我们在寻找体现智能的人工视觉皮层时处于什么阶段?
摘要
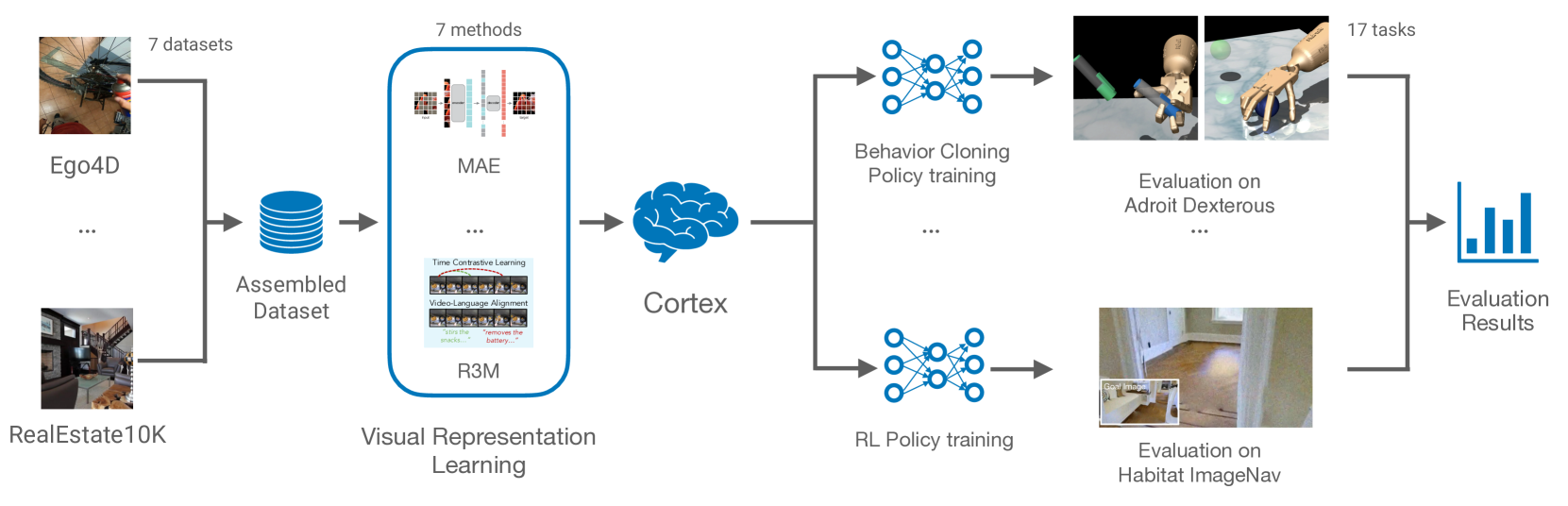
我们针对嵌入式人工智能的预训练视觉表示(PVR)或视觉“基础模型”提出了规模最大、最全面的实证研究。 首先,我们策划 CortexBench,包含 17 项不同的任务,涵盖运动、导航、灵巧和移动操作。 接下来,我们系统地评估现有的 PVR,发现没有一个是普遍占主导地位的。 为了研究预训练数据大小和多样性的影响,我们将来自 7 个不同来源的超过 小时的以自我为中心的视频(超过 M 张图像)和 ImageNet 结合起来,训练不同大小的数据视觉转换器在此数据切片上使用屏蔽自动编码 (MAE)。 与之前工作的推论相反,我们发现扩大数据集规模和多样性并不能普遍提高性能(但平均而言)。 我们最大的模型名为 VC-1,平均性能优于所有之前的 PVR,但也没有普遍占据主导地位。 接下来,我们表明 VC-1 的特定于任务或领域的适应会带来巨大的收益,其中 VC-1 (适应)实现了比最好的竞争或更好的性能CortexBench 中所有基准测试的已知结果。 最后,我们展示了真实世界的硬件实验,其中 VC-1 和 VC-1(改编版)的性能优于现有的最强 PVR。 总体而言,本文没有提出新技术,而是提出了严格的系统评估、有关 PVR 的广泛发现(在某些情况下,反驳了先前工作中在狭窄领域中得出的结论)以及开源代码和模型(需要 10,000 多个GPU 小时训练)为了研究社区的利益。
1简介
视觉皮层是生物体大脑的一个区域,它与运动皮层一起使视觉能够转化为运动。 在这项工作中,我们提出了福岛 Fukushima (1975, 1980) 近 50 年前提出的相同问题 – 我们如何设计一个人工视觉皮层,即计算系统(与策略一起)使代理能够将相机输入转换为动作? 在当代人工智能中,这个问题已被具体化为预训练视觉表示(PVR)或具体人工智能(EAI)视觉“基础模型”的设计。111我们使用嵌入式人工智能(EAI)作为所有研究视觉运动控制的社区的总称,例如机器人学习、基于视觉的强化学习、以自我为中心的计算机视觉等。 事实上,最近的研究表明,PVR 可以大幅提高导航性能和学习效率 Khandelwal 等人 (2022); Yadav 等人 (2022a, 2023) 和操作任务 Parisi 等人 (2022); Nair 等人 (2022); Radosavovic 等人 (2022);马等人(2022)。 不幸的是,之前的研究是不可通约的——在不同的预训练数据集上使用不同的自监督学习 (SSL) 算法,针对不同的下游 EAI 任务进行设计和评估。 人们自然会问:人工视觉皮层是否已经存在?222以我们衡量的能力程度。 此外,我们在这项工作中没有提出生物学合理性主张。 我们只是被生物视觉皮层广泛的泛化能力所激励。
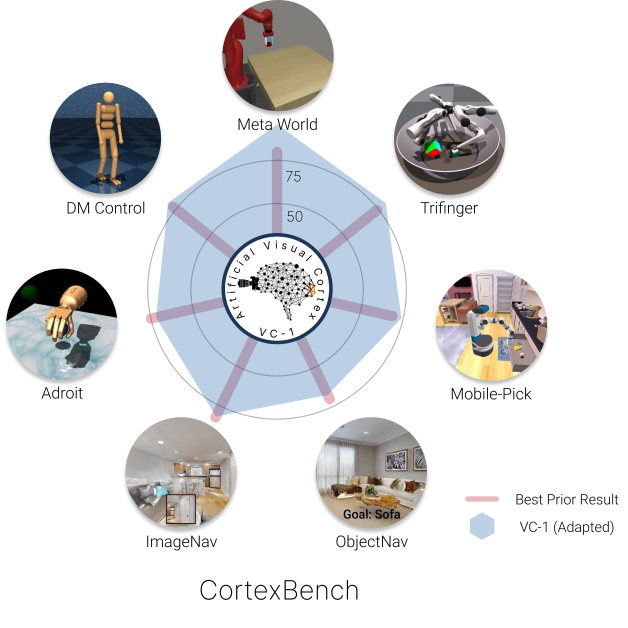
为了回答这个问题,我们对 EAI 的视觉基础模型进行了迄今为止最全面的实证研究。 我们策划了 CortexBench,这是一个评估 PVR 的基准,由 17 项任务组成,涵盖低级运动 Tassa 等人 (2018)、桌面操作 Yu 等人(2020)、灵巧操控Rajeswaran 等人 (2018)、多指协调操控Wüthrich 等人 (2020)、室内视觉导航Savva等人 (2019a),以及移动操控 Szot 等人 (2021)。 视觉环境涵盖从平坦的无限平面到桌面设置,再到真实世界室内空间的逼真 3D 扫描。 代理实施例从固定臂到灵巧手再到铰接式移动操纵器。 学习条件多种多样,从小样本模仿学习到大规模强化学习。 这项研究的详尽性使我们能够以前所未有的范围和信心得出结论。
我们的第一个发现是阴性结果。 我们发现,虽然现有的 PVR 通常优于从头开始学习的基线,但没有任何一个 PVR 能够普遍占据主导地位。 相反,我们发现 PVR 往往在其最初设计的领域(导航、操作等)中表现最佳。 我们注意到,之前的工作中没有提出普遍性的主张,因此这一发现是说明性的而不是反驳性的,但仍然是一个先验未知的重要发现。 总的来说,偶然性并没有实现--人造视觉皮层并不存在。22footnotemark: 2然而,奇怪的是,在 CortexBench 中局部占主导地位的 种 PVR 在预训练数据集的大小和类型上存在显著差异:CLIP Radford等人(2021年)使用了M个来自网络的图像-文本对;MVP Radosavovic等人(2022年)使用了M个来自网络图像的帧和许多以自我为中心的视频数据集--然而,在CortexBench中,每种PVR都在某些任务子集中表现最佳。 这引出了一个自然的问题: 缩放模型大小、数据集大小或多样性如何影响 CortexBench 上的性能? 我们能否使用缩放作为学习适用于 CortexBench 中所有不同任务的单个 PVR 的方法?
为了研究这些问题,我们将来自 7 个来源的超过 小时的以自我为中心的视频与 ImageNet 结合起来,其中包含人类操纵物体和导航室内空间的视频。 通过这个联合,我们创建了 4 个不同大小和多样性的预训练数据集,其中最大的数据集包含超过 M 幅图像。 我们使用 Masked Auto-Encoding (MAE) He 等人 (2021) 在这 4 个数据集上训练视觉转换器(ViT-B 和 ViT-L)Dosovitskiy 等人 (2020) >,并系统地分析它们在 CortexBench 上的性能。 为了使 EAI 社区受益,我们将开源这些模型,这些模型需要超过 10,000 个 GPU 小时来训练。
我们确实找到了支持缩放假设的证据,但出现的情况比肤浅的阅读所暗示的更加微妙。 我们最大的模型在所有数据上进行了训练,名为 VC-1,其性能比现有最好的 PVR 平均高出 1.2%。 然而,VC-1 并没有普遍占据主导地位——也就是说,在少量数据上训练的 PVR 在特定任务上的表现优于它。 数据多样性也出现了类似的趋势——平均而言越多越好,但并非普遍如此。 例如,Habitat 2.0 Szot 等人 (2021) 的 Mobile-Pick 任务的最佳性能是通过对专注于操作的视频数据子集进行预训练来实现的;大概是因为任务中涉及的机动性相当有限。 因此,我们的第二个关键发现是:单纯地扩展数据集大小和多样性并不能提高跨基准的性能统一。 我们注意到,这种广泛的评估驳斥了对机器人操作Radosavovic 等人 (2022) 先前工作中观察到的正缩放趋势的天真推断。
我们的研究结果揭示了社区面临的挑战和机遇——寻找 EAI 普遍主导(或“基础”)的 PVR 需要架构、学习范式、数据工程等方面的创新。 作为解决这个开放问题的第一步,我们研究适应 VC-1与特定任务的训练损失或数据集(来自 MAE He 等人 (2021) )来专门针对每个域的VC-1。 我们发现,采用 VC-1 会使其变得与 CortexBench 中的所有基准测试的最佳先前结果具有竞争力或优于它。 我们强调,这种比较是特别无情的,因为先前的最佳结果是高度特定于领域的,并且不限于共享其设计的任何方面。 据我们所知,VC-1(改编版)是第一个在如此多样化的 EAI 任务中与最先进的结果相媲美(或优于)的 PVR(图1)。
最后,我们使用 VC-1 在少样本模仿学习环境中使用两个平台进行概念验证硬件实验:TriFinger 机器人和 Franka Emika Panda 手臂。 在这个现实环境中,我们发现 VC-1 和 VC-1(改编版)大大优于现有的 PVR,例如 MVP Radosavovic 等人 (2022 )。 我们将发布 CortexBench 代码,使 EAI、机器人和 CV 社区能够对自己的模型进行基准测试,并分享我们的预训练模型(包括 VC-1)我们相信可以作为当今所有感兴趣的视觉运动任务的起点。
2相关工作
预先训练的视觉表示(PVR)。 过去几年,人们对视觉表征的自我监督学习(SSL)越来越感兴趣 He 等人 (2021); Caron 等人 (2020); Baevski 等人 (2022a);陈等人 (2020, 2021)。 这些算法使用对比Chen 等人(2020, 2021),基于蒸馏的Caron 等人(2020); Baevski 等人 (2022a),或重构 Bao 等人 (2021);他等人 (2021) 训练目标。 最近,一系列工作提出使用视觉变换器(ViTs)Dosovitskiy 等人(2021) 和掩模图像建模He 等人(2021); Baevski 等人 (2022b); Yao 等人 (2022),其好处之一是减少了预训练所需的计算时间。 在这项工作中,我们使用一种这样的预训练算法(MAE He 等人(2021))来探索缩放和适应预训练的视觉表示。
用于具体化 AI 的 PVR。 受自我监督学习进步的启发,最近的工作已将视觉表示学习纳入 EAI 代理 Parisi 等人的训练流程中 (2022); Nair 等人 (2022); Radosavovic 等人 (2022);马等人 (2022); Khandelwal 等人 (2022); Yadav 等人 (2022a, 2023)。 具体来说,Parisi 等人 (2022) 评估了几个在一系列 EAI 任务上经过监督或自监督学习训练的 PVR,在少样本模仿学习评估协议下展示了有希望的结果。 Nair 等人 (2022); Radosavovic 等人 (2022); Ma 等人 (2022) 介绍了使用以自我为中心的视频数据预训练视觉表示的新方法,针对机器人操作任务。 同样,Khandelwal 等人 (2022); Yadav 等人 (2022a, 2023) 使用预先训练的视觉表示来提高多个视觉导航任务的性能。 密切相关的是,Radosavovic 等人 (2022) 证明,对互联网规模视频和图像数据进行 MAE 预训练可以为机器人操作任务生成有效的视觉表示。 相比之下,我们的工作研究了更广泛的具体人工智能任务(在 CortexBench 中收集),以了解 PVR 如何为具体代理提供通用基础,并探索针对各种任务的域内模型适应。
EAI 中语言引导的基础模型。 最近在语言引导的控制表示学习领域也出现了一些工作。 Karamcheti 等人 (2023) 在图像帧和文本对上训练具有屏蔽编码目标的 ViT。 Ma 等人 (2023) 专注于使用语言对齐视频进行目标条件价值函数的自监督表示学习。 此外,Stone 等人 (2023); Yang 等人 (2023) 采用开放词汇检测器和视觉语言模型来检测桌面视图中的对象。 然后,将这些检测结果与图像和视觉语言模型训练指令一起用于制定策略。 在 Liu 等人 (2022) 中,多模态 Transformer 在网络规模的图像和文本数据上进行预训练,然后与基于 Transformer 的策略一起用于桌面操作任务。
缩放模型和数据集大小。 几项工作表明,缩放模型和数据集大小可以提高图像分类等视觉任务的性能 Zhai 等人 (2022);田等人 (2021);戈亚尔等人 (2021)。 在 EAI 中,Radosavovic 等人 (2022) 发现,缩放模型和数据大小持续提高机器人操作任务的下游策略性能。 我们的工作首次研究了广泛的 EAI 任务的扩展问题,并驳斥了对 Radosavovic 等人 (2022) 中观察到的积极扩展趋势的天真推断。
调整 PVR。 何时以及如何使 PVR 适应下游应用仍然是一个开放的研究问题 Kumar 等人 (2022); Wijmans 等人 (2022);基里琴科等人 (2022); Lee 等人 (2022);戈亚尔等人 (2022)。 在 EAI 的背景下,Parisi 等人 (2022) 和 Hansen 等人 (2022a) 表明,通过行为克隆简单地微调 PVR 会降低模拟性能,并且Radosavovic 等人 (2022) 观察到现实世界操作任务中的收益最小。 在大规模 RL 设置中,Yadav 等人 (2022a, 2023) 表明,端到端微调可显着提高室内视觉导航的性能。 相比之下,Pari 等人 (2021) 发现简单的-最近邻适应非常适合现实世界的视觉模仿任务。 我们的工作既不旨在也不期望成为这个丰富话题的最终定论。
3人工视觉皮层的基准进展
我们策划CortexBench(如图图1所示)来评估预训练视觉表示(PVR)的能力)以支持各种 EAI 应用。 具体来说,我们从 EAI 社区认为重要的 7 个现有 EAI 基准中选择了 17 个不同的任务。 对于每项任务,我们描绘了一个下游政策学习范式(例如,少样本模仿学习)和遵循每个领域社区标准的评估协议(部分 A.2)。 通过固定任务和下游学习方法(图 2),我们能够将评估重点放在 PVR 的贡献上,从而允许衡量用于体现智能的人工视觉皮层的开发进展。 我们使用 CortexBench 进行迄今为止规模最大、最全面的实证研究。
我们推荐两个评估指标:平均成功和平均排名。 平均成功率:所有基准的平均成功率。 平均排名:对于每个基准,我们根据 PVR 的成功率对其进行排名;然后我们对所有基准的这些排名进行平均。
3.1 在CortexBench中体现AI任务
|
|
|
|
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Adroit (AD) | RGB + proprio. | Continuous | - | IL | ||||||||||
| Metaworld (MW) | RGB + proprio. | Continuous | - | IL | ||||||||||
| DMControl (DMC) | RGB | Continuous | - | IL | ||||||||||
| TriFinger (TF) | RGB + proprio. | Continuous | Goal Image/Position | IL | ||||||||||
| ObjectNav (ON) | RGB + proprio. | Discrete | Object Category | IL | ||||||||||
| ImageNav (IN) | RGB | Discrete | Goal Image | RL | ||||||||||
| MobilePick (MP) | RGB + proprio. | Continuous | Goal Position | RL |
Adroit (AD) Rajeswaran 等人 (2018) 是一套灵巧的操作任务,其中代理必须控制 28 自由度的拟人手来执行各种任务。 我们研究了 Adroit 中两个最难的任务:Relocate 和 Reorient-Pen。 在这些任务中,代理必须将对象操纵到目标位置和方向,其中目标必须从场景中推断出来。
MetaWorld (MW) Yu 等人 (2020) 是一组任务的集合,其中代理命令 Sawyer 机器人手臂在桌面环境中操纵对象。 我们考虑 MetaWorld 中的五个任务:组装、Bin-Picking、Button-Press、Drawer-Open 和Hammer,遵循Nair 等人 (2022) 中的评估。
DeepMind Control (DMC) Tassa 等人 (2018) 是一种广泛研究的基于图像的连续控制基准,其中代理执行运动和对象操纵任务。 我们考虑五个 DMC 任务:Finger-Spin、Reacher-Hard、Cheetah-Run、Walker-Stand、和 Walker-Walk,继 Parisi 等人 (2022)。
TriFinger (TF) 是一个机器人,在 Wüthrich 等人 (2020) 中介绍,由三指手组成,每个手指有 3 个自由度。 我们重点关注 Push-Cube 任务,该任务是 Real Robot Challenge 2020 Real Robot Challenge (2020) 的一部分。 在此任务中,代理可以使用所有三个手指来推动立方体并将其移动到目标位置(Push-Cube)。 此外,我们考虑了更简单的 Reach-Cube 任务,Dittadi 等人 (2021) 也对此进行了研究。
Habitat Savva 等人 (2019a) 是一个模拟平台,其中包括多个视觉导航任务,在这些任务中,代理探索高度逼真的看不见的 3D 环境。 我们考虑 Habitat 中的两个任务:图像目标导航 (ImageNav) Zhu 等人 (2017) 和对象目标导航 (ObjectNav) Batra 等人 (2020). 在这两种情况下,代理都从未知 3D 环境中的随机位置开始,并且必须找到目标位置 - 使用 ImageNav 中目标位置的图像或对象名称(例如“椅子”)指定') 在 ObjectNav 中。
Habitat 2.0 Szot 等人 (2021) 包括移动操纵任务,其中代理控制带有 7-DoF 手臂的 Fetch 机器人、移动底座 Gu 等人 (2022 ),以及吸力夹具来重新排列公寓场景中的对象。 我们考虑 Habitat 2.0 中的 Mobile-Pick (MP) 任务的一个具有挑战性的版本,其中代理必须从杂乱的容器(例如柜台)中拾取目标对象,同时从一个位置开始其中物体位于机器人的范围之外(因此需要导航),使用宽松的密集目标规范(在部分A.3中描述) >)。
讨论 CortexBench 涵盖了广泛的任务,从导航到操纵和运动。 这些任务采用不同的策略学习方法,包括低级模仿学习(MW、DMC 和 TF)和大规模强化学习(ImageNav、ObjectNav 和 Habitat 2.0 )。 某些任务需要对语义场景信息(ImageNav 和 ObjectNav)有高级别的理解,而其他任务则侧重于代理姿势的微小变化以实现低级控制 (DMC) 。 CortexBench 中的这种多样性使我们能够得出有关现有和新 PVR 的通用新结论。
4我们是否已经有了 EAI 的视觉基础模型?
首先,我们在 CortexBench 上评估了几个现有的 PVR,以研究现有的开源视觉主干是否能够在所有任务中始终表现良好。 对于 Section 6 之前的所有评估,我们考虑冻结视觉表示,以将学习表示与下游任务学习的效果分开。 具体来说,我们包括以下型号:
-
–
CLIP Radford 等人 (2021) 对比图像语言预训练目标;使用来自互联网 (WIT) 的 4 亿个图像-文本对进行训练; ViT-B骨干。
-
–
R3M Nair 等人 (2022) 时间对比视频语言对齐预训练目标;使用 Ego4D 子集的 500 万张图像进行训练; ResNet-50 主干网。
-
–
MVP Radosavovic 等人 (2022)。 掩码自动编码(MAE)预训练目标;使用来自自我中心视频和 ImageNet 的 450 万张图像进行训练; ViT-B 和 ViT-L 骨干网。
-
–
VIP 马等人 (2022)。 目标条件价值函数预训练目标;使用 Ego4D 子集的 500 万张图像进行训练; ResNet-50 主干网。
这些模型形成了用于比较的代表性集合,涵盖不同的架构、预训练目标和数据集。 此外,我们还包括随机初始化的 ViT 以及冻结和微调的权重,以评估预训练的必要性和纯域内学习的局限性。
| Imitation Learning | Reinforcement Learning | Mean | ||||||||
| # | Model | Adroit | MetaWorld | DMControl | TriFinger | ObjectNav | ImageNav | Mobile Pick | Rank | Success |
| 1 | Best prior result (any setting) | 75 | 80 | 77 | - | 70.4 | 82.0 | - | ||
| 2 | Best prior result (Frozen PVR) | 75 | 80 | 77 | - | 54.4 | 61.8 | - | ||
| 3 | Random (ViT-B) Frozen | 2.0 2.0 | 0.5 0.5 | 10.1 0.6 | 57.8 0.5 | 19.2 0.9 | 42.1 0.8 | 10.8 1.4 | 7.2 | 20.4 |
| 4 | Random (ViT-L) Frozen | 2.7 1.8 | 0.5 0.5 | 9.1 0.2 | 57.2 0.9 | 19.3 0.9 | 45.2 0.8 | 20.6 1.8 | 6.9 | 22.1 |
| 5 | Random (ViT-B) Fine-tuned | 44.0 2.0 | 49.9 7.3 | 43.5 2.4 | 56.1 1.3 | 28.5 1.0 | 62.5 0.7 | 47.6 2.2 | 5.3 | 47.4 |
| 6 | MVP (ViT-B) | 48.0 3.3 | 91.2 2.9 | 65.9 2.4 | 59.7 0.3 | 51.2 1.1 | 64.7 0.7 | 56.0 2.2 | 3.1 | 62.4 |
| 7 | MVP (ViT-L) | 53.3 4.1 | 87.5 3.4 | 69.2 1.5 | 74.1 0.3 | 55.0 1.1 | 68.1 0.7 | 65.4 2.1 | 2.1 | 67.5 |
| 8 | CLIP (ViT-B) | 47.3 3.0 | 75.5 3.4 | 55.5 1.4 | 62.0 0.5 | 56.6 1.1 | 52.2 0.8 | 49.8 2.2 | 3.9 | 57.0 |
| 9 | VIP (RN-50) | 54.0 4.8 | 90.1 2.2 | 72.5 2.7 | 66.7 0.2 | 26.4 1.0 | 48.8 0.8 | 7.2 1.2 | 4.0 | 52.3 |
| 10 | R3M (RN-50) | 73.3 2.0 | 96.0 1.1 | 81.1 0.7 | 69.2 0.8 | 22.7 0.9 | 30.6 0.7 | 33.2 2.1 | 3.4 | 58.0 |
表2显示按基准汇总的评估结果;没有一个模型能够在所有情况下都表现出色。 在所有评估的模型中,R3M 在 Adroit、MetaWorld 和 DMControl 上表现最好。 而 MVP (ViT-L) 在 TriFinger、ImageNav 和 Mobile Pick 上表现最佳。 另一方面,CLIP 在 ObjectNav 上取得了最佳结果。 CortexBench 上现有 PVR 的性能差异在 中的图 5 中进一步说明 A.4 节强调我们还没有一个用于 EAI 的单一、性能强大的人工视觉皮层。
5 分析 EAI 的扩展假设
上一节研究了在不同大小和多样性的数据集上预训练的模型。 有趣的是,虽然在最大数据集 (CLIP) 上预训练的模型在一个基准 (ObjectNav) 上表现良好,但它在所有任务中都表现不佳。 我们现在问: 预训练数据集的相关性和多样性以及模型大小有多重要? 为了研究这个问题,我们固定了预训练目标 (MAE He 等人 (2021)) 并改变预训练数据集的组成和视觉主干的大小 (ViT-B with 86M和具有 307M 参数的 ViT-L)。 我们在 CortexBench 上测量了相应的性能变化。 由于 MVP Radosavovic 等人 (2022) 在 CortexBench 上表现出色(表 ,因此选择 MAE 进行这些实验2),它使用 MAE 预训练目标。
5.1 构建EAI预训练数据集
| Name | Frames Used |
|---|---|
| Ego4D | 2,790,520 |
| Ego4D+M (Manip) | 3,538,291 |
| Ego4D+N (Nav) | 3,593,049 |
| Ego4D+MN (Manip, Nav) | 4,340,820 |
| Ego4D+MNI (Manip, Nav, ImageNet) | 5,621,987 |
为了评估数据集大小和多样性对 CortexBench(涉及导航和操作任务)的影响,我们采用了 7 个数据集的组合。 一组数据集 – Ego4D Grauman 等人 (2022)、100 Days of Hands (100DOH) Shan 等人 (2020)、Something-Something v2 (SS-V2) Goyal 等人 (2017) 和 Epic Kitchens Damen 等人 (2018) – 包含人们操作物体的视频,与 MVP Radosavovic 中使用的数据集相当等人(2022)。 第二个集群由以自我为中心的室内导航数据集组成:房地产 10K 数据集 Zhou 等人 (2018) 和 OpenHouse24 数据集(在部分 A 中描述) .5.1)。 最后,我们包括 ImageNet Deng 等人 (2009)。 我们策略性地选择数据集组合(如表3所示)来回答以下问题:
-
–
扩展数据集大小和多样性会产生什么影响?
-
–
不太相关数据集如何影响 PVR 在 EAI 任务上的性能?
Ego4D Grauman 等人 (2022)(我们的基础数据集)包含各种以自我为中心的视频,其中包括日常生活活动,例如家庭、休闲、交通和工作场所活动。
Ego4D+M 使用来自 100DOH、SS-v2 和 Epic Kitchens 的视频扩展了 Ego4D,从而产生了 350 万帧,并使该数据集主要专注于对象操作场景。333虽然Ego4D确实包含导航数据,但它严重偏向于对象操作。
Ego4D+N 使用两个室内导航数据集扩展了 Ego4D:OpenHouse24 和 RealEstate10K。 该数据集的大小与 Ego4D+M(350 万帧)相似,但更加多样化,因为它比以操作为中心的数据集 Ego4D 包含更大比例的导航数据,并且Ego4D+M。
Ego4D+MN 将 Ego4D 与三个以对象操作为中心的数据集和两个室内导航数据集相结合,得到一个具有 430 万帧的数据集。 虽然大于 Ego4D+M 和 Ego4D+N,但它不包含除先前子集中的操作和导航视频之外的任何新类型的数据。 因此,它并不比 Ego4D+N (包括两种类型的数据)更加多样化。
Ego4D+MNI 包括 Ego4D、所有操作和导航数据集以及总共 560 万帧的 ImageNet。 该数据集用于研究互联网图像在我们的基准任务中的作用。
5.2 缩放假设结果
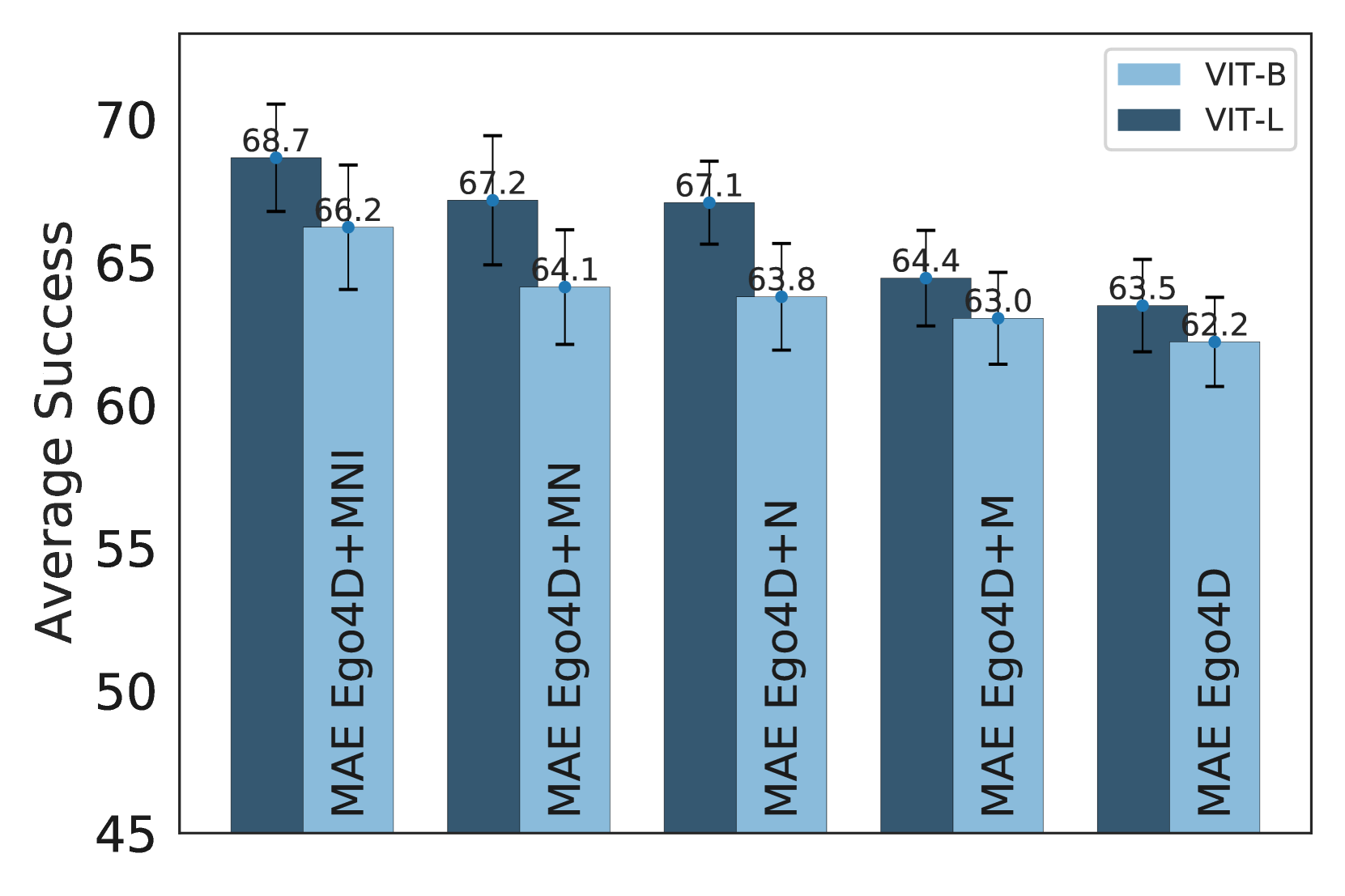
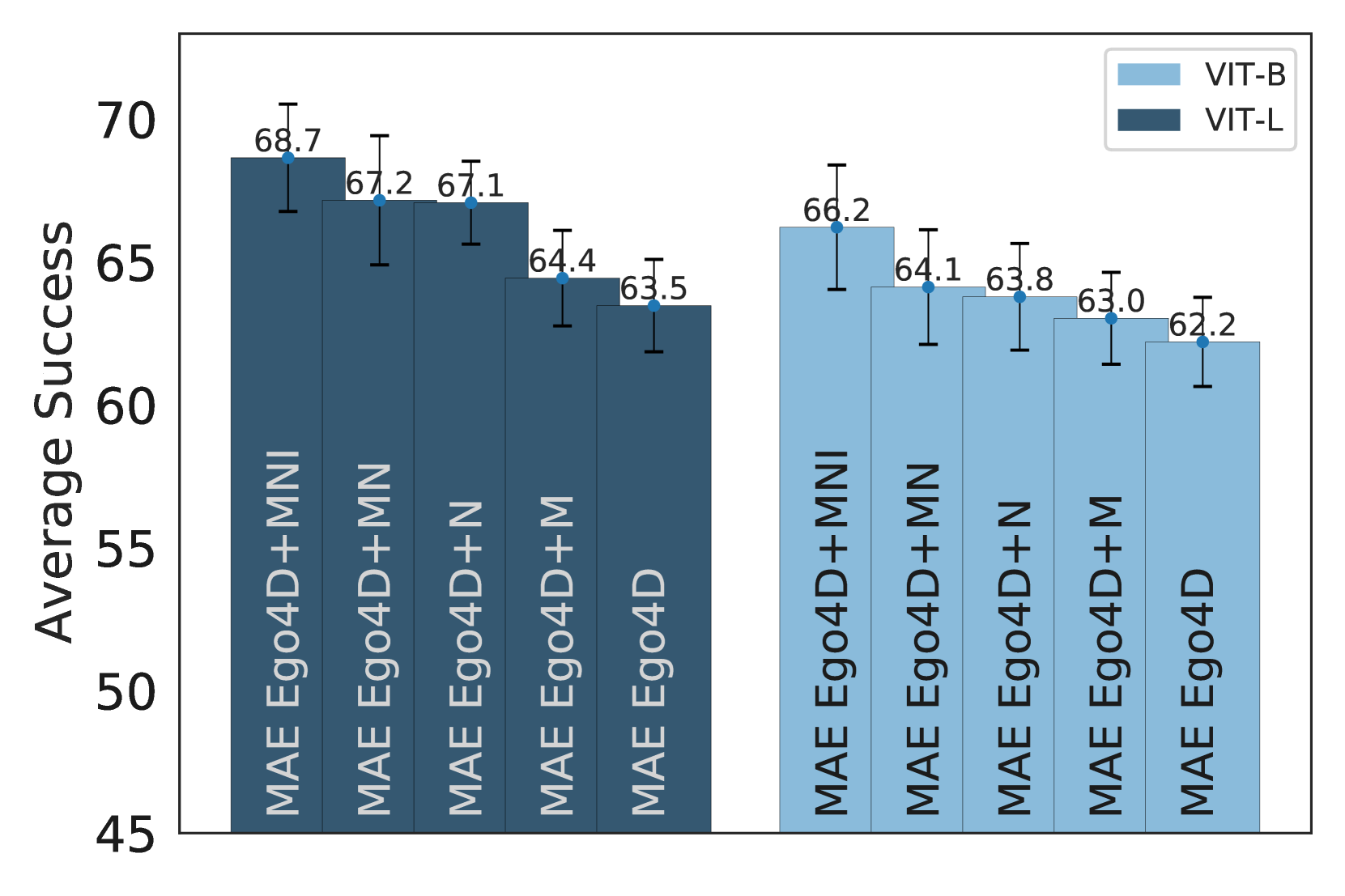
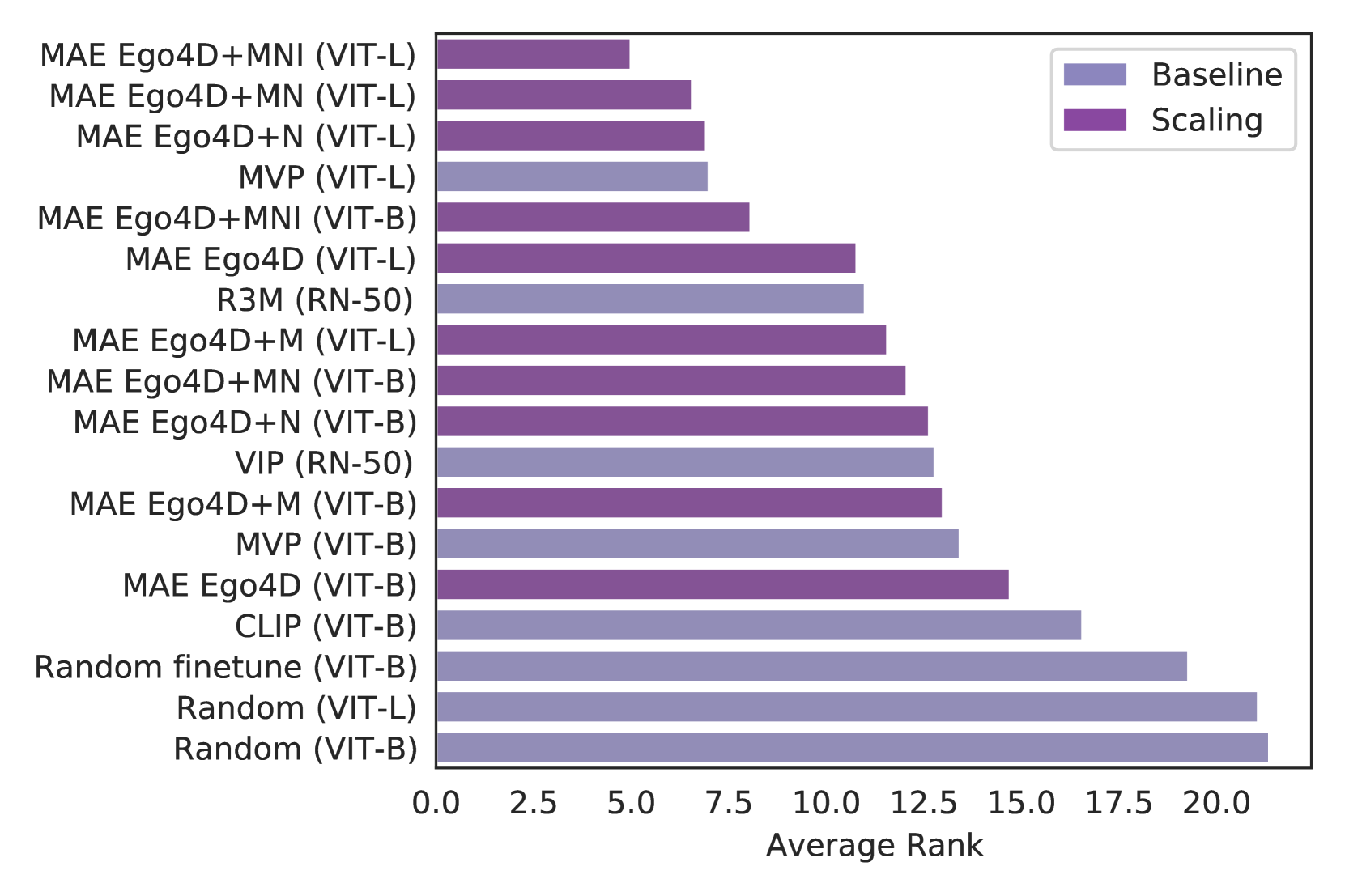
型号尺寸。 我们发现增加模型大小会对 CortexBench 上的性能产生积极影响。 具体来说,在图 2(a)中,我们发现在所有预训练数据集上,从 ViT-B 切换到 ViT-L 的效果有所改善CortexBench 上的平均性能。 然而,在Table4中,我们发现了这种总体趋势不成立的例外情况。 例如,在 Ego4D+MNI 上进行预训练时,ViT-B 模型在 MetaWorld 和 TriFinger 上的表现优于 ViT-L 模型。
| # | Model | Adroit | Meta-World | DMControl | TriFinger | ObjectNav | ImageNav | Mobile Pick | Mean Rank | Mean Success |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Best prior result (any setting) | 75 | 80 | 77 | - | 70.4 | 82.0 | - | ||
| 2 | Rand (ViT-B) fine-tuned | 44.0 | 49.9 | 34.2 | 55.0 | 28.5 | 65.0 | 47.6 | ||
| 3 | Best result Table 2 (Frozen PVR) | 73.3 | 96.0 | 81.1 | 74.1 | 56.6 | 68.1 | 65.4 | ||
| 4 | Ego4D (VIT-B) | 48.7 1.3 | 86.1 2.1 | 64.1 2.3 | 68.3 1.1 | 46.8 1.1 | 64.0 0.7 | 57.4 2.2 | 8.6 | 62.2 |
| 5 | Ego4D (VIT-L) | 50.0 1.2 | 92.9 2.4 | 60.8 3.3 | 69.7 0.5 | 47.6 1.1 | 55.8 0.8 | 67.6 2.1 | 5.9 | 63.5 |
| 6 | Ego4D+N (VIT-B) | 50.0 2.4 | 86.4 2.9 | 59.5 2.4 | 67.8 1.3 | 54.7 1.1 | 68.7 0.7 | 59.4 2.2 | 7.2 | 63.8 |
| 7 | Ego4D+N (VIT-L) | 54.0 1.2 | 89.1 2.9 | 66.4 1.7 | 66.9 0.4 | 57.4 1.1 | 70.5 0.7 | 65.2 2.1 | 3.5 | 67.1 |
| 8 | Ego4D+M (VIT-B) | 51.3 2.4 | 83.5 2.6 | 64.3 1.8 | 69.1 0.4 | 47.3 1.1 | 65.8 0.7 | 59.8 2.2 | 7.0 | 63.0 |
| 9 | Ego4D+M (VIT-L) | 52.0 1.3 | 88.3 3.2 | 64.7 2.4 | 64.7 0.9 | 47.3 1.1 | 65.5 0.7 | 68.6 2.1 | 6.0 | 64.4 |
| 10 | Ego4D+MN (VIT-B) | 48.7 2.4 | 85.3 5.2 | 64.2 1.9 | 70.3 0.5 | 52.8 1.1 | 68.9 0.7 | 58.6 2.2 | 6.9 | 64.1 |
| 11 | Ego4D+MN (VIT-L) | 52.7 4.2 | 86.7 3.9 | 69.7 3.3 | 72.4 0.5 | 58.4 1.1 | 69.1 0.7 | 61.2 2.2 | 3.1 | 67.2 |
| 12 | Ego4D+MNI (VIT-B) | 54.0 4.0 | 89.6 3.9 | 63.8 2.7 | 72.2 0.6 | 55.4 1.1 | 67.9 0.7 | 60.6 2.2 | 4.4 | 66.2 |
| 11 | VC-1: Ego4D + MNI (VIT-L) | 59.3 5.2 | 88.8 2.2 | 66.9 1.4 | 71.7 0.4 | 60.3 1.1 | 70.3 0.7 | 63.2 2.2 | 2.4 | 68.7 |
数据集大小和多样性。 图 2(b)显示,一般来说,增加数据集大小和多样性可以提高性能。 模型按照预训练数据集的大小和多样性从右到左排序,我们主要看到 ViT-B 和 ViT-L 的改进。例如,Ego4D+M 比 Ego4D 略微提高了 0.6 和 0.9 点(62.2 62.8 和 63.5 64.4)分别为 ViT-B 和 ViT-L 的情况。 Ego4D+N 的增益更大,使用 ViT-B 的效果比 Ego4D 好 1.6 个点(62.2 63.8),比使用 ViT 的效果好 3.6 个点-L(63.5 67.1)。 有趣的是,Ego4D+N 相对于基础 Ego4D 数据集比 Ego4D+M 有更大的改进,尽管 Ego4D +N 和 Ego4D+M 数据集大小相似。 在这些结果中,我们发现通过添加室内导航数据来增加多样性比向 Ego4D 添加额外的操作数据更能提高性能。
此外,我们发现 Ego4D+MN 上的预训练与 Ego4D+N 上的预训练大致相当。 尽管 Ego4D+MN 多了约 800K 训练帧,但我们看到 ViT-B 和 ViT-L 分别相差 0.3 和 0.1 个点(63.8 64.1 和 67.1 67.2)。 与上面的结果一起表明,增加数据多样性似乎比简单地增加数据集大小更重要。
接下来,我们发现添加 ImageNet 对 CortexBench 上的平均性能产生积极影响。 例如,对于 ViT,在 Ego4D+MNI 上预训练的模型比在 Ego4D+MN 上预训练的模型高出 1.9 点 (64.1 66.2) -B 和 ViT-L 1.5 分 (67.2 68.7)。有趣的是,这些结果表明,包含静态互联网图像可以显着提高 EAI 任务的性能。 这一发现进一步强调了寻求数据多样性以建立更好的表示的重要性。
最后,我们最大的模型 (ViT-L) 在所有数据集 (Ego4D+MNI) 上进行了预训练,在所有基准任务上进行平均时获得了最佳排名(表) > 4 第 11 行),平均排名为 2.4。 我们将此模型称为VC-1,并将开源它。 VC-1优于第二好的模型(Ego4D+MN ViT-L,Table 4 第 9 行),平均排名为 3.1。
然而,在进一步分解后,我们发现虽然 VC-1 平均表现最好,但对于每个基准测试来说,它并不是最好的。 例如,移动操作任务 Mobile Pick 的最佳模型是在 Ego4D+M 上训练的 ViT-L,室内导航任务 ImageNav 的最佳模型是训练有素的 ViT-L关于Ego4D+N。 这些发现表明,特定于任务的预训练数据集可以提高模型在单个任务上的性能。 然而,值得注意的是,这种方法将导致多个预训练模型,每个模型都针对特定任务进行定制,而不是统一的视觉基础模型。
5.3 VC-1 与现有 PVR 相比如何?
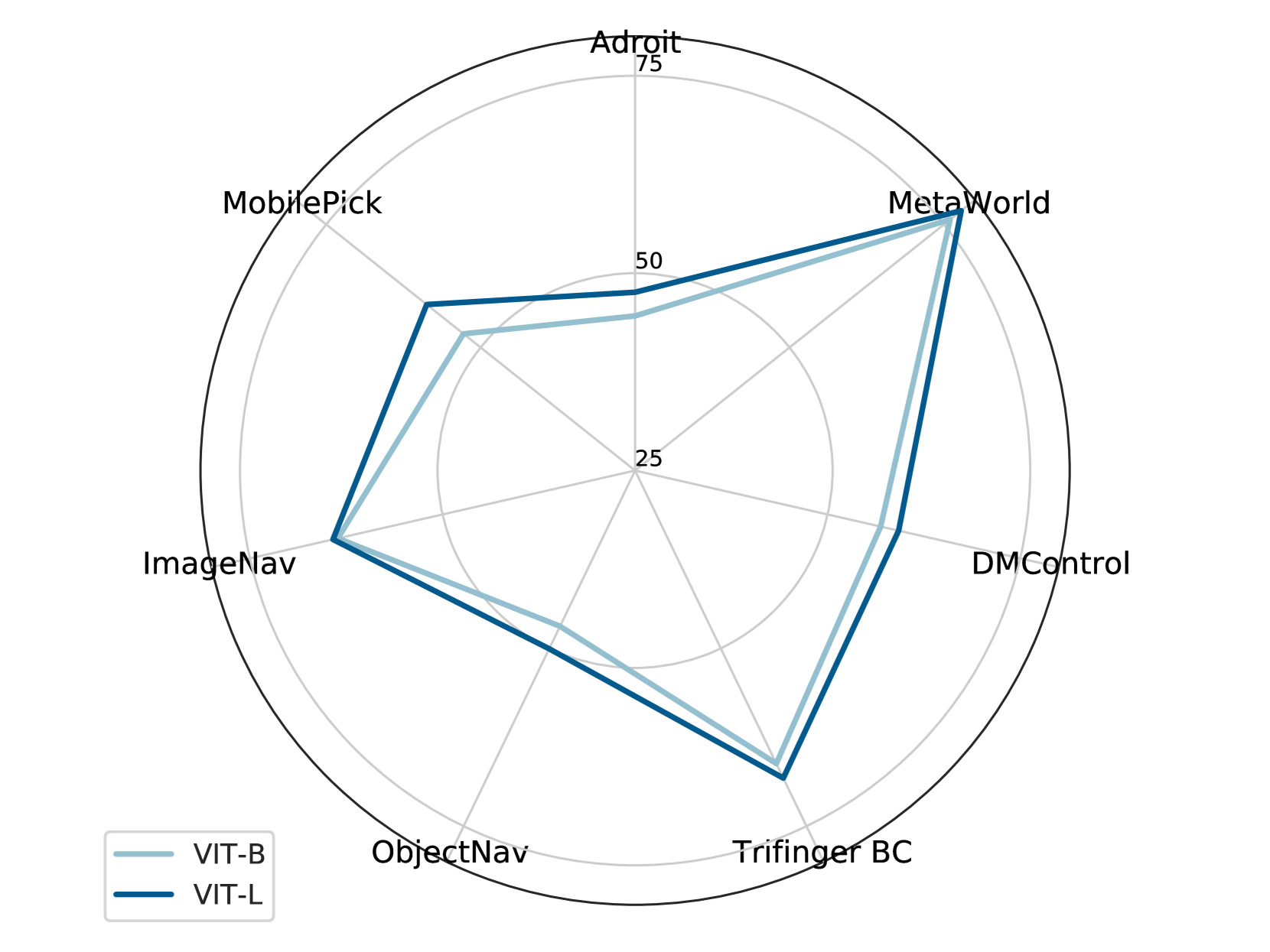
我们现在将 VC-1 与第 4 节中的 PVR 进行比较。 平均而言,VC-1 在所有基准测试中排名最高(图 2(c))。 就平均成功率而言,VC-1(表4第 11 行)优于 MVP (ViT-L) +1.2 点 (67.5 68.7),R3M +10.7 (58.0 68.7),CLIP +11.7 (57.0 68.7),然后结束-从头到尾的微调+19.6 (49.1 68.7)。
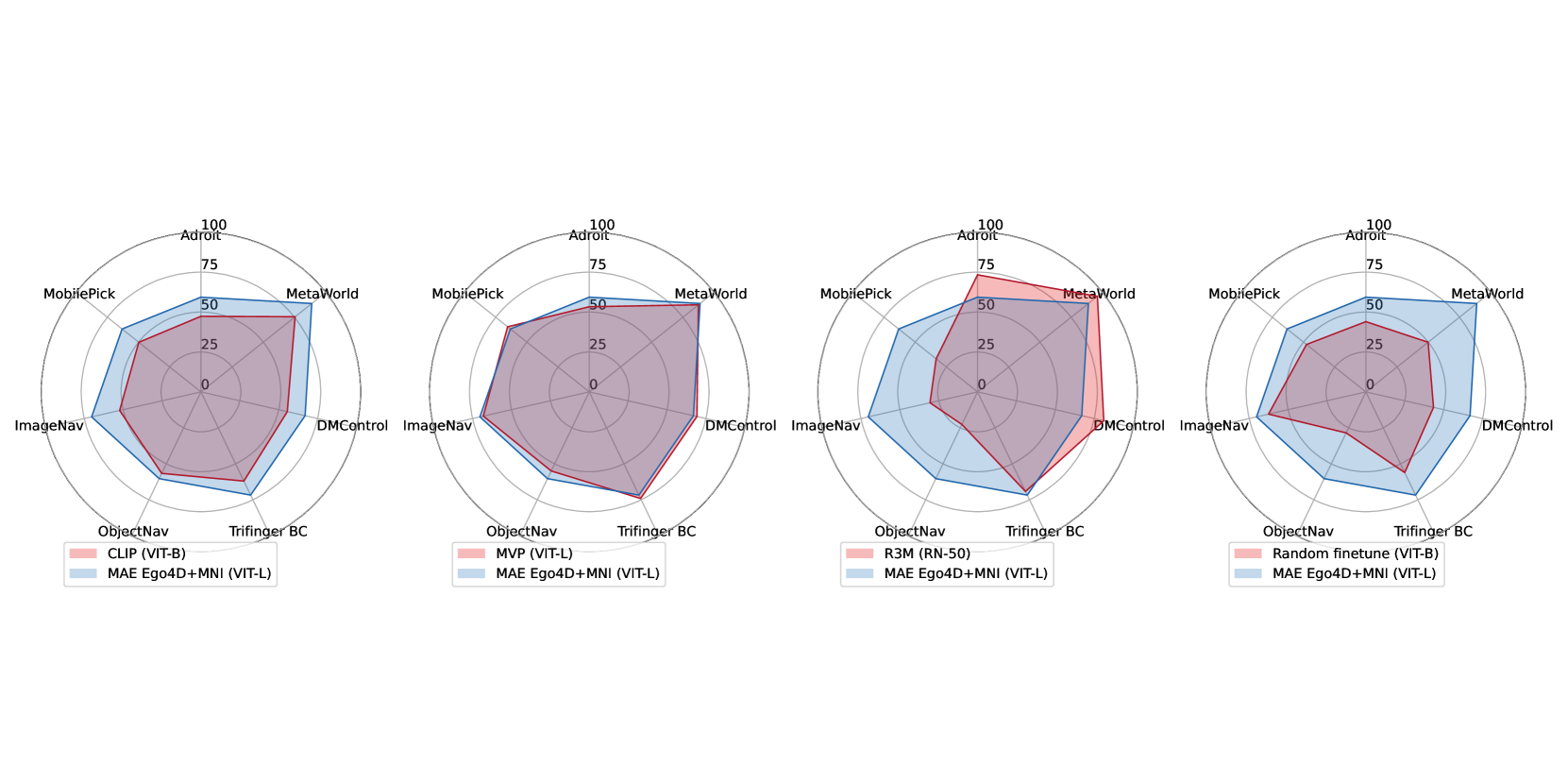
令人印象深刻的是,VC-1 在每个基准测试中都优于 CLIP (图 4),尽管在小 70 倍的数据集上进行训练,但强调了以自我为中心的交互数据集的重要性。 VC-1 在每个基准测试中也优于从头开始的微调,这表明使用域外数据训练的 PVR 可以优于域内的端到端学习。
MVP 模型在结果、架构和预训练目标方面与 VC-1 最为相似,主要区别在于 MVP 中增加了一个 卷积干。 VC-1 在平均成功率方面比 MVP VIT-L 高出 1.3 个百分点,并且在七个基准测试中的四个上表现更好(图 4 ),可能是由于使用了更多样化的数据集。
与 R3M 相比,VC-1 在平均水平和 7 个基准测试中的 4 个中表现出卓越的性能(图 4)。 然而,R3M 在 Adroit、MetaWorld 和 DMControl 基准测试中优于 VC-1。 这种差距的原因尚不清楚——可能是由于预训练目标、数据集或主干架构的差异造成的。 也就是说,使用基于 ResNet 的架构的 R3M 在某些任务上的表现比使用基于 Transformer 的主干的 VC-1 更好,这一事实表明探索集成的新架构的潜在价值两种方法的优点——归纳偏差和可扩展性。 总而言之,这些观察结果凸显了对 CortexBench 等基准进行更稳健和标准化评估的必要性。
总体而言,VC-1 在广泛的任务中都是有效的,因此是新的 EAI 问题的合理起点。 然而,它并不总是特定任务的最佳模型。 这使我们推测存在一个领域差距,可以通过数据集工程或 PVR 的适应来弥补。
6 调整VC-1
在前面的部分中,我们重点将 VC-1 作为冻结 PVR 进行评估。 我们现在研究适应 VC-1是否可以改善下游任务的结果。 我们使用广义的适应定义 Bommasani 等人 (2021),在大型预训练基础模型的背景下,它可以从简单的提示 Wei 等人 (2022) 采取多种形式,有选择地更新骨干网络的部分或全部权重Kumar等人(2022); Hansen 等人 (2022b); Yadav 等人 (2023)。
在 EAI 的 PVR 背景下,适应至少可以达到两个目的。 第一个是特征提取阶段的任务专业化。 由于 VC-1 是用 MAE He 等人 (2021) 进行训练的,因此它捕获了通常对重建图像有用的特征(参见 VC-1 部分 A.10中的注意图)。 适应可以使视觉主干专门化,以提取执行特定 EAI 任务所需的特征。 其次,适应还可以帮助缩小预训练和评估设置之间可能存在的领域差距。 一般来说,域差距的产生可能有多种原因,例如预训练数据集中的覆盖范围较差或在预训练数据(例如,以人为中心的视频数据集中)中未见的新条件(例如,在机器人上)中的部署。 域间隙在我们的设置中自然地实例化,因为 VC-1 是在现实世界的人类视频数据上进行预训练的,而我们在 CortexBench 中的下游评估使用模拟的 EAI 域不同的视觉特征。
在这项工作中,我们探索了两种适应方法:端到端(E2E)微调和 MAE 适应。 虽然我们没有探索基于提示的适应,因为我们的视觉编码器最初并不是为利用提示而设计的,但这可能是未来工作的一个有趣的方向。
具有特定任务损失函数的端到端(E2E)微调原则上可以捕获上述适应的好处,并且广泛应用于计算机视觉文献He等人 (2020); Caron 等人 (2021);他等人 (2021); Baevski 等人 (2022a)。 为了研究VC-1的端到端微调,我们使用部分 A.2中描述的相同策略学习方法t1>,但我们允许更新 VC-1 权重。 在 Table 5 中的 CortexBench 结果中,我们发现了一个有趣的混合结果。 在涉及大规模IL或RL(ObjectNav、ImageNav和Mobile Pick)的领域中,Yadav等人(2023)中提出的策略是将VC-1与与使用冻结的 VC-1 主干相比,E2E 微调显着提高了性能。 具体来说,我们看到 ObjectNav 成功率 (SR) 提高了 +7.4 (60.3 67.7),ImageNav SR 提高了 +11.3 (70.3 81.6),Mobile Pick SR 提高了+10.8 (63.2 74.0)。 这些结果表明VC-1的E2E微调可以实现任务专业化和领域适应的好处。 部分A.10中提供了适应前后VC-1注意图的比较。
然而,在少样本 IL 域(Adroit、MetaWorld、DMC 和 TriFinger)中,E2E 微调不会带来改进。 事实上,在这些领域,它会导致性能下降,这一发现与之前的工作 Parisi 等人 (2022) 一致;汉森等人 (2022a)。 我们假设少样本 IL 域中的 E2E 微调性能较差是由于过度拟合造成的,这是由于在小数据集( 帧)上微调具有 307M 参数的大型模型而导致的。
| CortexBench | Hardware | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| # | Method | Adroit | MetaWorld | DMControl | TriFinger | ObjectNav | ImageNav | Mobile Pick | TF Push-Cube | Franka |
| 1 | Best prior result | 75 | 80 | 77 | - | 70.4 | 82.0 | - | - | - |
| 2 | Best result (our exp.) | 73.3 2.0 | 96.0 1.1 | 81.1 0.7 | 74.1 0.3 | 60.3 1.1 | 70.5 0.7 | 68.6 2.1 | 31.9 4.3 | 55.0 10.4 |
| 3 | In-domain MAE (baseline) | 47.3 | 83.4 | 77.6 | 80.4 0.32 | 39.9 1.09 | 47.6 0.77 | 51.6 2.23 | 22.9 5.4 | 35.0 13.9 |
| 4 | VC-1 | 59.3 5.2 | 88.8 2.2 | 66.9 1.4 | 71.7 0.4 | 60.3 1.1 | 70.3 0.7 | 63.2 2.2 | 45.8 6.5 | 70.0 10.9 |
| 5 | VC-1 E2E fine-tuning | 15.9 9.8 | 22.7 9.7 | 6.7 3.8 | 70.9 0.5 | 67.7 1.05 | 81.6 0.6 | 74.0 1.96 | 52.7 9.2 | 67.5 13.4 |
| 6 | VC-1 MAE adaptation | 72.0 3.3 | 96.0 1.8 | 80.9 1.8 | 80.6 0.25 | 57.4 1.11 | 67.0 0.73 | 62.4 2.16 | 43.5 6.7 | 85.0 9.1 |
MAE 适应以缩小领域差距。 作为 E2E 微调的替代方案,我们探索通过自我监督学习 (SSL) 来调整 VC-1。 具体来说,在 MAE 适应中,我们继续使用 MAE He 等人 (2021) 针对特定任务数据的预训练目标来训练骨干网络。 然后,我们冻结这些适应的表示并使用它们来学习特定于任务的策略。 我们注意到,在 MAE 适应中,使用用于训练策略的相同数据(例如,来自专家演示的帧)来适应主干网,并且不使用额外的域内数据集。 虽然这种适应策略无法解决任务专业化问题,但它可能有助于缩小领域差距。
对于 MAE 适应,我们使用 VC-1 权重进行初始化,然后使用 MAE 进行 100 轮训练。 在可以进行专家演示的领域(即 Adroit、MetaWorld、DMControl、TriFinger 和 ObjectNav)中,我们使用这些演示中的 RGB 帧进行调整。 在剩下的两个基准测试(ImageNav 和 Mobile Pick)中,我们从训练环境中采样帧以创建适应数据集。 最后,为了隔离使用 VC-1 权重进行初始化的重要性,我们通过从随机初始化开始,然后遵循用于 MAE 适应的相同方法来训练域内 MAE 基线。
在 Table 5 中的 CortexBench 结果中,我们观察到 MAE 适应显着提高了少样本学习领域的性能。 具体来说,Adroit 性能提高了 +12.7 (59.3 72.0),MetaWorld 提高了 +7.2 (88.8 96.0),DMC 提高了 +14.0 (66.9 ) 80.9),TriFinger 为 +8.9 (71.7 80.6)。 有趣的是,在 DMC 和 TriFinger 中,域内 MAE 基线(第 3 行)表现出奇的好,凸显了域内数据对于表示学习的重要性。 最后,在大规模 IL 或 RL 领域(ObjectNav、ImageNav 和 Mobile Pick)中,我们发现 MAE 适应会导致 VC-1 的性能略有下降(第 4 行与第 6 行)。 在这些领域中,大量数据可用于特定任务的训练(大规模 IL 或 RL),我们发现端到端微调是更好的适应方法。 总的来说,这些结果表明,MAE 适应可以作为少样本领域或 E2E 微调失败的强大替代方案进行探索。
总体而言,我们发现适应VC-1模型可以提高所有基准领域的性能。 此外,在 MetaWorld、DMControl 和 TriFinger 上,采用 MAE 适应的 VC-1(第 6 行)可与已知结果 (SoTA) 以及之前部分的最佳结果(第 1 行和第 2 行)相媲美。 同样,在 ImageNav 和 Mobile Pick 上,具有 E2E 微调(第 5 行)的 VC-1 匹配或超过了最佳结果。 总之,这些结果表明 PVR 的适应可以成为 EAI 的强大范例,特别是与从头开始的训练表示相比。
7 概念验证硬件实验
除了使用 CortexBench 进行模拟实验之外,我们还利用 VC-1 作为 IL 训练策略的骨干 PVR 来探索概念验证硬件实验。 我们的硬件评估涵盖两个平台:TriFinger(1 项任务)和 Franka-Emika Panda 手臂(4 项任务)。 部分A.11和A.12中提供了设置详细信息。 我们通过研究少样本模仿学习,遵循与模拟对应物类似的实验协议,其中演示是通过远程操作或手工设计的控制器直接在现实世界中收集的。
我们研究了使用 VC-1 作为冻结 PVR、使用 MAE 适应的 VC-1 和使用 E2E 适应的 VC-1 的情况(如在 Section 6 中指定),并以 MVP 模型作为基线(来自 Section 的最佳 PVR 4)。 结果总结在表5的硬件部分中。 总体而言,我们观察到与部分6中的发现类似的趋势。 我们观察到,在冻结模式(第 4 行)下,VC-1 在两种机器人设置中均明显优于 MVP(第 2 行)和域内 MAE(第 3 行)。 我们还发现,通过 E2E 微调进行的适应可以提高现实世界中 TriFinger 的性能,并且 MAE 适应可以大大改进 Franka 任务。 我们注意到,虽然 MAE 适应对 TriFinger 的性能没有帮助,但这可能是因为只有 300 个真实的机器人图像可用于适应。 总之,这些结果表明,对于 TriFinger 来说,学习特定于任务的功能(通过微调)比缩小任何领域差距(通过 MAE 适应)更重要。 总体而言,这些结果表明 VC-1 可以有效地充当多个硬件平台的 PVR,并且可以超越在硬件上取得成功的现有 PVR(例如 MVP)。 此外,它强化了 Section 6 的发现,即采用 SSL 目标 (MAE) 调整 VC-1 可以改善表现。
8讨论
这项工作引入了 CortexBench,它包含 17 种不同的 EAI 任务,涵盖运动、室内导航、灵巧和移动操作;并对 EAI 的 PVR(或视觉基础模型)进行了迄今为止最全面的研究。 我们发现 (1) 尽管在许多狭窄领域取得了重大进展,但我们还没有为所有感兴趣的 EAI 任务提供通用的视觉主干,(2) 简单地缩放模型大小和预训练数据多样性并不能普遍提高性能在所有任务中,但平均而言,(3) 采用我们最大的预训练模型 (VC-1) 会产生与所有任务中最知名的结果相竞争或优于的性能CortexBench 中的基准测试,以及 (4) VC-1 和改编显示了硬件的概念验证推广。 我们的研究试图以感知模块为基石来统一各个 EAI 领域。 如今,感觉运动控制视觉表征的研究和开发似乎分散在不同的子社区中,研究以自我为中心的计算机视觉、运动、导航、灵巧和移动操纵。 然而,我们认为这并不是最终的解决方案。 生物有机体只有一个视觉皮层,而不是每个“任务”都有一个视觉皮层。 类似地,一个具体的人工智能代理必须有可能拥有一个通用的人工视觉皮层,支持各种感觉运动技能、环境和实施例。 我们推测,使用时间信号、3D 空间先验或客观性来学习视觉表示将有助于实现这一目标。 我们最后的论点是,为了让研究界开发这样的模型,我们需要创建测试广泛泛化能力的基准;我们希望 CortexBench 能够帮助社区在这方面取得进展。
致谢
佐治亚理工学院的努力得到了 ONR YIP 和 ARO PECASE 的部分支持。 本文包含的观点和结论是作者的观点和结论,不应被解释为必然代表美国政府或任何赞助商的官方政策或认可(无论明示或暗示)。
参考
- Fukushima [1975] Kunihiko Fukushima. Cognitron: A self-organizing multilayered neural network. Biological Cybernetics, 20(3):121–136, Sep 1975. ISSN 1432-0770. doi: 10.1007/BF00342633. URL https://doi.org/10.1007/BF00342633.
- Fukushima [1980] Kunihiko Fukushima. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 36(4):193–202, Apr 1980. ISSN 1432-0770. doi: 10.1007/BF00344251. URL https://doi.org/10.1007/BF00344251.
- Khandelwal et al. [2022] Apoorv Khandelwal, Luca Weihs, Roozbeh Mottaghi, and Aniruddha Kembhavi. Simple but effective: Clip embeddings for embodied ai. In CVPR, 2022.
- Yadav et al. [2022a] Karmesh Yadav, Ram Ramrakhya, Arjun Majumdar, Vincent-Pierre Berges, Sachit Kuhar, Dhruv Batra, Alexei Baevski, and Oleksandr Maksymets. Offline visual representation learning for embodied navigation. In arXiv preprint arXiv:2204.13226, 2022a.
- Yadav et al. [2023] Karmesh Yadav, Arjun Majumdar, Ram Ramrakhya, Naoki Yokoyama, Alexei Baevski, Zsolt Kira, Oleksandr Maksymets, and Dhruv Batra. Ovrl-v2: A simple state-of-art baseline for imagenav and objectnav. arXiv preprint arXiv:2303.07798, 2023.
- Parisi et al. [2022] Simone Parisi, Aravind Rajeswaran, Senthil Purushwalkam, and Abhinav Kumar Gupta. The Unsurprising Effectiveness of Pre-Trained Vision Models for Control. ICML, 2022.
- Nair et al. [2022] Suraj Nair, Aravind Rajeswaran, Vikash Kumar, Chelsea Finn, and Abhinav Gupta. R3M: A Universal Visual Representation for Robot Manipulation. CoRL, 2022.
- Radosavovic et al. [2022] Ilija Radosavovic, Tete Xiao, Stephen James, Pieter Abbeel, Jitendra Malik, and Trevor Darrell. Real world robot learning with masked visual pre-training. In 6th Annual Conference on Robot Learning, 2022.
- Ma et al. [2022] Yecheng Jason Ma, Shagun Sodhani, Dinesh Jayaraman, Osbert Bastani, Vikash Kumar, and Amy Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training. arXiv preprint arXiv:2210.00030, 2022.
- Tassa et al. [2018] Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, Timothy P. Lillicrap, and Martin A. Riedmiller. DeepMind Control Suite. arXiv:1801.00690, 2018.
- Yu et al. [2020] Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In Conference on robot learning, pages 1094–1100. PMLR, 2020.
- Rajeswaran et al. [2018] Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giulia Vezzani, John Schulman, Emanuel Todorov, and Sergey Levine. Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations. In Proceedings of Robotics: Science and Systems (R:SS), 2018.
- Wüthrich et al. [2020] Manuel Wüthrich, Felix Widmaier, Felix Grimminger, Joel Akpo, Shruti Joshi, Vaibhav Agrawal, Bilal Hammoud, Majid Khadiv, Miroslav Bogdanovic, Vincent Berenz, Julian Viereck, Maximilien Naveau, Ludovic Righetti, Bernhard Schölkopf, and Stefan Bauer. Trifinger: An open-source robot for learning dexterity. CoRR, abs/2008.03596, 2020. URL https://arxiv.org/abs/2008.03596.
- Savva et al. [2019a] Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. Habitat: A Platform for Embodied AI Research. In International Conference on Computer Vision (ICCV), 2019a.
- Szot et al. [2021] Andrew Szot, Alex Clegg, Eric Undersander, Erik Wijmans, Yili Zhao, John Turner, Noah Maestre, Mustafa Mukadam, Devendra Chaplot, Oleksandr Maksymets, Aaron Gokaslan, Vladimir Vondrus, Sameer Dharur, Franziska Meier, Wojciech Galuba, Angel Chang, Zsolt Kira, Vladlen Koltun, Jitendra Malik, Manolis Savva, and Dhruv Batra. Habitat 2.0: Training home assistants to rearrange their habitat. In Advances in Neural Information Processing Systems (NeurIPS), 2021.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning (ICML), 2021.
- Dosovitskiy et al. [2020] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- He et al. [2021] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. arXiv:2111.06377, 2021.
- Caron et al. [2020] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. Advances in Neural Information Processing Systems, 33:9912–9924, 2020.
- Baevski et al. [2022a] Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli. Data2vec: A general framework for self-supervised learning in speech, vision and language. arXiv preprint arXiv:2202.03555, 2022a.
- Chen et al. [2020] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey E. Hinton. A Simple Framework for Contrastive Learning of Visual Representations. arXiv:2002.05709, 2020.
- Chen et al. [2021] Xinlei Chen, Saining Xie, and Kaiming He. An empirical study of training self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021.
- Bao et al. [2021] Hangbo Bao, Li Dong, and Furu Wei. Beit: Bert pre-training of image transformers. ArXiv, abs/2106.08254, 2021.
- Dosovitskiy et al. [2021] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations (ICLR), 2021.
- Baevski et al. [2022b] Alexei Baevski, Arun Babu, Wei-Ning Hsu, and Michael Auli. Efficient self-supervised learning with contextualized target representations for vision, speech and language. arXiv preprint arXiv:2212.07525, 2022b.
- Yao et al. [2022] Yuchong Yao, Nandakishor Desai, and Marimuthu Palaniswami. Masked contrastive representation learning. arXiv preprint arXiv:2211.06012, 2022.
- Karamcheti et al. [2023] Siddharth Karamcheti, Suraj Nair, Annie S Chen, Thomas Kollar, Chelsea Finn, Dorsa Sadigh, and Percy Liang. Language-driven representation learning for robotics. arXiv preprint arXiv:2302.12766, 2023.
- Ma et al. [2023] Yecheng Jason Ma, William Liang, Vaidehi Som, Vikash Kumar, Amy Zhang, Osbert Bastani, and Dinesh Jayaraman. Liv: Language-image representations and rewards for robotic control. arXiv preprint arXiv:2306.00958, 2023.
- Stone et al. [2023] Austin Stone, Ted Xiao, Yao Lu, Keerthana Gopalakrishnan, Kuang-Huei Lee, Quan Vuong, Paul Wohlhart, Brianna Zitkovich, Fei Xia, Chelsea Finn, et al. Open-world object manipulation using pre-trained vision-language models. arXiv preprint arXiv:2303.00905, 2023.
- Yang et al. [2023] Jiange Yang, Wenhui Tan, Chuhao Jin, Bei Liu, Jianlong Fu, Ruihua Song, and Limin Wang. Pave the way to grasp anything: Transferring foundation models for universal pick-place robots. arXiv preprint arXiv:2306.05716, 2023.
- Liu et al. [2022] H Liu, L Lee, K Lee, and P Abbeel. Instruction-following agents with multimodal transformer. arXiv preprint arXiv:2210.13431, 2022.
- Zhai et al. [2022] Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. Scaling vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12104–12113, 2022.
- Tian et al. [2021] Yonglong Tian, Olivier J Henaff, and Aäron van den Oord. Divide and contrast: Self-supervised learning from uncurated data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10063–10074, 2021.
- Goyal et al. [2021] Priya Goyal, Mathilde Caron, Benjamin Lefaudeux, Min Xu, Pengchao Wang, Vivek Pai, Mannat Singh, Vitaliy Liptchinsky, Ishan Misra, Armand Joulin, et al. Self-supervised pretraining of visual features in the wild. arXiv preprint arXiv:2103.01988, 2021.
- Kumar et al. [2022] Ananya Kumar, Aditi Raghunathan, Robbie Jones, Tengyu Ma, and Percy Liang. Fine-tuning can distort pretrained features and underperform out-of-distribution. arXiv preprint arXiv:2202.10054, 2022.
- Wijmans et al. [2022] Erik Wijmans, Irfan Essa, and Dhruv Batra. VER: Scaling on-policy rl leads to the emergence of navigation in embodied rearrangement. In Conference on Neural Information Processing Systems (NeurIPS), 2022.
- Kirichenko et al. [2022] Polina Kirichenko, Pavel Izmailov, and Andrew Gordon Wilson. Last layer re-training is sufficient for robustness to spurious correlations. arXiv preprint arXiv:2204.02937, 2022.
- Lee et al. [2022] Yoonho Lee, Annie S Chen, Fahim Tajwar, Ananya Kumar, Huaxiu Yao, Percy Liang, and Chelsea Finn. Surgical fine-tuning improves adaptation to distribution shifts. arXiv preprint arXiv:2210.11466, 2022.
- Goyal et al. [2022] Sachin Goyal, Ananya Kumar, Sankalp Garg, Zico Kolter, and Aditi Raghunathan. Finetune like you pretrain: Improved finetuning of zero-shot vision models. arXiv preprint arXiv:2212.00638, 2022.
- Hansen et al. [2022a] Nicklas Hansen, Zhecheng Yuan, Yanjie Ze, Tongzhou Mu, Aravind Rajeswaran, Hao Su, Huazhe Xu, and Xiaolong Wang. On pre-training for visuo-motor control: Revisiting a learning-from-scratch baseline. arXiv preprint arXiv:2212.05749, 2022a.
- Pari et al. [2021] Jyothish Pari, Nur Muhammad Shafiullah, Sridhar Pandian Arunachalam, and Lerrel Pinto. The surprising effectiveness of representation learning for visual imitation. arXiv preprint arXiv:2112.01511, 2021.
- Real Robot Challenge [2020] Real Robot Challenge 2020. Real robot challenge 2020. https://real-robot-challenge.com/2020, 2020.
- Dittadi et al. [2021] Andrea Dittadi, Frederik Träuble, Manuel Wüthrich, Felix Widmaier, Peter Gehler, Ole Winther, Francesco Locatello, Olivier Bachem, Bernhard Schölkopf, and Stefan Bauer. The role of pretrained representations for the ood generalization of reinforcement learning agents, 2021. URL https://arxiv.org/abs/2107.05686.
- Zhu et al. [2017] Yuke Zhu, Roozbeh Mottaghi, Eric Kolve, Joseph J. Lim, Abhinav Kumar Gupta, Li Fei-Fei, and Ali Farhadi. Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning. ICRA, 2017.
- Batra et al. [2020] Dhruv Batra, Aaron Gokaslan, Aniruddha Kembhavi, Oleksandr Maksymets, Roozbeh Mottaghi, Manolis Savva, Alexander Toshev, and Erik Wijmans. Objectnav revisited: On evaluation of embodied agents navigating to objects. arXiv preprint arXiv:2006.13171, 2020.
- Gu et al. [2022] Jiayuan Gu, Devendra Singh Chaplot, Hao Su, and Jitendra Malik. Multi-skill mobile manipulation for object rearrangement. arXiv preprint arXiv:2209.02778, 2022.
- Ramrakhya et al. [2023] Ram Ramrakhya, Dhruv Batra, Erik Wijmans, and Abhishek Das. Pirlnav: Pretraining with imitation and rl finetuning for objectnav. arXiv preprint arXiv:2301.07302, 2023.
- Deitke et al. [2022a] Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Jordi Salvador, Kiana Ehsani, Winson Han, Eric Kolve, Ali Farhadi, Aniruddha Kembhavi, et al. Procthor: Large-scale embodied ai using procedural generation. arXiv preprint arXiv:2206.06994, 2022a.
- Grauman et al. [2022] Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18995–19012, 2022.
- Shan et al. [2020] Dandan Shan, Jiaqi Geng, Michelle Shu, and David F Fouhey. Understanding human hands in contact at internet scale. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9869–9878, 2020.
- Goyal et al. [2017] Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzyńska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, Florian Hoppe, Christian Thurau, Ingo Bax, and Roland Memisevic. The "something something" video database for learning and evaluating visual common sense, 2017.
- Damen et al. [2018] Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. Scaling egocentric vision: The epic-kitchens dataset. In Proceedings of the European Conference on Computer Vision (ECCV), pages 720–736, 2018.
- Zhou et al. [2018] Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view synthesis using multiplane images. arXiv preprint arXiv:1805.09817, 2018.
- Deng et al. [2009] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- Bommasani et al. [2021] Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, Erik Brynjolfsson, S. Buch, Dallas Card, Rodrigo Castellon, Niladri S. Chatterji, Annie S. Chen, Kathleen A. Creel, Jared Davis, Dora Demszky, Chris Donahue, Moussa Doumbouya, Esin Durmus, Stefano Ermon, John Etchemendy, Kawin Ethayarajh, Li Fei-Fei, Chelsea Finn, Trevor Gale, Lauren E. Gillespie, Karan Goel, Noah D. Goodman, Shelby Grossman, Neel Guha, Tatsunori Hashimoto, Peter Henderson, John Hewitt, Daniel E. Ho, Jenny Hong, Kyle Hsu, Jing Huang, Thomas F. Icard, Saahil Jain, Dan Jurafsky, Pratyusha Kalluri, Siddharth Karamcheti, Geoff Keeling, Fereshte Khani, O. Khattab, Pang Wei Koh, Mark S. Krass, Ranjay Krishna, Rohith Kuditipudi, Ananya Kumar, Faisal Ladhak, Mina Lee, Tony Lee, Jure Leskovec, Isabelle Levent, Xiang Lisa Li, Xuechen Li, Tengyu Ma, Ali Malik, Christopher D. Manning, Suvir Mirchandani, Eric Mitchell, Zanele Munyikwa, Suraj Nair, Avanika Narayan, Deepak Narayanan, Benjamin Newman, Allen Nie, Juan Carlos Niebles, Hamed Nilforoshan, J. F. Nyarko, Giray Ogut, Laurel J. Orr, Isabel Papadimitriou, Joon Sung Park, Chris Piech, Eva Portelance, Christopher Potts, Aditi Raghunathan, Robert Reich, Hongyu Ren, Frieda Rong, Yusuf H. Roohani, Camilo Ruiz, Jack Ryan, Christopher R’e, Dorsa Sadigh, Shiori Sagawa, Keshav Santhanam, Andy Shih, Krishna Parasuram Srinivasan, Alex Tamkin, Rohan Taori, Armin W. Thomas, Florian Tramèr, Rose E. Wang, William Wang, Bohan Wu, Jiajun Wu, Yuhuai Wu, Sang Michael Xie, Michihiro Yasunaga, Jiaxuan You, Matei A. Zaharia, Michael Zhang, Tianyi Zhang, Xikun Zhang, Yuhui Zhang, Lucia Zheng, Kaitlyn Zhou, and Percy Liang. On the opportunities and risks of foundation models. ArXiv, abs/2108.07258, 2021.
- Wei et al. [2022] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Huai hsin Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. ArXiv, abs/2201.11903, 2022.
- Hansen et al. [2022b] Nicklas Hansen, Yixin Lin, Hao Su, Xiaolong Wang, Vikash Kumar, and Aravind Rajeswaran. Modem: Accelerating visual model-based reinforcement learning with demonstrations. arXiv preprint, 2022b.
- He et al. [2020] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross B. Girshick. Momentum Contrast for Unsupervised Visual Representation Learning. In Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- Caron et al. [2021] Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
- Deitke et al. [2022b] Matt Deitke, Dhruv Batra, Yonatan Bisk, Tommaso Campari, Angel X. Chang, Devendra Singh Chaplot, Changan Chen, Claudia Pérez D’Arpino, Kiana Ehsani, Ali Farhadi, Li Fei-Fei, Anthony Francis, Chuang Gan, Kristen Grauman, David Hall, Winson Han, Unnat Jain, Aniruddha Kembhavi, Jacob Krantz, Stefan Lee, Chengshu Li, Sagnik Majumder, Oleksandr Maksymets, Roberto Martín-Martín, Roozbeh Mottaghi, Sonia Raychaudhuri, Mike Roberts, Silvio Savarese, Manolis Savva, Mohit Shridhar, Niko Sünderhauf, Andrew Szot, Ben Talbot, Joshua B. Tenenbaum, Jesse Thomason, Alexander Toshev, Joanne Truong, Luca Weihs, and Jiajun Wu. Retrospectives on the embodied ai workshop. arXiv preprint arXiv:2210.06849, 2022b.
- Yadav et al. [2022b] Karmesh Yadav, Ram Ramrakhya, Santhosh Kumar Ramakrishnan, Theo Gervet, John Turner, Aaron Gokaslan, Noah Maestre, Angel Xuan Chang, Dhruv Batra, Manolis Savva, et al. Habitat-matterport 3d semantics dataset. arXiv preprint arXiv:2210.05633, 2022b.
- Ramrakhya et al. [2022a] Ram Ramrakhya, Eric Undersander, Dhruv Batra, and Abhishek Das. Habitat-web: Learning embodied object-search from human demonstrations at scale. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022a.
- Wijmans et al. [2020] Erik Wijmans, Abhishek Kadian, Ari S. Morcos, Stefan Lee, Irfan Essa, Devi Parikh, Manolis Savva, and Dhruv Batra. DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames. In International Conference on Learning Representations (ICLR), 2020.
- Mezghani et al. [2021] Lina Mezghani, Sainbayar Sukhbaatar, Thibaut Lavril, Oleksandr Maksymets, Dhruv Batra, Piotr Bojanowski, and Karteek Alahari. Memory-augmented reinforcement learning for image-goal navigation. arXiv preprint arXiv:2101.05181, 2021.
- Savva et al. [2019b] Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9339–9347, 2019b.
- Xia et al. [2018] Fei Xia, Amir R Zamir, Zhiyang He, Alexander Sax, Jitendra Malik, and Silvio Savarese. Gibson env: Real-world perception for embodied agents. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 9068–9079, 2018.
- Al-Halah et al. [2022] Ziad Al-Halah, Santhosh K Ramakrishnan, and Kristen Grauman. Zero experience required: Plug & play modular transfer learning for semantic visual navigation. arXiv preprint arXiv:2202.02440, 2022.
- Ramakrishnan et al. [2021] Santhosh Kumar Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alexander Clegg, John M Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X Chang, et al. Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021.
- Yadav et al. [2022c] Karmesh Yadav, Santhosh Kumar Ramakrishnan, John Turner, Aaron Gokaslan, Oleksandr Maksymets, Rishabh Jain, Ram Ramrakhya, Angel X Chang, Alexander Clegg, Manolis Savva, et al. Habitat challenge 2022, 2022c.
- Gupta et al. [2018] Abhinav Gupta, Adithyavairavan Murali, Dhiraj Prakashchand Gandhi, and Lerrel Pinto. Robot learning in homes: Improving generalization and reducing dataset bias. Advances in neural information processing systems, 31, 2018.
- Ramrakhya et al. [2022b] Ram Ramrakhya, Eric Undersander, Dhruv Batra, and Abhishek Das. Habitat-web: Learning embodied object-search strategies from human demonstrations at scale. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5173–5183, 2022b.
- Mandi et al. [2022] Zhao Mandi, Homanga Bharadhwaj, Vincent Moens, Shuran Song, Aravind Rajeswaran, and Vikash Kumar. Cacti: A framework for scalable multi-task multi-scene visual imitation learning. ArXiv, abs/2212.05711, 2022.
- Rob [2020] Robohive – a unified framework for robot learning. https://sites.google.com/view/robohive, 2020. URL https://sites.google.com/view/robohive.
附录A附录
A.1限制
这项研究对视觉基础模型进行了彻底的检查,但有一些局限性。 首先,在提出基准时,我们试图在任务多样性和评估所需的计算资源之间找到平衡。 然而,实体人工智能中新的、具有挑战性的基准,例如 Deitke 等人 [2022b] 中提出的基准,不断出现,并可能值得纳入未来的研究中,以跟踪该领域的进展。 此外,虽然我们在研究中重点关注掩码自动编码器 (MAE) 作为预训练目标,将 ViT 作为架构,但可能还有其他 SSL 算法在我们的基准测试中提出的任务上表现出不同的扩展行为或卓越的性能。 最后,这项工作中研究的适应过程需要在域内数据集上进行单独的训练,以及仔细调整超参数,例如训练纪元的数量和数据集的采样率。 这导致我们需要付出巨大的努力,为我们的基准评估中的每个基准生成单独的自适应 PVR 模型,并且总体工作量随着研究中包含的基准数量成比例地增加。
总之,值得注意的是,尽管我们利用真实世界的图像和视频来预训练我们的视觉表示模型(PVR),但本研究中使用的评估基准充当实际机器人任务的代理,因此,性能真实机器人上的 PVR 模型的排名可能与本研究中建立的排名有所不同。 需要进一步的研究来充分评估这些模型在现实场景中的有效性。
A.2 CortexBench中下游策略学习概述
给定一个冻结的 PVR,代理需要学习每个任务的策略。 EAI 社区开发了一系列策略学习算法,从少样本模仿学习 (IL) 到大规模强化学习 (RL)。 对于 CortexBench 中的每项任务,我们都遵守在该领域实现最先进性能的社区标准。
“MuJoCo 任务” 对于 Adroit、MetaWorld 和 DMC 套件中的任务,我们在少量专家演示中使用行为克隆来训练策略(Adroit 和 DMC 为 100 个,MetaWorld 为 25 个),如下Parisi 等人[2022],Nair 等人[2022]。 具体来说,我们训练 100 个时期的策略,并报告训练期间最佳中间策略在测试集上的平均推出性能。 对于所有任务,我们使用帧堆叠和 3 层 MLP 策略网络。 当使用基于视觉变换器 (ViT) 的 PVR 时,我们使用 [CLS] 词符作为策略的输入,而对于 ResNet,我们使用全局平均池化后最终卷积层的特征。 这些设计选择遵循了之前的工作,例如Radosavovic 等人[2022]、Nair 等人[2022]。
“TriFinger 任务” 对于 TriFinger,我们使用行为克隆对每个任务进行 100 个演示来训练策略。 具体来说,我们训练了一个由 3 层 MLP 组成的策略网络,Reach-Cube 为 100 个 epoch,Push-Cube 为 1,000 个 epoch。 我们报告训练过程中最佳检查点的平均分数。 策略的输入是基于 ViT 的 PVR 的 [CLS] 词符,以及基于 ResNet 的模型的最后一个卷积层的平均池化特征。
“栖息地任务” 我们通过 Ramrakhya 等人收集的 77k 人类演示 Yadav 等人 [2022b] 的行为克隆来训练 ObjectNav 策略[2022a],总共 360M 环境步骤。 对于 ImageNav 和 Mobile-Pick,我们使用 RL 进行 500M 环境步骤以及 DD-PPO Wijmans 等人 [2020] 和 VER Wijmans 等人[2022]。 我们使用基于 ViT 的 PVR 的补丁表示和 ResNet 模型最后一个卷积层的网格特征,通过压缩层 Savva 等人 [2019a] 获得供策略层使用的较低维度表示,这是一个用于导航的 2 层 LSTM 和一个用于操作的 2 层 GRU。
A.3 CortexBench 中任务和下游学习的更多详细信息
在本节中,我们将讨论 CortexBench 中下游任务子集的更多详细信息。
图像导航。 我们的研究使用 Mezghani 等人 [2021] 中提供的标准数据集进行 ImageNav 实验。 该基准测试使用 Habitat 模拟器 Savva 等人 [2019b]、Szot 等人 [2021],并且位于 Gibson Xia 等人 [2018] 环境中,该环境包含 72 个训练场景和 14 个验证场景。 验证集包括每个场景 300 集,总共 4,200 集。 在此基准测试中,代理被建模为高度为 1.5m、半径为 0.1m 的圆柱体,传感器位于底座中心上方 1.25m 处。 RGB 摄像头的分辨率为 128128,视野为 90。 代理最多可以在环境中走 1000 步,如果到达目标位置 1m 以内的位置并调用 StopAction,则视为成功。
为了在 Gibson 环境中训练代理,我们利用 500M 时间步长(25k 更新)和 320 个并行运行的环境。 每个环境收集最多 64 帧经验,随后是使用 2 个小批量的 2 个 PPO 时期。 除非另有说明,我们对代理使用 的学习率,并使用 AdamW 优化器更新参数,权重衰减为 。 我们使用 Al-Halah 等人 [2022] 中提出的奖励函数来训练智能体,使用以下设置:成功权重 、角度成功权重 、目标半径、角度阈值和松弛惩罚。 我们每 25M 步训练评估一次性能,并根据验证集上实现的最高成功率 (SR) 报告指标。
对象导航。 我们使用 HM3D-Sem 数据集 Yadav 等人 [2022b] 评估对象导航 (ObjectNav)。 该数据集由 80 个训练、20 个验证和 20 个测试场景组成,并利用 Habitat 模拟器 Savva 等人 [2019b]、Szot 等人 [2021] 和 HM3D Ramakrishnan 等人 [2021] ] 环境。 我们的结果是在 v0.1 HM3D-Sem val 分割上报告的,该分割用于 2022 年栖息地挑战 Yadav 等人 [2022c] ObjectNav 基准测试。 本次评估中的智能体以 LocoBot Gupta 等人 [2018] 为模型,高度为 0.88m,半径为 0.18m,传感器放置在智能体的头顶。 RGB 摄像头的分辨率为 640480,水平视野为 79。 代理的任务是从 6 个类别之一定位对象:'chair'、'bed'、'plant'、“厕所”、“电视/显示器”和“沙发”在 500 步以内。 成功的情节由代理停止在视点 0.1m 范围内确定,该视点是 (a) 目标对象的任何实例的 1m 范围内,以及 (b) 从该对象可见的对象,如 Batra 的评估协议中所述等人[2020]。
我们利用人类演示数据集在 ObjectNav 任务中训练我们的模仿学习代理。 该数据集是通过 Habitat-Web Ramrakhya等人[2022b]、Yadav等人[2022b]和亚马逊Mechanical Turk收集的,包括来自HM3D-Sem数据集Yadav等人[2022c]的80个场景的演示。 每个场景包含大约 158 个片段,每个片段都有一个独特的目标对象类别和随机设置的起始位置,每个场景大约有 950 次演示。 该数据集总共包含 万步经验,平均每集 步。 通过利用这些人类演示数据,我们的模仿学习代理能够学习更有效的策略来导航到复杂环境中的对象。
我们在 HM3D 环境中使用 25,000 次更新和 512 个并行环境,训练了大约 4 亿步的对象导航 (ObjectNav) 代理。 与我们之前基于图像的导航 (ImageNav) 实验类似,我们采用了 的权重衰减,并对视觉编码器和模型的其他元素使用了不同的学习率。 具体来说,我们使用 AdamW 优化器对视觉编码器使用 学习率,对所有其他元素使用 学习率。 为了确保训练模型的质量,我们在每个 步骤后评估检查点,并仅报告验证成功率最高的检查点的指标。
移动选择。 我们研究了 Szot 等人[2021]提出的 Habitat 2.0 Rearrangement 任务。 该任务涉及一个移动操纵场景,其中 Fetch 机器人导航 ReplicaCAD 公寓,使用移动底座 Gu 等人 [2022] 从杂乱的容器中拾取目标对象。 机器人从一个不平凡的位置开始,必须利用各种传感器,包括以自我为中心的 RGB 摄像头、本体感受关节传感和物体抓取指示器。 机器人的动作空间包括对机器人的七自由度手臂、底座运动和吸力夹具的连续控制。 我们将密集目标规范(末端执行器和目标对象之间的相对位置必须在每一步都更新)放松为稀疏目标规范(仅在剧集开始时提供此信息)。 这种放松更加强调视觉输入,并使任务变得更具挑战性。
三指任务。 TriFinger 任务在 Pybullet 中实现。 对于Reach-Cube,BC策略的状态是,其中是当前指尖位置,是潜在视觉状态向量,通过将当前图像观察通过 PVR 获得。 成功指标捕获指尖距立方体中心的最佳距离有多近,占立方体的一半=宽度。 对于 Push-Cube,BC 策略的状态为 ,其中 是立方体的目标位置,指定为其初始位置的位移位置。 这里的成功是立方体中心到目标目标位置的距离。 我们训练了一个策略网络,其隐藏层大小为 2000,学习率为 ,可达任务最多 100 个时期,Push-Cube 任务最多 1000 个时期。
A.4现有预训练视觉表示 (PVR) 的额外分析
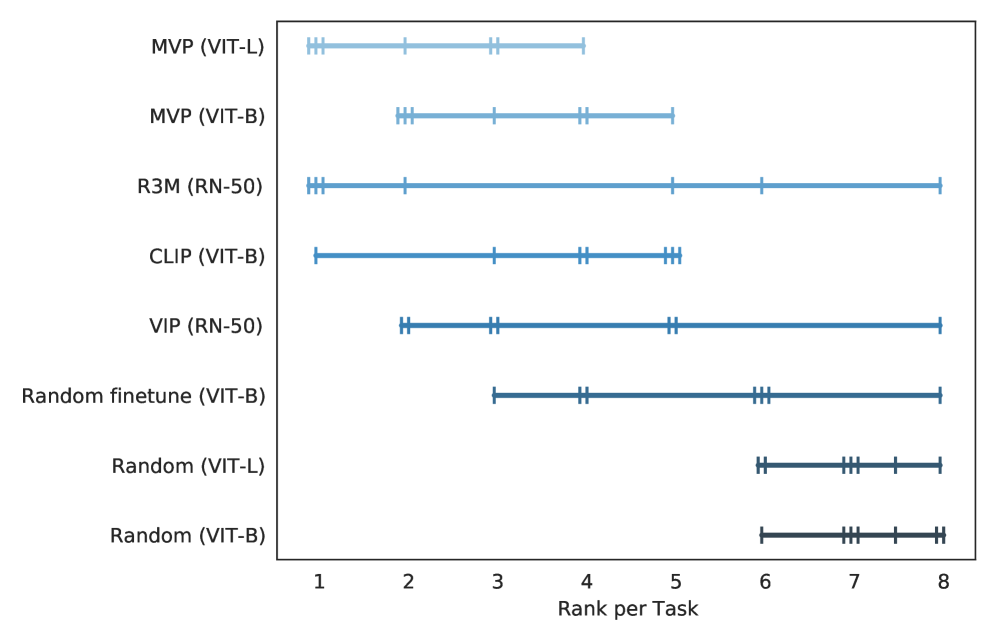
现有 PVR 的排名分布(如图 图 5 所示)表明模型的性能存在很大差异(来自之前的工作)跨越 CortexBench 中的基准测试。
A.5 缩放假设数据集
表 6中详细介绍了用于缩放假设实验的数据集。
| Name | Contains | Total Frames | Frames used |
|---|---|---|---|
| Ego4D | Ego4D | 418,578,043 | 2,790,520 |
| Ego4D+M (Manipulation) | Ego4D | 418,578,043 | 2,790,520 |
| 100DOH | 99,899 | 99,899 | |
| SS-v2 | 25,209,271 | 315,115 | |
| Epic Kitchens | 19,965,439 | 332,757 | |
| Total | 3,538,291 | ||
| Ego4D+N (Navigation) | Ego4D | 418,578,043 | 2,790,520 |
| OpenHouse24 | 27,806,971 | 499,442 | |
| RealEstate10K | 10,000,000 | 303,087 | |
| Total | 3,289,962 | ||
| Ego4D+MN (Manipulation, Navigation) | Ego4D+M | 3,538,291 | 3,538,291 |
| OpenHouse24 | 27,806,971 | 499,442 | |
| RealEstate10K | 10,000,000 | 303,087 | |
| Total | 4,340,820 | ||
| Ego4D+MNI (Manipulation, Navigation, ImageNet) | Ego4D+MN | 4,340,820 | 4,340,820 |
| ImageNet | 1,281,167 | 1,281,167 | |
| Total | 5,621,987 |
A.5.1 OpenHouse24数据集
OpenHouse24 (OH24) 数据集是带家具的住宅房地产的视频演练集合。 数据集中包含 1600 多个家庭,总共 139 小时的视频片段。 操作员使用稳定的 HD RGB 摄像机连续拍摄每个房屋,高效地访问每个房间。 该数据集代表了各种不同的属性,包括(但不限于)小型和大型郊区住宅、高层公寓、牧场住宅和公寓。 接下来的演练时长从 1 分钟到 14 分钟不等,平均需要 5 分 12 秒。 该数据集将由一个单独的研究项目开源。
A.6 缩放假设预详细信息
为了训练 MAE 模型,我们使用作者在 GitHub He 等人 [2021] 上发布的官方代码库,并使用存储库提供的默认超参数来训练 ViT -B 和 ViT-L 型号。 我们发现默认值在 CortexBench 上运行良好。 但是,考虑到不同的数据集大小,我们确实会改变用于训练 Section 5 中不同模型的时期数。 我们选择每次运行的轮数,以便模型更新的数量在所有运行中保持不变,并与 MAE 在 ImageNet 数据集上进行的模型更新的数量相匹配。 我们在表7中提供了有关数据集大小和为不同运行计算的历元的详细信息。
| Dataset Name | Epochs | Frames used |
|---|---|---|
| Ego4D+N (VIT-B) | 289 | 3,538,291 |
| Ego4D+N (VIT-L) | 289 | 3,538,291 |
| Ego4D+M (VIT-B) | 414 | 3,289,962 |
| Ego4D+M (VIT-L)) | 414 | 3,289,962 |
| Ego4D+MN (VIT-B) | 236 | 4,340,820 |
| Ego4D+MN (VIT-L) | 236 | 4,340,820 |
| Ego4D+MNI (VIT-B) | 182 | 5,621,987 |
| VC-1 (Ego4D+MNI (VIT-L)) | 182 | 5,621,987 |
A.7缩放假设结果的附加分析
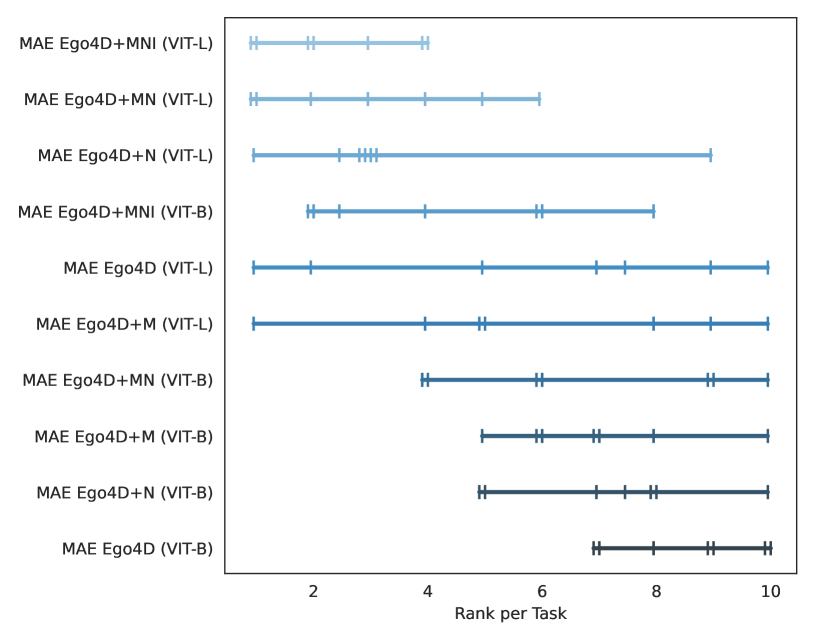
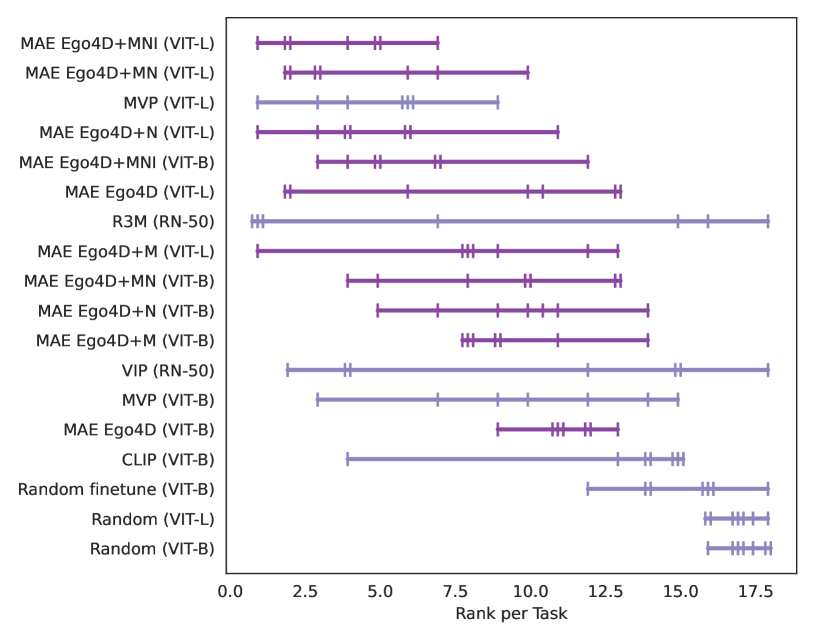
图 6(左)提供了预训练数据集多样性重要性的额外证据。 我们观察到,虽然在 Ego4D+M 和 Ego4D+N 数据集上训练的 ViT-L 模型在其中一个基准测试中取得了最佳结果,但它们的表现最差,位居第二。 - 在其他基准测试中最差。 然而,通过增加多样性,Ego4D+MN 和 Ego4D+MNI 模型的排名分布方差减少了。 值得注意的是,Ego4D+MNI 模型在所有基准测试中始终表现良好,并且跻身顶级模型之列。
A.8 对 CortexBench 上评估的所有模型进行额外分析
| TASK | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| model | assembly | bin_picking | button_press | cheetah_run | drawer_open | finger_spin | hammer | imagenav | mobile_pick | move_cube | objectnav | pen | reach_cube | reacher | relocate | walker_stand | walker_walk |
| CLIP (VIT-B) | 70.7 | 68.0 | 48.0 | 22.7 | 100.0 | 74.6 | 90.7 | 52.2 | 49.8 | 40.1 | 56.6 | 72.0 | 83.8 | 89.9 | 22.7 | 64.9 | 25.4 |
| MAE Ego4D (VIT-B) | 81.3 | 76.0 | 80.0 | 29.1 | 100.0 | 76.9 | 93.3 | 64.0 | 57.4 | 54.0 | 46.8 | 74.7 | 82.6 | 79.8 | 22.7 | 84.3 | 50.5 |
| MAE Ego4D (VIT-L) | 98.0 | 84.0 | 84.0 | 20.7 | 100.0 | 76.5 | 98.7 | 55.8 | 67.6 | 57.0 | 47.6 | 76.0 | 82.4 | 71.9 | 24.0 | 78.4 | 56.3 |
| MAE Ego4D+M (VIT-B) | 76.0 | 58.7 | 84.0 | 31.9 | 100.0 | 75.5 | 98.7 | 65.8 | 59.8 | 57.5 | 47.4 | 77.3 | 80.7 | 89.3 | 25.3 | 80.7 | 44.3 |
| MAE Ego4D+M (VIT-L) | 89.3 | 73.3 | 84.0 | 33.5 | 100.0 | 75.6 | 94.7 | 65.5 | 68.6 | 47.2 | 47.3 | 74.7 | 82.1 | 85.8 | 29.3 | 76.2 | 52.3 |
| MAE Ego4D+MN (VIT-B) | 82.7 | 74.7 | 77.3 | 32.0 | 100.0 | 77.5 | 92.0 | 68.9 | 58.6 | 62.1 | 52.8 | 73.3 | 78.5 | 85.6 | 24.0 | 84.1 | 41.8 |
| MAE Ego4D+MN (VIT-L) | 93.3 | 70.7 | 74.7 | 38.1 | 100.0 | 77.0 | 94.7 | 69.1 | 61.2 | 62.4 | 58.4 | 78.7 | 82.4 | 91.7 | 26.7 | 83.0 | 58.9 |
| MAE Ego4D+MNI (VIT-B) | 88.0 | 78.7 | 82.7 | 32.3 | 100.0 | 76.0 | 98.7 | 67.9 | 60.6 | 60.6 | 55.4 | 76.0 | 83.9 | 82.6 | 32.0 | 83.5 | 44.7 |
| MAE Ego4D+MNI (VIT-L) | 88.0 | 84.0 | 80.0 | 32.8 | 100.0 | 76.8 | 92.0 | 70.3 | 63.2 | 60.2 | 60.3 | 80.0 | 83.3 | 88.0 | 38.7 | 83.3 | 53.7 |
| MAE Ego4D+N (VIT-B) | 86.7 | 76.0 | 73.3 | 28.1 | 100.0 | 75.8 | 96.0 | 68.7 | 59.4 | 54.1 | 54.7 | 77.3 | 81.6 | 78.7 | 22.7 | 72.4 | 42.6 |
| MAE Ego4D+N (VIT-L) | 89.3 | 73.3 | 89.3 | 33.3 | 100.0 | 76.2 | 93.3 | 70.5 | 65.2 | 52.7 | 57.4 | 76.0 | 81.1 | 88.6 | 32.0 | 83.4 | 50.7 |
| MVP (VIT-B) | 92.0 | 73.3 | 92.0 | 33.9 | 100.0 | 76.9 | 98.7 | 64.7 | 56.0 | 44.3 | 51.2 | 69.3 | 75.0 | 86.3 | 26.7 | 84.7 | 47.9 |
| MVP (VIT-L) | 89.3 | 78.7 | 70.7 | 36.9 | 100.0 | 76.4 | 98.7 | 68.1 | 65.4 | 63.4 | 55.0 | 76.0 | 84.8 | 90.2 | 30.7 | 83.2 | 59.3 |
| R3M (RN-50) | 97.3 | 93.3 | 89.3 | 66.1 | 100.0 | 77.1 | 100.0 | 30.6 | 33.2 | 51.9 | 22.6 | 81.3 | 86.5 | 98.4 | 65.3 | 93.8 | 70.1 |
| Random (VIT-B) | 0.0 | 0.0 | 2.7 | 0.4 | 0.0 | 0.1 | 0.0 | 42.1 | 10.8 | 41.3 | 19.2 | 4.0 | 74.3 | 23.4 | 0.0 | 22.7 | 4.0 |
| Random (VIT-L) | 0.0 | 0.0 | 0.0 | 0.5 | 0.0 | 0.2 | 2.7 | 45.2 | 20.6 | 39.4 | 19.3 | 5.3 | 74.9 | 19.9 | 0.0 | 20.1 | 4.6 |
| Random finetune (VIT-B) | 61.3 | 34.7 | 20.0 | 10.2 | 40.0 | 48.6 | 93.3 | 62.5 | 47.6 | 37.6 | 28.5 | 73.3 | 74.5 | 26.8 | 14.7 | 73.6 | 58.1 |
| VIP (RN-50) | 93.3 | 76.0 | 88.0 | 53.2 | 100.0 | 76.1 | 93.3 | 48.8 | 7.2 | 47.2 | 26.4 | 81.3 | 86.2 | 83.2 | 26.7 | 86.6 | 63.4 |
A.9缩放模型大小的附加分析
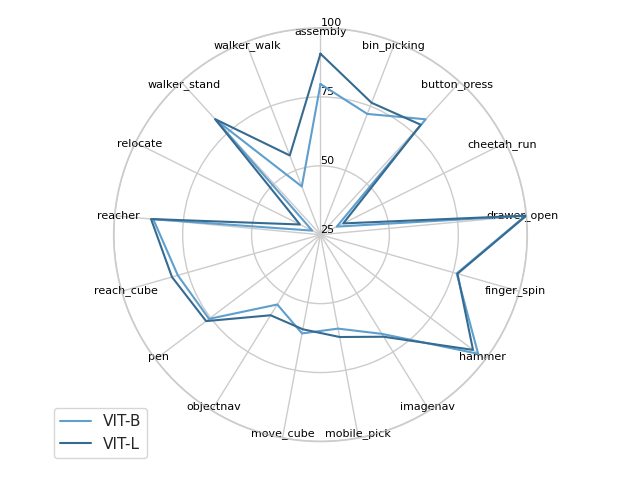
图 7 说明缩放模型大小对每个基准测试以及 17 项任务中的 15 项都有积极影响。
A.10 VC-1 的注意力可视化
为了可视化注意力,我们在下游任务的推理过程中对 ViT 编码器最后一层的注意力矩阵应用了平均池化操作。 然后将所得值叠加到图像上。
我们首先注意 MAE 预训练的效果;冻结的 VC-1 注意力图似乎专注于图像的轮廓和一般特征。 我们假设这是基于 MAE 重建的训练目标的结果,因为轮廓为重建图像提供了重要信息。
此外,我们研究了 VC-1 对下游任务进行端到端微调后的注意力图。 注意力似乎集中在对任务很重要的图像区域(例如,被操纵的对象)。 因此,通过适应(通过端到端微调),模型学会将注意力集中在与特定任务无关的区域。

A.11 TriFinger 硬件实验设置
我们在真实的 TriFinger 机器人(如图图9)上进行了Push-Cube任务的实验,在 30 个真实世界的演示中使用行为克隆训练模型后。 Push-Cube 的成功定义为立方体能够移动的距离相对于其到目标的起始距离,类似于 Dittadi 等人 [2021]。 此任务的剧集长度为 20 个步骤。 对于每个模型,我们选择 1 个种子,并在 12 种不同的起始和目标配置上运行,其中大部分集中在竞技场中。

该环境的动作空间由三个手指的末端执行器位移组成。 电机的控制频率为 1kHz,发送到机器人的动作是指定关节扭矩的 9 维矢量。 我们使用英特尔实感摄像头,放置在俯瞰场景的桌子旁边,类似于我们捕获模拟图像观察的方式。 为了检测立方体,我们确保绿色面始终朝上并检测该面的中心,并用它来跟踪立方体在碗中的位置。
A.12 Franka 硬件实验设置
我们在一个操纵平台上进行行为克隆实验,该平台包括 Franka 手臂和装有 Festo 自适应手指抓手的 Robotiq 抓手。 图 10显示了任务设置:
-
•
到达任务要求在给定目标图像提示的情况下,控制末端执行器到达机器人框架中 和 之间的随机选择点,误差范围在 5cm 内。
-
•
瓶子拾取任务需要用夹具到达并拾取瓶子。 瓶子随机放置在 10 厘米线上,方向相同)。
-
•
封闭式抽屉和烤面包机插入任务与 Cacti 设置 Mandi 等人 [2022] 类似。
对于所有任务,观察结果是单个 RGB 相机图像(420x224 分辨率)和本体感受信号(7 个自由度关节角度和 1 个自由度夹具宽度)。 3 个隐藏层,每个隐藏节点有 256 个隐藏节点,多层感知器策略将 PVR 编码图像与缩放的本体感受信号连接作为输入,并预测所需的绝对关节角度和夹具宽度作为动作。 低级 1kHz 实时联合空间 PD 控制器遵循策略生成的期望轨迹。 我们特别将增益保持在较低水平(出厂设置的一半),以便机器人即使被命令撞击桌子也不会损坏任何东西。 这导致轨迹跟踪性能较差,但人类远程操作员和学习策略都可以控制机器人完成任务。 我们使用 Robohive Rob [2020] 作为与所有传感器和机器人交互的中间件。
演示是使用 Quest 2 控制器从人类远程操作中收集的。 对于 PVR(冻结编码器),我们使用学习率 的 Adam 优化器来训练策略。 为了进行微调,我们对策略使用相同的学习率,但对视觉编码器使用较低的学习率 ()。 表9显示了行为克隆的成功率。




| Reaching | Bottle Pickup | Open Drawer | Plunge Toaster | Success Count | Success % | |
| Demos | 30 | 50 | 250 | 250 | ||
| Evals | 10 | 10 | 10 | 10 | ||
| VC-1 frozen | 80 | 100 | 60 | 40 | 28 | 70.0 |
| VC-1 E2E fine-tuning | 50 | 90 | 80 | 50 | 27 | 67.5 |
| VC-1 MAE adaption | 90 | 100 | 80 | 70 | 34 | 85.0 |
| MAE baseline | 30 | 10 | 50 | 50 | 14 | 35.0 |
| MVP | 70 | 100 | 30 | 20 | 22 | 55.0 |