什么使大型语言模型(LLM)在代码智能任务中具有良好的上下文演示?
摘要
预训练的源代码模型在许多代码智能任务中获得了广泛的应用。 最近,随着模型和语料库规模的扩大,大型语言模型展示了上下文学习(ICL)的能力。 ICL 使用任务指令和少量示例作为演示,然后将演示输入语言模型进行预测。 这种新的学习范式无需训练,并在各种自然语言处理和代码智能任务中表现出令人印象深刻的性能。 但是,ICL 的性能在很大程度上依赖于演示的质量,例如所选示例。 系统地研究如何为代码相关任务构建良好的演示非常重要。 在本文中,我们通过实验证明了三个关键因素对 ICL 在代码智能任务中性能的影响:演示示例的选择、顺序和数量。 我们对三个代码智能任务进行了广泛的实验,包括代码摘要、bug 修复和程序合成。 我们的实验结果表明,以上三个因素都会显著影响 ICL 在代码智能任务中的性能。 此外,我们总结了我们的发现,并提供了有关如何构建有效演示的建议,其中考虑了这三个方面的因素。 我们还表明,根据我们的发现精心设计的演示可以显著提高广泛使用的演示构建方法,例如,分别在代码摘要、bug 修复和程序合成方面将 BLEU-4、EM 和 EM 提高至少 9.90%、175.96% 和 50.81%。
我 介绍
最近,代码智能研究越来越受到关注,其目标是减轻软件开发人员的负担,提高编程效率 [1, 2]。 随着大规模开源代码语料库的出现和深度学习技术的进步, 各种神经源代码模型 已经被开发出来,并在各种代码智能任务中取得了最先进的性能,包括代码摘要 [3]、bug 修复 [4] 和程序合成 [5]。
近年来,预训练技术的出现极大地推动了这一领域的进展。 例如,CodeBERT [6],一个基于 BERT 的模型,在自然语言和编程语言数据上进行预训练,在各种代码智能任务中表现出良好的性能 [7, 4]。 其他随后的预训练代码模型,如 PLBART [8] 和 CodeT5 [9],在 CodeBERT 的基础上取得了进一步的提升。 然而,上述模型的规模和训练数据有限,这可能会阻碍模型发挥其全部潜力 [10]。 这些年来,我们见证了预训练模型规模的爆炸式增长。 各种数十亿级别的大型语言模型被提出,例如 GPT-3 [11] 和 PALM-E [12]。 例如,2023 年预训练模型 PALM-E [12](562B)的规模是 2018 年最大模型 BERT [13](223M)的 2000 多倍。
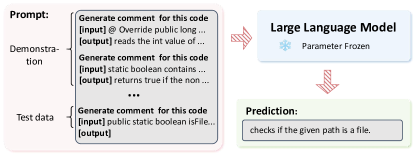
随着语言模型和训练数据的规模不断增长,大型语言模型 (LLM) 展示出各种新兴能力。 其中一项能力是上下文学习 (ICL) [11, 14],它允许模型仅从特定上下文中的几个示例中学习。 如图 1 所示,ICL 利用一个包含任务说明和几个示例的演示来描述任务,然后将它们与查询问题连接起来,形成语言模型进行预测的输入。 ICL 与传统调优方法(如微调 [6])之间最显著的区别在于,它是无训练的,不需要参数更新。 这种训练范式使 ICL 能够直接应用于任何 LLM,并显著降低了将模型适应新任务的训练成本 [11]。 最近的研究表明,ICL 在逻辑推理 [15]、对话系统 [16] 和程序修复 [17, 18, 19] 等各个领域都取得了令人印象深刻的结果,甚至可以胜过在大型特定任务数据上训练的监督微调方法。
尽管 ICL 已被证明在代码智能任务中很有用,但众所周知,ICL 的性能在很大程度上依赖于演示的质量 [20, 21]。 现有研究 [17, 19] 主要通过随机选择和排列演示示例来构建演示。 据我们所知,目前缺乏对 ICL 在代码智能任务中的深入研究。 鉴于 ICL 的出色性能,了解演示设计的影响并研究将 ICL 应用于代码智能任务的挑战是值得的。 在这项工作中,我们系统地分析了不同的演示构建方法如何影响 ICL 在代码智能任务中的性能,旨在回答以下问题: 什么构成了使用 LLM 进行代码智能任务的良好上下文演示? 通过分析上下文内演示的设计空间,我们的研究主要集中在上下文内演示的三个方面,包括演示示例的选择、顺序和数量。 我们在三个流行的代码智能任务上进行了实验研究,包括代码摘要、错误修复和程序合成。 具体来说,我们主要研究以下四个研究问题 (RQ):
-
1.
在代码智能任务中,哪些选择方法对 ICL 有帮助?
-
2.
在代码智能任务中,应如何排列演示示例以用于 ICL?
-
3.
提示中演示示例的数量如何影响 ICL 在代码智能任务中的性能?
-
4.
我们发现的结论的一般性如何?
为了回答第一个 RQ,我们比较了多种演示选择方法,例如随机选择、基于相似度的选择和基于多样性的选择。 我们还在基于相似度的选择中尝试了不同的检索方法,以找到哪些检索方法对 ICL 在代码智能任务中更有帮助。 为了回答第二个 RQ,我们比较了随机排序与其他两种排序方法,包括相似度和反相似度,旨在探索不同排序方法的影响。 为了回答 RQ3,我们更改了提示中演示示例的数量,并调查了 ICL 的性能是否也随着演示示例数量的增加而增长。 为了回答最后一个研究问题,我们在不同的 LLM 上进行了实验,并验证了我们在上述研究问题中获得的发现。
主要发现。 基于广泛的实验,我们的研究揭示了一些关键发现:
-
1.
在代码智能任务中,演示选择中的相似性和多样性都是 ICL 的重要因素。 它们不仅提高了整体性能,而且导致更稳定的预测。
-
2.
演示示例的顺序对 ICL 的性能有很大影响。 在大多数情况下,将相似样本放在提示的末尾可以获得更好的结果。
-
3.
增加演示示例的数量可以有利于 ICL,前提是示例不会因 LLM 的输入长度限制而被截断。 应特别注意这个问题,因为代码的长度通常比自然语言长。
我们还表明,基于已获得发现的精心设计的演示可以带来显著的改进,优于广泛使用的演示构建方法 [17, 19, 22],例如,在代码摘要、错误修复和程序合成方面,分别将 BLEU-4、EM 和 EM 至少提高了 9.90%、175.96% 和 50.81%。
贡献。 总之,这项工作的主要贡献如下:
-
1.
据我们所知,本文是关于如何为代码智能任务构建有效演示的第一个系统研究。
-
2.
我们对演示设计的全面探索突出了提高 ICL 在代码智能任务中性能的一系列发现。
-
3.
我们讨论了我们的发现对研究人员和开发人员以及大型语言模型时代代码智能任务的未来工作的意义。
II 背景
II-A 大型语言模型
由于其卓越的性能,大型语言模型 (LLM) 已成为自然语言处理 (NLP) 中无处不在的一部分 [11, 23]。 这些模型通常遵循 Transformer [24] 架构,并在使用自监督目标的大规模语料库上进行训练,例如掩蔽语言建模 [13]。 近年来,LLM 的规模显著增加。 例如,最近的 LLM(如 GPT-3 [11] 和 PALM-E [12])的参数超过了一千亿。 除了用于一般用途的 LLM 之外,还有一些在代码语料库上训练了数十亿参数的 LLM,例如 AlphaCode [25] 和 Codex [2]。 OpenAI 的 Codex 是一款大型预训练代码模型,能够为 Copilot 提供动力。 AlphaCode [25] 是一款 410 亿大型模型,经过训练可以在 Codeforces 等编程竞赛中生成代码。 最近,ChatGPT [26] 和 GPT-4 [23] 等 LLM 也在许多代码智能任务中展现出令人印象深刻的性能。
除了提出新的 LLM 外,如何有效地利用它们也成为一个重要的研究课题。 一种流行的方法是对模型进行微调,并在下游数据集上更新其参数 [13]。 最近,提出了基于提示的微调,旨在将下游任务的训练目标转换为与预训练阶段类似的形式 [27, 28]。 考虑到调整整个模型的成本,人们提出了各种参数高效调整方法,例如 Adapter [29]、Lora [30] 和前缀调整 [31]。 这些方法将模型中的大多数参数保持冻结,只调整其中一小部分。
II-B 上下文学习
对大型预训练模型进行微调可能既昂贵又不切实际,尤其是在某些任务可用的微调数据有限的情况下。 ICL 提供了一种新的替代方案,它使用语言模型执行下游任务,无需更新参数 [14, 11]。 它利用提示中的演示来帮助模型学习任务的输入-输出映射。 这种新的范式在逻辑推理和程序修复等各种任务中取得了令人印象深刻的结果 [15, 17, 19]。
具体而言,如图 1 所示,ICL 使用 演示示例 ,并通过自然语言指令和提示模板将其进一步重建为重建示例 ,其中 、、、 分别是输入、输出、重建输入和重建输出。 通常, 的值相对较小,即少于 50 个样本,这明显小于以前微调方法中训练集的大小 [6, 9]。 此设置被称为 少样本上下文学习。 特别地,当 的值为零时,它被称为 零样本上下文学习设置。 然后,ICL 将重建的演示示例 与 字面地连接到演示 中,并将测试样本添加到最后以构建输入提示 ,其中 表示字面连接操作。 此提示最终被输入到语言模型中,以预测测试样本的标签 。
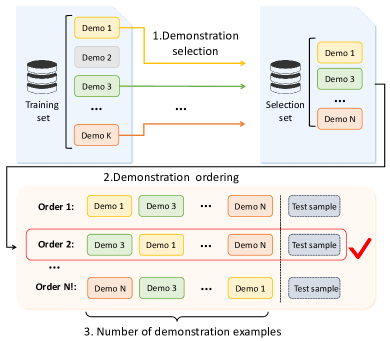
NLP 中以前的研究表明,ICL 的性能在很大程度上取决于演示的质量。 例如,Liu 等人 [20] 表明,选择具有更高相似性的演示示例或增加演示示例的数量可以提高 ICL 的性能。 [21] 中的结果表明,演示示例的顺序对结果也有很大影响。 遵循先前研究,我们总结了在设计 ICL 演示时需要考虑的三个关键因素:演示示例的选择、排序和数量,如图 2 所示。
我们想进一步澄清,ICL 中有两种演示类型:任务级 演示和 实例级 演示 [32, 33]。 任务级演示对所有测试样本使用相同的演示示例,并不考虑每个测试样本的差异,而实例级演示为不同的测试样本选择不同的演示示例。 尽管实例级演示通常比任务级演示表现更好,但它需要事先进行标注的训练集用于检索。 任务级演示更加灵活,因为它可以在数据很少被标注,甚至没有标注数据的情况下使用,通过选择少量代表性数据进行人工标注 [33]。 在本文中,我们研究了代码智能任务中任务级和实例级演示构建方法。
III 实验评估
III-A 研究问题
我们设计实验以研究演示选择、排序和数量对代码智能任务中 ICL 的影响。 我们的研究旨在回答以下问题:
-
RQ1:
代码智能任务中哪些选择方法对 ICL 有帮助?
-
RQ2:
代码智能任务中如何排列演示示例以用于 ICL?
-
RQ3:
提示中演示示例的数量如何影响代码智能任务中 ICL 的性能?
-
RQ4:
我们发现的结论的普遍性如何?
在 RQ1 中,我们旨在验证选择相似和不同的演示示例是否有帮助。 此外,我们还比较了不同的检索方法,以分析不同相似度测量方法对 ICL 的影响。 RQ2 旨在通过比较随机排序与基于相似度的排序来研究排序方法的影响。 在 RQ3 中,我们想探索增加示例数量是否可以为 ICL 带来更好的性能。 在 RQ4 中,我们评估了在 RQ1-RQ3 中取得的发现是否也适用于不同的 LLM,以验证发现的普遍性。
III-B 评估任务
我们在三个流行的代码智能任务上进行实验:代码摘要、错误修复和程序合成。
III-B1 代码摘要
代码摘要,也称为代码注释生成,旨在为给定的代码片段自动生成有用的注释 [7]。 最近的工作主要将其制定为一个序列到序列的神经机器翻译 (NMT) 任务,并涉及预训练技术以实现更好的性能 [9, 34]。
数据集。 为了评估代码摘要的性能,我们使用两个广泛使用的数据集:CodeSearchNet (CSN) [35] 和 TLCodeSum (TLC) [7]。 CSN 是一个从开源 GitHub 仓库中挖掘的大规模源代码数据集。 它包含六种编程语言的代码摘要数据,即 Java、Go、JavaScript、PHP、Python 和 Ruby。 该数据集按照 8:1:1 的比例划分为训练集、验证集和测试集。 在本研究中,考虑到时间和资源的限制,我们使用 CodeBERT [6] 中过滤后的 CSN 数据集的 Java 部分,该数据集包含 181,061 个样本,跨越训练集、验证集和测试集用于评估。 TLC 从 GitHub 上至少有 20 颗星的 9,732 个开源 Java 项目中爬取了 87,136 个代码-注释对。 代码片段都在方法级别,相应 Java 方法的注释被认为是代码摘要。 训练集、验证集和测试集的比例也是 8:1:1。 正如先前工作所报道的那样,训练集和测试集中存在重复数据。 因此,我们遵循先前的工作 [36] 并删除重复数据,最终得到一个包含 6,489 个样本的测试集。
指标。 我们使用三个广泛采用的指标进行代码摘要评估:BLEU-4 [37]、ROUGE-L [38] 和 METEOR [39] 用于评估。 这些指标评估生成的摘要与真实摘要之间的相似性,并在代码摘要中被广泛使用 [3, 36, 40]。
III-B2 错误修复
错误修复是自动修复给定代码片段中错误的任务。 它帮助软件开发人员找到并修复软件错误 [4, 41]。
数据集。 用于修复错误的数据集是 B2F,由 Tufano 等人 [4] 从 GitHub 中的错误修复提交中收集。 我们使用 MODIT [42] 中提出的多模型版本进行实验,因为它包含代码更改和修复指令。 该模型同时提供错误代码和自然语言修复指导,以预测修复后的代码。 我们按照他们最初的设置,根据代码标记的长度将数据集分成两部分 B2Fmedium 和 B2Fsmall(B2Fmedium 的代码长度在 50 到 100 个标记之间,而 B2Fsmall 的代码长度低于 50 个标记)。
指标。 我们遵循之前的工作 [43],对两个数据集都使用精确匹配 (EM) 和 BLEU-4。
| Task | Datasets | Train | Dev | Test |
|---|---|---|---|---|
| Code Summarization | CSN-Java | 164,923 | 5,183 | 10,955 |
| TLC | 69,708 | 8,714 | 6,489 | |
| Bug Fixing | B2Fsmall | 46,628 | 5,828 | 5,831 |
| B2Fmedium | 53,324 | 6,542 | 6,538 | |
| Program Synthesis | CoNaLa | 2,389 | - | 500 |
III-B3 程序合成
程序合成是根据给定的自然语言描述生成源代码的任务。 它为开发人员提供实际帮助,并提高他们的生产力 [2]。
数据集。 对于程序合成,我们使用 CoNaLa [44] 数据集进行评估。 此数据集包含从 Stack Overflow 中的 Python 代码中挖掘出的 2,889 个 意图、代码对。 我们直接使用数据集的原始分区,其中包括 2,389 个用于训练的样本和 500 个用于测试的样本。
指标。 我们遵循先前的工作[43],并使用四个指标来评估程序合成的性能,包括精确匹配(EM)、CodeBLEU(CB)、语法匹配(SM)和数据流匹配(DM)。 EM 衡量模型生成的代码是否与目标代码相同。 CB[45] 是 BLEU 的修改版本,专为代码设计,它利用抽象语法树 (AST) 和数据流等语法和语义信息来衡量两个代码片段的相似性。 SM 和 DM 是两个组件,分别计算匹配子树和数据流边的比例。
| Task | Template |
|---|---|
| Code Summarization | Generate comment (summarization) for this code |
| [input] {#code} [output] {#comment} | |
| Bug Fixing | Fix the bug according to the guidance [input] |
| {#buggy code} s {#instruction} [output] {#fixed code} | |
| Program Synthesis | Generate code based on the requirement |
| [input] {#requirement}[output] {#code} |
III-C 实现
我们在论文中使用 OpenAI Codex (code-davinci-002) API[2] 来进行前三个 RQ 的所有实验。 在 RQ4 中,我们进一步使用 GPT-3.5 (text-davinci-003) 的 API[11] 和 ChatGPT (gpt-3.5-turbo)[26] 来进行实验。 至于 API 的超参数,遵循先前的工作[46, 47], 我们将温度设置为 0 以获得确定性输出。 frequency_penalty 和 presence_penalty 也设置为 0。 Codex、GPT-3.5 和 ChatGPT 的输入长度限制分别为 8,001、4,096 和 4,097 个 Token 。 因此,我们将每个演示示例的输入代码分别截断为 、 和 标记,其中 表示演示示例的数量。 根据经验,评估 Codex 的 1,000 个示例大约需要 6 个小时。 为了避免过高的时间成本,我们从每个测试样本数量超过 2,000 个的数据集中随机抽取一个小测试集(2,000 个样本)。 我们在 RQ1 和 RQ2 中的演示中使用四个示例,并在 RQ3 中进一步讨论演示示例数量的影响。 本研究中使用的模板如表 II 所示。 我们还在我们的 GitHub 仓库 111https://github.com/gszsectan/ICL/tree/master/prompts 中展示了一些示例。 我们在一台配备 2 个 Nvidia RTX 3090 GPU 的服务器上进行所有实验。 这些 GPU 用于密集检索过程。
IV 实验结果
| Approach | Code Summarization | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CSN | TLC | |||||||||||
| BLEU-4 | ROUGE-L | METEOR | BLEU-4 | ROUGE-L | METEOR | |||||||
| Avg | CV | Avg | CV | Avg | CV | Avg | CV | Avg | CV | Avg | CV | |
| Task-level Demonstration | ||||||||||||
| Random | 19.64 | 1.44 | 35.46 | 1.88 | 15.30 | 1.54 | 17.29 | 0.71 | 34.28 | 0.61 | 12.48 | 0.67 |
| KmeansRND | 20.71 | 0.82 | 38.03 | 0.44 | 16.34 | 0.83 | 17.91 | 1.19 | 35.69 | 1.60 | 13.48 | 0.91 |
| Instance-level Demonstration | ||||||||||||
| BM-25 | 22.35 | 0.46 | 38.31 | 0.56 | 17.01 | 0.78 | 36.96 | 0.84 | 51.42 | 0.79 | 24.22 | 0.99 |
| SBERT | 22.27 | 0.23 | 38.39 | 0.42 | 16.91 | 0.22 | 36.42 | 0.61 | 50.47 | 0.40 | 23.86 | 0.68 |
| UniXcoder | 22.11 | 0.61 | 38.23 | 0.53 | 16.81 | 0.23 | 36.77 | 0.52 | 51.11 | 0.29 | 24.08 | 0.79 |
| CoCoSoDa | 21.92 | 0.46 | 37.85 | 0.22 | 16.78 | 0.24 | 36.91 | 0.69 | 50.69 | 0.53 | 24.08 | 0.39 |
| Oracle (BM-25) | 27.69 | 0.43 | 46.17 | 0.14 | 20.26 | 0.22 | 43.16 | 0.15 | 59.17 | 0.09 | 28.09 | 0.16 |
IV-A RQ1:演示选择
IV-A1 实验设计
我们首先探讨了演示选择方法对代码相关任务的ICL的影响。 为了进行全面研究,我们对三种代码智能任务采用了不同类型的演示选择方法。
对于任务级演示,我们需要为整个测试集选择一组演示示例,如第II-B节所示。 为了探讨不同上下文演示示例对ICL性能的影响,我们从训练集中随机选择了三组演示示例,并评估了它们在不同任务上的性能,记为Random。 此外,我们进一步研究了提高演示示例的多样性是否有利于ICL。 我们首先将所有样本分成个簇,然后从每个簇中随机选择一个样本,即KmeansRND,来选择演示示例。 具体来说,我们使用UniXcoder [48]进行向量化,并使用K-means++算法 [49] 进行聚类,其中 设置为 ,表示演示示例的数量。 与 Random 类似,我们也研究了不同示例组对 KmeansRND 的性能,并进行了三次选择过程,产生了三组演示示例。
对于实例级演示,我们需要为每个测试样本选择示例,如第II-B节所示。 遵循 [20],我们将选择过程制定为一个检索问题,并比较不同基于检索的方法的性能,包括:
| Approach | Bug Fixing | |||||||
| B2Fmedium | B2Fsmall | |||||||
| BLEU-4 | EM | BLEU-4 | EM | |||||
| Avg | CV | Avg | CV | Avg | CV | Avg | CV | |
| Task-level Demonstration | ||||||||
| Random | 86.96 | 0.16 | 7.26 | 16.18 | 71.18 | 0.56 | 9.95 | 6.33 |
| KmeansRND | 86.91 | 0.17 | 9.03 | 5.45 | 72.89 | 1.36 | 10.37 | 3.86 |
| Instance-level Demonstration | ||||||||
| BM-25 | 88.05 | 0.09 | 21.85 | 1.78 | 77.54 | 0.13 | 30.45 | 0.96 |
| SBERT | 87.98 | 0.06 | 19.00 | 2.88 | 76.26 | 0.16 | 26.15 | 0.87 |
| UniXcoder | 87.87 | 0.09 | 19.14 | 2.00 | 77.52 | 0.07 | 29.93 | 0.51 |
| CoCoSoDa | 87.73 | 0.07 | 19.23 | 0.74 | 76.45 | 0.07 | 27.40 | 1.04 |
-
1.
BM-25:BM-25是信息检索领域中的一种经典稀疏检索方法。 它也已被广泛应用于许多代码智能模型 [50, 51] 中。
-
2.
SBERT:SBERT [52] 是一种流行的句子建模方法,已被广泛应用于文本检索 [53, 52] 中。 具体来说,在本文中,我们使用在代码相关数据集上进一步训练的版本来获得代码和文本表示 [54]。
-
3.
UniXcoder: UniXcoder [48] 是一种统一的跨模态预训练模型,它通过三个序列建模任务和两个基于对比学习的任务进行预训练。 它在零样本代码到代码搜索方面表现出了良好的性能。
-
4.
CoCoSoDa: CoCoSoDa [55] 是一种最先进的代码搜索模型,它利用对比学习来学习代码和文本表示。
对于 BM-25,我们使用 gensim 包 [56] 通过从训练集中检索与测试样本相似度最高的样本来实现。 对于稠密检索方法,我们直接使用作者发布的复制包中的这些预训练模型,无需进一步微调。 基于预训练模型输出的代码/文本表示,我们选择与测试样本余弦相似度最高的训练样本。 我们还遵循之前的工作 [32] 并创建了一种名为 Oracle 的方法,该方法通过计算测试样本输出与所有训练集样本输出之间的相似度来选择演示示例。 考虑到在实践中测试样本的输出不可用,Oracle 方法通常被认为是性能的上限。 Oracle 中的检索过程由 BM-25 实现,因为与其他稠密检索方法相比,BM-25 表现出最佳性能,如表 III-V 所示。
为了避免演示示例不同顺序的影响,我们以不同的顺序运行每个实验三次,并报告每个指标的平均结果。 此外,我们进一步通过变异系数 (CV) [57] 评估每种方法对不同顺序的敏感性。 CV 通过 计算,其中 是标准差, 是平均值。 较低的 CV 表示较小的数据变异。 它考虑了数据的幅度,并已被广泛用于测量许多领域的数据分散程度,例如经济学和软件工程 [57, 58]。
IV-A2 分析
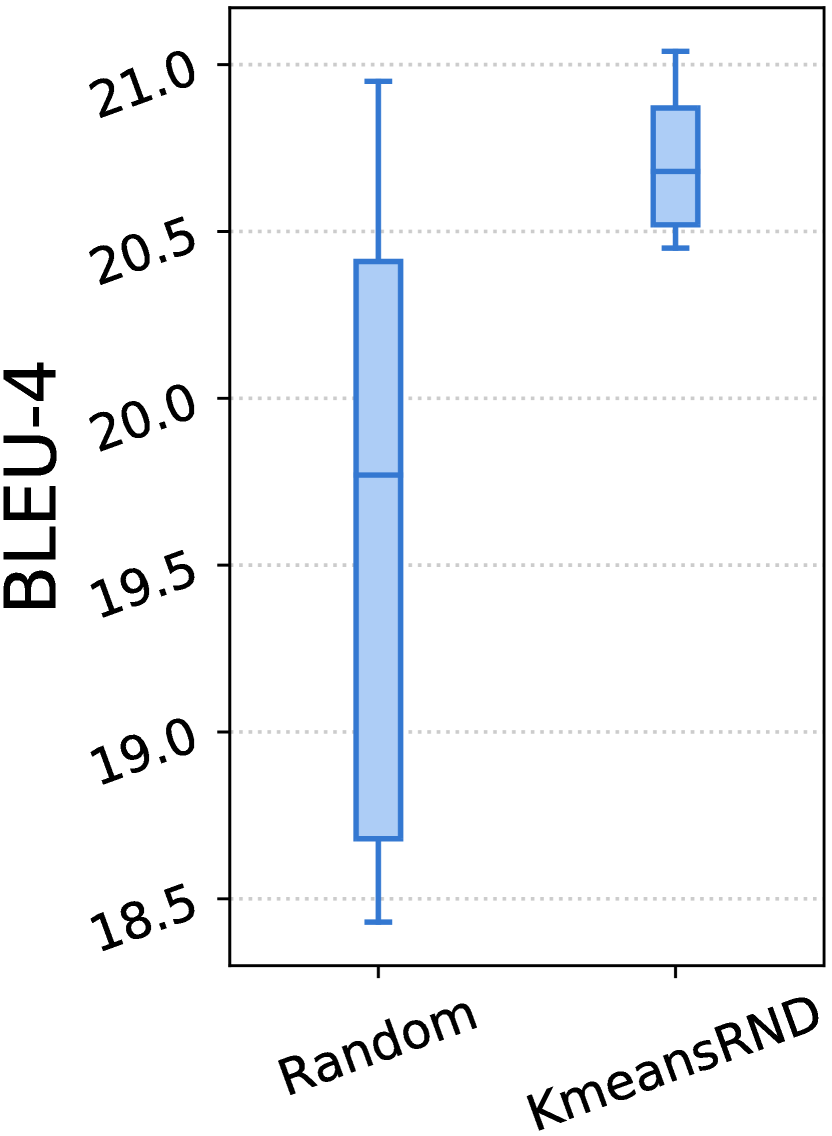
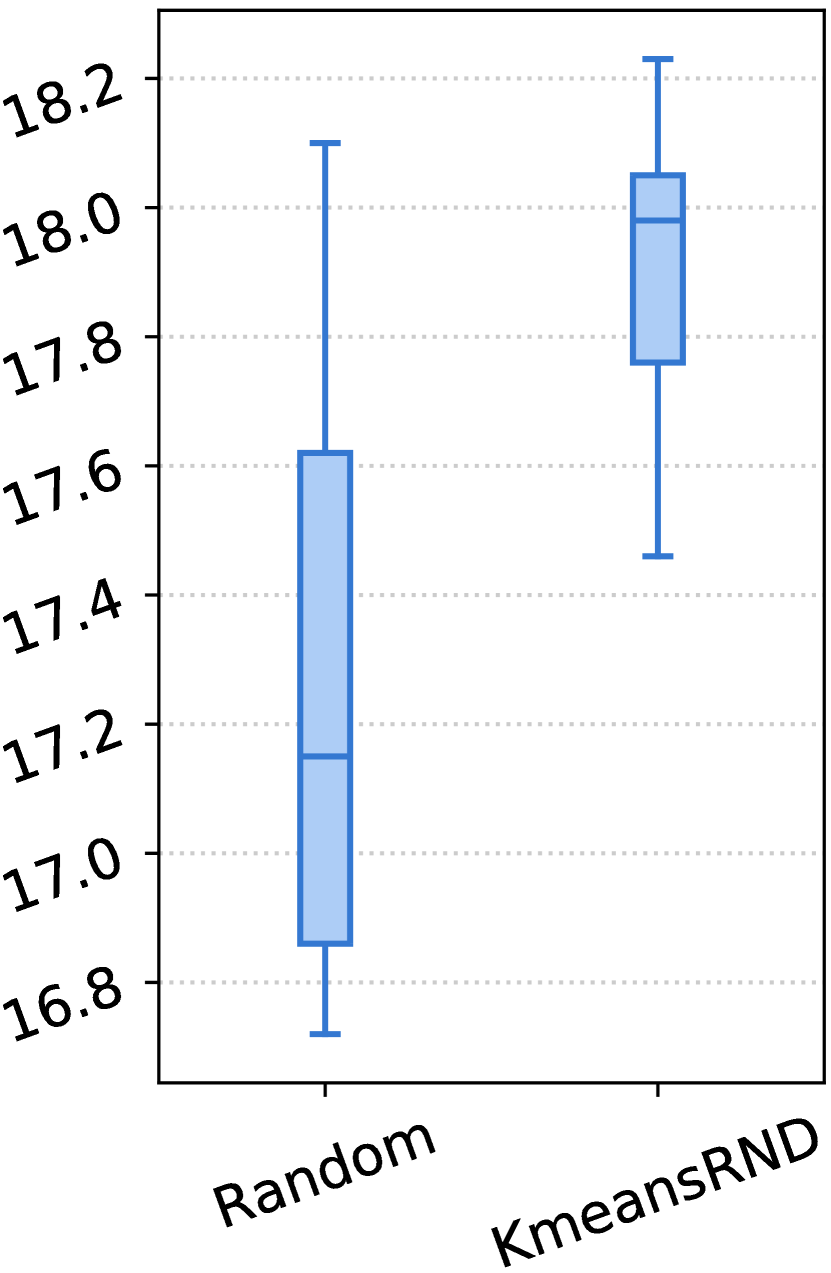
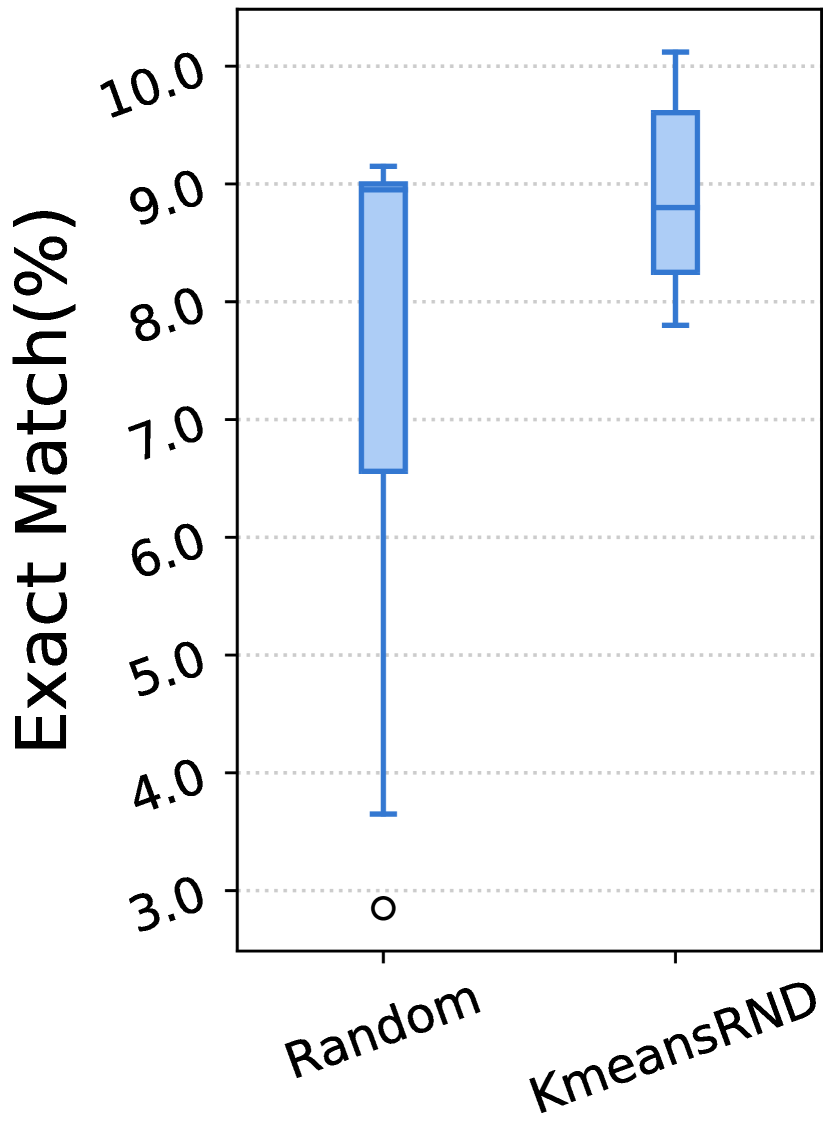
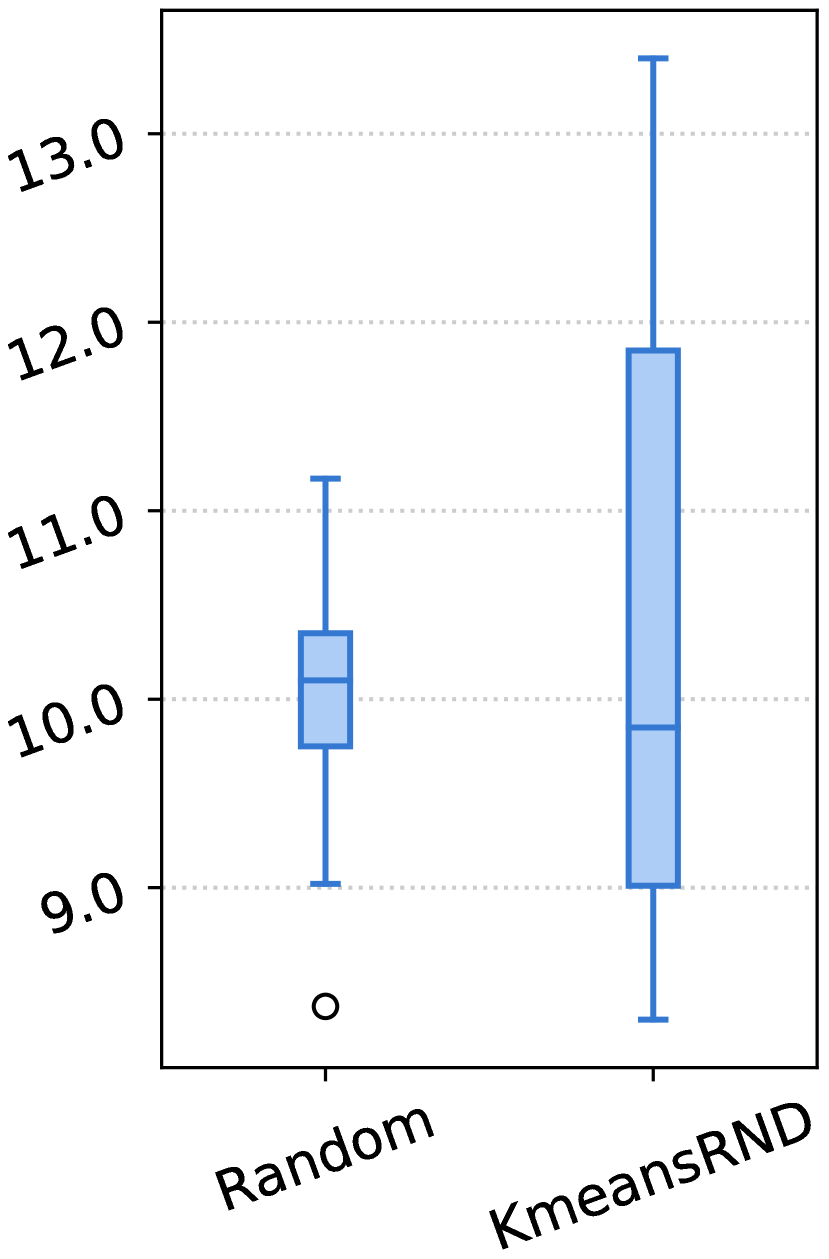
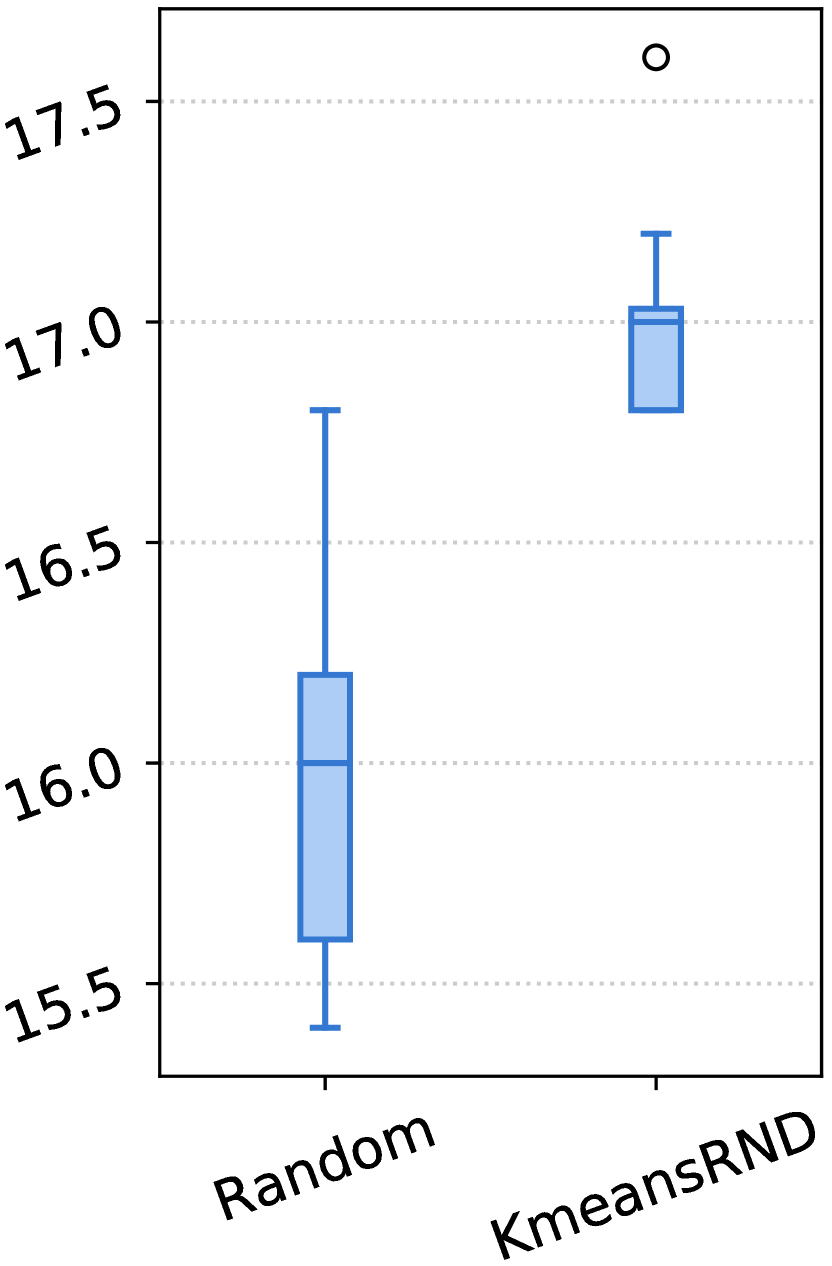
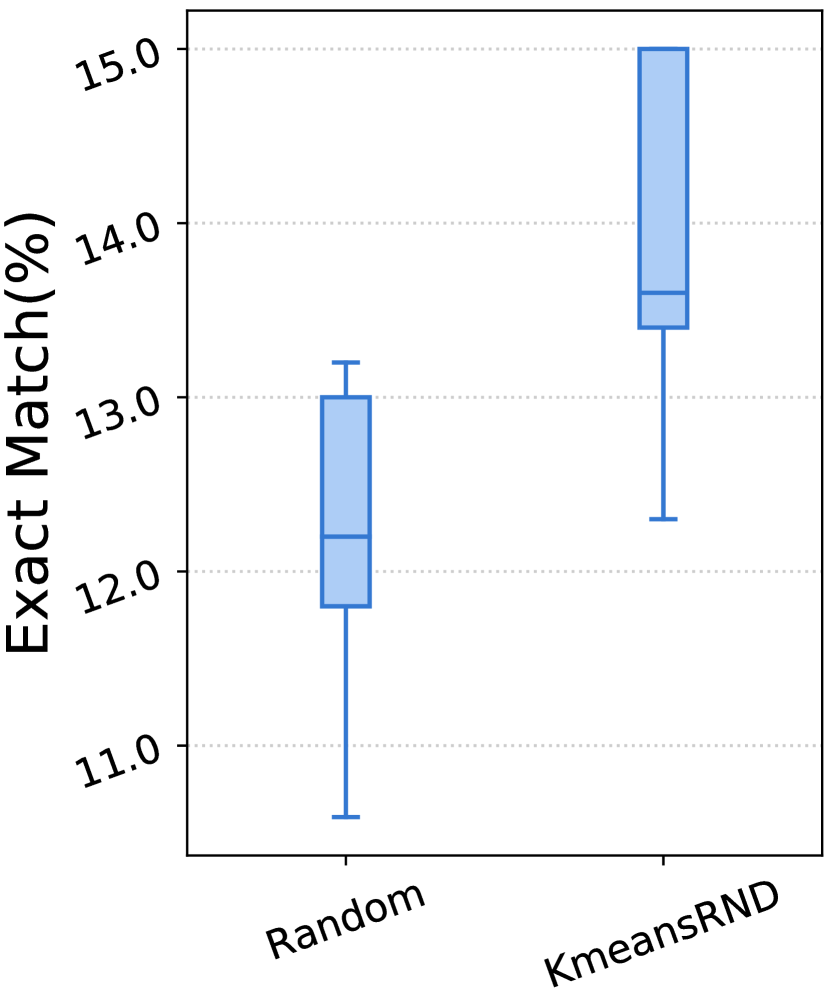
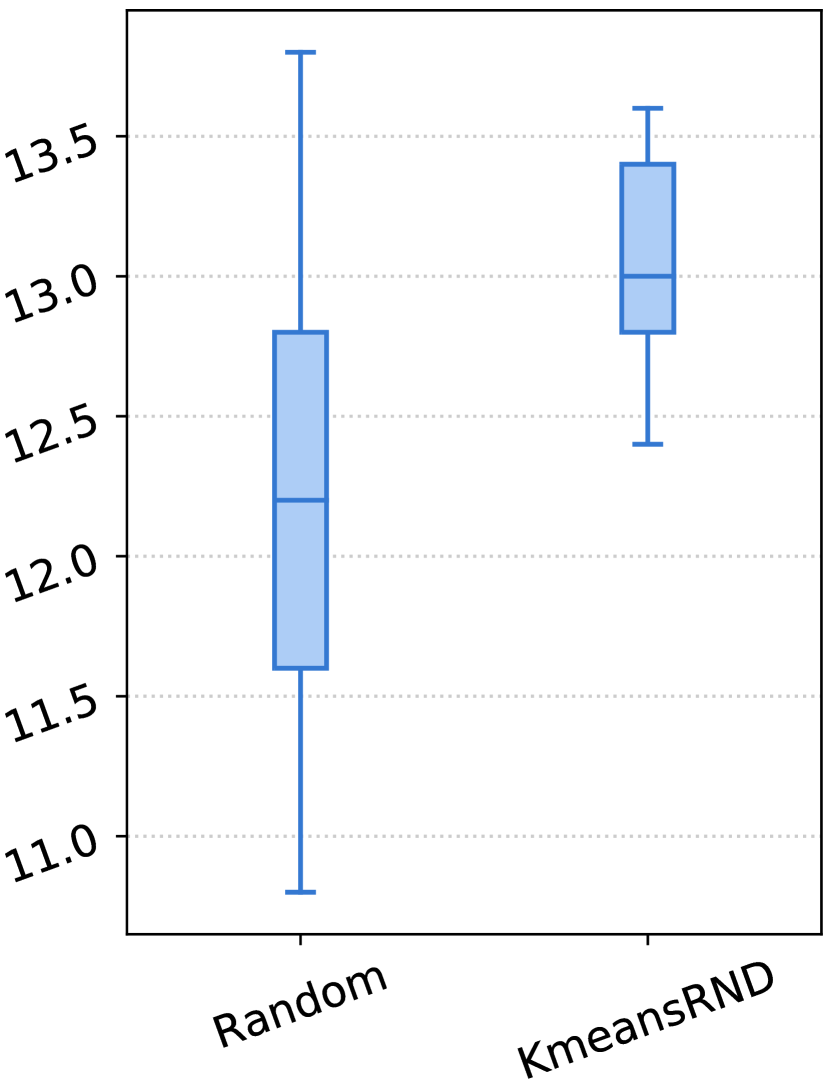
我们在表 III-V 中展示了实验结果。对于每个指标,我们报告了三个随机顺序的平均结果以及 CV,CV 度量了它们对不同顺序的敏感性。 在图 3 中,我们展示了随机和 KmeansRND 不同示例组的结果分布。
示例的多样性有利于任务级演示。 如表 III-V 和图 3 所示,通过比较随机和 KmeansRND 的结果,我们可以发现,在大多数情况下,提高任务级演示的多样性不仅可以提高 ICL 的平均性能,还可以减少不同示例组带来的波动。 例如,如表 III 所示,比较 CSN 上代码摘要的结果,KmeansRND 相对于随机的平均改进分别为 5.45%、7.25% 和 6.80%,分别对应 BLEU-4、ROUGE-L 和 METEOR。 此外,我们还可以发现,随机的不同上下文 演示示例的性能 差异很大,而提高所选示例的多样性通常可以减少这种差异。 例如,如图 3 (a) 所示,随机的最佳和最差 BLEU-4 分数之间的差距约为 2.5,而 KmeansRND 的差距仅约为 0.6。 这表明提高所选演示示例的多样性有利于构建任务级演示。
BM-25 是一种简单有效的实例级演示方法。 通过比较不同实例级演示方法的结果,我们可以发现,简单的 BM-25 方法在 ICL 中的演示选择方面可以实现与其他密集检索方法相当甚至更好的性能。 例如,BM-25 在程序合成的平均 EM 为 18.53,分别比三个强大的密集检索方法 SBERT、UniXcoder 和 CoCoSoDa 高出 14.88%、15.81% 和 13.68%。 这个结果表明,BM-25 是一种有效的 基线方法,可以在未来关于代码智能任务的演示选择研究中加以考虑。
| Approach | Program Synthesis | |||||||
|---|---|---|---|---|---|---|---|---|
| CB | SM | DM | EM | |||||
| Avg | CV | Avg | CV | Avg | CV | Avg | CV | |
| Task-level Demonstration | ||||||||
| Random | 28.36 | 1.30 | 44.37 | 0.83 | 39.70 | 1.33 | 16.00 | 1.60 |
| KmeansRND | 28.03 | 1.47 | 44.41 | 0.54 | 37.31 | 1.54 | 17.03 | 1.06 |
| Instance-level Demonstration | ||||||||
| BM-25 | 30.37 | 0.91 | 46.22 | 0.84 | 40.75 | 1.06 | 18.53 | 0.50 |
| SBERT | 29.08 | 0.70 | 44.91 | 0.31 | 39.81 | 3.01 | 16.13 | 2.54 |
| UniXcoder | 28.96 | 0.50 | 43.93 | 0.67 | 37.96 | 1.12 | 16.00 | 3.53 |
| CoCoSoDa | 29.42 | 0.82 | 44.62 | 0.70 | 40.91 | 1.12 | 16.30 | 0.86 |
| Approach | Code Summarization (CSN) | Bug Fix (B2Fsmall) | Program Synthesis (CoNaLa) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BLEU-4 | ROUGE-L | METEOR | BLEU-4 | EM | CB | SM | DM | EM | ||
| Random | Random | 20.46 | 36.71 | 16.17 | 72.40 | 9.52 | 27.72 | 44.46 | 37.53 | 15.53 |
| Similarity | 21.04 | 37.86 | 16.26 | 72.02 | 9.93 | 28.47 | 44.87 | 37.79 | 16.00 | |
| Reverse Similarity | 19.78 | 33.71 | 15.64 | 71.44 | 9.02 | 27.62 | 44.48 | 37.96 | 15.20 | |
| KmeansRND | Random | 20.67 | 37.64 | 15.97 | 72.29 | 8.60 | 26.64 | 42.97 | 37.24 | 16.87 |
| Similarity | 20.69 | 37.62 | 16.05 | 72.90 | 10.15 | 27.20 | 42.97 | 36.93 | 16.40 | |
| Reverse Similarity | 20.55 | 37.43 | 16.20 | 72.05 | 9.78 | 27.09 | 43.74 | 37.19 | 16.60 | |
| BM-25 | Random | 22.35 | 38.31 | 17.01 | 77.54 | 30.45 | 30.37 | 46.22 | 40.75 | 18.53 |
| Similarity | 22.23 | 38.12 | 17.01 | 77.76 | 30.95 | 30.83 | 46.41 | 41.33 | 17.60 | |
| Reverse Similarity | 22.13 | 38.26 | 16.91 | 77.60 | 29.80 | 30.01 | 45.72 | 39.60 | 18.20 | |
实例级演示明显优于任务级演示。 如表 III-V 所示,我们可以发现,实例级演示在所有任务中都能取得更好的性能。 具体来说,实例级选择方法将最佳任务级演示的精确匹配结果分别提高了 B2Fmedium 上的至少 141.97% 和 B2Fsmall 上的 193.64%。 这些结果表明,为每个测试样本专门选择类似的演示示例可以极大地有利于代码智能任务中的 ICL。
任务级演示比实例级演示对顺序更敏感。 通过比较任务级演示和实例级演示的 CV,我们可以发现,在不同的示例顺序方面,实例级演示的性能通常比任务级演示更稳定。 具体来说,如表 IV 所示,任务级演示 KmeansRND 对两个错误修复数据集上的顺序的 BLEU-4 的 CV 分别为 0.17 和 1.36,这远大于实例级演示方法的 CV(例如,BM-25 分别为 0.09 和 0.13)。 这表明,通过相似性选择示例对演示顺序的变化更稳健,并且在使用任务级演示时,我们应该仔细安排演示示例的顺序。
除了上述内容之外,我们还可以在表 III 中观察到,最佳演示选择方法 BM-25 仍然与 Oracle 有很大的差距。 这表明这些检索方法可能无法选择语义上相似的示例,并且在代码智能任务的演示选择方法方面存在很大的改进空间。
IV-B RQ2:演示顺序
IV-B1 实验设置
在 RQ1 中,我们发现演示示例的顺序会影响 ICL 在代码智能任务上的性能,尤其是在任务级演示上。 因此,在本节中,我们探讨如何在 ICL 中更好地安排演示示例。 受以下发现的启发,即任务级演示对示例顺序的敏感度高于实例级演示,我们假设每个演示示例与测试样本之间相似性的顺序在 ICL 中起着重要作用。
为验证这一点,在本 RQ 中,我们将随机顺序与两种基本排序方法进行比较,即 相似性 和 反向相似性。 在相似性方法中,我们比较每个示例与测试样本的相似性,相似性更高的示例将被放置在更靠近测试样本的位置。 相反,对于反向相似性方法,演示示例将根据它们与测试样本的相似性按降序排列。 我们在这里对三种演示选择方法进行了实验。 正如 RQ1 中所述,由于顺序排列对于任务级演示很重要,我们使用 Random 和 KmeansRND 两种方法进行实验。 对于实例级演示,我们在 BM-25 上进行实验,因为它在所有实例级演示选择方法中表现最佳。
IV-B2 分析
从表 VI 中的结果可以看出,将演示示例按与测试样本的相似度升序排列,通常比反序排列效果更好。 具体来说,相似度 在代码摘要和错误修复方面始终优于 反向相似度,BLEU-4 和 EM 分别至少提高了 0.45% 和 0.21%。 通过进一步比较所有结果,我们可以观察到相似度在大多数情况下都取得了最佳性能。 具体而言,它在 62.96% (17/27) 的指标和任务中取得了最佳性能。 然而,我们也观察到,在某些情况下,相似度 和 反向相似度 的性能都比使用随机顺序的平均结果差,这表明未来工作可以探索更复杂的演示排序方法。
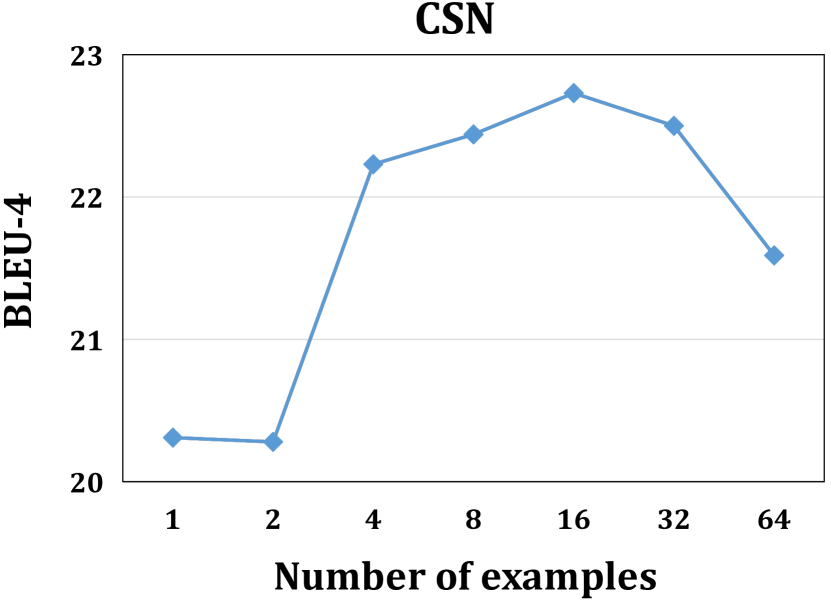
IV-C RQ3:演示示例的数量
IV-C1 实验设置
在本节中,我们研究了示例数量的增加是否会提高 ICL 在代码智能任务中的性能。 我们将演示示例的数量从 1 更改为 64。 我们使用 BM-25 和 相似度 分别作为演示选择和演示排序方法,基于上述发现。
IV-C2 分析
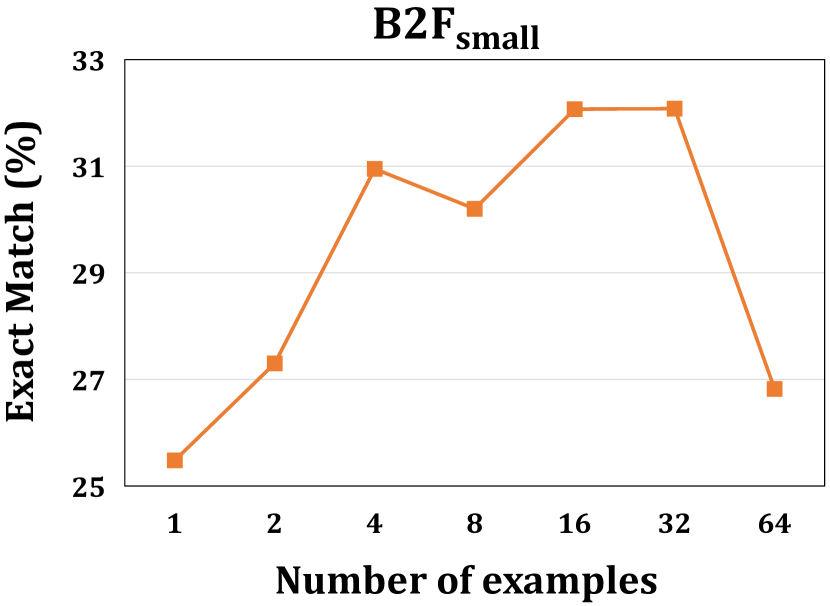
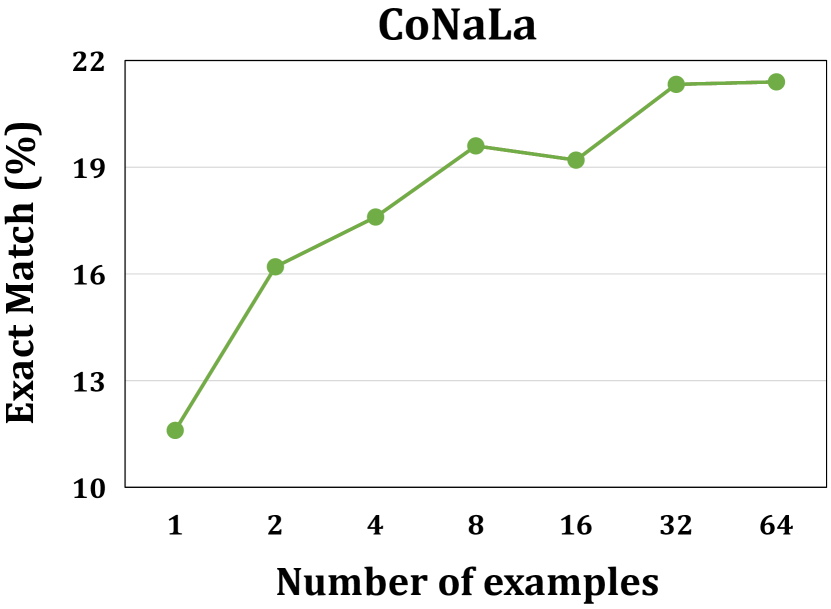
如图 4 所示,我们可以发现 ICL 在所有任务上的性能最初都随着演示示例数量的增加而提高。 但是,当示例数量超过 16 时,不同任务的结果呈现出不同的趋势。 例如,对于 bug 修复,当演示示例数量为 32 时,性能达到峰值,当进一步增加示例数量到 64 时,性能会大幅下降。 对于程序合成,性能持续提高,并且当示例数量超过 32 时趋于稳定。 我们认为这些不同的趋势是由 截断问题 [59, 60] 造成的。 如III-C节所示,当增加示例数量时,整个演示的长度将会增加,示例可能会被截断,以避免超出LLM的长度限制。 具体来说,对于 B2Fsmall 数据集,当示例数量低于 32 时,所有示例都是完整的,没有截断。 但是,当示例数量变为 32 时,2.33% 的演示示例被截断。 当进一步将示例数量增加到 64 时,超过 80% 的示例发生截断问题,并且这些示例中的 44.32% 的字符被丢弃,导致性能大幅下降。 由于 CSN 和 B2Fsmall 数据集中样本的长度远大于 CoNaLa 数据集,即 CSN、B2Fsmall 和 CoNaLa 的每个样本分别为 557、492、101 个字符,即使示例数量增长到 64,程序合成中也不会出现截断问题。 因此,对于 ICL 来说,平衡示例数量和随之而来的截断问题非常重要。
由于代码通常比自然语言长得多 [35],因此代码智能任务更容易出现截断问题。 此外,更多的示例也会导致使用外部 API 的成本更高,推理时间 [61] 更长。 对于代码智能任务来说,更少的示例可能更合适。 从结果(图 4)中,我们还可以发现使用四个演示示例的性能已经足够好,分别在三个任务上实现了最佳性能的 96.48%、97.80% 和 94.80%,分别对应于 EM、BLEU-4 和 CodeBLEU。 因此,考虑到上述权衡,在演示中使用四个示例是代码智能任务的一个不错的选择。
| Approach | CB | EM | |||
|---|---|---|---|---|---|
| Selection | Order | Avg | CV | Avg | CV |
| GPT-3.5 | |||||
| Random | Random | 26.60 | 3.01 | 12.32 | 4.73 |
| KmeansRND | Random | 28.26 | 1.93 | 13.60 | 1.65 |
| UniXcoder | Random | 30.06 | 0.53 | 13.73 | 1.13 |
| BM-25 | Random | 30.81 | 1.05 | 14.40 | 1.81 |
| BM-25 | Similarity | 30.69 | 0.00 | 15.20 | 0.00 |
| ChatGPT | |||||
| Random | Random | 28.17 | 1.98 | 11.88 | 4.24 |
| KmeansRND | Random | 28.25 | 2.31 | 12.92 | 1.78 |
| UniXcoder | Random | 29.33 | 1.85 | 14.32 | 2.87 |
| BM-25 | Random | 28.95 | 5.75 | 13.47 | 1.82 |
| BM-25 | Similarity | 30.03 | 0.00 | 14.20 | 0.00 |
| Approach | Code Summarization (CSN) | Bug Fix (B2Fsmall) | Program Synthesis (CoNaLa) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BLEU-4 | ROUGE-L | METEOR | BLEU-4 | EM | CB | SM | DM | EM | ||
| Codex | Zero-shot | 1.82 | 4.27 | 4.19 | 34.65 | 1.43 | 8.71 | 9.26 | 23.81 | 0.20 |
| Baseline demonstration | 17.37 | 32.04 | 13.43 | 69.07 | 9.70 | 27.54 | 44.56 | 37.07 | 14.20 | |
| Carefully-designed demonstration | 22.73 | 39.52 | 17.35 | 77.54 | 32.25 | 32.07 | 48.03 | 42.88 | 21.40 | |
| GPT-3.5 | Zero-shot | 6.34 | 15.05 | 14.08 | 2.81 | 0.15 | 0.06 | 0.26 | 0.00 | 0.20 |
| Baseline demonstration | 14.55 | 21.53 | 13.81 | 62.87 | 9.15 | 26.36 | 36.94 | 41.67 | 10.00 | |
| Carefully-designed demonstration | 15.99 | 26.78 | 16.70 | 71.70 | 25.25 | 30.69 | 43.95 | 44.78 | 15.20 | |
| ChatGPT | Zero-shot | 3.63 | 11.40 | 13.16 | 2.32 | 0.05 | 25.70 | 37.64 | 54.44 | 3.40 |
| Baseline demonstration | 10.76 | 20.02 | 14.83 | 41.57 | 4.60 | 27.62 | 41.83 | 46.85 | 9.40 | |
| Carefully-designed demonstration | 11.90 | 23.31 | 16.93 | 53.92 | 18.15 | 30.03 | 45.04 | 44.26 | 14.20 | |
IV-D RQ4:发现的泛化
IV-D1 实验设置
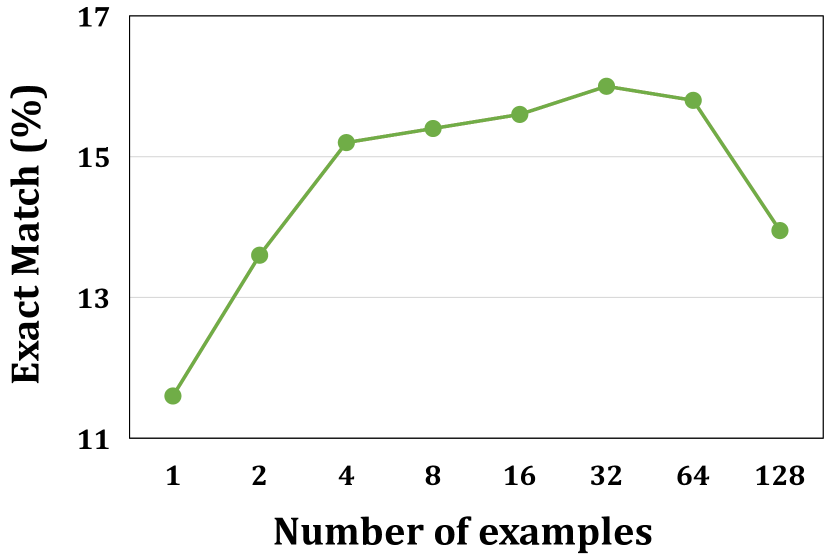
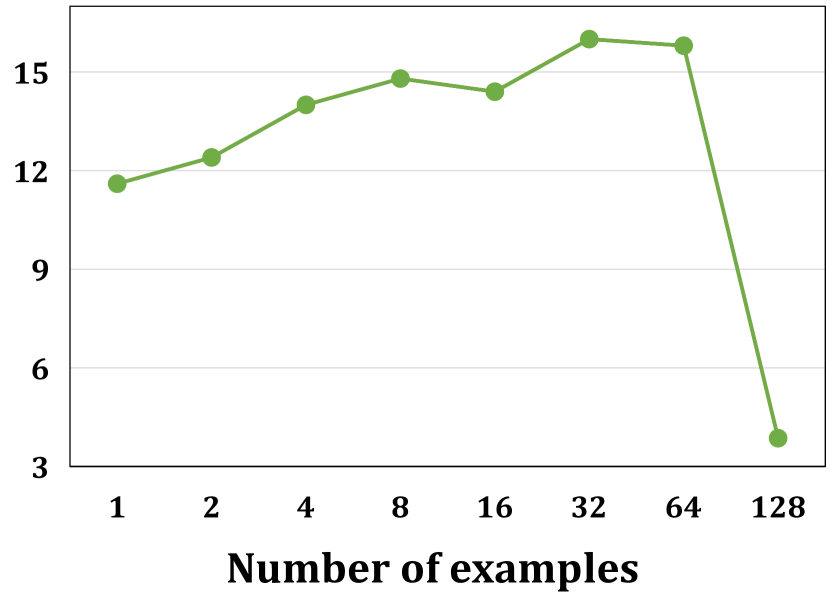
在本节中,我们评估了我们的发现对不同 LLM 的泛化。 除 Codex 外,我们还在另外两个 LLM 上进行了实验,包括 GPT-3.5 [11] 和 ChatGPT [26]。 为了验证发现 1-4, 我们对演示选择和排序方法的以下组合进行了实验:随机+随机、KmeansRND+随机、UniXcoder+随机、BM-25+随机和 BM-25+相似性。 关于 RQ3 中的发现 5, 我们使用 BM-25+Similarity 作为选择和排序方法,并将演示示例的数量从 1 更改为 128,以验证截断是否会导致性能下降。 由于成本限制, 我们选择程序合成任务进行评估。
我们还通过比较 ICL 的性能来衡量我们的发现可以带来多少改进,包括一个精心设计的演示,ICL 与广泛使用的演示构建方法 [17, 19, 22],以及零样本 ICL。 在精心设计的演示中,我们使用 BM-25 和 Similarity 作为演示选择和排序方法,并使用四个演示示例;而对于广泛使用的基线演示构建方法,我们使用先前工作中的设置 [17, 19, 22],并从训练集中随机选择两个演示示例,并随机排序。 至于零样本 ICL,如第 II-B 节所示,没有使用演示示例,模型仅根据指令进行预测。
IV-D2 分析
我们在表 VII 中展示了 GPT-3.5 和 ChatGPT 的平均结果和 CV。 在图 5 和图 6 中,我们分别展示了不同示例组的性能分布以及示例数量对这两个 LLM 的影响。 不同演示的比较如表 VIII 所示。 由于空间限制,我们只展示了 EM 和 CB 上的性能,其他指标的结果可以在我们的复制包中找到。 从这些结果中,我们可以观察到我们的发现也适用于 GPT-3.5 和 ChatGPT。
如表 VII 和图 6 所示,我们可以观察到 KmeansRND+Random 不仅在平均结果方面优于 Random+Random,而且在不同示例组的预测分布方面也更稳定。 以 GPT-3.5 为例,KmeansRND+Random 在 CB 和 EM 方面分别比 Random+Random 提高了 6.24% 和 10.39%。 这表明多样性对于这两个模型的演示构建也是有益的 (发现 1)。 同样,通过比较 BM-25+Random 和 UniXcoder+Random,我们也可以发现 BM-25 可以实现类似的性能,甚至在 GPT-3.5 上比 UniXcoder 在 CB 和 EM 方面分别提高了 2.50% 和 4.88%。 这表明 BM-25 也是这两个模型中一种简单有效的演示选择方法 (发现 2)。 此外,在 GPT-3.5 和 ChatGPT 上,实例级演示始终优于任务级演示,并且通常对不同顺序的 CV 较低。 这表明根据相似性选择演示示例对于这两个 LLM 也是有益的 (发现 3)。 关于示例顺序的影响,我们还可以发现 BM-25+Similarity 在所有指标和 LLM 上始终优于 BM-25+Random,例如,在 GPT-3.5 和 ChatGPT 上分别将平均 EM 提高了 5.56% 和 5.42% (发现 4)。 关于数量的影响,我们可以观察到 GPT-3.5 和 ChatGPT 上的类似趋势,如图 6 所示,EM 首先随着演示示例数量的增加而增加。 随着数量进一步增加到 128,25.05% 的示例遇到了截断问题,导致突然下降 (发现 5)。
表 VIII 展示了不同演示的比较。 我们还可以观察到,零样本 ICL 在所有任务上的表现都很差,这表明使用演示示例来引导 LLM 理解任务的重要性。 此外,通过比较精心设计的演示和基线演示的性能,我们可以发现,在代码摘要、错误修复和程序合成方面,使用精心设计的演示的 ChatGPT 在 BLEU-4、EM 和 EM 方面分别比基线演示高出至少 10.59%、294.57% 和 51.06%。 结果表明构建良好演示的重要性以及发现的普遍性。
V 讨论
V-A 发现的意义
在本节中,我们将讨论我们的工作对研究人员和开发人员的意义。
研究人员: 我们的研究表明,少样本上下文学习的性能高度依赖于演示的设计。 通过精心构建的演示,ICL 可以取得更好的性能。 我们的实验结果也为代码智能社区在 LLM 和 ICL 时代的研究方向提供了潜力。 具体来说:
-
•
如 RQ1 的结果所示,当前最先进的代码检索模型与 Oracle 仍然存在较大差距,表明这些模型未能选择具有最高语义相似性的示例。 因此,值得研究用于零样本代码到代码搜索的有效代码表示模型。 此外,基于每个任务的先验知识或源代码属性设计示例选择策略也是值得探索的有趣方向。
-
•
将相似的示例放在所有示例的后面比随机放置和反向放置导致的性能相对更好。 但是,这种改进并不一致。 因此,如何为代码智能任务自动设计更好的排序方法需要进一步研究。
-
•
与自然语言文本不同,代码片段的长度通常要长得多。 这限制了提示中示例的数量,并可能给 LLM 带来巨大的计算和时间成本。 因此,将程序切片和缩减技术纳入 ICL 以降低成本值得研究。
开发者: 上下文学习是一种范式,它允许从提示中的少量示例中学习,而无需更新参数。 这种新方法也吸引了语言模型即服务社区。 我们的研究结果表明,演示示例的选择、顺序和数量对 ICL 在代码智能任务中的性能有重大影响。 基于我们的研究结果,我们得出以下见解和结论,供开发人员在工作中使用 LLM:
-
•
在提示中包含演示示例,这有助于模型理解任务并指导输出格式。
-
•
当有标记的训练集可用时,使用检索方法选择演示示例。 对于检索方法,考虑使用 BM-25,因为它是一种简单但有效的 方法。
-
•
通过聚类来提高任务级演示示例的多样性,以获得更准确和稳定的预测。
-
•
在安排演示示例的顺序时,在大多数情况下,将相似的样本放在列表的末尾是一个不错的选择。
-
•
尽可能多地使用演示示例,但要注意最大长度限制,以避免截断问题。 为了节省成本,建议在演示中使用四个示例。
V-B 有效性威胁
我们确定了对本研究有效性存在的三大威胁:
-
1.
潜在的数据泄露。 在本文中,我们使用 OpenAI Codex、GPT-3.5 和 ChatGPT 的 API 进行实验。 但是,由于它们是闭源模型,其参数和训练集并未公开,这引发了对潜在数据泄露的担忧。 具体而言,存在模型可能已经在测试集上进行过训练,并且仅仅是记忆结果而不是预测结果的可能性。 但是,我们可以从我们的实验中观察到,模型在零样本设置下的性能是灾难性的,这表明直接记忆数据集的可能性很低。 此外,本文中的所有实验都是使用这些模型进行的,我们使用相对性能改进来衡量不同演示构建策略的有效性。 因此,我们论文的发现仍然令人信服。
-
2.
任务的选择。 在这项研究中,我们调查了演示在代表性三项任务上的构建,包括代码摘要、错误修复和程序合成。 这些任务涵盖了不同类型,例如代码 文本、代码+文本 代码和文本 代码。 因此,我们相信我们论文的发现可以推广到各种代码智能任务。 未来,我们计划对其他类型的任务进行实验,例如代码 类任务(例如,漏洞检测)和代码 代码任务(例如,代码翻译)。
-
3.
模型的选择。 在本文中,我们选择了三个 LLM 进行实验。 尽管如此,还有其他 LLM 可用,例如 CodeGen [62] 和 CodeGeeX [63]。 未来,我们计划对更广泛的 LLM 进行实验,以验证我们发现结果的普遍性。
-
4.
语言的选择。 对于每个任务,我们选择一个流行的数据集进行评估。 三个任务的数据集只包含两种编程语言,即 Java 和 Python。 未来,我们将验证演示构建方法在其他语言中的有效性。
VI 相关工作
VI-A 代码预训练模型
近年来,随着预训练技术的不断发展,代码预训练模型已被广泛应用,并在各种软件工程任务中取得了最先进的性能。 其中一个模型是 CodeBERT [6],它是一个仅编码器预训练模型,在六种编程语言上使用两个自监督任务进行训练。 另一个模型,CodeT5 [9] 是一个编码器-解码器预训练模型,其架构与 T5 相同。 CodeGPT [64] 是一个仅解码器模型,在编程语言数据集上进行预训练,其架构与 GPT-2 相同。 PLBART [8] 使用去噪序列到序列预训练,用于程序理解和生成。 UniXCoder [48] 涉及多模态对比学习和跨模态生成目标,以学习代码片段的表示。
除了学术界中这些较小的预训练模型之外,近年来,业界还提出了许多规模更大的预训练代码模型。 Codex [2] 是 OpenAI 提出的一个大型代码预训练模型,支持 Copilot 服务。 除了 Codex 之外,OpenAI 最近发布的模型,如 ChatGPT [26] 和 GPT-4 [23],也预先在源代码数据上进行了训练,并展示了令人印象深刻的编程能力。 AlphaCode [25] 经过训练,可以为 Codeforces 等编程竞赛生成代码,使用 715G 数据和 41B 参数。 CodeGen [62] 是一款用于多轮程序合成的超大型预训练模型,拥有超过 16B 参数,而 CodeGeeX [63] 则是最近提出的一种开源多语言代码生成模型,拥有 13B 参数。
VI-B 上下文学习
近年来,大型语言模型彻底改变了自然语言处理 (NLP)。 基于大型预训练数据和模型规模,LLM 显示出令人印象深刻的新兴能力,这些能力在小型模型中没有观察到 [10]。 Brown 等人 [11] 最初表明 GPT-3 能够从上下文中的几个示例中学习,而无需参数更新。 Liu 等人 [20] 首次探索将最近邻作为上下文示例进行选择。 最近,Levy 等人 [65] 提出改进上下文示例的多样性,并在 NLP 组合泛化任务上取得更好的性能。 Lu 等人 [21] 发现上下文示例的顺序对性能有很大影响,并提出了基于熵的两种方法 LocalE 和 GlobalE。 最近,一系列工作 [15, 66] 专注于复杂的推理任务,并通过引导模型输出其推理路径来提出思维链提示。
除了 NLP 之外,人们对将上下文学习应用于代码智能任务越来越感兴趣 [17, 19, 47, 22, 67, 68]。 例如,Xia 等人 [17] 评估了 LLM 在程序修复方面的有效性。 Nashid 等人 [47] 提出使用 BM-25 来检索类似的示例并构建断言生成和程序修复的演示。 但是,这些工作主要集中在对 LLM 在一个或两个任务上的评估,而没有深入讨论上下文演示的构建。 相反,我们的工作旨在对代码智能任务中 ICL 的演示设计进行系统研究。
VII 结论与未来工作
在本文中,我们通过实验研究了不同演示选择方法、不同演示排序方法以及演示示例数量对代码智能任务中上下文学习性能的影响。 我们的研究表明,经过精心设计的 ICL 演示比简单的演示效果好得多。 我们总结了我们的发现,并提供了一些建议,以帮助研究人员和开发人员为代码智能任务构建更好的演示。 在未来,我们将探索源代码在上下文学习性能中的更多方面,例如代码质量和代码的自然性。 此外,我们还将在其他大型语言模型上进一步验证我们的发现。 我们的源代码和完整的实验结果可在 https://github.com/shuzhenggao/ICL4code 找到。
参考文献
- [1] Z. Zeng, H. Tan, H. Zhang, J. Li, Y. Zhang, and L. Zhang, “An extensive study on pre-trained models for program understanding and generation,” in ISSTA ’22: 31st ACM SIGSOFT International Symposium on Software Testing and Analysis, Virtual Event, South Korea, July 18 - 22, 2022. ACM, 2022, pp. 39–51.
- [2] M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman et al., “Evaluating large language models trained on code,” CoRR, vol. abs/2107.03374, 2021.
- [3] W. U. Ahmad, S. Chakraborty, B. Ray, and K. Chang, “A transformer-based approach for source code summarization,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020. Association for Computational Linguistics, 2020, pp. 4998–5007.
- [4] M. Tufano, J. Pantiuchina, C. Watson, G. Bavota, and D. Poshyvanyk, “On learning meaningful code changes via neural machine translation,” in Proceedings of the 41st International Conference on Software Engineering, ICSE 2019, Montreal, QC, Canada, May 25-31, 2019. IEEE / ACM, 2019, pp. 25–36.
- [5] P. Yin and G. Neubig, “A syntactic neural model for general-purpose code generation,” in Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 - August 4, Volume 1: Long Papers. Association for Computational Linguistics, 2017, pp. 440–450.
- [6] Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jiang, and M. Zhou, “Codebert: A pre-trained model for programming and natural languages,” in Findings of the Association for Computational Linguistics: EMNLP 2020, ser. Findings of ACL, vol. EMNLP 2020. Association for Computational Linguistics, 2020, pp. 1536–1547.
- [7] X. Hu, G. Li, X. Xia, D. Lo, S. Lu, and Z. Jin, “Summarizing source code with transferred API knowledge,” in Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, July 13-19, 2018, Stockholm, Sweden. ijcai.org, 2018, pp. 2269–2275.
- [8] W. U. Ahmad, S. Chakraborty, B. Ray, and K. Chang, “Unified pre-training for program understanding and generation,” in Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, June 6-11, 2021. Association for Computational Linguistics, 2021, pp. 2655–2668.
- [9] Y. Wang, W. Wang, S. R. Joty, and S. C. H. Hoi, “Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021. Association for Computational Linguistics, 2021, pp. 8696–8708.
- [10] J. Wei, Y. Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzler et al., “Emergent abilities of large language models,” Trans. Mach. Learn. Res., vol. 2022, 2022.
- [11] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” in Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020.
- [12] D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu et al., “Palm-e: An embodied multimodal language model,” CoRR, vol. abs/2303.03378, 2023.
- [13] J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: pre-training of deep bidirectional transformers for language understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers). Association for Computational Linguistics, 2019, pp. 4171–4186.
- [14] Q. Dong, L. Li, D. Dai, C. Zheng, Z. Wu, B. Chang, X. Sun, J. Xu, and Z. Sui, “A survey for in-context learning,” arXiv preprint arXiv:2301.00234, 2022.
- [15] J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. H. Chi, Q. Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” in NeurIPS, 2022.
- [16] Y. Hu, C. Lee, T. Xie, T. Yu, N. A. Smith, and M. Ostendorf, “In-context learning for few-shot dialogue state tracking,” in Findings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022. Association for Computational Linguistics, 2022, pp. 2627–2643.
- [17] C. S. Xia, Y. Wei, and L. Zhang, “Automated program repair in the era of large pre-trained language models,” in 45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, May 14-20, 2023. IEEE, 2023, pp. 1482–1494.
- [18] Y. Peng, S. Gao, C. Gao, Y. Huo, and M. R. Lyu, “Domain knowledge matters: Improving prompts with fix templates for repairing python type errors,” CoRR, vol. abs/2306.01394, 2023.
- [19] J. A. Prenner, H. Babii, and R. Robbes, “Can openai’s codex fix bugs?: An evaluation on quixbugs,” in 3rd IEEE/ACM International Workshop on Automated Program Repair, APR@ICSE 2022, Pittsburgh, PA, USA, May 19, 2022. IEEE, 2022, pp. 69–75.
- [20] J. Liu, D. Shen, Y. Zhang, B. Dolan, L. Carin, and W. Chen, “What makes good in-context examples for gpt-3?” in Proceedings of Deep Learning Inside Out: The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, DeeLIO@ACL 2022, Dublin, Ireland and Online, May 27, 2022. Association for Computational Linguistics, 2022, pp. 100–114.
- [21] Y. Lu, M. Bartolo, A. Moore, S. Riedel, and P. Stenetorp, “Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022. Association for Computational Linguistics, 2022, pp. 8086–8098.
- [22] J. Y. Khan and G. Uddin, “Automatic code documentation generation using GPT-3,” in 37th IEEE/ACM International Conference on Automated Software Engineering, ASE 2022, Rochester, MI, USA, October 10-14, 2022. ACM, 2022, pp. 174:1–174:6.
- [23] OpenAI, “GPT-4 technical report,” CoRR, vol. abs/2303.08774, 2023.
- [24] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, 2017, pp. 5998–6008.
- [25] Y. Li, D. Choi, J. Chung, N. Kushman, J. Schrittwieser, R. Leblond, T. Eccles, J. Keeling, F. Gimeno, A. Dal Lago et al., Science, vol. 378, no. 6624, pp. 1092–1097, 2022.
- [26] ChatGPT, “Chatgpt,” https://chat.openai.com/, 2022.
- [27] P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashi, and G. Neubig, “Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing,” ACM Comput. Surv., vol. 55, no. 9, pp. 195:1–195:35, 2023.
- [28] C. Wang, Y. Yang, C. Gao, Y. Peng, H. Zhang, and M. R. Lyu, “No more fine-tuning? an experimental evaluation of prompt tuning in code intelligence,” in Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2022, Singapore, Singapore, November 14-18, 2022. ACM, 2022, pp. 382–394.
- [29] N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. de Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for NLP,” in Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, ser. Proceedings of Machine Learning Research, vol. 97. PMLR, 2019, pp. 2790–2799.
- [30] E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” in The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022.
- [31] X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for generation,” in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, August 1-6, 2021. Association for Computational Linguistics, 2021, pp. 4582–4597.
- [32] O. Rubin, J. Herzig, and J. Berant, “Learning to retrieve prompts for in-context learning,” in Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL 2022, Seattle, WA, United States, July 10-15, 2022. Association for Computational Linguistics, 2022, pp. 2655–2671.
- [33] H. Su, J. Kasai, C. H. Wu, W. Shi, T. Wang, J. Xin, R. Zhang, M. Ostendorf, L. Zettlemoyer, N. A. Smith, and T. Yu, “Selective annotation makes language models better few-shot learners,” 2023.
- [34] S. Gao, H. Zhang, C. Gao, and C. Wang, “Keeping pace with ever-increasing data: Towards continual learning of code intelligence models,” in 45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, May 14-20, 2023. IEEE, 2023, pp. 30–42.
- [35] H. Husain, H. Wu, T. Gazit, M. Allamanis, and M. Brockschmidt, “Codesearchnet challenge: Evaluating the state of semantic code search,” CoRR, vol. abs/1909.09436, 2019.
- [36] E. Shi, Y. Wang, L. Du, J. Chen, S. Han, H. Zhang, D. Zhang, and H. Sun, “On the evaluation of neural code summarization,” in 44th IEEE/ACM 44th International Conference on Software Engineering, ICSE 2022, Pittsburgh, PA, USA, May 25-27, 2022. ACM, 2022, pp. 1597–1608.
- [37] K. Papineni, S. Roukos, T. Ward, and W. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, July 6-12, 2002, Philadelphia, PA, USA. ACL, 2002, pp. 311–318.
- [38] C.-Y. Lin, “ROUGE: A package for automatic evaluation of summaries,” in Text Summarization Branches Out. Barcelona, Spain: Association for Computational Linguistics, Jul. 2004, pp. 74–81.
- [39] S. Banerjee and A. Lavie, “METEOR: an automatic metric for MT evaluation with improved correlation with human judgments,” in Proceedings of the Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization@ACL 2005, Ann Arbor, Michigan, USA, June 29, 2005. Association for Computational Linguistics, 2005, pp. 65–72.
- [40] S. Gao, C. Gao, Y. He, J. Zeng, L. Nie, X. Xia, and M. R. Lyu, “Code structure-guided transformer for source code summarization,” ACM Trans. Softw. Eng. Methodol., vol. 32, no. 1, pp. 23:1–23:32, 2023.
- [41] M. Tufano, C. Watson, G. Bavota, M. D. Penta, M. White, and D. Poshyvanyk, “An empirical study on learning bug-fixing patches in the wild via neural machine translation,” ACM Trans. Softw. Eng. Methodol., vol. 28, no. 4, pp. 19:1–19:29, 2019.
- [42] S. Chakraborty and B. Ray, “On multi-modal learning of editing source code,” in 36th IEEE/ACM International Conference on Automated Software Engineering, ASE 2021, Melbourne, Australia, November 15-19, 2021. IEEE, 2021, pp. 443–455.
- [43] S. Chakraborty, T. Ahmed, Y. Ding, P. T. Devanbu, and B. Ray, “Natgen: generative pre-training by ”naturalizing” source code,” in Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2022, Singapore, Singapore, November 14-18, 2022. ACM, 2022, pp. 18–30.
- [44] P. Yin, B. Deng, E. Chen, B. Vasilescu, and G. Neubig, “Learning to mine aligned code and natural language pairs from stack overflow,” in Proceedings of the 15th International Conference on Mining Software Repositories, MSR 2018, Gothenburg, Sweden, May 28-29, 2018. ACM, 2018, pp. 476–486.
- [45] S. Ren, D. Guo, S. Lu, L. Zhou, S. Liu, D. Tang, N. Sundaresan, M. Zhou, A. Blanco, and S. Ma, “Codebleu: a method for automatic evaluation of code synthesis,” CoRR, vol. abs/2009.10297, 2020.
- [46] Z. Cheng, T. Xie, P. Shi, C. Li, R. Nadkarni, Y. Hu, C. Xiong, D. Radev, M. Ostendorf, L. Zettlemoyer, N. A. Smith, and T. Yu, “Binding language models in symbolic languages,” 2023.
- [47] N. Nashid, M. Sintaha, and A. Mesbah, “Retrieval-based prompt selection for code-related few-shot learning,” in 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), 2023, pp. 2450–2462.
- [48] D. Guo, S. Lu, N. Duan, Y. Wang, M. Zhou, and J. Yin, “Unixcoder: Unified cross-modal pre-training for code representation,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022. Association for Computational Linguistics, 2022, pp. 7212–7225.
- [49] D. Arthur and S. Vassilvitskii, “k-means++: the advantages of careful seeding,” in Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2007, New Orleans, Louisiana, USA, January 7-9, 2007. SIAM, 2007, pp. 1027–1035.
- [50] J. Zhang, X. Wang, H. Zhang, H. Sun, and X. Liu, “Retrieval-based neural source code summarization,” in ICSE ’20: 42nd International Conference on Software Engineering, Seoul, South Korea, 27 June - 19 July, 2020. ACM, 2020, pp. 1385–1397.
- [51] B. Wei, Y. Li, G. Li, X. Xia, and Z. Jin, “Retrieve and refine: Exemplar-based neural comment generation,” in 35th IEEE/ACM International Conference on Automated Software Engineering, ASE 2020. IEEE, 2020, pp. 349–360.
- [52] N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019. Association for Computational Linguistics, 2019, pp. 3980–3990.
- [53] Y. Luan, J. Eisenstein, K. Toutanova, and M. Collins, “Sparse, dense, and attentional representations for text retrieval,” Trans. Assoc. Comput. Linguistics, vol. 9, pp. 329–345, 2021.
- [54] Sentence-transformers, “st-codesearch-distilroberta,” https://huggingface.co/flax-sentence-embeddings/st-codesearch-distilroberta-base, 2021.
- [55] E. Shi, Y. Wang, W. Gu, L. Du, H. Zhang, S. Han, D. Zhang, and H. Sun, “Cocosoda: Effective contrastive learning for code search,” pp. 2198–2210, 2023.
- [56] Gensim, “Gensim package,” https://github.com/RaRe-Technologies/gensim, 2010.
- [57] C. E. Brown, Coefficient of Variation. Springer Berlin Heidelberg, 1998, pp. 155–157.
- [58] M. Wei, N. S. Harzevili, Y. Huang, J. Wang, and S. Wang, “CLEAR: contrastive learning for API recommendation,” in 44th IEEE/ACM 44th International Conference on Software Engineering, ICSE 2022, Pittsburgh, PA, USA, May 25-27, 2022. ACM, 2022, pp. 376–387.
- [59] Z. Dai, Z. Yang, Y. Yang, J. G. Carbonell, Q. V. Le, and R. Salakhutdinov, “Transformer-xl: Attentive language models beyond a fixed-length context,” in Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers. Association for Computational Linguistics, 2019, pp. 2978–2988.
- [60] A. Bulatov, Y. Kuratov, and M. Burtsev, “Recurrent memory transformer,” in Advances in Neural Information Processing Systems, A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, Eds., 2022.
- [61] OpenAI-pricing, “Openai-pricing,” https://openai.com/pricing, 2022.
- [62] E. Nijkamp, B. Pang, H. Hayashi, L. Tu, H. Wang, Y. Zhou, S. Savarese, and C. Xiong, “Codegen: An open large language model for code with multi-turn program synthesis,” arXiv preprint arXiv:2203.13474, 2022.
- [63] Q. Zheng, X. Xia, X. Zou, Y. Dong, S. Wang, Y. Xue, Z. Wang, L. Shen, A. Wang, Y. Li et al., “Codegeex: A pre-trained model for code generation with multilingual evaluations on humaneval-x,” CoRR, vol. abs/2303.17568, 2023.
- [64] S. Lu, D. Guo, S. Ren, J. Huang, A. Svyatkovskiy, A. Blanco, C. Clement, D. Drain, D. Jiang, D. Tang et al., “Codexglue: A machine learning benchmark dataset for code understanding and generation,” in Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual, J. Vanschoren and S. Yeung, Eds., 2021.
- [65] I. Levy, B. Bogin, and J. Berant, “Diverse demonstrations improve in-context compositional generalization,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023. Association for Computational Linguistics, 2023, pp. 1401–1422.
- [66] T. Kojima, S. S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa, “Large language models are zero-shot reasoners,” in NeurIPS, 2022.
- [67] T. Ahmed and P. T. Devanbu, “Few-shot training llms for project-specific code-summarization,” in 37th IEEE/ACM International Conference on Automated Software Engineering, ASE 2022, Rochester, MI, USA, October 10-14, 2022. ACM, 2022, pp. 177:1–177:5.
- [68] G. Poesia, A. Polozov, V. Le, A. Tiwari, G. Soares, C. Meek, and S. Gulwani, “Synchromesh: Reliable code generation from pre-trained language models,” in The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022.