语言模型物理学:
第 1 部分,上下文无关语法
(版本 2)††谢谢:V1在这一天出现; V2 完善了文字并添加了Appendix G。
我们要感谢林晓、王思达和胡旭的许多有益的对话。 我们要特别感谢 W&B 的 Ian Clark、Gourab De、Anmol Mann 和 Max Pfeifer,以及 Nabib Ahmed、Giri Anantharaman、Lucca Bertoncini、Henry Estela、Liao Hu、Caleb Ho 、来自 Meta FAIR NextSys 的 Will Johnson、Apostolos Kokolis 和 Shubho Sengupta;没有他们的宝贵支持,本文中的实验是不可能实现的。 )
摘要
我们设计了受控实验来研究 生成式语言模型(如 GPT)如何学习上下文自由语法(CFG)--一种具有树状结构的多样化语言系统,可捕捉自然语言、程序和逻辑的许多方面。 CFG 与下推自动机一样困难,并且可能不明确,因此验证字符串是否满足规则需要动态编程。 我们构建了合成数据,并证明即使对于困难的(长且模糊的)CFG,预训练的 Transformer 也可以学习生成具有近乎完美的准确性和令人印象深刻的多样性的句子。
更重要的是,我们深入研究了 Transformer 如何学习 CFG 背后的物理原理。 我们发现 Transformer 中的隐藏状态隐式且精确编码 CFG 结构(例如将树节点信息精确地放在子树边界上),并学习形成类似于动态规划的“边界到边界”注意力。 我们还介绍了 CFG 的一些扩展以及 Transformer 针对语法错误的鲁棒性。 总的来说,我们的研究对 Transformer 如何学习 CFG 提供了全面和实证的理解,并揭示了 Transformer 用于捕获语言结构和规则的物理机制。
1简介
语言系统由许多结构组成,例如语法、编码、逻辑等,它们定义了如何排列和操作单词和符号以形成有意义且有效的表达。 这些结构反映了人类认知和交流的逻辑和推理,并能够生成和理解多样化和复杂的表达方式。
语言模型[43,34,9,31,10]是旨在学习自然语言的概率分布并生成文本的神经网络。 像 GPT [33] 这样的模型可以准确地遵循语言结构 [37, 41],即使在较小的模型 [7] 中也是如此。 然而,这些模型用于捕获语言规则和模式的机制和表示仍不清楚。 尽管最近在理解语言模型方面取得了理论进展[21,22,48,6,17],但大多数都仅限于简单的设置,无法解释语言的复杂结构。
在本文中,我们探讨了学习概率上下文无关语法 (CFG) 的生成语言模型背后的物理原理[25,5,20,36,11]。 CFG 能够生成一组不同的高度结构化 表达式,由终结符 (T) 和非终结符 (NT) 符号、根符号和产生式规则组成。 如果存在将根符号转换为 T 符号串的规则序列,则该字符串属于由 CFG 生成的语言。 例如,下面的 CFG 生成平衡括号的语言:
其中 表示空字符串。 该语言的示例包括。
语言中的许多结构都可以被视为 CFG,包括语法、代码结构、数学表达式、音乐模式、文章格式(用于诗歌、指令、法律文档)等。我们使用 Transformer [43] 作为生成语言模型并研究它如何学习 CFG。 Transformer 可以对一些 CFG 进行编码,尤其是那些对应于自然语言语法 [15, 38, 50, 26, 23, 44, 47, 4] 的 CFG。 然而, Transformer 如何有效学习此类 CFG 背后的物理机制仍不清楚。 之前的工作[12]研究了 Transformer 在乔姆斯基层次结构中的几种语言(包括 CFG)上的可学习性,但关于 Transformer 如何或不能解决这些任务的内部机制仍不清楚。

对于生成式语言模型来说,要学习冗长的 CFG(例如,数百个标记),它必须有效地掌握复杂的长期规划。
-
•
该模型不能仅仅生成“局部一致”的 Token 。 在平衡括号示例中,模型必须全局跟踪左括号和右括号的数量和类型。
-
•
对于不明确 CFG,“贪婪解析”会失败。 在Figure 1示例中,连续标记3 1 2并不一定表明它们的NT父代是7,尽管规则。 它们也可能源自 NT 符号 或 。
一般来说,即使验证属于已知 CFG 的序列也可能需要动态编程,拥有内存和访问它的机制来验证 CFG 的层次结构。 因此,学习 CFG 对 Transformer 模型提出了重大挑战,测试其学习和生成复杂、多样化表达式的能力。
在这项研究中,我们建议使用综合、受控实验来研究 Transformer 如何学习如此长、模糊的 CFG。 我们使用从几个非常重要的 CFG 中采样的大型字符串语料库对语言建模任务上的 GPT-2 [34] 进行预训练,这些 CFG 是我们以不同难度级别构建的 - 参见 Figure 1 为例。 我们通过从 CFG 中输入前缀来测试模型的准确性和多样性,并观察它是否可以生成准确的补全。
-
•
我们证明该模型可以实现近乎完美的 CFG 生成精度。
-
•
我们检查模型的输出分布/多样性,结果表明它接近真实的 CFG。
我们论文的关键贡献是分析 Transformer 如何恢复底层CFG的结构,检查注意力模式和隐藏状态。 具体来说,我们:
-
•
开发一种探测方法来验证模型的隐藏状态几乎完美地线性编码 NT 信息,这是一个重要的发现,因为预训练不会暴露 CFG 结构。
-
•
引入可视化和量化注意力模式的方法,证明 GPT 学习基于位置和基于边界的注意力,有助于理解 CFG 的规律性、周期性和层次结构。
-
•
建议 GPT 模型通过实现类似动态编程的算法来学习 CFG。 我们发现基于边界的注意力使得词符能够关注 CFG 树中最接近的 NT 符号,即使被数百个标记分开。 这类似于动态规划,其中序列上的CFG解析需要与另一个序列“连接”,以便形成。 有关说明,请参见Figure 2。

我们还探索了隐式 CFG [32],其中每个 T 符号都是一袋 Token ,数据是通过随机采样 Token 生成的。 这允许捕获额外的结构,例如单词类别。 我们证明该模型通过在其词符嵌入层中编码 T 符号信息来学习隐式 CFG。
我们使用 CFG 进一步探索模型稳健性 [27, 42],测试模型纠正错误并从损坏的前缀生成有效 CFG 的能力。 这一属性至关重要,因为它反映了模型处理现实世界数据的能力,包括那些有语法错误的数据。
-
•
我们观察到,根据语法准确的数据进行预训练的 GPT 模型可以产生中等稳健的准确性。 然而,在所有训练样本中引入仅 10% 的数据扰动或允许语法错误可以显着提高鲁棒准确性。 这意味着在预训练期间合并低质量数据的潜在优势。
-
•
我们还表明,当使用扰动数据进行预训练时,Transformer 会学习有意和无意的语法错误之间的“模式切换”。 这种现象在实践中也被观察到,例如在LLaMA模型上。
2 上下文无关语法
概率上下文无关语法 (CFG) 是使用产生式规则定义字符串分布的形式系统。 它由四个部分组成:终结符 ()、非终结符 ()、根符号 () 和产生式规则 ()。 我们将 CFG 表示为 ,其中 表示由 生成的字符串分布。
2.1 定义和符号
我们主要关注 级 CFG,其中每个级别 对应于一组符号 ,其中 对应 、 和 。 不同级别的符号是不相交的:代表。 我们考虑长度为 2 或 3 的规则,表示为 ,其中每个 由以下形式的规则组成:
给定一个非终结符号 和任何规则 ,我们说 。 对于每个,其关联的规则集是,其程度是,并且CFG的大小 是。
从 CFG 生成。 要从 生成样本 ,请执行以下步骤:
-
1.
以符号开始。
-
2.
对于每个层,保留符号序列。
-
3.
对于下一层,以均匀概率为每个 随机采样规则 。111为了简单起见,我们考虑统一情况,消除概率极低的规则。 这些规则使 CFG 的学习和 Transformer 内部工作原理的研究变得复杂(例如,需要更大的网络和更长的训练时间)。 当分布不是严重不平衡时,我们的结果确实可以扩展到非均匀情况。 如果,则将替换为;如果,则替换为。 令结果序列为。
-
4.
在生成过程中,当应用规则 时,定义父级 (如果 的规则长度为 3,则类似)。
-
5.
定义NT祖先索引和NT祖先符号,如图Figure 2:
最终的字符串是 ,带有 和长度 。 我们使用 来表示 及其关联的 NT 祖先索引和符号,根据生成过程进行采样。 当 和 从上下文中显而易见时,我们就写 。
Definition 2.1。
示例中的符号是级别处的NT边界/NT结束,如果或。 我们将表示为NT端边界指示函数。 的最深NT端是——另见Figure 2——
合成 CFG 系列。 我们重点关注深度的七个合成CFG,详细信息请参见Section A.1部分。 硬数据集的大小为并且难度不断增加。 简单数据集 和 的大小分别为 和 。 这些 CFG 生成的序列长度可达 。 通常,假设其他因素保持不变,CFG 的学习难度与 NT/T 符号或 CFG 规则的数量成反比(参见Figure 4) > 我们在Appendix G中讨论更多内容)。 因此,我们主要关注。




2.2 为什么要这样的CFG
在本文中,我们使用CFG作为代理来研究语言中一些丰富的递归结构,这些结构可以涵盖一些逻辑、语法、格式、表达式、模式等。这些结构多样但严格(例如,第3.1章应该是仅随后为第 3.1.1 章、第 4 章或第 3.2 章,而不是其他)。 我们创建了一个合成 CFG 来近似这种丰富性和结构。 我们考虑的 CFG 并不平凡,在长度为 300 或以上的总共超过 个可能字符串中, 中可能有超过 个字符串(请参阅Figure 4中的熵估计)。 随机字符串属于该语言的概率几乎为零,并且随机完成有效前缀不太可能满足 CFG。
为了进一步研究 Transformer 的内部工作原理,我们选择了一个具有“规范表示”的 CFG 系列,并证明了该表示与学习到的 Transformer 中的隐藏状态之间的强相关性。 这个对照实验增强了我们对学习过程的理解。 我们还创建了额外的 CFG 系列来检查“不那么规范”的 CFG 树,结果推迟到Appendix G。虽然我们并不声称我们的结果涵盖了所有 CFG,但我们认为我们的工作是一个有希望的起点。 我们的 CFG 对于 Transformer 来说已经相当具有挑战性了。 例如,在Appendix G中,我们展示了源自英语Penn TreeBank的CFG,平均长度为28个token,可以使用小模型很好地学习(例如具有 100k 参数的 GPT)。 相比之下,我们的系列平均长度超过200,需要具有 100M参数的GPT2。 尽管如此,我们仍然可以确定 Transformer 是如何学习它们的。
3 Transformer 学习此类 CFG
在本节中,我们通过测试 Transformer 从 中的字符串前缀完成序列的准确性来评估 Transformer 的生成能力。 我们还评估生成的输出的多样性,并验证这些字符串的分布是否与基本事实 一致。
型号。 我们将普通 GPT2 小型架构(12 层、12 头、768 维)表示为 GPT [34]。 鉴于 GPT2 由于其绝对位置嵌入而导致性能较弱,我们实现了两种现代变体。 我们将具有相对位置注意力[14]的GPT表示为,并将具有旋转位置嵌入[的GPT表示40, 8] 为 。
出于特定目的,我们在后面的部分中介绍了两个较弱的 GPT 变体。 将注意力矩阵替换为仅基于标记相对位置的矩阵,而 使用来自不同窗口长度的过去标记的恒定、统一平均值作为注意矩阵。 这些变体的详细说明请参见Section A.2。

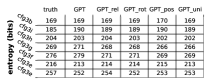
观察: 模糊性较小的 CFG(、,因为它们具有较少的 NT/T 符号)更容易学习。 使用相对位置嵌入( 或 )的现代 Transformer 变体更适合学习复杂的 CFG。 我们还提出了较弱的变体和,它们的注意力矩阵仅基于词符位置(在Section 5.1中服务于特定目的) >)。
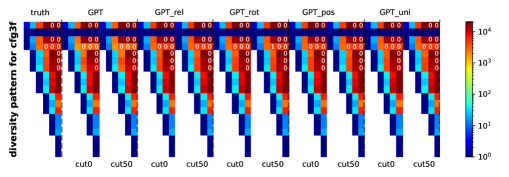
完成精度。 我们根据Section 2.1 节中所述的合成 CFG 生成大型语料库 。 模型 在此语料库上进行预训练,将每个终端符号视为单独的词符,使用自回归任务(Section A.3了解详情)。 为了进行评估, 从 中新生成的字符串 生成前缀 的补全。 生成精度测量为。 我们使用多项式采样而不使用波束搜索来生成。222最后一个 softmax 层将模型输出转换为(下一个)符号的概率分布。 我们遵循这个分布来生成下一个符号,反映 Transformer 学到的未改变的分布。 这是“ 的随机性”的来源,通常称为使用“温度 ”。
Figure 4(左)显示了切割和的生成精度。 结果测试Transformer在CFG中生成句子的能力,而测试其完成句子的能力。333我们的系列足够大,可以确保在预训练期间看到新采样的长度为50的前缀的机会可以忽略不计。 结果表明,预训练的 Transformer 可以生成符合 数据族的 CFG 规则的近乎完美的字符串。
世代多样性。 有没有可能经过训练的 Transformer 只记住了 CFG 中的一小部分字符串? 我们通过测量其生成的字符串的多样性来评估其学习能力。 高度多样性表明对 CFG 规则有更好的理解。
多样性可以通过熵来估计。 给定字符串分布 和从 中抽取的子集 ,对于任意字符串 ,用 表示其长度,所以 ,并用 表示。 的熵(以位为单位)可以通过以下方式估计
我们使用Figure 4(中)中的样本比较真实CFG分布和Transformer输出分布的熵。
还可以使用生日悖论来估计多样性,以降低分布 [3] 的支持大小。 给定字符串上的分布 和来自 的采样子集 ,如果 中的每对样本都是不同的,则 的支持度很有可能至少为 。 在Appendix B.1中,我们用进行了实验。 我们从每个符号 到其他某个级别 进行了生日悖论实验,并将其与基本事实进行了比较。 例如,我们确认对于 数据集,至少有 个不同的句子形式可以从符号 派生到级别 ——更不用说从中的根到级别的叶。 特别是,已经超过了模型中的参数数量。
从这两个实验中,我们得出的结论是,预训练模型并不依赖于简单地记忆一小组模式来学习 CFG。
分布比较。 为了充分学习 CFG,学习生成概率的分布至关重要。 然而,比较指数支持大小的分布可能具有挑战性。 一种简单的方法是比较边缘分布 ,它表示符号 出现在位置 的概率(即 )。 我们观察到生成概率和真实分布之间存在很强的一致性,请参阅Appendix B.2。
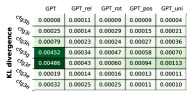
另一种方法是计算每个符号条件分布之间的 KL 散度。 令 为真实 CFG 中字符串的分布, 为来自 Transformer 模型的分布。 令 为真实 CFG 分布的样本。 然后,KL散度可以估计如下:444DuSell 和Chiang [13] 中也使用了几乎相同的公式。
在Figure 4(右)中,我们使用样本比较了真实CFG分布和Transformer输出分布之间的KL散度。
4变形金刚如何学习CFG?
在本节中,我们将深入研究 Transformer 的学习表示,以了解它如何对 CFG 进行编码。 我们采用各种测量来探究表征并获得见解。
回想一下解决 CFG 的经典方法。 给定 CFG ,验证序列 是否满足 的经典方法是使用动态编程 (DP) [35, 39] 。 DP 的一种可能实现涉及使用函数 ,该函数确定是否可以按照 CFG 规则从符号 生成 。 从这个 DP 表示中,可以很容易地导出 DP 循环公式。555例如,当且仅当存在 使得 存在时,才可以计算 > 对于所有和是CFG的规则。 简单地实现这一点将导致 CFG 的 算法的最大规则长度为 。 然而,通过引入辅助节点(例如,通过二值化),可以在 时间内更有效地实现它。
在本文中,任何满足 CFG 的序列 必须满足以下条件(回想一下 NT 边界 和 NT 祖先 来自Section 2.1节的概念):
| (4.1) |
请注意,(4.1) 不是“当且仅当”条件,因为可能存在不位于最终 CFG 上的子问题 解析树,但仍然可以通过某些有效的 CFG 子树进行本地解析。 然而,(4.1)提供了子问题的“主干”,其中验证其值证明句子 是来自 的有效字符串。 值得一提的是,根据 DP 程序的实现(例如,修剪或二值化的不同顺序),并非所有元组都需要在中计算。 只有“骨干”中的人才是必要的。
连接到 Transformer 。 在本节中,我们研究预训练的 Transformer 是否不仅生成语法正确的序列,而且还隐式编码 NT 祖先和边界信息。 如果是,则表明 Transformer 包含足够的信息来支持主干中的所有 值。 考虑到 Transformer 仅在自回归任务上进行训练,而没有接触任何 NT 信息,这是一个重要的发现。 如果预训练后确实对 NT 信息进行了编码,则意味着该模型既可以生成 CFG 语言的句子,又可以验证 CFG 语言的句子。
4.1 发现 1:Transformer 的隐藏状态编码 NT 祖先和边界

令为Transformer的最后一层(其他层在Appendix C.2中考虑)。 给定输入字符串 ,Transformer 在层 和位置 的隐藏状态表示为 。 我们研究线性函数是否可以仅使用 来预测 和 。 如果可能的话,这意味着最后一层隐藏状态将 CFG 的结构信息编码为线性变换。
我们的多头线性函数。 由于此线性函数的高维度(例如, 和 产生 维度)和 可变字符串长度,我们提出一种用于高效学习的多头线性函数。 我们考虑一组线性函数,其中和是“正面”的数量。 为了预测任何 ,我们应用:
| (4.2) |
其中 表示可训练参数 。 可以看作是线性函数上的“多头注意力”。 我们使用交叉熵损失训练来预测。 尽管有多个头,
| is still a linear function over |
因为线性权重 仅取决于位置 和 ,而不取决于 。 类似地,我们使用逻辑损失训练来预测值。 详细信息参见Section A.4部分。
结果。 我们的实验(Figure 5)表明预训练允许生成模型几乎完美地编码最后的NT祖先和NT边界信息Transformer 层的隐藏状态,最多可达线性 变换。
4.2 发现 2:Transformer 的隐藏状态编码 NT 祖先在 NT 边界
我们之前使用整个隐藏状态层来预测每个位置的 。 这对于生成/解码器模型至关重要,因为仅通过检查 或其 左侧 的隐藏状态不可能提取 的 NT 祖先,特别是如果词符 靠近 CFG 中字符串的开头或子树的起始词符。
然而,如果我们只考虑隐藏状态中位置 的邻域,例如 ,我们可以通过线性探测从中推断出什么? 我们可以将 (4.2) 中的 替换为将 替换为 的零(三对角掩码),或者 为零(对角线掩码)。
结果。 我们观察到两个关键点。 首先,对角线或三对角线掩蔽足以预测 NT 边界,即 ,而且准确度相当高(请参见 Appendix C.1 中的 Figure 17 )。 更重要的是,在NT边界(即),这种掩蔽足以准确预测NT祖先(参见Figure 6)。 因此,我们得出结论,当位于NT边界上时,位置的NT祖先的信息在位置周围进行本地编码.


相关工作。 我们的探测方法类似于 Hewitt 和 Manning [15] 的开创性工作,它使用线性探测来检查 BERT 隐藏状态和解析树距离度量之间的相关性(类似于我们的 NT 距离)语言)。 随后的研究[38,50,26,23,44,47,4]探索了各种探测技术,表明类似 BERT 的转换器可以从自然语言中近似 CFG。
我们的方法的不同之处在于,我们使用合成数据来证明线性探测可以几乎完美恢复 NT 祖先和边界,即使对于生成超过数百个标记的字符串的复杂 CFG 也是如此。 我们专注于预训练生成语言模型。 对于通过语言建模 (MLM) 预训练的非生成式 BERT 模型,例如当代变体 DeBERTa [14],学习深层 NT 信息( (即靠近CFG根)效果较差,如图Figure 5所示。 这是预期的,因为 MLM 任务可能只需要 Transformer 学习 20 个相邻标记的 NT 规则。 至关重要的是,类似 BERT 的模型不会在 NT 边界存储深度 NT 信息(参见Figure 6)。
我们的结果以及Section 5提供了证据,表明GPT-2等生成语言模型采用类似动态编程的方法来生成CFG,而基于编码器的模型,通常通过 MLM 进行训练,很难学习更复杂/更深的 CFG。
5变形金刚如何学习NT?
我们现在深入研究注意力模式。 我们证明这些模式反映了 CFG 的句法结构和规则,Transformer 使用不同的注意力头来学习不同 CFG 级别的 NT。
5.1 基于位置的注意力
我们首先注意到 Transformer 的注意力权重主要受标记相对距离的影响。 即使使用绝对位置嵌入在 CFG 数据上进行训练,这一点也成立。 这意味着 Transformer 通过位置信息了解 CFG 的规律性和周期性,然后将其用于生成。
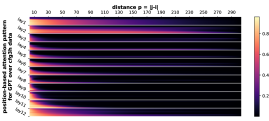
正式地,让 的 表示层 和头 的位置 的注意力权重。 Transformer,在输入序列 上。 对于每个层 、头部 和距离 ,我们计算所有数据 和成对 与 的部分和 的平均值。 我们在Figure 7中绘制了的累积总和。 我们观察到注意力模式与相对距离 之间存在很强的相关性。 注意力模式也是多尺度的,一些注意力头专注于较短的距离,而另一些注意力头则专注于较长的距离。
受此启发,我们探索基于位置的注意力是否可以单独学习 CFG。 在Figure 4中,我们发现(甚至)表现良好,超越了普通的GPT,但未充分发挥 的潜力。 这支持基于相对位置的 Transformer 变体(例如 、DeBERTa)比其基本模型(GPT 或 BERT)具有卓越的实际性能。 另一方面,这也表明 Transformer 学习 CFG 时仅靠位置注意力是不够的。
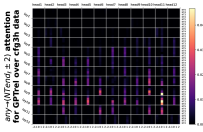
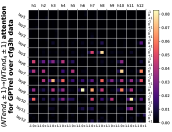
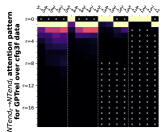
5.2 基于边界的注意力
接下来,我们从注意力矩阵中删除位置偏差来检查剩余部分。 我们发现 Transformer 还学习了一种强大的基于边界的注意模式,其中 NT 端边界上的标记通常关注“最相邻的”NT 端边界,类似于用于解析的标准动态编程CFG(参见Figure 2)。 这种注意力模式使 Transformer 能够有效地学习 CFG 的分层和递归结构,并根据 NT 符号和规则生成输出标记。
正式地,令 的 表示层 和头 的位置 的注意力权重。 Transformer,在输入序列 上。 给定一个样本池,我们计算每个层,头,666在本文中,我们使用来表示允许多重性的多集,例如。 这使我们可以方便地讨论其设定平均值。
代表样本池上任何距离 的词符对之间的平均注意力。 为了消除位置偏差,我们在本小节中重点关注 。 我们的观察可以分为三个步骤。
-
•
首先,对NT端的tokens at NT ends。 如 Figure 8(a)所示,我们给出了数据 和数据对 中 的平均值,其中 是 层中最深的 NT 端(象征性地表示为 )。 当 时,注意力权重最高,而周围标记的注意力权重迅速下降。
-
•
其次,也有利于在水平上both at NT ends的对。 在 Figure 8(b)中,我们显示了 在数据 和对 中的平均值,其中 为 的平均值。
-
•
第三,有利于“adjacent” NT-end token pairs 。 我们对 "邻接 "定义如下:我们引入 来表示 在样本 和词符对 上的平均值,这些样本分别位于 层上最深的 NT 端(符号为 ),并且根据 层上的祖先索引(符号为 ),它们之间的距离为 。 在Figure 8(c)中,我们观察到 随着 的增加而减小,当 时最高(对于没有 条目的 对,则为 )。777对于任何词符对 与 - 即 位于比 更靠近根的 NT 端 - 它满足 ,因此它们的距离 严格为正。
总之,与级别 的 NT 端相对应的标记在统计上对每个级别 的 最相邻 NT 端具有更高的注意力权重,即使在消除位置偏差之后。888如果不消除位置偏差,这样的声明可能毫无意义,因为位置偏差可能有利于“相邻”任何东西,包括 NT 端对。
连接到 DP。 回想一下,动态规划 (DP) 由两个部分组成:存储和循环公式。 虽然确定 Transformer 遵循的特定 DP 实现是不切实际的,因为实现 DP 的方法有无数种,但我们可以突出显示 DP 实现中的常见元素以及它们与 Transformer 的相关性。 在Section 4中,我们证明了生成式Transformer可以对DP的存储“主干”进行编码,涵盖所有必要的给定字符串的正确 CFG 解析树。
对于循环公式,考虑正确CFG解析树中的CFG规则。 如果非终结符 (NT) 跨越位置 21-30, 跨越位置 31-40, 跨越位置 41-50,则 DP 必须建立“位置 30-40 和 40-50 之间的“记忆链接”。 这可以通过在位置 40 存储 信息并将其与位置 50 处的 合并,或者通过在位置 50 存储 并将其与 在位置 30。 无论哪种方法,共同的特点是内存链接从30到40和从40到50。 因此,我们在本节中一直在研究相邻 NT 之间的 NT 端到 NT 端注意力链接。
Transformer 不仅是一种解析算法,也是一种生成算法。 假设 和 在正确的解析树上。 当生成符号时,模型尚未完成读取,必须从叔叔节点访问预先计算的知识。 这就是为什么我们还在不同级别上可视化从 NT 端到其最相邻的 NT 端的这些注意力。
总之,虽然为 DP 循环公式定义一个好的主干可能具有挑战性,但我们在本节中演示了几种注意力模式,无论 DP 实现如何,这些模式都很大程度上模仿了动态编程。
6 CFG 的扩展
6.1 隐式CFG

在隐式 CFG 中,终端符号表示具有共享属性的标记包。 例如,像 这样的终端符号对应于一袋名词的分布,而 对应于一袋动词的分布。 这些分布可以是不均匀的和重叠的,允许 Token 在不同的终端符号之间共享。 在预训练期间,模型学习将标记与其各自的句法或语义类别相关联,而无需事先了解它们在 CFG 中的特定角色。
形式上,我们考虑一组可观察标记,中的每个终结符号与一个子集 和 上的概率分布 。 集合 可以重叠。 为了从这个隐式 CFG 生成一个字符串,在生成 后,对于每个终端符号 ,我们独立采样一个元素 。 之后,我们观察新的字符串,并将这个新的分布称为
我们使用分布 中的样本来预训练语言模型。 在测试过程中,我们评估模型在给定输入前缀 的情况下生成属于 的字符串的成功概率。或者,用符号表示,
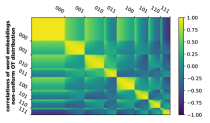
其中 表示给定前缀 的模型生成的完成。 (我们再次使用动态规划来确定输出字符串是否在中。) 我们的实验表明,语言模型也可以很好地学习隐式 CFG。 通过可视化词嵌入层的权重,我们观察到来自同一子集的标记的嵌入被分组在一起(参见Figure 9) ,表明 Transformer 通过使用其词符嵌入层来编码隐藏的终端符号信息来学习隐式 CFG。 详情请参阅Appendix E。
6.2 损坏 CFG 的稳健性

人们可能还希望对 Transformer 进行预训练,使其对于输入中的错误和不一致具有鲁棒性。 例如,如果输入数据是一个前缀,其中一些标记被损坏或丢失,那么人们可能希望 Transformer 纠正错误并仍然按照正确的 CFG 规则完成句子。 鲁棒性是一个重要的属性,因为它反映了 Transformer 处理现实世界训练数据的泛化和适应能力,这些数据可能并不总是完美遵循 CFG(例如存在语法错误)。
为了测试鲁棒性,对于属于 CFG 的长度为 的每个输入前缀 ,我们在该前缀中随机选择一组位置 — 每个位置概率——并翻转它们 i.i.d. 在 中带有随机符号。 调用生成的前缀 。接下来,我们将损坏的前缀 提供给Transformer ,并在未损坏的CFG中计算其生成精度:。
我们不仅考虑干净的预训练,还考虑某些版本的鲁棒预训练。 也就是说,我们随机选择训练数据的 部分并在输入预训练过程之前扰乱它们。 我们比较三种类型的数据扰动。999通过考虑其他类型的数据损坏(用于评估)和其他类型的数据扰动(用于训练),可以轻松扩展我们的实验。 我们不这样做,因为这超出了本文的范围。
-
•
(T 级随机扰动)。 每个 w.p. 我们将其替换为中的随机符号。
-
•
(NT 级随机扰动)。 令 并回忆 是 NT 级别 的符号序列。 对于每个 ,w.p. 我们将其扰动为中的随机符号;然后根据这个扰动序列生成。
-
•
(NT 级确定性扰动)。 设 并修复 中符号的排列 。 对于每个 ,w.p. 我们根据将其扰动到中的下一个符号;然后根据这个扰动序列生成。
我们关注具有广泛扰动率的。 我们在Figure 10中展示了我们的发现。 值得注意的观察结果包括:
- •
-
•
比较Figure 10的第3/6/9行的温度,我们看到预训练教会语言模型实际上包含模式开关。 当给定正确的前缀时,它处于正确模式,并使用 CFG 中的正确字符串完成句子(第 9 行);当给定损坏的前缀时,它总是完成有语法错误的句子(第6行);当没有给定前缀时,它会生成损坏的字符串,概率接近 (第 3 行)。
-
•
比较Figure 10中的第4/5行和第6行,我们发现使用低温生成时可以实现高鲁棒精度。101010回想一下,当温度时,生成是贪婪的和确定性的;当 时,它反映了 Transformer 学到的未改变的分布;当 很小时,它会鼓励 Transformer 输出“更有可能”的标记。 鉴于语言模型学习了“模式切换”,这应该不足为奇。使用低温可以鼓励模型为每个下一个词符选择一个更有可能的解决方案。 这使其能够实现良好的鲁棒精度,即使模型完全基于损坏的数据进行训练 ()。
请注意,这与实践是一致的:当向预先训练的大型语言模型(例如 LLaMA-30B)提供语法错误提示时,它往往会生成带有(甚至是新的!)的文本。 使用大温度时出现语法错误。
我们的实验似乎表明,如果希望模型始终处于“正确模式”,则可能需要进行额外的指令微调。这超出了本文的范围。
7结论
其他相关作品。 许多研究旨在揭示预训练 Transformer 的内部工作原理。 正如一项同时进行的研究[49]中所指出的,一些人观察到注意力头将右括号与左括号配对。 有些人研究了将逻辑运算应用于输入[30]的感应头。 Wang等人[45]探索了许多不同类型的注意力头,包括“复制头”和“名称移动头”。 虽然由于我们研究的任务不同,我们的论文与这些研究有所不同,但我们强调 CFG 是一项深度、递归任务。 尽管如此,我们仍然设法揭示内层以复杂的、递归的、类似动态编程的方式执行注意力,这在输入级别上并不立即明显。
另一方面,一些研究可以在训练后精确确定每个神经元的功能,通常是使用更简单的架构来完成更简单的任务。 例如,Nanda 等人[29]检查了上下文长度为3的1层或2层 Transformer 的算术加法。 我们的分析重点是 GPT2-small 的内部工作原理,它有 12 层,上下文长度超过 300。 虽然我们无法精确确定每个神经元的功能,但我们已经确定了一些神经元的角色和一些隐藏状态,它们与动态编程相关。
除了线性探测之外,Murty 等人[28]还探索了推导 Transformer 学习的树结构的替代方法。 他们开发了一个分数来量化变形金刚的“树状”性质,证明它在训练过程中变得越来越像树。 我们Appendix C.3中的Figure 19也证实了这些发现。
结论。 在本文中,我们设计了对照实验来研究基于 Transformer(特别是 GPT-2)的生成语言模型如何学习和生成上下文无关语法(CFG)。 语言中的 CFG 可以包括语法、格式、表达式、模式等。我们考虑一个合成的、但相当具有挑战性(冗长且模糊)的 CFG 系列,以展示在这些 CFG 上经过训练的 Transformer 模型的内部工作原理如何与用于解析这些 CFG 的动态规划算法的内部状态。 这项研究通过深入了解语言模型如何有效地学习和生成复杂多样的表达方式,为该领域做出了贡献。 它还为解释和理解这些模型的内部运作提供了有价值的工具。 我们的研究为未来的研究开辟了几个令人兴奋的途径,包括:
-
•
探索其他类别的语法,例如上下文相关语法 [18, 46],并研究网络如何学习上下文相关信息。
-
•
研究学习的网络表示向不同领域和任务的迁移和适应,特别是使用低秩更新[16],并评估网络如何利用从 CFG 学到的语法知识。
-
•
将网络的分析和可视化扩展到语言的其他方面,例如语义、语用和风格。
我们希望我们的论文能够激发更多关于理解和改进基于 Transformer 的生成语言模型的研究,并将其应用于自然语言、编码问题等。
附录
附录 A实验设置
A.1 数据集详细信息
我们构建了七个深度的合成CFG,具有不同的学习难度。 可以推断,T/NT符号的数量越多,学习CFG的难度就越大。 因此,为了将语言模型的能力发挥到极限,我们主要关注 ,其大小为 并且难度不断增加。 Figure 11中提供了有关这些CFG的详细信息:
-
•
在中,我们构造CFG,使得每个NT的度。 我们还确保在任何生成规则中,连续的 T/NT 符号对是不同的。
25%、50%、75% 和 95% 百分位字符串长度分别为 。
-
•
在中,我们为每个NT 设置。 我们取消了对独特性的要求,使数据比 更具挑战性。
25%、50%、75% 和 95% 百分位字符串长度分别为 。
-
•
在中,我们为每个NT设置,以使数据比更具挑战性。
25%、50%、75% 和 95% 百分位字符串长度分别为 。
-
•
在中,我们为每个NT设置,以使数据比更具挑战性。
25%、50%、75% 和 95% 百分位字符串长度分别为 。
-
•
在中,我们为每个NT设置,以使数据比更具挑战性。
25%、50%、75% 和 95% 百分位字符串长度分别为 。
Remark A.1.
从Figure 11中的例子,很明显,对于深度的语法,证明字符串 属于 是非常重要的,即使对于人类来说,甚至在 CFG 规则已知的情况下也是如此。 演示 的标准方法是通过动态规划。 我们在Appendix G中进一步讨论CFG“难度”的含义,并提供数据系列之外的其他实验。
Remark A.2.
是一个位于 GPT2-small 能够学习的难度边界上的数据集(有关训练参数,请参阅后续小节)。 虽然当然可以考虑更深、更复杂的 CFG,但这需要在更长的时间内训练更大的网络。 我们选择不这样做,因为我们的发现在 水平上足够令人信服。
同时,为了说明 Transformer 可以学习 或 较大的 CFG,我们分别构建了大小为 和 的数据集 和 。 它们太长而无法描述,因此我们将它们包含在Appendix G.2中的附加txt文件中。

A.2模型架构详细信息
我们将GPT定义为标准GPT2-small架构[34],它由12层组成,每层12个注意力头,768个(=) 隐藏尺寸。 我们从随机初始化开始,在上述数据集上预训练 GPT。 为了进行基线比较,我们还实现了 DeBERTa [14],调整其大小以匹配 GPT2 的维度——因此也包含 12 层、12 个注意力头和 768 个维度。
架构尺寸。 我们对不同大小的模型进行了实验,并观察到它们的学习能力随着 CFG 的复杂性而变化。 为了确保公平比较并提高可重复性,我们主要关注具有 12 层、12 个注意力头和 768 个维度的模型。 以这种方式构建的 Transformer 由 86M 个参数组成。
相对受关注的现代 GPT。 最近的研究[14,40,8]表明, Transformer 可以通过使用基于标记的相对位置差异(而不是绝对位置)的注意力机制来显着提高性能用于原始 GPT2 [34] 或 BERT [19] 中。 有两种主要方法可以实现这一目标。 第一种是在计算从 到 的注意力时在 上使用“相对位置嵌入层”(或使用存储桶嵌入来节省空间)。 这种方法是最有效的,但往往训练速度较慢。 第二种方法是对隐藏状态应用旋转位置嵌入(RoPE)变换[40];众所周知,这比相对方法的效果稍差,但训练速度要快得多。
我们已经实施了这两种方法。 我们采用了 GPT-NeoX-20B 项目中的 RoPE 实现(以及默认参数),但缩小了它的大小以适应 GPT2 小模型。 我们将此架构称为。 由于我们找不到使用相对注意力的 GPT 标准实现,因此我们使用 DeBERTa [14] 中的相对注意力框架重新实现了 GPT2。 (回想一下,DeBERTa 是 BERT 的一个变体,它有效地利用了相对位置嵌入。) 我们将此架构称为。
较弱的 GPT 仅利用基于位置的注意力。 出于分析目的,我们还考虑了 GPT 的两个明显较弱的变体,其中注意力矩阵完全取决于词符位置,而不取决于输入序列或隐藏嵌入。 换句话说,对于所有输入序列,注意力模式都保持不变。
我们实现了 ,它是 的变体,它限制仅使用(可训练的)相对位置嵌入来计算注意力矩阵。 这可以被视为 GPT 变体,它最大限度地利用基于位置的注意力。 我们还实现了,一个12层、8头、1024维的Transformer,其中注意力矩阵固定;对于每个 ,第 个头 始终 对之前的 标记使用固定、统一的注意力。 这可以被视为 GPT 变体,它采用最简单形式的基于位置的注意力。
Remark A.3.
毫不奇怪, 或 在现实维基百科预训练中的表现比其他 GPT 模型差得多。 然而,在本文中,我们再次将它们用于分析目的,因为我们希望演示仅使用基于位置的注意力来学习 CFG 时 GPT 的最大功率是多少,以及当一个人超越基于位置的注意力时产生边际效应。
随机 Transformer 的特征。 最后,我们还考虑随机初始化的,并使用这些随机特征来预测NT祖先和NT末端。 这作为基线,可以被视为所谓的(有限宽度)神经切线内核[2]的力量。 我们称之为。
A.3预训练详细信息
对于每个示例 ,我们将其附加到左侧的 BOS 词符和右侧的 EOS 词符。 然后,遵循语言建模(LM)预训练的传统,我们连接连续样本并随机切割数据以形成固定窗口长度512的序列。
作为基线比较,我们还将 DeBERTa 应用于数据集的掩码语言建模 (MLM) 任务。 我们使用标准MLM参数:屏蔽概率,其中使用屏蔽词符的机会,使用原始词符的机会为10%,使用随机词的机会为10%符。
我们使用 Huggingface 库中的标准初始化。 对于 GPT 预训练,我们使用 AdamW 以及 、权重衰减 、学习率 和批量大小 。 我们对模型进行 10 万次迭代预训练,学习率呈线性衰减。111111我们稍微调整了参数以使预训练效果最好。 我们注意到,对于 CFG 数据上的训练 GPT,不需要预热学习率计划。 对于 DeBERTa,我们使用更好的学习率 和学习率线性预热的 步。
在整个实验中,对于预训练和测试,我们仅使用 CFG 数据集中的新鲜样本(因此使用十亿个 Token =)。 我们还使用有限的 标记训练集测试了预训练;和本文的结论保持相似。 为了使这篇论文干净,我们选择在这个版本的论文中坚持无限数据制度,因为它使我们能够做出负面陈述(例如关于普通 GPT 或 DeBERTa,或者关于 NT 祖先 / NT 的可学习性)边界),而不用担心样本大小。 请注意,鉴于我们的 CFG 语言非常大(例如,长度为 2/3 规则且度数为 4 的长度为 300 的树至少具有 可能性),几乎不可能训练/测试命中同一句话。
A.4 预测NT祖先和NT边界
回想一下 Section 4.1 节,我们建议使用多头线性函数来探测 Transformer 的隐藏状态是否隐式编码 NT 祖先和 NT 边界每个词符位置的信息。 由于该线性函数的维度可以为 (当上下文长度为 512 且隐藏维度为 768 时),请回忆一下 (4.2),我们提出使用多头注意力来构建这样的线性函数以实现有效的学习目的。 这显着降低了样本复杂性,并使查找线性函数变得更加容易。
在我们的实现中,我们在 (4.2) 中构建基于位置的注意力时选择 头和隐藏维度 。 我们还尝试了其他参数,但 NT 祖先/边界预测精度对这种架构变化不是很敏感。 我们再次使用 AdamW 和 ,但这次使用学习率 、权重衰减 、批量大小 和 30k 迭代的训练。
在训练此类线性函数时,我们再次使用新样本。 在评估预测 NT 祖先/边界信息的准确性时,我们还使用新鲜的新样本。 回想一下,我们的 CFG 语言足够大,因此模型在训练过程中看到这样的字符串的可能性可以忽略不计。
附录B关于生成的更多实验
B.1 生日悖论的代际多样性
由于“多样性”受到输入前缀长度、输出长度和 CFG 规则的影响,因此我们要仔细定义我们测量的内容。
给定一个样本池 ,对于每个符号 和一些更接近叶子的更高级别 ,我们希望定义一个 multi-设置 ,描述此示例池中从到的所有可能世代。 正式地,
Definition B.1.
对于 和 ,我们使用 表示 层中从位置 到 的 NT 祖先符号序列,这些符号具有不同的祖先索引:121212了解。
Definition B.2.
对于符号和某些图层,定义多集 131313在本文中,我们使用来表示允许多重性的多集,例如. 这使我们能够方便地讨论其碰撞计数、不同元素的数量和集合平均值。
我们定义多集并集,它是从NT符号到深度可以推导出的所有句子形式的多重集。
(上面,当从真实CFG生成时,祖先索引和符号在Section 2.1。 如果 是 Transformer 的输出,那么我们让 使用动态编程进行计算,按字典顺序打破联系。)
当 独立同分布时,我们使用 表示基本事实 。 从真实分布中采样,并表示为
来自 Transformer 的。为了公平比较,对于每个 和 ,我们选择一个 使得 使得 能够生成几乎完全满足 CFG 规则的 句子。141414请注意 和 大致相同,给定
直观上,对于 Transformer 模型生成的 , 中不同序列的数量越多, 级别的 NT 集合就越多样化>(如果 则为 Ts)模型可以从 NT 开始生成。 此外,如果 仅具有不同的序列(因此碰撞计数 = 0),那么我们知道 的生成很有可能至少应包括 使用生日悖论论证的可能性。 151515深度的CFG,即使具有恒定的程度和恒定的大小,也可以生成不同的序列。
因此,如果我们比较 和 之间的不同序列的数量和碰撞计数,这可能是有益的。 请注意,我们考虑所有 而不是仅 ,因为我们希望更好地捕获模型在所有 CFG 级别的多样性。161616模型可能会生成相同的 NT 符号序列 ,然后从每个 NT 中随机生成不同的 T。 这样,模型仍然生成具有较大多样性的字符串 ,但 较小。 如果 对于每个 和 来说都很大,则模型的生成为 CFG 的任何级别都真正具有多样性。 我们在Figure 12中展示了我们的发现,其中包含数据集的样本。
在 Figure 13 中,我们介绍了 的情况;在 Figure 14 中,我们介绍了 的情况;在 Figure 15 中,我们介绍了 的情况。 我们注意到,不仅对于困难的、模糊的数据集,对于那些不太模糊的 () 数据集,语言模型也能够生成非常多样化的输出。






B.2 边际分布比较
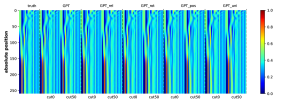
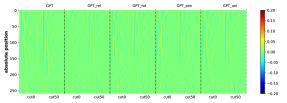
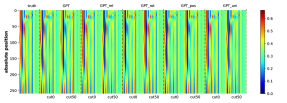
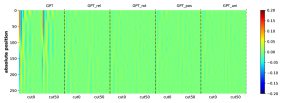
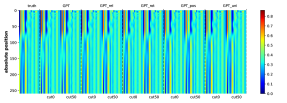
为了有效地学习CFG,匹配生成概率的分布也很重要。 虽然测量这一点可能具有挑战性,但我们至少对边际分布 进行了简单的测试,它表示符号 出现在位置 的概率(即 的概率)。 我们观察到生成的概率和真实分布之间存在很强的一致性。 参见Figure 16。
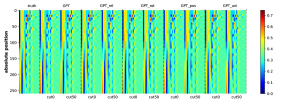
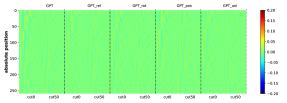
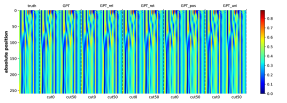
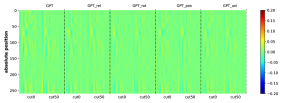
附录C关于NT祖先和NT边界预测的更多实验
C.1 NT 祖先和 NT 边界预测
早些时候,正如Figure 5中所确认的,我们确定(最终 Transformer 层的)隐藏状态已经隐式编码了 NT 祖先符号 每个CFG级别和词符位置使用线性变换。 在Figure 17(a)中,我们还证明了同样的结论也适用于NT端边界信息。 更重要的是,对于,我们表明该信息存储在本地,非常接近位置(例如在 )。 详细信息请参见Figure 17。
此外,正如Figure 6中回忆的那样,我们确认在任何的NT边界处,Transformer也本地编码了有关NT祖先的清晰信息符号,要么恰好在处,要么在处。 准确地说,这是一个条件语句——既然是NT边界,就可以预测NT祖先。 因此,原则上,我们还必须首先验证NT边界的预测任务是否成功。 事实上,此类缺失的实验包含在Figure 17(b)和Figure 17(c)中。



C.2 跨 Transformer 各层的 NT 预测
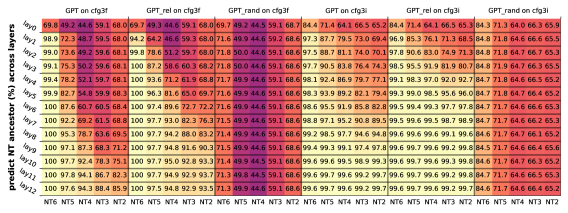
正如人们所想象的那样,较小 CFG 级别 (即更接近 CFG 根)的 NT 祖先和边界信息仅在那些较深的 Transformer 层 处学习。在Figure 18中,我们通过计算GPT中所有12个Transformer层的线性编码精度来展示这一发现t7> 和 。 我们确认生成模型能够分层地发现此类信息。

C.3 跨训练时期的 NT 预测
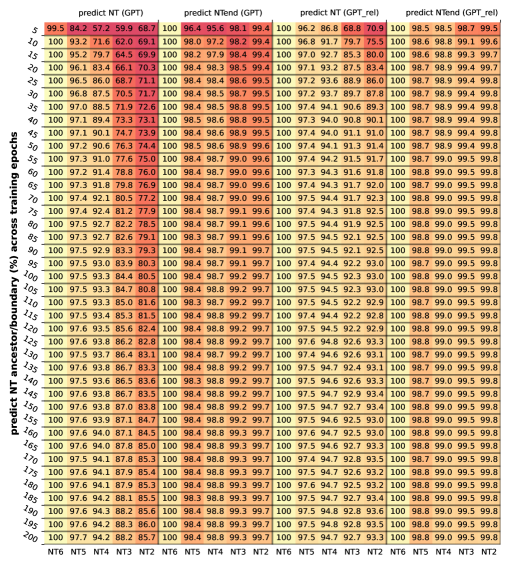
此外,人们可以推测,随着训练步数的增加,NT 祖先和 NT 边界信息是逐渐学习的。 我们已在Figure 19中确认了这一点。 我们强调,这并不意味着逐层训练适用于学习深度 CFG。 将所有层一起训练至关重要,因为更深 Transformer 层的训练过程可能有助于通过称为“向后特征校正”[1] 的过程向后校正在较低层中学到的特征。
附录D关于注意力模式的更多实验
D.1 基于位置的注意力模式
回想一下Figure 7,我们已经证明任意两个位置之间的注意力权重在相对差异方面有很强的偏差>。 不同的头或层对有不同的依赖关系。下面的Figure 20中,我们在更多数据集和上对这种现象进行了实验。
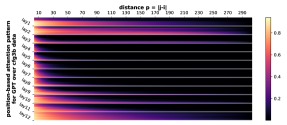
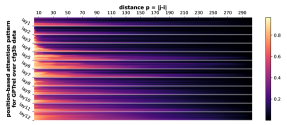
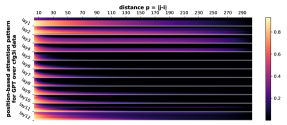
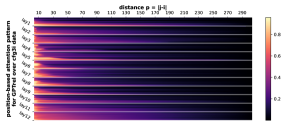
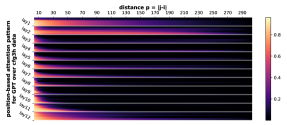
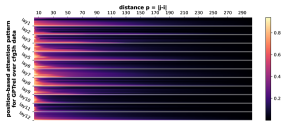
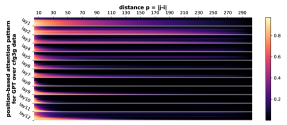
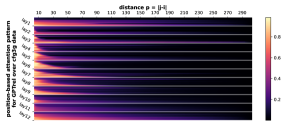
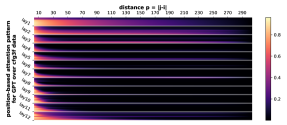
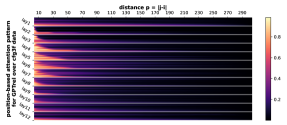
D.2 从任何地方到 NT 端
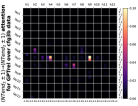
回想一下Figure 8(a),我们发现在去除位置偏差后,注意力权重对位于 NT 末端的标记。 在Figure 21中,我们用更多数据集补充了这个实验。
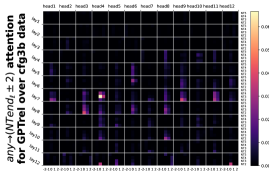
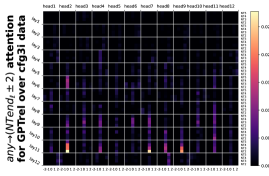
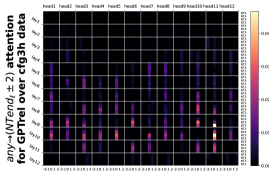
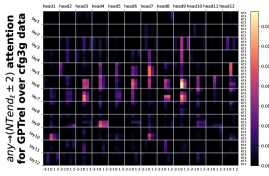
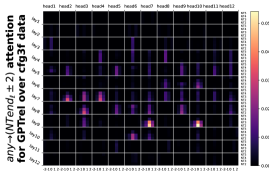
D.3 从 NT 端到 NT 端
正如Section 5.2节和Figure 8(b)中提到的, Token 不仅通常更多地关注NT-端,但在这些关注中,NT 端也更有可能关注 NT 端。 我们在Figure 22中包含了这个完整的实验,对于每个不同的水平,在任何两对之间都处于NT - 对于 数据集,级别 结束。
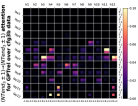
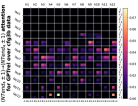
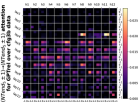
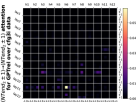
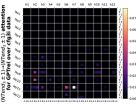
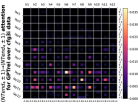
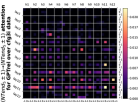
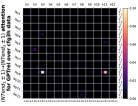
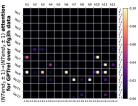
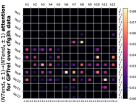
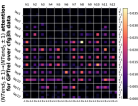
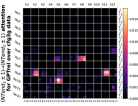
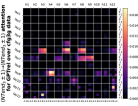
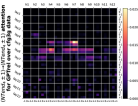
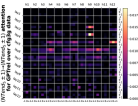
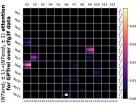
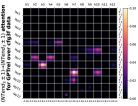
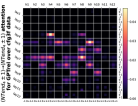
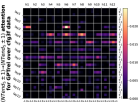
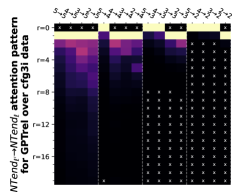
D.4 从 NT 端到相邻 NT 端
在Figure 8(c)中,我们展示了对词符对有强烈的偏见,是“相邻的”NT 端。 我们在 Section 5.2 中定义了 "邻接 "的含义,并引入了一个概念 ,以捕捉平均于样本 的 和所有词符对 ,以便、它们分别位于 层的最深 NT 端(用符号表示为 ),并且根据 层的祖先索引(用符号表示为 ),它们的距离为 。
之前,我们仅通过Figure 8(c)呈现单个数据集,并对所有 Transformer 层进行平均。 在完整的实验Figure 23中,我们展示了对于更多数据集的情况,Figure 24我们展示了对于各个层的情况。
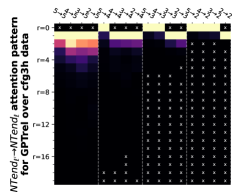
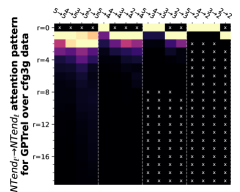
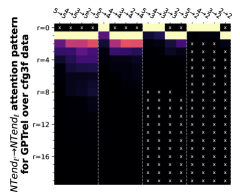




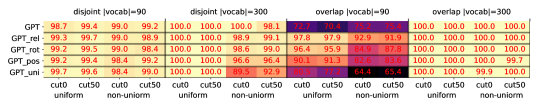
附录 E关于隐式 CFG 的更多实验
我们研究隐式 CFG,其中每个终端符号 都与一包可观察标记 相关联。 对于此任务,我们研究了隐式 CFG 的八种不同变体,所有变体均从完全相同的 数据集转换而来(请参阅Section A.1 节)。 回想一下 有三个终结符号 :
-
•
我们考虑词汇量或;
-
•
我们让 要么不相交,要么重叠;和
-
•
我们让 上的分布可以是均匀的,也可以是非均匀的。
我们在Figure 25中展示了学习此类隐式CFG相对于不同模型架构的生成精度,其中在每个单元中我们使用2000个生成样本来评估精度。 我们还在Figure 9中展示了模型的词嵌入层的相关矩阵(如果我们使用其他模型,相关性将类似) 。
附录F更多关于鲁棒性的实验
回想一下,在Figure 10中,我们比较了干净训练与三种类型的扰动数据的训练,在给定干净前缀和损坏前缀的情况下,它们的生成精度。 现在,我们在Figure 26中包含了针对更多数据集的更多实验。 对于图中的每个条目,我们生成了 2000 个样本来评估生成精度。



附录 GCFG3 数据系列之外
本文主要关注数据族,在Section A.1节中介绍。 本文不深入探讨 GPT 如何解析英语或其他自然语言。 事实上,我们的 CFG 比源自 Penn TreeBank (PTB) [24] 的英语 CFG 更“困难”。 我们所说的“困难”是指人类解析它们的难易程度。 例如,在PTB CFG中,如果连续遇到RB JJ或JJ PP,则它们的父级一定是ADJP。 相反,给定一个字符串
|
3322131233121131232113223123121112132113223113113223331231211121311331121321213333312322121312322211112133221311311311 3111111323123313313331133133333223121131112122111121123331233112111331333333112333313111133331211321131212113333321211 1121213223223322133221113221132323313111213223223221211133331121322221332211212133121331332212213221211213331232233312 |
即中,即使提供了所有CFG规则,也可能需要一大张草稿纸来手动执行动态编程以确定用于生成它的CFG树。
一般来说,CFG 的难度与字符串的平均长度成正比。 例如,我们的家族中CFG的平均长度超过200,而在英国Penn Treebank(PTB)中,它只有28。 然而,CFG 的难度可能与非终结符/终结符 (NT/T) 符号的数量成反比。 拥有过多的 NT/T 符号可以使用贪婪方法简化字符串的解析(回想一下前面提到的 RB JJ 或 JJ PP 示例)。 这就是为什么我们在 构造中最小化每个级别的 NT/T 符号数量。 为了进行比较,我们还考虑了 ,每个级别有许多 NT/T 符号。 Figure 4表明这种CFG非常容易学习。
为了扩大本文的范围,我们还简要介绍了其他一些 CFG 的结果。 我们包括来自 Penn Treebank 的现实生活 CFG,以及合成 CFG 的三个新系列 ()。 Figure 27中提供了这些示例,以便读者快速比较其难度级别。










G.1 宾夕法尼亚州树库 CFG




我们从 Penn TreeBank (PTB) 数据集 [24] 中导出英语 CFG。
为了让我们的实验运行得更快,我们删除了所有在数据中出现次数少于 50 次的 CFG 规则。171717 这是一大组稀有规则,每个规则出现的概率为 。 我们正在评估生成的句子是否属于CFG,这是一个需要CPU密集型动态规划的过程。 为了使计算时间易于处理,我们删除了一组罕见的规则。
请注意,也不包含罕见规则。 包含此类规则会使 CFG 学习过程变得复杂,需要更大的 Transformer 和更长的训练时间。 如果没有完全掌握这些罕见的规则,那么对 Transformer 内部工作原理的调查也会变得复杂。
这导致 44 个 T+NT 符号和 156 个 CFG 规则。 最大节点度为 65(对于非终结符 NP),最大 CFG 规则长度为 7(对于 S->“S,”NP VP。)。 如果执行二值化(以确保所有 CFG 规则的最大长度为 2),则会产生 132 个 T+NT 符号和 288 个规则。
Remark G.1。
遵循本文的概念,我们将NNS(普通名词,复数)、NN(普通名词,单数)等符号视为终结符号。 如果还希望考虑词袋(例如复数名词的词汇表),我们将其称为隐式CFG,并在Section 6.1。 简而言之,添加词袋并不会增加CFG的学习难度; (可能重叠的)词汇将被简单地编码在 Transformer 的嵌入层中。
对于此 PTB CFG,我们还考虑了尺寸小于小于 GPT2-small 的 Transformer 。 回想一下 GPT2-small 有 12 层、12 个头,每个头有 64 个维度。 更一般地,我们让 GPT--- 表示 层,- head, -dim-per-head (因此 GPT2-small 可以写为 GPT-12-12-64)。
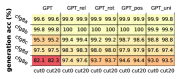
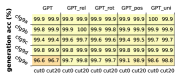
我们使用不同大小的 Transformer 对此 PTB CFG 进行预训练。 我们重复Figure 4中的实验(使用Appendix A.3中描述的相同预训练参数),也就是说,我们计算生成精度、完成精度(使用 cut )、输出熵和 KL 散度。 我们在Figure 28中报告了研究结果。 尤其:
G.2 更多合成 CFG
请记住, 系列看起来是“平衡的”,因为所有叶子都处于相同的深度,并且不同级别的非终结符 (NT) 符号是不相交的。 这一特性有助于我们研究学习这种语言的 Transformer 的内部工作原理。 我们引入了三个新的合成数据系列,我们将其称为(每个系列有五个数据集,总共 15 个数据集)。 这些都是“不平衡”CFG,支持长度为 1 的规则。181818当应用长度为1的CFG规则时,我们可以合并不同级别的两个节点,从而产生“不平衡”的CFG。 具体来说, 系列的深度为 11,规则长度为 1 或 2,而 系列的深度为 ,规则长度为 1/2 /3。 在所有这些家族中,我们在Figure 30中证明了 GPT 可以以令人满意的准确度来学习它们。
我们已将本文中使用的所有 CFG 树包含到此嵌入文件中:cfgs.txt。 可以使用 Adobe Reader 打开它。 下面,我们描述了我们如何选择它们。

CFG8家族。 族由五个CFG组成,即。 它们的构造与 类似,主要区别在于我们从 而不是 统一采样规则长度。 此外,
-
•
在中,我们为每个NT设置度数;我们还确保在任何生成规则中,连续的终结/非终结符号对是不同的。 大小为。
-
•
在中,我们为每个NT设置;我们删除了独特性要求,使数据比 更具挑战性。 大小为。
-
•
在中,我们为每个NT设置,以使数据比更具挑战性。 大小为。
-
•
在中,我们为每个NT 设置。 我们将大小更改为 ,因为否则随机字符串将与该语言太接近(在编辑距离上)。
-
•
在中,我们为每个NT 设置。 我们将大小更改为 ,因为否则随机字符串将过于接近该语言。
该数据族的一个显着特征是,由于引入了 length-1 规则,该语言中的字符串 可能全局不明确。 这意味着同一个 CFG 可以有多种方法对其进行解析,从而导致对于大多数符号其 NT 祖先/边界信息有多种解决方案。 因此,对该数据集执行线性探测没有意义,因为每个符号的 NT 信息大多是非唯一的。191919相比之下,数据族只是局部不明确,这意味着很难确定其隐藏的通过局部检查子串获取 NT 信息;然而,当将整个字符串视为一个整体时,每个符号的 NT 信息可以以很高的概率唯一地确定(如果使用例如动态编程)。
CFG9家族。 考虑到数据构造所产生的模糊性问题,我们的目标是构造一个不平衡但具有挑战性的CFG数据族,其中非终端(NT)信息大多是唯一的,从而实现线性探测。
为了实现这一点,我们首先将大小调整为 ,然后每层只允许一个 NT 具有长度为 1 的规则。 我们构建了五个CFG,表示为,它们的度数配置(即)与家族的度数配置相同。 然后,我们通过从这些 CFG 生成一些字符串并检查动态编程 (DP) 解决方案是否唯一来采用拒绝采样。 如果不是,我们继续生成一个新的CFG,直到满足这个条件。
中的示例如图 Figure 27 所示。 我们将对这个数据族进行线性探测实验。
CFG0家族。 由于上述所有 CFG 都支持长度为 3 的规则,因此我们将重点放在 上,以防止字符串长度变得过长。202020自然,当字符串长度超过时,更大的Transformer就能够解决此类CFG学习任务;我们对此进行了简要测试并发现它是正确的。 然而,进行如此长度的综合实验将非常昂贵,因此我们没有将它们包括在本文中。 在家族中,我们构建了五个CFG,表示为。 它们的深度均为 。 它们的规则长度是从 中随机选择的(与 的 或 的 相比)。 它们的度数配置(即 )与 系列的度数配置相同。 我们选择了它们的大小如下,注意我们已经扩大了大小,否则随机字符串将太接近该语言:
-
•
我们使用 大小来表示 。
-
•
我们使用 大小来表示 。
-
•
我们使用 大小来表示 。
再次强调,以这种方式生成的 CFG 与 系列一样是全局模糊的,因此我们无法对它们执行线性探测。 然而,展示 Transformer 学习此类 CFG 的能力将会很有趣。
额外的实验。 我们在Figure 30中展示了三个新数据族的生成精度(或切割的完整精度)。 很明显,GPT2-small 可以几乎完美地学习 系列,尤其是相对/旋转嵌入系列。
如前所述, 数据族不是全局模糊的,这使其成为测试 NT 祖先/边界信息编码的优秀合成数据集,类似于我们在 Section 4。 事实上,我们在Figure 31和Figure 32中复制了的探测实验数据家族。 这表明 我们的探测技术具有更广泛的适用性。



参考
- Allen-Zhu and Li [2023] Zeyuan Allen-Zhu and Yuanzhi Li. Backward feature correction: How deep learning performs deep learning. In COLT, 2023. Full version available at http://arxiv.org/abs/2001.04413.
- Allen-Zhu et al. [2019] Zeyuan Allen-Zhu, Yuanzhi Li, and Zhao Song. A convergence theory for deep learning via over-parameterization. In ICML, 2019. Full version available at http://arxiv.org/abs/1811.03962.
- Arora and Zhang [2017] Sanjeev Arora and Yi Zhang. Do gans actually learn the distribution? an empirical study. arXiv preprint arXiv:1706.08224, 2017.
- Arps et al. [2022] David Arps, Younes Samih, Laura Kallmeyer, and Hassan Sajjad. Probing for constituency structure in neural language models. arXiv preprint arXiv:2204.06201, 2022.
- Bhalse and Gupta [2012] Nisha Bhalse and Vivek Gupta. Learning cfg using improved tbl algorithm. Computer Science & Engineering, 2(1):25, 2012.
- Bhattamishra et al. [2020] Satwik Bhattamishra, Kabir Ahuja, and Navin Goyal. On the ability and limitations of transformers to recognize formal languages. arXiv preprint arXiv:2009.11264, 2020.
- Black et al. [2021] Sid Black, Leo Gao, Phil Wang, Connor Leahy, and Stella Biderman. GPT-Neo: Large Scale Autoregressive Language Modeling with Mesh-Tensorflow, March 2021. URL https://doi.org/10.5281/zenodo.5297715.
- Black et al. [2022] Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, and Samuel Weinbach. GPT-NeoX-20B: An open-source autoregressive language model. In Proceedings of the ACL Workshop on Challenges & Perspectives in Creating Large Language Models, 2022. URL https://arxiv.org/abs/2204.06745.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Bubeck et al. [2023] Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- Clark [2017] Alexander Clark. Computational learning of syntax. Annual Review of Linguistics, 3:107–123, 2017.
- Deletang et al. [2023] Gregoire Deletang, Anian Ruoss, Jordi Grau-Moya, Tim Genewein, Li Kevin Wenliang, Elliot Catt, Chris Cundy, Marcus Hutter, Shane Legg, Joel Veness, et al. Neural networks and the chomsky hierarchy. In ICLR, 2023.
- DuSell and Chiang [2022] Brian DuSell and David Chiang. Learning hierarchical structures with differentiable nondeterministic stacks. In ICLR, 2022.
- He et al. [2020] Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. Deberta: Decoding-enhanced bert with disentangled attention. arXiv preprint arXiv:2006.03654, 2020.
- Hewitt and Manning [2019] John Hewitt and Christopher D. Manning. A structural probe for finding syntax in word representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4129–4138, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1419. URL https://aclanthology.org/N19-1419.
- Hu et al. [2021] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Jelassi et al. [2022] Samy Jelassi, Michael Sander, and Yuanzhi Li. Vision transformers provably learn spatial structure. Advances in Neural Information Processing Systems, 35:37822–37836, 2022.
- Joshi et al. [1990] Aravind K Joshi, K Vijay Shanker, and David Weir. The convergence of mildly context-sensitive grammar formalisms. Technical Reports (CIS), page 539, 1990.
- Kenton and Toutanova [2019] Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL-HLT, pages 4171–4186, 2019.
- Lee [1996] Lillian Lee. Learning of context-free languages: A survey of the literature. Techn. Rep. TR-12-96, Harvard University, 1996.
- Li et al. [2023] Yuchen Li, Yuanzhi Li, and Andrej Risteski. How do transformers learn topic structure: Towards a mechanistic understanding. arXiv preprint arXiv:2303.04245, 2023.
- Liu et al. [2022] Bingbin Liu, Jordan T Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang. Transformers learn shortcuts to automata. arXiv preprint arXiv:2210.10749, 2022.
- Manning et al. [2020] Christopher D Manning, Kevin Clark, John Hewitt, Urvashi Khandelwal, and Omer Levy. Emergent linguistic structure in artificial neural networks trained by self-supervision. Proceedings of the National Academy of Sciences, 117(48):30046–30054, 2020.
- Marcus et al. [1993] Mitchell P. Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. Building a large annotated corpus of English: The Penn Treebank. Computational Linguistics, 19(2):313–330, 1993. URL https://aclanthology.org/J93-2004.
- Matsuzaki et al. [2005] Takuya Matsuzaki, Yusuke Miyao, and Jun’ichi Tsujii. Probabilistic cfg with latent annotations. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), pages 75–82, 2005.
- Maudslay and Cotterell [2021] Rowan Hall Maudslay and Ryan Cotterell. Do syntactic probes probe syntax? experiments with jabberwocky probing. arXiv preprint arXiv:2106.02559, 2021.
- Moradi and Samwald [2021] Milad Moradi and Matthias Samwald. Evaluating the robustness of neural language models to input perturbations. arXiv preprint arXiv:2108.12237, 2021.
- Murty et al. [2023] Shikhar Murty, Pratyusha Sharma, Jacob Andreas, and Christopher D Manning. Characterizing intrinsic compositionality in transformers with tree projections. In ICLR, 2023.
- Nanda et al. [2023] Neel Nanda, Lawrence Chan, Tom Liberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. arXiv preprint arXiv:2301.05217, 2023.
- Olsson et al. [2022] Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads. arXiv preprint arXiv:2209.11895, 2022.
- OpenAI [2023] OpenAI. Gpt-4 technical report, 2023.
- Post and Bergsma [2013] Matt Post and Shane Bergsma. Explicit and implicit syntactic features for text classification. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 866–872, 2013.
- Radford et al. [2018] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. 2018.
- Radford et al. [2019] Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019.
- Sakai [1961] Itiroo Sakai. Syntax in universal translation. In Proceedings of the International Conference on Machine Translation and Applied Language Analysis, 1961.
- Sakakibara [2005] Yasubumi Sakakibara. Learning context-free grammars using tabular representations. Pattern Recognition, 38(9):1372–1383, 2005.
- Shen et al. [2017] Yikang Shen, Zhouhan Lin, Chin-Wei Huang, and Aaron Courville. Neural language modeling by jointly learning syntax and lexicon. arXiv preprint arXiv:1711.02013, 2017.
- Shi et al. [2022] Hui Shi, Sicun Gao, Yuandong Tian, Xinyun Chen, and Jishen Zhao. Learning bounded context-free-grammar via lstm and the transformer: Difference and the explanations. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 8267–8276, 2022.
- Sipser [2012] Michael Sipser. Introduction to the Theory of Computation. Cengage Learning, 2012.
- Su et al. [2021] Jianlin Su, Yu Lu, Shengfeng Pan, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding, 2021.
- Tenney et al. [2019] Ian Tenney, Patrick Xia, Berlin Chen, Alex Wang, Adam Poliak, R Thomas McCoy, Najoung Kim, Benjamin Van Durme, Samuel R Bowman, Dipanjan Das, et al. What do you learn from context? probing for sentence structure in contextualized word representations. arXiv preprint arXiv:1905.06316, 2019.
- Tu et al. [2020] Lifu Tu, Garima Lalwani, Spandana Gella, and He He. An empirical study on robustness to spurious correlations using pre-trained language models. Transactions of the Association for Computational Linguistics, 8:621–633, 2020.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Vilares et al. [2020] David Vilares, Michalina Strzyz, Anders Søgaard, and Carlos Gómez-Rodríguez. Parsing as pretraining. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 9114–9121, 2020.
- Wang et al. [2022] Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in gpt-2 small. arXiv preprint arXiv:2211.00593, 2022.
- Weir [1988] David Jeremy Weir. Characterizing mildly context-sensitive grammar formalisms. University of Pennsylvania, 1988.
- Wu et al. [2020] Zhiyong Wu, Yun Chen, Ben Kao, and Qun Liu. Perturbed masking: Parameter-free probing for analyzing and interpreting bert. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4166–4176, 2020.
- Yao et al. [2021] Shunyu Yao, Binghui Peng, Christos Papadimitriou, and Karthik Narasimhan. Self-attention networks can process bounded hierarchical languages. arXiv preprint arXiv:2105.11115, 2021.
- Zhang et al. [2023] Shizhuo Dylan Zhang, Curt Tigges, Stella Biderman, Maxim Raginsky, and Talia Ringer. Can transformers learn to solve problems recursively? arXiv preprint arXiv:2305.14699, 2023.
- Zhao et al. [2023] Haoyu Zhao, Abhishek Panigrahi, Rong Ge, and Sanjeev Arora. Do transformers parse while predicting the masked word? arXiv preprint arXiv:2303.08117, 2023.