LINE:利用重要神经元进行分布外检测
摘要
量化输入样本的不确定性非常重要,特别是在自动驾驶和医疗保健等关键任务领域,对分布外(OOD)数据的失败预测可能会导致大问题。 OOD 检测问题从根本上来说是因为模型无法表达它不知道的内容。 事后 OOD 检测方法得到了广泛的探索,因为它们不需要额外的重新训练过程,而重新训练过程可能会降低模型的性能并增加训练成本。 在本研究中,从模型深层代表高级特征的神经元的角度出发,我们引入了一个新的方面来分析分布内数据和OOD数据之间模型输出的差异。 我们提出了一种新方法,即利用重要神经元(LINE)来进行事后分布外检测。 基于 Shapley 值的剪枝通过仅选择高贡献神经元来预测特定类别的输入数据并屏蔽其余神经元,从而减少噪声输出的影响。 激活剪裁将高于某个阈值的所有值固定为相同的值,允许 LINE 平等地对待所有特定于类的特征,并且只考虑分布内数据和 OOD 数据之间激活特征差异的数量之间的差异。 综合实验验证了该方法的有效性,在 CIFAR-10、CIFAR-100 和 ImageNet 数据集上优于最先进的事后 OOD 检测方法。 代码可在 https://github.com/LINE-OOD 上获取
1简介
近年来,深度学习在各个领域取得了巨大的进步。 这一进步吸引了众多研究人员,引发了许多将深度学习技术应用于现实世界的尝试。 然而,由于多种原因,将这些最先进的技术应用于实际应用通常受到限制。 一个主要障碍是训练期间存在看不见的样本类别。 这些样本被称为分布外 (OOD) 数据,可能会损害模型的稳定性,并且在某些情况下会严重损害其性能。 OOD 样本的固有特征可能会在自动驾驶和医疗应用等关键任务领域导致潜在的严重后果。 因此,有效处理这些 OOD 样本对于避免诸如车祸和误诊等问题至关重要。
对于 OOD 检测,人们已经探索了多种技术来分析分布内 (ID) 数据和 OOD 数据之间的区别。 OOD 检测有多种方法,包括基于置信度的方法 [29, 11, 7, 16, 19]、基于密度的方法 [27, 64, 1, 40, 42, 24, 63, 22, 51, 20, 38, 23],以及基于距离的方法[28, 47, 41, 49, 9, 59, 50, 18, 35] 。 事后方法是 OOD 检测中的一种方法,它在实际应用中具有显着的优势,因为它消除了重新训练过程的需要,重新训练过程可能会降低模型的性能并增加训练成本[57].
事后 OOD 检测方法[32,45,46]采用通常用于预测的模型逻辑或层激活等输出来计算 OOD 分数。 这些分数允许根据各自分数的差异来区分 ID 和 OOD 数据[57]。 增强 ID 和 OOD 数据之间的整体 OOD 分数分布差异是提高事后 OOD 检测方法性能的关键方面。 最近的研究[45, 46]发现,总体差异的扩大取决于减轻噪声信号的能力。 例如,ReAct [45] 表明 OOD 数据在倒数第二层激活中表现出相当大的值。 通过截断这些噪声激活,ReAct 有效提高了 OOD 检测性能。 类似地,DICE [46] 揭示了增加 OOD 分数分布方差的噪声信号的存在。 通过有选择地采用最显着的权重,DICE 增强了 OOD 检测性能,同时减少了噪声信号的影响。 最大限度地减少噪声模型输出的影响对于提高事后 OOD 检测性能至关重要。 在这项研究中,我们揭示了一个在 OOD 检测中也很重要的额外因素。
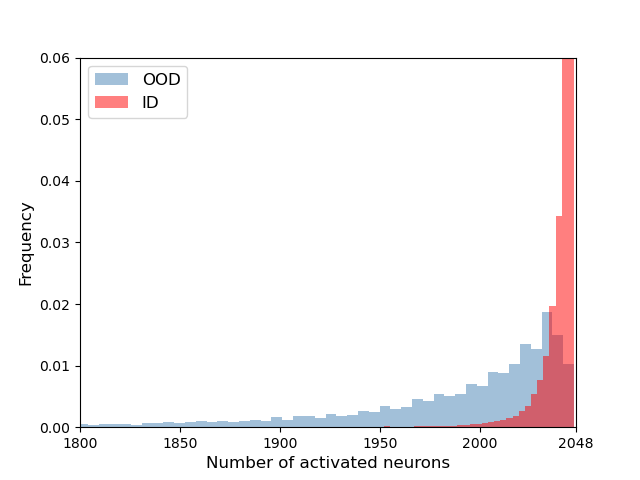
图1显示倒数第二层激活特征数量的直方图。 我们将激活值大于零的神经元定义为激活神经元。 如图所示,当模型遇到 ID 样本时,大多数神经元被激活。 然而,对于 OOD 样本,激活的神经元较少。 为了理解图1中观察到的主要原因,我们从神经元概念关联[4,5,53,21]的角度研究该模型。 根据[4],神经元被训练来检测卷积神经网络(CNN)深层中解开的高级特征,它们甚至可以从数据中学习新的未标记的抽象概念 [53]。 代表这些高级特征的神经元数量在更深的层中增加,并在倒数第二层[5]中成为最显着的数量。 由于倒数第二层中的激活表示这些高级特征[4]的存在,因此不同的输入图像以不同的方式激活高级特征,例如幅度和模式。 倒数第二层中这些不同的激活模式最终用于预测输入图像的类别。 由于每个类别都拥有与高级概念相关的独特特征,因此每个类别的相关高级特征也有所不同。 因此,每个关联的高级特征都可以分类为一个特定于类的特征组。 神经元中相关高级特征的差异导致 ID 和 OOD 样本之间倒数第二层激活的差异,这些样本被预测为同一类。 因此,考虑激活的必需神经元的数量可以作为区分 ID 和 OOD 样本的有用指标。
在本文中,我们提出了一种新颖的事后 OOD 检测方法,称为L平均I重要Neurons( 行)。 LINE 利用两个关键方面:考虑激活的重要神经元的数量和最小化噪声激活以增强 OOD 检测性能。 为了实现这一目标,我们在 LINE 中引入了两种强大的技术:1)基于 Shapley 的剪枝和 2)激活剪裁(AC)。
基于 Shapley 值的剪枝是一种通过选择推断输入数据类所必需的激活来减轻噪声输出影响的方法。 虽然存在多种识别重要激活的方法,但 Sun 等人 [46] 使用激活幅度来确定其重要性。 然而,仅这种方法不足以量化神经元的重要性。 因此,我们使用 Shapley 值 [44] 来更准确地测量每个神经元的贡献。 将 Shapley 值概念[44]应用于神经网络使我们能够量化每个神经元对识别特定类别的贡献。 此外,具有高 Shapley 值的神经元与关键输入图像特征[21]相关。 通过利用 Shapley 值 [44],我们可以识别代表每个类别重要高级特征的神经元,这对于减少噪声输出至关重要。
激活剪辑是 ReAct [45] 中引入的概念,是另一种强大的技术。 根据类特定特征来解释激活剪切可以提供对其在考虑 OOD 检测中激活的重要神经元数量方面的作用的新理解。 激活限幅将超过特定阈值的值调整为阈值。 这种修改使我们能够通过平等对待众多特定于类的特征来解释分布内数据和 OOD 数据之间激活特征数量的差异。 通过考虑激活的特定类别特征数量的变化,我们可以有效地扩大 ID 和 OOD 数据之间的整体 OOD 分数差异,从而提高性能。
我们的主要贡献总结如下:
-
•
我们提出了一种简单而有效的事后 OOD 检测方法,名为 LINE,它使用 Shapley 值对神经元的贡献进行排序,并为利用选定的重要类特定神经元提供了新的启发。
-
•
我们揭示了提高 OOD 评分的重要因素,并展示了一种理解激活剪切在 OOD 检测中的作用的新方法。 通过应用激活裁剪,我们可以充分考虑激活的特定类特征的数量,并实现更高的 OOD 检测性能。
-
•
我们在 CIFAR-10、CIFAR-100 和 ImageNet-1K 上进行了全面的实验来验证所提出方法的有效性。 与竞争性事后方法 DICE[46] 相比,LINe 将 FPR95 降低了 14.05。
2 背景及相关工作
2.1 神经元概念关联
神经元概念关联方法是一个研究领域,试图将 CNN 的内部计算解释为人类可理解的概念[37,8,3,14]。 多项研究表明,较浅层的神经元倾向于学习更简单和低级的概念,例如曲线和边缘,而较深层的神经元则学习更多抽象和高级的概念,例如手臂和面部[60, 61 ,53]。 [33,12,14]中还介绍了量化概念贡献的方法。 网络解剖[4,5,60]将每个神经元分配给一个概念以量化其角色。 Bau等人[6]通过观察生成模型中概念相关内容的变化来研究概念特异性神经元的作用。 最近,Wang 等人[53]表明模型可以学习诸如哺乳动物和食肉动物之类的抽象概念,这些概念不在训练数据的标签集中。
2.2沙普利值
Shapely value[44,26,48]是博弈论中的一个概念,它评估每个属性的个体和协作效果。 已有研究使用 CNN 中的 Shapley 值来衡量每个神经元的贡献并解释模型的行为[34,2,13,48,21]。 神经元 Shapley[13] 对 Shapley 值进行排序,以将所有隐藏层中最有影响力的神经元识别为图像类别。 Khazar 等人[21]表明,具有高 Shapley 值的神经元与输入图像的重要特征具有较高的相关性。 之前的研究启发我们通过根据 Shapley 值计算的贡献分数来选择重要的特定类别神经元。 LINE 可以通过利用选定的类特定神经元来有效消除噪声信号的负面影响。
2.3 分布外检测
OOD检测旨在从训练数据[57]中找到具有不同特征的输入。 大量的研究工作致力于开发一种有效的方法来区分 OOD 输入和 ID 输入。 基于置信度的方法通过根据不同的评分函数[29,11,7,16,19]量化OOD分数来执行OOD检测。 Hendrycks 等人[16]使用模型的最大softmax概率(MSP)作为基于置信度的基线OOD评分函数。 ODIN[30] 利用 softmax 层上的输入扰动和温度缩放来增加 ID 和 OOD 之间的差异。 为了增强基于置信度的评分的有效性,最近,刘等人[32]引入了基于能量的评分,并从似然角度进行了理论解释,该评分在[31]中得到了进一步采用, 54, 36] 区分 ID 和 OOD 样本。 基于距离的方法测量输入样本与典型 ID 样本或其质心之间的距离[28,47,41,49,9,59,50,18,35]。 这些方法基于简单的证据,即 OOD 样本应该比 ID 具有更大的距离。 类似地,基于密度的方法根据训练样本的分布来识别 OOD 样本,并使用密度(或似然)[27, 64, 1, 40, 42, 24, 63, 22, 51, 20, 38, 23]。
但上述方法都没有考虑激活特征的数量,而激活特征的数量可以作为区分ID和OOD样本的一个很好的指标。 与我们的研究最相似的研究是 DICE[46]。 DICE 通过有选择地使用激活 [46] 中的显着权重,利用稀疏化来减少噪声信号的影响。 在本研究中,我们利用 Shapley 值计算出的神经元贡献来精确选择神经元,从而有效消除噪声信号的结果[44, 21]。 此外,我们的方法通过考虑激活特征的数量来更有效地执行 OOD 检测。 已知神经元与概念相关,深层神经元的激活模式在ID和OOD中是不同的。 这为考虑 OOD 检测中的激活数量提供了理论背景。 据我们所知,我们的工作是第一个利用基于 Shapley 值的神经元贡献并考虑激活特征的数量来计算 OOD 分数的研究。
3方法
3.1方法概述
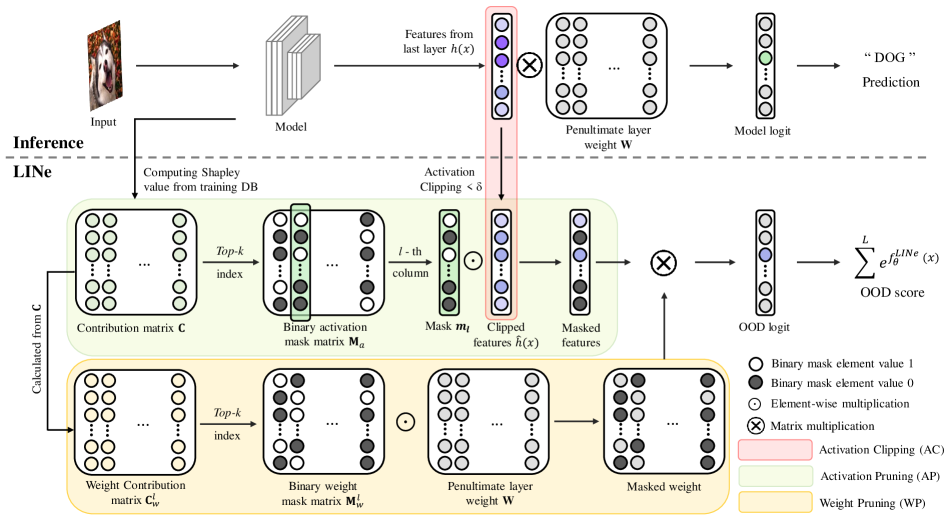
我们的方法主要由两部分组成:激活剪切和基于 Shapley 的剪枝。 激活限幅是一种当激活值超过特定阈值()时将每个神经元激活限幅到特定值的方法。 通过激活剪切,我们的方法可以在计算 OOD 分数时考虑高级特征的数量,并根据神经元概念关联进行分析。 接下来,基于 Shapley 的剪枝通过仅使用重要神经元测量神经网络的神经贡献来消除噪声信号的负面影响。 我们可以使用 Shapley 值来准确测量每个神经元的贡献,这是一种基于数学的方法。 此外,通过应用 Shapley 值,我们可以获得支持证据,证明贡献较大的神经元代表了识别输入图像的关键特征[21]。 这使我们能够汇总每个类别的所有贡献,并选择代表特定类别特征的重要特定类别神经元。 激活裁剪和基于 Shapley 的剪枝的更多细节将在3.2小节和3.3小节中描述。 在3.4小节中,我们将解释整体方法。
3.2 激活剪辑
对于由 参数化的预训练深度神经网络 , 对输入 进行编码,其中 表示输入的维度,并预测不同类的类分布,即。 网络倒数第二层的特征向量表示,其中代表倒数第二层输出的维度。 权重矩阵对中每个特征的重要性进行加权,并传输到输出,如下所示:
| (1) |
激活裁剪应用于倒数第二层中的特征向量。 对于每个在某个阈值以上激活的神经元,AC 限制激活的幅度。 正如我们在图 1 中讨论的,ID 和 OOD 样本中激活的特征数量是不同的。 通过将激活的幅度限制为相同的值 ,我们可以平等地对待每个激活的高级特征,这使我们能够考虑 OOD 分数中激活特征的数量。 这会增加 ID 和 OOD 样本之间的 OOD 分数差异,从而提高性能。
对于中的每个激活,倒数第二层特征可以表示为。 使用限幅阈值,限幅激活可以描述为。 裁剪后的特征向量是,
| (2) |
AC 后的模型输出可表示为:
| (3) |
3.3 基于 Shapley 的剪枝
基于 Shapley 的剪枝选择性地使用重要神经元激活和权重的子集。 为了选择这些子集,我们计算 Shapley 值[44],该值由删除单个单元(例如边际贡献)对所有可能的单元组合的影响的平均值定义。 然而,计算所有单元的组合在计算上是昂贵的,并且对于最近的大型神经网络来说实际上是不可行的。 因此,我们使用泰勒近似来计算Shapley值,这在[21]中介绍。 对于输入 ,其中 表示数据集 中 类的样本,-个神经元 在 , 类中的贡献(即 Shapley 值)计算公式为
| (4) |
3.3.1 激活修剪
激活修剪(AP)选择性地使用重要神经元激活的子集。 通过AP,我们可以有效降低噪声激活的影响。 根据每个神经元 的贡献(使用从所有训练数据获得的贡献),贡献矩阵 被定义为所有贡献 的特定于类的平均值。 贡献矩阵 的第 (,) 项定义为:
| (5) |
其中 表示类 中训练图像的数量。
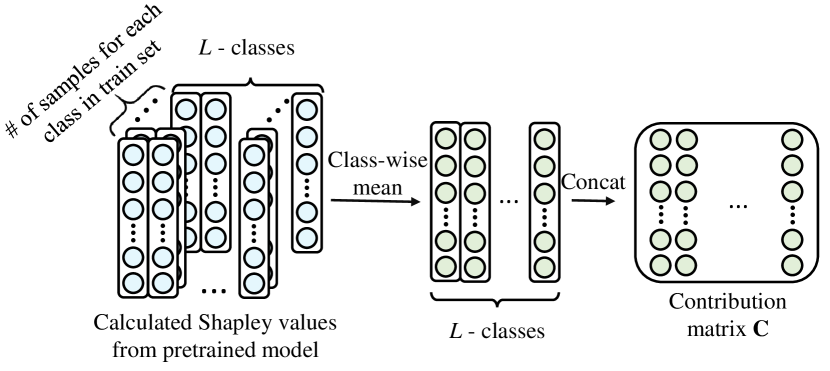
我们根据 中每列的 k 个最大元素,为每个类别选择 top-k 个神经元,并定义激活掩码矩阵 ,其中 中每列的 个最大元素设为 1,否则设为 0。 AP 后具有预测类别 的模型输出如下:
| (6) |
其中 表示掩码矩阵 的第 列, 表示逐元素乘法。
3.3.2 权重剪枝
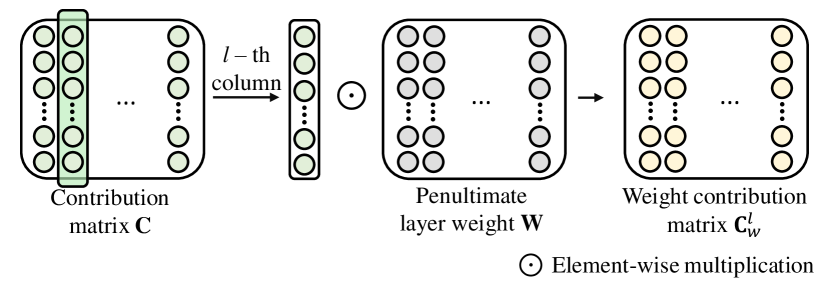
权重剪枝(WP)选择性地使用重要的倒数第二层权重的子集。 通过WP,我们可以有效地减少由于模型过度参数化而产生的噪声信号的影响。 神经元的贡献进一步用于细化权重矩阵作为 WP。 为此,我们将类 的权重贡献矩阵定义为 ,其中 表示贡献的第 列矩阵。 我们根据中的最大元素为每个类选择top-k权重,并为类定义一个掩码矩阵> 为 ,将 中的 k 个最大元素设置为 1,否则设置为 0。 具有预测类 的 WP 后的模型输出如下:
| (7) |
从基于 Shapley 的 AP 和 WP 中,我们可以确定代表每个类别的重要高级特征的神经元,这些神经元在减少噪声输出方面发挥着至关重要的作用。
3.4 利用重要的神经元 (LINE)
正如前面3.2和3.3小节中已经描述的,有两种想法可以提高事后OOD检测的性能。 一是考虑激活的高级特征的数量,二是减少来自不太重要的神经元的噪声信号。 LINE 通过上述过程实现了提高事后 OOD 检测性能的两种方法。 通过使 LINE 适应模型,我们可以有效地增加 ID 和 OOD 数据之间 OOD 分数的总体差异。 因此,具有预测类别 的 LINE 下的模型输出被描述为
| (8) |
请注意,模型本身没有参数变化,并且可以保留 ID 分类精度。
4实验
已经进行了全面的实验来评估我们的方法。 在4.1节中,我们使用了CIFAR[25]基准,它是OOD研究中著名的基准之一[45,32,46]。 在4.2节中,实验是基于大规模数据集ImageNet以及各种OOD数据集进行的。 4.3节通过各种消融实验分析了为什么我们的方法是有效的。
4.1 CIFAR基准评估
实施细节。 在本实验中,我们分别使用来自 CIFAR-10[25] 和 CIFAR-100[25] 的 10,000 张测试图像作为 ID 数据。 使用六个常用的 OOD 数据集作为 OOD 基准来评估模型的性能。 六个 OOD 数据集列表如下:SVHN[39]、Textures[10]、iSUN[56]、LSUN-Crop[58]、LSUN-Resize[58] 和 Places365[62]。 作为预训练模型,我们使用 DenseNet[17]。 如[46]所示,模型分别从 CIFAR-10[25] 和 CIFAR-100[25] 中使用 50,000 个训练图像进行训练。 在[46]之后,模型在 100 个时期内进行了训练,批量大小为 64,权重衰减为 0.0001,动量为 0.9,起始学习率为 0.1。 学习率在第 50、75 和 90 时期衰减了 10 倍。 我们使用整个训练数据集来估计贡献矩阵。
| Method | CIFAR-10 | CIFAR-100 | ||
|---|---|---|---|---|
| FPR95 | AUROC | FPR95 | AUROC | |
| MSP[16] | 48.73 | 92.46 | 80.13 | 74.36 |
| ODIN[30] | 24.57 | 93.71 | 58.14 | 84.49 |
| Mahalanobis[28] | 31.42 | 89.15 | 55.37 | 82.73 |
| Energy[32] | 26.55 | 94.57 | 68.45 | 81.19 |
| ReAct[45] | 26.45 | 94.95 | 62.27 | 84.47 |
| DICE[46] | 20.83 | 95.24 | 49.72 | 87.23 |
| DICE + ReAct | 16.48 | 96.64 | 49.57 | 85.08 |
| LINe (Ours) | 14.71 | 96.99 | 35.67 | 88.67 |
比较。 为了进行比较,我们采用了最新的事后 OOD 检测方法:MSP [16]、ODIN[30]、Mahalanobis distance[28]、能源[32]、ReAct[45]和DICE[46]。
对于所有方法,性能都是通过源自相同 DenseNet 模型的 OOD 分数来衡量的。
实验结果。 表1显示了 LINE 与其他事后 OOD 检测方法在 CIFAR-10 和 CIFAR-100 基准上的比较。 如表所示,我们的方法在 CIFAR-10 和 CIFAR-100 数据集上优于所有其他方法,从而实现了最先进的性能。 在 CIFAR-100 中,与竞争方法 DICE[46] 相比,LINE 将 FPR 95 降低了 14.05。 在 CIFAR-100 中,LINE 的 FPR 95 为 14.05,低于 DICE[46] (49.72%) 和 DICE + ReAct (49.57%) 的 FPR 95 。 DICE + ReAct 是在 DICE [46] 上应用 ReAct [45] 实现的方法。 DICE[46]通过使用激活幅度和权重去除噪声信号。 LINE 不仅使用特定类别的神经元去除噪声信号,而且还考虑了高级特征的激活数量。
4.2 ImageNet 评估
实施细节。 在现实应用中,模型会遇到具有各种场景和特征的高分辨率图像,对大规模数据集的评估可以提供有关实际应用中模型性能的线索。 因此,在本实验中,我们在大规模 ImageNet 数据集上评估了 LINE。 基于[19],消除了与ImageNet-1k所有重叠类别的四个数据集的子集作为OOD数据集。 四个 OOD 数据集如下:Textures[10]、Places365[62]、iNaturalist[52] 和 SUN[ 55]。 我们使用预训练的 ResNet-50 模型[15],该模型使用 ImageNet-1k 进行训练。 整个训练数据集用于估计贡献矩阵,所有图像在测试时都调整为224 224。
| Method | OOD Datasets | Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| iNaturalist | SUN | Places | Textures | |||||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| MSP[16] | 54.99 | 87.74 | 70.83 | 80.86 | 73.99 | 79.76 | 68.00 | 79.61 | 66.95 | 81.99 |
| ODIN[30] | 47.66 | 89.66 | 60.15 | 84.59 | 67.89 | 81.78 | 50.23 | 85.62 | 56.48 | 85.41 |
| Mahalanobis[28] | 97.00 | 52.65 | 98.50 | 42.41 | 98.40 | 41.79 | 55.80 | 85.01 | 87.43 | 55.47 |
| Energy[32] | 55.72 | 89.95 | 59.26 | 85.89 | 64.92 | 82.86 | 53.72 | 85.99 | 58.41 | 86.17 |
| ReAct[45] | 20.38 | 96.22 | 24.20 | 94.20 | 33.85 | 91.58 | 47.30 | 89.80 | 31.43 | 92.95 |
| DICE[46] | 25.63 | 94.49 | 35.15 | 90.83 | 46.49 | 87.48 | 31.72 | 90.30 | 34.75 | 90.77 |
| DICE + ReAct[46] | 18.64 | 96.24 | 25.45 | 93.94 | 36.86 | 90.67 | 28.07 | 92.74 | 27.25 | 93.40 |
| LINe (Ours) | 12.26 | 97.56 | 19.48 | 95.26 | 28.52 | 92.85 | 22.54 | 94.44 | 20.70 | 95.03 |
实验结果。 在表2中,我们分别报告了四个OOD测试数据集的性能。 还报告了四个 OOD 测试数据集的平均结果。 LINE 优于所有基线,包括 MSP[16]、ODIN[30]、马哈拉诺比斯距离[28]、能量分数[32] 、ReAct[45]、DICE[46] 和 DICE + ReAct[46]。 我们首先将 LINE 与 Energy[32] 进行比较。 LINE 将 FPR95 大幅降低了 37.71,这显示了在相同 OOD 评分函数下利用重要神经元的好处。 接下来,我们将 LINE 与 ReAct[45] 进行了比较。 LINE 将 FPR95 降低了 10.73,这让我们看到了利用 Shapley 值来利用重要神经元的优势。 LINE 的表现进一步优于近期的 DICE [46] 和 DICE + ReAct,分别高出 14.05% 和 6.55%。 实验结果表明,该方法可以应用于现实世界的大型数据集进行 OOD 检测。
4.3消融研究
在本节中,我们将讨论 LINE 中使用的每个部分的有效性以及与其他类似方法的详细差异。 我们还分析了超参数的影响。
4.3.1 LINE在ImageNet上的消融研究
表 3 显示了对 LINE 中使用的各个部件的消融研究。 如表所示,基于 Shapley 的剪枝的每个部分(AP 和 WP)都提高了性能。 通过比较 LINE w/o WP 与 Energy + AC,我们可以看到减少噪声激活的优势,从而将 FPR95 降低了 8.52。 接下来,我们将 LINE w/o AP 与 Energy + AC 进行了比较,这也显示了减少噪声权重的好处。 与 Energy + AC 相比,LINE w/o AP 将 FPR95 降低了 12.21。 最后,我们在表 2 中将 LINE w/o AP 与 DICE + ReAct[46] 进行了比较,这使我们能够看到在类似情况下利用类别贡献的好处。 没有 AP 的 LINE 将 FPR95 降低了 4.06,从 27.25 降至 23.19。 DICE + ReAct[46] 使用激活来选择重要权重,而 LINE w/o AP 使用从 Shapley 值[44] 导出的类贡献来选择重要权重。
| Method | AC | AP | WP | FPR95 | AUROC |
|---|---|---|---|---|---|
| Energy[32] | 58.41 | 86.17 | |||
| Energy + AC | ✓ | 35.40 | 91.86 | ||
| LINe w/o WP | ✓ | ✓ | 26.88 | 93.77 | |
| LINe w/o AP | ✓ | ✓ | 23.19 | 94.57 | |
| LINe (Ours) | ✓ | ✓ | ✓ | 20.70 | 95.03 |
4.3.2 更改 AC 阈值对 ImageNet 的影响
在3.2节中,我们从神经元概念关联的角度讨论了AC的含义。 AC 允许我们考虑倒数第二层中激活的高级特征的数量。 在表4中,我们通过改变阈值展示了模型的各种OOD检测性能。 从限幅阈值=开始,FPR95的值是表中最高的。 随着限幅阈值变小,OOD检测性能提高。 但在削波阈值 0.8,OOD检测性能下降。 这是因为,当限幅阈值接近0时,所有倒数第二个输出值也接近0。 很明显,当所有倒数第二个输出值接近零时,性能将会下降。
| Threshold () | FPR95 | AUROC |
|---|---|---|
| 41.18 | 88.44 | |
| 23.43 | 94.79 | |
| 20.70 | 95.03 | |
| 21.69 | 94.81 | |
| 26.96 | 93.99 | |
| 31.88 | 92.97 | |
| (no AC) | 44.88 | 89.14 |
4.3.3 更改剪枝百分位数对 ImageNet 的影响
在本节中,我们对 ImageNet 数据集上的修剪百分位数 () 变异作为 ID 数据进行了消融研究。 在表 5 中,我们展示了在 ImageNet 上更改剪枝百分位数( 和 )的效果。 表示AP的修剪百分位,表示WP的修剪百分位。 对于具有极高值的固定 WP 百分位 (例如, = 90),当 AP 百分位 下降时,性能往往会提高。 由于 LINE 考虑了用于检测 OOD 样本的激活特征的数量,因此修剪大部分激活或权重会对性能产生负面影响。 较低的修剪百分位可以更好地利用 ID 和 OOD 样本之间激活特征数量的差异。 但为了限制噪声信号的负面影响,我们需要一些可以消除噪声信号的部分。 因此,当 ImageNet 上的剪枝百分位数为 = 10 和 = 10 时,模型表现最佳。
| = 90 | = 70 | = 50 | = 30 | = 10 | |
|---|---|---|---|---|---|
| FPR95 | FPR95 | FPR95 | FPR95 | FPR95 | |
| = 90 | 27.56 | 24.79 | 24.74 | 24.55 | 24.54 |
| = 70 | 27.45 | 25.93 | 25.81 | 27.45 | 33.32 |
| = 50 | 33.69 | 27.78 | 26.28 | 25.90 | 27.45 |
| = 30 | 27.46 | 26.10 | 27.17 | 24.36 | 28.43 |
| = 10 | 27.64 | 26.75 | 27.75 | 25.41 | 20.70 |
4.3.4 更改剪枝百分位数对 CIFAR 基准的影响
在表 6 和表 7 中,我们展示了更改修剪百分位( 和 )对 CIFAR 基准的影响。 两个表都显示出相似的趋势。 对于所有 AP 百分位数 ,当 WP 百分位数 增加时,性能往往会提高。 在表 6 中,最高性能出现在 = 90 和 = 90 处。 另一方面,在表 7 中,最高性能出现在 = 90 和 = 10 处。 这个结果似乎与表5中的结果相冲突,我们在表8中的观察可以解释差异的原因。
| = 90 | = 70 | = 50 | = 30 | = 10 | |
|---|---|---|---|---|---|
| FPR95 | FPR95 | FPR95 | FPR95 | FPR95 | |
| = 90 | 14.72 | 15.00 | 15.00 | 15.00 | 14.99 |
| = 70 | 14.80 | 15.12 | 15.12 | 15.12 | 15.10 |
| = 50 | 14.80 | 15.12 | 15.11 | 15.11 | 15.10 |
| = 30 | 14.80 | 15.12 | 15.11 | 15.12 | 15.10 |
| = 10 | 14.80 | 15.13 | 15.13 | 15.12 | 15.73 |
| = 90 | = 70 | = 50 | = 30 | = 10 | |
|---|---|---|---|---|---|
| FPR95 | FPR95 | FPR95 | FPR95 | FPR95 | |
| = 90 | 38.75 | 37.81 | 37.81 | 37.75 | 35.67 |
| = 70 | 38.37 | 39.30 | 40.07 | 39.75 | 40.81 |
| = 50 | 38.37 | 39.19 | 40.54 | 40.27 | 42.14 |
| = 30 | 38.37 | 39.19 | 40.65 | 40.21 | 39.32 |
| = 10 | 38.40 | 39.31 | 40.76 | 40.91 | 38.17 |
4.3.5讨论
| Overlap | CIFAR-10 | CIFAR-100 | ImageNet |
|---|---|---|---|
| = 20 | 24.56 | 26.90 | 1.70 |
| = 30 | 23.39 | 0.58 | 0.15 |
在表8中,我们比较了三个数据集上多个类中类特定神经元重叠的百分比。 对于每个数据集,我们计算了该类中超过 的非常重要(前 10)神经元的比例。 这些神经元在具有语义不同特征的各种类别中激活。 因此,这些神经元的比例越高,可以被视为具有更多数量的普遍激活神经元的过度参数化模型。 这些过度参数化的模型会产生噪声信号,从而使 OOD 检测变得困难,而可以通过利用 AP 和 WP 来减少噪声信号。 为了从过度参数化模型中获得最佳结果,我们可以通过高 WP 百分位数来减轻过度参数化权重的影响。 此外,考虑激活的类特异性神经元数量的有效性可以在低 AP 百分位中最大化,如表 7 中所示的趋势。 但对于表 6 中所示的过度参数化模型,我们需要在 和 上设置较高的剪枝百分位数。
5结论
在本文中,我们提出了一种强大的 OOD 检测方法,称为 LINE。 LINE 采用神经概念关联,通过测量 Shapley 值的类贡献来选择性地使用重要的激活和权重。 通过LINE,我们可以有效地减少噪声信号的影响,并使ID和OOD样本分布之间的整体OOD得分有所不同。 我们进行了大量的实验,证明 LINE 优于最先进的 OOD 检测方法,并且在多个数据集上有效。 通过多项理论研究和见解,我们展示了我们的方法如何提高 OOD 检测的性能。 我们的方法是有效的,但有一些局限性。 修剪神经元以减少噪声输出和考虑特定于类的特征激活的数量从根本上来说是一种权衡关系。 用户必须考虑模型的过度参数化程度来检查权衡。 我们希望,由于我们的研究提出了一种从特征呈现角度看待 OOD 检测的有效方法,理解神经网络行为的尝试将被应用于多个领域,以发现其他有效的方法。
致谢
这项工作得到了韩国政府 (MSIT) 资助的信息和通信技术规划与评估研究所 (IITP) 赠款的部分支持(编号:2017)。 2022-0-00078:医学知识生成的可解释逻辑推理,No。 2021-0-02068:人工智能创新中心,No. RS-2022-00155911:人工智能融合创新人力资源开发(庆熙大学))并由韩国政府(MSIT)资助的韩国国家研究基金会(NRF)拨款(No. 2021R1G1A1094990)。
参考
- [1] Davide Abati, Angelo Porrello, Simone Calderara, and Rita Cucchiara. Latent space autoregression for novelty detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 481–490, 2019.
- [2] Marco Ancona, Cengiz Oztireli, and Markus Gross. Explaining deep neural networks with a polynomial time algorithm for shapley value approximation. In International Conference on Machine Learning, pages 272–281. PMLR, 2019.
- [3] Sarah Adel Bargal, Andrea Zunino, Vitali Petsiuk, Jianming Zhang, Kate Saenko, Vittorio Murino, and Stan Sclaroff. Guided zoom: Questioning network evidence for fine-grained classification. In British Machine Vision Conference (BMVC), 2019.
- [4] David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantifying interpretability of deep visual representations. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6541–6549, 2017.
- [5] David Bau, Jun-Yan Zhu, Hendrik Strobelt, Agata Lapedriza, Bolei Zhou, and Antonio Torralba. Understanding the role of individual units in a deep neural network. Proceedings of the National Academy of Sciences, 117(48):30071–30078, 2020.
- [6] David Bau, Jun-Yan Zhu, Hendrik Strobelt, Bolei Zhou, Joshua B Tenenbaum, William T Freeman, and Antonio Torralba. Gan dissection: Visualizing and understanding generative adversarial networks. ICLR, 2019.
- [7] Abhijit Bendale and Terrance E Boult. Towards open set deep networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1563–1572, 2016.
- [8] Chaofan Chen, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, and Jonathan K Su. This looks like that: deep learning for interpretable image recognition. Advances in neural information processing systems, 32, 2019.
- [9] Xingyu Chen, Xuguang Lan, Fuchun Sun, and Nanning Zheng. A boundary based out-of-distribution classifier for generalized zero-shot learning. In European Conference on Computer Vision, pages 572–588. Springer, 2020.
- [10] M. Cimpoi, S. Maji, I. Kokkinos, S. Mohamed, , and A. Vedaldi. Describing textures in the wild. In Proceedings of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2014.
- [11] Terrance DeVries and Graham W Taylor. Learning confidence for out-of-distribution detection in neural networks. arXiv preprint arXiv:1802.04865, 2018.
- [12] Amirata Ghorbani, James Wexler, James Y Zou, and Been Kim. Towards automatic concept-based explanations. Advances in Neural Information Processing Systems, 32, 2019.
- [13] Amirata Ghorbani and James Y Zou. Neuron shapley: Discovering the responsible neurons. Advances in Neural Information Processing Systems, 33:5922–5932, 2020.
- [14] Mara Graziani, Vincent Andrearczyk, and Henning Müller. Regression concept vectors for bidirectional explanations in histopathology. In Understanding and Interpreting Machine Learning in Medical Image Computing Applications, pages 124–132. Springer, 2018.
- [15] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. In Proceedings of the European conference on computer vision, pages 630–645. Springer, 2016.
- [16] Dan Hendrycks and Kevin Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks. Proceedings of International Conference on Learning Representations, 2017.
- [17] Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 4700–4708, 2017.
- [18] Haiwen Huang, Zhihan Li, Lulu Wang, Sishuo Chen, Bin Dong, and Xinyu Zhou. Feature space singularity for out-of-distribution detection. arXiv preprint arXiv:2011.14654, 2020.
- [19] Rui Huang and Yixuan Li. Towards scaling out-of-distribution detection for large semantic space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021.
- [20] Dihong Jiang, Sun Sun, and Yaoliang Yu. Revisiting flow generative models for out-of-distribution detection. In International Conference on Learning Representations, 2021.
- [21] Ashkan Khakzar, Soroosh Baselizadeh, Saurabh Khanduja, Christian Rupprecht, Seong Tae Kim, and Nassir Navab. Neural response interpretation through the lens of critical pathways. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13528–13538, 2021.
- [22] Durk P Kingma and Prafulla Dhariwal. Glow: Generative flow with invertible 1x1 convolutions. Advances in neural information processing systems, 31, 2018.
- [23] Polina Kirichenko, Pavel Izmailov, and Andrew G Wilson. Why normalizing flows fail to detect out-of-distribution data. Advances in neural information processing systems, 33:20578–20589, 2020.
- [24] Ivan Kobyzev, Simon JD Prince, and Marcus A Brubaker. Normalizing flows: An introduction and review of current methods. IEEE transactions on pattern analysis and machine intelligence, 43(11):3964–3979, 2020.
- [25] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- [26] Harold William Kuhn and Albert William Tucker. Contributions to the Theory of Games. Number 28. Princeton University Press, 1953.
- [27] Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. In Advances in Neural Information Processing Systems, pages 7167–7177, 2018.
- [28] Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. In Advances in Neural Information Processing Systems, pages 7167–7177, 2018.
- [29] Shiyu Liang, Yixuan Li, and Rayadurgam Srikant. Enhancing the reliability of out-of-distribution image detection in neural networks. In International conference on learning representations, 2018.
- [30] Shiyu Liang, Yixuan Li, and Rayadurgam Srikant. Enhancing the reliability of out-of-distribution image detection in neural networks. In Proceedings of International Conference on Learning Representations, 2018.
- [31] Ziqian Lin, Sreya Dutta Roy, and Yixuan Li. Mood: Multi-level out-of-distribution detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15313–15323, 2021.
- [32] Weitang Liu, Xiaoyun Wang, John Owens, and Yixuan Li. Energy-based out-of-distribution detection. Advances in Neural Information Processing Systems, 33:21464–21475, 2020.
- [33] Weizeng Lu, Xi Jia, Weicheng Xie, Linlin Shen, Yicong Zhou, and Jinming Duan. Geometry constrained weakly supervised object localization. In European Conference on Computer Vision, pages 481–496. Springer, 2020.
- [34] Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. Advances in neural information processing systems, 30, 2017.
- [35] Yifei Ming, Yiyou Sun, Ousmane Dia, and Yixuan Li. Cider: Exploiting hyperspherical embeddings for out-of-distribution detection. arXiv preprint arXiv:2203.04450, 2022.
- [36] Peyman Morteza and Yixuan Li. Provable guarantees for understanding out-of-distribution detection. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 8, 2022.
- [37] Jesse Mu and Jacob Andreas. Compositional explanations of neurons. Advances in Neural Information Processing Systems, 33:17153–17163, 2020.
- [38] Eric Nalisnick, Akihiro Matsukawa, Yee Whye Teh, Dilan Gorur, and Balaji Lakshminarayanan. Do deep generative models know what they don’t know? arXiv preprint arXiv:1810.09136, 2018.
- [39] Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y Ng. Reading digits in natural images with unsupervised feature learning. 2011.
- [40] Stanislav Pidhorskyi, Ranya Almohsen, and Gianfranco Doretto. Generative probabilistic novelty detection with adversarial autoencoders. Advances in neural information processing systems, 31, 2018.
- [41] Jie Ren, Stanislav Fort, Jeremiah Liu, Abhijit Guha Roy, Shreyas Padhy, and Balaji Lakshminarayanan. A simple fix to mahalanobis distance for improving near-ood detection. arXiv preprint arXiv:2106.09022, 2021.
- [42] Mohammad Sabokrou, Mohammad Khalooei, Mahmood Fathy, and Ehsan Adeli. Adversarially learned one-class classifier for novelty detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3379–3388, 2018.
- [43] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4510–4520, 2018.
- [44] Lloyd S Shapley. A value for n-person games. Classics in game theory, 69, 1997.
- [45] Yiyou Sun, Chuan Guo, and Yixuan Li. React: Out-of-distribution detection with rectified activations. Advances in Neural Information Processing Systems, 34:144–157, 2021.
- [46] Yiyou Sun and Yixuan Li. Dice: Leveraging sparsification for out-of-distribution detection. In European Conference on Computer Vision, 2022.
- [47] Yiyou Sun, Yifei Ming, Xiaojin Zhu, and Yixuan Li. Out-of-distribution detection with deep nearest neighbors. arXiv preprint arXiv:2204.06507, 2022.
- [48] Mukund Sundararajan and Amir Najmi. The many shapley values for model explanation. In International conference on machine learning, pages 9269–9278. PMLR, 2020.
- [49] Engkarat Techapanurak, Masanori Suganuma, and Takayuki Okatani. Hyperparameter-free out-of-distribution detection using cosine similarity. In Proceedings of the Asian Conference on Computer Vision, 2020.
- [50] Joost Van Amersfoort, Lewis Smith, Yee Whye Teh, and Yarin Gal. Uncertainty estimation using a single deep deterministic neural network. In International conference on machine learning, pages 9690–9700. PMLR, 2020.
- [51] Aäron Van Den Oord, Nal Kalchbrenner, and Koray Kavukcuoglu. Pixel recurrent neural networks. In International conference on machine learning, pages 1747–1756. PMLR, 2016.
- [52] Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alex Shepard, Hartwig Adam, Pietro Perona, and Serge Belongie. The inaturalist species classification and detection dataset. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 8769–8778, 2018.
- [53] Andong Wang, Wei-Ning Lee, and Xiaojuan Qi. Hint: Hierarchical neuron concept explainer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10254–10264, 2022.
- [54] Haoran Wang, Weitang Liu, Alex Bocchieri, and Yixuan Li. Can multi-label classification networks know what they don’t know? Advances in Neural Information Processing Systems, 34:29074–29087, 2021.
- [55] Jianxiong Xiao, James Hays, Krista A. Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 3485–3492. IEEE Computer Society, 2010.
- [56] Pingmei Xu, Krista A Ehinger, Yinda Zhang, Adam Finkelstein, Sanjeev R Kulkarni, and Jianxiong Xiao. Turkergaze: Crowdsourcing saliency with webcam based eye tracking. arXiv preprint arXiv:1504.06755, 2015.
- [57] Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu. Generalized out-of-distribution detection: A survey. arXiv preprint arXiv:2110.11334, 2021.
- [58] Fisher Yu, Ari Seff, Yinda Zhang, Shuran Song, Thomas Funkhouser, and Jianxiong Xiao. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365, 2015.
- [59] Alireza Zaeemzadeh, Niccolo Bisagno, Zeno Sambugaro, Nicola Conci, Nazanin Rahnavard, and Mubarak Shah. Out-of-distribution detection using union of 1-dimensional subspaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9452–9461, 2021.
- [60] Bolei Zhou, David Bau, Aude Oliva, and Antonio Torralba. Interpreting deep visual representations via network dissection. IEEE transactions on pattern analysis and machine intelligence, 41(9):2131–2145, 2018.
- [61] Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Object detectors emerge in deep scene cnns. arXiv preprint arXiv:1412.6856, 2014.
- [62] Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition. In IEEE Transactions on Pattern Analysis and Machine Intelligence, volume 40, pages 1452–1464. IEEE, 2017.
- [63] Ev Zisselman and Aviv Tamar. Deep residual flow for out of distribution detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13994–14003, 2020.
- [64] Bo Zong, Qi Song, Martin Renqiang Min, Wei Cheng, Cristian Lumezanu, Daeki Cho, and Haifeng Chen. Deep autoencoding gaussian mixture model for unsupervised anomaly detection. In International conference on learning representations, 2018.
LINE 的补充材料:
利用重要神经元进行分布外检测
附录 A详细的 CIFAR 基准测试结果
附录 B其他型号上的 LINE
在本节中,我们将展示 LINE 也可以与其他模型配合良好。 在正文中,我们分别在 CIFAR 和 ImageNet 数据集上展示了带有预训练 DenseNet[17] 和 ResNet-50[15] 的 LINE。 在本节中,我们将展示 LINE 可用于 MobileNetV2 [43],它是在 PyTorch 的 ImageNet-1k 数据集上进行预训练的。 实验设置与 4.2 节中的相同。 我们选择 LINE 的超参数作为剪枝百分位数 和剪裁阈值 。 如表11所示,我们在 MobileNetV2 上实现的方法优于所有其他方法。
附录 C LINE 与其他 Shapley 值近似
我们在正文中使用泰勒近似来计算 Shapley 值。 为了了解改变近似计算 Shapley 值的差异,我们使用 IntGrad 近似,这也在[21]中介绍。 对于输入 ,其中 表示数据集 中 类的样本,-个神经元 在 , 类中的贡献(即 Shapley 值)计算公式为
| (9) |
贡献矩阵可以通过等式9计算的贡献来定义。 有了这个贡献矩阵,我们就可以应用LINE。 表12显示了 LINE 的 Taylor 和 IntGrad 近似结果。 两种方法的结果是相同的。 两种方法计算的贡献不同,但 top-k 神经元的顺序仍然相同。 但IntGrad的预计算时间几乎比泰勒近似大11倍,因此最好选择泰勒作为近似方法。
附录D额外的理论分析
LINE 的出色表现基于相关工作部分(第 2.1-2.3 节)中三组不同的论文。 在网络剖析[4]和提示[53]中,深层(例如倒数第二层)的神经元代表特定的概念(例如窗口、哺乳动物)。 此外,在 Khazar 等人[21]中,具有高 Shapely 值的神经元具有编码输入信息的关键片段。 我们从上述研究中得出的结论是,对于特定类别具有高沙普利值的倒数第二层中的一组神经元具有对该类别进行分类的基本概念。 我们将这组神经元称为类特异性神经元。 因此,我们可以通过对神经元的贡献进行排序来选择重要的特定类别神经元并屏蔽不太重要的神经元。 LINE 中的修剪部分(即 AP 和 WP)通过屏蔽触发噪声输出的不太重要的神经元来提高性能。 由于类特定神经元仅针对每个类的基本概念被激活,因此具有不同视觉特征(即概念)的 OOD 样本无法激活大多数类特定神经元。 这个简单的想法通过限制激活的大小来激励 AC,这使得 AC 平等地对待特定于类的特征并提高了 OOD 检测性能。
| Method | OOD Datasets | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SVHN | Textures | iSUN | LSUN | LSUN-Crop | Places365 | |||||||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| MSP[16] | 47.24 | 93.48 | 64.15 | 88.15 | 42.31 | 94.52 | 42.10 | 94.51 | 33.57 | 95.54 | 63.02 | 88.57 | 48.73 | 92.46 |
| ODIN[30] | 25.29 | 94.57 | 57.50 | 82.38 | 3.98 | 98.90 | 3.09 | 99.02 | 4.70 | 98.86 | 52.85 | 88.55 | 24.57 | 93.71 |
| Mahalanobis[28] | 6.42 | 98.31 | 21.51 | 92.15 | 9.78 | 97.25 | 9.14 | 97.09 | 56.55 | 86.96 | 85.14 | 63.15 | 31.42 | 89.15 |
| Energy[32] | 40.61 | 93.99 | 56.12 | 86.43 | 10.07 | 98.07 | 9.28 | 98.12 | 3.81 | 99.15 | 39.40 | 91.64 | 26.55 | 94.57 |
| ReAct[45] | 41.64 | 93.87 | 43.58 | 92.47 | 12.72 | 97.72 | 11.46 | 97.87 | 5.96 | 98.84 | 43.31 | 91.03 | 26.45 | 94.67 |
| DICE[46] | 25.99 | 95.90 | 41.90 | 88.18 | 4.36 | 99.14 | 3.91 | 99.20 | 0.26 | 99.92 | 48.59 | 89.13 | 20.83 | 95.24 |
| DICE + ReAct[46] | 12.49 | 97.61 | 25.83 | 94.56 | 5.27 | 99.02 | 3.95 | 99.14 | 0.43 | 99.89 | 50.94 | 89.63 | 16.48 | 96.64 |
| LINe (Ours) | 11.38 | 97.75 | 23.44 | 95.12 | 4.90 | 99.01 | 4.19 | 99.09 | 0.61 | 99.83 | 43.78 | 91.12 | 14.72 | 96.99 |
| Method | OOD Datasets | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SVHN | Textures | iSUN | LSUN | LSUN-Crop | Places365 | |||||||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| MSP[16] | 81.70 | 75.40 | 84.79 | 71.48 | 85.99 | 70.17 | 85.24 | 69.18 | 60.49 | 85.60 | 82.55 | 74.31 | 80.13 | 74.36 |
| ODIN[30] | 41.35 | 92.65 | 82.34 | 71.48 | 67.05 | 83.84 | 65.22 | 84.22 | 10.54 | 97.93 | 82.32 | 76.84 | 58.14 | 84.49 |
| Mahalanobis[28] | 22.44 | 95.67 | 62.39 | 79.39 | 31.38 | 93.21 | 23.07 | 94.20 | 68.90 | 86.30 | 92.66 | 61.39 | 55.37 | 82.73 |
| Energy[32] | 87.46 | 81.85 | 84.15 | 71.03 | 74.54 | 78.95 | 70.65 | 80.14 | 14.72 | 97.43 | 79.20 | 77.72 | 68.45 | 81.19 |
| ReAct[45] | 83.81 | 81.41 | 77.78 | 78.95 | 65.27 | 86.55 | 60.08 | 87.88 | 25.55 | 94.92 | 82.65 | 74.04 | 62.27 | 84.47 |
| DICE[46] | 54.65 | 88.84 | 65.04 | 76.42 | 48.72 | 90.08 | 49.40 | 91.04 | 0.93 | 99.74 | 79.58 | 77.26 | 49.72 | 87.23 |
| DICE + ReAct[46] | 55.52 | 88.02 | 41.54 | 86.26 | 44.32 | 91.44 | 54.44 | 89.84 | 7.56 | 98.61 | 94.05 | 56.26 | 49.57 | 85.07 |
| LINe (Ours) | 31.10 | 91.90 | 39.29 | 87.84 | 24.07 | 94.85 | 25.32 | 94.63 | 5.72 | 98.87 | 88.50 | 63.93 | 35.67 | 88.67 |
| Method | OOD Datasets | Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| iNaturalist | SUN | Places | Textures | |||||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| MSP[16] | 64.29 | 85.32 | 77.02 | 77.10 | 79.23 | 76.27 | 73.51 | 77.30 | 73.51 | 79.00 |
| ODIN[30] | 55.39 | 87.62 | 54.07 | 85.88 | 57.36 | 84.71 | 49.96 | 85.03 | 54.20 | 85.81 |
| Mahalanobis[28] | 62.11 | 81.00 | 47.82 | 86.33 | 52.09 | 83.63 | 92.38 | 33.06 | 63.60 | 71.01 |
| Energy score[32] | 59.50 | 88.91 | 62.65 | 84.50 | 69.37 | 81.19 | 58.05 | 85.03 | 62.39 | 84.91 |
| ReAct [45] | 42.40 | 91.53 | 47.69 | 88.16 | 51.56 | 86.64 | 38.42 | 91.53 | 45.02 | 89.47 |
| DICE [46] | 43.09 | 90.83 | 38.69 | 90.46 | 53.11 | 85.81 | 32.80 | 91.30 | 41.92 | 89.60 |
| DICE + ReAct [46] | 32.30 | 93.57 | 31.22 | 92.86 | 46.78 | 88.02 | 16.28 | 96.25 | 31.64 | 92.68 |
| LINe (Ours) | 24.95 | 95.53 | 33.19 | 92.94 | 47.95 | 88.98 | 12.30 | 97.05 | 29.60 | 93.62 |
| Method | CIFAR-10 | CIFAR-100 | ImageNet | |||
|---|---|---|---|---|---|---|
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| Taylor | 14.71 | 96.99 | 35.67 | 88.67 | 20.70 | 95.03 |
| IntGrad | 14.71 | 96.99 | 35.67 | 88.67 | 20.70 | 95.03 |