探索指令数据扩展对大型语言模型的影响:对现实世界用例的实证研究
摘要
ChatGPT 的成功最近吸引了众多的努力来复制它,其中指令调整策略是取得显著成果的关键因素。
指令调优不仅显着增强了模型的性能和泛化能力,而且使模型生成的结果与人类语音模式更加一致。
然而,当前的研究很少研究不同数量的指令数据对模型性能的影响,特别是在现实世界的用例中。
在本文中,我们探讨了基于不同规模指令数据的指令调优的大型语言模型的性能。
实验中构建了由12个主要在线用例组成的评估数据集。
以 Bloomz-7B1-mt 作为基础模型,结果表明:1)仅仅增加指令数据量就可以在开放式生成等任务中带来持续改进,2)在数学和代码等任务中,模型性能在增加数据量的同时,曲线仍然相当平坦。
我们进一步分析了这些现象的可能原因,并提出了未来潜在的研究方向,例如有效选择高质量的训练数据、扩展基础模型和专门针对困难任务的训练方法。
我们将发布训练和评估数据集,以及模型检查点1†† #同等贡献
*通讯作者
1https://github.com com/链家科技/百丽
.
1简介
指令调优的目的 Wei 等人 (2021); Sanh 等人 (2021);等人 (2022);欧阳等人(2022)的目的是让模型能够理解并正确响应各种人类指令。 关键是通过在输入文本之前连接描述任务的文本作为指令来引导模型理解任务要求。 与微调模型来解决特定的 NLP 任务不同,指令调优的目的是提高模型对未见过的任务的泛化能力,这是通过使用各种类型的指令生成和训练的方式处理所有任务来实现的。
最近,利用人类反馈训练的模型Ouyang 等人 (2022); Bai 等人 (2022); Ziegler 等人 (2020); Stiennon 等人 (2022);甘古利等人;中野等人 (2022); Korbak 等人 (2023)(尤其是 ChatGPT 和 GPT-4)引起了人工智能领域研究人员的极大关注,因为它可以对人类输入生成高质量的响应,甚至可以基于随后的对话。 指令调优策略是 ChatGPT 取得显著成果的关键因素之一。 为了复制 ChatGPT,研究社区 Taori 等人 (2023); Computer(2023)专注于主要通过在多样化和高质量的指令数据集上微调大型语言模型来获得有能力的指令跟踪模型。
然而,指令数据大小的影响尚未得到很好的探讨,特别是对于来自在线 ChatGPT 用户的典型用例的评估。 梁等人 (2022);秦等人 (2023);叶等人 (2023); Bang 等人 (2023); Srivastava 等人 (2022); Suzgun等人(2022)评估了可用的大型语言模型,但没有关注训练策略的影响。 与此同时,大多数评估集中在传统的 NLP 任务上,并使用英语数据集进行。 为了填补这些空白,我们构建了多样化、高质量的汉语教学训练和评估数据集,并进行了大量的实验来分析模型在不同规模的教学数据上的性能。 最终我们得到以下重要的实验结果:
-
•
在头脑风暴、翻译等任务中,200万甚至更少样本的数据集就可以使模型获得令人满意的性能。
-
•
增加数据大小仍然会导致开放 QA 和提取等任务的性能提高,这表明尚未达到瓶颈。 但改进的潜力可能有限。
-
•
该模型的数学和代码性能仍然很差,并且增加数据大小不再带来性能提升。 这表明了未来的一些研究方向,例如有效选择高质量的训练数据,在参数和基本能力方面扩展基础模型,以及专门针对数学和代码等任务的训练方法。
综上所述,我们针对训练数据大小对指令跟随模型性能的影响进行了实验,得到了一些初步的知识结论,为今后的工作提供了方向。 同时,我们将开源我们的训练和评估数据,以及我们模型的检查点。
2相关工作
2.1 大型语言模型
基于 Transformer 的语言模型,特别是生成式大语言模型极大地推动了自然语言处理的发展 Vaswani 等人 (2017); Devlin 等人 (2018);兰等人 (2019);杨等人 (2019);董等人 (2019);克拉克等人 (2020);拉斐尔等人 (2020);布朗等人 (2020);张等人 (2022); Chowdhery 等人 (2022);布莱克等人 (2022); Hoffmann 等人 (2022); Glaese 等人 (2022); Srivastava 等人 (2022)。 GPT(生成式预训练 Transformer )模型系列就是一个显着的例子,RLHF Ouyang 等人 (2022) 增强了其理解和遵守人类指令的能力; Bai 等人 (2022); Ziegler 等人 (2020); Stiennon 等人 (2022);甘古利等人;中野等人 (2022); ChatGPT 中的 Korbak 等人 (2023)。 因此,ChatGPT 已经从一个基本的 NLP 任务求解器发展成为一个完整的自然语言助手,可以执行诸如生成对话和检测代码片段中的错误等职责。
2.2指令调优
指令调优是来自 Wei 等人 (2021) 的新趋势; Sanh 等人 (2021); Mishra 等人 (2021),旨在通过教语言模型遵循自然语言来提高语言模型的性能。 通过将所有任务格式化为自然语言,生成语言模型能够处理几乎所有 NLP 任务。 早期研究主要集中在对通用 NLP 任务求解器进行指令调整,并且有一种趋势是将越来越多的 NLP 数据集转换为统一的数据集,然后进行多任务训练 Xu 等人 (2022);谢等人 (2022);王等人 (2022a); Khashabi 等人 (2020);敏等人 (2021);叶等人 (2021);刘等人 (2019);钟 等人 (2021);钟等人(2022)。 然而,这些模型仍然难以理解一般的人类指令,尤其是在现实世界的用例中。 直到像 RLHF Ouyang 等人 (2022) 这样的训练方法的出现; Bai 等人 (2022); Ziegler 等人 (2020); Stiennon等人(2022),模型真正开始理解各种人类指令并产生良好的响应。 最近,研究界在复制 ChatGPT Taori 等人 (2023) 方面付出了巨大的努力;计算机(2023)。 在他们的工作中,数据量和任务类型差异很大,这些因素对模型性能的影响尚未得到很好的探讨。
2.3 大语言模型评估
大语言模型的评测有很多,比如 OPT Zhang 等人 (2022)、BLOOM Workshop 等人 (2022)、GLM Zeng 等人 (2023) ),以及 GPT-3 Brown 等人 (2020),在各种任务中。 Liang等人(2022)对30个大型语言模型进行了全面评估。 Qin 等人 (2023) 评估了 ChatGPT 在各种 NLP 任务上的性能。 Ye等人(2023)比较了GPT和GPT-3.5系列模型的能力。 Bang等人(2023)比较了ChatGPT在多种语言和模式下的推理、幻觉减少和交互能力。 然而,这些评估主要关注现有模型的性能,并没有评估模型在不同规模的指令数据下的性能。 此外,许多评估数据由传统的 NLP 任务组成,与现实世界的人类使用场景不同。 Srivastava等人(2022)提供了204个任务,这些任务被认为超出了当前大型语言模型的能力。 Suzgun等人(2022)从BIG-Bench中选出23个最困难的任务,形成BIG-Bench Hard(BBH)。 我们提出的评估数据集更接近真实世界的人类使用场景,并且致力于华人社区。
| Use case | #Nums | Average prompt length |
| Math | 200 | 49.15 |
| Code | 174 | 66.18 |
| COT | 197 | 23.92 |
| Classification | 200 | 54.75 |
| Extraction | 194 | 73.89 |
| Open QA | 190 | 22.55 |
| Closed QA | 189 | 181.79 |
| Generation | 187 | 43.19 |
| Brainstorming | 190 | 22.03 |
| Rewrite | 200 | 53.51 |
| Translation | 147 | 37.28 |
| Summarization | 142 | 105.53 |
3方法
本节我们将介绍获取高质量指令调优数据的方法,以及构造多样化测试指令的方法。 与我们之前的工作 Ji 等人 (2023) 相同,ChatGPT 也需要评估指令跟随模型生成的响应。 提示信息列在附录6.1中。
3.1 生成训练数据
高质量教学数据的手动标注需要大量资源。 凭借强大的上下文学习能力,大型语言模型可以基于高质量的种子集Wang等人(2022b)生成大量多样化的指令数据。 在本文中,我们采用与 Taori 等人 (2023) 相同的方法。 我们将Taori等人(2023)提供的开源种子数据翻译成中文,并修改了一些大量涉及西方文化和背景知识的数据,使其更符合中国文化和背景知识。 然后,使用这些种子数据作为上下文示例,我们需要 ChatGPT 生成更多样本。
3.2生成评估数据
我们选择 ChatGPT 生成的一部分数据进行评估。 注释者被要求纠正 ChatGPT 的响应以获得测试指令的黄金响应。 我们的测试说明分为 12 类,涵盖了在线用户最常见的用例。 表1显示了这些测试指令的详细信息。 此外,我们计划继续扩大我们的评估数据集,因为更多的数据会带来更可靠的评估结果。
4实验
4.1 指令跟随模型
本文重点研究中文文本上的模型性能。 而 LLAMA Touvron 等人 (2023)、OPT Zhang 等人 (2022) 和 GPT-J Wang 和 Komatsuzaki (2021) 尚未被纳入特别针对中文进行优化,我们选择 Bloomz-7b1-mtWorkshop 等人 (2022); Muennighoff 等人 (2022) 作为我们的基础模型,它有 71 亿个参数,并在基于 Bloom-7b1 的 xP3mt 数据集上进一步微调。 如表2所示,我们用20万、60万、100万、200万个指令示例训练Bloomz-7b1-mt,得到BELLE-7B-0.2M、BELLE-7B-0.6M,分别为 BELLE-7B-1M 和 BELLE-7B-2M。 在本文中,我们仅探讨数据规模的影响,将模型规模的影响留给未来的工作。 我们使用 64 个批量大小、2 个时期、3e-6 的恒定学习率、0.001 的权重衰减来训练这些模型。 对于每条指令,我们的指令跟踪模型都需要生成一次响应。 尽管模型对同一指令生成的响应可能有所不同,但我们认为这种波动对实验结果影响不大。
| Datasize | Instruction-following model |
| 200,000 | BELLE-7B-0.2M |
| 600,000 | BELLE-7B-0.6M |
| 1,000,000 | BELLE-7B-1M |
| 2,000,000 | BELLE-7B-2M |
4.2指标
如6.1中所述,ChatGPT 被要求评估指令跟踪模型生成的响应。 对于所有指令,ChatGPT 给出 0 到 1 之间的分数,其中 0 分是最差的,1 分是最好的。 对于每种类型的指令,我们计算模型在测试示例上的平均得分。 此外,考虑到ChatGPT各代的波动性,每个模型响应评估3次,并取平均分。 值得注意的是,我们不采用自洽Wang等人(2022b),因为我们的测试集中的许多类型的指令没有唯一的标准答案。 评估是在2023年3月25日调用gpt-3.5-turbo API实现的。
4.3分析
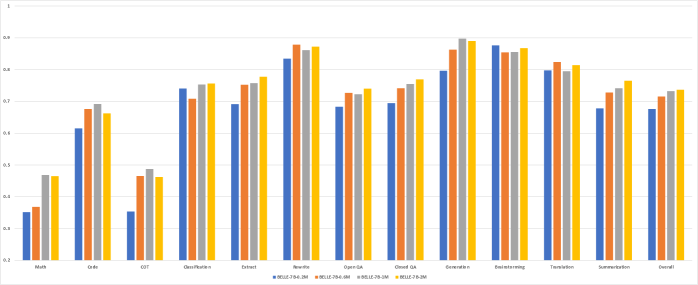
就总体得分而言,随着数据量的增加,模型的性能不断提高,但这种持续改进并不总是在所有类型的指令上都是可预期的。 同时,我们发现该模型仅用 200k 个训练样例就已经取得了良好的性能。
数学、代码和 COT 对于数学、代码和 COT 指令,模型在 20 万个训练示例中的性能较差。 当训练样本数量增加到100万个后,模型的性能有所提高,但性能进一步提高就变得困难,远远没有达到令人满意的水平。 原因可能有两个:1)这三类训练数据质量较差,随着数据量的增加,性能提升被错误的训练数据抑制。 2)模型规模不够大,无法实现能力的涌现,因此无法对这三类需要推理能力的指令进行进一步的改进。
提取、分类、封闭式问答和摘要 对于提取、分类、封闭式问答和摘要这些常见的 NLP 任务的指令,增加训练数据量可以不断带来性能提升。 这表明我们仍然可以通过在未来计划中简单地增加训练示例来获得进一步的性能提升。 但需要注意的是,增加这几种数据的比例是否会导致其他类型指令的性能下降。
开放式QA对于开放式QA,模型的性能随着数据量的增加而不断提高。 解决此任务需要模型的参数知识,因此我们可以得出结论,增加训练数据量可以使模型更好地产生事实答案并减少幻觉。
翻译 在翻译任务中,Belle-7b-0.2m取得了不错的表现,表明模型的翻译能力可能来自于Bloomz-7b1-mt的多语言能力。
重写 在重写任务中,模型需要纠正语法错误或解释原文,使其更加流畅和简洁。 此类任务相对简单,模型仅需要 60 万个训练样本就表现良好,因此我们可以在未来专注于其他任务。
生成 在生成任务中(例如生成某个主题的文章、写一封电子邮件),将数据量从 20 万增加到 100 万会导致性能显着提升,之后性能趋于平稳。
头脑风暴 在头脑风暴任务中,20万的数据集被证明是模型性能的最佳大小。 这可能是由于对此类指令的响应多种多样,且缺乏明确的判断响应质量的标准,导致 ChatGPT 在评分时往往给出较高的分数。 这也表明大型语言模型擅长响应此类指令。
综上所述,对于翻译、重写、生成和头脑风暴任务,200万甚至更少的数据量就可以使模型表现良好。 对于提取、分类、封闭式问答和摘要任务,模型的性能可以随着数据量的增加而不断提高,这表明我们仍然可以通过简单地增加训练数据量来提高模型的性能。 但改进的潜力可能有限。 模型在数学、代码和COT指令上的表现仍然较差,在数据质量、模型规模和训练策略上还需要进一步探索。
5 结论和未来的工作
在本文中,我们评估了不同数量的指令数据对模型性能的影响。 我们发现数十万个训练示例可以在翻译、重写、生成和头脑风暴任务上取得良好的结果。 增加数据规模仍然会导致提取、分类、封闭式 QA 和摘要等任务的性能提高,表明尚未达到瓶颈。 然而,在数学、代码和COT等任务中,模型性能较差,并且数据量的增加不再带来性能提升。
上述发现为我们今后的工作指明了三个方向。 首先,我们将继续探索在提取、分类、封闭式 QA 和摘要任务中增加数据量的限制。 其次,我们将提高训练数据的质量,进一步增强模型性能,特别是在数学、代码和 COT 方面,ChatGPT 生成的训练数据质量较低。 此外,有效选择高质量数据也值得研究。 最后,我们将评估基础模型对性能的影响,包括模型参数的数量和预训练语言模型的基础能力。
参考
- Wei et al. [2021] Jason Wei, Maarten Bosma, Vincent Y. Zhao, et al. Finetuned language models are zero-shot learners. arXiv:2109.01652 [cs], September 2021.
- Sanh et al. [2021] Victor Sanh, Albert Webson, Colin Raffel, et al. Multitask prompted training enables zero-shot task generalization. arXiv:2110.08207 [cs], October 2021.
- Chung et al. [2022] Hyung Won Chung, Le Hou, Shayne Longpre, et al. Scaling instruction-finetuned language models, October 2022.
- Ouyang et al. [2022] Long Ouyang, Jeff Wu, Xu Jiang, et al. Training language models to follow instructions with human feedback, March 2022.
- Bai et al. [2022] Yuntao Bai, Saurav Kadavath, Sandipan Kundu, et al. Constitutional ai: Harmlessness from ai feedback, December 2022.
- Ziegler et al. [2020] Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, et al. Fine-tuning language models from human preferences, January 2020.
- Stiennon et al. [2022] Nisan Stiennon, Long Ouyang, Jeff Wu, et al. Learning to summarize from human feedback, February 2022.
- [8] Deep Ganguli, Liane Lovitt, Jackson Kernion, et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned.
- Nakano et al. [2022] Reiichiro Nakano, Jacob Hilton, Suchir Balaji, et al. Webgpt: Browser-assisted question-answering with human feedback, June 2022.
- Korbak et al. [2023] Tomasz Korbak, Kejian Shi, Angelica Chen, et al. Pretraining language models with human preferences, February 2023.
- Taori et al. [2023] Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- Computer [2023] Together Computer. OpenChatKit: An Open Toolkit and Base Model for Dialogue-style Applications, 3 2023. URL https://github.com/togethercomputer/OpenChatKit.
- Liang et al. [2022] Percy Liang, Rishi Bommasani, Tony Lee, et al. Holistic evaluation of language models, November 2022.
- Qin et al. [2023] Chengwei Qin, Aston Zhang, Zhuosheng Zhang, et al. Is chatgpt a general-purpose natural language processing task solver?, February 2023.
- Ye et al. [2023] Junjie Ye, Xuanting Chen, Nuo Xu, Can Zu, Zekai Shao, Shichun Liu, Yuhan Cui, Zeyang Zhou, Chao Gong, Yang Shen, et al. A comprehensive capability analysis of gpt-3 and gpt-3.5 series models. arXiv preprint arXiv:2303.10420, 2023.
- Bang et al. [2023] Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, et al. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv preprint arXiv:2302.04023, 2023.
- Srivastava et al. [2022] Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615, 2022.
- Suzgun et al. [2022] Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, et al. Challenging big-bench tasks and whether chain-of-thought can solve them. arXiv preprint arXiv:2210.09261, 2022.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Devlin et al. [2018] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Lan et al. [2019] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942, 2019.
- Yang et al. [2019] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Russ R Salakhutdinov, and Quoc V Le. Xlnet: Generalized autoregressive pretraining for language understanding. Advances in neural information processing systems, 32, 2019.
- Dong et al. [2019] Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. Unified language model pre-training for natural language understanding and generation. Advances in neural information processing systems, 32, 2019.
- Clark et al. [2020] Kevin Clark, Minh-Thang Luong, Quoc V Le, and Christopher D Manning. Electra: Pre-training text encoders as discriminators rather than generators. arXiv preprint arXiv:2003.10555, 2020.
- Raffel et al. [2020] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
- Brown et al. [2020] Tom B. Brown, Benjamin Mann, Nick Ryder, et al. Language models are few-shot learners, July 2020.
- Zhang et al. [2022] Susan Zhang, Stephen Roller, Naman Goyal, et al. Opt: Open pre-trained transformer language models, June 2022.
- Chowdhery et al. [2022] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, et al. Palm: Scaling language modeling with pathways, October 2022.
- Black et al. [2022] Sid Black, Stella Biderman, Eric Hallahan, et al. Gpt-neox-20b: An open-source autoregressive language model, April 2022.
- Hoffmann et al. [2022] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, et al. Training compute-optimal large language models, March 2022.
- Glaese et al. [2022] Amelia Glaese, Nat McAleese, Maja Trębacz, John Aslanides, Vlad Firoiu, Timo Ewalds, Maribeth Rauh, Laura Weidinger, Martin Chadwick, Phoebe Thacker, et al. Improving alignment of dialogue agents via targeted human judgements. arXiv preprint arXiv:2209.14375, 2022.
- Mishra et al. [2021] Swaroop Mishra, Daniel Khashabi, Chitta Baral, and Hannaneh Hajishirzi. Cross-task generalization via natural language crowdsourcing instructions. arXiv preprint arXiv:2104.08773, 2021.
- Xu et al. [2022] Hanwei Xu, Yujun Chen, Yulun Du, Nan Shao, Yanggang Wang, Haiyu Li, and Zhilin Yang. Zeroprompt: Scaling prompt-based pretraining to 1,000 tasks improves zero-shot generalization. arXiv preprint arXiv:2201.06910, 2022.
- Xie et al. [2022] Tianbao Xie, Chen Henry Wu, Peng Shi, Ruiqi Zhong, Torsten Scholak, Michihiro Yasunaga, Chien-Sheng Wu, Ming Zhong, Pengcheng Yin, Sida I Wang, et al. Unifiedskg: Unifying and multi-tasking structured knowledge grounding with text-to-text language models. arXiv preprint arXiv:2201.05966, 2022.
- Wang et al. [2022a] Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Atharva Naik, Arjun Ashok, Arut Selvan Dhanasekaran, Anjana Arunkumar, David Stap, et al. Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5085–5109, 2022a.
- Khashabi et al. [2020] Daniel Khashabi, Sewon Min, Tushar Khot, Ashish Sabharwal, Oyvind Tafjord, Peter Clark, and Hannaneh Hajishirzi. Unifiedqa: Crossing format boundaries with a single qa system. arXiv preprint arXiv:2005.00700, 2020.
- Min et al. [2021] Sewon Min, Mike Lewis, Luke Zettlemoyer, and Hannaneh Hajishirzi. Metaicl: Learning to learn in context. arXiv preprint arXiv:2110.15943, 2021.
- Ye et al. [2021] Qinyuan Ye, Bill Yuchen Lin, and Xiang Ren. Crossfit: A few-shot learning challenge for cross-task generalization in nlp. arXiv preprint arXiv:2104.08835, 2021.
- Liu et al. [2019] Xiaodong Liu, Pengcheng He, Weizhu Chen, and Jianfeng Gao. Multi-task deep neural networks for natural language understanding. arXiv preprint arXiv:1901.11504, 2019.
- Zhong et al. [2021] Ruiqi Zhong, Kristy Lee, Zheng Zhang, and Dan Klein. Adapting language models for zero-shot learning by meta-tuning on dataset and prompt collections. arXiv preprint arXiv:2104.04670, 2021.
- Workshop et al. [2022] BigScience Workshop, Teven Le Scao, Angela Fan, et al. Bloom: A 176b-parameter open-access multilingual language model, December 2022.
- Zeng et al. [2023] Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, Weng Lam Tam, Zixuan Ma, Yufei Xue, Jidong Zhai, Wenguang Chen, Zhiyuan Liu, Peng Zhang, Yuxiao Dong, and Jie Tang. GLM-130b: An open bilingual pre-trained model. In The Eleventh International Conference on Learning Representations (ICLR), 2023. URL https://openreview.net/forum?id=-Aw0rrrPUF.
- Ji et al. [2023] Yunjie Ji, Yan Gong, Yiping Peng, Chao Ni, Peiyan Sun, Dongyu Pan, Baochang Ma, and Xiangang Li. Exploring chatgpt’s ability to rank content: A preliminary study on consistency with human preferences. arXiv preprint arXiv:2303.07610, 2023.
- Wang et al. [2022b] Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language model with self generated instructions. arXiv preprint arXiv:2212.10560, 2022b.
- Touvron et al. [2023] Hugo Touvron, Thibaut Lavril, Gautier Izacard, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Wang and Komatsuzaki [2021] Ben Wang and Aran Komatsuzaki. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. https://github.com/kingoflolz/mesh-transformer-jax, May 2021.
- Muennighoff et al. [2022] Niklas Muennighoff, Thomas Wang, Lintang Sutawika, et al. Crosslingual generalization through multitask finetuning, November 2022.
6 附录 A
6.1 提示 ChatGPT 作为评估者
我们之前的工作Ji等人[2023]已经证明ChatGPT的排名偏好在一定程度上与人类一致。 因此,在本文中,我们将 ChatGPT 也视为注释器来评估指令跟踪模型生成的响应。 表3列出了我们用于不同类型指令的提示。
| Use case | Prompt |
| Math | 你是一个数学老师,给定一道数学问题,你需要判断学生答案和标准答案是否一致。如果学生的答案结果和标准答案结果一致,则得 1分,如果不一致,则直接得0分。请按照"得分:"这样的形式输出学生分数。 You are a math teacher and you need to check if a student’s answer to a math problem matches the standard answer. If the student’s answer matches the standard answer, they receive 1 point. If not, they receive 0 points. Please output the student’s score in the format of "Score:". |
| Code | 你是一个计算机科学老师,给定一道编程问题,你需要判断学生答案是否能够顺利执行并取得满足题目要求的结果。如果可以,则得 1分,不可以则得0分。你可以参考标准答案中的代码。请按照"得分:"这样的形式输出学生分数。 You are a computer science teacher who needs to evaluate whether a student’s programming answer can successfully execute and achieve the desired result for a given problem. If it can, the student gets 1 point, otherwise they get 0 points. You can refer to the code in the standard answer. Please output the student’s score in the format of "score:". |
| COT | 你是一个逻辑学家,给定一个问题,你需要判断模型回答是否在符合常识、逻辑的前提下,很好的回答了这个问题。如果模型回答符 合逻辑,则模型回答得1分,如果模型回答不符合逻辑,则得0分。你可以参考标准回答中的内容。请按照"得分 :"这样的形式输出分数。 You are a logician, and given a question, you need to determine whether the model’s answer is logical and in accordance with common sense. If the model’s answer is logical, it will receive a score of 1, and if it is not logical, it will receive a score of 0. You can refer to the content of the standard answer. Please output the score in the format of "Score:". |
| Classification | 你需要通过参考标准答案,来对模型的答案给出分数,满分为1分,最低分为0分。请按照"得分:"这样的形式输出分数。评价标准要求 分类结果越准确,分数越高。 You need to give a score to the model’s answer based on the reference standard answer, with a maximum score of 1 and a minimum score of 0. Please output the score in the format of "Score:". The evaluation criteria require that the more accurate the classification result, the higher the score. |
| Extraction | 你需要通过参考标准答案,来对模型的答案给出分数,满分为1分,最低分为0分。请按照"得分:"这样的形式输出分数。评价标准要求 需要保证抽取出来的结果来自文本,并且符合问题的要求。 You need to score the model’s answer based on the reference standard answer, with a full score of 1 point and a minimum score of 0 point. Please output the score in the format of "Score:". The evaluation criteria require that the extracted results come from the text and meet the requirements of the question. |
| Open QA | 你需要通过参考标准答案,来对模型的答案给出分数,满分为1分,最低分为0分。请按照"得分:"这样的形式输出分数。评价标准要求 回答的结果越接近正确答案分数越高。 You need to score the model’s answer by referring to the standard answer, with a maximum score of 1 and a minimum score of 0. Please output the score in the format of "Score: ". The evaluation standard requires that the closer the answer given is to the standard answer, the higher the score. |
| Closed QA | 你需要通过参考标准答案,来对模型的答案给出分数,满分为1分,最低分为0分。请按照"得分:"这样的形式输出分数。评价标准要 求回答的结果准确,且回答结果来自问题里面提供的信息。 You need to score the model’s answer by referencing the standard answer. The full score is 1 point, and the lowest score is 0 point. Please output the score in the format of "Score:". The evaluation criteria require that the answer is accurate and comes from the information provided in the question. |
| Generation | 假设你是一个作家,你需要研究评价标准来对模型的答案给出分数,满分为1分,最低分为0分。请按照"得分:"这样的形式输出分数。 评价标准要求生成的结果语句通顺,内容主题符合要求。 Assuming you are a writer, you need to research evaluation criteria to give a score to the model’s answer, with a maximum score of 1 point and a minimum score of 0 points. Please output the score in the format of "Score:". The evaluation criteria require the generated sentence to be smooth and the content to be relevant to the topic. |
| Brainstorming | 你需要研究评价标准来对模型的答案给出分数,满分为1分,最低分为0分。请按照"得分:"这样的形式输出分数。评价标准要求要求 回答的内容对于问题有帮助,并且是真实没有恶意的。 You need to study the evaluation criteria to give a score to the model’s answer, with a maximum score of 1 point and a minimum score of 0 points. Please output the score in the format of "Score:". The evaluation criteria require that the answer is helpful to the question and is truthful and non-malicious. |
| Rewrite | 假设你是一个作家,你需要研究评价标准来对模型的答案给出分数,满分为1分,最低分为0分。请按照"得分:"这样的形式输出分数 。 评价标准要求重写过后的句子保持原有的意思,并且重写过后的句子越通顺分数越高。 Assuming that you are a writer, you need to research the evaluation criteria to give a score for the model’s answer, with a maximum score of 1 point and a minimum score of 0 points. Please output the score in the format of "Score:". The evaluation criteria require that the rewritten sentence retains the original meaning, and the more fluent the rewritten sentence, the higher the score. |
| Translation | 假设你是一个语言学家,你需要通过参考标准答案,来对模型的答案给出分数,满分为1分,最低分为0分。请按照"得分:"这样的形 式输出分数 。评价标准要求翻译过后的句子保持原有的意思,并且翻译过后的句子越通顺分数越高。 Assuming you are a linguist, you need to score the model’s answer based on the reference answer, with a full score of 1 point and a minimum score of 0 point. Please output the score in the form of "Score:". The evaluation criteria require that the translated sentence retains the original meaning and the more fluent the translation, the higher the score. |
| Summarization | 假设你是一个作家,你需要通过参考标准答案,来对模型的答案给出分数,满分为1分,最低分为0分。请按照"得分:"这样的形式输出 分数。评价标准要求生成的摘要内容能包含输入文本信息的重点. Assuming you are a writer, you need to score the model’s answer by referring to the standard answer, with a full score of 1 point and a minimum score of 0 points. Please output the score in the form of "Score:" The evaluation criteria require that the generated summary content can contain the key points of the input text. |