CodeT5+:用于代码理解和生成的开放代码大型语言模型
摘要
在大量源代码上预训练的大型语言模型(大语言模型)在代码智能方面取得了显着进展。 然而,现有的代码大语言模型在架构和预训练任务方面存在两个主要局限性。 首先,它们通常采用特定的架构(仅编码器或仅解码器)或依赖统一的编码器-解码器网络来完成不同的下游任务。 前一种范式受到应用程序不灵活性的限制,而在后一种范式中,模型被视为所有任务的单个系统,导致任务子集的性能不佳。 其次,他们经常采用一组有限的预训练目标,这些目标可能与某些下游任务无关,从而导致性能大幅下降。 为了解决这些限制,我们提出了“CodeT5+”,这是一个编码器-解码器大语言模型家族,其中的组件模块可以灵活组合以适应广泛的下游代码任务。 这种灵活性是通过我们提出的预训练目标组合来实现的,以减轻预训练与微调之间的差异。 这些目标涵盖单峰和双峰多语言代码语料库上的跨度去噪、对比学习、文本代码匹配和因果 LM 预训练任务。 此外,我们建议使用冻结的现成大语言模型来初始化 CodeT5+,无需从头开始训练,以有效地扩展我们的模型,并探索指令调整以与自然语言指令保持一致。 我们在不同设置下对超过 个代码相关基准进行了广泛的评估 CodeT5+,包括零样本、微调和指令调优。 我们观察了各种代码相关任务的最先进 (SoTA) 模型性能,例如代码生成和完成、数学编程以及文本到代码检索任务。 特别是,我们的指令调优CodeT5+ 16B在HumanEval代码生成任务上与其他开放代码大语言模型相比取得了 pass@1和 pass@10的新SoTA结果,甚至超越了OpenAI 代码-cushman-001 模型。
1简介
大型语言模型(大语言模型)(Chen 等人,2021;Wang 等人,2021b;Nijkamp 等人,2023b) 最近在代码领域的一系列下游任务中取得了显着的成功(Husain 等人,2019;Lu 等人,2021;Hendrycks 等人,2021)。 通过对大量基于代码的数据(例如 GitHub 公共数据)进行预训练,这些代码大语言模型可以学习丰富的上下文表示,这些表示可以转移到各种与代码相关的下游任务。 然而,我们发现许多现有模型的设计只能在一部分任务中表现良好。 我们认为这主要是由于架构和预训练任务方面的两个限制。
从架构的角度来看,现有的代码大语言模型通常采用仅编码器或仅解码器模型,这些模型仅在某些理解或生成任务上表现良好。 具体来说,仅编码器模型(Feng 等人,2020;Guo 等人,2021)通常用于促进理解文本到代码检索等任务(Lu 等人,2021) )。 对于代码生成等生成任务(Chen 等人,2021;Hendrycks 等人,2021),仅解码器模型(Chen 等人,2021;Nijkamp 等人,2023b) 常常表现出更强的性能。 然而,与仅编码器模型(Nijkamp等人,2023a)相比,这些仅解码器模型通常不适合理解检索和检测任务等任务。 此外,最近的一些模型采用了更统一的编码器-解码器架构(Wang等人,2021b;Ahmad等人,2021)来适应不同类型的任务。 虽然这些模型可以支持理解和生成任务,但它们在某些任务上仍然表现不佳。 Guo 等人 (2022) 发现编码器-解码器模型无法分别在检索和代码完成任务上击败最先进的 (SoTA) 仅编码器或仅解码器基线。 这种缺陷是由于通常适用于所有任务的单模块架构的限制造成的。 总之,现有方法的设计并未考虑组合性,因此可以激活各个组件以更好地适应不同类型的下游任务。
从学习目标的角度来看,当前模型采用了一组有限的预训练任务。 由于预训练和微调阶段之间的差异,这些任务可能会导致某些下游任务的性能下降。 例如,基于 T5 的模型,例如 (Wang 等人, 2021b) 通常使用跨度去噪目标进行训练。 然而,在代码生成等下游任务中(Chen等人,2021;Hendrycks等人,2021),大多数最先进的模型都使用下一个 Token 预测目标进行预训练,该目标自动-通过词符回归预测程序词符。 此外,许多模型没有经过训练来学习对比代码表示,这对于理解文本到代码检索等任务至关重要。 尽管最近的尝试(Guo等人,2022;Wang等人,2021a)引入了对比学习任务来缓解这个问题,但这些方法忽略了文本和代码表示之间的细粒度跨模态对齐。
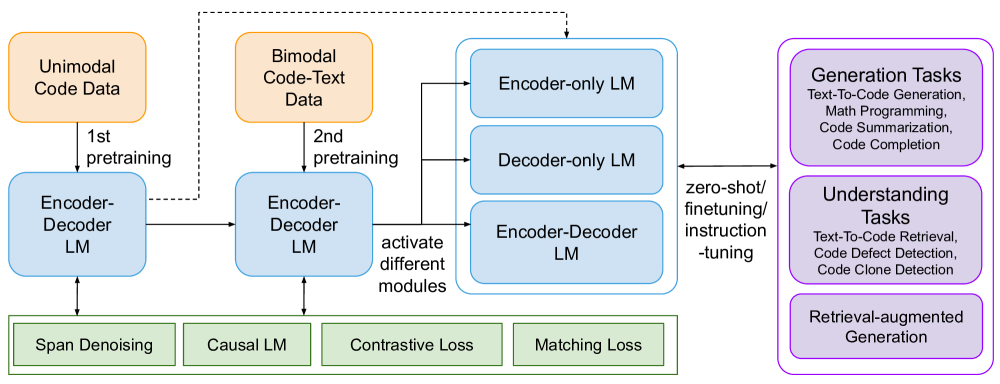
为了解决上述限制,我们提出了“CodeT5+”,一个新的编码器-解码器代码基础大语言模型家族,用于广泛的代码理解和生成任务(参见图 1 概述)。 尽管是基于编码器-解码器的模型,我们的 CodeT5+ 可以灵活地在仅编码器、仅解码器和编码器-解码器模式下运行,以适应不同的下游应用。 这种灵活性是通过我们提出的预训练任务实现的,其中包括代码数据上的跨度去噪和因果语言建模(CLM)任务以及文本代码数据上的文本代码对比学习、匹配和 CLM 任务。 我们发现如此广泛的预训练任务可以帮助从代码和文本数据中学习丰富的表示,并弥合各种应用中的预训练与微调之间的差距。 此外,我们表明,匹配任务与对比学习的集成对于捕获细粒度的文本代码对齐和提高检索性能至关重要。
此外,我们利用现成的代码大语言模型 (Nijkamp 等人,2023b) 来初始化 CodeT5+ 的组件,通过计算高效的预训练策略扩大了 CodeT5+ 的模型大小。 具体来说,我们采用“浅层编码器和深度解码器”架构(Li等人,2022b),其中编码器和解码器都是从预训练的检查点初始化并通过交叉注意层连接。 我们冻结了深层解码器大语言模型,只训练浅层编码器和交叉注意层,大大减少了可训练参数的数量,以实现高效调优。 最后,NLP 领域的最新工作(Taori 等人,2023;Wang 等人,2022b;Ouyang 等人,2022) 启发我们通过指令调整来探索 CodeT5+,以更好地使模型与自然语言保持一致指示。
我们在各种设置(包括零样本、微调和指令调优)下对超过 个代码相关基准测试对 CodeT5+ 进行了广泛评估。 结果表明,与 SoTA 基线相比,CodeT5+ 在许多下游任务上产生了显着的性能提升,例如 文本到代码检索任务( avg. MRR), 行级代码完成任务 ( avg. 精确匹配)和 检索增强代码生成任务( avg. BLEU-4)。 在MathQA和GSM8K基准上的数学编程任务(Austin等人,2021;Cobbe等人,2021)中,参数大小低于10亿的CodeT5+模型明显优于许多大语言模型多达 137B 个参数。 特别是,在 HumanEval 基准测试 (Chen 等人,2021) 上的零样本文本到代码生成任务中,我们的指令调整 CodeT5+ 16B 设置了 通过的新 SoTA 结果@1和通过@10对抗其他开放代码大语言模型,甚至超越了闭源OpenAI代码-cushman-001模型。 最后,我们展示了 CodeT5+ 可以无缝地采用作为半参数检索增强生成系统,其在代码生成方面显着优于类似方法。 所有 CodeT5+ 模型都将开源,以支持研究和开发者社区。
2相关工作
继 BERT (Devlin 等人, 2019) 和 GPT (Radford 等人, 2019)等大型语言模型在自然语言处理领域取得成功之后( NLP)近年来见证了大语言模型在代码领域的研究工作激增,在广泛的代码相关任务上产生了新的 SoTA 结果。 通常,基于代码的大语言模型可以分为三种架构:仅编码器模型(Feng 等人,2020;Guo 等人,2021;Wang 等人,2022a)、仅解码器模型(Lu 等人, 2021; Chen 等人, 2021; Fried 等人, 2022; Nijkamp 等人, 2023b),以及编码器-解码器模型 (Ahmad 等人, 2021; Wang 等人,2021b;牛等人,2022;Chakraborty 等人,2022)。 对于仅编码器和仅解码器模型,它们通常非常适合代码检索等理解任务(Husain等人,2019)或代码合成等生成任务(Chen等人) , 2021; Hendrycks 等人, 2021) 分别。 对于编码器-解码器模型,它们可以适应代码理解和生成,但并不总是比仅解码器或编码器获得更好的性能(Wang等人,2021b;Ahmad等人,2021)只有型号。 在这项工作中,我们提出了一系列新的编码器-解码器代码大语言模型,可以灵活地在各种模式下运行,包括仅编码器、仅解码器和编码器-解码器模型。
之前的大语言模型也受到预训练任务的限制,无法完美地将模型迁移到一些下游任务。 例如,基于 T5 的模型,例如使用跨度去噪目标进行预训练的 (Wang 等人, 2021b) 对于下一行代码补全等自回归生成任务来说并不理想 (Lu 等人,2021;Svyatkovskiy 等人,2020b),因为这些模型经过训练以恢复有限长度的短跨度而不是整个程序。111最近,Tabachnyk 和 Nikolov (2022); Fried 等人 (2022) 演示了使用编码器-解码器模型进行填充式代码补全,其中提供了光标后的代码上下文。 这样的代码完成设置不是我们这项工作的重点。 受 NLP 研究最新进展(Tay 等人,2022;Soltan 等人,2022)的启发,我们探索将跨度去噪与 CLM 任务相结合,以改进具有更好因果生成能力的模型(乐等人,2022)。 此外,大多数模型没有特定的预训练任务(例如对比学习)来促进学习能够区分不同语义的代码样本的上下文表示。 这可能会导致代码理解任务(例如代码检索)(Husain 等人,2019) 的性能不佳。 根据这一观察,在我们的预训练目标中,我们包括了一个对比学习任务来学习更好的单峰表示,以及一个匹配任务来学习更丰富的双峰表示。 这些任务在相关视觉语言预训练(Li 等人, 2021)中表现出了积极的影响。
与我们的工作更相关的是 UniXcoder (Guo 等人, 2022),它采用 UniLM 风格的设计 (Dong 等人, 2019),通过操作输入来支持各种任务注意面具。 然而,由于该模型试图依赖单个编码器来支持所有任务,UniXcoder 会受到任务间干扰的影响,导致性能下降,尤其是在代码生成等序列到序列任务上。 UniXcoder 及相关工作(Wang 等人,2021b;Guo 等人,2022;Wang 等人,2022a) 还使用了特定于代码的功能,例如 Abstract 语法树和标识符。 在CodeT5+中,我们有效地激活不同任务的组件模块,并且不依赖于特定于代码的功能。
最后,与我们的工作相关的是参数高效大语言模型训练的研究,旨在使用有限的计算资源扩展大语言模型。 实现这一目标的常见策略是仅训练少量(额外)模型参数,同时冻结大部分大语言模型(Hu等人,2022;Sung等人,2022)。 另一个常见特征是使用连续或离散提示的提示,以有效地将模型与下游任务对齐(Liu 等人,2021;Lester 等人,2021;Liu 等人,2022;Ponti 等人,2023 )。 在这项工作中,我们利用大语言模型通过预训练的模型检查点初始化 CodeT5+ 的编码器和解码器组件来扩展模型。 我们采用Li等人(2022b)提出的“浅层编码器和深度解码器”架构,仅保持小型编码器和交叉注意层可训练,同时冻结深度解码器大语言模型。 然后,我们将此训练方案与指令调整(Taori等人,2023;Wang等人,2022b;Ouyang等人,2022)结合起来,仅使用Chaudhary (2023),有效指导 CodeT5+ 更好地与下游任务保持一致。
3 CodeT5+:开放代码大型语言模型
我们开发了 CodeT5+,这是一个新的开放代码大型语言模型系列,用于代码理解和生成任务(请参阅图1了解概述和更多信息图 2和图 3中的架构/预训练详细信息)。 基于编码器-解码器架构(Wang等人,2021b),CodeT5+通过我们提出的单峰和双峰数据混合预训练目标,增强了针对不同下游任务以各种模式运行的灵活性。
在单峰预训练的第一阶段,我们使用计算高效的目标(Sec. 3.1)用大量代码数据预训练模型。 在双模态预训练的第二阶段,我们继续使用较小的一组具有跨模态学习目标的代码文本数据来预训练模型(Sec. 3.2)。 对于每个阶段,我们共同优化多个具有相同权重的预训练目标。 我们发现这种分阶段训练方法可以有效地将我们的模型暴露给更多样化的数据,以学习丰富的上下文表示。 此外,我们探索使用现成的代码大语言模型初始化CodeT5+,以有效地扩展模型(秒 3.3)。 最后,CodeT5+ 中的模型组件可以动态组合以适应不同的下游应用程序任务(Sec. 3.4)。
3.1 代码数据上的单峰预训练
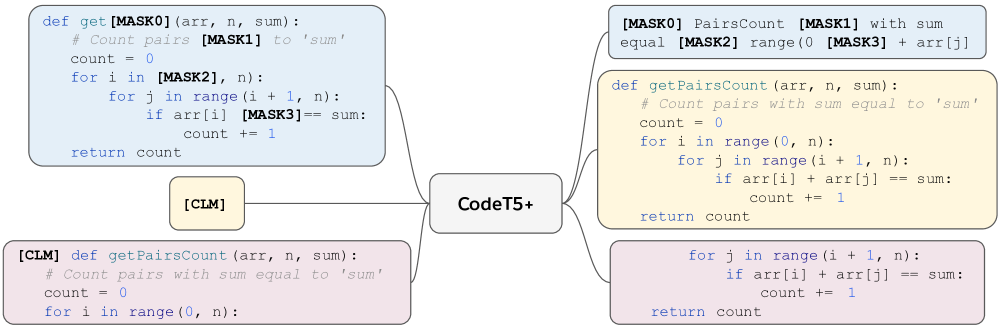
第一阶段,我们在大规模代码单峰数据上预训练CodeT5+,这些数据可以从GitHub等开源平台获得。 尽管这些数据还包含用户编写的代码注释等文本,但我们表示单峰数据,以将其与第二预训练阶段中的文本代码对的双峰数据区分开。 由于程序员的注释风格不同以及语言的注释语法不同,将代码和文本分开并非易事。 在此阶段,我们使用跨度去噪和 CLM 任务的混合从头开始预训练模型,如 图 3 所示。 这些任务使模型能够学习恢复不同规模的代码上下文:代码跨度、部分程序和完整程序。
跨度去噪。 与 T5 (Raffel 等人, 2020) 类似,我们将标记中的 随机替换为索引哨兵标记(例如 [MASK0])编码器输入,并要求解码器通过生成这些跨度的组合来恢复它们。 我们按照 CodeT5 在子词标记化之前通过采样跨度(跨度长度由平均值为 的均匀分布确定)来采用全字屏蔽,以避免屏蔽部分单词。 为了加速训练,我们将不同的代码文件连接成序列,并将它们截断为固定长度的块。
因果语言模型(CLM)。 灵感来自Tay 等人 (2022); Soltan 等人 (2022),我们引入了两种 CLM 变体来优化我们的自回归生成模型。 在第一个变体中,我们随机选择一个枢轴位置,并将其之前的上下文视为源序列,将其之后的序列视为目标输出。 我们将此变体表示为序列到序列 (Seq2Seq) 因果 LM 目标。 我们限制枢轴位置在整个序列的 和 之间均匀采样,并在源序列前面添加一个特殊的词符 [CLM]。 第二个 CLM 变体是仅解码器生成任务,可以视为第一个变体的极端情况。 在此任务中,我们总是将 [CLM] 词符传递给编码器输入,并要求解码器生成完整的代码序列。 与第一个变体相比,该任务旨在提供更密集的监督信号来将解码器训练为独立的成熟代码生成模块。
3.2 文本代码数据的双峰预训练
在第二阶段,我们在函数级别使用文本代码双峰数据预训练模型(Husain等人,2019)。 在此设置中,每个文本代码对都包含一个代码函数及其相应的描述其语义的文档字符串。 这种双模态数据格式有利于跨模态理解和生成的模型训练。 双模态预训练任务由跨模态对比学习、匹配和因果LM任务组成,如图图 2
文本代码对比学习。
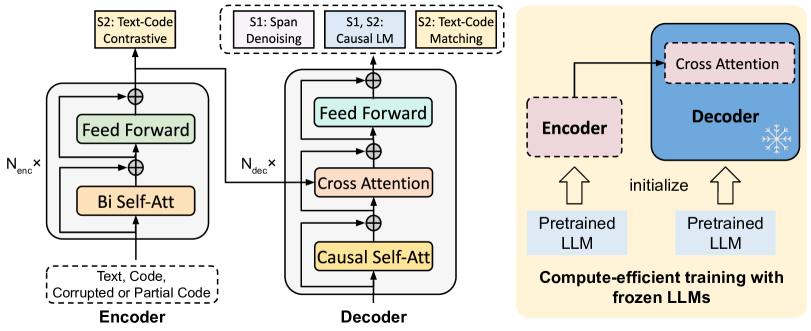
该任务旨在通过将正文本-代码对的表示拉在一起并拉开负对的表示来对齐文本和代码表示的特征空间。 Guo 等人 (2022) 展示了此类学习任务对于代码理解的好处。 该任务仅激活编码器,编码器通过双向自注意力将文本或代码片段编码为连续表示(Vaswani等人,2017)。 与 BERT (Devlin 等人, 2019) 类似,我们在输入前面添加一个特殊的词符 [CLS] ,并将其在最终 Transformer 层的输出嵌入视为表示相应的输入文本或代码。 我们进一步添加一个线性层并使用 L2 归一化将输出映射到 256 维嵌入。 为了丰富负样本,我们使用动量编码器来存储之前小批量样本的嵌入,与 He 等人 (2020) 所采用的类似;李等人(2022a)。 具体来说,动量编码器维护一个排队系统,该系统将当前小批量中的样本入队,并将最旧小批量中的样本出队。 我们通过原始编码器训练和动量编码器的线性插值来更新动量编码器,以确保跨步骤表示的一致性。
文本代码匹配。
此任务激活解码器,旨在预测文本和代码片段是否共享相同的语义。 此类任务使模型能够学习更好的双模态表示,从而捕获文本和代码模态之间的细粒度对齐。 给定一个代码样本,解码器首先将其传递到嵌入层和因果自注意力层。 然后,自注意力表示被传递到交叉注意力层,该层从文本表示(从编码器接收)查询相关信号。 特定于任务的 [Match] 词符被添加到代码输入序列中,以通知解码器文本代码匹配功能,并且 [EOS] 词符是附加到代码输入的末尾。 由于解码器采用因果自注意力掩码,并且只有最后一个解码器词符可以关注整个上下文,因此我们将最后一个解码器层的 [EOS] 的输出嵌入视为文本代码交叉-模态对齐表示。 最后,我们在解码器的输出嵌入之上使用线性层来执行二进制匹配任务,预测文本代码对是正(匹配)还是负(不匹配)。
为了找到更多信息丰富的负例,我们采用了硬负例挖掘策略(Li等人,2021)。 具体来说,我们根据动量编码器维护的队列中当前样本和先前样本之间基于对比的相似度分数对硬负例进行采样。 因此,更难的底片更有可能被选择。 对于一批正对,我们通过使用代码/文本查询从文本/代码队列中挖掘负对来构造两批负对。
文本代码因果 LM。
该任务激活编码器和解码器,并通过双重多模态转换专注于跨模态生成目标:文本到代码生成和代码到文本生成。 具体来说,当输入是文本样本时,我们在解码器的输入序列前面添加一个 [CDec] 词符。 在这种情况下,解码器在代码生成功能下运行。 或者,当输入是代码示例时,我们将 [TDec] 词符添加到解码器的输入序列中。 在这种情况下,解码器在文本生成功能下运行。 这种类型的因果 LM 已被证明是一种有效的学习目标,可以缩小代码摘要等多模态生成下游任务的预训练-微调差距(Wang 等人,2021b)。
3.3 使用 Frozen 现成的大语言模型进行高效的预训练
为了有效地扩展模型而不需要从头开始预训练,我们提出了一种计算高效的预训练策略,用现成的预训练大语言模型 ( Nijkamp 等人, 2023b)(参见图2最右图)。 对于此扩展,受(Li等人,2022b)的启发,我们采用“浅层编码器和深度解码器”架构,而不是传统T5模型中相同大小的编码器和解码器(Raffel等人,2020;王等人,2021b)。 正如 Li 等人 (2022b) 所指出的,基于 T5 的模型中的解码器通常需要处理更高级别的复杂性生成任务,因此应该通过更多数量的解码器来增强神经参数。
为了连接单独预训练的编码器和解码器,我们在自注意层之后将随机初始化的交叉注意层插入到解码器块中。 为了有效调整的目的,我们只将交叉注意力层插入到顶部解码器层(在我们的实验中=1)。 我们只保留小型编码器和交叉注意力层的可训练性,同时冻结大多数解码器参数。 我们还探索了其他先进的设计,例如添加门函数以提高训练稳定性或以特定频率插入多个交叉注意层(Alayrac等人,2022)。 然而,我们没有观察到显着的性能改进,更糟糕的是,这些设计选择会带来过于昂贵的计算开销。
3.4适应下游理解和生成任务
经过两个阶段的预训练,CodeT5+可以灵活地以各种模式运行以支持不同的任务,包括Seq2Seq生成任务、仅解码器任务和基于理解的任务:
Seq2Seq 生成任务。 作为编码器-解码器模型,CodeT5+可以自然地适应各种Seq2Seq生成任务,例如代码生成和摘要。 我们还采用 CodeT5+ 作为检索增强生成模型,使用编码器检索代码片段,然后由编码器和解码器使用它们来生成代码。
仅解码器任务。 在此设置中,我们始终将 [CLM] 词符提供给编码器输入,并将源序列作为前缀上下文传递给解码器。 我们冻结编码器和解码器中交叉注意力层的权重。 该策略仅激活部分解码器,并且从技术上讲减少了大约一半的总模型参数。 我们使用下一行代码完成任务来评估 CodeT5+ 的仅解码器生成能力。
了解任务。 CodeT5+可以通过两种方式支持这些理解任务:首先,它使用编码器来获取文本/代码嵌入,可以将其传递给二元分类器以进行检测任务或检索任务;或者,编码器可以与解码器结合起来预测文本到代码检索任务的文本到代码匹配分数。
4 预训练和指令调节
4.1 预训练数据集
我们用最近发布的 GitHub Code 数据集222https://huggingface.co/datasets/codeparrot/github-code扩大了 CodeSearchNet 的预训练数据集(Husain 等人,2019 年)。 我们选择九个 PL(Python、Java、Ruby、JavaScript、Go、PHP、C、C++、C#),并通过仅保留许可的代码来过滤数据集333Permissive licenses: “mit”, “apache-2”, “bsd-3-clause”, “bsd-2-clause”, “cc0-1.0”, “unlicense”, “isc” 以及具有 50 到 2000 个 Token 的文件。 此外,我们通过检查 GitHub 存储库名称来过滤掉与 CodeSearchNet 和我们评估中涵盖的其他下游任务重叠的子集。 请注意,尽管我们采用重复数据删除版本,其中根据精确匹配(忽略空格)过滤掉重复项,但可能仍存在一些潜在的剩余重复项。 然而,我们预计任何剩余的重复不会显着影响我们的模型性能。 我们使用 CodeT5 标记器对多语言数据集进行标记,生成 51.5B 个标记,比 CodeSearchNet 大 50 倍。
| Dataset | Language | # Sample | Total size |
| Ours | Ruby | 2,119,741 | 37,274,876 files |
| JavaScript | 5,856,984 | ||
| Go | 1,501,673 | ||
| Python | 3,418,376 | ||
| Java | 10,851,759 | ||
| PHP | 4,386,876 | ||
| C | 4,187,467 | ||
| C++ | 2,951,945 | ||
| C# | 4,119,796 | ||
| CSN | Ruby | 49,009 | 1,929,817 text-code pairs at function level |
| JavaScript | 125,166 | ||
| Go | 319,132 | ||
| Python | 453,772 | ||
| Java | 457,381 | ||
| PHP | 525,357 |
我们在表1中报告了单峰代码和双峰文本代码预训练数据集的数据统计。 从表中我们可以看到,我们从 GitHub 代码中整理的数据集在文件级别的数据量比 CodeSearchNet 在函数级别的双峰数据大得多,这使得我们的模型能够在预训练的第一阶段学习丰富的表示。 与 CodeSearchNet Husain 等人 (2019) 中同时使用单峰和双峰数据的 CodeT5 (Wang 等人, 2021b) 不同,我们在第二阶段仅使用其双峰子集我们的 CodeT5+ 的预训练。 我们使用此阶段主要使我们的模型适应文本代码相关的任务,例如文本到代码的检索和生成。
4.2 预训练设置
我们预训练了两组 CodeT5+ 模型:1)CodeT5+ 220M 和 770M,它们是按照 T5 的架构(Raffel 等人,2020)(分别是 T5-base 和 Large)从头开始训练的,2)CodeT5+ 2B,如图6B、16B所示,其中解码器从CodeGen-mono 2B、6B、16B模型(Nijkamp等人,2023b)初始化,其编码器从CodeGen-mono 350M初始化。 请注意,按照我们的模型缩放策略,与原始 CodeGen 模型相比,后一组 CodeT5+ 模型引入了微不足道的可训练参数(350M 编码器加上一个分别用于 2B、6B、16B 模型的 36M、67M、151M 交叉注意力层)。 我们分别对这两组模型使用 CodeT5 分词器和 CodeGen 分词器。 在预训练中,我们采用分阶段策略,首先在大规模单峰数据集上预训练 CodeT5+,然后在 Google Cloud Platform 上具有 16 个 A100-40G GPU 的集群上的较小双峰数据集上预训练 CodeT5+。
在第一阶段,我们使用 步骤的跨度去噪任务训练模型,然后将 步骤与两个具有相同权重的 CLM 任务联合训练。 我们采用峰值学习率为 2e-4 的线性衰减学习率 (LR) 调度程序,并将批量大小设置为 2048(用于去噪)和 512(用于 CLM)。 为了准备输入和输出数据,我们将去噪任务的最大长度设置为 ,并将源数据和输出数据的最大长度设置为 和 。代码完成 CLM 的目标序列、仅解码器生成 CLM 的 和 。 在第二阶段,我们针对批量大小为 的 时期,联合优化对比学习、匹配的四个损失和两个具有相同权重的 CLM 损失。 我们采用 1e-4 的峰值学习率,并将代码和文本序列的最大序列长度设置为 和 。
在所有实验中,我们采用具有 权重衰减的 AdamW 优化器 (Loshchilov 和 Hutter,2019)。 我们还采用 DeepSpeed 的 ZeRO Stage 2 训练 (Rasley 等人, 2020) 以及 FP16 的混合精度训练来实现加速。 对于 CodeT5+ 2B、6B 和 16B 的训练,我们使用 FP16 冻结解码器权重,并将其他可训练权重保留在 FP32 中。 我们对 CodeT5+ 6B 和 16B 模型使用 DeepSpeed ZeRO Stage 3 的参数分区。
4.3 配置参数

在 NLP 领域,最近的工作(Wang 等人,2022b;Taori 等人,2023) 研究了数据增强技术对具有合成指令数据的预训练 LM 的好处。 使用此类数据进行微调的模型可以更好地理解自然语言指令,并展示与相应任务的更好一致性(Wang等人,2022b;Ouyang等人,2022)。 我们有动力将这项技术转移到代码领域来改进我们的 CodeT5+ 模型。 继Taori等人(2023)之后,我们在Chaudhary(2023)策划的代码域中使用了超过k指令数据。 数据是通过让预训练的大语言模型(即text-davinci-003)生成新颖的任务来生成的,包括任务指令、输入(如果有)和预期输出。 我们在这个增强数据集上训练我们的模型最多 3 个时期,并将指令调整模型表示为“InstructCodeT5+”。 请注意,指令数据的生成完全独立于任何下游评估任务,我们仍然以零样本的方式评估指令调整的模型。 图4示出了所生成的指令数据的一些示例。 请注意,由于我们依赖 LM 生成的数据(包括预期输出的注释),因此并非所有数据都完全正确。 例如,图4中的代码优化任务示例包含错误的输出。 Wang 等人 (2022b) 将这些示例视为数据噪声,调整后的模型仍然受益于大部分合成指令数据集。
5实验
我们对跨 9 种不同编程语言 (PL) 的 20 多个代码相关数据集的各种代码理解和生成任务进行了全面的实验。 此外,我们考虑了各种评估设置,包括零样本、指令调整、特定于任务的微调。 其他结果和详细的微调设置可以在附录C和D中找到。
基线。 我们实现了一系列CodeT5+模型,模型大小从220M到16B不等。 请注意,CodeT5+ 220M 和 770M 采用与 T5 (Raffel 等人,2020) 相同的架构,并且从头开始预训练,而 CodeT5+ 2B、6B、16B 采用“浅层编码器和深度解码器”架构编码器分别从 CodeGen-mono 350M 初始化,解码器分别从 CodeGen-mono 2B、6B、16B 初始化。 我们将 CodeT5+ 与最先进的代码大语言模型进行比较,大语言模型可以分为 类型:仅编码器模型、仅解码器模型和编码器-解码器模型。
-
•
对于仅编码器模型,我们考虑使用掩码语言训练的 RoBERTa (Liu 等人, 2019)、CodeBERT (Feng 等人, 2020)建模,GraphCodeBERT (Guo 等人, 2021) 使用从代码的 Abstract 语法树 (AST) 中提取的数据流,SYNCOBERT (Wang 等人, 2021a) 和 UniXcoder (Guo 等人, 2022) 结合了 AST 和对比学习。 请注意,UniXcoder 也可以被视为仅解码器模型,因为它采用 UniLM 样式掩码(Dong 等人,2019)。
-
•
对于仅解码器模型,我们考虑 GPT-2 (Radford 等人, 2019) 和 CodeGPT (Lu 等人, 2021)。 两者均使用 CLM 目标进行预训练。 在此模型范式中,我们还考虑了超大规模(最多 540B 个参数)的模型,例如 PaLM (Chowdhery 等人, 2022)、GPT-4 (OpenAI, 2023) t1>、Codex (Chen 等人, 2021)、LLaMA (Touvron 等人, 2023)、CodeGen (Nijkamp 等人, 2023b) ,Incoder (Fried 等人,2022),GPT-J (Wang 和 Komatsuzaki,2021),GPT-Neo 和 GPT-NeoX (Black 等人, 2022)、MIM (Nguyen 等人, 2023)、CodeGeeX (Zheng 等人, 2023)。 我们还与与本工作同时发布的 Replit (replit, 2023) 和 StarCoder (Li 等人, 2023) 进行了比较。
-
•
对于编码器-解码器模型,我们考虑 PLBART (Ahmad 等人, 2021) 和 CodeT5 (Wang 等人, 2021b),它们采用支持理解和生成任务的统一框架。
请注意,十亿参数的大语言模型(例如 Codex 和 CodeGen)通常使用 GitHub 中的大部分源代码进行模型训练,并且不会像我们那样消除与本工作中涵盖的下游任务的任何重叠。 因此,很难确保在这些任务中与这些模型进行公平比较,特别是代码摘要和完成任务。 此外,这些模型执行特定任务的微调非常昂贵,因此,它们通常仅用于零样本评估。 在这项工作中,我们主要在零样本HumanEval代码生成任务(Sec. 5.1)中将CodeT5+与这些大语言模型进行比较。 在其他实验中,我们专注于微调设置,并将我们的模型与较小规模的 LM 进行比较,包括 CodeGen-multi-350M,尽管它在预训练期间存在潜在的数据泄漏问题。 在一些微调评估中,例如代码摘要(Sec. 5.3)和文本到代码检索任务(Sec. 5.5),我们发现随着模型尺寸的增加,性能提升已经变得相对饱和。 这意味着,如果有足够的数据进行微调,与零样本评估设置相比,这些任务可能不会从模型缩放(数十亿个参数)中受益匪浅。
| Model | Model size | pass@1 | pass@10 | pass@100 |
|---|---|---|---|---|
| Closed-source models | ||||
| LaMDA | 137B | 14.0 | - | 47.3 |
| AlphaCode | 1.1B | 17.1 | 28.2 | 45.3 |
| MIM | 1.3B | 22.4 | 41.7 | 53.8 |
| MIM | 2.7B | 30.7 | 48.2 | 69.6 |
| PaLM | 8B | 3.6 | - | 18.7 |
| PaLM | 62B | 15.9 | - | 46.3 |
| PaLM | 540B | 26.2 | - | 76.2 |
| PaLM-Coder | 540B | 36.0 | - | 88.4 |
| Codex | 2.5B | 21.4 | 35.4 | 59.5 |
| Codex | 12B | 28.8 | 46.8 | 72.3 |
| code-cushman-001 | - | 33.5 | 54.3 | 77.4 |
| code-davinci-002 | - | 47.0 | 74.9 | 92.1 |
| GPT-3.5 | - | 48.1 | - | - |
| GPT-4 | - | 67.0 | - | - |
| Open-source models | ||||
| GPT-Neo | 2.7B | 6.4 | 11.3 | 21.4 |
| GPT-J | 6B | 11.6 | 15.7 | 27.7 |
| GPT-NeoX | 20B | 15.4 | 25.6 | 41.2 |
| InCoder | 1.3B | 8.9 | 16.7 | 25.6 |
| InCoder | 6B | 15.2 | 27.8 | 47.0 |
| CodeGeeX | 13B | 22.9 | 39.6 | 60.9 |
| LLaMA | 7B | 10.5 | - | 36.5 |
| LLaMA | 13B | 15.8 | - | 52.5 |
| LLaMA | 33B | 21.7 | - | 70.7 |
| LLaMA | 65B | 23.7 | - | 79.3 |
| Replit | 3B | 21.9 | - | - |
| StarCoder | 15B | 33.6 | - | - |
| CodeGen-mono | 2B | 23.7 | 36.6 | 57.0 |
| CodeGen-mono | 6B | 26.1 | 42.3 | 65.8 |
| CodeGen-mono | 16B | 29.3 | 49.9 | 75.0 |
| CodeT5+ | 220M | 12.0 | 20.7 | 31.6 |
| CodeT5+ | 770M | 15.5 | 27.2 | 42.7 |
| CodeT5+ | 2B | 24.2 | 38.2 | 57.8 |
| CodeT5+ | 6B | 28.0 | 47.2 | 69.8 |
| CodeT5+ | 16B | 30.9 | 51.6 | 76.7 |
| InstructCodeT5+ | 16B | 35.0 | 54.5 | 77.9 |
| Open-source models + generation strategies | ||||
| StarCoder (prompted) | 15B | 40.8 | - | - |
| CodeGen-mono w/ CodeT | 16B | 36.7 | 59.3 | - |
| CodeT5+ w/ CodeT | 16B | 38.5 | 63.6 | 77.1 |
| InstructCodeT5+ w/ CodeT | 16B | 42.9 | 67.8 | 78.7 |
5.1文本到代码生成任务的零样本评估
我们首先评估模型在零样本设置中根据给定自然语言规范生成 Python 代码的能力。 在此任务中,我们从 CodeT5+ 激活编码器和解码器模块,编码器对输入文本序列进行编码,解码器根据输入文本生成相应的程序。 我们使用 HumanEval 基准(Chen 等人, 2021),该基准由 164 个 Python 问题组成。 为了评估代码生成模型,精确匹配或 BLEU 分数可能会受到限制,因为正确的程序解决方案可能有多个版本。 此外,Chen 等人 (2021) 发现生成代码的功能正确性与其 BLEU 分数相关性较差。 因此,我们通过针对单元测试测试生成的代码来评估模型性能。 我们在表2中报告了通过率pass@k。 遵循此基准测试中的先前方法,我们在推理过程中采用了核采样, 的温度为 、 和 。 在这个实验中,我们按照 Nijkamp 等人 (2023b) 继续使用因果 LM 目标在 Python 子集数据的另一个纪元上预训练我们的 CodeT5+ 模型,以更好地使其适应 Python 代码生成。
在零样本设置中,指令调整的CodeT5+(“InstructCodeT5+”)16B模型可以比其他开放代码大语言模型提高性能,实现 pass@1和 其的pass@100结果与当前SoTA开源模型LLaMA 65B (Touvron等人, 2023)相差不远。 特别是,作为一个开放模型,我们的 InstructCodeT5+ 16B 在所有指标上甚至优于 OpenAI code-cushman-001 模型。 我们还观察到,我们的 220M 和 770M 小型模型已经匹配或优于更大的代码大语言模型,例如,CodeT5+ 770M 的 pass@1 与 Incoder 6B 的 相比, GPT-NeoX 20B 的 和 PaLM 62B 的 。 此外,我们观察到,与相似大小的 CodeGen 模型(Nijkamp 等人,2023b)相比,CodeT5+ 从 2B 到 16B 模型变体获得了一致的性能提升。 这些相对于仅解码器基线的优异结果证明了 CodeT5+ 编码器-解码器架构的优势,并验证了我们提出的使用冻结现成代码大语言模型的计算高效预训练策略的有效性。
最后,我们按照 CodeT Chen 等人 (2023) 的增强生成策略评估了模型。 在此设置中,我们让模型生成额外的测试用例(通过使用 assert 语句提示模型)。 然后,我们使用这些生成的测试用例来过滤和采样生成的代码样本以进行评估。 我们观察到该策略可以选择更好的候选代码并带来性能提升,达到 pass@1 和 pass@10。 我们确实注意到 CodeT5+ 与 GPT-4 (OpenAI,2023) 和 code-davinci-002 等闭源模型的性能差距。 然而,由于这些模型的实现细节和模型权重/大小尚未发布,因此很难诊断性能差距的根本原因。
5.2 数学编程任务的评估
我们考虑其他代码生成任务,特别是两个数学编程基准 MathQA-Python (Austin 等人,2021) 和 GSM8K (Cobbe 等人,2021)。 任务是生成Python程序来解决自然语言描述中描述的数学问题,其中根据生成的程序的执行输出来衡量代码的正确性。 我们按照(Austin 等人, 2021)将GSM8K中的解决方案转换为Python程序(以下称为GSM8K-Python,一个例子如图图 5)。 我们使用 pass@k 来衡量使用 生成的程序解决每个问题的问题的百分比。 我们将我们的模型与非常大规模的仅解码器模型进行比较,包括 LaMDA (Austin 等人, 2021)、LLaMA (Touvron 等人, 2023)、Minerva (Lewkowycz 等人, 2022)、code-davinci (Chen 等人, 2021)、GPT-Neo (Black 等人, 2021) 和 CodeGen (Nijkamp 等人,2023b)。 一些先前的方法通过生成策略得到增强,例如自采样优化(Ni等人,2022)和多数投票(Lewkowycz等人,2022)。

| Model | Model size | MathQA-Python | GSM8K-Python |
|---|---|---|---|
| pass@80 | pass@100 | ||
| Few-shot learning results | |||
| code-davinci | - | 42.0 | 71.0 |
| LLaMA | 13B | - | 29.3 |
| LLaMA | 33B | - | 53.1 |
| LLaMA | 65B | - | 69.7 |
| Minerva | 8B | - | 28.4 |
| Minerva | 62B | - | 68.5 |
| Minerva | 540B | - | 78.5 |
| Finetuning results | |||
| LaMDA | 137B | 81.2 | - |
| GPT-Neo | 125M | 84.7 | - |
| GPT-Neo | 2.7B | - | 41.4 |
| CodeGen-mono | 350M | 83.1 | 38.7 |
| CodeGen-mono | 2B | 85.6 | 47.8 |
| CodeT5 | 220M | 71.5 | 58.4 |
| CodeT5+ | 220M | 85.6 | 70.5 |
| CodeT5+ | 770M | 87.4 | 73.8 |
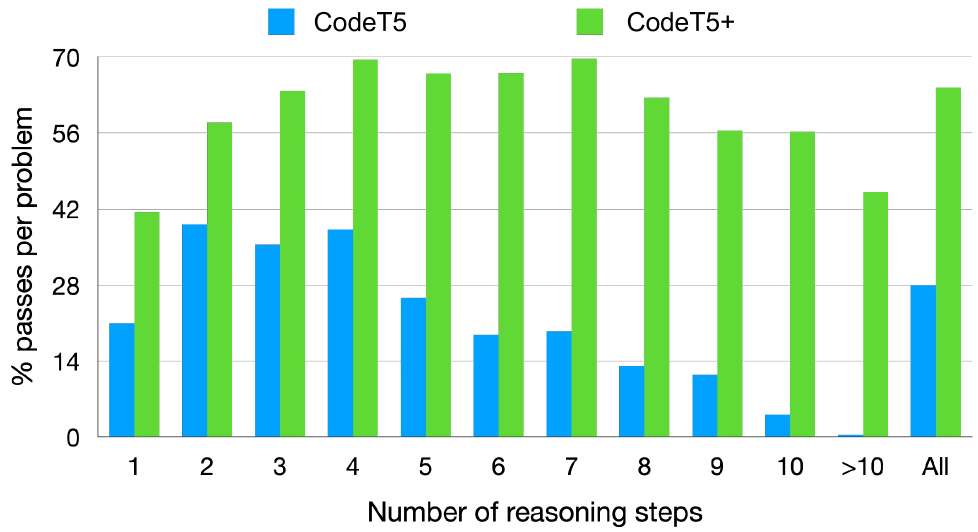
表3显示CodeT5+取得了显着的性能提升,优于许多规模更大的代码大语言模型。 具体来说,我们的 CodeT5+ 770M 在 MathQA-Python 上取得了新的 SoTA 结果 pass@80,在 GSM8K-Python 上取得了非常有竞争力的结果 pass@100。 在 GSM8K-Python 上,CodeT5+ 770M 相对于其他较大模型(例如 GPT-Neo 2.7B 和 CodeGen-mono 2B)实现了最佳微调结果,并且在少样本评估设置中优于 LaMDA 137B 和 code-davinci。 我们确实观察到我们的模型与 Minerva (Lewkowycz 等人,2022) 仍然存在一些性能差距。 请注意,该模型是使用预训练的 PaLM (Chowdhery 等人,2022) 进行初始化,并使用大规模科学语料库进行进一步微调。 该模型还采用多数投票策略来选择最常见的答案作为最终预测。
5.3 代码摘要任务评估
| Model | Ruby | JS | Go | Python | Java | PHP | Overall |
|---|---|---|---|---|---|---|---|
| RoBERTa 125M | 11.17 | 11.90 | 17.72 | 18.14 | 16.47 | 24.02 | 16.57 |
| CodeBERT 125M | 12.16 | 14.90 | 18.07 | 19.06 | 17.65 | 25.16 | 17.83 |
| UniXcoder 125M | 14.87 | 15.85 | 19.07 | 19.13 | 20.31 | 26.54 | 19.30 |
| CodeGen-multi 350M | 13.48 | 16.54 | 18.09 | 18.31 | 19.41 | 24.41 | 18.37 |
| PLBART 140M | 14.11 | 15.56 | 18.91 | 19.30 | 18.45 | 23.58 | 18.32 |
| CodeT5 220M | 15.24 | 16.16 | 19.56 | 20.01 | 20.31 | 26.03 | 19.55 |
| CodeT5+ 220M | 15.51 | 16.27 | 19.60 | 20.16 | 20.53 | 26.78 | 19.81 |
| CodeT5+ 770M | 15.63 | 17.93 | 19.64 | 20.47 | 20.83 | 26.39 | 20.15 |
代码摘要任务旨在将代码片段摘要为自然语言文档字符串。 我们使用六种编程语言的 CodeSearchNet 数据集(Husain 等人,2019) 的干净版本来评估我们针对此任务的模型。 我们采用 BLEU-4 (Lin 和 Och,2004) 作为性能指标,衡量预测和真实摘要之间基于标记的相似性。 从预训练的 CodeT5+ 中,我们为此任务激活编码器和解码器。
从表4中,我们发现编码器-解码器模型(CodeT5和CodeT5+)通常优于仅编码器模型(Feng等人,2020)和仅解码器模型(Nijkamp等人,2023b),以及UniLM风格的模型UniXcoder(Guo等人,2022)。 这一观察结果证明了在 CodeT5+ 中使用编码器-解码器架构可以更好地编码代码上下文并生成更准确的代码摘要的好处。 最后,我们还观察到相对于 CodeT5 (Wang 等人,2021b) 的一些性能提升,这表明除了 CodeT5 中的跨度去噪目标之外,我们提出的混合预训练学习目标的优势。
5.4代码完成任务评估
| Model | PY150 | JavaCorpus | ||
|---|---|---|---|---|
| EM | Edit Sim | EM | Edit Sim | |
| CodeGPT 124M | 42.37 | 71.59 | 30.60 | 63.45 |
| UniXcoder 125M | 43.12 | 72.00 | 32.90 | 65.78 |
| CodeGen-multi 350M | 42.47 | 70.67 | 35.47 | 69.22 |
| PLBART 140M | 38.01 | 68.46 | 26.97 | 61.59 |
| CodeT5 220M | 36.97 | 67.12 | 24.80 | 58.31 |
| CodeT5+ 220M | 43.42 | 73.69 | 35.17 | 69.48 |
| CodeT5+ 770M | 44.86 | 74.22 | 37.90 | 72.25 |
我们通过行级代码完成任务来评估 CodeT5+ 的仅解码器生成能力,该任务旨在基于先前的代码上下文完成下一个代码行。 我们使用 CodeXGLUE 中的 PY150 (Raychev 等人,2016) 和 GitHub JavaCorpus (Allamanis 和 Sutton,2013),并使用精确匹配 (EM) 准确性和 Levenshtein 编辑相似度 (Svyatkovskiy 等人, 2020a) 作为评估指标。 在此任务中,我们采用 CodeT5+ 中的仅解码器模型,以便仅激活总模型参数的大约一半。
表 5显示CodeT5+(仅解码器模式)和仅解码器模型(顶部块)的性能显着优于编码器-解码器模型(中间块),验证仅解码器模型可以更好地适应本质上的代码完成任务。 具体来说,CodeT5+ 220M 已经超越了 UniXcoder,并实现了与 CodeGen-multi 350M 相当的性能,而 770M 在这两个指标上都进一步创下了新的 SoTA 结果。 特别是,CodeT5+ 220M 比相同大小的 CodeT5 模型有了显着的改进,在 PY150 和 JavaCorpus 上分别获得 +6.5 EM 和 +10.4 EM 分数。 这主要是由于我们在第一阶段预训练中的因果LM训练目标,它允许解码器看到更长的序列,而不是CodeT5中离散跨度的组合,从而获得更好的因果生成能力。
5.5 文本到代码检索任务的评估
| Model | CodeSearchNet | CosQA | AdvTest | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Ruby | JS | Go | Python | Java | PHP | Overall | |||
| CodeBERT 125M | 67.9 | 62.0 | 88.2 | 67.2 | 67.6 | 62.8 | 69.3 | 65.7 | 27.2 |
| GraphCodeBERT 125M | 70.3 | 64.4 | 89.7 | 69.2 | 69.1 | 64.9 | 71.3 | 68.4 | 35.2 |
| SYNCOBERT 125M | 72.2 | 67.7 | 91.3 | 72.4 | 72.3 | 67.8 | 74.0 | - | 38.3 |
| UniXcoder 125M | 74.0 | 68.4 | 91.5 | 72.0 | 72.6 | 67.6 | 74.4 | 70.1 | 41.3 |
| CodeGen-multi 350M | 66.0 | 62.2 | 90.0 | 68.6 | 70.1 | 63.9 | 70.1 | 64.8 | 34.8 |
| PLBART 140M | 67.5 | 61.6 | 88.7 | 66.3 | 66.3 | 61.1 | 68.6 | 65.0 | 34.7 |
| CodeT5 220M | 71.9 | 65.5 | 88.8 | 69.8 | 68.6 | 64.5 | 71.5 | 67.8 | 39.3 |
| CodeT5+ 220M | 77.7 | 70.8 | 92.4 | 75.6 | 76.1 | 69.8 | 77.1 | 72.7 | 43.3 |
| CodeT5+ 770M | 78.0 | 71.3 | 92.7 | 75.8 | 76.2 | 70.1 | 77.4 | 74.0 | 44.7 |
我们通过跨多个 PL 的文本到代码检索任务来评估 CodeT5+ 的代码理解能力。 该任务旨在基于自然语言查询从候选代码集合中找到功能级别上语义最相关的代码片段。 我们考虑三个数据集进行评估:CodeSearchNet (Husain 等人, 2019)、CosQA (Huang 等人, 2021) 和 AdvTest (Lu 等人, 2021) ),它们是从原始的 CodeSearchNet 中通过过滤低质量查询的数据、采用现代搜索引擎的真实查询以及混淆标识符来标准化代码而策划的。 在此任务中,我们激活 CodeT5+ 的编码器和解码器,并使用平均倒数排名(MRR)作为评估指标。
从表6来看,我们的CodeT5+ 220M显着优于所有现有的仅编码器/仅解码器(顶部块)和编码器-解码器模型(中间的块)。 我们的 CodeT5+ 770M 进一步设定了新的 SoTA 结果,在 8 个数据集的所有 3 项任务上超过了之前的 SoTA UniXcoder 超过 3 个绝对 MRR 点。 这意味着 CodeT5+ 是一个强大的代码检索器模型,可以处理具有不同格式和 PL 的查询。 此外,CodeT5+ 220M 比相同大小的 CodeT5 模型具有显着的性能提升。 这些收益可归因于文本代码对比学习和匹配目标,促进更好的单峰和双峰表示学习。 特别是,与同样通过对比学习进行预训练的 SYNCOBERT 和 UniXcoder 相比,我们的模型取得了更好的结果,这可以归因于我们的文本代码匹配预训练任务,它能够利用更细粒度的文本代码对齐。
5.6消融研究
| Model | Code Completion | Math Programming | ||
|---|---|---|---|---|
| PY150 | JavaCorpus | MathQA-PY | GSM8K-PY | |
| EM | EM | pass@80 | pass@100 | |
| CodeT5+ 770M | 44.9 | 37.9 | 87.4 | 73.8 |
| a) no causal LM | 36.2 | 24.8 | 72.3 | 61.4 |
| Model | Text-to-code Retrieval | |||||||
|---|---|---|---|---|---|---|---|---|
| Ruby | JS | Go | Python | Java | PHP | Overall | ||
| CodeT5+ 770M | 78.0 | 71.3 | 92.7 | 75.8 | 76.2 | 70.1 | 77.4 | |
| b) | no matching | 76.2 | 68.5 | 91.2 | 72.8 | 73.6 | 66.3 | 74.8 |
| no causal LM | 77.3 | 70.6 | 92.4 | 75.7 | 75.6 | 68.9 | 76.8 | |
我们进行了一项消融研究,以分析我们提出的预训练目标的影响:a)第一阶段单峰预训练的休闲 LM 目标,涉及两项生成任务,包括代码完成和数学编程,b)文本代码匹配和因果 LM 目标第 2 阶段关于文本到代码检索的理解任务的双峰预训练。 我们采用 CodeT5+ 770M 并在 Table 7 中报告 10 个数据集的三个代表性任务的结果。 在 CodeT5+ 中,我们发现因果 LM 目标在代码完成和数学编程任务中起着至关重要的作用,删除它后性能显着下降。 这表明因果 LM 可以补充跨度去噪目标并提高模型的生成能力。 此外,我们发现文本代码匹配目标对于检索性能至关重要(平均 下降)。 MRR 超过 6 个数据集(没有它),这意味着这个目标可以学习更好的双峰表示,捕获文本和代码之间的细粒度对齐。 此外,我们发现检索任务也可以从具有因果 LM 目标的联合训练中受益,尽管它们的任务存在差异。
| Model | Java | Python | ||||
|---|---|---|---|---|---|---|
| EM | B4 | CB | EM | B4 | CB | |
| Retrieval-based | ||||||
| BM25 | 0.00 | 4.90 | 16.00 | 0.00 | 6.63 | 13.49 |
| SCODE-R 125M | 0.00 | 25.34 | 26.68 | 0.00 | 22.75 | 23.92 |
| CodeT5+ 220M | 0.00 | 28.74 | 31.00 | 0.00 | 27.30 | 26.51 |
| Generative | ||||||
| CodeBERT 125M | 0.00 | 8.38 | 14.52 | 0.00 | 4.06 | 10.42 |
| GraphCodeBERT 125M | 0.00 | 7.86 | 14.53 | 0.00 | 3.97 | 10.55 |
| PLBART 140M | 0.00 | 10.10 | 14.96 | 0.00 | 4.89 | 12.01 |
| CodeT5+ 220M | 0.00 | 10.33 | 20.54 | 0.00 | 4.40 | 13.88 |
| Retrieval-Augmented Generative | ||||||
| REDCODER-EXT 125M+140M | 10.21 | 28.98 | 33.18 | 9.61 | 24.43 | 30.21 |
| CodeT5+ 220M | 11.66 | 33.83 | 40.60 | 11.83 | 31.14 | 36.39 |
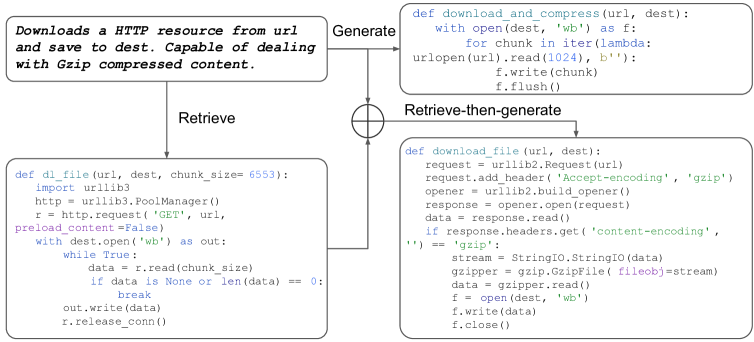
5.7统一检索-增强生成范式
由于我们的模型能够进行代码检索和生成,因此它可以自然地用作统一的半参数检索增强生成器。 为了探索这种适应,我们按照Parvez等人(2021)通过反转Java和Python上代码摘要的输入和输出顺序并使用其发布的重复数据删除检索代码库来评估两个代码生成任务。 我们在三种设置中评估我们的模型:基于检索、生成和检索增强(RA)生成。 对于基于检索的设置,我们激活编码器来检索 top-1 代码样本作为给定文本查询的预测,而对于 RA 生成设置,我们附加 top- 检索样本的组合(在我们的工作中=1)到编码器输入并激活解码器。
如表 8所示,我们发现我们的CodeT5+在所有类别中都取得了更好的结果,特别是在基于检索和RA生成设置中。 虽然之前的 SoTA 模型 REDCODER-EXT (Parvez 等人, 2021) 分别采用 GraphCodeBERT 作为检索器和 PLBART 作为生成器,但我们的模型可以灵活地用作端到端系统检索和生成能力。 我们进一步在图7中包含一个定性案例,我们发现检索到的代码提供了关键的上下文(例如,使用“urllib3” HTTP 请求)来指导生成过程以实现更正确的预测。 相比之下,仅生成模型给出了错误的预测,仅捕获了“下载”和“压缩”的概念。 此外,我们还分析了各种 top- 检索对代码生成性能的影响(参见附录C.2)。
6结论
我们推出了 CodeT5+,这是一个新的开放代码大语言模型系列,具有编码器-解码器架构,可以在不同模式(仅编码器、仅解码器和编码器-解码器)下灵活运行,以支持广泛的代码理解和生成任务。 对于训练 CodeT5+,我们引入了预训练任务的混合,包括跨度去噪、因果语言建模、对比学习和文本代码匹配,以从单峰代码数据和双峰代码文本数据中学习丰富的表示。 此外,我们提出了一种简单而有效的计算效率训练方法,用冻结的现成大语言模型来初始化我们的模型,以有效地扩展模型。 我们探索进一步的指令调整,以使模型与自然语言指令保持一致。 在 数据集上对广泛的代码智能任务进行的广泛实验验证了我们模型的优越性。 特别是,在零样本HumanEval代码生成任务中,我们的指令调整CodeT5+ 16B针对其他开放代码建立了新的SoTA结果 pass@1和 pass@10甚至超越了 OpenAI code-cushman-001 模型。 最后,我们展示了 CodeT5+ 部署为统一检索增强生成系统的灵活性。
参考
- Ahmad et al. (2021) W. U. Ahmad, S. Chakraborty, B. Ray, and K. Chang. Unified pre-training for program understanding and generation. In NAACL-HLT, pages 2655–2668. Association for Computational Linguistics, 2021.
- Alayrac et al. (2022) J. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y. Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynolds, R. Ring, E. Rutherford, S. Cabi, T. Han, Z. Gong, S. Samangooei, M. Monteiro, J. L. Menick, S. Borgeaud, A. Brock, A. Nematzadeh, S. Sharifzadeh, M. Binkowski, R. Barreira, O. Vinyals, A. Zisserman, and K. Simonyan. Flamingo: a visual language model for few-shot learning. In NeurIPS, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/960a172bc7fbf0177ccccbb411a7d800-Abstract-Conference.html.
- Allamanis and Sutton (2013) M. Allamanis and C. Sutton. Mining source code repositories at massive scale using language modeling. In MSR, pages 207–216. IEEE Computer Society, 2013.
- Amini et al. (2019) A. Amini, S. Gabriel, S. Lin, R. Koncel-Kedziorski, Y. Choi, and H. Hajishirzi. MathQA: Towards interpretable math word problem solving with operation-based formalisms. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2357–2367, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1245. URL https://aclanthology.org/N19-1245.
- Austin et al. (2021) J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
- Black et al. (2021) S. Black, G. Leo, P. Wang, C. Leahy, and S. Biderman. Gpt-neo: Large scale autoregressive language modeling with mesh-tensorflow, march 2021. URL https://doi. org/10.5281/zenodo, 5297715, 2021.
- Black et al. (2022) S. Black, S. Biderman, E. Hallahan, Q. Anthony, L. Gao, L. Golding, H. He, C. Leahy, K. McDonell, J. Phang, M. Pieler, U. S. Prashanth, S. Purohit, L. Reynolds, J. Tow, B. Wang, and S. Weinbach. GPT-NeoX-20B: An open-source autoregressive language model. In Proceedings of the ACL Workshop on Challenges & Perspectives in Creating Large Language Models, 2022. URL https://arxiv.org/abs/2204.06745.
- Chakraborty et al. (2022) S. Chakraborty, T. Ahmed, Y. Ding, P. Devanbu, and B. Ray. Natgen: generative pre-training by “naturalizing” source code. Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2022.
- Chaudhary (2023) S. Chaudhary. Code alpaca: An instruction-following llama model for code generation. https://github.com/sahil280114/codealpaca, 2023.
- Chen et al. (2023) B. Chen, F. Zhang, A. Nguyen, D. Zan, Z. Lin, J.-G. Lou, and W. Chen. Codet: Code generation with generated tests. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=ktrw68Cmu9c.
- Chen et al. (2021) M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- Chowdhery et al. (2022) A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, P. Schuh, K. Shi, S. Tsvyashchenko, J. Maynez, A. Rao, P. Barnes, Y. Tay, N. Shazeer, V. Prabhakaran, E. Reif, N. Du, B. Hutchinson, R. Pope, J. Bradbury, J. Austin, M. Isard, G. Gur-Ari, P. Yin, T. Duke, A. Levskaya, S. Ghemawat, S. Dev, H. Michalewski, X. Garcia, V. Misra, K. Robinson, L. Fedus, D. Zhou, D. Ippolito, D. Luan, H. Lim, B. Zoph, A. Spiridonov, R. Sepassi, D. Dohan, S. Agrawal, M. Omernick, A. M. Dai, T. S. Pillai, M. Pellat, A. Lewkowycz, E. Moreira, R. Child, O. Polozov, K. Lee, Z. Zhou, X. Wang, B. Saeta, M. Diaz, O. Firat, M. Catasta, J. Wei, K. Meier-Hellstern, D. Eck, J. Dean, S. Petrov, and N. Fiedel. Palm: Scaling language modeling with pathways. CoRR, abs/2204.02311, 2022.
- Cobbe et al. (2021) K. Cobbe, V. Kosaraju, M. Bavarian, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems. CoRR, abs/2110.14168, 2021.
- Devlin et al. (2019) J. Devlin, M. Chang, K. Lee, and K. Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pages 4171–4186, 2019.
- Dong et al. (2019) L. Dong, N. Yang, W. Wang, F. Wei, X. Liu, Y. Wang, J. Gao, M. Zhou, and H. Hon. Unified language model pre-training for natural language understanding and generation. In H. M. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. B. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pages 13042–13054, 2019.
- Feng et al. (2020) Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jiang, and M. Zhou. Codebert: A pre-trained model for programming and natural languages. In EMNLP (Findings), volume EMNLP 2020 of Findings of ACL, pages 1536–1547. Association for Computational Linguistics, 2020.
- Fried et al. (2022) D. Fried, A. Aghajanyan, J. Lin, S. Wang, E. Wallace, F. Shi, R. Zhong, W. Yih, L. Zettlemoyer, and M. Lewis. Incoder: A generative model for code infilling and synthesis. CoRR, abs/2204.05999, 2022.
- Guo et al. (2021) D. Guo, S. Ren, S. Lu, Z. Feng, D. Tang, S. Liu, L. Zhou, N. Duan, A. Svyatkovskiy, S. Fu, M. Tufano, S. K. Deng, C. B. Clement, D. Drain, N. Sundaresan, J. Yin, D. Jiang, and M. Zhou. Graphcodebert: Pre-training code representations with data flow. In ICLR. OpenReview.net, 2021.
- Guo et al. (2022) D. Guo, S. Lu, N. Duan, Y. Wang, M. Zhou, and J. Yin. Unixcoder: Unified cross-modal pre-training for code representation. In ACL (1), pages 7212–7225. Association for Computational Linguistics, 2022.
- He et al. (2020) K. He, H. Fan, Y. Wu, S. Xie, and R. B. Girshick. Momentum contrast for unsupervised visual representation learning. In CVPR, pages 9726–9735. Computer Vision Foundation / IEEE, 2020.
- Hendrycks et al. (2021) D. Hendrycks, S. Basart, S. Kadavath, M. Mazeika, A. Arora, E. Guo, C. Burns, S. Puranik, H. He, D. Song, and J. Steinhardt. Measuring coding challenge competence with apps. NeurIPS, 2021.
- Hu et al. (2022) E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9.
- Huang et al. (2021) J. Huang, D. Tang, L. Shou, M. Gong, K. Xu, D. Jiang, M. Zhou, and N. Duan. Cosqa: 20, 000+ web queries for code search and question answering. In ACL/IJCNLP (1), pages 5690–5700. Association for Computational Linguistics, 2021.
- Husain et al. (2019) H. Husain, H. Wu, T. Gazit, M. Allamanis, and M. Brockschmidt. Codesearchnet challenge: Evaluating the state of semantic code search. CoRR, abs/1909.09436, 2019.
- Johnson et al. (2019) J. Johnson, M. Douze, and H. Jégou. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 7(3):535–547, 2019.
- Karpukhin et al. (2020) V. Karpukhin, B. Oguz, S. Min, P. S. H. Lewis, L. Wu, S. Edunov, D. Chen, and W. Yih. Dense passage retrieval for open-domain question answering. In EMNLP (1), pages 6769–6781. Association for Computational Linguistics, 2020.
- Krause et al. (2021) B. Krause, A. D. Gotmare, B. McCann, N. S. Keskar, S. Joty, R. Socher, and N. F. Rajani. GeDi: Generative discriminator guided sequence generation. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 4929–4952, Punta Cana, Dominican Republic, Nov. 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.findings-emnlp.424. URL https://aclanthology.org/2021.findings-emnlp.424.
- Le et al. (2022) H. Le, Y. Wang, A. D. Gotmare, S. Savarese, and S. C. H. Hoi. Coderl: Mastering code generation through pretrained models and deep reinforcement learning. In NeurIPS, 2022.
- Lester et al. (2021) B. Lester, R. Al-Rfou, and N. Constant. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, Online and Punta Cana, Dominican Republic, Nov. 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.243. URL https://aclanthology.org/2021.emnlp-main.243.
- Lewkowycz et al. (2022) A. Lewkowycz, A. J. Andreassen, D. Dohan, E. Dyer, H. Michalewski, V. V. Ramasesh, A. Slone, C. Anil, I. Schlag, T. Gutman-Solo, Y. Wu, B. Neyshabur, G. Gur-Ari, and V. Misra. Solving quantitative reasoning problems with language models. In A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=IFXTZERXdM7.
- Li et al. (2021) J. Li, R. R. Selvaraju, A. Gotmare, S. R. Joty, C. Xiong, and S. C. Hoi. Align before fuse: Vision and language representation learning with momentum distillation. In NeurIPS, pages 9694–9705, 2021.
- Li et al. (2022a) J. Li, D. Li, C. Xiong, and S. C. H. Hoi. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation. In ICML, volume 162 of Proceedings of Machine Learning Research, pages 12888–12900. PMLR, 2022a.
- Li et al. (2023) R. Li, L. B. Allal, Y. Zi, N. Muennighoff, D. Kocetkov, C. Mou, M. Marone, C. Akiki, J. Li, J. Chim, Q. Liu, E. Zheltonozhskii, T. Y. Zhuo, T. Wang, O. Dehaene, M. Davaadorj, J. Lamy-Poirier, J. Monteiro, O. Shliazhko, N. Gontier, N. Meade, A. Zebaze, M. Yee, L. K. Umapathi, J. Zhu, B. Lipkin, M. Oblokulov, Z. Wang, R. M. V, J. Stillerman, S. S. Patel, D. Abulkhanov, M. Zocca, M. Dey, Z. Zhang, N. Fahmy, U. Bhattacharyya, W. Yu, S. Singh, S. Luccioni, P. Villegas, M. Kunakov, F. Zhdanov, M. Romero, T. Lee, N. Timor, J. Ding, C. Schlesinger, H. Schoelkopf, J. Ebert, T. Dao, M. Mishra, A. Gu, J. Robinson, C. J. Anderson, B. Dolan-Gavitt, D. Contractor, S. Reddy, D. Fried, D. Bahdanau, Y. Jernite, C. M. Ferrandis, S. Hughes, T. Wolf, A. Guha, L. von Werra, and H. de Vries. Starcoder: may the source be with you! CoRR, abs/2305.06161, 2023.
- Li et al. (2022b) Y. Li, D. H. Choi, J. Chung, N. Kushman, J. Schrittwieser, R. Leblond, T. Eccles, J. Keeling, F. Gimeno, A. D. Lago, T. Hubert, P. Choy, C. de Masson d’Autume, I. Babuschkin, X. Chen, P. Huang, J. Welbl, S. Gowal, A. Cherepanov, J. Molloy, D. J. Mankowitz, E. S. Robson, P. Kohli, N. de Freitas, K. Kavukcuoglu, and O. Vinyals. Competition-level code generation with alphacode. CoRR, abs/2203.07814, 2022b.
- Lin and Och (2004) C. Lin and F. J. Och. ORANGE: a method for evaluating automatic evaluation metrics for machine translation. In COLING, 2004.
- Liu et al. (2021) X. Liu, Y. Zheng, Z. Du, M. Ding, Y. Qian, Z. Yang, and J. Tang. Gpt understands, too. arXiv preprint arXiv:2103.10385, 2021.
- Liu et al. (2022) X. Liu, K. Ji, Y. Fu, W. Tam, Z. Du, Z. Yang, and J. Tang. P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 61–68, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-short.8. URL https://aclanthology.org/2022.acl-short.8.
- Liu et al. (2019) Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov. Roberta: A robustly optimized BERT pretraining approach. CoRR, abs/1907.11692, 2019.
- Loshchilov and Hutter (2019) I. Loshchilov and F. Hutter. Decoupled weight decay regularization. In ICLR (Poster). OpenReview.net, 2019.
- Lu et al. (2021) S. Lu, D. Guo, S. Ren, J. Huang, A. Svyatkovskiy, A. Blanco, C. B. Clement, D. Drain, D. Jiang, D. Tang, G. Li, L. Zhou, L. Shou, L. Zhou, M. Tufano, M. Gong, M. Zhou, N. Duan, N. Sundaresan, S. K. Deng, S. Fu, and S. Liu. Codexglue: A machine learning benchmark dataset for code understanding and generation. In NeurIPS Datasets and Benchmarks, 2021.
- Nguyen et al. (2023) A. Nguyen, N. Karampatziakis, and W. Chen. Meet in the middle: A new pre-training paradigm. arXiv preprint arXiv:2303.07295, 2023.
- Ni et al. (2022) A. Ni, J. P. Inala, C. Wang, O. Polozov, C. Meek, D. R. Radev, and J. Gao. Learning from self-sampled correct and partially-correct programs. CoRR, abs/2205.14318, 2022.
- Nijkamp et al. (2023a) E. Nijkamp, H. Hayashi, C. Xiong, S. Savarese, and Y. Zhou. Codegen2: Lessons for training llms on programming and natural languages. arXiv preprint, 2023a.
- Nijkamp et al. (2023b) E. Nijkamp, B. Pang, H. Hayashi, L. Tu, H. Wang, Y. Zhou, S. Savarese, and C. Xiong. Codegen: An open large language model for code with multi-turn program synthesis. In The Eleventh International Conference on Learning Representations, 2023b. URL https://openreview.net/forum?id=iaYcJKpY2B_.
- Niu et al. (2022) C. Niu, C. Li, V. Ng, J. Ge, L. Huang, and B. Luo. Spt-code: Sequence-to-sequence pre-training for learning source code representations. In ICSE, pages 1–13. ACM, 2022.
- OpenAI (2023) OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- Ouyang et al. (2022) L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Gray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, and R. Lowe. Training language models to follow instructions with human feedback. In A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=TG8KACxEON.
- Parvez et al. (2021) M. R. Parvez, W. U. Ahmad, S. Chakraborty, B. Ray, and K. Chang. Retrieval augmented code generation and summarization. In EMNLP (Findings), pages 2719–2734. Association for Computational Linguistics, 2021.
- Ponti et al. (2023) E. M. Ponti, A. Sordoni, Y. Bengio, and S. Reddy. Combining parameter-efficient modules for task-level generalisation. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 687–702, Dubrovnik, Croatia, May 2023. Association for Computational Linguistics. URL https://aclanthology.org/2023.eacl-main.49.
- Radford et al. (2019) A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Raffel et al. (2020) C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21:140:1–140:67, 2020.
- Rasley et al. (2020) J. Rasley, S. Rajbhandari, O. Ruwase, and Y. He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In KDD, pages 3505–3506. ACM, 2020.
- Raychev et al. (2016) V. Raychev, P. Bielik, and M. T. Vechev. Probabilistic model for code with decision trees. In OOPSLA, pages 731–747. ACM, 2016.
- replit (2023) replit. replit-code-v1-3b, 2023. URL https://huggingface.co/replit/replit-code-v1-3b.
- Soltan et al. (2022) S. Soltan, S. Ananthakrishnan, J. FitzGerald, R. Gupta, W. Hamza, H. Khan, C. Peris, S. Rawls, A. Rosenbaum, A. Rumshisky, C. S. Prakash, M. Sridhar, F. Triefenbach, A. Verma, G. Tür, and P. Natarajan. Alexatm 20b: Few-shot learning using a large-scale multilingual seq2seq model. CoRR, abs/2208.01448, 2022.
- Sung et al. (2022) Y.-L. Sung, J. Cho, and M. Bansal. Vl-adapter: Parameter-efficient transfer learning for vision-and-language tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5227–5237, June 2022.
- Svajlenko et al. (2014) J. Svajlenko, J. F. Islam, I. Keivanloo, C. K. Roy, and M. M. Mia. Towards a big data curated benchmark of inter-project code clones. In 2014 IEEE International Conference on Software Maintenance and Evolution, pages 476–480. IEEE, 2014.
- Svyatkovskiy et al. (2020a) A. Svyatkovskiy, S. K. Deng, S. Fu, and N. Sundaresan. Intellicode compose: code generation using transformer. In ESEC/SIGSOFT FSE, pages 1433–1443. ACM, 2020a.
- Svyatkovskiy et al. (2020b) A. Svyatkovskiy, S. K. Deng, S. Fu, and N. Sundaresan. Intellicode compose: code generation using transformer. In ESEC/SIGSOFT FSE, pages 1433–1443. ACM, 2020b.
- Tabachnyk and Nikolov (2022) M. Tabachnyk and S. Nikolov. Ml-enhanced code completion improves developer productivity, 2022.
- Taori et al. (2023) R. Taori, I. Gulrajani, T. Zhang, Y. Dubois, X. Li, C. Guestrin, P. Liang, and T. B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- Tay et al. (2022) Y. Tay, M. Dehghani, V. Q. Tran, X. Garcia, D. Bahri, T. Schuster, H. S. Zheng, N. Houlsby, and D. Metzler. Unifying language learning paradigms. CoRR, abs/2205.05131, 2022.
- Touvron et al. (2023) H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Vaswani et al. (2017) A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Wang and Komatsuzaki (2021) B. Wang and A. Komatsuzaki. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. https://github.com/kingoflolz/mesh-transformer-jax, May 2021.
- Wang et al. (2021a) X. Wang, Y. Wang, F. Mi, P. Zhou, Y. Wan, X. Liu, L. Li, H. Wu, J. Liu, and X. Jiang. Syncobert: Syntax-guided multi-modal contrastive pre-training for code representation. arXiv preprint arXiv:2108.04556, 2021a.
- Wang et al. (2022a) X. Wang, Y. Wang, Y. Wan, J. Wang, P. Zhou, L. Li, H. Wu, and J. Liu. CODE-MVP: Learning to represent source code from multiple views with contrastive pre-training. In Findings of the Association for Computational Linguistics: NAACL 2022, pages 1066–1077, Seattle, United States, July 2022a. Association for Computational Linguistics. doi: 10.18653/v1/2022.findings-naacl.80. URL https://aclanthology.org/2022.findings-naacl.80.
- Wang et al. (2021b) Y. Wang, W. Wang, S. R. Joty, and S. C. H. Hoi. Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation. In EMNLP (1), pages 8696–8708. Association for Computational Linguistics, 2021b.
- Wang et al. (2022b) Y. Wang, Y. Kordi, S. Mishra, A. Liu, N. A. Smith, D. Khashabi, and H. Hajishirzi. Self-instruct: Aligning language model with self generated instructions. arXiv preprint arXiv:2212.10560, 2022b.
- Xu et al. (2020) J. Xu, D. Ju, M. Li, Y.-L. Boureau, J. Weston, and E. Dinan. Recipes for safety in open-domain chatbots. arXiv preprint arXiv:2010.07079, 2020.
- Zheng et al. (2023) Q. Zheng, X. Xia, X. Zou, Y. Dong, S. Wang, Y. Xue, Z. Wang, L. Shen, A. Wang, Y. Li, T. Su, Z. Yang, and J. Tang. Codegeex: A pre-trained model for code generation with multilingual evaluations on humaneval-x, 2023.
- Zhou et al. (2019) Y. Zhou, S. Liu, J. Siow, X. Du, and Y. Liu. Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks. Advances in neural information processing systems, 32, 2019.
附录 A道德声明
代码理解和生成系统的进步具有巨大的潜力,可以通过自然语言界面提高编程的可访问性和提高开发人员的生产力,从而产生积极的社会影响。 然而,大规模部署此类系统需要仔细考虑各种道德方面,正如 Chen 等人 [2021] 所广泛讨论的那样。
一个关键问题是生成的代码摘要或注释包含有毒或不敏感语言的潜在风险,这可能会产生有害影响。 一些研究探索了解决这个问题的技术,例如强化学习[Ouyang等人,2022]、加权解码[Krause等人,2021]和安全特定控制 Token [Xu 等人, 2020]。 这些方法旨在确保无毒的自然语言生成,促进对代码的大型语言模型的负责任和合乎道德的使用。
此外,在部署之前必须认识到代码生成和检索系统更广泛的知识产权影响。 生成代码的深度学习模型可能会无意中引入安全漏洞。 为了减轻这种风险,在采用此类代码之前进行专家审查和严格的安全评估至关重要。 此审查过程可确保生成的代码符合必要的安全标准,从而防止潜在的漏洞和漏洞。 在代码检索场景中,提供适当的来源归属以及检索结果至关重要。 这种归属不仅尊重代码作者的权利,而且还增强了编程社区内的透明度、可追溯性和协作。 通过承认原作者并促进协作、道德和合法的环境,代码检索系统可以促进知识共享并为信誉良好的编程生态系统做出贡献。
通过考虑这些道德因素,我们可以促进负责任地部署大型代码语言模型,最大限度地提高其潜在利益,同时减轻对个人、社区和整个软件生态系统的潜在危害。 在开发和部署这些系统时必须优先考虑安全、无毒、知识产权、安保和协作,确保它们符合道德原则和社会需求。
附录B双峰预训练详细信息
为了在更多样化的预训练数据集上公开模型,我们采用分阶段的预训练过程,首先在具有跨度去噪和因果语言建模 (CLM) 任务的大规模纯代码数据上进行 CodeT5+,然后在较小的任务上进行预训练使用文本代码对比学习、匹配和因果 LM 任务的文本代码双模型数据集。 下面,我们提供了第二阶段文本代码对预训练的文本代码对比学习和匹配任务的详细公式。
文本-代码对比学习
激活编码器通过计算相似性分数来学习更好的单峰(文本/代码)表示,使得并行文本代码对具有更高的分数。 给定文本 T 和代码 C,我们首先学习文本 的表示 ,以及代码 的表示 ,方法是将 [CLS] 嵌入映射到编码器的归一化低维 (256-d) 表示。 给定一批文本-代码对,我们获得文本向量和代码向量来计算文本到代码和代码到文本和相似之处:
| (1) |
| (2) |
其中 表示第 对的文本和第 对的代码的文本到代码的相似性,以及 是代码到文本的相似度,是学习到的温度参数。 和 是第 个文本和代码的 softmax 归一化文本到代码和代码到文本相似度。
令 和 表示真实的单热相似度,其中负对的概率为 0,正对的概率为 1。 文本代码对语料库 的文本代码对比损失定义为 和 之间的交叉熵 H:
| (3) |
文本代码匹配
激活具有双模匹配功能的解码器,以预测一对文本和代码是正(匹配)还是负(不匹配)。 我们使用 [EOS] 词符的输出嵌入作为文本代码对(,)的融合双峰表示,如下所示词符关注文本代码对输入的所有先前上下文。 接下来是线性层和 softmax,我们计算二类概率 并定义匹配损失:
| (4) |
其中 是表示真实标签的二维单热向量。
文本代码因果 LM。
该任务重点关注通过双重多模态转换实现文本和代码之间的跨模态因果 LM 目标:文本到代码生成和代码到文本生成(即代码摘要)。 让 和 表示文本到代码和代码到文本生成的损失。 我们的 CodeT5+ 的完整第二阶段预训练损失是:
| (5) |
附录C其他实验结果
在本节中,我们提供了额外的实验结果,包括来自 CodeXGLUE 基准测试的代码缺陷检测和克隆检测的两个理解任务[Lu 等人,2021](Sec.) > C.1),分析检索增强代码生成任务中 top-k 检索的效果(Sec. C .2),以及数学编程任务中的更多定性结果(Sec. C.3)。
C.1 CodeXGLUE 的代码缺陷检测和克隆检测
| Model | Defect | Clone Detection | ||
|---|---|---|---|---|
| Acc | Rec | Prec | F1 | |
| CodeBERT 125M | 62.1 | 94.7 | 93.4 | 94.1 |
| GraphCodeBERT 125M | - | 94.8 | 95.2 | 95.0 |
| UniXcoder 125M | - | 92.9 | 97.6 | 95.2 |
| CodeGen-multi 350M | 63.1 | 94.1 | 93.2 | 93.6 |
| PLBART 140M | 63.2 | 94.8 | 92.5 | 93.6 |
| CodeT5 220M | 65.8 | 95.1 | 94.9 | 95.0 |
| CodeT5+ 220M | 66.1 | 96.4 | 94.1 | 95.2 |
| CodeT5+ 770M | 66.7 | 96.7 | 93.5 | 95.1 |
缺陷检测是为了预测代码是否容易受到软件系统的攻击,而克隆检测的目的是衡量两个代码片段之间的相似性并预测它们是否具有共同的功能。 我们使用 CodeXGLUE [Lu 等人, 2021] 的基准,并使用准确性和 F1 分数作为指标。 在表9中,我们可以看到CodeT5+模型在缺陷检测任务上实现了66.7%的新SoTA准确率。 对于克隆检测任务,我们的模型取得了与 SoTA 模型相当的结果,通过多个基线之间的紧密性能差距观察到,性能增长趋于饱和。
C.2Top-k检索在检索增强代码生成中的效果分析
| Model | Java | Python | ||||
|---|---|---|---|---|---|---|
| EM | B4 | CB | EM | B4 | CB | |
| SOTA (top-10) | 10.21 | 28.98 | 33.18 | 9.61 | 24.43 | 30.21 |
| Ours | ||||||
| top-1 | 11.66 | 33.83 | 40.60 | 11.83 | 31.14 | 36.39 |
| top-2 | 11.57 | 33.26 | 40.74 | 11.78 | 31.21 | 36.58 |
| top-3 | 12.29 | 33.10 | 41.71 | 12.48 | 30.92 | 37.31 |
| top-4 | 12.42 | 32.08 | 41.94 | 12.73 | 30.40 | 37.60 |
| top-5 | 13.02 | 32.42 | 42.28 | 12.93 | 30.52 | 37.87 |
| top-10 | 12.86 | 31.38 | 42.24 | 12.84 | 29.79 | 37.79 |
我们进一步进行了消融研究,以分析 top- 检索在检索增强代码生成任务中的效果,并在 Table 10 中报告结果t3>。 我们发现增加检索次数可以提高模型性能,当 =5 时,模型性能变得饱和。 这种饱和是由于 的最大序列长度造成的,它可能无法容纳大量检索到的代码示例。 总体而言,我们的 CodeT5+ 显着优于之前的 SOTA 基线,后者在所有情况下都使用 top-10 检索,即使只检索了 top-1 代码。
C.3 数学编程任务的定性结果
对于数学编程任务,我们在图8和图中提供了模型预测的定性示例> 9。 总的来说,我们发现 CodeT5+ 能够生成不错的程序,可以解决各种难度级别的数学问题,即从简单的数学运算到具有多个推理步骤的更复杂的问题。 从图9最右边的示例中,我们发现CodeT5+能够利用一些外部库,例如math 综合解决方案时。
附录D下游任务微调详细信息
D.1 文本到代码检索
文本到代码检索(或代码搜索)是从候选代码集合中查找与自然语言查询最相关的最佳代码示例的任务。 我们使用三个主要基准测试 CodeT5+:CodeSearchNet (CSN) [Husain 等人, 2019]、CosQA [Huang 等人, 2021] 和 AdvTest [Lu等人,2021]。 CSN 总共由六种编程语言组成,数据集是按照[郭等人,2021]通过手工规则过滤低质量查询来管理的。 例如,手工规则的示例是过滤查询中的标记数量小于或大于的示例。
CosQA 和 AdvTest 是源自 CSN 数据的两个相关基准。 具体来说,CosQA 不使用自然语言查询,而是使用 Microsoft Bing 搜索引擎的日志作为查询,每个查询由 3 名人工注释者[Huang 等人,2021] 进行注释。 AdvTest 是根据 CSN 数据的 Python 分割创建的,但代码示例使用模糊变量名称进行标准化,以更好地评估当前模型的理解能力。
对于训练,我们将代码和文本的最大序列设置为 350 和 64。 我们将学习率设置为 2e-5,并对模型进行 10 个 epoch 的微调。 我们在 8 台 A100 上采用分布式训练,总批量大小为 64。 对于动量编码器,我们维护一个大小为 57600 的单独文本/代码队列,并允许匹配解码器从队列中检索 64 个硬负数以进行硬负数挖掘。
D.2 代码总结
代码摘要是生成代码片段的自然语言摘要的任务。 我们使用 CodeXGLUE [Lu 等人, 2021] 中的任务数据集,该数据集根据 CSN 数据 [Husain 等人, 2019] 策划了代码摘要基准。 该基准测试由六个 PL 组成:Ruby、JavaScript、Go、Python、Java 和 PHP。 它与我们用于文本到代码检索任务的 CSN 数据相同。 对于训练,我们将源和目标的最大序列长度分别设置为 256 和 128。 我们使用 2e-5 的学习率,批量大小为 64,进行 10 轮的微调。 我们在推断中将光束尺寸设置为5。
D.3 代码缺陷检测
缺陷检测是对代码样本是否包含漏洞点进行分类的任务。 我们采用 CodeXGLUE [Lu 等人, 2021] 中的缺陷检测基准,该基准从 Devign 数据集 [Zhou 等人, 2019] 中整理数据。 该数据集总共包含超过 27,000 个带注释的 C 编程语言函数。 所有样本均来自流行的开源项目,例如 QEMU 和 FFmpeg。 我们遵循Lu等人[2021]并采用数据集的80%/10%/10%作为训练/验证/测试分割。 对于训练,我们将学习率设置为 2e-5,批量大小为 32,最大序列长度为 512,以对模型进行 10 个时期的微调。
D.4 代码克隆检测
克隆检测的任务旨在检测任意两个代码样本是否具有相同的功能或语义。 我们使用 CodeXGLUE [Lu 等人, 2021] 中的克隆检测基准进行实验。 该基准测试是根据 BigClone 基准数据集 [Svajlenko 等人,2014] 策划的,生成的策划数据分别包含 901,724/416,328/416,328 个训练/验证/测试分割的示例。 所有示例都分为 10 个不同的功能。 对于微调,我们将学习率设置为 2e-5,并对模型进行 2 个 epoch 的微调。 我们将批量大小设置为 10,最大序列长度设置为 400。
D.5 代码完成
在代码完成中,给定包含部分代码示例的源序列,需要一个模型来生成代码示例的剩余部分。 我们使用两个主要基准进行行级代码补全实验:PY150 [Raychev 等人, 2016] 和 JavaCorpus [Allamanis and Sutton, 2013]。 PY150 [Raychev 等人, 2016] 包含从 Github 收集的 150,000 个 Python 源文件。 在这些样本中,Lu等人[2021]从PY150的测试集中的不同文件中选择了10,000个样本,然后随机采样用于代码完成任务预测的行。 源序列和目标序列中的平均标记数分别为 489.1 和 6.6。 JavaCorpus [Allamanis 和 Sutton,2013] 包含从 GitHub 收集的 14,000 多个 Java 项目。 与PY150类似,Lu等人[2021]从数据集的测试集中的不同文件中选择了3000个样本,并随机采样行来预测代码完成任务。 源序列和目标序列中的平均标记数分别为 350.6 和 10.5。
对于这两个任务,我们将学习率设置为 2e-5,批量大小设置为 32,并将解码器的最大序列长度设置为 1024。 我们对模型进行了 30 个时期的微调。 在推理过程中,我们采用波束大小为 5 的波束搜索。
D.6 数学编程
数学编程是通过编程解决基于数学的问题的任务。 与传统的代码生成任务相比,该任务更注重计算推理技能。 此类任务中的问题描述也比传统的代码生成任务更复杂。 我们针对此任务采用了两个主要基准:MathQA-Python [Austin 等人,2021] 和 GradeSchool-Math [Cobbe 等人,2021]。
MathQA-Python [Austin 等人, 2021] 是根据 MathQA 数据集 [Amini 等人, 2019] 开发的,其中给定自然语言的数学问题描述,系统是需要通过生成返回最终答案的程序来解决这个问题。 Austin 等人 [2021] 将这些程序翻译成 Python 程序,并过滤出更干净的问题。 MathQA-Python 总共包含 24,000 个问题,其中包括 19,209/2,822/1,883 个用于/验证/测试拆分的样本。
GradeSchool-Math [Cobbe 等人, 2021](也称为 GSM8K)与 MathQA 具有相似的性质。 该基准侧重于普通小学生应该能够解决的中等难度的问题。 GSM 数据总共包含 8,500 个问题,分为 7,500 个训练问题和 1,000 个测试问题。 我们按照Austin等人[2021]的MathQA-Python构建过程,将自然语言描述的解决方案翻译成Python程序。 最后,我们成功转换了 7,500 个训练样本中的 5,861 个。
对于训练,我们将 MathQA-Python 的源和目标的最大序列长度设置为 256 和 256,将 GSM8k-Python 设置为 246、138。 我们使用 2e-5 的学习率和 32 的批量大小进行 30 轮的微调。 在推理过程中,我们采用光束大小为 5 来获得 pass@1 结果。 对于pass@80和pass@100,我们发现他们对世代的多样性非常敏感。 我们采用温度为 和 top-= 的核采样。
D.7 检索增强代码生成
开发人员经常从 GitHub 或 StackOverflow 等网络资源中搜索相关代码片段,作为帮助其软件开发过程的参考。 受这种行为的启发,我们探索了一种检索增强的代码生成设置,在给定自然语言描述的情况下,检索器首先在搜索代码库中检索相似的候选者,然后增强生成器的输入以生成目标代码。 这种检索增强生成(或检索然后生成)范式已广泛应用于 NLP 中的开放域问答[Karpukhin 等人,2020],并且最近扩展到一些与代码相关的任务,例如代码生成和摘要[Parvez 等人, 2021] 有了显着改进。 由于我们的 CodeT5+ 能够检索和生成,因此它可以无缝地适应为统一的检索增强生成器。 这可以带来独特的好处,例如与采用不同检索器和生成器的先前工作相比,计算成本更低。 我们根据 Parvez 等人 [2021] 在 CodeXGLUE Lu 等人 [2021] 基准测试中的两个 Java 和 Python 代码生成数据集上评估 CodeT5+。
具体来说,我们利用编码器对检索库中的代码片段进行编码,并使用 faiss 库[Johnson 等人, 2019] 构建搜索索引。 搜索索引是检索代码库中所有代码片段的一组表示( 维度)。 让 表示一个训练实例,其中 是输入文本描述, 是相应的目标代码片段。 我们使用相同的编码器来获取 的嵌入,并使用 L-2 相似度度量从搜索库中检索前 相似的代码样本,其中 作为一个超参数。 我们确保训练示例的目标字符串 () 不存在于任何这些 检索到的示例中。
检索到这些 top- 相关代码示例后,我们将它们与特殊的词符 [SEP] 结合起来,并将其连接到源输入 的末尾>。 与 Parvez 等人 [2021] 不同,我们不会增加文档字符串或文本描述,只是为了简单起见增加代码片段。 然后,我们在此增强数据集上微调 CodeT5+。 在推理过程中,我们从搜索库中检索类似的代码示例并将其扩充到输入 。 对于训练,我们将源和目标的最大序列长度设置为 600 和 320。 我们使用 2e-5 的学习率、32 的批量大小对模型进行 10 个 epoch 的微调。 在使用波束搜索进行推理时,我们将波束大小设置为 5。