生成和服务大型开放领域知识图
摘要。
大型开放领域知识图(KG)在现实世界问题中的应用带来了许多独特的挑战。 在本文中,我们提出了对 Saga (Ilyas 等人,2022) 平台的扩展,用于大规模持续构建和服务知识。 特别是,我们描述了训练知识图嵌入的管道,该管道支持事实排名、事实验证、相关实体服务和实体链接支持等关键功能。 然后,我们描述如何利用我们的平台(包括图嵌入)来创建语义标注服务,将非结构化 Web 文档链接到我们的 KG 中的实体。 Web 的语义标注有效地将我们的知识图谱扩展到开放域 Web 内容,可用于各种搜索和排名问题。 最后,我们利用带注释的 Web 文档来驱动开放域知识提取。 这个有针对性的提取框架识别知识图谱中的重要覆盖问题,然后在网络上找到目标实体的相关数据源并提取缺失的信息以丰富知识图谱。
最后,我们描述了在设备上构建和提供私人个人知识所需的知识平台的调整。 这包括私有增量知识图谱构建、跨设备知识同步和全局知识丰富。
1. 介绍
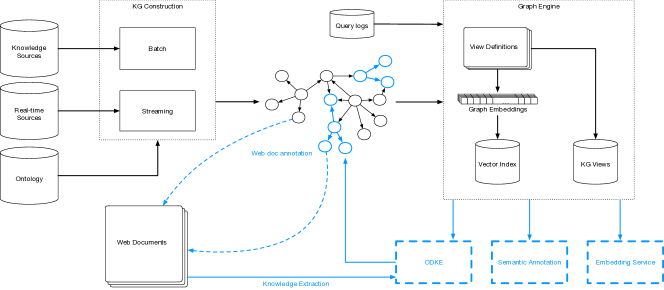
构建和服务大型知识图谱(KG)已成为许多重要的现实应用场景的常见组成部分,例如搜索、问答、实体链接和信息提取。 在这些用例中,知识图谱中的知识用于构建查询、文档和实体的丰富表示,以支持基于事实知识的语义推理。 例如,查询“benicio del toro movie”可以用以下语义注释:
“本尼西奥·德尔·托罗” entityid_123,
“电影” ontology_type_movie
支持从 KG 中检索匹配实体(即 Benicio Del Toro 导演的电影);对 KG 中的事实进行排名(即,本尼西奥·德尔·托罗 (Benicio Del Toro) 导演的哪些电影最重要);提及本尼西奥·德尔·托罗及其电影的网络文档的检索和排名;以及可用于向用户建议相关查询的相关实体(例如,其他类似的电影导演)。
我们之前介绍过 Saga (Ilyas 等人, 2022),这是一个用于大规模构建和服务知识的最先进的平台。 在这项工作中,我们描述了 Saga 的应用和扩展,它们利用基于 ML 的 KG 技术来解决与增长和服务知识图相关的一组重要问题。 尤其:
-
•
我们提出了一个基于 Saga 图形查询引擎构建的图形嵌入管道,它训练 KG 实体的嵌入并为其建立索引。 这些图嵌入有许多直接用例,例如事实排名、事实验证、实体链接和计算相关实体。
-
•
我们描述了一个可扩展的文本语义标签平台。 特别是,我们解决了扩展语义标注的挑战,以解决链接网络的问题;对大量 Web 文档中出现的实体进行注释。
-
•
许多知识图谱用例依赖于事实和实体的良好覆盖。 为了提高知识图谱覆盖率,我们描述了开放域知识提取(ODKE)的方法,这是一种有针对性的信息提取技术,旨在用高价值的事实和实体扩展知识图谱。
-
•
最后,我们讨论了在设备上应用我们的平台所面临的挑战。 在这种情况下,数据是私有的,所有计算都必须在设备本地进行。 在资源有限的环境中构建和服务 KG 会带来许多独特的挑战;包括隐私、资源限制、跨设备同步和全球知识丰富。
概述
图 1 概述了我们对 Saga 的扩展。 嵌入服务提供对学习的实体向量化表示的访问,并允许相似性计算以及高效的最近邻检索。 接下来,我们的语义标注服务利用图嵌入将文本中的实体提及链接到知识图。 我们大规模应用这项服务来“链接网络”,通过将 KG 实体链接到非结构化 Web 文档的边缘来扩展我们的 KG。 最后,我们利用带注释的 Web 文档以及传统的检索方法来查找缺失 KG 信息的来源。 然后,我们提取缺失的 KG 事实,提高 KG 数据的覆盖范围。
2. 知识图嵌入
知识图 (KG) 对于虚拟助手中的许多下游机器学习 (ML) 应用程序非常有用。 这些应用的示例包括:
-
•
事实验证。 工业规模的知识图谱根据来自不同来源和不同领域的新数据不断更新。 因此,有必要大规模地推理这些事实的正确性和完整性。
-
•
事实排名。 KG 中的实体可能有多个与特定关系相关的事实。 例如,一个人可能在 KG 中记录了多种职业。 因此,对于诸如“X的职业是什么?”之类的查询,虚拟助理需要推断图表中事实的基于重要性的排名,以生成高质量的答案。
-
•
相关实体。 当虚拟助理被查询特定实体时,它们可以帮助用户发现事实并了解其相关实体。 这种主动的信息表示方式提供了更丰富的用户体验。
-
•
实体链接。 为了对查询给出正确的答案,或者有时给出更丰富的答案,虚拟助理需要识别用户查询中存在的一组 KG 实体以及相应的答案。 因此,他们应该能够检测提及并将其正确链接到知识图谱中的实体。
图 2 描述了每个应用程序的示例查询和答案。 在所有这些应用程序中,我们都有一个 ML 系统,它在推理过程中使用 KG 作为输入。 因此,设计此类系统的一个主要成功因素是在机器学习模型易于使用的空间中表示知识图谱。 鉴于大多数现代机器学习模型都基于基于向量的表示进行操作,我们使用连续向量空间来表示知识图谱的实体和谓词,以便保留它们的固有结构。 知识图谱表示学习也有其自身的挑战,例如在知识图谱中可能存在的不相关或噪声数据上训练向量、训练和推理的可扩展性以及嵌入模型的设计。
开放领域知识图包括来自不同来源的数据。 除了展示丰富的语义结构(考虑多个模式的联合)之外,知识图谱中的事实也可能是有噪声的。 在这种情况下,许多事实可能与特定的下游嵌入任务无关。 例如,捕获实体数值的事实可能对于生成对相关实体服务有用的嵌入没有用处。 此类事实的示例可以对应于一个人的身高、一本书的国家图书馆 ID、或名人的社交媒体关注者数量,这些虽然对于回答问题有用,但对于学习实体的嵌入可能并不重要。 因此,在训练过程中可能需要忽略这些事实。 如果想要对特定下游任务实现高精度,这一过程在微调基础模型中也很常见(Xie等人,2023)。
过滤掉不相关的事实后,图中某些谓词的频率可能会下降到阈值以下,我们可能没有足够的关于这些谓词的信息来学习它们的高质量表示。 因此,具有这些谓词的三元组可能会在学习过程中产生噪音,将它们过滤掉可以产生更干净的训练集。
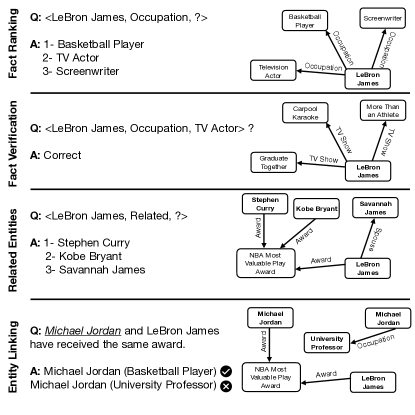
工业规模的知识图谱可以扩展到数十亿个事实和实体。 因此,训练方法的可扩展性是学习高质量表示需要考虑的主要问题之一。 在高层次上,我们考虑两种主要类型的知识图谱嵌入模型(Hamilton等人,2017):1)浅层嵌入模型和2)基于推理的嵌入模型。 对于浅嵌入模型,基于随机边缘的图划分是应对可扩展性挑战的主要技术,因此,它们可以轻松地从多节点分布式训练中受益。 浅嵌入模型通常通过优化图中现有和不存在边的对比目标来学习实体和谓词的嵌入矩阵。 另一方面,基于推理的嵌入模型用于涉及多跳推理与逻辑运算符相结合的更复杂的任务。 在这种情况下,基于边的图划分可能会导致图邻域的局部性较差,因此需要不同的方法来获得高质量的模型。 有多种解决方案可以应对这一挑战:1)许多系统选择具有足够主内存或 GPU 内存的基础设施来保存整个图,2)其他系统使用 IO 优化的基于磁盘的图操作来实现图邻域的全局采样,以及3)一些建议通过预计算图遍历来构建样本。
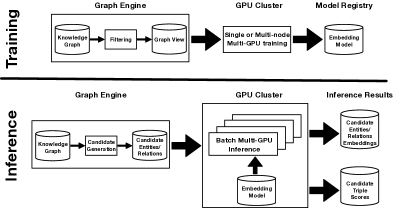
在我们的设置中,我们根据模型和下游任务考虑后两种方法的变化。 对于一般的 KG 嵌入,我们使用基于磁盘的训练,而对于专门的相关实体嵌入,我们使用图形引擎的可扩展图形处理功能来预先计算图形遍历。 图3描述了用于嵌入训练和推理的设计系统的概述。 在训练过程中,我们利用计算图引擎通过过滤掉不相关的事实和可能的噪音来生成知识图谱的视图。 根据应用程序,图形引擎可能会执行额外的过滤以生成图形中所需的三元组视图。 一旦我们获得了图表的过滤视图,根据我们用于学习嵌入的 ML 模型,我们使用单节点或多节点多 GPU 集群来训练嵌入模型。 在推理过程中,与训练阶段类似,我们使用图引擎生成一组候选实体和/或谓词。 该集合表示对应于特定查询的候选者。 例如,它可能包括我们需要验证其正确性甚至对它们进行排名的事实;或者它可能包含我们需要推断它们之间的相关性的实体对。 一旦我们具体化了候选者,我们就使用批量推理设置从学习模型中检索嵌入,并获得每个候选者的分数,以表明其合理性。
3. 语义注释
在本节中,我们概述了基于 ML 的服务,这些服务使用 KG 来支持各种下游用例,例如问答和改进的 Web 搜索。 我们统称为“语义标注服务”,指的是提及检测、命名和名义实体识别和实体链接、上下文实体排名等任务> 和搜索相关实体。 让我们考虑一个命名实体识别和实体链接的例子。 我们的语义标注服务可以根据提及的上下文消除两个不同实体之间的歧义,例如,“迈克尔·乔丹统计数据”应链接到篮球运动员迈克尔·乔丹的 KG 实体,而“迈克尔·乔丹学生”应链接到篮球运动员迈克尔·乔丹的 KG 实体。迈克尔·乔丹教授(请参见图2)。 这是一项非常具有挑战性的任务,因为在这些场景中仅基于词汇相似性的特征无法消除歧义。 具有与文本中提到的实体相似的名称的不同实体之间的这种上下文重新排序(或消歧)可以通过计算 KG 实体的文本特征(例如名称、描述、流行度)的嵌入并计算与文本中的实体的相似度来实现。查询嵌入。 此类服务可用于在问答系统中生成更相关的答案或提高 Web 文档排名。
3.1. 将 Web 链接到 KG
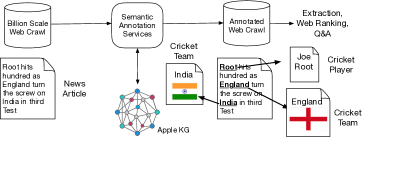
万维网是结构化、半结构化和非结构化(文本)数据的大量来源,在许多重要的用户体验中发挥着重要作用。 然而,原始形式的网络的实用性有限。 为了增强 Web 文档的表示,我们使用 KG 中的语义注释来扩展它们(图4)。 例如,我们将所有提及的命名或名义实体链接到相应的知识图谱实体,包括相应的实体类型和附加元数据,例如来自各种数据源的这些实体的流行度分数。 这种丰富的网络视图可用于改进问题解答、对相关任务进行排名以及有针对性地提取新事实和实体(请参阅第 4 节)等。 然而,将语义注释应用于整个 Web 是非常具有挑战性的,原因如下:
-
•
规模:网络包含数千亿个网页。 我们的服务需要能够以这种规模运营。
-
•
多样性:网络包含不同类型的数据,包括文本、表格、图像和视频。 网页也可以用不同或混合语言编写。 我们的服务需要能够处理不同的数据模式并且需要是多语言的。
-
•
变化率: 网络不是静态的。 新网页不断创建,现有网页经常更新。 服务需要及时高效地处理增量变更。
-
•
价格/性能:从金钱角度来看,对整个网络进行注释是一项非常昂贵的操作。 我们的服务必须能够以有效的方式驾驭性价比曲线,即它应该以尽可能最低的成本提供最佳性能。
3.2. 可扩展的语义注释服务
鉴于上述挑战,我们正在实施可扩展的语义标注服务,该服务可以以良好的性价比注释数十亿个网页。 我们的可扩展语义标注服务支持各种经典和基于神经的组件,用于诸如提及检测、命名实体识别以及与上下文重新排名的实体链接等任务。 这些服务是(1)模块化的,允许针对不同的用例进行自定义部署;例如,平衡质量(精度和召回率)和性能(延迟和吞吐量)的要求,以满足各种下游应用程序的需求。 (2) 是动态的,即能够从知识图谱中显示新的和更新的实体,从而确保注释的新鲜度。
为了提高可扩展性,我们使用第 2 节中描述的方法预先计算实体嵌入,以进行上下文重新排序,并将结果缓存在低延迟键值存储中。 在查询期间,我们仅计算查询嵌入及其与缓存实体嵌入的相似度。 我们还致力于将服务扩展到多种语言。 我们的标注管道能够以给定的频率(例如每天或每周)有效地仅处理已更改的网页。 最后,我们还通过使用最先进的模型蒸馏和压缩技术训练更好、更高效的模型来突破价格/性能的界限,这些技术可以针对不同的硬件(例如 CPU、GPU 或 TPU)以满足不同的价格/性能SLA。
4. 开放领域知识提取
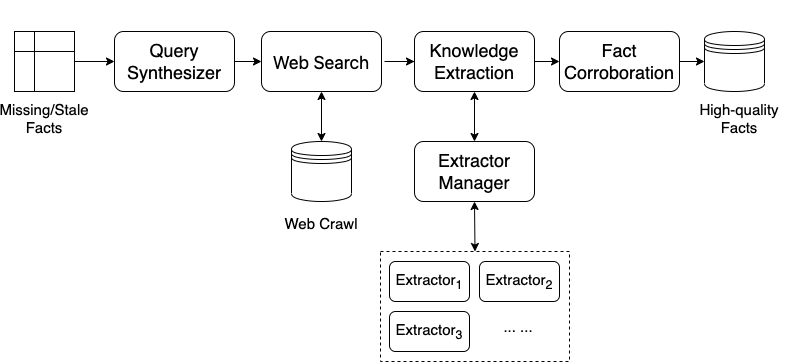
任何知识图谱面临的持续挑战是执行持续更新,以确保图中实体和事实的完整性和新鲜度。 知识图的覆盖范围和新鲜度直接影响下游应用的质量(例如使用图可以正确回答的问题数量)。 开放领域知识提取(ODKE)的目标是从网络中获取高质量的事实,以大规模提高开放领域知识图的覆盖范围和新鲜度。 ODKE 需要解决以下关键挑战:
-
•
数据量。 网络上包含的数据和事实数量巨大且不断增长。 我们需要应对网络规模数据带来的可扩展性挑战。
-
•
各种数据和任务。 Web 包含各种各样的数据,从纯文本到半结构化数据以及两者的混合。 同时,开放领域知识图包含许多不同类型的实体以及有关这些实体的事实。 为了从网络中提取高质量的事实,我们需要创建能够从不同数据源为不同类型的实体提取各种高质量事实的提取器。
-
•
真实性。 网络是嘈杂的,并且经常包含错误和相互矛盾的事实。 此外,某些事实,例如某人的婚姻状况或净资产,也可能随着时间的推移而改变。 因此,我们需要确定最准确和最新的事实。
图5描述了我们为解决上述挑战而设计的系统。 为了解决数据量挑战,我们专注于最重要的缺失和陈旧事实,并利用 Web 搜索来查找相关文档(查询合成器和 Web 搜索)。 重要的缺失/陈旧事实可以通过三种不同的方式来识别。 首先,我们可以通过分析查询日志并查找由于丢失或过时的事实而未正确回答的用户查询来被动地识别丢失和过时的事实。 我们还可以通过知识图谱分析主动识别现有知识图谱中潜在的覆盖率和新鲜度问题。 此外,我们可以通过分析潜在的趋势查询或新用例的需求来预测当前知识图中缺失的新事实。
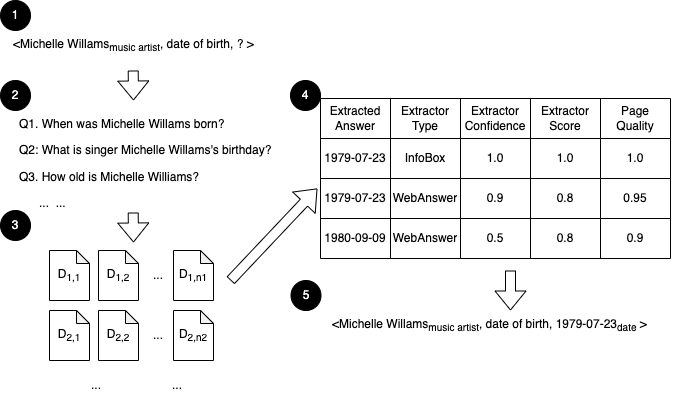
重要的缺失或过时的事实将作为 OKDE 的输入给出。 然后,我们使用查询合成器自动生成搜索查询,以识别可能包含这些事实的相关文档。 如图6所示,对于每个缺失/过时的事实,使用与(Kamath等人,2022)类似的方法,我们自动组合多个搜索查询来获取相关的收集感兴趣事实的文件。 这种有针对性的搜索策略使我们能够有效地利用现有的网络搜索功能来显着减少我们需要处理的数据量,同时最大限度地减少对最终结果的影响。
为了克服第二个挑战并正确处理我们需要支持的各种数据和任务,我们专注于设计不同的提取器来处理具有不同类型模型的不同类型的数据源。 例如,简单的基于规则的模型可用于从嵌入符合 schema.org 类型的结构化数据的网页中提取键值对,而基于大型语言模型的更复杂的神经模型可用于从纯文本和文本中提取事实。利用网络规模语义标注服务生成的注释作为弱标签。 此外,如3节所述,网页已经通过语义标注链接到知识图谱,并且可以利用注释来提高检索和提取质量。
最后,为了解决准确性挑战,我们通过训练有素的机器学习模型利用不同的证据和信号作为特征,从之前提取的候选者列表中确认和识别高质量的事实。 例如,如图6所示,使用相应的提取器从各种相关数据源中提取候选事实后,我们可以正确确定音乐艺术家缺失的出生日期> 米歇尔·威廉姆斯是 1979-07-23 而不是 1980-09-09(这是女演员米歇尔·威廉姆斯的出生日期)基于证据的组合,例如支持数量、提取器类型和置信度以及源页面的质量。
5. 设备上的知识
个人设备提供丰富的私人和个人信息来源,可用于个性化设备上的体验,例如搜索、导航和推荐。 由于这些数据是私有的,因此所有计算都必须在用户的设备上执行,与我们的服务器端知识平台解决的知识构建和服务任务相比,这引入了许多独特的挑战(Ilyas等人,2022)。
-
•
隐私:设备上的数据源是私有的,所有计算都必须在设备本身上进行。
-
•
资源受限环境:设备具有广泛的功能,基于知识的服务必须在每个硬件环境的资源限制内发挥作用。
-
•
同步:用户的数据生态系统可能跨越多个链接设备,在允许的情况下,知识必须在设备之间保持一致,或者根据用户的每个源同步偏好进行隔离。
-
•
全局知识丰富:用户的个人知识图谱需要以保护隐私的方式利用全局知识进行个性化。 全球知识有助于丰富用户偏好的背景,例如偏好的音乐流派、新闻主题或体育偏好。
我们对设备上知识的目标是在私有、分散、资源受限的环境中支持 Saga 平台的全部功能。
个人KG建设
个人设备具有多个必须链接的重叠信息源。 例如,联系人列表、消息发送者和日历受邀者都提供不同格式和命名空间的 Person 实体源。 这些来源必须被集成和链接,以在统一的本体中提供统一的表示。 作为一个激励示例,请考虑用户话语“向 Tim 发送消息”。 用户的联系人列表中可能有一个“Tim”,一个向用户发送短信的“Tim”,以及一个即将到来的日历事件的受邀者“Tim”。 如果我们知道消息发送者和联系人有相同的电话号码;联系人和日历受邀者具有相同的电子邮件地址;并且都有相似的名字;那么我们可以将这三个源实体链接为单个Person实体的统一表示。 这允许文章理解算法将对“Tim”的引用解释为对具有源自不同来源的多个属性的单个实体的引用,而不是让用户在三个不同的假设“Tims”之间消除歧义。图7说明了这种集成场景。
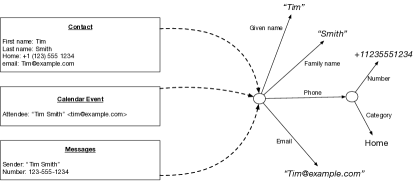
这个知识图构建任务与我们的服务器端开放领域知识平台解决的图构建任务有很多相似之处(Ilyas等人,2022)。 然而,在设备上的环境中,我们必须调整知识平台架构以适应隐私、同步和资源限制。
隐私
为了确保所有用户数据的私密性,我们完全在设备上构建用户的个人知识图谱。 这需要在用户设备上运行源摄取、实体链接和图融合,如 Saga (Ilyas 等人,2022) 中所述。 由于资源有限且与其他设备上的后台进程竞争激烈,我们实现了增量连续构建管道。 该管道可以在任何时候暂停和恢复,而不会丢失状态,从而允许推迟构建过程以支持任何其他更高优先级的任务(例如,用户向设备发送请求或另一个后台任务需要调度)。
同步
如果可能,用户的个人知识图谱应在其设备上保持一致。 这涉及以允许在每个设备上构建一致的 KG 的方式私下同步 KG 数据。 虽然分布式一致性是一个经过充分研究的问题,但个人 KG 同步存在一些独特的挑战。 具体地,用户可以决定基于每个源同步或不同步。 例如,用户可以将其联系人和电子邮件同步到所有设备,但选择不同步其日历。 这意味着包含日历源的设备将具有其他设备上不存在的其他实体和交互。 然而,同步源仍然需要在不同设备上保持一致。 其次,设备具有广泛的计算能力(例如,将笔记本电脑与手表进行比较)。 确保跨设备的一致知识体验可能需要将昂贵的计算卸载到更强大的设备,例如昂贵的视图或大型模型的推理(参见 Saga (Ilyas 等人,2022)第 3 节),并同步结果。
资源限制
为了适应设备上处理带来的严格资源限制,我们将构建管道优化为面向磁盘且内存缓冲区大小可调。 在构造管道中的任何给定点,所使用的内存量是有限的,并且昂贵的计算(例如,Saga (Ilyas 等人,2022)第 1 节中描述的成对阻塞和实体匹配)溢出到必要时磁盘。 此外,我们还针对设备上的部署优化了机器学习模型。 通过设计更小的模型架构(例如,更少且更窄的神经层)来保持设备上的 ML 模型较小;压缩学习模型(例如,通过降低浮点精度);或蒸馏(Gou 等人, 2021)。 我们还利用 CoreML 来优化我们的硬件平台的模型。
语义标注
与我们的服务器端对应部分类似,我们需要在设备上使用语义注释来注释文本。 语义标注可用于帮助查询和文档理解。 正如3部分所述,我们还需要上下文相关性排名。 例如,假设一个用户有两个名为“Tim”的联系人。 如果用户发出以下话语:“向 Tim 发送消息,我已将评论添加到 SIGMOD 草稿”,我们希望使用与查询上下文最相关的联系人来注释“Tim”。 在这种情况下,与用户就“SIGMOD”进行会议和对话的同事应该排在其他名为 Tim 的不太相关的联系人之上。 我们通过移植 Saga 第 5 节中描述的相同语义标注架构来实现这一点,并使用针对设备上部署进行优化的较小模型。 这包括紧凑的神经提及生成和重新排序模型。
全球知识丰富
虽然用户的个人知识图私下捕获有关个人实体及其关系的上下文,但用个性化知识来补充它是有价值的。 有关用户的音乐、运动和习惯偏好的信息提供了重要的背景信息,使 KG 能够用于设备上的私人个性化体验。 例如,了解用户喜欢听的音乐的典型流派和发行年份可以帮助个性化音乐推荐。 然而,向服务器查询此信息会破坏用户隐私。 为了解决这个问题,我们通过三个全球知识丰富路径扩展了设备上的知识平台。
-
(1)
静态知识资产:可以将与许多用户相关的一组流行实体和事实发送到每个设备。 由于不需要客户端请求来获取此工件,因此它不会泄漏任何私人信息。 这个全局知识子图在 Saga 中被实现为图引擎视图。 随着流行实体集随着时间的推移而变化,视图会自动维护并可以发送到设备。
-
(2)
用户服务器交互的动态丰富:用户与全局知识的交互已经涉及到对服务器的请求,例如查询“蓝鸟队比赛的得分是多少?”。 在这些场景中,我们可以利用有关引用实体的一般知识来丰富用户的个人图。 即,我们可以包含以下事实:蓝鸟队 是一支位于多伦多的棒球队。
-
(3)
私有知识检索:在我们需要静态知识资产或用户请求的动态丰富未涵盖的全局知识的情况下,我们可以利用差异私有(Dwork,2006)知识查询或私有信息检索(Chor等人,1998)以获取具有可证明隐私保证的全球知识。 虽然此类方法成本高昂,但它们可以用于高价值用例。
6. 相关工作
与 KG 嵌入相关的两个方向已被广泛研究。 首先是新嵌入模型的发展,如平移距离嵌入模型及其泛化(Zhang 等人,2019;Bordes 等人,2013)、语义匹配嵌入模型(Yang 等人) ,2014),以及基于推理的模型(任等人,2020)。 第二个方向是大规模学习嵌入。 由于近年来知识图谱规模的显着增长,人们对设计能够处理大规模知识图谱嵌入训练的系统进行了积极的研究,例如 Marius (Mohoney 等人, 2021; Waleffe 等人, 2023)、Pytorch Biggraph (Lerer 等人, 2019) 和 DGL-KE (Zheng 等人, 2020)。
各种语义标注任务,包括实体链接和消歧,重新引起了研究界的兴趣,特别是基于深度学习的方法(Kolitsas等人,2018;Ganea和Hofmann,2017;Le和Titov,2018;Raiman和雷曼,2018)。 之前的工作还讨论了语义注释在丰富网页方面的应用,以改进问答和网络搜索(Balog,2018)。
从互联网来源获取知识是一个经过充分研究的问题(Weikum 等人,2019)。 许多现有的知识库,例如Yago (yago-knowledge.org)、Google Knowledge Graph (Dong 等人, 2014)、Amazon Product Knowledge Graph (Dong ,2018),IBM 金融内容知识库(Bharadwaj 等人,2017) 以及许多其他内容,至少部分是基于互联网资源自动构建的。 许多努力都是基于远程监督方法,以模式-事实二元性原则为中心。 最流行的知识收集来源是维基百科,包括 InfoBox 等半结构化元素以及纯文本。 网络规模的资源也被利用,但程度要小得多,并且主要集中在从表中提取(Dong等人,2014)。 我们不知道有任何已发表的工作专注于网络规模语义标注之上的网络规模提取,并利用更复杂的提取器(例如基于神经网络的提取器)利用各种来源。
7. 结论
我们已经对我们的知识平台 Saga 进行了重要的扩展。 图嵌入形成了一项核心功能,我们在此基础上构建了事实排名、事实验证、相关实体服务和实体链接支持等功能。 特别是,实体链接可以用作通用语义标注服务的一部分。 我们已经描述了如何利用该服务将 Web 文档链接到我们的知识图谱,从而扩展我们的知识图概念以包括从实体到非结构化文档的链接。 最后,我们描述了我们的知识图谱如何通过使用开放领域知识提取的目标事实提取来增长。
我们还提出了对我们的知识平台进行的调整,以在设备上构建和提供私人个人知识。 这包括私有增量知识图谱构建、知识图谱同步和全局知识丰富的独特挑战。
致谢
这项工作是通过苹果公司许多人的辛勤工作才得以实现的。 我们要感谢整个知识平台和智能平台团队所做的许多贡献。
参考
- (1)
- Balog (2018) Krisztian Balog. 2018. Entity-oriented search. Springer Nature.
- Bharadwaj et al. (2017) Shreyas Bharadwaj, Laura Chiticariu, Marina Danilevsky, Samarth Dhingra, Samved Divekar, Arnaldo Carreno-Fuentes, Himanshu Gupta, Nitin Gupta, Sang-Don Han, Mauricio A. Hernández, Howard Ho, Parag Jain, Salil Joshi, Hima Karanam, Saravanan Krishnan, Rajasekar Krishnamurthy, Yunyao Li, Satishkumaar Manivannan, Ashish R. Mittal, Fatma Ozcan, Abdul Quamar, Poornima Raman, Diptikalyan Saha, Karthik Sankaranarayanan, Jaydeep Sen, Prithviraj Sen, Shivakumar Vaithyanathan, Mitesh Vasa, Hao Wang, and Huaiyu Zhu. 2017. Creation and Interaction with Large-scale Domain-Specific Knowledge Bases. Proc. VLDB Endow. 10, 12 (2017), 1965–1968. https://doi.org/10.14778/3137765.3137820
- Bordes et al. (2013) Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. Advances in neural information processing systems 26 (2013).
- Chor et al. (1998) Benny Chor, Eyal Kushilevitz, Oded Goldreich, and Madhu Sudan. 1998. Private information retrieval. Journal of the ACM (JACM) 45, 6 (1998), 965–981.
- Dong et al. (2014) Xin Dong, Evgeniy Gabrilovich, Geremy Heitz, Wilko Horn, Ni Lao, Kevin Murphy, Thomas Strohmann, Shaohua Sun, and Wei Zhang. 2014. Knowledge vault: a web-scale approach to probabilistic knowledge fusion. In The 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’14, New York, NY, USA - August 24 - 27, 2014, Sofus A. Macskassy, Claudia Perlich, Jure Leskovec, Wei Wang, and Rayid Ghani (Eds.). ACM, 601–610. https://doi.org/10.1145/2623330.2623623
- Dong (2018) Xin Luna Dong. 2018. Challenges and Innovations in Building a Product Knowledge Graph. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, August 19-23, 2018, Yike Guo and Faisal Farooq (Eds.). ACM, 2869. https://doi.org/10.1145/3219819.3219938
- Dwork (2006) Cynthia Dwork. 2006. Differential privacy. In Automata, Languages and Programming: 33rd International Colloquium, ICALP 2006, Venice, Italy, July 10-14, 2006, Proceedings, Part II 33. Springer, 1–12.
- Ganea and Hofmann (2017) Octavian-Eugen Ganea and Thomas Hofmann. 2017. Deep Joint Entity Disam- biguation with Local Neural Attention. In EMNLP’18. 2619–2629.
- Gou et al. (2021) Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. 2021. Knowledge distillation: A survey. International Journal of Computer Vision 129 (2021), 1789–1819.
- Hamilton et al. (2017) William L. Hamilton, Rex Ying, and Jure Leskovec. 2017. Representation Learning on Graphs: Methods and Applications. IEEE Data Eng. Bull. 40, 3 (2017), 52–74. http://sites.computer.org/debull/A17sept/p52.pdf
- Ilyas et al. (2022) Ihab F. Ilyas, Theodoros Rekatsinas, Vishnu Konda, Jeffrey Pound, Xiaoguang Qi, and Mohamed Soliman. 2022. Saga: A Platform for Continuous Construction and Serving of Knowledge at Scale. In Proceedings of the 2022 International Conference on Management of Data (Philadelphia, PA, USA) (SIGMOD ’22). Association for Computing Machinery, New York, NY, USA, 2259–2272. https://doi.org/10.1145/3514221.3526049
- Kamath et al. (2022) Pranav Kamath, Yiwen Sun, Thomas Semere, Adam Green, Scott Manley, Xiaoguang Qi, Kun Qian, and Yunyao Li. 2022. Improving Human Annotation Effectiveness for Fact Collection by Identifying the Most Relevant Answers. In Proceedings of the Fourth Workshop on Data Science with Human-in-the-Loop (Language Advances). Association for Computational Linguistics, Abu Dhabi, United Arab Emirates (Hybrid), 74–80. https://aclanthology.org/2022.dash-1.10
- Kolitsas et al. (2018) Nikolaos Kolitsas, Octavian-Eugen Ganea, and Thomas Hofmann. 2018. End-to- End Neural Entity Linking. In CoNNL’18. 519–529.
- Le and Titov (2018) Phong Le and Ivan Titov. 2018. Improving Entity Linking by Modeling Latent Relations between Mentions. In ACL’18. 1595–1604.
- Lerer et al. (2019) Adam Lerer, Ledell Wu, Jiajun Shen, Timothee Lacroix, Luca Wehrstedt, Abhijit Bose, and Alex Peysakhovich. 2019. Pytorch-biggraph: A large scale graph embedding system. Proceedings of Machine Learning and Systems 1 (2019), 120–131.
- Mohoney et al. (2021) Jason Mohoney, Roger Waleffe, Henry Xu, Theodoros Rekatsinas, and Shivaram Venkataraman. 2021. Marius: Learning massive graph embeddings on a single machine. In 15th USENIX Symposium on Operating Systems Design and Implementation (OSDI) 21.
- Raiman and Raiman (2018) Jonathan Raiman and Olivier Raiman. 2018. DeepType: Multilingual Entity Linking by Neural Type System Evolution. In AAAI’18.
- Ren et al. (2020) Hongyu Ren, Weihua Hu, and Jure Leskovec. 2020. Query2box: Reasoning over knowledge graphs in vector space using box embeddings. arXiv preprint arXiv:2002.05969 (2020).
- Waleffe et al. (2023) Roger Waleffe, Jason Mohoney, Theodoros Rekatsinas, and Shivaram Venkataraman. 2023. MariusGNN: Resource-Efficient Out-of-Core Training of Graph Neural Networks. EuroSys‘23 (2023).
- Weikum et al. (2019) Gerhard Weikum, Johannes Hoffart, and Fabian M. Suchanek. 2019. Knowledge Harvesting: Achievements and Challenges. In Computing and Software Science - State of the Art and Perspectives, Bernhard Steffen and Gerhard J. Woeginger (Eds.). Lecture Notes in Computer Science, Vol. 10000. Springer, 217–235. https://doi.org/10.1007/978-3-319-91908-9_13
- Xie et al. (2023) Sang Michael Xie, Shibani Santurkar, Tengyu Ma, and Percy Liang. 2023. Data Selection for Language Models via Importance Resampling.
- Yang et al. (2014) Bishan Yang, Wen-tau Yih, Xiaodong He, Jianfeng Gao, and Li Deng. 2014. Embedding entities and relations for learning and inference in knowledge bases. arXiv preprint arXiv:1412.6575 (2014).
- Zhang et al. (2019) Shuai Zhang, Yi Tay, Lina Yao, and Qi Liu. 2019. Quaternion knowledge graph embeddings. Advances in neural information processing systems 32 (2019).
- Zheng et al. (2020) Da Zheng, Xiang Song, Chao Ma, Zeyuan Tan, Zihao Ye, Jin Dong, Hao Xiong, Zheng Zhang, and George Karypis. 2020. Dgl-ke: Training knowledge graph embeddings at scale. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 739–748.