RecurrentGPT:
交互式生成(任意)长文本
Zhenxin Xiao Yifan Hou
{wangchunshu.zhou, yuchen.jiang, peng.cui}@inf.ethz.ch
hugothebestwang@gmail.com, alanshawzju@gmail.com
{yifan.hou, ryan.cotterell, mrinmaya.sachan}@inf.ethz.ch
摘要
Transformer 的固定大小上下文使得 GPT 模型无法生成任意长的文本。 在本文中,我们介绍了RecurrentGPT,这是一种基于语言的 RNN 递归机制模拟。 RecurrentGPT基于ChatGPT等大型语言模型(大语言模型)构建,并使用自然语言来模拟LSTM中的长短期记忆机制。 在每个时间步,RecurrentGPT 都会生成一段文本,并分别更新存储在硬盘和提示上的基于语言的长期短期记忆。 这种循环机制使得RecurrentGPT能够生成任意长度的文本而不会忘记。 由于人类用户可以轻松观察和编辑自然语言记忆,因此 RecurrentGPT 是可解释的,并且能够交互式生成长文本。 RecurrentGPT 是超越本地编辑建议的下一代计算机辅助写作系统的第一步。 除了制作人工智能生成的内容 (AIGC) 之外,我们还演示了使用 RecurrentGPT 作为直接与消费者互动的互动小说的可能性。 我们将这种生成模型的使用称为“AI as C内容”(AIAC),我们认为这是是传统 AIGC 的下一种形式。 我们进一步证明了使用RecurrentGPT创建个性化互动小说的可能性,该小说直接与读者互动,而不是与作家互动。 更广泛地说,RecurrentGPT展示了借鉴认知科学和深度学习中流行模型设计的思想来促进大语言模型的效用。 我们的代码可在 https://github.com/aiwaves-cn/RecurrentGPT 获取,在线演示可在 https://www.aiwaves.org/recurrentgpt 获取。
1简介
大型语言模型 (大语言模型)[1,2,3,4,5](例如 ChatGPT)已被证明是辅助各种日常写作任务(包括电子邮件和博客文章)的高效工具。 然而,由于Transformer[6]架构固有的固定大小的上下文设计,仅通过提示大语言模型来生成长文本(例如小说)是不可行的。 相比之下,循环神经网络 (RNN) [7, 8] 理论上具有生成任意长度序列的能力,这要归功于其循环机制:RNN 保持隐藏状态,并在每个时间步,使用当前时间步的输出作为后续时间步的输入。 然而,在实践中,RNN 面临梯度消失和爆炸的问题,并且难以扩展。
为此,许多作品[9,10,11]尝试为Transformers配备类似RNN的递归机制。 虽然在长文本建模和生成方面取得了有希望的结果,但这些循环增强的 Transformer 需要大量的架构修改,而这些修改尚未被证明可以很好地扩展。 当前的大语言模型大部分继续采用原始的 Transformer 架构,并进行了极少的改动。
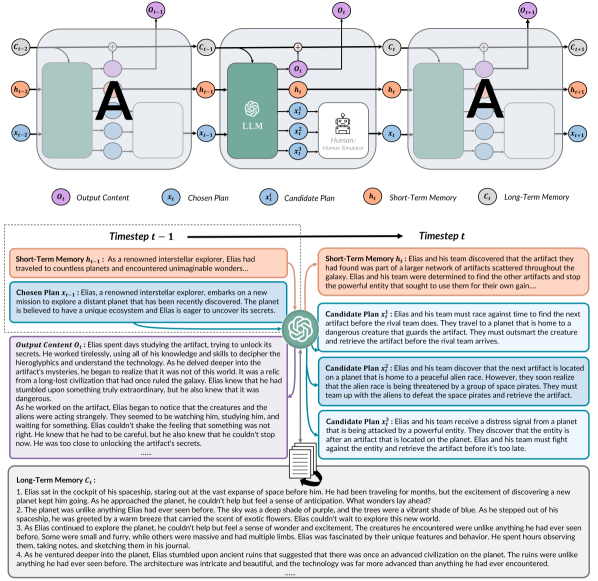
在本文中,我们介绍了RecurrentGPT,这是一种基于语言的 RNN 递归机制模拟。 如图 1 所示,RecurrentGPT 替换了长短期记忆 RNN (LSTM) 中的向量化元素(即单元状态、隐藏状态、输入和输出) [8]用自然语言(即文本段落),并通过即时工程模拟递归机制。 在每个时间步,RecurrentGPT接收一段文本和下一段的简要计划,它们都是在步骤中生成的。 然后,它会处理长期记忆,其中包含所有先前生成的段落的摘要,可以存储在硬盘驱动器上,并且可以通过语义搜索检索相关段落。 RecurrentGPT 还维护短期记忆,以自然语言总结最近时间步内的关键信息,并在每个时间步更新。 RecurrentGPT 在提示中组合所有上述输入,并要求主干大语言模型生成一个新段落、下一段的简短计划,并通过重写短期记忆来更新长期短期记忆记忆并将输出段落的摘要附加到长期记忆中。 然后,这些组件将在下一个时间步骤中重新使用,从而形成生成过程的递归机制。 凭借基于语言的递归机制,RecurrentGPT减少了任何架构修改的需要,并且可以集成到任何强大的大语言模型中,使其能够生成超出固定大小上下文窗口的任意长文本。
除了超越固定大小的上下文限制之外,与 RNN 中采用的基于向量的递归机制相比,RecurrentGPT 还增强了递归机制的可解释性。 这种改进源于通过简单的检查观察长期记忆的特定部分以及短期记忆更新方式的能力。 更重要的是,采用自然语言作为构建块使人类能够与 RecurrentGPT 互动,从而允许人类操纵其记忆和为后代制定计划。 人机交互还可以防止 RecurrentGPT 偏离期望的行为,这是最近基于 GPT 的自主代理(例如 AutoGPT111https://github.com/Significant-Gravitas/Auto-GPT。 鉴于当前最先进的计算机辅助写作系统[12, 13]主要关注本地化编辑建议并将大语言模型视为黑匣子,我们相信RecurrentGPT 代表了向下一代交互式长文本生成计算机辅助书写系统迈出的一步,该系统还提供可解释性。
然后,我们通过探索其与消费者直接互动(而不仅仅是与内容创作者互动)的潜力,将 RecurrentGPT 的用途扩展到其作为生成人工智能生成内容 (AIGC) 的工具的角色之外。 具体来说,我们将 RecurrentGPT 转换为个性化的互动小说,其中它为后续行动生成多个预期计划,允许玩家选择和探索吸引他们兴趣的计划。 此外,除了从模型生成的计划中进行选择之外,玩家还可以制定自己的计划。 这种能力在传统的互动小说中是无法实现的,因为叙事和选项通常都是预先确定的。 我们将这种新范式称为“AI As Content”,意味着利用生成式人工智能作为与消费者积极互动的媒介,而不仅仅局限于内容创作者的工具角色。 通过RecurrentGPT,我们感知到人工智能模型最终将成为我们创造性工作中的合作伙伴的未来的知识进步。
在我们的实验中,我们在 ChatGPT 的基础上构建了 RecurrentGPT,并发现它具有自主生成非常广泛的文本的能力,涵盖数千个标记,同时保持一致性和参与度。 与此形成鲜明对比的是,普通的 ChatGPT 在遇到重复内容或连贯性下降等问题之前只能生成几百个标记。此外,RecurrentGPT 可以帮助人类作家轻松生成任意长的文本,从而减少撰写小说等长篇创意文本需要人类付出很大的努力。 本文的贡献可概括如下:
-
•
我们提出了RecurrentGPT,这是一种基于语言的 RNN 中递归机制的模拟,可以缓解大语言模型(例如 ChatGPT)的固定大小上下文限制。
-
•
我们证明 RecurrentGPT 可以单独生成很长的文本,也可以作为交互式写作助手,帮助人类作家编写任意长的文本。
-
•
我们引入了生成式 AI 的新用例,它使用生成模型直接与文本消费者进行交互,而不是使用它们作为内容创建工具的传统做法,通过使用 RecurrentGPT 作为个性化交互内容策划的小说。
此外,需要强调的是,RecurrentGPT说明了从认知科学和深度学习领域成熟的模型设计中汲取灵感的可能性,其目的是通过提示生成长文本。语言模型。
2 循环GPT
我们将在本节中详细描述 RecurrentGPT。 RecurrentGPT 是 RNN 中递归机制的基于自然语言的对应物。 RecurrentGPT 通过 (1) 对 LSTM 中所有基于向量的组件进行建模来模拟 LSTM,包括输入向量 、输出向量 、隐藏状态 和细胞状态 ,使用自然语言; (2) 使用自然语言提示对 LSTM 中的循环计算图进行建模,以及 (3) 用冻结的大语言模型替换 RNN 中的可训练参数。 理论上,RecurrentGPT的骨干可以是任何大语言模型或文本到文本模型,我们选择ChatGPT是因为它的能力和受欢迎程度。
形式上,我们将RecurrentGPT定义为由带有参数和提示模板的大语言模型参数化的计算函数。 回想一下,LSTM 的循环计算图可以概括为:
| (1) |
其中表示模型参数,等于,是时间步,分别。
以此类推,我们模型中的递归机制可以表示为:
| (2) |
其中 和 表示基于自然语言的构建块,包括时间步骤 的内容、计划、短期记忆和长期记忆, 分别。 这里不等于,而是单独生成的,这与传统的RNN不同。 我们首先描述 RecurrentGPT 中的每个构建块,然后介绍我们的提示 如何使 RecurrentGPT 能够循环生成任意长的文本。
2.1 基于语言的构建块
输入输出
RecurrentGPT 在每个时间步的输入和输出包括附加到生成的最终文本的文本段落以及要生成的下一个段落的大纲。 我们将这两者分别称为“内容”和“计划”。 如图1所示,内容通常由 200-400 个单词组成,大部分应该可供阅读。 而计划是下一个内容的大纲,通常由 3-5 个句子组成。 在每个时间步,前一个时间步生成的内容和计划都用作 RecurrentGPT 的输入,从而允许循环计算。 RecurrentGPT 旨在除了内容之外还生成计划,因为允许用户阅读和编辑计划可提高可解释性并促进人机交互。
长短期记忆
与 LSTM 类似,RecurrentGPT 跨时间步长保持长期短期记忆。 如图1所示,长期记忆总结了所有先前生成的内容,以最大限度地减少生成长文本时丢失的信息。 由于生成的内容可以是任意长并且无法适应大语言模型的上下文大小,因此我们通过将每个时间步生成的内容与句子嵌入,使用VectorDB方法在RecurrentGPT中实现长期记忆- Transformer [14]。 与之前基于内存的 Transformer [9, 11] 相比,这种方法使 RecurrentGPT 能够存储更长的内存,因为它可以将内存存储在磁盘空间而不是 GPU 内存中。 这在用户的设备中可能没有高端 GPU 的多种用例中可能很重要。
另一方面,短期记忆是一小段文本,总结了最近时间步长的关键信息。 短期记忆的长度控制在10-20个句子,以适应提示并可由大语言模型主干更新。 通过结合长短期记忆,RecurrentGPT 可以保持与最近生成的内容的连贯性,还可以回忆起很久之前生成的关键信息。 这对于普通的大语言模型来说是不可能的,因为它们只能在输入中获取一些先前生成的文本。
RecurrentGPT 可以使用一个简单的提示来初始化,指示大语言模型生成上述组件,其中包含指定小说主题和其他背景信息的文本。 当使用RecurrentGPT继续写小说时,用户可以写下(或提示ChatGPT生成)短期记忆和初始计划。
2.2 基于语言的循环计算
RNN 通过在计算图中实现反馈循环来实现循环计算,而 RecurrentGPT 则依赖即时工程来模拟循环计算方案。 如图1所示,RecurrentGPT使用提示模板(如附录图1所示)和一些简单的Python代码来模拟RNN中的计算图222由于篇幅限制,我们将提示放在附录A中。.
在每个时间步,RecurrentGPT 通过用输入内容/计划及其内部长短期记忆填充提示模板来构造输入提示。 特别是,由于长期记忆无法适应上下文大小,因此我们使用输入计划作为查询对基于 VectorDB 的长期记忆执行语义搜索,并将一些最相关的内容放入提示中。 然后,提示指示大语言模型骨干生成新的内容、计划和更新的短期记忆。 如附录图 1 所示,我们的提示鼓励大语言模型通过丢弃不再相关的信息并添加有用的新信息来更新短期记忆,同时将其长度保持在一定范围内,以便始终适合上下文大小。 值得注意的是,我们提示大语言模型生成多个(例如,我们的实验中为 3 个)计划。 这提高了输出的多样性,并允许人类用户选择最合适的计划,使人机交互更加友好。 如果生成的计划都不理想,我们还为用户提供自行编写计划的选项。 为了使 RecurrentGPT 能够在无需人工干预的情况下自主生成长文本,我们添加了一个基于提示的人体模拟器来选择一个好的计划并针对下一个时间步对其进行修改。
2.3 使用RecurrentGPT生成交互式长文本
虽然RecurrentGPT可以通过递归机制自行生成长文本,但其基于语言的计算方案提供了独特的可解释性和交互性。 与传统的使用语言模型作为黑匣子、仅给出下一个短语/句子建议的计算机辅助写作系统相比,RecurrentGPT具有以下优势:
-
•
它在减少人力方面更有效,因为它提供段落/章节级别的进度,而不是本地写作建议。
-
•
它是可解释的,因为用户可以直接观察其基于语言的内部状态。
-
•
它是交互式的,因为人类可以用自然语言编辑他们的构建块。
-
•
它是可定制的,因为用户可以根据自己的兴趣轻松修改提示来定制模型(例如,输出文本的样式、每个时间步要取得多少进度等)
此外,人机交互还可以帮助纠正RecurrentGPT在自主生成长文本时所犯的意外错误,并防止错误传播,这是长文本生成的主要瓶颈。
3实验
3.1实验设置
任务
我们在本节中测试 RecurrentGPT 的实证有效性。 特别是,我们在三种不同的设置中评估 RecurrentGPT,包括:
-
•
无需人工交互即可自动生成长文本。
-
•
与人类作家协作生成长文本
-
•
作为互动小说直接与文本消费者互动。
在每项任务中,我们都测试了多种类型的小说,包括科幻小说、浪漫小说、奇幻小说、恐怖小说、神秘小说和惊悚小说。 为了测试 RecurrentGPT 对不同长度文本的有效性,我们为恐怖、神秘和惊悚小说生成中等长度( 3000 字)的小说,并生成较长的小说( 6000 字),适合科幻、浪漫和奇幻。
基线
虽然RecurrentGPT是第一个使用大语言模型生成任意长文本的工作,但我们仍然可以将其与一些合理的基线和消融变体进行比较,如下所示:
-
•
Rolling-ChatGPT,一个简单的基线,提示ChatGPT在给定一种文学体裁和一些大纲或背景设置的情况下开始写小说,然后在达到上下文长度限制后迭代提示ChatGPT继续写作。 该基线大致相当于使用滑动上下文窗口技巧通过 Transformer 生成长文本。
-
•
RE3 [15]是一个分层长故事生成基线,首先提示大语言模型生成故事大纲,然后生成故事遵循大纲,并进行了一些重新排序和重写流程。 我们用 ChatGPT 重新实现它以确保公平比较。
-
•
DOC [16] 是最先进的长篇故事生成基线,它改进了 RE3轮廓控制。 我们通过用 ChatGPT 替换 OPT-175B [17] 并删除详细控制器来重新实现 DOC,该控制器无法使用,因为我们无法访问 ChatGPT 权重。 总的来说,我们发现由于主干大语言模型的改进,我们的重新实现质量稍好一些。
值得注意的是,原则上,这两个基线都不能在保持连贯性的同时生成任意长的文本。 这是因为 Rolling-ChatGPT 基线很快就会忘记以前生成的内容。 另一方面,RE3和DOC固定了第一阶段的轮廓,这限制了生成故事的整体长度。
| Novel genres | Sci-fi | Romance | Fantasy | |||
|---|---|---|---|---|---|---|
| 6000 words | Interesting | Coherent | Interesting | Coherent | Interesting | Coherent |
| RecurrentGPT | 94.7 | 86.5 | 91.4 | 84.8 | 95.9 | 85.1 |
| Rolling-ChatGPT | 7.8 | 14.3 | 9.0 | 18.2 | 6.5 | 13.7 |
| RecurrentGPT | 68.3 | 65.7 | 71.4 | 69.2 | 63.8 | 62.0 |
| RE3 | 31.9 | 28.5 | 28.1 | 25.3 | 35.1 | 33.8 |
| RecurrentGPT | 66.1 | 59.3 | 77.2 | 63.4 | 61.0 | 56.5 |
| DOC | 30.7 | 38.1 | 25.3 | 29.8 | 31.2 | 40.3 |
| Novel genres | Horror | Mystery | Thriller | |||
| 3000 words | Interesting | Coherent | Interesting | Coherent | Interesting | Coherent |
| RecurrentGPT | 88.3 | 84.9 | 87.1 | 82.0 | 91.5 | 82.7 |
| Rolling-ChatGPT | 13.5 | 17.1 | 14.5 | 20.1 | 11.9 | 17.7 |
| RecurrentGPT | 64.1 | 64.5 | 66.8 | 63.2 | 61.0 | 61.4 |
| RE3 | 34.6 | 30.2 | 27.9 | 28.8 | 38.3 | 37.9 |
| RecurrentGPT | 65.8 | 60.7 | 72.1 | 66.8 | 60.2 | 58.1 |
| DOC | 29.1 | 39.7 | 27.2 | 25.6 | 33.8 | 37.0 |
评估指标
为了进行评估,我们遵循Yang等人[15],通过将RecurrentGPT与基线根据两个维度进行比较来进行人类评估:
-
•
有趣:生成的小说对于普通读者来说有多有趣?
-
•
连贯:段落的组织和相互连接的程度如何?
我们省略了Yang等人[16]之后的“质量”或“类人”指标,因为所有基线都基于 ChatGPT,它在大多数情况下可以生成高质量的文本。 我们通过成对比较来评估比较模型。 具体来说,我们将通过不同比较方法生成的两本小说(A和B,随机顺序)交给具有良好英语水平的人类注释者,并指示他们标记小说A或小说B在趣味性方面是否更好,或者它们无法区分和连贯性。 按照Yang等人[16]中的人类评估设置,我们为每种类型抽取了 20 部生成的小说,并为每部小说分配了 3 个注释者。
3.2结果
如表1所示,我们发现RecurrentGPT因其趣味性和连贯性而受到人类读者的青睐,与滚动窗口基线和先前状态相比,其裕度相对较大RE3 和 DOC 等最先进的技术。 这证实了我们的直觉,即循环计算对于长文本生成很重要。 对于较长的小说,差距更大,这证实了 RecurrentGPT 在生成超长文本方面的优势。 最后,人类注释者在所有小说类型中都更喜欢 RecurrentGPT。 这证实了它对不同类型的长文本的鲁棒性。
为了更好地了解 RecurrentGPT 的有效性,我们还进行了一项消融研究,将 RecurrentGPT 与没有短期或长期记忆的消融变体以及具有短期记忆和长期记忆的变体进行比较。使用GPT-4作为骨干模型。 结果如表2所示。 我们可以看到,长/短期记忆主要有助于生成文本的连贯性,这与我们的直觉很好地相关。 与使用 ChatGPT/GPT-3.5-turbo 的对应模型相比,以 GPT-4 为骨干的RecurrentGPT大语言模型受到极大青睐。 这证实了RecurrentGPT在配备更强大的大语言模型时的潜力。 我们在附录中提供了一些 RecurrentGPT 生成的小说样本进行定性评估。

| Novel genres | Sci-Fi | Fantasy | ||
|---|---|---|---|---|
| 6000 words | Interesting | Coherent | Interesting | Coherent |
| RecurrentGPT | 58.9 | 65.1 | 55.3 | 64.1 |
| w/o Short term memory | 44.2 | 31.0 | 47.7 | 33.5 |
| RecurrentGPT | 51.4 | 71.3 | 57.5 | 68.9 |
| w/o Long term memory | 40.0 | 27.8 | 46.2 | 38.7 |
| RecurrentGPT | 21.3 | 28.1 | 27.1 | 24.8 |
| w/ GPT-4 | 73.4 | 64.9 | 71.7 | 70.5 |
3.3 RecurrentGPT 作为交互式写作助手
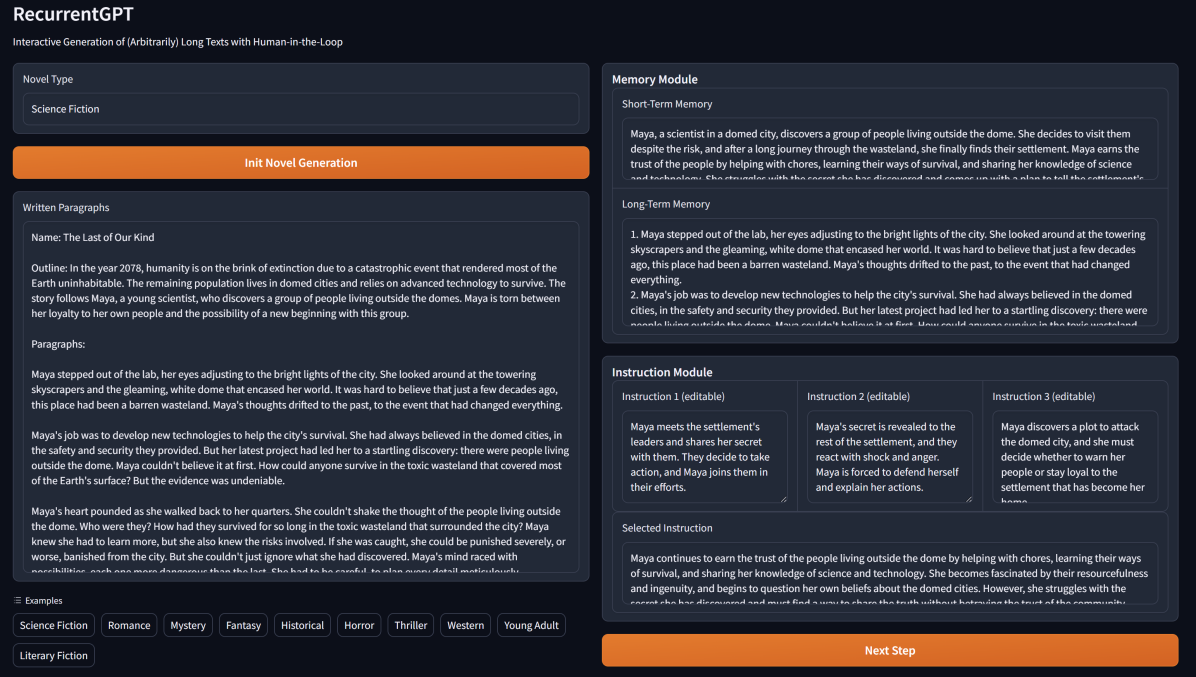
然后,我们从人机交互的角度测试 RecurrentGPT 作为交互式写作助手的实用性。 如图2所示,人类作家首先选择他/她想要写的主题,并写一个简短的段落来描述这本书的背景和大纲。 然后RecurrentGPT自动生成第一段,并为作者提供一些可能的选项来继续故事。 作者可以从中选择一项并根据需要进行编辑。 如果生成的计划都不合适,他或她还可以自己为接下来的几段写一个简短的计划,这使得人类与人工智能共同编写的过程更加灵活。 我们显示一个渐变333https://gradio.app/基于 的界面,允许人类作家通过与附录 B 中的 RecurrentGPT 交互来编写不同类型的小说。
根据一项小规模人类用户研究,RecurrentGPT 显着提高了人类作家的生产力444我们将进行更大规模的用户研究,并在修订版本中呈现细节和结果。,改进主要来自于:(1)通过编写或选择短计划并让RecurrentGPT生成实际文本来减少输入长文本的时间; (2) 根据用户反馈,通过从 RecurrentGPT 生成的计划中选择计划,减少设计不太重要的绘图的时间。 此外,用户认为与充当黑匣子的传统人工智能写作助手相比,RecurrentGPT 更具可解释性和可控性,因为 RecurrentGPT 中基于语言的组件对于用户来说是透明且可编辑的。用户。 最后,与之前分层生成长文本的方法(例如 DOC 和 RE3)相比,人类用户更喜欢我们的系统,因为迭代和交互地编写长文本更加灵活和可控。 最后,我们的系统与大多数现有的人工智能写作助手有很大不同,因为它们专注于在短语或几个句子中提供本地写作建议,而 RecurrentGPT 可以一次生成几个段落。
3.4 RecurrentGPT 作为互动小说
我们还测试了使用 RecurrentGPT 作为个性化互动小说的可能性。 这个用例与作为 AI 写作助手的 RecurrentGPT 非常相似。 主要区别有两个,如图2所示:(1)从第三人称视角到第一人称视角的转变,旨在培养人类玩家的沉浸感, (2) 让 RecurrentGPT 生成涉及主角重要选择的计划,而不是下一段的总体计划。 通过稍微修改提示即可轻松实现适配。
我们的用户研究表明,RecurrentGPT 可以与人类玩家互动,并直接为人类消费者提供优质内容。 人类玩家还发现了编写自由格式文本的可能性,因为他们在互动小说中的行为很大程度上提高了他们的趣味性。 这证实了直接使用生成式人工智能作为内容的潜力,而不是使用它们作为生产内容的工具。 但是,我们还发现 RecurrentGPT 有时会产生不太一致的内容和不太相关或不合理的低质量选项。 我们相信,这可以通过使用更强大的大语言模型主干、通过监督微调或来自人类反馈的强化学习来微调大语言模型主干、或者设计更好的提示来改进。 我们把这个留到以后的工作中。
4相关作品
4.1 超越固定大小上下文的变形金刚
Transformer 的一大限制是上下文大小是固定的,这阻碍了它们处理和生成长文本的能力。 之前的工作尝试从两种不同的方式解决这个问题:设计有效的注意力机制来训练和使用具有更大上下文窗口的 Transformer [18,19,20,21],以及在计算图中添加内存机制在 Transformer 中,以允许其处理来自多个上下文窗口 [9, 22, 23, 11] 的信息。 虽然这些方法使 Transformer 能够处理很长的文本,但它们都需要对原始 Transformer 架构进行重大架构更改。 因此,这些方法无法集成到强大的预训练大语言模型(例如ChatGPT和LLAMA)中,这大大限制了它们的实用性。 最近,Press 等人[24]引入了 ALiBi,它为注意力添加了线性偏差,以允许输入长度外推。 然而,该方法主要支持更长的输入而不是更长的输出。 此外,它还需要访问模型参数和推理代码,而这通常是不可能的,因为许多最先进的大语言模型(例如 ChatGPT、GPT-4 和 PaLM)都是闭源的。
4.2 长文本生成
除了架构修改之外,许多作品还以分层方式研究长文本生成。 Fan等人[25]首先提出通过首先生成故事的简短摘要来生成故事,然后通过添加生成大纲的中间步骤来改进该方法,大纲是故事的谓词-论元结构故事[26]。 Tan等人[27]和Sun等人[28]进一步改进了这种分层长文本生成方法。 Yao等人[29]也提出先生成故事情节,然后完成故事。 RE3[15]及其变体DOC[16]进一步完善了这一研究方向,提出了递归提示大语言模型以计划和编写的方式生成长篇故事。 然而,他们最终故事的情节和长度仍然受到预定计划的限制。 相比之下,RecurrentGPT通过循环生成克服了上述限制,实现了人类与LM的有效协作,并提高了长文本生成的灵活性和可控性。
4.3 人工智能辅助写作系统
AI写作助手已应用于多种应用,包括故事补全[12]、论文写作[30]、诗歌生成[31]。 现有系统大致可分为交互式生成和自动生成。 交互系统[32,33,34]主要旨在提供短语或句子级别的本地建议或修改。 因此,它们不太能够减轻人类作家的创作负担。 另一方面,自动生成[26,35,36]旨在通过序列到序列框架根据给定的提示或主题编写全文。 尽管大语言模型的进步已经展示了这些系统的巨大潜力,但缺乏透明度、可控性和协作意识可能会损害用户对作者感知所有权的体验[12, 37]。 此外,它们中的大多数都仅限于提供从几个短语到几个句子[38, 39]的本地编辑建议,部分原因是NLG模型的长度限制,部分原因是维护的挑战长程相干性。
5 限制
这项工作的一个限制是,虽然 RecurrentGPT 可以生成任意长的文本,但我们仅在生成的文本最多约为 5000 个单词的设置上对其进行评估。 这是因为对很长的文本进行定性和定量评估都非常困难。 另一个限制是RecurrentGPT仅适用于足够强大的骨干大语言模型,例如ChatGPT和GPT-4。 我们相信,当开发出更强大、更小的大语言模型时,这个问题可以得到缓解。 最后,我们评估 RecurrentGPT 作为人工智能写作助手和互动小说的用户研究受到小规模研究的限制。 我们将在修订版的用户研究中添加更多内容。 从社会影响来看,RecurrentGPT可以提高人工智能生成长文本的质量,提高人类作家的生产力。 然而,它也可能被滥用来产生垃圾或有害内容,从而导致负面的社会影响。 然而,这是生成式人工智能的一个已知限制,我们将尽最大努力促进生成式人工智能的负责任使用。
6 结论
我们提出了RecurrentGPT,这是一种基于语言的 RNN 中递归机制的模拟,它使用基于语言的组件并通过提示工程定义了一个递归计算图。 RecurrentGPT 使大语言模型能够自主地或通过与人类作者交互来生成任意长的文本。 其基于语言的组件提高了其可解释性和可控性,基于提示的计算图使其易于定制。 关于使用 RecurrentGPT 作为 AI 写作助手和基于文本的游戏的用户研究表明,其作为下一代 AI 写作助手的第一步的潜力超出了本地写作建议,并直接使用生成式 AI 作为可通过以下方式消费的内容相互作用。 最后,我们的工作还证明了借鉴认知科学和深度学习文献中流行模型设计的思想,使用大语言模型生成长文本的可能性。
参考
- Radford et al. [2018] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. 2018.
- Radford et al. [2019] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf.
- Ouyang et al. [2022] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Gray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=TG8KACxEON.
- OpenAI [2023] OpenAI. Gpt-4 technical report, 2023.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.
- Elman [1990] Jeffrey L. Elman. Finding structure in time. Cognitive Science, 14(2):179–211, 1990. ISSN 0364-0213. doi: https://doi.org/10.1016/0364-0213(90)90002-E. URL https://www.sciencedirect.com/science/article/pii/036402139090002E.
- Hochreiter and Schmidhuber [1997] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- Dai* et al. [2019] Zihang Dai*, Zhilin Yang*, Yiming Yang, William W. Cohen, Jaime Carbonell, Quoc V. Le, and Ruslan Salakhutdinov. Transformer-XL: Language modeling with longer-term dependency, 2019. URL https://openreview.net/forum?id=HJePno0cYm.
- Rae et al. [2020] Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, Chloe Hillier, and Timothy P. Lillicrap. Compressive transformers for long-range sequence modelling. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=SylKikSYDH.
- Bulatov et al. [2022] Aydar Bulatov, Yuri Kuratov, and Mikhail Burtsev. Recurrent memory transformer. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=Uynr3iPhksa.
- Lee et al. [2022] Mina Lee, Percy Liang, and Qian Yang. Coauthor: Designing a human-ai collaborative writing dataset for exploring language model capabilities. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, CHI ’22, New York, NY, USA, 2022. Association for Computing Machinery. ISBN 9781450391573. doi: 10.1145/3491102.3502030. URL https://doi.org/10.1145/3491102.3502030.
- Dang et al. [2023] Hai Dang, Sven Goller, Florian Lehmann, and Daniel Buschek. Choice over control: How users write with large language models using diegetic and non-diegetic prompting. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, CHI ’23, New York, NY, USA, 2023. Association for Computing Machinery. ISBN 9781450394215. doi: 10.1145/3544548.3580969. URL https://doi.org/10.1145/3544548.3580969.
- Reimers and Gurevych [2019] Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019. URL https://arxiv.org/abs/1908.10084.
- Yang et al. [2022a] Kevin Yang, Yuandong Tian, Nanyun Peng, and Dan Klein. Re3: Generating longer stories with recursive reprompting and revision. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 4393–4479, Abu Dhabi, United Arab Emirates, December 2022a. Association for Computational Linguistics. URL https://aclanthology.org/2022.emnlp-main.296.
- Yang et al. [2022b] Kevin Yang, Dan Klein, Nanyun Peng, and Yuandong Tian. Doc: Improving long story coherence with detailed outline control, 2022b.
- Zhang et al. [2022] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- Beltagy et al. [2020] Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv:2004.05150, 2020.
- Kitaev et al. [2020] Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. In ICLR. OpenReview.net, 2020.
- Child et al. [2019] Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers, 2019.
- Zaheer et al. [2020] Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontañón, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. Big bird: Transformers for longer sequences. In NeurIPS, 2020.
- Wang et al. [2019] Zhiwei Wang, Yao Ma, Zitao Liu, and Jiliang Tang. R-transformer: Recurrent neural network enhanced transformer, 2019.
- Cui and Hu [2021] Peng Cui and Le Hu. Sliding selector network with dynamic memory for extractive summarization of long documents. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5881–5891, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main.470. URL https://aclanthology.org/2021.naacl-main.470.
- Press et al. [2022] Ofir Press, Noah A. Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. In ICLR. OpenReview.net, 2022.
- Fan et al. [2018] Angela Fan, Mike Lewis, and Yann Dauphin. Hierarchical neural story generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 889–898, 2018.
- Fan et al. [2019] Angela Fan, Mike Lewis, and Yann Dauphin. Strategies for structuring story generation. arXiv preprint arXiv:1902.01109, 2019.
- Tan et al. [2021] Bowen Tan, Zichao Yang, Maruan Al-Shedivat, Eric Xing, and Zhiting Hu. Progressive generation of long text with pretrained language models. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4313–4324, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main.341. URL https://aclanthology.org/2021.naacl-main.341.
- Sun et al. [2022] Xiaofei Sun, Zijun Sun, Yuxian Meng, Jiwei Li, and Chun Fan. Summarize, outline, and elaborate: Long-text generation via hierarchical supervision from extractive summaries. In Proceedings of the 29th International Conference on Computational Linguistics, pages 6392–6402, Gyeongju, Republic of Korea, October 2022. International Committee on Computational Linguistics. URL https://aclanthology.org/2022.coling-1.556.
- Yao et al. [2019a] Lili Yao, Nanyun Peng, Ralph M. Weischedel, Kevin Knight, Dongyan Zhao, and Rui Yan. Plan-and-write: Towards better automatic storytelling. In AAAI, pages 7378–7385. AAAI Press, 2019a.
- Liu et al. [2019] Yuanchao Liu, Bo Pang, and Bingquan Liu. Neural-based Chinese idiom recommendation for enhancing elegance in essay writing. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5522–5526, Florence, Italy, July 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1552. URL https://aclanthology.org/P19-1552.
- Ghazvininejad et al. [2017] Marjan Ghazvininejad, Xing Shi, Jay Priyadarshi, and Kevin Knight. Hafez: an interactive poetry generation system. In Proceedings of ACL 2017, System Demonstrations, pages 43–48, Vancouver, Canada, July 2017. Association for Computational Linguistics. URL https://aclanthology.org/P17-4008.
- Coenen et al. [2021] Andy Coenen, Luke Davis, Daphne Ippolito, Emily Reif, and Ann Yuan. Wordcraft: a human-ai collaborative editor for story writing. arXiv preprint arXiv:2107.07430, 2021.
- Chung et al. [2022] John Joon Young Chung, Wooseok Kim, Kang Min Yoo, Hwaran Lee, Eytan Adar, and Minsuk Chang. Talebrush: sketching stories with generative pretrained language models. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, pages 1–19, 2022.
- Goldfarb-Tarrant et al. [2019] Seraphina Goldfarb-Tarrant, Haining Feng, and Nanyun Peng. Plan, write, and revise: an interactive system for open-domain story generation. arXiv preprint arXiv:1904.02357, 2019.
- Tian and Peng [2022] Yufei Tian and Nanyun Peng. Zero-shot sonnet generation with discourse-level planning and aesthetics features. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3587–3597, Seattle, United States, July 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.naacl-main.262. URL https://aclanthology.org/2022.naacl-main.262.
- Li et al. [2013] Boyang Li, Stephen Lee-Urban, George Johnston, and Mark Riedl. Story generation with crowdsourced plot graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 27, pages 598–604, 2013.
- Birnholtz et al. [2013] Jeremy Birnholtz, Stephanie Steinhardt, and Antonella Pavese. Write here, write now! an experimental study of group maintenance in collaborative writing. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pages 961–970, 2013.
- Han et al. [2022] Rujun Han, Hong Chen, Yufei Tian, and Nanyun Peng. Go back in time: Generating flashbacks in stories with event temporal prompts. arXiv preprint arXiv:2205.01898, 2022.
- Yao et al. [2019b] Lili Yao, Nanyun Peng, Ralph Weischedel, Kevin Knight, Dongyan Zhao, and Rui Yan. Plan-and-write: Towards better automatic storytelling. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 7378–7385, 2019b.
附录A提示

附录 B演示