零样本文档图像问答的布局和任务感知指令提示
摘要
布局感知预训练模型在文档图像问答方面取得了重大进展。 他们将额外的可学习模块引入到现有语言模型中,以从 OCR 工具获得的文本边界框坐标中捕获文档图像中的布局信息。 然而,额外的模块需要对大量文档图像进行预训练。 这阻止了这些方法直接利用现成的指令调整语言基础模型,这些模型最近在零样本学习中显示出了巨大的潜力。 相反,在本文中,我们发现像 Claude 和 ChatGPT 这样的指令调整语言模型可以理解空格和换行符的布局。 基于这一观察,我们提出LAyout和Task意识In指令提示(拉丁语-Prompt),由布局感知文档内容和任务感知指令组成。 具体来说,前者使用适当的空格和换行符来恢复 OCR 工具获取的文本段之间的布局信息,后者确保生成的答案符合格式要求。 此外,我们建议LA您并T询问In指令调整(LATIN-Tuning) 来提高 Alpaca 等小型指令调优模型的性能。 实验结果表明,LATIN-Prompt使得Claude和ChatGPT的零样本性能可以与SOTA在文档图像问答上的微调性能相媲美,并且LATIN-Tuning显着增强了Alpaca的零样本性能。 例如,LATIN-Prompt 将 Claude 和 ChatGPT 在 DocVQA 上的性能分别提高了 和 。 LATIN-Tuning 将 Alpaca 在 DocVQA 上的性能提高了 。 定量和定性分析证明了 LATIN-Prompt 和 LATIN-Tuning 的有效性。 我们发布代码以方便未来的研究111https://github.com/WenjinW/LATIN-Prompt。
1简介
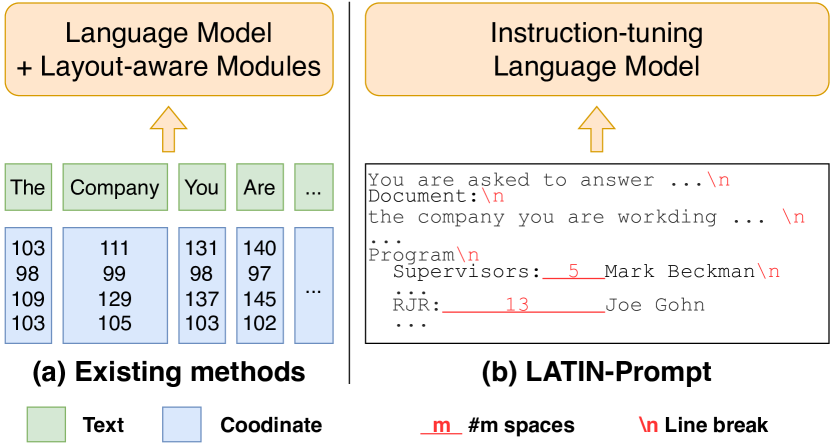
智能文档图像问答作为文档智能的重要应用,旨在开发基于文档图像理解自动回答自然语言问题的人工智能系统。 与文本文档相比,文档图像包含文本、视觉和布局信息,这对机器理解提出了独特的挑战。
最近,布局感知预训练模型在文档图像问答方面取得了重大进展。 他们在语言模型的基础上引入了额外的可学习模块(Devlin 等人 2019; Liu 等人 2019b; Raffel 等人 2020; Bao 等人 2020),以从文本边界坐标捕获文档图像中的布局信息OCR工具获取的框(图1(a))。 LayoutLM (Xu 等人 2020) 通过 2D 位置嵌入将坐标信息引入到模型输入中。 LayoutLMv2 (Xu 等人 2021b)、LayoutLMv3 (Huang 等人 2022) 和 ERNIE-Layout (Peng 等人 2022) 捕获布局通过布局感知注意机制从坐标获取信息。 这些方法对新引入的布局感知模块的大量文档图像进行预训练。
然而,预训练的需要使得这些方法无法直接利用现成的指令调优语言基础模型,而这些模型最近在零样本学习中显示出了巨大的潜力。 一方面,像 Claude (Anthropic 2023) 和 ChatGPT (OpenAI 2022) 这样的商业大型指令调优模型是闭源的,阻碍了进一步的预训练。 另一方面,开源指令调优模型的规模比传统模型大得多。 例如,Alpaca (Rohan Taori 等人 2023) 由 70 亿个参数组成,而 BERT (Devlin 等人 2019) 仅包含 300 多个参数万个参数。 现有方法(Xu 等人 2020, 2021b; Huang 等人 2022; Peng 等人 2022) 从 IIT-CDIP 测试集数据集中选择超过 1000 万个页面(Lewis 等人 2006) 用于预训练。 但像 Alpaca 这样的 1000 万页预训练指令调优模型的成本太昂贵了。
相反,在这项工作中,我们发现像 Claude 和 ChatGPT 这样的指令调整语言模型可以理解空格和换行符的布局(图 1 (b))。 基于这一观察,我们提出LAyout和Task意识In指令提示(拉丁语-Prompt),由布局感知文档内容和任务感知指令组成。 具体来说,根据 OCR 结果,我们使用适当的空格和换行符将所有文本段连接在一起,从而生成布局感知的文档内容。 坐标中包含的布局信息被转换为空格和换行符。 此外,我们将任务指令集成到布局感知的文档内容中,确保模型生成符合格式要求的答案。 虽然简单,但我们的方法很直观并且符合人类行为。 人类使用空白区域来表示和理解布局。
我们还发现像 Alpaca 这样的小型指令调优语言基础模型不擅长理解空间布局。 因此,我们建议您使用LA并T询问In说明调整(LATIN-Tuning) 来提高它们的性能。 我们将 CSV 格式的表转换为包含空格和换行符的字符串,并由 Claude 从这些字符串构建指令调整数据。
我们的贡献总结如下:
-
•
我们发现像 Claude 和 ChatGPT 这样的指令调整模型可以通过空格和换行来捕获布局,并提出 LATIN-Prompt 对文档图像问答任务进行零样本推理。
-
•
我们提出拉丁语调音以增强羊驼理解空格和换行布局的能力。
-
•
三个数据集上的实验结果表明,LATIN-Prompt使得Claude和ChatGPT的零样本性能可以与SOTA在文档图像问答上的微调性能相媲美,并且LATIN-Tuning显着增强了Alpaca的零样本性能。 定量和定性分析证明了 LATIN-Prompt 和 LATIN-Tuning 的有效性。
2相关工作
| #Line | Prompt |
|---|---|
| 1 | You are asked to answer questions asked on a document image. |
| 2 | The answers to questions are short text spans taken verbatim from the document. This means that the answers comprise a set of contiguous text tokens present in the document. |
| 3 | Document: |
| 4 | {Layout Aware Document placeholder} |
| 5 | |
| 6 | Question: {Question placeholder} |
| 7 | |
| 8 | Directly extract the answer of the question from the document with as few words as possible. |
| 9 | |
| 10 | Answer: |
2.1 视觉丰富的文档理解
视觉丰富的文档理解 (VrDU) 专注于识别和理解带有语言、视觉和布局信息的扫描或数字生成的文档图像。 VrDU 中的传统作品采用 CNN (Yang 等人 2017;Katti 等人 2018;Denk 和 Reisswig 2019;Zhao 等人 2019;Sarkhel 和 Nandi 2019;Zhang 等人 2020;Wang 等人 2021;Lin 等人 2021 )、GNN (Liu 等人 2019a;Qian 等人 2019;Yu 等人 2020;Wei、He、Zhang 2020;Carbonell 等人 2021),以及语言 Transformer (Majumder 等人 2020; Wang 等人 2020) 从文档图像中挖掘信息。
最近,提出了布局感知的预训练 Transformer (Appalaraju 等人 2021; Garncarek 等人 2021; Hwang 等人 2021; Li 等人 2021a, b, c; Xu 等人 2021a; Hong 等人 2022; Lee 等人 2022a;Peng 等人 2022;Bai 等人 2022a;Lee 等人 2022b;罗 等人 2023;Dhouib、Bettaieb 和 Shabou 2023)。 LayoutLM (Xu 等人 2020) 将 2D 位置信息引入输入嵌入,LayoutLMv2 (Xu 等人 2021b) 提出了空间感知的自注意力机制。 然后,LayoutLMv3 (Huang 等人 2022) 通过学习离散图像标记重建的视觉特征提取来去除 CNN,ERNIE-Layout (Peng 等人 2022) 引入了将知识布局到预训练中。 此外,(Zhang 等人 2021; Gu 等人 2022; Wang 等人 2022a) 在微调过程中引入了额外的设计,使布局感知的预训练模型能够更好地适应下游任务。
然而,所有现有方法都试图通过 OCR 工具获得的边界框坐标来理解文档图像内的布局。 相反,在这项工作中,我们尝试通过空格和换行符直接理解布局。 我们提出 LATIN-Prompt 和 LATIN-Tuning 来探索零样本文档图像问答。
并行工作 ICL-D3IE (He 等人 2023) 也在文档图像理解中利用了大型指令调整模型,但它与我们的方法有很大不同。 它侧重于少样本文档信息提取,但本文重点关注零样本文档图像问答。
2.2指令调优语言模型
理想的人工智能系统应该能够根据人类指令学习并完成各种任务。 为此,人们提出了许多指令调优数据集和语言基础模型(Thoppilan 等人 2022; Chung 等人 2022; Wei 等人 2022; Sanh 等人 2022; Mishra 等人 2022; Wang 等人 2022c; Xu、Shen、Huang 2022;Iyer 等人 2023;Longpre 等人 2023)。 为了使模型与人类意图和价值观完全一致,教学中引入了基于人类反馈和人工智能反馈的强化学习(Bai 等人 2022b; Ouyang 等人 2022; Bai 等人 2022c; Open AI 2023) -调整。 为了减少指令调优数据的手动标注成本,一些方法使用现成的语言模型自动构建指令调优数据(Honovich 等人 2022; Wang 等人 2022b; Rohan Taori 等人 2023; Peng等人 2023;周等人 2023;徐等人 2023)。 最近,一些方法(Zhu 等人 2023; Dai 等人 2023) 将指令微调扩展到多模态领域。
在本文中,我们提出了 LATIN-Prompt,允许现成的指令调整语言模型进行零样本文档图像问答。 此外,我们提出拉丁语调音以增强羊驼理解空格和换行布局的能力。
3方法
我们提出了 LATIN-Prompt 和 LATIN-Tuning 用于指令调整语言模型,以对文档图像问答任务进行零样本推理。
3.1 拉丁语提示
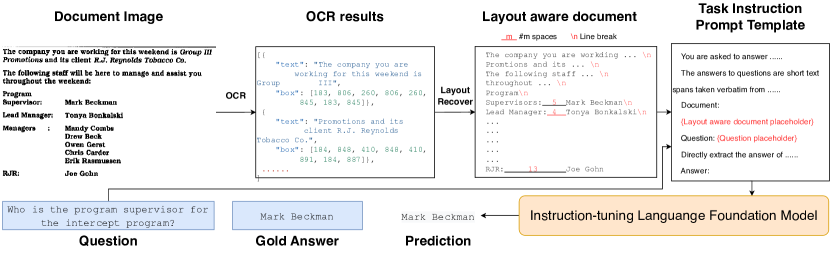
LATIN-Prompt 的关键思想如下: (1) 通过空格和换行符捕获布局信息 (2) 通过任务指令生成符合格式要求的答案。 图2说明了LATIN-Prompt的流程。 给定文档图像的 OCR 结果,我们通过使用适当的空格和换行符将所有文本段连接在一起来恢复其中的布局信息,从而生成布局感知的文档内容。 然后我们将布局感知文档内容和问题插入到任务指令提示模板中。 指令调整语言模型将填充的模板作为输入,并以所需的格式预测问题的答案。
形式上,给定文档图像和问题答案对和,我们通过OCR工具处理文档图像。 提取的文本段和相应的边界框表示为和,其中表示文本段的数量。
布局感知文档
我们使用适当的空格和换行符将所有文本段连接在一起,从而产生布局感知的文档内容。 流程如下:
步骤1。 根据坐标从上到下、从左到右的顺序重新排列文本段和边界框。
第2步。 根据坐标,将第行的文本段和边界框从左到右分别放入列表和中,并计算第 行的字符数 和宽度 。 等于列表 中边界框并集的宽度。
步骤 3. 计算文档的字符宽度,定义如下:
| (1) |
其中 -row 具有所有行中的最大字符数。
步骤4。 用空格从左到右连接同一行中的文本段。 给定两个相邻的文本段 和 ,连接它们的空格数等于 ,其中 是它们之间的水平距离两个边界框 和 。
步骤 5。 通过换行符连接不同的行以获得布局感知文档内容(表示为)。
通过空格和换行符恢复布局信息简单而直观。 事实上,人们确实通过文本元素之间的空白区域来表示和理解布局,而不是精确的边界框坐标。
任务意识指导
与开放式问答不同,文档图像问答通常会对答案格式有明确的要求。 例如,DocVQA (Mathew、Karatzas 和 Jawahar 2021) 是一项提取式 QA 任务,需要从文档中提取答案。 然而,仅通过布局感知的文档内容和问题,模型可以轻松生成文档中没有的答案,并生成不必要的描述或解释。
因此,我们将任务指令集成到布局感知的文档内容中,确保模型生成符合格式要求的答案。 具体来说,我们针对不同的任务手动设计了不同的指令提示模板。 每个模板 包含任务的要求以及布局感知文档内容 和问题 的占位符。
Table 7显示DocVQA的提示模板。 在第一行和第二行中,我们根据DocVQA中的任务描述向模型详细解释了提取的含义。 第 3 行到第 6 行为布局感知文档和问题提供占位符。 为了避免模型因文档内容的干扰而忘记其任务,第8行总结并重申了任务要求。 InfographicVQA (Mathew 等人 2021) 和 MP-DocVQA (Tito, Karatzas, and Valveny 2023) 的提示模板请参阅补充材料。
零样本推理
最后,指令调优语言模型将填充模板作为输入并预测答案如下:
| (2) |
其中表示预测,表示模型的解码过程。
3.2 拉丁语调音
| Paradigm | Method | Parameters | Text | Vision | Layout | Fine-tuning Set | ANLS | ANLS |
| Fine-tuning | BERT | 340M | train | 0.6768 | ||||
| RoBERTa | 355M | train | 0.6952 | |||||
| UniLMv2 | 340M | train | 0.7709 | |||||
| LayoutLM | 343M | train | 0.7259 | |||||
| LayoutLMv2 | 426M | train | 0.8348 | |||||
| LayoutLMv3 | 368M | train | 0.8337 | |||||
| ERNIE-Layout | 507M | train | 0.8321 | |||||
| LayoutLMv2 | 426M | train + dev | 0.8529 | |||||
| ERNIE-Layout | 507M | train + dev | 0.8486 | |||||
| Zero-shot | Alpaca+Plain Prompt | 7B | - | 0.3567 | ||||
| Alpaca+LATIN-Prompt | - | 0.4200 | +0.0633 | |||||
| Claude+Plain Prompt | Unknown | - | 0.2298 | |||||
| Claude+LATIN-Prompt | - | 0.8336 | +0.6038 | |||||
| ChatGPT-3.5+Plain Prompt | Unknown | - | 0.6866 | |||||
| ChatGPT-3.5+LATIN-Prompt | - | 0.8255 | +0.1389 | |||||
| GPT-4∗ | Unknown | not clearly described | - | 0.8840 | ||||
| * represents that we report the result of GPT-4 presented in OpenAI blog (OpenAI 2023). Although lacking a technical detail description, compared with Claude and ChatGPT-3.5, GPT-4 utilizes visual information. The LATIN-Prompt is orthogonal to GPT-4 and can be used to further improve the performance of GPT-4. However, due to API permission limitations, we are unable to evaluate the performance of GPT-4 + LATIN-Prompt and leave it in future. | ||||||||
| Paradigm | Method | Overall | Answer type | ||||
|---|---|---|---|---|---|---|---|
| ANLS | ANLS | Image span | Question span | Multiple spans | Non span | ||
| Fine-tuning | BERT | 0.2078 | 0.2625 | 0.2333 | 0.0739 | 0.0259 | |
| LayoutLM | 0.2720 | 0.3278 | 0.2386 | 0.0450 | 0.1371 | ||
| LayoutLMv2 | 0.2829 | 0.3430 | 0.2763 | 0.0641 | 0.1114 | ||
| BROS | 0.3219 | 0.3997 | 0.2317 | 0.1064 | 0.1068 | ||
| pix2struct | 0.4001 | 0.4308 | 0.4839 | 0.2059 | 0.3173 | ||
| TILT | 0.6120 | 0.6765 | 0.6419 | 0.4391 | 0.3832 | ||
| Zero-shot | Claude + Plain Prompt | 0.0798 | 0.0951 | 0.0913 | 0.0203 | 0.0280 | |
| Claude + LATIN-Prompt | 0.5451 | +0.4653 | 0.5992 | 0.5861 | 0.3985 | 0.3544 | |
| ChatGPT-3.5 + Plain Prompt | 0.3335 | 0.3749 | 0.4505 | 0.0950 | 0.1822 | ||
| ChatGPT-3.5 + LATIN-Prompt | 0.4898 | +0.1563 | 0.5457 | 0.5639 | 0.3458 | 0.2798 | |
| Method | Evidence | Operation | ||||||
| Table/List | Textual | Visual object | Figure | Map | Comparison | Arithmetic | Counting | |
| BERT | 0.1852 | 0.2995 | 0.0896 | 0.1942 | 0.1709 | 0.1805 | 0.0160 | 0.0436 |
| LayoutLM | 0.2400 | 0.3626 | 0.1705 | 0.2551 | 0.2205 | 0.1836 | 0.1559 | 0.1140 |
| LayoutLMv2 | 0.2449 | 0.3855 | 0.1440 | 0.2601 | 0.3110 | 0.1897 | 0.1130 | 0.1158 |
| BROS | 0.2653 | 0.4488 | 0.1878 | 0.3095 | 0.3231 | 0.2020 | 0.1480 | 0.0695 |
| pix2struct | 0.3833 | 0.5256 | 0.2572 | 0.3726 | 0.3283 | 0.2762 | 0.4198 | 0.2017 |
| TILT | 0.5917 | 0.7916 | 0.4545 | 0.5654 | 0.4480 | 0.4801 | 0.4958 | 0.2652 |
| Claude + Plain Prompt | 0.0849 | 0.1099 | 0.0858 | 0.0695 | 0.0496 | 0.0589 | 0.0271 | 0.0368 |
| Claude + LATIN-Prompt | 0.5421 | 0.6725 | 0.4897 | 0.5027 | 0.4982 | 0.4598 | 0.4311 | 0.2708 |
| ChatGPT-3.5 + Plain Prompt | 0.3481 | 0.3893 | 0.3670 | 0.3114 | 0.1843 | 0.2349 | 0.1466 | 0.2320 |
| ChatGPT-3.5 + LATIN-Prompt | 0.4917 | 0.6016 | 0.4491 | 0.4585 | 0.3614 | 0.4312 | 0.3157 | 0.2660 |
| Paradigm | Method | Setup | ANLS |
|---|---|---|---|
| Fine-tuning | BERT | Max Conf | 0.5347 |
| Concat | 0.4183 | ||
| Longformer | Max Conf | 0.5506 | |
| Concat | 0.5287 | ||
| Big Bird | Max Conf | 0.5854 | |
| Concat | 0.4929 | ||
| LayoutLMv3 | Max Conf | 0.5513 | |
| Concat | 0.4538 | ||
| T5 | Max Conf | 0.4028 | |
| Concat | 0.5050 | ||
| Hi-VT5 | Multipage | 0.6201 | |
| Zero-shot | Claude+LATIN-Prompt | Max Conf | 0.6129 |
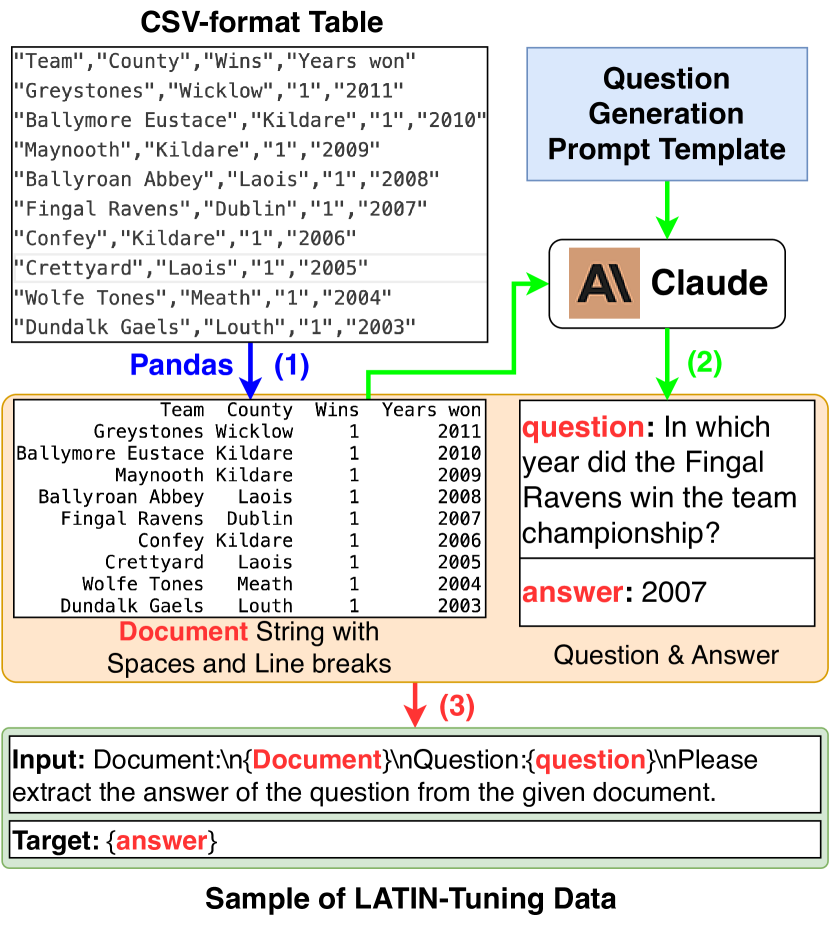
尽管 Claude 和 ChatGPT 等指令调优模型可以很好地理解和利用 LATIN-Prompt,但我们发现 Alpaca (7B) 等较小模型的性能达不到标准。 因此,我们建议拉丁语调音来增强他们理解空格和换行布局的能力。 如图图3所示,我们使用Pandas222https://pandas.pydata.org 和 Claude 从 CSV 格式的表构建指令调整数据集。 流程如下:
(1) 对于每个 CSV 表,我们通过 Pandas 将其转换为带有空格和换行符的文档字符串。 代码实现请参见附录。 (2) 我们将文档字符串插入到问题生成提示模板中,并由 Claude 生成问答对。 (3) 将文档字符串和问题插入指令提示模板中形成输入,以答案作为目标。 问题生成提示模板和指令提示模板的详细信息请参见附录。
最后,我们在指令调整数据集上对 Alpaca 进行了处理,以增强其理解空格和换行布局的能力。
4实验

4.1 实验设置
数据集
我们在三个文档图像问答数据集上评估我们的方法:DocVQA (Mathew、Karatzas 和 Jawahar 2021) 是一项提取式问答任务,由在 12,767 个文档图像上定义的 50,000 个问题组成; InfographicVQA (Mathew 等人 2021) 由 5,485 个信息图表组成,通过文本、图形和视觉元素共同传达信息; MP-DocVQA (Tito、Karatzas 和 Valveny 2023) 将 DocVQA 扩展到更现实的多页面场景,其中文档通常由应一起处理的多个页面组成。 按照惯例,我们使用 DUE (Borchmann 等人 2021) 提供的 Azure OCR 结果进行 DocVQA,并使用官方 OCR 结果333https://rrc.cvc.uab.es/?ch=17&com=introduction InfographicVQA 和 MP-DocVQA。 对于所有数据集,我们采用平均归一化编辑相似度(ANLS)(Biten等人2019)作为评估指标。
拉丁语-提示基线
为了评估 LATIN-Prompt 的零样本性能,我们将其与三种指令调优语言模型上的 Plain Prompt 进行比较: Claude444我们使用claude-v1.3 API。, 聊天GPT-3.5555我们使用 Azure OpenAI 中的 gpt-3.5-turbo API。和羊驼。 Plain Prompt 的模板如下:“文档:{文档}n问题:{问题}n直接从文档中提取问题的答案。nAnswer:”,其中 {document} 和 {question} 是 OCR 工具和问题的原始文本片段的占位符。 我们还将 LATIN-Prompt 的零样本性能与预训练微调方法的微调性能进行了比较。 此外,我们报告了 OpenAI 博客 (OpenAI 2023) 中提出的多模态 GPT-4 的结果。 由于API权限限制,我们将对GPT-4+LATIN-Prompt的探索留作未来的工作。
我们只在 DocVQA 上评估 Alpaca,因为其他两个任务对它来说太复杂了。 羊驼无法遵循这两个任务的任务指令。 事实上,Alpaca 在 InfographicVQA 上表现不佳(参考 选项卡。 5)并且无法生成满足 MP-DocVQA 格式要求的答案。 我们排除了 MP-DocVQA 上的 ChatGPT-3.5,因为它需要处理太多文档页面,并且实验成本超出了我们可以承受的范围。
拉丁调音
我们从 WikiTableQuestions (Pasupat 和 Liang 2015) 中随机抽取 5000 个 CSV 格式的表并进行替换,以创建指令调整数据集。 我们使用 AdamW (Loshchilov 和 Hutter 2018) 优化器,在 Alpaca (Rohan Taori 等人 2023) 之后,以 0.03 的预热比率,在创建的数据集上对 Alpaca 进行了 3 个周期的训练。 >。 我们使用的批量大小和的学习率。 所得模型表示为 Alpaca+LATIN-Tuning,我们将其与 Alpaca 进行比较以评估 LATIN-Tuning 的性能。
4.2 拉丁语提示的表现
表 2展示了DocVQA上的实验结果。 (1)在预训练微调范式中,布局感知多模态预训练模型比纯语言模型表现更好。 (2)进一步地,增加微调数据量可以提高模型的性能。 (3)指令调优语言模型在基于OCR工具获取的原始文本片段的简单提示下表现不佳。 (4)本文提出的LATIN-Prompt显着提高了指令调优语言模型的零样本性能。 它使 Claude 和 ChatGPT-3.5 的零样本性能显着优于微调的布局感知 LayoutLM。 此外,尽管仅使用文本和布局信息,但它们的零样本性能与微调的布局感知多模态预训练模型的性能相当。 (5)虽然未知,但Claude和GPT-3.5的参数数量应该比Alpaca大得多。 实验结果表明,最终的零样本性能与指令调优模型的大小和能力呈正相关。 (6) GPT-4的零样本性能与最佳微调性能相匹配。 虽然缺乏技术细节描述,但与 Claude 和 GPT-3.5 相比,GPT-4 利用了视觉信息,体现了视觉信息对于文档图像理解的重要性。 LATIN-Prompt 与 GPT-4 正交。 不过,由于 API 权限限制,我们只能留待以后使用 LATIN-Prompt 来武装 GPT-4。
表 3 呈现 InfographicVQA 上的结果。 实验结果表明,LATIN-Prompt使得Claude和GPT-3.5的零样本性能超过了除TILT之外的所有微调基线的性能。 我们发现 Claude 在使用 Plain Prompt 时表现不佳,但在使用 LATIN-Prompt 时其性能显着提高。
表 4呈现 MP-DocVQA 的结果。 结果表明,使用 LATIN-Prompt,Claude 的零样本性能超过了 Longformer (Beltagy、Peters 和 Cohan 2020) 和 Big Bird (Zaheer 等人 2021)的微调性能 t1> 专为长序列而设计。 此外,其零样本性能可与 Hi-VT5 (Tito、Karatzas 和 Valveny 2023)(一种用于多页文档图像的布局感知多模态模型)的微调性能相媲美。
4.3 拉丁调音的性能
| Method | DocVQA | InfographicVQA | ||
|---|---|---|---|---|
| Valid | Test | Valid | Test | |
| Alpaca | 0.3506 | 0.3567 | 0.1083 | 0.1419 |
| Alpaca+LATIN-Tuning | 0.6668 | 0.6697 | 0.2873 | 0.3028 |
| Claude | 0.8311 | 0.8336 | 0.5218 | 0.5451 |
表 5 表明 LATIN-Tuning 将 Alpaca 在 DocVQA 上的性能提高了 ,在 InfographicVQA 上提高了 。 尽管如此,其表现仍落后于克劳德。 未来我们将探索更有效的指令调优方法。
4.4定量和定性分析
| Prompt | DocVQA | InfographicVQA | ||
|---|---|---|---|---|
| Claude | ChatGPT | Claude | ChatGPT | |
| LATIN-Prompt | 0.8311 | 0.8135 | 0.5218 | 0.4708 |
| w/o Layout | 0.7825 | 0.7491 | 0.4638 | 0.4341 |
| w/o Task | 0.3637 | 0.7561 | 0.1234 | 0.4296 |
| w/o Task+Layout | 0.2144 | 0.6795 | 0.0702 | 0.3103 |
LATIN-Prompt 组件的效果
LATIN-Prompt 由布局感知文档内容(Layout)和任务指令(Task)组成。 表 6呈现了 LATIN-Prompt with Claude 和 ChatGPT-3.5 在 DocVQA 和 InfographicVQA 上的消融研究结果。 结果表明,布局感知文档内容和任务指令都可以显着提高 Claude 和 ChatGPT-3.5 的零样本性能。 任务指令带来的改进在 Claude 中更为显着,因为它保证了模型生成的答案的格式满足任务要求。 在正确格式的基础上,布局感知文档内容进一步提高了模型的性能,因为它使模型能够利用文本段之间的布局信息。
指令调整数据大小对 LATIN-Tuning 的影响
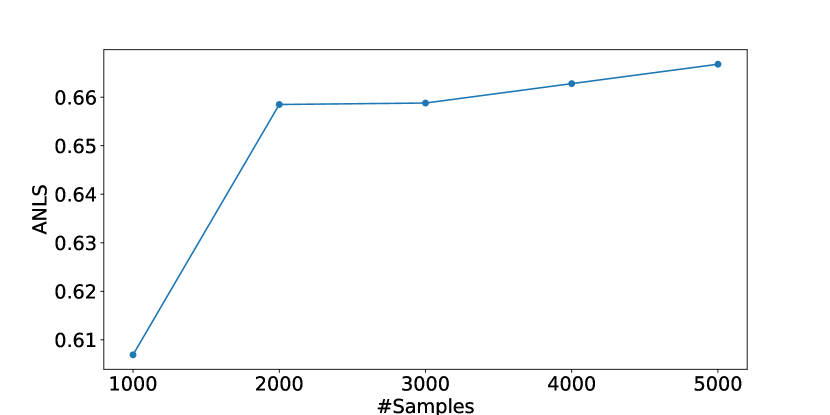
图4显示,LATIN-Tuning的性能随着样本数量的增加而提高。 当样本数超过 2000 时,改进速度减慢。
拉丁语提示案例研究
图 5提供了Claude在DocVQA上的案例。 与 Plain Prompt 相比,LATIN-Prompt 使模型能够更有效地理解布局并生成满足格式要求的答案。
LATIN-Tuning 案例研究
DocVQA 的案例研究表明,LATIN-Tuning 使 Alpaca 能够理解空间布局。 详情请参阅附录。
5结论
在这项工作中,我们为理解文档图像中的布局信息提供了一个新的视角。 我们发现像 Claude 和 ChatGPT 这样的指令调整语言模型可以通过空格和换行符来理解布局,而不是通过边界框的坐标来捕获布局。 基于这一观察,我们提出了 LATIN-Prompt,它使 Claude 和 ChatGPT 的零样本性能能够与 SOTA 在文档图像问答上的微调性能相媲美。 此外,我们提出了 LATIN-Tuning,它增强了 Alpaca 通过空格和换行来理解布局的能力。 未来,我们将探索将视觉信息融入到 LATIN-Prompt 中,并为 LATIN-Tuning 创建更有效的指令调优数据集。
参考
- Anthropic (2023) Anthropic. 2023. Claude. https://www.anthropic.com/product.
- Appalaraju et al. (2021) Appalaraju, S.; Jasani, B.; Kota, B. U.; Xie, Y.; and Manmatha, R. 2021. DocFormer: End-to-End Transformer for Document Understanding. In ICCV 2021, 993–1003.
- Bai et al. (2022a) Bai, H.; Liu, Z.; Meng, X.; Li, W.; Liu, S.; Xie, N.; Zheng, R.; Wang, L.; Hou, L.; Wei, J.; Jiang, X.; and Liu, Q. 2022a. Wukong-Reader: Multi-modal Pre-training for Fine-grained Visual Document Understanding. arxiv:2212.09621.
- Bai et al. (2022b) Bai, Y.; Jones, A.; Ndousse, K.; Askell, A.; Chen, A.; DasSarma, N.; Drain, D.; Fort, S.; Ganguli, D.; Henighan, T.; Joseph, N.; Kadavath, S.; Kernion, J.; Conerly, T.; El-Showk, S.; Elhage, N.; Hatfield-Dodds, Z.; Hernandez, D.; Hume, T.; Johnston, S.; Kravec, S.; Lovitt, L.; Nanda, N.; Olsson, C.; Amodei, D.; Brown, T.; Clark, J.; McCandlish, S.; Olah, C.; Mann, B.; and Kaplan, J. 2022b. Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. arxiv:2204.05862.
- Bai et al. (2022c) Bai, Y.; Kadavath, S.; Kundu, S.; Askell, A.; Kernion, J.; Jones, A.; Chen, A.; Goldie, A.; Mirhoseini, A.; McKinnon, C.; Chen, C.; Olsson, C.; Olah, C.; Hernandez, D.; Drain, D.; Ganguli, D.; Li, D.; Tran-Johnson, E.; Perez, E.; Kerr, J.; Mueller, J.; Ladish, J.; Landau, J.; Ndousse, K.; Lukosuite, K.; Lovitt, L.; Sellitto, M.; Elhage, N.; Schiefer, N.; Mercado, N.; DasSarma, N.; Lasenby, R.; Larson, R.; Ringer, S.; Johnston, S.; Kravec, S.; Showk, S. E.; Fort, S.; Lanham, T.; Telleen-Lawton, T.; Conerly, T.; Henighan, T.; Hume, T.; Bowman, S. R.; Hatfield-Dodds, Z.; Mann, B.; Amodei, D.; Joseph, N.; McCandlish, S.; Brown, T.; and Kaplan, J. 2022c. Constitutional AI: Harmlessness from AI Feedback. arxiv:2212.08073.
- Bao et al. (2020) Bao, H.; Dong, L.; Wei, F.; Wang, W.; Yang, N.; Liu, X.; Wang, Y.; Gao, J.; Piao, S.; Zhou, M.; and Hon, H.-W. 2020. UniLMv2: Pseudo-Masked Language Models for Unified Language Model Pre-Training. In Proceedings of the 37th International Conference on Machine Learning, 642–652. PMLR.
- Beltagy, Peters, and Cohan (2020) Beltagy, I.; Peters, M. E.; and Cohan, A. 2020. Longformer: The Long-Document Transformer. arxiv:2004.05150.
- Biten et al. (2019) Biten, A. F.; Tito, R.; Mafla, A.; Gomez, L.; Rusiñol, M.; Valveny, E.; Jawahar, C. V.; and Karatzas, D. 2019. Scene Text Visual Question Answering. In ICCV 2019. arXiv.
- Borchmann et al. (2021) Borchmann, Ł.; Pietruszka, M.; Stanislawek, T.; Jurkiewicz, D.; Turski, M.; Szyndler, K.; and Graliński, F. 2021. DUE: End-to-End Document Understanding Benchmark. In NeurIPS 2021.
- Carbonell et al. (2021) Carbonell, M.; Riba, P.; Villegas, M.; Fornes, A.; and Llados, J. 2021. Named Entity Recognition and Relation Extraction with Graph Neural Networks in Semi Structured Documents. In ICPR 2020, 9622–9627. Milan, Italy: IEEE. ISBN 978-1-72818-808-9.
- Chung et al. (2022) Chung, H. W.; Hou, L.; Longpre, S.; Zoph, B.; Tay, Y.; Fedus, W.; Li, Y.; Wang, X.; Dehghani, M.; Brahma, S.; Webson, A.; Gu, S. S.; Dai, Z.; Suzgun, M.; Chen, X.; Chowdhery, A.; Castro-Ros, A.; Pellat, M.; Robinson, K.; Valter, D.; Narang, S.; Mishra, G.; Yu, A.; Zhao, V.; Huang, Y.; Dai, A.; Yu, H.; Petrov, S.; Chi, E. H.; Dean, J.; Devlin, J.; Roberts, A.; Zhou, D.; Le, Q. V.; and Wei, J. 2022. Scaling Instruction-Finetuned Language Models. arxiv:2210.11416.
- Dai et al. (2023) Dai, W.; Li, J.; Li, D.; Tiong, A. M. H.; Zhao, J.; Wang, W.; Li, B.; Fung, P.; and Hoi, S. 2023. InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning. arxiv:2305.06500.
- Denk and Reisswig (2019) Denk, T. I.; and Reisswig, C. 2019. BERTgrid: Contextualized Embedding for 2D Document Representation and Understanding. In NeurIPS 2019 Workshop.
- Devlin et al. (2019) Devlin, J.; Chang, M.-W.; Lee, K.; and Toutanova, K. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–4186. Minneapolis, Minnesota: Association for Computational Linguistics.
- Dhouib, Bettaieb, and Shabou (2023) Dhouib, M.; Bettaieb, G.; and Shabou, A. 2023. DocParser: End-to-end OCR-free Information Extraction from Visually Rich Documents. In ICDAR 2023.
- Garncarek et al. (2021) Garncarek, Ł.; Powalski, R.; Stanisławek, T.; Topolski, B.; Halama, P.; Turski, M.; and Graliński, F. 2021. LAMBERT: Layout-Aware Language Modeling for Information Extraction. In Lladós, J.; Lopresti, D.; and Uchida, S., eds., ICDAR 2021, Lecture Notes in Computer Science, 532–547. Cham: Springer International Publishing. ISBN 978-3-030-86549-8.
- Gu et al. (2022) Gu, Z.; Meng, C.; Wang, K.; Lan, J.; Wang, W.; Gu, M.; and Zhang, L. 2022. XYLayoutLM: Towards Layout-Aware Multimodal Networks For Visually-Rich Document Understanding. In CVPR 2022, 10.
- He et al. (2023) He, J.; Wang, L.; Hu, Y.; Liu, N.; Liu, H.; Xu, X.; and Shen, H. T. 2023. ICL-D3IE: In-Context Learning with Diverse Demonstrations Updating for Document Information Extraction. arxiv:2303.05063.
- Hong et al. (2022) Hong, T.; Kim, D.; Ji, M.; Hwang, W.; Nam, D.; and Park, S. 2022. BROS: A Pre-Trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents. In AAAI 2022.
- Honovich et al. (2022) Honovich, O.; Scialom, T.; Levy, O.; and Schick, T. 2022. Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor. arxiv:2212.09689.
- Huang et al. (2022) Huang, Y.; Lv, T.; Cui, L.; Lu, Y.; and Wei, F. 2022. LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking. In ACM MM 2022.
- Hwang et al. (2021) Hwang, W.; Yim, J.; Park, S.; Yang, S.; and Seo, M. 2021. Spatial Dependency Parsing for Semi-Structured Document Information Extraction. In ACL-Findings 2021.
- Iyer et al. (2023) Iyer, S.; Lin, X. V.; Pasunuru, R.; Mihaylov, T.; Simig, D.; Yu, P.; Shuster, K.; Wang, T.; Liu, Q.; Koura, P. S.; Li, X.; O’Horo, B.; Pereyra, G.; Wang, J.; Dewan, C.; Celikyilmaz, A.; Zettlemoyer, L.; and Stoyanov, V. 2023. OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization. arxiv:2212.12017.
- Katti et al. (2018) Katti, A. R.; Reisswig, C.; Guder, C.; Brarda, S.; Bickel, S.; Höhne, J.; and Faddoul, J. B. 2018. Chargrid: Towards Understanding 2D Documents. In EMNLP 2018.
- Lee et al. (2022a) Lee, C.-Y.; Li, C.-L.; Dozat, T.; Perot, V.; Su, G.; Hua, N.; Ainslie, J.; Wang, R.; Fujii, Y.; and Pfister, T. 2022a. FormNet: Structural Encoding beyond Sequential Modeling in Form Document Information Extraction. In ACL 2022.
- Lee et al. (2022b) Lee, K.; Joshi, M.; Turc, I.; Hu, H.; Liu, F.; Eisenschlos, J.; Khandelwal, U.; Shaw, P.; Chang, M.-W.; and Toutanova, K. 2022b. Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding. arxiv:2210.03347.
- Lewis et al. (2006) Lewis, D.; Agam, G.; Argamon, S.; Frieder, O.; Grossman, D.; and Heard, J. 2006. Building a Test Collection for Complex Document Information Processing. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, 665–666. Seattle Washington USA: ACM. ISBN 978-1-59593-369-0.
- Li et al. (2021a) Li, C.; Bi, B.; Yan, M.; Wang, W.; Huang, S.; Huang, F.; and Si, L. 2021a. StructuralLM: Structural Pre-training for Form Understanding. In ACL 2021.
- Li et al. (2021b) Li, P.; Gu, J.; Kuen, J.; Morariu, V. I.; Zhao, H.; Jain, R.; Manjunatha, V.; and Liu, H. 2021b. SelfDoc: Self-Supervised Document Representation Learning. In CVPR 2021, 5652–5660.
- Li et al. (2021c) Li, Y.; Qian, Y.; Yu, Y.; Qin, X.; Zhang, C.; Liu, Y.; Yao, K.; Han, J.; Liu, J.; and Ding, E. 2021c. StrucTexT: Structured Text Understanding with Multi-Modal Transformers. In ACM MM 2021.
- Lin et al. (2021) Lin, W.; Gao, Q.; Sun, L.; Zhong, Z.; Hu, K.; Ren, Q.; and Huo, Q. 2021. ViBERTgrid: A Jointly Trained Multi-modal 2D Document Representation for Key Information Extraction from Documents. In Lladós, J.; Lopresti, D.; and Uchida, S., eds., ICDAR 2021, Lecture Notes in Computer Science, 548–563. Cham: Springer International Publishing. ISBN 978-3-030-86549-8.
- Liu et al. (2019a) Liu, X.; Gao, F.; Zhang, Q.; and Zhao, H. 2019a. Graph Convolution for Multimodal Information Extraction from Visually Rich Documents. In NAACL-HLT 2019, 32–39. Minneapolis, Minnesota: Association for Computational Linguistics.
- Liu et al. (2019b) Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; and Stoyanov, V. 2019b. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arxiv:1907.11692.
- Longpre et al. (2023) Longpre, S.; Hou, L.; Vu, T.; Webson, A.; Chung, H. W.; Tay, Y.; Zhou, D.; Le, Q. V.; Zoph, B.; Wei, J.; and Roberts, A. 2023. The Flan Collection: Designing Data and Methods for Effective Instruction Tuning. arxiv:2301.13688.
- Loshchilov and Hutter (2018) Loshchilov, I.; and Hutter, F. 2018. Decoupled Weight Decay Regularization. In International Conference on Learning Representations.
- Luo et al. (2023) Luo, C.; Cheng, C.; Zheng, Q.; and Yao, C. 2023. GeoLayoutLM: Geometric Pre-training for Visual Information Extraction. In CVPR 2023.
- Majumder et al. (2020) Majumder, B. P.; Potti, N.; Tata, S.; Wendt, J. B.; Zhao, Q.; and Najork, M. 2020. Representation Learning for Information Extraction from Form-like Documents. In ACL 2020, 6495–6504. Online: Association for Computational Linguistics.
- Mathew et al. (2021) Mathew, M.; Bagal, V.; Tito, R. P.; Karatzas, D.; Valveny, E.; and Jawahar, C. V. 2021. InfographicVQA. In WACV 2022.
- Mathew, Karatzas, and Jawahar (2021) Mathew, M.; Karatzas, D.; and Jawahar, C. V. 2021. DocVQA: A Dataset for VQA on Document Images. In WACV 2021, 2199–2208. Waikoloa, HI, USA: IEEE. ISBN 978-1-66540-477-8.
- Mishra et al. (2022) Mishra, S.; Khashabi, D.; Baral, C.; and Hajishirzi, H. 2022. Cross-Task Generalization via Natural Language Crowdsourcing Instructions. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 3470–3487. Dublin, Ireland: Association for Computational Linguistics.
- Open AI (2023) Open AI. 2023. GPT-4 Technical Report.
- OpenAI (2022) OpenAI. 2022. ChatGPT. https://openai.com/blog/chatgpt.
- OpenAI (2023) OpenAI. 2023. GPT-4. https://openai.com/research/gpt-4.
- Ouyang et al. (2022) Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Gray, A.; Schulman, J.; Hilton, J.; Kelton, F.; Miller, L.; Simens, M.; Askell, A.; Welinder, P.; Christiano, P.; Leike, J.; and Lowe, R. 2022. Training Language Models to Follow Instructions with Human Feedback. In NeurIPS 2022.
- Pasupat and Liang (2015) Pasupat, P.; and Liang, P. 2015. Compositional Semantic Parsing on Semi-Structured Tables. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 1470–1480. Beijing, China: Association for Computational Linguistics.
- Peng et al. (2023) Peng, B.; Li, C.; He, P.; Galley, M.; and Gao, J. 2023. Instruction Tuning with GPT-4. arxiv:2304.03277.
- Peng et al. (2022) Peng, Q.; Pan, Y.; Wang, W.; Luo, B.; Zhang, Z.; Huang, Z.; Cao, Y.; Yin, W.; Chen, Y.; Zhang, Y.; Feng, S.; Sun, Y.; Tian, H.; Wu, H.; and Wang, H. 2022. ERNIE-Layout: Layout Knowledge Enhanced Pre-training for Visually-rich Document Understanding. In Findings of the Association for Computational Linguistics: EMNLP 2022, 3744–3756. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics.
- Qian et al. (2019) Qian, Y.; Santus, E.; Jin, Z.; Guo, J.; and Barzilay, R. 2019. GraphIE: A Graph-Based Framework for Information Extraction. In NAACL-HLT 2019, 751–761. Minneapolis, Minnesota: Association for Computational Linguistics.
- Raffel et al. (2020) Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; and Liu, P. J. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research, 21(140): 1–67.
- Rohan Taori et al. (2023) Rohan Taori; Ishaan Gulrajani; Tianyi Zhang; Yann Dubois; Xuechen Li; Carlos Guestrin; and Tatsunori B. Hashimoto. 2023. Stanford Alpaca: An Instruction-following LLaMA Model. GitHub.
- Sanh et al. (2022) Sanh, V.; Webson, A.; Raffel, C.; Bach, S. H.; Sutawika, L.; Alyafeai, Z.; Chaffin, A.; Stiegler, A.; Scao, T. L.; Raja, A.; Dey, M.; Bari, M. S.; Xu, C.; Thakker, U.; Sharma, S. S.; Szczechla, E.; Kim, T.; Chhablani, G.; Nayak, N.; Datta, D.; Chang, J.; Jiang, M. T.-J.; Wang, H.; Manica, M.; Shen, S.; Yong, Z. X.; Pandey, H.; Bawden, R.; Wang, T.; Neeraj, T.; Rozen, J.; Sharma, A.; Santilli, A.; Fevry, T.; Fries, J. A.; Teehan, R.; Bers, T.; Biderman, S.; Gao, L.; Wolf, T.; and Rush, A. M. 2022. Multitask Prompted Training Enables Zero-Shot Task Generalization. In ICLR 2022.
- Sarkhel and Nandi (2019) Sarkhel, R.; and Nandi, A. 2019. Deterministic Routing between Layout Abstractions for Multi-Scale Classification of Visually Rich Documents. In IJCAI 2019, 3360–3366. Macao, China: International Joint Conferences on Artificial Intelligence Organization. ISBN 978-0-9992411-4-1.
- Thoppilan et al. (2022) Thoppilan, R.; De Freitas, D.; Hall, J.; Shazeer, N.; Kulshreshtha, A.; Cheng, H.-T.; Jin, A.; Bos, T.; Baker, L.; Du, Y.; Li, Y.; Lee, H.; Zheng, H. S.; Ghafouri, A.; Menegali, M.; Huang, Y.; Krikun, M.; Lepikhin, D.; Qin, J.; Chen, D.; Xu, Y.; Chen, Z.; Roberts, A.; Bosma, M.; Zhao, V.; Zhou, Y.; Chang, C.-C.; Krivokon, I.; Rusch, W.; Pickett, M.; Srinivasan, P.; Man, L.; Meier-Hellstern, K.; Morris, M. R.; Doshi, T.; Santos, R. D.; Duke, T.; Soraker, J.; Zevenbergen, B.; Prabhakaran, V.; Diaz, M.; Hutchinson, B.; Olson, K.; Molina, A.; Hoffman-John, E.; Lee, J.; Aroyo, L.; Rajakumar, R.; Butryna, A.; Lamm, M.; Kuzmina, V.; Fenton, J.; Cohen, A.; Bernstein, R.; Kurzweil, R.; Aguera-Arcas, B.; Cui, C.; Croak, M.; Chi, E.; and Le, Q. 2022. LaMDA: Language Models for Dialog Applications. arxiv:2201.08239.
- Tito, Karatzas, and Valveny (2023) Tito, R.; Karatzas, D.; and Valveny, E. 2023. Hierarchical Multimodal Transformers for Multi-Page DocVQA. arxiv:2212.05935.
- Wang et al. (2021) Wang, J.; Liu, C.; Jin, L.; Tang, G.; Zhang, J.; Zhang, S.; Wang, Q.; Wu, Y.; and Cai, M. 2021. Towards Robust Visual Information Extraction in Real World: New Dataset and Novel Solution. In AAAI 2021, volume 35, 2738–2745.
- Wang et al. (2022a) Wang, W.; Huang, Z.; Luo, B.; Chen, Q.; Peng, Q.; Pan, Y.; Yin, W.; Feng, S.; Sun, Y.; Yu, D.; and Zhang, Y. 2022a. mmLayout: Multi-grained MultiModal Transformer for Document Understanding. In Proceedings of the 30th ACM International Conference on Multimedia, MM ’22, 4877–4886. New York, NY, USA: Association for Computing Machinery. ISBN 978-1-4503-9203-7.
- Wang et al. (2022b) Wang, Y.; Kordi, Y.; Mishra, S.; Liu, A.; Smith, N. A.; Khashabi, D.; and Hajishirzi, H. 2022b. Self-Instruct: Aligning Language Model with Self Generated Instructions. arxiv:2212.10560.
- Wang et al. (2022c) Wang, Y.; Mishra, S.; Alipoormolabashi, P.; Kordi, Y.; Mirzaei, A.; Arunkumar, A.; Ashok, A.; Dhanasekaran, A. S.; Naik, A.; Stap, D.; Pathak, E.; Karamanolakis, G.; Lai, H. G.; Purohit, I.; Mondal, I.; Anderson, J.; Kuznia, K.; Doshi, K.; Patel, M.; Pal, K. K.; Moradshahi, M.; Parmar, M.; Purohit, M.; Varshney, N.; Kaza, P. R.; Verma, P.; Puri, R. S.; Karia, R.; Sampat, S. K.; Doshi, S.; Mishra, S.; Reddy, S.; Patro, S.; Dixit, T.; Shen, X.; Baral, C.; Choi, Y.; Smith, N. A.; Hajishirzi, H.; and Khashabi, D. 2022c. Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks. In EMNLP 2022.
- Wang et al. (2020) Wang, Z.; Zhan, M.; Liu, X.; and Liang, D. 2020. DocStruct: A Multimodal Method to Extract Hierarchy Structure in Document for General Form Understanding. In EMNLP 2020 Findings, 898–908. Online: Association for Computational Linguistics.
- Wei et al. (2022) Wei, J.; Bosma, M.; Zhao, V. Y.; Guu, K.; Yu, A. W.; Lester, B.; Du, N.; Dai, A. M.; and Le, Q. V. 2022. Finetuned Language Models Are Zero-Shot Learners. In ICLR 2022. arXiv.
- Wei, He, and Zhang (2020) Wei, M.; He, Yi.; and Zhang, Q. 2020. Robust Layout-aware IE for Visually Rich Documents with Pre-trained Language Models. In ACM SIGIR 2020, SIGIR ’20, 2367–2376. New York, NY, USA: Association for Computing Machinery. ISBN 978-1-4503-8016-4.
- Xu et al. (2023) Xu, C.; Sun, Q.; Zheng, K.; Geng, X.; Zhao, P.; Feng, J.; Tao, C.; and Jiang, D. 2023. WizardLM: Empowering Large Language Models to Follow Complex Instructions. arxiv:2304.12244.
- Xu et al. (2020) Xu, Y.; Li, M.; Cui, L.; Huang, S.; Wei, F.; and Zhou, M. 2020. LayoutLM: Pre-training of Text and Layout for Document Image Understanding. In KDD 2020, 1192–1200.
- Xu et al. (2021a) Xu, Y.; Lv, T.; Cui, L.; Wang, G.; Lu, Y.; Florencio, D.; Zhang, C.; and Wei, F. 2021a. LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding. arXiv:2104.08836 [cs].
- Xu et al. (2021b) Xu, Y.; Xu, Y.; Lv, T.; Cui, L.; Wei, F.; Wang, G.; Lu, Y.; Florencio, D.; Zhang, C.; Che, W.; Zhang, M.; and Zhou, L. 2021b. LayoutLMv2: Multi-modal Pre-training for Visually-rich Document Understanding. In ACL 2021, 2579–2591. Online: Association for Computational Linguistics.
- Xu, Shen, and Huang (2022) Xu, Z.; Shen, Y.; and Huang, L. 2022. MultiInstruct: Improving Multi-Modal Zero-Shot Learning via Instruction Tuning. arxiv:2212.10773.
- Yang et al. (2017) Yang, X.; Yumer, E.; Asente, P.; Kraley, M.; Kifer, D.; and Giles, C. L. 2017. Learning to Extract Semantic Structure from Documents Using Multimodal Fully Convolutional Neural Networks. In CVPR 2017, 4342–4351.
- Yu et al. (2020) Yu, W.; Lu, N.; Qi, X.; Gong, P.; and Xiao, R. 2020. PICK: Processing Key Information Extraction from Documents Using Improved Graph Learning-Convolutional Networks. In ICPR 2020.
- Zaheer et al. (2021) Zaheer, M.; Guruganesh, G.; Dubey, A.; Ainslie, J.; Alberti, C.; Ontanon, S.; Pham, P.; Ravula, A.; Wang, Q.; Yang, L.; and Ahmed, A. 2021. Big Bird: Transformers for Longer Sequences. arxiv:2007.14062.
- Zhang et al. (2020) Zhang, P.; Xu, Y.; Cheng, Z.; Pu, S.; Lu, J.; Qiao, L.; Niu, Y.; and Wu, F. 2020. TRIE: End-to-End Text Reading and Information Extraction for Document Understanding. In ACM MM 2020, 1413–1422. Seattle WA USA: ACM. ISBN 978-1-4503-7988-5.
- Zhang et al. (2021) Zhang, Y.; Bo, Z.; Wang, R.; Cao, J.; Li, C.; and Bao, Z. 2021. Entity Relation Extraction as Dependency Parsing in Visually Rich Documents. In EMNLP 2021, 2759–2768. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics.
- Zhao et al. (2019) Zhao, X.; Niu, E.; Wu, Z.; and Wang, X. 2019. CUTIE: Learning to Understand Documents with Convolutional Universal Text Information Extractor. arXiv:1903.12363 [cs].
- Zhou et al. (2023) Zhou, Y.; Muresanu, A. I.; Han, Z.; Paster, K.; Pitis, S.; Chan, H.; and Ba, J. 2023. Large Language Models Are Human-Level Prompt Engineers. In ICLR 2023.
- Zhu et al. (2023) Zhu, D.; Chen, J.; Shen, X.; Li, X.; and Elhoseiny, M. 2023. MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models. arxiv:2304.10592.
附录A提示模板
| #Line | Prompt |
|---|---|
| 1 | You are asked to answer questions asked on a document image. |
| 2 | The answers to questions are short text spans taken verbatim from the document. This means that the answers comprise a set of contiguous text tokens present in the document. |
| 3 | Document: |
| 4 | {Layout Aware Document placeholder} |
| 5 | |
| 6 | Question: {Question placeholder} |
| 7 | |
| 8 | Directly extract the answer of the question from the document with as few words as possible. |
| 9 | |
| 10 | Answer: |
| #Line | Prompt |
|---|---|
| 1 | You are asked to answer questions asked on a document image. |
| 2 | The answer for a question in this can be any of the following types: |
| 3 | 1. Answer is a piece contiguous text from the document. |
| 4 | 2. Answer is a list of ”items” , where each item is a piece of text from the document (multiple spans). In such cases your model/method is expected to output an answer where each item is separated by a comma and a space. For example if the question is ”What are the three common symptoms of COVID-19?” Answer must be in the format ”fever, dry cough, tiredness”. In such cases ”and” should not be used to connect last item and the penultimate item and a space after the comma is required so that your answer match exactly with the ground truth. |
| 5 | 3. Answer is a contiguous piece of text from the question itself (a span from the question) |
| 6 | 4. Answer is a number ( for example ”2”, ”2.5”, ”2%”, ” 2/3” etc..). For example there are questions asking for count of something or cases where answer is sum of two values given in the image. |
| 7 | Document: |
| 8 | {Layout Aware Document placeholder} |
| 9 | |
| 10 | Question: {Question placeholder} |
| 11 | |
| 12 | Directly answer the answer of the question from the document with as few words as possible. |
| 13 | |
| 14 | Answer: |
| #Line | Prompt |
|---|---|
| 1 | You are asked to answer questions asked on a document image. |
| 2 | The answers to questions are short text spans taken verbatim from the document. This means that the answers comprise a set of contiguous text tokens present in the document. |
| 3 | Document: |
| 4 | {Layout Aware Document placeholder} |
| 5 | |
| 6 | Question: {Question placeholder} |
| 7 | |
| 8 | Directly extract the answer of the question from the document with as few words as possible. |
| 9 | |
| 10 | You also need to output your confidence in the answer, which must be an integer between 0-100. |
| 11 | The output format is as follows, where [] indicates a placeholder and does not need to be actually output: |
| 12 | [Confidence score], [Extracted Answer] |
| #Line | Prompt |
|---|---|
| 1 | Document: |
| 2 | {Document string with spaces and line from CSV table} |
| 3 | Randomly generate a question and corresponding answer for the above document. The answer to the question must be unique, and must be extracted from the document. To answer this question, the layout of the document must be understood. The output should be in the following format without any other text: |
| 4 | Question: [Question content] |
| 5 | Answer: [Answer content] |
| #Line | Prompt |
|---|---|
| 1 | Document: |
| 2 | {Document string with spaces and line from CSV table} |
| 3 | Question: {Question} |
| 4 | Please extract the answer of the question from the given document. |
表 7显示了 DocVQA(Mathew、Karatzas 和 Jawahar 2021)的提示模板。 在第一行和第二行中,我们根据DocVQA (Mathew, Karatzas, and Jawahar 2021)中的任务描述向模型详细解释了提取的含义。 第 3 行到第 6 行为布局感知文档和问题提供占位符。 为了避免模型因文档内容的干扰而忘记其任务,第8行总结并重申了任务要求。
表格 8显示InfographicVQA(Mathew 等人 2021) 的提示模板。 与DocVQA相比,InfographicVQA的答案来源更加复杂。 我们在第1至6行详细描述了答案要求,其余部分与DocVQA提示模板类似。
附录 B数据集
为了评估 LATIN-Prompt,我们在三个文档图像问答数据集上进行了实验,包括 DocVQA (Mathew, Karatzas, and Jawahar 2021)、InfographicVQA (Mathew 等人 2021)和 MP-DocVQA (Tito、Karatzas 和 Valveny 2023)。
DocVQA 是一项提取式问答任务,由在 12,767 个文档图像上定义的 50,000 个问题组成。 训练拆分有 39,463 个问题,验证拆分有 5,349 个问题,测试拆分有 5,188 个问题。 DocVQA包含大量与图像中的表单、布局、表格和列表相关的问题,对模型理解文档图像布局的能力提出了很高的要求。
InfographicVQA 由 5,485 个信息图表组成,它们通过文本、图形和视觉元素共同传达信息。 与DocVQA相比,InfographicVQA强调需要基本推理和算术技能的问题,并且答案来源更加复杂,包括Document(Image)-Span、Question-Span、Multi-Span和Non-extractive。
MP-DocVQA 将 DocVQA 扩展到更现实的多页面场景,其中文档通常由应一起处理的多个页面组成。 它包含 46,000 个问题,涉及 6,000 份行业文档的 48,000 多个扫描页面,页面图像包含不同的布局。 MP-DocVQA 中文档之间的可变性非常高。 每个文档的页数从 1 到 20 不等,识别的 OCR 单词数量从 1 到 42,313 不等。
按照惯例,我们使用 DUE (Borchmann 等人 2021) 提供的 DocVQA Azure OCR 结果。 对于 InfographicVQA 和 MP-DocVQA,我们使用官方 OCR 结果666https://rrc.cvc.uab.es/?ch=17&com=introduction。
附录C案例研究
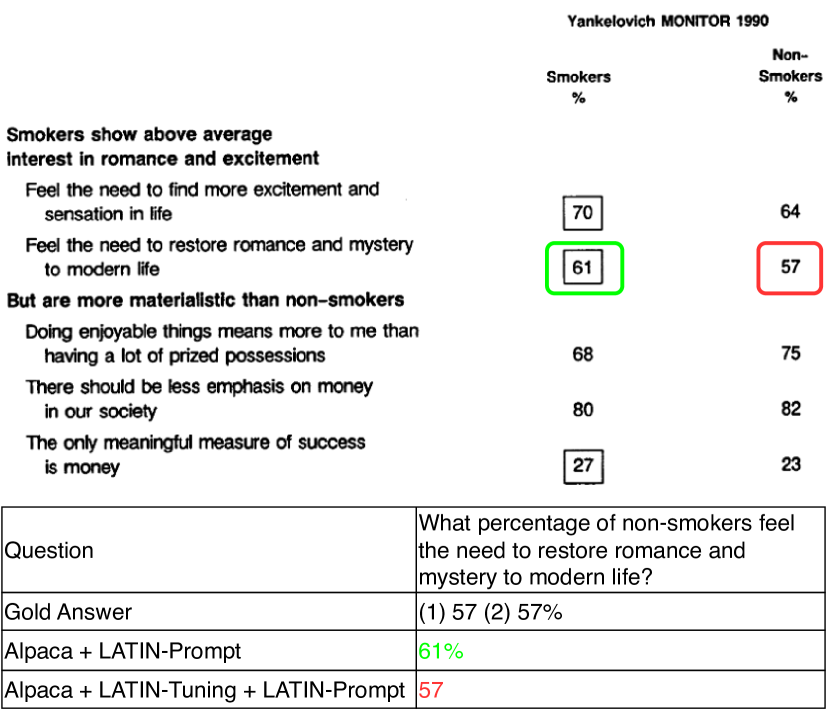
图6提供了一个比较Alpaca和Alpaca + LATIN-Tuning性能的案例。 经过拉丁语调音后,羊驼可以更有效地理解布局。