DoReMi:优化数据混合加速语言模型预训练
摘要
预训练数据域(例如维基百科、书籍、网络文本)的混合比例极大地影响语言模型(LM)的性能。 在本文中,我们提出了采用最小最大优化的域重新加权(DoReMi),它首先使用域上的组分布鲁棒优化(Group DRO)来训练一个小型代理模型,以在不了解下游任务的情况下产生域权重(混合比例)。 然后,我们使用这些域权重对数据集进行重新采样,并训练一个更大的全尺寸模型。 在我们的实验中,我们在训练 280M 参数代理模型上使用 DoReMi,以更有效地查找 8B 参数模型(大 30 倍)的域权重。 在 The Pile 上,DoReMi 改善了所有域的复杂性,即使它降低了域的权重。 与使用 The Pile 默认域权重训练的基线模型相比,DoReMi 将平均少样本下游准确度提高了 6.5%,并以减少 2.6 倍的训练步骤达到基线准确度。 在 GLaM 数据集上,不了解下游任务的 DoReMi 甚至可以与使用针对下游任务调整的域权重的性能相匹配。
1简介
训练语言模型 (LM) 的数据集通常从多个领域的混合中采样(Gao 等人,2020,Du 等人,2021,Chowdhery 等人,2022,Brown 等人,2020)。 例如,大型公开数据集 The Pile (Gao 等人, 2020) 由 24% 的 Web 数据、9% 的 Wikipedia、4% 的 GitHub 等组成。111本文中基于词符计数的域权重因分词器而异;请参阅附录C。 预训练数据的组成极大地影响了语言模型的有效性(Du 等人, 2021, Hoffmann 等人, 2022, Xie 等人, 2023)。 然而,尚不清楚每个领域需要包含多少内容才能生成一个能够很好地执行各种下游任务的模型。
现有的工作通过使用直觉或一组下游任务来确定域权重(每个域的采样概率)。 例如,The Pile 使用启发式选择的域权重,这可能不是最优的。 另一方面,现有的 LM,例如 PaLM (Chowdhery 等人,2022) 和 GLaM (Du 等人,2021) 根据一组下游参数调整域权重任务,但需要在不同的域权重上训练可能数千个 LM,并且存在过度拟合特定下游任务集的风险。
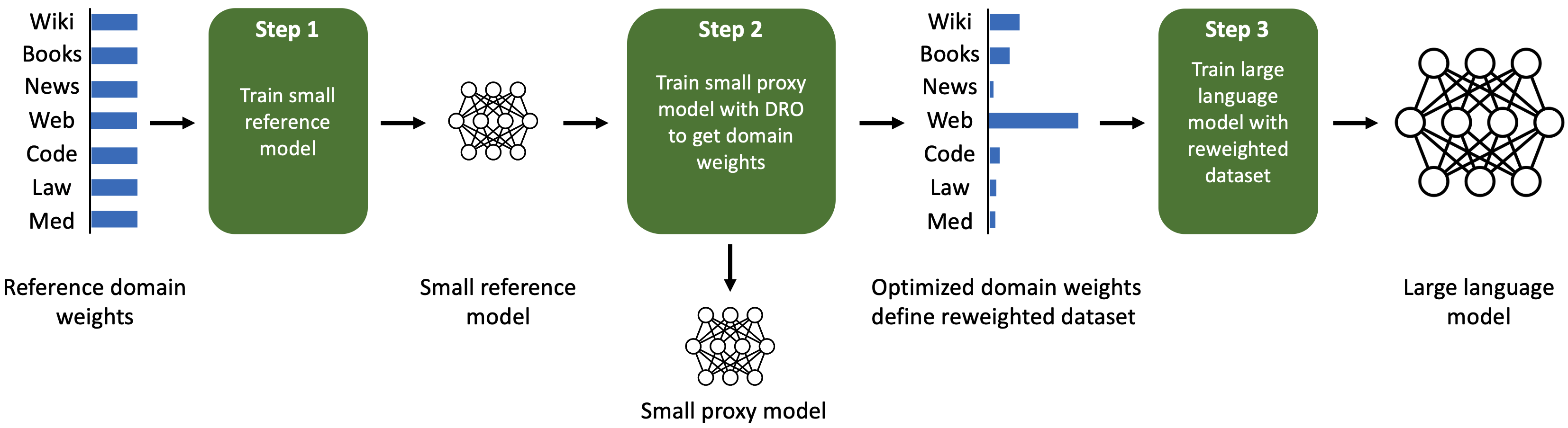
我们的方法不是基于一组下游任务来优化域权重,而是旨在通过最小化域上最坏情况的损失来找到域权重,从而产生在所有域上表现良好的模型。 一种天真的最坏情况方法会增加具有最多噪声数据的域的权重,因为每个域都有不同的最佳损失(又名熵)。 为了使领域复杂度具有可比性,我们遵循Oren等人(2019),Mindermann等人(2022)并优化最坏情况额外损失,即损失差距正在评估的模型和预训练的参考模型之间。
这激发了我们的算法,Domain Reweighting with Minimax Optimization (DoReMi),它利用分布鲁棒优化 (DRO) 来调整域在不了解下游任务的情况下进行权重(图1)。 首先,DoReMi以标准方式训练一个小型参考模型(例如280M参数)。 其次,我们训练了一个小型分布式鲁棒语言模型(DRO-LM)(Oren等人,2019),它最大限度地减少了所有领域最坏情况的额外损失(相对于参考模型的损失)。 值得注意的是,我们没有使用稳健 LM,而是使用了 DRO 训练产生的域权重。 最后,我们在由这些域权重定义的新数据集上训练大型 (8B) LM。
我们的方法采用 DRO-LM 框架(Oren 等人,2019) 来优化域权重,而不是生成稳健的模型。 为此,我们使用 Group DRO (Sakawa 等人,2020,Nemirovski 等人,2009) 中基于在线学习的优化器,它根据每个域的损失动态更新域权重以进行重新缩放训练目标,而不是像 Oren 等人 (2019)、Mindermann 等人 (2022) 中那样从小批量中子选择示例。 最后,DoReMi 在 DRO 训练步骤上获取平均域权重。
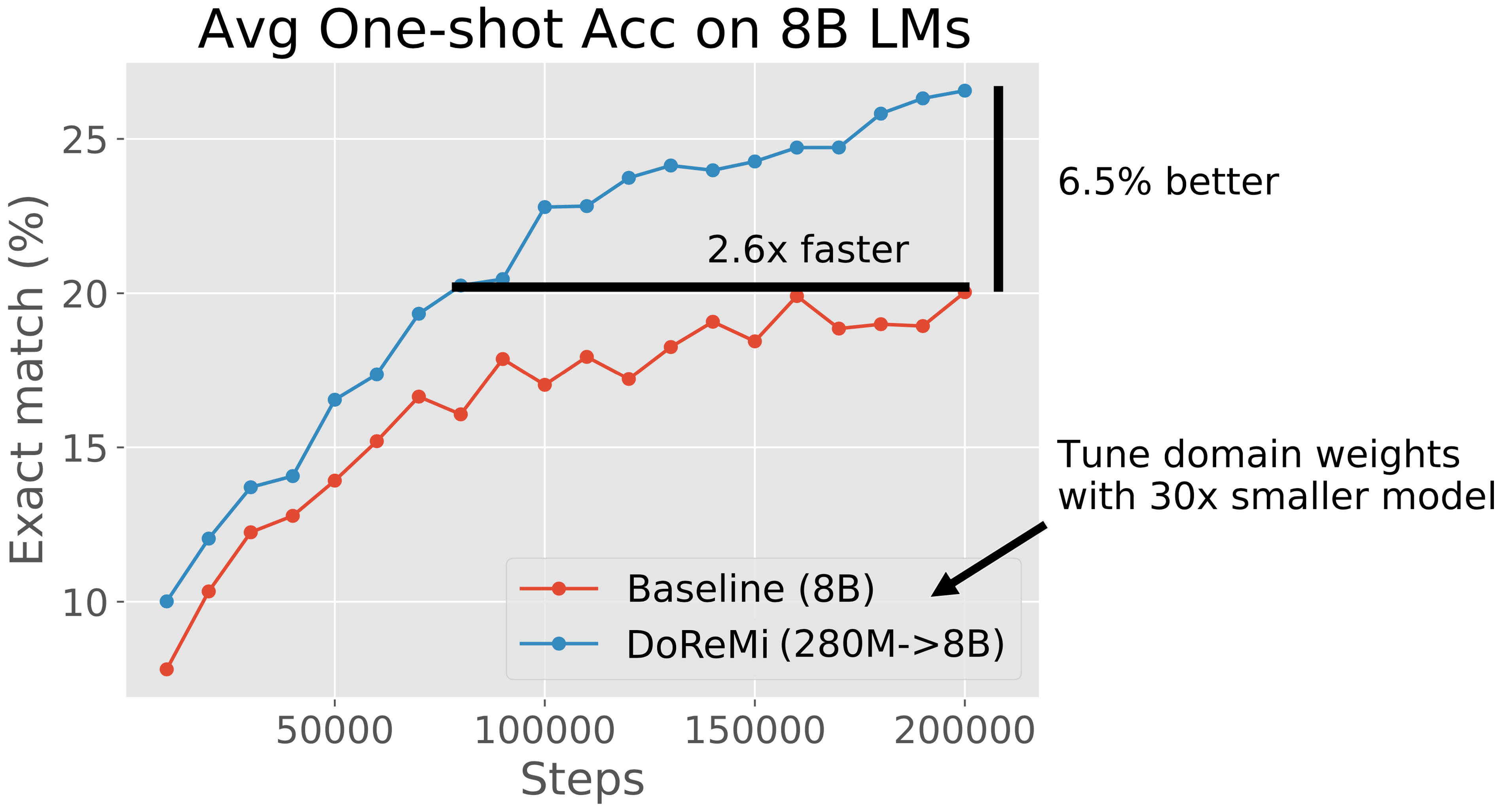
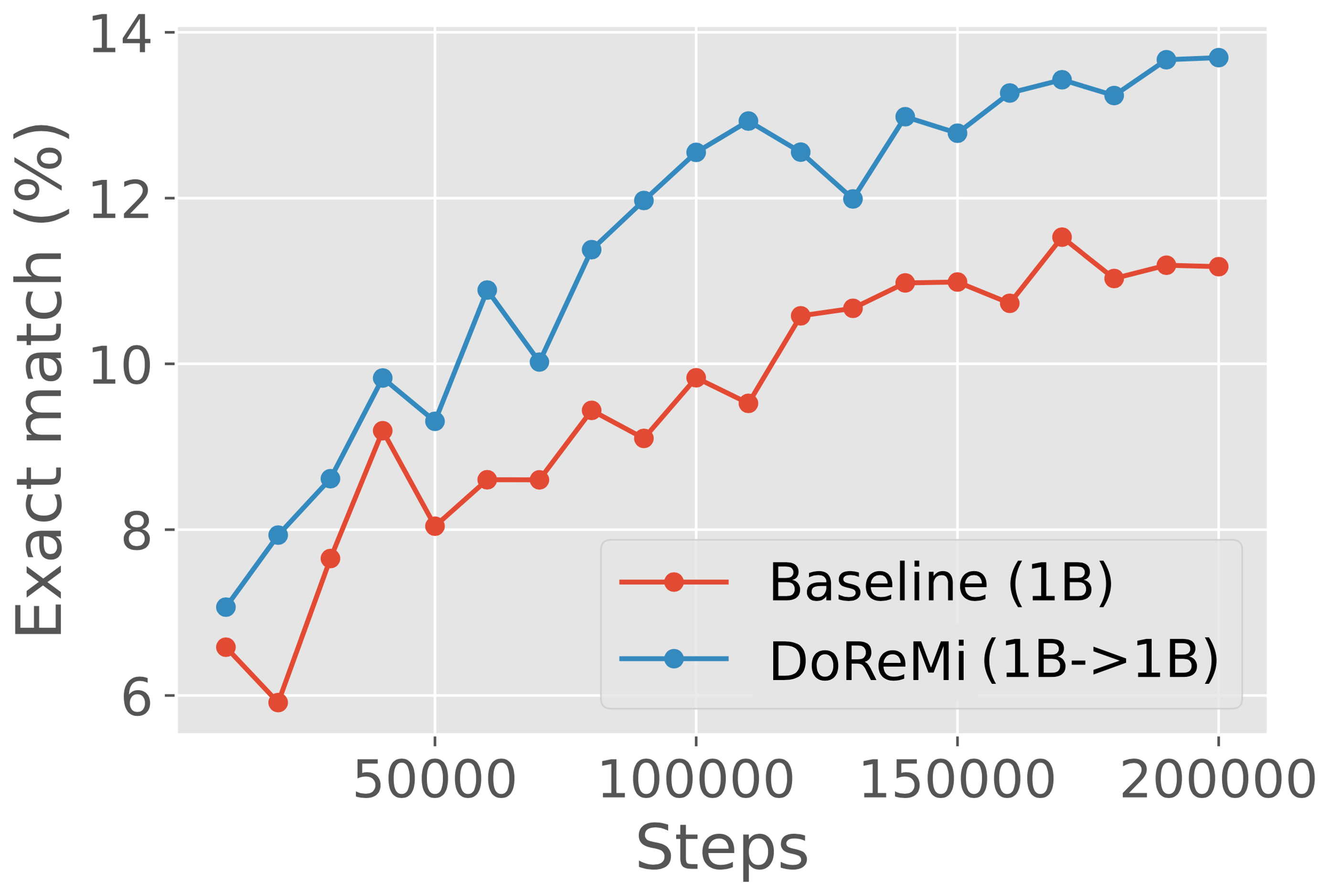
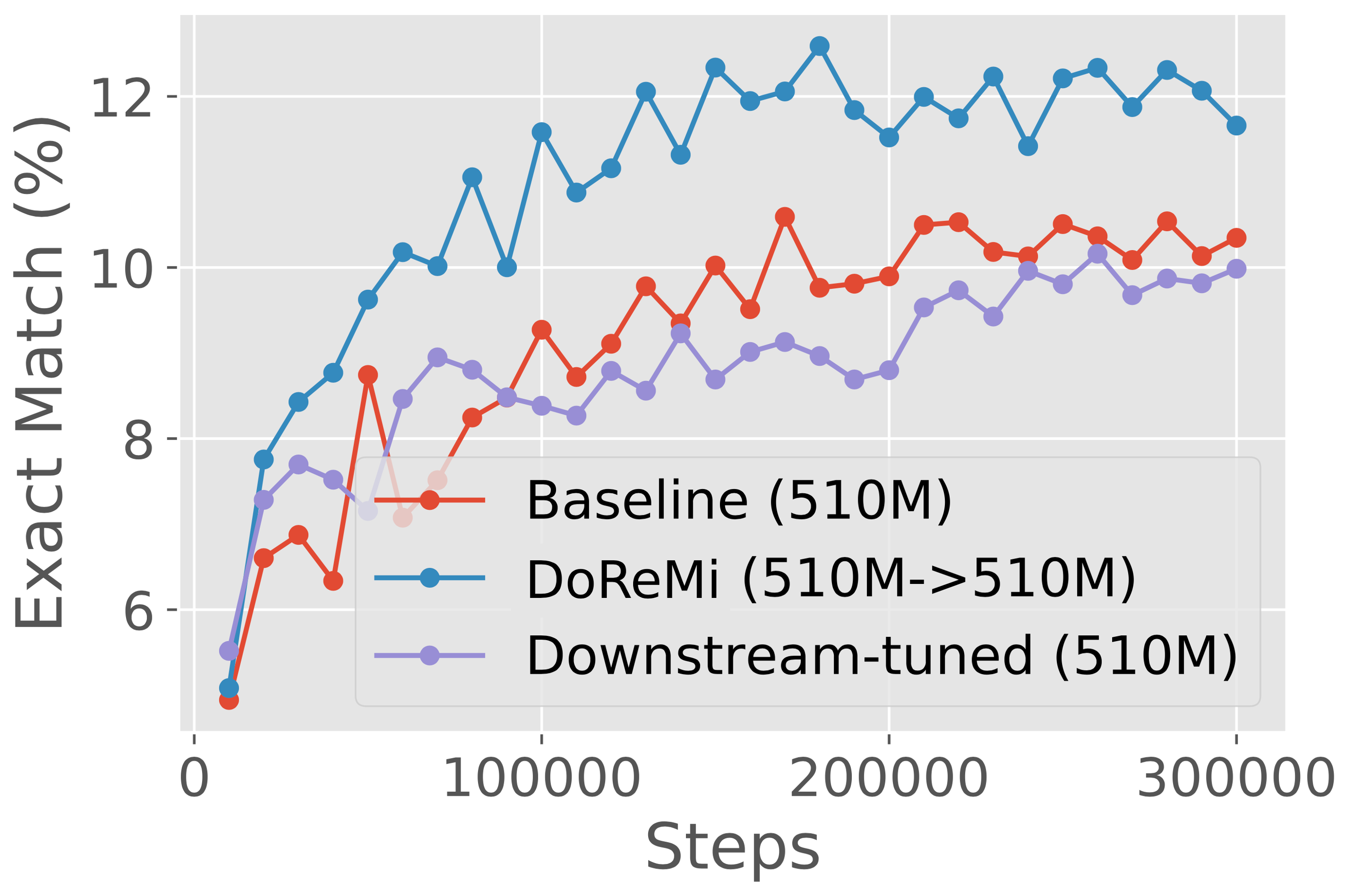
在第 3 节中,我们在 280M 代理和参考模型上运行 DoReMi,以优化 The Pile (Gao 等人,2020) 和 GLaM 数据集 (Du等人, 2021)(用于PaLM (Chowdhery 等人, 2022))。 DoReMi 域权重用于训练 8B 参数 LM(大 30 倍以上)。 在 The Pile 上,DoReMi 降低了所有域对基准域权重的困惑,即使它降低了域的权重。 在生成少样本任务中,DoReMi 与在 The Pile 默认域权重上训练的基线模型相比,平均下游准确度提高了 6.5%,并将基线下游准确度提高了 2.6 倍(图 2)。 我们发布了 The Pile 的调整域权重,以改进未来使用 The Pile 训练的 LM(表 1)。 在第 4 节中,我们发现,当改变代理模型和使用优化域权重训练的主模型的大小时,DoReMi 持续改进了 LM 训练。 在可以对下游任务调整域权重的 GLaM 数据集上,DoReMi 甚至可以与调整下游任务性能的域权重相媲美。
2 使用极小极大优化进行域重新加权 (DoReMi)
在本节中,我们定义 DoReMi,一种使用小型代理模型来优化语言建模数据集的域权重的算法,从而改进大型模型的训练。
设置。
假设我们有 个域(例如,Wikipedia、GitHub),其中对于每个域 ,我们有一组示例 。 域权重 指定了 域的概率分布,并由此指定了训练数据的分布:其中是对 中的示例的均匀分布,并且 是 1。如果为 1,否则为 0。
多雷米。
DoReMi 的输入是数据 、参考域权重 ,以及大型全尺寸模型的训练超参数(训练步数 和批量大小 )。 DoReMi 返回优化的域权重 ,最终返回在 。
步骤1:获得一个小的参考模型。
我们首先在一些参考域权重 上训练一个模型 , 步,批量大小 。 该模型用作步骤 2 的参考模型,并捕获每个示例/域的难度基线水平。 参考模型可以是一个相对较小的模型(在我们的实验中为280M参数)。
步骤2:使用Group DRO训练代理模型以获得域权重。
To obtain domain weights, we train a small proxy model in the distributionally robust language modeling (DRO-LM) (Oren et al., 2019) framework with the Group DRO optimizer (Sagawa et al., 2020), where are the weights of the proxy model. 该框架通过优化域上最坏情况的损失来训练鲁棒模型,这相当于以下极小极大目标:
| (1) |
其中的损失和为负对数分别为本文中代理模型和参考模型的负对数似然值、是实例 的词符长度。 该目标旨在最小化跨域的最坏情况超额损失,因为 上的内部最大化将所有权重放在具有最高超额损失的域上。
直观上,多余的损失 ()测量代理模型相对于参考模型的改进空间,例如 具有较高超额损失的示例是那些参考模型实现低损失(例如该示例是“可学习的”)但代理模型仍然具有高损失的示例。 超额损失低的例子可能是非常高的熵(即最优损失高,因此参考损失高)或非常低的熵(即易于学习,因此代理损失低)。 组 DRO 优化器的工作原理是,将域权重 的指数梯度上升更新与代理模型权重 在训练步骤 上的梯度更新交错进行。优化器更新,以提高具有高过量损失的域的权重,从而扩大代理模型在这些域的示例上的梯度更新。 继 Nemirovski 等人(2009 年) 之后。(2009),我们返回训练轨迹的平均权重作为步骤 3 中使用的优化域权重。
第 3 步:使用新的域权重训练大型模型。
调整后的域权重 定义新的训练分布 。 我们使用标准程序根据这个新分布的数据训练一个主模型(大于训练参考/代理模型)。
步骤 2 的详细信息。
算法 1 提供步骤 2 的伪代码。 算法1的主要结构是一个训练循环,它通过步更新代理模型。 在每一步中,我们遵循 Sakawa 等人 (2020) 并以统一的域权重对小批量进行采样(无论参考域权重如何,仅影响参考模型)。 然后,我们计算每个域的超额损失,通过每个域中的令牌总数进行归一化,并使用它们来更新域权重 在每一步。 我们首先在每个词符级别计算每个域的超额损失,然后汇总,其中索引 的词符级别损失为 and . 我们将每个代币的超额损失削减为 0,以维持非负损失值,这对于 Group DRO 优化器的基本保证是必要的(佐川等人,2020),并且在以下情况中很少需要:实践,但这意味着我们没有严格优化极小极大目标。 最后,我们更新目标 使用标准优化器,例如 Adam (Kingma 和 Ba,2015)8> 或 Adafactor (Shazeer 和 Stern,2018)9>。 我们将域权重更新步长设置为 并将平滑参数设置为 1e-4 在我们所有的实验中,并没有广泛调整这些超参数。
迭代DoReMi。
我们通过运行多轮来扩展 DoReMi,将下一轮的参考域权重 设置为 。 我们称之为迭代DoReMi。 整个迭代过程仍然只使用小模型来调整域权重。 当域权重收敛时,我们停止迭代,我们将其定义为任何域权重 小于 1e-3。 根据经验,这在 GLaM 数据集上只需要 3 轮(第 3.2 节)。
3 DoReMi 提高 LM 训练效率和性能
在本节中,我们使用通过 280M 参数代理模型优化的 DoReMi 域权重训练到 8B 参数主模型(大 30 倍)。 我们考虑两个数据集:The Pile (Gao 等人, 2020) 和 GLaM 训练集 (Du 等人, 2021)。 在 The Pile 上,DoReMi 显着降低了每个领域的困惑度,将生成式一次性任务的平均下游精度提高了 6.5%,并将基线精度提高了 2.6 倍。 在 GLaM 数据集上,可以在下游数据集上调整域权重,DoReMi 发现域权重的性能与下游调整的域权重相当。
3.1实验设置
桩数据集。
GLaM 数据集。
GLaM 数据集 (Du 等人, 2021)(也用于训练 PaLM (Chowdhery 等人, 2022))包含来自 8 个域的文本(表 2)。 为了进行比较,根据在每个域上训练的模型的下游性能和每个域的大小(Du等人,2021)来调整GLaM域权重(下游调整)。 我们对 DoReMi 的训练基线和参考域权重 使用统一的域权重。
训练设置。
我们使用标准的下一个令牌语言建模损失来训练 Transformer (Vaswani 等人, 2017) 仅解码器的 LM。 我们通过均衡计算量(通过训练期间处理的令牌数量来衡量)来进行受控比较。 对于 The Pile,我们将每个模型训练 20 万步;对于 GLaM 数据集,我们将每个模型训练 30 万步。 所有模型均使用批量大小 512 和最大词符长度 1024。 代理模型和参考模型有 280M 参数。 所有模型都是从头开始训练的(其他超参数见附录C)。
评估。
我们使用保留的验证数据来衡量每个领域的困惑度。 对于下游评估,我们使用 GPT-3 论文 (Brown 等人, 2020) 中的生成式一次性任务:TriviaQA (Joshi 等人, 2017)、NaturalQuestions (Kwiatkowski 等人, 2019)、WebQuestions (Berant 等人, 2013)、SQuADv2 (Rajpurkar 等人, 2018) 和 LAMBADA (Paperno等人,2016)。 我们对这些数据集使用标准的精确匹配精度指标。
用于优化域权重的计算。
我们训练两个 280M 模型(参考模型和代理模型)来优化域权重。 这是训练主要 8B 模型所需的 FLOP 的 8%。 所有的 FLOP 都来自标准的向前和向后传递。
DoReMi 中模型尺寸的表示法。
我们将参考/代理模型的大小(在我们的实验中始终相同大小)和使用 DoReMi 域权重训练的主模型的大小表示为“DoReMi(参考/代理的大小主模型尺寸)”:例如DoReMi(280M8B)。 当我们讨论独立于主模型的优化域权重时,我们仅包含一个数字(例如 DoReMi (280M)),它指的是参考/代理模型大小。
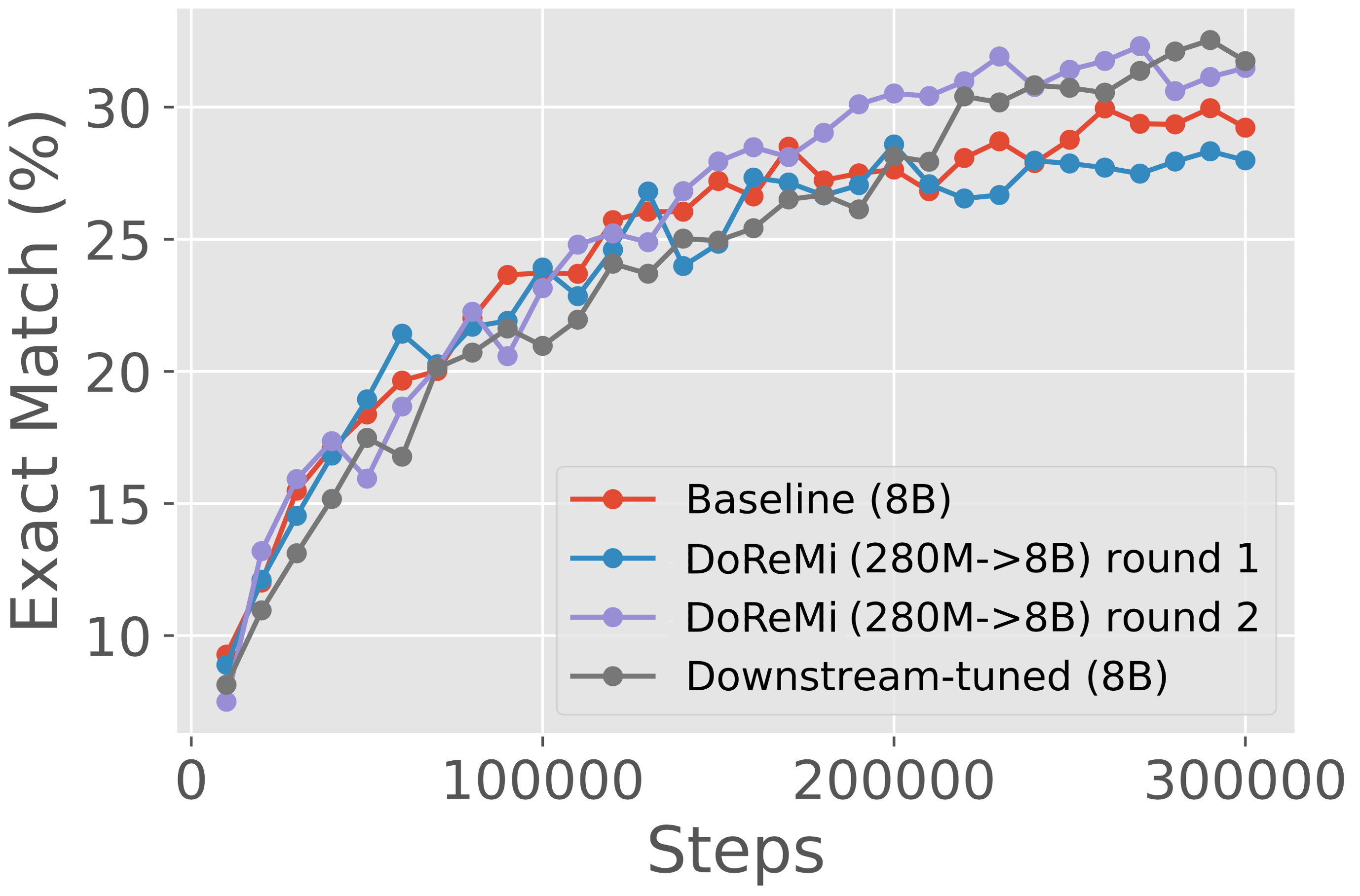
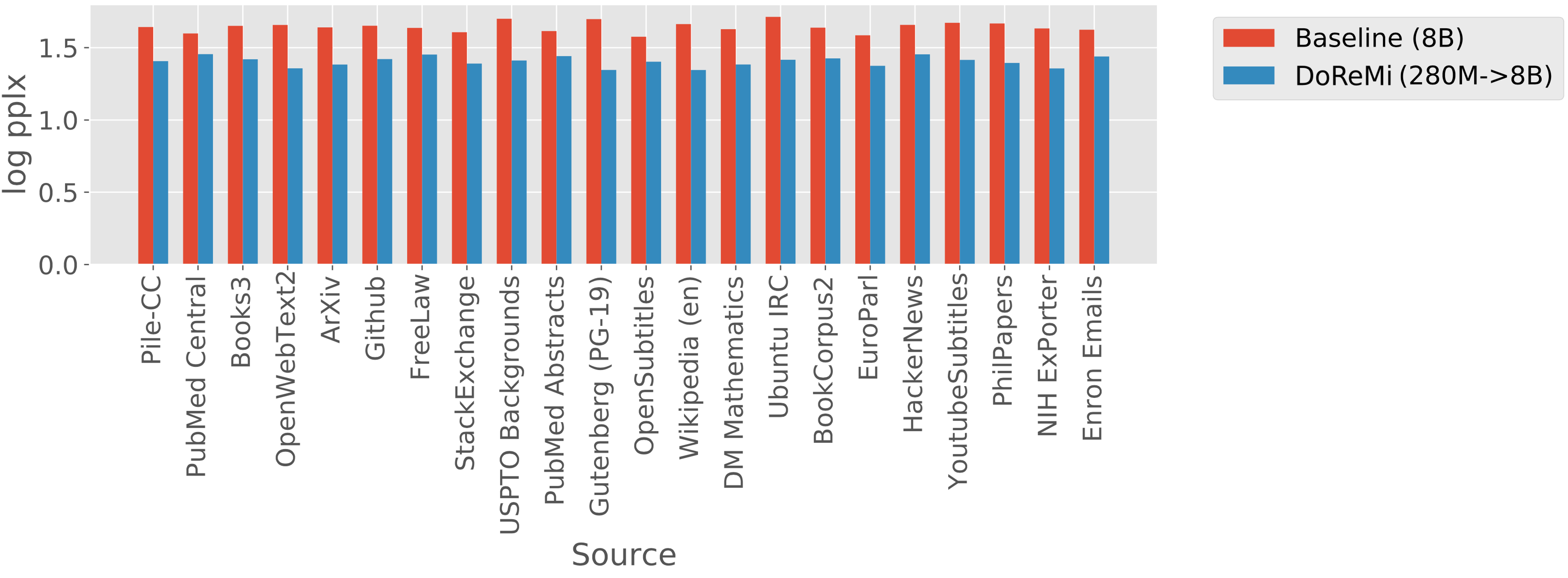
3.2 DoReMi 提高了困惑度和下游准确性
我们表明,DoReMi 显着提高了在 The Pile 和 GLaM 数据集上训练的 8B 模型相对于各自基线域权重的困惑度和下游准确性。
The Pile 的下游精度有所提高。
图 3(左)显示了 The Pile 上基准模型和 DoReMi (280M8B) 模型的平均下游性能。 DoReMi 将下游精度提高了 6.5%,并在 75k 步内实现了基线精度,比基线(200k 步)快了 2.6 倍。 因此,DoReMi 可以显着加快训练速度并提高下游性能。
DoReMi 可以减少所有领域的困惑,无需权衡。
图 4 显示了 The Pile 上 8B 模型的每个域的困惑度。 尽管为某些域分配了较低的权重,DoReMi 仍显着降低了所有域的基线的困惑度。 怎么会发生这种情况呢? 直观上,熵最低和最高的域可以被降低权重,而不会太大影响困惑度。 从统计上看,最低熵域需要很少的样本来学习。 最高熵域的词符分布接近常见的统一先验——例如,随机初始化的模型倾向于输出统一的下一个词符分布。 因此,我们需要更少的样本来适应这些领域。 从分配更多样本到中等熵域的正向转移可以改善所有域的困惑度。 在附录D中,我们提供了一个简单的示例,其中重新加权域可以改善所有域的困惑度,并且DoReMi在模拟中找到这样的域权重。
基线 DoReMi (280M) 桩CC 0.1121 0.6057 PubMed 中心 0.1071 0.0046 书籍3 0.0676 0.0224 OpenWebText2 0.1247 0.1019 ArXiv 0.1052 0.0036 Github 0.0427 0.0179 FreeLaw 0.0386 0.0043 StackExchange 0.0929 0.0153 美国专利商标局背景 0.0420 0.0036 PubMed 摘要 0.0845 0.0113 古腾堡(PG-19) 0.0199 0.0072
基线 DoReMi (280M) 开放字幕 0.0124 0.0047 维基百科(en) 0.0919 0.0699 DM数学 0.0198 0.0018 Ubuntu IRC 0.0074 0.0093 BookCorpus2 0.0044 0.0061 欧洲帕尔 0.0043 0.0062 黑客新闻 0.0075 0.0134 Youtube字幕 0.0042 0.0502 菲尔论文 0.0027 0.0274 NIH 导出器 0.0052 0.0063 安然电子邮件 0.0030 0.0070
第 1 轮 第 2 轮 第 3 轮 下游调整 维基百科 0.09 0.05 0.05 0.06 过滤的网页 0.44 0.51 0.51 0.42 对话 0.10 0.22 0.22 0.27 论坛 0.16 0.04 0.04 0.02 书籍 0.11 0.17 0.17 0.20 新闻 0.10 0.02 0.02 0.02
迭代的 DoReMi 在 GLaM 数据集上实现了下游调整权重的性能。
检查 DoReMi 域权重。
4 跨尺度的消融和分析
之前在第 3 节中,我们展示了 DoReMi 使用 280M 模型找到域权重,可以提高 8B 模型的训练。 在本节中,我们对 DoReMi 进行分析,其中我们改变了代理模型相对于主模型的规模,并消除了超额损失目标的组成部分。
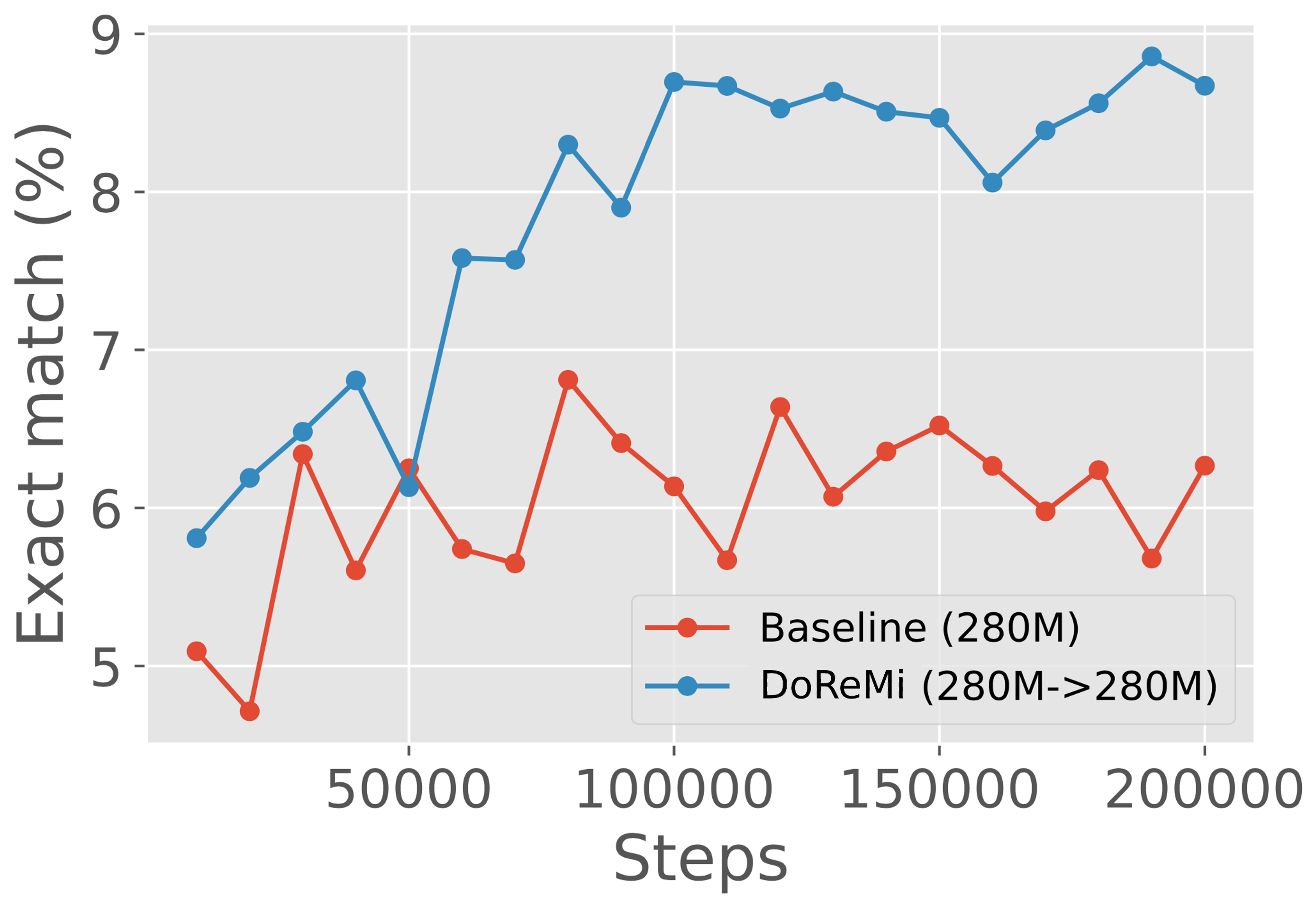
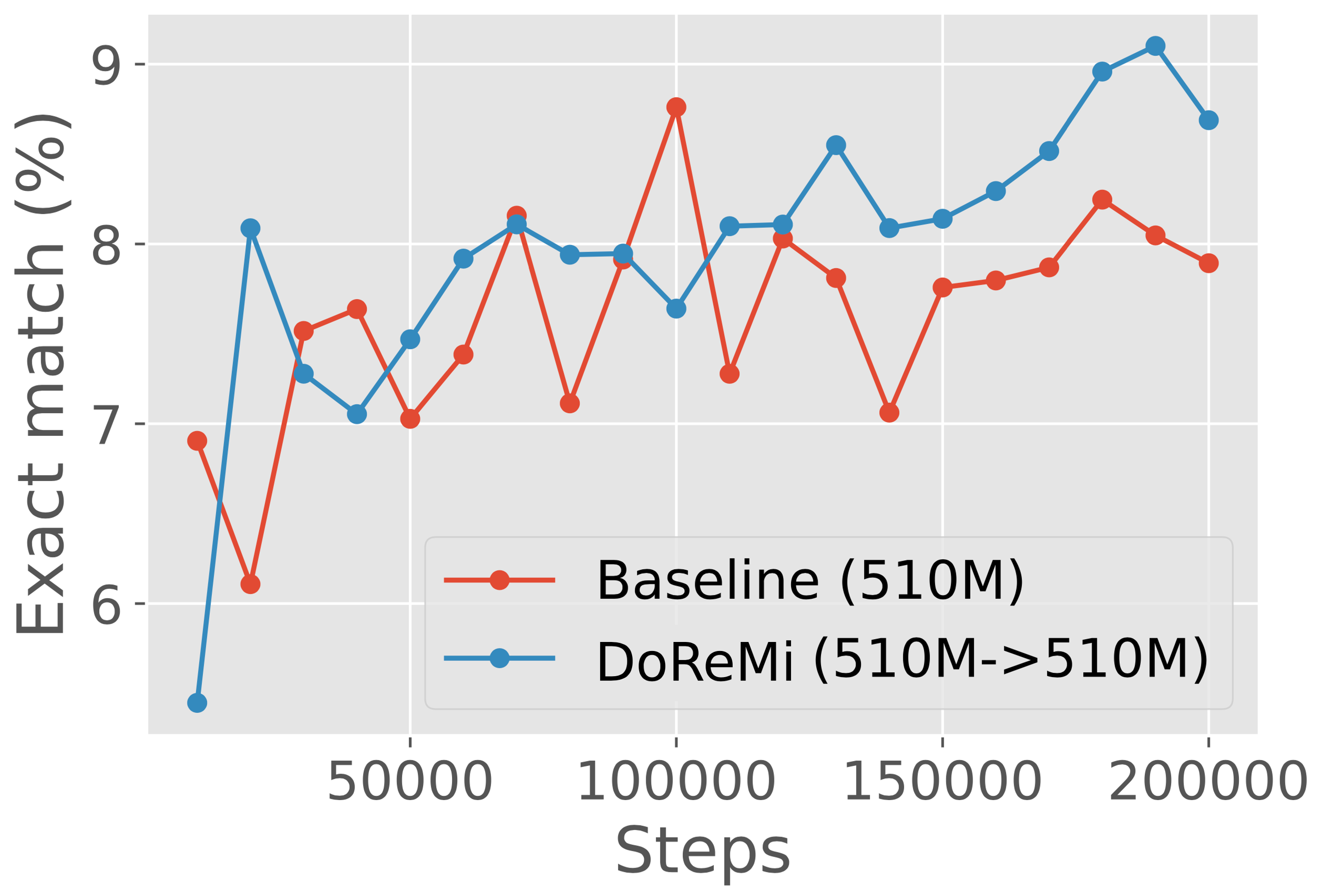
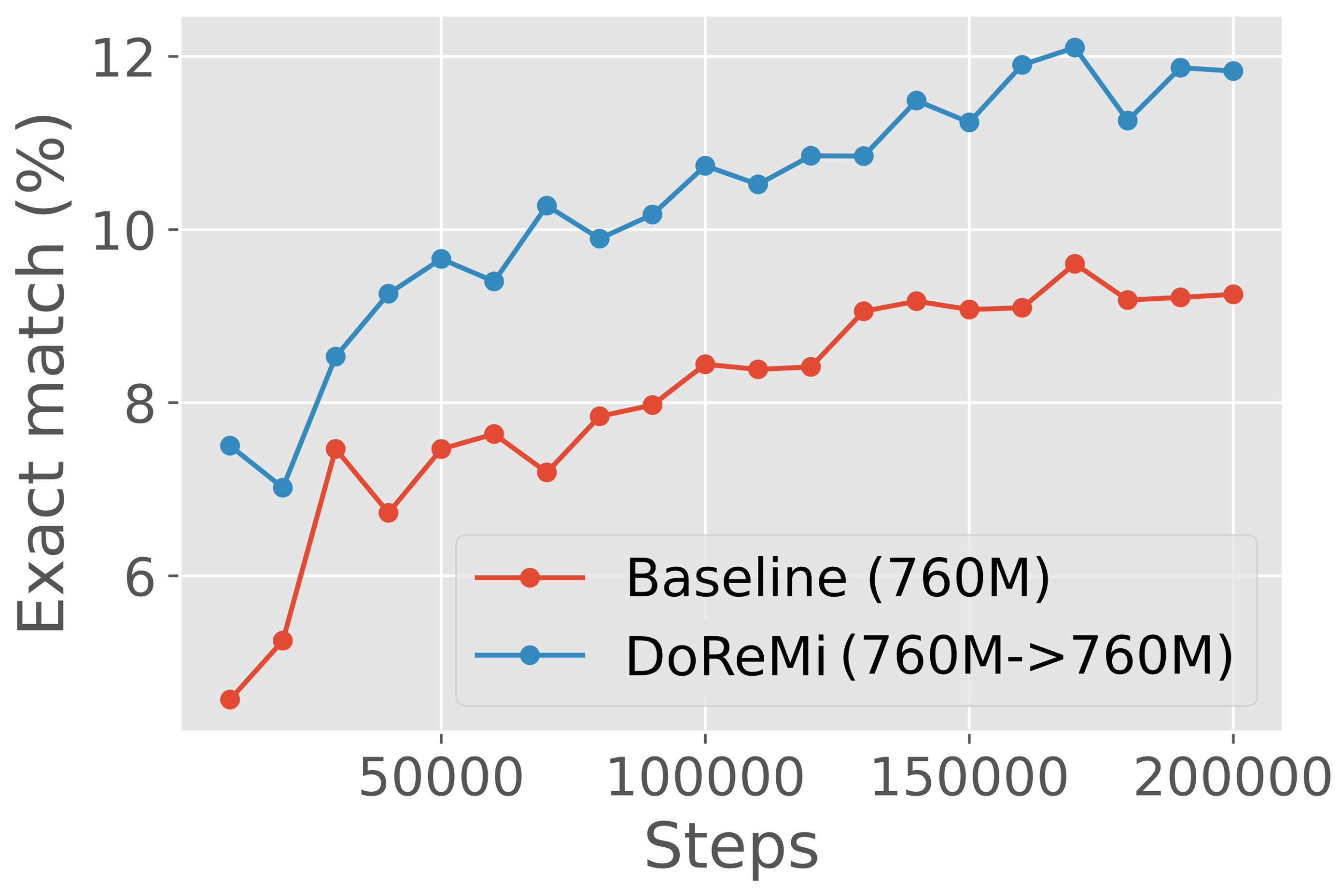
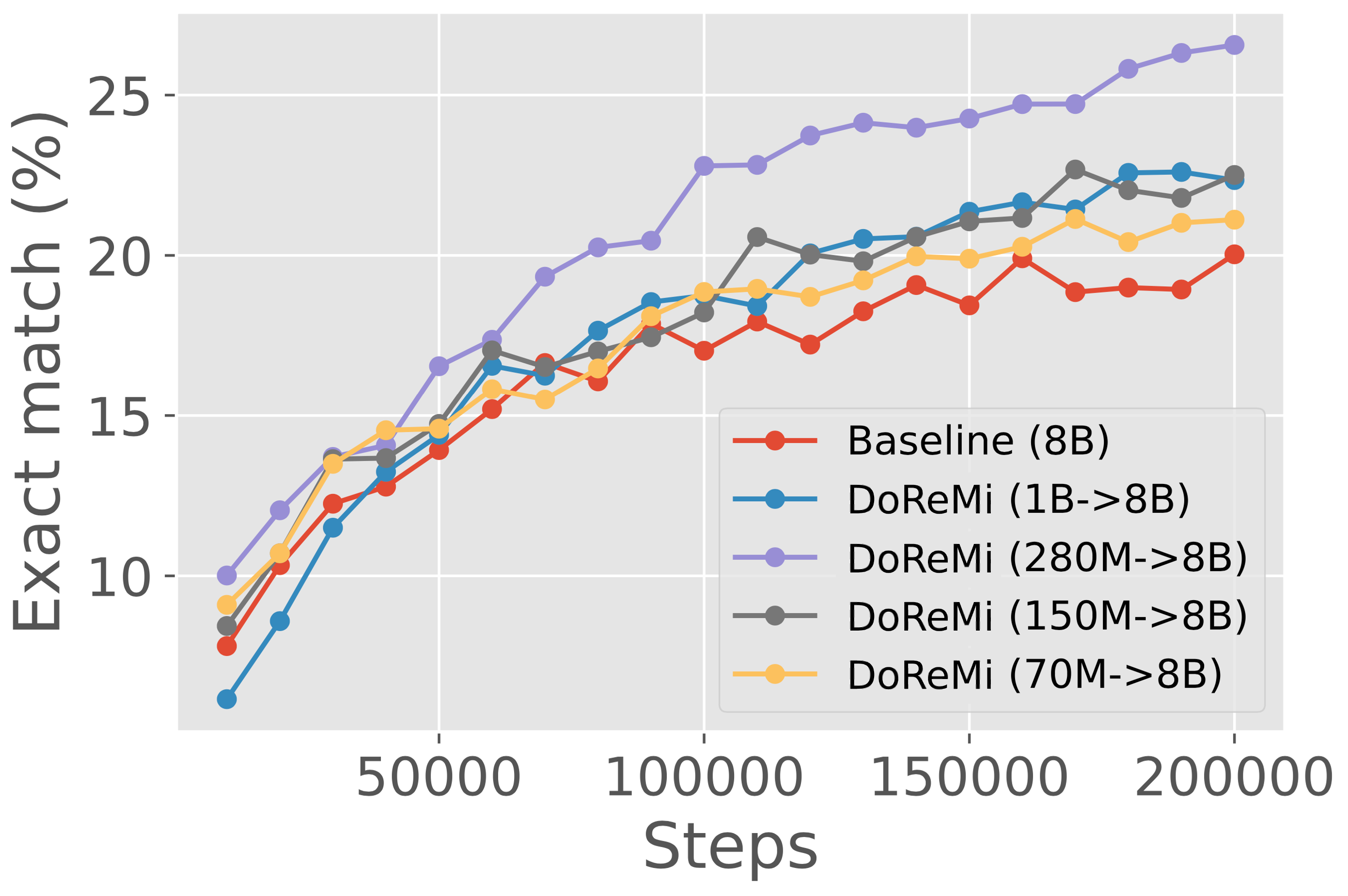
DoReMi 在各个尺度上一致地改进 LM。
代理模型的性能低于主模型,尤其是在较大尺寸的情况下。
回想一下,DoReMi 使用 Group DRO 来训练代理模型,该模型使用域权重重新加权目标。 相比之下,主模型是通过对 DoReMi 的域权重进行重采样来训练的。 当代理模型和主模型大小相同时,哪个模型更好? 表6(b)显示在这种情况下代理模型通常表现不佳。 代理模型和主模型之间的差距随着规模的增大而增大,因为 1B 代理模型不仅表现不佳于 1B 主模型,而且表现也低于 1B 基线模型,而 280M 代理模型在 19/22 域上比 280M 基线模型实现了更好的困惑度。 尽管 1B 代理模型的质量相对较差,但域权重仍然允许 1B 主模型以超过 2 倍的速度实现基线性能。 这表明 DoReMi 对于极小极大优化过程中的任何次优性都非常稳健。 然而,我们假设代理和主模型训练之间的不匹配(损失重新加权与重采样)解释了它们的性能差异,因此基于重采样的 Group DRO 优化器可能会改进较大代理模型的 DoReMi。
最坏情况 pplx 平均人数 # 个域 最佳基线 基线 (8B) 1.71 1.64 0/22 DoReMi(70M->8B) 1.63 1.53 22/22 DoReMi(150M->8B) 1.56 1.52 22/22 DoReMi(280M->8B) 1.46 1.40 22/22 DoReMi(1B->8B) 1.58 1.54 22/22
最坏情况 pplx 平均人数 # 个域 最佳基线 基线(280M) 2.39 2.32 0/22 DoReMi(280M->280M) 2.19 2.13 22/22 代理(280M) 2.33 2.27 19/22 基线 (1B) 1.94 1.87 0/22 DoReMi(1B->1B) 1.92 1.83 19/22 代理(1B) 2.11 2.02 0/22
代理模型规模对较大主模型性能的影响。
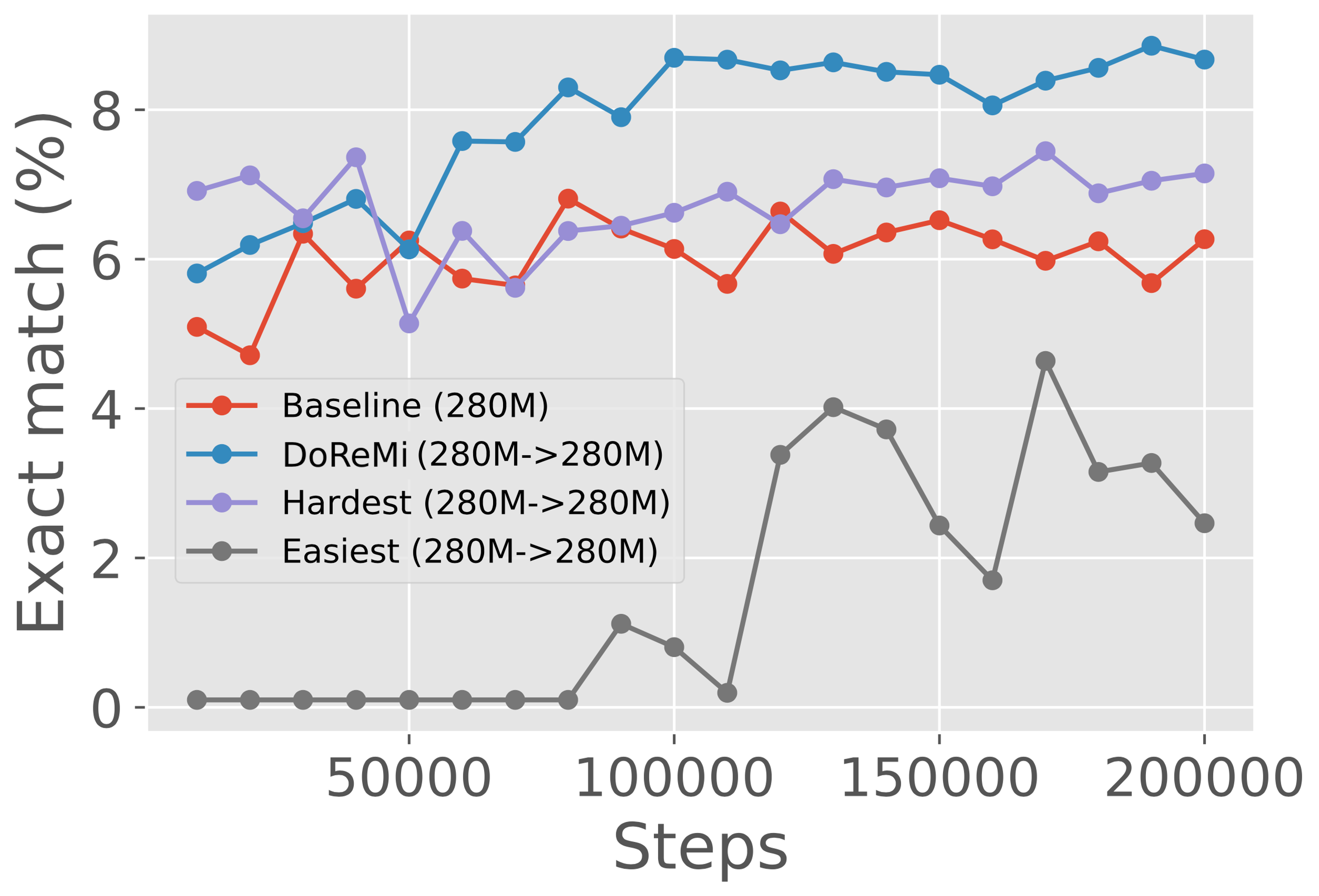
选择最简单或最难的领域是不够的。
我们消融过量损失度量的成分在实例 上仅使用代理模型 的损失运行 DoReMi、i.e.(首选代理模型的最硬域),或只选择负损失的(优先选择最简单的领域作为参考模型)。 图6(右)显示,单独的超额损失的组成部分都不足以实现DoReMi的收益。
5相关工作
为 LM 整理预训练数据。
最密切相关的是 GLaM 数据集 (Du 等人, 2021)(也用于训练 PaLM (Chowdhery 等人, 2022)),它具有经过调整的域权重使用下游数据。 优化下游任务的域权重可能成本高昂,并且可能需要搜索/零阶优化(Snoek 等人,2012)、RL (Zoph 和 Le,2016),或关于域之间的正/负转移如何工作的启发式假设。 示例级过滤也为 LM 训练带来好处。 C4 数据集(Raffel 等人,2019) 显示通过启发式数据清理方法比 CommonCrawl 取得了进步。 Du 等人 (2021), Xie 等人 (2023) 表明,在示例级别过滤数据以获取类似于维基百科和书籍的高质量文本可以显着提高 LM 的下游性能。 与这些作品相比,DoReMi 仅通过 2 个小型 LM 训练运行自动设置域权重,并且不对首选数据类型做出假设(类似维基百科等)。
一般数据选择方法。
Moore-Lewis 选择(Moore and Lewis, 2010, Axelrod, 2017, Feng 等人, 2022) 选择在目标上训练的语言模型之间具有高交叉熵差异(类似于过度对数困惑)的示例和原始数据。 Coleman 等人 (2020) 基于主动学习的小型代理模型的不确定性来选择示例。 Mindermann 等人 (2022) 根据过量损失,通过在小批量中选取前 个示例,以在线方式选择示例。 视觉中还有许多其他关于数据选择的工作(Sorscher 等人, 2022, Kaushal 等人, 2019, Killamsetty 等人, 2021b, a, c, Wang 等人, 2020, Wei 等人, 2015, Paul 等人,2021,Mirzasoleiman 等人,2020,Sener 和 Savarese,2018)。 总的来说,这些方法没有解决预训练的数据选择问题,其中下游数据分布可能与预训练有很大不同。 DoReMi 旨在通过 DRO 解决预训练/下游分配转移问题。
分布稳健优化。
在深度学习的 DRO 方法中(Ben-Tal 等人,2013,Sinha 等人,2018,Oren 等人,2019,Sakawa 等人,2020),我们的目标是一种称为组的限制形式的转变shifts (Duchi 等人, 2019, Oren 等人, 2019, Sakawa 等人, 2020),其中测试分布可以是未知的组(域)混合。 我们遵循 DRO-LM (Oren 等人, 2019),它在组轮班设置中对 LM 使用 DRO。 DRO-LM 还使用基线损失,但使用简单的二元参考模型。 DoReMi 使用与代理模型相同大小和架构的参考模型,以确保损失可以进行比较。 在优化过程中,DRO-LM 采用每个小批量的最坏情况子集来更新模型,而我们使用不需要子选择的 Group DRO 优化器(佐川等人,2020)。 子选择的成本很高,因为它需要在大批量上评估模型,同时只选择一小部分来更新模型。 总体而言,与这些旨在生成稳健模型的 DRO 方法相比,我们使用 DRO 来优化数据,以便更有效地训练更大的模型。
6 讨论和限制
依赖于训练算法。
理想情况下,DoReMi 将独立于训练算法,但 DoReMi 运行训练算法来训练参考/代理模型。 尽管如此,DoReMi 在某些方面实现了算法独立性:在第 3.2 节中,我们证明了 DoReMi 域权重跨尺度传递增益。 一般来说,我们期望 DoReMi 找到的域权重能够在广泛的模型规模、计算预算和其他训练超参数之间转移。
通过外推法在 DoReMi 中保存计算。
参考模型的选择。
参考模型的选择会影响DoReMi找到的域权重。 例如,迭代 DoReMi(第 3 节)通过使用在上一轮 DoReMi 的调整域权重上训练的参考模型来提高性能。 进一步的方向包括改变参考模型大小以及使用专门的参考模型来优化特定应用领域的域权重。
什么是域名?
我们在实验中通过数据来源定义域,但这只能实现粗粒度控制。 使用细粒度域可以提高 DoReMi 的收益。 例如,DoReMi 在 The Pile(22 个域)上比 GLaM 数据集(8 个域)更有效。
更广泛的影响。
我们希望提高训练效率并减少训练大型LM对环境的影响(Strubell 等人, 2019, Lacoste 等人, 2019, Patterson 等人, 2021, Ligozat 等人, 2021)。 然而,大型语言模型也被充分证明存在风险和偏见(Abid 等人,2021,Nadeem 等人,2020,Bommasani 等人,2021,Blodgett 和 OConnor,2017,Gehman 等人,2020). DRO 式训练旨在产生在所有领域都具有良好性能的模型,可能会对公平性产生有利影响,但这需要进一步研究。
7结论
我们引入了 DoReMi,一种为训练语言模型重新加权数据域的算法。 DoReMi 能够在小型模型上运行,并将优势转移到 30 倍大的模型上,只需更改域上的采样概率,即可将 Pile 上的训练速度提高 2.6 倍。 我们希望发起更多以数据为中心的训练方法的研究,以提高语言模型的效率。
致谢
我们感谢陈翔宁、戴安德、Zoubin Ghahramani、Balaji Lakshminarayanan、Paul Michel、吴永辉、Steven Cheng、Chen Zhu 以及更广泛的 Google Bard 团队成员的富有洞察力的讨论和指导。
参考
- Abid et al. (2021) Abubakar Abid, Maheen Farooqi, and James Zou. Persistent anti-muslim bias in large language models. arXiv preprint arXiv:2101.05783, 2021.
- Axelrod (2017) Amittai Axelrod. Cynical selection of language model training data. CoRR, abs/1709.02279, 2017. URL http://arxiv.org/abs/1709.02279.
- Ben-Tal et al. (2013) Aharon Ben-Tal, Dick den Hertog, Anja De Waegenaere, Bertrand Melenberg, and Gijs Rennen. Robust solutions of optimization problems affected by uncertain probabilities. Management Science, 59:341–357, 2013.
- Berant et al. (2013) Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. Semantic parsing on Freebase from question-answer pairs. In Empirical Methods in Natural Language Processing (EMNLP), 2013.
- Blodgett and OConnor (2017) Su Lin Blodgett and Brendan OConnor. Racial disparity in natural language processing: A case study of social media African-American English. arXiv preprint arXiv:1707.00061, 2017.
- Bommasani et al. (2021) Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, Erik Brynjolfsson, Shyamal Buch, Dallas Card, Rodrigo Castellon, Niladri Chatterji, Annie Chen, Kathleen Creel, Jared Quincy Davis, Dorottya Demszky, Chris Donahue, Moussa Doumbouya, Esin Durmus, Stefano Ermon, John Etchemendy, Kawin Ethayarajh, Li Fei-Fei, Chelsea Finn, Trevor Gale, Lauren Gillespie, Karan Goel, Noah Goodman, Shelby Grossman, Neel Guha, Tatsunori Hashimoto, Peter Henderson, John Hewitt, Daniel E. Ho, Jenny Hong, Kyle Hsu, Jing Huang, Thomas Icard, Saahil Jain, Dan Jurafsky, Pratyusha Kalluri, Siddharth Karamcheti, Geoff Keeling, Fereshte Khani, Omar Khattab, Pang Wei Koh, Mark Krass, Ranjay Krishna, Rohith Kuditipudi, Ananya Kumar, Faisal Ladhak, Mina Lee, Tony Lee, Jure Leskovec, Isabelle Levent, Xiang Lisa Li, Xuechen Li, Tengyu Ma, Ali Malik, Christopher D. Manning, Suvir Mirchandani, Eric Mitchell, Zanele Munyikwa, Suraj Nair, Avanika Narayan, Deepak Narayanan, Ben Newman, Allen Nie, Juan Carlos Niebles, Hamed Nilforoshan, Julian Nyarko, Giray Ogut, Laurel Orr, Isabel Papadimitriou, Joon Sung Park, Chris Piech, Eva Portelance, Christopher Potts, Aditi Raghunathan, Rob Reich, Hongyu Ren, Frieda Rong, Yusuf Roohani, Camilo Ruiz, Jack Ryan, Christopher Ré, Dorsa Sadigh, Shiori Sagawa, Keshav Santhanam, Andy Shih, Krishnan Srinivasan, Alex Tamkin, Rohan Taori, Armin W. Thomas, Florian Tramèr, Rose E. Wang, William Wang, Bohan Wu, Jiajun Wu, Yuhuai Wu, Sang Michael Xie, Michihiro Yasunaga, Jiaxuan You, Matei Zaharia, Michael Zhang, Tianyi Zhang, Xikun Zhang, Yuhui Zhang, Lucia Zheng, Kaitlyn Zhou, and Percy Liang. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
- Chowdhery et al. (2022) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, A. Rao, Parker Barnes, Yi Tay, Noam M. Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, B. Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, M. Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, S. Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier García, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, D. Luan, Hyeontaek Lim, Barret Zoph, A. Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, T. S. Pillai, Marie Pellat, Aitor Lewkowycz, E. Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, K. Meier-Hellstern, D. Eck, J. Dean, Slav Petrov, and Noah Fiedel. PaLM: Scaling language modeling with pathways. arXiv, 2022.
- Coleman et al. (2020) Cody Coleman, Christopher Yeh, Stephen Mussmann, Baharan Mirzasoleiman, Peter Bailis, Percy Liang, Jure Leskovec, and Matei Zaharia. Selection via proxy: Efficient data selection for deep learning. In International Conference on Learning Representations (ICLR), 2020.
- Du et al. (2021) Nan Du, Yanping Huang, Andrew M. Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, M. Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, Barret Zoph, Liam Fedus, Maarten Bosma, Zongwei Zhou, Tao Wang, Yu Emma Wang, Kellie Webster, Marie Pellat, Kevin Robinson, K. Meier-Hellstern, Toju Duke, Lucas Dixon, Kun Zhang, Quoc V. Le, Yonghui Wu, Zhifeng Chen, and Claire Cui. GLaM: Efficient scaling of language models with mixture-of-experts. arXiv, 2021.
- Duchi et al. (2019) John Duchi, Tatsunori Hashimoto, and Hongseok Namkoong. Distributionally robust losses against mixture covariate shifts. https://cs.stanford.edu/~thashim/assets/publications/condrisk.pdf, 2019.
- Feng et al. (2022) Yukun Feng, Patrick Xia, Benjamin Van Durme, and João Sedoc. Automatic document selection for efficient encoder pretraining, 2022. URL https://arxiv.org/abs/2210.10951.
- Gao et al. (2020) Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The pile: An 800gb dataset of diverse text for language modeling. arXiv, 2020.
- Gehman et al. (2020) Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A Smith. Realtoxicityprompts: Evaluating neural toxic degeneration in language models. arXiv preprint arXiv:2009.11462, 2020.
- Hoffmann et al. (2022) Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre. An empirical analysis of compute-optimal large language model training. In Advances in Neural Information Processing Systems (NeurIPS), 2022.
- Joshi et al. (2017) Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Association for Computational Linguistics (ACL), 2017.
- Kaushal et al. (2019) Vishal Kaushal, Rishabh Iyer, Suraj Kothawade, Rohan Mahadev, Khoshrav Doctor, and Ganesh Ramakrishnan. Learning from less data: A unified data subset selection and active learning framework for computer vision. IEEE/CVF Winter Conference on Applicatios of Computer Vision (WACV), 2019.
- Killamsetty et al. (2021a) Krishnateja Killamsetty, Durga S, Ganesh Ramakrishnan, Abir De, and Rishabh Iyer. GRAD-MATCH: Gradient matching based data subset selection for efficient deep model training. In International Conference on Machine Learning (ICML), 2021a.
- Killamsetty et al. (2021b) Krishnateja Killamsetty, Durga Sivasubramanian, Ganesh Ramakrishnan, and Rishabh Iyer. Glister: Generalization based data subset selection for efficient and robust learning. In Association for the Advancement of Artificial Intelligence (AAAI), 2021b.
- Killamsetty et al. (2021c) Krishnateja Killamsetty, Xujiang Zhao, Feng Chen, and Rishabh Iyer. Retrieve: Coreset selection for efficient and robust semi-supervised learning. In Advances in Neural Information Processing Systems (NeurIPS), 2021c.
- Kingma and Ba (2015) Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In International Conference on Learning Representations (ICLR), 2015.
- Kwiatkowski et al. (2019) Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Matthew Kelcey, Jacob Devlin, Kenton Lee, Kristina N. Toutanova, Llion Jones, Ming-Wei Chang, Andrew Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research. In Association for Computational Linguistics (ACL), 2019.
- Lacoste et al. (2019) Alexandre Lacoste, Alexandra Luccioni, Victor Schmidt, and Thomas Dandres. Quantifying the carbon emissions of machine learning. arXiv preprint arXiv:1910.09700, 2019.
- Ligozat et al. (2021) Anne-Laure Ligozat, Julien Lefèvre, Aurélie Bugeau, and Jacques Combaz. Unraveling the hidden environmental impacts of AI solutions for environment. CoRR, abs/2110.11822, 2021. URL https://arxiv.org/abs/2110.11822.
- Mindermann et al. (2022) Sören Mindermann, Jan Brauner, Muhammed Razzak, Mrinank Sharma, Andreas Kirsch, Winnie Xu, Benedikt Höltgen, Aidan N. Gomez, Adrien Morisot, Sebastian Farquhar, and Yarin Gal. Prioritized training on points that are learnable, worth learning, and not yet learnt. In International Conference on Machine Learning (ICML), 2022.
- Mirzasoleiman et al. (2020) Baharan Mirzasoleiman, Jeff Bilmes, and Jure Leskovec. Coresets for data-efficient training of machine learning models. In International Conference on Machine Learning (ICML), 2020.
- Moore and Lewis (2010) Robert C. Moore and William Lewis. Intelligent selection of language model training data. In Proceedings of the ACL 2010 Conference Short Papers, pages 220–224, Uppsala, Sweden, July 2010. Association for Computational Linguistics. URL https://aclanthology.org/P10-2041.
- Nadeem et al. (2020) Moin Nadeem, Anna Bethke, and Siva Reddy. Stereoset: Measuring stereotypical bias in pretrained language models. arXiv preprint arXiv:2004.09456, 2020.
- Nemirovski et al. (2009) Arkadi Nemirovski, Anatoli Juditsky, Guanghui Lan, and Alexander Shapiro. Robust stochastic approximation approach to stochastic programming. SIAM Journal on optimization, 19(4):1574–1609, 2009.
- Oren et al. (2019) Yonatan Oren, Shiori Sagawa, Tatsunori Hashimoto, and Percy Liang. Distributionally robust language modeling. In Empirical Methods in Natural Language Processing (EMNLP), 2019.
- Paperno et al. (2016) Denis Paperno, German Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernandez. The LAMBADA dataset: Word prediction requiring a broad discourse context. In Association for Computational Linguistics (ACL), 2016.
- Patterson et al. (2021) David A. Patterson, Joseph Gonzalez, Quoc V. Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David R. So, Maud Texier, and Jeff Dean. Carbon emissions and large neural network training. CoRR, abs/2104.10350, 2021. URL https://arxiv.org/abs/2104.10350.
- Paul et al. (2021) Mansheej Paul, Surya Ganguli, and Gintare Karolina Dziugaite. Deep learning on a data diet: Finding important examples early in training. In Association for the Advancement of Artificial Intelligence (AAAI), 2021.
- Raffel et al. (2019) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683, 2019.
- Rajpurkar et al. (2018) Pranav Rajpurkar, Robin Jia, and Percy Liang. Know what you don’t know: Unanswerable questions for SQuAD. In Association for Computational Linguistics (ACL), 2018.
- Sagawa et al. (2020) Shiori Sagawa, Pang Wei Koh, Tatsunori B. Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. In International Conference on Learning Representations (ICLR), 2020.
- Sener and Savarese (2018) Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach. In International Conference on Learning Representations (ICLR), 2018.
- Shazeer and Stern (2018) Noam Shazeer and Mitchell Stern. 2018.
- Sinha et al. (2018) Aman Sinha, Hongseok Namkoong, and John Duchi. Certifiable distributional robustness with principled adversarial training. In International Conference on Learning Representations (ICLR), 2018.
- Snoek et al. (2012) Jasper Snoek, Hugo Larochelle, and Ryan P. Adams. Practical Bayesian optimization of machine learning algorithms. In Advances in Neural Information Processing Systems (NeurIPS), 2012.
- Sorscher et al. (2022) Ben Sorscher, Robert Geirhos, Shashank Shekhar, Surya Ganguli, and Ari S. Morcos. Beyond neural scaling laws: beating power law scaling via data pruning. arXiv, 2022.
- Strubell et al. (2019) Emma Strubell, Ananya Ganesh, and Andrew McCallum. Energy and policy considerations for deep learning in NLP. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3645–3650, Florence, Italy, July 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1355. URL https://aclanthology.org/P19-1355.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. arXiv preprint arXiv:1706.03762, 2017.
- Wang et al. (2020) Xinyi Wang, Hieu Pham, Paul Michel, Antonios Anastasopoulos, Jaime Carbonell, and Graham Neubig. Optimizing data usage via differentiable rewards. In International Conference on Machine Learning (ICML), 2020.
- Wei et al. (2015) Kai Wei, Rishabh Iyer, and Jeff Bilmes. Submodularity in data subset selection and active learning. In International Conference on Machine Learning (ICML), 2015.
- Xie et al. (2023) Sang Michael Xie, Shibani Santurkar, Tengyu Ma, and Percy Liang. Data selection for language models via importance resampling. arXiv preprint arXiv:2302.03169, 2023.
- Zoph and Le (2016) Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. arXiv preprint arXiv:1611.01578, 2016.
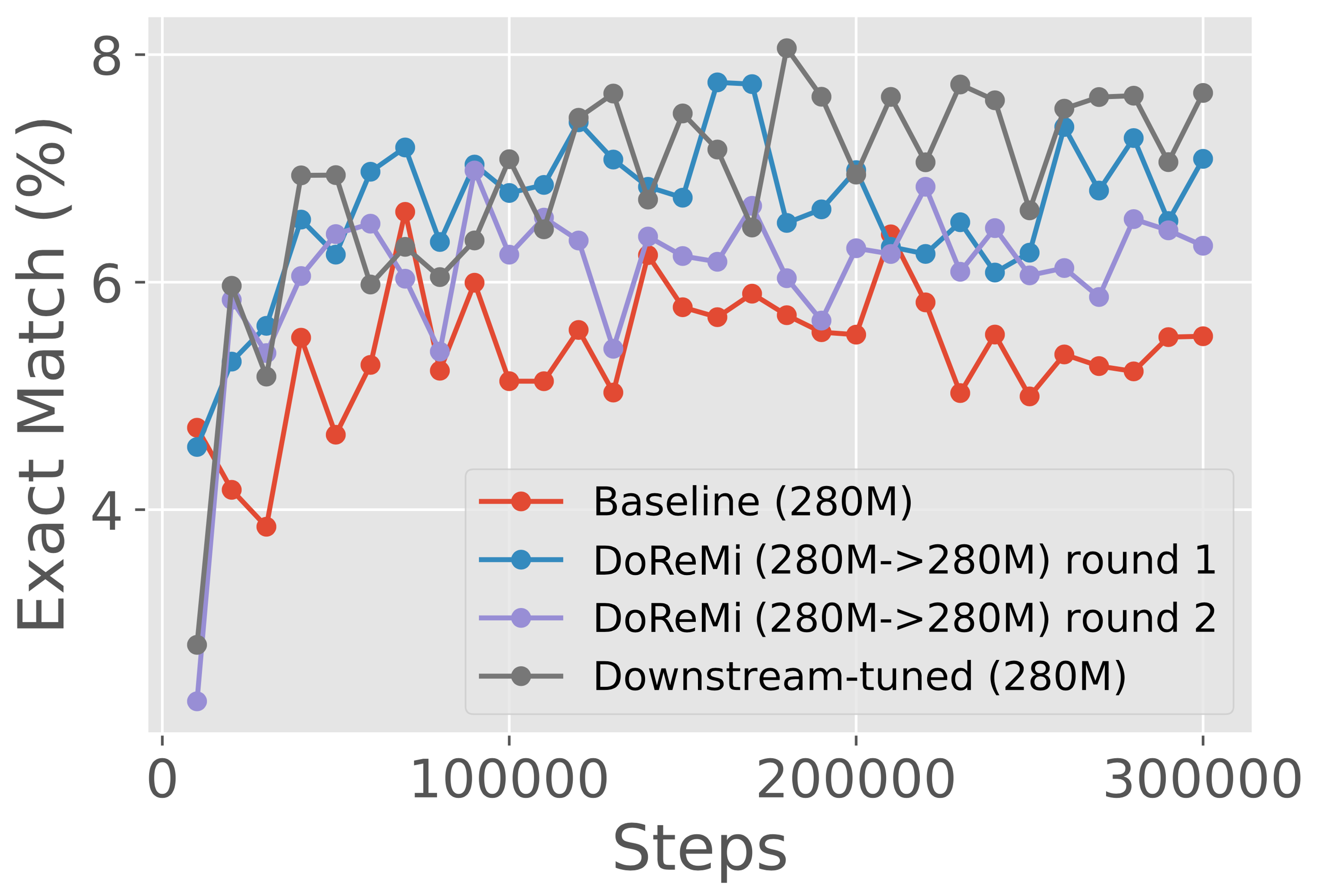
附录 A GLaM 数据集上的跨尺度结果
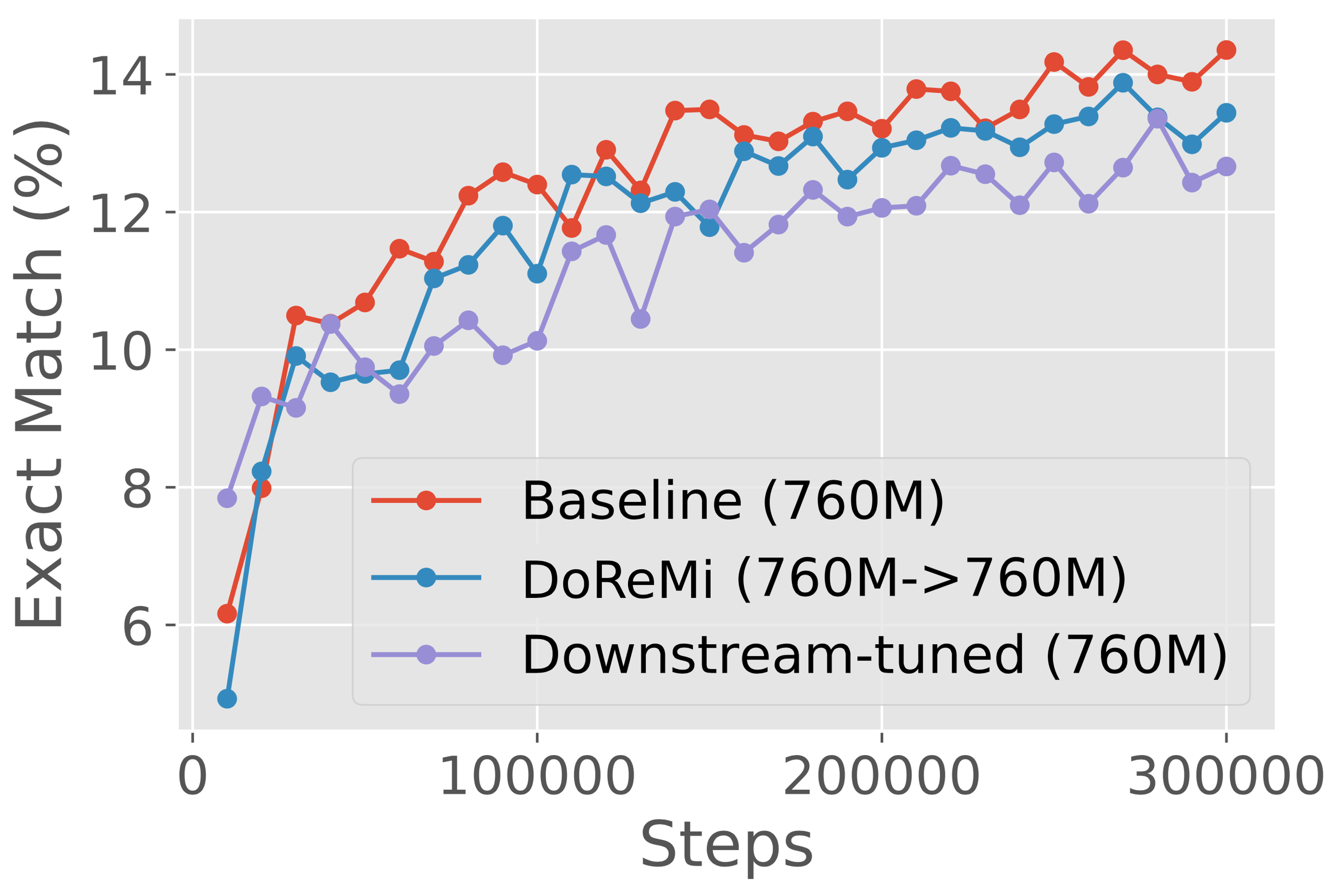
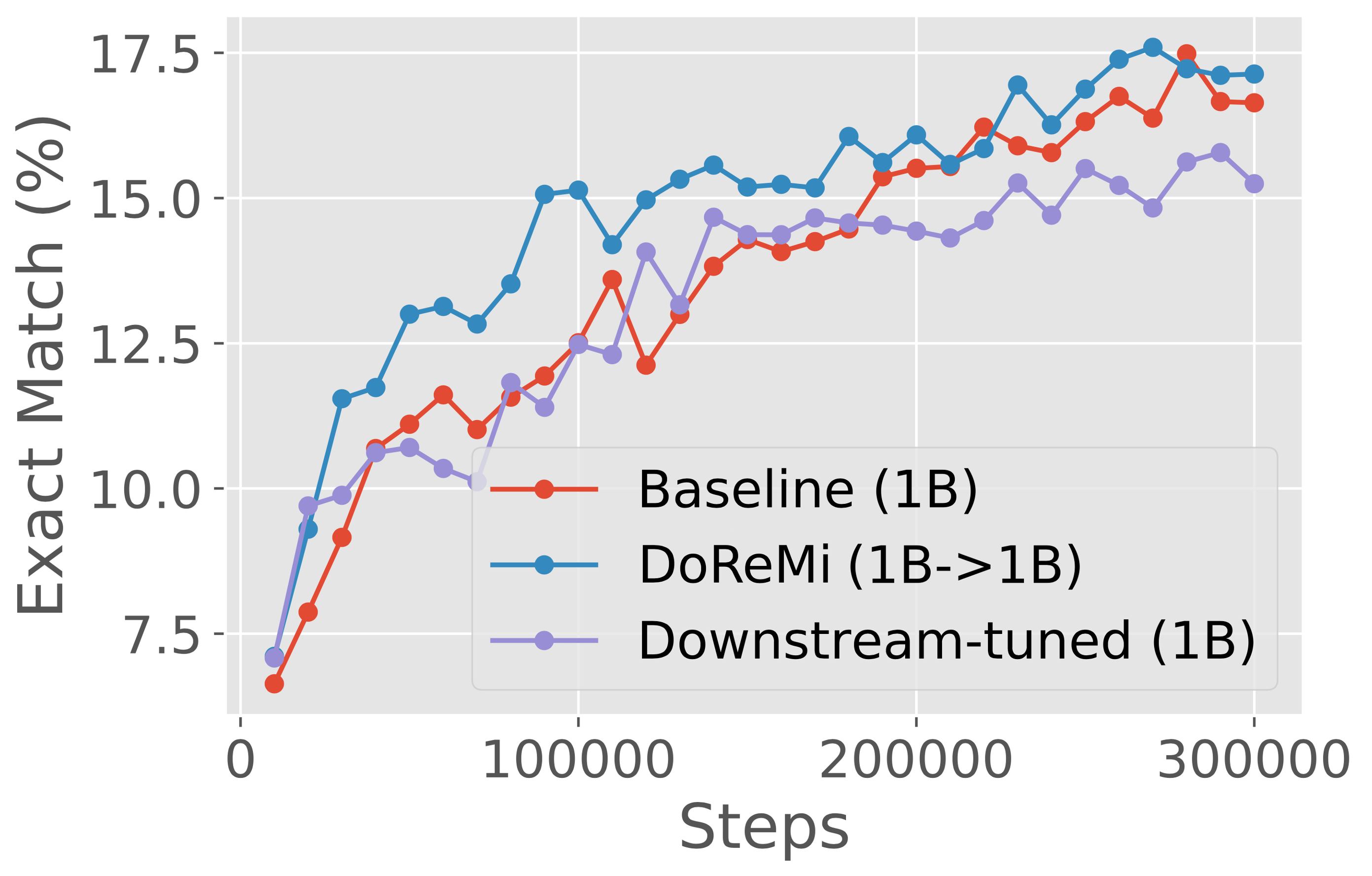
图7展示了GLaM数据集上不同尺度(280M、510M、760M、1B)的结果,其中代理/参考模型与使用DoReMi域权重训练的主模型大小相同。 在所有尺度上,DoReMi 与基线(统一)域权重和下游调整的域权重相当或更好。 有趣的是,对于 280M 规模的迭代 DoReMi,当用于训练 280M 模型时,第二轮权重的下游精度比第一轮权重稍差,但转移到训练 8B 模型时效果更好。
基线(8B) DoReMi(70M->8B) DoReMi(150M->8B) DoReMi(280M->8B) DoReMi (1B->8B) 桩CC 1.64 1.51 1.48 1.41 1.55 PubMed 中心 1.60 1.58 1.54 1.46 1.56 书籍3 1.65 1.52 1.50 1.42 1.57 OpenWebText2 1.66 1.48 1.54 1.36 1.58 ArXiv 1.64 1.56 1.53 1.38 1.51 Github 1.65 1.55 1.54 1.42 1.53 FreeLaw 1.64 1.55 1.54 1.45 1.55 StackExchange 1.61 1.52 1.54 1.39 1.55 美国专利商标局背景 1.70 1.53 1.50 1.41 1.56 PubMed 摘要 1.61 1.56 1.51 1.44 1.55 古腾堡(PG-19) 1.70 1.56 1.54 1.35 1.52 开放字幕 1.58 1.56 1.52 1.40 1.55 维基百科(zh) 1.66 1.49 1.53 1.35 1.56 DM数学 1.63 1.50 1.56 1.38 1.48 Ubuntu IRC 1.71 1.53 1.49 1.42 1.48 BookCorpus2 1.64 1.57 1.54 1.43 1.57 EuroParl 1.59 1.52 1.51 1.37 1.53 黑客新闻 1.66 1.50 1.55 1.45 1.55 Youtube字幕 1.67 1.63 1.55 1.42 1.53 菲尔论文 1.67 1.55 1.49 1.39 1.53 NIH 导出器 1.63 1.51 1.48 1.36 1.52 安然电子邮件 1.62 1.48 1.52 1.44 1.56
基线 DoReMi (1B->8B) DoReMi (280M->8B) DoReMi (150M->8B) DoReMi(70M->8B) 兰巴达20.1022.5529.1920.5926.20 自然问题 4.35 6.01 7.73 6.26 5.10 SQuADv2 44.43 42.22 51.89 46.53 40.99 TriviaQA 24.55 32.25 34.86 30.01 26.30 网络问题 6.74 8.71 9.15 9.15 6.99 平均 20.03 22.35 26.56 22.51 21.11
最坏情况的 pplx 平均 pplx # 个域最佳基准 基线(280M) 2.39 2.32 0/22 DoReMi(280M->280M) 2.19 2.13 22/22 代理(280M) 2.33 2.27 19/22 基线(510M) 2.14 2.08 0/22 DoReMi(510M->510M) 2.14 2.06 15/22 代理(510M) 2.23 2.18 0/22 基线(760M) 2.05 1.97 0/22 DoReMi(760M->760M) 2.00 1.94 17/22 代理(760M) 2.15 2.10 0/22 基线 (1B) 1.94 1.87 0/22 DoReMi(1B->1B) 1.92 1.83 19/22 代理(1B) 2.11 2.02 0/22
最坏情况的 pplx 平均 pplx # 个域最佳基准 基线(280M) 2.39 2.32 0 DoReMi(280M->280M) 2.19 2.13 22/22 最难(280M->280M) 2.66 2.62 0/22 最简单(280M->280M) 4.27 4.18 0/22
附录 B该堆的详细结果
8B 模型的每个域的困惑。
表 4 显示了在 Pile 上训练的 8B 模型的每个域的困惑度。 本例中的参考/代理模型为 70M、150M、280M 和 1B。 与基线域权重相比,DoReMi 提高了每个域的困惑度。
8B 模型的每任务精度。
表 5 显示了从 70M 到 1B 的各种参考/代理模型大小的一次性生成任务的准确性。 所有 DoReMi 模型都比基线显着提高了下游性能。
跨尺度的困惑结果总结。
表 6 显示了 DoReMi 跨 4 个尺度(280M、510M、760M、1B)的每个域困惑度的摘要。 在这里,参考/代理模型的大小与使用 DoReMi 域权重训练的主模型相同。 平均而言,DoReMi 改善了 The Pile 中 22 个域中 18.25 个域的困惑度。 相对于基线域权重,最坏情况的困惑度总是会降低(或在 510M 情况下相当)。
消融带来困惑。
表7显示了 DRO 物镜上消融的困惑度。 我们更改 DRO 目标并使用它们来调整 280M 参考/代理模型上的域权重。 然后使用这些调整的域权重来训练主要的 280M 模型。 最难是指在不使用参考模型作为基线的情况下优化域级日志困惑度。 最简单是指在参考模型下优化对数困惑度最低的领域。 两种消融都不会改善任何领域超过基线的困惑度。 针对“最难”领域的优化实际上并不会改善最坏情况的困惑度,这支持了 Oren 等人 (2019) 的结果,该结果还采用 DRO 进行具有基线损失的语言建模。
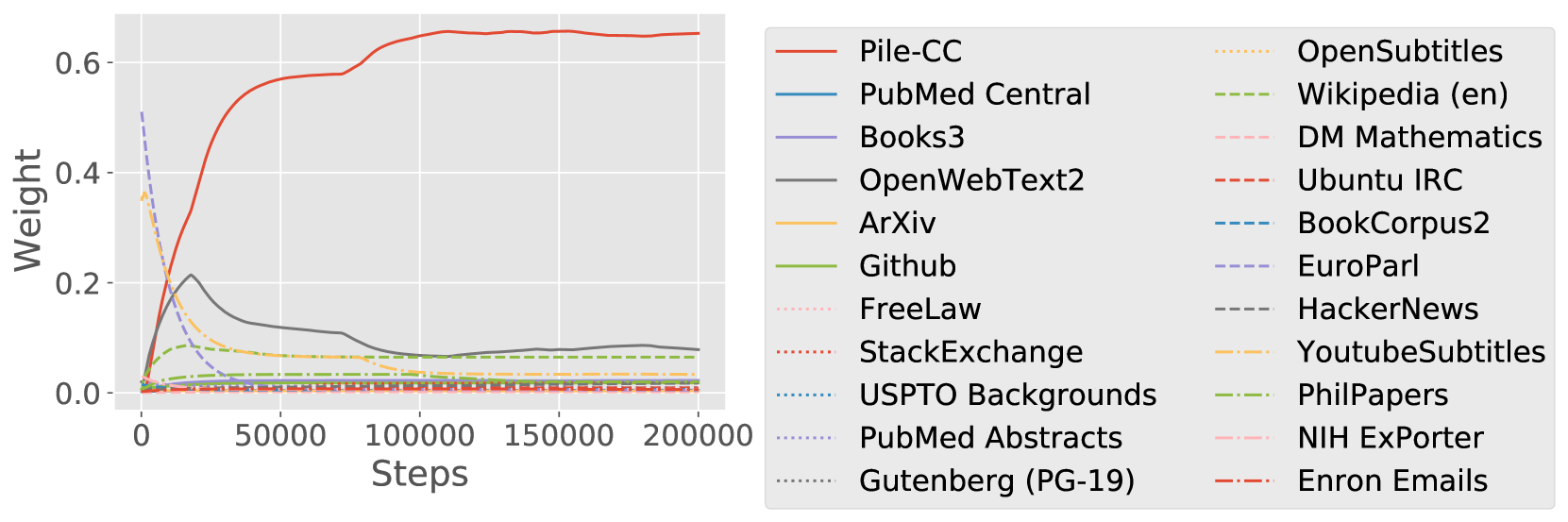
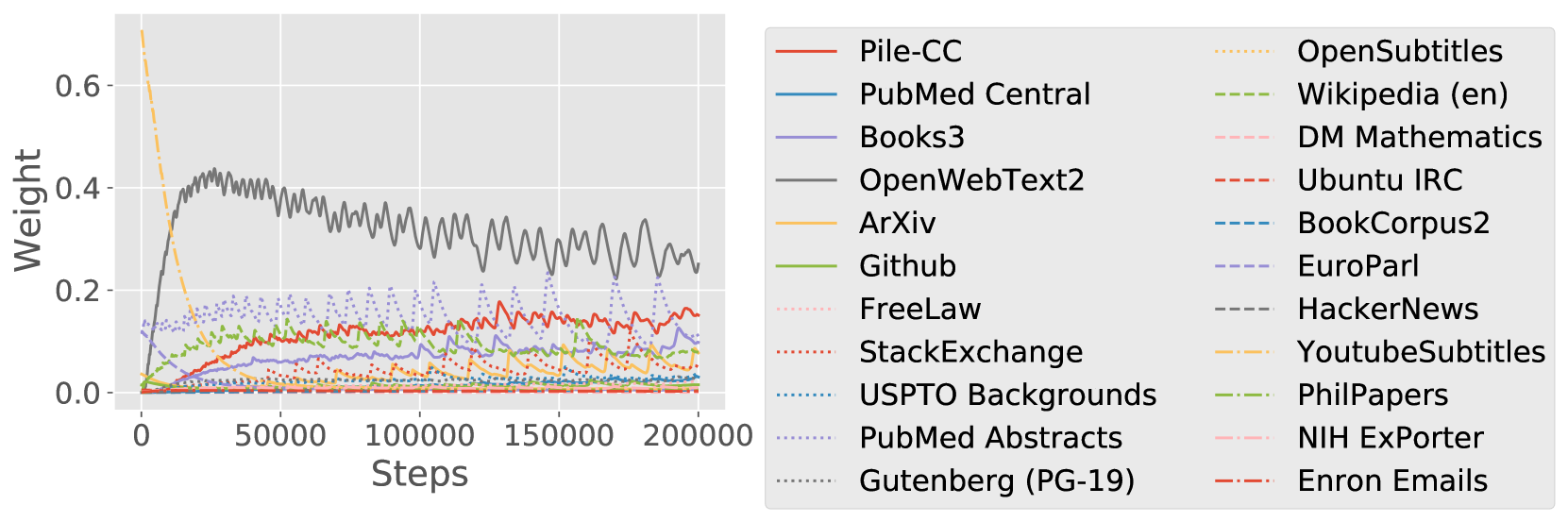
域权重的轨迹。
图8显示了DoReMi运行期间域权重的指数移动平均值(平滑参数0.99)。 在这两种情况下,有些域最初的权重非常高,但权重很快下降(在 50k 步内)。 由于我们通过对这些曲线进行步骤积分和归一化来计算最终的域权重,这表明如果我们有较小的计算预算,这些域可能会变得更加重要 - 这突出了混合权重对计算预算的依赖性。 同时,域权重在 50k 步后往往会快速稳定,这表明对于较大的计算预算,最佳域权重应该相似。 我们还可以在 50k 步后利用这种稳定性,以更少的步数运行 DoReMi,并推断域权重以节省计算量。
基线 DoReMi (280M) DoReMi (1B) 桩CC 0.1121 0.6057 0.1199 PubMed 中心 0.1071 0.0046 0.0149 书籍3 0.0676 0.0224 0.0739 OpenWebText2 0.1247 0.1019 0.3289 ArXiv 0.1052 0.0036 0.0384 Github 0.0427 0.0179 0.0129 FreeLaw 0.0386 0.0043 0.0148 StackExchange 0.0929 0.0153 0.0452 美国专利商标局背景 0.0420 0.0036 0.0260 PubMed 摘要 0.0845 0.0113 0.1461 古腾堡(PG-19) 0.0199 0.0072 0.0250 开放字幕 0.0124 0.0047 0.0017 维基百科(zh) 0.0919 0.0699 0.0962 DM数学 0.0198 0.0018 0.0004 Ubuntu IRC 0.0074 0.0093 0.0044 BookCorpus2 0.0044 0.0061 0.0029 欧洲帕尔 0.0043 0.0062 0.0078 黑客新闻 0.0075 0.0134 0.0058 Youtube字幕 0.0042 0.0502 0.0159 菲尔论文 0.0027 0.0274 0.0063 NIH 导出器 0.0052 0.0063 0.0094 安然电子邮件 0.0030 0.0070 0.0033
280M 和 1B 的域权重比较。
表8显示了 The Pile 在 280M 和 1B 代理模型下的 DoReMi 域权重。 不同的代理模型大小可能会导致不同的域权重,这表明域权重空间中可能存在多个局部最小值。 采用280M代理模型,大部分权重放在Pile-CC Web文本域上,而采用1B代理模型的DoReMi则将大部分权重放在OpenWebText2上。 其余域的域权重的总体模式类似。
附录C培训详情
数据预处理。
对于所有数据集,我们通过使用具有 256k 词汇量的 SentencePiece 分词器将数据分块为长度为 1024 个示例来对数据进行预处理。 这些示例按域分隔,以便于分层采样(首先根据某些域权重对域进行采样,然后从该域中随机采样示例)。 为了减少填充标记的数量,我们努力将示例(可能来自不同的域)打包到同一序列中。 当进行这样的打包时,我们在 DoReMi 中计算每个令牌级别的域困惑度。
The Pile 的基线域权重。
The Pile 的基线域权重是根据 The Pile 数据集和 Gao 等人 (2020) 中给出的每个域的历元数计算得出的。 在分成长度为 1024 个示例后,我们计算了每个域中的示例数,并乘以 Gao 等人 (2020) 中指定的域的纪元数。 然后,我们对这些计数进行归一化以获得基线域权重。
训练设置。
对于所有训练运行(包括 DRO 运行),我们使用批量大小为 512、初始学习率为 1e-3、权重衰减为 1e-2、梯度裁剪为范数 1 进行训练。 我们以指数方式衰减学习率,直到训练结束时达到最小值 1e-4,线性热身占总训练步数的 6%。 我们在 The Pile 上训练 200k 步,在 GLaM 数据集上训练 300k 步。 1B参数下的模型使用TPUv3加速器进行训练,而1B和8B模型则使用TPUv4进行训练。
模型架构。
表 9 显示了本文中使用的模型大小的架构超参数。 我们使用的所有模型都是纯 Transformer 解码器模型,词汇量为 256k。
层 注意头 注意头暗淡 模型暗淡 隐藏暗淡 70M 3 4 64 256 1024 150M 6 8 64 512 2048 280M 12 12 64 768 3072 510M 12 16 64 1024 8192 760M 12 20 64 1280 8192 1B 16 32 64 2048 8192 8B 32 32 128 4096 24576
附录 D 数据重新加权无需权衡的简单示例
受 3.2 节中的发现的启发,我们提出了一个简单的语言建模示例,其中重新加权来自不同领域的训练数据可以提高所有领域的困惑度。 该示例表明,DoReMi 降低了熵极高或极低的域的权重。
设置。
假设文本 的基本真实分布是 域上的混合分布,其中每个域 由不同的单字符分布定义 over 词符。 给定 训练样本的预算、我们的目标是选择域权重(加起来为 1 的标量)来对数据进行采样训练,以便我们学习到单字符串分布的参数很好地适用于从 到 的所有 。值得注意的是,我们并不打算估计跨域的基本真实混合比例。
数据。
Given some domain weights , we sample training data hierarchically: first we determine the number of samples per domain by drawing from a multinomial distribution over possibilities with probabilities defined by and total trials. 然后,对于每个域 ,我们从 中抽取 词符、形成长度为 的词符向量 。
模型。
对于每个域 ,我们将考虑单字符分布的贝叶斯模型 with a Dirichlet prior 上的单字符分布参数 。 狄利克雷先验的超参数为 ,可以看作是每个词符的“伪计数”。 对于每个域,我们估计参数 通过计算以数据为条件的后验分布的平均值:
| (2) |
其中 是伪计数的总和。
对于域,我们可以将该估计器的参数误差写为“难度”的函数 预测下一个词符和之前的 的“质量”,定义如下。
Lemma 1.
对于具有 样本的域索引 ,参数错误为
| (3) |
在哪里
| (4) | ||||
| (5) |
证明。
参数错误为
| (6) |
单独评估这些条款,
| (7) | ||||
| (8) | ||||
| (9) | ||||
| (10) |
将它们放在一起,参数错误可以写为
| (11) | ||||
| (12) | ||||
| (13) |
∎
无需权衡的示例。
假设有 3 个域 和词汇符 . 我们使用对称 Dirichlet 先验(更倾向于使用均匀词符分布),其中适用于所有词符 和域 。 这里,。 在此设置中,我们表明有一组域权重的参数误差严格低于基线,其中我们从每个域中采样相同数量的令牌:对于所有域来说都是相同的。
假设一元分布的基本事实参数是
| (17) |
其中行 包含域 的参数。 例如,词符 1 在域 1 的一元分布下的概率为 1。
对于 (中间熵域),我们有 和 参数误差相对于样本数的导数为
| (20) |
当
| (21) |
这种不等式在这种情况下成立,因为 和 因此,参数误差随着样本数 的增加而减少。
因此,将示例从域 3 重新分配到域 1 和 2 的任何域权重都会减少所有域的参数误差。
什么样的域名被降权?
直观上,我们可以降低非常嘈杂(高熵/难度)的域 3 的权重,因为初始化与地面事实完全匹配。 这使我们能够将样本重新分配到其他域 1 和 2。 在这些之间,域 1 需要较少的额外样本,因为参数误差随着样本数量(难度 为零)。 因此,最简单的领域也应该获得相对较小的权重。 在实践中,域之间的正向转移(此处未捕获)也可能导致重新加权导致跨域不进行权衡的情况。
使用 DoReMi 进行模拟。
我们考虑在上述简单示例的无权衡实例上运行 DoReMi,并使用方程 17 中的地面真值一元分布。 请注意,DoReMi 的域重新加权步骤(步骤 2,算法 1)涉及 迭代模型更新的循环,而方程 2 的估计量为以封闭形式计算。 为了适应 DoReMi 的估计器,我们考虑一个迭代版本,其中平均值以在线方式计算。 我们在 训练示例中以 的最小批量大小 1 运行 DoReMi, 步。 对于来自域 的示例 的步骤 中的模型更新、我们通过与域 对应的当前域权重 来增加伪计数 。 我们没有使用小批量中的示例(大小仅为 1,并不代表所有域),而是使用固定的独立评估集来计算算法 1 中的每个域的过量对数困惑度共 30 个示例。
我们将 DoReMi 与使用基线域权重训练的模型进行比较,该模型在 3 个域上是统一的。 所有模型均在 训练示例上进行训练。 我们使用地面真值一元分布参数以封闭形式评估模型在每个域上的对数困惑度。
在这个简单的示例中,DoReMi 返回域权重 四舍五入到小数点后两位。 这些权重符合我们的直觉——第一个域(无噪声)增加少量,第三个域(有噪声)权重减少到 0,大部分权重分配给第二个域。 我们使用这些域权重生成包含 500 个示例的新数据集。 使用这个新数据集训练的模型在所有领域的困惑度上都比基线模型有所改进。