赛蒙 ![[Uncaptioned image]](emoji.png) :针对新颖性进行优化的科学灵感机器
:针对新颖性进行优化的科学灵感机器
摘要
我们探索并增强神经语言模型的能力,以生成基于文献的新颖的科学方向。 基于文献的假设生成工作传统上侧重于二元链接预测,这严重限制了假设的表达能力。 这一系列工作也不注重优化新颖性。 我们采用了一种新颖的设置,其中模型用作输入背景上下文(例如问题、实验设置、目标),并输出基于文献的自然语言思想。 我们提出了 SciMON,这是一个建模框架,它使用从过去的科学论文中检索“灵感”,并通过迭代地与先前的论文进行比较并更新想法建议来显式优化新颖性,直到实现足够的新颖性。 综合评估表明,GPT-4 倾向于产生整体技术深度和新颖性较低的想法,而我们的方法部分缓解了这个问题。 我们的工作代表了评估和开发语言模型的第一步,这些模型可以从科学文献中产生新的想法。111代码、数据和资源可公开用于研究目的:https://github.com/eaglew/clbd。
赛蒙 ![]() :针对新颖性进行优化的科学灵感机器
:针对新颖性进行优化的科学灵感机器
Qingyun Wang, Doug Downey, Heng Ji, Tom Hope University of Illinois at Urbana-Champaign Allen Institute for Artificial Intelligence (AI2) The Hebrew University of Jerusalem {tomh,doug}@allenai.org, {qingyun4,hengji}@illinois.edu
1简介
机器可以挖掘科学论文并学习提出新方向吗? 文献中的信息可用于自动生成假设的想法已经存在了数十年Swanson (1986)。 迄今为止,焦点一直集中在一个特定的环境上:假设概念对之间的联系(通常在药物发现应用中 Henry 和 McInnes (2017),例如新药物与疾病的联系),其中概念是从先前源自论文 Sybrandt 等人 (2020) 的论文或知识库获得; Nadkarni 等人 (2021)。
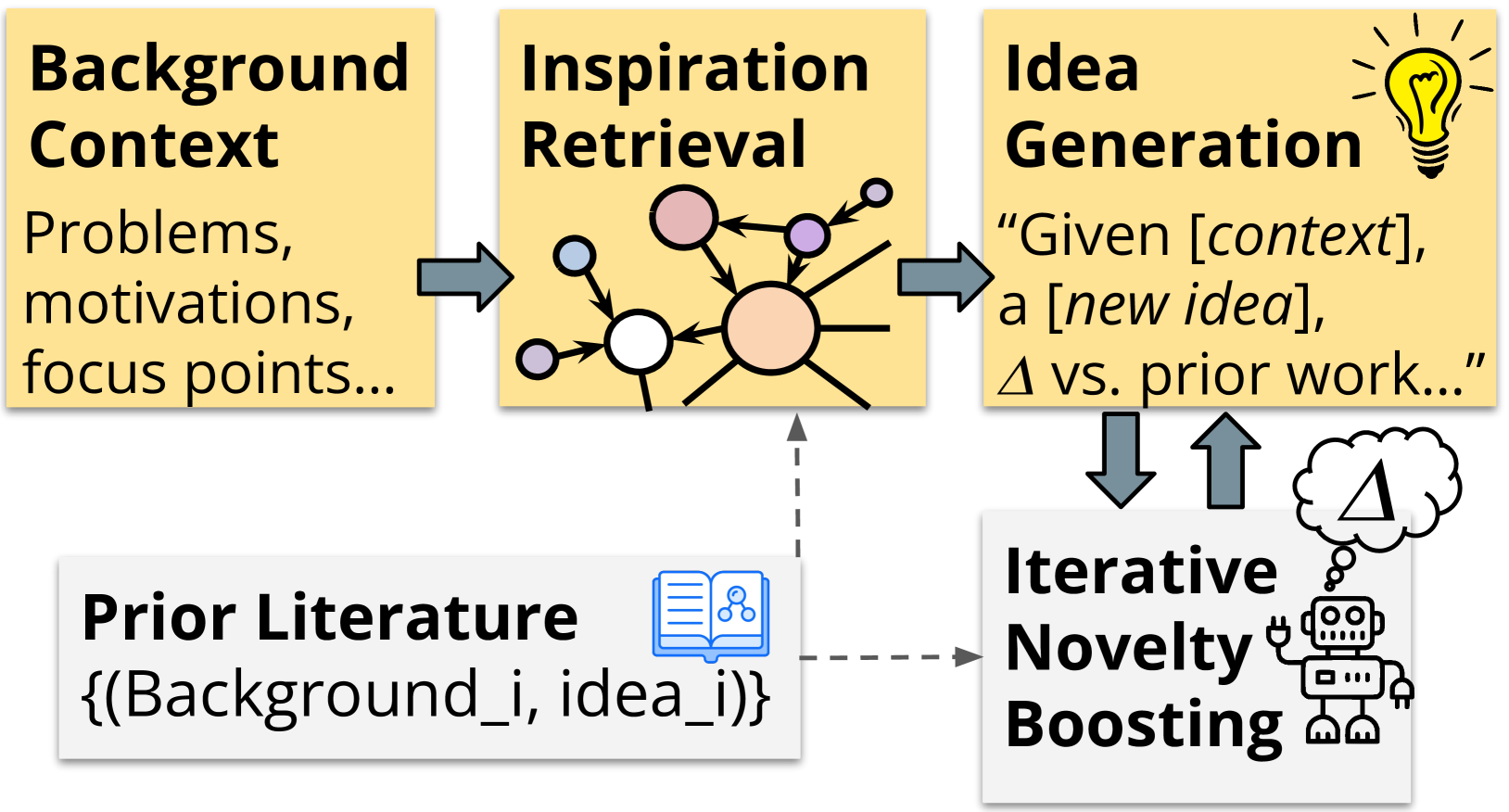
这种常见的设置有根本性的缺点。 将“科学思想的语言”Hope 等人 (2023) 简化为这种简单化的形式限制了我们希望生成的假设的表达能力,并且无法捕捉细致入微的上下文科学家考虑的因素:目标应用设置、要求和限制、动机和挑战。 鉴于最近在大型语言模型(大语言模型)方面取得的巨大进展,在本文中,我们探索了一种截然不同的设置:采用问题上下文描述的模型,并返回新颖的自然语言建议以文献为基础的科学方向。
我们开发了一个名为 SciMON(具有新颖性优化的科学灵感机器)的框架,以诺贝尔奖获得者和人工智能先驱赫伯特·西蒙 (Herbert Simon) 的名字命名,他撰写了自动化科学发现的早期基础工作Newell 和 Simon (1956) ;西蒙(1973)。 我们首先提出一种自动数据收集方法,该方法收集过去问题的示例并从科学论文中提出想法。 然后,我们使用这些数据对大语言模型进行微调和上下文训练,训练它们接受问题描述并输出解决问题的建议想法。 我们观察到最先进的大语言模型(例如 GPT-4 OpenAI (2023))在产生新颖的科学思想方面遇到了困难,并贡献了一个新的建模框架来生成假设,从而在改进大语言模型的假设生成能力(图1)。 给定背景问题描述,模型首先以相关问题及其解决方案的形式从过去的文献中动态检索灵感,以及科学知识图谱中的上下文。 这些检索到的灵感有助于为现有文献中产生的想法奠定基础。 然后,我们赋予模型迭代提升所产生想法的新颖性的能力。 给定大语言模型在步骤产生的想法,该模型将与文献中现有的研究进行比较;如果发现研究存在强烈重叠,该模型的任务是更新其想法,使其相对于之前的工作更加新颖(就像一个优秀的研究人员会做的那样)。 我们还引入了一种上下文对比模型,该模型鼓励背景上下文的新颖性。
我们对在新的生成语境环境中生成科学思想的语言模型进行了首次全面评估。 我们专注于 AI/NLP 想法,以方便 AI 研究人员自己进行分析,并展示对生物医学领域的推广。 我们使用具有领域专业知识的人类注释者设计了广泛的评估实验,以评估相关性、实用性、新颖性和技术深度。 我们的方法大大提高了大语言模型在我们任务中的能力;然而,分析表明,在新颖性、深度和实用性方面,想法仍然远远落后于科学论文,这对构建产生科学想法的模型提出了根本性挑战。
2 背景和新设置
我们首先简要描述相关工作和背景。 然后我们展示我们的小说背景。
基于文献的发现 自从 Don Swanson 开创基于文献的发现 (LBD) 以来,已经过去了近四十年了,该发现的前提是文献可用于生成假设Swanson (1986). LBD 一直专注于一种非常具体、狭隘的假设:概念对(通常是药物/疾病)之间的联系。 LBD 的经典形式化可以追溯到 Swanson (1986),他提出了“ABC”模型,其中两个概念(术语)A 和 C 假设为链接的,如果它们都与某个中间概念 B 同时出现在论文中。 最近的工作使用了词向量 Tshitoyan 等人 (2019) 或链接预测模型 Wang 等人 (2019); Sybrandt 等人 (2020) 发现科学假设作为概念之间的成对联系。 紧密相关的研究机构集中于科学知识图链接预测 Nadkarni 等人 (2021),其中预测的链接可能对应于新的假设,而知识库是现有假设的反映特定领域的科学知识源自文献。 这一工作领域的一个根本差距是缺乏对微妙背景 Sosa 和 Altman (2022)(例如,药物可能与疾病相关的特定环境)进行建模的方法,以生成具有无限假设空间的开放式问题设置中的想法,以及优化新颖性的想法。 我们的设置可以被视为解决现有设置的局限性的根本背离。
科学创新大语言模型 大语言模型在解释和生成自然语言内容以及处理医学领域等知识密集型任务方面取得了显着进展Nori 等人(2023)。 最近的工作Boiko等人(2023)探索了大语言模型在机器人化学实验室环境中的使用,规划已知化合物的化学合成并执行实验。 机器人实验室设置本质上仅限于此类实验可能且相关的狭窄分区。 最近的其他工作 Huang 等人 (2023) 使用大语言模型为 Kaggle 竞赛等机器学习任务生成代码,发现 GPT-4 代理在 BabyLM 等研究挑战中实现了 0% 的准确率Warstadt 等人 (2023)。 据传闻,GPT-4 具有“不像人类合著者的优势,而更像是使用计算器的数学家”Carlini (2023)。 我们的目标是对大语言模型进行非轶事评估和增强产生新颖的开放式科学思想的能力。
2.1 SciMON问题设置
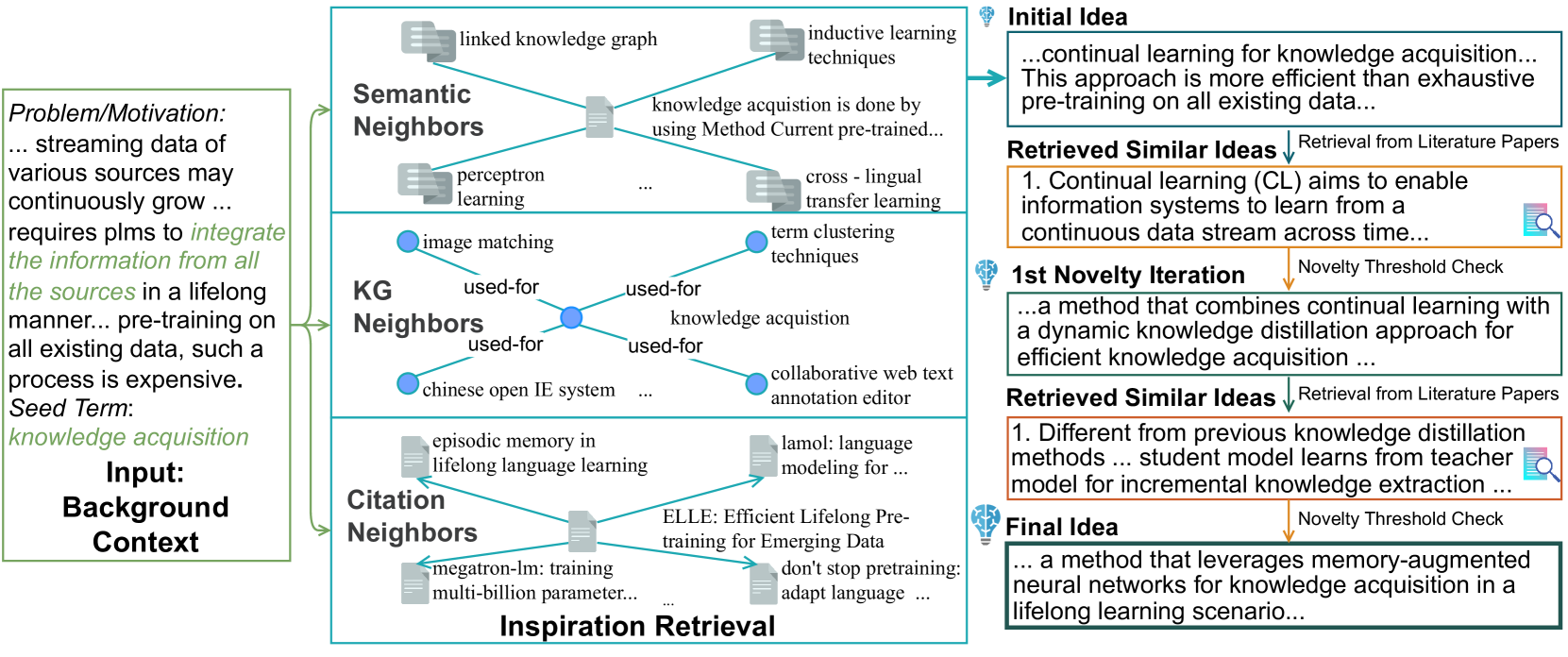
我们的动机是想象一个基于人工智能的助手,用自然语言提出想法。 助手将背景上下文作为输入,其中包括(1)当前问题、动机、实验设置和约束,表示为;以及(2)可选的种子术语,它应该是生成的想法的焦点。 种子项的动机是考虑用户为模型提供的提示以限制其假设空间。 重要的是,产生的想法不应该仅仅解释背景——相对于和更广泛的文献语料库,输出应该是新颖。 图2说明了该设置,显示了描述信息源终身集成中“预训练语言模型”问题的背景文本,包括计算成本。 助理的目标是在此背景下产生执行“知识获取”的想法。 给定这个输入,我们的目标是生成一个完整的句子来描述一个新的想法。
2.2 自动化训练数据收集
我们使用科学信息提取(IE)模型从论文中获取训练数据——提取背景句子的过去示例和相应的想法(例如,背景句子中用于特定问题的方法的描述),以及作为种子术语的显着实体。 该数据用于上下文学习和微调设置中的训练。
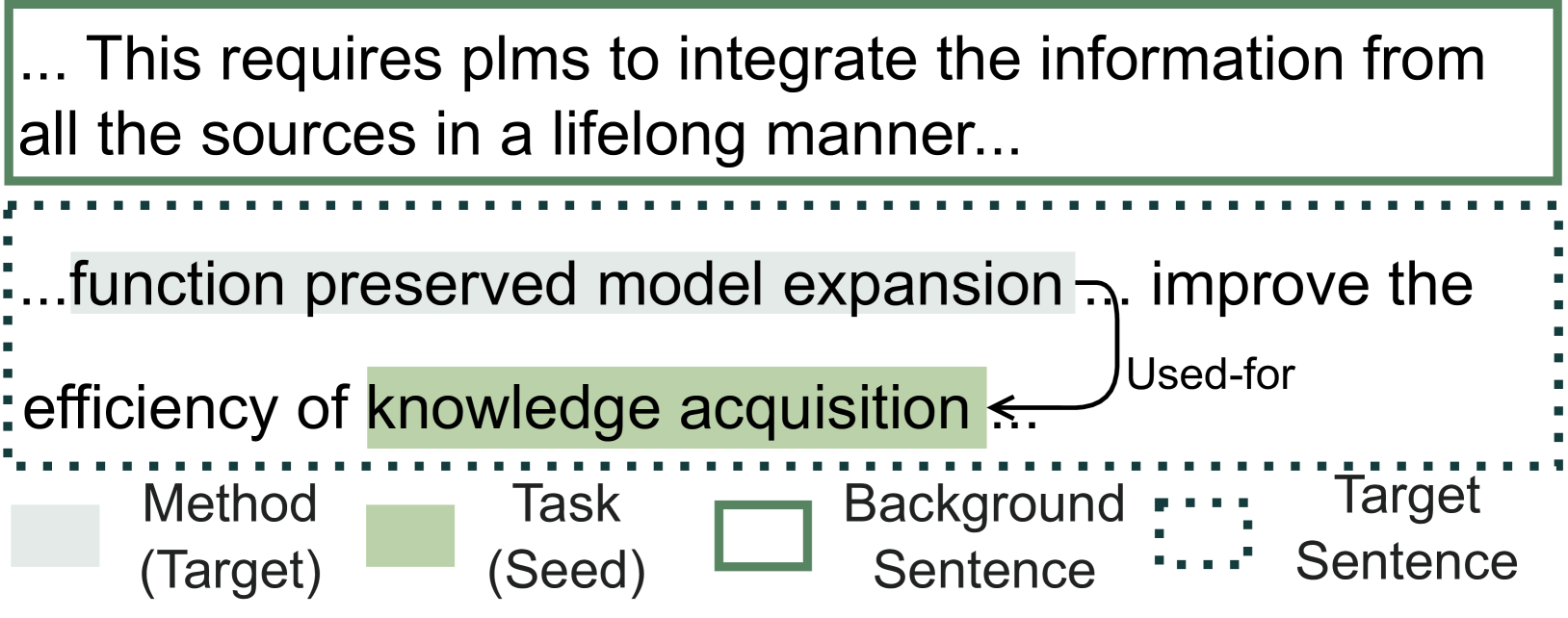
我们根据 S2ORC Lo 等人 (2020) 的 67,408 篇 ACL Anthology 论文构建了一个语料库 (我们后来还用生物医学语料库 §4.1 进行了实验) >)。 给定文档 中的标题和相应摘要,为了选择问题/动机句子 ,我们首先执行科学句子分类 Cohan 等人 (2019)将摘要中的句子分类为{背景、方法、目标}之一,选择带有背景标签的句子> 并将剩余句子视为目标句子,它将作为所需的输出示例(图3)。
对于种子术语选择,我们应用最先进的科学IE系统Ye等人(2022)到来提取相应的实体表单的任务、方法、评估指标、材料和关系 [method,used-for,task]——提及方法及其用于的任务、用于任务的材料等。我们将头部(例如方法)或尾部(例如任务)实体作为种子项,并将另一个实体(分别是尾部/头)命名为目标0>项 继续图 2 中的示例,图 3 显示了种子项和目标项(“知识获取”和“函数”如何保留模型)扩展”)是从中提取的。 训练过程中,每个实例包含 (,) 对;在评估过程中,目标信息被删除。
我们使用 SciCo Cattan 等人 (2021) 来获取实体规范化的共指链接,并使用 ScispaCy Neumann 等人 (2019) 将缩写词替换为信息更丰富的长形式。 我们还收集论文元数据,包括引用网络。 我们暂时分割数据集(训练/开发/测试分别对应于 2021 / 2021 / 2022 年的论文)。 在我们的实验中,我们使用了根据 2022 年之前的数据训练的模型检查点,避免了数据污染的风险 (§6)。 表1显示了数据统计。222更多详细信息请参见附录C。
IE 预处理的质量 在预处理过程中,我们只保留 IE 模型的高置信度输出,以减少错误。 我们观察到这消除了许多嘈杂的情况。 为了验证这一点,我们在随机的论文样本上手动评估每个预处理步骤的精度,并观察到除了关系提取(65%)之外,所有步骤都产生高精度(91%-100%);总共,实例通过所有步骤的率为 79.7%。333参见附录中的表6。
金牌测试装置 我们创建了高质量、干净的测试装置。 我们删除了那些模型可以轻易利用表面背景信息推断出地面实况的测试实例,以创建一个更具挑战性的集合,选择背景句子和地面实况句子之间相似度较低的实例。 我们计算测试集中每个实例的背景与相应的真实句子之间的余弦相似度,并采用相似度 的对,相当于对的第十个百分位。 我们进一步注释这个子集以创建一个黄金子集。 我们手动排除真实情况和背景之间存在微小重叠的实例,删除具有不相关背景的实例,并仅保留目标关系(从中获取种子术语)对目标句子显着的实例。 我们还删除了背景中具有无法解释的术语的测试对。 我们总共获得 194 个实例。444完整的标注详细信息参见附录C。
| Split | Forward | Backward | Total |
|---|---|---|---|
|
Train |
55,884 |
58,426 |
114,310 |
|
Valid |
7,938 |
8,257 |
16,195 |
|
Test |
2,623 |
2,686 |
5,309 |
3 SciMON 模型
我们提出了一个新模块来检索灵感作为上下文输入(§3.1)。 然后,我们描述另一个模块来根据上下文+灵感产生想法(§3.2)。 最后,我们引入了一种新的迭代新颖性优化方法来进一步提高创意质量(§3.3)。555 训练和超参数详细信息参见附录 B。
3.1灵感检索模块
我们从创新的认知方面获得广泛的灵感Hope等人(2023):当研究人员产生一个新想法时,他们的基础是与新想法相关的现有概念和论文网络。 我们的目标是通过检索“灵感”(可以指导假设生成的信息)来丰富每个背景的背景。 如图2所示,对于SciMON任务的给定实例,我们的检索增强可以从三种类型的源中检索。 每个源使用不同形式的查询和输出。
语义邻居 对于给定的问题/动机作为输入,训练集中针对相关问题提出的想法可以作为生成新想法的指导参考。 考虑到带有种子词 和问题/动机 的背景语境 ,我们构建了基础输入 : 与属于两种模板之一的提示符 的连接:"用于"或"通过使用 完成",其中 是 Task/Method/Material/Metric 中的一个。 简而言之, 上下文:. 例如,在图2中,串联为“知识获取是通过使用方法完成的;背景:...需要 plms 集成信息...终生方式...”。
然后,我们从训练集中检索与新的基本输入 语义相关的输入,并获取与每个检索到的输入相对应的目标句子 。 我们提取与 (§2.2) 中的种子术语匹配的目标术语 作为输入 的灵感。 简而言之,这意味着我们将 中提出的解决方案的显着方面用作灵感,我们根据经验发现它有助于消除 中的噪声/不相关信息。 例如,在图2中,我们发现“信息实体是通过使用方法上下文来完成的:在这项工作中,我们的目标是为预先训练的语言模型配备结构化知识。” 类似的输入和使用 “链接知识图”作为灵感。
从技术上讲,我们首先根据训练集构建一个完全连接的图 ,其中每个节点都是一对输入文本 和目标术语 。 我们根据 SentenceBERT 的表示,将两个节点 和 之间的权重定义为 和 之间的余弦相似度(Reimers 和 Gurevych,2019)(all-mpnet-base-v2)。 给定,我们首先将其插入并计算其连接边的权重。 然后,我们从具有最大边缘权重的训练集中检索邻居输入文本 ,其中 是检索到的实例的数量。 我们将相应的目标术语视为语义灵感。
KG 邻居 我们还探索通过将其链接到包含相关方法和任务信息的背景 KG 来丰富上下文。 使用与提取受训示例相同的 IE 流程(§2.2),我们创建了一个 global background KG ,它涵盖了特定年份 之前的语料库 中的所有论文(即 中的节点对应于任务/方法/材料/度量,而边则是如前所述从整个语料库中提取并归一化的二手关系、中的节点对应于任务/方法/材料/度量,而边则是used-for关系,如前所述,这些关系是从整个语料库中提取并规范化的)。 然后,在查询时给定种子项 ,我们从 中选择相邻节点 作为灵感。 以图2为例,“知识获取”的邻居节点包括“协作网页文字标注编辑器”、“图像匹配”等,我们选择这些作为灵感。
引文邻居我们探索的上下文相关性的另一个概念是通过引文图链接。 在这里,给定输入背景上下文 ,我们假设访问从中提取 的原始源文档 ,并考虑其 引用 论文标题设置 作为潜在候选者。 这可以被视为对模型可用信息的更强有力的假设——假设使用该模型的研究人员提供了可以汇集想法的相关候选文档。 由于训练集仅包含年之前的论文,因此我们只选择年之前的论文。 然后,我们根据前面的 SentenceBERT 嵌入,从 中检索与 具有最高余弦相似度的顶部 标题。 例如,图2中,ELLE Qin 等人 (2022) 论文引用了 de Masson d'Autume 等人 (2019) 论文。 因此,我们选择标题“终身语言学习中的情景记忆”作为启发信息。
3.2生成模块
想法生成模块被给予检索到的灵感以及上下文作为输入。
情境学习 我们尝试了最新的大语言模型 GPT3.5 davinci-003 Ouyang 等人 (2022) 和 GPT4 gpt-4-0314 检查点 OpenAI (2023)。 我们首先要求模型根据零样本设置中的种子术语和上下文生成句子,而无需任何上下文示例(GPT3.5ZS、GPT4ZS)。 然后,我们要求模型通过提示从集合中随机选择的输入和输出对(GPT3.5FS,GPT4FS)来在少训练样本设置中生成句子。 受 Liu 等人 (2022) 的启发,我们进一步采用了使用语义相似示例的少样本设置。 我们使用与查询具有最高余弦相似度的训练集中的 top- 示例,而不是随机的上下文示例 (GPT3.5Retr)。 这个少样本检索设置与上面讨论的语义邻居不同,因为我们提供每个实例的输入和输出,而不是仅仅提供目标实体作为附加输入。
微调我们调节T5Raffel等人(2020)(也可以使用更新的模型;请参阅我们的生物医学实验§4.1微调大语言模型)。 我们观察到生成模型倾向于从背景上下文中复制短语。 例如,给定上下文 “...分层表挑战数字推理...”,模型将生成 “用于问答的分层表推理” 作为顶部预测。 为了生成新颖想法的建议,我们希望阻止从背景上下文中过度复制。 我们引入了一个新的上下文对比目标,其中负面示例是从输入中的文本中获取的(例如,在图 2 中,上下文中的负面示例是 plms, 预训练等)。 我们在解码器的隐藏状态上计算 InfoNCE 损失 Oord 等人 (2018),旨在最大化真实情况相对于上下文负数的概率:
| (1) | ||||
其中 和 是来自正样本和 个负样本的解码器隐藏状态, 和 是可学习参数, 是 sigmoid 函数, 是温度超参数, 表示基于目标序列长度的平均池化函数。 我们使用对比损失 和交叉熵损失进行优化。
3.3 通过检索迭代新颖性提升
我们通过新的迭代retrieve-compare-update方案进一步提高了生成想法的新颖性。 从概念上讲,我们考虑一种新颖性惩罚,它惩罚与文献参考示例中现有想法过于“接近”的想法。 包含在上下文学习和推理过程中,以反映与现有工作相似性的分数形式提供数字反馈。 我们希望最小化这个分数,同时确保 与背景上下文 保持相关;我们通过以下方式迭代地执行此操作:(1) 从 中检索相关工作,(2) 测量新颖程度,(3) 指示模型更新 以使 ,以 为条件。
具体来说,在我们的实现中,我们根据集合中的所有论文构建了一个参考训练语料库。 然后,我们提出一种迭代算法,将生成的想法与 进行比较。 我们从生成模块生成的初始想法开始。 在每个时间步骤,我们使用生成的想法作为查询,从文献参考语料库中检索最近的想法基于 SentenceBERT,与 的余弦相似度得分最高的 (我们使用 )。 对于每个检索到的真实文献想法,我们将其余弦相似度得分与阈值(我们使用)进行比较。 我们提供所有检索到的通过阈值的基本事实想法作为大型语言模型的附加负面示例,并带有以下指令提示:“您的想法与现有研究有相似之处,如这些 句子: 确保您提出的想法与上述句子中提到的现有研究有显着不同。 让我们再试一次。一旦所有都低于,我们就停止迭代。 图2和表5展示了新颖的迭代。
4实验
4.1人类评价
我们提出了四项人类评估研究,探索我们的问题和方法的不同方面。
研究 I 我们招募了六名具有研究生水平教育的志愿者 NLP 专家来对系统进行评分。 评分者被要求设想一个可以提出新论文想法的人工智能助手。 我们从黄金子集中随机选择 50 个实例(背景+种子)。 每个注释器接收十个实例,每个实例与来自不同模型变体的系统输出配对(表2)。 我们要求评估者通过考虑每个输出与背景的相关性、新颖性、清晰度以及想法是否合理来评估想法质量(积极的评级被称为“有帮助”的简写,表明他们通过了多重考虑)。 我们观察到评分者的一致性程度较高。666一致性分数见表13附录C。 评估者对情况视而不见,系统输出在实例之间随机洗牌。
我们指示注释者仅对与输入上下文完全不同的想法提供积极的评级。 在研究一中,我们要求评估者不要预期系统具有突破性的新颖性,而是对质量和实用性的更狭隘的期望;在下面的研究二中,我们丰富了分析,以检查顶级模型之间的排名,并“提高标准”并与论文中的实际想法进行比较。777完整的评估者指南位于附录C中。示例注释在表11中。
在一个小知识实验中,我们还使用相同的标准收集了对GPT4-ZS(零样本)与GPT4-FS(少样本)的人类评分,发现GPT4-FS 在 65% 的案例中排名较高,其余大部分并列;因此,零样本 GPT-4 被排除在研究 I 的其余部分和后续研究之外,以减少标注工作量和成本。
研究 I:结果 总体而言,GPT4FS 和 GPT4FS+KG 大幅优于其他模型(表2) 。 除了 GPT4 之外,T5+SN+CL 与其他基线相比表现最好,因为它对有用背景引用有更强的先验知识。 总的来说,GPT3.5 模型的表现比微调后的 T5 及其变体差,这与科学 NLP 领域的其他工作 Jimenez Gutierrez 等人 (2022) 的结果相呼应。 GPT4 输出往往更长,这可能部分解释了人类更高的偏好。
| Type | 3FS | 3Rt | 3FS+CT | 3FS+KG | 4 | 4+KG | T5 | T5+SN |
|---|---|---|---|---|---|---|---|---|
|
H |
33 |
25 |
16 |
33 |
73 |
66 |
22 |
48 |
|
U |
67 |
75 |
84 |
67 |
27 |
34 |
78 |
52 |
研究 II:GPT4 与真实论文的比较 我们对接近的竞争对手 GPT4FS 和 GPT4FS+KG 进行了后续人体研究,其中包含注释者。 在本研究中,模型输出现在已排序,这与研究 I 中有用/无用的二元分类不同。 根据相互比较的技术细节和创新程度对建议进行排名,即对 GPT4FS 和 GPT4FS+KG 中哪一个具有更高的技术细节程度和创新程度进行排名新颖性,或者它们是否大致相同(并列)。 最后,根据建议的技术细节和创新水平是否与原始论文的想法大致处于相同水平,或者显着较低,对输出结果与真实想法进行评级。
研究 II:结果 总体而言,GPT4FS+KG 在 48% 的比较配对中被发现具有更高的技术细节,并且在 45 个配对中发现增量较少(更新颖) % 的对。 剩下的52%/55%(分别)中,绝大多数是平局,这表明每当GPT4FS+KG不被青睐时,它的质量与GPT4FS大致相同>,但反之则不然。 然而,最关键的方面是将结果与创新质量的原始真实想法进行比较。 在这里,我们发现在 85% 的比较中,groundtruth 被认为具有明显更高的技术水平和新颖性;剩下的 15% 的事实是不明确的,或者缺乏论文摘要中的额外背景。 这表明使用现有最先进的模型获得高质量的创意是一项重大挑战。
研究三:迭代新颖性提升 我们要求五位注释者进一步将新颖性增强的结果与最初生成的想法进行比较。 我们从句子生成黄金子集中随机选择 70 个实例(背景+种子)。 我们要求注释者检查新想法是否与最初的想法不同(例如,添加新信息或方法),以及它们是否更新颖(即,一个新的想法)想法可以不同,但不一定更新颖)。 由于GPT4FS+SN优于其他模型,因此对于该模型,我们进一步指示注释者将第二次迭代结果与第一次迭代结果的新颖性进行比较。
| Type | GPT4FS | +SN | +CT | +KG |
|---|---|---|---|---|
|
1st Novelty (%) |
+54.4 |
+55.6 |
+47.8 |
+46.7 |
|
2nd Novelty (%) |
- |
+57.8 |
- |
- |
|
1st new terms |
+23.1 |
+22.8 |
+22.1 |
+21.9 |
|
2nd new terms |
- |
+21.5 |
- |
- |
研究 III:结果 对于 SN,在第一次迭代中,88.9% 的更新想法与最初的想法有很大不同,对于 55.6%,我们能够增加新颖性/创造力(这意味着,例如,如果 100示例已更新,我们将获得 56 个更新颖的示例)。 第二次迭代进一步增加了 57.8% 继续到另一次迭代的想法的新颖性。 对于应用我们的方法后不被认为更新颖的想法,我们没有观察到新颖性下降——该方法要么增加或保持新颖性。
新颖迭代后的想法比最初的想法更长。 我们检查了过滤 359 个单词后添加的新术语(包括停用词),因为我们发现经常添加许多通用单词和术语(例如“新颖的模型/方法/方法”)。 虽然我们的方法有助于提高新颖性,但总体而言,该模型通常倾向于建议流行概念之间的组合(§4.2)。 新颖性的提升似乎经常侧重于添加动态/自适应建模、图形模型和表示、多种模式和来源的融合,有时甚至是一次性的(例如,“动态语法感知图形融合网络(DSAGFN)”),并与文献中的现有想法进行明确比较(表5)。
| Type | Meditron | +SN | +CT | +KG |
|---|---|---|---|---|
|
Helpful(%) |
35 |
80 |
60 |
50 |
|
Unhelpful(%) |
65 |
20 |
40 |
50 |
|
vs. GT(%) |
30 |
45 |
50 |
35 |
| Type | Content |
|---|---|
|
Input Dong et al. (2022) |
seed term: speech unit boundaries ; context (abridged): … generate partial sentence translation given a streaming speech input. existing approaches … break the acoustic units in speech, as boundaries between acoustic units in speech are not even. … |
|
Initial idea |
A pause prediction model to identify speech unit boundaries … |
|
Iteration 1 |
A method that leverages acoustic and linguistic features to predict speech unit boundaries dynamically, ensuring smooth transitions … differs from the existing research as it combines both acoustic properties and linguistic context … adapting to variations in speaker characteristics, speaking styles, and languages. |
|
Iteration 2 |
A novel method called Adaptive Speech Unit Boundary Detection (ASUBD) … a combination of attention mechanisms to focus on relevant acoustic and linguistic features and reinforcement learning to guide the system to make optimal predictions of unit boundaries based on previous decisions… |
|
Ground Truth |
… an efficient monotonic segmentation module … accumulate acoustic information incrementally and detect proper speech unit boundaries. |
领域泛化案例研究 我们的框架与领域无关,可以通过更改预处理过程中使用的 IE 系统来应用于其他领域。 为了证明这一点,我们在生化领域进行了额外的初步实验。 我们遵循与 NLP 论文类似的数据创建过程。 我们从 PubMed 论文中收集数据集并使用 PubTator 3 Islamaj 等人 (2021); Wei 等人 (2022);罗等人 (2023); Wei 等人 (2023); Lai 等人 (2023) 作为一个 IE 系统,从论文摘要中提取 KG。 我们使用在带注释的摘要 Huang 等人 (2020) 上训练的句子分类器来选择背景上下文。 我们在我们的数据上使用了最先进的生物医学大语言模型 Chen 等人 (2023),并对超过其预训练截止日期的测试分割进行评估。888更多数据和训练详情参见附录A.2、B.2.3。 我们请两位具有研究生学历的生化领域专家像以前一样评估结果的质量,发现他们对生成的方向的总体评价为 80%。 最后,与 NLP 领域的实验相比,在技术细节方面,评估者对生成的输出比真实情况更满意。 详细结果见表4。 然而,这个初步知识实验主要是为了证明我们方法的通用性,对实用性和质量的更深入探索留待未来的工作。
4.2 错误分析,自动化指标
错误分析模型通常会提出通用建议,并与直接从上下文中复制的具体细节结合在一起(例如,针对某些问题 X 的“具有 ML 算法和情感分析的 NLP”,或者Y 为“数据增强和迁移学习”,Z 为“BERT 或 RoBERTa”)。 我们的技术减少了这种行为,但并没有完全解决它。 尤其是 GPT4 模型,似乎生成了 NLP 工作流程中常见步骤的通用描述(例如,“数据预处理:清理文本数据、删除不必要的字符、执行标记化……”)。 所有模型通常都直接从上下文中复制和改写。 在某些情况下,模型对上下文应用了简单的逻辑修改;例如,当上下文描述“高延迟”或“效率限制”等问题时,建议将包括“低延迟”等短语或“高效”。
自动评估分析 在像我们这样的开放式任务中,将系统输出与真实文本进行比较的自动评估可能会受到限制。 尽管如此,诸如 ROUGE Lin (2004)、BERTScore Zhang* 等人 (2020) 和 BARTScore Yuan 等人 (2021) 等自动化指标,检查真实情况和生成输出之间的相似性,可能会出现有趣的发现。 我们发现基于 GPT 的模型的性能优于基于 T5 的模型; GPT4 输出比 T5 长得多,这解释了为什么它们在自动指标中表现不佳,但在人工评估中表现优于 (§4.1)。 生成的句子通常遵循某些模板(例如,“在本文中,我们提出了一个新的... for ...”),这也有助于解释为什么T5在许多示例上进行微调表面上得分更高。 与此同时,我们的上下文对比示例鼓励了背景上下文的新颖性,通过减少对复制的依赖,帮助模型比基线微调表现得更好。 结果见表9(附录B.3)。
5 结论和未来方向
我们提出了一种新的设置、模型和综合评估,以使用基于文献并针对新颖性进行优化的语言模型来生成科学假设。 我们提出了一个名为 SciMON 的新框架,其中模型采用背景问题上下文并提供基于文献的新颖建议。 模型从语义相似性图、知识图和引文网络中检索灵感。 我们引入了一种新的迭代新颖性提升机制,通过将想法与先前的工作进行明确比较并加以改进,帮助 GPT-4 等大型语言模型(大语言模型)产生更多新颖的想法。 我们的实验表明,生成自然语言科学假设的任务非常具有挑战性。 虽然我们的方法在基线大语言模型的基础上进行了改进,但生成的想法往往是增量的且细节不足。 生成新颖且有意义的科学概念及其组合仍然是一个基本问题Hope 等人 (2023)。 这种环境下的评估也极具挑战性,因为用自然语言提出的潜在合理假设空间巨大。 一个有趣的方向是通过公式、表格和图形的多模态分析来扩展 SciMON,以提供更全面的背景背景。
6 限制
我们在整篇论文中广泛讨论了局限性,例如评估挑战和数据质量方面的局限性。 在这里,我们提供了有关限制的更多详细信息。
6.1 数据收集的局限性
我们使用语义学者学术图 API 抓取了 1952 年至 2022 年 6 月期间的论文。 可用论文的数量受到我们从语义学者学术图谱中爬取的数据的限制。 我们还抓取了从 PubMed 1988 到 2024/01 的论文。 我们删除非英文论文。 我们还会从纸质 PDF 中删除摘要未正确解析的论文。 未来我们将把我们的模型扩展到用其他语言和其他领域编写的论文。
6.2 系统性能的限制
我们的数据集基于最先进的 IE 系统,可能会有噪音。 例如,共指和 SciSpacy 缩写解析模型无法将 A2LCTC 链接到 Action-to-Language Connectionist Temporal Classification。 背景上下文检测也可能存在错误:例如,句子分类组件未能处理“例如,语言模型总体上对股票市场更加积极,但两个行业部门之间的偏好存在显着差异,甚至在一个部门内。” 作为背景上下文。 在我们经过人工审查的黄金数据子集中,我们确保过滤此类情况,但它们仍保留在训练数据中。 SentenceBert Reimers 和 Gurevych (2019) 和 GPT3.5/4 未进行微调,可能会偏向于预训练数据集。 想法新颖性提升方法受到检索模型质量的限制。 未来可能会探索更好的检索模型。 由于硬件限制,我们主要研究了多达 70 亿个参数的模型。 由于 API 更改和模型随机性,我们的 GPT3.5/4 结果可能不容易重现。
6.3 评估的局限性
我们从博士中招募注释者。学生;他们的观点可能与具有不同领域知识水平的注释者不同。 我们的设置使用从真实情况中获取的种子项作为输入,来模拟人类向助理模型提供指导的场景。 未来的工作可以在没有种子项的情况下探索方法,这是一项更加艰巨的任务,或者在交互式环境中使用用户提供的种子项进行评估。 此外,虽然种子是从真实情况中采样的,但在我们人工注释的黄金子集中,我们确保在任何情况下输入上下文都不会轻易泄漏输出。
6.4记忆检查
Carlini 等人 (2023) 报告称,大语言模型倾向于记住部分训练数据,这是评估当前大语言模型时众所周知的问题。 因此,我们检查每个模型的预训练数据:
-
•
T5:Raffel 等人 (2020) 显示 T5 在 C4 上进行预训练,C4 是 2019 年 4 月之前从网络爬取的。
-
•
GPT3.5:基于文档,999platform.openai.com/docs/model-index-for-researchers GPT-3.5 系列是根据 2021 年第四季度之前的测试和代码组合进行预训练的。
-
•
GPT4:OpenAI (2023) 显示我们使用的 GPT-4 检查点利用了 2021 年 9 月之前的大多数相关数据。 尽管如此,预训练和训练后数据仍包含“少量”最新数据。101010参见OpenAI (2023)第10页脚注10。
由于我们根据 2022 年发表的论文评估我们的模型,因此测试论文出现在模型预训练语料库中的可能性大大降低。 我们还根据 2022 年 ACL Anthology 论文对我们的黄金集中的 GPT-4 记忆进行了手动检查,看看 GPT-4 是否可以完成方法名称等信息或生成强烈模仿真实论文的文本,但没有发现任何证据发生这种情况。 Meditron-7b Chen 等人 (2023) 使用 PubMed,截止日期为 2023 年 8 月,我们的生化测试集仅包含 2023/08 之后的 PubMed 论文。
参考
- Boiko et al. (2023) Daniil A Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. 2023. Autonomous chemical research with large language models. Nature, 624(7992):570–578.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
- Carlini (2023) Nicholas Carlini. 2023. A llm assisted exploitation of ai-guardian. arXiv preprint arXiv:2307.15008.
- Carlini et al. (2023) Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. 2023. Quantifying memorization across neural language models. In The Eleventh International Conference on Learning Representations.
- Cattan et al. (2021) Arie Cattan, Sophie Johnson, Daniel S Weld, Ido Dagan, Iz Beltagy, Doug Downey, and Tom Hope. 2021. Scico: Hierarchical cross-document coreference for scientific concepts. In 3rd Conference on Automated Knowledge Base Construction.
- Chen et al. (2023) Zeming Chen, Alejandro Hernández Cano, Angelika Romanou, Antoine Bonnet, Kyle Matoba, Francesco Salvi, Matteo Pagliardini, Simin Fan, Andreas Köpf, Amirkeivan Mohtashami, et al. 2023. Meditron-70b: Scaling medical pretraining for large language models. Computation and Language Repository, arXiv:2311.16079.
- Cohan et al. (2019) Arman Cohan, Iz Beltagy, Daniel King, Bhavana Dalvi, and Dan Weld. 2019. Pretrained language models for sequential sentence classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3693–3699, Hong Kong, China. Association for Computational Linguistics.
- de Masson d'Autume et al. (2019) Cyprien de Masson d'Autume, Sebastian Ruder, Lingpeng Kong, and Dani Yogatama. 2019. Episodic memory in lifelong language learning. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc.
- Dong et al. (2022) Qian Dong, Yaoming Zhu, Mingxuan Wang, and Lei Li. 2022. Learning when to translate for streaming speech. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 680–694.
- Henry and McInnes (2017) Sam Henry and Bridget T McInnes. 2017. Literature based discovery: models, methods, and trends. Journal of biomedical informatics, 74:20–32.
- Hope et al. (2023) Tom Hope, Doug Downey, Oren Etzioni, Daniel S Weld, and Eric Horvitz. 2023. A computational inflection for scientific discovery. CACM.
- Hu et al. (2021) Zhe Hu, Zuohui Fu, Yu Yin, and Gerard de Melo. 2021. Context-aware interaction network for question matching. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3846–3853, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Huang et al. (2023) Qian Huang, Jian Vora, Percy Liang, and Jure Leskovec. 2023. Benchmarking large language models as ai research agents. arXiv preprint arXiv:2310.03302.
- Huang et al. (2020) Ting-Hao Kenneth Huang, Chieh-Yang Huang, Chien-Kuang Cornelia Ding, Yen-Chia Hsu, and C. Lee Giles. 2020. CODA-19: Using a non-expert crowd to annotate research aspects on 10,000+ abstracts in the COVID-19 open research dataset. In Proceedings of the 1st Workshop on NLP for COVID-19 at ACL 2020, Online. Association for Computational Linguistics.
- Islamaj et al. (2021) Rezarta Islamaj, Robert Leaman, Sun Kim, Dongseop Kwon, Chih-Hsuan Wei, Donald C. Comeau, Yifan Peng, David Cissel, Cathleen Coss, Carol Fisher, Rob Guzman, Preeti Gokal Kochar, Stella Koppel, Dorothy Trinh, Keiko Sekiya, Janice Ward, Deborah Whitman, Susan Schmidt, and Zhiyong Lu. 2021. Nlm-chem, a new resource for chemical entity recognition in pubmed full text literature. Scientific Data, 8(1):91.
- Jimenez Gutierrez et al. (2022) Bernal Jimenez Gutierrez, Nikolas McNeal, Clayton Washington, You Chen, Lang Li, Huan Sun, and Yu Su. 2022. Thinking about GPT-3 in-context learning for biomedical IE? think again. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 4497–4512, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Lai et al. (2023) Po-Ting Lai, Chih-Hsuan Wei, Ling Luo, Qingyu Chen, and Zhiyong Lu. 2023. Biorex: Improving biomedical relation extraction by leveraging heterogeneous datasets. Journal of Biomedical Informatics, 146:104487.
- Lin (2004) Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
- Liu et al. (2022) Jiachang Liu, Dinghan Shen, Yizhe Zhang, Bill Dolan, Lawrence Carin, and Weizhu Chen. 2022. What makes good in-context examples for GPT-3? In Proceedings of Deep Learning Inside Out (DeeLIO 2022): The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, pages 100–114, Dublin, Ireland and Online. Association for Computational Linguistics.
- Lo et al. (2020) Kyle Lo, Lucy Lu Wang, Mark Neumann, Rodney Kinney, and Daniel Weld. 2020. S2ORC: The semantic scholar open research corpus. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4969–4983, Online. Association for Computational Linguistics.
- Loshchilov and Hutter (2019) Ilya Loshchilov and Frank Hutter. 2019. Decoupled weight decay regularization. In Proceedings of the 7th International Conference on Learning Representations.
- Luan et al. (2018) Yi Luan, Luheng He, Mari Ostendorf, and Hannaneh Hajishirzi. 2018. Multi-task identification of entities, relations, and coreference for scientific knowledge graph construction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3219–3232, Brussels, Belgium. Association for Computational Linguistics.
- Luo et al. (2023) Ling Luo, Chih-Hsuan Wei, Po-Ting Lai, Robert Leaman, Qingyu Chen, and Zhiyong Lu. 2023. AIONER: all-in-one scheme-based biomedical named entity recognition using deep learning. Bioinformatics, 39(5):btad310.
- Nadkarni et al. (2021) Rahul Nadkarni, David Wadden, Iz Beltagy, Noah A Smith, Hannaneh Hajishirzi, and Tom Hope. 2021. Scientific language models for biomedical knowledge base completion: an empirical study. AKBC.
- Neumann et al. (2019) Mark Neumann, Daniel King, Iz Beltagy, and Waleed Ammar. 2019. ScispaCy: Fast and robust models for biomedical natural language processing. In Proceedings of the 18th BioNLP Workshop and Shared Task, pages 319–327, Florence, Italy. Association for Computational Linguistics.
- Newell and Simon (1956) Allen Newell and Herbert Simon. 1956. The logic theory machine–a complex information processing system. IRE Transactions on information theory, 2(3):61–79.
- Nori et al. (2023) Harsha Nori, Nicholas King, Scott Mayer McKinney, Dean Carignan, and Eric Horvitz. 2023. Capabilities of GPT-4 on medical challenge problems. arXiv preprint arXiv:2303.13375.
- Oord et al. (2018) Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation learning with contrastive predictive coding. Machine Learning Repository, arXiv:1807.03748.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report. Computation and Language Repository, arXiv:2303.08774.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Qin et al. (2022) Yujia Qin, Jiajie Zhang, Yankai Lin, Zhiyuan Liu, Peng Li, Maosong Sun, and Jie Zhou. 2022. ELLE: Efficient lifelong pre-training for emerging data. In Findings of the Association for Computational Linguistics: ACL 2022, pages 2789–2810, Dublin, Ireland. Association for Computational Linguistics.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67.
- Reimers and Gurevych (2019) Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, Hong Kong, China. Association for Computational Linguistics.
- Simon (1973) Herbert A Simon. 1973. Does scientific discovery have a logic? Philosophy of science, 40(4):471–480.
- Sosa and Altman (2022) Daniel N Sosa and Russ B Altman. 2022. Contexts and contradictions: a roadmap for computational drug repurposing with knowledge inference. Briefings in Bioinformatics, 23(4):bbac268.
- Swanson (1986) Don R Swanson. 1986. Undiscovered public knowledge. The Library Quarterly, 56(2):103–118.
- Sybrandt et al. (2020) Justin Sybrandt, Ilya Tyagin, Michael Shtutman, and Ilya Safro. 2020. Agatha: automatic graph mining and transformer based hypothesis generation approach. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, pages 2757–2764.
- Tshitoyan et al. (2019) Vahe Tshitoyan, John Dagdelen, Leigh Weston, Alexander Dunn, Ziqin Rong, Olga Kononova, Kristin A Persson, Gerbrand Ceder, and Anubhav Jain. 2019. Unsupervised word embeddings capture latent knowledge from materials science literature. Nature, 571(7763):95–98.
- Wang et al. (2019) Qingyun Wang, Lifu Huang, Zhiying Jiang, Kevin Knight, Heng Ji, Mohit Bansal, and Yi Luan. 2019. PaperRobot: Incremental draft generation of scientific ideas. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 1980–1991, Florence, Italy. Association for Computational Linguistics.
- Warstadt et al. (2023) Alex Warstadt, Aaron Mueller, Leshem Choshen, Ethan Wilcox, Chengxu Zhuang, Juan Ciro, Rafael Mosquera, Bhargavi Paranjabe, Adina Williams, Tal Linzen, et al. 2023. Findings of the babylm challenge: Sample-efficient pretraining on developmentally plausible corpora. In Proceedings of the BabyLM Challenge at the 27th Conference on Computational Natural Language Learning, pages 1–34.
- Wei et al. (2022) Chih-Hsuan Wei, Alexis Allot, Kevin Riehle, Aleksandar Milosavljevic, and Zhiyong Lu. 2022. tmvar 3.0: an improved variant concept recognition and normalization tool. Bioinformatics, 38(18):4449–4451.
- Wei et al. (2023) Chih-Hsuan Wei, Ling Luo, Rezarta Islamaj, Po-Ting Lai, and Zhiyong Lu. 2023. GNorm2: an improved gene name recognition and normalization system. Bioinformatics, 39(10):btad599.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
- Ye et al. (2022) Deming Ye, Yankai Lin, Peng Li, and Maosong Sun. 2022. Packed levitated marker for entity and relation extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4904–4917, Dublin, Ireland. Association for Computational Linguistics.
- Yuan et al. (2021) Weizhe Yuan, Graham Neubig, and Pengfei Liu. 2021. BARTScore: Evaluating generated text as text generation. In Advances in Neural Information Processing Systems.
- Zhang* et al. (2020) Tianyi Zhang*, Varsha Kishore*, Felix Wu*, Kilian Q. Weinberger, and Yoav Artzi. 2020. Bertscore: Evaluating text generation with bert. In Proceedings of the 8th International Conference on Learning Representations.
- Zhou et al. (2022) Ran Zhou, Xin Li, Ruidan He, Lidong Bing, Erik Cambria, Luo Si, and Chunyan Miao. 2022. MELM: Data augmentation with masked entity language modeling for low-resource NER. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2251–2262, Dublin, Ireland. Association for Computational Linguistics.
附录A数据集集合
A.1 NLP数据集收集
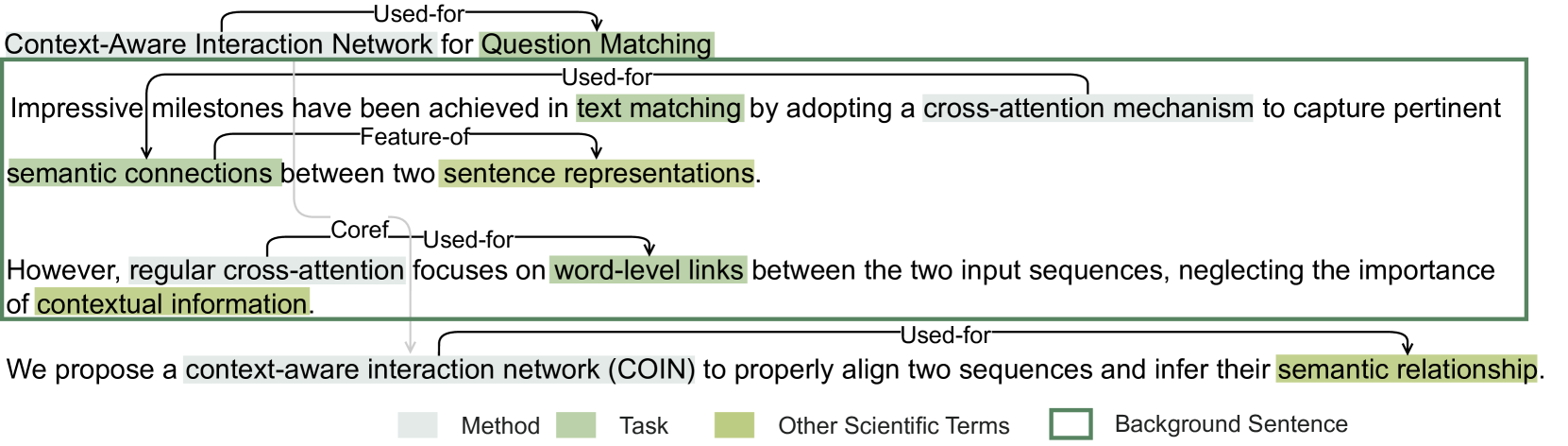
我们使用语义学者学术图 API 下载 1952 年至 2022 年的 ACL Anthology 论文。111111www.semanticscholar.org/product/api 我们过滤掉没有摘要和非英文论文,得到 67,408 篇论文。 我们的数据集包含 2021 年之前的 58,874 篇论文、2021 年以来的 5,946 篇论文和 2022 年之后的 2,588 篇论文。 我们首先使用在 SciERC Luan 等人 (2018) 上预训练的 PL-Marker Ye 等人 (2022) 来提取属于六种类型的节点:Task、方法、评估指标、材料、其他科学术语和通用术语。 然后,该模型预测属于七种关系类型的节点之间的关系:Used-for、Feature-of、Evaluate-for、Hyponym -of、部分、比较和连接。 因为我们想要产生新的想法,所以我们关注论文中的used-for关系。 接下来,我们使用 SciCo Cattan 等人 (2021) 以及来自 Hugging Face121212huggingface.co/allenai/longformer-scico 获取实体共指来合并相同节点。 然后,我们使用 ScispaCy Neumann 等人 (2019) 进行无监督缩写检测,将缩写替换为信息更丰富的长形式。 最后,我们进行科学句子分类Cohan 等人 (2019)131313github.com/allenai/sequential_sentence_classification将摘要中的句子分为五类,包括背景、方法、 目标0>、其他1>和结果2>。 我们选择带有 Background 和 Other 标签的句子作为背景上下文。 在预处理过程中,我们只保留 IE 模型的高置信度输出。 图4 显示了 IE 系统管道的示例。
| Stage | PL-Maker Entities | PL-Maker Used-for Relations | SciCo Coreference | Scispacy Abbreviation Detection | Sentence Classification |
|
Precision |
91.3 |
65.4 |
97.2 |
100 |
100 |
A.2 生化数据集收集
我们使用 Entrez Planning Utilities API141414www.ncbi.nlm.nih.gov/books/NBK25501/,了解以下主题,包括 Yarrowia、Saccharomyces cerevisiae、东方伊萨氏菌和圆红冬孢酵母0>。 我们使用 PubTator 3 Islamaj 等人 (2021); Wei 等人 (2022);罗等人 (2023); Wei 等人 (2023);赖等人(2023)。 PubTator 3 对数据集中的摘要执行命名实体识别、关系提取、实体共指和链接以及实体规范化。 PubTator 3 识别属于七种类型的生物实体:基因、化学、染色体、细胞系、变异、疾病和物种l以及属于13种类型的关系:关联、原因、 比较、转化0>、收缩1>、药物相互作用2>、抑制3>、相互作用4>、负相关5>、正相关6>、预防7>、刺激8>和治疗9>. 最后,我们使用在 CODA-19 Huang 等人 (2020) 上训练的句子分类器将摘要中的句子分类为 背景、目的、方法、发现和其他。 我们选择带有 background 标签的句子作为背景上下文,并删除带有 other 标签的句子。 我们将至少具有一个实体的其余句子视为目标句子。 我们只保留背景上下文和相应的真实句子之间相似度较低的样本。151515相似度通过all-mpnet-base-v2计算。 我们的最终数据集包含 2023/02 之前的 4,767 篇论文,2023/02 到 2023/08 的 642 篇论文,以及 2023/08 之后的 299 篇论文。
附录 B微调和自动评估详细信息
B.1 灵感检索模块
| Type | Train | Valid | Test |
|---|---|---|---|
|
SN |
10.8 |
10.0 |
10.0 |
|
KG |
8.3 |
8.0 |
8.1 |
|
CT |
4.9 |
5.0 |
5.0 |
B.1.1 语义邻居
我们使用 SentenceBert (Reimers 和 Gurevych,2019) 中的 all-mpnet-base-v2,它在语义搜索中表现最佳,可以根据查询从训练集中检索相似节点§3.1中的。 我们从每个实例的训练集中检索最多 20 个相关语义邻居 。 我们将 中的目标节点视为语义邻居。
B.1.2 KG邻居
我们使用在 2021 年之前的论文(即训练集中的论文)上构建的背景 KG 中的一跳连接邻居。 由于KG邻居的稀缺性,我们不限制KG邻居的数量。
B.1.3 引用邻居
与语义邻居类似,我们使用 SentenceBert (Reimers 和 Gurevych,2019) 中的 来检索与查询 类似的被引用论文标题。 我们仅限制 2021 年之前的引用论文。 我们从论文的引文网络中检索最多 5 个相关的引文邻居。
B.2生成模块
我们的 T5 模型及其变体是基于 Huggingface 框架(Wolf 等人,2020)构建的。161616github.com/huggingface/transformers 我们通过 AdamW 优化这些模型(Loshchilov 和 Hutter,2019)使用线性预热调度程序。170>1717huggingface.co/docs/transformers/main_classes/optimizer_schedules#transformers.get_linear_schedule_with_warmup 这些模型在 4 个 NVIDIA A6000 48GB GPU 上通过分布式数据并行进行微调。187>1818pytorch.org/tutorials/intermediate/ddp_tutorial.html
B.2.1 情境学习
我们选择GPT3.5 davinci-003191919openai.com/api/ Brown 等人 (2020) 作为我们开箱即用的因果语言建模基线。 我们从训练集中选择 实例作为少样本设置的示例。 我们为 GPT3.5FS 随机选择这些示例。 对于 GPT3.5Retr,与语义邻居类似,我们使用 SentenceBert (Reimers 和 Gurevych,2019) 中的 all-mpnet-base-v2,它在语义搜索中表现最佳,可以根据第 §3.1 中的查询 从训练集中检索相似实例。 由于 OpenAI API 限制,输入长度限制为 Token 。 我们选择 gpt-4-0314 作为我们的 GPT4 模型。 我们对 GPT4 的输入与 GPT3.5 类似。
对于从具有 forward 关系的训练集中选择的每个示例,模板为 “考虑以下上下文: 在该上下文中,哪个 可以用于 ,为什么? ”,其中 是背景上下文, 是目标节点类型, 是种子项, 是目标想法句子;对于向后关系,模板是 “考虑以下上下文: 在该上下文中,我们使用哪个 ,为什么? ”. 对于具有额外检索灵感的选定示例,我们将以下附加模板连接到 :“检索结果为:”,其中 是检索到的灵感。 对于最终提示,模板与上面的示例模板类似。 但是,目标句子将不被包括在内。 我们要求模型生成 输出。 我们将选择最佳输出并跳过空输出。
B.2.2微调
给定没有任何灵感的输入,输入结合了提示 和上下文 ,如第 §3.1 中所示(即 |上下文:)。 给定带有灵感的输入,输入为 |检索: |上下文:,以 作为检索到的灵感。 输入长度限制为 标记。 对于这两个任务,我们基于 T5-large 微调模型,学习率为 和 。 每个 GPU 的批量大小为 。 所有模型的最大训练周期为 ,需要 耐心。 在解码过程中,我们使用波束搜索来生成波束大小为 5 和重复惩罚为 的结果。
上下文对比增强
我们随机选择输入中出现的 句子作为上下文否定。 例如,在图1中,上下文中的否定可能是“知识获取是通过使用方法完成的”,“这需要plms整合来自终生使用所有来源。”。
B.2.3 生化案例研究
我们的 Meditron-7b Chen 等人 (2023) 及其变体是基于 Huggingface 框架(Wolf 等人, 2020)构建的。202020github.com/huggingface/transformers 我们使用它的 epfl-llm/meditron-7b 作为基本模型。 我们使用 和 的学习率对这些模型进行微调。 所有模型的最大训练周期为。 所有模型均在 4 个 NVIDIA A100 80 GB GPU 上进行微调,具有完全分片数据并行功能。212121https://huggingface.co/docs/accelerate/usage_guides/fsdp每个模型的训练时间约为20小时。
| Type | Content |
|---|---|
|
Seed Term Prompt |
data augmentation is used for Task |
|
Context |
data augmentation is an effective solution to data scarcity in low - resource scenarios. however, when applied to token-level tasks such as ner , data augmentation methods often suffer from token-label misalignment, which leads to unsatsifactory performance. |
|
Semantic Neighbors |
st and automatic speech recognition (asr), low-resource tagging tasks, end-to-end speech translation, neural online chats response selection, neural machine translation, semi-supervised ner, entity and context learning, semi-supervised setting, dependency parsing, low-resource machine translation, slot filling, dialog state tracking, visual question answering, visual question answering (vqa), low-resource neural machine translation |
|
KG Neighbors |
nmt-based text normalization, task-oriented dialog systems, task-oriented dialogue system, low-resource languages (lrl), end-to-end speech translation, visual question answering (vqa), multiclass utterance classification, clinical semantic textual similarity, neural online chats response selection, context-aware neural machine translation |
|
Citation Neighbors |
Contextual Augmentation: Data Augmentation by Words with Paradigmatic Relations, An Analysis of Simple Data Augmentation for Named Entity Recognition, Data Augmentation for Low-Resource Neural Machine Translation, DAGA: Data Augmentation with a Generation Approach for Low-resource Tagging Tasks, EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks |
|
Ground Truth |
ELM: Data Augmentation with Masked Entity Language Modeling for Low-Resource NER |
B.3 自动评估
我们将 BERTScore Zhang* 等人 (2020) 与 SciBERT 检查点一起用于这两项任务。 检查点的哈希值为 allenai/scibert_scivocab_uncased_L8 _no-idf_version=0.3.12(hug_trans=4.19.2)。 自动评估结果见表9。
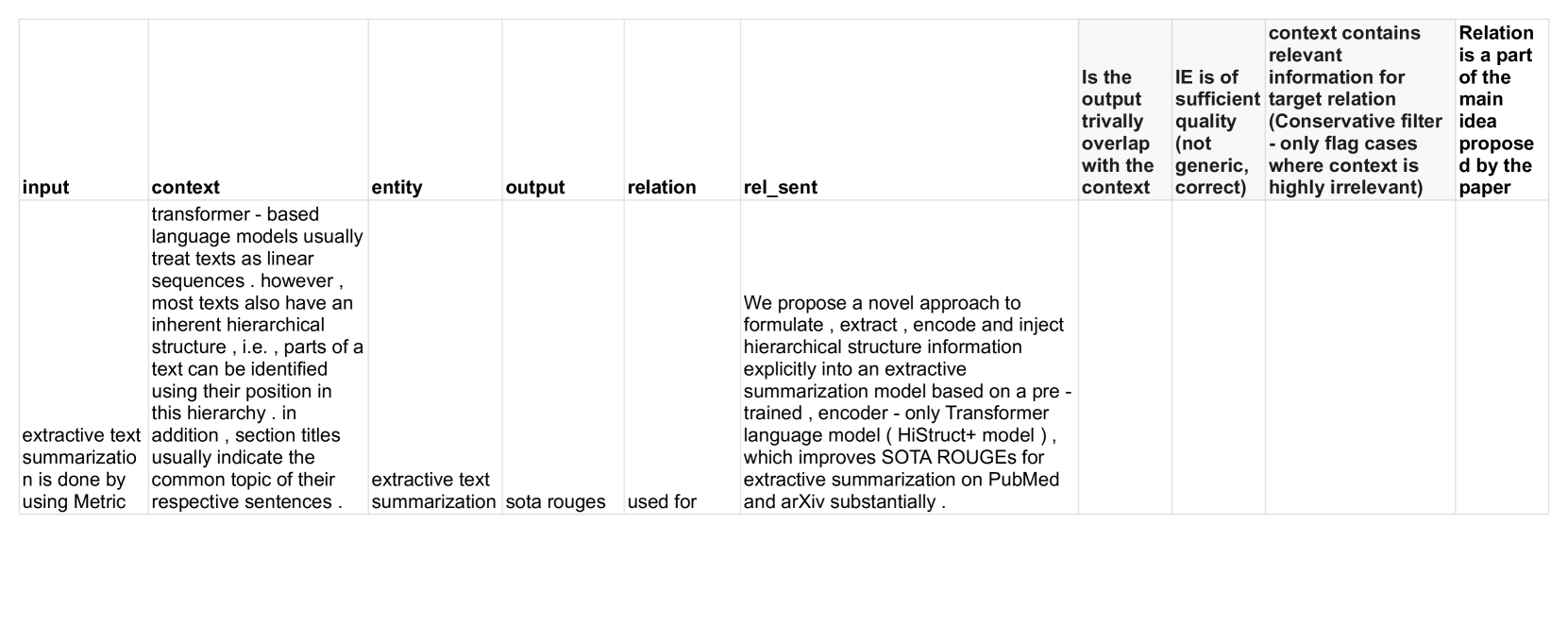
| Subset | Challenging | Gold | ||
|---|---|---|---|---|
| Model | R-L | BERT | R-L | BERT |
| GPT4ZS |
0.120 |
0.581 |
0.130 |
0.583 |
| GPT4FS |
0.143 |
0.618 |
0.151 |
0.624 |
| T5 |
0.223 |
0.672 |
0.246 |
0.685 |
|
GPT4FS+SN |
0.144 |
0.620 |
0.149 |
0.627 |
| GPT4FS+KG |
0.143 |
0.619 |
0.152 |
0.626 |
| GPT4FS+CT |
0.144 |
0.617 |
0.149 |
0.622 |
|
T5+CL |
0.225 |
0.671 |
0.251 |
0.686 |
| T5+SN+CL | 0.228 |
0.671 |
0.258 |
0.686 |
| T5+KG+CL |
0.223 |
0.669 |
0.248 |
0.681 |
| T5+CT+CL |
0.225 |
0.671 |
0.250 |
0.686 |
| Type | Content |
|---|---|
|
Seed Term Prompt |
Irish language learning is done by using Method |
|
Context |
Irish is a minority language which means that l2 learners have limited opportunities for exposure to the language, and additionally, there are also limited (digital) learning resources available. |
| Model | Output | Label |
|---|---|---|
| GPT3.5FS |
The use of Social Media in Irish Language Learning: A Case Study |
helpful |
|
GPT3.5Retr |
One method that could be used for Irish language learning is computer assisted language learning (CALL) |
unhelpful |
|
GPT3.5FS+CT |
In that context, the most appropriate task for precision grammar would be the development of a part-of-speech tagger for Irish using finite-state morphology and constraint grammar disambiguation. |
unhelpful |
|
GPT3.5FS+KG |
Cló: An Irish Language Learning Platform - Leveraging Digital Resources and Human Expertise |
unhelpful |
|
GPT4FS |
We propose using a technology-enhanced approach, such as computer-assisted language learning (CALL) or natural language processing (NLP) techniques, to create interactive and engaging Irish language learning resources, as these methods can provide personalized learning experiences and enhance learners’ exposure to the language despite limited resources available. |
helpful |
|
GPT4FS+KG |
Exploiting Social Media for Irish Language Learning: An Analysis of Twitter Data. In this context, we use social media data, particularly from Twitter, as a method for Irish language learning, because it provides a rich source of authentic and diverse language examples that can be used to enhance learning opportunities for L2 learners in a minority language setting. |
helpful |
|
T5 |
In this paper, we present a novel machine translation approach to Irish language learning. |
unhelpful |
|
T5+SN+CL |
A conversational virtual environment for Irish language learning |
helpful |
| Type | Content |
|---|---|
|
Seed Term |
ARO10 |
|
Context |
Huangjiu is known for its unique aroma, primarily attributed to its high concentration of b-phenylethanol (ranging from 40 to 130 mg/L). |
|
Meditron |
We then selected six key genes involved in the phenylalanine metabolism pathway and predicted that their product flux may affect the synthesis of b-phenylethanol. |
|
Meditron + CT |
We found that the key amino acid residue that controls the activity of Aro10p was not conserved in wine yeast strains, which may explain the lower b-phenylethanol production in wine fermentation compared with that in Chinese huangjiu. |
|
Meditron + KG |
Both target genes, SSA1 and ARO10, were deleted using the CRISPR-Cas9 genome editing system. |
|
Meditron + SN |
Herein, we report that the key barrier for b-phenylethanol production in Huangjiu is ARO10, the only bi-functional amino acid decarboxylase in Saccharomyces cerevisiae. |

附录C人类色素及评估详情
黄金数据集标注详情
黄金数据集标注界面如图5。 测试集中实例的质量根据三个标准进行判断:(1)地面真值句子是否与背景上下文轻微重叠; (2)背景上下文是否包含目标关系的相关信息; (3) 目标关系(从中获取种子项)是否是目标论文中提出的想法的一个显着方面。
研究一
研究三
我们向人类注释者提出以下问题来评估再生结果的质量:(1) 再生后的想法与原来的想法有本质上的不同吗? (2) 再生的想法是否比原始想法更新颖、更有创意? (3) 第二次迭代是否增加了新颖性? 人类标注一致性见表14。
| Annotator Pair | 1-2 | 1-3 | 1-4 | 1-5 | 1-6 |
| Agreement % |
68.8 |
75.0 |
56.2 |
43.8 |
75.0 |
| Annotator Pair | 1-2 | 1-3 | 1-4 | 1-5 |
| Agreement % |
92.5 |
93.3 |
87.5 |
90.0 |
附录 D 科学文物
我们列出了本文所用科学工具的许可证:语义学者学术图API(API许可协议222222api.semanticscholar.org/license/)、Huggingface Transformers(Apache License 2.0), SBERT (Apache-2.0 license), BERTScore (MIT license), Meditron-7b (Llama2), Entrez Programming Utilities API (Copyright232323www.ncbi.nlm.nih.gov/books/about/copyright/)、PubTator 3(数据使用政策242424www.ncbi.nlm.nih.gov/home/about/policies/)和 OpenAI(使用条款252525openai.com/policies/terms-of-use)。
附录E道德考虑
我们在本文中设计的SciMON任务和相应模型仅限于自然语言处理(NLP)和生化领域,可能不适用于其他场景。
E.1使用要求
本文旨在为科学领域(特别是自然语言处理)提供研究线索。 最终结果未经人工审核不得使用。 因此,领域专家可能会使用此工具作为研究写作助手来发展想法。 然而,我们的系统不会利用外部知识进行任何事实核查。 此外,我们在 ACL 选集和用英语撰写的 PubMed 论文上训练我们的模型,这可能会疏远那些历史上在 NLP/生化领域代表性不足的读者。
E.2数据收集
我们根据 API 许可协议262626https://api.semanticscholar.org/license/。 我们确保我们的数据收集程序遵循 https://allenai.org/terms 上的使用条款。 根据协议,我们的数据集只能用于非商业目的。 如第 §4 中所述,我们执行人工评估。 所有参与人工评估的注释者都是自愿参与者,并享有公平的工资。 我们使用 Entrez Planning Utilities API272727www.ncbi.nlm.nih.gov/books/NBK25501/。 我们遵循他们的数据使用指南282828www.ncbi.nlm.nih.gov/books/about/copyright/。