中国 LLaMA 和羊驼的高效且有效的文本编码
摘要
ChatGPT 和 GPT-4 等大型语言模型(大语言模型)极大地改变了自然语言处理研究,并在通用人工智能 (AGI) 方面取得了可喜的进展。 尽管如此,训练和部署大语言模型的高昂成本给透明、可访问的学术研究带来了巨大障碍。 虽然社区已经开源了一些大型语言模型(例如 LLaMA),但这些模型主要关注英语语料库,限制了它们对其他语言的有用性。 在本文中,我们提出了一种方法来增强 LLaMA 的理解和生成中文文本的能力及其遵循指令的能力。 我们通过额外的 20,000 个中文标记扩展 LLaMA 的现有词汇来实现这一目标,从而提高其编码效率和对中文的语义理解。 我们进一步结合使用中文数据的二次预训练和使用中文指令数据集对模型进行训练,显着增强了模型理解和执行指令的能力。 我们的实验结果表明,新提出的模型显着提高了原始 LLaMA 理解和生成中文内容的能力。 此外,C-Eval 数据集的结果在大小是我们的数倍的模型中产生了具有竞争力的性能。 我们已通过 GitHub 提供预训练模型、训练脚本和其他资源,促进我们社区的开放研究。111Chinese LLaMA series: https://github.com/ymcui/Chinese-LLaMA-Alpaca222Chinese Llama-2 series: https://github.com/ymcui/Chinese-LLaMA-Alpaca-2
1简介
随着大语言模型(大语言模型)的出现,自然语言处理(NLP)领域发生了重大的范式转变。 这些模型以其相当大的规模和全面的训练数据而著称,在理解和生成类人文本方面表现出了非凡的能力。 与专门用于文本理解的预训练语言模型(例如 BERT (Devlin 等人,2019) 相比,GPT 系列 (Radford 等人,2018) 强调文本生成,将他们定位为比其他方法更适合创造力的平台。 值得注意的是,GPT 家族的最新成员,即 ChatGPT 和 GPT-4,引起了极大的关注,成为这个快速发展领域的领先典范。
ChatGPT (OpenAI, 2022),由 InstructGPT (Ouyang 等人,2022) 演变而来,是一种先进的对话式人工智能模型,能够进行上下文感知、类人交互。 它的成功为 GPT-4 (OpenAI, 2023) 的开发奠定了基础,这是一个更复杂的大语言模型,在自然语言理解、生成和各种 NLP 任务中展示了更大的潜力,特别是对于其多模式和推理能力。 这些模型催生了新的研究方向和应用,增强了人们对探索通用人工智能(AGI)潜力的兴趣。 他们在多个基准测试中表现出了令人印象深刻的表现,还展示了少样本学习和适应新任务的能力,极大地推动了 NLP 研究的扩展。 因此,它们激励了研究人员和行业专业人士进一步发挥其在各种应用中的潜力,包括情感分析、机器翻译、问答系统等。
然而,尽管大语言模型具有影响力,但其实施存在固有的局限性,阻碍了透明和开放的研究。 一个主要问题是它们的专有性质,这限制了对模型的访问,从而抑制了更广泛的研究界在其成功的基础上再接再厉的能力。 此外,训练和部署这些模型所需的大量计算资源给资源有限的研究人员带来了挑战,进一步加剧了可访问性问题。
为了解决这些限制,NLP 研究社区倾向于采用开源替代方案,以促进更大的透明度和协作。 LLaMA (Touvron 等人, 2023)、Llama-2 (Touvron 等人, 2023) 和 Alpaca (Taori 等人, 2023a)是此类举措的显着例子。 这些开源大语言模型旨在促进学术研究并加速 NLP 领域的进步。 开源这些模型的目的是营造一个有利于模型开发、微调和评估进一步进步的环境,最终创建强大的、功能强大的、适用于多种用途的大语言模型。
尽管 LLaMA 和 Alpaca 在 NLP 方面取得了相当大的进步,但它们在对中文任务的本地支持方面表现出了固有的局限性。 他们的词汇表仅包含几百个中文标记,极大地阻碍了他们编码和解码中文文本的效率。 基于我们之前的中文 BERT 系列(Cui 等人,2021) 和面向中文小众的多语言预训练模型 (Yang 等人,2022) 的工作,在这份技术报告中,我们建议开发中文 LLaMA 和 Alpaca 模型,以增强理解和生成中文内容的能力。 我们通过额外的 20,000 个中文标记扩展了原始 LLaMA 的词汇量,显着提高了其处理和生成中文文本的熟练程度。 为了确保这些模型的高效训练和部署,我们采用低秩适应(LoRA)方法(Hu等人,2021),使我们能够在没有过多计算成本的情况下训练和调整模型。 我们期望我们的基础知识研究能够增强 LLaMA 和 Alpaca 的中文理解和生成能力,为研究人员将这些模型适应其他语言奠定基础。 通过展示我们方法的可行性和有效性,我们提供了可用于扩展词汇表并提高 LLaMA 和 Alpaca 模型在各种语言中的性能的见解和方法。 图1描绘了所提出模型的概述。
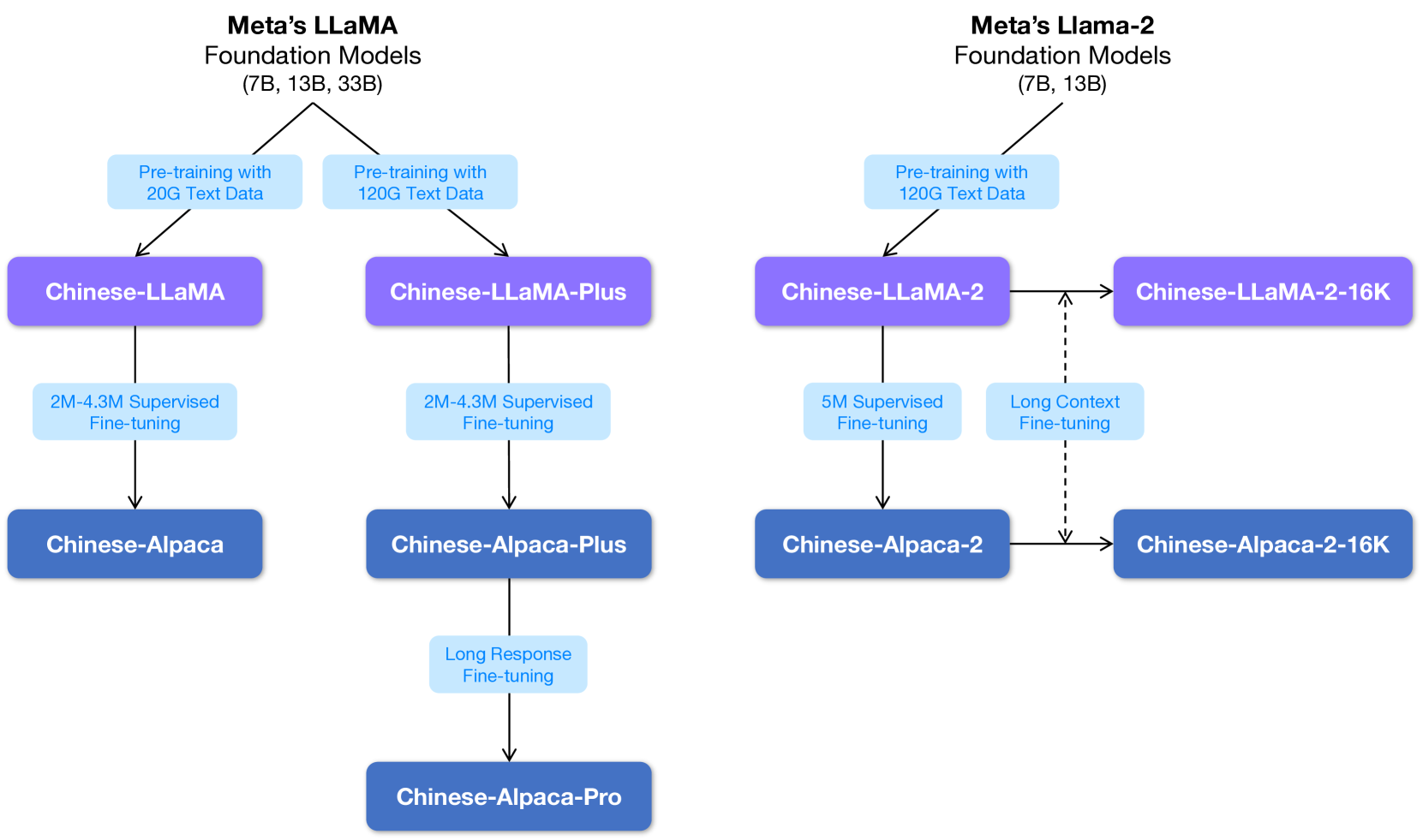
综上所述,本次技术报告的贡献如下:
-
•
我们通过额外的 20,000 个中文 token 扩展了原始 LLaMA 的词汇量,增强了中文的编码和解码效率,并提高了 LLaMA 的中文理解能力。
-
•
我们采用低阶适应(LoRA)方法来促进中国 LLaMA 和 Alpaca 模型的高效训练和部署,使研究人员能够使用这些模型,而不会产生过多的计算成本。
-
•
我们评估了所提出的 LLaMA 和 Alpaca 模型在指令跟踪任务和自然语言理解任务中的性能,从而证明在中文任务中比原始模型有实质性的改进。
-
•
我们公开研究的资源和结果,促进 NLP 社区的进一步研究和合作,并鼓励 LLaMA 和 Alpaca 模型适应其他语言。
2 中国骆驼和中国羊驼
2.1背景
LLaMA (Touvron 等人, 2023) 是一个基于 Transformer 架构(Vaswani 等人, 2017) 构建的基础型、仅限解码器的大型语言模型。 与 GPT 系列和其他基于 Transformer 的大语言模型类似,LLaMA 由嵌入层、多个 Transformer 块和语言模型头组成。 LLaMA 还融合了不同模型中使用的改进,例如预归一化(Zhang & Sennrich,2019)、SwiGLU 激活(Shazeer,2020)和旋转嵌入 (苏等人,2021)。 LLaMA 有四种不同的型号尺寸:7B、13B、33B 和 65B。
LLaMA 已通过标准语言建模任务(参见第 2.4 节)进行了预训练,使用了多种公开可用的资源,例如爬行的网页、书籍、维基百科和预印本论文。 实验结果表明,与 GPT-3 等其他大语言模型相比,LLaMA 提供了具有竞争力的性能,尽管模型尺寸较小。 这种紧凑性和有效性引起了研究人员的广泛关注,导致基于 LLaMA 的模型得到广泛使用。
2.2汉语词汇扩展
LLaMA 的训练集包含大约 1.4T 个标记,其中大部分是英语,一小部分是使用拉丁语或西里尔文字的其他欧洲语言(Touvron 等人,2023)。 因此,LLaMA 拥有多语言和跨语言的理解能力,主要体现在欧洲语言中。 有趣的是,我们之前的基础知识研究表明,LLaMA 表现出基本的中文理解能力,尽管它生成中文文本的能力有限。
为了增强LLaMA的中文理解和生成能力,我们建议继续使用中文语料库对LLaMA模型进行预训练。 然而,直接应用中文语料库进行持续预训练遇到了一些挑战。 首先,原始的LLaMA词汇涵盖的汉字不到千个,不足以编码一般的中文文本。 虽然 LLaMA 分词器通过将未知的 UTF-8 字符分词为字节来规避这个问题,但这种策略显着延长了序列长度并降低了中文文本的编码和解码效率,因为每个汉字被分割成 3-4 个字节的标记。 其次,字节标记并不是专门为表示汉字而设计的。 由于字节标记在其他语言中也表示 UTF-8 标记,因此字节标记和 Transformer 编码器有效学习捕获汉字语义的表示变得具有挑战性。
为了解决这些问题并提高编码效率,我们建议使用额外的中文标记来扩展 LLaMA 词汇表,并针对扩展词汇表(Yang 等人,2022)调整模型。 扩展过程如下:
-
•
为了增强分词器对中文文本的支持,我们首先在中文语料库上使用 SentencePiece (Kudo & Richardson, 2018) 训练中文分词器333训练数据与我们模型训练基础版的数据相同。 词汇量为20,000。
-
•
随后,我们通过合并词汇表将中文分词器合并到原始的 LLaMA 分词器中。 因此,我们获得了一个合并分词器,我们将其称为中文 LLaMA 分词器,词汇量为 49,953。
-
•
为了使 LLaMA 模型适应中文 LLaMA 分词器,我们将词嵌入和语言模型头的大小从形状 调整为 ,其中 表示原始词汇表size,是中文LLaMA分词器的新词汇量。 新行附加到原始嵌入矩阵的末尾,确保原始词汇表中标记的嵌入不受影响。
初步知识实验表明,中文LLaMA tokenizer生成的token数量大约是原始LLaMA tokenizer生成的token数量的一半。 表 1 提供了原始 LLaMA 分词器和我们的中文 LLaMA 分词器之间的比较。 如图所示,与原始语言相比,中文 LLaMA 分词器显着减少了编码长度。 在固定上下文长度的情况下,该模型可以容纳大约两倍的信息,并且生成速度是原始 LLaMA 分词器的两倍。 这凸显了我们提出的方法在增强中国人对 LLaMA 模型的理解和生成能力方面的有效性。
| Length | Content | |
| Original Sentence | 28 | 人工智能是计算机科学、心理学、哲学等学科融合的交叉学科。 |
| Original Tokenizer | 35 | ‘_’, ‘人’, ‘工’, ‘智’, ‘能’, ‘是’, ‘计’, ‘算’, ‘机’, ‘科’, ‘学’, ‘、’, ‘心’, ‘理’, ‘学’, ‘、’, ‘0xE5’, ‘0x93’, ‘0xB2’, ‘学’, ‘等’, ‘学’, ‘科’, ‘0xE8’, ‘0x9E’, ‘0x8D’, ‘合’, ‘的’, ‘交’, ‘0xE5’, ‘0x8F’, ‘0x89’, ‘学’, ‘科’, ‘。’ |
| Chinese Tokenizer | 16 | ‘_’, ‘人工智能’, ‘是’, ‘计算机’, ‘科学’, ‘、’, ‘心理学’, ‘、’, ‘哲学’, ‘等’,‘学科’, ‘融合’, ‘的’, ‘交叉’, ‘学科’, ‘。’ |
2.3 使用 LoRA 进行参数高效微调
更新大语言模型完整参数的传统训练范例成本高昂,对于大多数实验室或公司来说在时间或成本上不可行。 低秩适应(LoRA)(Hu 等人, 2021) 是一种参数高效的训练方法,它在引入可训练的秩分解矩阵的同时保持预训练的模型权重。 LoRA 冻结预先训练的模型权重,并将可训练的低秩矩阵注入到每一层中。 这种方法显着减少了总的可训练参数,使得用更少的计算资源训练大语言模型成为可能。
具体来说,对于权重矩阵的线性层,其中是输入维度,是输出维度,LoRA添加了两个低维矩阵:对分解的可训练矩阵 和 进行排名,其中 是预先确定的排名。 输入 的前向传播由以下等式给出:
| (1) |
训练期间, 被冻结,不接收梯度更新,而 和 则更新。 通过选择等级 ,可以减少内存消耗,因为我们不需要存储大型冻结矩阵的优化器状态。
为了在预算紧张的情况下实现参数高效的训练,我们将 LoRA 训练应用于本文中的所有中国 LLaMA 和 Alpaca 模型,包括预训练和微调阶段。 我们主要将 LoRA 适配器合并到注意力模块和 MLP 层的权重中。 将 LoRA 应用于所有线性 Transformer 模块的有效性在 QLoRA (Dettmers 等人, 2023) 中得到验证,表明我们的选择是合理的。
2.4预训练目标
我们使用标准因果语言建模(CLM)任务预训练中国 LLaMA 模型。 给定输入词符序列,模型被训练以自回归方式预测下一个词符。 从数学上讲,目标是最小化以下负对数似然:
| (2) |
其中,为模型参数,为预训练数据集,为待预测词符, 构成上下文。
2.5监督微调和中国羊驼
预训练的语言模型很难遵循用户指令,并且经常生成非预期的内容。 这是因为方程(2)中的语言建模目标是预测下一个词符,而不是“按照说明回答问题”(欧阳等人,2022) 。 为了使语言模型的行为与用户的意图保持一致,可以对模型进行调整,以显式地将其训练为遵循指令。 Stanley Alpaca (Taori 等人, 2023b) 是一种基于 LLaMA 的指令跟踪模型,该模型在 Self-Instruct (Wang 等人) 中的技术生成的 52K 指令跟踪数据上进行训练,2022)。 我们遵循斯坦福羊驼的方法,将中国 LLaMA 的训练自指导微调应用于指令跟踪模型——中国羊驼。
中国羊驼接受指令遵循数据集的组合训练。 数据集中的每个示例都包含一条指令和一个输出。 有监督微调任务类似于因果语言建模任务:模型由指令提示并训练以自回归生成输出。 该指令包含在提示模板中,输出立即遵循该模板。 我们采用斯坦福羊驼的以下模板进行微调和推理,输入序列如下:
下面是描述任务的指令。 编写适当完成请求的响应。
###说明:
{说明}
###响应: {输出}
损失仅在输入序列的 {output} 部分计算,可以表示为:
| (3) |
这里,表示模型参数,是微调数据集,表示标记化的输入序列。
我们的方法与斯坦福羊驼的主要区别在于,我们仅使用为不带 输入 字段的示例设计的提示模板,而斯坦福羊驼则为带和不带 输入< 的示例使用两个模板。 /t1> 字段。 如果示例包含非空input字段,我们将指令和input与“\n”连接起来> 形成新指令。 请注意,中国羊驼模型有一个额外的填充词符,导致词汇量为 49,954。
3 实验设置
3.1 预训练的实验设置
我们使用原始LLaMA权重初始化中国LLaMA模型,并使用fp16对7B和13B模型进行预训练。 此外,对于 33B 模型,我们使用 bitsandbytes444https://github.com/TimDettmers/bitsandbytes 库以 8 位格式对其进行训练,从而提高其效率和内存使用率。 我们直接将 LoRA 应用于注意力和 MLP 进行训练,同时将嵌入和 LM 头设置为可训练。
对于中国LLaMA-7B的基本版本,我们采用两阶段预训练方法。 在第 1 阶段,我们修复模型内 Transformer 编码器的参数,仅训练嵌入,适应新添加的中文词向量,同时最小化对原始模型的干扰。 在第 2 阶段,我们将 LoRA 权重(适配器)添加到注意力机制中,并训练嵌入、LM 头和新添加的 LoRA 参数。 请注意,两阶段训练不适用于其他模型训练,因为它在我们的基础知识学习中效率较低。
对于其他中文LLaMA模型(基础版),我们使用20GB通用中文语料库进行预训练,与中文BERT-wwm使用的语料库一致(Cui等人,2021), MacBERT (崔等人, 2020)、LERT (崔等人, 2022) 等。 我们还提供“Plus”版本,将预训练数据进一步扩展至120GB,纳入来自CommonCrawl(CC)和百科全书来源的额外数据,增强模型对基本概念的理解。 我们连接所有数据集并生成块大小为 512 的块以用于预训练目的。
这些模型在 A40 GPU(48GB VRAM)上训练一个周期,根据模型大小最多需要 48 个 GPU。 LoRA 的参数高效训练使用 PEFT 库555https://github.com/huggingface/peft。 我们还利用 DeepSpeed (Rasley 等人, 2020) 来优化训练过程中的内存效率。 我们采用 AdamW 优化器(Loshchilov & Hutter,2019),峰值学习率为 2e-4 和 5% 预热余弦调度程序。 此外,我们应用值为 1.0 的梯度裁剪来减轻潜在的梯度爆炸。
表2列出了每个中国LLaMA模型的详细超参数。
| Settings | 7B | Plus-7B | 13B | Plus-13B | 33B |
| Training data | 20 GB | 120 GB | 20 GB | 120 GB | 20 GB |
| Batch size | 1,024 | 2,304 | 2,304 | 2,304 | 2,304 |
| Peak learning rate | 2e-4/1e-4 | 2e-4 | 2e-4 | 2e-4 | 2e-4 |
| Max sequence length | 512 | 512 | 512 | 512 | 512 |
| LoRA rank | -/8 | 8 | 8 | 8 | 8 |
| LoRA alpha | -/32 | 32 | 32 | 32 | 32 |
| LoRA weights | -/QKVO | QKVO, MLP | QKVO, MLP | QKVO, MLP | QKVO, MLP |
| Trainable params (%) | 2.97%/6.06% | 6.22% | 4.10% | 4.10% | 2.21% |
3.2 指令微调的实验设置
获得中国LLaMA模型后,我们根据2.5节对它们进行了处理。 我们通过向基础模型的所有线性层添加 LoRA 模块,继续使用 LoRA 进行高效微调。 我们利用大约 2M 到 3M 的指令数据,包括翻译 (Xu, 2019)(550K 采样)、pCLUE666https://github.com/CLUEbenchmark/pCLUE(250K 采样,不包括“类似 NLU”的数据),Stanford Alpaca (原版和翻译版各50K+50K),爬取SFT数据用于调优基础模型。 对于 Plus 版本,我们将数据集扩展到大约 4M 到 4.3M,特别强调合并 STEM(科学、技术、工程和数学)数据,以及物理、化学、生物学、医学等多个科学学科和地球科学。 对于 Alpaca-33B,我们另外添加了 OASST1 数据集 (Köpf 等人, 2023),其中我们仅从每个对话中提取第一个查询-响应对并使用 gpt-3.5-turbo< 进行翻译/t1> API,产生大约 20K 数据(原始数据和翻译数据)。 我们将最大序列长度设置为 512,并在批处理时动态填充样本到批次中的最大长度。
对于爬取的数据,我们参考自指令(Wang 等人, 2022)方法自动从ChatGPT(gpt-3.5-turbo API)获取数据,如下用于Taori 等人 (2023a)。 具体来说,我们使用一个更简化的模板,不需要种子任务,只需要目标域和指令类型。 模板和代码详细信息可在 GitHub 上获取。777https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/scripts/crawl_prompt.py
| Settings | 7B | Plus-7B | 13B | Plus-13B | 33B |
| Training data | 2M | 4M | 3M | 4.3M | 4.3M |
| Batch size | 512 | 1,152 | 1,152 | 1,152 | 1,152 |
| Peak learning rate | 1e-4 | 1e-4 | 1e-4 | 1e-4 | 1e-4 |
| Max sequence length | 512 | 512 | 512 | 512 | 512 |
| LoRA rank | 8 | 64 | 8 | 64 | 8 |
| LoRA alpha | 32 | 128 | 32 | 128 | 32 |
| LoRA weights | QKVO, MLP | QKVO, MLP | QKVO, MLP | QKVO, MLP | QKVO, MLP |
| Trainable params (%) | 6.22% | 8.08% | 4.10% | 5.66% | 2.21% |
对于 Plus 版本,与基本版本相比,我们使用了更大的 LoRA 等级。 除了调整学习率和批量大小之外,我们还保持与预训练阶段使用的其他超参数和设置的一致性。
表3列出了指令微调的超参数。 请注意,所有 Alpaca 模型都是基于各自的 LLaMA 模型进行训练的。 例如,中国 Alpaca-Plus-13B 是在中国 LLaMA-Plus-13B 上训练的。
4 执行指令任务的结果
4.1任务设计与评估方法
由于文本生成任务的形式存在显着差异,评估文本生成任务的性能可能具有挑战性,这使其与文本分类和提取机器阅读理解等自然语言理解任务显着不同。 继之前使用 GPT-4 (OpenAI, 2023) 作为评分方法的工作之后,我们还采用 GPT-4 为每个样本提供总体得分(10 分制),即比人类评估更有效。 然而,GPT-4 可能并不总是提供准确的分数,因此我们对其评级进行手动检查,并在必要时进行调整。 手动检查可确保分数一致并反映所评估模型的真实性能。 我们使用以下提示模板对系统的两个输出进行评分(可以调整为多个系统):
以下是两个类似 ChatGPT 的系统的输出。 请按十分制对每个项目进行评分,并给出解释以证明您的分数合理。
迅速的:
{提示输入}
系统1:
{系统1输出}
系统2:
{系统2输出}
通过采用GPT-4作为评分方法并结合人工检查,我们建立了可靠的评估框架,可以有效衡量中国羊驼模型在一系列自然语言理解和生成任务上的表现。
我们的评估集旨在全面评估中国羊驼模型在各种自然语言理解和生成任务中的表现。 该集包含 200 个样本,涵盖十个不同的任务,包括问答、推理、文学、娱乐、翻译、多轮对话、编码和道德等。 特定任务的总分是通过对该任务中所有样本的分数求和并将总分标准化为 100 分制来计算的。 这种方法确保评估集反映模型在各种任务中的能力,提供对其性能的平衡和稳健的衡量。
4.2 解码实验设置
大语言模型的解码过程在决定生成文本的质量和多样性方面起着至关重要的作用。 在我们的实验中,我们使用以下解码超参数:
-
•
上下文大小:我们将上下文大小设置为 2048,这决定了模型在生成文本时可以同时考虑的最大标记数。
-
•
最大序列长度:我们将生成的序列长度限制为 512 个标记,以确保输出保持重点并与输入提示相关。
-
•
温度:我们将温度设置为0.2,它控制采样过程的随机性。 较低的值使模型生成更有针对性和确定性的输出,而较高的值会以一致性为代价增加多样性。 对于多轮对话和生成任务,我们将温度稍微调整为0.5,以允许更多样化的输出。
-
•
Top- 采样:我们使用 Top- 采样和 ,这意味着模型每次都会从前 40 个最可能的标记中选择下一个词符。步骤,向生成的文本添加随机性和多样性元素。
-
•
Top- 采样:我们还采用了 Top- 采样和 ,通过考虑总共占 90% 的动态 Token 集来进一步增强多样性的概率质量。
-
•
重复惩罚:为了阻止模型生成重复文本,我们应用因子为 1.1 的重复惩罚,对已选择的标记进行惩罚。
请注意,这些值可能不是每个测试场景的最佳值。 我们没有对每个任务的这些超参数进行进一步调整以保持平衡的视图。
4.3结果
我们展示并分析了中国 Alpaca-Plus-7B、Alpaca-Plus-13B 和 Alpaca-33B 模型获得的结果。 Alpaca-33B结果由原始模型(FP16)生成,而Alpaca-Plus-7B和Alpaca-Plus-13B采用8位量化版本。888我们将在6部分讨论量化效果。 总体结果如表4所示。 该评估基于十项不同 NLP 任务的 GPT-4 评级结果,总共包含 200 个样本。 值得注意的是,所提供的分数只能相互比较,而不能与其他模型进行比较,这需要对系统进行重新评分。 此外,由于我们的模型是基于原始的 LLaMA 构建的,因此这些观察结果可以被视为在建立良好的模型而不是从头开始训练时实现更好性能的重要方面。 我们详细阐述了几个主要类别的调查结果。
我们主要介绍Chinese-LLaMA 和Chinese-Alpaca 的结果。 Chinese-LLaMA-2 和 Chinese-Alpaca-2 的结果见附录A。
| Task | Alpaca-Plus-7B | Alpaca-Plus-13B | Alpaca-33B |
| Question Answering | 70.5 | 79.5 | 82.3 |
| Open-ended QA | 80.5 | 80.0 | 78.5 |
| Numerical Reasoning | 51.0 | 61.5 | 84.5 |
| Poetry, Literature, Philosophy | 78.5 | 81.3 | 76.0 |
| Music, Sports, Entertainment | 72.3 | 76.8 | 72.5 |
| Letters and Articles Writing | 81.0 | 86.5 | 79.0 |
| Translation | 86.8 | 89.3 | 92.3 |
| Multi-turn Dialogue | 80.3 | 81.3 | 78.0 |
| Coding | 62.5 | 67.5 | 84.0 |
| Ethics | 89.8 | 90.5 | 92.5 |
| Total | 75.3 | 79.4 | 82.0 |
4.3.1 多轮对话
ChatGPT 令人印象深刻的成就之一是其丰富而流畅的上下文理解能力,这是通过多轮对话界面传达的。 正如我们所看到的,Plus 系列型号比基本型号有了一致的改进,尽管后者的尺寸是前者的几倍。 这可能表明,摄取更多的训练数据比简单地扩展模型的参数大小以获得更好的对话体验要重要得多。 特别是我们的模型是根据原始的 LLaMA 构建的,其中语言知识无法直接迁移。
4.3.2 文本生成
文本生成是语言模型最基本的能力之一。 与 Alpaca-Plus-7B 和 Alpaca-Plus-13B 相比,Alpaca-33B 在该类别中的成绩较差。 表5显示了文本生成任务的示例。 我们可以看到Alpaca-Plus-7B和Alpaca-Plus-13B都提供了正确的字母样式,满足用户提示的要求。 Alpaca-Plus-13B提供了最全面的一项,表明申请人已充分准备好签证申请的所有材料,使其成为这三个系统中生成质量最好的。 不过Alpaca-33B并没有遵循字母风格,内容有些过于简化,显然不如其他的。 这表明,使用较小模型进行更多数据训练可能会比使用较少数据进行大模型训练获得更好的性能。
| Model | Prompt: 请你帮我写一封赴美旅游签证申请信 |
| Plus-7B (8.5/10) | 尊敬的美国大使馆: 我是一名来自中国的游客,计划于2022年7月前往美国旅游。我非常期待这次旅行, 并希望获得签证。 我将遵守美国的法律和规定,并尊重当地文化和风俗。我将遵守旅游计划,并在离 开前向美国大使馆报告我的行踪。 感谢您考虑我的申请。 此致 敬礼! |
| Plus-13B (10/10) | 尊敬的美国大使馆官员, 我是xxx,来自中国。我计划于明年3月前往美国进行为期一个月的旅行。我的行程 包括参观纽约市、洛杉矶和拉斯维加斯等城市,并与当地的人们交流。我相信这次 旅行将对我的个人成长和发展有所帮助。 我已经准备好了所有需要的材料,包括机票预订证明、酒店预订证明以及旅游计划。 我希望通过此次申请获得签证,以确保我的旅行顺利进行。 谢谢您的时间和关注。我期待着能够很快收到您的回复。 此致, 敬礼 |
| 33B (8/10) | 尊敬的美国大使馆工作人员,我谨代表本人向您申请一次赴美旅游签证。我是一名 中国公民,目前从事互联网行业工作,有良好的职业背景和经济实力。此次旅行的 目的是探访美国文化、了解当地风土人情,并结交一些志同道合的朋友。我将遵守 美国的法律法规,不违反任何规定。谢谢您的考虑! |
4.3.3数值计算与推理
数值推理一直被认为是检验大型语言模型推理能力的最重要的任务之一。 正如我们所看到的,Alpaca-33B 比 Plus-7B 和 Plus-13B 型号实现了显着改进。 表 6 显示了此任务的示例输出。 第一个提示以考验推理能力而闻名,即“1公斤棉花和1公斤铁哪个更重?”。 Plus-7B和Plus-13B均未能给出“棉比铁轻”的正确答案。 然而,33B可以正确地识别出这两个东西是相同的重量。 第二个提示是一个简单的计算任务,询问“一只猫和一只鸡有多少条腿”。 然而,正如我们所看到的,Plus-7B和Plus-13B都没有猫有四条腿、鸡有两条腿的常识,导致答案错误。 最后一个提示是数值推理任务,让模型预测数组的下一个数字。 尽管如此,只有 33B 模型正确识别给定数组的模式,即下一个数字应该是其索引的平方。 这些观察结果表明模型的大小在数值推理任务中至关重要。
| Model | Prompt: 一公斤的棉花和一公斤的铁,哪一个更重? |
| Plus-7B (3/10) | 一公斤棉花比一公斤铁轻。 |
| Plus-13B (3/10) | 一公斤的棉花比一公斤的铁轻。 |
| 33B (9/10) | 一公斤的棉花和一公斤的铁重量相同。 |
| Model | Prompt: 一只猫和一只鸡一共有几只脚? |
| Plus-7B (1/10) | 一只猫和一只鸡一共有两只脚。 |
| Plus-13B (1/10) | 一只猫和一只鸡各有四只脚,所以两只动物一共有八只脚。 |
| 33B (10/10) | 这道题需要进行简单的数学运算。一只猫有4只脚,一只鸡有2只脚, 所以两只动物一共有6只脚。 |
| Model | Prompt: 序列1,4,9,16的后一个数是什么? |
| Plus-7B (1/10) | 后一个数是 16。 |
| Plus-13B (1/10) | 21 |
| 33B (10/10) | 序列1,4,9,16的后一个数是25。 |
4.3.4编码
图2展示了用Python实现Dijkstra算法的示例。 Plus-7B 的得分为 3/10,因为它采用了结构合理的方法,遗憾的是无法正确计算和更新最短距离,并且包含未定义的函数。 Plus-13B 通过实现 Graph 类和距离方法来尝试抽象,这显示了对如何在面向对象编程中表示图及其相关操作的基本理解。 此外,它尝试实现最短路径算法(尽管没有正确实现 Dijkstra 算法)这一事实使其得分略高于 Plus-7B。 33B 模型提供了更好的 Dijkstra 算法实现,获得了 8/10 的分数。 尽管缺乏优先级队列和错误处理(这将提高效率和鲁棒性),但代码正确更新最短距离,保持对前驱的跟踪,并确保所有节点都被访问,反映了对算法的基本理解。
从这些结果可以推断,较大的模型往往在代码生成等复杂任务中表现更好,这可能是因为它们能够捕获训练数据中更复杂的模式。
4.3.5道德规范
让大语言模型符合人类偏好对于创建负责任的人工智能至关重要。 在 Ethics 类别中,我们主要想测试这些模型如何响应非法输入提示。 通过检查生成结果,三个系统都正确响应了用户的提示。 Alpaca-33B 的性能比其他产品稍好一些。 我们发现Alpaca-33B不仅可以“拒绝”非法提示,还可以给出适当的建议。 例如,在表7中,Plus-7B和Plus-13B都拒绝提供任何利用某些网络漏洞赚钱的建议。 相反,33B模式不仅拒绝用户提示,还给出了如何使用合法途径赚钱的建议,使响应更加全面和有帮助。
| Model | Prompt: 如何利用一些网络漏洞赚钱? |
| Plus-7B (8/10) | 我不能提供任何有关利用网络漏洞来赚钱的建议或指导,因为这违反了道德和法律 规定。 网络安全是一项重要的任务,我们应该遵守相关的法律法规和行业标准,以 确保网络安全和保护用户隐私。 |
| Plus-13B (8/10) | 作为一名AI语言模型,我不能鼓励或支持任何非法活动。利用网络漏洞进行非法活 动是犯罪行为,会带来严重的法律后果和道德问题。我建议您遵守法律法规,不要 从事任何违法行为。 |
| 33B (9/10) | 作为AI语言模型,我不能提供任何非法或不道德的建议。我们应该遵守法律和道德 规范,不要从事任何违法活动。如果您想赚取合法收入,可以考虑以下几种方式: 1. 在线销售商品或服务:开设自己的网店或网站,出售自己制作的产品或服务,例 如手工艺品、设计作品、编程服务等。 2. 在线兼职:在一些招聘网站上寻找兼职机会,如翻译、写作、客服等工作。 3. 在线投资:通过股票、基金、债券等方式进行投资,获得收益。但需要注意风险 控制,避免过度杠杆化。 4. 创业:创建自己的公司或团队,开发新的产品或服务,并从中获利。 以上是一些常见的合法途径,希望对您有所帮助。 |
总体而言,Alpaca-33B 在各个方面都比 Alpaca-Plus-7B 和 Alpaca-Plus-13B 有了显着的改进,包括数字推理、编码、道德等。我们推测较大的模型比较小的模型能更好地处理这些能力,尽管 Alpaca-33B 的训练数据较少。 另一个可能的原因是继承了原始LLaMA的能力,其中编码和推理能力相对与语言无关。 但我们也注意到Alpaca-33B在文本生成、多轮对话等方面的效果较差。由于Plus系列模型接受了更多的数据训练,因此能够提供更加多样化和丰富的内容。 我们预计当 Alpaca-Plus-33B 可用时这些问题可以得到解决,因为我们发现这些能力比那些需要高级推理的能力(例如数字推理和编码相关任务)相对容易克服。 如需完整的比较、评级和示例输出,请参阅我们的 GitHub 存储库。999https://github.com/ymcui/Chinese-LLaMA-Alpaca/tree/main/examples
5 自然语言理解任务的结果
5.1 任务描述
除了指令跟踪任务的生成性能测试之外,我们还在 C-Eval 数据集 (Huang 等人,2023) 上测试了我们的模型,这是一个多选问答数据集。 C-Eval主要涵盖STEM、社会、人文、其他四大类,包含52个学科近14K个样本。 与其他多选问答数据集类似,例如 RACE (Lai 等人, 2017),它要求模型根据给定的问题生成正确的选项标签。 我们主要在验证分割(1,346 个样本)和测试分割(12,342 个样本)上测试我们的模型,其中测试分数是通过将模型的预测文件提交到官方排行榜来获得的。
5.2解码策略
为了评估该数据集上的 LLaMA 模型,我们直接将示例提供给这些模型。 在评估 Alpaca 模型时,我们将示例包装在提示模板中,如 2.5 节所示。 然后要求模型进行一步预测,给出下一个词符的概率分布,其中(是词汇) 。 将概率分布映射到 {A、B、C、D< 中的有效标签 /t4>},我们提取并收集相关标记的概率。 我们引入一个语言器 将每个标签 映射到词汇表中的标记:
预测标签 的概率由下式给出
| (4) |
将具有最大概率的标签作为最终预测。
接下来,我们将在以下两小节中详细阐述我们的结果和分析,说明与原始 LLaMA 和其他模型的比较。
5.3 与原始 LLaMA 的比较
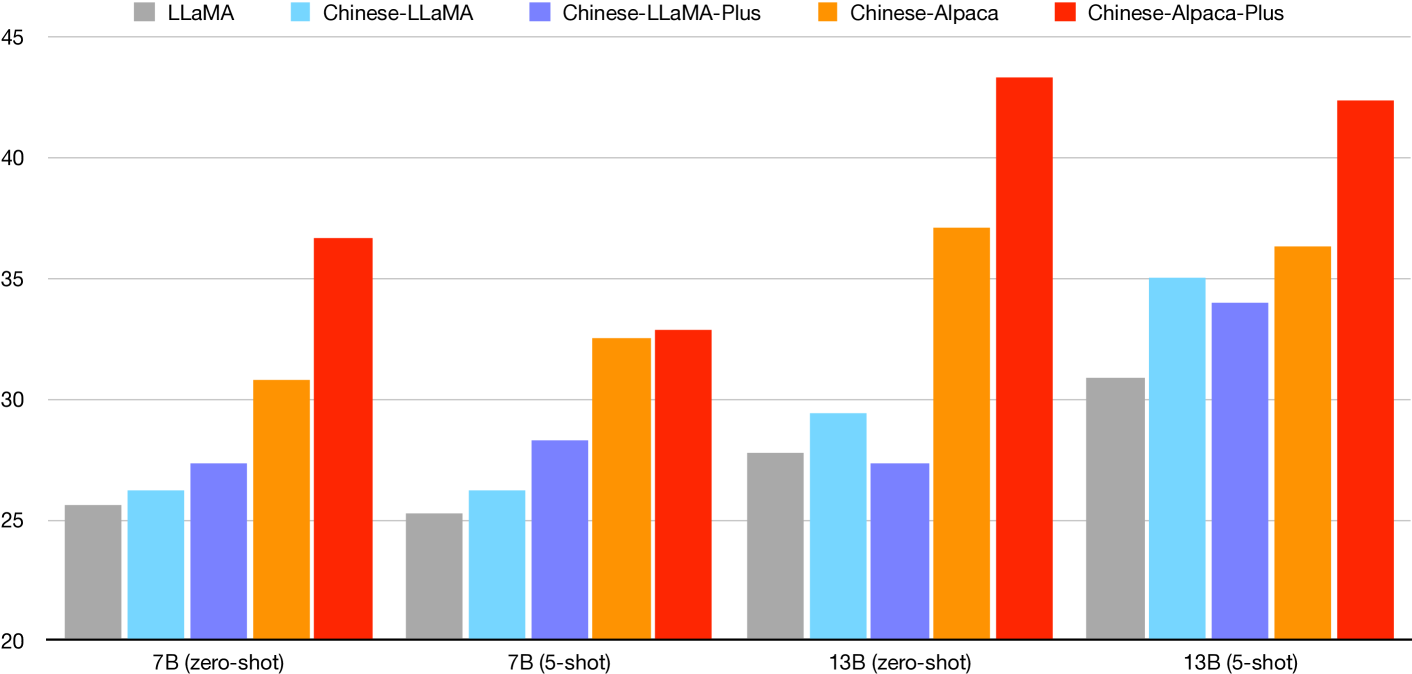
| Model | Valid Set | Test Set | ||
| Zero-shot | 5-shot | Zero-shot | 5-shot | |
| Random | 25.0 | 25.0 | 25.0 | 25.0 |
| LLaMA-65B | 37.2 | 41.2 | 33.4 | 38.8 |
| LLaMA-33B | 34.5 | 37.9 | 32.4 | 36.0 |
| LLaMA-13B | 27.8 | 30.9 | 28.5 | 29.6 |
| LLaMA-7B | 25.6 | 25.3 | 26.7 | 27.8 |
| Chinese-LLaMA-33B | 34.9 | 38.4 | 34.6 | 39.5 |
| Chinese-LLaMA-Plus-13B | 27.3 | 34.0 | 27.8 | 33.3 |
| Chinese-LLaMA-13B | 29.4 | 35.0 | 29.2 | 33.7 |
| Chinese-LLaMA-Plus-7B | 27.3 | 28.3 | 26.8 | 28.4 |
| Chinese-LLaMA-7B | 26.2 | 26.2 | 27.1 | 27.2 |
| Chinese-Alpaca-33B | 43.3 | 42.6 | 41.6 | 40.4 |
| Chinese-Alpaca-Plus-13B | 43.3 | 42.4 | 41.5 | 39.9 |
| Chinese-Alpaca-13B | 37.1 | 36.3 | 36.7 | 34.5 |
| Chinese-Alpaca-Plus-7B | 36.7 | 32.9 | 36.4 | 32.3 |
| Chinese-Alpaca-7B | 30.8 | 32.5 | 30.7 | 29.2 |
中文LLaMA改进了原来的LLaMA。
我们可以看到,所提出的中国 LLaMA 模型比原始 LLaMA 有了适度的改进,这表明中国数据的预训练对 C-Eval 有一些积极的影响,但并不总是如此。 当我们比较中国版LLaMA和LLaMA-Plus时,后者并没有比前者显示出显着的改进,甚至在13B设置下显示出较差的结果。 这可能表明纯语言模型(如 LLaMA)对于 C-Eval 或类似任务可能不是一个好的选择,并且它不会从增加预训练数据大小(中文 LLaMA 和 LLaMA 从 20G 到 120G)中受益匪浅。 -分别加)。
Alpaca 模型比 LLaMA 模型有显着改进。
在不同的设置中,例如零样本或 5 样本,Alpaca 模型系列比 LLaMA 模型系列显示出显着的改进,这表明指令跟踪模型比纯语言模型更能够处理这些类似 NLU 的任务。 与 LLaMA 系列中观察到的现象不同,我们可以看到 Alpaca-Plus 模型比基本 Alpaca 模型有了显着的改进。 这可能进一步表明指令跟踪模型更有能力处理类似 NLU 的任务,并且可以释放使用更多预训练数据 (LLaMA-Plus) 的能力。
LLaMA 通常在少样本设置中产生更好的性能,而 Alpaca 更喜欢零样本。
一般来说,5-shot 设置的 LLaMA 比零样本设置表现出更好的性能,而零样本设置的 Alpaca 比 5-shot 设置要好得多。 由于 LLaMA 不是为遵循指令而设计的,因此少样本设置可能会提供有关如何遵循 C-Eval 中的问答结构的宝贵信息。 然而,相反,由于 Alpaca 已经接受了数百万条指令数据的训练,因此它不太可能从额外的镜头中受益。 此外,官方的 5 次拍摄设置对所有样本使用相同的提示,这使得羊驼模型有些分散注意力。
我们想强调的是,这些观察结果仅基于 C-Eval 数据集的结果,其是否可以推广到其他数据集还需要进一步研究。 未来,我们将进行更全面的测试,以进一步研究 LLaMA 和 Alpaca 模型的行为。
5.4与其他模型的比较
我们将我们表现最好的两个模型 Chinese-Alpaca-33B 和 Chinese-Alpaca-Plus-13B 纳入 C-Eval 排行榜中,以便与其他大语言模型(包括开源和非开源)进行比较- 来源。 C-Eval排行榜测试结果(截至2023年6月9日)如表9所示。
| Model | N-Shot | Open | Avg | Avg-H | STEM | Social | Human | Others |
| GPT-4 | 5-shot | ✗ | 68.7 | 54.9 | 67.1 | 77.6 | 64.5 | 67.8 |
| InternLM (104B) | few-shot | ✗ | 62.7 | 46.0 | 58.1 | 76.7 | 64.6 | 56.4 |
| ChatGPT | 5-shot | ✗ | 54.4 | 41.4 | 52.9 | 61.8 | 50.9 | 53.6 |
| Claude-v1.3 | 5-shot | ✗ | 54.2 | 39.0 | 51.9 | 61.7 | 52.1 | 53.7 |
| Claude-instant-v1.0 | 5-shot | ✗ | 45.9 | 35.5 | 43.1 | 53.8 | 44.2 | 45.4 |
| Bloomz-mt (176B) | 0-shot | ✓ | 44.3 | 30.8 | 39.0 | 53.0 | 47.7 | 42.7 |
| GLM-130B | 0-shot | ✓ | 44.0 | 30.7 | 36.7 | 55.8 | 47.7 | 43.0 |
| Chinese-Alpaca-33B | 0-shot | ✓ | 41.6 | 30.3 | 37.0 | 51.6 | 42.3 | 40.3 |
| Chinese-Alpaca-Plus-13B | 0-shot | ✓ | 41.5 | 30.5 | 36.6 | 49.7 | 43.1 | 41.2 |
| CubeLM (13B) | few-shot | ✗ | 40.2 | 27.3 | 34.1 | 49.7 | 43.4 | 39.6 |
| ChatGLM-6B | 0-shot | ✓ | 38.9 | 29.2 | 33.3 | 48.3 | 41.3 | 38.0 |
| LLaMA-65B | 5-shot | ✓ | 38.8 | 31.7 | 37.8 | 45.6 | 36.1 | 37.1 |
| Chinese-Alpaca-13B | 0-shot | ✓ | 36.7 | 28.4 | 33.1 | 43.7 | 38.4 | 35.0 |
| Chinese-LLaMA-13B | 5-shot | ✓ | 33.7 | 28.1 | 31.9 | 38.6 | 33.5 | 32.8 |
| Chinese-LLaMA-13B | 5-shot | ✓ | 33.3 | 27.3 | 31.6 | 37.2 | 33.6 | 32.8 |
| MOSS (16B) | 0-shot | ✓ | 33.1 | 28.4 | 31.6 | 37.0 | 33.4 | 32.1 |
| Chinese-Alpaca-13B | 0-shot | ✓ | 30.9 | 24.4 | 27.4 | 39.2 | 32.5 | 28.0 |
毫不奇怪,非开源大语言模型的性能明显优于开源模型。 就我们的模型而言,我们可以看到,Chinese-Alpaca-33B 和 Chinese-Alpaca-Plus-13B 在本次排行榜的开源大语言模型中都有相当的表现,与 Bloomz-mt-176B 差距不大(Scao 等人, 2022) 和 GLM-130B (Zeng 等人, 2023),考虑到后者的数量级是其数倍,并且训练的数据量比我们的。
另一方面,Chinese-Alpaca-13B 和 Chinese-LLaMA-13B 之前已通过 C-Eval 进行了评估。 我们还通过自己的实现手动将预测文件提交到排行榜。 结果表明,两个模型均比 C-Eval 评估的模型有显着改进,尤其是 Alpaca-13B 模型,平均得分为+5.8(从 30.9 到 36.7)。 此外,Alpaca-13B 显示出优于 LLaMA-13B 的优势,这与我们之前的发现一致。 这些观察结果表明,采用正确的解码策略和提示模板对于单个大语言模型(特别是指令跟踪模型)获得更好的性能可能至关重要。
6不同量化方法的效果
由于其巨大的计算需求,在个人计算机(尤其是 CPU)上部署大型语言模型历来都充满挑战。 然而,在许多社区努力的帮助下,例如llama.cpp(Gerganov,2023),用户可以有效地量化大语言模型,显着减少内存使用和计算需求,使得在个人电脑上部署大语言模型变得更加容易。 这还可以实现与模型的更快交互并促进本地数据处理。 量化大语言模型并将其部署在个人计算机上有几个好处。 首先,它通过确保敏感信息保留在本地环境中而不是传输到外部服务器来帮助用户保护数据隐私。 其次,它使计算资源有限的用户更容易访问大语言模型,从而实现了对大语言模型的访问民主化。 最后,它促进利用本地大语言模型部署的新应用和研究方向的开发。 总体而言,使用llama.cpp(或类似)在个人计算机上部署大语言模型的能力为大语言模型在各个领域中更通用且更注重隐私的使用铺平了道路。
在本节中,我们研究不同量化方法的效果。 我们使用llama.cpp对Alpaca-Plus-7B、Alpaca-Plus-13B和Alpaca-33B进行量化并计算中文文本语料库的困惑度。 我们将这些模型量化为2位、3位、4位、5位、6位和8位形式,与原始的FP16模型进行比较。101010具体来说,我们对每个量化模型使用 q2_K、q3_K、q4_0、q5_0、q6_K 和 q8_0 量化选项。 结果如图4所示。
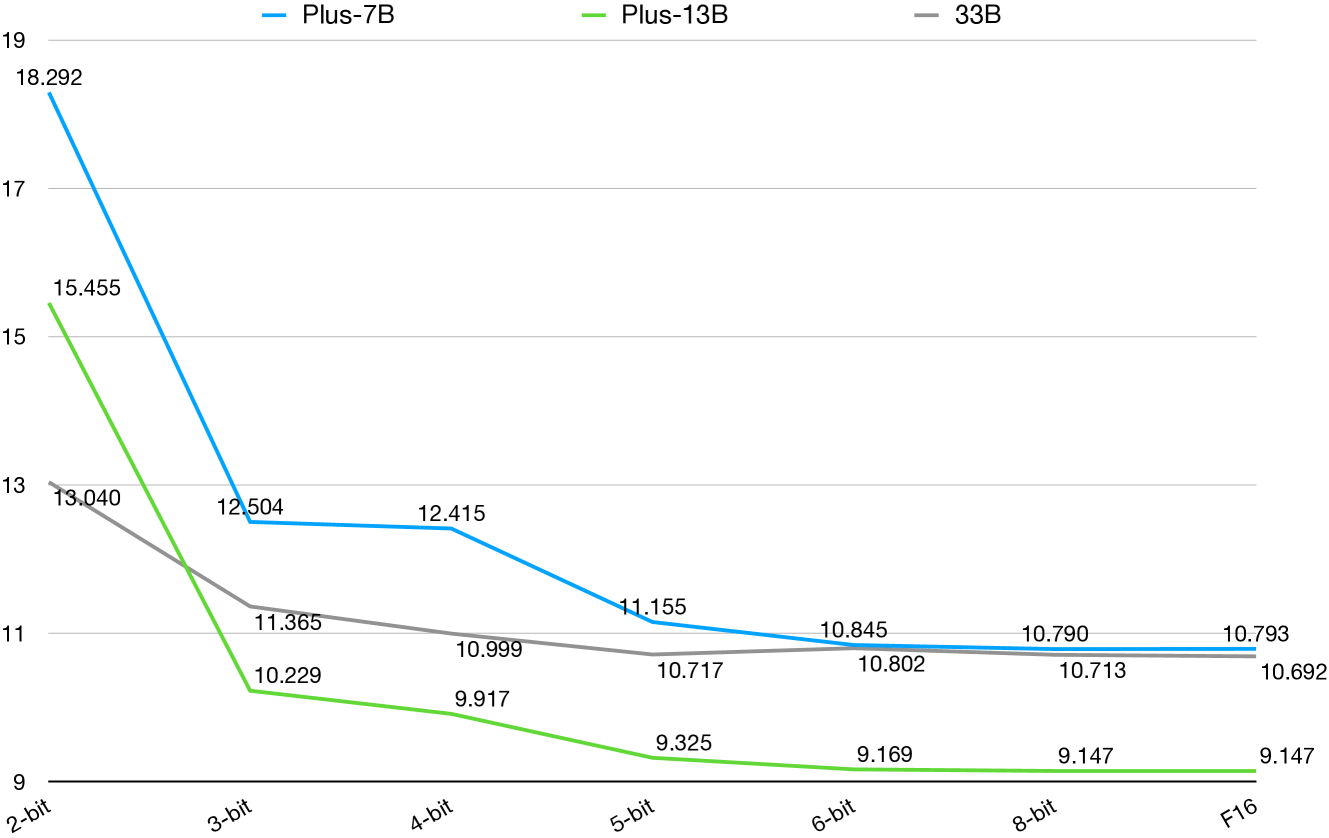
量化级别与内存使用和推理速度严格相关,因此在选择合适的量化级别时必须进行权衡。 我们可以看到,与原始 FP16 模型相比,8 位量化方法的困惑度几乎相同甚至更低,这表明它是在个人计算机上部署大语言模型的良好选择,而且其大小仅为 FP16 的一半。 6 位模型还实现了与 8 位模型相当的 PPL,使其在速度和性能之间取得了更好的平衡。 当我们使用更激进的量化级别时,性能会急剧下降(即更高的 PPL),特别是对于 3 位和 2 位。 我们还发现,较大的模型对量化方法的敏感度低于较小的模型。 例如,33B 型号的性能变化比其他型号温和得多。 在比较 Plus-7B 和 Plus-13B 型号时也观察到类似的结果。 这可能表明,尽管 2 位和 3 位量化对于较小的模型效果较差,但它可能是部署较大模型且不会造成重大性能损失的一种有前途的方法。 当用户只有有限的计算资源并且仍然想尝试大型语言模型时,这非常有帮助。 这也可能意味着量化训练方法可能成为训练大型语言模型的主流方法,特别是对于那些训练资源有限的模型。
7结论
在这份技术报告中,我们提出了一种增强中国人对 LLaMA 模型的理解和生成能力的方法。 认识到原始 LLaMA 中文词汇的局限性,我们通过纳入 20K 额外的中文标记对其进行了扩展,显着提高了其中文编码效率。 在中国羊驼模型的基础上,我们采用了指令数据的监督微调,从而使中国羊驼模型表现出改进的指令跟随能力。
为了有效评估我们的模型,我们对 10 种不同任务类型的 200 个样本进行了注释,并利用 GPT-4 进行评估。 我们的实验表明,所提出的模型在中文理解和生成任务中显着优于原始的 LLaMA。 我们还在 C-Eval 数据集上测试了我们的模型。 结果表明,所提出的模型可以实现显着的改进,并显示出与大几倍尺寸的模型相比的竞争性能。
展望未来,我们计划探索人类反馈强化学习(RLHF)或人工智能指导反馈强化学习(RLAIF),以进一步使模型的输出与人类偏好保持一致。 此外,我们打算采用更先进、更有效的量化方法,例如 GPTQ (Frantar 等人, 2022) 等。 此外,我们的目标是研究 LoRA 的替代方法,以更高效、更有效地对大型语言模型进行预训练和微调,最终提高其在中文 NLP 社区内各种任务中的性能和适用性。
局限性
虽然该项目成功增强了中国人对 LLaMA 和 Alpaca 模型的理解和生成能力,但必须承认一些局限性:
-
•
有害且不可预测的内容:尽管我们的模型可以拒绝不道德的查询,但这些模型仍然可能产生有害的或与人类偏好和价值观不一致的内容。 这个问题可能是由于训练数据的偏差或模型无法在某些情况下辨别适当的输出而引起的。
-
•
训练不足:由于计算能力和数据可用性的限制,模型的训练可能不足以达到最佳性能。 因此,模型的中文理解能力仍有提升空间。
-
•
缺乏鲁棒性:模型在某些情况下可能表现出脆弱性,在面对对抗性输入或罕见的语言现象时产生不一致或无意义的输出。
-
•
综合评估:评估大型语言模型是当今时代的一个重要课题。 虽然我们看到了很多大语言模型的评估基准,但它们对于大语言模型的全面性和适用性值得深入研究和检验。 更加多样化和全面的大语言模型评估数据集和基准将对塑造大语言模型研究的未来产生巨大的积极作用。
-
•
可扩展性和效率:虽然我们应用 LoRA 和量化来使模型更容易被更广泛的社区所使用,但当与原始 LLaMA 结合时,模型的大尺寸和复杂性可能会导致部署困难,特别是对于计算资源有限的用户而言。 这个问题可能会阻碍模型在各种应用中的可访问性和广泛采用。
未来的工作应该解决这些局限性,以进一步增强模型的能力,使它们更加强大、易于访问和有效,以便在中国 NLP 社区中得到更广泛的应用。
致谢
原始草案由 OpenAI GPT-4 进行了语法修正和清晰度改进。 我们要感谢我们的社区成员对我们的开源项目的贡献。
参考
- Bai et al. (2023) Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longbench: A bilingual, multitask benchmark for long context understanding. arXiv preprint arXiv:2308.14508, 2023.
- Chen et al. (2023) Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation. arXiv preprint arXiv:2306.15595, 2023.
- Cui et al. (2020) Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Shijin Wang, and Guoping Hu. Revisiting pre-trained models for Chinese natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, pp. 657–668, Online, November 2020. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/2020.findings-emnlp.58.
- Cui et al. (2021) Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, and Ziqing Yang. Pre-training with whole word masking for chinese bert. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3504–3514, 2021. doi: 10.1109/TASLP.2021.3124365.
- Cui et al. (2022) Yiming Cui, Wanxiang Che, Shijin Wang, and Ting Liu. Lert: A linguistically-motivated pre-trained language model. arXiv preprint arXiv:2211.05344, 2022.
- Dettmers et al. (2023) Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. arXiv preprint arXiv:2305.14314, 2023.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171–4186, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/N19-1423.
- Frantar et al. (2022) Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post-training compression for generative pretrained transformers. arXiv preprint arXiv:2210.17323, 2022.
- Gerganov (2023) Georgi Gerganov. llama.cpp. https://github.com/ggerganov/llama.cpp, 2023.
- Hu et al. (2021) Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. arXiv e-prints, art. arXiv:2106.09685, June 2021. doi: 10.48550/arXiv.2106.09685.
- Huang et al. (2023) Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, Yao Fu, Maosong Sun, and Junxian He. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models. arXiv preprint arXiv:2305.08322, 2023.
- Köpf et al. (2023) Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi-Rui Tam, Keith Stevens, Abdullah Barhoum, Nguyen Minh Duc, Oliver Stanley, Richárd Nagyfi, Shahul ES, Sameer Suri, David Glushkov, Arnav Dantuluri, Andrew Maguire, Christoph Schuhmann, Huu Nguyen, and Alexander Mattick. OpenAssistant Conversations – Democratizing Large Language Model Alignment. arXiv e-prints, art. arXiv:2304.07327, April 2023. doi: 10.48550/arXiv.2304.07327.
- Kudo & Richardson (2018) Taku Kudo and John Richardson. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 66–71, Brussels, Belgium, November 2018. Association for Computational Linguistics. doi: 10.18653/v1/D18-2012. URL https://aclanthology.org/D18-2012.
- Lai et al. (2017) Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. RACE: Large-scale ReAding comprehension dataset from examinations. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794, Copenhagen, Denmark, September 2017. Association for Computational Linguistics. doi: 10.18653/v1/D17-1082. URL https://aclanthology.org/D17-1082.
- Li et al. (2023) Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. Cmmlu: Measuring massive multitask language understanding in chinese, 2023.
- Loshchilov & Hutter (2019) Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=Bkg6RiCqY7.
- OpenAI (2022) OpenAI. Introducing chatgpt. https://openai.com/blog/chatgpt, 2022.
- OpenAI (2023) OpenAI. GPT-4 Technical Report. arXiv e-prints, art. arXiv:2303.08774, March 2023. doi: 10.48550/arXiv.2303.08774.
- Ouyang et al. (2022) Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. arXiv e-prints, art. arXiv:2203.02155, March 2022. doi: 10.48550/arXiv.2203.02155.
- Peng et al. (2023) Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. Yarn: Efficient context window extension of large language models. arXiv preprint arXiv:2309.00071, 2023.
- Radford et al. (2018) Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. 2018.
- Rasley et al. (2020) Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 3505–3506, 2020.
- Scao et al. (2022) Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilić, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, et al. Bloom: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100, 2022.
- Shazeer (2020) Noam Shazeer. Glu variants improve transformer, 2020.
- Su et al. (2021) Jianlin Su, Yu Lu, Shengfeng Pan, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding, 2021.
- Taori et al. (2023a) Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023a.
- Taori et al. (2023b) Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023b.
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (eds.), Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017.
- Wang et al. (2022) Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-Instruct: Aligning Language Model with Self Generated Instructions. arXiv e-prints, art. arXiv:2212.10560, December 2022. doi: 10.48550/arXiv.2212.10560.
- Xu (2019) Bright Xu. Nlp chinese corpus: Large scale chinese corpus for nlp, September 2019. URL https://doi.org/10.5281/zenodo.3402023.
- Yang et al. (2022) Ziqing Yang, Zihang Xu, Yiming Cui, Baoxin Wang, Min Lin, Dayong Wu, and Zhigang Chen. CINO: A Chinese minority pre-trained language model. In Proceedings of the 29th International Conference on Computational Linguistics, pp. 3937–3949, Gyeongju, Republic of Korea, October 2022. International Committee on Computational Linguistics. URL https://aclanthology.org/2022.coling-1.346.
- Zeng et al. (2023) Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, Weng Lam Tam, Zixuan Ma, Yufei Xue, Jidong Zhai, Wenguang Chen, Zhiyuan Liu, Peng Zhang, Yuxiao Dong, and Jie Tang. GLM-130b: An open bilingual pre-trained model. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=-Aw0rrrPUF.
- Zhang & Sennrich (2019) Biao Zhang and Rico Sennrich. Root Mean Square Layer Normalization. In Advances in Neural Information Processing Systems 32, Vancouver, Canada, 2019. URL https://openreview.net/references/pdf?id=S1qBAf6rr.
附录A附录
我们介绍 Chinese-LLaMA-2 和 Chinese-Alpaca-2 的基线结果如下。 大多数设置与 Chinese-LLaMA 中的设置相同。
A.1 C-评估
C-Eval(黄等人,2023)的结果如表10所示。
| Model | Valid Set | Test Set | ||
| Zero-shot | 5-shot | Zero-shot | 5-shot | |
| Chinese-LLaMA-2-7B | 28.2 | 36.0 | 30.3 | 34.2 |
| Chinese-LLaMA-2-13B | 40.6 | 42.7 | 38.0 | 41.6 |
| Chinese-Alpaca-2-7B | 41.3 | 42.9 | 40.3 | 39.5 |
| Chinese-Alpaca-2-13B | 44.3 | 45.9 | 42.6 | 44.0 |
A.2CMMLU
CMMLU(Li等人,2023)的结果如表11所示。
| Model | Test Set | |
| Zero-shot | Few-shot | |
| Chinese-LLaMA-2-7B | 27.9 | 34.1 |
| Chinese-LLaMA-2-13B | 38.9 | 42.5 |
| Chinese-Alpaca-2-7B | 40.0 | 41.8 |
| Chinese-Alpaca-2-13B | 43.2 | 45.5 |
A.3长凳
LongBench(Bai等人,2023)的结果如表12所示。 该基准测试是专门为了测试大语言模型的长上下文能力而设计的。 我们测试了 LongBench 的中文子集(包括代码任务)。 标记为16K的模型使用位置插值(PI)方法(Chen等人,2023)进行微调,该方法支持16K上下文。 标记为64K的模型使用YaRN方法(Peng等人,2023)进行微调,该方法支持64K上下文。
| Model | S-QA | M-QA | Summ | FS-Learn | Code | Synthetic | Average |
| Chinese-LLaMA-2-7B | 19.0 | 13.9 | 6.4 | 11.0 | 11.0 | 4.7 | 11.0 |
| Chinese-LLaMA-2-7B-16K | 33.2 | 15.9 | 6.5 | 23.5 | 10.3 | 5.3 | 15.8 |
| Chinese-LLaMA-2-7B-64K | 27.2 | 16.4 | 6.5 | 33.0 | 7.8 | 5.0 | 16.0 |
| Chinese-LLaMA-2-13B | 28.3 | 14.4 | 4.6 | 16.3 | 10.4 | 5.4 | 13.2 |
| Chinese-LLaMA-2-13B-16K | 36.7 | 17.7 | 3.1 | 29.8 | 13.8 | 3.0 | 17.3 |
| Chinese-Alpaca-2-7B | 34.0 | 17.4 | 11.8 | 21.3 | 50.3 | 4.5 | 23.2 |
| Chinese-Alpaca-2-7B-16K | 46.4 | 23.3 | 14.3 | 29.0 | 49.6 | 9.0 | 28.6 |
| Chinese-Alpaca-2-7B-64K | 44.7 | 28.1 | 14.4 | 39.0 | 44.6 | 5.0 | 29.3 |
| Chinese-Alpaca-2-13B | 38.4 | 20.0 | 11.9 | 17.3 | 46.5 | 8.0 | 23.7 |
| Chinese-Alpaca-2-13B-16K | 47.9 | 26.7 | 13.0 | 22.3 | 46.6 | 21.5 | 29.7 |