RSFNet:使用特定区域滤色器的白盒图像修饰方法
摘要
修饰图像是增强照片视觉吸引力的重要方面。 尽管用户通常具有共同的审美偏好,但他们的修饰方法可能会根据个人喜好而有所不同。 因此,需要一种白盒方法来产生令人满意的结果,并使用户能够同时方便地编辑图像。 最近的白盒修饰方法依赖于级联全局过滤器,这些过滤器提供图像级过滤器参数,但无法执行细粒度修饰。 相比之下,调色师通常采用分而治之的方法,在使用 Davinci Resolve 等传统工具时执行一系列特定于区域的细粒度增强。 我们利用这一见解开发了一个使用并行区域特定滤镜进行照片修饰的白盒框架,称为 RSFNet。 我们的模型同时生成过滤器参数(例如饱和度、对比度、色调)和每个过滤器区域的注意图。 RSFNet 采用滤波器的线性求和,而不是级联滤波器,从而可以更轻松地训练更多样化的滤波器类别。 我们的实验表明,RSFNet 实现了最先进的结果,提供了令人满意的审美吸引力,并增加了可编辑白盒修饰的用户便利性。 代码可在 https://github.com/Vicky0522/RSFNet 获取。
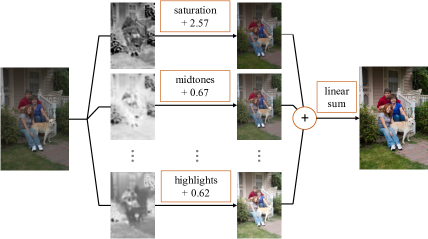
1简介
由于拍摄条件差和摄影师经验不足,相机录制的照片和视频通常缺乏审美品质。 艺术家经常使用专业级软件(例如。、用于图像的 PhotoShop、用于视频的 Davinci Resolve)来提高图像和视频质量。 然而,它需要专业的修图技巧来进行一系列复杂的手动调整。 使用提供各种风格模板的万无一失的应用程序简化了修图程序,但由于缺乏增强能力而无法达到最佳效果。
最近基于学习的方法证明了深度神经网络在自动照片修饰方面的强大能力。 建立自动系统以生成端到端的最佳结果。 然而,最重要的考虑因素之一是,修饰并不是唯一解决方案的问题。 人们有不同的修饰偏好。 即使同一位艺术家也可能对同一图像进行不同风格的修饰,以满足不同的需求。 为了给手动编辑提供便利,自动修饰系统不仅必须提供建议的结果,还必须以人类可以理解的方式提供修饰策略。
考虑到这些因素,我们提出了一个白盒框架,该框架使用艺术家在传统修饰工具中采用的分而治之的策略。 我们的模型生成区域的注意力图以及这些区域的传统编辑的过滤器参数。 这允许用户根据自己的喜好更改建议的结果。
这项工作的主要贡献如下:
-
•
我们根据分而治之的策略重新定义修饰问题,重点是寻找区域的注意力图和每个图人类可理解的过滤器调整以达到最佳结果。
-
•
我们提出 RSFNet,它同时生成区域和过滤器参数的像素级注意力图。 通过对过滤结果进行线性求和,我们的模型展示了优于全局白盒修饰方法的性能,具有更广泛的过滤器类别用于细粒度增强和更简单的训练过程。
-
•
我们提出了一种允许用户编辑 RSFNet 建议结果的方案,证明了其在图像应用中的有效性和便利性。
2相关作品
深度图像增强。 使用基于学习的方法在图像增强方面已经进行了许多尝试。 这些方法大致可以分为两类:基于深度卷积的模型和物理启发模型。 前者[3,4,6,27,32]将增强视为综合问题,并使用全卷积生成器[15]来实现密集的图像到图像的转换。 虽然这些方法表现出强大的生成和增强细节的能力,但它们存在结构繁重和推理速度低的问题。 后一类工作将增强定义为物理模型的参数预测,并使用深度学习策略来拟合模型。 这些模型包括 3D-LUT [23, 31, 30]、参数滤波器 [17]、条件顺序全局调制 [8]、仿射颜色变换 [7, 22],一维映射曲线 [20, 12, 18]。 它们的增强能力取决于物理模型涵盖的变换函数的范围。 其中,基于全局3D-LUT [30, 31]的模型经过精心设计,可以实现高性能和快速的推理速度。 然而,由于缺乏细粒度的局部调整,它们在平滑区域中的过渡不均匀。 空间感知 3D-LUT [23] 通过计算像素级权重图缓解全局 3D-LUT 问题。 所有这些方法都具有黑盒结构或不直观的参数,人类难以理解。 DeepLPF [17] 是通过局部参数滤波器进行区域特定颜色增强领域的一个重要里程碑,但其推理速度慢且滤波器形状有限。 三种类型的过滤器具有三种实现方式,每种都会产生难以理解的复杂映射。
白盒图像编辑。 最近的白盒方法[10,11,29,33]已将图像编辑解耦为一系列人类可理解的操作和深度学习策略来预测它们。 其中,我们的工作与[11, 10]最相关。 然而,他们使用级联滤波器参数预测模块训练网络来逐步执行全局修饰。 我们的模型利用逐像素区域特定的滤波器来捕获局部特征,并采用线性求和来组合滤波器,从而具有更强的能力来覆盖更广泛的颜色变换函数。
3方法
3.1设计动机
传统的修饰策略。 传统的修图过程中,都是对不同区域分别进行局部调整,然后聚合在一起,完成细粒度的增强。 所有调整都可以在一个层中完成,其中过滤器全部在同一图像上进行,而不是先前过滤器的结果。 我们采用这种分而治之的策略来构建我们的框架。 我们从传统工具(例如、、Davinci Resolve)中选择常用的修饰滤镜来表示调整操作,包括对比度、饱和度、色调、色温、阴影、中间调、高光和偏移。 有关过滤器的更多详细信息,请参阅附录A。 因此,修饰被定义为找到像素级的注意力图,并对每个图进行相应的调整,以达到最理想的结果。 我们采用这种约定,并将修饰结果 表示为将滤镜产生的增量的线性总和添加到原始图像中:
| (1) |
其中, 和 分别是输入图像 的 第 1 个注意力图的 过滤器的参数值和过滤器函数, 是图像 的 第 1 个注意力图。 应该注意的是,这种线性表示使我们的优化过程比其他白盒方法简单得多。
3.2架构
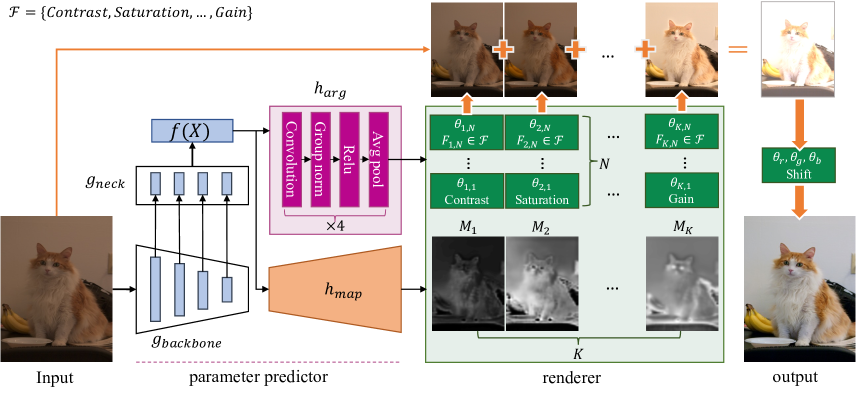
我们的模型由两个模块组成:参数预测器和渲染器。 参数预测器的架构与之前的分割模型[24, 25]具有相似的整体结构。 如图2所示,网络由主干、FPN 颈、用于注意力地图预测的地图生成器和用于参数回归的参数回归器组成。 我们将地图生成器的最后一层 设置为 sigmoid,然后是上采样层以匹配原始输入图像的大小。 我们使用来表示FPN颈部的输出特征。 上采样后生成的地图为:
| (2) |
是最后一层的输出通道数。 参数回归器 由卷积模块的 单元组成。 每个模块由一个卷积层组成,后面是组归一化、激活和平均池化。 输出特征 最终被 缩减为 向量,表示每个映射的所有过滤器的参数:
| (3) |
是每个贴图的滤色器数量。 给定来自参数预测器的映射和参数,渲染器将过滤器函数 应用于输入图像,并通过增量的线性求和合并过滤结果。 方程1中的最终输出图像为:
| (4) |
在我们的实现中,我们将每个映射的过滤器数量设置为,表示为每个映射分配一个特定的过滤器。 图2 中的第二行过滤器框对此进行了说明。 我们还将过滤器 Shift 视为应用于整个图像的全局函数,无需注意图。 通过我们的实验,我们发现这种配置足以产生令人满意的结果,同时也为用户编辑提供了便利。
训练损失。 整个框架可以进行端到端的训练。 我们的训练损失函数定义如下:
| (5) |
其中是重建的损失。
3.3 具有受控区域形状的 RSFNet 变体

| input | Result(Args & Masks) | Result(Image) | Edit Version 1. | Edit Version 2. | Edit Version 3. | GroundTruths |
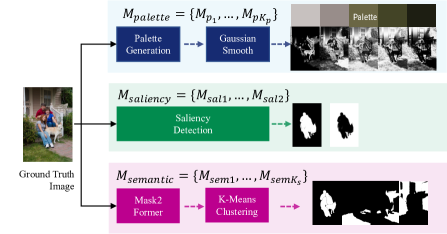
我们提出的框架能够生成具有受控训练形状的区域掩模,并对数据和损失函数进行最小程度的修改。 根据我们的观察,艺术家倾向于根据主要颜色、显着性或其他高级语义信息来选择区域。 为了利用这种洞察力,我们利用基于调色板的方法[2]、显着性检测[14]和全景分割网络[5]来生成用于 的输入图像的基于调色板、显着性和语义的训练掩码,如图 3 所示。 进一步的实现细节可以在附录B中找到。 我们将方程 5 中的训练损失函数修改如下:
| (6) |
其中是重建的损失。 当使用基于调色板的掩模和显着性掩模进行训练时,是遵循[24, 25]中的损失函数的掩模预测的Dice损失。 当地图生成器 以 softmax 层结束时,我们将其更改为使用语义掩码训练时的交叉熵损失。
该模型同时为输入图像生成区域掩模和相应的滤波器参数。 用户可以选择区域地图并调整过滤器参数来编辑结果。 我们在图 4 中展示了使用显着性掩码训练的 RSFNet-saliency 示例。
|
|
|
|
|
mask type | PSNR | SSIM | ||
|---|---|---|---|---|---|
| w/ | saliency(1) | 23.83 | 0.906 | ||
| w/ | palette(5) | 23.45 | 0.903 | ||
| w/ | semantic(10) | 21.65 | 0.866 | ||
| w/ | semantic(5) | 21.77 | 0.867 | ||
| w/o | saliency(1) | 24.01 | 0.909 | ||
| w/o | palette(5) | 24.14 | 0.906 | ||
| w/o | semantic(10) | 24.09 | 0.908 | ||
| w/o | semantic(5) | 24.17 | 0.909 | ||
| w/o | semantic(133) | 23.75 | 0.905 |
|
masktype | PSNR | SSIM | ||
|---|---|---|---|---|---|
| w/ | saliency(1) | 23.26 | 0.890 | ||
| w/o | saliency(1) | 24.01 | 0.909 |
| backbone |
|
PSNR | Runtime | ||
|---|---|---|---|---|---|
| resnet18 | x8 | 24.65 | 9.98 | ||
| resnet18 | x4 | 24.83 | 12.38 | ||
| resnet10 | x8 | 24.50 | 7.98 | ||
| resnet10 | x4 | 24.38 | 8.71 |
4实验
4.1 数据集和应用程序设置
我们在两个公开可用的数据集上进行了实验:MIT-Adobe FiveK [1] 和 PPR10K [13]。 MIT-Adobe FiveK 由 5,000 张 RAW 图像及其修饰版本组成。 我们遵循之前的工作[8,12,31,30],采用专家C修饰的图像作为基本事实,并将数据集分为4,500对用于训练和500对用于验证。 在训练阶段将图像大小调整为 480p,而在验证过程中同时使用 480p 分辨率和原始分辨率。 我们按照官方分割[13]将PPR10K数据集分割成8,875对用于训练和2,286对用于测试。 图像大小调整为 360p 分辨率以进行训练和验证。
对于 MIT-Adobe FiveK 数据集,我们对两种输入设置进行实验:使用 ExpertC 白平衡进行归零的输入和按镜头进行归零的输入。 第二组输入更具挑战性,因为它的白平衡也恶化了。 因此,为了恢复其视觉吸引力,我们的框架需要具有执行色温校正和色调调整的能力。
4.2实现细节
为了实现第 2 节中描述的我们提出的框架,我们采用 ResNet18 [9] 作为主干,并利用层 的输出特征作为连接FPN 颈部的 通道输入。 FPN 颈部将特征缩减为 通道,并将它们输入到映射生成器和参数回归器中。 我们将 Adobe-MIT FiveK 和 PPR10K 数据集的区域图输出编号 分别设置为 和 。 每个地图的过滤器数量设置为,其中过滤器用于MIT-Adobe FiveK,每个用于阴影、中间调、高光,其中 RGB 通道的参数设置为相等。 对于 PPR10K,我们使用 滤镜, 分别用于阴影、中间调、高光,其中 RGB 通道的参数设置不同。
为了实现 RSFNet 与受控区域形状的变化,如第 3 节中所述,我们为 MIT-Adobe FiveK 数据集生成地面实况掩码。 具体来说,我们为每个图像生成五个基于调色板的掩模、一个显着性掩模和五个语义掩模。 对于 PPR10K 数据集,我们直接使用数据集中提供的人类区域掩模作为 的真实掩模进行训练。 地图生成器被设计为输出基于调色板的版本的 通道、用于显着性版本的 通道以及用于语义版本的 通道。 如上所述,我们对 MIT-Adobe FiveK 使用 过滤器,对 PPR10K 使用 过滤器。
我们使用标准 Adam 优化器 [19] 来最小化方程 5 和 6 中的损失函数。 小批量大小为。 我们以初始学习率 训练模型进行 1,000,000 次迭代。 我们使用余弦策略,每 250,000 次迭代逐渐衰减学习率。 所有实验均在 NVIDIA Tesla V100 GPU 上进行。
在接下来的章节中,我们将第 2 节中的主要模型表示为 RSFNet-map。 3 节中描述的变体表示为 RSFNet-palette、RSFNet-saliency 和 RSFNet-semantic。
| Method |
|
|
|
|||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | Runtime | PSNR | SSIM | Runtime | |||||||||
| UPE [22] | 21.88* | 0.853* | 10.80* | / | / | / | / | / | / | / | ||||||
| DPE [4] | 23.75* | 0.908* | 9.34* | / | / | / | / | / | / | / | ||||||
| HDRNet [7] | 24.66* | 0.915* | 8.06* | / | / | / | / | / | / | / | ||||||
| DeepLPF [17] | 24.73* | 0.916* | 7.99* | 23.38 | 0.880 | 10.03 | 44.25 | 23.40 | 0.863 | 1133.90 | ||||||
| CSRNet [8] | 25.17* | 0.924* | 7.75* | 24.24 | 0.910 | 9.70 | 3.49 | 23.04 | 0.874 | 80.6 | ||||||
| SA-3DLUT [23] | 25.50* | / | / | / | / | / | / | / | / | / | ||||||
| 3D-LUT [31] | 25.29* | 0.923* | 7.55* | / | / | / | / | / | / | / | ||||||
| 3D-LUT+AdaInt [30] | 25.49* | 0.926* | 7.47* | 24.50 | 0.912 | 9.22 | 1.59 | 24.24 | 0.857 | 1.80 | ||||||
| Harmonizer [11] | 24.11 | 0.904 | 8.23 | 23.23 | 0.893 | 10.14 | 16.74 | 22.57 | 0.870 | 27.98 | ||||||
| RSFNet-map | 25.49 | 0.924 | 7.23 | 24.64 | 0.915 | 9.16 | 9.98 | 24.39 | 0.894 | 12.35 | ||||||
| RSFNet-palette | 25.01 | 0.914 | 7.62 | 24.22 | 0.911 | 9.52 | 19.76 | 23.88 | 0.888 | 68.57 | ||||||
| RSFNet-saliency | 24.78 | 0.916 | 7.86 | 24.20 | 0.912 | 9.42 | 14.09 | 24.00 | 0.890 | 59.42 | ||||||
| RSFNet-semantic | 24.76 | 0.915 | 7.77 | 24.19 | 0.912 | 9.45 | 24.07 | 23.89 | 0.891 | 71.18 | ||||||
| RSFNet-global | 24.31 | 0.911 | 8.21 | 23.43 | 0.904 | 10.16 | 9.42 | 23.26 | 0.885 | 10.99 | ||||||
| Method |
|
|
|
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |||||||
| DeepLPF [17] | 23.47 | 0.892 | 22.77 | 0.875 | 23.73 | 0.896 | ||||||
| CSRNet [8] | 24.01 | 0.936 | 23.91 | 0.938 | 24.31 | 0.931 | ||||||
| 3D-LUT+AdaInt [30] | 25.98 | 0.947 | 24.91 | 0.936 | 25.48 | 0.919 | ||||||
| Harmonizer [11] | 24.76 | 0.929 | 22.79 | 0.885 | 24.56 | 0.902 | ||||||
| RSFNet-map | 25.58 | 0.949 | 24.81 | 0.945 | 25.52 | 0.939 | ||||||
| RSFNet-saliency | 25.53 | 0.946 | 24.72 | 0.944 | 25.11 | 0.939 | ||||||
4.3消融研究
在本节中,我们评估框架在不同设置下的能力。

| input | CSRNet | DeepLPF | AdaInt | Harmonizer | RSFNet-map | GroundTruths |
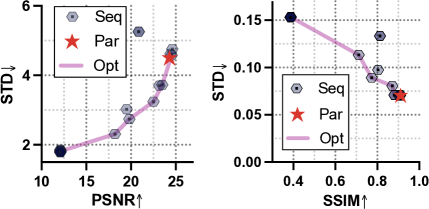
并行和顺序方法的比较研究。 我们进行实验来比较同一组过滤器函数和主干结构下的并行方法和顺序方法。 对于顺序实现,我们修改网络结构以模仿艺术工作流程并类似于 Harmonizer [11]。 我们使用随机打乱的 20 个独特的过滤函数序列来训练网络。 结果如图5所示。 并行方法显示出具有接近最大 PSNR 和较低 PSNR 标准差 (std) 的帕累托最优性。 在 SSIM 和 SSIM 标准方面,它也优于所有顺序方法。 我们发现改变应用过滤器的顺序可以导致性能的显着变化。 这些序列中近一半未能产生令人满意的结果。 此外,在训练过程中,并行方法比顺序方法收敛得更快。 此外,并行方法比顺序方法更快。
分别训练地图生成和参数回归。 为了训练具有受控区域形状的模型,我们尝试使用预训练的 PoolNet [14] 并添加 FPN 颈部,然后将参数回归器添加到主干,而不是从头开始训练。 在训练过程中,我们固定主干网的权重以保持网络生成的显着性掩码不变。 定量结果如表1(b)所示,这表明与从头开始训练相比并没有优越性。 其原因可能是仅接受语义数据训练的网络缺乏足够的信息进行修饰。 因此,最好同时训练地图生成和参数回归任务。
使用掩码作为输入。 对于具有受控区域形状的训练模型,我们可以使用与图像连接的掩模作为模型的输入。 我们分别使用三组掩码作为输入来训练三个模型。 结果如表1(a)所示。 在 PSNR 和 SSIM [26] 上评估的修饰结果低于其他设置。 这可能是因为地面实况掩码是由现成的模型生成的,这可能与数据集的底层真实掩码不同。 地图生成器在推理阶段对掩模进行轻微修改,以达到更好的修饰效果。 因此,与我们同时生成掩码和过滤器参数的 RSFNet 变体设计相比,掩码与输入图像的简单串联可能会导致性能更差。
速度和准确性之间的权衡。 随着我们减少主干中的下采样操作数量,特征尺寸会变大,时间成本也会增加。 然而,修饰的定量结果也变得更好,如1(c)所示。 速度以毫秒为单位。
|
 |
|
| RSFNet-saliency | ||
|
||
| Harmonizer | ||
|
||
| input | ||
| RSFNet-semantic | ||
|
||
| Harmonizer | ||
|
4.4与最先进技术的比较
我们将我们的方法与黑盒和白盒图像修饰任务的最先进方法进行比较。 对所选方法的 PSNR、SSIM [26]、CIE LAB 色彩空间中的 距离 () 和推理速度进行了比较。 我们按照[30]中的做法来测量 100 张图像上的 GPU 推理时间并报告平均值。 定量结果如表2和3所示。 RSFNet-map指的是我们在2节中的主要模型,RSFNet-saliency,RSFNet-palette和RSFNet-semantic指的是3节中分别使用三组掩码训练的模型。 此外,我们评估了没有地图生成器的全局修饰模型,表示为RSFNet-global。 其他模型使用其官方公共代码和默认配置进行训练。 所有实验均在 NVIDIA Tesla V100 GPU 上执行。
我们提出的方法RSFNet-map展示了其在温度校正和色彩增强方面的有效性,特别是对于更恶化的拍摄条件下的第二组输入。 尽管RSFNet-map以微不足道的增长实现了最先进的结果,而其他 RSFNet 变体落后于最先进的技术,但值得注意的是,我们的白盒框架提供了人类易于理解的修图方式,与其他黑盒方法相比,使用户更方便地编辑和评估修图结果。 与 Harmonizer [11] 等最先进的白盒方法相比,我们所有的模型都表现出更好的性能和更快的速度。 此外,使用 3D-LUT 编码滤镜功能可能会加速我们的模型,这是传统修饰工具中常用的技术。 对于 PPR10K [13],我们还使用随机分割设置来评估我们的方法。 结果在附录C中提供,一致强化了从之前的实验中得出的结论。
图 6 中呈现的定性结果表明,与 3D-map 相比,我们提出的方法 RSFNet-map 在处理跨区域的颜色过渡(特别是在高亮区域)方面表现出卓越的性能。基于LUT的方法,例如AdaInt,如图第一行所示。 此外,我们在可编辑修饰方面与Harmonizer[11]进行了比较,如图8所示。 我们的白盒框架提供了比全局修饰操作更多的自由度,以实现特定区域的修饰。 例如,当使用 Harmonizer 全局调整温度时,第一张图像中的天空会变成黄色。 另一方面,我们的 RSFNet-saliency 模型可以修改前景女孩的温度,同时使其他区域不受影响。 在第二张图片中,Harmonizer 的全局温度调整将湖泊和山脉变成了蓝色。 相比之下,RSFNet-semantic仅修改天空温度,而山脉和湖泊保持不变。
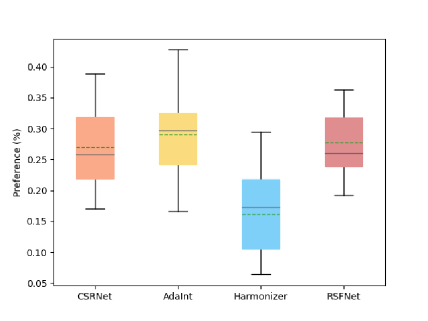
为了进一步验证我们提出的框架的有效性,我们进行了一项用户研究来评估人类对 RSFNet 和其他最先进方法的偏好,包括 CSRNet [8]、AdaInt [ 30] 和激素[11]。 为了形成测试集,我们使用 使用 ExpertC 白平衡归零的输入 和 作为镜头归零的输入从 Adobe-MIT FiveK 的验证集中随机选择 图像 设置,以及从互联网下载的附加 图像。 在实验过程中,我们向 参与者展示通过所有方法(包括原始输入)生成的修饰图像。 要求参与者从所有方法生成的一组随机打乱的修饰图像中选择最佳结果。 我们计算参与者对每种方法的偏好,并使用箱线图绘制结果,如图7所示。
在比较的方法中,AdaInt [30] 实现了更高的平均值和中位数百分比。 与其他方法相比,RSFNet 表现出更稳定的性能,具有更高的底部百分比和最小的标准方差百分比。 与白盒方法 Harmonizer [11] 相比,RSFNet 表现出了优异的用户偏好百分比。 箱线图说明了不同用户的不同偏好,突出了可编辑功能的重要性。 由于RSFNet利用传统的滤色镜进行修饰,因此可以轻松集成到传统的修饰工具中。 用户可以根据自己的喜好通过界面进一步增强修饰结果的视觉吸引力。
视频修饰。 我们提出的 RSFNet 模型还展示了对视频修饰的适用性,如图 8 所示。 过滤器参数在单个视频剪辑中的所有帧中保持不变,确保整个修饰过程的一致性。 然而,对于具有受控区域形状的 RSFNet 变体,例如 RSFNet-saliency,跨帧的修饰一致性依赖于跨帧的区域掩模的一致性。 虽然滤镜参数可以缓解遮罩带来的不一致问题,但遮罩严重的不一致问题仍然可能会影响修饰结果。 在更鲁棒的跟踪算法的帮助下,这些模型可以在可编辑视频修饰中取得更好的性能,凸显了RSFNet在各种修饰应用中的潜力。
5限制与结论
我们开发框架的假设是所有调整都在一个层中完成,然后通过所有过滤器增量的线性求和来组合以获得最终结果。 因此,虽然我们的模型提供了一个符合人类艺术家直觉的白盒修饰框架,但它无法涵盖艺术家可以使用专业软件进行的所有调整。 然而,我们认为,如果艺术家修饰过程中的缓存数据可用,例如用于特定区域修饰的区域掩模,我们的模型配备了更复杂的结构,例如中的级联结构[10 , 11],通过从这些数据中学习,可以表现得更类似于真正的人类艺术家。
本文介绍了 RSFNet,这是一种用于图像修饰的白盒框架,它利用分而治之的策略来生成区域图和人类可理解的滤波器参数。 生成的滤波图像使用线性求和进行组合,允许更广泛的滤波器类别并实现具有卓越性能的细粒度增强。 为了方便用户,还提出了具有受控形状区域掩模的 RSFNet 变体。 大量的实验证明了 RSFNet 的有效性。
致谢 这项工作得到了阿里巴巴集团通过阿里巴巴创新研究 (AIR) 计划和新加坡南洋理工大学阿里巴巴-南洋理工大学新加坡联合研究院 (JRI) 的支持。 我们感谢王玉玺先生在反驳期间为产生更多实验结果所做的努力。
参考
- [1] Vladimir Bychkovsky, Sylvain Paris, Eric Chan, and Frédo Durand. Learning photographic global tonal adjustment with a database of input / output image pairs. In CVPR 2011, pages 97–104, 2011.
- [2] Huiwen Chang, Ohad Fried, Yiming Liu, Stephen DiVerdi, and Adam Finkelstein. Palette-based photo recoloring. SIGGRAPH, 34(4), July 2015.
- [3] Chen Chen, Qifeng Chen, Jia Xu, and Vladlen Koltun. Learning to see in the dark. In CVPR, pages 3291–3300, 2018.
- [4] Yu Sheng Chen, Yu Ching Wang, Man Hsin Kao, and YungYu Chuang. Deep photo enhancer: Unpaired learning for image enhancement from photographs with gans. In CVPR, pages 6306–6314, 2018.
- [5] Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. In CVPR, pages 1290–1299, 2021.
- [6] Yubin Deng, Chen Change Loy, and Xiaoou Tang. Aestheticdriven image enhancement by adversarial learning. In Susanne Boll, Kyoung Mu Lee, Jiebo Luo, Wenwu Zhu, Hyeran Byun, Chang Wen Chen, Rainer Lienhart, and Tao Mei, editors, ACM MM, pages 870–878. ACM, 2018.
- [7] Michaël Gharbi, Jiawen Chen, Jonathan T. Barron, Samuel W. Hasinoff, and Frédo Durand. Deep bilateral learning for real-time image enhancement. ACM TOG, 36(4):118:1–118:12, 2017.
- [8] Jingwen He, Yihao Liu, Yu Qiao, and Chao Dong. Conditional sequential modulation for efficient global image retouching. In ECCV, pages 679–695, 2020.
- [9] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2022.
- [10] Yuanming Hu, Hao He, Chenxi Xu, Baoyuan Wang, and Stephen Lin. Exposure: A white-box photo post-processing framework. ACM TOG, 37(2):26, 2018.
- [11] Zhanghan Ke, Chunyi Sun, Lei Zhu, Ke Xu, and Rynson W.H. Lau. Harmonizer: Learning to perform white-box image and video harmonization. In ECCV, pages 690–706, 2022.
- [12] Hanul Kim, Su-Min Choi, Chang-Su Kim, and Yeong Jun Koh. Representative color transform for image enhancement. In ICCV, pages 4459–4468, 2021.
- [13] Jie Liang, Hui Zeng, Miaomiao Cui, Xuansong Xie, and Lei Zhang. Ppr10k: A large-scale portrait photo retouching dataset with human-region mask and group-level consistency. In CVPR, pages 653–661, 2021.
- [14] Jiang-Jiang Liu, Qibin Hou, Ming-Ming Cheng, Jiashi Feng, and Jianmin Jiang. A simple pooling-based design for real-time salient object detection. In CVPR, pages 3917–3926, 2019.
- [15] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In CVPR, pages 3431–3440, 2015.
- [16] Caron Mathilde, Touvron Hugo, Misra Ishan, Jégou Hervé, Mairal Julien, Bojanowski Piotr, and Joulin Armand. Emerging properties in self-supervised vision transformers. In ICCV, pages 3917–3926, 2021.
- [17] Sean Moran, Pierre Marza, Steven McDonagh, Sarah Parisot, and Gregory G. Slabaugh. Deeplpf: Deep local parametric filters for image enhancement. In CVPR, pages 12823–12832, 2020.
- [18] Sean Moran, Steven McDonagh, and Gregory G. Slabaugh. Curl: Neural curve layers for global image enhancement. In ICPR, pages 9796–9803. IEEE, 2020.
- [19] Kingma Diederik P. and Ba Jimmy. Adam: A method for stochastic optimization. In Bengio Yoshua and LeCun Yann, editors, ICLR, 2015.
- [20] Yuda Song, Hui Qian, and Xin Du. Starenhancer: Learning real-time and style-aware image enhancement. In ICCV, pages 4106–4115, 2021.
- [21] Lloyd Stuart. Least squares quantization in pcm. IEEE TIT, 28(2):129–137, 1982.
- [22] Ruixing Wang, Qing Zhang, Chi-Wing Fu, Xiaoyong Shen, Wei-Shi Zheng, and Jiaya Jia. Underexposed photo enhancement using deep illumination estimation. In CVPR, pages 6849–6857, 2019.
- [23] Tao Wang, Yong Li, Jingyang Peng, Yipeng Ma, Xian Wang, Fenglong Song, and Youliang Yan. Real-time image enhancer via learnable spatial-aware 3d lookup tables. In ICCV, pages 2451–2460, 2021.
- [24] Xinlong Wang, Tao Kong, Chunhua Shen, Yuning Jiang, and Lei Li. Solo: Segmenting objects by locations. In ECCV, pages 649–665, 2020.
- [25] Xinlong Wang, Rufeng Zhang, Tao Kong, Lei Li, and Chunhua Shen. Solov2: Dynamic and fast instance segmentation. NeurIPS, 33:17721–17732, 2020.
- [26] Zhou Wang, Bovik A.C., Sheikh H.R., and Simoncelli E.P. Image quality assessment: from error visibility to structural similarity. IEEE TIP, 13(4):600–612, 2004.
- [27] Chen Wei, Wenjing Wang, Wenhan Yang, and Jiaying Liu. Deep retinex decomposition for low-light enhancement. In BMVC, page 155. BMVA Press, 2018.
- [28] Van Gansbeke Wouter, Vandenhende Simon, and Van Gool Luc. Discovering object masks with transformers for unsupervised semantic segmentation. arXiv preprint arXiv:2206.06363, 2022.
- [29] Zhicheng Yan, Hao Zhang, Baoyuan Wang, Sylvain Paris, and Yizhou Yu. Automatic photo adjustment using deep neural networks. ACM TOG, 35(2):11:1–11:15, 2016.
- [30] Canqian Yang, Meiguang Jin, Xu Jia, Yi Xu, and Ying Chen. Adaint: Learning adaptive intervals for 3d lookup tables on real-time image enhancement. In CVPR, pages 17501–17510, 2022.
- [31] Hui Zeng, Jianrui Cai, Lida Li, Zisheng Cao, and Lei Zhang. Learning image-adaptive 3d lookup tables for high performance photo enhancement in real-time. IEEE TPAMI, 2020.
- [32] Yonghua Zhang, Jiawan Zhang, and Xiaojie Guo. Kindling the darkness: A practical low-light image enhancer. In Laurent Amsaleg, Benoit Huet, Martha A. Larson, Guillaume Gravier, Hayley Hung, Chong-Wah Ngo, and Wei Tsang Ooi, editors, ACM MM, pages 1632–1640. ACM, 2019.
- [33] Zhengxia Zou, Tianyang Shi, Shuang Qiu, Yi Yuan, and Zhenwei Shi. Stylized neural painting. In CVPR, pages 15689–15698, 2021.
附录A过滤功能
修饰后的结果表示为等式:
| (7) |
对于不同的过滤器,有不同的表达方式:
| (8) | ||||
其中表示整个图像的平均值,而表示图像在CIE LAB色彩空间中的L通道。 另外,表示图像的RGB颜色通道。 调整因子用表示,是满足的标量。 在我们的实验中,的值是根据传统的颜色分级工具确定的。
附录 B 具有受控区域形状的 RSFNet 变体
地面真相面具生成。 我们采用[2]中提出的基于调色板的方法来生成图像的主颜色,以及从像素到颜色的距离图中心。 我们通过对这些距离图应用高斯平滑函数来获得区域掩模,从而得到 。 我们还使用来自 [14] 的预训练网络来预测显着性掩模,产生 。
由于之前的全景分割工作将对象分为一百多个类,这对于我们的任务来说是多余的,因此我们的目标是识别最重要的像素分组。 为了实现这一目标,我们遵循 [16, 28] 中的实践以及具有成对修饰数据的自注意力网络。 首先,我们使用 [5] 中提出的网络预测语义掩码。 然后,我们将聚类算法(例如,K-means [21])应用于以蒙版图像作为输入的自注意力网络的输出特征。 分配有相同簇索引的掩码被合并,得到。 对于三组掩码中的每一组,我们都训练一个具有相应输出通道号的单独模型。 整个流程如图3所示。
可微自适应平滑核。 为了确保跨掩模边缘的平滑过渡,我们在主网络中加入了可微的自适应平滑内核模块。 我们将高斯平滑核固定为合适的大小,例如分辨率为的原始输入的。 核的标准方差是一个可学习的参数,它适应输入。
附录 C其他结果
定量结果。 我们使用 PPR10K [13] 的随机分割设置来评估我们的方法。 结果如表4所示。 有关更多实现细节,请参阅我们的代码库:https://github.com/Vicky0522/RSFNet。
| Method |
|
|
|
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |||||||
| DeepLPF [17] | 24.97 | 0.939 | 24.33 | 0.930 | 24.65 | 0.926 | ||||||
| CSRNet [8] | 24.38 | 0.938 | 24.41 | 0.940 | 24.53 | 0.931 | ||||||
| 3D-LUT+AdaInt [30] | 27.31 | 0.954 | 26.62 | 0.945 | 26.67 | 0.929 | ||||||
| Harmonizer [11] | 25.02 | 0.916 | 23.84 | 0.895 | 25.22 | 0.920 | ||||||
| RSFNet-map | 27.25 | 0.956 | 26.61 | 0.954 | 26.76 | 0.945 | ||||||
| RSFNet-saliency | 25.98 | 0.946 | 25.87 | 0.948 | 25.88 | 0.937 | ||||||

| input | Result(Args & Masks) | Result(Image) | Edit Version 1. | Edit Version 2. | Edit Version 3. | GroundTruths |
