调整大小[2][!] 重新缩放[2][]
使用
TiDE 进行长期预测:时间序列密集编码器
摘要
最近的工作表明,在长期时间序列预测中,简单的线性模型可以优于几种基于 Transformer 的方法。 受此启发,我们提出了一种基于多层感知器(MLP)的编码器-解码器模型,Time-seriesDenseEncoder( TiDE),用于长期时间序列预测,具有线性模型的简单性和速度,同时还能够处理协变量和非线性依赖性。 从理论上讲,我们证明了我们模型的最简单的线性模拟可以在某些假设下实现线性动力系统(LDS)的接近最佳错误率。 根据经验,我们表明我们的方法可以在流行的长期时间序列预测基准上匹配或优于先前的方法,同时比最好的基于 Transformer 的模型快 5-10 倍。††作者姓名按姓氏字母顺序排列。
1简介
长期预测是在长期背景或回顾的情况下预测未来的几个步骤,是时间序列分析中最基本的问题之一,在能源、金融和交通领域有着广泛的应用。 深度学习模型(Wu等人,2021;Nie等人,2022)已成为预测丰富的多元时间序列数据的流行方法,通常优于ARIMA或GARCH等经典统计方法(Box等人,2015)。 在M5竞赛(Makridakis等人,2020)和IARAI Traffic4cast竞赛(Kreil等人,2020)等多个预测竞赛中,深度神经网络表现得相当不错。
人们已经探索了各种用于预测的神经网络架构,从循环神经网络到卷积网络再到图神经网络。 对于语言、语音和视觉等领域的序列建模任务,Transformers (Vaswani 等人, 2017) 已成为最成功的模型,甚至优于循环神经网络 (LSTM)(Hochreiter和 Schmidhuber,1997)。 随后,时间序列社区中出现了大量基于 Transformer 的预测论文(Wu 等人,2021;Zhou 等人,2021;2022),这些论文声称达到了最先进的水平art (SoTA) 预测长期任务的性能。 然而,最近的工作(Zeng等人,2023)表明,这些基于 Transformerss 的架构在时间序列预测方面可能没有人们预期的那么强大,并且很容易被简单的线性模型超越关于预测基准。 然而,这种线性模型存在缺陷,因为它不适合对时间序列序列和时间无关协变量之间的非线性依赖性进行建模。 事实上,最近的一篇论文(Nie等人,2022)提出了一种新的基于 Transformer 的架构,该架构可以在标准多元预测基准上获得深度神经网络的 SoTA 性能。
在本文中,我们提出了一种用于长期预测的简单有效的深度学习架构,与时间序列预测基准上现有的基于 SoTA 神经网络的模型相比,该架构获得了卓越的性能。 我们基于多层感知器(MLP)的模型非常简单,没有任何自注意力、循环或卷积机制。 因此,与许多基于 Transformer 的解决方案不同,它在上下文和范围长度方面享有线性计算缩放。
这项工作的主要贡献如下:
-
•
我们提出了用于长期时间序列预测的Time-series Dense Encoder (TiDE)模型架构。 TiDE 使用密集 MLP 对时间序列的过去和协变量进行编码,然后再次使用密集 MLP 对时间序列和未来协变量进行解码。
-
•
我们分析了模型的简化线性模拟,并证明当 LDS 的设计矩阵具有最大奇异值时,该线性模型可以在线性动力系统 (LDS) (Kalman,1963) 中实现接近最优的误差率值远离 。 我们在模拟数据集上凭经验验证了这一点,其中线性模型优于 LSTM 和 Transformer。
-
•
在流行的真实世界长期预测基准上,我们的模型与之前基于神经网络的基准相比,取得了更好或相似的性能(在最大的数据集上,平均平方误差降低了10%)。 同时,与基于 Transformer 的最佳模型相比,TiDE 的推理速度提高了 5 倍,训练速度提高了 10 倍以上。
2 背景及相关工作
长期预测模型大致可分为多变量模型或单变量模型。
多变量模型使用所有相互关联的时间序列变量的过去,并将所有时间序列的未来预测为这些过去的联合函数。 这包括经典的 VAR 模型(Zivot 和 Wang,2006)。 我们将主要关注基于神经网络的长期预测模型的先前工作。 LongTrans (Li 等人, 2019a) 使用具有 LogSparse 设计的注意力层来捕获具有接近线性空间和计算复杂度的局部信息。 Informer (Zhou 等人, 2021) 使用 ProbSparse 自注意力机制实现对上下文长度的次二次依赖。 Autoformer (Wu 等人, 2021) 使用趋势和季节性分解以及次二次自注意力机制。 FEDFormer (Zhou 等人, 2022) 使用频率增强结构,而 Pyraformer (Liu 等人, 2021) 使用金字塔自注意力,具有线性复杂度,可以关注不同的情况粒度。 上述工作的共同主题是使用次二次近似来实现完全自注意力机制,该机制也已用于其他领域(Wang 等人,2020)。
另一方面,单变量模型将时间序列变量的未来预测为仅作为相同时间序列和协变量特征的过去的函数。 换句话说,其他时间序列的过去不是推理过程中输入的一部分。 单变量模型有两种,局部和全局。 局部单变量模型通常按时间序列变量进行训练,并且也按时间序列进行推理。 不同的变量有不同的模型。 AR、ARIMA、指数平滑模型(McKenzie,1984)和 Box-Jenkins 方法(Box 和 Jenkins,1968) 等经典模型都属于这一类。 我们建议读者参考(Box 等人, 2015)来深入讨论这些方法。
全局单变量模型忽略变量信息,并为整个数据集上的所有时间序列训练一个共享模型。 该类别主要包括基于深度学习的架构,例如(Salinas等人,2020)。 在长期预测的背景下,最近发现简单的线性全局单变量模型在长期预测方面可以优于基于 Transformer 的多元方法(Zeng 等人,2023)。 DLinear (Zeng 等人, 2023) 学习从上下文到地平线的线性映射,指出自注意力机制的次二次近似的缺陷。 事实上,最近的一个模型 PatchTST (Nie 等人,2022) 已经表明,将连续的时间序列补丁作为 token 提供给普通的自注意力机制可以在长期表现中击败 DLinear 的性能。期限预测基准。 MLP 已在流行的 N-BEATS 模型中用于时间序列预测(Oreshkin 等人,),并在后续工作中得到扩展(Challu 等人,2023) 使用多速率采样来提高效率。 然而,这些方法没有明确提及支持协变量,并且在长期基准测试中达不到 PatchTST。
最近的工作提高了 RNN (Kag 等人,2020;Lukoševičius 和 Uselis,2022;Rusch 和 Mishra,2020;Li 等人,2019b) 的效率,并应用了参数高效的 SSM (Gu等人, ; Gupta 等人, 2022) 对序列中的长程依赖性进行建模。 他们在序列建模基准(包括语音和一维像素级图像分类任务)上展示了对一些基于 Transformer 的架构的改进。 我们将我们的方法与 S4 模型 (Gu 等人, ) 进行比较,这是唯一已应用于全局单变量和全局多变量预测的方法。
请注意,如果在同一任务的同一测试集上对所有类别的模型进行评估,则可以在多元长期预测任务上公平地比较所有类别的模型,这是我们在第 5 节中遵循的协议。
3问题设置
在描述问题设置之前,我们需要设置一些通用符号。
3.1 符号
我们将用粗体大写字母表示矩阵,例如 。 切片符号表示集合和。 除非另有说明,否则各个行和列始终被视为列向量。 我们还可以使用集合来选择子矩阵,即 表示行在 中、列在 中的子矩阵。 表示选择第 列,而 表示选择第 行。 符号 将表示两个列向量的串联,并且相同的符号可用于沿维度的矩阵。
3.2多变量预测
在本节中,我们首先总结出长期多元预测的核心问题。 数据集中有 个时间序列。 第 个时间序列的回顾将由 表示,而范围由 表示。 预测者的任务是预测可以进行回顾的范围时间点。
在许多预测场景中,可能存在预先已知的动态和静态协变量。 稍微滥用符号,我们将使用 来表示时间序列 在时间 的 维动态协变量。例如,它们可以是全局协变量(对所有时间序列通用),例如星期几、节假日等,也可以是特定于时间序列的变量,例如需求预测用例中特定日期特定产品的折扣。 我们还可以拥有由 表示的时间序列的静态属性,例如零售中产品的不随时间变化的特征。 在许多应用中,这些协变量对于准确预测至关重要,良好的模型架构应该具备处理这些协变量的能力。
预测器可以被认为是一个将历史、动态协变量和静态属性映射到对未来的准确预测的函数, IE。,
| (1) |
预测的准确性将通过量化其与实际值的接近程度的指标来衡量。 例如,如果指标是均方误差 (MSE),则拟合优度的衡量标准为:
| (2) |
4模型
最近,人们发现简单的线性模型(Zeng 等人,2023) 在几个长期预测基准中可以优于基于 Transformers 的模型。 另一方面,当未来对过去的依赖存在固有的非线性时,线性模型就会失效。 此外,线性模型无法对预测对协变量的依赖性进行建模,(Zeng 等人,2023)不使用时间协变量,因为它们会损害性能,这一事实证明了这一点。
在本节中,我们将介绍一种简单高效的基于 MLP 的架构,用于长期时间序列预测。 在我们的模型中,我们以 MLP 的形式添加非线性,以能够处理过去的数据和协变量。 该模型被称为 TiDE(Time-series Dense Encoder),因为它使用以下方法对时间序列的过去以及协变量进行编码密集的 MLP,然后解码编码的时间序列以及未来的协变量。
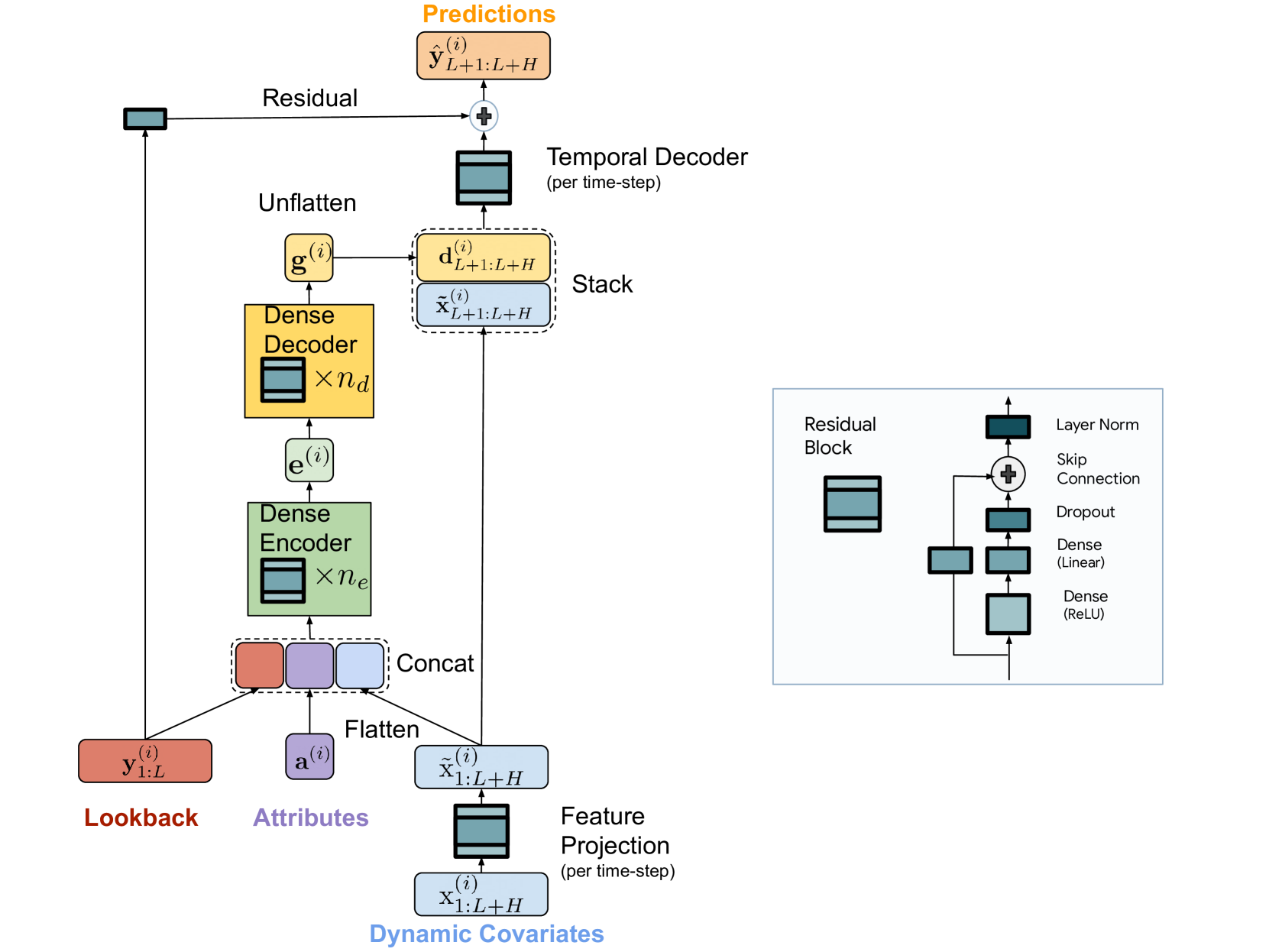
图 1 概述了我们的架构。 我们的模型以与通道无关的方式应用(该术语用于(Nie等人,2022)),即模型的输入是一次一个时间序列的过去和协变量 并将其映射到该时间序列 的预测。 请注意,模型的权重是使用整个数据集进行全局训练的。 我们模型中的一个关键组件是图右侧的 MLP 残差块。
剩差块。 我们使用残差块作为我们架构中的基本层。 它是一种具有一个带有 ReLU 激活的隐藏层的 MLP。 它还具有完全线性的跳跃连接。 我们在将隐藏层映射到输出的线性层上使用 dropout,并在输出处使用层范数。
我们将模型分为编码和解码部分。 编码部分有一个新颖的特征投影步骤,后面是一个密集的 MLP 编码器。 解码器部分由密集解码器和新颖的时间解码器组成。 请注意,图 1 中的密集编码器(具有 ne 层的绿色块)和解码器块(具有 nd 层的黄色块)可以合并为单个块。 为了便于说明,我们在分别调整两个块中的隐藏层大小时将它们分开。 此外,解码器块的最后一层是唯一的,因为在重塑操作之前其输出维度需要为 。
4.1编码
编码步骤的任务是将时间序列的过去和协变量映射到特征的密集表示。 我们模型中的编码有两个关键步骤。
特征投影。 我们使用残差块将每个时间步(在回溯和地平线中)的 映射到大小为 (temporalWidth)。 该操作可以描述为,
| (3) |
这本质上是一个降维步骤,因为展平整个回溯和视野的动态协变量将导致大小为 的输入向量可能过大。 另一方面,展平减少的特征只会导致尺寸为。
密集编码器。 作为密集编码器的输入,我们堆叠并展平所有过去和未来的投影协变量,将它们与静态属性和时间序列的过去连接起来。 然后我们使用包含多个残差块的编码器将它们映射到嵌入。 这可以写成,
| (4) |
编码器内部层大小均设置为 hiddenSize,编码器中的总层数设置为 (numEncoderLayers)。
4.2解码
我们模型中的解码将编码的隐藏表示映射到时间序列的未来预测。 它还包括两个操作,密集解码器和时间解码器。
密集解码器。 第一个解码单元是几个残差块的堆叠,就像具有相同隐藏层大小的编码器一样。 它将编码 作为输入,并将其映射到大小为 的向量 ,其中 是 decoderOutputDim 。 然后将该向量重塑为矩阵 。 第 列,即 可以看作是所有 的视平线中第 个时间段的解码向量。 整个操作可以描述为,
密集解码器中的层数为 (numDecoderLayers)。
时间解码器。 最后,我们使用时间解码器来生成最终预测。 时间解码器只是一个输出大小为 的残差块,它将解码向量 映射到 水平时间步长,与投影协变量 即
此操作将时间步 处的未来协变量的“高速公路”添加到时间步 处的预测中。 如果某些协变量对特定时间步长的实际值有强烈的直接影响,这可能会很有用。 例如,在零售需求中,预测母亲节等节日可能会严重影响某些礼品的销售。 在没有这样的高速公路的情况下,这样的信号可能会丢失或者模型需要更长的时间来学习。 我们将控制时间解码器隐藏大小的超参数表示为temporalDecoderHidden。
最后,我们添加一个全局残差连接,将回溯线性映射到水平线大小的向量,该向量被添加到预测中。 这确保了像 (Zeng 等人, 2023) 中的纯线性模型始终是我们模型的子类。
训练和评估。 该模型使用小批量梯度下降进行训练,其中每个批次由 batchSize 数量的时间序列以及相应的回顾和地平线时间点组成。 我们使用 MSE 作为训练损失。 每个时期都包含可以从该时期构建的所有回顾和地平线对,即两个小批量可以具有重叠的时间点。 这是之前所有长期预测工作的标准做法(曾等人,2023;刘等人,2021;吴等人,2021;李等人,2019a)。
该模型在可以从测试集构建的每个(回顾、水平)对的测试集上进行评估。 这通常称为滚动验证/评估。 可以选择使用对验证集的类似评估来调整模型选择的参数。
5实验结果
在本节中,我们将介绍流行的长期预测基准的主要实验结果。 我们还进行了一项消融研究,显示了时间解码器的有用性。
5.1 长期时间序列预测
数据集。 我们使用七个常用的长期预测基准数据集:天气、交通、电力和 4 个 ETT 数据集(ETTh1、ETTh2、ETTm1、ETTm2)。 我们建议读者参考(Wu 等人, 2021) 以获取有关数据集的详细讨论。 在表1中,我们提供了有关数据集的一些统计数据。 请注意,交通和电力是最大的数据集,具有 和 时间序列,每个时间序列都有数万个时间点。 由于我们只对本节中的长期预测结果感兴趣,因此我们省略了较短期限的 ILI 数据集。
| Dataset | #Time-Series | #Time-Points | Frequency |
|---|---|---|---|
| Electricity | 321 | 26304 | 1 Hour |
| Traffic | 862 | 17544 | 1 Hour |
| Weather | 21 | 52696 | 10 Minutes |
| ETTh1 | 7 | 17420 | 1 Hour |
| ETTh2 | 7 | 17420 | 1 Hour |
| ETTm1 | 7 | 69680 | 15 Minutes |
| ETTm2 | 7 | 69680 | 15 Minutes |
| Models | TiDE | PatchTST/64 | N-HiTS | DLinear | FEDformer | Autoformer | Informer | Pyraformer | LogTrans | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | |
| Weather | 96 | 0.166 | 0.222 | 0.149 | 0.198 | 0.158 | 0.195 | 0.176 | 0.237 | 0.238 | 0.314 | 0.249 | 0.329 | 0.354 | 0.405 | 0.896 | 0.556 | 0.458 | 0.490 |
| 192 | 0.209 | 0.263 | 0.194 | 0.241 | 0.211 | 0.247 | 0.220 | 0.282 | 0.275 | 0.329 | 0.325 | 0.370 | 0.419 | 0.434 | 0.622 | 0.624 | 0.658 | 0.589 | |
| 336 | 0.254 | 0.301 | 0.245 | 0.282 | 0.274 | 0.300 | 0.265 | 0.319 | 0.339 | 0.377 | 0.351 | 0.391 | 0.583 | 0.543 | 0.739 | 0.753 | 0.797 | 0.652 | |
| 720 | 0.313 | 0.340 | 0.314 | 0.334 | 0.401 | 0.413 | 0.323 | 0.362 | 0.389 | 0.409 | 0.415 | 0.426 | 0.916 | 0.705 | 1.004 | 0.934 | 0.869 | 0.675 | |
| Traffic | 96 | 0.336 | 0.253 | 0.360 | 0.249 | 0.402 | 0.282 | 0.410 | 0.282 | 0.576 | 0.359 | 0.597 | 0.371 | 0.733 | 0.410 | 2.085 | 0.468 | 0.684 | 0.384 |
| 192 | 0.346 | 0.257 | 0.379 | 0.256 | 0.420 | 0.297 | 0.423 | 0.287 | 0.610 | 0.380 | 0.607 | 0.382 | 0.777 | 0.435 | 0.867 | 0.467 | 0.685 | 0.390 | |
| 336 | 0.355 | 0.260 | 0.392 | 0.264 | 0.448 | 0.313 | 0.436 | 0.296 | 0.608 | 0.375 | 0.623 | 0.387 | 0.776 | 0.434 | 0.869 | 0.469 | 0.734 | 0.408 | |
| 720 | 0.386 | 0.273 | 0.432 | 0.286 | 0.539 | 0.353 | 0.466 | 0.315 | 0.621 | 0.375 | 0.639 | 0.395 | 0.827 | 0.466 | 0.881 | 0.473 | 0.717 | 0.396 | |
| Electricity | 96 | 0.132 | 0.229 | 0.129 | 0.222 | 0.147 | 0.249 | 0.140 | 0.237 | 0.186 | 0.302 | 0.196 | 0.313 | 0.304 | 0.393 | 0.386 | 0.449 | 0.258 | 0.357 |
| 192 | 0.147 | 0.243 | 0.147 | 0.240 | 0.167 | 0.269 | 0.153 | 0.249 | 0.197 | 0.311 | 0.211 | 0.324 | 0.327 | 0.417 | 0.386 | 0.443 | 0.266 | 0.368 | |
| 336 | 0.161 | 0.261 | 0.163 | 0.259 | 0.186 | 0.290 | 0.169 | 0.267 | 0.213 | 0.328 | 0.214 | 0.327 | 0.333 | 0.422 | 0.378 | 0.443 | 0.280 | 0.380 | |
| 720 | 0.196 | 0.294 | 0.197 | 0.290 | 0.243 | 0.340 | 0.203 | 0.301 | 0.233 | 0.344 | 0.236 | 0.342 | 0.351 | 0.427 | 0.376 | 0.445 | 0.283 | 0.376 | |
| ETTh1 | 96 | 0.375 | 0.398 | 0.379 | 0.401 | 0.378 | 0.393 | 0.375 | 0.399 | 0.376 | 0.415 | 0.435 | 0.446 | 0.941 | 0.769 | 0.664 | 0.612 | 0.878 | 0.740 |
| 192 | 0.412 | 0.422 | 0.413 | 0.429 | 0.427 | 0.436 | 0.412 | 0.420 | 0.423 | 0.446 | 0.456 | 0.457 | 1.007 | 0.786 | 0.790 | 0.681 | 1.037 | 0.824 | |
| 336 | 0.435 | 0.433 | 0.435 | 0.436 | 0.458 | 0.484 | 0.439 | 0.443 | 0.444 | 0.462 | 0.486 | 0.487 | 1.038 | 0.784 | 0.891 | 0.738 | 1.238 | 0.932 | |
| 720 | 0.454 | 0.465 | 0.446 | 0.464 | 0.472 | 0.561 | 0.501 | 0.490 | 0.469 | 0.492 | 0.515 | 0.517 | 1.144 | 0.857 | 0.963 | 0.782 | 1.135 | 0.852 | |
| ETTh2 | 96 | 0.270 | 0.336 | 0.274 | 0.337 | 0.274 | 0.345 | 0.289 | 0.353 | 0.332 | 0.374 | 0.332 | 0.368 | 1.549 | 0.952 | 0.645 | 0.597 | 2.116 | 1.197 |
| 192 | 0.332 | 0.380 | 0.338 | 0.376 | 0.353 | 0.401 | 0.383 | 0.418 | 0.407 | 0.446 | 0.426 | 0.434 | 3.792 | 1.542 | 0.788 | 0.683 | 4.315 | 1.635 | |
| 336 | 0.360 | 0.407 | 0.363 | 0.397 | 0.382 | 0.425 | 0.448 | 0.465 | 0.400 | 0.447 | 0.477 | 0.479 | 4.215 | 1.642 | 0.907 | 0.747 | 1.124 | 1.604 | |
| 720 | 0.419 | 0.451 | 0.393 | 0.430 | 0.625 | 0.557 | 0.605 | 0.551 | 0.412 | 0.469 | 0.453 | 0.490 | 3.656 | 1.619 | 0.963 | 0.783 | 3.188 | 1.540 | |
| ETTm1 | 96 | 0.306 | 0.349 | 0.293 | 0.346 | 0.302 | 0.350 | 0.299 | 0.343 | 0.326 | 0.390 | 0.510 | 0.492 | 0.626 | 0.560 | 0.543 | 0.510 | 0.600 | 0.546 |
| 192 | 0.335 | 0.366 | 0.333 | 0.370 | 0.347 | 0.383 | 0.335 | 0.365 | 0.365 | 0.415 | 0.514 | 0.495 | 0.725 | 0.619 | 0.557 | 0.537 | 0.837 | 0.700 | |
| 336 | 0.364 | 0.384 | 0.369 | 0.392 | 0.369 | 0.402 | 0.369 | 0.386 | 0.392 | 0.425 | 0.510 | 0.492 | 1.005 | 0.741 | 0.754 | 0.655 | 1.124 | 0.832 | |
| 720 | 0.413 | 0.413 | 0.416 | 0.420 | 0.431 | 0.441 | 0.425 | 0.421 | 0.446 | 0.458 | 0.527 | 0.493 | 1.133 | 0.845 | 0.908 | 0.724 | 1.153 | 0.820 | |
| ETTm2 | 96 | 0.161 | 0.251 | 0.166 | 0.256 | 0.176 | 0.255 | 0.167 | 0.260 | 0.180 | 0.271 | 0.205 | 0.293 | 0.355 | 0.462 | 0.435 | 0.507 | 0.768 | 0.642 |
| 192 | 0.215 | 0.289 | 0.223 | 0.296 | 0.245 | 0.305 | 0.224 | 0.303 | 0.252 | 0.318 | 0.278 | 0.336 | 0.595 | 0.586 | 0.730 | 0.673 | 0.989 | 0.757 | |
| 336 | 0.267 | 0.326 | 0.274 | 0.329 | 0.295 | 0.346 | 0.281 | 0.342 | 0.324 | 0.364 | 0.343 | 0.379 | 1.270 | 0.871 | 1.201 | 0.845 | 1.334 | 0.872 | |
| 720 | 0.352 | 0.383 | 0.362 | 0.385 | 0.401 | 0.413 | 0.397 | 0.421 | 0.410 | 0.420 | 0.414 | 0.419 | 3.001 | 1.267 | 3.625 | 1.451 | 3.048 | 1.328 | |
基线和设置。 我们选择基于 SOTA Transformers 的时间序列模型,包括 Fedformer (Zhou 等人, 2022)、Autoformer (Wu 等人, 2021)、Informer (Zhou 等)人, 2021)、Pyraformer (刘等人, 2021) 和 LongTrans (李等人, 2019a)。 最近,DLinear (Zeng 等人, 2023) 表明简单的线性模型可以优于上述方法,因此 DLinear 可以作为重要的基线。 我们包括 N-HiTS (Challu 等人, 2023),它是对著名的 NBeats (Oreshkin 等人, ) 模型的改进。 最后,我们与 PatchTST (Nie 等人,2022) 进行比较,他们表明,应用于时间序列补丁的普通 Transformer 可以非常有效。 所有基于 Transformer 的基线的结果均来自(Nie 等人,2022)。
对于每种方法,回顾窗口都在 中进行了调整。 我们直接从原始论文(Zeng等人,2023)报告DLinear数。 对于我们的方法,我们始终使用 的上下文长度来表示 中的所有水平线长度。 所有模型均使用 MSE 作为训练损失进行训练。 在所有数据集中,按照之前的工作规定,训练:验证:测试比率为 7:1:2。 请注意,所有实验都是在标准归一化数据集上进行的(使用训练期间的平均值和标准差),以便与之前的工作(Wu等人,2021)保持一致。
我们的模型。 我们使用图1中描述的架构。 我们使用验证集滚动验证错误来调整超参数。 我们在附录B.3中提供了有关超参数的详细信息。 作为全局动态协变量,我们使用简单的时间派生特征,例如一小时中的分钟、一天中的小时、一周中的某一天等,这些特征类似于 (Alexandrov 等人, 2020) 进行归一化。 请注意,这些功能在 DLinear 中被关闭,因为观察到它会损害线性模型的性能,但我们的模型可以轻松处理这些功能。 我们的模型在 Tensorflow 中进行训练(Abadi,2016),并使用 Adam 优化器的默认设置进行优化(Kingma 和 Ba,2014)。 我们在补充文件中提供了我们的实现,并带有脚本来重现表 2 中的结果。
结果。 我们在表 2 中列出了所有数据集和方法的均方误差 (MSE) 和平均绝对误差 (MSE)。 对于我们的模型,我们报告每个设置的 5 次独立运行的平均指标。 粗体数字来自最佳模型或在两个标准误差区间的最佳模型的统计显着性范围内。 请注意,不同的预测统计数据对于不同的目标指标(Awasthi等人,2021;Gneiting,2011)是最佳的,因此我们应该考虑与本例中的训练损失密切相关的目标指标。 由于所有模型都是使用 MSE 进行训练的,让我们重点关注该列进行比较。
我们可以看到,TiDE、PatchTST、N-HiTS 和 DLinear 在所有数据集中都比其他基线好得多。 这可以归因于这样一个事实:完全自注意力机制的次二次近似可能并不最适合长期预测。 在 PatchTST (Nie 等人,2022) 中也观察到了同样的情况,其中表明,即使以通道依赖的方式应用,对补丁的完全自我关注也更加有效。 为了更深入地讨论预测背景下次二次注意力近似的陷阱,我们建议读者参阅(Zeng等人,2023)的第3节。 在附录A中,我们证明,与序列模型相比,我们模型的线性模拟可以是预测线性动力系统的最佳选择,从而阐明为什么我们的模型甚至更简单的模型(如 DLinear)可以对于长期背景和/或地平线预测来说非常有竞争力。
此外,除了 ETTh1 中的地平线 192 性能相同之外,我们在所有设置中都显着优于 DLinear。 这显示了我们模型中额外非线性的价值。 在某些数据集(例如 Weather 和 ETTh1)中,N-HiTS 在 Horizon 96 上的表现与 TiDE 和 PatchTST 类似,但无法维持更长范围内的性能。 在除 Weather 之外的所有数据集中,我们要么优于 PatchTST,要么在大多数范围内表现在其统计显着性范围内。 在天气数据集中,PatchTST 在地平线 96-336 上表现最好,而我们的模型在地平线 720 上表现最好。 在最大的数据集(流量)中,我们在所有设置中都显着优于 PatchTST。 例如,对于地平线 720,我们的预测在 MSE 中比 PatchTST 好 10.6%。 我们在附录5中提供了其他结果,包括与表6中的S4模型(Gu等人,)的比较。
5.2需求预测
为了展示我们的模型处理静态属性和复杂动态协变量的能力,我们使用 M5 预测竞赛基准(Makridakis 等人,2022)。 我们遵循示例笔记本中的约定333https://github.com/awslabs/gluonts/blob/dev/examples/m5_gluonts_template.ipynb 由(Alexandrov等人,2020)的作者发布。 该数据集由超过 30k 个时间序列组成,具有分层类别等静态属性和促销等动态协变量。 有关设置的更多详细信息,请参阅附录5。
我们在表3中展示了与私人排行榜相对应的测试集上的竞争指标(WRMSSE)结果。 我们与 DeepAR (Salinas 等人, 2020) 进行比较,其实现可以处理所有协变量以及 PatchTST(表 2 中的最佳模型)。 请注意,PatchTST (Nie 等人, 2022) 的实现不处理协变量。 我们报告 3 次独立运行的得分以及相应的标准误差。 我们可以看到 PatchTST 表现不佳,因为它不使用协变量。 我们使用所有协变量的模型比 DeepAR(也使用所有协变量)的性能高出 20% 之多。 为了消融,我们还为我们的模型提供了仅使用日期派生特征作为协变量的指标。 由于不使用数据集特定的协变量,性能会下降,但即便如此,该版本的模型也优于其他基线。
| Model | Covariates | Test WRMSSE |
|---|---|---|
| TiDE | Static + Dynamic | |
| TiDE | Date only | |
| DeepAR | Static + Dynamic | |
| PatchTST | None |
5.3训练和推理效率
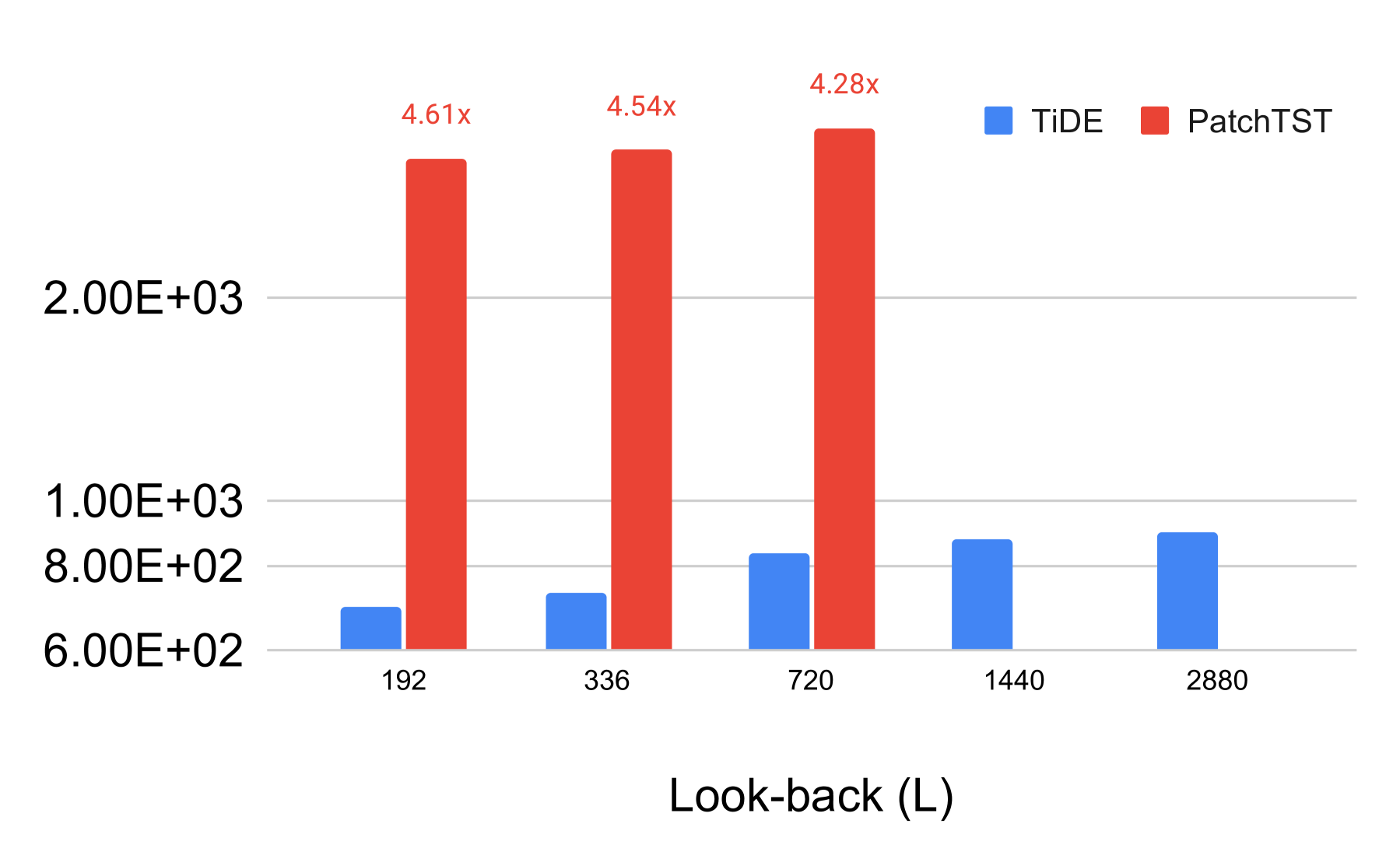
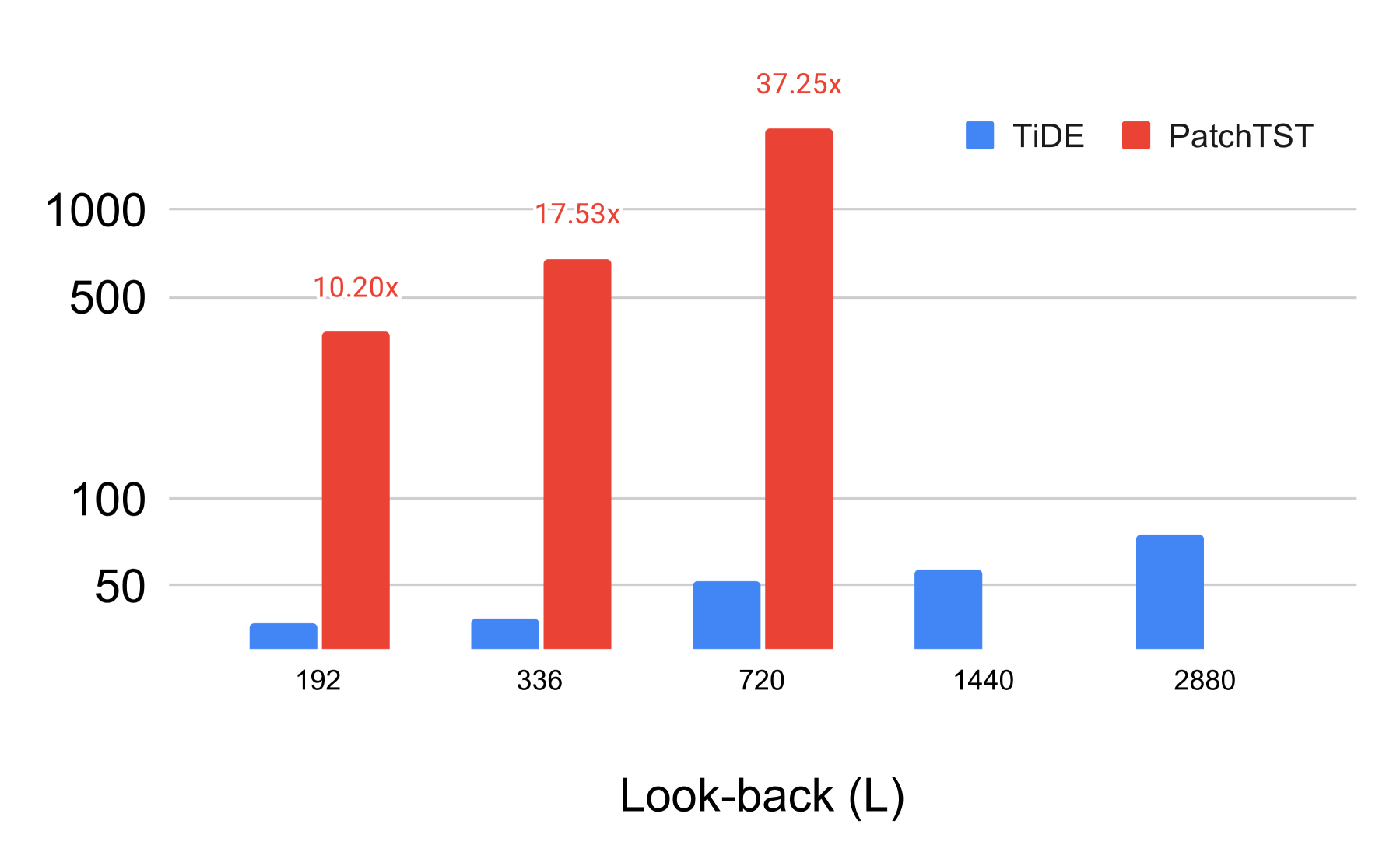
在上一节中,我们已经看到 TiDE 大幅优于除 PatchTST 之外的所有方法,同时它在除 Weather 之外的所有数据集中都比 PatchTST 表现更好或相当。 接下来,我们想证明 TiDE 在训练和推理时间方面比 PatchTST 更高效。
首先,我们要注意,TiDE 中编码器的推理尺度为 ,其中 是编码器中的层数, 是编码器中的层数。内部层的隐藏大小,是回顾。 另一方面,PatchTST 编码器中的推理将缩放为 ,其中 是自注意力中密钥的大小, 是 patch- size 和 是注意力层的数量。 对于很长的上下文, 中的二次缩放可能会令人望而却步。 此外,对于 PatchTST 中使用的普通 Transformer 架构,所需的内存量是 的二次方 444注意,次二次记忆注意力机制确实存在(Dao 等人, 2022),但尚未在 PatchTST 中使用。 二次计算似乎是不可避免的,因为像 Pyraformer 这样的近似值似乎比 PatchTST 的性能差得多。.
我们在图 2 中实际演示了这些效果。 为了公平比较,我们使用所有后续论文中使用的 Autoformer (Wu 等人,2021) 代码库中的数据加载器进行实验。 我们使用批次大小为 的电力数据集,即每个批次的形状为 ,因为电力数据集具有 时间序列。 随着回溯 () 从 增加到 ,我们报告了 TiDE 和 PatchTST 一批的推理时间和一个 epoch 的训练时间>。 我们可以看到,推理时间存在数量级的差异。 训练时间的差异甚至更加明显,PatchTST 对回溯大小更加敏感。 此外,PatchTST 的 内存不足。 因此,我们的模型实现了更好或相似的准确性,同时计算和内存效率更高。 本节中的所有实验都是在配备 64 核 Intel(R) Xeon(R) CPU @ 2.30GHz 的同一台机器上使用单个 NVIDIA T4 GPU 执行的。
5.4消融研究
时间解码器。
使用时间解码器来适应未来的协变量可能是我们模型中最有趣的组成部分之一。 因此,在本节中,我们希望通过使用电力数据集的半合成示例来展示该组件的有用性。
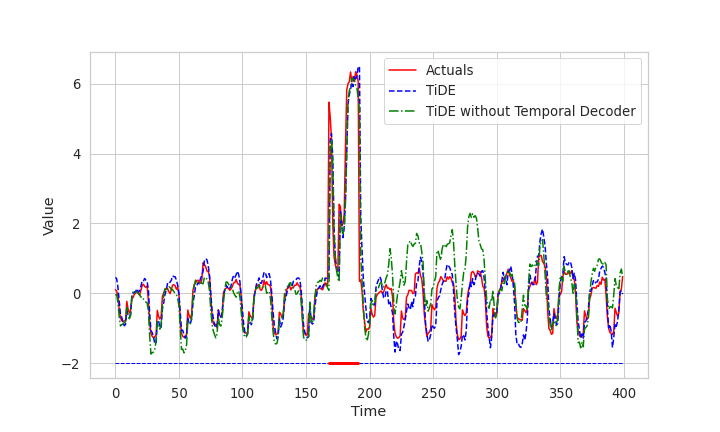
我们从电力数据集中派生出一个新的数据集,其中我们添加了两种事件的数值特征。 当类型 A 的事件发生时,时间序列的值会增加一个在 之间统一选择的因子。 当 B 类事件发生时,时间序列的值会减少一个在 之间统一选择的因子。 只有 80% 的时间序列受到这些事件的影响,并且落在该括号中的时间序列 ID 是随机选择的。 有 4 个数值协变量表示 A 型,4 个数值协变量表示 B 型。 当 A 类事件发生时,A 类协变量是从各向同性高斯函数中绘制的,每个坐标的均值为 和方差 。 另一方面,在没有 A 类事件的情况下,A 类协变量是从均值 的各向同性高斯分布中得出的。 因此,这些协变量充当事件的噪声指标。 对于 B 型事件和协变量,我们遵循类似的模式,但采用不同的方法。 每当这些事件发生时,它们都会连续 24 小时发生。
为了展示使用时间解码器训练可以更快地学习从协变量导出的此类模式,我们在修改后的电力数据集上绘制了经过一个时期后使用和不使用时间解码器的 TiDE 模型的预测,如图 3。 水平线的红色部分表示A类事件的发生。 我们可以看到,在该时间段内,使用时间解码器具有轻微的优势。 但更重要的是,在事件发生后的时间实例中,没有时间解码器的模型可能会被抛弃,因为它尚未将其过去重新调整为没有事件时应有的状态。 在使用时间解码器的模型中,即使仅经过一个训练周期,这种影响也可以忽略不计。
| Models | TiDE | TiDE (no res.) | |||
|---|---|---|---|---|---|
| Electricity | 96 | ||||
| 192 | |||||
| 336 | |||||
| 720 | |||||
上下文大小。
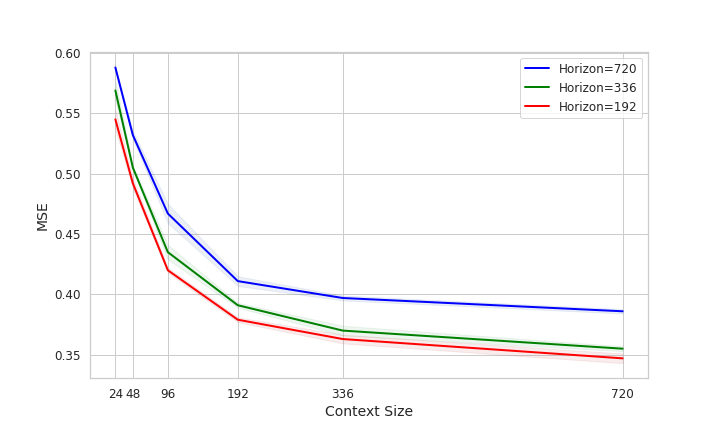
在图5中,我们研究了预测准确度与上下文大小对流量数据集的依赖性。 我们绘制了多个水平长度任务的结果,并表明在所有情况下,我们的方法性能随着上下文大小的增加而变得更好(如预期)。 这与 (Zeng 等人, 2023) 中所示的一些基于 Transformer 的方法(例如 Fedformer、Informer)形成对比。
剩余连接。
在表5中,我们对电力数据集上的残余连接进行了消融研究。 在名为 TiDE(无 res)的模型中,我们删除了所有残差连接,包括残差块中的残差连接以及全局线性残差连接。 在视野 96-336 中,我们看到在没有剩余连接的情况下,性能出现统计上的显着下降。
6结论
我们提出了一种简单的基于 MLP 的编码器解码器模型,该模型可匹配或取代现有神经网络基线在流行的长期预测基准上的性能。 同时,我们的模型比最好的基于 Transformer 的基线快 5-10 倍。 我们的研究表明,至少对于这些长期预测基准来说,学习周期性和趋势模式可能不需要自我关注。
我们的理论分析部分解释了为什么会出现这种情况,证明当从线性动力系统生成地面实况时,线性模型可以达到接近最优的速率。 然而,对于未来的工作来说,在一些简单的时间序列数据数学模型下严格分析 MLP 和 Transformer(包括非线性)并潜在地量化这些架构对于不同水平的季节性和趋势的(不利)优势将会很有趣。 另请注意, Transformer 通常比 MLP 具有更高的参数效率,同时内存和计算密集度更高。 在训练超大规模预训练模型时,这可能是一个限制,但该工作的好处在时间序列预测中并不清楚,并且超出了本工作的范围。
参考
- Abadi [2016] Martín Abadi. Tensorflow: learning functions at scale. In Proceedings of the 21st ACM SIGPLAN International Conference on Functional Programming, pages 1–1, 2016.
- Alexandrov et al. [2020] Alexander Alexandrov, Konstantinos Benidis, Michael Bohlke-Schneider, Valentin Flunkert, Jan Gasthaus, Tim Januschowski, Danielle C Maddix, Syama Rangapuram, David Salinas, Jasper Schulz, et al. Gluonts: Probabilistic and neural time series modeling in python. The Journal of Machine Learning Research, 21(1):4629–4634, 2020.
- Awasthi et al. [2021] Pranjal Awasthi, Abhimanyu Das, Rajat Sen, and Ananda Theertha Suresh. On the benefits of maximum likelihood estimation for regression and forecasting. In International Conference on Learning Representations, 2021.
- Bartlett and Mendelson [2002] Peter L Bartlett and Shahar Mendelson. Rademacher and gaussian complexities: Risk bounds and structural results. Journal of Machine Learning Research, 3(Nov):463–482, 2002.
- Box and Jenkins [1968] George EP Box and Gwilym M Jenkins. Some recent advances in forecasting and control. Journal of the Royal Statistical Society. Series C (Applied Statistics), 17(2):91–109, 1968.
- Box et al. [2015] George EP Box, Gwilym M Jenkins, Gregory C Reinsel, and Greta M Ljung. Time series analysis: forecasting and control. John Wiley & Sons, 2015.
- Challu et al. [2023] Cristian Challu, Kin G. Olivares, Boris N. Oreshkin, Federico Garza, Max Mergenthaler, and Artur Dubrawski. NHITS: Neural Hierarchical Interpolation for Time Series forecasting. In The Association for the Advancement of Artificial Intelligence Conference 2023 (AAAI 2023), 2023. URL https://arxiv.org/abs/2201.12886.
- Dao et al. [2022] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
- Gneiting [2011] Tilmann Gneiting. Making and evaluating point forecasts. Journal of the American Statistical Association, 106(494):746–762, 2011.
- [10] Albert Gu, Karan Goel, and Christopher Re. Efficiently modeling long sequences with structured state spaces. In International Conference on Learning Representations.
- Gupta et al. [2022] Ankit Gupta, Albert Gu, and Jonathan Berant. Diagonal state spaces are as effective as structured state spaces. Advances in Neural Information Processing Systems, 35:22982–22994, 2022.
- Hazan et al. [2017] Elad Hazan, Karan Singh, and Cyril Zhang. Learning linear dynamical systems via spectral filtering. Advances in Neural Information Processing Systems, 30, 2017.
- Hochreiter and Schmidhuber [1997] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- Kag et al. [2020] Anil Kag, Ziming Zhang, and Venkatesh Saligrama. Rnns incrementally evolving on an equilibrium manifold: A panacea for vanishing and exploding gradients? In International Conference on Learning Representations, 2020.
- Kalman [1963] Rudolf Emil Kalman. Mathematical description of linear dynamical systems. Journal of the Society for Industrial and Applied Mathematics, Series A: Control, 1(2):152–192, 1963.
- Kim et al. [2021] Taesung Kim, Jinhee Kim, Yunwon Tae, Cheonbok Park, Jang-Ho Choi, and Jaegul Choo. Reversible instance normalization for accurate time-series forecasting against distribution shift. In International Conference on Learning Representations, 2021.
- Kingma and Ba [2014] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Kreil et al. [2020] David P Kreil, Michael K Kopp, David Jonietz, Moritz Neun, Aleksandra Gruca, Pedro Herruzo, Henry Martin, Ali Soleymani, and Sepp Hochreiter. The surprising efficiency of framing geo-spatial time series forecasting as a video prediction task–insights from the iarai traffic4cast competition at neurips 2019. In NeurIPS 2019 Competition and Demonstration Track, pages 232–241. PMLR, 2020.
- Li et al. [2019a] Shiyang Li, Xiaoyong Jin, Yao Xuan, Xiyou Zhou, Wenhu Chen, Yu-Xiang Wang, and Xifeng Yan. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. Advances in neural information processing systems, 32, 2019a.
- Li et al. [2019b] Shuai Li, Wanqing Li, Chris Cook, and Yanbo Gao. Deep independently recurrent neural network (indrnn). arXiv preprint arXiv:1910.06251, 2019b.
- Liu et al. [2021] Shizhan Liu, Hang Yu, Cong Liao, Jianguo Li, Weiyao Lin, Alex X Liu, and Schahram Dustdar. Pyraformer: Low-complexity pyramidal attention for long-range time series modeling and forecasting. In International conference on learning representations, 2021.
- Lukoševičius and Uselis [2022] Mantas Lukoševičius and Arnas Uselis. Time-adaptive recurrent neural networks. arXiv preprint arXiv:2204.05192, 2022.
- Makridakis et al. [2020] S Makridakis, E Spiliotis, and V Assimakopoulos. The m5 accuracy competition: Results, findings and conclusions. Int J Forecast, 2020.
- Makridakis et al. [2022] Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. M5 accuracy competition: Results, findings, and conclusions. International Journal of Forecasting, 38(4):1346–1364, 2022.
- McKenzie [1984] ED McKenzie. General exponential smoothing and the equivalent arma process. Journal of Forecasting, 3(3):333–344, 1984.
- Nie et al. [2022] Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. International conference on learning representations, 2022.
- [27] Boris N Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio. N-beats: Neural basis expansion analysis for interpretable time series forecasting. In International Conference on Learning Representations.
- Rusch and Mishra [2020] T Konstantin Rusch and Siddhartha Mishra. Coupled oscillatory recurrent neural network (cornn): An accurate and (gradient) stable architecture for learning long time dependencies. arXiv preprint arXiv:2010.00951, 2020.
- Salinas et al. [2020] David Salinas, Valentin Flunkert, Jan Gasthaus, and Tim Januschowski. Deepar: Probabilistic forecasting with autoregressive recurrent networks. International Journal of Forecasting, 36(3):1181–1191, 2020.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Wang et al. [2020] Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768, 2020.
- Wu et al. [2021] Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Advances in Neural Information Processing Systems, 34:22419–22430, 2021.
- Zeng et al. [2023] Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series forecasting? Proceedings of the AAAI conference on artificial intelligence, 2023.
- Zhou et al. [2021] Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI conference on artificial intelligence, 2021.
- Zhou et al. [2022] Tian Zhou, Ziqing Ma, Qingsong Wen, Xue Wang, Liang Sun, and Rong Jin. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. In International Conference on Machine Learning, pages 27268–27286. PMLR, 2022.
- Zivot and Wang [2006] Eric Zivot and Jiahui Wang. Vector autoregressive models for multivariate time series. Modeling financial time series with S-PLUS®, pages 385–429, 2006.
附录A线性动力系统下的理论分析
为了深入了解我们的设计,我们现在将分析我们模型的最简单的线性模拟。 在我们的模型中,如果所有残差连接都是活动的,并且编码的大小大于或等于地平线的长度,那么它会简化为从上下文和协变量到地平线的线性映射。 我们研究这个版本的情况是数据是从线性动力系统 (LDS) 生成的,线性动力系统是随时间演化的系统的流行数学模型[Kalman, 1963]。 我们将证明,在某些条件下,将过去和有限上下文的协变量映射到未来的线性模型对于 LDS 中的预测可能是最佳的。
A.1理论结果
我们正式定义线性动力系统(LDS)如下:
Definition A.1.
线性动力系统 (LDS) 是从一系列输入向量 到输出(响应)向量 的映射,其形式如下
| (5) | ||||
| (6) |
其中 是隐藏状态序列, 是适当维度的矩阵, 是(可能是随机的)噪声向量。 可以被视为时间序列 的协变量。
给定一个带有参数的LDS,我们定义LDS预测器如下,
Definition A.2 (LDS 预测器)。
| (7) |
对于固定序列长度,我们将系统的推出视为单个示例。 特别是,我们定义 ,其中 包含可用于模型预测观察值 的完整信息。 在 i.i.d. 上进行训练 样本 ,模型的目标是从 预测 。
我们假设样本满足常数 的 条件。我们与 中的函数类竞争,该类函数受限于包含 LDS 的参数 ,其中 其中 为常数, 为绝对常数 。对于误差度量,我们考虑损失平方函数 。 对于经验样本集,令。 类似地,对于分布,令。
现在我们定义自回归假设类。 令 为连接向量
和。 我们的假设类定义为。
我们准备好陈述我们的主要定理。
Proposition A.3 (用自回归算法学习LDS的泛化界限)。
选择任意。 令 为独立同分布的集合。 从分布 中训练样本。 让 选择 。 令 为 预测变量集的损失最小化。 那么,以至少的概率,它成立
上述结果表明,具有短回顾窗口的线性自回归预测器与最佳 LDS 预测器具有竞争力,其中转换矩阵 的最大特征值严格小于 。 在附录A.2中,我们将线性模型与 LSTM 和 Transformer 在 LDS 生成的数据的长期预测任务上进行比较,从而验证了我们的理论结果。
命题证明A.3。
证明过程如下:首先,我们证明具有窗口长度 的自回归模型可以近似具有误差 的 LDS。 其次,我们证明了我们所考虑的自回归模型类的 Rademacher 复杂度的简单界限,这意味着我们算法的泛化界限。 结合这两个结果得出我们的主要结果。
Proposition A.4 (用自回归模型逼近LDS)。
令 为 LDS 所做的预测。 那么,对于任何,如果选择,则存在一个,使得
证明。
这个命题类似于[Hazan 等人, 2017]中的定理3。 我们将 构造为分块矩阵
其中块的尺寸被选择为与连接向量对齐
这样预测就是块矩阵向量乘积
我们的建设如下:
-
•
,对于每个 。
-
•
。
LDS 的预测根据定义
我们的结论是
这意味着
∎
样本上 的经验 Rademacher 复杂度,以及 的限制,满足
很容易检查 ,它属于我们算法的可行集。 模型类 中假设的最大损失 以 为界。 矩阵中损失函数的lipschitz常数为
有了所有这些事实,标准的 Rademacher 复杂性相关泛化界限在不正确的假设类 中成立(例如,参见 [Bartlett 和 Mendelson,2002]):
Lemma A.5 (通过 Rademacher 复杂性进行概括)。
概率至少为,则成立
A.2 合成数据集的实验结果
数据集。 我们在线性动力系统生成的合成数据集上评估了多个模型。 转移矩阵 是一个 维 Wishart 随机矩阵,经过归一化,运算符范数等于 。 状态转换中的噪声遵循维高斯分布。 每个时间步 的输入均遵循模型可观察到的 维标准高斯分布。 最后,我们通过添加余弦信号作为线性动力系统的输入来添加 不同周期的季节性,但在预测模型中隐藏。 我们生成 不同的时间序列,它们共享相同的模型参数、输入 和季节性输入,唯一的区别来自状态转换的随机性。 我们将回顾窗口的长度设置为,并将水平线设置为长度。 对于每个时间序列,我们使用前 步骤进行训练,接下来的 步骤进行验证,最后的 步骤进行测试,这会导致 训练示例, 验证示例,以及 测试示例。
基线和设置。 我们在合成数据集上评估了三个模型:线性、长短期记忆 (LSTM) 和 Transformer。 我们的线性模型是回顾窗口中的历史与未来之间的直接线性映射。 我们使用维度为 128 的单层 LSTM。 对于 Transformer,我们使用维度为 128 的两层自注意力层,结合具有 128 个隐藏单元的单隐藏层前馈网络。
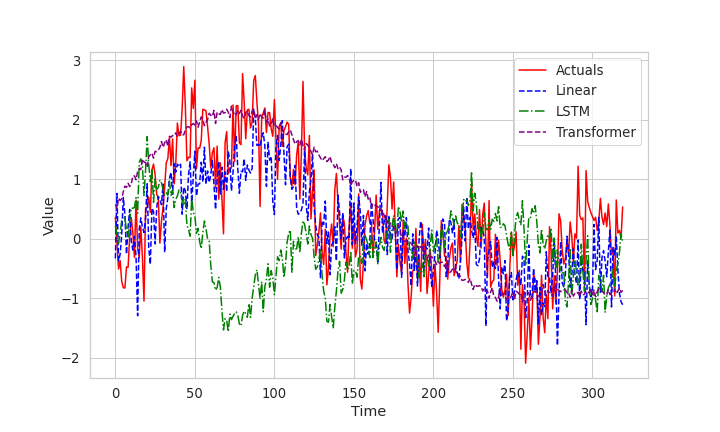
结果。 我们在表 4 中列出了所有模型的均方误差 (MSE)。 对于所有模型,我们报告每个设置的 3 次独立运行的平均值和标准差。 粗体数字来自最佳模型或在两个标准误差区间的最佳模型的统计显着性范围内。 我们还绘制了实际值(基本事实)与 Linear、LSTM 和 Transformer 模型的预测。 我们看到 Transformer 捕获了时间序列的低频季节性,但似乎无法利用输入/协变量来预测值的短期变化,LSTM 似乎无法正确捕获趋势/季节性,而线性模型的预测最接近真实情况,与表4中的度量结果相匹配。
| Model | MSE |
|---|---|
| Linear | |
| LSTM | |
| Transformer |
附录 B更多实验细节
B.1 额外实验
与S4的比较。
在表 6 中,我们展示了我们模型的结果以及 S4 模型 [Gu 等人, ] 的结果。 S4的编号直接取自原论文的Table-14。 可以看出,TiDE 在时间序列基准上远远优于 S4 模型。
M5 预测。
我们现在将提供有关 M5 预测实验的更多详细信息。 我们遵循 5 部分链接的笔记本中使用的设置,该笔记本由 [Alexandrov 等人,2020] 的作者发布。 动态特征列表包括日期派生特征、促销特征,例如 snap_CA、snap_TX、snap_WI、even_type_1 和 event_type_2。 它还包括静态属性,如category_id、store_id、department_id 和item_id。 分类特征被嵌入到可学习的嵌入中。
DeepAR [Salinas 等人, 2020] 建议使用零膨胀负二项损失似然作为数据集中稀疏计数数据的损失函数。 因此,我们将这个损失函数用于我们的模型和 DeepAR 模型。 所有模型最多训练 100 个 epoch,提前停止耐心为 5。
| Models | TiDE | ||
|---|---|---|---|
| Electricity | 96 | ||
| 192 | |||
| 336 | |||
| 720 | |||
| Traffic | 96 | ||
| 192 | |||
| 336 | |||
| 720 | |||
| Weather | 96 | ||
| 192 | |||
| 336 | |||
| 720 | |||
| ETTm2 | 96 | ||
| 192 | |||
| 336 | |||
| 720 | |||
| ETTm1 | 96 | ||
| 192 | |||
| 336 | |||
| 720 | |||
| ETTh1 | 96 | ||
| 192 | |||
| 336 | |||
| 720 | |||
| ETTh2 | 96 | ||
| 192 | |||
| 336 | |||
| 720 | |||
| Models | TiDE | S4 | |||
|---|---|---|---|---|---|
| Metric | MSE | MAE | MSE | MAE | |
| Weather | 336 | 0.254 | 0.301 | 0.531 | 0.539 |
| 720 | 0.313 | 0.340 | 0.578 | 0.578 | |
| ETTh1 | 336 | 0.435 | 0.433 | 1.407 | 0.910 |
| 720 | 0.454 | 0.465 | 1.162 | 0.842 | |
| ETTh2 | 336 | 0.360 | 0.407 | 0.531 | 0.539 |
| 720 | 0.419 | 0.451 | 2.650 | 1.340 | |
| Electricity | 336 | 0.161 | 0.261 | 0.531 | 0.539 |
| 720 | 0.196 | 0.294 | 0.578 | 0.578 | |
B.2 数据加载器
每个训练批次由回顾 和水平线 组成。 这里,的范围可以是训练集结束之前的到步。 表示批次中时间序列的索引,batchSize 可以设置为超参数。 当batchSize大于时,所有时间序列都会批量加载。
我们还将时间导出的特征加载为协变量。 与时间索引 对应的时间戳被转换为周期性特征,例如一小时中的分钟、一天中的小时、一周中的一天等,并标准化为比例 完成在 GluonTS [Alexandrov 等人, 2020] 中。 我们总共有 8 个这样的特征,其中许多可以根据数据集的粒度保持不变。
B.3 超参数
回想一下,在第 4 节中,我们有以下超参数 temporalWidth、hiddenSize、numEncoderLayers、 numDecoderLayers、decoderOutputDim 和 temporalDecoderHidden。 我们还有超参数 layerNorm 和 dropoutLevel 表示全局模型级别层范数开/关和 dropout 的概率。 我们还调整了最大learningRate,它是余弦衰减学习率计划的输入。 在我们所有的实验中,batchSize 固定为 ,temporalWidth 固定为 。 我们还调整可逆实例归一化[Kim 等人, 2021] 是打开还是关闭。 hparams 的调整范围在表7中提供。 我们使用验证损失来调整每个数据集的超参数。
| Parameter | Range |
|---|---|
| hiddenSize | [256, 512, 1024] |
| numEncoderLayers | [1, 2, 3] |
| numDecoderLayers | [1, 2, 3] |
| decoderOutputDim | [4, 8, 16, 32] |
| temporalDecoderHidden | [32, 64, 128] |
| dropoutLevel | [0.0, 0.1, 0.2, 0.3, 0.5] |
| layerNorm | [True, False] |
| learningRate | Log-scale in [1e-5, 1e-2] |
| revIn | [True, False] |
我们在表 8 中报告了为每个数据集选择的特定超参数。
| Dataset | hiddenSize | numEncoderLayers | numDecoderLayers | decoderOutputDim | temporalDecoderHidden | dropoutLevel | layerNorm | learningRate | revIn |
|---|---|---|---|---|---|---|---|---|---|
| Traffic | 256 | 1 | 1 | 16 | 64 | 0.3 | False | 6.55e-5 | True |
| Electricity | 1024 | 2 | 2 | 8 | 64 | 0.5 | True | 9.99e-4 | False |
| ETTm1 | 1024 | 1 | 1 | 8 | 128 | 0.5 | True | 8.39e-5 | False |
| ETTm2 | 512 | 2 | 2 | 16 | 128 | 0.0 | True | 2.52e-4 | True |
| ETTh1 | 256 | 2 | 2 | 8 | 128 | 0.3 | True | 3.82e-5 | True |
| ETTh2 | 512 | 2 | 2 | 32 | 16 | 0.2 | True | 2.24e-4 | True |
| Weather | 512 | 1 | 1 | 8 | 16 | 0.0 | True | 3.01e-5 | False |