CLIP 对红圈了解多少?
视觉公关![[Uncaptioned image]](circle.png) VLM 的 mpt 工程
VLM 的 mpt 工程
摘要
大规模视觉语言模型(例如 CLIP)可以学习强大的图像文本表示,这些表示已找到许多应用,从零样本分类到文本到图像生成。 尽管如此,它们通过提示解决新颖的判别性任务的能力仍落后于大型语言模型,例如 GPT-3。 在这里,我们探索视觉提示工程的想法,通过在图像空间而不是文本中进行编辑来解决分类之外的计算机视觉任务。 特别是,我们发现了 CLIP 的一种新兴功能,只需在物体周围画一个红色圆圈,我们就可以将模型的注意力引导到该区域,同时还保留全局信息。 我们通过在零样本引用表达式理解中实现最先进的技术以及在关键点定位任务中的强大性能来展示这种简单方法的力量。 最后,我们提请注意大型语言视觉模型的一些潜在的伦理问题。
1简介
GPT-2/3 [7, 39] 和 ChatGPT [1] 等大型语言模型(大语言模型)已经表现出令人惊讶的新兴行为。 例如,这些模型可以以零样本的方式执行语言翻译,而无需经过明确的训练。 这可以部分解释为,所需行为的发生,例如两种语言之间的翻译,自然发生在他们庞大的训练语料库中,本质上就是互联网。
在像 CLIP [38] 这样的大型视觉语言模型 (VLM) 中也观察到了有趣的突发行为。 例如,CLIP 可用于零样本分类,通过检查给定图像与提示的兼容性,例如“ 的图像”,其中 是一组中的一个要测试的类别假设。
通过向 VLM 提供适当设计的输入(通常称为提示)来引发紧急行为。 正如上面的例子,研究人员主要关注设计文本提示,操纵模型的文本输入。 这种方法受到大语言模型的启发,其中操纵文本模态是唯一可用的选择。 然而,VLM 本质上是多模式的,并且提供了操纵文本和视觉两种模式的可能性。 虽然文本模态是表达语义的自然选择,但视觉模态可以更好地表达几何属性(例如位置)。

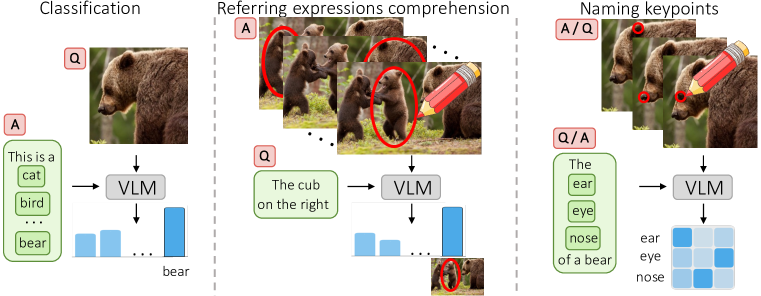
在本文中,我们因此探索视觉提示工程 111注意视觉提示调整和视觉提示工程之间的区别,前者是之前探索过的一种设置,其中的提示是针对特定任务的可学习词符,而后者我们在像素空间中应用了固定的增强。. 我们这样做有两个目标。 第一个目标是提供一个更实用的工具,以零样本的方式从 VLM 中提取有用的信息。 我们通过工程视觉提示在引用表达理解中获得最先进的零样本结果来证明这一点。 第二个目标是描述 VLM 及其训练数据的有趣且意想不到的特性,包括识别一些可能引起道德问题的行为。
也许我们的发现中最令人惊讶的是特定类型的视觉提示的有效性:在图像顶部绘制一个纯红色圆圈(图 1)。 我们表明,这种简单的干预引导 VLM 分析/讨论圆圈中包含的图像区域。 然后,此行为可用于诸如命名特定对象或对象部分或基于描述检测特定图像区域等任务。 例如,后者是通过用红色圆圈标记每个对象提案并使用 VLM 找到与所提供的引用表达式相关的最佳匹配来实现的,从而在无监督的情况下在多个基准上取得了良好的结果。 此外,我们还表明,用圆圈进行提示也适用于更细粒度的定位,标记特定的对象部分或关键点,而不仅仅是整个对象。
我们进一步将标记图像与裁剪图像的替代方案进行对比,从滑动窗口分类器到区域神经网络,裁剪图像是将图像级预测器的焦点引导到特定图像区域的规范方法。 我们表明,至少对于 VLM 来说,标记比裁剪更有效,可能是因为它不会像后者那样丢失上下文信息。
除了实际应用之外,我们的研究结果还揭示了 VLM 意想不到且有趣的特性。 我们根据经验表明,在一系列可能的标记(圆圈、方框、箭头等的变体)中,用红色圆圈进行标记是最佳的。 据推测,VLM 可以立即理解红色圆圈,因为这些圆圈在训练语料库(即互联网)中出现得足够频繁。 虽然我们无法访问 CLIP 的完整训练数据,但我们通过在 YFCC15M(CC-BY 图像数据集)中查找此类图像的示例来证实这一直觉。
我们的分析表明,即使在像 YFCC15M 这样的(相对较小的)图像数据集中,红色圆圈确实也存在,但它们很少。 无需明确关注即可从此类罕见事件中学习这种行为,这证明了 VLM 的非凡能力。 我们测试了不同尺寸/容量的模型,并表明只有较大的模型才能可靠地表现出这种行为,这符合我们的直觉。
最后,我们注意到,VLM 甚至可以从罕见事件(例如“红圈”)中学习的能力可以获得理想和不良行为。 尤其是红色圆圈,在训练数据中可能具有负面含义,因为新闻媒体经常使用它们来标记失踪人员或罪犯,显然,该模型是从此类示例中学习的。 结果,我们发现在图像中绘制红色圆圈会增加模型将一个人定性为罪犯或失踪人员的可能性。
总而言之,我们做出了以下主要贡献:(1)我们提出将标记作为一种新形式的视觉提示工程,可以有效地提取像 CLIP 这样的 VLM 中有用的紧急行为; (2) 我们使用后者通过 VLM 实现最先进的零样本引用表达式理解; (3) 我们分析了为什么标记对这些模型有效,并将其与训练数据和大模型容量联系起来; (4) 我们表明,视觉提示工程也可能引发不良行为,例如引发 VLM 中的问题偏差,揭示潜在的道德问题。
2相关工作
大规模预训练的突现行为主要在大语言模型中观察到。 最值得注意的是,GPT-2 [39]、GPT-3 [7] 和 ChatGPT [1] 已被证明能够诸如零样本翻译、问答、算术以及实体代理的规划行动等任务[18]。 微调大语言模型还可以生成可以从文档字符串[8]生成代码或解决数学问题[13, 23]的模型。 对于像 CLIP 这样的 VLM,仅报告了一些新兴的零样本行为,主要用于分类 [38] 和 OCR [33]。 像 FLAMINGO [3] 和 BLIP [24] 这样的生成式 VLM 在字幕和视觉问答任务方面表现出色,但也无法解决像素级计算机视觉任务。
提示 VLM 最常见的方式是在文本输入 [16, 21, 65, 66]、视觉输入 [19, 46 之前添加一组可学习标记, 64],或文本和视觉输入 [41, 60],以便轻松引导冻结的 CLIP 模型来解决所需的任务。 [4] 学习像素空间中的增强,例如图像周围的填充或更改图像的补丁,这些都是通过下游任务的梯度下降进行优化的。 [5] 使用基于学术论文中的图形训练的生成模型,将图像修复作为一项视觉提示任务。 图像的着色区域已用于 VCR 任务 [61],其中模型在带注释的图像 [62] 上进行微调。 彩色提示调整 (CPT) [57] 图像的颜色区域,并使用字幕模型通过预测其颜色来预测表达式所指的图像中的哪个对象。 与 CPT 类似,我们在像素空间中增强输入图像并执行零样本推断。 然而,我们以类人的方式注释图像,并表明我们的方法比 CPT 更强大、更灵活。
引用表达理解(REC)旨在定位图像中与文本描述相对应的目标对象。 大多数 REC 方法都是从对象提案开始,例如使用 Faster-RCNN [40] 生成的对象提案,并学习对它们进行评分 [17, 31, 30, 54, 48]。 REC 有时与引用表达式生成一起考虑——生成给定区域的描述的任务。 [31] 使用理解模型来指导生成器,而 [9] 联合训练检测器和标题生成器。 一些作品将场景建模为图形 [30, 54, 48] 或使用语言解析器和基于语法的方法 [12, 29],从而产生更易于解释的结果。 最近,Transformer 架构已被使用[25,22,14,55,50]。 [25, 22, 14, 55] 执行文本调制对象检测,其中 Transformer 解码器将引用表达式作为输入并预测边界框。 [50] 使用文本到像素对比损失进行训练,允许在测试时进行文本驱动的分割或检测。
无监督引用表达理解是一个较少探索的领域,只有通过引入大型预训练模型(例如 CLIP [38])才能实现。 ReCLIP [44] 裁剪对象提案,并在临时后处理步骤之前使用 CLIP 对它们进行排名,以考虑左/右、较小/较大等关系。 CPT [57] 为对象提案框着色,并使用预训练的字幕模型 [63] 自动回归预测哪个颜色提案对应于查询描述。 Pseudo-Q [20] 生成图像中多个对象的描述,用于训练 REC 网络。 然而,该模型并非完全无监督,因为它使用的伪描述是使用在 COCO 上训练的字幕模型生成的。
使用大型预训练模型进行视觉推理在过去几年中一直是人们非常感兴趣的领域。 除了指代表达检测[44]之外,CLIP [38]还被用于语义分割[37, 27]。 [37] 在 GAN 的潜在空间中进行部分共分割后,使用 CLIP 为对象部分分配文本标签。 [27] 通过使用通用掩码提议网络和 CLIP 作为分类器,利用 CLIP 进行开放词汇分割。 CLIP 还被用于无监督对象提议生成[42]和开集检测[15]。 语义分割也来自仅图像 [34, 49] 或图像文本 [53] 自我监督。
VLM 的偏差 是一个越来越受欢迎的研究领域,因为下游应用程序存在使训练数据中存在的偏差和刻板印象永久化的风险。 然而,评估 VLM 偏差的方法尚未建立。 [2]衡量CLIP对非人类和犯罪类别的不同种族人脸的错误分类率,而[6,11,47]衡量检索的公平性结果。 在这里,我们展示了一种不同的偏见,在一个人身上添加红色圆圈可能会引发负面含义。
3方法
我们的目标是在视觉语言模型 (VLM) 中开发视觉提示。 VLM 解决涉及联合处理文本和图像的预测任务。 例如,CLIP 等模型经过训练可以匹配文本和图像样本。 这种 VLM 的输入是图像 和文本 ,其中 是字母表。 输出是一个分数 ,表示所提供的图像和文本之间的兼容性程度。
3.1及时工程
VLM 最引人注目的功能之一是它们能够以零样本的方式解决各种分类任务,而几乎不需要进一步的训练。 这是通过将感兴趣的任务减少到在适当设计的图像和文本对上评估 VLM 来完成的。
例如,给定图像标题对 ,考虑定位图像中命名对象关键点的问题。 我们可以将其视为问答问题,其中问题 是对象关键点的名称(例如,“右耳”、“左前腿”……),答案 是一组离散的图像位置之一。
由于 VLM 计算图像 和文本 之间的兼容性分数 ,因此它不能用于映射问题 直接回答。 然而,通过提示工程,我们可以使用 VLM 在问题和答案之间构建兼容性分数 ,以输入图像-文本对 为条件。 该分数通常由表达式给出
| (1) |
其中 和 是输入图像和文本的版本,通过将后者转换为反映问答对 来获得。
Eq. 1应用于问题的具体方式取决于问题的具体性质。 例如,在定位命名关键点的问题中,很自然地通过文本模态对关键点的名称进行编码,并通过视觉模态对关键点的 2D 位置进行编码。 例如,为了回答带有标题 的给定输入图像 的问题 ,我们可以设计文本提示 对命名实体的描述进行编码。 同样,我们可以使用 中讨论的方法之一来设计视觉提示 ,以便“选择”图像中的位置 第 3.2节。 有了这个,我们可以通过找到最大化得分 的 来回答问题,该得分专门针对 Eq. 1 。
在以下部分中,我们将提供更多详细信息并将这些想法应用到一些具体任务中。
3.2 通过标记进行视觉提示
在视觉提示中编码位置信息的常用方法是在所需位置周围裁剪图像,这意味着 是在 周围裁剪的图像。 这个想法已广泛用于 VLM,包括解释引用表达式,其中最大化 形式的分数寻求与引用表达式 最匹配的图像裁剪。
在本文中,我们探索了一种视觉提示的替代方法,该方法使用标记图像中所需区域的概念。 从字面上看,标记意味着在图像上覆盖一个圆圈、一个方框或一个箭头,直观地指示所需的位置。
虽然标记的想法听起来很奇怪,但它很有趣,原因有两个。 首先,与裁剪不同,标记图像 保留了输入图像 中包含的几乎所有信息,包括裁剪缺少的上下文信息。 其次,我们证明标记与 VLM 配合良好,在某些预测任务中优于基于裁剪的提示工程。
虽然由红色圆圈组成的最简单标记特别有效,但在部分 4中,我们探索了几种不同的生成标记的方法。 我们建议读者参阅该部分以获取更多详细信息和示例。
3.3任务
我们通过考虑几个零样本预测任务来研究基于标记的提示工程的思想,从简单的任务(例如将关键点与其名称匹配)到更复杂的任务(例如引用表达理解)。
命名关键点。
我们考虑的第一个也是最简单的任务是将对象关键点的名称与其在图像中的 2D 位置进行匹配。 输入是图像 、一组关键点名称 和一组相应的关键点位置 。 名称和位置的数量相同 (),目标是使两者匹配。 我们将后者表示为预测将每个名称 与其相应位置 (即 )相关联的方排列矩阵 。
为了预测 ,我们使用 Eq. 1 将名称 与位置 关联的成本定义为 ,其中 是通过裁剪或标记获得的,而 只是以 "一幅图像的 "字符串为前缀的关键点名称。 对于这个问题,问题和答案的角色是对称的,我们通过最优传输将成本矩阵 解码为置换矩阵 :
| (2) |
其中是温度参数。 该优化问题可通过 Sinkhorn-Knopp 算法[43] 有效解决,该算法对矩阵 进行重新归一化。
关键点定位。
第二个任务是第一个任务的更有用和更困难的变体。 目标仍然是定位图像中的命名关键点 ,但这次位置 是 常规网格的子集。 这些进一步限制为使用[49]的无监督显着性方法提取的显着图像区域,以避免测试背景中不相关的位置。 与命名关键点相比,不同之处在于该版本的问题不假设先验知识关键点的可能位置。 给定关键点的名称 ,即可获得其位置 作为 ,其中 和 如之前所定义。
| Method | Name-to-keypoint | Keypoint-to-name | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CUB | Spair71k | CUB | SPair71k | |||||||||||
| Random | 8.2 | 16.8 | 15.0 | 10.5 | 9.4 | 15.1 | 11.9 | 8.2 | 16.8 | 15.0 | 10.5 | 9.4 | 15.1 | 11.9 |
| Crop w/o SK | 15.8 | 28.5 | 28.5 | 28.5 | 20.1 | 26.1 | 29.7 | 18.7 | 22.4 | 19.1 | 24.0 | 14.9 | 27.3 | 25.1 |
| Crop w/ SK | 25.5 | 35.1 | 37.5 | 34.6 | 23.9 | 32.9 | 36.3 | 25.8 | 36.1 | 32.5 | 32.7 | 19.8 | 35.3 | 32.5 |
| Red Circle w/o SK | 46.5 | 54.8 | 53.1 | 51.6 | 40.1 | 47.4 | 45.2 | 29.5 | 26.8 | 24.9 | 36.9 | 18.8 | 31.8 | 28.9 |
| Red Circle w/ SK | 58.2 | 67.6 | 60.1 | 59.3 | 53.1 | 56.7 | 52.8 | 56.5 | 67.2 | 54.4 | 59.7 | 49.8 | 56.6 | 53.0 |
参考表达理解。
理解引用表达意味着检测图像中与明确引用它的文本规范相对应的对象(例如,“右侧第四只狗”)。 与之前的工作 [57, 44, 20] 类似,给定图像 ,我们通过使用 [ 中的方法首先提取一组对象建议来解决这个问题58] 并将它们解释为可能答案的集合。 相反,问题集 是从给定基准数据集中提取的引用表达式的集合。 对于每个引用表达式,最佳匹配建议由下式给出
| (3) |
工程提示和的定义如部分3.3中所示。 在这种情况下,我们发现从分数中减去所有可能的引用表达式 的平均值很有用。 这会削弱假设,例如在视觉上非常显着并且往往对所有问题做出强烈反应的面孔。
4实验
我们首先考虑部分3.3的三个任务来研究VLM中视觉标记的属性:命名关键点、定位关键点和引用表达理解。
4.1 命名关键点
命名关键点是一个相对简单的问题,没有直接的应用;然而,它的评估比其他任务更简单、更快,因此我们用它来消除我们方法的各个方面。
数据和实施细节。
对于此任务,我们考虑 CUB-200-2011 (CUB) [51] 和 SPair71k [35] 数据集。 第一个包含每个图像的命名关键点注释,而第二个仅注释图像对中的匹配关键点,但不命名它们。 因此,我们增强了后者,手动命名每个动物图像中的每个关键点实例。 我们使用提供的边界框进一步裁剪 SPair71k 中的图像。 对于 VLM,我们使用 ViT-L/14@336px 主干网。 请参阅sup。 马特。 了解详情。
结果。
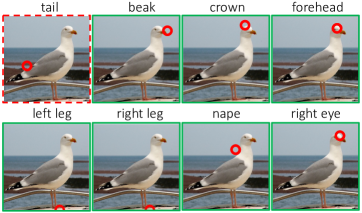
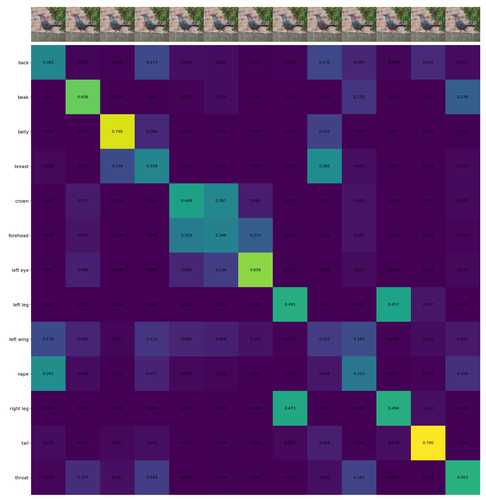
回想一下,在此任务中,预测器的输出是将每个关键点位置与相应名称相关联的置换矩阵 。 我们报告(i)映射到正确位置的关键点名称的比率和(ii)映射到正确名称的关键点位置的比率。 据我们所知,之前没有任何作品将关键点与其名称相关联。 因此,我们将这个新任务的结果与(a)随机选择和(b)通过裁剪获得 的基线进行比较。
如表1所示,通过视觉标记(红色圆圈)进行提示的效果显着优于基线,实现了几乎两倍的准确度。 使用 Sinkhorn-Knopp (SK) 算法对匹配分数进行归一化可进一步提升结果,主要改善模糊且彼此接近的点的结果,例如。、嘴巴和鼻子。
最好的视觉标记是什么?
我们比较了 (i) 不同形状突出显示位置的情况:圆形、矩形、十字形、箭头,(ii) 不同大小,以及 (iii) 不同颜色的注释,并在 中显示了一些示例图4。 我们比较 Table 2 中的不同形状和颜色,发现红色圆圈表现最好。 红色是最好的颜色,尽管它是图像中常见的颜色,与紫色等颜色不同,紫色在自然界中很少见,因此更独特,但会导致性能较差。 我们将此归因于这样一个事实:CLIP 的这种新兴功能的存在是由于对其训练数据进行以人为中心的操作,并且人类可能会使用红色圆圈进行注释,如下所示。
| Marker shape | Mean | Best |
|---|---|---|
| Circle | 33.5 4.5 | 46.5 |
| Arrow | 28.3 3.1 | 36.3 |
| Square | 24.1 3.6 | 36.3 |
| Cross | 21.5 6.3 | 34.5 |
| Circle color | Mean | Best |
|---|---|---|
| Red | 36.4 5.1 | 46.5 |
| Green | 34.3 4.2 | 43.3 |
| Purple | 34.0 3.7 | 41.9 |
| Blue | 32.7 3.9 | 41.1 |
| Yellow | 32.4 4.0 | 40.8 |

训练数据中是否有视觉标记?
为了探索 CLIP 由于训练中看到的类似示例而可以对图像上的注释进行零样本分类的假设,我们在 YFCC15M 中找到包含标记的图像(YFCC15M 是 CLIP 训练数据的子集)。 为此,我们使用 ViT-B/16 和 RN50x16 CLIP 视觉编码器的集合来训练二元分类器,以对 YFCC15M 中包含注释的图像进行分类。 然后,我们使用它来过滤 YFCC15M 的 6M 子集,并获取得分最高的前 10k 图像。 最后,我们手动检查 10k 图像并找到 70 张在其上绘制了注释的图像。 我们在图5中展示了3个这样的图像。 因此,训练数据包含标记的示例,但它们非常罕见(0.001%),这表明这种行为只能通过高容量模型从非常大的数据集中学习。 接下来对此进行进一步探讨。

不同的 VLM 有什么不同?
| Method | Backbone | Data | Params | Name-to-keypoint | Keypoint-to-name | ||
| CUB | Spair71k | CUB | SPair71k | ||||
| CLIP [38] | ViT-B/32 | 400M | 87M | 19.1 | 26.7 | 19.1 | 25.6 |
| CLIP [38] | ViT-B/16 | 400M | 86M | 22.2 | 34.0 | 22.1 | 33.6 |
| CLIP [38] | RN50x16 | 400M | 167M | 30.6 | 41.0 | 29.7 | 40.0 |
| CLIP [38] | ViT-L/14 | 400M | 304M | 47.9 | 54.3 | 48.0 | 51.2 |
| CLIP [38] | ViT-L/14 | 400M | 304M | 58.2 | 58.3 | 56.5 | 56.8 |
| OpenCLIP [10] | ViT-B/32 | 2B | 87M | 19.4 | 27.5 | 20.7 | 27.2 |
| OpenCLIP [10] | ViT-L/14 | 2B | 304M | 33.9 | 42.4 | 33.3 | 41.5 |
| OpenCLIP [10] | ViT-H/14 | 2B | 632M | 45.0 | 53.7 | 42.8 | 50.5 |
| OpenCLIP [10] | ViT-g/14 | 2B | 1.01B | 44.2 | 47.2 | 42.5 | 43.6 |
| OpenCLIP [10] | ViT-G/14 | 2B | 1.84B | 50.4 | 52.5 | 48.9 | 48.6 |
| SLIP [36] | ViT-S/16 | 15M | 22M | 13.0 | 17.8 | 12.0 | 16.7 |
| SLIP [36] | ViT-B/16 | 15M | 86M | 17.3 | 16.5 | 16.7 | 17.1 |
| SLIP [36] | ViT-L/16 | 15M | 303M | 24.6 | 26.3 | 24.1 | 25.0 |
| CLIP [36, 38] | ViT-S/16 | 15M | 22M | 11.4 | 16.5 | 12.4 | 15.8 |
| CLIP [36, 38] | ViT-B/16 | 15M | 86M | 14.0 | 18.4 | 14.8 | 17.8 |
| CLIP [36, 38] | ViT-L/16 | 15M | 303M | 15.0 | 20.5 | 15.8 | 20.4 |
| FILIP [26, 56] | ViT-B/32 | 15M | 90M | 8.9 | 15.6 | 8.7 | 15.6 |
| DeFILIP [26] | ViT-B/32 | 15M | 90M | 12.5 | 19.5 | 12.5 | 19.4 |
| CLIP [26, 38] | ViT-B/32 | 15M | 90M | 10.6 | 14.1 | 11.0 | 14.3 |
| DeCLIP [26] | ViT-B/32 | 15M | 90M | 15.8 | 19.9 | 15.8 | 18.7 |
| DeCLIP [26] | ViT-B/32 | 88M | 90M | 19.4 | 23.6 | 19.7 | 22.3 |
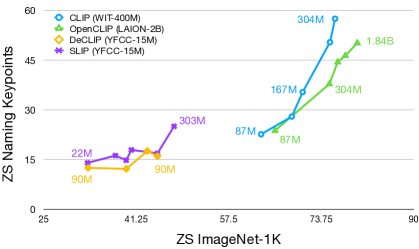
我们在图6中比较了一些CLIP模型。 一般来说,我们观察到关键点匹配的性能随着(i)预训练数据集的大小和(ii)视觉编码器的大小而提高。 前者适用于在 WIT-400M 与 YFCC-15M(WIT-400M 的子集)上训练的 CLIP 模型。 然而,使用 LAION-2B 数据集进行预训练会导致更糟糕的结果。 我们怀疑这个结果来自于创建 WIT-400M 和 LAION-2B 时过滤的差异,在后者中,由于更注重生成模型的美学图像,注释的示例可能已被丢弃。 同样,当我们增加视觉编码器的尺寸时,我们看到性能的巨大提升,并且这种增益似乎并没有与最大的可用模型收敛。 我们强调 WIT-400M 预训练 CLIP 性能的显着提升——最大模型在 ZS 关键点匹配上比最小模型的性能提高了 250%,而在 ZS ImageNet-1K 分类上的改进仅为 20%。 我们将此任务与 NLP 领域的任务相似,例如零样本或一次性算术,其中只有最大的 GPT 模型才能表现良好[7]。 我们认为,以类似的方式,视觉编码器需要足够的容量和数据才能显示这种突发行为。
4.2 本地化关键点
| Method | Mask | CUB | Spair71k | |||||
|---|---|---|---|---|---|---|---|---|
| Random | ✗ | 1.1 | 3.1 | 1.8 | 3.6 | 3.0 | 3.0 | 3.4 |
| Random | ✓ | 8.3 | 6.7 | 4.7 | 4.6 | 5.5 | 3.3 | 4.3 |
| Crop | ✗ | 16.9 | 25.5 | 27.3 | 22.6 | 16.1 | 20.0 | 22.7 |
| Crop | ✓ | 21.3 | 28.4 | 28.8 | 21.9 | 16.0 | 23.4 | 24.5 |
| Red Circle | ✗ | 32.3 | 50.7 | 52.7 | 55.9 | 38.3 | 42.4 | 38.0 |
| Red Circle | ✓ | 45.2 | 53.4 | 54.5 | 56.4 | 40.9 | 43.2 | 42.2 |
在本实验中,我们使用与前一个实验相同的数据和网络架构,但报告正确关键点的百分比 (PCK) 作为指标,因为后者在评估语义对应时被广泛使用。 给定一组真实点和预测,PCK由下式给出:
这里,是由给出的距离阈值,其中是比率,是边界框大小。 对于所有数据集,我们使用 。 关键点定位还利用无监督的显着性掩模来忽略背景位置。
4.3 引用表达式理解
| Method | ZS | RefCOCO | RefCOCO+ | RefCOCOg | |||||
| Val | TestA | TestB | Val | TestA | TestB | Val | Test | ||
| DTWREG [45] | ✗ | 39.2 | 41.1 | 37.7 | 39.2 | 40.1 | 38.1 | – | – |
| Pseudo-Q [20] | ✗ | 56.0 | 58.3 | 54.1 | 38.9 | 45.1 | 32.1 | 46.3 | 47.4 |
| CPT [57] | ✓ | 32.2 | 36.1 | 30.3 | 31.9 | 35.2 | 28.8 | 36.7 | 36.5 |
| ReCLIP [44] | ✓ | 42.0 | 43.5 | 39.0 | 47.4 | 50.1 | 43.9 | 57.8 | 57.2 |
| ReCLIP [44] | ✓ | 45.8 | 46.1 | 47.1 | 47.9 | 50.1 | 45.1 | 59.3 | 59.0 |
| Red Circle | ✓ | 49.8 | 58.6 | 39.9 | 55.3 | 63.9 | 45.4 | 59.4 | 58.9 |
数据集和实施细节。
引用表达式理解通常在 RefCOCO [59]、RefCOCO+ [59] 和 RefCOCOg [32] 数据集上进行评估,所有这些数据集都包含来自 MS-COCO 数据集 [28] 的图像以及引用图像中唯一对象的表达式,这些表达式也使用边界框进行注释。 RefCOCO+ 仅包含基于外观的表达式,而 RefCOCO 和 RefCOCOg 包含基于关系的表达式(例如,包含单词 left/closer/bigger)。 RefCOCO 和 RefCOCO+ 的测试集分为两部分,其中“testA”和“testB”分别仅包含人和非人。 我们使用正确预测的百分比进行评估,如果一个框与真实框的交并集超过 0.5,则该框被正确预测。
对于引用表达式任务,我们使用集成 RN50x16 和 ViT-L/14@336 CLIP 主干。 继之前的工作[44, 57]之后,我们对 MAttNet [58] 的边界框提案进行评分。
结果。
| Model | Red Circle | FaceSynthetics | COCO | ||||
|---|---|---|---|---|---|---|---|
| Positive | Neutral | Criminal | Positive | Neutral | Criminal | ||
| ViT-L/14@336px | ✗ | 0.5% | 35.6% | 63.9% | 22.7% | 47.5% | 29.8% |
| ViT-L/14@336px | ✓ | 0.0% | 19.1% | 80.9% (+17.0%) | 1.6% | 505.% | 47.9 (+18.1%) |
| ViT-L/14 | ✗ | 1.3% | 40.8% | 57.9% | 25.0% | 46.5% | 28.6% |
| ViT-L/14 | ✓ | 0.0% | 32.5% | 67.5% (+9.6%) | 2.7% | 43.1% | 54.2 (+25.6%) |
| ViT-B/16 | ✗ | 0.7% | 49.1% | 50.2% | 19.4% | 56.7% | 23.9% |
| ViT-B/16 | ✓ | 0.0% | 37.1% | 62.9 (+12.7%) | 4.7% | 39.3% | 56.0 (+32.1%) |
| ViT-B/32 | ✗ | 0.0% | 85.2% | 14.8% | 15.3% | 61.8% | 22.9% |
| ViT-B/32 | ✓ | 0.0% | 70.5% | 29.5% (+14.7%) | 4.9% | 48.2% | 46.9 (+24.0%) |
| RN50x16 | ✗ | 0.7% | 46.4% | 52.9% | 26.5% | 30.5% | 43.0% |
| RN50x16 | ✓ | 0.1% | 52.2% | 47.7% (-5.2%) | 13.6% | 39.5% | 46.9 (+3.9%) |

使用红色圆圈,我们在零样本设置中的大多数引用表达式理解基线上实现了最先进的水平,如 Table 5 所示t0>. 有趣的是,这甚至优于 ReCLIP [44],后者基于对图像裁剪进行评分,然后使用手动设计的关系规则进行后处理。 尽管 Pseudo-Q 明确地针对此任务进行了训练,但红色圆圈在大多数基准测试中也优于 Pseudo-Q。
4.4 模型偏见和道德规范
虽然在图像上画圆圈可以从 VLM 中提取有用的行为来执行各种合法的图像分析任务,但它也可以提取不需要的行为,并且不得用于分析敏感数据。
为了证明这一事实,在 Fig. 8 中,我们从 COCO 中随机获取一张图像,其中包含一个看起来像男性的个体和一个看起来像女性的个体,并且零样本将图像以及每个人身上带有圆圈的图像分为 4 类:男性、女性、失踪人员和疑似凶手。 虽然这可以正确解析带注释的人的明显性别,但带注释的图像更有可能被分类为包含失踪人员或凶手。 虽然我们无法确定,但我们假设这是由于 CLIP 模型训练数据中存在失踪人员报告、警察录像或类似的数据,其中人员已被标记。

我们在 [2] 之后,使用 FaceSynthetics [52] 的合成面孔和 COCO [28] 的人物裁剪进一步量化这些偏差。 对于 FaceSyntetics,我们采用 1000 个随机合成面孔,对于 COCO,我们从验证集中裁剪 person 类的所有边界框,其面积至少占图像总面积的 10% ,总共有 1352 种作物。 按照[2],我们测量了零样本的犯罪类别分类率。 我们引入“正面”类别(诚实的男人/女人/人)、“中立”类别(男人/女人/人)和“犯罪”类别(犯罪分子/小偷/可疑人员)。 最后,我们对原始图像和带圆圈的图像进行零样本分类。 在表6中,我们展示了犯罪类别的分类率。 我们看到,对于所有 ViT 编码器,人们被分类为犯罪分子的比率明显更高。 这是有问题的,因为现有的偏见可能会导致有害的后果。 请注意,此分析存在各种限制,包括二元性别的使用。
5结论
我们已经证明,通过标记进行视觉提示工程可以以零样本方式从 VLM(例如 CLIP)中提取有用的行为,实现最先进的零样本引用表达理解性能,并显着优于图像裁剪等传统技术。 我们的分析表明,出现这种行为是因为 VLM 的训练数据中存在相关的标记样本,但这些样本非常罕见。 因此,这种行为只能通过在非常大的数据集上训练的非常大的模型来学习。 分析还表明,VLM 也会出现不良行为,仅在图像中添加红色圆圈就会增加模型对图像具有负面含义的信念。
数据集伦理。
我们以与其术语兼容的方式使用 RefCOCO、RefCOCO+、MS-COCO、FaceSynthetics、YFCC15M、CUB、SPair71k。 其中一些图像可能包含个人数据(面部)。 在部分、4.1、4.2和4.3中,没有提取生物特征数据。 在部分 4.4中,我们使用MS-COCO来证明由于预训练的偏差,这种方法无法可靠地提取有关人的信息CLIP模型(没有标识)。 用于相同目的的 FaceSynthetics 是合成面孔的数据集,因此不会引起隐私问题。 有关道德、数据保护和版权的更多详细信息,请参阅https://www.robots.ox.ac.uk/~vedaldi/research/union/ethics.html。
致谢。
我们感谢 Luke Melas-Kyriazi、Tim Franzmeyer、Rhydian Windsor 和 Bruno Korbar 校对 A. Shtedritski 得到 EPSRC EP/S024050/1 的支持。 A. Vedaldi 和 C. Rupprecht 得到 ERC-CoG UNION 101001212 的支持。 C. Rupprecht 也得到 VisualAI EP/T028572/1 的部分支持。
参考
- [1] Chatgpt. https://chat.openai.com/.
- [2] Sandhini Agarwal, Gretchen Krueger, Jack Clark, Alec Radford, Jong Wook Kim, and Miles Brundage. Evaluating clip: towards characterization of broader capabilities and downstream implications. arXiv preprint arXiv:2108.02818, 2021.
- [3] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. arXiv preprint arXiv:2204.14198, 2022.
- [4] Hyojin Bahng, Ali Jahanian, Swami Sankaranarayanan, and Phillip Isola. Visual prompting: Modifying pixel space to adapt pre-trained models. arXiv preprint arXiv:2203.17274, 2022.
- [5] Amir Bar, Yossi Gandelsman, Trevor Darrell, Amir Globerson, and Alexei A Efros. Visual prompting via image inpainting. arXiv preprint arXiv:2209.00647, 2022.
- [6] Hugo Berg, Siobhan Mackenzie Hall, Yash Bhalgat, Wonsuk Yang, Hannah Rose Kirk, Aleksandar Shtedritski, and Max Bain. A prompt array keeps the bias away: Debiasing vision-language models with adversarial learning. arXiv preprint arXiv:2203.11933, 2022.
- [7] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [8] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- [9] Yi-Wen Chen, Yi-Hsuan Tsai, Tiantian Wang, Yen-Yu Lin, and Ming-Hsuan Yang. Referring expression object segmentation with caption-aware consistency. arXiv preprint arXiv:1910.04748, 2019.
- [10] Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. arXiv preprint arXiv:2212.07143, 2022.
- [11] Ching-Yao Chuang, Varun Jampani, Yuanzhen Li, Antonio Torralba, and Stefanie Jegelka. Debiasing vision-language models via biased prompts. arXiv preprint arXiv:2302.00070, 2023.
- [12] Volkan Cirik, Taylor Berg-Kirkpatrick, and Louis-Philippe Morency. Using syntax to ground referring expressions in natural images. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018.
- [13] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- [14] Zi-Yi Dou, Aishwarya Kamath, Zhe Gan, Pengchuan Zhang, Jianfeng Wang, Linjie Li, Zicheng Liu, Ce Liu, Yann LeCun, Nanyun Peng, et al. Coarse-to-fine vision-language pre-training with fusion in the backbone. arXiv preprint arXiv:2206.07643, 2022.
- [15] Sepideh Esmaeilpour, Bing Liu, Eric Robertson, and Lei Shu. Zero-shot open set detection by extending clip. arXiv preprint arXiv:2109.02748, 2021.
- [16] Zixian Guo, Bowen Dong, Zhilong Ji, Jinfeng Bai, Yiwen Guo, and Wangmeng Zuo. Texts as images in prompt tuning for multi-label image recognition. arXiv preprint arXiv:2211.12739, 2022.
- [17] Ronghang Hu, Huazhe Xu, Marcus Rohrbach, Jiashi Feng, Kate Saenko, and Trevor Darrell. Natural language object retrieval. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4555–4564, 2016.
- [18] Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. In International Conference on Machine Learning, pages 9118–9147. PMLR, 2022.
- [19] Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Visual prompt tuning. arXiv preprint arXiv:2203.12119, 2022.
- [20] Haojun Jiang, Yuanze Lin, Dongchen Han, Shiji Song, and Gao Huang. Pseudo-q: Generating pseudo language queries for visual grounding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15513–15523, 2022.
- [21] Chen Ju, Tengda Han, Kunhao Zheng, Ya Zhang, and Weidi Xie. Prompting visual-language models for efficient video understanding. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXV, pages 105–124. Springer, 2022.
- [22] Aishwarya Kamath, Mannat Singh, Yann LeCun, Gabriel Synnaeve, Ishan Misra, and Nicolas Carion. Mdetr-modulated detection for end-to-end multi-modal understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1780–1790, 2021.
- [23] Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models. arXiv preprint arXiv:2206.14858, 2022.
- [24] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023.
- [25] Muchen Li and Leonid Sigal. Referring transformer: A one-step approach to multi-task visual grounding. Advances in Neural Information Processing Systems, 34:19652–19664, 2021.
- [26] Yangguang Li, Feng Liang, Lichen Zhao, Yufeng Cui, Wanli Ouyang, Jing Shao, Fengwei Yu, and Junjie Yan. Supervision exists everywhere: A data efficient contrastive language-image pre-training paradigm. arXiv preprint arXiv:2110.05208, 2021.
- [27] Feng Liang, Bichen Wu, Xiaoliang Dai, Kunpeng Li, Yinan Zhao, Hang Zhang, Peizhao Zhang, Peter Vajda, and Diana Marculescu. Open-vocabulary semantic segmentation with mask-adapted clip. arXiv preprint arXiv:2210.04150, 2022.
- [28] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014.
- [29] Daqing Liu, Hanwang Zhang, Feng Wu, and Zheng-Jun Zha. Learning to assemble neural module tree networks for visual grounding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4673–4682, 2019.
- [30] Yongfei Liu, Bo Wan, Xiaodan Zhu, and Xuming He. Learning cross-modal context graph for visual grounding. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 11645–11652, 2020.
- [31] Ruotian Luo and Gregory Shakhnarovich. Comprehension-guided referring expressions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7102–7111, 2017.
- [32] Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 11–20, 2016.
- [33] Joanna Materzyńska, Antonio Torralba, and David Bau. Disentangling visual and written concepts in clip. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16410–16419, 2022.
- [34] Luke Melas-Kyriazi, Christian Rupprecht, Iro Laina, and Andrea Vedaldi. Deep spectral methods: A surprisingly strong baseline for unsupervised semantic segmentation and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8364–8375, 2022.
- [35] Juhong Min, Jongmin Lee, Jean Ponce, and Minsu Cho. Spair-71k: A large-scale benchmark for semantic correspondence. arXiv preprint arXiv:1908.10543, 2019.
- [36] Norman Mu, Alexander Kirillov, David Wagner, and Saining Xie. Slip: Self-supervision meets language-image pre-training. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXVI, pages 529–544. Springer, 2022.
- [37] Daniil Pakhomov, Sanchit Hira, Narayani Wagle, Kemar E Green, and Nassir Navab. Segmentation in style: Unsupervised semantic image segmentation with stylegan and clip. arXiv preprint arXiv:2107.12518, 2021.
- [38] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
- [39] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- [40] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 28, 2015.
- [41] Sheng Shen, Shijia Yang, Tianjun Zhang, Bohan Zhai, Joseph E Gonzalez, Kurt Keutzer, and Trevor Darrell. Multitask vision-language prompt tuning. arXiv preprint arXiv:2211.11720, 2022.
- [42] Hengcan Shi, Munawar Hayat, Yicheng Wu, and Jianfei Cai. Proposalclip: Unsupervised open-category object proposal generation via exploiting clip cues. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9611–9620, 2022.
- [43] Richard Sinkhorn and Paul Knopp. Concerning nonnegative matrices and doubly stochastic matrices. Pacific Journal of Mathematics, 21(2):343–348, 1967.
- [44] Sanjay Subramanian, Will Merrill, Trevor Darrell, Matt Gardner, Sameer Singh, and Anna Rohrbach. Reclip: A strong zero-shot baseline for referring expression comprehension. arXiv preprint arXiv:2204.05991, 2022.
- [45] Mingjie Sun, Jimin Xiao, Eng Gee Lim, Si Liu, and John Y Goulermas. Discriminative triad matching and reconstruction for weakly referring expression grounding. IEEE transactions on pattern analysis and machine intelligence, 43(11):4189–4195, 2021.
- [46] Cheng-Hao Tu, Zheda Mai, and Wei-Lun Chao. Visual query tuning: Towards effective usage of intermediate representations for parameter and memory efficient transfer learning. arXiv preprint arXiv:2212.03220, 2022.
- [47] Jialu Wang, Yang Liu, and Xin Eric Wang. Are gender-neutral queries really gender-neutral? mitigating gender bias in image search. arXiv preprint arXiv:2109.05433, 2021.
- [48] Peng Wang, Qi Wu, Jiewei Cao, Chunhua Shen, Lianli Gao, and Anton van den Hengel. Neighbourhood watch: Referring expression comprehension via language-guided graph attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1960–1968, 2019.
- [49] Yangtao Wang, Xi Shen, Yuan Yuan, Yuming Du, Maomao Li, Shell Xu Hu, James L Crowley, and Dominique Vaufreydaz. Tokencut: Segmenting objects in images and videos with self-supervised transformer and normalized cut. arXiv preprint arXiv:2209.00383, 2022.
- [50] Zhaoqing Wang, Yu Lu, Qiang Li, Xunqiang Tao, Yandong Guo, Mingming Gong, and Tongliang Liu. Cris: Clip-driven referring image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11686–11695, 2022.
- [51] Peter Welinder, Steve Branson, Takeshi Mita, Catherine Wah, Florian Schroff, Serge Belongie, and Pietro Perona. Caltech-ucsd birds 200. 2010.
- [52] Erroll Wood, Tadas Baltrušaitis, Charlie Hewitt, Sebastian Dziadzio, Matthew Johnson, Virginia Estellers, Thomas J. Cashman, and Jamie Shotton. Fake it till you make it: Face analysis in the wild using synthetic data alone, 2021.
- [53] Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, and Xiaolong Wang. Groupvit: Semantic segmentation emerges from text supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18134–18144, 2022.
- [54] Sibei Yang, Guanbin Li, and Yizhou Yu. Dynamic graph attention for referring expression comprehension. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4644–4653, 2019.
- [55] Zhengyuan Yang, Zhe Gan, Jianfeng Wang, Xiaowei Hu, Faisal Ahmed, Zicheng Liu, Yumao Lu, and Lijuan Wang. Crossing the format boundary of text and boxes: Towards unified vision-language modeling. arXiv preprint arXiv:2111.12085, 2021.
- [56] Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. Filip: fine-grained interactive language-image pre-training. arXiv preprint arXiv:2111.07783, 2021.
- [57] Yuan Yao, Ao Zhang, Zhengyan Zhang, Zhiyuan Liu, Tat-Seng Chua, and Maosong Sun. Cpt: Colorful prompt tuning for pre-trained vision-language models. arXiv preprint arXiv:2109.11797, 2021.
- [58] Licheng Yu, Zhe Lin, Xiaohui Shen, Jimei Yang, Xin Lu, Mohit Bansal, and Tamara L Berg. Mattnet: Modular attention network for referring expression comprehension. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1307–1315, 2018.
- [59] Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expressions. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14, pages 69–85. Springer, 2016.
- [60] Yuhang Zang, Wei Li, Kaiyang Zhou, Chen Huang, and Chen Change Loy. Unified vision and language prompt learning. arXiv preprint arXiv:2210.07225, 2022.
- [61] Rowan Zellers, Yonatan Bisk, Ali Farhadi, and Yejin Choi. From recognition to cognition: Visual commonsense reasoning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6720–6731, 2019.
- [62] Rowan Zellers, Ximing Lu, Jack Hessel, Youngjae Yu, Jae Sung Park, Jize Cao, Ali Farhadi, and Yejin Choi. Merlot: Multimodal neural script knowledge models. Advances in Neural Information Processing Systems, 34:23634–23651, 2021.
- [63] Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, and Jianfeng Gao. Vinvl: Revisiting visual representations in vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5579–5588, 2021.
- [64] Sheng Zhang, Salman Khan, Zhiqiang Shen, Muzammal Naseer, Guangyi Chen, and Fahad Khan. Promptcal: Contrastive affinity learning via auxiliary prompts for generalized novel category discovery. arXiv preprint arXiv:2212.05590, 2022.
- [65] Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Conditional prompt learning for vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16816–16825, 2022.
- [66] Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models. International Journal of Computer Vision, 130(9):2337–2348, 2022.
附录
| Method | Backbone | RefCOCO | RefCOCO+ | RefCOCOg | |||||
|---|---|---|---|---|---|---|---|---|---|
| Val | TestA | TestB | Val | TestA | TestB | Val | Test | ||
| ReCLIP | RN5016 | 37.61 | 38.32 | 37.19 | 44.12 | 46.02 | 41.81 | 55.94 | 54.36 |
| ViT-B/32 | 40.69 | 43.98 | 37.55 | 45.00 | 48.15 | 41.65 | 55.25 | 54.35 | |
| ViT-B/16 | 38.23 | 40.53 | 37.00 | 41.53 | 42.91 | 41.32 | 55.19 | 55.16 | |
| ViT-L/14 | 34.40 | 33.52 | 34.35 | 37.86 | 37.53 | 37.70 | 53.82 | 52.25 | |
| ViT-L/14@336px | 35.90 | 37.72 | 35.66 | 40.06 | 42.49 | 39.07 | 54.25 | 53.92 | |
| RN5016,ViT-B/32 | 41.96 | 43.52 | 39.00 | 47.44 | 50.11 | 43.93 | 57.76 | 57.15 | |
| RN5016,ViT-B/1 | 39.94 | 41.61 | 38.71 | 45.06 | 47.17 | 43.63 | 57.93 | 56.85 | |
| RN5016,ViT-L/14 | 37.98 | 38.08 | 37.51 | 42.87 | 44.57 | 41.66 | 56.78 | 56.02 | |
| RN5016,ViT-L/14@336px | 38.79 | 39.49 | 37.82 | 44.27 | 46.44 | 42.46 | 57.86 | 56.28 | |
| ViT-B/32,ViT-B/16 | 41.34 | 44.25 | 38.55 | 45.20 | 48.01 | 43.36 | 57.37 | 56.52 | |
| ViT-B/32,ViT-L/14 | 39.68 | 41.65 | 37.84 | 43.74 | 46.25 | 41.17 | 56.74 | 56.07 | |
| ViT-B/32,ViT-L/14@336px | 40.82 | 43.47 | 39.22 | 45.41 | 48.52 | 42.83 | 58.09 | 56.94 | |
| ViT-B/16,ViT-L/14 | 37.69 | 38.29 | 37.53 | 40.87 | 42.07 | 40.93 | 56.35 | 55.76 | |
| ViT-B/16,ViT-L/14@336px | 39.18 | 41.01 | 38.35 | 42.81 | 44.32 | 42.07 | 57.82 | 56.21 | |
| ViT-L/14,ViT-L/14@336px | 35.47 | 36.26 | 35.70 | 39.52 | 40.69 | 38.70 | 54.51 | 54.04 | |
| Red Circle | RN5016 | 45.52 | 52.99 | 38.59 | 49.98 | 57.55 | 42.11 | 53.94 | 54.35 |
| ViT-B/32 | 38.72 | 45.09 | 33.52 | 42.85 | 49.46 | 36.53 | 45.81 | 45.57 | |
| ViT-B/16 | 45.30 | 52.70 | 36.51 | 49.39 | 57.67 | 40.60 | 53.72 | 53.26 | |
| ViT-L/14 | 46.71 | 55.03 | 39.24 | 52.07 | 58.63 | 42.83 | 57.00 | 56.40 | |
| ViT-L/14@336 | 48.27 | 56.44 | 39.71 | 53.59 | 59.99 | 43.28 | 59.95 | 58.51 | |
| RN5016, ViT-B/32 | 45.62 | 54.04 | 37.13 | 50.73 | 60.46 | 41.69 | 54.00 | 53.84 | |
| RN5016, ViT-B/16 | 49.98 | 57.15 | 38.04 | 52.98 | 61.95 | 42.99 | 56.01 | 55.78 | |
| RN5016, ViT-L/14 | 48.50 | 58.03 | 39.76 | 54.56 | 63.17 | 44.41 | 58.17 | 57.76 | |
| RN5016, ViT-L/14@336 | 49.84 | 58.57 | 39.96 | 55.28 | 63.92 | 45.35 | 59.40 | 58.93 | |
| ViT-B/32,ViT-B/16 | 44.62 | 53.03 | 35.90 | 49.13 | 58.96 | 40.21 | 52.23 | 51.61 | |
| ViT-B/32,ViT-L/14 | 47.19 | 56.27 | 38.14 | 52.75 | 62.07 | 42.69 | 56.66 | 55.54 | |
| ViT-B/32,ViT-L/14@336px | 48.59 | 58.05 | 38.69 | 54.61 | 63.45 | 43.28 | 57.80 | 57.48 | |
| ViT-B/16,ViT-L/14 | 48.18 | 57.49 | 39.33 | 53.66 | 62.38 | 43.36 | 57.56 | 57.45 | |
| ViT-B/16,ViT-L/14@336px | 49.86 | 58.41 | 39.92 | 55.35 | 62.43 | 44.34 | 59.05 | 58.82 | |
| ViT-L/14,ViT-L/14@336px | 48.82 | 57.03 | 40.35 | 53.62 | 60.65 | 44.04 | 59.03 | 58.27 | |
在本补充材料中,我们提供了有关我们使用的数据集、实施细节和消融的更多详细信息,以及进一步的定性和定量评估。
6 数据集
正如主论文中所述,我们为一些实验的 Spair71k 数据集提供了额外的注释。 我们从它们的关键点注释开始,它们在原始数据集中没有关键点名称注释。 然后,我们手动命名 Spair71k 中动物类的所有关键点,如 Table 8 所示。 我们故意省略了一些注释:
-
•
所有动物都有左鼻孔和右鼻孔注释——我们在所有类别中都取右鼻孔并将其注释为nose,而将左鼻孔排除在外。
-
•
所有尾巴在尾巴的开始处(附着在身体上)和尾巴的结束处都有点注释。 由于缺乏词语来精确描述这两点,我们将not附着在body上的点注释为tail,而忽略另一个点。
-
•
所有耳朵在耳朵的起点(附着在头部)和尖端都有点注释。 由于缺乏词语来精确描述这两个点,我们将not附着在头部的点注释为ear,而忽略另一个点。
-
•
鸟类对 (i) 脚、(ii) 脚踝、(iii) 膝盖有注释,这些注释通常不明确且非常接近。 我们只保留脚标注。
请注意,我们为可能不明确的关键点明确定义了不同的名称,例如眼睛、耳朵、腿等 这确保了部分3.3中问题和答案的作用得到满足。
7 发现的注释
在 YFCC-15M 中发现的注释中,44% 包含红色圆圈。 总体而言,73% 的注释是圆形,其余的是矩形。 所有注释中 65% 为红色、10% 黄色、7% 蓝色、7% 白色,其余为黑色、绿色和紫色。
8 其他实施细节
8.1 引用表达式检测。
骨干
注释
额外细节
我们通过在前面添加 “This is” 来增强文本查询。 当减去其他引用表达式的平均值时,我们使用 随机采样的表达式。
8.2 关键点任务
骨干
我们在主论文的表 3 中评估了不同的主干网,发现 ViT-L/14@336 表现最好。
注释
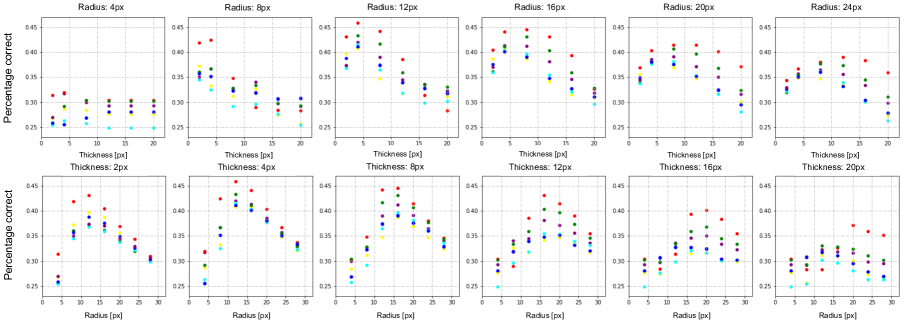
我们在主论文的图 4 中展示了我们使用的标记示例。 我们比较了大范围的尺寸和颜色,如主论文中的表 2 所示。 我们发现圆圈是最好的标记,在兴趣点上画十字是最差的。 其中性能最好的标记是红色圆圈,这就是我们最终使用的标记。 在图10中,我们展示了使用圆形标注时不同颜色、直径和厚度的更详细比较。 我们看到细红色圆圈是效果最好的标记。 我们在图11中展示了该圆圈在图像上的样子。
鉴于此,我们在图像上绘制红色圆圈,半径 和厚度 ,其中 H 是图像的短边。 对于我们使用的主干,输入大小为 px,这将变为 px 和 px。
额外细节
对于关键点定位任务,我们在应用伪掩码之前设置 ,总共 个查询位置。 我们使用的模板是 CUB 的 “这是 { 部分} 鸟的部分” 和 “这张图片显示了 SPair71k 的 t3>{部分}{动物}”。 我们使用温度参数。
9定性评估
| Part No | Bird | Cat | Cow | Dog | Horse | Sheep |
|---|---|---|---|---|---|---|
| 0 | crown | — | — | — | — | — |
| 1 | right wing | — | — | — | — | — |
| 2 | left wing | right ear | right ear | right ear | right ear | right ear |
| 3 | beak | left ear | left ear | left ear | left ear | left ear |
| 4 | — | right eye | right eye | right eye | right eye | right eye |
| 5 | — | left eye | left eye | left eye | left eye | left eye |
| 6 | forehead | nose | nose | nose | nose | nose |
| 7 | right eye | — | — | forehead | — | — |
| 8 | left eye | mouth | mouth | mouth | mouth | mouth |
| 9 | nape | front right paw | front right hoof | front right paw | forehead | front right hoof |
| 10 | right foot | front left paw | front left hoof | front left paw | front right hoof | front left hoof |
| 11 | left foot | hind right paw | hind right hoof | hind right paw | front left hoof | hind left hoof |
| 12 | — | hind left paw | hind left hoof | hind left paw | hind right hoof | hind right hoof |
| 13 | tail | tail | tail | tail | hind left hoof | tail |
| 14 | — | — | — | — | tail | — |
| 15 | — | — | front right knee | neck | — | front right knee |
| 16 | — | — | front left knee | — | front right knee | front left knee |
| 17 | — | — | hind right knee | — | front left knee | hind right knee |
| 18 | — | — | hind left knee | — | hind right knee | hind left knee |
| 19 | — | — | right horn | — | hind left knee | right horn |
| 20 | — | — | left horn | — | — | — |

| Component | RefCOCO | RefCOCO+ | RefCOCOg | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Red Circle | Subtract | Ensemble | Val | TestA | TestB | Val | TestA | TestB | Val | Test |
| ✓ | ✗ | ✗ | 42.01 | 48.58 | 36.90 | 47.55 | 53.56 | 41.05 | 50.84 | 51.47 |
| ✓ | ✓ | ✗ | 43.67 | 50.20 | 38.59 | 48.98 | 54.70 | 43.06 | 54.29 | 52.98 |
| ✓ | ✓ | ✓ | 49.84 | 58.57 | 39.96 | 55.28 | 63.92 | 45.35 | 59.40 | 58.93 |
| Annotation Type | RefCOCO | RefCOCO+ | RefCOCOg | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Shape | Color | Size | Val | TestA | TestB | Val | TestA | TestB | Val | Test |
| Circle | Red | 1 | 38.7 | 45.1 | 34.0 | 44.4 | 50.0 | 39.1 | 48.1 | 50.0 |
| Circle | Red | 2 | 32.2 | 35.9 | 29.1 | 37.6 | 40.9 | 33.5 | 45.3 | 46.4 |
| Circle | Red | 4 | 37.4 | 43.6 | 31.5 | 43.3 | 47.8 | 37.3 | 43.7 | 48.0 |
| Circle | Red | 8 | 36.3 | 42.6 | 31.3 | 42.1 | 47.3 | 36.3 | 45.2 | 45.4 |
| Rectangle | Red | 1 | 35.1 | 38.3 | 33.5 | 39.2 | 41.4 | 37.3 | 44.3 | 43.4 |
| Rectangle | Red | 2 | 35.1 | 38.3 | 33.2 | 39.1 | 41.8 | 37.3 | 44.8 | 44.1 |
| Rectangle | Red | 4 | 34.1 | 37.8 | 32.3 | 39.0 | 41.3 | 36.5 | 43.7 | 44.1 |
| Rectangle | Red | 8 | 33.7 | 37.6 | 32.7 | 37.9 | 40.3 | 34.9 | 41.1 | 40.1 |
| Circle | Green | 1 | 39.3 | 45.4 | 34.8 | 43.8 | 49.9 | 38.1 | 47.2 | 47.4 |
| Circle | Purple | 1 | 38.9 | 44.8 | 34.0 | 44.5 | 49.4 | 39.2 | 49.5 | 49.2 |
| Circle | Blue | 1 | 37.7 | 44.9 | 33.5 | 43.4 | 49.1 | 37.3 | 48.2 | 48.3 |
| Circle | Yellow | 1 | 38.5 | 44.1 | 34.6 | 43.7 | 49.0 | 38.9 | 48.6 | 48.1 |