporal difference modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17411–17420, 2022.
- [23] Boyuan Jiang, MengMeng Wang, Weihao Gan, Wei Wu, and Junjie Yan. Stm: Spatiotemporal and motion encoding for action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2000–2009, 2019.
- [24] Chenru Jiang, Kaizhu Huang, Shufei Zhang, Xinheng Wang, and Jimin Xiao. Pay attention selectively and comprehensively: Pyramid gating network for human pose estimation without pre-training. In Proceedings of the 28th ACM International Conference on Multimedia, pages 2364–2371, 2020.
- [25] Sheng Jin, Wentao Liu, Wanli Ouyang, and Chen Qian. Multi-person articulated tracking with spatial and temporal embeddings. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5664–5673, 2019.
- [26] Lipeng Ke, Ming-Ching Chang, Honggang Qi, and Siwei Lyu. Multi-scale structure-aware network for human pose estimation. In Proceedings of the european conference on computer vision (ECCV), pages 713–728, 2018.
- [27] Muhammed Kocabas, Salih Karagoz, and Emre Akbas. Multiposenet: Fast multi-person pose estimation using pose residual network. In Proceedings of the European conference on computer vision (ECCV), pages 417–433, 2018.
- [28] Sven Kreiss, Lorenzo Bertoni, and Alexandre Alahi. Pifpaf: Composite fields for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 11977–11986, 2019.
- [29] Yan Li, Bin Ji, Xintian Shi, Jianguo Zhang, Bin Kang, and Limin Wang. Tea: Temporal excitation and aggregation for action recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 909–918, 2020.
- [30] Yanjie Li, Shoukui Zhang, Zhicheng Wang, Sen Yang, Wankou Yang, Shu-Tao Xia, and Erjin Zhou. Tokenpose: Learning keypoint tokens for human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11313–11322, 2021.
- [31] Weiyao Lin, Huabin Liu, Shizhan Liu, Yuxi Li, Rui Qian, Tao Wang, Ning Xu, Hongkai Xiong, Guo-Jun Qi, and Nicu Sebe. Human in events: A large-scale benchmark for human-centric video analysis in complex events. arXiv preprint arXiv:2005.04490, 2020.
- [32] Zhenguang Liu, Haoming Chen, Runyang Feng, Shuang Wu, Shouling Ji, Bailin Yang, and Xun Wang. Deep dual consecutive network for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 525–534, 2021.
- [33] Zhenguang Liu, Runyang Feng, Haoming Chen, Shuang Wu, Yixing Gao, Yunjun Gao, and Xiang Wang. Temporal feature alignment and mutual information maximization for video-based human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11006–11016, 2022.
- [34] Zhaoyang Liu, Donghao Luo, Yabiao Wang, Limin Wang, Ying Tai, Chengjie Wang, Jilin Li, Feiyue Huang, and Tong Lu. Teinet: Towards an efficient architecture for video recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 11669–11676, 2020.
- [35] Yue Luo, Jimmy Ren, Zhouxia Wang, Wenxiu Sun, Jinshan Pan, Jianbo Liu, Jiahao Pang, and Liang Lin. Lstm pose machines. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5207–5215, 2018.
- [36] Joe Yue-Hei Ng and Larry S Davis. Temporal difference networks for video action recognition. In 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1587–1596. IEEE, 2018.
- [37] Yanwei Pang, Yazhao Li, Jianbing Shen, and Ling Shao. Towards bridging semantic gap to improve semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4230–4239, 2019.
- [38] Tomas Pfister, James Charles, and Andrew Zisserman. Flowing convnets for human pose estimation in videos. In Proceedings of the IEEE International Conference on Computer Vision, pages 1913–1921, 2015.
- [39] Yaadhav Raaj, Haroon Idrees, Gines Hidalgo, and Yaser Sheikh. Efficient online multi-person 2d pose tracking with recurrent spatio-temporal affinity fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4620–4628, 2019.
- [40] Umer Rafi, Andreas Doering, Bastian Leibe, and Juergen Gall. Self-supervised keypoint correspondences for multi-person pose estimation and tracking in videos. In European Conference on Computer Vision, pages 36–52. Springer, 2020.
- [41] Benjamin Sapp, Alexander Toshev, and Ben Taskar. Cascaded models for articulated pose estimation. In European conference on computer vision, pages 406–420. Springer, 2010.
- [42] Luca Schmidtke, Athanasios Vlontzos, Simon Ellershaw, Anna Lukens, Tomoki Arichi, and Bernhard Kainz. Unsupervised human pose estimation through transforming shape templates. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2484–2494, 2021.
- [43] Jie Song, Limin Wang, Luc Van Gool, and Otmar Hilliges. Thin-slicing network: A deep structured model for pose estimation in videos. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4220–4229, 2017.
- [44] Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5693–5703, 2019.
- [45] Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. In European conference on computer vision, pages 402–419. Springer, 2020.
- [46] Xudong Tian, Zhizhong Zhang, Shaohui Lin, Yanyun Qu, Yuan Xie, and Lizhuang Ma. Farewell to mutual information: Variational distillation for cross-modal person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1522–1531, 2021.
- [47] Alexander Toshev and Christian Szegedy. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2014.
- [48] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017.
- [49] Fang Wang and Yi Li. Beyond physical connections: Tree models in human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 596–603, 2013.
- [50] Limin Wang, Zhan Tong, Bin Ji, and Gangshan Wu. Tdn: Temporal difference networks for efficient action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1895–1904, 2021.
- [51] Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment networks: Towards good practices for deep action recognition. In European conference on computer vision, pages 20–36. Springer, 2016.
- [52] Manchen Wang, Joseph Tighe, and Davide Modolo. Combining detection and tracking for human pose estimation in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11088–11096, 2020.
- [53] Yang Wang and Greg Mori. Multiple tree models for occlusion and spatial constraints in human pose estimation. In European Conference on Computer Vision, pages 710–724. Springer, 2008.
- [54] Shih-En Wei, Varun Ramakrishna, Takeo Kanade, and Yaser Sheikh. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
- [55] Jiamin Wu, Tianzhu Zhang, Zhe Zhang, Feng Wu, and Yongdong Zhang. Motion-modulated temporal fragment alignment network for few-shot action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9151–9160, 2022.
- [56] Bin Xiao, Haiping Wu, and Yichen Wei. Simple baselines for human pose estimation and tracking. In Proceedings of the European conference on computer vision (ECCV), pages 466–481, 2018.
- [57] Junfei Xiao, Longlong Jing, Lin Zhang, Ju He, Qi She, Zongwei Zhou, Alan Yuille, and Yingwei Li. Learning from temporal gradient for semi-supervised action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3252–3262, 2022.
- [58] Yuliang Xiu, Jiefeng Li, Haoyu Wang, Yinghong Fang, and Cewu Lu. Pose flow: Efficient online pose tracking. arXiv preprint arXiv:1802.00977, 2018.
- [59] Sen Yang, Zhibin Quan, Mu Nie, and Wankou Yang. Transpose: Keypoint localization via transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11802–11812, 2021.
- [60] Yiding Yang, Zhou Ren, Haoxiang Li, Chunluan Zhou, Xinchao Wang, and Gang Hua. Learning dynamics via graph neural networks for human pose estimation and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8074–8084, 2021.
- [61] Dongdong Yu, Kai Su, Jia Sun, and Changhu Wang. Multi-person pose estimation for pose tracking with enhanced cascaded pyramid network. In Proceedings of the European Conference on Computer Vision (ECCV), pages 0–0, 2018.
- [62] Lei Yuan, Shu Zhang, Feng Fubiao, Naike Wei, and Huadong Pan. Combined distillation pose. In Proceedings of the 28th ACM International Conference on Multimedia, pages 4635–4639, 2020.
- [63] Yuhui Yuan, Rao Fu, Lang Huang, Weihong Lin, Chao Zhang, Xilin Chen, and Jingdong Wang. Hrformer: High-resolution vision transformer for dense predict. Advances in Neural Information Processing Systems, 34:7281–7293, 2021.
- [64] Wang Zeng, Sheng Jin, Wentao Liu, Chen Qian, Ping Luo, Wanli Ouyang, and Xiaogang Wang. Not all tokens are equal: Human-centric visual analysis via token clustering transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11101–11111, 2022.
- [65] Dingwen Zhang, Guangyu Guo, Dong Huang, and Junwei Han. Poseflow: A deep motion representation for understanding human behaviors in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6762–6770, 2018.
- [66] Jiabin Zhang, Zheng Zhu, Wei Zou, Peng Li, Yanwei Li, Hu Su, and Guan Huang. Fastpose: Towards real-time pose estimation and tracking via scale-normalized multi-task networks. arXiv preprint arXiv:1908.05593, 2019.
- [67] Xiaoqin Zhang, Changcheng Li, Xiaofeng Tong, Weiming Hu, Steve Maybank, and Yimin Zhang. Efficient human pose estimation via parsing a tree structure based human model. In 2009 IEEE 12th International Conference on Computer Vision, pages 1349–1356. IEEE, 2009.
- [68] Long Zhao, Yuxiao Wang, Jiaping Zhao, Liangzhe Yuan, Jennifer J Sun, Florian Schroff, Hartwig Adam, Xi Peng, Dimitris Metaxas, and Ting Liu. Learning view-disentangled human pose representation by contrastive cross-view mutual information maximization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12793–12802, 2021.
- [69] Yue Zhao, Yuanjun Xiong, and Dahua Lin. Recognize actions by disentangling components of dynamics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6566–6575, 2018.
- [70] Xizhou Zhu, Han Hu, Stephen Lin, and Jifeng Dai. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9308–9316, 2019.