GenerateCT:文本条件下生成3D胸部CT体积
摘要
文本条件下的医学图像生成在放射学领域具有重要意义,例如增强小型真实世界医学数据集、保护数据隐私、特定患者数据建模等。 然而,由于图像和文本描述之间的显著分布差异,该领域落后于文本到自然图像生成。 一种方法是微调预训练的视觉语言模型(在 2D 自然图像-文本对上训练)以用于医学应用。 但是,这种方法在处理 3D 医学图像(如 CT 和 MRI,对危重症患者至关重要)方面存在不足。
在本文中,我们介绍了GenerateCT,一种根据自由形式医学文本提示生成 CT 体积的新方法。 GenerateCT 包含一个文本编码器和三个关键组件:一个用于编码 CT 体积的新型因果视觉 Transformer、一个用于对齐 CT 和文本符元文本-图像 Transformer,以及一个文本条件超分辨率扩散模型。 GenerateCT 可以生成逼真、高分辨率和高保真度的 3D 胸部 CT 体积,经低 FID 和 FVD 分数验证。 为了探索 GenerateCT 的临床应用,我们评估了它在多病变分类任务中的效用。 首先,我们通过在我们真实数据集上训练多病变分类器建立基线。 为了进一步评估模型对外部数据集的泛化能力以及它在零样本场景中对看不见提示的性能,我们使用外部数据集训练分类器,设置了另一个基准。 我们进行了两项实验,其中我们通过使用 GenerateCT 为每个集合合成相同数量的体积来使训练数据集翻倍。 第一个实验表明,当在真实体积和生成体积上联合训练分类器时,AP 分数有所提高。 第二个实验表明,当在基于看不见提示的真实体积和生成体积上进行训练时,有所提高。 此外,GenerateCT 能够将合成训练数据集扩展到任意大小。 例如,我们生成了 100,000 个 CT 体积,是真实数据集数量的五倍,并且仅使用这些合成体积训练了分类器。 令人印象深刻的是,此分类器的性能超过了在所有可用真实数据上训练的分类器的性能,其优势为 。 最后,领域专家评估了生成的体积,确认其与文本提示的高度一致性。 我们的代码和预训练模型可在以下位置获取:https://github.com/ibrahimethemhamamci/GenerateCT。
![[Uncaptioned image]](x1.png)
1 引言
合成医学图像的生成对医学领域具有重要意义。 它促进了机器学习的大规模应用,增强了放射学工作流程,加速了医学研究,并改善了患者护理。 此外,它还解决了医学图像分析中的关键挑战,例如数据稀缺、由于患者隐私问题而需要匿名化、类别分布不平衡以及需要训练有素的临床医生 [24]。
在自然图像生成领域,生成式建模近年来取得了显著进展,特别是在从自由流动的文本中生成图像方面 [10, 30, 31, 34, 45, 2, 7, 12, 16, 26]。 尽管取得了这些进展,但医学领域尚未充分利用大规模基础模型的潜力 [22]。 尤其值得关注的是使用扩散模型从放射学报告中生成 2D 胸部 X 光片 [5],这可以通过微调预训练的开源文本到图像模型 [31] 来实现。 然而,将此方法推广到对护理至关重要的空间更丰富的模态(例如 3D 计算机断层扫描 (CT) 或磁共振成像)具有挑战性。 主要原因是 3D 生成式建模的计算需求呈指数级增长 [8]。 此外,与 2D 生成不同,没有可用于微调的预训练 3D 模型 [46]。 生成二维切片也面临着空间上下文缺失的挑战。 此外,与放射学报告配对的 3D 医学影像数据稀缺 [25]。
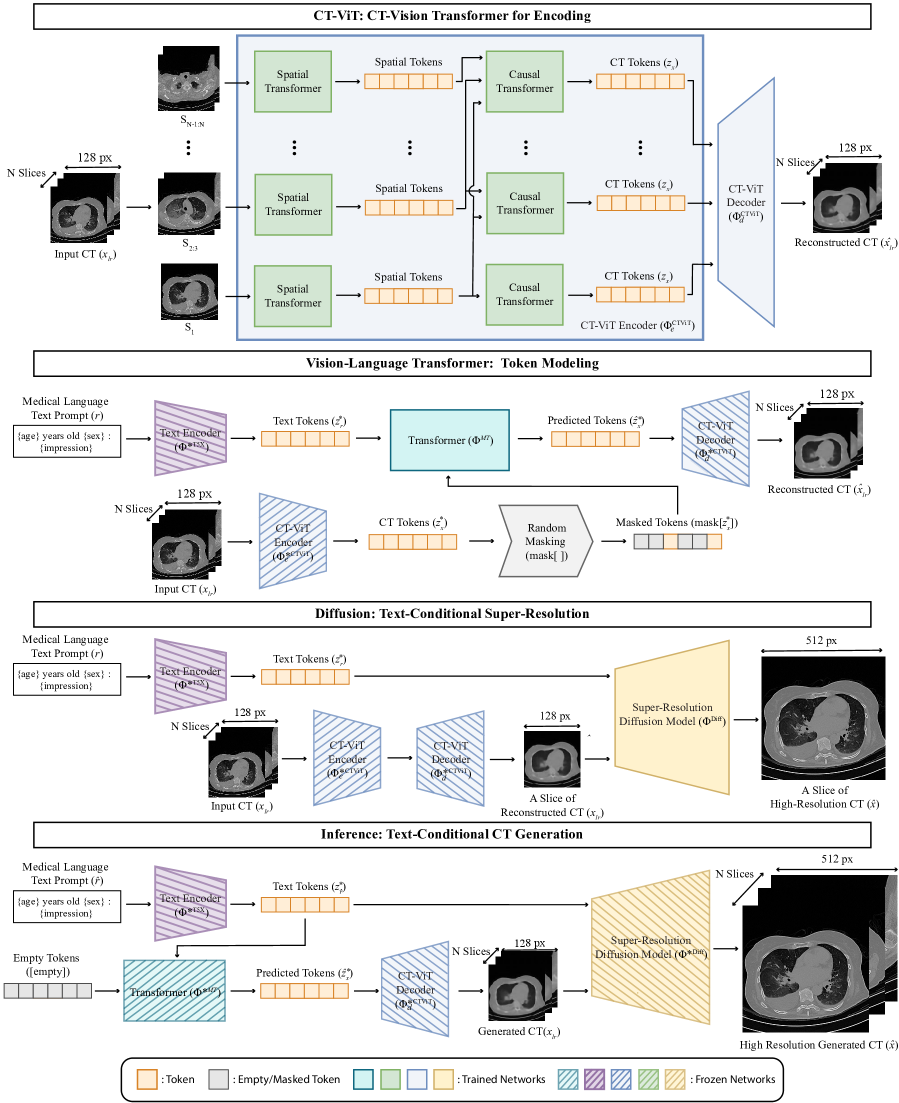
我们提出 GenerateCT,一个用于合成以自由形式文本提示为条件的高分辨率 3D CT 体积的新型文本到图像基础模型(参见 图 1)。 我们将 3D CT 体积的合成概念化为按顺序生成轴向切片的挑战。 它包含三个关键组件:第一个是因果视觉转换器 CT-ViT,它将 CT 体积编码为符元。 CT-ViT 被训练为自回归地重建二维轴向切片,这使我们能够保持高轴向分辨率并生成可变数量的轴向切片,从而提供可变的轴向视场 [1]。 其次,一个双向文本图像转换器将 CT 符元与自由形式放射学文本的编码符元对齐。 这种对齐是使用掩码 CT 符元预测实现的 [6]。 第三,我们采用级联扩散模型 [16] 来增强生成的低分辨率轴向切片的平面内分辨率。 此步骤也是文本条件的,确保基于输入提示进行忠实的解析度增强 [34]。
一旦训练完成,GenerateCT 就可以从自由形式的文本提示生成逼真的高保真 3D 胸部 CT 体积。 据我们所知,这是首个探索文本到 3D 图像生成的方案,尤其是在医学领域。 我们的贡献可以总结如下:
-
•
我们提出了一种新的文本到 CT 生成框架和训练机制,能够生成以医学语言文本提示为条件的 3D 胸部 CT 体积。
-
•
GenerateCT 的核心是 CT-ViT,它能够对 3D CT 体积进行自回归编码和解码,从而实现灵活的任意轴向视场处理。
-
•
我们使用多个图像质量指标对我们方法的生成能力进行了全面评估。 我们还通过在两种情况下执行多异常分类任务来评估与输入文本的一致性:(a) 数据增强,增加幅度高达五倍;(b) 零样本场景,其中不使用来自训练集的提示进行合成数据生成。
-
•
为了方便开箱即用的胸部 CT 生成,我们将所有训练模型(和代码)公开发布。
2 相关工作
文本条件医疗图像生成。
由于对高保真医疗数据需求的不断增长,医疗图像生成已成为一个重要的研究方向。 最近的研究 [5, 24] 探索了基于医疗语言文本提示生成 2D 医疗图像。 这些研究已成功地适应了预训练的潜在扩散模型 [31],利用公开可用的胸部 X 光片和相应的放射学报告 [19]。 通过 GenerateCT,我们将这种能力扩展到包括文本条件的 3D 医疗图像生成。
文本条件视频生成。
已经取得了重大进展,并分为两个主要的研究方向:基于扩散的 [15, 4, 43, 38, 17] 和基于变换器的自回归方法 [37, 41, 18, 40]。 基于扩散的技术,利用 3D U-Net 架构,通常生成较短的低分辨率视频,帧数预设,但可以通过级联扩散模型增强分辨率和持续时间 [15]。 相反,基于 Transformer 的方法具有适应性,可以处理可变的帧数并生成更长的视频,尽管尺寸较小 [42]。 在这种情况下,我们的方法将文本条件视频生成的理念扩展到 3D 医学影像,本质上将 CT 体积视为一系列 2D 图像。 GenerateCT 结合了基于 Transformer 的 [37] 和基于扩散的方法 [15],这使得能够生成具有灵活性和更多切片数的高分辨率 CT 体积。
用于文本条件医学图像生成的 数据集。
训练模型从文本生成医学图像需要配对的图像数据和相应的放射学报告。 虽然像 MIMIC-CXR [19] 这样的公开 2D 影像数据集存在,但公开可用的 3D 医学影像数据集及其报告却很稀缺。 创建此类数据集具有挑战性,因为它们的大小更大,标注 3D 图像需要专业知识,而且数据共享限制严格。 此类数据集的有限可用性显而易见,即使是关注胸部 CT 体积多病变检测的研究 [11] 也只公开了一小部分数据集。 这突出了对更多公开可用的 3D 医学影像数据以及文本条件 3D 医学影像数据生成的迫切需求,这可以推动该领域进一步的研究。 为了应对这一挑战,我们已将我们完全训练的模型公开发布。 我们希望这将使研究人员能够使用文本提示生成自己的数据集,几乎没有限制。
3 方法
3.1 数据集准备
我们的数据集包含 25,701 个非对比 3D 胸部 CT 体积,分辨率为 ,轴向切片数量从 100 到 600 不等。 这些体积来自 21,314 个独特的患者,并使用适合不同窗口设置的多种方法进行重建 [39]。 这导致总共 49,138 个 CT 体积,考虑到不同的重建方法。 我们将这些体积划分为一个训练集,包含 20,000 个独特的患者,以及一个测试集,包含 1,314 个独特的患者,确保患者之间没有重叠。 每个 CT 体积都附带元数据,其中包括患者的年龄、性别和成像细节。 此外,这些体积与放射学报告配对,这些报告被分类到不同的部分:临床信息、技术、发现和印象。 文本提示的格式为 {age} years old {sex}: {impression},使用印象部分和元数据,如 Fig. 1 所示。 我们使用从元数据中检索到的斜率和截距值将 CT 体积转换为相应的 Hounsfield 单位 (HU)。 这些值被剪裁到范围 ,代表 HU 量表的实际下限和上限 [9, 23]。 数据集的使用已获得伦理委员会的批准。
3.2 GenerateCT:文本条件 CT 生成
GenerateCT,如 Fig. 2 所示,由三个主要组件组成,每个组件在不同的阶段进行训练:(1)用于 CT 体积编码的 CT-ViT(第 3.2.1 节),(2)用于文本和图像对齐的掩码生成图像文本转换器(第 3.2.2 节),以及(3)用于超分辨率的文本条件扩散模型(第 3.2.3 节)。 它处理一个 3D CT 体积,,涵盖矢状 ()、冠状 () 和轴向 () 尺寸,以及相应的放射学文本报告,。GenerateCT 经过训练,可以从医疗文本提示创建 CT 体积,在我们的实验中,尺寸设置为 、 和 。
3.2.1 CT-ViT:用于编码的 CT-Vision Transformer
我们引入 CT-ViT 来实现 CT 体积的紧凑潜在表示。 受 ViViT [1] 和 C-ViViT [37] 等视频转换器的启发,CT-ViT 从 CT 体积中提取时空标记。 这些标记通过全对全空间注意和因果注意层进行编码,从而生成编码的 CT 标记。 随后,一个解码器网络在这些标记上进行操作以重建输入 CT 体积,形成一个自回归编码器-解码器网络。 这种设计有利于处理具有可变颅尾覆盖范围的真实世界 CT 体积。
CT-ViT 编码器网络 () 接受低分辨率 CT 体积 并输出嵌入的 CT 符元 。 解码器网络 () 使用这些嵌入的 CT 符元在同一空间中重建 CT 体积 ()。 简而言之:
编码器网络首先从第一层提取 像素的非重叠块,并从其余层提取 块。 然后,每个块被线性变换到 维空间,其中 是潜在空间维度,设置为 。 对于第一帧,数据从 重塑为 。 这里, 代表批次大小, 代表通道数, 和 代表切片的宽度和高度, 和 代表空间块大小。 然后,一个线性层将最终维度变换为 ,生成一个维度为 的张量。 其余切片经过类似的重塑和线性变换,从 变换为 ,最终变为 ,其中 代表时间块大小, 代表时间块数量。
在组合初始帧和后续帧嵌入后,生成的张量为 。 该张量依次由两个 Transformer 网络处理。 空间 Transformer 在一个重塑后的张量 上操作,输出一个相同大小的张量。 然后,因果 Transformer 处理此输出,将其重塑为 ,并产生一个保持这些维度的输出。 这在每个 Transformer 层之后都保留了空间和潜在维度,确保了在整个网络处理阶段都保留了体积信息。
CT-ViT 解码器通过将符元转换回其原始体素空间来镜像编码过程,从而允许重建 CT 体积,同时保留输入的轴向维度。 此功能允许生成具有不同切片数量的 CT 体积。 此外,CT-ViT 模型包含向量量化技术以创建离散潜在空间。 该技术将编码器输出量化为从学习代码簿中获取的一组条目,如 [36] 中所述。
该模型的自回归训练过程结合了多种损失函数,包括来自 ViT-VQGAN [44] 的 L2 损失以确保重建一致性,图像感知损失 [20] 用于感知相似性,以及与 StyleGAN [21] 一致的对抗性损失。
3.2.2 视觉语言 Transformer:符号建模
在 GenerateCT 的第二阶段,我们使用掩码视觉符号建模 [6] 对齐 CT 和文本空间。 这涉及先前训练的 CT-ViT 编码器 () 及其产生的 CT 符号 (),它们被掩码 () 并输入到双向 Transformer () 中。 放射学报告 (),使用 T5X 文本编码器 () 编码,作为条件输入 [29]。 Transformer 的作用是根据文本嵌入预测这些掩码的 CT 符号,并结合输入 CT 符号的交叉注意力。 这些预测的 CT 符号随后由冻结的 CT-ViT 解码器 () 处理,预计可以准确地重建输入的 CT 体积。 文本-CT 对齐阶段的前向传递,利用经过训练的 CT-ViT 的掩码符号建模,表示如下:
该阶段的训练整合了重建损失和符号批评损失。 重建损失评估模型在序列中预测掩码视频代码簿 ID 的能力,使用交叉熵来量化预测符号和实际符号之间的差异。 此外,批评损失还包含一个评估视频代码簿 ID 序列是真实还是伪造的组件,采用二元交叉熵来衡量预测批评者概率与实际标签之间的对齐程度。
在推理期间,所有 CT 符号都被掩码,并由双向 Transformer 根据文本嵌入和先前预测的 CT 符号进行预测。 然后使用 CT-ViT 解码器重建这些符号。
3.2.3 扩散:文本条件下的超分辨率
GenerateCT 的最终阶段采用了一种基于扩散的文本条件二维超分辨率模型 () 来增强最初生成的低分辨率 CT 体积的分辨率。 使用级联扩散方法 [16],此过程按顺序采用扩散模型,这些模型通过上采样和引入更精细的细节来增强图像分辨率。 此方法在内存效率方面优于传统的 U-Net 扩散模型 [27, 33],这是通过在瓶颈阶段将一个跨注意力层与 T5 嵌入文本符元结合,从而替代自注意力层 [3] 来实现的。 此层将扩散条件化为编码的文本提示和初始低分辨率图像。 通过消融研究确定了最佳级联步骤 (表 2)。 值得注意的是,使用 CT-ViT 重建的体积作为输入,而不是原始降采样的体积,可以提高性能,这与噪声条件 [15] 的原理一致。 该过程表示为:
其中 表示大小为 的最终生成的完整分辨率 CT 体积。
模型的训练采用了一种损失函数,该函数旨在最小化去噪图像与实际高分辨率图像之间的差异。 该函数包含一个均方误差 (MSE) 分量,用于像素精度,并将噪声水平整合到损失权重中,确保对噪声样本进行适当的考虑。 总体损失是这些噪声加权 MSE 值的平均值,量化了去噪切片与实际切片之间的偏差。
3.2.4 推理
在训练 GenerateCT 后,从新的放射学文本提示 () 生成合成 CT 体积 () 的过程如下:
其中 表示完全屏蔽的 CT 符元占位符。 此过程涉及对提示进行编码,使用屏蔽的 Transformer 预测 CT 符元,然后解码这些符元以创建合成 CT 体积。
4 实验
4.1 实现细节
CT-ViT 模型在 49,138 个 CT 体积上进行训练(参见 Sec. 3.1)。 Transformer 模型训练使用与相应文本提示配对的相同 CT 体积(Fig. 2)。 扩散模型使用了 9,876,738 个 CT 切片,并使用来自匹配 CT 体积的文本提示进行条件化。 每个模型的训练参数在 Tab. 1 中详细说明。
| CT-ViT | Transformer | Diffusion | |
| Optimizer | Adam | Adam | Adam |
| 1 | 0.9 | 0.9 | 0.9 |
| 2 | 0.99 | 0.99 | 0.99 |
| Learning Rate | 0.00003 | 0.00003 | 0.0005 |
| Batch Size | 32 | 4 | 10 |
| Scheduler | N/A | Cosine Annealing | N/A |
| Warmup Steps | N/A | 10,000 | N/A |
| Max Steps | N/A | 4,000,000 | N/A |
| GPUs Utilized | 8 | 8 | 8 |
| Train Duration | 1 week | 1 week | 1 week |
| Iterations | 100,000 | 500,000 | 275,000 |
4.2 实验结果
| Output Resolution of Each Submodel | Performance Metrics | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | S. Time (s) | Transformer | 1st SR | 2nd SR | 3rd SR | FVD | FVD | FID | CLIP |
| 1SCM | 23 | 512512 | N/A | N/A | N/A | 1886.8 | 9.5534 | 104.3 | 25.2 |
| 2SCM | 102 | 256256 | 512512 | N/A | N/A | 1661.4 | 8.9021 | 86.9 | 25.9 |
| 3SCM | 184 | 128128 | 256256 | 512512 | N/A | 1092.3 | 8.1745 | 55.8 | 27.1 |
| 4SCM | 244 | 6464 | 128128 | 256256 | 512512 | 1201.4 | 8.5869 | 71.3 | 26.6 |
定量评估。
我们使用三个指标评估了生成 CT 体积的质量,请参阅 表 2:
-
•
Fréchet 视频距离 (FVD) 通过使用 I3D 模型 [35](它非常适合视频数据集,表示为 )提取图像特征,量化了生成 CT 体积与真实 CT 体积之间的差异。 认识到它在医学数据集方面的局限性,我们还采用了在我们的训练数据集上训练的 3D CT-Net 模型 [11],用于多异常分类(详细介绍在 第 4.2 节中)。 这种方法(表示为 )允许进行领域相关的特征提取和距离计算,从而提供更合适的比较。
-
•
Fréchet 感知距离 (FID) 评估了生成图像的质量,但使用 InceptionV3 模型 [14] 在切片级别进行评估。 必须注意的是,FID 可能不完全适合我们的 3D 生成,因为单个 CT 切片可能无法准确反映体积级别的发现,这可能会导致误导性结果。
-
•
CLIP 得分衡量文本报告与生成体积之间的对齐程度 [13]。 此测量是通过利用预训练的 CLIP 模型 [28] 实现的,该模型是一个基础文本-图像模型,经过训练以关联视觉和文本内容。 在我们的训练数据集中,包括配对的体积和文本,图像-文本对齐实现了 CLIP 得分 ,作为基准。
消融研究。
GenerateCT 的级联架构在不同的阶段进行了评估,如 表 2 所示。 我们测试了四种 阶段级联模型 (SCM),它将基于 transformer 的文本条件生成模型与 基于扩散的超分辨率步骤相结合,以生成高分辨率 CT 体积。 1SCM 模型专门使用 transformer 模型(Phenaki [37] 的一个适应版本)来直接生成最终分辨率。
在性能指标方面, 与 相比,始终显示出较低的得分,这是由于 CT-Net 对 CT 体积的特定训练造成的。 和 以及 FID 和 CLIP 分数通常随着超分辨率步骤数量的增加而降低,4SCM 模型是一个例外,因为它初始分辨率显着低。 3SCM 模型实现了 的 CLIP 得分,接近 的基线,表明文本与生成体积之间具有极好的对齐。 因此,3SCM 模型在所有关键指标上都优于其他模型,因此被选用于进一步的 GenerateCT 实验。
| First Radiologist (4 years of experience) | ||
| Task | Real Volumes | Synthetic Volumes |
| Reality Prediction | Real: 74 | Real: 41 |
| Synthetic: 26 | Synthetic: 59 | |
| Text Prompt | Matched: 82 | Matched: 66 |
| Mismatched: 18 | Mismatched: 34 | |
| Second Radiologist (11 years of experience) | ||
| Task | Real Volumes | Synthetic Volumes |
| Reality Prediction | Real: 71 | Real: 36 |
| Synthetic: 29 | Synthetic: 64 | |
| Text Prompt | Matched: 83 | Matched: 70 |
| Mismatched: 17 | Mismatched: 30 | |
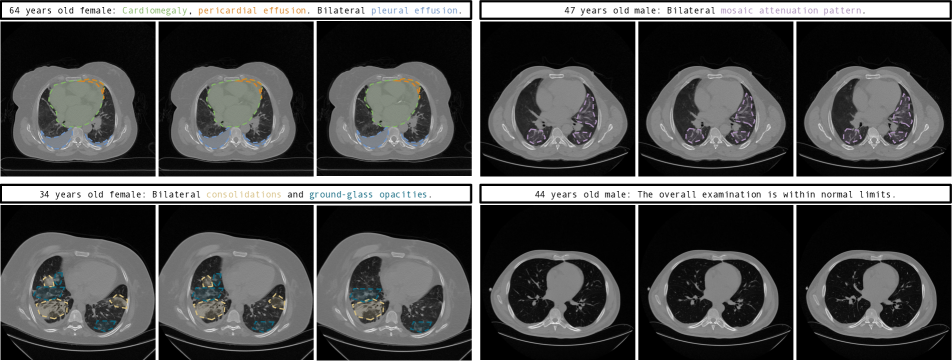
定性结果。
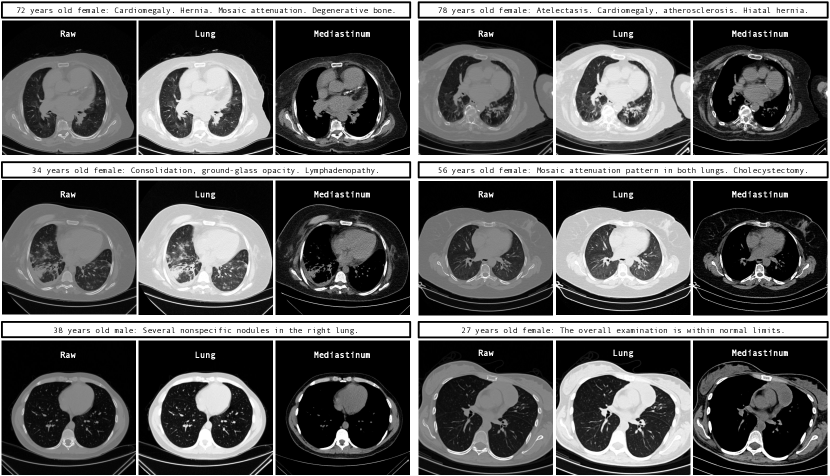
本节展示了 GenerateCT 在 的原始 HU 范围内生成的 CT 体积,与标准窗口不同,更真实地表示数据。 补充材料提供了各种窗口示例以供比较。
如 图 3 所示,GenerateCT 有效地将特定的文本提示转换为 3D 胸部 CT 体积。 前三个体积显示出不同的病理,用彩色文本和区域标记,在切片之间一致,与第四个健康肺部的体积形成对比。 这些体积在大小、方向、年龄和性别方面显示出多样性,强调了从文本提示中可生成的数据范围。
专家评估。
一项涉及两名放射科医生的盲法研究评估了200个胸部CT体积,包括100个真实体积和100个合成体积的等量混合,以评估生成体积的视觉质量及其与文本提示的对齐。 放射科医生被要求识别每个体积是真实的还是合成的,并验证文本提示和体积发现之间的匹配(详见表 3)。
在第一个任务中,尽管知道一半的体积是合成的,但两位放射科医生都有显著的误分类率,突出了GenerateCT能够创建高度难以区分的合成体积的能力。 真实体积和合成体积之间假阴性率的差异在统计学上不显著(,非配对T检验),突出了合成体积令人信服的真实性。
在第二个任务中,放射科医生发现,与真实体积相似,相当数量的合成体积,例如,准确地匹配了给定的文本提示。 这表明生成的CT体积与其相应的文本提示之间存在高度一致性。
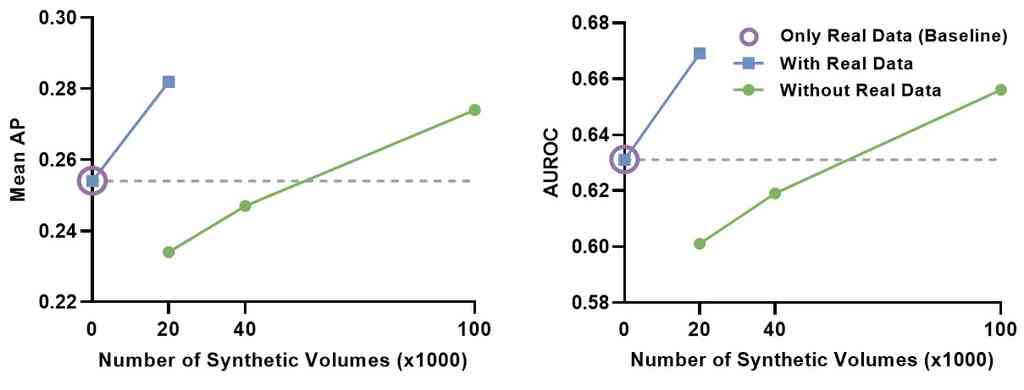
在数据增强中利用GenerateCT。
我们评估了GenerateCT在放射学框架内的临床应用潜力。 一个多异常分类模型最初使用我们数据集中的20,000个真实胸部CT体积进行训练,每个体积代表一个独特的患者概况(见第 3.1节)。 该模型作为我们的基线,获得了的平均平均精度(AP)和的接收者操作特征曲线下面积(AUROC)。
然后,我们使用文本提示生成了 20,000 个合成体积,并在真实和合成数据的混合数据集上训练分类器。 结果表明,与仅在真实数据上训练相比,平均 AP 提高,平均 AUROC 提高。 进一步的实验涉及使用重复提示将合成数据集扩展到 100,000 个体积。 仅在该合成数据上训练导致平均 AP 提高,平均 AUROC 上升,与真实数据模型相比。
结果如 6 所示,证明了 GenerateCT 在临床环境中的有效性。 首先,即使是通过单个因素进行的数据增强也能显著提高性能,这突出了它对拥有真实世界数据并旨在提高性能的研究人员的潜力。 其次,在五倍增加后,在更大的、完全合成的数据集上进行训练,与仅使用真实数据模型相比,获得了明显更好的分数,突出了 GenerateCT 对数据隐私的贡献。 这种方法使研究人员能够训练和共享生成模型(如我们的模型),从而促进使用文本提示创建合成数据,从而在没有隐私或数据共享问题的情况下获得更好的性能。 第三,使用重复提示进行数据生成的得分增加表明,GenerateCT 能够使用相同的提示生成可变数据。 附加材料中提供了有关训练过程和每种异常类型的具体准确度的更多详细信息。
在零样本环境中使用 GenerateCT。
为了评估 GenerateCT 对外部数据集的泛化能力,我们使用 RadChestCT [11] 进行了一项实验,该实验包括 3,630 个胸部 CT 体积,包含 83 种不同的异常,平均异常标签频率为 。 我们使用在 GenerateCT 训练中未包含的文本提示创建了一个新数据集,该数据集在体积计数和异常分布方面与 RadChestCT 的训练集相匹配。 分类器 [11] 在该合成数据集、原始 RadChestCT 数据集以及两者的组合上进行了训练。
结果令人鼓舞:在合成数据上训练的模型实现了与在真实患者数据上训练的模型相近的性能指标,平均 AP 为 (真实)与 (合成),平均 AUROC 为 (真实)与 (合成)。 在组合数据集上进行训练显著提高了性能(平均 AUROC ,平均 AP )。 这表明 GenerateCT 的关键优势扩展到外部数据集,即使在从未见过的提示下,它在临床应用方面也具有潜力。 在补充材料中,我们提供了有关训练过程和每种异常的具体准确性的信息。
5 结论与讨论
在本文中,我们介绍了 GenerateCT,这是第一个专门针对胸部 CT 的文本条件 3D 医学图像生成框架。 我们的实验表明它能够从文本提示生成逼真的高质量胸部 CT 体积,以及其在多异常分类中的临床应用。 作为该领域的一项重大进步,我们使 GenerateCT 完全开源,为未来的研究和开发奠定坚实的基础。
限制。
尽管 GenerateCT 具有创新性,但它也面临着一些挑战。 缺乏基准限制了它的全面评估。 我们使用了一种二维超分辨率方法来提高计算效率并处理不同的切片数量,但这可能会降低与放射学报告的比对精度,因为三维方法可能更精确。 虽然 GenerateCT 旨在深入处理不同尺寸的 3D 图像,但对其功能的详细定量评估尚未进行。 我们的单机构数据集可能不够多样,存在偏差和适用性有限的风险。 扩大训练范围,超越放射学报告中的印象部分,可以提高结果。 最后,GenerateCT 的巨大计算需求是一个关键因素。
参考文献
- Arnab et al. [2021] Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, and Cordelia Schmid. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6836–6846, 2021.
- Balaji et al. [2022] Yogesh Balaji, Seungjun Nah, Xun Huang, Arash Vahdat, Jiaming Song, Karsten Kreis, Miika Aittala, Timo Aila, Samuli Laine, Bryan Catanzaro, et al. ediffi: Text-to-image diffusion models with an ensemble of expert denoisers. arXiv preprint arXiv:2211.01324, 2022.
- Beltagy et al. [2020] Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020.
- Blattmann et al. [2023] Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. arXiv preprint arXiv:2304.08818, 2023.
- Chambon et al. [2022] Pierre Chambon, Christian Bluethgen, Jean-Benoit Delbrouck, Rogier Van der Sluijs, Małgorzata Połacin, Juan Manuel Zambrano Chaves, Tanishq Mathew Abraham, Shivanshu Purohit, Curtis P Langlotz, and Akshay Chaudhari. Roentgen: Vision-language foundation model for chest x-ray generation. arXiv preprint arXiv:2211.12737, 2022.
- Chang et al. [2022] Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. Maskgit: Masked generative image transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11315–11325, 2022.
- Chen et al. [2022] Wenhu Chen, Hexiang Hu, Chitwan Saharia, and William W Cohen. Re-imagen: Retrieval-augmented text-to-image generator. arXiv preprint arXiv:2209.14491, 2022.
- Clark et al. [2019] Aidan Clark, Jeff Donahue, and Karen Simonyan. Adversarial video generation on complex datasets. arXiv preprint arXiv:1907.06571, 2019.
- DenOtter and Schubert [2019] Tami D DenOtter and Johanna Schubert. Hounsfield unit, 2019.
- Ding et al. [2021] Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, et al. Cogview: Mastering text-to-image generation via transformers. Advances in Neural Information Processing Systems, 34:19822–19835, 2021.
- Draelos et al. [2021] Rachel Lea Draelos, David Dov, Maciej A Mazurowski, Joseph Y Lo, Ricardo Henao, Geoffrey D Rubin, and Lawrence Carin. Machine-learning-based multiple abnormality prediction with large-scale chest computed tomography volumes. Medical image analysis, 67:101857, 2021.
- Gu et al. [2022] Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, and Baining Guo. Vector quantized diffusion model for text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10696–10706, 2022.
- Hessel et al. [2021] Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. arXiv preprint arXiv:2104.08718, 2021.
- Heusel et al. [2017] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017.
- Ho et al. [2022a] Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303, 2022a.
- Ho et al. [2022b] Jonathan Ho, Chitwan Saharia, William Chan, David J Fleet, Mohammad Norouzi, and Tim Salimans. Cascaded diffusion models for high fidelity image generation. J. Mach. Learn. Res., 23(47):1–33, 2022b.
- Ho et al. [2022c] Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. arXiv preprint arXiv:2204.03458, 2022c.
- Hong et al. [2022] Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers. arXiv preprint arXiv:2205.15868, 2022.
- Johnson et al. [2019] Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Roger G Mark, and Steven Horng. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports. Scientific data, 6(1):317, 2019.
- Johnson et al. [2016] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14, pages 694–711. Springer, 2016.
- Karras et al. [2020] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8110–8119, 2020.
- Kebaili et al. [2023] Aghiles Kebaili, Jérôme Lapuyade-Lahorgue, and Su Ruan. Deep learning approaches for data augmentation in medical imaging: A review. Journal of Imaging, 9(4):81, 2023.
- Lamba et al. [2014] Ramit Lamba, John P McGahan, Michael T Corwin, Chin-Shang Li, Tien Tran, J Anthony Seibert, and John M Boone. Ct hounsfield numbers of soft tissues on unenhanced abdominal ct scans: variability between two different manufacturers’ mdct scanners. AJR. American journal of roentgenology, 203(5):1013, 2014.
- Lee et al. [2023] Hyungyung Lee, Wonjae Kim, Jin-Hwa Kim, Tackeun Kim, Jihang Kim, Leonard Sunwoo, and Edward Choi. Unified chest x-ray and radiology report generation model with multi-view chest x-rays. arXiv preprint arXiv:2302.12172, 2023.
- Linna and Kahn Jr [2022] Nathaniel Linna and Charles E Kahn Jr. Applications of natural language processing in radiology: A systematic review. International Journal of Medical Informatics, page 104779, 2022.
- Nichol et al. [2021] Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741, 2021.
- Nichol and Dhariwal [2021] Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In International Conference on Machine Learning, pages 8162–8171. PMLR, 2021.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Raffel et al. [2020] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
- Ramesh et al. [2022] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022.
- Ruder [2016] Sebastian Ruder. An overview of gradient descent optimization algorithms. arXiv preprint arXiv:1609.04747, 2016.
- Saharia et al. [2022a] Chitwan Saharia, William Chan, Huiwen Chang, Chris Lee, Jonathan Ho, Tim Salimans, David Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. In ACM SIGGRAPH 2022 Conference Proceedings, pages 1–10, 2022a.
- Saharia et al. [2022b] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. Advances in Neural Information Processing Systems, 35:36479–36494, 2022b.
- Unterthiner et al. [2019] Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. Fvd: A new metric for video generation, 2019.
- Van Den Oord et al. [2017] Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. Advances in neural information processing systems, 30, 2017.
- Villegas et al. [2022] Ruben Villegas, Mohammad Babaeizadeh, Pieter-Jan Kindermans, Hernan Moraldo, Han Zhang, Mohammad Taghi Saffar, Santiago Castro, Julius Kunze, and Dumitru Erhan. Phenaki: Variable length video generation from open domain textual description. arXiv preprint arXiv:2210.02399, 2022.
- Voleti et al. [2022] Vikram Voleti, Alexia Jolicoeur-Martineau, and Christopher Pal. Masked conditional video diffusion for prediction, generation, and interpolation. arXiv preprint arXiv:2205.09853, 2022.
- Willemink and Noël [2019] Martin J Willemink and Peter B Noël. The evolution of image reconstruction for ct—from filtered back projection to artificial intelligence. European radiology, 29:2185–2195, 2019.
- Wu et al. [2021] Chenfei Wu, Lun Huang, Qianxi Zhang, Binyang Li, Lei Ji, Fan Yang, Guillermo Sapiro, and Nan Duan. Godiva: Generating open-domain videos from natural descriptions. arXiv preprint arXiv:2104.14806, 2021.
- Wu et al. [2022] Chenfei Wu, Jian Liang, Lei Ji, Fan Yang, Yuejian Fang, Daxin Jiang, and Nan Duan. Nüwa: Visual synthesis pre-training for neural visual world creation. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XVI, pages 720–736. Springer, 2022.
- Yan et al. [2021] Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157, 2021.
- Yang et al. [2022] Ruihan Yang, Prakhar Srivastava, and Stephan Mandt. Diffusion probabilistic modeling for video generation. arXiv preprint arXiv:2203.09481, 2022.
- Yu et al. [2021] Jiahui Yu, Xin Li, Jing Yu Koh, Han Zhang, Ruoming Pang, James Qin, Alexander Ku, Yuanzhong Xu, Jason Baldridge, and Yonghui Wu. Vector-quantized image modeling with improved vqgan. arXiv preprint arXiv:2110.04627, 2021.
- Yu et al. [2022] Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, et al. Scaling autoregressive models for content-rich text-to-image generation. arXiv preprint arXiv:2206.10789, 2022.
- Zhang et al. [2023] Chenshuang Zhang, Chaoning Zhang, Mengchun Zhang, and In So Kweon. Text-to-image diffusion model in generative ai: A survey. arXiv preprint arXiv:2303.07909, 2023.
补充材料
本补充文件扩展了主论文中介绍的结果,重点关注三个关键方面:
-
•
我们提供了更多带有不同窗口设置的示例以供比较,展示了 GenerateCT 如何有效地从文本描述中生成 3D 医学图像。
-
•
我们对 GenerateCT 的一个实际临床应用进行了详细的探索,特别是它在多异常分类中用于数据扩充。
-
•
我们还对 GenerateCT 的另一个实际临床应用进行了详细的探索,其中我们展示了它泛化到外部数据集的能力以及它从未见过的提示生成 CT 体积的熟练程度。
1 全面的定性结果
本节展示了 GenerateCT 生成的胸部 CT 体积的广泛范围。 在 图 1 中,我们展示了生成的 3D CT 体积的轴向切片,既包括 的原始豪斯菲尔德单位 (HU) 范围,也包括通过不同的窗口技术,以增强与临床实践的一致性,并清晰地显示基于医学文本描述的生成细节。 这强调了 GenerateCT 不仅在空间细节方面,而且在动态范围方面的准确性。
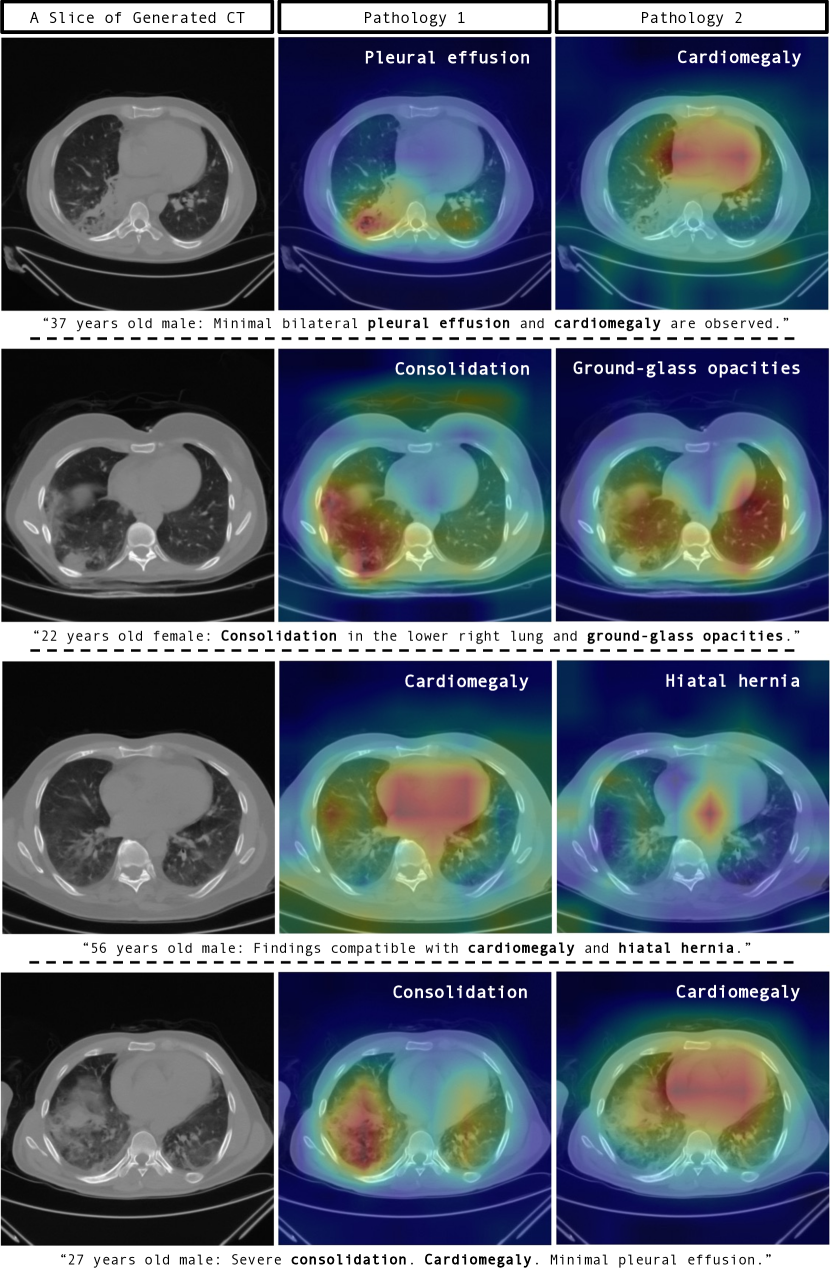
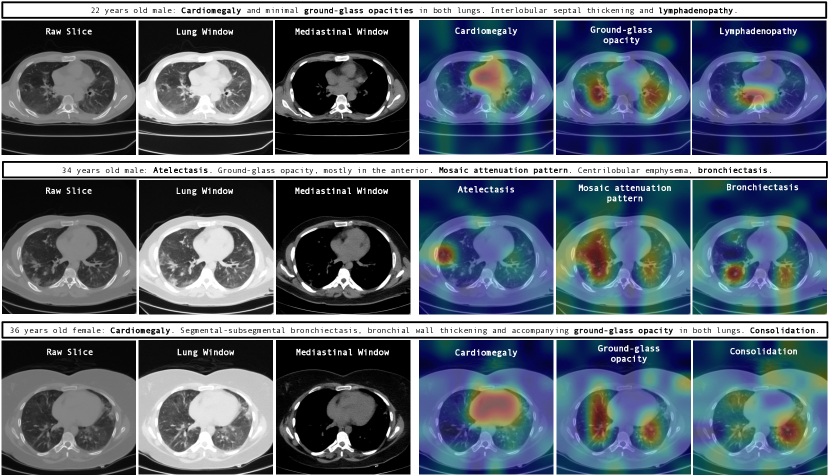
此外, 图 2 突出了 GenerateCT 有效的交叉注意力机制,该机制将文本提示中提到的特定病理准确地映射到不同窗口设置下生成体积的相关区域。 这些可视化展示了模型将医学语言精确地转化为临床相关的、空间上准确的图像特征的能力,强调了它能够从文本提示生成详细准确的 3D 图像。
| 20k Real | 20k Real + 20k Synthetic | 20k Synthetic | 40k Synthetic | 100k Synthetic | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Abnormality | AUROC | AP | AUROC | AP | AUROC | AP | AUROC | AP | AUROC | AP | Test Set Ratio |
| Medical material | 0.650 | 0.143 | 0.702 | 0.156 | 0.594 | 0.109 | 0.623 | 0.141 | 0.656 | 0.149 | 0.082 |
| Arterial wall calcification | 0.648 | 0.434 | 0.605 | 0.452 | 0.714 | 0.445 | 0.705 | 0.415 | 0.715 | 0.405 | 0.292 |
| Cardiomegaly | 0.804 | 0.310 | 0.745 | 0.352 | 0.590 | 0.142 | 0.593 | 0.154 | 0.599 | 0.184 | 0102 |
| Pericardial effusion | 0.667 | 0.044 | 0.685 | 0.056 | 0.642 | 0.079 | 0.690 | 0.094 | 0.662 | 0.152 | 0.026 |
| Coronary artery wall calcification | 0.649 | 0.384 | 0.691 | 0.452 | 0.794 | 0.428 | 0.790 | 0.493 | 0.825 | 0.493 | 0.246 |
| Hiatal hernia | 0.544 | 0.159 | 0.542 | 0.152 | 0.638 | 0.298 | 0.652 | 0.325 | 0.685 | 0.345 | 0.140 |
| Lymphadenopathy | 0.616 | 0.345 | 0.679 | 0.399 | 0.591 | 0.301 | 0.612 | 0.351 | 0.642 | 0.345 | 0.245 |
| Emphysema | 0.522 | 0.202 | 0.621 | 0.254 | 0.512 | 0.235 | 0.542 | 0.254 | 0.582 | 0.288 | 0.193 |
| Atelectasis | 0.609 | 0.314 | 0.585 | 0.352 | 0.595 | 0.284 | 0.550 | 0.276 | 0.625 | 0.297 | 0.231 |
| Lung nodule | 0.560 | 0.483 | 0.621 | 0.456 | 0.523 | 0.415 | 0.562 | 0.420 | 0.685 | 0.452 | 0.449 |
| Lung opacity | 0.603 | 0.477 | 0.785 | 0.490 | 0.549 | 0.485 | 0.542 | 0.506 | 0.598 | 0.545 | 0.395 |
| Pulmonary fibrotic sequela | 0.531 | 0.256 | 0.638 | 0.258 | 0.558 | 0.241 | 0.592 | 0.240 | 0.624 | 0.245 | 0.241 |
| Pleural effusion | 0.777 | 0.323 | 0.815 | 0.365 | 0.632 | 0.198 | 0.678 | 0.205 | 0.725 | 0.286 | 0.125 |
| Mosaic attenuation pattern | 0.739 | 0.152 | 0.712 | 0.195 | 0.594 | 0.097 | 0.612 | 0.087 | 0.661 | 0.125 | 0.056 |
| Peribronchial thickening | 0.513 | 0.073 | 0.503 | 0.152 | 0.551 | 0.084 | 0.580 | 0.099 | 0.604 | 0.158 | 0.069 |
| Consolidation | 0.655 | 0.235 | 0.693 | 0.264 | 0.592 | 0.154 | 0.599 | 0.168 | 0.6355 | 0.185 | 0.146 |
| Bronchiectasis | 0.573 | 0.111 | 0.658 | 0.132 | 0.535 | 0.098 | 0.582 | 0.095 | 0.598 | 0.098 | 0.093 |
| Interlobular septal thickening | 0.699 | 0.132 | 0.768 | 0.141 | 0.614 | 0.121 | 0.645 | 0.124 | 0.691 | 0.185 | 0.070 |
| Mean | 0.631 | 0.254 | 0.669 | 0.282 | 0.601 | 0.234 | 0.619 | 0.247 | 0.656 | 0.274 | 0.179 |
| Real Data | Synthetic Data | Composite Data | |||||
|---|---|---|---|---|---|---|---|
| Abnormality | AUROC | AP | AUROC | AP | AUROC | AP | Test Set |
| Air trapping | 0.561 | 0.044 | 0.621 | 0.050 | 0.633 | 0.051 | 0.031 |
| Airspace disease | 0.605 | 0.258 | 0.571 | 0.210 | 0.607 | 0.233 | 0.171 |
| Aneurysm | 0.577 | 0.015 | 0.493 | 0.012 | 0.587 | 0.020 | 0.011 |
| Arthritis | 0.515 | 0.284 | 0.510 | 0.298 | 0.505 | 0.282 | 0.279 |
| Aspiration | 0.616 | 0.091 | 0.518 | 0.051 | 0.624 | 0.092 | 0.049 |
| Atelectasis | 0.575 | 0.349 | 0.579 | 0.356 | 0.596 | 0.408 | 0.290 |
| Atherosclerosis | 0.550 | 0.314 | 0.473 | 0.281 | 0.525 | 0.297 | 0.294 |
| Bandlike or linear | 0.461 | 0.156 | 0.511 | 0.191 | 0.483 | 0.166 | 0.177 |
| Breast implant | 0.387 | 0.016 | 0.325 | 0.012 | 0.550 | 0.066 | 0.017 |
| Breast surgery | 0.499 | 0.030 | 0.504 | 0.026 | 0.484 | 0.037 | 0.023 |
| Bronchial thickening | 0.556 | 0.080 | 0.474 | 0.074 | 0.566 | 0.086 | 0.070 |
| Bronchiectasis | 0.704 | 0.313 | 0.543 | 0.179 | 0.666 | 0.234 | 0.154 |
| Bronchiolectasis | 0.739 | 0.068 | 0.475 | 0.021 | 0.683 | 0.044 | 0.021 |
| Bronchiolitis | 0.443 | 0.024 | 0.492 | 0.025 | 0.509 | 0.026 | 0.025 |
| Bronchitis | 0.533 | 0.010 | 0.567 | 0.023 | 0.570 | 0.011 | 0.008 |
| CABG | 0.754 | 0.118 | 0.504 | 0.068 | 0.764 | 0.115 | 0.041 |
| Calcification | 0.426 | 0.669 | 0.501 | 0.727 | 0.428 | 0.676 | 0.721 |
| Cancer | 0.593 | 0.614 | 0.523 | 0.575 | 0.618 | 0.636 | 0.563 |
| Cardiomegaly | 0.752 | 0.238 | 0.622 | 0.142 | 0.798 | 0.314 | 0.094 |
| Catheter or port | 0.660 | 0.218 | 0.591 | 0.120 | 0.681 | 0.266 | 0.084 |
| Cavitation | 0.604 | 0.056 | 0.493 | 0.058 | 0.589 | 0.056 | 0.040 |
| Chest tube | 0.864 | 0.123 | 0.640 | 0.037 | 0.881 | 0.173 | 0.018 |
| Clip | 0.488 | 0.098 | 0.532 | 0.117 | 0.491 | 0.106 | 0.092 |
| Congestion | 0.885 | 0.042 | 0.701 | 0.015 | 0.951 | 0.266 | 0.005 |
| Consolidation | 0.690 | 0.286 | 0.565 | 0.193 | 0.680 | 0.256 | 0.139 |
| Coronary artery disease | 0.567 | 0.608 | 0.500 | 0.568 | 0.582 | 0.607 | 0.566 |
| Cyst | 0.497 | 0.169 | 0.469 | 0.156 | 0.488 | 0.162 | 0.167 |
| Debris | 0.697 | 0.081 | 0.572 | 0.048 | 0.697 | 0.111 | 0.038 |
| Deformity | 0.580 | 0.062 | 0.475 | 0.051 | 0.551 | 0.057 | 0.052 |
| Density | 0.536 | 0.106 | 0.499 | 0.095 | 0.538 | 0.116 | 0.092 |
| Dilation or ectasia | 0.571 | 0.063 | 0.458 | 0.051 | 0.589 | 0.066 | 0.046 |
| Distention | 0.592 | 0.020 | 0.653 | 0.056 | 0.641 | 0.019 | 0.011 |
| Emphysema | 0.623 | 0.329 | 0.421 | 0.230 | 0.614 | 0.352 | 0.275 |
| Fibrosis | 0.792 | 0.332 | 0.574 | 0.152 | 0.775 | 0.259 | 0.118 |
| Fracture | 0.601 | 0.094 | 0.536 | 0.075 | 0.588 | 0.097 | 0.070 |
| GI tube | 0.900 | 0.192 | 0.710 | 0.067 | 0.910 | 0.269 | 0.018 |
| Granuloma | 0.448 | 0.071 | 0.411 | 0.066 | 0.450 | 0.071 | 0.080 |
| Groundglass | 0.594 | 0.415 | 0.524 | 0.341 | 0.589 | 0.422 | 0.325 |
| Hardware | 0.447 | 0.022 | 0.513 | 0.028 | 0.416 | 0.021 | 0.026 |
| Heart failure | 0.878 | 0.056 | 0.585 | 0.013 | 0.951 | 0.199 | 0.009 |
| Heart valve replacement | 0.745 | 0.043 | 0.721 | 0.059 | 0.858 | 0.165 | 0.014 |
| Hemothorax | 0.889 | 0.125 | 0.721 | 0.011 | 0.833 | 0.032 | 0.005 |
| Hernia | 0.523 | 0.120 | 0.488 | 0.126 | 0.548 | 0.126 | 0.115 |
| Honeycombing | 0.903 | 0.258 | 0.566 | 0.045 | 0.846 | 0.105 | 0.032 |
| Infection | 0.539 | 0.355 | 0.448 | 0.301 | 0.538 | 0.354 | 0.317 |
| Infiltrate | 0.413 | 0.015 | 0.438 | 0.021 | 0.352 | 0.014 | 0.018 |
| Inflammation | 0.529 | 0.087 | 0.429 | 0.076 | 0.521 | 0.086 | 0.082 |
| Interstitial lung disease | 0.739 | 0.362 | 0.565 | 0.196 | 0.742 | 0.304 | 0.152 |
| Lesion | 0.467 | 0.234 | 0.487 | 0.246 | 0.482 | 0.235 | 0.251 |
| Lucency | 0.574 | 0.028 | 0.567 | 0.028 | 0.556 | 0.041 | 0.018 |
| Lung resection | 0.519 | 0.222 | 0.516 | 0.236 | 0.545 | 0.242 | 0.229 |
| Lymphadenopathy | 0.682 | 0.260 | 0.580 | 0.191 | 0.686 | 0.272 | 0.151 |
| Mass | 0.498 | 0.123 | 0.541 | 0.149 | 0.505 | 0.128 | 0.128 |
| Mucous plugging | 0.519 | 0.028 | 0.413 | 0.027 | 0.480 | 0.027 | 0.028 |
| Nodule | 0.649 | 0.858 | 0.600 | 0.855 | 0.682 | 0.873 | 0.800 |
| Nodule >1cm | 0.515 | 0.136 | 0.544 | 0.158 | 0.499 | 0.121 | 0.128 |
| Opacity | 0.369 | 0.456 | 0.539 | 0.571 | 0.634 | 0.667 | 0.543 |
| Pacemaker/defibrillator | 0.778 | 0.128 | 0.563 | 0.079 | 0.857 | 0.261 | 0.049 |
| Pericardial effusion | 0.626 | 0.207 | 0.544 | 0.167 | 0.629 | 0.236 | 0.143 |
| Pericardial thickening | 0.501 | 0.024 | 0.551 | 0.076 | 0.538 | 0.026 | 0.025 |
| Plaque | 0.608 | 0.034 | 0.408 | 0.023 | 0.566 | 0.031 | 0.024 |
| Pleural effusion | 0.770 | 0.424 | 0.656 | 0.308 | 0.792 | 0.507 | 0.199 |
| Pleural thickening | 0.583 | 0.120 | 0.573 | 0.125 | 0.549 | 0.118 | 0.100 |
| Pneumonia | 0.629 | 0.079 | 0.569 | 0.067 | 0.664 | 0.096 | 0.050 |
| Pneumonitis | 0.677 | 0.070 | 0.578 | 0.034 | 0.689 | 0.052 | 0.027 |
| Pneumothorax | 0.780 | 0.196 | 0.576 | 0.030 | 0.815 | 0.193 | 0.024 |
| Postsurgical | 0.554 | 0.525 | 0.517 | 0.503 | 0.537 | 0.521 | 0.485 |
| Pulmonary edema | 0.816 | 0.144 | 0.638 | 0.081 | 0.852 | 0.217 | 0.034 |
| Reticulation | 0.747 | 0.211 | 0.559 | 0.121 | 0.710 | 0.165 | 0.090 |
| Scarring | 0.448 | 0.193 | 0.462 | 0.219 | 0.531 | 0.247 | 0.227 |
| Scattered calcifications | 0.519 | 0.187 | 0.506 | 0.190 | 0.491 | 0.187 | 0.183 |
| Scattered nodules | 0.497 | 0.216 | 0.463 | 0.211 | 0.494 | 0.225 | 0.223 |
| Secretion | 0.587 | 0.019 | 0.530 | 0.019 | 0.599 | 0.021 | 0.014 |
| Septal thickening | 0.793 | 0.176 | 0.612 | 0.105 | 0.794 | 0.195 | 0.060 |
| Soft tissue | 0.475 | 0.166 | 0.558 | 0.206 | 0.466 | 0.160 | 0.171 |
| Staple | 0.501 | 0.032 | 0.536 | 0.040 | 0.462 | 0.033 | 0.031 |
| Stent | 0.580 | 0.040 | 0.550 | 0.064 | 0.554 | 0.037 | 0.032 |
| Sternotomy | 0.743 | 0.186 | 0.536 | 0.086 | 0.779 | 0.241 | 0.068 |
| Suture | 0.507 | 0.028 | 0.534 | 0.022 | 0.466 | 0.022 | 0.020 |
| Tracheal tube | 0.937 | 0.234 | 0.710 | 0.033 | 0.931 | 0.232 | 0.013 |
| Transplant | 0.701 | 0.174 | 0.574 | 0.099 | 0.713 | 0.178 | 0.074 |
| Tree in bud | 0.573 | 0.064 | 0.399 | 0.020 | 0.591 | 0.035 | 0.023 |
| Tuberculosis | 0.534 | 0.005 | 0.366 | 0.003 | 0.467 | 0.006 | 0.003 |
| Mean | 0.613 | 0.177 | 0.536 | 0.146 | 0.623 | 0.190 | 0.129 |
2 利用 GenerateCT 进行数据增强
在本节中,我们将更仔细地研究 GenerateCT 的实际临床应用。 通过案例研究,我们展示了使用从医疗文本提示生成的合成胸部 CT 体积训练多异常分类模型。 这种详细的检查强调了 GenerateCT 在数据增强方面的巨大潜力,特别是在获取真实患者数据有限或具有挑战性的情况下。 此外,我们强调了 GenerateCT 对数据隐私的贡献。 我们的方法使研究人员能够训练和共享与我们类似的模型,从而促进通过文本提示创建合成数据,从而在不损害隐私或数据共享问题的情况下提高性能。 此外,我们表明 GenerateCT 即使重复使用相同的提示,也能可靠地生成多样化的数据。
2.1 实验设置
我们的第一步是在我们所有可用的训练数据上训练一个多异常分类模型,这些数据包含 20,000 个独特的患者资料,具有 18 个不同的异常标签,使用真实的胸部 CT 体积。 此基线模型实现了 的平均平均精度 (AP) 和 的接收者操作特征曲线下面积 (AUROC)。 为了说明 GenerateCT 在有真实患者数据的情况下有效性,我们通过使用 GenerateCT 创建等量的合成体积来扩充训练数据集,从而有效地将其扩大一倍。 此外,为了证明 GenerateCT 在缺乏真实患者数据的情况下有效性,以及它生成大量合成体积的能力,我们通过重复使用相同的提示生成了 100,000 个 CT 体积,是原始数据集的五倍,并在仅此合成数据上训练分类器。
我们的实验使用了 CT-Net 模型 [11],其默认参数用于对 18 种不同的异常进行分类。 采用随机梯度下降优化器 [32],学习率为 0.001,权重衰减为 0.0000001。 所有训练阶段均跨越 15 个纪元,批次大小为 12,在三台 A6000 48G GPU 上进行。 为了保持一致性,所有体积均调整为 ,并且 HU 值校准到 范围,重点关注心脏和肺部异常 [9]。
2.2 实验结果
表 1 详细介绍了模型在各种训练场景下的性能,突出了 18 种异常的 AUROC 和 AP 指标。 与仅使用真实数据相比,在真实数据和等量合成体积上训练时,我们观察到平均 AP 改善,平均 AUROC 提高。 将合成数据集扩展到 100,000 个体积,并在仅此数据上训练,与在所有可用真实数据上训练的模型相比,平均 AP 上升,平均 AUROC 提高。 在所有训练场景中,都对同一个真实患者数据集进行验证。
这些结果表明 GenerateCT 在临床环境中的有效性。 数据增强,即使只是将数据集大小增加一倍,也会显着提高性能,证明这对拥有现实世界数据的研究人员来说是有益的。 此外,使用更大的、完全合成的数据集训练比仅使用真实数据的模型产生了更好的结果,强调了 GenerateCT 在确保数据隐私方面的作用。 这种方法促进了像我们这样的模型的训练和共享,允许使用文本提示生成合成数据,从而提高性能,同时避免隐私或数据共享问题。 此外,即使重复使用相同的提示,性能指标的持续改进也说明了 GenerateCT 从相同输入中生成不同数据的能力。
总之,表 1 中的结果表明 GenerateCT 是数据增强中的一项宝贵资产。 我们的实验结果强调了 GenerateCT 生成详细且逼真的 3D 胸部 CT 图像的能力,这些图像与不同的文本提示准确地对齐。 这些结果标志着医学影像的重大进步,表明 GenerateCT 可以成为增强诊断和治疗计划过程的有力工具。 此外,GenerateCT 根据文本描述模拟逼真、高分辨率医学图像的潜力为未来的研究和医疗保健应用开辟了新的途径。
3 在零样本场景中使用 GenerateCT
在本节中,我们将深入探讨 GenerateCT 在零样本场景中的应用,评估该模型对外部数据集的泛化能力及其对未见提示的性能。 作为外部数据集,我们使用了 RadChestCT [11],其中包含 3,630 个胸部 CT 图像,具有 83 种不同的异常,平均异常标签频率为 。
3.1 实验设置
最初,我们在 RadChestCT 上训练了分类器以建立基线。 该数据集包括 2,286 个 CT 图像用于训练和 1,344 个用于验证,每个图像都与 83 种独特异常的异常标签相关联。 然后,我们生成了一个新的数据集,复制了真实患者数据训练集的图像数量和异常分布,产生了 2,286 个合成 CT 图像。 生成过程遵循医学语言文本提示的预定义结构, {年龄}岁{性别}:{印象} ,其中 {impression} 反映了异常标签。 这些文本提示,特别是就其异常分布而言是新颖的,没有包含在我们最初的 GenerateCT 训练中。 由于 RadChestCT 中没有年龄和性别参数,因此它们是随机分配的。 该分类器在该合成数据集以及合成和真实数据的组合上进行训练。 为了确保一致性,应用了与Sec. 2中相同的预处理和模型参数。
3.2 实验结果
选项卡。 2 显示了所有 83 种异常情况的每次训练的性能,并注意到在合成数据和真实数据上训练的模型之间存在可比的结果:合成数据的平均 AP 为 ,AUROC 为 ,而真实数据的 AP 为 ,AUROC 为 。 鉴于这两种情况都使用相同的真实患者数据集进行验证,并且这些数据集源自与 GenerateCT 训练所用数据集不同的机构设置,因此这种相似性非常重要。 与合成和真实患者数据联合训练显示,平均 AUROC () 和平均 AP () 均有适度提高,这强调了合成数据在模型训练中的价值。