:
自我反馈迭代细化
摘要
与人类一样,大型语言模型(大语言模型)并不总是在第一次尝试时生成最佳输出。 受人类如何改进书面文本的启发,我们引入了一种通过迭代反馈和改进来改进大语言模型的初始输出的方法。 主要思想是使用大语言模型生成初始输出;然后,同一个大语言模型为其输出提供反馈,并使用它迭代地优化本身。 不需要任何监督训练数据、额外训练或强化学习,而是使用单个大语言模型作为生成器、精炼器和反馈提供者。 我们使用最先进的(GPT-3.5 和 GPT-4)大语言模型 评估 7 种不同的任务,从对话响应生成到数学推理s。在所有评估的任务中,与使用传统一步生成的相同大语言模型生成的输出相比,人类和自动度量生成的输出更受人类和自动指标的青睐,绝对提高了20%任务绩效的平均水平。 我们的工作表明,即使是像 GPT-4 这样最先进的大语言模型,也可以使用我们简单、独立的方法在测试时得到进一步改进。111Code and data at https://selfrefine.info/。
1简介
尽管大型语言模型(大语言模型)可以生成连贯的输出,但它们通常无法满足复杂的需求。 这主要包括具有多方面目标的任务,例如对话响应生成,或具有难以定义目标的任务,例如增强程序可读性。 在这些场景中,现代大语言模型可能会产生可理解的初始输出,但可能会受益于进一步的迭代细化(即迭代地将候选输出映射到改进的输出),以确保所需的质量实现了。 迭代细化通常涉及训练依赖于特定领域数据的细化模型(例如,Reid and Neubig (2022); Schick 等人 (2022a); Welleck 等人 (2022))。 其他依赖外部监督或奖励模型的方法需要大量训练集或昂贵的人工注释(Madaan 等人,2021;Ouyang 等人,2022),这可能并不总是可行的。 这些限制强调需要一种有效的细化方法,该方法可以应用于各种任务,而不需要广泛的监督。
迭代自我完善是人类解决问题的基本特征(Simon,1962;Flower and Hayes,1981;Amabile,1983)。 迭代自我完善是一个涉及创建初始草稿并随后根据自我提供的反馈对其进行完善的过程。 例如,在起草电子邮件以向同事请求文档时,个人最初可能会写一个直接请求,例如“尽快向我发送数据”。 然而,经过反思,作者认识到这种措辞可能存在不礼貌的地方,并将其修改为“你好,阿什利,你能尽快把数据发给我吗?”。 在编写代码时,程序员可能会实现最初的“快速而肮脏”的实现,然后经过反思,将其代码重构为更高效和可读的解决方案。 在本文中,我们证明大语言模型可以提供迭代自我完善,无需额外的训练,从而在广泛的任务上产生更高质量的输出。
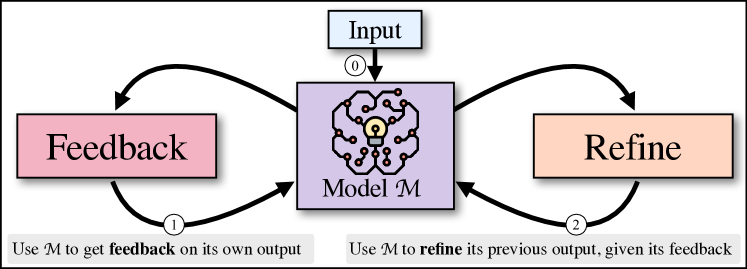
我们提出:一种迭代的自我细化算法,它在两个生成步骤之间交替——反馈和细化。 这些步骤协同工作以产生高质量的输出。 给定模型 生成的初始输出,我们将其传递回同一模型 以获取反馈。 然后,反馈被传回同一模型以完善之前生成的草稿。 重复此过程指定的迭代次数或直到 确定不需要进一步细化。 我们使用少样本提示(Brown等人,2020)来指导生成反馈并将反馈纳入改进的草案中。 图 1说明了高级思想,即使用相同的底层语言模型来生成反馈并改进其输出。
我们评估跨越不同领域的 7种生成任务,包括自然语言和源代码生成。 我们证明,它的性能优于来自强大语言模型的直接生成,例如GPT-3.5 (text-davinci-003和gpt-3.5-turbo;OpenAI,;Ouyang等人,2022) 和 GPT-4 (OpenAI,2023) 绝对提升 5-40%。 在代码生成任务中,应用于 Codex (code-davinci-002; Chen 等人, 2021) 等强代码模型时,初始生成速度提高了 13%。 我们发布了所有的代码,可以很容易地扩展到其他大语言模型。 本质上,我们的结果表明,即使大语言模型无法在第一次尝试中生成最佳输出,大语言模型通常可以提供有用的反馈并改进其自身相应地输出。 反过来,它提供了一种有效的方法,通过迭代(自)反馈和细化,从单个模型获得更好的输出,而无需任何额外的训练。
2 迭代细化
给定输入序列,生成初始输出,提供输出反馈,并根据反馈细化输出。 在反馈和细化之间迭代,直到满足所需的条件。 依赖于合适的语言模型和三个提示(用于初始生成、反馈和细化),并且不需要 . 如图1和算法1所示。 接下来,我们进行更详细的描述。
初次输出
给定输入 、提示 和模型 ,生成初始输出 :
| (1) |
例如,在图2(d)中,模型为给定输入生成功能正确的代码。 这里,是初始生成的特定于任务的少样本提示(或指令),表示串联。 少样本提示包含任务的输入输出对 。222少镜头提示(也称为“上下文学习”)为模型提供由 上下文组成的提示目标任务的示例,每个示例均以输入输出对的形式 (Brown 等人, 2020)。
反馈
接下来,使用相同的模型 为其自己的输出提供反馈 ,并给出用于生成反馈的特定于任务的提示 :
| (2) |
直观上,反馈可以涉及输出的多个方面。 例如,在代码优化中,反馈可能涉及代码的效率、可读性和整体质量。
这里,提示以输入-输出-反馈三元组的形式提供反馈示例。 我们通过 提示模型编写可操作且具体的反馈。 我们所说的“可操作”是指反馈应包含可能提高产出的具体行动。 “具体”是指反馈应该识别输出中要更改的具体短语。 例如图2(e)中的反馈是“这段代码很慢,因为它使用了暴力循环。 更好的方法是使用公式... (n(n+1))/2”。 这种反馈是可行的,因为它建议采取“使用公式……”的行动。 反馈很具体,因为它提到了“for 循环”。
精炼
接下来,根据自己的反馈,使用 优化其最新输出:
| (3) |
例如,在图 2(f)中,给定初始输出和生成的反馈,模型生成更短的重新实现并且运行速度比最初的实现快得多。 提示以输入-输出-反馈-细化四元组的形式提供了基于反馈改进输出的示例。
迭代在反馈和细化步骤之间交替,直到满足停止条件。 停止条件 要么在指定的时间步长 处停止,要么从反馈中提取停止指标(例如标量停止分数)。 在实践中,可以提示模型在中生成停止指示符,并且条件根据任务确定。
为了告知模型有关先前迭代的信息,我们通过将先前反馈和输出的历史记录附加到提示中来保留它们。 直观上,这使得模型能够从过去的错误中学习并避免重蹈覆辙。 更准确地说,Equation 3 实际上被实例化为:
| (4) |
最后,我们使用最后一次细化 作为 的输出。
3评估
我们评估了 7 项不同的任务:对话响应生成(附录 M;Mehri 和 Eskenazi,2020)、代码优化 (附录 N;Madaan 等人,2023)、代码可读性进步(附录L;Puri等人,2021),数学推理(附录O;Cobbe等人,2021),情绪逆转(附录P;Zhang等)人,2015),我们引入了两个新任务:首字母缩略词生成(附录 Q)和约束生成(更难的版本) Lin 等人 (2020) 的关键字限制为 20-30 个,而不是 3-5 个;附录0> R1>)
3.1 实例化
我们按照部分2中的高级描述进行实例化。 反馈-细化迭代持续进行,直到达到所需的输出质量或特定于任务的标准,最多迭代 4 次。 为了使我们的评估在不同模型之间保持一致,我们将反馈和细化作为少样本提示,即使模型对指令响应良好,例如ChatGPT和GPT -4。
大语言模型基础
我们的主要目标是评估我们是否可以使用 来提高任何强基础大语言模型的性能。 因此,我们与相同的基础大语言模型进行比较,但没有反馈细化迭代。 我们在所有任务中使用了三个主要的强基础大语言模型:GPT-3.5 (text-davinci-003)、ChatGPT (gpt-3.5-turbo) t2>)和GPT-4 (OpenAI,2023)。 对于基于代码的任务,我们还尝试了 Codex (code-davinci-002)。 在所有任务中,GPT-3.5 或 GPT-4 是之前的最先进技术。333A comparison with other few-shot and fine-tuned approaches is provided in Appendix F我们使用了之前工作中可用的相同提示(例如代码优化和数学推理);否则,我们将按照附录2>S3>1>中详细说明创建提示。我们对所有设置都使用温度为 0.7 的贪婪解码。
3.2指标
我们报告三种类型的指标:
-
任务特定指标:如果可用,我们使用之前工作中的自动化指标(数学推理:解决率%;代码优化:优化程序%;约束生成:覆盖率%)
-
人类偏好:在对话响应生成、代码可读性改进、情绪反转和首字母缩略词生成中,由于没有可用的自动化指标,我们对输出的子集进行盲目的人类 A/B 评估以选择首选输出。 附录C中提供了更多详细信息。
-
GPT-4-pref:除了 human-pref 之外,我们根据之前的工作 (Fu 等人,2023)使用 GPT-4 作为人类偏好的代理;Chiang 等人, 2023; Geng 等人, 2023; Sun 等人, 2023),并发现与人类优先。 为了提高代码可读性,我们提示 GPT-4 计算在给定上下文中适当命名的变量的比例(例如 )。 附录D中提供了更多详细信息。
| GPT-3.5 | ChatGPT | GPT-4 | ||||
|---|---|---|---|---|---|---|
| Task | Base | + | Base | + | Base | + |
| Sentiment Reversal | 8.8 | 30.4 (21.6) | 11.4 | 43.2 (31.8) | 3.8 | 36.2 (32.4) |
| Dialogue Response | 36.4 | 63.6 (27.2) | 40.1 | 59.9 (19.8) | 25.4 | 74.6 (49.2) |
| Code Optimization | 14.8 | 23.0 (8.2) | 23.9 | 27.5 (3.6) | 27.3 | 36.0 (8.7) |
| Code Readability | 37.4 | 51.3 (13.9) | 27.7 | 63.1 (35.4) | 27.4 | 56.2 (28.8) |
| Math Reasoning | 64.1 | 64.1 (0) | 74.8 | 75.0 (0.2) | 92.9 | 93.1 (0.2) |
| Acronym Generation | 41.6 | 56.4 (14.8) | 27.2 | 37.2 (10.0) | 30.4 | 56.0 (25.6) |
| Constrained Generation | 28.0 | 37.0 (9.0) | 44.0 | 67.0 (23.0) | 15.0 | 45.0 (30.0) |
3.3结果
Table 1 显示了我们的主要结果:
在所有模型尺寸上持续改进基础模型,并且在所有任务上都优于之前的最先进技术。 例如,GPT-4+ 在代码优化方面比基础 GPT-4 提高了 8.7%(绝对值),优化百分比从 27.3% 提高到 36.0%。 附录J中提供了置信区间。 对于基于代码的任务,我们在使用 Codex 时发现了类似的趋势;这些结果包含在附录F中。
与基本模型相比,我们观察到收益最高的任务之一是约束生成,其中要求模型生成最多包含 30 个给定概念的句子。 我们相信这项任务会受益匪浅,因为在第一次尝试时有更多机会错过一些概念,从而允许模型随后修复这些错误。 此外,该任务具有大量合理输出,因此可以更好地探索可能输出的空间。
在基于偏好的任务中,例如对话响应生成、情绪逆转和首字母缩略词生成,会带来特别高的收益。 例如,在对话响应生成中,GPT-4 偏好得分提高了 49.2%,从 25.4% 提高到 74.6%。 同样,我们看到所有模型中其他基于偏好的任务都有显着改进。
数学推理中的适度性能提升可以追溯到无法准确识别是否存在任何错误。 在数学中,错误可能很细微,有时仅限于单行或不正确的操作。 此外,看起来一致的推理链可以欺骗大语言模型认为“一切看起来都很好”(例如,94%的实例的ChatGPT反馈是“一切看起来都很好”)。 在部分 H.1中,我们表明,如果外部来源可以识别,数学推理的收益会大得多(5%+)如果当前的数学答案不正确。
各个基本大语言模型尺寸的改进是一致的一般来说,GPT-4+的性能优于GPT-3.5 + 和 ChatGPT+ 跨所有任务,即使在 GPT-4 初始基本结果低于 GPT-3.5 或 ChatGPT 的任务中也是如此。 因此,我们相信这可以让更强大的模型(例如GPT-4)发挥其全部潜力,即使这种潜力没有在标准、单通道输出生成中表达出来。 附录F中提供了与其他强基线的比较。
4分析
三个主要步骤是反馈、细化以及迭代地重复它们。 在本节中,我们进行额外的实验来分析每个步骤的重要性。
| Task | feedback | Generic feedback | No feedback |
|---|---|---|---|
| Code Optimization | 27.5 | 26.0 | 24.8 |
| Sentiment Reversal | 43.2 | 31.2 | 0 |
| Acronym Generation | 56.4 | 54.0 | 48.0 |
反馈质量的影响
反馈质量在其中起着至关重要的作用。 为了量化其影响,我们将使用具体的、可操作的反馈与两种消融进行比较:一种使用通用反馈,另一种不使用反馈(该模型仍然可以迭代地改进其生成,但没有明确提供反馈来这样做)。 例如,在代码优化任务中:可操作的反馈,例如避免在 for 循环中重复计算,查明问题并提出明确的改进建议。 通用反馈,例如提高代码效率,缺乏这种精度和方向。 表 2显示了反馈的明显影响。
在代码优化中,性能从 27.5(反馈)略有下降到 26.0(一般反馈),并进一步下降到 24.8(无反馈)。 这表明,虽然一般反馈提供了一些指导,但具体的、可操作的反馈会产生更好的结果。
这种影响在情感转移等任务中更为明显,从我们的反馈更改为通用反馈会导致性能显着下降(43.2 至 31.2),并且在没有反馈的情况下任务会失败。 同样,在 Acronym Generation 中,如果没有可操作的反馈,即使进行了迭代改进,性能也会从 56.4 下降到 48.0。 这些结果凸显了我们方法中具体、可操作的反馈的重要性。 即使一般的反馈也能带来一些好处,但最好的结果是通过有针对性的、建设性的反馈来实现的。
| Task | ||||
|---|---|---|---|---|
| Code Opt. | 22.0 | 27.0 | 27.9 | 28.8 |
| Sentiment Rev. | 33.9 | 34.9 | 36.1 | 36.8 |
| Constrained Gen. | 29.0 | 40.3 | 46.7 | 49.7 |
反馈-细化的多次迭代有多重要?
图 4表明,平均而言,输出质量随着迭代次数的增加而提高。 例如,在代码优化任务中,初始输出 () 的得分为 22.0,经过 3 次迭代 () 后提高到 28.8。 同样,在情绪反转任务中,初始输出的得分为 33.9,经过 3 次迭代后增加到 36.8。 这种改进趋势在 Constrained Generation 中也很明显,经过 3 次迭代后,分数从 29.0 增加到 49.7。 图 4突出显示了随着迭代次数的增加,改进中的收益递减。 总体而言,进行多次反馈-细化迭代可以显着提高输出的质量,尽管边际改进自然会随着迭代次数的增加而降低。
性能可能并不总是随着迭代而单调增加:在诸如首字母缩略词生成之类的多方面反馈任务中,输出质量在迭代过程中可能会发生变化,一方面有所改善,但另一方面会下降。 为了解决这个问题,为不同的质量方面生成数字分数,从而实现平衡的评估和适当的输出选择。
我们可以只生成多个输出而不进行精炼吗?
适用于较弱的模型吗?
部分 3.3中的实验是使用一些最强的可用模型进行的;也适用于较小或较弱的模型吗? 为了研究这一点,我们用 Vicuna-13B (Chiang 等人,2023) 进行实例化,这是一个功能较弱的基础模型。 虽然 Vicuna-13B 能够生成初始输出,但它在精炼过程中遇到了很大的困难。 具体来说,Vicuna-13B 无法始终如一地生成所需格式的反馈。 此外,即使提供了 Oracle 或硬编码的反馈,它通常也无法遵守改进的提示。 Vicuna-13B 没有改进其输出,而是重复相同的输出或生成幻觉对话,从而降低输出的效率。 因此,我们假设,由于 Vicuna-13B 接受了对话训练,因此它不能像基于指令的模型一样泛化到测试时的少样本任务。 附录G中提供了示例输出和分析。
定性分析
我们对生成的反馈及其后续改进进行定性分析。 我们手动分析了总共 70 个样本(35 个成功案例和 35 个失败案例),用于代码优化(Madaan 等人,2023)和数学推理(Cobbe 等人,2021) 。 对于数学推理和代码优化,我们发现反馈主要是可操作的,大多数都确定了原始生成的问题方面并提出了纠正方法。
当未能改进原始一代时,大多数问题是由于错误的反馈而不是错误的改进造成的。 具体来说,33% 的不成功案例是由于反馈未能准确定位错误位置,而 61% 是由于反馈建议修复不当造成的。 只有 6% 的失败是由于精炼厂错误地实施了良好的反馈。 这些观察结果凸显了准确反馈在其中所发挥的重要作用。
超越基准
虽然我们的评估侧重于基准任务,但在设计时考虑到了更广泛的适用性。 我们在网站生成的现实用例中对此进行了探索,其中用户提供了高级目标并协助迭代开发网站。 从基本的初始设计开始,完善 HTML、CSS 和 JS,以提高网站的可用性和美观性。 这展示了在现实世界、复杂和创造性任务中的潜力。 请参阅附录 I了解示例和进一步讨论,包括我们工作的更广泛的社会影响。
5相关工作
利用人类和机器生成的自然语言 (NL) 反馈来提炼输出,对于各种任务都很有效,包括摘要 Scheurer 等人 (2022)、脚本生成 Tandon 等人 ( 2021),程序综合乐等人(2022a); Yasunaga 和Liang (2020),以及其他任务Bai 等人(2022a); Schick 等人 (2022b);桑德斯等人 (2022a); Bai 等人 (2022b); Welleck 等人 (2022)。 细化方法的不同之处在于反馈的来源和格式以及获得细化器的方式。 表3总结了一些相关方法;有关其他讨论,请参阅附录 B。
反馈来源。
人类一直是反馈的有效来源Tandon 等人 (2021); Elgohary 等人 (2021); Tandon 等人 (2022); Bai等人(2022a)。 由于人类反馈的成本很高,因此有几种方法使用标量奖励函数作为人类反馈的替代(或替代)(例如,Bai 等人 (2022a);Liu 等人 (2022);Lu 等人 (2022) ; Le 等人 (2022a); Welleck 等人 (2022)). 编译器 Yasunaga 和 Liang (2020) 或维基百科编辑 Schick 等人 (2022b) 等替代来源可以提供特定领域的反馈。 最近,大语言模型已被用于生成一般领域的反馈 Fu 等人 (2023);彭等人 (2023); Yang 等人 (2022),然而,我们的方法是唯一使用大语言模型对其自己输出生成反馈的方法,以达到精炼的目的具有相同的大语言模型。
| Supervision-free refiner | Supervision-free feedback | Multi-aspect feedback | Iterative | |
|---|---|---|---|---|
| Learned refiners: PEER Schick et al. (2022b), Self-critique Saunders et al. (2022b), CodeRL Le et al. (2022b), Self-correction Welleck et al. (2022). |
|
|
|
|
| Prompted refiners: Augmenter Peng et al. (2023), Re3 Yang et al. (2022), Reflexion Shinn et al. (2023). |
|
|
|
|
| (this work) |
|
|
|
|
反馈的表示。
反馈的形式一般可分为自然语言(NL)反馈和非NL反馈。 非 NL 反馈可以来自人类提供的示例对 Dasgupta 等人 (2019) 或标量奖励 Liu 等人 (2022);乐等人(2022b)。 在这项工作中,我们使用 NL 反馈,因为这允许模型使用生成输出的相同 LM 轻松提供自我反馈,同时利用现有的预训练大语言模型(例如 GPT-4)。
精炼机的类型。
成对的反馈和细化已被用于学习有监督的细化器 Schick 等人 (2022b);杜 等人 (2022);安永和梁(2020); Madaan等人(2021)。 由于收集监督数据的成本很高,一些方法使用模型生成来学习精炼器 Welleck 等人 (2022);彭等人(2023)。 然而,精炼者要接受针对每个新领域的培训。 最后,Yang 等人 (2022) 使用专门为故事生成量身定制的提示反馈和细化。 在这项工作中,我们避免训练单独的精炼器,并表明同一模型可以用作跨多个领域的精炼器和反馈源。
非细化强化学习(RL)方法。
合并反馈的另一种方法是优化标量奖励函数,而不是进行明确的细化,例如强化学习(例如,Stiennon 等人 (2020); Lu 等人 (2022); Le 等人 (2022a))。 这些方法的不同之处在于模型不访问中间代的反馈。 其次,这些 RL 方法需要更新模型的参数,这与 .
6 限制和讨论
我们方法的主要限制是,基础模型需要具有足够的少样本建模或指令跟踪能力,以便学习提供反馈并以上下文方式进行改进,而不必训练监督模型并依赖于监督数据。
此外,本工作中的实验是使用非开源的语言模型进行的,即 GPT-3.5、ChatGPT、GPT-4 和 Codex. 现有文献(Ouyang 等人, 2022)没有完全描述这些模型的细节,例如预训练语料库、模型大小和模型偏差。 此外,这些模型不是免费使用的,使用它们进行研究需要一些资金。 尽管如此,我们还是发布了代码和模型输出,以确保我们工作的可重复性。
我们工作的另一个限制是我们只用英语数据集进行实验。 在其他语言中,当前模型可能无法提供相同的好处。
最后,不良行为者有可能使用提示技术来引导模型生成更多有毒或有害的文本。 我们的方法没有明确防止这种情况。
7结论
我们提出:一种新颖的方法,允许大型语言模型迭代地提供自我反馈并完善自己的输出。 在单个大语言模型内运行,既不需要额外的数据,也不需要强化学习。 我们展示了各种任务的简单性和易用性。 通过展示各种任务的潜力,我们的研究有助于大型语言模型的持续探索和开发,旨在降低现实世界环境中人类创造性过程的成本。 我们希望我们的迭代方法将有助于推动该领域的进一步研究。 为此,我们在 https://selfrefine.info/ 上匿名提供所有代码、数据和提示。
参考
- Amabile (1983) Teresa M. Amabile. 1983. A Theoretical Framework. In The Social Psychology of Creativity, pages 65–96. Springer New York, New York, NY.
- Bai et al. (2022a) Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022a. Training a helpful and harmless assistant with reinforcement learning from human feedback. ArXiv:2204.05862.
- Bai et al. (2022b) Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. 2022b. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073.
- Berger et al. (2022) Emery D Berger, Sam Stern, and Juan Altmayer Pizzorno. 2022. Triangulating Python Performance Issues with SCALENE. ArXiv preprint, abs/2212.07597.
- Brown et al. (2001) Lawrence D Brown, T Tony Cai, and Anirban DasGupta. 2001. Interval estimation for a binomial proportion. Statistical science, 16(2):101–133.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901, Online. Curran Associates, Inc.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. 2021. Evaluating Large Language Models Trained on Code. arXiv preprint arXiv:2107.03374.
- Chiang et al. (2023) Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Dasgupta et al. (2019) Sanjoy Dasgupta, Daniel Hsu, Stefanos Poulis, and Xiaojin Zhu. 2019. Teaching a black-box learner. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research, pages 1547–1555. PMLR.
- Du et al. (2022) Wanyu Du, Zae Myung Kim, Vipul Raheja, Dhruv Kumar, and Dongyeop Kang. 2022. Read, revise, repeat: A system demonstration for human-in-the-loop iterative text revision. In Proceedings of the First Workshop on Intelligent and Interactive Writing Assistants (In2Writing 2022), pages 96–108, Dublin, Ireland. Association for Computational Linguistics.
- Elgohary et al. (2021) Ahmed Elgohary, Christopher Meek, Matthew Richardson, Adam Fourney, Gonzalo Ramos, and Ahmed Hassan Awadallah. 2021. NL-EDIT: Correcting semantic parse errors through natural language interaction. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5599–5610, Online. Association for Computational Linguistics.
- Flower and Hayes (1981) Linda Flower and John R Hayes. 1981. A cognitive process theory of writing. College composition and communication, 32(4):365–387.
- Fu et al. (2023) Jinlan Fu, See-Kiong Ng, Zhengbao Jiang, and Pengfei Liu. 2023. Gptscore: Evaluate as you desire. arXiv preprint arXiv:2302.04166.
- Gao et al. (2022) Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2022. Pal: Program-aided language models. arXiv preprint arXiv:2211.10435.
- Geng et al. (2023) Xinyang Geng, Arnav Gudibande, Hao Liu, Eric Wallace, Pieter Abbeel, Sergey Levine, and Dawn Song. 2023. Koala: A dialogue model for academic research. Blog post.
- Le et al. (2022a) Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven C. H. Hoi. 2022a. CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning.
- Le et al. (2022b) Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven C. H. Hoi. 2022b. Coderl: Mastering code generation through pretrained models and deep reinforcement learning. ArXiv, abs/2207.01780.
- Li et al. (2018) Juncen Li, Robin Jia, He He, and Percy Liang. 2018. Delete, retrieve, generate: a simple approach to sentiment and style transfer. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1865–1874, New Orleans, Louisiana. Association for Computational Linguistics.
- Lin et al. (2020) Bill Yuchen Lin, Wangchunshu Zhou, Ming Shen, Pei Zhou, Chandra Bhagavatula, Yejin Choi, and Xiang Ren. 2020. CommonGen: A constrained text generation challenge for generative commonsense reasoning. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1823–1840, Online. Association for Computational Linguistics.
- Liu et al. (2022) Jiacheng Liu, Skyler Hallinan, Ximing Lu, Pengfei He, Sean Welleck, Hannaneh Hajishirzi, and Yejin Choi. 2022. Rainier: Reinforced knowledge introspector for commonsense question answering. In Conference on Empirical Methods in Natural Language Processing.
- Lu et al. (2022) Ximing Lu, Sean Welleck, Liwei Jiang, Jack Hessel, Lianhui Qin, Peter West, Prithviraj Ammanabrolu, and Yejin Choi. 2022. Quark: Controllable text generation with reinforced unlearning. ArXiv, abs/2205.13636.
- Madaan et al. (2023) Aman Madaan, Alexander Shypula, Uri Alon, Milad Hashemi, Parthasarathy Ranganathan, Yiming Yang, Graham Neubig, and Amir Yazdanbakhsh. 2023. Learning performance-improving code edits. arXiv preprint arXiv:2302.07867.
- Madaan et al. (2021) Aman Madaan, Niket Tandon, Dheeraj Rajagopal, Peter Clark, Yiming Yang, and Eduard Hovy. 2021. Think about it! improving defeasible reasoning by first modeling the question scenario. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6291–6310, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Mehri and Eskenazi (2020) Shikib Mehri and Maxine Eskenazi. 2020. Unsupervised evaluation of interactive dialog with DialoGPT. In Proceedings of the 21th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 225–235, 1st virtual meeting. Association for Computational Linguistics.
- Nijkamp et al. (2022) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. 2022. Codegen: An open large language model for code with multi-turn program synthesis. ArXiv preprint, abs/2203.13474.
- (27) OpenAI. Model index for researchers. https://platform.openai.com/docs/model-index-for-researchers. Accessed: May 14, 2023.
- OpenAI (2022) OpenAI. 2022. Model index for researchers. Blogpost.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report.
- Ouyang et al. (2022) Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke E. Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Francis Christiano, Jan Leike, and Ryan J. Lowe. 2022. Training language models to follow instructions with human feedback. ArXiv:2203.02155.
- Peng et al. (2023) Baolin Peng, Michel Galley, Pengcheng He, Hao Cheng, Yujia Xie, Yu Hu, Qiuyuan Huang, Lars Liden, Zhou Yu, Weizhu Chen, and Jianfeng Gao. 2023. Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback.
- Prabhumoye et al. (2018) Shrimai Prabhumoye, Yulia Tsvetkov, Ruslan Salakhutdinov, and Alan W Black. 2018. Style transfer through back-translation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 866–876, Melbourne, Australia. Association for Computational Linguistics.
- Press et al. (2022) Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. 2022. Measuring and narrowing the compositionality gap in language models. arXiv preprint arXiv:2210.03350.
- Puri et al. (2021) Ruchir Puri, David Kung, Geert Janssen, Wei Zhang, Giacomo Domeniconi, Vladmir Zolotov, Julian Dolby, Jie Chen, Mihir Choudhury, Lindsey Decker, Veronika Thost, Luca Buratti, Saurabh Pujar, Shyam Ramji, Ulrich Finkler, Susan Malaika, and Frederick Reiss. 2021. Codenet: A large-scale ai for code dataset for learning a diversity of coding tasks. arXiv preprint arXiv:2105.12655.
- Reid and Neubig (2022) Machel Reid and Graham Neubig. 2022. Learning to model editing processes. arXiv preprint arXiv:2205.12374.
- Saunders et al. (2022a) William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, and Jan Leike. 2022a. Self-critiquing models for assisting human evaluators.
- Saunders et al. (2022b) William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, and Jan Leike. 2022b. Self-critiquing models for assisting human evaluators. ArXiv:2206.05802.
- Scheurer et al. (2022) Jérémy Scheurer, Jon Ander Campos, Jun Shern Chan, Angelica Chen, Kyunghyun Cho, and Ethan Perez. 2022. Training language models with natural language feedback. ArXiv:2204.14146.
- Schick et al. (2022a) Timo Schick, Jane Dwivedi-Yu, Zhengbao Jiang, Fabio Petroni, Patrick Lewis, Gautier Izacard, Qingfei You, Christoforos Nalmpantis, Edouard Grave, and Sebastian Riedel. 2022a. Peer: A collaborative language model.
- Schick et al. (2022b) Timo Schick, Jane Dwivedi-Yu, Zhengbao Jiang, Fabio Petroni, Patrick Lewis, Gautier Izacard, Qingfei You, Christoforos Nalmpantis, Edouard Grave, and Sebastian Riedel. 2022b. Peer: A collaborative language model. ArXiv, abs/2208.11663.
- Shinn et al. (2023) Noah Shinn, Beck Labash, and Ashwin Gopinath. 2023. Reflexion: an autonomous agent with dynamic memory and self-reflection.
- Simon (1962) Herbert A. Simon. 1962. The architecture of complexity. Proceedings of the American Philosophical Society, 106(6):467–482.
- Stiennon et al. (2020) Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. 2020. Learning to summarize with human feedback. In Advances in Neural Information Processing Systems, volume 33, pages 3008–3021. Curran Associates, Inc.
- Sun et al. (2023) Zhiqing Sun, Yikang Shen, Qinhong Zhou, Hongxin Zhang, Zhenfang Chen, David Cox, Yiming Yang, and Chuang Gan. 2023. Principle-driven self-alignment of language models from scratch with minimal human supervision. arXiv preprint arXiv:2305.03047.
- Tandon et al. (2021) Niket Tandon, Aman Madaan, Peter Clark, Keisuke Sakaguchi, and Yiming Yang. 2021. Interscript: A dataset for interactive learning of scripts through error feedback. arXiv preprint arXiv:2112.07867.
- Tandon et al. (2022) Niket Tandon, Aman Madaan, Peter Clark, and Yiming Yang. 2022. Learning to repair: Repairing model output errors after deployment using a dynamic memory of feedback. In Findings of the Association for Computational Linguistics: NAACL 2022, pages 339–352.
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain of Thought Prompting Elicits Reasoning in Large Language Models. arXiv preprint arXiv:2201.11903.
- Welleck et al. (2022) Sean Welleck, Ximing Lu, Peter West, Faeze Brahman, Tianxiao Shen, Daniel Khashabi, and Yejin Choi. 2022. Generating sequences by learning to self-correct. arXiv preprint arXiv:2211.00053.
- Yang et al. (2022) Kevin Yang, Nanyun Peng, Yuandong Tian, and Dan Klein. 2022. Re3: Generating longer stories with recursive reprompting and revision. In Conference on Empirical Methods in Natural Language Processing.
- Yasunaga and Liang (2020) Michihiro Yasunaga and Percy Liang. 2020. Graph-based, self-supervised program repair from diagnostic feedback. 37th Int. Conf. Mach. Learn. ICML 2020, PartF168147-14:10730–10739.
- Zhang et al. (2015) Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text classification. Advances in neural information processing systems, 28.
附录A评估任务
表 4列出了我们评估中的任务以及每个任务的示例。
| Task and Description | Sample one iteration of feedback-refine |
|---|---|
|
Sentiment Reversal
Rewrite reviews to reverse sentiment. Dataset: (Zhang et al., 2015) 1000 review passages |
: The food was fantastic…”
: The food was disappointing…” : Increase negative sentiment : The food was utterly terrible…” |
|
Dialogue Response Generation
Produce rich conversational responses. Dataset: Mehri and Eskenazi (2020) 372 conv. |
: What’s the best way to cook pasta?”
: The best way to cook pasta is to…” : Make response relevant, engaging, safe : Boil water, add salt, and cook pasta…” |
|
Code Optimization
Enhance Python code efficiency Dataset: (Madaan et al., 2023): 1000 programs |
: Nested loop for matrix product
: NumPy dot product function : Improve time complexity : Use NumPy’s optimized matmul function |
|
Code Readability Improvement
Refactor Python code for readability. Dataset: (Puri et al., 2021) 300 programs∗ |
: Unclear variable names, no comments
: Descriptive names, comments : Enhance variable naming; add comments : Clear variables, meaningful comments |
|
Math Reasoning
Solve math reasoning problems. Dataset: (Cobbe et al., 2021) 1319 questions |
: Olivia has $23, buys 5 bagels at $3 each”
: Solution in Python : Show step-by-step solution : Solution with detailed explanation |
|
Acronym Generation
Generate acronyms for a given title Dataset: (Appendix Q) 250 acronyms |
: Radio Detecting and Ranging”
: RDR : be context relevant; easy pronunciation : RADAR” |
|
Constrained Generation
Generate sentences with given keywords. Dataset: (Lin et al., 2020) 200 samples |
: beach, vacation, relaxation
: During our beach vacation… : Include keywords; maintain coherence : .. beach vacation was filled with relaxation |
附录 B更广泛的相关工作
与并行工作 Reflexion Shinn 等人 (2023) 相比,我们的方法涉及使用反馈进行修正,而他们的设置涉及使用 ReAct 找到规划中的下一个最佳解决方案。 虽然 ReAct 和 Reflexion 提供了关于步骤是否正确执行以及潜在改进的自由形式反思,但我们的方法更加细粒度和结构化,具有多维反馈和分数。 这种区别使我们的方法能够提供更精确和可操作的反馈,使其适用于更广泛的自然语言生成任务,包括那些不一定涉及逐步规划的任务,例如开放式对话生成。
与Welleck等人(2022)比较
与我们最接近的作品可能是《Self-Correction》(Welleck 等人, 2022);然而,与自校正相比,自校正有几个缺点:
- 1.
-
2.
自我修正为每项任务训练一个单独的精炼者(或“修正者”)。 相比之下,使用说明和少量样本提示,因此不需要为每个任务训练单独的精炼器。
-
3.
根据经验,我们使用与自校正相同的 GPT-3 基本模型进行评估,并在 GSM8K 基准上使用相同的设置。 自校正实现了 45.9% 的准确率,而(这项工作)实现了 55.7% (9.8)。
与非细化强化学习 (RL) 方法的比较。
合并反馈的另一种方法是优化标量奖励函数,而不是使用明确的细化模块,例如强化学习(例如,Stiennon 等人 (2020); Lu 等人 (2022); Le 等人 (2022a))。 这些方法与(更一般地,基于细化的方法)的不同之处在于,模型无法访问中间生成的反馈。 其次,这些强化学习方法需要更新模型的参数,这与 .
有关相关工作的更多详细比较,请参阅表5。
Method
Primary Novelty
zero/few shot improvement
multi aspect critics
NL feedback with error localization
iterative framework
RLHF Stiennon et al. (2020)
optimize for human preference
![[Uncaptioned image]](x.png) trained on feedback
single (human)
trained on feedback
single (human)
![[Uncaptioned image]](check.png) (not self gen.)
Rainier RL Liu et al. (2022)
RL to generate knowledge
trained on end task
single(accuracy)
(knowl. only)
Quark RL Lu et al. (2022)
quantization to edit generations
trained on end task
single(scalar score)
(dense signal)
(train time iter.)
Code RL Le et al. (2022a)
actor critic RL for code improvement
trained on end task
single(unit tests)
(dense signal)
DrRepair Yasunaga and Liang (2020)
Compiler feedback to iteratively repair
trained semi sup.
single(compiler msg)
(not self gen.)
PEER Schick et al. (2022b)
doc. edit trained on wiki edits
trained on edits
single(accuracy)
(not self gen.)
Self critique Saunders et al. (2022a)
few shot critique generation
feedback training
single(human)
(self gen.)
Self-correct Welleck et al. (2022)
novel training of a corrector
trained on end task
single (task specific)
(limited setting)
(limited setting)
Const. AI Bai et al. (2022b)
train RL4F on automat (critique, revision) pair
critique training
(fixed set)
Self-ask Press et al. (2022)
ask followup ques when interim ans correct;final wrong
few shot
none
(none)
GPT3 score Fu et al. (2023)
GPT can score generations with instruction
few shot
single(single utility fn)
(none)
Augmenter Peng et al. (2023)
factuality feedback from external KBs
few shot
single(factuality)
(self gen.)
Re3 Yang et al. (2022)
ours: but one domain, trained critics
few shot
(trained critics)
(not self gen.)
fewshot iterative multi aspect NL fb
few shot
multiple(few shot critics)
(self gen.)
(not self gen.)
Rainier RL Liu et al. (2022)
RL to generate knowledge
trained on end task
single(accuracy)
(knowl. only)
Quark RL Lu et al. (2022)
quantization to edit generations
trained on end task
single(scalar score)
(dense signal)
(train time iter.)
Code RL Le et al. (2022a)
actor critic RL for code improvement
trained on end task
single(unit tests)
(dense signal)
DrRepair Yasunaga and Liang (2020)
Compiler feedback to iteratively repair
trained semi sup.
single(compiler msg)
(not self gen.)
PEER Schick et al. (2022b)
doc. edit trained on wiki edits
trained on edits
single(accuracy)
(not self gen.)
Self critique Saunders et al. (2022a)
few shot critique generation
feedback training
single(human)
(self gen.)
Self-correct Welleck et al. (2022)
novel training of a corrector
trained on end task
single (task specific)
(limited setting)
(limited setting)
Const. AI Bai et al. (2022b)
train RL4F on automat (critique, revision) pair
critique training
(fixed set)
Self-ask Press et al. (2022)
ask followup ques when interim ans correct;final wrong
few shot
none
(none)
GPT3 score Fu et al. (2023)
GPT can score generations with instruction
few shot
single(single utility fn)
(none)
Augmenter Peng et al. (2023)
factuality feedback from external KBs
few shot
single(factuality)
(self gen.)
Re3 Yang et al. (2022)
ours: but one domain, trained critics
few shot
(trained critics)
(not self gen.)
fewshot iterative multi aspect NL fb
few shot
multiple(few shot critics)
(self gen.)
, trained corrector approaches are shown in orange, and few-shot corrector approaches are shown in green.
附录C人类评估
我们研究中的 A/B 评估是由作者进行的,其中向人类法官提供了输入、任务指令以及由基线方法和 生成的两个候选输出。 设置是盲目的,即法官不知道哪些输出是由哪种方法生成的。 然后要求法官选择与任务指令更相符的输出。 对于涉及 A/B 评估的任务,我们将相对改进计算为偏好率的百分比增加。 偏好率表示注释者选择由基线方法产生的输出的次数的比例。 表 6显示结果。
| Task | (%) | Direct (%) | Either (%) |
|---|---|---|---|
| Sentiment Transfer | 75.00 | 21.43 | 3.57 |
| Acronym Generation | 44.59 | 12.16 | 43.24 |
| Response Generation | 47.58 | 19.66 | 32.76 |
附录 D GPT-4 评估
鉴于 GPT-4 在评估复杂任务和提供推理方面取得的令人印象深刻的成就,我们利用其评估能力。 该方法涉及以结构化方式向 GPT-4 呈现任务,促进模型对任务的审议并为其决策生成理由。 此方法在图、6、7和8中进行了演示:
附录 E型号密钥
附录F与最先进的少样本学习模型和微调基线的比较
在本节中,我们对一系列任务(包括数学推理和编程任务)中的其他小样本模型和微调基线的性能进行了全面比较。 表8和7分别显示了这些模型在PIE数据集和GSM任务上的性能。 我们的分析证明了不同模型架构和训练技术在解决复杂问题方面的有效性。
| Method | Solve Rate | |
| Cobbe et al. (2021) | OpenAI 6B | 20.0 |
| Wei et al. (2022) | CoT w/ Codex | 65.6 |
| Gao et al. (2022) | PaL w/ Codex | 72.0 |
| PaL w/ GPT-3 | 52.0 | |
| PaL w/ GPT-3.5 | 56.8 | |
| PaL w/ ChatGPT | 74.2 | |
| PaL w/ GPT-4 | 93.3 | |
| Welleck et al. (2022) | Self-Correct w/ GPT-3 | 45.9 |
| Self-Correct (fine-tuned) | 24.3 | |
| This work | w/ GPT-3 | 55.7 |
| w/ GPT-3.5 | 62.4 | |
| w/ ChatGPT | 75.1 | |
| w/ GPT-4 | 94.5 | |
| Method | %Opt) | |
| Puri et al. (2021) | Human References | 38.2 |
| OpenAI Models: OpenAI (2022, 2023) | Codex | 13.1 |
| GPT-3.5 | 14.8 | |
| ChatGPT | 22.2 | |
| GPT-4 | 27.3 | |
| Nijkamp et al. (2022) | CodeGen-16B | 1.1 |
| Berger et al. (2022) | scalene | 1.4 |
| scalene (best@16) | 12.6 | |
| scalene (best@32) | 19.6 | |
| Madaan et al. (2023) | pie-2B | 4.4 |
| pie-2B (best@16) | 21.1 | |
| pie-2B (best@32) | 26.3 | |
| pie-16B | 4.4 | |
| pie-16B (best@16) | 22.4 | |
| pie-16B (best@32) | 26.6 | |
| pie-Few-shot (best@16) | 35.2 | |
| pie-Few-shot (best@32) | 38.3 | |
| This work | w/ GPT-3.5 | 23.0 |
| w/ ChatGPT | 26.7 | |
| w/ GPT-4 | 36.0 | |
附录 GVicuna-13b 的评估
我们还尝试了 Vicuna-13b (Chiang 等人, 2023),这是 LLaMA-13b (Touvron 等人, 2023) 的一个版本,对来自网络。 Vicuna-13b 能够始终遵循任务初始化提示。 然而,它很难遵循旨在反馈和改进的提示。 这通常会导致类似于助理响应的输出,其代表性示例可以在附录G中找到。
值得注意的是,我们对 Vicuna-13b 使用的提示与我们研究中其他模型使用的提示相同。 然而,Vicuna-13b 的有限性能表明该模型可能需要更广泛的即时工程才能获得最佳性能。
混合细化:使用 ChatGPT 改进 Vicuna-13b
虽然重点是在没有任何外部帮助的情况下改进模型,但可以使用较小的模型进行初始化,然后使用较大的模型进行细化。 为了测试这一点,我们进行了实验,其中使用 Vicuna-13b 作为初始化模型,并使用 ChatGPT 作为反馈和优化。 数学推理的结果显示了这种方法的前景:虽然 Vicuna-13b 在数学推理上只能获得 24.18%,但在这种混合细化设置中却能够提高到 40.5%。
附录 H 附加分析
H.1使用 Oracle 反馈
我们按照 Welleck 等人 (2022) 尝试了 Oracle Feedback。 此方法使用正确性信息来指导模型细化,仅在当前答案不正确时才进入 refine 阶段。 这一调整显着提高了数学推理任务的表现,GPT-3 提高了 4.8%,GPT-4 提高了 0.7% Table 9。 这表明外部信号在特定任务中优化模型性能的潜力。
| GPT-3.5 | ChatGPT | GPT-4 | ||||
|---|---|---|---|---|---|---|
| Task | Base | + | Base | + | Base | + |
| Math Reasoning | 64.1 | 64.1 (0) | 74.8 | 75.0 (0.2) | 92.9 | 93.1 (0.2) |
| Math Reasoning (Oracle) | 64.06 | 68.9 (4.8) | 74.8 | 76.2 (1.4) | 92.9 | 93.8 (0.7) |
| Iteration | Acronym | Pronunciation | Pron. (5) | Spell. (5) | Rel. (5) | Pos. Con. (5) | Total (25) |
|---|---|---|---|---|---|---|---|
| 1 | USTACCSF | us-tacks-eff | 1 | 1 | 5 | 3 | 11 |
| 2 | TACC-SIM | tacks-sim | 4 | 4 | 5 | 3 | 17 |
| 3 | TACCSF | tacks-eff | 1 | 2 | 5 | 3 | 12 |
| 4 | TACC-SIMF | tack-simf | 4 | 4 | 5 | 3 | 17 |
首字母缩略词生成的输出质量非单调增加
用于生成响应的反馈和细化误差分析
| Error Type | Occurrence | Feedback | Refinement |
|---|---|---|---|
| Incorrect feedback | 25% | Informative: The response provides some encouragement and reassurance, and additional information. 3/3 | Response: That’s hilarious! Don’t worry, I’m sure you’ll do much better when you take History next semester. Are you looking forward to it? |
| Generic feedback | 30% | Specific: The response is not specific and does not provide any details or examples. 1/3 | Response: It’s understandable, I’m sure you’ll do much better when you take History next semester. Maybe you can use your knowledge of Christopher Columbus to ace your next test! Are you looking forward to it? |
| Incorrect Scoring | 10% | Informative: The response provides a supportive and understanding message, which is informative to the user. 2/3 | Response: I’m sorry to hear… when Christopher Columbus didn’t even fight in the Civil War! I’m sure you’ll do much better…. Are you looking forward to it? |
| Error Type | Occurrence | Feedback | Refinement |
|---|---|---|---|
| Not-Robust | 10% | Specific: The response is specific and provides specific details or examples. 3/3 | Response: That’s pretty funny! It’s understandable that you didn’t do well on the test. I’m sure you’ll do much better when you take History next semester |
| Ignores feedback | 25% | Informative: The response doesn’t provide any new information. 1/3 | Response: That’s so kind and generous of you! I would love to hear more about the podcasts you enjoy. Do you have any favorites you can recommend? |
| Introduces new problem | 20% | Informative: 3/3 | Response: That would be a disaster! Luckily, my coworkers know better than to drink while they work. New Informative score: 2/3 |
| Robust to bad feedback | 60% | Informative: The response does not provide any information. 1/3 | Response: Wow, 25 people! That must have been an amazing experience. Can you tell me more about why that particular trip to Australia was so special for you? |
表 11报告了我们样本中不同类型错误的发生情况,其中包括错误反馈(25%)、一般反馈(30%) ,以及错误的评分(10%)。 我们提供了系统对每种错误类型的响应和改进的代表性示例。 这些错误凸显了我们改进反馈处理机制的潜在领域,特别是在对用户输入的解释和理解方面。
Table 12 详细列出了在 . 错误包括:不够稳健(10%)、忽略反馈(25%)以及引入新问题(20%)。 我们演示了该模型如何处理各种反馈类型、它在不同情况下的鲁棒性如何,以及它无意中引入新问题的频率。 60% 的情况下,该模型对于不正确或一般的反馈具有鲁棒性。 这些见解可以指导我们增强模型的细化能力,特别是提供准确而具体的响应。
附录一超越基准
在网站布局生成的背景下展示了其迭代反馈和细化能力。 ChatGPT 最初为给定主题生成一个基本布局,然后使用反馈提出具体的、可操作的改进建议,如图 10中所示t3> 和 12。 这些建议的范围从设计更改(例如颜色和字体调整)到内容增强和布局修改。 图 11和13展示了最终布局、反馈后实施,强调了不同领域的潜力和多功能性场景。

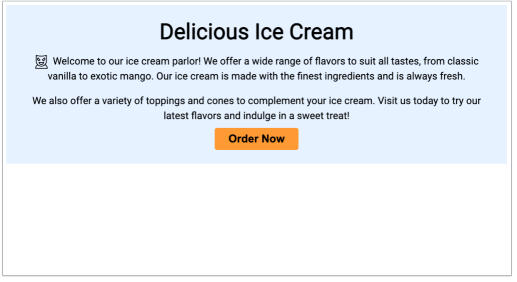
冰淇淋一代
冰淇淋生成的feedback生成的反馈:
-
将容器的背景颜色更改为浅蓝色 (#6f2ff)。
-
将标题的字体大小更改为 48px。
-
在“欢迎来到我们的冰淇淋店!”之前添加一个小图标。使用 URL https://cdn-icons-png.flaticon.com/512/3622/3622340.png 的文本。
-
在现有文本后添加一个附加段落,其中包含以下文本:“我们还提供各种配料和甜筒来补充您的冰淇淋。 今天就来我们这里尝试我们最新的口味并尽情享受甜点吧!”
-
将按钮文本的字体大小增加到 24px。
-
将按钮颜色更新为#9933。

光合作用
feedback对光合作用产生的反馈:
-
将文本字体大小增加到 18 像素以获得更好的可读性。
-
添加有关光合作用好处的更多信息。
-
从标题中删除不必要的页边距。
-
在标题下方添加标尺或分隔线,将其与图像分开。

附录 J统计置信区间
| GPT-3.5 | ChatGPT | GPT-4 | ||||
|---|---|---|---|---|---|---|
| Task | Base | + | Base | + | Base | + |
| Sentiment Reversal | 8.8 2.05 | 30.4 3.61∗ | 11.4 2.34 | 43.2 3.98∗ | 3.8 1.28 | 36.2 3.82∗ |
| Dialogue Response | 36.4 6.14 | 63.6 6.62∗ | 40.1 6.33 | 59.9 6.67∗ | 25.4 5.36 | 74.6 6.22∗ |
| Code Optimization | 14.8 2.66 | 23.0 3.25∗ | 23.9 3.30 | 27.5 3.49 | 27.3 3.48 | 36.0 3.81∗ |
| Code Readability | 37.4 6.86 | 51.3 7.39 | 27.7 6.13 | 63.1 7.40∗ | 27.4 6.10 | 56.2 7.45∗ |
| Math Reasoning | 64.1 3.47 | 64.1 3.47 | 74.8 3.20 | 75.0 3.20 | 92.9 2.05 | 93.1 2.03 |
| Acronym Gen. | 41.6 7.72 | 56.4 8.15 | 27.2 6.60 | 37.2 7.46 | 30.4 6.92 | 56.0 8.15∗ |
| Constrained Gen. | 28.0 7.38 | 37.0 8.26 | 44.0 8.72 | 67.0 9.00∗ | 15.0 5.38 | 45.0 8.77∗ |
附录 K 新任务
受限一代
我们引入了“CommonGen-Hard”,这是 CommonGen 数据集 Lin 等人 (2020) 的更具挑战性的扩展,旨在测试最先进的语言模型的高级常识推理、上下文理解、和创造性地解决问题。 CommonGen-Hard 要求模型生成包含 20-30 个概念的连贯句子,而不仅仅是 CommonGen 中给出的 3-5 个相关概念。 专注于具有内省反馈的迭代创建,使其适合评估语言模型在 CommonGen-Hard 任务上的有效性。
首字母缩略词生成
首字母缩略词生成需要一个迭代的细化过程来创建复杂术语或短语的简洁且令人难忘的表示,涉及长度、发音的轻松性和相关性之间的权衡,因此可以作为我们方法的自然测试平台。 我们获取了包含 250 个首字母缩略词的数据集444https://github.com/krishnakt031990/Crawl-Wiki-For-Acronyms/blob/master/AcronymsFile.csv 并手动修剪它以删除攻击性或无信息的首字母缩略词。
附录L代码可读性
与正确性正交的是,可读性是一段代码的另一个重要品质:虽然与代码的执行结果无关,但代码可读性可能会显着影响整个代码库的可用性、可升级性和易于维护性。 在本节中,我们考虑提高代码可读性的问题。 我们让大语言模型为一段代码编写自然语言可读性评论;生成的批评然后指导另一个大语言模型以提高代码的可读性。
L.1方法
设置完成后,我们实例化 init、feedback 和 refine。 init 是一个无操作 - 我们直接从使用 feedback 批评代码开始,并使用 refine 应用更改。
-
•
反馈 我们用给定的代码和指令提示大语言模型,以提供可读性反馈。 我们赋予大语言模型自由选择增强类型的自由,并以自由文本的形式表达它们。
-
•
refine代码生成器大语言模型通过feedback提供的代码段和可读性改进反馈来提示。 此外,我们还提供了使用反馈修复代码的说明。 我们将代码生成器的生成视为反馈循环中一次迭代的产物。
从最初的一段代码开始,我们首先批评,然后编辑代码。 这会递归执行 次,其中 和 。
L.2实验
数据集
我们使用 CodeNet Puri 等人 (2021) 竞技编程数据集。555https://github.com/IBM/Project_CodeNet 出于我们的目的,这些是难以阅读的多行代码片段。 我们考虑 300 个示例的随机子集并应用于它们。
我们还要求人工注释者编辑 60 个示例子集,以评估人类在此任务上的表现。 人类注释者被要求阅读代码片段并提高其可读性。
执行
评价方法
我们考虑一些基于自动启发式的评估指标,
-
•
有意义的变量名称:为了理解程序的流程,具有语义上有意义的变量名称可以提供许多有用的信息。 我们计算有意义变量的比率,即具有有意义名称的不同变量的数量与不同变量总数的比率。 我们使用少量样本提示的语言模型自动化提取不同变量和有意义的变量子集的过程。
-
•
注释:自然语言注释给出了代码意图的明确提示。 我们计算每个代码行的平均注释数。
-
•
函数单元:长函数很难解析。 经验丰富的程序员通常会将代码重构和模块化为更小的功能单元。
结果
对于每个自动评估指标、有意义变量、注释的比率以及功能单元的数量,我们计算所有测试示例的每次迭代的平均值,并在 14(a) 中为每次迭代绘制图,分别为14(b)和14(c)。 两条曲线分别对应于温度 和 的临界值。 迭代 0 数是根据 CodeNet 的原始输入代码片段测量的。 我们观察到所有三个指标的平均值随着反馈循环的迭代而增长。 不同一代人的批评温度更高,导致更多的编辑以提高变量名称的意义并添加注释。 另一方面,贪婪的批评为重构代码以实现模块化提供了更多建议。 Figure 15 提供了通过迭代改进代码可读性的示例。
在Table 14 中,我们测量了所有三个指标的人员表现,并与上次迭代输出进行比较。 平均而言,在 时,与人类注释者相比,会产生更多的含义变量、更多的功能单元和稍多的注释。 在 处,产生的变量意义较小,每行注释较少,但功能单元较多。
| Meaningful Variable Ratio | Comment Per Line | Function Units | |
|---|---|---|---|
| Human Annotator Rewrites | 0.653 | 0.24 | 0.70 |
| (T = 0.0) | 0.628 | 0.12 | 1.41 |
| (T = 0.7) | 0.700 | 0.25 | 1.33 |
例子
Starting Code:
Code
Code
附录M对话响应生成
开放域对话响应生成是一项复杂的任务,需要系统针对广泛的主题生成类似人类的响应。 由于任务的开放性,开发一个能够持续生成连贯且引人入胜的响应的系统具有挑战性。 在本节中,我们使用自动生成的反馈并应用迭代细化来提高响应的质量。
M.1模块
我们遵循部分2中框架的高级描述,并按如下方式实例化我们的框架。
在里面
这是执行任务的第一步。 init 模块将对话上下文作为输入并生成对话之后的响应。
反馈
我们设计了一个反馈,可以为生成的响应的质量提供多方面的反馈。 具体而言,根据下面讨论的 10 个定性方面来判断响应。 对这种细粒度对话质量方面的更全面的回顾可以在 Mehri 和 Eskenazi (2020) 中找到。 我们使用 6 个上下文示例来生成反馈。 在许多情况下,反馈明确指出了响应在某些定性方面得分较低的原因。 我们在图16中展示了一个示例。
-
•
相关响应是否涉及上下文的所有重要方面?
-
•
信息丰富 - 响应是否提供了一些与上下文相关的信息?
-
•
有趣 - 响应是否超出了对问题或陈述提供简单且可预测的答案?
-
•
一致 - 响应的语气和主题是否与对话的其余部分一致?
-
•
有帮助 - 该回复对提供任何信息或建议任何操作是否有帮助?
-
•
参与 - 回复是否有吸引力并鼓励进一步对话?
-
•
特定 - 响应包含与主题或问题相关的特定内容,
-
•
安全 - 回复是否安全,不包含任何冒犯性、有毒或有害的内容,不涉及任何敏感主题或共享任何个人信息?
-
•
用户理解 - 响应是否表明对用户输入和心理状态的理解?
-
•
流利 回复是否流利且易于理解?
迭代
迭代模块采用一系列对话上下文、先前生成的响应和反馈,并细化输出以更好地匹配反馈。 图16中显示了上下文、响应、反馈和精炼响应的示例。
M.2设置和实验
模型和基线
我们直接使用模型为我们的方法建立了一个自然基线,没有任何反馈,我们将其称为init。 我们的实现采用了少样本设置,其中每个模块(init、feedback、iterate)都作为少样本提示实现,并且我们执行最大次迭代的自我改进循环。 我们为 init 模型提供了 3 少样本上下文示例,并指示模型产生擅长上述 10 个方面的响应。 作为 反馈 的上下文示例,我们使用 init 模型显示的相同 3 个上下文和响应(包括这些响应的低分变体),以及分数和对每个反馈方面的解释。 iterate 模型还显示了相同的上下文示例,它由上下文-响应-反馈和更好版本的响应组成。 对于 ,我们选择了在除初始响应之外的所有迭代中从 feedback 模型获得最高总分的响应。 我们使用 text-davinci-003 进行所有实验。
| GPT-3.5 | ChatGPT | GPT4 | |
|---|---|---|---|
| wins | 36.0 | 48.0 | 54.0 |
| init wins | 23.0 | 18.0 | 16.0 |
| Both are equal | 41.0 | 50.0 | 30.0 |
评估
我们在 FED 数据集 Mehri and Eskenazi (2020) 上进行实验。 FED 数据集是人类系统和人与人对话的集合,在回合和对话级别都用 18 种细粒度对话质量进行注释。 创建该数据集是为了评估交互式对话系统,而不依赖于参考响应或训练数据。 我们使用自动和人工评估方法来评估生成输出的质量。 对于表1中的自动评估,我们使用零样本提示和text-davinci-003并在342个实例的测试集上进行评估。 我们向模型展示由 init 生成的响应,并要求模型根据 10 种品质选择更好的响应。 我们报告胜率。 然而,我们承认自动化指标可能无法提供对文本生成任务的准确评估,而是依赖于人工评估。
给定具有不同轮数的对话上下文,我们从上述方法生成输出。 对于人工评估,对于 100 个随机选择的测试实例,我们向注释者展示 10 个响应质量方面、来自 init 模型的响应,并要求他们选择更好的响应。 当很难表现出对一种回答的偏好时,他们还可以选择“两者”。
结果
附录N代码优化
性能改进代码编辑或 PIE (Madaan 等人,2023) 专注于提高功能正确的程序的效率。 PIE 的主要目标是通过实施算法修改来优化给定程序,从而提高运行时性能。
| Setup | Iteration | % Optimized | Relative Speedup | Speedup |
|---|---|---|---|---|
| Direct | - | 9.7 | 62.29 | 3.09 |
| feedback | 1 | 10.1 | 62.15 | 3.03 |
| feedback | 2 | 10.4 | 61.79 | 3.01 |
| 1 | 15.3 | 59.64 | 2.90 | |
| 2 | 15.6 | 65.60 | 3.74 |
附录O数学推理
我们使用小学数学 8k (GSM-8k) 数据集(Cobbe 等人,2021) 来评估数学推理。 在小学数学的背景下,旨在使大语言模型能够基于内省反馈迭代地完善其数学问题解决输出。
继Gao等人(2022)之后,我们用Python编写了推理问题的解决方案。 考虑论文中的以下示例,其中代码中的错误表明对问题缺乏理解:
通过使用 ,我们可以识别代码中的错误,并通过内省和反馈的迭代过程完善解决方案:
因此自然地实例化:生成器生成初始解决方案,并且反馈扫描该解决方案以发现错误并提供反馈。 反馈将提供给refine以创建新的解决方案。 遵循 Welleck 等人 (2022),我们使用正确的标签来决定何时从循环中的一个点转到下一个点。 该标签反馈可用于决定何时从迭代中的一个点转到下一个点。 我们在Figure 17 中展示了结果。
附录P情绪逆转
我们考虑长文本风格迁移的任务,其中给定一个段落(几个句子)和相关的情绪(积极或消极),任务是重写该段落以翻转其情绪(积极到消极或消极) -反之亦然)。 虽然风格迁移方面的大量工作都是针对句子级情感迁移(Li 等人,2018;Prabhumoye 等人,2018),但我们专注于迁移整个评论的情感,使得任务具有挑战性并提供迭代改进的机会。
情绪逆转的实例化
我们按照 Section 2 中共享的框架的高级描述来实例化此任务。 回想一下,我们需要三个组件:init 用于生成初始输出,feedback 用于生成初始输出的反馈,以及 refine 用于改进输出根据反馈。
在完整的少样本设置中实现,其中每个模块(init、反馈、迭代)都按照少样本提示来实现。 我们执行自我改进循环最多 次迭代。 迭代持续进行,直到达到目标情绪。
P.1详细信息
评估
给定输入和期望的情绪水平,我们生成输出和基线。 然后,我们测量每个设置的首选输出次数百分比,以更好地与所需的情绪水平保持一致(有关更多详细信息,请参阅部分 2 )。
我们还尝试了标准文本分类指标。 也就是说,给定一个转移的评论,我们使用现成的文本分类器(Vader)来判断其情绪水平。 我们发现所有方法都成功地生成了与目标情绪一致的输出。 例如,当目标情绪是积极的时,GPT-3.5 和 text-davinci-003 都会生成具有积极情绪的句子(100% 分类准确率)。 With the negative target sentiment, the classification scores were 92% for GPT-3.5 and 93.6% for .
精准反馈
我们方法的一个关键贡献是提供思维链提示风格反馈。 也就是说,反馈不仅表明目标情绪尚未达到,而且还进一步指出评论中应更改的短语和单词以达到期望的情绪水平。 我们尝试对我们的设置进行消融,其中反馈模块只是简单地说“出了点问题”。在这种情况下,对于情绪评估,73% 的时间首选输出(低于信息反馈的 85%)。 对于戏剧性反应评估,我们发现偏好率从 80.09% 急剧下降至 58.92%。 这些结果清楚地表明了精准反馈的重要性。
评估
我们使用GPT-4评估任务。 具体来说,我们使用以下提示:
当双方都获胜时,我们将获胜率添加到其中一方。
附录 Q首字母缩略词生成
好的首字母缩略词提供了一种简洁且令人难忘的方式来传达复杂的想法,使它们更容易理解和记住,最终导致更高效和有效的沟通。 与电子邮件写作一样,首字母缩略词生成也需要迭代细化过程,以实现复杂术语或短语的简洁且令人难忘的表示。 首字母缩略词通常涉及长度、发音的难易程度以及与原始术语或短语的相关性之间的权衡。 因此,首字母缩略词生成是我们方法的自然方法测试平台。
我们从 https://github.com/krishnakt031990/Crawl-Wiki-For-Acronyms/blob/master/AcronymsFile.csv 获取此任务的数据集,并手动修剪文件以删除潜在的攻击性内容或完全无信息的缩写词。 此练习生成了 250 个首字母缩略词的列表。 完整的列表在我们的代码存储库中给出。
反馈
对于反馈,我们设计了一个可以提供多方面反馈的反馈。 具体来说,每个缩写词都是从五个维度来判断的:
-
•
发音容易程度: 缩写词的发音有多容易或困难? 是否有任何困难或尴尬的声音或字母组合可能使大声说出来变得困难?
-
•
拼写的难易程度: 拼写缩写词有多容易或困难? 是否有任何不寻常或不常见的字母组合可能会导致书写或记忆变得困难?
-
•
与标题的关系: 首字母缩略词在多大程度上反映了相关标题、短语或概念的内容或主题? 首字母缩略词是否与原始术语明显相关,或者看起来无关或随机?
-
•
积极内涵: 该首字母缩略词是否有任何积极或消极的关联或含义? 它的语气或含义听起来是乐观的、中立的还是消极的?
-
•
众所周知:目标受众对该缩写词有多熟悉或可识别? 它是一个常见或广泛使用的术语,还是晦涩或陌生的术语?
其中一些标准很难量化,并且是人类偏好的问题。 与其他模块一样,我们利用现代大语言模型的卓越指令跟踪功能来提供每个任务的一些演示。 至关重要的是,反馈包括一系列思维风格推理——在为特定标准的首字母缩略词生成分数之前,我们生成一个推理链,明确说明分数的原因。 我们使用人工评估来判断首字母缩略词的最终质量。 Table 18 中给出了生成的首字母缩略词和相关反馈的示例。
Criteria output from GPT3: STSLWN output from : Seq2Seq Ease of pronunciation Pronounced as ess-tee-ess-ell-double-you-enn which is very difficult. Pronounced as seq-two-seq which is easy. Ease of spelling Very difficult to spell. Easy to spell. Relation to title No relation to the title. Mentions sequence which is somewhat related to the title. Positive connotation Meaningless acronym. Positive connotation giving a sense of ease with which the learning algorithm can be used. Well-known Not a well-known acronym. Close to the word sequence which is a well-known word. Total score 5/25 20/25
附录 R约束生成
在这项工作中,我们引入了 CommonGen 任务的更具挑战性的变体,称为“CommonGen-Hard”,旨在突破最先进语言模型的界限。 CommonGen-Hard 要求模型生成包含 20-30 个概念的连贯且语法正确的句子,而不是呈现一组 3-5 个相关概念的原始任务。 概念数量的显着增加测试了模型执行高级常识推理、上下文理解和创造性解决问题的能力,因为它必须生成包含更广泛想法的有意义的句子。 这个新数据集为大型语言模型及其在复杂的现实场景中的潜在应用的持续改进提供了宝贵的基准。
CommonGen-Hard 任务复杂性的增加使其成为评估我们提出的框架有效性的理想测试平台,该框架侧重于具有内省反馈的迭代创建。 鉴于语言模型的初始输出可能并不总是满足所需的质量、连贯性或敏感性水平,应用使模型能够对其自己生成的输出提供多维反馈,并随后根据提供的内省反馈对其进行改进。 通过迭代创建和自我反思,该框架使语言模型能够逐步提高其输出质量,紧密模仿人类的创作过程,并展示其在复杂且要求严格的自然语言生成任务(如 CommonGen-Hard)上改进生成文本的能力(Figure 18)。
附录S提示
- •
- •
- •
- •
- •
- •
- •
回想一下,Base 大语言模型需要一个带有输入输出对 的生成提示 ,反馈模块需要一个带有输入输出对的反馈提示 。反馈三元组 ,细化模块 (refine) 需要带有输入-输出-反馈细化四元组 的细化提示 >。
-
•
情绪反转训练 我们从集合中创建单个评论的正面和负面变体,并手动编写将负面变体转换为正面变体的描述,反之亦然。 对于每个变体,作者都会生成响应并根据转换描述创建反馈。
-
•
对话响应生成我们采样了六个示例作为基本大语言模型的少样本提示。 对于每个输出 ,作者创建一个响应,根据标题对其进行评估以生成 ,并生成改进版本 。
-
•
缩略词生成 我们为大语言模型基础提供了总共15个(标题、缩略词)示例。 然后,对于一个标题 (),我们使用 ChatGPT 生成首字母缩略词 ()。 然后,作者根据 5 分制对首字母缩写词进行评分,以创建相应的 ,并编写缩写词的改进版本以创建 。 3个这样的例子用于细化和反馈。
-
•
代码优化我们使用Madaan等人(2023)发布的程序的慢速()和快速()版本> 用于大语言模型基础。 我们使用他们提供的解释(Madaan 等人,2023)来进行反馈和细化。
-
•
数学推理 大语言基础模型的提示源自PaL (Gao 等人, 2022),如。 我们从训练集中选择两个在使用 PaL 风格的提示时 Codex 失败的示例,并手动编写正确的解决方案 () 和推理 ()用于细化和反馈。
-
•
约束生成我们为大语言基础模型提供了十个示例。 我们从约束生成的训练集中抽取了六个示例,并创建了缺少概念或不连贯输出的变体。 缺失的概念和不连贯的原因形成。
-
•
TODO: 添加剩余任务的相关信息。