通过
预训练语言模型完成文本增强的开放知识图谱
摘要
开放知识图谱(KG)补全的使命是从已知事实中得出新的发现。 现有的增强知识图谱补全的工作需要(1)事实三元组来扩大图形推理空间,或者(2)手动设计的提示从预先训练的语言模型(PLM)中提取知识,表现出有限的性能并且需要专家付出昂贵的努力。 为此,我们提出TagReal,它自动生成质量查询提示并从大型文本语料库中检索支持信息,以从 PLM 中探测知识以完成 KG。 结果表明,TagReal 在两个基准数据集上实现了最先进的性能。 我们发现,即使训练数据有限,TagReal 也具有出色的性能,优于现有的基于嵌入、基于图形和基于 PLM 的方法。
通过
预训练语言模型完成文本增强的开放知识图谱
1简介
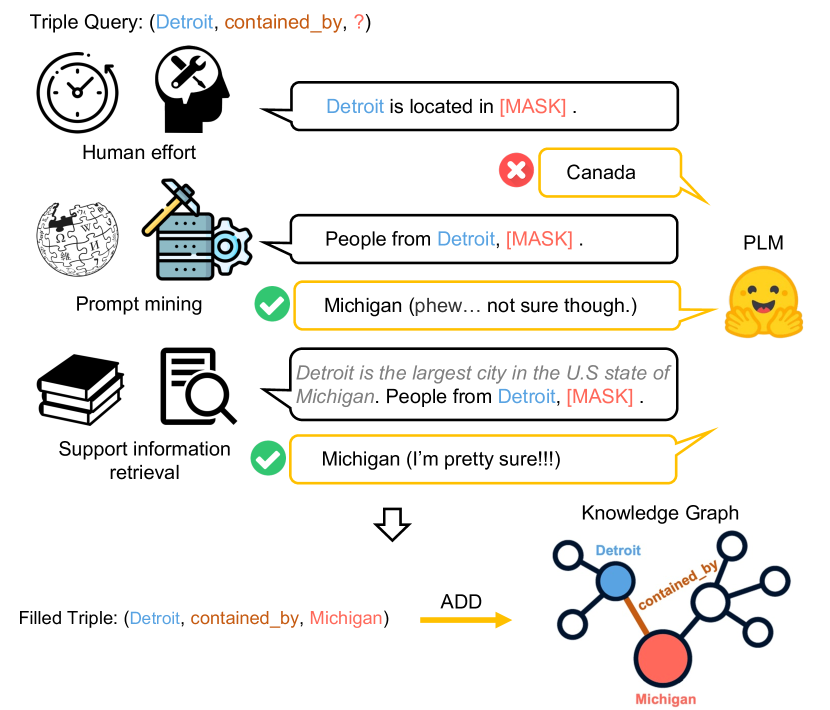
知识图 (KG) 是一种异构图,它以实体-关系-实体三元组的形式对事实信息进行编码,其中 关系 连接 head 实体和 tail 实体(例如,“Miami- located_in-USA”)Wang 等人 (2017); Hogan 等人 (2021)。 KG Dai 等人 (2020) 在许多 NLP 应用中发挥着核心作用,包括问答 Hao 等人 (2017); Yasunaga 等人 (2021)、推荐系统 Zhou 等人 (2020) 和药物发现 Zitnik 等人 (2018)。 然而,现有作品Wang等人(2018); Hamilton等人(2018)表明,大多数大规模知识图谱都是不完整的,无法完全覆盖海量的现实世界知识。 这一挑战激发了知识图谱补全,其目的是在给定主题实体和关系 Lin 等人 (2015) 的情况下找到一个或多个对象实体。 例如,在图1中,我们的目标是预测以“Detroit”为主题实体、以“contained_by”为主体实体的对象实体。关系。
然而,现有的 KG 完成度接近 Trouillon 等人 (2016b); Das 等人 (2018) 有几个局限性 Fu 等人 (2019)。 首先,它们的性能很大程度上取决于图的密度。 它们通常在具有丰富结构信息的密集图上表现良好,但在现实应用中更常见的稀疏图上表现不佳。 其次,以前的方法(例如,Bordes 等人(2013))假设一个封闭世界的知识图谱,没有考虑外部资源中大量的开放知识。 事实上,在很多情况下,KG 通常与富文本语料库 Bodenreider (2004) 相关联,其中包含大量尚未提取的事实数据。 为了克服这些挑战,我们研究了开放知识图谱完成的任务,其中可以使用知识图谱外部的新事实来构建知识图谱。 最近的文本丰富解决方案Fu等人(2019)专注于使用一组预定义的事实来丰富知识图谱。 尽管如此,预定义的事实集通常是嘈杂且受限的,也就是说,它们不能提供足够的信息来有效地更新知识图谱。
预训练语言模型 (PLM) Devlin 等人 (2019); Liu 等人 (2019a) 已被证明能够通过学习大量无标签文本 Petroni 等人 (2019b) 隐式捕获事实知识。 由于 PLM 在文本编码方面非常出色,因此可以利用它们来促进使用外部文本信息完成知识图谱。 最近的知识图谱补全方法Shin 等人 (2020); Lv 等人 (2022) 重点关注使用手动制作的提示(例如,图 1 中的“底特律位于 [MASK]”)来查询 PLM 的图形补全(例如,“密歇根”)。 然而,手动创建提示的成本可能很高,而且质量有限(例如,PLM 使用手工制作的提示对查询给出了错误的答案“加拿大”,如图 1 所示)。
基于标准 KG 的上述限制和 PLM 的巨大力量 Devlin 等人 (2019); Liu等人(2019a),我们的目标是使用PLM来完成开放知识图谱。 我们提出了一种端到端框架,联合利用 PLM 中的隐式知识和语料库中的文本信息来执行知识图补全(如图 1 所示)。 与现有作品(例如,Fu 等人 (2019); Lv 等人 (2022))不同,我们的方法不需要手动预先定义一组事实和提示,这更通用、更容易以适应现实世界的应用。
我们的贡献可以概括为:
-
•
我们研究开放知识图谱补全问题,该问题可以通过从 PLM 捕获的事实来辅助。 为此,我们提出了一个新的框架TagReal,表示text augmented开放KG完成PLM 中的真实知识。
-
•
我们开发了提示生成和信息检索方法,使TagReal能够自动为PLM知识探测和搜索支持信息创建高质量的提示,使其更加实用,尤其是在PLM缺乏某些领域知识的情况下。
-
•
通过对 Freebase111https://github.com/thunlp/OpenNRE我们展示了我们框架的适用性和优势222Our code is available at: https://github.com/pat-jj/TagReal。
2相关工作
2.1 KG补全方式
KG补全方法可以分为基于嵌入的方法和基于PLM的方法。 基于嵌入的方法将实体和关系表示为嵌入向量,并在向量空间中维护它们的语义关系。 TransE Bordes 等人 (2013) 将三元组的头、关系和尾向量化到欧几里得空间中。 DistMult Yang 等人 (2014) 将所有关系嵌入转换为双线性模型中的对角矩阵。 RotatE Sun 等人 (2019) 将每个关系嵌入表示为复杂向量空间中从头实体到尾实体的旋转。
近年来,研究人员意识到PLM可以作为知识库Petroni等人(2019a);张等人 (2020); AlKhamassi 等人 (2022)。 基于 PLM 的 KG 补全方法Yao 等人 (2019); Kim 等人 (2020); Chang 等人 (2021); Lv等人(2022)开始受到关注。 作为先驱,KG-BERT Yao 等人 (2019) 对每个三元组中连接头、关系和尾部的 PLM 进行了微调,在链路预测任务中优于传统的基于嵌入的方法。 Lv 等人(2022) 提出 PKGC,它使用手动设计的三重提示和精心选择的支持提示作为 PLM 的输入。 他们的结果表明,PLM 可用于大幅提高知识图谱补全性能,尤其是在开放世界 Shi 和 Weninger (2018) 设置中。 与 PKGC 相比,我们的框架 TagReal 无需任何领域专家知识即可自动生成更高质量的提示。 此外,我们不是预先假设支持信息的存在,而是通过信息检索方法从语料库中搜索相关文本信息来支持PLM知识探查。
2.2 使用提示进行知识探究
LAMA Petroni 等人 (2019a) 是第一个 PLM 知识探索框架。 提示是使用主题占位符和对象的未填充空间手动创建的。 例如,三重查询 (Miami, location, ?) 可能会提示 "迈阿密位于 [MASK]",其中"<主题>位于 [MASK]"是 "位置 "关系的模板。 训练目标是使用 PLM 的预测正确填充 [MASK]。 另一项工作 BertNet Hao 等人 (2022) 提出了一种应用 GPT-3 Brown 等人 (2020) 自动生成带有输入实体对和手动种子提示。 然后,它再次使用 PLM 来搜索并选择排名靠前的实体对以及用于 KG 补全的集成。
2.3提示挖矿方法
当有多个关系需要解释时,由于需要领域专家知识,手动提示设计的成本很高。 此外,及时质量也无法得到保证。 因此,质量提示挖掘引起了研究人员的兴趣。 Jiang 等人 2020提出了一种 MINE 方法,该方法在大型文本语料库(例如维基百科)中搜索给定输入和输出之间的中间词或依赖路径。 他们还提出了一种合理的方法,通过对提示个体在 PLM 上的表现进行加权来优化挖掘提示的整体。
在 PLM 出现和广泛使用之前,文本模式挖掘执行类似的功能来查找信息提取的可靠模式。 例如,MetaPAD Jiang 等人 (2017) 通过上下文感知分割和模式质量函数生成质量元模式,而 TruePIE Li 等人 (2018) 提出了这一概念模式嵌入和自我训练框架,自动发现积极的模式。
3方法论
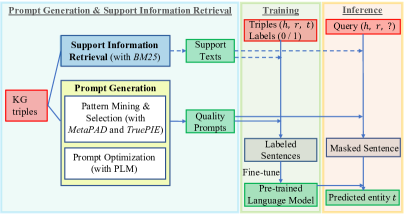
我们提出了TagReal,一个基于PLM的框架来处理KG完成任务。 与之前的工作相比,我们的框架不依赖于手工制作的提示或预定义的相关事实。 如图2所示,我们自动创建适当的提示并搜索相关支持信息,这些信息进一步用作模板来探索 PLM 中的隐式知识。
3.1问题表述
知识图谱补全就是向KG现有的三元组集合添加新的三元组(事实)。 实现这一目标有两项任务。 第一个是三元分类,这是一个二元分类任务,用于预测三元组是否属于知识图谱,其中表示头实体,关系和分别是尾部实体。 第二个任务是链接预测,其目标是使用查询预测尾部实体 或带有查询的头实体。
3.2 提示生成
先前的研究(例如,Jiang 等人 (2020))表明,从 PLM 中提取的关系知识的准确性在很大程度上依赖于查询提示的质量。 为此,我们开发了一种以 KG 中的三元组作为唯一输入的自动质量提示生成的综合方法,如图 3 所示。 我们使用文本模式挖掘方法从大型语料库中挖掘质量模式,作为 PLM 知识探索的提示。 据我们所知,我们是使用文本模式挖掘方法进行LM提示挖掘的先驱。 我们相信这种方法的适用性,原因如下。
-
•
类似的数据源。 我们在大型语料库(例如维基百科)上应用模式挖掘,这是大多数 PLM 预训练的数据源。
-
•
类似的目标。 文本模式挖掘是从大型语料库中挖掘模式以提取新信息;提示挖掘是挖掘提示以探究PLM中的隐含知识。
-
•
类似的性能标准。 模式或提示的可靠性取决于它可以从语料库/PLM 中提取多少准确的事实。
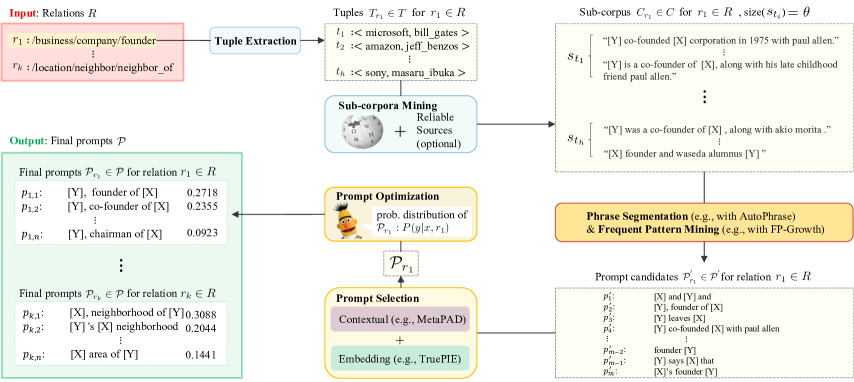
子语料挖掘是为模式挖掘创建数据源的第一步。 具体来说,给定一个具有关系集 的 KG,我们首先从 KG 中提取由每个关系 的头实体和尾实体配对的元组 。 例如,对于关系 :/business/company/founder,我们将从 KG 中提取该关系中像 <microsoft, bill_gates> 这样的所有图元。 对于每个元组,我们从大型语料库(例如维基百科)和其他可靠来源中搜索包含头和尾的句子,并将其添加到子语料库中。 我们将每个元组的每个集合的大小限制为 ,以便为未来的应用程序挖掘更多通用模式。
短语分割和频繁模式挖掘应用于从子语料库中挖掘模式作为提示候选。 我们使用 AutoPhrase Shang 等人 (2018) 将语料分割为更自然且明确的语义短语,并使用 FP-Growth 算法 Han 等人 (2000) 挖掘频繁出现的内容组成候选集的模式。 该集的规模很大,因为有很多凌乱的文字图案。
提示选择。 为了从候选集中选择质量模式,我们应用了两种文本挖掘方法:MetaPAD Jiang 等人 (2017) 和 TruePIE Li 等人 (2018)。 MetaPAD 应用模式质量函数,引入多个上下文特征标准来估计模式的可靠性。 我们解释为什么这些特征也可以适用于 LM 提示估计: (1) 频率和一致性:由于 PLM 在预训练阶段学习了频繁模式和实体之间的更多上下文关系,因此会出现模式在后台语料库中更频繁地使用可以从 PLM 中探究更多事实。 同样,如果由高度关联的子模式组成的模式频繁出现,则应将其视为一个好的模式,因为 PLM 会熟悉子模式之间的上下文关系。 (2) 信息量:信息量低的模式(如图3中的),其PLM知识探查能力较弱,如下关系:它不能很好地解释主体或客体实体之间的关系。 (3) 完整性:模式的完整性对 PLM 知识探测有很大影响,特别是当缺少任何占位符时(如图 3 中的 ),PLM 甚至无法给出答案。 (4) 覆盖范围:质量模式应该能够从 PLM 中尽可能多地探查准确的事实。 因此,像 这样只适合少数或仅一种情况的模式应该具有较低的质量分数。 然后,我们将 TruePIE 应用于 MetaPAD 选择的提示(模式)。 TruePIE 过滤与正样本具有低余弦相似度的提示(例如, 和 被过滤),这对于提示集合的创建很重要,因为我们希望提示位于ensemble 在语义上彼此接近,以便一些质量较差的提示不会显着影响 PLM 的预测结果。 因此,我们根据提示给出的平均概率创建一个更可靠的提示集合 :
| (1) |
其中 是 关系, 是 中的第 提示。 除了提示选择之外,还采用了提示优化流程。 Jiang等人2020指出,ensemble中的一些提示更可靠,应该给予更多的权重。 因此,我们将方程 1 更改为:
| (2) |
其中 是第 个关系的第 个提示的权重。 在我们的设置中,所有权重 都是通过 PLM 学习的,以便在训练过程之前针对 优化 。
3.3支持信息检索
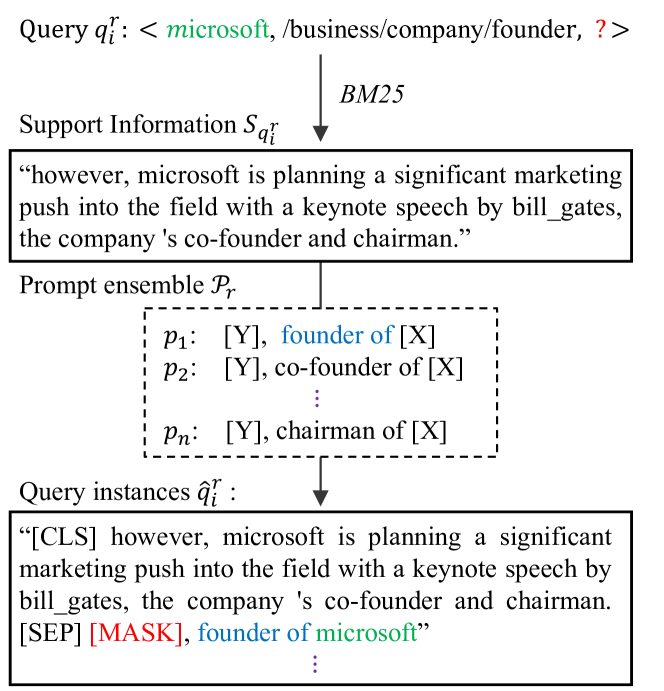
除了提示挖掘之外,我们还在提示中附加了一些查询式和三重式支持文本信息,以帮助 PLM 理解我们想要探究的知识,并帮助训练三重分类能力。 如图4所示,对于关系中的第个查询,我们使用BM25 Robertson等人(1995)从可靠语料库中检索得分大于且长度小于的高排名支持文本,并随机选择其中一个作为支持信息。 为了将输入完形填空 编写到 PLM,我们将支持文本连接到通过前面的步骤获得的优化整体中的每个提示,并填充主语并屏蔽宾语。 [CLS]和[SEP]是序列分类的标记,相应地支持信息提示分离。
在训练阶段,我们使用三元组而不是查询来搜索文本,并且 [MASK] 将由对象实体填充。 值得注意的是,TagReal中的支持文本是可选的,如果没有找到匹配的数据,我们将其留空。
3.4训练
为了训练我们的模型,除了给定的正三元组之外,我们还按照 PKGC Lv 等人 (2022) 引入的想法创建负三元组,以处理三元组分类任务。 我们通过用 KGE 模型实现高概率的“不正确”实体替换每个正三元组中的头部和尾部来创建负三元组。 我们还通过随机替换头和尾来创建随机负样本,以扩大负训练/验证三元组的集合。 标记的训练三元组组装为 ,其中 是正集, 和 是我们通过嵌入创建的两个负集分别基于模型和随机方法。 然后,我们将每个关系 的所有训练三元组转换为带有提示集合 和 BM25 检索到的三元组支持信息(如果有)的句子。 在训练阶段,[MASK]被每个正/负三元组中的对象实体替换。 然后,查询实例 用于通过更新参数来调节 PLM。 应用交叉熵损失Lv 等人 (2022) 进行优化:
| (3) |
其中是词符[CLS]对于三元组的softmax分类分数,是groundtruth标签是三元组的数量,是正三元组和负三元组的数量之比。 在使用训练集中的正/负三元组对 PLM 进行微调后,与原始 PLM 相比,它在对数据集中的三元组进行分类时应该具有更好的性能。 此功能也使其能够执行 KG 补全。
3.5推理
给定查询 ,我们应用与头实体 和关系 相关的查询支持信息,因为我们假设我们不知道尾部实体(我们的预测目标)。 然后,我们制作包含[MASK]的相应查询实例,同时包含支持信息和提示集合,如图4所示。 为了利用 PLM 的三重分类功能进行链接预测,我们将查询实例中的 [MASK] 替换为已知实体集中的每个实体,并按降序排列它们的分类分数以创建 1- d 向量作为每个查询的预测结果。 这表明向量中索引较低的实体更有可能与输入查询组成正三元组。 对于即时集成,我们在对它们进行排名之前按实体索引汇总分数。 详细说明参见附录E。
| Model | 20% | 50% | 100% | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Hits@5 | Hits@10 | MRR | Hits@5 | Hits@10 | MRR | Hits@5 | Hits@10 | MRR | ||
| KGE-based | TransE Bordes et al. (2013) | 29.13 | 32.67 | 15.80 | 41.54 | 45.74 | 25.82 | 42.53 | 46.77 | 29.86 |
| DisMult Yang et al. (2014) | 3.44 | 4.31 | 2.64 | 15.98 | 18.85 | 13.14 | 37.94 | 41.62 | 30.56 | |
| ComplEx Trouillon et al. (2016a) | 4.32 | 5.48 | 3.16 | 15.00 | 17.73 | 12.21 | 35.42 | 38.85 | 28.59 | |
| ConvE Dettmers et al. (2018) | 29.49 | 33.30 | 24.31 | 40.10 | 44.03 | 32.97 | 50.18 | 54.06 | 40.39 | |
| TuckER Balažević et al. (2019) | 29.50 | 32.48 | 24.44 | 41.73 | 45.58 | 33.84 | 51.09 | 54.80 | 40.47 | |
| RotatE Sun et al. (2019) | 15.91 | 18.32 | 12.65 | 35.48 | 39.42 | 28.92 | 51.73 | 55.27 | 42.64 | |
| Text&KGE-based | RC-Net Xu et al. (2014) | 13.48 | 15.37 | 13.26 | 14.87 | 16.54 | 14.63 | 14.69 | 16.34 | 14.41 |
| TransE+Line Fu et al. (2019) | 12.17 | 15.16 | 4.88 | 21.70 | 25.75 | 8.81 | 26.76 | 31.65 | 10.97 | |
| JointNRE Han et al. (2018) | 16.93 | 20.74 | 11.39 | 26.96 | 31.54 | 21.24 | 42.02 | 47.33 | 32.68 | |
| RL-based | MINERVA Das et al. (2017) | 11.64 | 14.16 | 8.93 | 25.16 | 31.54 | 22.24 | 43.80 | 44.70 | 34.62 |
| CPL Fu et al. (2019) | 15.19 | 18.00 | 10.87 | 26.81 | 31.70 | 23.80 | 43.25 | 49.50 | 33.52 | |
| PLM-based | PKGC Lv et al. (2022) | 35.77 | 43.82 | 28.62 | 41.93 | 46.70 | 31.81 | 41.98 | 52.56 | 32.11 |
| TagReal (our method) | 45.59 | 51.34 | 35.41 | 48.98 | 55.64 | 38.03 | 50.85 | 60.64 | 38.86 | |
4实验
4.1 数据集和比较方法
数据集。 我们使用Fu等人提供的数据集FB60K-NYT10和UMLS-PubMed,其中FB60K和UMLS是知识图,NYT10和PubMed是语料库。 FB60K-NYT10 包含更一般的关系(例如,“人的国籍”),而 UMLS-PubMed 侧重于生物医学领域特定的关系(例如,“映射到疾病的基因”)。 我们应用预处理的数据集333https://github.com/INK-USC/CPL#datasets(训练/验证/测试数据大小为 8:1:1),使我们方法的评估与基线保持一致。 由于 FB60K-NYT10 和 UMLS-PubMed 中存在不平衡分布和噪声,分别选择 16 和 8 个关系进行性能评估。
我们在附录A中放置了数据集的更多详细信息。
比较方法。 我们将我们的模型 TagReal 与四类方法进行比较。 对于(1)传统的基于 KG 嵌入的方法,我们评估 TransE Bordes 等人 (2013)、DisMult Yang 等人 ( 2014), ComplEx Trouillon 等人 (2016a), ConvE Dettmers 等人 (2018) 、TuckER Balažević 等人 (2019) 和 RotatE0> Sun 等人 (2019)1> 其中 TuckER 是新添加的模型。 对于(2)联合文本和图形嵌入方法,我们评估 RC-Net Xu 等人 (2014), TransE+LINE Fu 等人 (2019) 和 JointNRE Han 等人 (2018)。 对于(3)基于强化学习(RL)的寻路方法,我们评估 MINERVA Das 等人 (2017) 和 CPL 付等人(2019)。 对于 (4) 基于 PLM 的方法,我们评估 PKGC Lv 等人 (2022) 和我们的方法 TagReal。 我们保留Fu等人2019报告的(2)和(3)数据,同时在不同设置下重新评估(1)中的所有模型以进行更严格的比较(详情请参见附录12)。 在我们的设置中,PKGC 可以被视为带有手动提示且没有支持信息的 TagReal。
| Model | 20% | 40% | 70% | 100% | |||||
|---|---|---|---|---|---|---|---|---|---|
| Hits@5 | Hits@10 | Hits@5 | Hits@10 | Hits@5 | Hits@10 | Hits@5 | Hits@10 | ||
| KGE-based | TransE Bordes et al. (2013) | 19.70 | 30.47 | 27.72 | 41.99 | 34.62 | 49.29 | 40.83 | 53.62 |
| DisMult Yang et al. (2014) | 19.02 | 28.35 | 28.28 | 40.48 | 32.66 | 47.01 | 39.53 | 53.82 | |
| ComplEx Trouillon et al. (2016a) | 11.28 | 17.17 | 24.64 | 35.15 | 25.89 | 38.19 | 34.54 | 49.30 | |
| ConvE Dettmers et al. (2018) | 20.45 | 30.72 | 27.90 | 42.49 | 30.67 | 45.91 | 29.85 | 45.68 | |
| TuckER Balažević et al. (2019) | 19.94 | 30.82 | 25.79 | 41.00 | 26.48 | 42.48 | 30.22 | 45.33 | |
| RotatE Sun et al. (2019) | 17.95 | 27.55 | 27.35 | 40.68 | 34.81 | 48.81 | 40.15 | 53.82 | |
| Text&KGE-based | RC-Net Xu et al. (2014) | 7.94 | 10.77 | 7.56 | 11.43 | 8.31 | 11.81 | 9.26 | 12.00 |
| TransE+Line Fu et al. (2019) | 23.63 | 31.85 | 24.86 | 38.58 | 25.43 | 34.88 | 22.31 | 33.65 | |
| JointNRE Han et al. (2018) | 21.05 | 31.37 | 27.96 | 40.10 | 30.87 | 44.47 | - | - | |
| RL-based | MINERVA Das et al. (2017) | 11.55 | 19.87 | 24.65 | 35.71 | 35.80 | 46.26 | 57.63 | 63.83 |
| CPL Fu et al. (2019) | 15.32 | 24.22 | 26.96 | 38.03 | 37.23 | 47.60 | 58.10 | 65.16 | |
| PLM-based | PKGC Lv et al. (2022) | 31.08 | 43.49 | 41.34 | 52.44 | 47.39 | 55.52 | 55.05 | 59.43 |
| TagReal (our method) | 35.83 | 46.45 | 46.26 | 55.99 | 53.46 | 60.40 | 60.68 | 62.88 | |
| Condition | FB60K-NYT10 | UMLS-PubMed | |||||
|---|---|---|---|---|---|---|---|
| 20% | 50% | 100% | 20% | 40% | 70% | 100% | |
| man | (35.77, 43.82) | (41.93, 46.70) | (41.98, 52.56) | (31.08, 43.49) | (41.34, 52.44) | (47.39, 56.52) | (55.05, 59.43) |
| man+supp | (43.23, 47.74) | (47.10, 52.02) | (48.66, 57.46) | (32.95, 44.42) | (44.37, 54.96) | (51.98, 59.09) | (59.99, 61.23) |
| mine+supp | (44.54, 49.53) | (47.43, 53.87) | (49.03, 58.82) | (35.56, 45.33) | (45.35, 55.44) | (53.12, 59.65) | (60.27, 61.70) |
| optim+supp | (45.59, 51.34) | (48.98, 55.64) | (50.85, 60.64) | (35.83, 46.45) | (46.26, 55.99) | (53.46, 60.40) | (60.68, 62.88) |
4.2实验设置
对于 FB60K-NYT10,我们使用 LUKE Yamada 等人 (2020),这是一种使用 RoBERTa Liu 等人 (2019b) 对更多维基百科数据进行预训练的 PLM。 对于 UMLS-PubMed,我们使用 SapBert Liu 等人 (2021),它使用 BERT Devlin 等人 (2019) 在 UMLS 和 PubMed 上进行了预训练。 对于子语料库挖掘,我们使用具有 6,458,670 个文档示例的维基百科作为通用语料库,并使用 NYT10/PubMed 作为可靠来源,并且我们为每个元组最多挖掘 500 个句子()。 对于提示选择,我们应用 MetaPAD 的默认设置,并应用具有不频繁模式惩罚的 TruePIE,并将正模式和负模式的阈值分别重置为 {0.5, 0.7, 0.3}。 为了支持信息检索,我们使用 BM25 在语料库 NYT10/PubMed 中搜索与 和 相关的文本。 我们遵循与 PKGC 相同的微调过程。 我们使用TuckER作为KGE模型来创建负三元组,并将设置为正/负三元组的比率。 为了与基线进行比较,我们在训练集上测试我们的模型,FB60K-NYT10 的比例为 [20%, 50%, 100%],UMLS-PubMed 的比例为 [20%, 40%, 70%, 100%]。 评估指标在附录F中描述。
5结果
5.1性能比较
我们在表 1 和 2 中展示了与最先进方法的性能比较。 正如我们所观察到的,TagReal 在大多数情况下都优于现有的作品。 给定密集的训练数据,基于 KGE 的方法(例如 RotatE)和基于 RL 的方法(例如 CPL)仍然可以实现相对较高的性能。 然而,当训练数据有限时,这些方法就会受到影响,而基于 PLM 的方法(PKGC 和 TagReal)则不会受到太大影响。 在这种情况下,我们的方法的性能明显优于当前非基于 PLM 的方法。 这是因为 KGE 模型无法在数据不足的情况下进行有效训练,并且由于 KG 中证据和一般路径不足,基于 RL 的路径查找模型无法识别潜在模式。 另一方面,PLM已经拥有可以直接使用的隐含信息,微调时数据不足的负面影响不会比从头训练时那么严重。 TagReal 优于 PKGC,因为它能够自动挖掘质量提示并检索支持信息,而手动注释通常受到限制。 接下来,我们分析支持信息和提示生成对TagReal性能的影响。
5.2模型分析
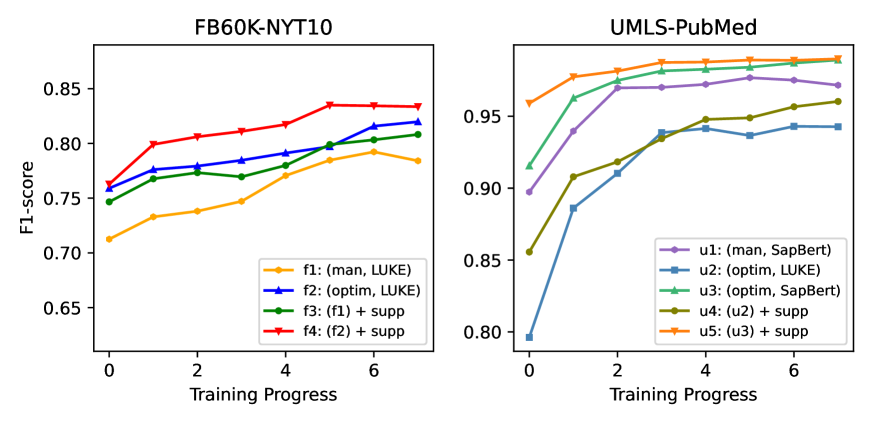

支持信息。 如表3所示,对于FB60K-NYT10,支持信息有助于将Hits@5和Hits@10分别提高[5.2%, 7.5%]和[3.8%, 5.3%]范围。 对于 UMLS-PubMed,它有助于将 Hits@5 和 Hits10 分别提高 [1.9%, 4.94%] 和 [0.9%, 3.6%] 范围。 尽管 UMLS 和 PubMed 之间的重叠度高于 FB60K 和 NYT10 Fu 等人 (2019) 之间的重叠度,但 PubMed 中的文本信息无法像 NYT10 那样提供帮助,因为:(1)SapBert 已经拥有关于 UMLS 和 PubMed 的隐性知识足够多,因此大部分额外的支持文本可能毫无用处。
图 5 中的“u2”、“u3”、“u4”和“u5”行表明,使用 LUKE 作为 PLM 时支持信息的帮助更大,因为它包含较少的特定领域知识。 它还推断支持信息可以推广到任何应用程序,特别是在资源匮乏的情况下很难微调 PLM 时 Arase 和 Tsujii (2019); mahabadi 等人 (2021)。 (2) UMLS 包含比 FB60K 更多具有多个正确答案的查询(请参阅附录 A),这意味着某些查询可能被“误导”到另一个答案,因此不会计入 Hits@N 指标。
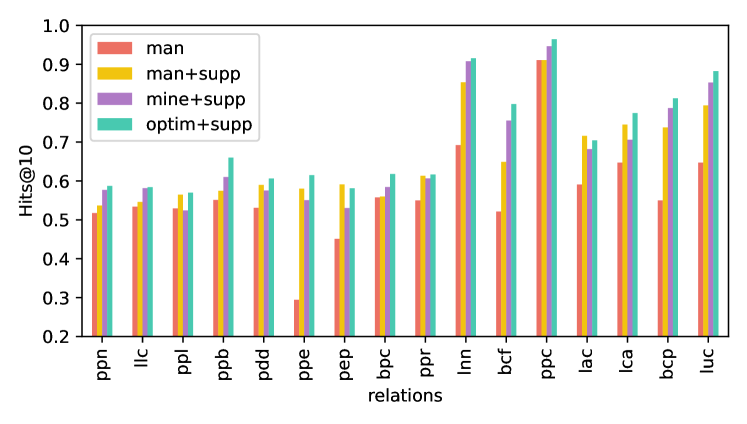
提示生成。 几乎所有的关系,如图6所示,都可以通过我们的提示挖掘和优化转化为更好的提示,尽管由于以下事实,其中一些关系可能比手动创建的提示稍差。 一些挖掘的提示的质量低于手动创建的提示,可能会对具有相同权重的整体的预测分数产生显着的负面影响。 基于 PLM 的加权减少了不良提示对优化整体的负面影响,并使它们能够超越大多数手工制作的提示。 此外,表 3 显示了这三种类型提示的整体改进,表明对于这两个数据集,优化的集成优于同等权重的集成,而同等权重的集成又优于手动创建的提示。 此外,通过比较图 5 中的“f1”行与“f2”行,或“u1”行与“u3”行,我们发现使用手动提示的 PLM 与使用优化集成的 PLM 之间存在性能差距对于三重分类,突出了我们方法的有效性。
5.3案例研究
图 7 显示了使用 TagReal 通过查询 (?, /location/location/ contains, alba) 进行链接预测的示例,其中“皮埃蒙特”是基本事实。 通过比较不同对的预测结果,我们发现提示生成和支持信息都可以提高 KG 完成性能。 通过手工制作的提示,PLM 仅列出与主题实体“alba”有某些联系的术语,而没有意识到我们正在尝试查找它所在的位置。 不同的是,通过优化的提示集合,PLM 列出了与我们的目标高度相关的实体,其中“cuneo”、“italy”、“northern_italy” t2>”是正确的现实答案,表明我们的意图很好地传达给了 PLM。 利用支持信息,PLM 会增加与文本中的关键字(“italy”、“piedmont”)相关的实体的分数。 此外,优化后的整体从列表中删除了“德克萨斯”和“苏格兰”,只留下与意大利相关的位置。 更多示例位于附录H中。
6 结论和未来的工作
在本研究中,我们提出了一种新颖的框架来利用 PLM 中的隐式知识来完成开放 KG。 实验结果表明,我们的方法优于现有方法,特别是当训练数据有限时。 我们表明,在 PLM 知识探索中,使用我们的方法优化的提示优于手工制作的提示。 还证明了支持信息检索辅助提示的有效性。 将来,我们可能会利用 QA 模型的能力来检索更可靠的支持信息。 另一个潜在的扩展是通过探索路径查找任务使我们的模型更易于解释。
7 限制
由于深度学习的性质,我们的方法比基于路径查找的知识图谱补全方法(例如 CPL)更难以解释,后者为目标实体提供了具体的推理路径。 用多个查询组成路径可能是一种值得研究的适用策略,以便扩展我们在知识图谱推理任务上的工作。
对于链接预测任务,我们采用了 PKGC Lv 等人 (2022) 中的“召回和重新排序”策略,这带来了预测效率和准确性之间的权衡。 我们通过在给定不同大小的训练数据的情况下应用不同的超参数来缓解这个问题,附录C对此进行了详细讨论。
作为现有 KG 补全模型的一个常见问题,当输入 KG 包含噪声数据时,我们模型的性能也会下降。 我们解决这个问题的方法的优点是它可以使用基于语料库的文本信息和隐式 PLM 知识来减少噪音。
8 道德声明
在本研究中,我们使用两个数据集 FB60K-NYT10 和 UMLS-PubMed,其中包括知识图 FB60K 和 UMLS 以及文本语料库 NYT10 和 PubMed。 数据全部公开。 我们的任务是知识图补全,这是通过在给定现有知识的情况下查找缺失的事实来执行的。 本作品仅与NLP研究相关,不会被普通人不当使用。
9致谢
研究得到了美国 DARPA KAIROS 计划的部分支持。 FA8750-19-2-1004 和 INCAS 程序编号 HR001121C0165、国家科学基金会 IIS-19-56151、IIS-17-41317 和 IIS 17-04532 以及分子制造实验室研究所:由 NSF 支持的人工智能研究机构计划,奖项编号: 2019897,以及 NSF 的综合发现环境地理空间理解研究所 (I-GUIDE),奖项号:2019897 2118329,以及 NSF 奖 SCH-2205289、SCH-2014438、IIS-2034479。
参考
- AlKhamissi et al. (2022) Badr AlKhamissi, Millicent Li, Asli Celikyilmaz, Mona Diab, and Marjan Ghazvininejad. 2022. A review on language models as knowledge bases. arXiv preprint arXiv:2204.06031.
- Arase and Tsujii (2019) Yuki Arase and Jun’ichi Tsujii. 2019. Transfer fine-tuning: A BERT case study. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China. Association for Computational Linguistics.
- Balažević et al. (2019) Ivana Balažević, Carl Allen, and Timothy M Hospedales. 2019. Tucker: Tensor factorization for knowledge graph completion. arXiv preprint arXiv:1901.09590.
- Bodenreider (2004) Olivier Bodenreider. 2004. The unified medical language system (umls): integrating biomedical terminology. Nucleic acids research, 32(suppl_1):D267–D270.
- Bordes et al. (2013) Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. Advances in neural information processing systems, 26.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Chang et al. (2021) Ting-Yun Chang, Yang Liu, Karthik Gopalakrishnan, Behnam Hedayatnia, Pei Zhou, and Dilek Hakkani-Tur. 2021. Incorporating commonsense knowledge graph in pretrained models for social commonsense tasks. arXiv preprint arXiv:2105.05457.
- Dai et al. (2020) Yuanfei Dai, Shiping Wang, Neal Naixue Xiong, and Wenzhong Guo. 2020. A survey on knowledge graph embedding: Approaches, applications and benchmarks. Electronics, 9:750.
- Das et al. (2017) Rajarshi Das, Shehzaad Dhuliawala, Manzil Zaheer, Luke Vilnis, Ishan Durugkar, Akshay Krishnamurthy, Alex Smola, and Andrew McCallum. 2017. Go for a walk and arrive at the answer: Reasoning over paths in knowledge bases using reinforcement learning. arXiv preprint arXiv:1711.05851.
- Das et al. (2018) Rajarshi Das, Shehzaad Dhuliawala, Manzil Zaheer, Luke Vilnis, Ishan Durugkar, Akshay Krishnamurthy, Alex Smola, and Andrew McCallum. 2018. Go for a walk and arrive at the answer: Reasoning over paths in knowledge bases using reinforcement learning. In International Conference on Learning Representations.
- Dettmers et al. (2018) Tim Dettmers, Pasquale Minervini, Pontus Stenetorp, and Sebastian Riedel. 2018. Convolutional 2d knowledge graph embeddings. In Proceedings of the AAAI conference on artificial intelligence, volume 32.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Fu et al. (2019) Cong Fu, Tong Chen, Meng Qu, Woojeong Jin, and Xiang Ren. 2019. Collaborative policy learning for open knowledge graph reasoning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2672–2681, Hong Kong, China. Association for Computational Linguistics.
- Hamilton et al. (2018) Will Hamilton, Payal Bajaj, Marinka Zitnik, Dan Jurafsky, and Jure Leskovec. 2018. Embedding logical queries on knowledge graphs. Advances in neural information processing systems, 31.
- Han et al. (2000) Jiawei Han, Jian Pei, and Yiwen Yin. 2000. Mining frequent patterns without candidate generation. ACM sigmod record, 29(2):1–12.
- Han et al. (2018) Xu Han, Zhiyuan Liu, and Maosong Sun. 2018. Neural knowledge acquisition via mutual attention between knowledge graph and text. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32.
- Hao et al. (2022) Shibo Hao, Bowen Tan, Kaiwen Tang, Hengzhe Zhang, Eric P Xing, and Zhiting Hu. 2022. Bertnet: Harvesting knowledge graphs from pretrained language models. arXiv preprint arXiv:2206.14268.
- Hao et al. (2017) Yanchao Hao, Yuanzhe Zhang, Kang Liu, Shizhu He, Zhanyi Liu, Hua Wu, and Jun Zhao. 2017. An end-to-end model for question answering over knowledge base with cross-attention combining global knowledge. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 221–231, Vancouver, Canada. Association for Computational Linguistics.
- Hogan et al. (2021) Aidan Hogan, Eva Blomqvist, Michael Cochez, Claudia D’amato, Gerard De Melo, Claudio Gutierrez, Sabrina Kirrane, José Emilio Labra Gayo, Roberto Navigli, Sebastian Neumaier, Axel-Cyrille Ngonga Ngomo, Axel Polleres, Sabbir M. Rashid, Anisa Rula, Lukas Schmelzeisen, Juan Sequeda, Steffen Staab, and Antoine Zimmermann. 2021. Knowledge graphs. ACM Comput. Surv., 54(4).
- Jiang et al. (2017) Meng Jiang, Jingbo Shang, Taylor Cassidy, Xiang Ren, Lance M Kaplan, Timothy P Hanratty, and Jiawei Han. 2017. Metapad: Meta pattern discovery from massive text corpora. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 877–886.
- Jiang et al. (2020) Zhengbao Jiang, Frank F Xu, Jun Araki, and Graham Neubig. 2020. How can we know what language models know? Transactions of the Association for Computational Linguistics, 8:423–438.
- Kim et al. (2020) Bosung Kim, Taesuk Hong, Youngjoong Ko, and Jungyun Seo. 2020. Multi-task learning for knowledge graph completion with pre-trained language models. In Proceedings of the 28th International Conference on Computational Linguistics, pages 1737–1743.
- Li et al. (2018) Qi Li, Meng Jiang, Xikun Zhang, Meng Qu, Timothy P Hanratty, Jing Gao, and Jiawei Han. 2018. Truepie: Discovering reliable patterns in pattern-based information extraction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1675–1684.
- Lin et al. (2015) Yankai Lin, Zhiyuan Liu, Maosong Sun, Yang Liu, and Xuan Zhu. 2015. Learning entity and relation embeddings for knowledge graph completion. In AAAI.
- Liu et al. (2021) Fangyu Liu, Ehsan Shareghi, Zaiqiao Meng, Marco Basaldella, and Nigel Collier. 2021. Self-alignment pretraining for biomedical entity representations. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4228–4238.
- Liu et al. (2019a) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019a. Roberta: A robustly optimized bert pretraining approach. ArXiv, abs/1907.11692.
- Liu et al. (2019b) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019b. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- Lv et al. (2018) Xin Lv, Lei Hou, Juanzi Li, and Zhiyuan Liu. 2018. Differentiating concepts and instances for knowledge graph embedding. arXiv preprint arXiv:1811.04588.
- Lv et al. (2022) Xin Lv, Yankai Lin, Yixin Cao, Lei Hou, Juanzi Li, Zhiyuan Liu, Peng Li, and Jie Zhou. 2022. Do pre-trained models benefit knowledge graph completion? a reliable evaluation and a reasonable approach. In Findings of the Association for Computational Linguistics: ACL 2022, pages 3570–3581.
- mahabadi et al. (2021) Rabeeh Karimi mahabadi, Yonatan Belinkov, and James Henderson. 2021. Variational information bottleneck for effective low-resource fine-tuning. In International Conference on Learning Representations.
- Petroni et al. (2019a) Fabio Petroni, Tim Rocktäschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H Miller, and Sebastian Riedel. 2019a. Language models as knowledge bases? arXiv preprint arXiv:1909.01066.
- Petroni et al. (2019b) Fabio Petroni, Tim Rocktäschel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander Miller. 2019b. Language models as knowledge bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2463–2473, Hong Kong, China. Association for Computational Linguistics.
- Robertson et al. (1995) Stephen E Robertson, Steve Walker, Susan Jones, Micheline M Hancock-Beaulieu, Mike Gatford, et al. 1995. Okapi at trec-3. Nist Special Publication Sp, 109:109.
- Shang et al. (2018) Jingbo Shang, Jialu Liu, Meng Jiang, Xiang Ren, Clare R Voss, and Jiawei Han. 2018. Automated phrase mining from massive text corpora. IEEE Transactions on Knowledge and Data Engineering, 30(10):1825–1837.
- Shi and Weninger (2018) Baoxu Shi and Tim Weninger. 2018. Open-world knowledge graph completion. In Proceedings of the AAAI conference on artificial intelligence, volume 32.
- Shin et al. (2020) Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace, and Sameer Singh. 2020. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4222–4235, Online. Association for Computational Linguistics.
- Sun et al. (2019) Zhiqing Sun, Zhi-Hong Deng, Jian-Yun Nie, and Jian Tang. 2019. Rotate: Knowledge graph embedding by relational rotation in complex space. In International Conference on Learning Representations.
- Trouillon et al. (2016a) Théo Trouillon, Johannes Welbl, Sebastian Riedel, Éric Gaussier, and Guillaume Bouchard. 2016a. Complex embeddings for simple link prediction. In International conference on machine learning, pages 2071–2080. PMLR.
- Trouillon et al. (2016b) Théo Trouillon, Johannes Welbl, Sebastian Riedel, Eric Gaussier, and Guillaume Bouchard. 2016b. Complex embeddings for simple link prediction. In Proceedings of The 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pages 2071–2080, New York, New York, USA. PMLR.
- Wang et al. (2018) Meng Wang, Ruijie Wang, Jun Liu, Yihe Chen, Lei Zhang, and Guilin Qi. 2018. Towards empty answers in sparql: approximating querying with rdf embedding. In International semantic web conference, pages 513–529. Springer.
- Wang et al. (2017) Quan Wang, Zhendong Mao, Bin Wang, and Li Guo. 2017. Knowledge graph embedding: A survey of approaches and applications. IEEE Transactions on Knowledge and Data Engineering, 29:2724–2743.
- Xu et al. (2014) Chang Xu, Yalong Bai, Jiang Bian, Bin Gao, Gang Wang, Xiaoguang Liu, and Tie-Yan Liu. 2014. Rc-net: A general framework for incorporating knowledge into word representations. In Proceedings of the 23rd ACM international conference on conference on information and knowledge management, pages 1219–1228.
- Yamada et al. (2020) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, and Yuji Matsumoto. 2020. Luke: Deep contextualized entity representations with entity-aware self-attention. In EMNLP.
- Yang et al. (2014) Bishan Yang, Wen-tau Yih, Xiaodong He, Jianfeng Gao, and Li Deng. 2014. Embedding entities and relations for learning and inference in knowledge bases. arXiv preprint arXiv:1412.6575.
- Yao et al. (2019) Liang Yao, Chengsheng Mao, and Yuan Luo. 2019. Kg-bert: Bert for knowledge graph completion. arXiv preprint arXiv:1909.03193.
- Yasunaga et al. (2021) Michihiro Yasunaga, Hongyu Ren, Antoine Bosselut, Percy Liang, and Jure Leskovec. 2021. QA-GNN: Reasoning with language models and knowledge graphs for question answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 535–546, Online. Association for Computational Linguistics.
- Zhang et al. (2020) Yunyi Zhang, Jiaming Shen, Jingbo Shang, and Jiawei Han. 2020. Empower entity set expansion via language model probing. arXiv preprint arXiv:2004.13897.
- Zhou et al. (2020) Sijing Zhou, Xinyi Dai, Haokun Chen, Weinan Zhang, Kan Ren, Ruiming Tang, Xiuqiang He, and Yong Yu. 2020. Interactive recommender system via knowledge graph-enhanced reinforcement learning. Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval.
- Zitnik et al. (2018) Marinka Zitnik, Monica Agrawal, and Jure Leskovec. 2018. Modeling polypharmacy side effects with graph convolutional networks. Bioinformatics, 34(13):i457–i466.
附录A数据集概述
我们使用 Fu 等人 (2019) 4 提供的数据集 FB60K-NYT10 和 UMLS-PubMed >44https://github.com/INK-USC/CPL#datasets 。 他们采取以下步骤来拆分数据:(1)将每个KG(FB60K或UMLS)的数据按照8:1:1的比例拆分为训练/验证/测试数据。 (2) 对于训练数据,他们保留任何关系中的所有三元组。 (3)对于验证/测试数据,他们只保留他们关注的16/8关系中的三元组(参见表5中的关系)。 处理后的数据有 FB60K 的 {train: 268280, valid: 8765, test: 8918} 和 UMLS 的 {train: 2030841, valid: 8756, test: 8689}。 至于语料库,NYT10 和 PubMed 中分别有 742536 篇和 5645558 篇文档。
| FB60K-NYT10 | UMLS-PubMed | |
| #query_tail | 57279 | 12956 |
| #query_head | 23319 | 12956 |
| #triples/#queries | 2.22 | 6.81 |
| relations | #triples(all) | #queries(all) | ratio(all) | #triples(test) | #queries(test) | ratio(test) |
| FB60K-NYT10 | ||||||
| /people/person/nationality | 44186 | 20215 | 2.19 | 4438 | 2282 | 1.94 |
| /location/location/contains | 42306 | 11971 | 3.53 | 4244 | 2373 | 1.79 |
| /people/person/place_lived | 29160 | 12760 | 2.29 | 3094 | 2066 | 1.50 |
| /people/person/place_of_birth | 28108 | 16341 | 1.72 | 2882 | 2063 | 1.40 |
| /people/deceased_person/place_of_death | 6882 | 4349 | 1.58 | 678 | 518 | 1.31 |
| /people/person/ethnicity | 5956 | 2944 | 2.02 | 574 | 305 | 1.88 |
| /people/ethnicity/people | 5956 | 2944 | 2.02 | 592 | 318 | 1.86 |
| /business/person/company | 4334 | 2370 | 1.83 | 450 | 379 | 1.19 |
| /people/person/religion | 3580 | 1688 | 2.12 | 300 | 175 | 1.71 |
| /location/neighborhood/neighborhood_of | 1275 | 547 | 2.33 | 130 | 91 | 1.43 |
| /business/company/founders | 904 | 709 | 1.28 | 94 | 87 | 1.08 |
| /people/person/children | 821 | 711 | 1.15 | 56 | 56 | 1.00 |
| /location/administrative_division/country | 829 | 498 | 1.66 | 88 | 72 | 1.22 |
| /location/country/administrative_divisions | 829 | 498 | 1.66 | 102 | 79 | 1.29 |
| /business/company/place_founded | 754 | 548 | 1.38 | 80 | 73 | 1.10 |
| /location/us_county/county_seat | 264 | 262 | 1.01 | 32 | 32 | 1.00 |
| UMLS-PubMed | ||||||
| may_be_treated_by | 71424 | 7703 | 9.27 | 7020 | 3118 | 2.25 |
| may_treat | 71424 | 7703 | 9.27 | 6956 | 3091 | 2.25 |
| may_be_prevented_by | 10052 | 3232 | 3.11 | 1014 | 584 | 1.74 |
| may_prevent | 10052 | 3232 | 3.11 | 1034 | 586 | 1.76 |
| gene_mapped_to_disease | 6164 | 1732 | 3.56 | 596 | 331 | 1.80 |
| disease_mapped_to_gene | 6164 | 1732 | 3.56 | 652 | 357 | 1.82 |
| gene_associated_with_disease | 536 | 289 | 1.85 | 58 | 49 | 1.18 |
| disease_has_associated_gene | 536 | 289 | 1.85 | 48 | 41 | 1.17 |
子训练集分割。 为了以 FB60K-NYT10 的 20%/50% 的比例或 UMLS-PubMed 的 20%/40%/70% 的比例分割训练数据,我们使用与 Fu 相同的随机种子 (55, 83, 5583)等人使用,并报告平均结果。
查询三重比。 在我们关注的关系中,我们通过查询计算三元组的比率(包括 和)来指示查询平均可能有的正确答案数。 结果如表4所示。 对于 UMLS-PubMed,由于关系是成对对称的,因此头预测和尾预测的查询数量是相同的。 表5展示了更详细设置中的计数。 两个表都显示 UMLS-PubMed 中的多答案查询比 FB60K-NYT10 中的多答案查询多,这解释了为什么前者的支持信息可能不如后者有用,如表 3并在5.2节中讨论。
附录B文本模式挖掘

模式挖掘的目的是找到描述数据中特定模式的规则。 信息抽取是模式挖掘和提示挖掘的共同目标,前者侧重于从海量文本语料库中提取事实,后者侧重于从PLM中提取事实。 在本节中,我们使用另一个示例(图8)来详细解释如何使用MetaPAD Jiang 等人(2017)和TruePIE Li等文本模式挖掘方法等人(2018)被实现来挖掘质量提示。 在示例中,输入关系 location/neighborhood/neighborhood_of,我们首先从 KG(即 FB60K)中提取关系中的图元(如 <east new york, brooklyn>)。 然后,我们通过搜索大型语料库(例如维基百科)和 KG 相关语料库(例如 FB60 的 NYT10)中的句子来构建子语料库。 创建子语料库后,我们应用短语分割和频繁模式挖掘来挖掘原始提示候选者。 由于候选集充满噪音,因为一些提示的完整性较低(例如,在较低的[Y]中),信息量较低(例如,[Y],[X])且存在低覆盖率(例如,[X]、曼哈顿、[Y]),我们使用 MetaPAD 来处理提示过滤,其质量函数引入了这些上下文特征。 MetaPAD 处理提示后,我们选择其中一个作为种子提示(例如,[Y] 的 [X] 邻域),以便其他提示可以与它进行比较:计算它们的余弦相似度。 由于积极的种子提示是手动选择的,我们可以看出未来仍有改进的空间。
附录 C 对 KGE 模型的召回进行重新排名
重新排名框架。 根据我们在图 9 中展示的推理过程,我们用实体集 中的每个实体 填充占位符([MASK])。但是,正如 Lv 等人2022提到的,基于 PLM 的模型的推理速度比 KGE 模型慢得多,这是使用 PLM 完成 KG 的缺点。 为了解决这个问题,他们使用了 KGE 模型的召回,即使用 KGE 模型运行 KG 补全,并为每个查询选择 排名靠前的实体作为实体集 。然后,他们使用基于 PLM 的模型对这些实体进行重新排序并重新排序。 在我们的工作中,我们采用这种重新排序框架来加速推理和评估,因为每种情况的时间复杂度都是 PKGC Lv 等人 (2018) 的 倍其中 是提示集合的大小。 我们对两个数据集都使用 TuckER Balažević 等人 (2019) 的召回结果。
限制。 尽管如此,实施重新排名框架需要在效率和 Hits@N 性能之间进行权衡。 当训练数据很大(例如100%)时,KGE模型可以得到很好的训练,使得地面实况实体更有可能包含在排名最高的中那些。 然而,当训练数据有限(例如20%)时,训练好的KGE模型在链接预测上表现不佳,如表1和2所示。 在这种情况下,如果我们继续使用相同的 ,无论训练的大小如何, 都有可能不在顶级 实体之列。数据。 为了减轻这种副作用,我们针对不同大小的训练数据测试并选择不同的超参数 值,如表 6 所示。
| Daatset | 20% | 40% | 50% | 70% | 100% |
|---|---|---|---|---|---|
| FB60K-NYT10 | 70 | - | 40 | - | 20 |
| UMLS-PubMed | 50 | 50 | - | 30 | 30 |
为了检查还有多少改进空间,我们手动将地面实况实体添加到召回中(我们不应该在评估 TagReal 时这样做,因为我们假设对象实体是未知的)并测试TagReal 在 UMLS-PubMed 上的性能。 结果如表7所示。 通过将此数据与 UMLS-PubMed 的表 3 进行比较,我们发现更改 的值并不能完美解决该问题。 我们将改进作为我们未来的主要工作之一。
| Condition | 20% | 40% | 70% | 100% |
|---|---|---|---|---|
| man | (44.83, 60.99) | (50.81, 67.69) | (52.98, 69.21) | (60.19, 72.58) |
| mine | (44.98, 61.56) | (52.81, 68.66) | (56.30, 70.20) | (61.29, 74.76) |
| optim | (45.71, 63.61) | (54.22, 69.03) | (58.18, 71.05) | (63.67, 75.55) |
附录 D计算基础设施和预算
我们在 7 个并行运行的 NVIDIA RTX A6000 上训练和评估 TagReal,因为我们支持多 GPU 计算。 在整个 FB60K-NYT10 数据集(使用 LUKE Yamada 等人 (2020))和整个 UMLS-PubMed 数据集上训练 TagReal 以获得良好的性能大约需要 22 和 14 小时(分别与 SapBert Liu 等人 (2021))。 训练时间与训练数据的大小(比率)成正比。 当超参数 时,使用 LUKE 的 FB60K-NYT10 的评估大约需要 12 分钟,而当 时,使用 SapBert 的 UMLS-PubMed 的评估大约需要 16 分钟。 评估时间与成正比,这解释了为什么我们应用重排序框架(附录C)来提高预测效率。
附录 E与 Ensemble 的链接预测
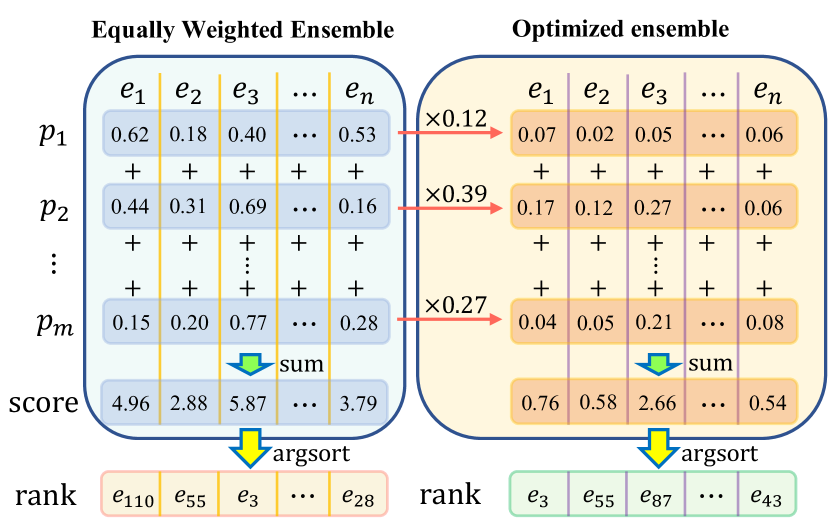
对于等权或优化集成的链路预测,我们应用图9所示的方法。 具体来说,对于每个 [MASK] 填充实体 的句子,我们使用微调的 PLM 计算其分类分数。 对于每个查询,我们得到一个 矩阵,其中 是集合中提示的数量, 是实体集中实体的数量(其中如果应用重新排名框架,则为 )。 对于权重相等的集成,我们只需将从不同提示获得的每个实体的分数相加,而对于优化的集成,我们将提示的权重乘以相加之前的分数。 将大小的向量按降序排序后,我们可以得到实体的排名作为链接预测的结果。
附录F评估指标
继之前的 KG 竣工作品Fu 等人 (2019); Lv 等人 (2022),我们使用 Hits@N 和平均倒数排名 (MRR) 作为我们的评估指标。 正如3.5节中提到的,每个查询的预测 是实体索引的一维向量,按其分数降序排列。 具体来说,对于查询,我们将对象实体的排名记录为,那么我们有:
| (4) |
| (5) |
其中 是评估中的查询数。
附录G代码解释
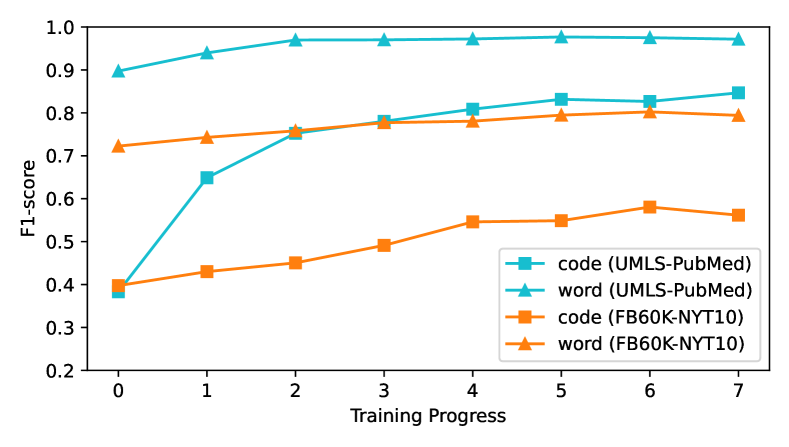

为了发挥PLM的威力,我们需要将KG/语料库中的代码(entity_id)映射到单词中(图10显示了使用单词和使用代码之间的PLM性能差异)。 对于 FB60K-NYT10,我们使用 JointNRE Han 等人 (2018) 555https://github.com/thunlp/JointNRE,涵盖了所有实体的翻译。 对于 UMLS-PubMed,我们联合使用三个映射 666https://evs.nci.nih.gov/ftp1/NCI_Thesaurus/,777https://www.ncbi.nlm.nih.gov/books/NBK9685/,5> 87>88https://bioportal.bioontology.org/ontologies/VANDF
附录 H案例研究
除了图7之外,我们还在图11中展示了在链接预测上应用TagReal的更多示例。 我们可以看到,在所有情况下,优化提示集合的预测都优于手动提示的预测,甚至在某些情况下优于手动提示和支持信息的预测。 在所有这些示例中,支持信息以不同的方式帮助 PLM 知识探索。 对于第一个示例,我们认为 PLM 捕获了单词“brother james_murray”和“his wedding jenny”,并意识到我们正在谈论苏格兰词典编纂者“james_murray”,但根据我们的调查,不是同名的美国喜剧演员。 对于第二个示例,PLM 可能捕获与疾病“高血糖”高度相关的“血糖控制”。 对于第三个示例,可能会捕获术语“antiemetic”(抗呕吐的药物),以便可以正确预测答案“vomiting”。 因此,支持信息不必包括对象实体本身,仅包括一些与其相关的文本也可能会有所帮助。
附录一知识图嵌入模型的重新评估
我们发现,由于实体和关系的嵌入维度设置较低,Fu 等人2019低估了一些KGE模型的性能。 根据我们的重新评估(表8),许多模型在更高的维度上可以表现得更好,我们在表1和2 基于我们的实验。 对于之前评估的模型,我们使用相同的代码 999https://github.com/thunlp/OpenKE,101010https://github.com/DeepGraphLearning/KnowledgeGraphEmbedding,111111https://github.com/TimDettmers/ConvE如Fu 等人所用,以确保比较的公平性。 对于TuckER Balažević 等人 (2019),我们使用作者提供的代码121212https://github.com/ibalazevic/TuckER。 与Fu 等人相同,为了使比较更加严谨,我们不应用过滤设置Bordes 等人(2013); Sun等人(2019)对包括TagReal在内的所有模型进行Hits@N评估。
附录 J纸张代码
TagReal 的源代码作为补充材料附在本文的提交中。
| FB60K-NYT10 | Fu et al.’s setting | Our setting | ||
| (edim, rdim, filter) | Ratio: (Hits@5, Hits@10, MRR) | (edim, rdim, filter) | Ratio: (Hits@5, Hits@10, MRR) | |
| TransE Bordes et al. (2013) | (100, 100, n/a) | 20%: (15.12, 18.83, 12.57) | (600, 600, n/a) | 20%: (29.13, 32.67, 15.80) |
| 50%: (19.38, 23.20, 13.36) | 50%: (41.54, 45.74. 25.82) | |||
| 100%: (38.53, 43.38, 29.90) | 100%: (42.53, 46.77, 29.86) | |||
| DisMult Yang et al. (2014) | (100, 100, n/a) | 20%: (1.42, 2.55, 1.05) | (600, 600, n/a) | 20%: (3.44, 4.31, 2.64) |
| 50%: (15.23, 19.05, 12.36) | 50%: (15.98, 18.85, 13.14) | |||
| 100%: (32.11, 35.88, 24.95) | 100%: (37.94, 41.62, 30.56) | |||
| ComplEx Trouillon et al. (2016a) | (100, 100, n/a) | 20%: (4.22, 5.97, 3.44) | (600, 600, n/a) | 20%: (4.32, 5.48, 3.16) |
| 50%: (19.10, 23.08, 12.99) | 50%: (15.00, 17.73, 12.21) | |||
| 100%: (32.91, 34.62, 24.67) | 100%: (35.42, 38.85, 28.59) | |||
| ConvE Dettmers et al. (2018) | (200, 200, n/a) | 20%: (20.60, 26.90, 11.96) | (100, 100, n/a) | 20%: (22.91, 26.29, 19.48) |
| 50%: (24.39, 30.59, 18.51) | 50%: (26.52, 29.84, 22.67) | |||
| 100%: (33.02, 39.78, 24.45) | 100%: (31.71, 35.66, 25.58) | |||
| (600, 600, n/a) | 20%: (29.49, 33.30, 24.31) | |||
| 50%: (40.10, 44.03, 32.97) | ||||
| 100%: (50.18, 54.06, 40.39) | ||||
| TuckER Balažević et al. (2019) | - | - | (100, 100, n/a) | 20%: (20.04, 23.02, 16.27) |
| 50%: (24.04, 27.88, 20.21) | ||||
| 100%: (34.54, 38.77, 28.19) | ||||
| (600, 600, n/a) | 20%: (29.50, 32.48, 24.44) | |||
| 50%: (41.73, 45.58, 33.84) | ||||
| 100%: (51.09, 54.80, 40.47) | ||||
| RotatE Sun et al. (2019) | (200, 100, ?) | 20%: (9.25, 11.83, 8.04) | (100, 50, n/a) | 20%: (1.34, 2.13, 1.08) |
| 50%: (25.96, 31.63, 23.34) | 50%: (2.54, 4.03, 1.91) | |||
| 100%: (58.32, 60.66, 51.85) | 100%: (5.42, 7.87, 2.09) | |||
| (200, 100, n/a) | 20%: (7.47, 9.14, 5.81) | |||
| 50%: (21.68, 25.45, 17.35) | ||||
| 100%: (47.96, 52.02, 39.17) | ||||
| (600, 300, n/a) | 20%: (15.91, 18.32, 12.65) | |||
| 50%: (35.48, 39.42, 28.92) | ||||
| 100%: (51.73, 55.27, 42.64) | ||||
| UMLS-PubMed | Fu et al.’s setting | Our setting | ||
| (edim, rdim, filter) | Ratio: (Hits@5, Hits@10) | (edim, rdim, filter) | Ratio: (Hits@5, Hits@10) | |
| TransE Bordes et al. (2013) | (100, 100, n/a) | 20%: (7.12, 11.17) | (600, 600, n/a) | 20%: (19.70, 30.47) |
| 40%: (26.86, 38.08) | 40%: (27.72, 41.99) | |||
| 70%: (31.32, 43.58) | 70%: (34.62, 49.29) | |||
| 100%: (32.28, 45.52) | 100%: (40.83, 53.62) | |||
| DisMult Yang et al. (2014) | (100, 100, n/a) | 20%: (14.66, 21.16) | (600, 600, n/a) | 20%: (19.02, 28.35) |
| 40%: (26.90, 38.35) | 40%: (28.28, 40.48) | |||
| 70%: (31.65, 44.98) | 70%: (32.66, 47.01) | |||
| 100%: (32.80, 47.50) | 100%: (39.53, 53.82) | |||
| ComplEx Trouillon et al. (2016a) | (100, 100, n/a) | 20%: (18.18, 19.58) | (600, 600, n/a) | 20%: (11.28, 17.17) |
| 40%: (23.77, 34.15) | 40%: (24.64, 35.15) | |||
| 70%: (30.04, 43.60) | 70%: (25.89, 38.19) | |||
| 100%: (31.84, 46.57) | 100%: (34.54, 49.30) | |||
| ConvE Dettmers et al. (2018) | (200, 200, n/a) | 20%: (20.51, 30.11) | (200, 200, n/a) | 20%: (20.45, 30.72) |
| 40%: (28.01, 42.04) | 40%: (27.90, 42.49) | |||
| 70%: (31.01, 45.81) | 70%: (30.67, 45.91) | |||
| 100%: (30.35, 45.35) | 100%: (29.85, 45.68) | |||
| (600, 600, n/a) | 20%: (20.26, 30.29) | |||
| 40%: (26.85, 41.57) | ||||
| 70%: (26.97, 42.44) | ||||
| 100%: (25.43, 41.58) | ||||
| TuckER Balažević et al. (2019) | - | - | (100, 100, n/a) | 20%: (5.13, 8.06) |
| 40%: (20.48, 31.20) | ||||
| 70%: (29.66, 42.89) | ||||
| 100%: (31.56, 44.72) | ||||
| (256, 256, n/a) | 20%: (19.94, 30.82) | |||
| 40%: (25.79, 41.00) | ||||
| 70%: (26.48, 42.48) | ||||
| 100%: (30.22, 45.33) | ||||
| (600, 600, n/a) | 20%: (18.84, 27.94) | |||
| 40%: (24.57, 37.79) | ||||
| 70%: (25.50, 41.32) | ||||
| 100%: (24.41, 40.56) | ||||
| RotatE Sun et al. (2019) | (200, 100, n/a) | 20%: (4.03, 6.50) | (600, 300, n/a) | 20%: (17.95, 27.55) |
| 40%: (8.65, 13.21) | 40%: (27.35, 40.68) | |||
| 70%: (14.90, 21.67) | 70%: (34.81, 48.81) | |||
| 100%: (20.75, 27.82) | 100%: (40.15, 53.82) | |||