,
NeRF:神经射频辐射场
摘要。
尽管麦克斯韦在 160 年前就发现了电磁波的物理定律,但如何在庞大而复杂的电气环境中精确模拟射频信号的传播仍然是一个长期存在的问题。 困难在于射频信号和障碍物之间的复杂相互作用(例如反射、衍射等)。 受到使用神经网络描述计算机视觉中光场的巨大成功的启发,我们提出了一种神经射频辐射场,NeRF,它代表连续的体积理解射频信号传播的场景函数。 特别是,经过几次信号测量训练后,NeRF 在知道发射器的位置时,可以知道在任何位置接收到的信号是如何/是什么信号的。 作为物理层神经网络,NeRF可以利用学习到的统计模型加上光线追踪的物理模型来生成满足应用训练需求的综合数据集-层人工神经网络(ANN)。 因此,我们可以通过所提出的涡轮学习来提高人工神经网络的性能,该学习将真实数据集和合成数据集混合以强化训练。 我们的实验结果表明,涡轮学习可以将性能提高大约 50%。 我们还展示了 NeRF 在室内定位和 5G MIMO 领域的强大功能。
1. 介绍
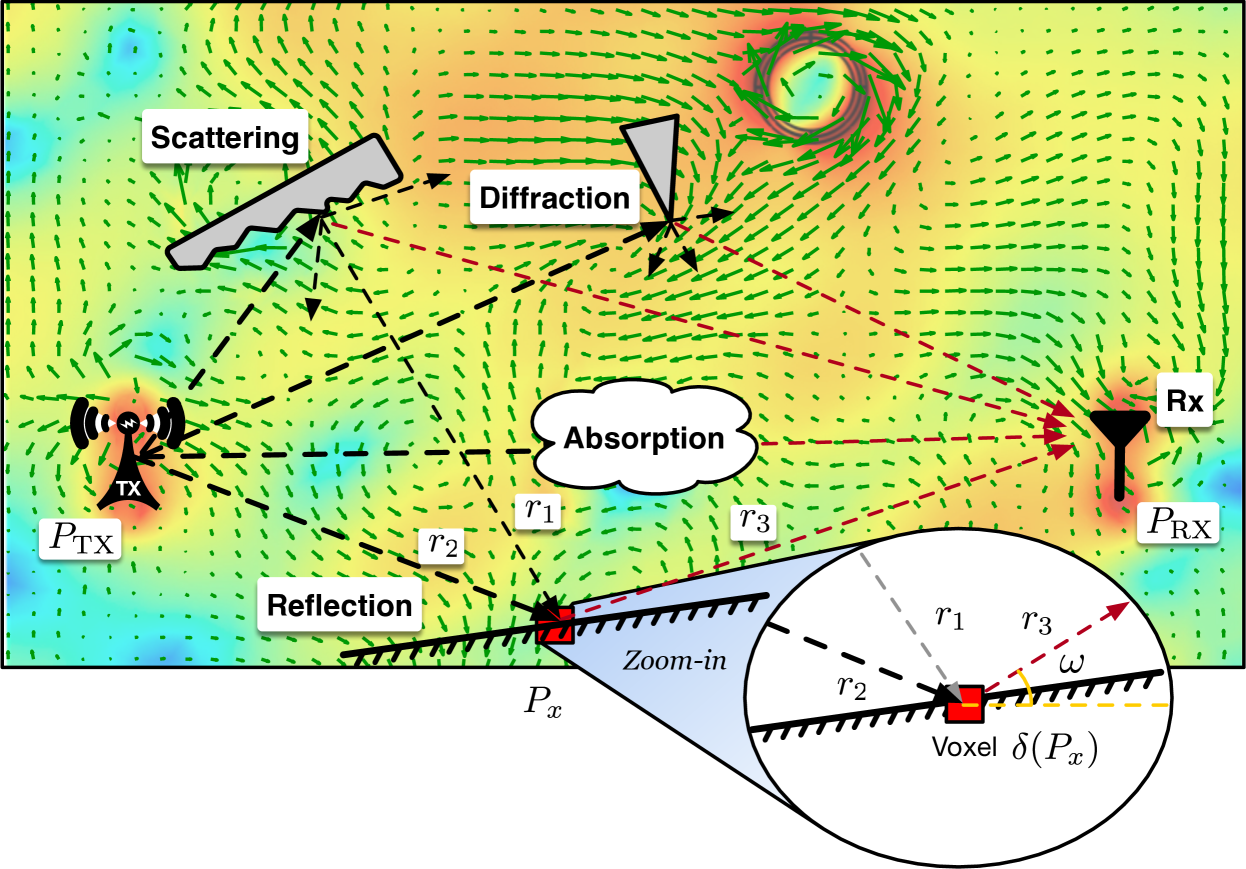
在自由空间中,射频信号的传播可以通过麦克斯韦方程和弗里斯方程精确建模。 然而,当物体伸入由 TX 和 RX 位置定义的第一个菲涅尔区域时,自由空间模型将失败(yun2015ray, )。 如图1所示,整个辐射场受到吸收、反射、衍射和/或散射效应的干扰,使得电磁射线追踪变得极其复杂。 具体来说,(1)反射发生在一些准镜面表面(如墙壁、地面、天花板等),并遵循反射定律,即光线以与入射角相同的角度反射。 (2) 衍射存在于障碍物的边缘,遵循衍射均匀理论(kouyoumjian1974uniform, ),即边缘上的单条入射光线可以在凯勒锥上产生数千条新光线。 (3) 入射光线也可能在表面粗糙的小障碍物处发生散射,光线可能被反射到多个角度。
为了解决上述问题,传统算法使用 LiDAR 扫描的给定 3D 场景模型进行电磁 (EM) 射线追踪(remcom,;egea2021opal,)。 他们模拟真实的电磁射线来追踪实际射频信号在现实世界中所采取的路径,从而可以更好地模拟信号如何与场景中的障碍物相互作用。 追踪质量很大程度上取决于光线追踪的深度以及场景模型构建的真实程度。 不幸的是,射频传播不仅取决于障碍物的位置和大小,还取决于它们的材料和物理特性。 使用激光雷达技术对现实世界进行精确建模在实践中几乎是不可能的任务。
最近,Google 研究人员提出了神经辐射场 (NeRF) (mildenhall2020nerf, ) 来解决光的光线追踪问题。 作为计算机视觉领域的重要突破之一,NeRF在视图合成(mildenhall2020nerf, ; tancik2020fourier, ; barron2021mipnerf, )、3D模型渲染(srinivasan2021nerv, ; muller2022instant, ) 和沉浸式街景 (tancik2022block, ; martin2021nerf, )。 大量演示可以在(nerf-demo, )找到。 NeRF 的基本思想是从不同角度捕获场景中的一些图像作为输入,然后训练 MLP(即全连接类前馈人工神经网络)来拟合光辐射场。 NeRF将图像的每个像素视为一次光线追踪的结果,反映了场景相关的光辐射场的特征。 经过几张图像的训练后,NeRF 可以准确预测来自任何其他方向的光线追踪结果,并进一步从给定的观察方向合成整个图像。
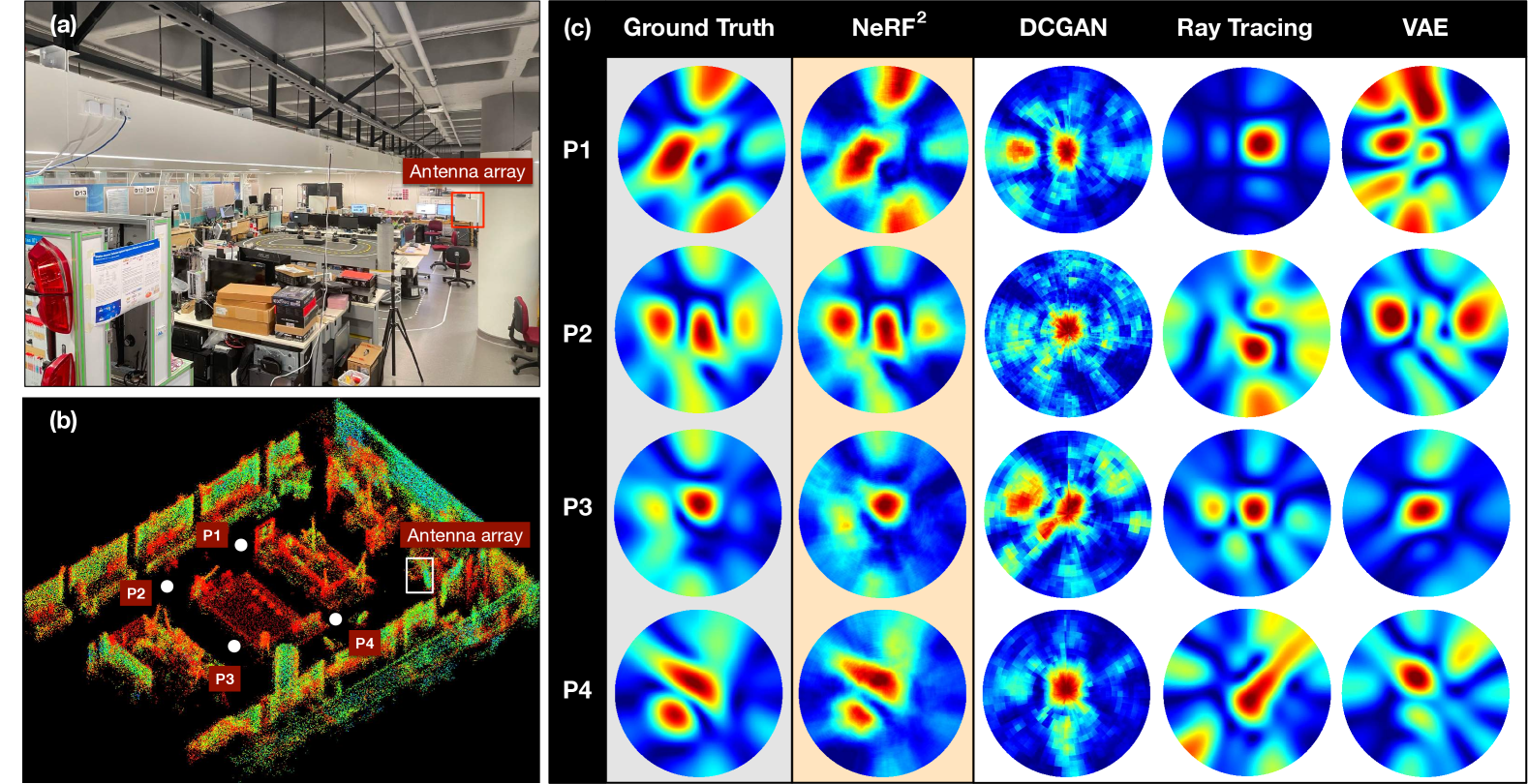
基于光是电磁波的一种,我们提出神经Radio-F频率Radiance Ffields (NeRF),将神经辐射场从光学扩展到电磁场。 类似地,NeRF 通过使用稀疏的输入信号测量集优化底层连续体积场景函数,将场景表示为神经辐射场。 具体来说,NeRF 可以预测当发射器 (TX) 位于已知位置时接收到的 RF 信号是什么以及如何接收。 为了直观地理解NeRF的能力,我们在图2中展示了一个例子。 使用四种算法来合成(或预测)空间频谱(即多径分布),反映当 TX 位于四个不同位置时 RX 如何从不同方向接收信号。 显然,NeRF的预测与地面实况最为相似,地面实况是通过天线阵列接收到的真实信号生成的。 更多示例可以在我们的演示视频https://xpengzhao.github.io/NeRF2中找到。
然而,将 NeRF 转化为 RF 领域需要解决许多挑战。 首先,工作在 UHF 或微波频谱(例如 800MHz、2.4GHz 或 6GHz)的 RF 信号更容易被反射、衍射和散射,因为它们的频率远低于可见光。 其次,光学 NeRF 中仅考虑幅度(即光强度)。 光的相位被忽略,因为它每传播 600-800 nm 就会重复一次。 相比之下,在厘米或毫米波长射频信号中,由于多径效应,相位在相长或相消叠加中发挥着至关重要的作用,因此不能再被忽视。 第三,可见光的测量是使用百万像素相机进行的,但由于尺寸限制(即天线的尺寸与波长)。 为了解决这些问题,我们首先更新物理跟踪模型以适应射频信号的特性。 然后,我们将相位与幅度分开,为 NeRF 建立复值 MLP。 我们最终提出了两种针对单天线和阵列天线接收器的训练方法。
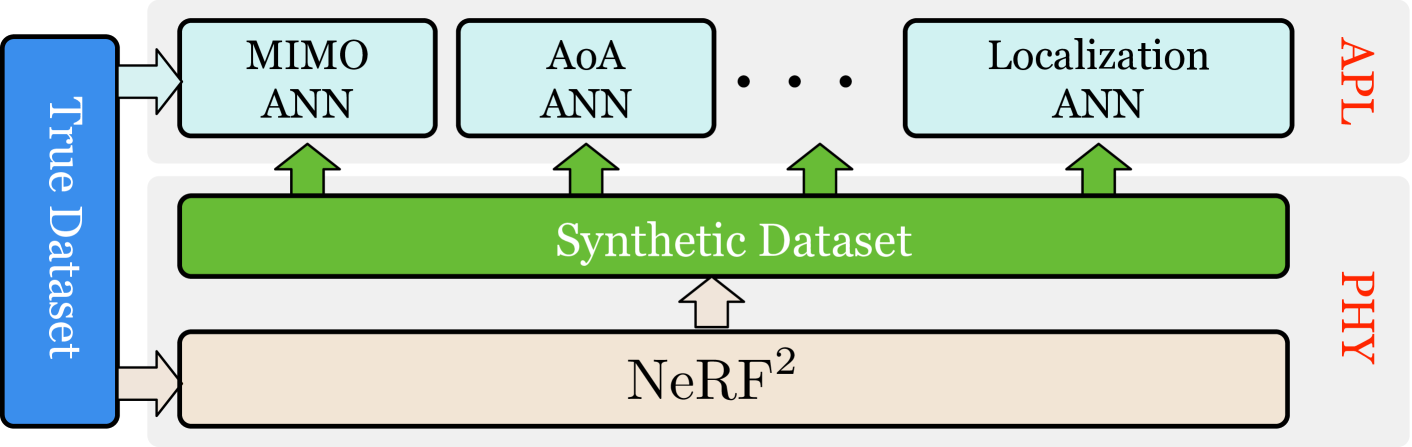
作为物理层神经网络,NeRF可以提升许多关键射频应用的性能,例如室内定位、信道估计、无线电力传输、5G基站部署、无线传感等。 为了满足各种应用层需求,我们提出了turbo-learning,它利用NeRF的物理性质来生成大量的根据物理模型的合成数据集。 该合成数据集与真实数据集混合在一起,以强化应用层人工神经网络(ANN)的训练。 涡轮学习不仅允许人工神经网络收集更少的训练数据集,而且还保证了高水平的学习准确性。
结果摘要。 我们使用 天线阵列作为 RX 来预测微基准中的空间频谱(即多径分布)。 结果表明,NeRF生成的空间谱与groundtruth的中值相似度高达82%,远高于其他合成算法。 我们还使用视距 (LOS) AoA 估计作为应用程序来量化涡轮学习的优势。 实验结果表明,仅使用10%的真实训练数据集,准确率就可以提高47.9%。 我们在14个场景、530K个位置采集射频信号的大规模实验进一步验证了turbo学习的强大威力。 总体而言,14 个场景的平均迎角准确度提高了 49.5%。
实地研究。 我们提出了两项现场研究来展示 NeRF 如何使两个经典应用受益:(1) BLE 本地化。 在室内精确定位 RF 设备具有挑战性 (yang2014tagoram, ; ma2017minding, ; xie2019md, ; xie2018swan, ; adib20133d, ; adib2014multi, ; zhao2018rf, ; zhao2018through, ; ma2014accurate, ; hui2019radio, ; han iz2017novel, ; youssef2005horus, ; sen2012you, ; yang2012locing, ; liu2012push, ; wang2012no, ; ni2004landmarc, ; wang2013dude, ; pan2008transfer, ),特别是当视线传播被阻挡时。 与图形中的光线追踪问题类似,如果使用NeRF对射频信号的传播进行深度追踪,定位精度可以大大提高。 我们的实验结果表明,启用 NeRF 的涡轮学习可以将中值误差降低 50%,将标准方差降低 40%。 (2)5G MIMO。 大规模 MIMO(即 5G 网络)严重依赖于准确的信道状态信息 (CSI) 进行波束成形,即基站必须了解从天线到每个客户端设备的下行无线信道(liu2021fire, ) 。 为此,客户端设备需要将信道估计结果发送回基站,从而造成巨大的开销。 NeRF 可以完全满足需求信道估计,因为它可以预测从学习的辐射场导出的任何位置的 CSI。 我们的实验结果表明,在信道预测和 MU-MIMO 性能方面,NeRF 的 SNR 比现有技术的 SNR 提高了 5.97 dB,SINR 提高了 4.32 dB 。
贡献。 我们的贡献总结如下。
-
•
我们将 NeRF 从光学领域转移到射频领域。 具体来说,(1)我们更新复值输入参数的神经网络; (2)用Friis方程代替光传播模型; (3)我们发明了基于单天线和多天线的电磁射线追踪方法。
-
•
我们提出了启用 NeRF 的涡轮学习。 Turbo-learning的好处不仅限于性能提升,更重要的是解决了深度学习的痛点——显着减少训练数据集的数量以及相应的收集数据集的工作量。
-
•
我们针对 RFID、BLE 和 5G 系统进行现实生活中的现场研究。 所提出的 Turbo 学习在室内定位和 FDD 大规模 MIMO 信道预测上进行了评估。
2. NeRF设计
按照 NeRF 的常见做法,我们做出以下类似的假设:(1)接收器(例如 5G 基站、蓝牙站和 RFID 阅读器)位于已知位置,而发射器(例如智能手机、iBeacon 和RFID标签)可在有限范围内移动。 (2)各场景中的主要障碍物(建筑物、墙壁、家具等)保持不变。 (3) 移动障碍物可能会对辐射场产生暂时的微小扰动,可以通过上层滤波算法(如卡尔曼滤波器)进行平滑处理,因此不考虑其影响。
NeRF 的核心是两个关键组件:神经辐射网络和光线追踪算法:
-
•
神经辐射网络:该网络用于使用两个 MLP 来表示场景和辐射场。 它可以预测射频信号在场景中的分布情况。
-
•
光线追踪:给定射频分布,我们必须追踪从所有潜在方向发送的信号,以了解 RX 接收到的信号。
在本节中,我们将详细阐述上述两个组件的细节并介绍训练方法。 最后,我们提出了 NeRF 支持的涡轮学习。
2.1. 神经辐射网络
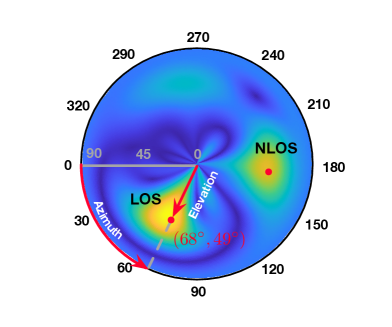
为了对辐射场进行建模,我们将感兴趣的场景离散化为空间中有限数量的小型 3D 体素。 惠更斯-菲涅耳原理表明,当原始射频信号从所有可能的路径到达时,体素可以被视为重新传输射频信号的新辐射源。 为了更好地理解这一原理,我们在图 1 的放大中显示了一个示例体素。 让下标表示场景中的任意体素。 位置的体素接收到来自和两条路径的射频信号,成为新的TX,重新发送RF 信号沿着路径 到达 RX。 在我们的模型中,每个体素都用三个属性来描述:位置、衰减和重传的射频信号。 是一个与材料有关的变量,表示如果射频信号在 时通过体素,振幅会降低 ,相位会旋转 。 作为新的射频发射器,位置处的体素重新发射新的复值信号,即,其中和是初始相位和初始幅度。 体素不能简单地建模为全向辐射源。 相反,它可能会以角度不均匀的方式辐射电磁波。 为了解决这个问题,我们引入了另一个称为测量方向 的变量,其中 和 是方位角和仰角。 如图1放大所示,体素位于相对于RX位置的方向。
NeRF旨在预测从处的体素向方向重传的射频信号当给定 TX 的位置时。 为此,我们利用神经网络来拟合辐射场。 形式上,辐射场表示如下:
| (1) |
其中表示可学习的神经网络权重。 与假设环境光保持不变的视觉 NeRF 不同,我们引入 TX 的位置作为附加输入,因为我们的发射器(例如智能手机或物联网设备)是可移动的。 这样,我们可以通过将 TX 放置在不同且足够的位置来创建场景的数据集。 神经网络包含两个输出。 一是体素在处的衰减,与体素的物理特性高度相关。 另一个是从处的体素向方向重传的RF信号。 因此,神经网络不仅代表场景,还代表射频分布。
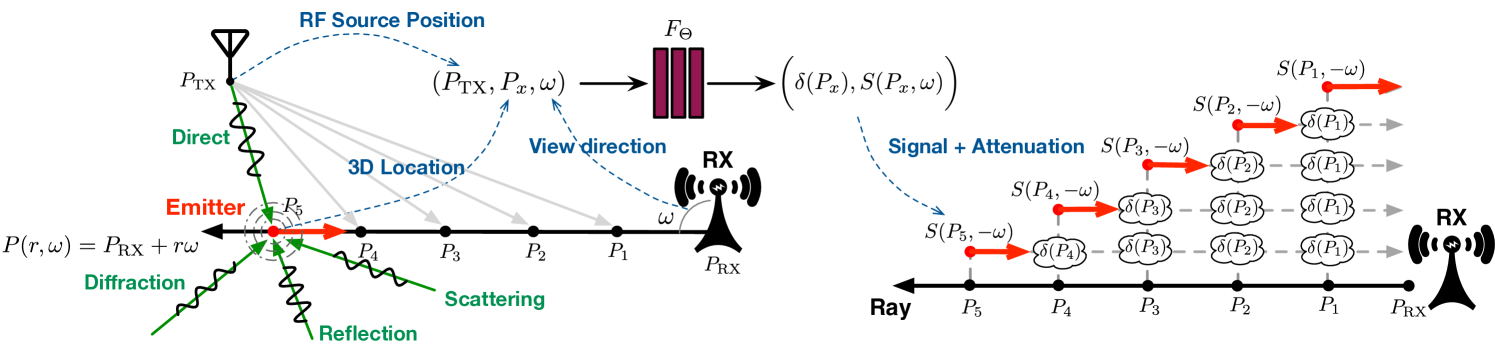
网络架构。 为了构建神经网络,我们采用两个MLP:衰减网络和辐射网络,如图3所示。 衰减特性与体素的材料高度相关并且与输入信号无关,因此我们分离衰减网络来预测作为位置的函数的衰减。 衰减网络由八个全连接层(使用 ReLU 激活和每层 256 个通道)组成,输出 和 256 维特征向量。 然后将该特征向量与与 相关的 RX 方向 以及 TX 位置 连接起来。 该组合被传递到辐射网络,这是另外两个完全连接的层(使用 ReLU 激活并包括 256 和 128 个通道),输出方向相关的 RF 信号 ,该信号从体素沿着方向。 网络架构与光NeRF类似,但有两个方面不同。 首先,视觉 NeRF 假设 TX(即光源)的位置保持不变,而我们的 TX 是可移动的。 其次,考虑到幅度和相位,我们的两个网络都是复值网络。
讨论。 辐射场只与场景有关,包括障碍物和TX的位置,与RX的位置无关。 人们可能关心如何处理射频信号的多次反射。 NeRF 的技巧在于,每个体素都被视为一个新的发射器,它“重新发射”从所有可能路径接收到的组合信号。 这样的模型简化了光线追踪的后续计算。
2.2. 电磁射线追踪
要训练 NeRF,一种简单的方法是在大量 RX 位置探测 RF 信号。 显然,这种方法在实践中是不可扩展的。 视觉 NeRF 将场景的每个图像视为光线行进的结果 111光线追踪和光线行进是计算机图形学中的两种渲染技术。 光线追踪通过追踪光线并考虑对象交互来计算结果颜色,而光线行进则通过评估沿光线的函数来估计场景的颜色和不透明度。,其中每个像素反映了由于相机的针孔模型而从特定方向传播的光的强度。 同样,RX 处接收到的信号是电磁射线追踪的结果,其中该信号是从所有可能方向传输的信号的组合。 接下来,我们介绍如何跟踪特定方向的信号。
RF信号从发射器(TX)到接收器(RX)的传播符合如下Friis方程:
| (2) |
其中是接收信号,是通道衰减。 其中,和是TX到RX距离引起的幅度衰减和相位旋转。 从数学上讲,与 RX 相关的方向 可以建模为一条射线,该射线从 RX 出发,指向 。 该射线上的点对应描述如下:
| (3) |
其中 是从 RX 到射线上的点的径向距离。 请注意。 射线追踪的目的是累积该射线上所有体素发出的射频信号。 即RX端从方向接收到的信号可以表示为:
| (4) |
在上式中,表示从处的体素传输到处的RX的信号。 它的传输方向与光线方向相反,因此我们取方程中的负值。 是跨场景的最大距离。 由上式可知,RX最终从方向接收到的信号是射线上所有体素发射的射频信号的累加,即从到。 是从点传播到RX的信号的衰减。 它的定义如下:
| (5) | ||||
上式意味着总衰减等于处体素和处体素之间的所有体素引起的衰减的乘积,即。 为了便于计算,我们将上式转换为等效的对数尺度形式如下:
| (6) |
其中表示的对数尺度衰减,定义如下:
| (7) |
对数尺度的形式使得乘积成为两个体素之间所有衰减的总和,这极大地方便了计算。 代入方程。 6 代入方程式。 4,来自方向的信号由下式给出
| (8) |
其中前一部分涉及的项由衰减网络预测,后一部分涉及的项由辐射网络预测。 简单来说,沿着一个方向的射线追踪的结果就是聚合这条射线上体素重传的信号,每个体素都被视为一个新的源。 同时,来自某个体素的每次传输都必须被当前体素和 RX 之间的其他体素衰减。 假设光线上有 体素,光线追踪将采用 聚合。
为了直观地理解光线追踪算法,我们在图4中展示了一个示例。 假设水平射线从 RX 到左侧(即 )。 在射线上,有五个体素,分别位于 、、、 和 ,无论这些体素如何点亮,所有这些都被视为新的发射器。 结果,RX沿射线相反方向接收到的信号(即)是从这五个体素重传的五个信号的组合。 特别是,从位于 的体素重新传输的信号 依次被位于 、、 和 的体素衰减。 累积衰减等于。 类似地,从、、和处的体素重传的信号被衰减>、、 和 分别。
摘要。 NeRF并不完全依赖于神经网络,而是结合了物理模型和统计模型。 具体来说,光线追踪采用了众所周知的信号传播物理模型,同时深度学习提供了射频信号与周围障碍物之间复杂相互作用的统计模型。
2.3. 网络训练
前面介绍了射线追踪算法,通过该算法我们可以使用NeRF来预测RX从特定方向接收到的信号。 关于 RX 配备哪种类型的天线,我们介绍两种类型的训练方法。
2.3.1. 案例一:单天线RX模型
我们考虑一种简化的情况,其中 RX 配备单个全向或单向天线。 显然,单个天线无法辨别方向。 因此,RX最终接收到的信号是来自所有潜在方向的信号的组合,如下所示:
| (9) |
其中表示天线方向性(即天线在每个方向上提供的增益),表示天线可以覆盖的方向。 令 和 分别表示 NeRF 通过光线追踪和真实接收信号预测的信号。 然后我们可以使用以下损失函数来训练 NeRF:
| (10) |
损失函数旨在缩小真实信号与预测信号之间的差距。
2.3.2. 案例二:多天线RX模型
接下来,我们考虑第二种情况,即 RX 配备相控天线阵列,它可以形成非常窄的波束并引导其从特定方向接收信号(stoica2005spectral, )。 然后 RX 可以区分信号的方向。 假设天线阵列统一配备个单元。 选择元素作为参考,我们可以计算以下将接收信号投射到方向的相对功率:
| (11) |
其中 是将光束转向特定角度 的复数权重。 上式中,是使用和处接收信号计算出的相位差,而是它们的理论相位差异(an2020general,)。 总和汇总了 元素对(即 )的相对功率。 当与对齐时,即信号来自方向时,归一化相对功率应达到最大值。 然后可以生成热图来显示接收到的 RF 信号可能来自的 可能方向上的相对功率。 我们将这样的二维热图称为空间谱,用表示。 是取决于角度分辨率的自定义参数。 如果接受1度分辨率,则,空间谱定义如下:
| (12) |
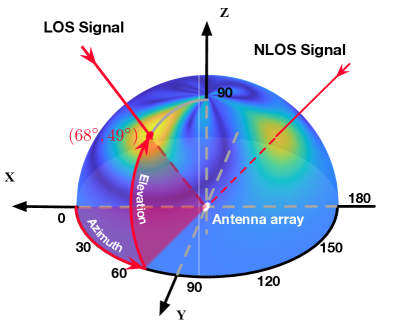
有时,空间频谱也称为多径剖面(wang2013dude, ),因为它反映了信号如何来自多个方向。 图5(a)展示了3D空间谱,所有方向均匀分布;图5(b)显示了将3D投影到X-Y平面上的2D频谱,其中径向距离表示,因此仰角分布不均匀。
NeRF 会自发地预测来自特定方向的信号功率并生成预测的空间频谱 ,如下所示:
| (13) |
相对功率与上面计算的真实功率成正比。 即使它们之间可能存在恒定的偏移,但使用以下损失函数不会影响网络的训练:
| (14) |
该训练的目的是减少从所有可能的方向接收到的信号的功率差异。
2.4. 涡轮学习
NeRF作为物理层神经网络,描述了辐射场的分布。 它不能直接满足应用层需求,例如预测接收器位置或波束成形参数。 通常,会建立额外的神经网络来满足特定的应用需求(例如,MIMO ANN、AoA ANN、定位 ANN 等)。 相反,我们采用 NeRF 作为增强剂来提高应用层 ANN 的性能。 图6说明了这个基本思想。 首先,我们使用真实数据集训练 NeRF训练。 其次,NeRF生成了大量的合成数据集,满足应用层人工神经网络的需求。 最后,我们将真实数据集和合成数据集混合在一起来训练上层人工神经网络。 我们将这种训练方法称为涡轮学习,即应用更多额外的合成数据来强化学习。 涡轮学习在数据科学领域也被称为数据增强。 在接下来的章节中,我们将逐个案例详细阐述涡轮学习。
3. NeRF 实现
我们为每个场景训练一个单独的 NeRF。 这需要场景中捕获的 RF 信号或空间频谱、TX 和 RX 的相应位置以及场景边界(即 和 )的数据集。 位置相关参数由高精度红外定位系统OptiTrack (optitrack, )获取。 在每次迭代中,我们都会进行以下优化:
(1)位置编码:NeRF接受两个3D位置和一个2D方向作为输入。 遵循使用编码位置的光学 NeRF 的实践,我们还使用后续的编码函数将输入的维度提高到 L:
| (15) |
该函数分别应用于或中的三个坐标值中的每一个,以及笛卡尔方向单位向量的三个分量。 在我们的实验中,我们为 和 设置 ,为 设置 。
(2)体素大小:设置体素的大小需要权衡。 一方面,细粒度体素可以为NeRF提供更高的分辨率和光线追踪的准确性。 另一方面,体素的数量对计算复杂性有重大影响。 在我们的实验中,我们将体素的大小设置为波长的。
(3) 网络配置训练:在每个数据集中,我们随机抽取 80% 的样本到神经网络,并使用剩余的 20% 进行测试。 我们采用与 NeRF (mildenhall2020nerf, ) 类似的配置。 具体来说,批量大小设置为4096。 采用Adam优化器(kingma2014adam, )。 学习率从 开始,呈指数下降到 。 其他超参数保持默认值(例如,、 和 )。 单个场景的网络训练通常需要大约 - 次迭代才能在单个 NVIDIA 3080Ti GPU 上收敛(大约 10 小时)。 相比之下,单个样品的测试可以在大约 0.2 秒内完成。
4. 微基准测试
我们从微基准实验开始,以深入了解本节中 NeRF 的工作情况。
4.1. 实验装置
我们部署了一个基于 USRP 的 RX,配备了 天线阵列。 RX 的工作频率为 915 MHz,目标是接收移动 RFID 标签反向散射的信号。 RFID 标签由附近的读取器(即 1 m 外)激活,并重复传输 RN16 回复。 无花果。 2-(a)和(b)显示了激光雷达扫描的场景照片和相应的3D模型(由点云组成)。 这是一个演示室,里面布满了金属书桌、架子、桌子、电脑等反光板。 通过将标签放置在随机位置来创建数据集。 对于每个位置,天线阵列使用方程式生成空间频谱。 11,由在天线阵列前半球采样的视点的 像素表示。 我们在这个场景中总共收集了 10K 数据,其中 8K 用于训练,2K 用于测试。 我们使用(miesen2013360,)中介绍的方法来估计接收到的反向散射信号的相位和幅度,并使用方程1。 14 作为训练神经辐射场的损失函数。
4.2. 光谱合成
原始光学 NeRF 的目标是合成从任意方向拍摄的场景照片。 类似地,NeRF具有当TX位于任意位置时合成RF空间频谱的能力。 为了直观地理解这一目的,我们利用 NeRF 来合成天线阵列接收到的空间频谱。 合成的空间谱帮助我们直观地验证神经辐射场是否能够成功预测场景中的信号传播。 我们将 NeRF 与其他四种基线方案进行比较。
- •
-
•
RayTracing:我们使用Matlab中的RayTracking工具箱(raytracing, )来生成空间谱。 特别地,该工具箱需要导入场景的3D模型(即图2-(b))。 给定 TX 的位置,工具箱可以预测 RX 接收到的 RF 信号。
-
•
深度卷积生成对抗网络(DCGAN)。 DCGAN 是最流行的 GAN 之一,其中两个模型(即生成器和鉴别器)通过对抗过程同时训练。 生成器模型生成看起来像训练图像的“假”图像。 鉴别器模型确定图像是真实的训练图像还是来自生成器的假图像。 我们将预测的空间频谱视为图像,并使用 DCGAN 来学习和生成给定 TX 位置的频谱。
-
•
变分自动编码器(VAE)。 VAE是著名的生成模型之一。 它用于解决无线系统中的类似问题,例如液体传感(ha2020food, )和信道估计(liu2021fire, )。 采用 FIRE (liu2021fire, ) 中类似的架构,编码器网络学习训练集在较低维潜在空间中的概率分布。 随后,对从解码器网络抽取的样本进行解码,以生成符合学习分布的数据。
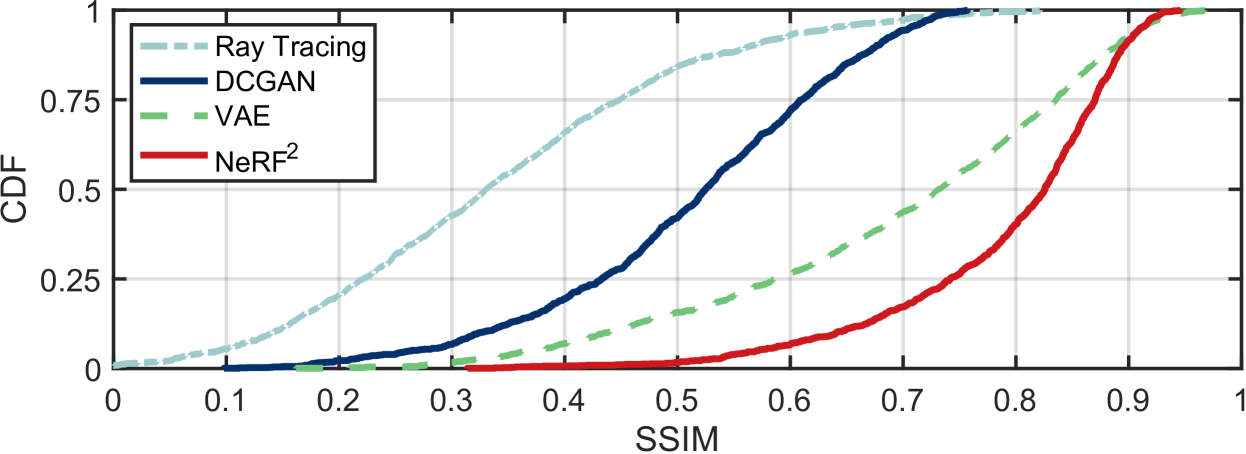
结果如图2-(c)所示,其中当TX位于四个位置时,使用上述方案生成空间谱。 从视觉上看,NeRF 生成的空间谱显然比其他生成模型更接近真实情况。 我们进一步使用称为结构相似性指数测量(SSIM)的通用标准来量化两个图像的相似性。 由于篇幅限制,我们省略了SSIM的定义,但鼓励读者参考(wang2004image, )了解详细信息。 SSIM 越高表示两幅图像越相似。 我们随机选择 100 个位置来使用四种算法合成空间谱。 这些合成空间谱与地面实况之间的SSIM的CDF如图8所示。 其中,RayTracking、DCGAN、VAE和NeRF的中值SSIM分别为0.33、0.52、0.73和0.82,其90分位数分别为0.56、0.67、0.89和 0.91。 即使提供了场景的几何模型,光线追踪仍表现不佳,因为它缺乏材质信息。 DCGAN 和 VAE 将空间频谱视为与 TX 位置相关的一种签名,因此他们并没有真正“理解”其背后的基本原理。 NeRF的卓越表现在于符合基本物理定律的精确辐射场模型。
4.3. 涡轮学习的表现
为了量化 NeRF 的优势,我们将涡轮学习应用于 AoA 估计,旨在确定视线传播的方向。 希望在空间光谱的峰值处实现迎角。 不幸的是,由于多径传播和信号的破坏性叠加,峰值明显偏离真实的LOS方向。 为了解决这个问题,角度人工神经网络 (AANN) 求助于识别 AoA (ayyalasomayajula2020deep, ; an2020general, ; babakhani2021bluetooth, ; comiter2018localization, )。 与iArk (an2020general, )类似,我们基于ResNet卷积网络(he2016deep, )建立了AANN,如图10 AANN 接受图像格式的空间谱并输出 AoA。 在AANN中,采用ResNet-50网络作为特征提取器,随后采用全连接网络进行回归。 我们使用以下两种方法训练 AANN:
-
•
朴素学习。 我们使用真实训练数据集(TS,总共 8 K)的 10% 来直接训练 AANN。 在这种方法中,不涉及 NeRF。
-
•
涡轮学习。 我们使用真实数据集的相同 来训练 NeRF。 然后,我们使用训练有素的 NeRF 生成其余的 合成数据集(SS)。 最后,将 真实数据集和 合成数据集(即涡轮增压器)混合以训练 AANN。

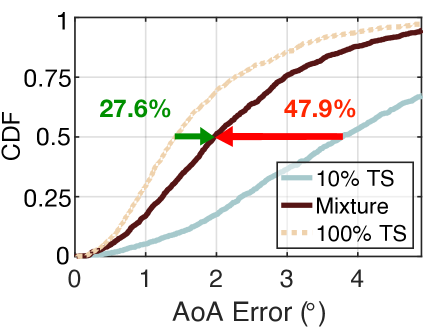
为了公平起见,这两种学习方法完全使用相同的真实训练数据集的 10%,即 两者都包含来自真实数据集的相同信息量。 我们还使用 训练集来训练 AANN 作为基线。 结果如图7(a)所示。 朴素学习和涡轮学习的中值误差分别为和。 NeRF 将朴素学习的结果提高了 47.9%。 另一方面,turbo 学习的精度非常接近基线达到的 误差。 该结果表明 NeRF 生成的合成数据集的质量与真实数据集一样好。 显然,turbo-learning所需的真实训练数据集数量远小于基线,但准确率仍保持在较高水平。 此功能非常有用,因为对于当今的深度学习来说,收集训练数据集是一项重要但繁琐且痛苦的任务。 NeRF的强大之处在于显着减少了真实训练集的数量和相应的工作量。
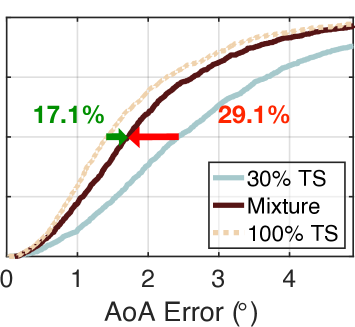
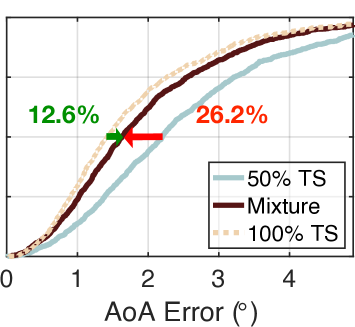
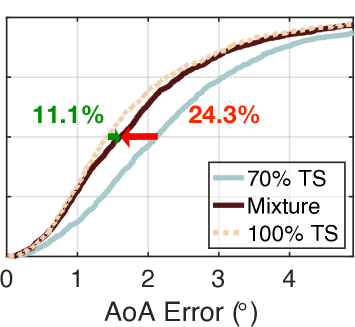
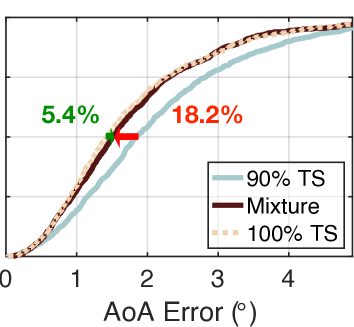
我们还使用相同的方法测试了其他混合比例(30% TS+70% SS、50% TS+50% SS、70% TS+30% SS 和 90% TS+10% SS)。 结果如图7(b)-(e)所示。 根据需要,turbo学习的误差从减少到、、和。 显然,随着真实数据集数量的增加,准确性也随之提高。 这是可以理解的,因为 NeRF 和 AANN 的准确性随着真实信息量的增加而提高。 另一方面,涡轮学习的表现优于朴素学习 47.9%、29.1%、26.2%、24.3% 和 18.2%。 这表明,当提供更多百分比的合成数据时,可以获得更多好处。 即使只输入 10% 的合成数据,与朴素学习相比,中值误差也可以减少 18.2%。 有人可能想知道为什么不尝试 0% TS 加 100% SS 的混合物。 这是不可能的,因为 NeRF 的训练必须需要少量的真实数据集。 为了达到精度和数量之间的权衡,实际中建议采用30% TS加70% SS的混合物。
4.4. 大规模实验
| Env. (#) | Scene (#) | RSS (dBm) | Total (#) | Density | Space | Distance |
| Semi | A | 84,392 | 3,843.0 | 78.5 | 5 | |
| B | 50,186 | 10,490.4 | 7,854.0 | 50 | ||
| C | 18,726 | 6,079.9 | 1,256.6 | 20 | ||
| D | 77,538 | 4,345.1 | 530.9 | 13 | ||
| Full | E | 78,635 | 27,924.4 | 314.2 | 10 | |
| F | 48,467 | 22,627.0 | 153.9 | 7 | ||
| G | 10,521 | 4,911.8 | 78.5 | 5 | ||
| H | 5,102 | 912.7 | 113.1 | 6 | ||
| I | 7,466 | 823.0 | 113.1 | 6 | ||
| J | 25,543 | 1,576.7 | 78.5 | 5 | ||
| K | 28,882 | 1,380.6 | 1256.6 | 20 | ||
| L | 52,634 | 935.9 | 1963.5 | 25 | ||
| M | 21,683 | 1,335.2 | 3217.0 | 32 | ||
| N | 21,729 | 848.1 | 254.5 | 9 |
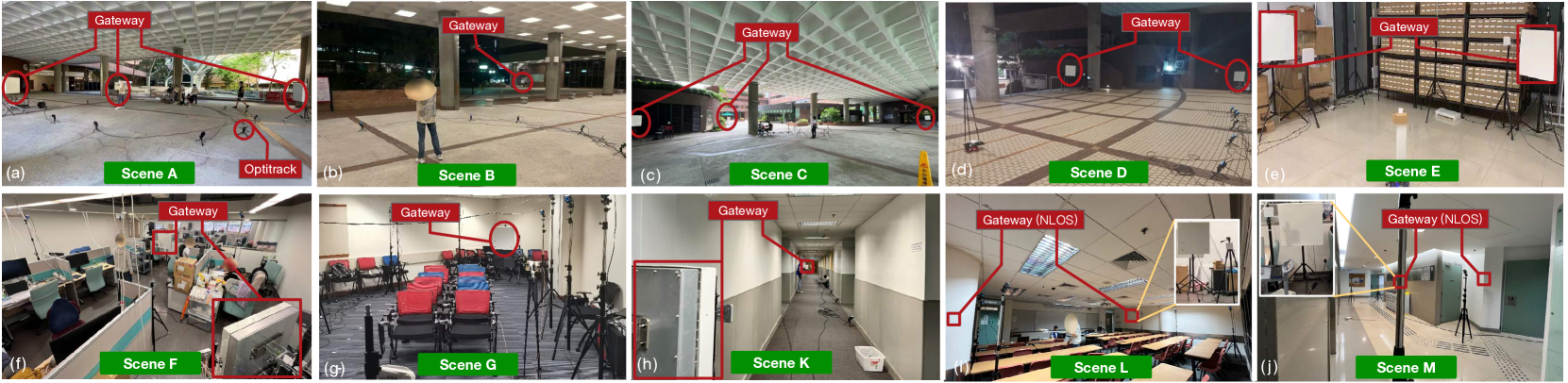
无论NeRF还是NeRF,两者都是场景相关的,因为辐射场与场景布局高度相关。 涡轮学习在不同场景中是否仍能取得优异的性能尚不清楚。 因此,我们进行了大规模的实验。 我们使用相同的天线阵列从 14 个场景(标记为 AN)的 531,504 个位置收集了庞大的数据集。 表1中列出了这些设置。 图9展示了其中的八个(由于篇幅限制)。 我们首先在大面积的半室内环境中收集数据,目的是量化距离的影响。 在这样的环境下,天线阵列部署在A、B、C、D四个场景中,即大面积、半封闭的大厅,如图9 在这些场景中,距离从 5 到 50 m 不等。该距离是场景中心与天线阵列之间的平均值。 然后我们在全室内环境中收集数据。 我们将平台部署在 10 个房间(即场景 E-N)中。 场景 E 是仓库,场景 F 是实验室,场景 G-I 是教室。 场景J、N为办公室,场景K为走廊,场景L为会议室,场景M为电梯大堂,如图9(e)-(j)所示。 场景覆盖范围5~32m。特别是场景L、M、N中,网关部署在墙后。这些数据大部分是在人流经过、各种反光板的场景中收集的。
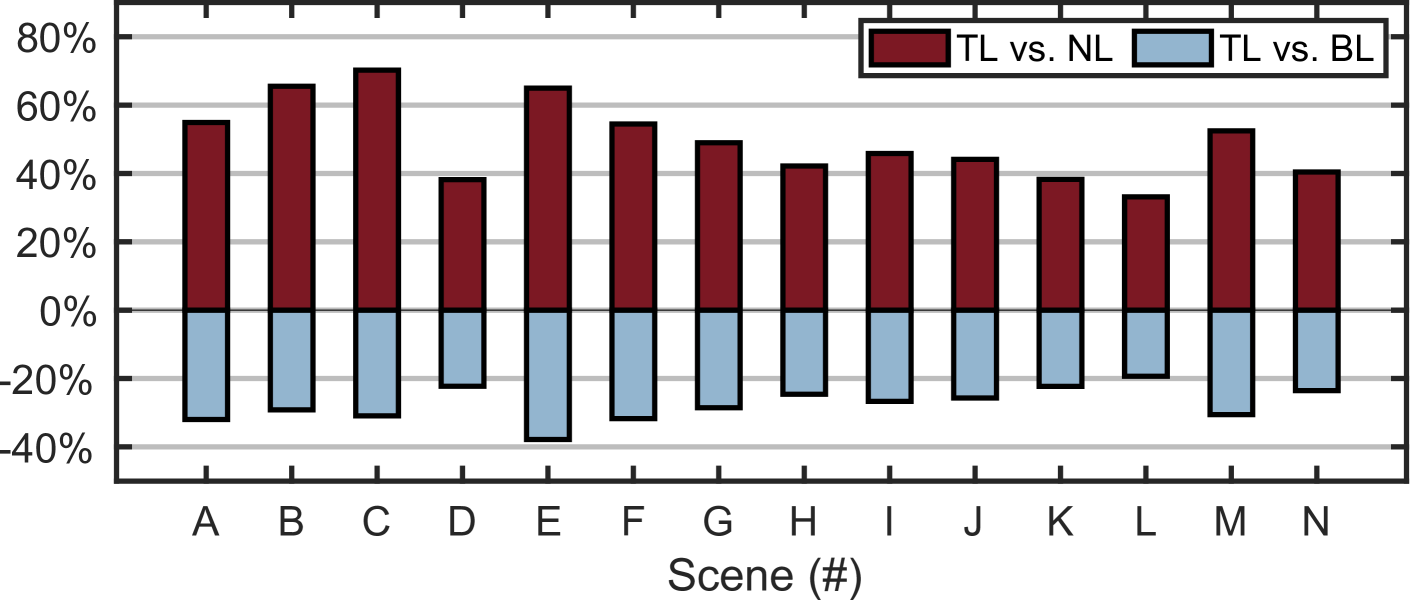
同样,我们在每个场景中选择 80% 的数据集用于训练,20% 的数据集用于测试。 使用整个 80% 真实数据集的朴素学习作为基线。 Turbo 学习是使用 10%(80% 中)的真实训练数据集加上 90% 的合成数据集进行的。 迎角精度结果如图11所示。 从图中我们有以下两个发现:
-
•
与朴素学习(NL)相比,涡轮学习(TL)可以提供-改进。 平均为49.5%。 这表明涡轮学习的性能提升是跨场景的普遍现象。
-
•
与基线(BL)相比,turbo学习可以保持%的差距,其中负号表示“精度低于”。 然而,涡轮学习为数据集收集节省了 90% 的工作量,因为只使用了 10% 的训练集。
我们的实验揭示了影响涡轮学习性能的两个关键因素:(1)数据集的数量。 NeRF能够降低应用层神经网络任务中对数据采集的要求。 然而,如果提供足够的数据,应用层神经网络可以有效地训练模型,从而降低 NeRF 的优势。 (2) 数据集的质量。 NeRF的性能也会受到环境干扰的影响,例如经过的人或其他信号。 尽管如此,我们的结果表明,涡轮学习仍然将应用层神经网络的性能提高了 30% 以上。 综上所述,turbo-learning的优异性能主要来源于NeRF提供的物理模型。 朴素学习对 AoA 和频谱之间的“基于特征(特征)”的关系进行建模,但 NeRF 学习该关系背后的物理原理,因此可以提供更合理的样本为了学习。
5. 现场研究:BLE 本地化
在本节中,我们将讨论在接收机没有可用天线阵列的情况下,NeRF如何帮助室内定位。 我们在一家养老院使用 50 个 BLE 网关进行了大规模实验。 该项目旨在追踪 COVID-19 的潜在传播情况,以更好地保护老年人免受感染。
5.1. 实验设置
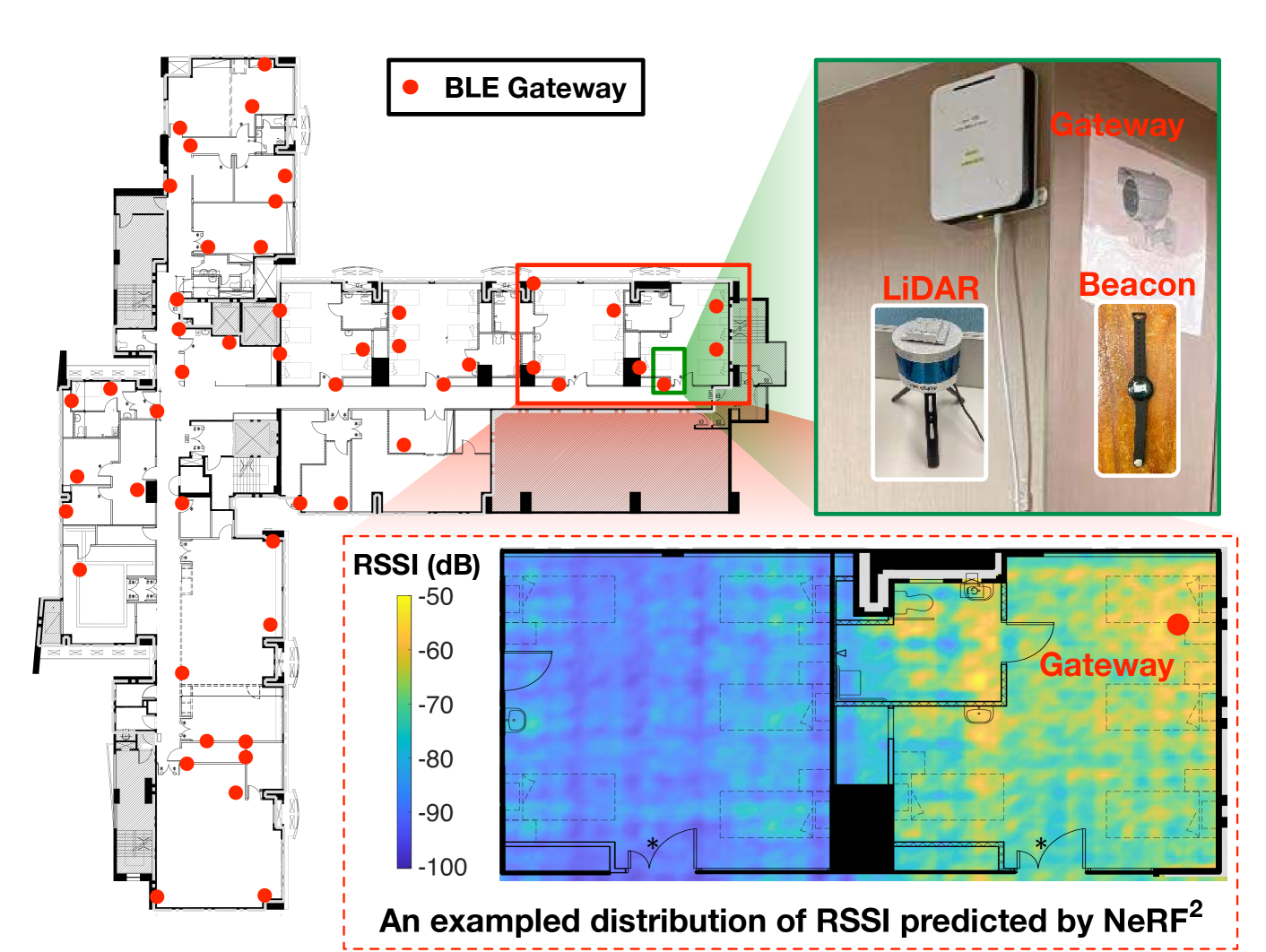
图12显示了该设施的平面图,占地15,000英尺。 总共部署了 50 个 BLE 网关(红圈)来收集 BLE 信标的 ID 和 RSSI。 每个网关的尺寸均为,工作频率为2.4 GHz,并采用Nordic Semiconductor 的NRF52832 蓝牙SoC (ble-soc, )。 部署冗余网关,保证每个位置至少有3个网关覆盖。 BLE 节点嵌入访客卡或老年人的腕带中。 它们每 500 毫秒广播一次,发射功率为 4 dBm。
地面真相。 Velodyne VLP-16 LiDAR 加上 9 轴 IMU 用于为 LIO-SAM(即公开可用的 SLAM 算法(liosam2020shan, ))提供定位和地图构建服务。 网关和节点由 LiDAR 系统定位作为地面实况。 采用 30 个 BLE 节点,我们随机走进房子并总共创建一个涉及场景中 6 K 个位置的数据集。 每个数据集项都是一个 50 维元组,包括 50 个网关检测到的 RSSI 值,以及 BLE 节点的位置。 如果网关未检测到来自节点的任何信号,则 RSSI 值默认设置为 -100 dB。 70% (4.2 K) 和 30% (1.8 K) 的数据集选自训练数据集和测试数据集。
5.2. RSSI 预测
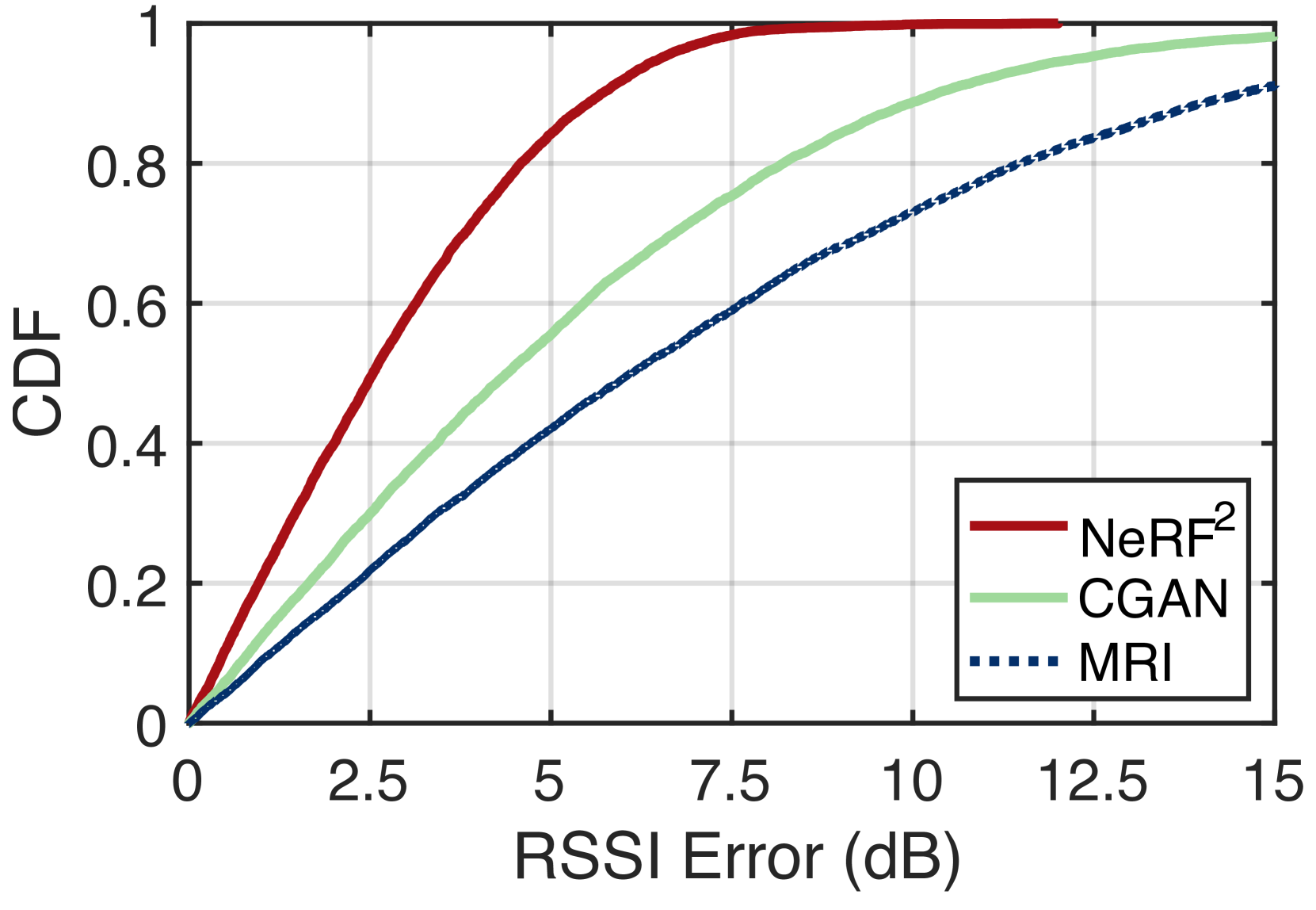
数据驱动方法正在成为 BLE 本地化的有前途的解决方案,例如 KNN、SVM 和 MLP。 这些方法需要准确的数据集进行指纹匹配或网络训练。 在这里,我们将涡轮学习应用于 BLE 定位,其中 NeRF 使用单天线 RX 模型进行训练(参见 2.3.1)。 训练过程比之前的情况更复杂,因为我们这里有 50 个 RX。 同一BLE节点的信标可能同时被多个网关接收。 在这种情况下,我们必须多次进行光线追踪,每次结果都是从所有可能方向到达相应 RX 的信号的聚合(公式 1)。 9)。 同样,给定 BLE 节点在场景中的位置,我们必须借助 NeRF 通过光线追踪来预测任意网关接收到的信号的 RSSI 。 图 12 显示了最右侧两个房间的预测 RSSI 分布示例。 可以看出,网关的覆盖范围并没有手册声称的那么好(即10m)。 过了墙后信号就变得很弱。 因此,我们在每个房间部署了3-4个网关,以保证全覆盖。 为了进行比较,我们还采用了另外两种提出的预测方法,MRI (shin2014mri, ) 和 CGAN (parralejo2021comparative, )。 MRI 使用基本无线电传播模型对未采样位置的 RSSI 值进行插值。 CGAN 使用条件生成对抗网络直接预测 RSSI 值,而不考虑任何物理模型。 预测误差定义为 1.8 K 测试位置处的预测 RSSI 值与收集的 RSSI 值之间的差异。 预测误差的CDF如图15所示。 结果,NeRF 的中位数为 2.6 dB( 百分位:0.5 dB; 百分位:5.7 dB) 。 相比之下,CGAN 和 MRI 的中值误差分别为 4.5 dB 和 6.2 dB。 显然,NeRF 的性能远远优于其他两者,因为它结合了深度学习(例如 CGAN)和物理模型(例如 MRI)的优点。 物理模型提供有关信号传播的先验知识,而深度学习则使用统计模型来描述复杂的射频交互。

5.3. 本地化结果
我们使用训练有素的 NeRF 在随机位置生成 20 K 合成数据集,并将它们提供给以下两种定位算法。
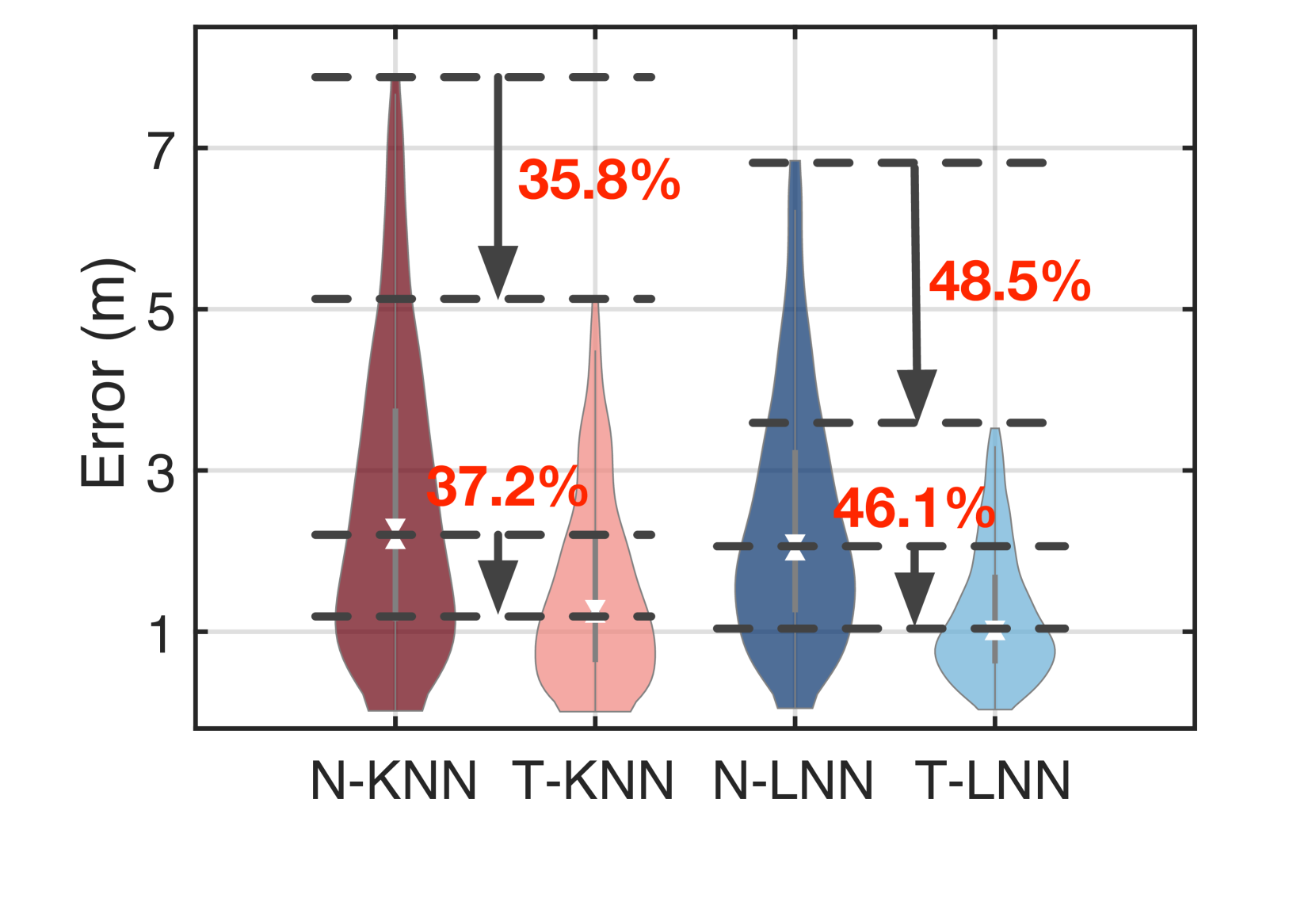
Turbo-KNN (T-KNN):我们首先评估基于指纹的定位方法,该方法假设 RSSI 值与节点的位置高度相关。 选择最近的位置来计算目标节点的位置,其中从这些位置(保存在数据库中)收集的RSSI值最接近从未知的位置。 该节点位于 位置 (ni2003landmarc, ) 的加权平均值处。 图15显示了naive-KNN(N-KNN)和T-KNN的定位精度。 N-KNN 仅采用 4.2K 真实数据集,而 T-KNN 使用 20K 合成数据集。 T-KNN 的中位误差为 1.41 m( 百分位:0.27 m; 百分位:3.3 m),而 N-KNN 的中位误差为 2.52 m( 百分位数:0.61 m; 百分位数:5.38 m)。 Turbo-learning 帮助基于 KNN 的定位方法将误差降低了 44%。
Turbo-LNN (T-LNN):我们构建另一个神经网络来学习 RSSI 元组和位置之间的映射。 我们将此网络称为定位神经网络(LNN),它接受 50 维 RSSI 元组作为输入并输出位置。 LNN 由具有 ReLU 激活函数的五层全连接层组成。 同样,LNN 分别使用 4.2 K 真实数据集和 20 K 合成数据集进行训练。 我们称它们为 naive-LNN (N-LNN) 和 T-LNN。 图15显示了他们的结果。 T-LNN 的中位误差为 1.11 m( 百分位:0.34 m, 百分位:3.46 m),而 N-LNN 的中位误差为 2.26 m( 百分位数:0.75 m, 百分位数:6.78 m)。 Turbo-learning 将误差降低了 50.8%(即 1.2 m 误差)。 特别是,T-LNN 比 T-KNN 进一步减少了 30 cm 的中值误差。
总之,无论使用哪种数据驱动方法,NeRF驱动的涡轮学习都可以有效地将定位错误减少%。 它还将标准方差降低了,因为训练数据的规模扩大了,并且更多的样本显然有利于收敛。
5.4. 标签错误的影响
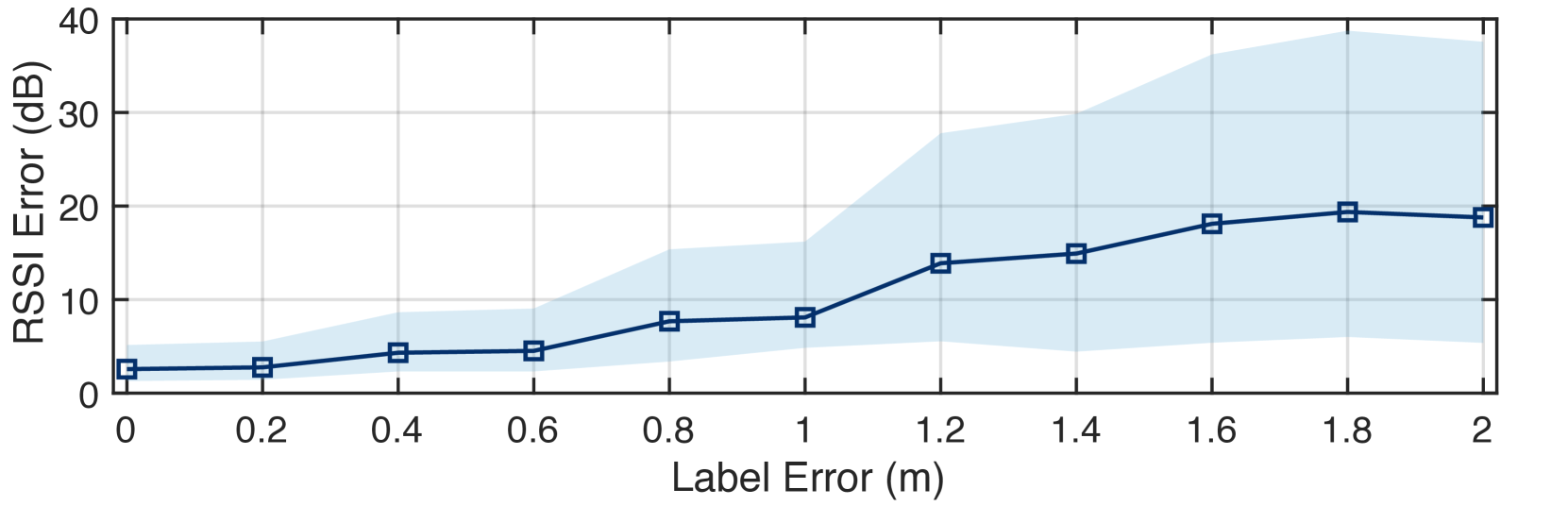
标签准确性严重影响深度学习算法的性能,因此我们研究了信标位置标签错误对 RSSI 预测准确性的影响。 图15显示了结果,代表中值预测误差和四分位数。 我们向位置标签引入均匀分布的噪声来模拟误差,从而报告标签的半径为 的圆形误差。误差从0 m以0.2 m的步长增加到2 m,相应的中值RSSI预测误差从2.6 dB下降到18.8 dB,增加了近 。 标准偏差也从 1.9 dB 增加到 9 dB。 当标签误差超过1 m时,RSSI的预测精度严重下降。 这主要是因为当误差超过1m时,标签可能不准确地位于另一个房间。 另一方面,当标签误差小于0.6 m时,RSSI预测误差低于4.5 dB,与没有误差的情况相比仅为1.9 dB。 因此,我们采用保证标签误差小于0.2 m的SLAM算法作为我们收集地面实况数据的首选方法。
6. 实地研究:5G MIMO
在本节中,我们将讨论 NeRF 如何帮助 5G 频域双工 (FDD) 系统进行大规模 MIMO 信道估计,其中上行链路和下行链路传输在不同的频率上运行。 因此,两个链路通道相等的互易原理不再成立(liu2021fire, )。 为了估计用于波束成形的下行链路CSI,客户端设备必须接收由配备有大规模天线阵列的基站发送的额外符号,然后将估计结果发送回基站,从而导致不可持续的开销。 为了解决这个问题,大量研究致力于通过观察上行链路信道来预测下行链路信道状态,基于路径共享假设,即两个链路信道都是由相同的底层物理环境和相同的路径创建的( vasisht2016消除,;bakshi2019fast,;liu2021fire,)。 例如,FNN (bakshi2019fast, ) 和 FIRE (liu2021fire, ) 利用全连接网络和 VAE 将估计的 CSI 从上行链路传输到下行链路,分别。
这个问题自然属于 NeRF 的范畴,因为 NeRF 使用 RF 辐射场来表示场景。 给定客户端设备的位置,NeRF可以准确预测基站将接收(或发送)哪种信号。 关键问题是我们如何知道客户端设备的位置。 正如之前所研究的(kotaru2015spotfi, ; xie2019md, ),CSI与物理环境高度相关,因此客户端设备的位置与其上行信号的CSI之间应该存在某种唯一的映射,这类似于基于指纹的定位。 与之前的工作尝试将上行链路 CSI 传输到下行链路 CSI 不同,我们使用上行链路 CSI 作为位置指示器来训练 NeRF,然后直接预测下行链路 CSI 。 正式地,方程。 16 重写为:
| (16) |
其中 是位置指示符(即上行链路 CSI)。 然而,以下光线追踪在下行链路频率下工作,并且网络使用收集的下行链路CSI进行训练。 因此,我们的解决方案不再依赖于路径共享假设。
6.1. 实验设置
我们选择公开可用的 Argos 通道数据集 (shepard2016understanding, ) 进行评估。 Argos 数据集是一个真实世界的多用户 MIMO (MU-MIMO) 数据集,包含基站的 104 个天线和 8 个用户,包括移动和静态轨迹收集。 该数据集包含两个不同的工作频率版本,即2.4 GHz和5 GHz。 我们需要为它们训练两个独立的 NeRF 网络。 该数据集是在ArgosV2平台(shepard2012argos,)上收集的,该平台使用2.4 GHz半波长(即63.5 mm)间距的全向单极天线。 该系统具有高达 20 MHz 的带宽和 64 个 OFDM 子载波。 为了估计 CSI,系统在每个帧的开头发送 802.11 长训练符号导频,其中包含 52 个子载波。 与之前的工作(liu2021fire, )类似,我们使用52个子载波的前半部分(即26个子载波)作为上行信道,而剩下的一半作为下行信道。 此外,上行链路和下行链路信道被保护带分开。 我们的目标是在没有任何反馈的情况下根据上行链路 CSI 预测下行链路 CSI。 该数据集是在具有大量非视距传播的复杂环境中收集的。 数据集总共包含 100 K 个项目; 70%用于训练,30%用于测试。 我们选择FIRE (liu2021fire, )、R2F2 (vasisht2016elimination, )、OptML (bakshi2019fast, )和FNN (huang2019deep, ) 进行比较。 为了公平起见,这四种算法的实验结果(包括SNR和SINR)均取自(liu2021fire, ),也是基于同一数据集测得的。
6.2. 频道预测精度
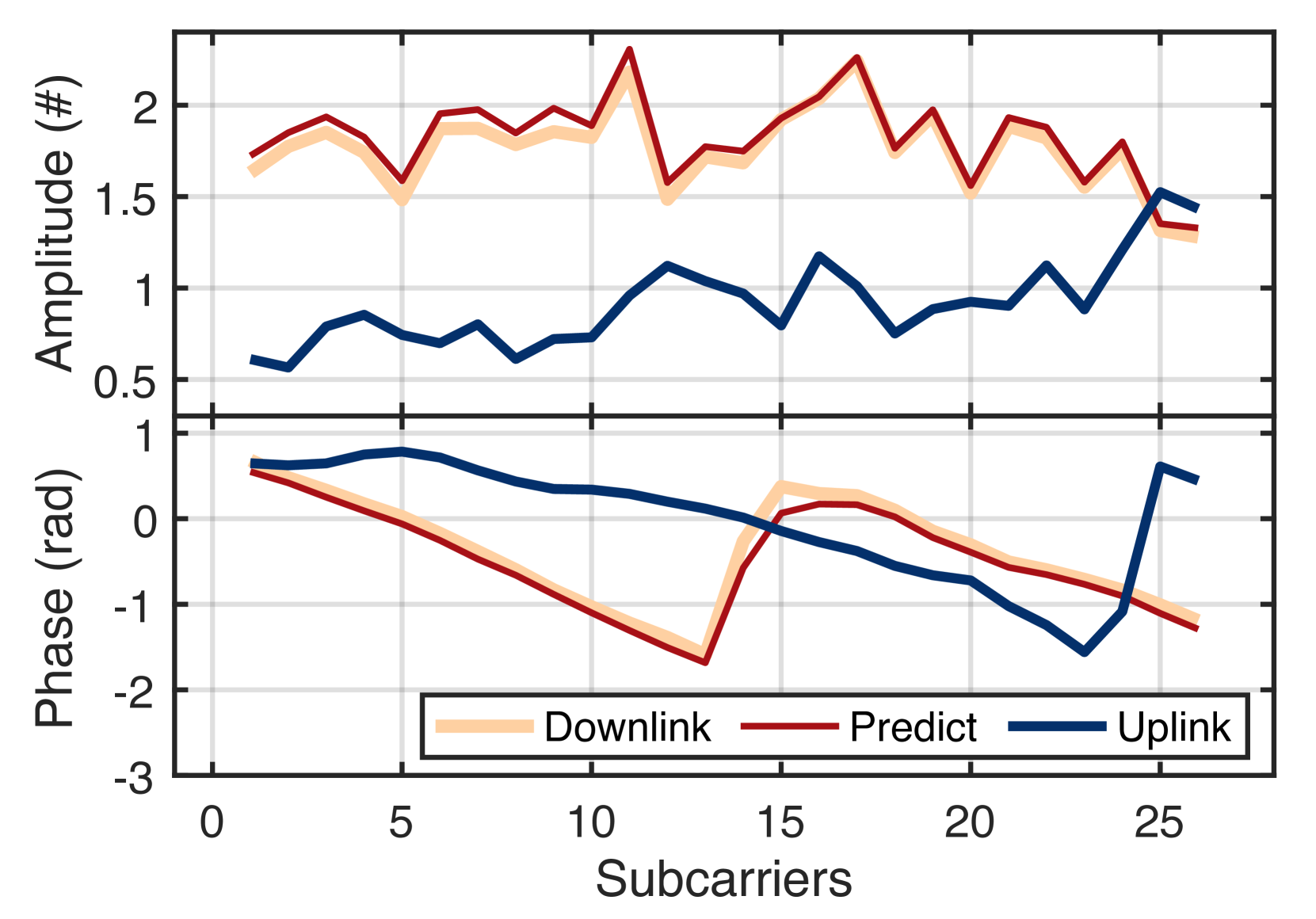
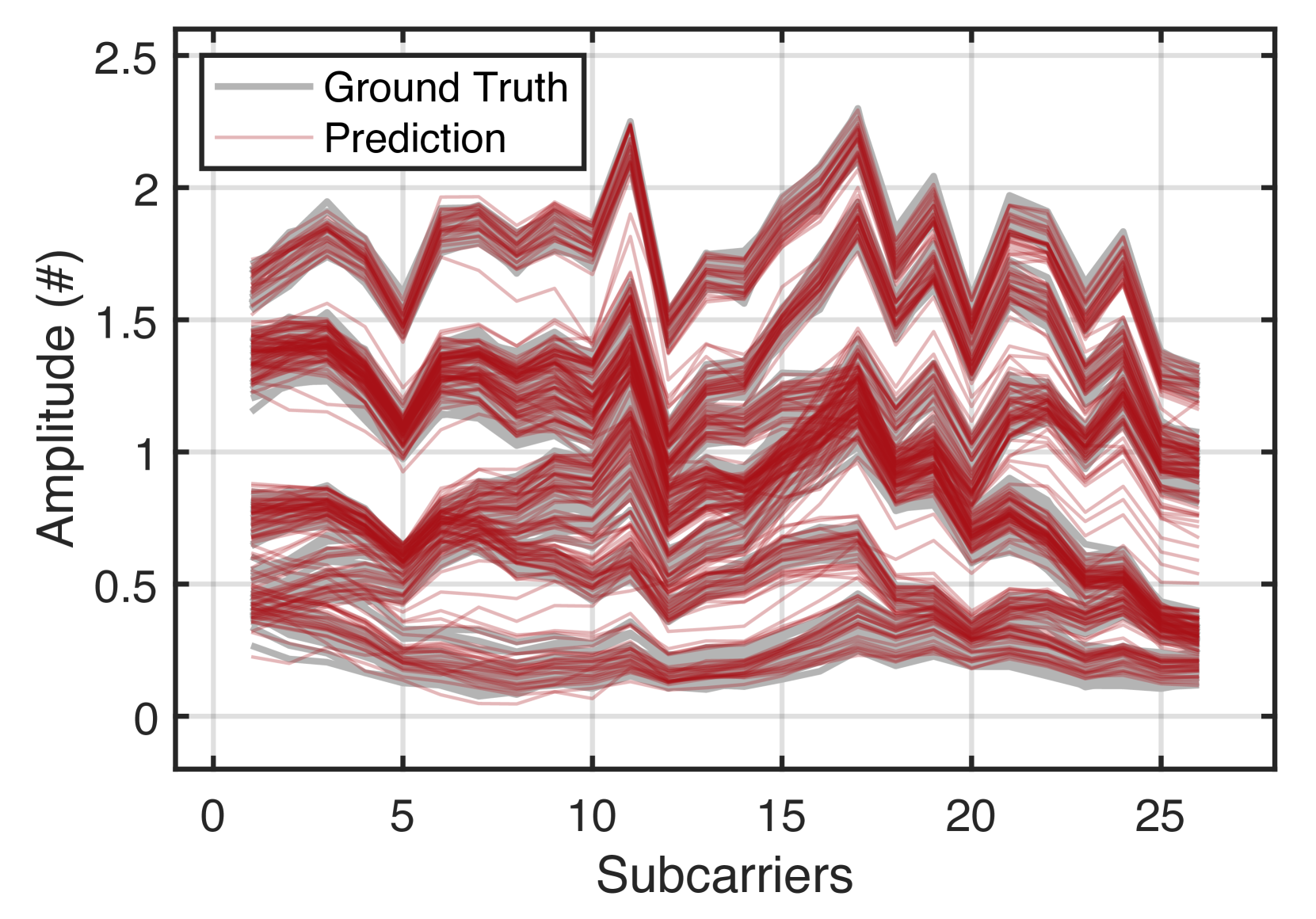
首先,我们使用 NeRF 评估下行信道预测的准确性。 我们在图19中展示了一个预测示例。 蓝色的上行CSI,包括26个子载波的相位和幅度,被馈入NeRF,输出的下行CSI显示为黄色。 红色地面实况由真实天线阵列收集。 两条曲线几乎重叠,表现出令人难以置信的高精度预测。 图19绘制了移动客户端在2秒内所有地面真实值和预测下行链路CSI的幅度。 每条红色曲线同时显示 26 个子载波的预测结果。 NeRF在客户端移动时仍能实现高精度预测。 为了量化准确性,我们采用预测信噪比(在(liu2021fire, )中提出),它将预测通道H与地面真实通道进行比较> 如下:
| (17) |
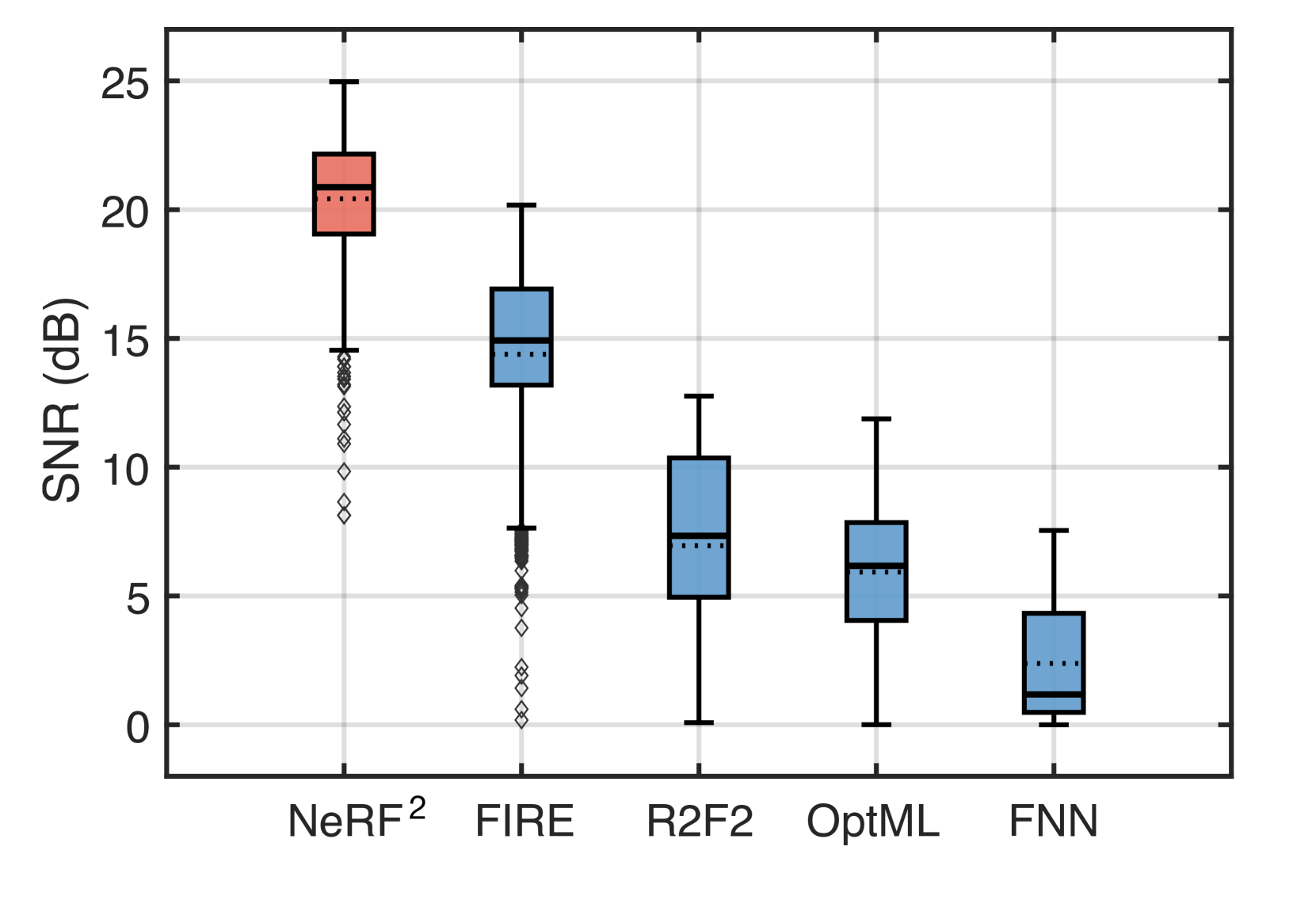
当预测的通道更接近地面真实值时,获得更高的正信噪比。 图19显示了五种预测算法的SNR CDF。 显然,与其他方法相比,NeRF 实现了更高的 SNR。 具体来说,NeRF 的中值 SNR 为 20.87 dB( 百分位:17.19 dB, 百分位:23.14 dB)。 FIRE、R2F2、OptML 和 FNN 的中值 SNR 分别为 14.9 dB、7.3 dB、16.1 dB 和 1.2 dB。 NeRF比基于VAE的FIRE好5.97 dB,比R2F2好13.57 dB,比OptML好4.77 dB,比FNN好19.67 dB。 这再次证明了NeRF的高精度预测能力。
6.3. MU-MIMO 性能
最后,我们评估 NeRF 对于 MU-MIMO 的性能。 在MU-MIMO系统中,基站通过分离的波束成形同时向多个客户端进行传输。 MU-MIMO 需要高度准确的信道估计,因为一个客户端设备的 CSI 估计产生的微小误差可能会对其他客户端设备造成泄漏干扰。 由于篇幅限制,我们建议读者参考(liu2021fire, ; spencer2004zero, )来详细了解基站如何对数据进行编码以实现MU-MIMO。 这里,我们随机选择两个客户端与配备8根天线的基站进行通信,从而构建了MU-MIMO系统。 信号干扰噪声比 (SINR) 用于指示 MU-MIMO 系统的性能。 图19显示了结果。 NeRF 可以实现中值 SINR 29.22 dB。 相比之下,FIRE、R2F2 和 OptML 的中值误差分别为 24.90 dB、13.33 dB 和 11.53 dB。 NeRF在MU-MIMO中的优异性能源于精确的信道估计。
7. 相关工作
我们的工作属于广泛的信道测量和无线定位研究。
光学神经辐射场。 随着相关研究的发展,NeRF在计算机视觉领域引起了广泛的关注。 它在 3D 模型和环境重建 (liu2020neural, ; tancik2022block, ; rematas2022urban, )、场景重新照明和视图合成 (srinivasan2021nerv, ; martin2021nerf, ) 等方面显示出巨大的潜力在。 据我们所知,NeRF 是第一个基于 RF 信号对神经辐射场进行建模的模型。 与光学 NeRF 不同,NeRF 考虑 RF 信号的相位,这需要不同的物理跟踪模型。 此外,由于与相机相比天线阵列的尺寸有限,NeRF提出了两种不同的训练方法。 通过精确预测 RF 信号,NeRF 使许多 RF 应用受益,例如无线定位和 MIMO 信道预测。
信道估计。 信道估计是无线系统中的一项关键任务,过去的工作采用训练导频(marzetta2006fast, )、反馈(fan2020towards, )、参数或经验模型(vasisht2016elimination , ),以及盲目或机会主义方法(ma2018enabling, )。 随着天线数量的猛增,经典的基于反馈的估计方法带来了过多的开销(vasisht2016elimination, )。 最近的作品(liu2021fire, ; bakshi2019fast, ; huang2019deep, ; liaskos2020end, )尝试使用深度学习来填补这一空白。 NNCONFIG (liaskos2020end, ) 提出了一种将经过训练的神经网络映射到智能表面的方案。 最先进的工作 FIRE (liu2021fire, ) 提出了一种基于 VAE 的生成模型,从上行链路反馈中学习下行链路信道。 然而,它们是纯粹数据驱动的机器学习模型,高度依赖海量数据。 与它们不同的是,NeRF 将物理模型(射频辐射场)纳入学习过程,通过先验的波传输知识增强可解释性和通道学习准确性。
无线本地化。 无线定位是一个长期研究的主题,有大量的著作(ni2003landmarc, ; yang2013rssi, ; yang2014tagoram, )。 过去的工作通过在接收到的射频信号的位置和各种指标之间建立传输模型来定位设备:RSSI (ni2003landmarc, ),相位 (ma2017drone, ; yang2014tagoram, ), CSI (yang2013rssi, ; xie2019md, )、飞行时间 (mariakakis2014sail, ) 和 AoA (an2020general, ; ayyalasomayajula2018bloc, ; xiong2013arraytrack, ; xie2018swan, )。 它们广泛应用于 Wi-Fi (kotaru2015spotfi, ; ayyalasomayajula2020deep, ; xie2018swan, )、蓝牙 (ayyalasomayajula2018bloc, ; cominelli2019dead, )、RFID (an2020general, ; wang2014rf, ; wang2017d, ) 和 LoRa (bnilam2020loray, )。 然而,经典的几何或经验定位模型存在环境引起的问题(例如复杂的多径效应、非视线等)。 这些问题在文献(wang2013dude, ; ayyalasomayajula2020deep, )中得到了广泛的研究。 最近最先进的方法利用深度学习训练模型来提高复杂室内场景的准确性(ayyalasomayajula2020deep, ; an2020general, ; zheng2019zero, ; raza2019dataset, ),但需要大量数据,限制了现实世界应用程序。 相比之下,NeRF将物理波传输知识嵌入到学习网络中,通过涡轮学习提高模型效率,并在保持定位精度的同时减少原始训练数据,从而提供更实用的解决方案。
8. 结论和未来的工作
我们提出了 NeRF,一种用于无线信道理解的新型深度学习架构。 NeRF首先将整个电磁波传输物理模型嵌入到信道学习模型中。 我们大量的实验表明,NeRF 可以提升许多基于深度学习的应用层任务的性能,包括室内定位和大规模 MIMO 通信。 未来的工作将重点解决以下挑战和改进:
普遍性。 在不同场景之间传输 NeRF 仍然是一个巨大的挑战。 潜在的解决方案包括对来自多个场景的大型数据集进行预训练以提高通用性,采用增量学习来适应周围的噪声或动态环境,以及利用迁移学习来最大限度地提高模型在不同场景中的可重用性。
时间消耗。 NeRF 需要几个小时来训练模型。 然而,最近的大量研究致力于通过压缩方法来减少时间。 例如,Instant-NGP (muller2022instant, ) 可以在 5 秒内训练光学 NeRF。 因此,未来的工作将探索通过这些方法优化训练时间消耗。
致谢。
本研究得到国家自然科学基金重点项目(No. 61932017),国家自然科学基金委优秀青年科学基金(港澳)(编号:61932017) 62022003),国家自然科学基金面上项目(No. 61972331) 和 UGC/GRF (No. 61972331) 15204820、15215421)。 我们感谢所有匿名审稿人和牧羊人提出的宝贵意见和有益的建议。参考
- (1) Z. Yun and M. F. Iskander, “Ray tracing for radio propagation modeling: Principles and applications,” IEEE Access, vol. 3, pp. 1089–1100, 2015.
- (2) R. G. Kouyoumjian and P. H. Pathak, “A uniform geometrical theory of diffraction for an edge in a perfectly conducting surface,” Proceedings of the IEEE, vol. 62, no. 11, pp. 1448–1461, 1974.
- (3) “Electromagnetic Simulation Software,” https://www.remcom.com/.
- (4) E. Egea-Lopez, J. M. Molina-Garcia-Pardo, M. Lienard, and P. Degauque, “Opal: An open source ray-tracing propagation simulator for electromagnetic characterization,” Plos one, vol. 16, no. 11, p. e0260060, 2021.
- (5) B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,” in ECCV 2020. Springer, 2020, pp. 405–421.
- (6) M. Tancik, P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ramamoorthi, J. Barron, and R. Ng, “Fourier features let networks learn high frequency functions in low dimensional domains,” Advances in Neural Information Processing Systems, vol. 33, pp. 7537–7547, 2020.
- (7) J. T. Barron, B. Mildenhall, M. Tancik, P. Hedman, R. Martin-Brualla, and P. P. Srinivasan, “Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields,” ICCV, 2021.
- (8) P. P. Srinivasan, B. Deng, X. Zhang, M. Tancik, B. Mildenhall, and J. T. Barron, “Nerv: Neural reflectance and visibility fields for relighting and view synthesis,” in Proc. of IEEE/CVF CVPR, 2021, pp. 7495–7504.
- (9) T. Müller, A. Evans, C. Schied, and A. Keller, “Instant neural graphics primitives with a multiresolution hash encoding,” ACM Transactions on Graphics (ToG), vol. 41, no. 4, pp. 1–15, 2022.
- (10) M. Tancik, V. Casser, X. Yan, S. Pradhan, B. Mildenhall, P. P. Srinivasan, J. T. Barron, and H. Kretzschmar, “Block-nerf: Scalable large scene neural view synthesis,” in Proc. of IEEE/CVF CVPR, 2022, pp. 8248–8258.
- (11) R. Martin-Brualla, N. Radwan, M. S. Sajjadi, J. T. Barron, A. Dosovitskiy, and D. Duckworth, “Nerf in the wild: Neural radiance fields for unconstrained photo collections,” in Proc. of IEEE/CVF CVPR, 2021, pp. 7210–7219.
- (12) “NeRF Demonstration,” https://www.matthewtancik.com/nerf.
- (13) L. Yang, Y. Chen, X.-Y. Li, C. Xiao, M. Li, and Y. Liu, “Tagoram: Real-time tracking of mobile rfid tags to high precision using cots devices,” in Proc. of ACM MobiCom, 2014, pp. 237–248.
- (14) Y. Ma, N. Selby, and F. Adib, “Minding the billions: Ultra-wideband localization for deployed rfid tags,” in Proceedings of the 23rd annual international conference on mobile computing and networking, 2017, pp. 248–260.
- (15) Y. Xie, J. Xiong, M. Li, and K. Jamieson, “md-track: Leveraging multi-dimensionality for passive indoor wi-fi tracking,” in Proc. of ACM MobiCom, 2019, pp. 1–16.
- (16) Y. Xie, Y. Zhang, J. C. Liando, and M. Li, “Swan: Stitched wi-fi antennas,” in Proc. of ACM MobiCom, 2018.
- (17) F. Adib, Z. Kabelac, D. Katabi, and R. C. Miller, “3d tracking via body radio reflections,” in Proc. of USENIX NSDI, vol. 14, 2013.
- (18) F. Adib, Z. Kabelac, and D. Katabi, “Multi-person motion tracking via rf body reflections,” in Proc. of USENIX NSDI, 2015.
- (19) M. Zhao, Y. Tian, H. Zhao, M. A. Alsheikh, T. Li, R. Hristov, Z. Kabelac, D. Katabi, and A. Torralba, “Rf-based 3d skeletons,” in Proc. of ACM SIGCOMM, 2018, pp. 267–281.
- (20) M. Zhao, T. Li, M. Abu Alsheikh, Y. Tian, H. Zhao, A. Torralba, and D. Katabi, “Through-wall human pose estimation using radio signals,” in Proc. of IEEE/CVF CVPR, 2018, pp. 7356–7365.
- (21) Y. Ma and E. C. Kan, “Accurate indoor ranging by broadband harmonic generation in passive nltl backscatter tags,” IEEE Transactions on Microwave Theory and Techniques, vol. 62, no. 5, pp. 1249–1261, 2014.
- (22) X. Hui and E. C. Kan, “Radio ranging with ultrahigh resolution using a harmonic radio-frequency identification system,” Nature Electronics, vol. 2, no. 3, p. 125, 2019.
- (23) A. Haniz, G. K. Tran, K. Saito, K. Sakaguchi, J.-i. Takada, D. Hayashi, T. Yamaguchi, and S. Arata, “A novel phase-difference fingerprinting technique for localization of unknown emitters,” IEEE Transactions on Vehicular Technology, vol. 66, no. 9, pp. 8445–8457, 2017.
- (24) M. Youssef and A. Agrawala, “The horus wlan location determination system,” in Proc. of ACM MobiSys, 2005, pp. 205–218.
- (25) S. Sen, B. Radunovic, R. R. Choudhury, and T. Minka, “You are facing the mona lisa: Spot localization using phy layer information,” in Proc. of ACM MobiSys, 2012, pp. 183–196.
- (26) Z. Yang, C. Wu, and Y. Liu, “Locating in fingerprint space: wireless indoor localization with little human intervention,” in Proc. of ACM MobiCom, 2012, pp. 269–280.
- (27) H. Liu, Y. Gan, J. Yang, S. Sidhom, Y. Wang, Y. Chen, and F. Ye, “Push the limit of wifi based localization for smartphones,” in Proc. of ACM MobiCom, 2012, pp. 305–316.
- (28) H. Wang, S. Sen, A. Elgohary, M. Farid, M. Youssef, and R. R. Choudhury, “No need to war-drive: Unsupervised indoor localization,” in Proc. of ACM MobiSys, 2012, pp. 197–210.
- (29) L. Ni, Y. Liu, Y. Lau, and A. Patil, “Landmarc: Indoor location sensing using active rfid,” Wireless networks, 2004.
- (30) J. Wang and D. Katabi, “Dude, where’s my card?: Rfid positioning that works with multipath and non-line of sight,” in Proc. of ACM SIGCOMM, 2013.
- (31) S. J. Pan, V. W. Zheng, Q. Yang, and D. H. Hu, “Transfer learning for wifi-based indoor localization,” in Proc. of ACM AAAI workshop, vol. 6, 2008.
- (32) Z. Liu, G. Singh, C. Xu, and D. Vasisht, “Fire: enabling reciprocity for fdd mimo systems,” in Proceedings of the 27th Annual International Conference on Mobile Computing and Networking, 2021, pp. 628–641.
- (33) P. Stoica, R. L. Moses et al., Spectral analysis of signals. Pearson Prentice Hall Upper Saddle River, NJ, 2005, vol. 452.
- (34) Z. An, Q. Lin, P. Li, and L. Yang, “General-purpose deep tracking platform across protocols for the internet of things,” in Proc. of ACM MobiSys, 2020, pp. 94–106.
- (35) “OptiTrack,” https://optitrack.com/.
- (36) D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- (37) R. Miesen, A. Parr, J. Schleu, and M. Vossiek, “360 carrier phase measurement for uhf rfid local positioning,” in 2013 IEEE International Conference on RFID-Technologies and Applications (RFID-TA). IEEE, 2013, pp. 1–6.
- (38) “RayTracing Toolbox,” https://www.mathworks.com/help/antenna/ref/rfprop.raytracing.html.
- (39) U. Ha, J. Leng, A. Khaddaj, and F. Adib, “Food and liquid sensing in practical environments using rfids,” in Proc. of USENIX NSDI, 2020.
- (40) Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE transactions on image processing, vol. 13, no. 4, pp. 600–612, 2004.
- (41) R. Ayyalasomayajula, A. Arun, C. Wu, S. Sharma, A. R. Sethi, D. Vasisht, and D. Bharadia, “Deep learning based wireless localization for indoor navigation,” in Proc. of ACM MobiCom, 2020, pp. 1–14.
- (42) P. Babakhani, T. Merk, M. Mahlig, I. Sarris, D. Kalogiros, and P. Karlsson, “Bluetooth direction finding using recurrent neural network,” in Proc. of IEEE IPIN. IEEE, 2021, pp. 1–7.
- (43) M. Comiter and H. Kung, “Localization convolutional neural networks using angle of arrival images,” in Proc. of IEEE GLOBECOM. IEEE, 2018, pp. 1–7.
- (44) K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. of the IEEE/CVF CVPR, 2016, pp. 770–778.
- (45) “NRF52832,” https://www.nordicsemi.com/products/nrf52832.
- (46) T. Shan, B. Englot, D. Meyers, W. Wang, C. Ratti, and R. Daniela, “Lio-sam: Tightly-coupled lidar inertial odometry via smoothing and mapping,” in Proc. of IEEE/RSJ IROS. IEEE, 2020, pp. 5135–5142.
- (47) H. Shin, Y. Chon, Y. Kim, and H. Cha, “Mri: Model-based radio interpolation for indoor war-walking,” IEEE Transactions on Mobile Computing, vol. 14, no. 6, pp. 1231–1244, 2014.
- (48) F. Parralejo, F. J. Aranda, J. A. Paredes, F. J. Álvarez, and J. Morera, “Comparative study of different ble fingerprint reconstruction techniques,” in Proc. of IEEE IPIN. IEEE, 2021, pp. 1–8.
- (49) L. M. Ni, Y. Liu, Y. C. Lau, and A. P. Patil, “Landmarc: Indoor location sensing using active rfid,” in Proc. of IEEE PerCom. IEEE, 2003, pp. 407–415.
- (50) D. Vasisht, S. Kumar, H. Rahul, and D. Katabi, “Eliminating channel feedback in next-generation cellular networks,” in Proc of ACM SIGCOMM, 2016, pp. 398–411.
- (51) A. Bakshi, Y. Mao, K. Srinivasan, and S. Parthasarathy, “Fast and efficient cross band channel prediction using machine learning,” in Proc. of ACM MobiCom, 2019, pp. 1–16.
- (52) M. Kotaru, K. Joshi, D. Bharadia, and S. Katti, “Spotfi: Decimeter level localization using wifi,” in Proc. of ACM SIGCOMM, 2015, pp. 269–282.
- (53) C. Shepard, J. Ding, R. E. Guerra, and L. Zhong, “Understanding real many-antenna mu-mimo channels,” in 2016 50th Asilomar Conference on Signals, Systems and Computers. IEEE, 2016, pp. 461–467.
- (54) C. Shepard, H. Yu, N. Anand, E. Li, T. Marzetta, R. Yang, and L. Zhong, “Argos: Practical many-antenna base stations,” in Proc. of ACM MobiCom. ACM, 2012, pp. 53–64.
- (55) C. Huang, G. C. Alexandropoulos, A. Zappone, C. Yuen, and M. Debbah, “Deep learning for ul/dl channel calibration in generic massive mimo systems,” in Proc. of IEEE ICC. IEEE, 2019, pp. 1–6.
- (56) Q. H. Spencer, A. L. Swindlehurst, and M. Haardt, “Zero-forcing methods for downlink spatial multiplexing in multiuser mimo channels,” IEEE transactions on signal processing, vol. 52, no. 2, pp. 461–471, 2004.
- (57) L. Liu, J. Gu, K. Zaw Lin, T.-S. Chua, and C. Theobalt, “Neural sparse voxel fields,” Advances in Neural Information Processing Systems, vol. 33, pp. 15 651–15 663, 2020.
- (58) K. Rematas, A. Liu, P. P. Srinivasan, J. T. Barron, A. Tagliasacchi, T. Funkhouser, and V. Ferrari, “Urban radiance fields,” in Proc. of IEEE/CVF CVPR, 2022, pp. 12 932–12 942.
- (59) T. L. Marzetta and B. M. Hochwald, “Fast transfer of channel state information in wireless systems,” IEEE Transactions on Signal Processing, vol. 54, no. 4, pp. 1268–1278, 2006.
- (60) X. Fan, L. Shangguan, R. Howard, Y. Zhang, Y. Peng, J. Xiong, Y. Ma, and X.-Y. Li, “Towards flexible wireless charging for medical implants using distributed antenna system,” in Proc of ACM MobiCom, 2020, pp. 1–15.
- (61) Y. Ma, Z. Luo, C. Steiger, G. Traverso, and F. Adib, “Enabling deep-tissue networking for miniature medical devices,” in Proc. of ACM SIGCOMM, 2018, pp. 417–431.
- (62) C. Liaskos, S. Nie, A. Tsioliaridou, A. Pitsillides, S. Ioannidis, and I. Akyildiz, “End-to-end wireless path deployment with intelligent surfaces using interpretable neural networks,” IEEE Transactions on Communications, vol. 68, no. 11, pp. 6792–6806, 2020.
- (63) Z. Yang, Z. Zhou, and Y. Liu, “From rssi to csi: Indoor localization via channel response,” ACM Computing Surveys (CSUR), vol. 46, no. 2, pp. 1–32, 2013.
- (64) Y. Ma, N. Selby, and F. Adib, “Drone relays for battery-free networks,” in Proc. of ACM SIGCOMM, 2017, pp. 335–347.
- (65) A. T. Mariakakis, S. Sen, J. Lee, and K.-H. Kim, “Sail: Single access point-based indoor localization,” in Proc. of ACM MobiSys, 2014, pp. 315–328.
- (66) R. Ayyalasomayajula, D. Vasisht, and D. Bharadia, “Bloc: Csi-based accurate localization for ble tags,” in Proc. of ACM CoNEXT, 2018, pp. 126–138.
- (67) J. Xiong and K. Jamieson, “Arraytrack: A fine-grained indoor location system,” in Proc. of USENIX NSDI, 2013, pp. 71–84.
- (68) M. Cominelli, P. Patras, and F. Gringoli, “Dead on arrival: An empirical study of the bluetooth 5.1 positioning system,” in Proc. of WiNTECH, 2019, pp. 13–20.
- (69) J. Wang, D. Vasisht, and D. Katabi, “Rf-idraw: Virtual touch screen in the air using rf signals,” Proc. of ACM SIGCOMM, vol. 44, no. 4, pp. 235–246, 2014.
- (70) J. Wang, J. Xiong, H. Jiang, X. Chen, and D. Fang, “D-watch: Embracing “bad” multipaths for device-free localization with cots rfid devices,” IEEE/ACM Transactions on Networking, vol. 25, no. 6, pp. 3559–3572, 2017.
- (71) N. BniLam, D. Joosens, M. Aernouts, J. Steckel, and M. Weyn, “Loray: Aoa estimation system for long range communication networks,” IEEE Transactions on Wireless Communications, vol. 20, no. 3, pp. 2005–2018, 2020.
- (72) Y. Zheng, Y. Zhang, K. Qian, G. Zhang, Y. Liu, C. Wu, and Z. Yang, “Zero-effort cross-domain gesture recognition with wi-fi,” in Proc. of ACM Mobisys, 2019, pp. 313–325.
- (73) U. Raza, A. Khan, R. Kou, T. Farnham, T. Premalal, A. Stanoev, and W. Thompson, “Dataset: Indoor localization with narrow-band, ultra-wideband, and motion capture systems,” in Proceedings of the 2nd Workshop on Data Acquisition to Analysis, 2019, pp. 34–36.