用于随机人体轨迹预测的无监督采样促进
摘要
人体运动的不确定性要求轨迹预测系统使用概率模型来制定多模态现象并推断一组有限的未来轨迹。 然而,大多数现有方法的推理过程依赖于蒙特卡罗随机采样,由于预测分布的长尾效应,不足以用有限的样本覆盖现实路径。 为了促进随机预测的采样过程,我们提出了一种称为 BOsampler 的新方法,以无监督的方式通过贝叶斯优化自适应地挖掘潜在路径,作为一种顺序设计策略,其中新的预测依赖于之前抽取的样本。 具体来说,我们将轨迹采样建模为高斯过程,并构造一个采集函数来测量潜在的采样值。 该获取函数将原始分布应用为先验,并鼓励探索长尾区域中的路径。 这种采样方法可以与现有的随机预测模型集成,无需重新训练。 各种基线方法的实验结果证明了我们方法的有效性。 源代码在此链接中发布。
1简介
由于内在意图的变化或外部环境的影响,人类的行为通常是不确定的。 它需要人类轨迹预测系统来表述人类的多模态本质,并推断出不是单一的未来状态,而是所有可能的状态[16, 32]。
面对这一挑战,许多现有方法将随机人类轨迹预测表述为生成问题,其中使用潜在随机变量来表示多模态。 一类典型的方法[18,46,67,10]基于生成对抗网络(GAN),它通过多模态分布中的噪声生成可能的未来轨迹。 另一类利用变分自动编码器 (VAE) [41, 21, 26, 51, 30],它使用观察到的历史轨迹作为学习潜在变量的条件。 除了这两个主流类别之外,其他生成模型也用于轨迹预测,例如扩散模型[16],归一化流[39],甚至简单的高斯模型[35, 43]。
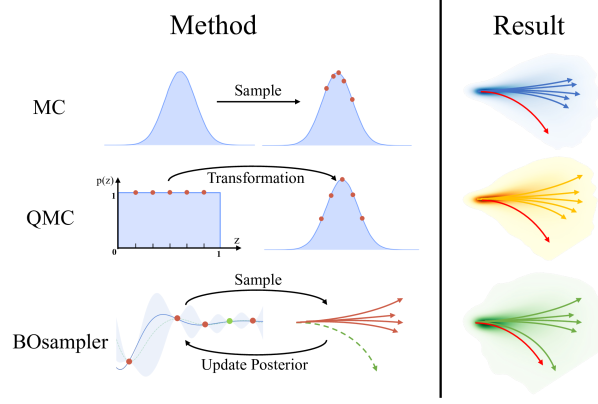
这些随机预测方法的推理过程不是单一预测,而是通过蒙特卡罗 (MC) 随机采样产生一组有限的合理未来轨迹。 然而,分布总是不均匀和有偏差的,像“直走”这样的常见选择的概率很高。 相比之下,许多其他选择,例如“左转/右转”和“掉头”的概率很低。 由于预测分布的长尾效应,有限的样本不足以覆盖现实路径。 例如,如图1所示,MC采样倾向于生成高概率的冗余轨迹,但忽略了潜在的低概率选择。 为了解决这个问题,一些方法[31, 4]使用客观项来训练模型以增加样本的多样性,例如,最大化预测样本之间的距离。 虽然提高了采样多样性,但这些方法需要通过添加损失项来重新训练模型。 它具有时效性,并且在仅给出模型(源数据不可访问)时可能会失败。
在本文中,我们提出了一种无监督方法来促进随机预测的采样过程,而无需访问源数据。 它被命名为 BOsampler ,它通过贝叶斯优化 (BO) 细化采样以进行更多探索。 具体来说,我们首先将采样过程表述为高斯过程(GP),其中后验由先前的采样轨迹决定。 然后,我们定义一个获取函数来测量潜在样本的值,其中很好地拟合训练分布或远离现有样本的样本获得高值。 通过这个获取函数,我们可以鼓励模型探索长尾区域的路径,实现准确性和多样性之间的权衡。 如图1所示,我们将BOsampler与MC和另一种采样方法QMC[4]进行比较,后者首先从均匀空间,然后将其转移到先验分布以进行轨迹采样。 与它们相比,BOsampler可以根据现有样本自适应更新高斯后验,更加灵活。 我们强调,BOsampler 作为一个即插即用模块,可以与现有的多模态随机预测模型集成,以促进采样过程而无需重新训练。 在实验中,我们将BOsampler应用于许多流行的基线方法,包括Social GAN [18]、PECNet [33]、Trajectron ++ [41] 和 Social-STGCNN [35],并在 ETH-UCY 数据集上对其进行评估。 本文的主要贡献总结如下:
-
•
我们提出了一种用于随机轨迹预测的无监督采样提示方法,该方法通过贝叶斯优化自适应地和顺序地挖掘潜在的合理路径。
-
•
该方法可以与现有的随机预测器集成,无需重新训练。
-
•
我们使用多种基线方法评估该方法并显示出显着的改进。
2相关工作
具有社交互动的轨迹预测。 人类轨迹预测的目标是通过观察到的人类路径推断出合理的未来位置。 除了目的地之外,行人的运动状态还受到与其他智能体(例如其他行人和环境)的交互的影响。 Social-LSTM [2] 应用社交池层来合并来自社区的社交互动。 为了从复杂的交互信息中突出有价值的线索,应用注意力模型来挖掘关键邻域[13,53,58,68,1]。 此外,由于复杂关系的强大表征能力,一些方法将图模型应用于社交交互[20,47,7,56,60,3]。 为了更好地建模社交互动和时间依赖性,提出了不同的模型架构用于轨迹预测,例如 RNN/LSTM [64]、CNN [37, 35] 和 Transformer [28,61,52,62]。 除了人与人的交互之外,人与环境的交互对于分析人体运动也至关重要。 为了融入环境知识,一些方法使用卷积神经网络[55,49,48,34,69,57]对场景图像或交通地图进行编码。
随机轨迹预测。 上述确定性轨迹预测方法仅生成一种可能的预测,忽略了人体运动的多模态性质。 为了解决这个问题,提出了随机预测方法来通过生成模型来表示多模态。 社交 GAN [18] 首先引入生成对抗网络 (GAN) 来对不确定性进行建模并预测社会上可行的未来。 接下来,提出了一些基于 GAN 的方法来整合更多线索[40, 10]或设计更有效的模型[24,12,46]。 另一种方法[21,8,25,9,59,19,63]将轨迹预测公式化为CVAE[45],它应用观测到的轨迹作为条件,学习潜在的随机变量来建模多模态。 此外,一些方法显式使用端点 [33, 65, 32, 66, 15, 14] 来建模可能的目的地或学习基于网格的位置编码器 [29, 11, 17 ] 生成可接受的路径。 最近,Gu 等人 [16]提出使用去噪扩散概率模型(DDPM)逐渐丢弃不确定性以获得所需的轨迹区域。 除了学习更好的人体运动概率分布之外,一些方法[31, 4]专注于学习采样网络以生成更多样化的轨迹。 然而,这些方法需要重新训练模型,这是一种时间成本,并且只有在给定源数据的情况下才能起作用。
贝叶斯优化。 贝叶斯优化 (BO) [42] 的关键思想是通过自适应模型驱动优化决策。 从根本上来说,它是一个寻找未知目标函数的全局优化结果的序列模型。 具体来说,它初始化目标函数的先验信念,然后用贝叶斯后验选择的数据顺序更新该模型。 BO已成为超参数调优[44]、自动机器学习[54, 23]和强化学习等广泛领域的优秀工具[6]。 在这里,我们引入BO来提示随机轨迹预测模型的采样过程。 我们将采样过程表示为顺序高斯过程,并定义采集函数来测量潜在样本的值。 通过 BO,我们可以鼓励模型探索长尾区域的路径。
3方法
在本节中,我们将介绍我们的无监督采样提升方法 BOsampler ,该方法受贝叶斯优化启发,在给定先前样本的情况下顺序更新采样模型。 首先,我们将采样过程表示为高斯过程,其中新样本以先前样本为条件。 然后我们展示如何通过贝叶斯优化自适应地挖掘有价值的轨迹。 最后,我们提供了我们方法的详细优化算法。
3.1问题定义
给定场景中 行人的观察轨迹,时间步为 t=1,…,, 的轨迹为 ,轨迹预测器将为每个行人生成 N 个可能的未来轨迹 ,其中 和 都是 2D 位置。 为了简单起见,我们删除了行人索引 和时间序列 和 而不进行特殊说明,例如使用 和 分别表示观察到的轨迹和生成的未来路径之一。 那么轨迹预测系统可以表述为:
| (1) |
其中 表示具有学习参数 的预测变量,z 是具有分布 的潜在变量,用于对人类的多模态进行建模运动。 对于基于 GAN 的模型, 是多元正态分布,对于基于 CVAE 的模型, 是潜在分布。 在推理阶段,我们将对潜在变量 的值序列进行采样,以生成一组有限的未来轨迹作为 。

3.2BO采样器
传统的随机轨迹预测方法基于学习的分布以蒙特卡罗方式对潜在变量进行采样。 尽管学习得很好,但分布总是不均匀和有偏差的,其中“直行”等常见选择的概率较高,而“掉头”等其他选择的概率较低。 由于分布的长尾特性,具有重叠的高概率路径和较少的低概率路径的有限轨迹无法覆盖实际分布。 尽管低概率情况在现实世界中是少数,但它们可能会引发潜在的严重安全问题,这对于自动驾驶等应用非常重要。
为了解决这个问题,我们建议通过贝叶斯优化来选择有价值的样本。 优化目标可以表述为:
| (2) |
其中表示生成的轨迹,是评估采样质量的指标,例如轨迹的平均距离误差(ADE)。 给定采样空间,BOsampler的目标是找到一个,以使用有限数量的样本获得评估指标的最佳分数。 为了简单起见,我们将上述目标函数定义为。
3.2.1 高斯过程
为了优化 ,我们将采样制定为在域 上定义的顺序高斯过程,其特征是均值函数 和协方差函数(由内核定义)。 该高斯过程可以作为目标函数的概率代理,如下所示:
| (3) |
在哪里
| (4) | ||||
给定之前 生成的路径和相应的评估分数 ,其中 是样本, 是真实的评估分数,可能测量噪声,我们要计算下一个生成的样本的分布和分数。 定义向量、。 然后定义核矩阵与和是来自的两个向量和。 先前分数和下一个分数的联合分布可以表示为:
| (5) |
这里,利用高斯过程的性质,后验分布仍然是高斯分布。 该后验分布的均值和协方差函数可以表示为:
| (6) | ||||
后验过程的封闭式解表明我们可以轻松地用新样本 更新 的概率模型。 如图2所示,我们可以迭代地使用后验分布来选择新样本并使用新样本来更新分布。 具体来说,给定采样轨迹和相应的潜在变量,我们首先获得一个数据库。 然后我们就可以计算出可能的评价分数的后验分布,并利用这个后验分布来选择下一个样本。 然后我们将该样本添加到数据库中,得到,并进一步选择。
3.2.2获取函数
为了选择下一个样本,我们应用这个后验分布来定义一个采集函数来测量每个样本的值。 一方面,好的样本应该得到较高的评价分数。 另一方面,我们鼓励模型探索以前从未接触过的区域。 为了实现这个目标,我们将获取函数定义为:
| (7) |
其中第一项表示我们希望选择分数期望较高的样本,第二项表示选择具有更多不确定性(方差)的样本。 这两项都来自后验分布。 我们使用超参数 来平衡准确性(高分期望)和多样性(高不确定性)。 然后,我们将该采集函数最大化为 以选择下一个样本。
然而,与典型的贝叶斯优化不同,我们的任务发现得分函数不可访问,因为我们在采样过程中无法获得真实轨迹。 为了解决这个问题,我们提出了一个伪分数评估函数来近似真实值函数。 具体来说,我们假设训练和测试环境之间只存在轻微的偏差,并且使用最可能的预测轨迹和伪地面实况也是如此。 以ADE为例,我们计算评估分数为:
| (8) |
其中 表示最有可能的预测。 这意味着我们信任经过训练的模型,而无需任何信息更新。
| Baseline Model | Sampling | ETH | HOTEL | UNIV | ZARA1 | ZARA2 | AVG | Gain | |||||||
| ADE | FDE | ADE | FDE | ADE | FDE | ADE | FDE | ADE | FDE | ADE | FDE | ADE | FDE | ||
| Social-GAN [18] | MC | 1.52 | 2.37 | 0.61 | 1.21 | 0.91 | 1.86 | 0.78 | 1.63 | 0.90 | 1.97 | 0.94 | 1.80 | / | / |
| QMC | 1.56 | 2.74 | 0.60 | 1.12 | 0.91 | 1.85 | 0.77 | 1.60 | 0.92 | 2.00 | 0.95 | 1.86 | -1% | -3% | |
| BOSampler | 1.14 | 2.04 | 0.52 | 1.03 | 0.80 | 1.62 | 0.68 | 1.41 | 0.75 | 1.60 | 0.78 | 1.54 | 18% | 15% | |
| Trajectron++ [41] | MC | 0.59 | 1.41 | 0.20 | 0.44 | 0.37 | 0.87 | 0.15 | 0.35 | 0.22 | 0.47 | 0.30 | 0.71 | / | / |
| QMC | 0.61 | 1.45 | 0.20 | 0.43 | 0.36 | 0.86 | 0.15 | 0.35 | 0.22 | 0.48 | 0.31 | 0.71 | -1% | -1% | |
| BOSampler | 0.52 | 0.95 | 0.19 | 0.39 | 0.30 | 0.67 | 0.14 | 0.33 | 0.20 | 0.45 | 0.27 | 0.56 | 11% | 21% | |
| PECNet [33] | MC | 2.80 | 5.38 | 0.59 | 0.94 | 1.14 | 2.04 | 0.76 | 1.52 | 0.76 | 1.51 | 1.21 | 2.33 | / | / |
| QMC | 2.81 | 5.35 | 0.59 | 0.98 | 1.13 | 2.28 | 0.68 | 1.36 | 0.78 | 1.56 | 1.20 | 2.31 | 1% | 1% | |
| BOSampler | 2.11 | 3.73 | 0.46 | 0.72 | 0.97 | 1.87 | 0.66 | 1.27 | 0.65 | 1.18 | 0.97 | 1.75 | 19% | 25% | |
| Social-STGCNN [35] | MC | 2.18 | 4.14 | 0.30 | 0.51 | 0.57 | 1.05 | 0.56 | 1.03 | 0.50 | 0.96 | 0.82 | 1.54 | / | / |
| QMC | 2.20 | 3.66 | 0.26 | 0.42 | 0.45 | 0.80 | 0.48 | 0.86 | 0.44 | 0.79 | 0.77 | 1.31 | 7% | 15% | |
| BOSampler | 0.87 | 1.13 | 0.18 | 0.32 | 0.58 | 1.06 | 0.52 | 0.96 | 0.45 | 0.86 | 0.52 | 0.87 | 37% | 44% | |
| STGAT [20] | MC | 1.73 | 3.49 | 0.60 | 1.10 | 0.92 | 1.94 | 0.69 | 1.41 | 0.90 | 1.87 | 0.97 | 1.96 | / | / |
| QMC | 1.80 | 3.61 | 0.56 | 0.98 | 0.89 | 1.87 | 0.67 | 1.33 | 0.88 | 1.85 | 0.96 | 1.93 | 1% | 2% | |
| BOSampler | 0.97 | 1.57 | 0.56 | 1.01 | 0.83 | 1.74 | 0.63 | 1.23 | 0.83 | 1.71 | 0.76 | 1.45 | 21% | 26% | |
3.3技术细节
为了顺利优化采样过程,我们对 BOsampler 应用了一些技术技巧。
热身。 首先,我们使用热启动来构建高斯过程。 它随机采样 w 潜在变量并生成轨迹,以获得对 的先验理解。 这个暖阶段和原来的MC随机采样是一样的。 我们选择预热次数为实验中采样总数的一半。 在Sec. 4.4中,我们提供了关于热身次数的定量分析
计算。 为了使 BOsampler 在 GPU 上的计算与预训练的神经网络相同,我们使用 BoTorch[5] 作为基础实现。 另外,我们还对一些与采集功能和批量计算相关的部分进行了相应的修改。
4实验
在本节中,我们首先使用五种流行方法作为完整 ETH-UCY 数据集及其硬子集的基线,对 BOsampler 的性能与其他采样方法进行定量比较。 然后,我们定性地可视化采样的轨迹及其分布。 最后,我们提供了消融研究和参数分析以进一步研究我们的方法。
4.1 实验设置
数据集。 我们在使用最广泛的公共人类轨迹预测基准数据集之一:ETH-UCY [38, 27] 上评估了我们的方法。 ETH-UCY是两个数据集的组合,总共有5个不同的场景,其中ETH数据集[38]包含ETH和HOTEL两个场景,有750个行人,UCY数据集[27 ]由UNIV、ZARA1、ZARA2三个场景组成,共有786名行人。 所有场景都是在道路、十字路口和几乎空旷的区域等不受约束的环境中捕获的。 在每个场景中,行人轨迹均按世界坐标序列提供。 ETH-UCY 的数据分割遵循 Social-GAN 和 Trajectron++ [18, 41] 中的协议。 轨迹以 0.4 秒的间隔进行采样,其中前 3.2 秒(8 帧)用作观测数据来预测接下来的 4.8 秒(12 帧)未来轨迹。
为了评估不常见轨迹的性能(例如行人在观察后突然掉头),我们选择一个异常子集,其中包含从 ETH/UCY 中选择的最不常见的轨迹。 为了量化异常率,我们使用线性方法[22](一种现成的卡尔曼滤波器)来给出参考轨迹。 由于它是线性模型,因此预测可以视为正常预测。 然后我们计算真实轨迹和参考轨迹之间的 FDE 作为偏差度量。 如果导数较高,则意味着行人随后进行了突然移动或急转弯。 最后,我们从 UCY/ETH 的每个数据集中选择前 4% 最偏离的轨迹作为异常子集。
| Baseline Model | Sampling | AVG | |
| ADE | FDE | ||
| Social-GAN [18] | MC | 0.53 | 1.05 |
| QMC | 0.53 | 1.03 | |
| BOSampler | 0.52 | 1.01 | |
| BOSampler + QMC | 0.52 | 1.00 | |
| Trajectron++ [41] | MC | 0.21 | 0.41 |
| QMC | 0.21 | 0.40 | |
| BOSampler | 0.18 | 0.36 | |
| BOSampler + QMC | 0.18 | 0.36 | |
| Trajectron++ [41] * | MC | 0.28 | 0.54 |
| QMC | 0.28 | 0.54 | |
| BOSampler | 0.25 | 0.45 | |
| BOSampler + QMC | 0.25 | 0.45 | |
| PECNet [33] | MC | 0.32 | 0.56 |
| QMC | 0.31 | 0.54 | |
| BOSampler | 0.30 | 0.51 | |
| BOSampler + QMC | 0.30 | 0.50 | |
| Social-STGCNN [35] | MC | 0.45 | 0.75 |
| QMC | 0.39 | 0.65 | |
| BOSampler | 0.41 | 0.69 | |
| BOSampler + QMC | 0.37 | 0.62 | |
| STGAT [20] | MC | 0.46 | 0.90 |
| QMC | 0.45 | 0.89 | |
| BOSampler | 0.44 | 0.85 | |
| BOSampler + QMC | 0.44 | 0.84 | |
评估指标。 我们遵循先前随机轨迹预测方法[18,33,43,20,16]采用的相同评估指标,该方法使用广泛使用的评估指标:最小平均位移误差(minADE)和最小最终位移误差 (minFDE)。 ADE 表示所有地面真实位置与估计位置之间的平均误差,而 FDE 计算端点之间的位移。 由于随机预测模型生成一组有限轨迹 (),而不是单个轨迹,因此我们使用遵循 [18, 41] 的 轨迹的最小 ADE 和 FDE ],称为 Best-of-20 策略。 对于 ETH-UCY 数据集,我们使用留一法交叉验证评估策略,其中四个场景用于训练,其余一个用于测试。 此外,对于所有实验,我们评估方法 10 次并报告稳健评估的平均性能。
基线方法。 我们使用五种主流随机行人轨迹预测方法来评估我们的BOsampler,包括Social-GAN [18]、PECNet [33]、Trajectron ++ [41]、Social-STGCNN [35] 和 STGAT [20]。 Social-GAN [18] 使用正常高斯噪声输入学习 GAN 模型来表示人类多模态。 BOsampler 优化采样噪声以鼓励多样性。 STGAT [20]是Social-GAN的改进版本,它也学习运动多模态的GAN模型,并应用图注意力机制来编码空间交互。 PECNet [33] 应用不同的端点来生成多个轨迹。 我们优化这些端点,其先验是学习的端点 VAE。 Trajectron++ [41] 使用观察结果作为条件,通过学习到的离散潜变量来学习 CVAE。 Social-STGCNN [35] 直接学习每个点的高斯分布参数并从中获取样本。 在这里,我们可以直接优化点的位置。 所有这些基线方法都使用蒙特卡罗(MC)世代采样方法。 我们可以直接将采样方式从 MC 更改为我们的 BOsampler 及其经过训练的模型,即我们的方法不需要任何训练数据来改进采样过程。 除了 MC 采样之外,我们还将 BOsampler 与 [4] 中引入的准蒙特卡罗 (QMC) 采样进行比较,后者使用低差异准随机序列来代替随机序列采样。 它可以生成均匀分布的点,实现更均匀的采样。

4.2定量比较
ETH-UCY 异常子集上的性能。 我们方法的目标是帮助模型生成更全面、更可靠的样本。 因此,我们重点关注左转、右转或掉头等异常情况。 尽管这些情况在所有轨迹中只占少数,但由于其安全性和可靠性,对于智能交通和自动驾驶等应用仍然至关重要。 异常子集的详细选择过程在Sec.4.1中解释。 如图所示 选项卡。 1,我们基于五种基线方法,在不同的采样方法(包括 MC、QMC 和 BOsampler)中使用相同的预训练模型给出 minADE 和 minFDE 结果。 与 MC 和 QMC 相比,BOsampler 在异常轨迹方面显示出显着改进。 五个基线模型中BOsampler对ADE/FDE上MC的平均性能增益率分别为23.71%和27.49%。 这意味着BOsampler相对于原始固定预训练模型的提升主要在于稀有轨迹。
ETH-UCY 上的表现。 除了特殊情况外,我们还在原始 ETH-UCY 数据集上对 BOsampler 与 MC 和 QMC 采样方法进行了定量比较。 如图所示 选项卡。 2,我们使用相同的预训练模型和不同的采样方法提供 minADE 和 minFDE 结果。 在这里,我们仅报告所有五个场景的平均结果。 请参阅补充材料了解每个场景的完整实验结果。 对于所有基线方法,BOsampler 始终优于 MC 采样方法,这表明了所提出方法的有效性,尽管不是很多。 不同采样方法的固定模型的所有结果都是具有可比性的,因为只有一小部分轨迹是不常见的(属于低概率),而大多数测试轨迹是正常的。 但我们想强调的是,这些低概率的轨迹可能会增加自动驾驶系统的安全风险。 结果表明,BOsampler 可以为可能的低概率情况提供更好的预测,而不会降低大多数正常轨迹的准确性。 此外,BOsampler 在大多数基线上也显示出相对于 QMC 方法的改进。 对于Social-STGCNN [35],虽然BOsampler比MC方法取得了更大的进步,但仍然略低于QMC方法。 这是因为Social-STGCNN在每个位置上添加了不确定性,其变量维度对于贝叶斯优化来说太大()。 此外,我们还表明所提出的BOsampler与QMC方法并不矛盾。 在预热阶段使用 QMC,我们可以进一步提高 BOsampler 的性能。 例如,对于Social-STGCNN,BOsampler + QMC可以进一步改进QMC方法,达到0.37 ADE和0.62 FDE。 请注意,我们不与 NPSN 方法[4]进行比较,因为它是一种需要访问源数据并重新训练模型的监督方法。
4.3定性比较
我们通过三个定性实验进一步研究我们的方法。 首先,我们可视化不同样本数的 MC、QMC 和 BOsampler 的采样轨迹。 其次,我们可视化并比较真实环境中 MC、QMC 和 BOsampler 采样轨迹的最佳预测。 第三,我们还提供了一些失败案例的可视化。
具有不同样本数的轨迹。 在这个实验中,我们的目的是研究采样(后验)分布如何随着采样数量的增加而变化。 如图3所示,我们提供了MC、QMC和BOsampler的采样结果,样本编号为,其中浅色区域表示采样(后)分布。 我们可以观察到 MC 和 QMC 的采样分布没有变化。 唯一的区别是 QMC 平滑了原始分布。 这表明当采样数量较小时,由于分布突然变化,QMC 可能无法很好地工作。 与它们不同的是,BOsampler随着样本数量的增加逐渐探索概率较低的样本,可以实现多样性和准确性之间的自适应平衡。 当采样数量较小时,BOsampler倾向于采样接近先验分布的值。 当较大时,鼓励模型选择那些低概率的样本。

可视化。 我们还比较了不同采样方法的最佳预测,以直观地了解 BOsampler 在哪种情况下效果良好。 如图4所示,我们给出了不同采样方法的最佳预测以及ETH-UCY数据集中五个场景的地面真实轨迹。 我们观察到 BOsampler 可以在低概率(远离正常路径)下提供社会可接受的路径。 例如,当行人左转或右转时,葫芦真值会与MC和QMC的采样结果相去甚远,但我们的方法的采样结果通常能够覆盖这种情况。 这表明BOsampler鼓励模型探索低概率的选择。 此外,我们还提供了失败案例的可视化,以更好地理解该方法。 我们发现,当最有可能的预测远离地面实况时,BOsampler可能会丢失地面实况轨迹。
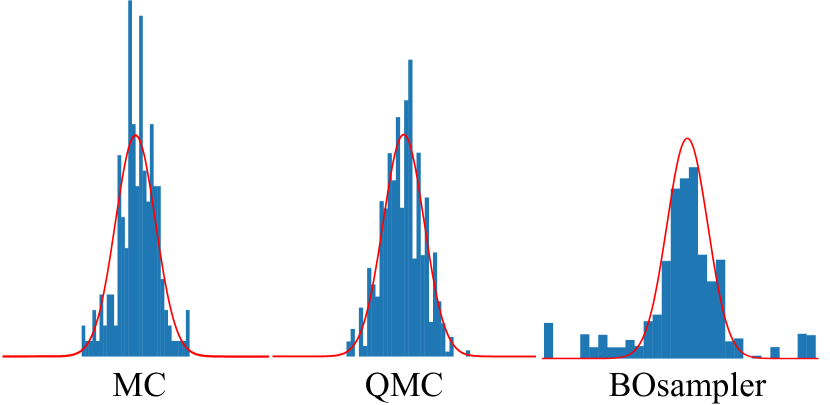
此外,如图5所示,我们用原始标准高斯分布可视化了MC、QMC和BOsampler的优化采样分布。 通过仿真结果,我们表明 BOsampler 可以减轻长尾特性,而 MC 和 QMC 则不能。

右:PECNet 上 BOsampler 使用不同超参数 的 ADE 和 FDE。
4.4消融研究和参数分析
在本小节中,我们进行消融研究和参数分析,以研究不同超参数的稳健性。 然后,我们对不同数量样本的采样过程进行了详细分析。
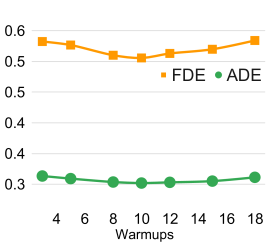
热身分析: 我们在预热次数中进行选择,然后使用PECNet作为基线模型。 采用 Best-of-20 策略在 ETH/UCY 数据集上的结果如图 6 的顶行所示。 对于所有数量的预热,BOsampler 实现了比 MC 基线更好的性能。 当预热次数接近样本数的一半(即10)时,相应的ADE/FDE优于其他选项。 尽管减少预热次数会通过增加 BOsampler 的数量来鼓励更多的探索,但总体性能会受到损害,因为异常轨迹仅占整个数据集的相对较小部分。 将预热数量设置为整个样本数量的一半有助于平衡探索和利用。
具有采集功能的分析: 我们通过选择来分析超参数的鲁棒性,在这个范围内均匀分开。 我们选择 PECNet 作为基础模型,并使用 Best-of-20 策略在 ETH/UCY 数据集上进行评估。 5个采集因子之间的性能比较接近,这意味着当采集因子设置在合理的范围内时,BOsampler的性能是稳定的。
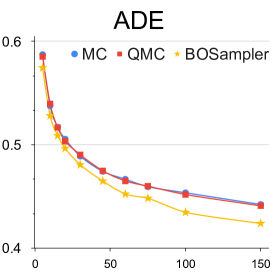
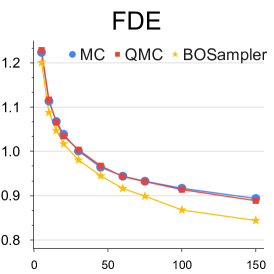
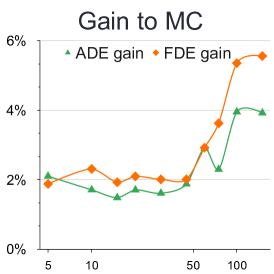
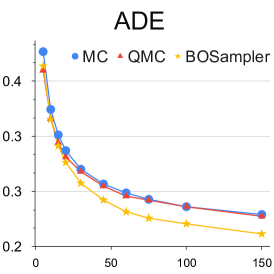
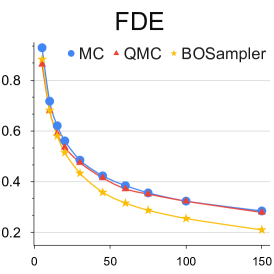
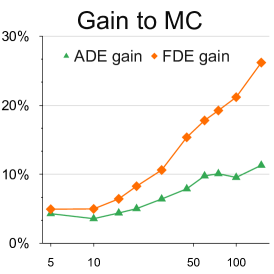
不同样本数量的分析: 我们提供了关于样本数量的定量实验,以更好地理解 BOsampler 的简化过程。 如图7所示,我们将MC、QMC和BOsampler的ETH-UCY数据集上的ADE和FDE与Social GAN和PECNet上不同数量的样本进行了比较。 我们选择一些样本。 BOsampler 在所有设置下都表现良好,这展示了多样性和准确性之间的自适应平衡。 它还表明,即使预热步骤非常小(如本例所示少于五个),BOsampler 也能正常工作。 此外,我们发现当样本数量增加时,我们的 BOsampler 对 MC 的改进比 QMC 的改进更大。 通过高斯过程,BOsampler可以随着采样过程逐渐细化后验分布。
5结论
在本文中,我们提出了一种无监督采样方法,称为BOsampler,以促进随机轨迹预测系统的采样过程。 在这种方法中,我们将采样表示为顺序高斯过程,其中当前预测以先前的样本为条件。 使用贝叶斯优化,我们定义了一个获取函数来自适应地探索低概率的潜在路径。 实验结果证明了BOsampler相对于MC和QMC等其他采样方法的优越性。
更广泛的影响和限制: BOsampler 可以与现有的随机轨迹预测模型集成,无需重新训练。 提供合理多样的轨迹采样,有助于智能交通和自动驾驶的安全可靠。 尽管无需训练,但由于顺序建模,这种推理时间采样提升方法仍然需要时间成本。 以 Social GAN 作为基线,我们的方法需要 来预测 512 条轨迹,而 MC 需要 。 更好的计算技术可以缓解这个问题。
致谢
该项目得到了美国国立卫生研究院 (NIH) 根据合同 R01HL159805、NSF 融合加速器 Track-D 奖 #2134901、Apple Inc. 的资助、KDDI Research Inc. 的资助以及来自以下机构的慷慨捐赠的部分支持Salesforce Inc.、微软研究院和亚马逊研究院。 感谢MBZUAI的同事Zunhao为部分实验提供了计算资源。
参考
- [1] Vida Adeli, Mahsa Ehsanpour, Ian Reid, Juan Carlos Niebles, Silvio Savarese, Ehsan Adeli, and Hamid Rezatofighi. Tripod: Human trajectory and pose dynamics forecasting in the wild. In ICCV, pages 13390–13400, 2021.
- [2] Alexandre Alahi, Kratarth Goel, Vignesh Ramanathan, Alexandre Robicquet, Li Fei-Fei, and Silvio Savarese. Social lstm: Human trajectory prediction in crowded spaces. In CVPR, pages 961–971, 2016.
- [3] Inhwan Bae, Jin-Hwi Park, and Hae-Gon Jeon. Learning pedestrian group representations for multi-modal trajectory prediction. In ECCV, pages 270–289, 2022.
- [4] Inhwan Bae, Jin-Hwi Park, and Hae-Gon Jeon. Non-probability sampling network for stochastic human trajectory prediction. In CVPR, pages 6477–6487, 2022.
- [5] Maximilian Balandat, Brian Karrer, Daniel R. Jiang, Samuel Daulton, Benjamin Letham, Andrew Gordon Wilson, and Eytan Bakshy. BoTorch: A Framework for Efficient Monte-Carlo Bayesian Optimization. In Advances in Neural Information Processing Systems 33, 2020.
- [6] Eric Brochu, Vlad M Cora, and Nando De Freitas. A tutorial on bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. arXiv preprint arXiv:1012.2599, 2010.
- [7] Guangyi Chen, Junlong Li, Jiwen Lu, and Jie Zhou. Human trajectory prediction via counterfactual analysis. In ICCV, pages 9824–9833, 2021.
- [8] Guangyi Chen, Junlong Li, Nuoxing Zhou, Liangliang Ren, and Jiwen Lu. Personalized trajectory prediction via distribution discrimination. In ICCV, pages 15580–15589, 2021.
- [9] Yuxiao Chen, Boris Ivanovic, and Marco Pavone. Scept: Scene-consistent, policy-based trajectory predictions for planning. In CVPR, pages 17103–17112, 2022.
- [10] Patrick Dendorfer, Sven Elflein, and Laura Leal-Taixé. Mg-gan: A multi-generator model preventing out-of-distribution samples in pedestrian trajectory prediction. In ICCV, pages 13158–13167, 2021.
- [11] Nachiket Deo and Mohan M Trivedi. Trajectory forecasts in unknown environments conditioned on grid-based plans. arXiv preprint arXiv:2001.00735, 2020.
- [12] Liangji Fang, Qinhong Jiang, Jianping Shi, and Bolei Zhou. Tpnet: Trajectory proposal network for motion prediction. In CVPR, 2020.
- [13] Tharindu Fernando, Simon Denman, Sridha Sridharan, and Clinton Fookes. Soft+ hardwired attention: An lstm framework for human trajectory prediction and abnormal event detection. Neural Networks, 108:466–478, 2018.
- [14] Harshayu Girase, Haiming Gang, Srikanth Malla, Jiachen Li, Akira Kanehara, Karttikeya Mangalam, and Chiho Choi. Loki: Long term and key intentions for trajectory prediction. In ICCV, pages 9803–9812, 2021.
- [15] Junru Gu, Chen Sun, and Hang Zhao. Densetnt: End-to-end trajectory prediction from dense goal sets. In ICCV, pages 15303–15312, 2021.
- [16] Tianpei Gu, Guangyi Chen, Junlong Li, Chunze Lin, Yongming Rao, Jie Zhou, and Jiwen Lu. Stochastic trajectory prediction via motion indeterminacy diffusion. In CVPR, pages 17113–17122, 2022.
- [17] Ke Guo, Wenxi Liu, and Jia Pan. End-to-end trajectory distribution prediction based on occupancy grid maps. In CVPR, pages 2242–2251, 2022.
- [18] Agrim Gupta, Justin Johnson, Li Fei-Fei, Silvio Savarese, and Alexandre Alahi. Social gan: Socially acceptable trajectories with generative adversarial networks. In CVPR, pages 2255–2264, 2018.
- [19] Marah Halawa, Olaf Hellwich, and Pia Bideau. Action-based contrastive learning for trajectory prediction. In ECCV, pages 143–159, 2022.
- [20] Yingfan Huang, HuiKun Bi, Zhaoxin Li, Tianlu Mao, and Zhaoqi Wang. Stgat: Modeling spatial-temporal interactions for human trajectory prediction. In ICCV, pages 6272–6281, 2019.
- [21] Boris Ivanovic and Marco Pavone. The trajectron: Probabilistic multi-agent trajectory modeling with dynamic spatiotemporal graphs. In ICCV, pages 2375–2384, 2019.
- [22] Rudolph Emil Kalman. A new approach to linear filtering and prediction problems. 1960.
- [23] Kirthevasan Kandasamy, Willie Neiswanger, Jeff Schneider, Barnabas Poczos, and Eric P Xing. Neural architecture search with bayesian optimisation and optimal transport. NeurIPS, 31, 2018.
- [24] Vineet Kosaraju, Amir Sadeghian, Roberto Martín-Martín, Ian Reid, Hamid Rezatofighi, and Silvio Savarese. Social-bigat: Multimodal trajectory forecasting using bicycle-gan and graph attention networks. In NeurIPS, pages 137–146, 2019.
- [25] Mihee Lee, Samuel S Sohn, Seonghyeon Moon, Sejong Yoon, Mubbasir Kapadia, and Vladimir Pavlovic. Muse-vae: Multi-scale vae for environment-aware long term trajectory prediction. In CVPR, pages 2221–2230, 2022.
- [26] Namhoon Lee, Wongun Choi, Paul Vernaza, Christopher B Choy, Philip HS Torr, and Manmohan Chandraker. Desire: Distant future prediction in dynamic scenes with interacting agents. In CVPR, pages 336–345, 2017.
- [27] Alon Lerner, Yiorgos Chrysanthou, and Dani Lischinski. Crowds by example. In Computer Graphics Forum, volume 26, pages 655–664, 2007.
- [28] Lihuan Li, Maurice Pagnucco, and Yang Song. Graph-based spatial transformer with memory replay for multi-future pedestrian trajectory prediction. In CVPR, pages 2231–2241, 2022.
- [29] Junwei Liang, Lu Jiang, Kevin Murphy, Ting Yu, and Alexander Hauptmann. The garden of forking paths: Towards multi-future trajectory prediction. In CVPR, pages 10508–10518, 2020.
- [30] Yuejiang Liu, Qi Yan, and Alexandre Alahi. Social nce: Contrastive learning of socially-aware motion representations. In ICCV, pages 15118–15129, 2021.
- [31] Yecheng Jason Ma, Jeevana Priya Inala, Dinesh Jayaraman, and Osbert Bastani. Likelihood-based diverse sampling for trajectory forecasting. In ICCV, pages 13279–13288, 2021.
- [32] Karttikeya Mangalam, Yang An, Harshayu Girase, and Jitendra Malik. From goals, waypoints & paths to long term human trajectory forecasting. In ICCV, pages 15233–15242, 2021.
- [33] Karttikeya Mangalam, Harshayu Girase, Shreyas Agarwal, Kuan-Hui Lee, Ehsan Adeli, Jitendra Malik, and Adrien Gaidon. It is not the journey but the destination: Endpoint conditioned trajectory prediction. In ECCV, 2020.
- [34] Mancheng Meng, Ziyan Wu, Terrence Chen, Xiran Cai, Xiang Sean Zhou, Fan Yang, and Dinggang Shen. Forecasting human trajectory from scene history. NeurIPS, 2022.
- [35] Abduallah Mohamed, Kun Qian, Mohamed Elhoseiny, and Christian Claudel. Social-stgcnn: A social spatio-temporal graph convolutional neural network for human trajectory prediction. In CVPR, 2020.
- [36] Harald Niederreiter. Random number generation and quasi-Monte Carlo methods. SIAM, 1992.
- [37] Nishant Nikhil and Brendan Tran Morris. Convolutional neural network for trajectory prediction. In ECCVW, pages 0–0, 2018.
- [38] Stefano Pellegrini, Andreas Ess, and Luc Van Gool. Improving data association by joint modeling of pedestrian trajectories and groupings. In ECCV, pages 452–465, 2010.
- [39] Nicholas Rhinehart, Kris M Kitani, and Paul Vernaza. R2p2: A reparameterized pushforward policy for diverse, precise generative path forecasting. In ECCV, pages 772–788, 2018.
- [40] Amir Sadeghian, Vineet Kosaraju, Ali Sadeghian, Noriaki Hirose, Hamid Rezatofighi, and Silvio Savarese. Sophie: An attentive gan for predicting paths compliant to social and physical constraints. In CVPR, pages 1349–1358, 2019.
- [41] Tim Salzmann, Boris Ivanovic, Punarjay Chakravarty, and Marco Pavone. Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data. In ECCV, 2020.
- [42] Bobak Shahriari, Kevin Swersky, Ziyu Wang, Ryan P Adams, and Nando De Freitas. Taking the human out of the loop: A review of bayesian optimization. Proceedings of the IEEE, 104(1):148–175, 2015.
- [43] Liushuai Shi, Le Wang, Chengjiang Long, Sanping Zhou, Mo Zhou, Zhenxing Niu, and Gang Hua. Sgcn: Sparse graph convolution network for pedestrian trajectory prediction. In CVPR, pages 8994–9003, 2021.
- [44] Jasper Snoek, Hugo Larochelle, and Ryan P Adams. Practical bayesian optimization of machine learning algorithms. NeurIPS, 25, 2012.
- [45] Kihyuk Sohn, Honglak Lee, and Xinchen Yan. Learning structured output representation using deep conditional generative models. In NeurIPS, pages 3483–3491, 2015.
- [46] Hao Sun, Zhiqun Zhao, and Zhihai He. Reciprocal learning networks for human trajectory prediction. In CVPR, 2020.
- [47] Jianhua Sun, Qinhong Jiang, and Cewu Lu. Recursive social behavior graph for trajectory prediction. In CVPR, June 2020.
- [48] Jianhua Sun, Yuxuan Li, Liang Chai, Hao-Shu Fang, Yong-Lu Li, and Cewu Lu. Human trajectory prediction with momentary observation. In CVPR, pages 6467–6476, 2022.
- [49] Qiao Sun, Xin Huang, Junru Gu, Brian C Williams, and Hang Zhao. M2i: From factored marginal trajectory prediction to interactive prediction. In CVPR, pages 6543–6552, 2022.
- [50] Yu Sun, Xiaolong Wang, Zhuang Liu, John Miller, Alexei Efros, and Moritz Hardt. Test-time training with self-supervision for generalization under distribution shifts. In ICML, pages 9229–9248, 2020.
- [51] Charlie Tang and Russ R Salakhutdinov. Multiple futures prediction. In NeurIPS, pages 15398–15408, 2019.
- [52] Li-Wu Tsao, Yan-Kai Wang, Hao-Siang Lin, Hong-Han Shuai, Lai-Kuan Wong, and Wen-Huang Cheng. Social-ssl: Self-supervised cross-sequence representation learning based on transformers for multi-agent trajectory prediction. In ECCV, pages 234–250, 2022.
- [53] Anirudh Vemula, Katharina Muelling, and Jean Oh. Social attention: Modeling attention in human crowds. In ICRA, pages 1–7, 2018.
- [54] Colin White, Willie Neiswanger, and Yash Savani. Bananas: Bayesian optimization with neural architectures for neural architecture search. In AAAI, volume 35, pages 10293–10301, 2021.
- [55] Conghao Wong, Beihao Xia, Ziming Hong, Qinmu Peng, Wei Yuan, Qiong Cao, Yibo Yang, and Xinge You. View vertically: A hierarchical network for trajectory prediction via fourier spectrums. In ECCV, pages 682–700, 2022.
- [56] Chenxin Xu, Maosen Li, Zhenyang Ni, Ya Zhang, and Siheng Chen. Groupnet: Multiscale hypergraph neural networks for trajectory prediction with relational reasoning. In CVPR, pages 6498–6507, 2022.
- [57] Chenfeng Xu, Tian Li, Chen Tang, Lingfeng Sun, Kurt Keutzer, Masayoshi Tomizuka, Alireza Fathi, and Wei Zhan. Pretram: Self-supervised pre-training via connecting trajectory and map. ECCV, 2022.
- [58] Chenxin Xu, Weibo Mao, Wenjun Zhang, and Siheng Chen. Remember intentions: Retrospective-memory-based trajectory prediction. In CVPR, pages 6488–6497, 2022.
- [59] Pei Xu, Jean-Bernard Hayet, and Ioannis Karamouzas. Socialvae: Human trajectory prediction using timewise latents. ECCV, 2022.
- [60] Yi Xu, Lichen Wang, Yizhou Wang, and Yun Fu. Adaptive trajectory prediction via transferable gnn. In CVPR, pages 6520–6531, 2022.
- [61] Cunjun Yu, Xiao Ma, Jiawei Ren, Haiyu Zhao, and Shuai Yi. Spatio-temporal graph transformer networks for pedestrian trajectory prediction. In ECCV, 2020.
- [62] Ye Yuan, Xinshuo Weng, Yanglan Ou, and Kris M Kitani. Agentformer: Agent-aware transformers for socio-temporal multi-agent forecasting. pages 9813–9823, 2021.
- [63] Jiangbei Yue, Dinesh Manocha, and He Wang. Human trajectory prediction via neural social physics. In ECCV, pages 376–394, 2022.
- [64] Pu Zhang, Wanli Ouyang, Pengfei Zhang, Jianru Xue, and Nanning Zheng. Sr-lstm: State refinement for lstm towards pedestrian trajectory prediction. In CVPR, pages 12085–12094, 2019.
- [65] Hang Zhao, Jiyang Gao, Tian Lan, Chen Sun, Benjamin Sapp, Balakrishnan Varadarajan, Yue Shen, Yi Shen, Yuning Chai, Cordelia Schmid, et al. Tnt: Target-driven trajectory prediction. 2020.
- [66] He Zhao and Richard P Wildes. Where are you heading? dynamic trajectory prediction with expert goal examples. In ICCV, pages 7629–7638, 2021.
- [67] Tianyang Zhao, Yifei Xu, Mathew Monfort, Wongun Choi, Chris Baker, Yibiao Zhao, Yizhou Wang, and Ying Nian Wu. Multi-agent tensor fusion for contextual trajectory prediction. In CVPR, pages 12126–12134, 2019.
- [68] Fang Zheng, Le Wang, Sanping Zhou, Wei Tang, Zhenxing Niu, Nanning Zheng, and Gang Hua. Unlimited neighborhood interaction for heterogeneous trajectory prediction. In ICCV, pages 13168–13177, 2021.
- [69] Yiqi Zhong, Zhenyang Ni, Siheng Chen, and Ulrich Neumann. Aware of the history: Trajectory forecasting with the local behavior data. ECCV, 2022.
BoSampler 附录
附录ABOsampler的算法
我们给出的算法对 BOsampler 进行了简短但清晰的总结。 详细算法参见算法1。
附录BETH/UCY完整的定量实验结果
我们在 ETH/UCY 数据集的五个场景上展示了完整的实验结果 选项卡。 4. 对于所有基线方法,BOsampler 始终优于 MC 采样方法,这表明了所提出方法的有效性,尽管不是很多。 BOsampler 在大多数基线上也显示出相对于 QMC 方法的改进。 与异常子集相比,BOsampler 在完整的 ETH/UCY 集中没有相同水平的性能增益。 这是因为不常见的轨迹仅占数据集的一小部分。 BOsampler 在 ETH 数据集上实现了更多性能提升。 原因可能是相同的:与 ETH/UCY 中的其他四个数据集相比,不常见轨迹在 ETH 数据集中出现的频率更高。 虽然BOsampler在整个集合上没有实现巨大的改进,但考虑到BOsampler在异常子集中有显着的增益,很明显BOsampler平衡基线模型分布的利用和边缘情况的探索。 因此BOsampler有助于提高基线模型采样过程的稳健性。 我们强调 BOsampler 专注于低概率的轨迹。 尽管这些案例是少数,但在智能交通和自动驾驶中考虑它们是有意义且至关重要的。

| top 4% | top 12% | full | |
| MC | 1.21/2.33 | 0.88/1.76 | 0.32/0.56 |
| QMC | 1.20/2.33 | 0.86/1.70 | 0.31/0.54 |
| BOsampler | 0.97/1.75 | 0.74/1.38 | 0.30/0.51 |
附录C不同比例异常子集的实验
在主稿的4.2节中,我们将例外设置的比例设置为4%。 为了验证所选子集的有效性,我们进一步提供了12%的变异,这表明与原始子集的性能趋势一致,从而证实了我们实验的比率设置的代表性和适当性。 实验结果呈现在 选项卡。 3. 当比率达到 12% 时,BOsampler 仍然实现了比基线好得多的性能。
附录D失败案例的可视化
我们提供失败案例的可视化,以更好地理解该方法。 从图8的可视化中,我们发现BOsampler可能会在最有可能的情况下丢失地面真实轨迹预测与真实情况相差甚远。 这并不奇怪,因为我们的方法是基于良好先验分布的假设。 在不访问更多数据的情况下解决这个问题并非易事。 一个可能的解决方案是在推理[50]期间使用测试数据修改先验分布。
| Baseline Model | Sampling | ETH | HOTEL | UNIV | ZARA1 | ZARA2 | AVG | ||||||
| ADE | FDE | ADE | FDE | ADE | FDE | ADE | FDE | ADE | FDE | ADE | FDE | ||
| Social-GAN [18] | MC | 0.77 | 1.40 | 0.43 | 0.88 | 0.75 | 1.50 | 0.35 | 0.69 | 0.36 | 0.72 | 0.53 | 1.05 |
| QMC | 0.76 | 1.38 | 0.43 | 0.87 | 0.75 | 1.50 | 0.34 | 0.69 | 0.35 | 0.72 | 0.53 | 1.03 | |
| BOSampler | 0.73 | 1.28 | 0.43 | 0.87 | 0.75 | 1.50 | 0.34 | 0.69 | 0.35 | 0.71 | 0.52 | 1.01 | |
| BOSampler + QMC | 0.72 | 1.26 | 0.43 | 0.87 | 0.74 | 1.49 | 0.34 | 0.69 | 0.35 | 0.71 | 0.52 | 1.00 | |
| Trajectron++ [41] | MC | 0.43 | 0.86 | 0.12 | 0.19 | 0.22 | 0.43 | 0.17 | 0.32 | 0.12 | 0.25 | 0.21 | 0.41 |
| QMC | 0.43 | 0.84 | 0.12 | 0.19 | 0.22 | 0.42 | 0.17 | 0.31 | 0.12 | 0.24 | 0.21 | 0.40 | |
| BOSampler | 0.34 | 0.64 | 0.12 | 0.21 | 0.18 | 0.40 | 0.14 | 0.30 | 0.11 | 0.24 | 0.18 | 0.36 | |
| BOSampler + QMC | 0.34 | 0.64 | 0.12 | 0.21 | 0.18 | 0.40 | 0.14 | 0.30 | 0.11 | 0.24 | 0.18 | 0.36 | |
| Trajectron++ [41]* | MC | 0.57 | 1.06 | 0.16 | 0.26 | 0.30 | 0.61 | 0.22 | 0.42 | 0.16 | 0.33 | 0.28 | 0.54 |
| QMC | 0.57 | 1.05 | 0.16 | 0.26 | 0.30 | 0.61 | 0.22 | 0.42 | 0.16 | 0.33 | 0.28 | 0.54 | |
| BOSampler | 0.49 | 0.82 | 0.15 | 0.23 | 0.27 | 0.53 | 0.20 | 0.38 | 0.15 | 0.29 | 0.25 | 0.45 | |
| BOSampler + QMC | 0.49 | 0.82 | 0.15 | 0.23 | 0.27 | 0.53 | 0.20 | 0.38 | 0.15 | 0.29 | 0.25 | 0.45 | |
| PECNet [33] | MC | 0.61 | 1.07 | 0.22 | 0.39 | 0.34 | 0.56 | 0.25 | 0.45 | 0.19 | 0.33 | 0.32 | 0.56 |
| QMC | 0.60 | 1.04 | 0.21 | 0.38 | 0.33 | 0.53 | 0.24 | 0.43 | 0.18 | 0.31 | 0.31 | 0.54 | |
| BOSampler | 0.56 | 0.92 | 0.21 | 0.38 | 0.32 | 0.52 | 0.24 | 0.42 | 0.18 | 0.31 | 0.30 | 0.51 | |
| BOSampler + QMC | 0.56 | 0.91 | 0.21 | 0.37 | 0.31 | 0.51 | 0.24 | 0.41 | 0.18 | 0.31 | 0.30 | 0.50 | |
| Social-STGCNN [35] | MC | 0.65 | 1.10 | 0.50 | 0.86 | 0.44 | 0.80 | 0.34 | 0.53 | 0.31 | 0.48 | 0.45 | 0.75 |
| QMC | 0.62 | 1.03 | 0.38 | 0.57 | 0.36 | 0.63 | 0.32 | 0.52 | 0.29 | 0.50 | 0.39 | 0.65 | |
| BOSampler | 0.57 | 0.90 | 0.44 | 0.82 | 0.43 | 0.76 | 0.34 | 0.54 | 0.26 | 0.45 | 0.41 | 0.69 | |
| BOSampler + QMC | 0.49 | 0.74 | 0.39 | 0.73 | 0.41 | 0.72 | 0.32 | 0.52 | 0.26 | 0.40 | 0.37 | 0.62 | |
| STGAT [20] | MC | 0.74 | 1.34 | 0.35 | 0.68 | 0.56 | 1.20 | 0.34 | 0.68 | 0.29 | 0.59 | 0.46 | 0.90 |
| QMC | 0.73 | 1.32 | 0.35 | 0.67 | 0.56 | 1.20 | 0.34 | 0.68 | 0.29 | 0.59 | 0.45 | 0.89 | |
| BOSampler | 0.70 | 1.15 | 0.35 | 0.67 | 0.55 | 1.17 | 0.34 | 0.68 | 0.29 | 0.59 | 0.44 | 0.85 | |
| BOSampler + QMC | 0.68 | 1.11 | 0.35 | 0.67 | 0.55 | 1.17 | 0.33 | 0.67 | 0.30 | 0.59 | 0.44 | 0.84 | |