神经元激活覆盖率:重新思考分布外检测和泛化
摘要
当神经网络遇到显着偏离训练数据分布的数据时,通常会出现分布外 (OOD) 问题,i.e.,分布内 (InD )。 在本文中,我们从神经元激活的角度研究了 OOD 问题。 我们首先通过考虑神经元输出及其对模型决策的影响来制定神经元激活状态。 然后,为了描述神经元和 OOD 问题之间的关系,我们引入了神经元激活覆盖率 (NAC)——一个用于衡量 InD 数据下神经元行为的简单指标。 利用我们的 NAC,我们发现 1) 基于神经元行为,可以将 InD 和 OOD 输入在很大程度上区分开来,这大大简化了 OOD 检测问题,并在三个基准测试 (CIFAR-10、CIFAR-100 和 ImageNet-1K) 上超越了 21 种先前方法。 2) NAC 与模型泛化能力之间存在正相关关系,这种关系在各种架构和数据集上始终保持一致,这使得基于 NAC 的标准能够评估模型的鲁棒性。 与流行的 InD 验证标准相比,我们发现 NAC 不仅可以选择更鲁棒的模型,而且与 OOD 测试性能有更强的相关性。 我们的代码可在以下地址获取:https://github.com/BierOne/ood_coverage。
1 引言
机器学习系统近期的进展依赖于一个隐含的假设,即训练数据和测试数据共享相同的分布,被称为分布内 (InD) (Dosovitskiy 等人,2021;Szegedy 等人,2015;He 等人,2016;Simonyan & Zisserman,2015)。 然而,这个假设

在现实世界场景中很少出现,因为存在分布外 (OOD) 数据,e.g., 来自看不见的类的样本 (Blanchard 等人,2011)。 这种 OOD 和 InD 之间的分布变化通常会极大地挑战训练有素的模型,导致性能大幅下降 (Recht 等人,2019; D’Amour 等人,2020)。
以前解决此 OOD 问题的努力主要来自两个方面:1) OOD 检测和 2) OOD 泛化。 前者旨在设计工具来区分 InD 和 OOD 数据输入,从而避免使用不可靠的模型预测 (Hendrycks & Gimpel, 2017; Liang 等人,2018; Liu 等人,2020; Huang 等人,2021b)。 相反,OOD 泛化侧重于开发鲁棒网络来泛化看不见的 OOD 数据,仅依赖 InD 数据进行训练 (Blanchard 等人,2011; Sun & Saenko, 2016; Sagawa 等人,2020; Kim 等人,2021; Shi 等人,2022)。 尽管出现了大量研究,但事实证明,现有方法仍然难以提供对 OOD 问题根本原因和缓解措施的见解 (Sun 等人,2021; Gulrajani & Lopez-Paz, 2021)。
正如 Sun 等人 (2021); Ahn 等人 (2023) 所表明的那样,神经元在暴露于来自 InD 和 OOD 的数据输入时可能会表现出不同的激活模式(参见图 4)。 这揭示了利用神经元行为来表征模型状态(就 OOD 问题而言)的潜力。 然而,尽管有几项研究认识到这一重要性,但它们要么选择修改神经网络 (Sun 等人,2021),要么缺乏对神经元激活状态的适当定义 (Ahn 等人,2023; Tian 等人,2023)。 例如,Sun 等人 (2021) 提出了一种神经元截断策略,该策略将神经元输出剪切以分离 InD 和 OOD 数据,从而提高 OOD 检测。 然而,这种截断意外地降低了模型的分类能力 (Djurisic 等人,2023)。 111 虽然有人可能会争辩说,保持神经元输出以进行双重传播可以以低计算成本保持 InD 准确性,但它依赖于仅在神经元修剪中使用后层这一假设,因此削弱了这些基于神经元的方法的潜力。 . 最近,Ahn 等人 (2023) 和 Tian 等人 (2023) 使用阈值将神经元划分为二元状态(i.e., 激活或不激活),基于神经元输出。 然而,这种表征丢弃了宝贵的神经元分布细节。 与它们不同,本文表明,通过利用自然神经元激活状态,神经元分布的一个简单统计属性可以有效地促进 OOD 解决方案。
我们首先提出通过考虑神经元输出及其对模型决策的影响来制定神经元激活状态。 具体来说,受 Huang 等人 (2021b) 的启发,我们对神经元
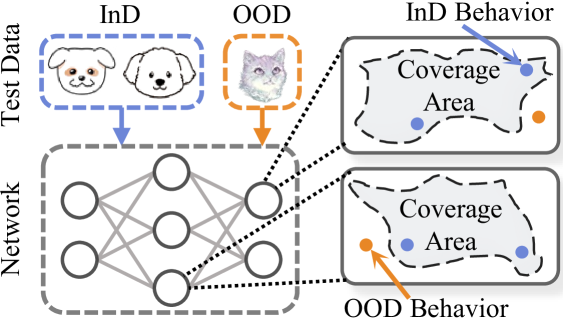
影响作为从网络输出和均匀向量之间的 Kullback-Leibler (KL) 散度 (Kullback & Leibler, 1951) 导出的梯度。 然后,为了描述神经元行为与 OOD 问题之间的关系,我们从系统测试中的覆盖率分析中汲取了见解 (Pei 等人,2017;Ma 等人,2018),这表明 训练集很少激活(覆盖)的神经元可能在测试阶段触发未检测到的错误,例如错误分类。 从这个意义上说,我们引入了 神经元激活覆盖率 (NAC) 的概念, 它量化了 InD 训练数据下神经元状态的覆盖程度(参见图 2)。 特别地,如果神经元状态经常被 InD 训练输入激活,NAC 将为其分配更高的覆盖分数,表明这种状态下的潜在缺陷更少。 本文将 NAC 应用于两个 OOD 任务:
OOD 检测。 由于 OOD 数据可能触发异常的神经元激活,因此与 InD 测试数据相比,它们应该呈现更小的覆盖分数(图 2)。 因此,我们提出了 NAC 用于 Uncertainty Estimation (NAC-UE),它直接将所有神经元的覆盖分数平均作为数据不确定性。 我们在三个基准(CIFAR-10、CIFAR-100 和 ImageNet-1k)上评估了 NAC-UE,在 21 种以前最好的 OOD 检测方法中建立了新的最先进性能。 值得注意的是,我们的 NAC-UE 在 CIFAR-100 上实现了 FPR95 的 10.60% 提高(AUROC 提高了 4.58%),优于竞争对手 ViM (Wang 等人,2022)(参见图 1)。
OOD泛化。 鉴于潜在缺陷可能存在于覆盖区域之外 (Pei et al., 2017),我们假设网络的鲁棒性随着覆盖区域的扩大而增强。 为此,我们采用 NAC 用于 Model Evaluation (NAC-ME),通过整合所有神经元的覆盖分布来衡量模型的鲁棒性。 通过在 DomainBed (Gulrajani & Lopez-Paz, 2021) 上进行的实验,我们发现 NAC 与模型泛化能力之间存在正相关性,这种相关性在各种架构和数据集上都始终存在。 此外,与 InD 验证标准相比,NAC-ME 不仅选择了更鲁棒的模型,而且与 OOD 测试性能表现出更强的相关性。 例如,在 Vit-b16 (Dosovitskiy et al., 2021) 上,NAC-ME 在与 OOD 测试准确率的秩相关性方面,比验证标准高出 11.61%。
2 NAC:神经元激活覆盖率
本文研究多类别分类中的 OOD 问题,其中 表示输入空间, 表示输出空间。 令 为训练集,包含来自联合分布 的 i.i.d. 样本。 由 、 参数化的神经网络在从 中抽取的样本上进行训练,生成用于分类的对数几率向量。 我们在图 3 中说明了基于 NAC 的方法。 接下来,我们首先制定神经元激活状态(第 2.1 节),然后介绍 NAC 的详细信息(第 2.2 节)。 最后,我们展示如何将 NAC 应用于两个 OOD 问题(第 4 节):OOD 检测和泛化。

2.1 神经元激活状态的公式
神经元输出通常取决于从网络输入到神经元所在层的传播。 但是,这没有考虑神经元在后续传播中的影响。 因此,我们引入了从网络输出到均匀向量之间的 KL 散度反向传播的梯度 (Huang 等人,2021b),以模拟神经元的影响。 形式上,我们将特定层的输出向量表示为 (第 3.1 节讨论了这种层的选择),其中 是神经元的数量, 是该层中第 个神经元的原始输出。 通过设置均匀向量 ,期望的 KL 散度可以给出如下:
| (1) |
其中 和 表示 在 中的元素。 是一个常数。 通过将 KL 梯度与神经元输出相结合,我们随后将 神经元激活状态 公式化为:
| (2) |
其中 是具有陡峭度控制器 的 sigmoid 函数。 在本文的其余部分,我们还将使用符号 来表示神经元状态函数。
的基本原理。 在这里,我们进一步分析了 KL 散度的梯度,以展示这部分如何促成了神经元激活状态 。 不失一般性,令网络为 ,其中 是 之后的预测器。 由于 ,我们可以将等式(2)改写如下(更多细节见附录 B):
| (3) |
其中 (1) 对应于被称为 输入 梯度 (Ancona 等人,2018) 的简单解释方法,它量化了神经元对模型预测 的贡献。 这也是许多流行的解释方法的通用形式,例如 -LRP (Bach 等人,2015)、DeepLIFT (Shrikumar 等人,2017) 和 IG (Sundararajan 等人,2017); (2) 衡量模型预测与均匀分布的偏差,从而表示样本置信度 (Huang 等人,2021b)。 通过这种方式,我们构建 ,同时考虑了神经元对模型预测的重要性以及模型对输入数据的置信度。 直观地说,如果神经元对输出的贡献较小(或模型对输入数据的置信度较低),则该神经元将被认为活性较低。
2.2 神经元激活覆盖率 (NAC)
通过神经元激活状态的公式,我们现在引入 神经元激活覆盖率 (NAC) 来描述 InD 和 OOD 数据下神经元的行为。 受系统测试 (Pei 等人,2017; Ma 等人,2018; Xie 等人,2019) 的启发,NAC 旨在量化 InD 训练数据下神经元状态的覆盖程度。 直觉是 如果神经元状态很少被任何 InD 输入激活(覆盖),则在这种状态下触发错误(例如,错误分类)的可能性很高。 由于 NAC 直接衡量神经元状态分布的统计属性 (i.e., 覆盖率),我们从概率密度函数 (PDF) 推导出 NAC 函数。 形式上,给定第 个神经元的某个状态 ,以及它在 InD 集 上的 PDF ,NAC 的函数可以表示为:
| (4) |
其中 是 在集 上的概率密度, 表示相对于状态 达到完全覆盖的 нижняя граница w.r.t.。 在神经元状态 被 InD 训练数据频繁激活的情况下,覆盖率分数 将为 1,表示这种状态下潜在缺陷更少。 值得注意的是,如果 太低,噪声激活将主导覆盖率,从而降低覆盖率分数的意义。 相反, 的过大值也会使 NAC 函数容易受到数据偏差的影响。 例如,给定一个包含大量相似样本的同质数据集,神经元状态 的覆盖率分数可能会被错误地表征为异常高,从而边缘化其他有意义状态的影响。 我们将在第 3.1 节分析 的影响。
2.3 应用
在对InD训练数据建模NAC函数后,我们可以直接应用它来解决现有的OOD问题。 以下,我们展示了两个应用场景。
用于OOD检测的不确定性估计。 由于OOD数据通常会触发异常的神经元行为(参见图4),我们采用NAC进行Uncertainty Estimation(NAC-UE), 它直接

将所有神经元的覆盖率得分平均作为测试样本的不确定性。 形式上,给定一个测试数据,NAC-UE的函数可以表示为,
| (5) |
其中是神经元数量;表示第个神经元的态;是NAC函数的控制器。 如果由触发的神经元状态经常被InD训练样本激活,则覆盖率得分会很高,表明很可能来自InD分布。 通过考虑网络中的多层,我们建议使用NAC-UE进行OOD检测,遵循Liu et al. (2020); Huang et al. (2021b); Sun et al. (2021):
| (6) |
其中是阈值,表示层的神经元状态函数。不确定性得分小于的测试样本将被归类为OOD;否则,InD。
用于OOD泛化的模型评估。 OOD 数据可能触发超出 InD 数据覆盖范围的神经元状态(图 2 和图 4),从而导致错误分类。 从这个角度来看,我们假设网络的鲁棒性可能与覆盖范围的大小呈正相关。 例如,随着覆盖范围的缩小,更大的非活动空间将保留下来,从而增加触发潜在错误的可能性。 因此,我们提出 NAC 用于 Model Evaluation(NAC-ME),它基于神经元覆盖分布的积分来表征模型的泛化能力。 形式上,给定 InD 训练集 ,NAC-ME 将模型的泛化能力(由 参数化)衡量为积分 w.r.t. NAC 分布:
| (7) |
其中 是神经元的数量,而 是 NAC 函数的控制器。 给定训练集 ,如果神经元在整个激活空间中始终处于活跃状态,我们认为它被 InD 训练数据充分锻炼,因此触发错误的可能性较低,即有利于鲁棒性。
近似值。 为了能够有效地处理大规模数据集,我们采用了一种简单的基于直方图的方法来建模概率密度函数 (PDF) 函数。 这种方法将神经元激活空间划分为 个区间,并自然地支持小批量近似。 我们在附录 C 中提供了更多细节。 此外,我们使用黎曼近似 (Krantz, 2005) 有效地计算 ,
| (8) |
Method MINIST SVHN Textures Places365 Average FPR95 AUROC FPR95 AUROC FPR95 AUROC FPR95 AUROC FPR95 AUROC CIFAR-10 Benchmark OpenMax 23.334.67 90.500.44 25.401.47 89.770.45 31.504.05 89.580.60 38.522.27 88.630.28 29.691.21 89.620.19 ODIN 23.8312.34 95.241.96 68.610.52 84.580.77 67.7011.06 86.942.26 70.366.96 85.071.24 57.624.24 87.960.61 MDS 27.303.55 90.102.41 25.962.52 91.180.47 27.944.20 92.691.06 47.674.54 84.902.54 32.223.40 89.721.36 MDSEns 1.300.51 99.170.41 74.341.04 66.560.58 76.070.17 77.400.28 94.160.33 52.470.15 61.470.48 73.900.27 RMDS 21.492.32 93.220.80 23.461.48 91.840.26 25.250.53 92.230.23 31.200.28 91.510.11 25.350.73 92.200.21 Gram 70.308.96 72.642.34 33.9117.35 91.524.45 94.642.71 62.348.27 90.491.93 60.443.41 72.346.73 71.733.20 ReAct 33.7718.00 92.813.03 50.2315.98 89.123.19 51.4211.42 89.381.49 44.203.35 90.350.78 44.908.37 90.421.41 VIM 18.361.42 94.760.38 19.290.41 94.500.48 21.141.83 95.150.34 41.432.17 89.490.39 25.050.52 93.480.24 KNN 20.051.36 94.260.38 22.601.26 92.670.30 24.060.55 93.160.24 30.380.63 91.770.23 24.270.40 92.960.14 ASH 70.0010.56 83.164.66 83.646.48 73.466.41 84.591.74 77.452.39 77.897.28 79.893.69 79.034.22 78.492.58 SHE 42.2220.59 90.434.76 62.744.01 86.381.32 84.605.30 81.571.21 76.365.32 82.891.22 66.485.98 85.321.43 GEN 23.007.75 93.832.14 28.142.59 91.970.66 40.746.61 90.140.76 47.033.22 89.460.65 34.731.58 91.350.69 NAC-UE 15.142.60 94.861.36 14.331.24 96.050.47 17.030.59 95.640.44 26.730.80 91.850.28 18.310.92 94.600.50 CIFAR-100 Benchmark OpenMax 53.824.74 76.011.39 53.201.78 82.071.53 56.121.91 80.560.09 54.851.42 79.290.40 54.500.68 79.480.41 ODIN 45.943.29 83.791.31 67.413.88 74.540.76 62.372.96 79.331.08 59.710.92 79.450.26 58.860.79 79.280.21 MDS 71.722.94 67.470.81 67.216.09 70.686.40 70.492.48 76.260.69 79.610.34 63.150.49 72.261.56 69.391.39 MDSEns 2.830.86 98.210.78 82.572.58 53.761.63 84.940.83 69.751.14 96.610.17 42.270.73 66.741.04 66.000.69 RMDS 52.056.28 79.742.49 51.653.68 84.891.10 53.991.06 83.650.51 53.570.43 83.400.46 52.810.63 82.920.42 Gram 53.537.45 80.714.15 20.061.96 95.550.60 89.512.54 70.791.32 94.670.60 46.381.21 64.442.37 73.361.08 ReAct 56.045.66 78.371.59 50.412.02 83.010.97 55.040.82 80.150.46 55.300.41 80.030.11 54.201.56 80.390.49 VIM 48.321.07 81.891.02 46.225.46 83.143.71 46.862.29 85.910.78 61.570.77 75.850.37 50.741.00 81.700.62 KNN 48.584.67 82.361.52 51.753.12 84.151.09 53.562.32 83.660.83 60.701.03 79.430.47 53.650.28 82.400.17 ASH 66.583.88 77.230.46 46.002.67 85.601.40 61.272.74 80.720.70 62.950.99 78.760.16 59.202.46 80.580.66 SHE 58.782.70 76.761.07 59.157.61 80.973.98 73.293.22 73.641.28 65.240.98 76.300.51 64.122.70 76.921.16 GEN 53.925.71 78.292.05 55.452.76 81.411.50 61.231.40 78.740.81 56.251.01 80.280.27 56.711.59 79.680.75 NAC-UE 21.976.62 93.151.63 24.394.66 92.401.26 40.651.94 89.320.55 73.571.16 73.050.68 40.141.86 86.980.37
3 实验
3.1 案例研究 1:OOD 检测
设置. 我们的实验设置与 OpenOOD 的最新版本一致222https://github.com/Jingkang50/OpenOOD. (Yang 等人,2022;Zhang 等人,2023a). 我们在三个基准数据集上评估了我们的 NAC-UE:CIFAR-10、CIFAR-100 和 ImageNet-1k。 对于 CIFAR-10 和 CIFAR-100,InD 数据集对应于各自的 CIFAR,并包含 4 个 OOD 数据集:MNIST (Deng, 2012), SVHN (Netzer 等人,2011), Textures (Cimpoi 等人,2014), 和 Places365 (Zhou 等人,2018). 对于 ImageNet 实验,ImageNet-1k 作为 InD,以及 3 个 OOD 数据集:iNaturalist (Horn 等人,2018), Textures (Cimpoi 等人,2014), 和 OpenImage-O (Wang 等人,2022). 我们使用预训练的 ResNet-50 和 Vit-b16 进行 ImageNet 实验,以及 ResNet-18 进行 CIFAR 实验。 对于所有使用的基准数据集,我们将我们的 NAC-UE 与 21 种 SoTA OOD 检测方法进行比较。 我们在附录 D 中提供了更多详细信息。
指标. 我们在评估中使用两个无阈值指标:1) FPR95:当 ID 样本的真阳性率为 95% 时,OOD 样本的假阳性率;2) AUROC:接收者操作特征曲线下的面积。 在我们的所有实现中,所有预训练模型都保持不变,在 OOD 检测阶段保留了它们的分类能力。
实现细节. 我们首先使用 InD 训练数据构建 NAC 函数,利用 1,000 张训练图像用于 ResNet-18 和 ResNet-50,以及 50,000 张图像用于 Vit-b16。 请注意,在这个阶段,我们仅使用少于训练集 5% 的训练样本(有关更多分析,请参见附录 G.1)。 接下来,我们在测试阶段使用 NAC-UE 来计算不确定性分数。 遵循 OpenOOD,我们使用验证集来选择超参数并在测试集上评估 NAC-UE。
结果。 表 1 和表 2 主要说明了我们在 CIFAR 和 ImageNet 基准测试上的结果,其中我们将 NAC-UE 与 21 种 SoTA 方法进行了比较。 可以看出,我们的 NAC-UE 在平均性能方面始终优于所有 SoTA 方法,在 3 个基准测试中取得了破纪录的性能。 具体而言,NAC-UE 在 CIFAR-100 和 CIFAR-10 上分别将 FPR95 比最具竞争力的对手 (Wang 等人,2022;Sun 等人,2022) 降低了 10.60% 和 5.96%。 在大规模 ImageNet 基准测试中,NAC-UE 也始终提高了跨骨干和 OOD 数据集的 AUROC 分数。 此外,由于NAC-UE以事后方式执行,因此它保留了模型分类能力(i。e., InD 精度)在 OOD 检测阶段。 相反,ReAct (Sun 等人,2021) 和 ASH (Djurisic 等人,2023) 等高级方法表现出有希望的 OOD 检测结果,但以牺牲 InD 性能为代价 (Djurisic 等人,2023)。
Dataset Backbone OpenMax MDS RMDS ReAct VIM KNN ASH SHE GEN NAC-UE iNaturalist ResNet-50 92.05 63.67 87.24 96.34 89.56 86.41 97.07 92.65 92.44 96.52 Vit-b16 94.93 96.01 96.10 86.11 95.72 91.46 50.62 93.57 93.54 93.72 Average 93.49 79.84 91.67 91.23 92.64 88.94 73.85 93.11 92.99 95.12 OpenImage-O ResNet-50 87.62 69.27 85.84 91.87 90.50 87.04 93.26 86.52 89.26 91.45 Vit-b16 87.36 92.38 92.32 84.29 92.18 89.86 55.51 91.04 90.27 91.58 Average 87.49 80.83 89.08 88.08 91.34 88.45 74.39 88.78 89.77 91.52 Textures ResNet-50 88.10 89.80 86.08 92.79 97.97 97.09 96.90 93.60 87.59 97.9 Vit-b16 85.52 89.41 89.38 86.66 90.61 91.12 48.53 92.65 90.23 94.17 Average 86.81 89.61 87.73 89.73 94.29 94.11 72.72 93.13 88.91 96.04
NAC-UE 结合训练方法。 训练时间正则化是潜在的方向之一
| Training | Method | FPR95 | AUROC |
| ConfBranch | Baseline | 50.98 | 83.94 |
| NAC-UE | 31.04 | 93.90 | |
| RotPred | Baseline | 36.67 | 90.00 |
| NAC-UE | 30.24 | 93.28 | |
| GODIN | Baseline | 50.87 | 85.51 |
| NAC-UE | 26.86 | 94.61 |
OOD 检测。 在这里,我们进一步表明 NAC-UE 可以与现有的训练方法相结合。 表 3 展示了我们使用三种训练方案的结果:ConfBranch (DeVries & Taylor, 2018),RotPred (Hendrycks et al., 2019b) 和 GODIN (Hsu et al., 2020),其中我们将 NAC-UE 与原始论文中采用的检测方法进行了比较,i.e., 表 3 中的 Baseline。 值得注意的是,NAC-UE 在所有三种训练方法中都显著优于基线方法,这再次突出了它在 OOD 检测中的有效性。
在哪里应用 NAC-UE? 由于 NAC-UE 是基于网络中的神经元进行操作的,因此我们进一步研究了它在使用不同层的神经元时的效果。 表 4 展示了结果,其中 ResNet 被用作分析的骨干网络。 可以得出以下结论: (1) NAC-UE 的性能与所用层的数量呈正相关。 这是直观的,因为包含更多层可以考虑更多数量的神经元,从而提高 NAC-UE 在估计模型状态方面的准确性; (2) 即使使用单层神经元,NAC-UE 也能获得良好的性能。 例如,通过使用 layer4,NAC-UE 已经达到了 23.50% FPR95,这超过了之前在 CIFAR-10 上表现最好的方法 KNN。
| Layer Combinations | CIFAR-10 | CIFAR-100 | ImageNet | ||||||
| Layer4 | Layer3 | Layer2 | Layer1 | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC |
| 23.50 | 93.21 | 85.84 | 58.37 | 26.89 | 94.57 | ||||
| 21.32 | 94.35 | 44.92 | 85.25 | 23.51 | 95.05 | ||||
| 18.50 | 94.46 | 39.96 | 86.94 | 22.69 | 95.23 | ||||
| 18.31 | 94.60 | 40.14 | 86.98 | 22.49 | 95.29 | ||||
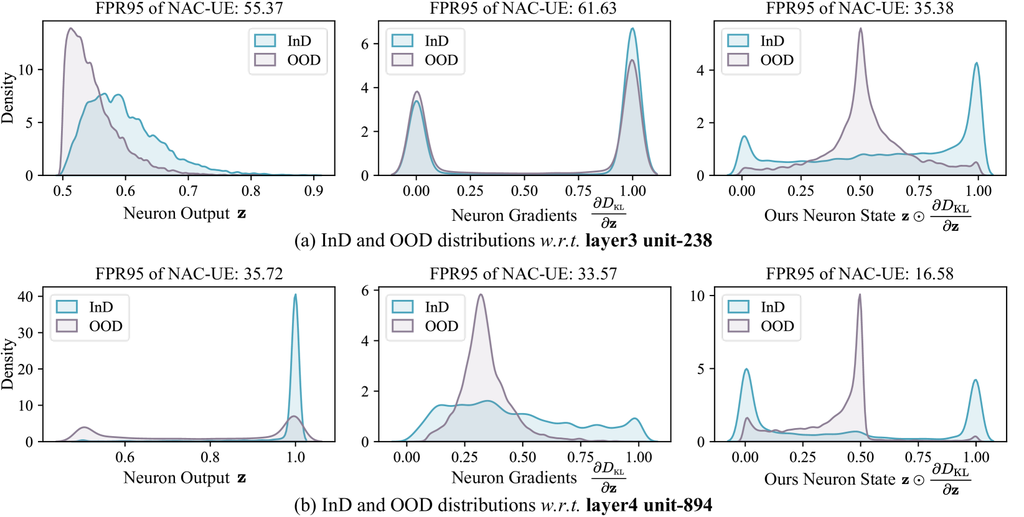
神经元激活状态的优越性 。 第 2.1 节 通过将神经元输出 与其 KL 梯度 相结合,来制定神经元激活状态 。 在这里,我们对这种公式进行了消融研究,以检验 的优越性。 特别地,我们分析了神经元行为 w.r.t. 1) 原始神经元输出:,2) 神经元输出的 KL 梯度:,以及 3) 我们提出的神经元状态:。
图 5 展示了结果,其中我们可视化了 ImageNet 基准中不同神经元在 InD 和 OOD 分布。 可以看到,在 的形式下,神经元在暴露于 InD 和 OOD 数据时,倾向于呈现不同的激活模式。 这种独特性极大地促进了 InD 和 OOD 之间的可分离性,从而在 NAC-UE 上实现了最佳的 OOD 检测性能,e.g., 16.58% FPR95 () vs. 35.72% FPR95 () 在 layer4 上。 相反,当考虑 和 的普通形式时,神经元在 InD 和 OOD 下的行为在很大程度上是重叠的,这进一步突出了我们 的独特特性。 更详细的分析可以在附录 G.2 中找到。
| Sigmoid Steepness () | FPR95 | AUROC |
| 40.07 | 85.48 | |
| 25.64 | 92.11 | |
| 23.50 | 93.21 | |
| 48.99 | 86.00 | |
| 92.69 | 54.69 |
| Lower Bound () | FPR95 | AUROC |
| 27.10 | 91.51 | |
| 24.16 | 92.79 | |
| 23.50 | 93.21 | |
| 28.35 | 92.17 | |
| 36.70 | 90.38 |
| No. of Intervals () | FPR95 | AUROC |
| 25.19 | 91.80 | |
| 23.50 | 93.21 | |
| 24.23 | 93.09 | |
| 33.87 | 91.11 | |
| 40.36 | 89.69 |
参数分析。 表 7-7 系统地分析了 sigmoid 斜率 ()、全覆盖的下界 () 以及 PDF 近似的区间数 () 的影响。 可以观察到以下几点: 1) 相对陡峭的 sigmoid 函数可以使 NAC-UE 表现更好。 我们推测这是因为神经元激活状态通常分布在一个较小的范围内,因此需要更陡峭的函数来区分它们更细微的变化; 2) NAC-UE 对 的选择很敏感。 如前所述,小的 r 将允许噪声激活主导 NAC,从而降低覆盖分数的影响。 此外,较大的 使 NAC 容易受到数据偏差 e.g 的影响。在具有大量相似样本的数据集中,神经元状态可以是不准确地表征高覆盖分数,忽略其他有意义的神经元状态。 3) NAC-UE 在中等 下效果更好。 这是直观的,因为较低的 可能不足以近似 PDF 函数,而较高的 很容易导致对所用训练样本的过拟合。
3.2 案例研究 2:OOD 泛化
设置。 我们的实验设置遵循 Domainbed 基准 (Gulrajani & Lopez-Paz, 2021)。 我们没有使用数字图像,而是采用了四个数据集: VLCS (Fang et al., 2013) (4 个领域,10,729 张图像)、PACS (Li et al., 2017) (4 个领域,9,991 张图像)、OfficeHome (Venkateswara et al., 2017) (4 个领域,15,588 张图像) 和 TerraInc (Beery et al., 2018) (4 个领域,24,788 张图像)。 对于所有数据集,我们报告 留一法 测试精度,遵循 (Gulrajani & Lopez-Paz, 2021),其中结果是在使用单个领域进行测试并将其他领域用于训练的情况下平均得到的。 对于所有使用的骨干网络,我们使用 (Cha et al., 2021) 中建议的超参数对其进行微调。 除非另有说明,训练策略为 ERM (Vapnik, 1999)。 我们将总训练步骤设置为 5000,并将所有模型的评估频率设置为 300 步。 我们使用验证集来选择 NAC-ME 的超参数。 更多细节请参见附录 E。
模型评估标准。 由于在模型训练期间假设 OOD 数据不可用,现有方法通常采用 InD 验证精度来评估模型 (Ramé et al., 2022; Yao et al., 2022; Shi et al., 2022; Kim et al., 2021)。 因此,我们主要将 NAC-ME 与普遍的 验证标准 (Gulrajani & Lopez-Paz, 2021) 进行比较。 我们还利用 oracle 标准 (Gulrajani & Lopez-Paz, 2021) 作为上限,该标准直接使用 OOD 测试数据来评估模型。
指标。 在这里,我们利用两个指标:1) OOD 测试准确性和模型评估分数之间的 Spearman Rank Correlation (RC)(i.e.、InD 验证准确性或 NAC-ME 分数),在训练过程中定期评估间隔(i.e.,每 300 步)采样; 2) 单次训练中按标准选择的最佳模型的 OOD 测试准确性 (ACC)。
Bakbone Method VLCS PACS OfficeHome TerraInc Average RC ACC RC ACC RC ACC RC ACC RC ACC Oracle - 77.67 - 80.51 - 56.18 - 44.51 - 64.72 Validation 34.27 75.12 68.71 79.01 83.50 55.60 39.58 37.36 56.52 61.77 NAC-ME 50.29 75.83 74.16 78.85 84.91 55.76 40.42 39.45 62.45 62.47 ResNet-18 (+16.02) (+0.71) (+5.45) (-0.16) (+1.41) (+0.16) (+0.84) (+2.09) (+5.93) (+0.70) Oracle - 79.79 - 86.10 - 65.95 - 50.76 - 70.65 Validation 31.43 77.70 58.54 84.57 67.93 65.04 37.07 46.07 48.74 68.34 NAC-ME 28.68 76.41 62.07 85.28 69.16 65.23 40.16 47.10 50.02 68.51 ResNet-50 (-2.75) (-1.29) (+3.53) (+0.71) (+1.23) (+0.19) (+3.09) (+1.03) (+1.28) (+0.17) Oracle - 79.11 - 71.99 - 61.44 - 41.29 - 63.46 Validation 37.95 77.43 89.34 69.83 98.71 61.22 22.71 36.28 62.18 61.19 NAC-ME 49.59 77.97 90.67 70.99 99.14 61.26 23.26 36.69 65.67 61.73 Vit-t16 (+11.64) (+0.54) (+1.33) (+1.16) (+0.43) (+0.04) (+0.55) (+0.41) (+3.49) (+0.54) Oracle - 80.96 - 90.23 - 81.23 - 52.23 - 76.16 Validation 18.81 78.70 41.38 87.80 58.29 80.11 0.92 45.49 29.85 73.03 NAC-ME 37.42 79.20 45.04 88.83 63.17 80.52 20.22 47.86 41.46 74.10 Vit-b16 (+18.61) (+0.50) (+3.66) (+1.03) (+4.88) (+0.41) (+19.30) (+2.37) (+11.61) (+1.07)
结果。 如表 8 所示,我们主要将我们的 NAC-ME 与四个骨干网络上的典型验证标准进行比较:ResNet-18、ResNet-50、Vit-t16 和 Vit-b16。 我们在以下方面提供主要观察结果: 1) NAC-ME 与 OOD 测试性能之间存在正相关关系 (i.e., RC 0),这种关系在所有架构和数据集中始终存在; 2) 与验证标准相比,NAC-ME 不仅选择了更稳健的模型(具有更高的 OOD 准确率),而且还表现出与 OOD 测试性能更强的相关性。 例如,在 TerraInc 数据集上,NAC-ME 与 OOD 测试准确率之间的秩相关系数为 20.22%,在 Vit-b16 上超过了验证标准 19.30%。 同样,在 VLCS 数据集上,NAC-ME 也显示出 52.29% 的秩相关系数,在 ResNet-18 上超过了验证标准 16.02%。 这些结果突出了 NAC-ME 在评估模型泛化能力方面的潜力。
| Algorithm | Method | RC | ACC |
| Validation | 61.76 | 80.66 | |
| NAC-ME | 66.85 | 80.92 | |
| SelfReg | (+5.09) | (+0.26) | |
| Validation | 70.06 | 80.68 | |
| NAC-ME | 76.55 | 81.54 | |
| CORAL | (+6.49) | (+0.86) |
NAC-ME 可以与 SoTA 学习算法协同工作。 最近的文献表明,许多学习算法可以提高模型的鲁棒性 (Ganin 等人,2016;Shi 等人,2022;Ramé 等人,2022)。 从这个意义上讲,我们通过将 NAC-ME 与两种最新的 SoTA 算法:CORAL (Sun & Saenko, 2016) 和 SelfReg (Kim 等人,2021) 相结合,进一步研究了它的潜力。 结果如表 9 所示。 可以看到,NAC-ME 作为评估标准,与验证标准相比,仍然表现出更好的性能,再次突出了其有效性。

OOD 测试数据量是否会阻碍秩相关 (RC)? 如表 8 所示,虽然在大多数情况下 NAC-ME 在模型选择方面优于验证标准, 但我们可以发现,秩相关 (RC) 仍然没有达到其最大值,e。g。,在使用 ResNet-18 的 VLCS 数据集上,RC 仅达到 50%,而最大值为 100%。 鉴于 Domainbed 最多只提供 6 个 OOD 域,我们假设 OOD 测试数据的数量/方差可能是原因:不足的 OOD 测试数据可能无法可靠地反映模型的泛化能力,从而阻碍 RC 的有效性。 为此,我们在 iWildCam 数据集 (Koh 等人,2021) 上进行了额外的实验,该数据集总共包含 323 个域和 203,029 张图像。 图 6 说明了结果,其中我们通过随机抽取不同比例的 OOD 数据来计算 RC,分析了 RC 与 OOD 测试数据量之间的关系。 可以看出,测试数据比例的增加也导致 RC 的提高,这证实了我们关于 OOD 数据影响的假设。 此外,我们可以观察到,在大多数情况下,NAC-ME 仍然可以优于验证标准。 这些观察结果再次突出了我们 NAC 的能力。
4 相关工作
系统测试中的神经元覆盖。 传统的系统测试通常利用覆盖率标准来发现软件程序中的缺陷 (Ammann & Offutt, 2008)。 这些标准衡量了特定代码或组件被执行的程度,从而揭示了可能存在缺陷的区域。 为了模拟神经网络中的这种程序测试, Pei 等人 (2017) 首次引入了神经元覆盖率,它衡量了给定输入集中激活的神经元的比例。 其基本理念是,如果网络在测试期间以较高的神经元覆盖率执行,则它可能具有更少的未检测到的错误, e。g。,错误分类。 与此一致,Ma 等人 (2018) 通过考虑训练数据中的神经元输出,扩展了神经元覆盖率,并提出了更细粒度的标准。 Yuan 等人 (2023) 引入了逐层神经元覆盖率,重点关注同一层内神经元之间的相互作用。 与我们的论文相关的最新工作是 Tian 等人 (2023),他们提出通过在训练期间最大化神经元覆盖率来提高模型的泛化能力。 然而,这些现有的神经元覆盖率定义仍然集中于 整个网络 中激活的神经元的比例,而忽略了单个神经元的激活细节。 与此相反,在本文中,我们专门为 单个神经元 定义了神经元激活覆盖率 (NAC),它描述了 InD 数据下每个神经元状态的覆盖程度。 这为理解 InD 和 OOD 场景下的神经元行为提供了更全面的视角。
OOD 检测。 OOD 检测的目标是在 InD 和 OOD 数据输入之间进行区分,从而避免在部署期间使用不可靠的模型预测。 现有的检测方法可以大体上分为三类:1)基于置信度的 (Bendale & Boult, 2016; Hendrycks & Gimpel, 2017; Huang & Li, 2021),2)基于距离的 (Huang 等人,2021a; Chen 等人,2020; van Amersfoort 等人,2020),以及 3)基于密度的 (Zisselman & Tamar, 2020; Jiang 等人,2022; Kirichenko 等人,2020) 方法。 基于置信度的方法通常利用模型输出的置信度水平来检测 OOD 样本,e。g。,最大 softmax 概率 (Hendrycks & Gimpel, 2017)。 相反,基于距离的方法通过测量输入样本与典型 InD 中心点或原型之间的距离 (e。g。,马氏距离 (Lee 等人,2018)) 来识别 OOD 样本。 同样,基于密度的方法使用概率模型来显式地建模 InD 分布,并将位于低密度区域的测试数据分类为 OOD。
特别是在神经元行为方面,ReAct (Sun 等人,2021) 最近提出对神经元激活进行截断,以分离 InD 和 OOD 数据。 但是,这种截断会导致模型分类能力下降 (Djurisic 等人,2023)。 同样,LINe (Ahn 等人,2023) 试图使用 Shapley 值 (Shapley,1997) 找到重要的神经元,然后执行激活剪切。 然而,这种方法依赖于基于阈值的策略,将神经元分类为二元状态,而忽略了宝贵的神经元分布细节。 与它们不同,在这项工作中,我们展示了通过使用自然神经元状态,分布属性 (i。e。,覆盖率) 极大地促进了 OOD 检测。
OOD 泛化。 OOD 泛化的目标是训练能够克服 InD 和 OOD 数据之间分布偏移的模型。 虽然已经出现了许多研究来解决这个问题 (Li 等人,2018b;Sun 和 Saenko,2016;Sagawa 等人,2020;Parascandolo 等人,2021;Arjovsky 等人,2019;Ganin 等人,2016;Li 等人,2018a;Krueger 等人,2021),Gulrajani 和 Lopez-Paz (2021) 最近提出了模型评估标准的重要性,并证明了普通的 ERM (Vapnik,1999) 以及适当的标准可以优于大多数最先进的方法。 与此一致,Arpit 等人 (2022) 发现使用验证精度作为评估标准对于模型选择可能不稳定,因此提出了移动平均值来稳定模型训练。 与此相反,这项工作阐明了神经元激活覆盖率在模型评估方面的潜力,表明它在各种情况下优于验证标准。
5 结论
在这项工作中,我们提出了一个神经元激活视图来反映 OOD 问题。 我们已经表明,通过我们制定的神经元激活状态,神经元激活覆盖率 (NAC) 的概念可以有效地促进两种 OOD 任务:OOD 检测和 OOD 泛化。 具体来说,我们已经证明:1)InD 和 OOD 输入可以基于神经元激活覆盖率更可分离,从而显着提高 OOD 检测性能; 2)NAC 与模型泛化能力之间存在正相关性,这种相关性在各种架构和数据集上始终存在,这突出了基于 NAC 的标准在模型评估方面的潜力。 沿着这些思路,我们希望这篇论文能进一步激励社区在 OOD 问题中考虑神经元行为。 这也是最终带来的最可观的益处。
致谢
本工作部分由研究资助委员会 9229106 资助,部分由 ITF MSRP 资助 ITS/018/22MS 和 ITF 项目 GHP/044/21SZ 资助,部分由国家自然科学基金资助 62022002,部分由深圳科技计划资助项目 JCYJ20220530140816037 资助,部分由香港研究资助委员会一般研究基金 11203220 资助,部分由城大战略跨学科研究基金 7020055 资助,部分由加拿大 CIFAR 人工智能主席计划、加拿大自然科学与工程研究理事会 (NSERC 编号 RGPIN-2021-02549, 编号 RGPAS-2021-00034, 编号 DGECR-2021-00019) 资助,部分由 JST-Mirai 计划资助 编号 JPMJMI20B8,以及部分由 JSPS KAKENHI 资助 编号 JP21H04877,编号 JP23H03372 资助。
参考文献
- Ahn et al. (2023) Yong Hyun Ahn, Gyeong-Moon Park, and Seong Tae Kim. Line: Out-of-distribution detection by leveraging important neurons. In CVPR, pp. 19852–19862. IEEE, 2023.
- Ammann & Offutt (2008) Paul Ammann and Jeff Offutt. Introduction to Software Testing. Cambridge University Press, 2008.
- Ancona et al. (2018) Marco Ancona, Enea Ceolini, Cengiz Öztireli, and Markus Gross. Towards better understanding of gradient-based attribution methods for deep neural networks. In ICLR, 2018.
- Arjovsky et al. (2019) Martín Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk minimization. arXiv preprint arXiv:1907.02893, 2019.
- Arpit et al. (2022) Devansh Arpit, Huan Wang, Yingbo Zhou, and Caiming Xiong. Ensemble of averages: Improving model selection and boosting performance in domain generalization. In NeurIPS, 2022.
- Averly & Chao (2023) Reza Averly and Wei-Lun Chao. Unified out-of-distribution detection: A model-specific perspective. In ICCV. IEEE, 2023.
- Bach et al. (2015) Sebastian Bach, Alexander Binder, Grégoire Montavon, Frederick Klauschen, Klaus-Robert Müller, and Wojciech Samek. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLOS ONE, 10:1–46, 07 2015.
- Bai et al. (2023) Haoyue Bai, Gregory Canal, Xuefeng Du, Jeongyeol Kwon, Robert D. Nowak, and Yixuan Li. Feed two birds with one scone: Exploiting wild data for both out-of-distribution generalization and detection. In ICML, pp. 1454–1471. PMLR, 2023.
- Beery et al. (2018) Sara Beery, Grant Van Horn, and Pietro Perona. Recognition in terra incognita. In ECCV, pp. 472–489. Springer, 2018.
- Bendale & Boult (2016) Abhijit Bendale and Terrance E. Boult. Towards open set deep networks. In CVPR, pp. 1563–1572. IEEE, 2016.
- Bitterwolf et al. (2023) Julian Bitterwolf, Maximilian Müller, and Matthias Hein. In or out? fixing imagenet out-of-distribution detection evaluation. In ICML, pp. 2471–2506. PMLR, 2023.
- Blanchard et al. (2011) Gilles Blanchard, Gyemin Lee, and Clayton Scott. Generalizing from several related classification tasks to a new unlabeled sample. In NeurIPS, pp. 2178–2186, 2011.
- Cha et al. (2021) Junbum Cha, Sanghyuk Chun, Kyungjae Lee, Han-Cheol Cho, Seunghyun Park, Yunsung Lee, and Sungrae Park. SWAD: domain generalization by seeking flat minima. In NeurIPS, pp. 22405–22418, 2021.
- Chen et al. (2020) Xingyu Chen, Xuguang Lan, Fuchun Sun, and Nanning Zheng. A boundary based out-of-distribution classifier for generalized zero-shot learning. In ECCV, pp. 572–588. Springer, 2020.
- Cimpoi et al. (2014) Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. In CVPR, pp. 3606–3613. IEEE, 2014.
- D’Amour et al. (2020) Alexander D’Amour, Katherine A. Heller, Dan Moldovan, Ben Adlam, Babak Alipanahi, Alex Beutel, Christina Chen, Jonathan Deaton, Jacob Eisenstein, Matthew D. Hoffman, Farhad Hormozdiari, Neil Houlsby, Shaobo Hou, Ghassen Jerfel, Alan Karthikesalingam, Mario Lucic, Yi-An Ma, Cory Y. McLean, Diana Mincu, Akinori Mitani, Andrea Montanari, Zachary Nado, Vivek Natarajan, Christopher Nielson, Thomas F. Osborne, Rajiv Raman, Kim Ramasamy, Rory Sayres, Jessica Schrouff, Martin Seneviratne, Shannon Sequeira, Harini Suresh, Victor Veitch, Max Vladymyrov, Xuezhi Wang, Kellie Webster, Steve Yadlowsky, Taedong Yun, Xiaohua Zhai, and D. Sculley. Underspecification presents challenges for credibility in modern machine learning. arXiv preprint arXiv:2011.03395, 2020.
- Deng et al. (2009) Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, pp. 248–255. IEEE, 2009.
- Deng (2012) Li Deng. The mnist database of handwritten digit images for machine learning research [best of the web]. IEEE Signal Processing Magazine, 29(6):141–142, 2012.
- DeVries & Taylor (2018) Terrance DeVries and Graham W. Taylor. Learning confidence for out-of-distribution detection in neural networks. arXiv preprint arXiv:1802.04865, 2018.
- Djurisic et al. (2023) Andrija Djurisic, Nebojsa Bozanic, Arjun Ashok, and Rosanne Liu. Extremely simple activation shaping for out-of-distribution detection. In ICLR, 2023.
- Dong et al. (2022) Xin Dong, Junfeng Guo, Ang Li, Wei-Te Ting, Cong Liu, and H. T. Kung. Neural mean discrepancy for efficient out-of-distribution detection. In CVPR, pp. 19195–19205. IEEE, 2022.
- Dosovitskiy et al. (2021) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
- Dubey et al. (2018) Abhimanyu Dubey, Otkrist Gupta, Ramesh Raskar, and Nikhil Naik. Maximum-entropy fine grained classification. In NeurIPS, pp. 635–645, 2018.
- Fang et al. (2013) Chen Fang, Ye Xu, and Daniel N. Rockmore. Unbiased metric learning: On the utilization of multiple datasets and web images for softening bias. In ICCV, pp. 1657–1664. IEEE, 2013.
- Fort et al. (2021) Stanislav Fort, Jie Ren, and Balaji Lakshminarayanan. Exploring the limits of out-of-distribution detection. In NeurIPS, pp. 7068–7081, 2021.
- Ganin et al. (2016) Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, and Victor S. Lempitsky. Domain-adversarial training of neural networks. J. Mach. Learn. Res., 17:59:1–59:35, 2016.
- Gulrajani & Lopez-Paz (2021) Ishaan Gulrajani and David Lopez-Paz. In search of lost domain generalization. In ICLR, 2021.
- Guo et al. (2017) Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. In ICML, pp. 1321–1330. PMLR, 2017.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, pp. 770–778. IEEE, 2016.
- Hendrycks & Gimpel (2017) Dan Hendrycks and Kevin Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks. In ICLR, 2017.
- Hendrycks et al. (2019a) Dan Hendrycks, Mantas Mazeika, and Thomas G. Dietterich. Deep anomaly detection with outlier exposure. In ICLR, 2019a.
- Hendrycks et al. (2019b) Dan Hendrycks, Mantas Mazeika, Saurav Kadavath, and Dawn Song. Using self-supervised learning can improve model robustness and uncertainty. In NeurIPS, pp. 15637–15648, 2019b.
- Hendrycks et al. (2022) Dan Hendrycks, Steven Basart, Mantas Mazeika, Andy Zou, Joseph Kwon, Mohammadreza Mostajabi, Jacob Steinhardt, and Dawn Song. Scaling out-of-distribution detection for real-world settings. In ICML, pp. 8759–8773. PMLR, 2022.
- Horn et al. (2018) Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alexander Shepard, Hartwig Adam, Pietro Perona, and Serge J. Belongie. The inaturalist species classification and detection dataset. In CVPR, pp. 8769–8778. IEEE, 2018.
- Hsu et al. (2020) Yen-Chang Hsu, Yilin Shen, Hongxia Jin, and Zsolt Kira. Generalized ODIN: detecting out-of-distribution image without learning from out-of-distribution data. In CVPR, pp. 10948–10957. IEEE, 2020.
- Huang et al. (2021a) Haiwen Huang, Zhihan Li, Lulu Wang, Sishuo Chen, Xinyu Zhou, and Bin Dong. Feature space singularity for out-of-distribution detection. In SafeAI@AAAI, 2021a.
- Huang & Li (2021) Rui Huang and Yixuan Li. MOS: Towards scaling out-of-distribution detection for large semantic space. In CVPR, pp. 8710–8719. IEEE, 2021.
- Huang et al. (2021b) Rui Huang, Andrew Geng, and Yixuan Li. On the importance of gradients for detecting distributional shifts in the wild. In NeurIPS, pp. 677–689, 2021b.
- Jiang et al. (2022) Dihong Jiang, Sun Sun, and Yaoliang Yu. Revisiting flow generative models for out-of-distribution detection. In ICLR, 2022.
- Kim et al. (2021) Daehee Kim, Youngjun Yoo, Seunghyun Park, Jinkyu Kim, and Jaekoo Lee. Selfreg: Self-supervised contrastive regularization for domain generalization. In ICCV, pp. 9599–9608. IEEE, 2021.
- Kirichenko et al. (2020) Polina Kirichenko, Pavel Izmailov, and Andrew Gordon Wilson. Why normalizing flows fail to detect out-of-distribution data. In NeurIPS, pp. 20578–20589, 2020.
- Koh et al. (2021) Pang Wei Koh, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, Tony Lee, Etienne David, Ian Stavness, Wei Guo, Berton Earnshaw, Imran S. Haque, Sara M. Beery, Jure Leskovec, Anshul Kundaje, Emma Pierson, Sergey Levine, Chelsea Finn, and Percy Liang. WILDS: A benchmark of in-the-wild distribution shifts. In ICML, pp. 5637–5664. PMLR, 2021.
- Kong & Ramanan (2021) Shu Kong and Deva Ramanan. Opengan: Open-set recognition via open data generation. In ICCV, pp. 793–802. IEEE, 2021.
- Krantz (2005) Steven G. Krantz. Real Analysis and Foundations. Chapman Hall/CRC, 2005.
- Krizhevsky (2009) Alex Krizhevsky. Learning multiple layers of features from tiny images. 2009.
- Krueger et al. (2021) David Krueger, Ethan Caballero, Jörn-Henrik Jacobsen, Amy Zhang, Jonathan Binas, Dinghuai Zhang, Rémi Le Priol, and Aaron C. Courville. Out-of-distribution generalization via risk extrapolation (rex). In ICML, pp. 5815–5826. PMLR, 2021.
- Kullback & Leibler (1951) S. Kullback and R. A. Leibler. On Information and Sufficiency. The Annals of Mathematical Statistics, 22(1):79 – 86, 1951.
- Le & Yang (2015) Ya Le and Xuan S. Yang. Tiny imagenet visual recognition challenge. CS 231N, 7(7):3, 2015.
- Lee et al. (2019) Gunhee Lee, Hanmin Park, Namhyung Kim, Joonsang Yu, Sujeong Jo, and Kiyoung Choi. Acceleration of DNN backward propagation by selective computation of gradients. In DAC, pp. 85. ACM, 2019.
- Lee et al. (2018) Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. In NeurIPS, pp. 7167–7177, 2018.
- Li et al. (2017) Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy M. Hospedales. Deeper, broader and artier domain generalization. In ICCV, pp. 5543–5551. IEEE, 2017.
- Li et al. (2018a) Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy M. Hospedales. Learning to generalize: Meta-learning for domain generalization. In AAAI, pp. 3490–3497. AAAI, 2018a.
- Li et al. (2018b) Haoliang Li, Sinno Jialin Pan, Shiqi Wang, and Alex C. Kot. Domain generalization with adversarial feature learning. In CVPR, pp. 5400–5409. IEEE, 2018b.
- Liang et al. (2018) Shiyu Liang, Yixuan Li, and R. Srikant. Enhancing the reliability of out-of-distribution image detection in neural networks. In ICLR, 2018.
- Liu et al. (2020) Weitang Liu, Xiaoyun Wang, John D. Owens, and Yixuan Li. Energy-based out-of-distribution detection. In NeurIPS, pp. 21464–21475, 2020.
- Liu et al. (2023) Xixi Liu, Yaroslava Lochman, and Christopher Zach. GEN: pushing the limits of softmax-based out-of-distribution detection. In CVPR, pp. 23946–23955. IEEE, 2023.
- Ma et al. (2018) Lei Ma, Felix Juefei-Xu, Fuyuan Zhang, Jiyuan Sun, Minhui Xue, Bo Li, Chunyang Chen, Ting Su, Li Li, Yang Liu, Jianjun Zhao, and Yadong Wang. Deepgauge: multi-granularity testing criteria for deep learning systems. In ASE, pp. 120–131. ACM, 2018.
- Netzer et al. (2011) Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y. Ng. Reading digits in natural images with unsupervised feature learning. In NeurIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2011.
- Parascandolo et al. (2021) Giambattista Parascandolo, Alexander Neitz, Antonio Orvieto, Luigi Gresele, and Bernhard Schölkopf. Learning explanations that are hard to vary. In ICLR, 2021.
- Pei et al. (2017) Kexin Pei, Yinzhi Cao, Junfeng Yang, and Suman Jana. Deepxplore: Automated whitebox testing of deep learning systems. In SOSP, pp. 1–18. ACM, 2017.
- Ramé et al. (2022) Alexandre Ramé, Corentin Dancette, and Matthieu Cord. Fishr: Invariant gradient variances for out-of-distribution generalization. In ICML, pp. 18347–18377. PMLR, 2022.
- Recht et al. (2019) Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do imagenet classifiers generalize to imagenet? In ICML, pp. 5389–5400. PMLR, 2019.
- Ren et al. (2021) Jie Ren, Stanislav Fort, Jeremiah Z. Liu, Abhijit Guha Roy, Shreyas Padhy, and Balaji Lakshminarayanan. A simple fix to mahalanobis distance for improving near-ood detection. arXiv preprint arXiv:2106.09022, 2021.
- Rostami & Galstyan (2023) Mohammad Rostami and Aram Galstyan. Overcoming concept shift in domain-aware settings through consolidated internal distributions. In AAAI, pp. 9623–9631. AAAI Press, 2023.
- Sagawa et al. (2020) Shiori Sagawa, Pang Wei Koh, Tatsunori B. Hashimoto, and Percy Liang. Distributionally robust neural networks. In ICLR, 2020.
- Sastry & Oore (2020) Chandramouli Shama Sastry and Sageev Oore. Detecting out-of-distribution examples with gram matrices. In ICML, pp. 8491–8501. PMLR, 2020.
- Shapley (1997) Lloyd S. Shapley. A value for n-person games. Classics in game theory, 69, 1997.
- Shi et al. (2022) Yuge Shi, Jeffrey Seely, Philip H. S. Torr, Siddharth Narayanaswamy, Awni Y. Hannun, Nicolas Usunier, and Gabriel Synnaeve. Gradient matching for domain generalization. In ICLR, 2022.
- Shrikumar et al. (2017) Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. Learning important features through propagating activation differences. In ICML, pp. 3145–3153. PMLR, 2017.
- Simonyan & Zisserman (2015) Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
- Song et al. (2022) Yue Song, Nicu Sebe, and Wei Wang. Rankfeat: Rank-1 feature removal for out-of-distribution detection. In NeurIPS, 2022.
- Sun & Saenko (2016) Baochen Sun and Kate Saenko. Deep CORAL: correlation alignment for deep domain adaptation. In ECCV, pp. 443–450. Springer, 2016.
- Sun & Li (2022) Yiyou Sun and Yixuan Li. DICE: leveraging sparsification for out-of-distribution detection. In ECCV, pp. 691–708. Springer, 2022.
- Sun et al. (2021) Yiyou Sun, Chuan Guo, and Yixuan Li. React: Out-of-distribution detection with rectified activations. In NeurIPS, pp. 144–157, 2021.
- Sun et al. (2022) Yiyou Sun, Yifei Ming, Xiaojin Zhu, and Yixuan Li. Out-of-distribution detection with deep nearest neighbors. In ICML, pp. 20827–20840. PMLR, 2022.
- Sundararajan et al. (2017) Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In ICML, pp. 3319–3328. PMLR, 2017.
- Szegedy et al. (2015) Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott E. Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In CVPR, pp. 1–9. IEEE, 2015.
- Tian et al. (2023) Chris Xing Tian, Haoliang Li, Xiaofei Xie, Yang Liu, and Shiqi Wang. Neuron coverage-guided domain generalization. IEEE Trans. Pattern Anal. Mach. Intell., 45(1):1302–1311, 2023.
- Tian et al. (2021) Junjiao Tian, Yen-Chang Hsu, Yilin Shen, Hongxia Jin, and Zsolt Kira. Exploring covariate and concept shift for out-of-distribution detection. In NeurIPS Workshops, 2021.
- van Amersfoort et al. (2020) Joost van Amersfoort, Lewis Smith, Yee Whye Teh, and Yarin Gal. Uncertainty estimation using a single deep deterministic neural network. In ICML, pp. 9690–9700. PMLR, 2020.
- Vapnik (1999) Vladimir Vapnik. An overview of statistical learning theory. IEEE Trans. Neural Networks, 10(5):988–999, 1999.
- Venkateswara et al. (2017) Hemanth Venkateswara, Jose Eusebio, Shayok Chakraborty, and Sethuraman Panchanathan. Deep hashing network for unsupervised domain adaptation. In CVPR, pp. 5385–5394. IEEE, 2017.
- Wang et al. (2022) Haoqi Wang, Zhizhong Li, Litong Feng, and Wayne Zhang. Vim: Out-of-distribution with virtual-logit matching. In CVPR, pp. 4911–4920. IEEE, 2022.
- Xie et al. (2019) Xiaofei Xie, Lei Ma, Felix Juefei-Xu, Minhui Xue, Hongxu Chen, Yang Liu, Jianjun Zhao, Bo Li, Jianxiong Yin, and Simon See. Deephunter: a coverage-guided fuzz testing framework for deep neural networks. In ISSTA, pp. 146–157. ACM, 2019.
- Xie et al. (2022) Xiaofei Xie, Tianlin Li, Jian Wang, Lei Ma, Qing Guo, Felix Juefei-Xu, and Yang Liu. NPC: neuron path coverage via characterizing decision logic of deep neural networks. ACM Trans. Softw. Eng. Methodol., 31(3):47:1–47:27, 2022.
- Yang et al. (2022) Jingkang Yang, Pengyun Wang, Dejian Zou, Zitang Zhou, Kunyuan Ding, Wenxuan Peng, Haoqi Wang, Guangyao Chen, Bo Li, Yiyou Sun, Xuefeng Du, Kaiyang Zhou, Wayne Zhang, Dan Hendrycks, Yixuan Li, and Ziwei Liu. Openood: Benchmarking generalized out-of-distribution detection. In NeurIPS Datasets and Benchmarks, 2022.
- Yang et al. (2023) Jingkang Yang, Kaiyang Zhou, and Ziwei Liu. Full-spectrum out-of-distribution detection. Int. J. Comput. Vis., 131(10):2607–2622, 2023.
- Yao et al. (2022) Xufeng Yao, Yang Bai, Xinyun Zhang, Yuechen Zhang, Qi Sun, Ran Chen, Ruiyu Li, and Bei Yu. Pcl: Proxy-based contrastive learning for domain generalization. In CVPR, pp. 7097–7107. IEEE, 2022.
- Yuan et al. (2023) Yuanyuan Yuan, Qi Pang, and Shuai Wang. Revisiting neuron coverage for dnn testing: A layer-wise and distribution-aware criterion. In ICSE. ACM, 2023.
- Zhang et al. (2023a) Jingyang Zhang, Jingkang Yang, Pengyun Wang, Haoqi Wang, Yueqian Lin, Haoran Zhang, Yiyou Sun, Xuefeng Du, Kaiyang Zhou, Wayne Zhang, Yixuan Li, Ziwei Liu, Yiran Chen, and Hai Li. Openood v1.5: Enhanced benchmark for out-of-distribution detection. arXiv preprint arXiv:2306.09301, 2023a.
- Zhang et al. (2023b) Jinsong Zhang, Qiang Fu, Xu Chen, Lun Du, Zelin Li, Gang Wang, Xiaoguang Liu, Shi Han, and Dongmei Zhang. Out-of-distribution detection based on in-distribution data patterns memorization with modern hopfield energy. In ICLR, 2023b.
- Zhang et al. (2023c) Xingxuan Zhang, Yue He, Renzhe Xu, Han Yu, Zheyan Shen, and Peng Cui. NICO++: towards better benchmarking for domain generalization. In CVPR, pp. 16036–16047. IEEE, 2023c.
- Zhou et al. (2018) Bolei Zhou, Àgata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell., 40(6):1452–1464, 2018.
- Zhou et al. (2022) Xiao Zhou, Yong Lin, Weizhong Zhang, and Tong Zhang. Sparse invariant risk minimization. In ICML, pp. 27222–27244. PMLR, 2022.
- Zisselman & Tamar (2020) Ev Zisselman and Aviv Tamar. Deep residual flow for out of distribution detection. In CVPR, pp. 13991–14000. IEEE, 2020.
section0em2em 小节2em2.5em
附录
附录 A 潜在社会影响
本研究介绍了神经元激活覆盖率 (NAC) 作为一种有效的工具来促进分布外 (OOD) 解决方案。 通过改进 OOD 检测和泛化,NAC 有潜力显著提高现代机器学习模型的可靠性和安全性。 因此,这项研究的社会影响可能非常广泛,涵盖数字内容理解的消费者和商业应用,包括驾驶辅助和自动驾驶在内的交通系统,以及识别未知疾病的医疗保健应用。 此外,通过公开分享我们的代码,我们努力为机器学习从业人员提供一个现成的资源,用于负责任的 AI 开发,最终造福整个社会。 虽然我们预计不会出现负面影响,但我们致力于在未来的工作中扩展我们的框架。
附录 B 其他理论细节
样本置信度的推导。 需要提醒的是,在主要论文中,我们介绍了网络输出与均匀向量 之间的 Kullback-Leibler (KL) 散度 (Kullback & Leibler, 1951),如下所示:
其中 ,并且 表示 中的第 个元素。 是一个常数。 令 表示 中的第 个元素,我们有 。 然后,通过替换 的表达式,我们可以将 KL 散度重写为:
随后,我们可以导出 KL 散度 w.r.t. 输出 logit 的梯度为:
由于 ,我们最终得到:
| (9) |
公式 (3) 的推导。 如上所示,我们有 。 通过替换此表达式,我们可以将神经元激活状态 的公式重写为:
| (10) |
附录 C 近似细节
在本节中,我们将展示 PDF 函数近似的细节,并进一步展示我们 NAC 函数中选择 的见解。
C.1 预备知识
概率密度函数 (PDF)。 概率密度函数 (PDF),用 表示,度量连续随机变量在给定范围内取特定值的概率。 因此, 应该具备以下关键属性:
-
(1)
非负性:,对于所有;
-
(2)
归一化:;
-
(3)
概率解释:,
其中 表示随机变量 在范围 内取值的概率。
累积分布函数 (CDF)。 与 PDF 一致,累积分布函数 (CDF),用 表示,计算给定 值的累积概率。 形式上, 给出了概率密度函数在指定 之前的面积,
| (13) |
根据微积分基本定理,我们可以将函数 重写为,
| (14) |
注意,在主文中,我们用 表示 PDF,用 表示在训练数据集 上第 个神经元的 NAC 函数。 在这个附录中,为了简单起见,我们将省略上标 和下标 。
C.2 近似
与主文一致,我们通过一个简单的基于直方图的方法来近似神经元状态的 PDF,其中神经元激活空间被划分为 个以对数刻度表示的区间/箱。 形式上,假设一个 bin 的宽度为 ,我们可以将 PDF 函数改写为,
| (15) |
其中 是神经元激活状态, 是激活 的 bin 中的样本数量。 在 PDF 建模过程中,我们迭代地取一批随机的神经元状态作为输入,并为它们分配相应的 bin。
的选择。 通过对 PDF 的近似,我们可以将 NAC 函数改写为,
| (16) |
其中 表示实现对状态 的完全覆盖 w.r.t. 的下界。 然而,对于上述公式,寻找合适的 可能会很困难,因为各种因素(e.g。,InD 数据集大小 )会影响 NAC 分数 的显著性。 从这个意义上讲,为了在实际部署中进一步简化这个公式,我们将 设置为,
| (17) |
其中 表示 bin 填充所需的最小样本数, 是 bin 中激活神经元状态 的样本数。 通过这种方式,我们可以在实际部署中直接操作 来控制 NAC 函数。
附录 D OOD 检测的实验细节
我们按照 OpenOOD 的最新版本 333https://github.com/Jingkang50/OpenOOD. 进行实验。 (Yang 等人,2022; Zhang 等人,2023a)。 在本节中,我们首先提供更多关于所使用基线(第 D.1 节)、数据集和评估协议(第 D.2 节)以及模型架构(第 D.3 节)的详细信息。 然后,我们演示了 NAC-UE 的超参数及其相应的搜索空间(第 D.4 节)。
D.1 基线方法
由于 NAC-UE 以事后方式执行,我们主要在三个基准数据集上与 21 种事后 OOD 检测方法进行比较,包括 OpenMax (Bendale & Boult, 2016)、MSP (Hendrycks & Gimpel, 2017)、TempScale (Guo et al., 2017)、ODIN (Liang et al., 2018)、MDS (Lee et al., 2018)、MDSEns (Lee et al., 2018)、RMDS (Ren et al., 2021)、Gram (Sastry & Oore, 2020)、EBO (Liu et al., 2020)、OpenGAN (Kong & Ramanan, 2021)、GradNorm (Huang et al., 2021b)、ReAct (Sun et al., 2021)、MLS (Hendrycks et al., 2022)、KLM (Hendrycks et al., 2022)、VIM (Wang et al., 2022)、KNN (Sun et al., 2022)、DICE (Sun & Li, 2022)、RankFeat (Song et al., 2022)、ASH (Djurisic et al., 2023)、SHE (Zhang et al., 2023b)、GEN (Liu et al., 2023)。 特别是,ReAct 和 ASH 是基于神经元的方法,它们修改神经元激活以进行 OOD 检测。 表格 20-22 中呈现的结果来自 OpenOOD 实现。
D.2 OOD 基准数据集
我们主要利用 OpenOOD 的 Far-OOD 轨道进行评估,因为它定义明确,并得到许多现有研究的支持,e.g., Wang et al. (2022) 和 Bitterwolf et al. (2023)。
CIFAR 基准数据集
CIFAR-10 和 CIFAR-100 在现有研究中被广泛用作分布内 (InD) 数据集。 CIFAR-10 包含 10 个类别,而 CIFAR-100 包含 100 个类别。 与 OpenOOD 一致,我们对 CIFAR-10 和 CIFAR-100 基准数据集采用相同的拆分设置。 具体而言,对于 CIFAR-10 和 CIFAR-100,我们都利用官方训练集,其中包含 50,000 张训练图像,并从测试集中保留 1,000 个样本作为 InD 验证集。 剩余的 9,000 张测试图像用作 InD 测试 集。 从 Tiny ImageNet (Le & Yang, 2015) 中保留 1,000 张图像,涵盖 20 个类别,用作 OOD 验证 集。 为了评估 OOD 检测方法的性能,我们对 OOD 测试 使用四个常用的数据集,这些数据集与 OOD 验证 集不重叠。 以下是它们的详细信息:
-
1.
MNIST (Deng, 2012): 这是一个包含 10 个类别的手写数字数据集,包含 60,000 张图像用于训练和 10,000 张图像用于测试。 我们将整个测试集用于 OOD 检测。
-
2.
SVHN (Netzer 等人,2011): 此数据集包含描绘房屋号码的彩色图像,涵盖代表数字 0 到 9 的十个类别。 我们使用整个测试集,包含 26,032 张图像。
-
3.
纹理 (Cimpoi 等人,2014): 纹理数据集包含 5,640 张真实世界纹理图像,分为 47 个类别。 我们将整个数据集用于评估目的。
-
4.
Places365 (Zhou 等人,2018): Places365 包含大量描绘场景的照片,分为 365 个场景类别。 测试集包含每个类别 900 张图像。 对于 OOD 检测,我们使用整个测试数据集,其中删除了 1,305 张图像,因为根据 (Yang 等人,2022) 存在语义重叠。
| Architecture | Parameter | Denotation | Values |
| ResNet-18 | - | layer choice | layer4 / layer3 / layer2 / layer1 |
| number of bins for PDF estimation | 50 / 500 / 50 / 500 | ||
| sigmoid steepness | 100 / 1000 / 0.001 / 0.001 | ||
| number of samples required for bin filling | 50 / 100 / 5 / 100 |
| Architecture | Parameter | Denotation | Values |
| ResNet-18 | - | layer choice | layer4 / layer3 / layer2 / layer1 |
| number of bins for PDF estimation | 50 / 1000 / 50 / 50 | ||
| sigmoid steepness | 50 / 10 / 1 / 0.005 | ||
| number of samples required for bin filling | 50 / 500 / 500 / 5 |
| Architecture | Parameter | Denotation | Values |
| Vit-b16 | - | layer choice | before_head / block11 / block10 / block9 |
| number of bins for PDF estimation | 50 / 500 / 500 / 1000 | ||
| sigmoid steepness | 100 / 1 / 10 / 1 | ||
| number of samples required for bin filling | 500 / 50 / 10 / 10 | ||
| ResNet-50 | - | layer choice | layer4 / layer3 / layer2 / layer1 |
| number of bins for PDF estimation | 50 / 50 / 500 / 1000 | ||
| sigmoid steepness | 3000 / 300 / 0.01 / 1 | ||
| number of samples required for bin filling | 10 / 500 / 50 / 5000 |
大规模 ImageNet 基准测试
我们使用 ImageNet-1k (Deng 等人,2009) 作为分布内数据集,其中包含大约 120 万张训练图像。 遵循 OpenOOD,我们利用来自 ImageNet 验证集的 45,000 张图像作为 分布内测试 集,剩余的 5,000 个样本作为 分布内验证 集。 为了搜索超参数,从 OpenImage-O (Wang 等人,2022) 中挑选出 1,763 张图像用于 分布外验证。 最后,我们利用三个常用的数据集作为 分布外测试 进行评估:
-
1.
iNaturalist (Horn 等人,2018):该数据集包含 859,000 张植物和动物图像,涵盖 5,000 多个不同物种。 每个图像都被调整为最大尺寸为 800 像素。 遵循 (Huang & Li, 2021; Yang 等人,2022),我们在随机选择的 10,000 张图像的子集上评估我们的方法,这些图像来自 110 个与 ImageNet-1k 不重叠的类别。
-
2.
纹理 (Cimpoi 等人,2014):该数据集包含 5,640 张真实世界的纹理图像,分为 47 个类别。 我们利用整个数据集进行评估。
-
3.
OpenImage-O (Wang 等人,2022):该数据集根据 OpenImage-v3 的测试集进行整理,因此拥有自然类统计数据,以避免初始设计偏差。 它包含 17,632 张大规模图像。 遵循 OpenOOD,我们利用整个数据集进行分布外检测,除了用于分布外验证的图像。
D.3 模型架构
对于 CIFAR-10 和 CIFAR-100 基准测试,我们使用功能强大的 ResNet-18 (He 等人,2016) 架构。 与 OpenOOD (Yang 等人,2022; Zhang 等人,2023a) 一致,我们训练 ResNet-18 100 个 epochs,并在三个检查点评估分布外检测方法。 请参考 OpenOOD 获取更多训练细节。
遵循 OpenOOD,我们针对 ImageNet 基准的实验采用了两种模型架构:
-
•
ResNet-50 (He 等人,2016) 在 ImageNet-1k 上进行预训练。 对于此模型,所有图像在测试阶段都被调整为 224 224。 我们使用来自 Pytorch 的官方检查点。
-
•
Vit-b16 (Dosovitskiy 等人,2021) 也是在 ImageNet-1k 上进行预训练的。 与 ResNet-50 相似,测试图像被调整为 224 224。 采用来自 Pytorch 的检查点。
D.4 超参数
在我们所有的实验中,我们利用 InD 和 OOD 验证集来搜索最佳超参数。 一般来说,我们搜索 在 [50, 500, 1000] 中,而 在 [5, 10, 50, 100, 500, 5000] 中,跨越不同的架构和基准。 由于更深层网络层中的神经元(e.g., layer4)通常在一个较小的范围内变化(参见图 5 中的 为例),我们搜索 在 [50, 100, 300, 1000, 3000] 中,以获得更陡峭的 sigmoid 函数。 否则,我们搜索 在 [0,001, 0.005, 0.01, 0.1, 1, 10] 中。
附录 E OOD 泛化实验细节
E.1 Domainbed 基准
数据集
我们在 DomainBed (Gulrajani & Lopez-Paz, 2021) 基准上进行实验,它被认为是 OOD 泛化中更公平的基准444https://github.com/facebookresearch/DomainBed.。 我们没有使用数字图像,而是使用了四个数据集:
-
1.
VLCS (Fang 等人,2013) 由摄影领域组成,即 Caltech101、LabelMe、SUN09 和 VOC2007。 该数据集包含 10,729 个示例,尺寸为 (3, 224, 224),有 5 个类别。
-
2.
PACS 数据集 (Li 等人,2017) 包含四个领域:艺术、卡通、照片 和 素描。 它包含总共 9,991 个示例,尺寸为 (3, 224, 224),有 7 个类别。
-
3.
OfficeHome (Venkateswara 等人,2017) 包含领域:艺术、剪贴画、产品、真实。 该 数据集包含 15,588 个示例,尺寸为 (3, 224, 224),有 65 个类别。
-
4.
TerraInc (Beery 等人,2018) 是一个野生动物照片集合,由相机陷阱在不同地点捕获:L100、L38、L43 和 L46。 我们版本的该数据集包含 24,788 个示例,尺寸为 (3, 224, 224),有 10 个类别。
设置
为了确保最终结果的可靠性,每个领域的数据被分成两部分:80% 用于训练或测试,20% 用于验证。 这个过程用不同的种子重复三次,这样报告的数字代表了这三次运行的平均值和标准误差。 在我们的实验中,我们报告了 留一法 测试准确率分数,其中结果是通过使用单个域进行测试而将其他域用于训练的案例来平均计算得出的。 此外,我们将总训练步骤设置为 5000,并将所有运行的评估频率设置为 300 步。
模型评估标准
为了进行模型评估,我们主要将我们的方法与 验证标准 进行比较,该标准衡量模型在 20% 源域 (i.e., InD) 验证数据上的准确率。 此外,我们还采用 oracle 标准 作为上限,该标准直接利用 20% 测试域数据上的准确率来进行模型评估。 为了获得更多详细信息,我们建议参考 Gulrajani & Lopez-Paz (2021)。
E.2 指标:等级相关性
等级相关性指标被广泛用于衡量两个随机变量之间的关系。 这些指标的目的是提供一种定量方法来评估变量之间观察结果排名中的相似性。 遵循 Arpit 等人 (2022),我们利用斯皮尔曼等级相关性 (RC) 来评估 OOD 测试准确率与模型评估分数之间的关系,i.e., InD 验证准确率或 InD NAC-ME 分数。
这种选择的理由是,在训练阶段,最佳模型的选择通常基于模型性能的排名,例如验证准确率。 因此,利用 RC 分数使我们能够直接衡量评估标准在模型选择中的有效性(这自然会转化为提前停止)。 RC 的值介于 -1 和 1 之间,其中 -1 的值表示两个随机变量的排名完全相反;而 +1 的值表示排名完全相同。 此外,RC 分数为 0 表示两个变量之间没有线性关系。
| Dataset | No. of bins | Sigmoid steepness | No. of samples for bin filling |
| VLCS / | [50, 1000] | [1, 500, 5000] / | [1, 500, 5000, 10000] if not TerraInc else [5, 10, 30, 50] |
| PACS / | [0.01, 0.1, 0.5] / | ||
| OfficeHome / | [0.01, 1, 100] / | ||
| TerraInc | [0.01, 0.1] |
E.3 模型架构
在我们的实验中,我们采用了四种模型架构:ResNet-18 (He 等人,2016)、ResNet-50 (He 等人,2016)、Vit-t16 (Dosovitskiy 等人,2021) 和 Vit-b16 (Dosovitskiy 等人,2021)。 它们都在 ImageNet 数据集上进行了预训练,并被用作初始权重。 关于参数选择,我们建议参考 Cha 等人 (2021)。
E.4 超参数
在 ResNet 架构的情况下,NAC-ME 计算是通过使用 layer-4 中的神经元来执行的。 对于 ResNet-50,layer-4 包含 2048 个神经元,而 ResNet-18 则包含 512 个神经元。 关于视觉转换器,NAC-ME 计算利用了 block-11 的注意力层中的神经元。 在 Vit-b16 的情况下,我们利用了 768 个神经元,而对于 Vit-t16,我们则使用了 192 个神经元。 在这系列实验中,我们使用源域训练数据来构建 NAC 函数。 此外,为了减轻训练样本中的噪声,我们只使用能够被正确分类的训练数据来构建 NAC 函数。
为了确定所有模型 NAC-ME 的最佳超参数,我们利用 InD 验证数据进行参数搜索,搜索基于表 13 中概述的分布。 具体来说,鉴于在这种情况下无法获得 OOD 数据,我们根据与 InD 验证精度的等级相关性来选择 NAC-ME 超参数。 这背后的动机是,验证精度可以提供一些关于模型学习进度的见解。
附录 F 可重复性
我们将公开发布我们的代码,并提供详细的说明。
F.1 软件和硬件
所有实验都在一台 NVIDIA GeForce RTX 3090 GPU 上进行,Python 版本为 3.8.11。 使用的深度学习框架是 PyTorch 1.10.0,并且使用 Torchvision 版本 0.11.1 进行图像处理。 我们利用 CUDA 11.3 进行 GPU 加速。
F.2 运行时分析
实验的总运行时间取决于任务和数据集。 以下内容提供了使用单个 NVIDIA GeForce RTX 3090 GPU 的两个 OOD 任务的 resent50 架构的详细信息。 对于 OOD 检测,实验(e。g。,测试阶段的推理)在所有基准测试中大约需要 10 分钟。 对于 OOD 泛化,PACS 和 VLCS 上的实验平均需要大约 4 个小时,OfficeHome 需要 8 个小时,TerraInc 需要 8.5 个小时。

附录 G 其他实验结果
G.1 效率分析
高效的 NAC 建模。 如主论文中所述,NAC 函数是使用 InD 训练数据构建的。 具体来说,我们利用 CIFAR-10 和 CIFAR-100 基准测试中包含 1,000 张训练图像的子集,这大约占整个训练集的 2%。 对于 ImageNet,我们分别为 ResNet-50 和 Vit-b16 使用 1,000 张和 50,000 张图像,分别对应于完整训练集的大约 0.1% 和 5%。
在这里,为了进一步了解我们方法的效率,我们分析了 NAC-UE 在使用不同数量的训练样本构建 NAC 函数时的性能。 图 7 展示了 CIFAR-10 和 CIFAR-100 基准测试的结果,我们在其中以不同的比例随机抽取训练图像,并重复此过程五次以确保结果的有效性。 值得注意的是,即使只使用 1% 的训练数据,NAC-UE 也表现出卓越的性能,与使用 100% 训练数据的情况相当。 这证明了我们方法的效率,尤其是在数据可用性有限的情况下。
计算成本分析。 为了全面了解我们的方法,我们进一步分析了我们提出的 NAC-UE 方法的计算成本。 具体来说,我们从表 2 中选择了排名前三的方法作为基线,并根据 ImageNet 基准测试的预处理和推理时间将它们与 NAC-UE 进行比较。 从表 14 中展示的结果中,可以得出以下两个观察结果:
1) 预处理时间:从表 14 中可以看出,与最具竞争力的 ViM 和 SHE 相比,NAC-UE 显着减少了预处理时间,e.g。,7.75 秒(NAC-UE)与 1019.34 秒(ViM)。 这一发现与我们之前的实验(图 7)一致,我们在其中表明,即使只使用 1% 的训练数据进行 NAC 建模,NAC-UE 也能取得良好的性能。 2) 推理时间: 虽然 NAC-UE 在层数增加时需要更多推理时间,但它能够在推理时间和检测性能方面都优于 SOTA 方法。 值得注意的是,在只使用一层(layer4)的情况下,NAC-UE 的 AUROC 为 94.57%,推理时间为 39.63 秒。 相比之下,GEN 的 AUROC 仅为 89.76%,推理时间为 43.33 秒。 这突出了我们方法的效率。
除了以上分析,还值得注意的是,有许多正在进行的研究工作致力于促进梯度计算(例如,Lee 等人(2019)),这可能有助于补充我们提出的方法。

Method Preprocessing Time (s) Total Inference Time (s) AUROC GEN (Liu et al., 2023) 0.00 ± 0.0 43.33 ± 0.3 89.76 ViM (Wang et al., 2022) 1087.82 ± 9.0 48.10 ± 0.4 92.68 SHE (Zhang et al., 2023b) 1019.34 ± 2.2 41.85 ± 0.5 90.92 NAC-UE (layer4) 5.43 ± 0.3 39.63 ± 0.2 94.57 NAC-UE (layer4+layer3) 6.75 ± 0.3 46.09 ± 0.7 95.05 NAC-UE (layer4+layer3+layer2) 7.75 ± 0.2 69.73 ± 0.4 95.23
G.2 神经元激活状态消融
在主论文(图 5)中,我们分析了使用两个神经元示例的神经元激活状态 的公式。 在本节中,我们提供额外的实验来进一步验证 的优越性。
InD 和 OOD 下的覆盖率分数分布。 为了补充之前主要集中在单个神经元上的分析,我们首先研究了不同形式的神经元状态下的整体神经元活动,i.e., 原始神经元输出 ,神经元梯度 和我们的 。 图 8 说明了结果,其中我们可视化了 ImageNet 基准上所有神经元平均覆盖率分数的 InD 和 OOD 分布 w.r.t(参见公式(5))。 我们在以下内容中提供主要观察结果:
首先,在所有三种变体中, 方法表现最佳,因为它继承了 和 的优点。 这再次突出了我们定义的神经元状态的优越性。 其次,还可以发现,与 InD 样本相比,OOD 样本通常呈现较低的覆盖率得分。 这表明,与 InD 数据相比,OOD 数据倾向于引发异常的神经元行为,这证实了我们基于 NAC 的方法背后的原理。

不同 下 InD 和 OOD 的神经元状态分布。 如表 7 所示,选择合适的 sigmoid 陡度 对于 NAC-UE 的 OOD 检测至关重要。 为了进一步调查该因素是否也会影响其他形式的神经元状态(e。g。,),我们在 InD 和 OOD 下可视化了不同神经元状态随不同 的分布。
我们在图 9 中展示了结果。 可以观察到,当 sigmoid 陡度 增加时,InD 和 OOD 的神经元行为在 的形式上变得更加可区分。 这导致 NAC-UE 在 OOD 检测中表现出色。 另一方面,当使用 和 的普通形式时,不同数量的 的影响较小。 此结果与我们在图 5 中的先前发现一致,这进一步证明了我们神经元激活状态 在区分 InD 和 OOD 数据点方面的独特特征。
Method CIFAR-100 Tiny ImageNet Average FPR95 AUROC FPR95 AUROC FPR95 AUROC OpenMax 48.063.25 86.910.31 39.181.44 88.320.28 43.622.27 87.620.29 MSP 53.084.86 87.190.33 43.273.00 88.870.19 48.173.92 88.030.25 TempScale 55.815.07 87.170.40 46.113.63 89.000.23 50.964.32 88.090.31 ODIN 77.005.74 82.181.87 75.386.42 83.551.84 76.196.08 82.871.85 MDS 52.813.62 83.592.27 46.994.36 84.812.53 49.903.98 84.202.40 MDSEns 91.870.10 61.290.23 92.660.42 59.570.53 92.260.20 60.430.26 RMDS 43.863.49 88.830.35 33.911.39 90.760.27 38.892.39 89.800.28 Gram 91.682.24 58.334.49 90.061.59 58.985.19 90.871.91 58.664.83 EBO 66.604.46 86.360.58 56.084.83 88.800.36 61.344.63 87.580.46 OpenGAN 94.843.83 52.817.69 94.114.21 54.627.68 94.484.01 53.717.68 GradNorm 94.541.11 54.431.59 94.890.60 55.370.41 94.720.82 54.900.98 ReAct 67.407.34 85.930.83 59.717.31 88.290.44 63.567.33 87.110.61 MLS 66.594.44 86.310.59 56.064.82 88.720.36 61.324.62 87.520.47 KLM 90.555.83 77.890.75 85.187.60 80.490.85 87.866.37 79.190.80 VIM 49.193.15 87.750.28 40.491.55 89.620.33 44.842.31 88.680.28 KNN 37.640.31 89.730.14 30.370.65 91.560.26 34.010.38 90.640.20 DICE 73.717.67 77.010.88 66.377.68 79.670.87 70.047.64 78.340.79 RankFeat 65.323.48 77.982.24 56.445.76 80.942.80 60.884.60 79.462.52 ASH 87.312.06 74.111.55 86.251.58 76.440.61 86.781.82 75.271.04 SHE 81.003.42 80.310.69 78.303.52 82.760.43 79.653.47 81.540.51 GEN 58.753.97 87.210.36 48.592.34 89.200.25 53.673.14 88.200.30 NAC-UE 35.060.30 89.780.31 26.530.21 91.980.24 30.800.13 90.880.25
| FPR95 | AUROC | |||
| 45.70 | 89.42 | |||
| 84.20 | 64.13 | |||
| 59.39 | 80.96 | |||
| 43.43 | 88.9 | |||
| 49.29 | 87.85 | |||
| 44.71 | 89.47 | |||
| 26.89 | 94.57 |
、 和 的各自效力。 . 为了评估我们神经元状态中不同组件的个体贡献,我们进行了消融研究以评估每个组件的各自效力:1) 神经元输出 ,2) 神经元梯度 ,以及 3) 模型预测偏差 。 我们在表 16 中提供了结果。
这些结果揭示了两个关键发现。 首先,包含所有三个组件的公式在所有变体中表现最佳,证明了我们状态 的优越性。 此外,、 和 的任意组合与单独使用单个组件相比可以带来改进。 例如,使用 比单独使用 或 产生更好的性能。 这表明所有三个组件都在 OOD 场景中编码有意义的信息,进一步支持了我们提出的状态背后的理论依据。
G.3 近 OOD 分析
近似 OOD 检测考虑了更具挑战性的场景,其中 OOD 数据点通常表现出与 InD 数据分布接近的特征 (Fort 等人,2021)。 在本节中,我们进行了一系列实验,以探索我们的方法在处理近似 OOD 场景中的潜力。 我们使用在 CIFAR-10 上训练的 ResNet-18 作为我们实验的基础。 OOD 检测方法的评估是在两个近似 OOD 数据集上进行的:CIFAR-100 (Krizhevsky,2009) 和 Tiny ImageNet (Le & Yang,2015)。 我们严格遵循 OpenOOD 的评估协议,并在表 15 中说明了结果。 值得注意的是,NAC-UE 继续在两个近似 OOD 数据集上优于现有的 21 个最先进方法。 与表现最佳的方法 KNN 相比,我们的 NAC-UE 实现了 30.80% 的 FPR95,增益为 3.3%。 这一发现进一步证实了我们提出的方法的有效性和鲁棒性。
G.4 用于 OOD 检测的加权 NAC
如等式 (6) 所示,我们通过考虑多个层并对跨层的覆盖分数进行平均来计算 NAC-UE,以获得测试数据的最终不确定性。 但是,由于不同的层可能对模型预测的贡献不同,因此值得探索一个考虑层差异的加权 NAC 版本。 为此,我们在 CIFAR-10 基准上进行了一系列实验,在加权版本中检查了我们的 NAC-UE。 具体来说,我们在同一空间中随机搜索每层的权重:[0.2,0.4,0.6,0.8,1.0],并将这些加权的神经层组合起来进行不确定性估计。 请注意,与我们之前的实验一致,我们首先利用验证集来搜索超参数,然后测试我们的 NAC-UE。
表 17 说明了结果。 可以看到,NAC-UE 在这个加权版本中可以得到进一步改进, e。g ., 平均 FPR95 提高了 2.47%。 这再次证明了我们基于 NAC 的方法的潜力。 有趣的是,我们还注意到,为更深层分配更大的权重通常会导致 NAC-UE 的性能更好。 例如,在随机搜索中找到的最佳权重集是 [0.4, 0.8, 0.2, 0.4],对应于 [layer4, layer3, layer2, layer1]。 我们推测这是因为更深层通常比浅层编码更丰富的语义信息,这使得它们在检测问题中至关重要。
Method MINIST SVHN Textures Places365 Average FPR95 AUROC FPR AUROC FPR95 AUROC FPR95 AUROC FPR95 AUROC NAC-UE 15.142.6 94.861.4 14.331.2 96.050.5 17.030.6 95.640.4 26.730.8 91.850.3 18.310.92 94.600.5 NAC-UE (weighted) 13.942.4 95.551.1 9.901.1 98.100.2 13.360.7 97.250.2 26.160.8 92.310.3 15.840.7 95.800.2
G.5 最大 NAC 熵用于 OOD 泛化
除了使用 NAC-ME 评估模型鲁棒性之外,在本节中,我们还研究了 NAC 在训练和正则化中的潜力。 具体来说,我们建议使用 NAC 熵来提高模型泛化能力:
| (18) |
其中 表示与第 个神经元输出 在其 NAC 分布上的概率相关联,而 是神经元总数。 为了简化计算,我们直接使用原始神经元输出 进行 NAC 建模,而不是使用我们的修正神经元状态 。 这是因为优化 可能涉及二阶梯度计算,这可能会导致额外的计算负担并减慢学习速度。 具体来说,我们提出了两个包含 NAC 熵以进行正则化的损失函数,1) 最小 NAC 熵损失: 和 2) 最大 NAC 熵损失:,其中 表示传统的交叉熵损失, 是正则化系数。
我们使用 ResNet-18 主干网络在 PACS 数据集上进行了实验,表 18 展示了结果。 有趣的是,我们可以看到最大化 NAC 熵会导致性能提升。 这一发现也与 Dubey 等人(2018) 中提出的直观理解一致。 通过最大化 NAC 熵,我们鼓励在 NAC 分布上未探索区域的神经元激活,从而使神经元活动多样化,提高模型鲁棒性。 相反,最小化熵可能会导致神经元行为崩溃。
Algorithm Art Cartoon Photo Sketch Average ERM 77.320.7 71.910.7 72.361.1 94.440.2 79.01 NAC (Minimizing Entropy) 77.280.2 69.170.2 93.210.2 66.731.2 76.60 NAC (Maximizing Entropy) 78.640.5 72.970.3 72.390.3 95.090.1 79.77
G.6 不确定性校准分析
不确定性校准在实现可靠和准确的预测中起着至关重要的作用。 在本节中,我们评估我们的 NAC-UE,特别关注其不确定性校准能力。 我们遵循 Hendrycks 等人(2019a) 中概述的实验设置,并采用两个校准误差指标:均方根 (RMS) 和平均绝对偏差 (MAD) 校准误差。 我们主要将 NAC-UE 与两个简单的基线进行比较,即 MSP (Hendrycks & Gimpel, 2017) 和 Temperature (Guo et al., 2017),它们由 OpenOOD 正式实现。
为了进行校准评估,我们使用在 CIFAR-10 数据集上预训练的模型作为基础,并在 InD 和 OOD 测试数据上评估校准误差。 由于 OOD 点通常被错误分类,并且它们的标签通常不包含在模型的输出空间中,因此置信度估计方法应该将这些 OOD 点分配给低置信度。 我们在表 19 中展示了结果。 如图所示,NAC-UE 明显优于两种基线方法,这证明了其在预测校准方面的潜力。
OOD Dataset RMS Calibration Error MAD Calibration Error MSP Temperature NAC-UE MSP Temperature NAC-UE CIFAR100 50.62 43.01 33.04 42.56 36.64 26.92 Tiny ImageNet 48.01 40.25 31.99 38.86 32.88 26.25 MNIST 71.74 60.91 51.30 67.81 57.16 49.45 SVHN 65.82 56.41 45.32 59.57 51.05 41.60 Texture 42.65 35.19 28.74 32.37 26.90 23.72 Places365 68.85 59.67 48.65 64.65 56.02 45.33
附录 H 讨论
NAC 与 SparseIRM。 对于 OOD 泛化,NAC 与 SparseIRM (Zhou 等人,2022) 在两个方面有所不同:1) SparseIRM 专注于改进模型训练。 相反,我们的 NAC 专注于现有模型的鲁棒性评估,这提供了一个不同的视角; 2) 与系统测试覆盖率标准相提并论,NAC 跟踪整个网络中的神经元行为。 然而,SparseIRM 中讨论的特征稀疏性主要关注特征表示,特别是在识别大多数特征为零或不相关的地方。 因此,这两种方法在测量和目标方面有所不同。
NAC 与神经均值差异 (NMD)。 我们从三方面概述了 NAC 与 NMD (Dong 等人,2022) 之间的差异: 首先,NMD 主要研究原始神经元输出,而我们的论文则集中在神经元状态的新公式上,该公式可以解耦为神经元梯度、神经元输出和模型预测偏差。 这为 OOD 场景中的神经元提供了一种新的解释。 其次,我们的 NAC 特别关注神经元状态的分布,而 NMD 检查神经元输出的均值。 这种独特的视角使我们的 NAC 在理解神经元行为方面更全面、更出色。 第三,虽然 NMD 可以有效地检测 OOD 样本,但它在推理阶段需要一个额外的分类器。 相反,NAC 以无参数的方式直接计算覆盖率分数,作为 OOD 检测和泛化的有效度量。
NAC 与 SCONE。 虽然我们的 NAC 和 SCONE (Bai et al., 2023) 都侧重于 OOD 检测和泛化,但它们在目标、设计选择和实验设置方面实际上有所不同。 具体来说,1) 目标:我们的 NAC 旨在提供一种现成的/事后工具,以有效地检测 OOD 数据并评估模型鲁棒性。 相反,SCONE 针对一种有效的学习策略,该策略训练网络克服 OOD 场景。 2) 设计:NAC 直接利用神经元分布来反映 OOD 场景下的模型状态,而 SCONE 在训练阶段强制执行能量裕度。 3) 实验设置:我们的论文侧重于普遍的 OOD 检测和泛化设置,其中 InD 和 OOD 数据被清晰地分离。 相反,SCONE 集中于野外场景,其中数据分布是 InD 和 OOD 的混合版本,将 OOD 转化为宝贵的学习资源。
什么使 NAC 对 OOD 检测和泛化都有效? 传统上,OOD 检测和泛化被认为是不同的问题:前者主要解决语义(概念)偏移,而后者则考虑协变量偏移。 尽管我们同意这种传统观点,但我们也应该认识到这两个问题领域的重叠性质。 事实上,许多先前的研究已经检查了协变量偏移在 OOD 检测中的作用 (Tian et al., 2021; Averly & Chao, 2023; Yang et al., 2023),以及语义偏移对 OOD 泛化的影响 (Zhang et al., 2023c; Rostami & Galstyan, 2023)。 这种重叠构成了 NAC 能够有效解决这两个 OOD 挑战的基本原理。 此外,NAC 还具有以下独特优势:
1) NAC 受益于数据中心建模 : 我们的 NAC 方法植根于以数据为中心的方法,利用 InD 训练数据中的神经元分布来描述模型状态。 这种以数据为中心的建模使 NAC 能够有效地捕获模型的内在模式和特征(即从神经元级别),从而成为不确定性估计(OOD 检测)和模型鲁棒性评估(OOD 泛化)的有效工具。 这也符合系统测试中 DNN 缺陷检测/网络质量评估的原则 (Xie 等人,2022;Ma 等人,2018)。
2) 浅层到深层考虑了协变量和语义的变化 : 根据研究 (杨等,2023),模型中的浅层通常与图像风格信息(协变量级别)密切相关,而深层捕获语义信息。 由于我们的 NAC 通常通过利用从浅层到深层的多个层来工作,因此它自然地考虑了协变量和语义的变化。 这证明了它在解决各种 OOD 问题方面的潜力。
为什么 NAC-UE 在 CIFAR 上表现出比 ImageNet 更高的改进? 从表 1 和 2 中,我们可以看到 NAC-UE 在 CIFAR 上通常比 ImageNet 基准测试显示出更高的改进。 我们推测这种现象可以归因于模型的内在偏差,其中模型在具有挑战性的 ImageNet 数据集上通常表现不佳。 例如,模型在 CIFAR-10 上的 InD 准确率为 95.06,而在 ImageNet 上的准确率为 76.18。 ImageNet 上的这种糟糕性能表明模型学习得更差,因此可能会导致神经元行为不稳定,从而影响 NAC-UE 的性能。 这也解释了 NAC-UE 在 Places365 上 CIFAR-10 和 CIFAR-100 之间的性能差距。 由于在 CIFAR-100 上训练的模型仅达到 77.25 的准确率,因此会导致神经元不稳定性更高,并随后影响 NAC-UE 的性能。
附录 I CIFAR 全部结果
Method MINIST SVHN Textures Places365 Average FPR95 AUROC FPR95 AUROC FPR95 AUROC FPR95 AUROC FPR95 AUROC CIFAR-10 Benchmark OpenMax 23.334.67 90.500.44 25.401.47 89.770.45 31.504.05 89.580.60 38.522.27 88.630.28 29.691.21 89.620.19 MSP 23.645.81 92.631.57 25.821.64 91.460.40 34.964.64 89.890.71 42.473.81 88.920.47 31.721.84 90.730.43 TempScale 23.537.05 93.111.77 26.972.65 91.660.52 38.165.89 90.010.74 45.274.50 89.110.52 33.482.39 90.970.52 ODIN 23.8312.34 95.241.96 68.610.52 84.580.77 67.7011.06 86.942.26 70.366.96 85.071.24 57.624.24 87.960.61 MDS 27.303.55 90.102.41 25.962.52 91.180.47 27.944.20 92.691.06 47.674.54 84.902.54 32.223.40 89.721.36 MDSEns 1.300.51 99.170.41 74.341.04 66.560.58 76.070.17 77.400.28 94.160.33 52.470.15 61.470.48 73.900.27 RMDS 21.492.32 93.220.80 23.461.48 91.840.26 25.250.53 92.230.23 31.200.28 91.510.11 25.350.73 92.200.21 Gram 70.308.96 72.642.34 33.9117.35 91.524.45 94.642.71 62.348.27 90.491.93 60.443.41 72.346.73 71.733.20 EBO 24.9912.93 94.322.53 35.126.11 91.790.98 51.826.11 89.470.70 54.856.52 89.250.78 41.695.32 91.210.92 OpenGAN 79.5419.71 56.1424.08 75.2726.93 52.8127.60 83.9514.89 56.1418.26 95.324.45 53.345.79 83.5211.63 54.6115.51 GradNorm 85.414.85 63.727.37 91.652.42 53.916.36 98.090.49 52.074.09 92.462.28 60.505.33 91.902.23 57.553.22 ReAct 33.7718.00 92.813.03 50.2315.98 89.123.19 51.4211.42 89.381.49 44.203.35 90.350.78 44.908.37 90.421.41 MLS 25.0612.87 94.152.48 35.096.09 91.690.94 51.736.13 89.410.71 54.846.51 89.140.76 41.685.27 91.100.89 KLM 76.2212.09 85.002.04 59.477.06 84.991.18 81.959.95 82.350.33 95.582.12 78.370.33 78.314.84 82.680.21 VIM 18.361.42 94.760.38 19.290.41 94.500.48 21.141.83 95.150.34 41.432.17 89.490.39 25.050.52 93.480.24 KNN 20.051.36 94.260.38 22.601.26 92.670.30 24.060.55 93.160.24 30.380.63 91.770.23 24.270.40 92.960.14 DICE 30.8310.54 90.375.97 36.614.74 90.021.77 62.424.79 81.862.35 77.1912.60 74.674.98 51.764.42 84.231.89 RankFeat 61.8612.78 75.875.22 64.497.38 68.157.44 59.719.79 73.466.49 43.707.39 85.993.04 57.447.99 75.875.06 ASH 70.0010.56 83.164.66 83.646.48 73.466.41 84.591.74 77.452.39 77.897.28 79.893.69 79.034.22 78.492.58 SHE 42.2220.59 90.434.76 62.744.01 86.381.32 84.605.30 81.571.21 76.365.32 82.891.22 66.485.98 85.321.43 GEN 23.007.75 93.832.14 28.142.59 91.970.66 40.746.61 90.140.76 47.033.22 89.460.65 34.731.58 91.350.69 NAC-UE 15.142.60 94.861.36 14.331.24 96.050.47 17.030.59 95.640.44 26.730.80 91.850.28 18.310.92 94.600.50
Method MINIST SVHN Textures Places365 Average FPR95 AUROC FPR95 AUROC FPR95 AUROC FPR95 AUROC FPR95 AUROC CIFAR-100 Benchmark OpenMax 53.824.74 76.011.39 53.201.78 82.071.53 56.121.91 80.560.09 54.851.42 79.290.40 54.500.68 79.480.41 MSP 57.234.68 76.081.86 59.072.53 78.420.89 61.881.28 77.320.71 56.620.87 79.220.29 58.701.06 77.760.44 TempScale 56.054.61 77.271.85 57.712.68 79.791.05 61.561.43 78.110.72 56.460.94 79.800.25 57.941.14 78.740.51 ODIN 45.943.29 83.791.31 67.413.88 74.540.76 62.372.96 79.331.08 59.710.92 79.450.26 58.860.79 79.280.21 MDS 71.722.94 67.470.81 67.216.09 70.686.40 70.492.48 76.260.69 79.610.34 63.150.49 72.261.56 69.391.39 MDSEns 2.830.86 98.210.78 82.572.58 53.761.63 84.940.83 69.751.14 96.610.17 42.270.73 66.741.04 66.000.69 RMDS 52.056.28 79.742.49 51.653.68 84.891.10 53.991.06 83.650.51 53.570.43 83.400.46 52.810.63 82.920.42 Gram 53.537.45 80.714.15 20.061.96 95.550.60 89.512.54 70.791.32 94.670.60 46.381.21 64.442.37 73.361.08 EBO 52.623.83 79.181.37 53.623.14 82.031.74 62.352.06 78.350.83 57.750.86 79.520.23 56.591.38 79.770.61 OpenGAN 63.0923.25 68.1418.78 70.352.06 68.402.15 74.771.78 65.843.43 73.758.32 69.137.08 70.497.38 67.887.16 GradNorm 86.971.44 65.351.12 69.907.94 76.954.73 92.510.61 64.580.13 85.320.44 69.690.17 83.681.92 69.141.05 ReAct 56.045.66 78.371.59 50.412.02 83.010.97 55.040.82 80.150.46 55.300.41 80.030.11 54.201.56 80.390.49 MLS 52.953.82 78.911.47 53.903.04 81.651.49 62.392.13 78.390.84 57.680.91 79.750.24 56.731.33 79.670.57 KLM 73.096.67 74.152.59 50.307.04 79.340.44 81.805.80 75.770.45 81.401.58 75.700.24 71.652.01 76.240.52 VIM 48.321.07 81.891.02 46.225.46 83.143.71 46.862.29 85.910.78 61.570.77 75.850.37 50.741.00 81.700.62 KNN 48.584.67 82.361.52 51.753.12 84.151.09 53.562.32 83.660.83 60.701.03 79.430.47 53.650.28 82.400.17 DICE 51.793.67 79.861.89 49.583.32 84.222.00 64.231.65 77.630.34 59.391.25 78.330.66 56.250.60 80.010.18 RankFeat 75.015.83 63.033.86 58.492.30 72.141.39 66.873.80 69.403.08 77.421.96 63.821.83 69.451.01 67.101.42 ASH 66.583.88 77.230.46 46.002.67 85.601.40 61.272.74 80.720.70 62.950.99 78.760.16 59.202.46 80.580.66 SHE 58.782.70 76.761.07 59.157.61 80.973.98 73.293.22 73.641.28 65.240.98 76.300.51 64.122.70 76.921.16 GEN 53.925.71 78.292.05 55.452.76 81.411.50 61.231.40 78.740.81 56.251.01 80.280.27 56.711.59 79.680.75 NAC-UE 21.976.62 93.151.63 24.394.66 92.401.26 40.651.94 89.320.55 73.571.16 73.050.68 40.141.86 86.980.37
附录 J 完整 ImageNet 结果
Method iNaturalist OpenImage-O Textures ResNet-50 Vit-b16 Average ResNet-50 Vit-b16 Average ResNet-50 Vit-b16 Average OpenMax 92.05 94.93 93.49 87.62 87.36 87.49 88.10 85.52 86.81 MSP 88.41 88.19 88.30 84.86 84.86 84.86 82.43 85.06 83.75 TempScale 90.50 88.54 89.52 87.22 85.04 86.13 84.95 85.39 85.17 ODIN 91.17 / 91.17 88.23 / 88.23 89.00 / 89.00 MDS 63.67 96.01 79.84 69.27 92.38 80.83 89.80 89.41 89.61 MDSEns 61.82 / 61.82 60.80 / 60.80 79.94 / 79.94 RMDS 87.24 96.10 91.67 85.84 92.32 89.08 86.08 89.38 87.73 Gram 76.67 / 76.67 74.43 / 74.43 88.02 / 88.02 EBO 90.63 79.30 84.97 89.06 76.48 82.77 88.70 81.17 84.94 OpenGAN / / / / / / / / / GradNorm 93.89 42.42 68.16 84.82 37.82 61.32 92.05 44.99 68.52 ReAct 96.34 86.11 91.23 91.87 84.29 88.08 92.79 86.66 89.73 MLS 91.17 85.29 88.23 89.17 81.60 85.39 88.39 83.74 86.07 KLM 90.78 89.59 90.19 87.30 87.03 87.17 84.72 86.49 85.61 VIM 89.56 95.72 92.64 90.50 92.18 91.34 97.97 90.61 94.29 KNN 86.41 91.46 88.94 87.04 89.86 88.45 97.09 91.12 94.11 DICE 92.54 82.50 87.52 88.26 82.22 85.24 92.04 82.21 87.13 RankFeat 40.06 / 40.06 50.83 / 50.83 70.90 / 70.90 ASH 97.07 50.62 73.85 93.26 55.51 74.39 96.90 48.53 72.72 SHE 92.65 93.57 93.11 86.52 91.04 88.78 93.60 92.65 93.13 GEN 92.44 93.54 92.99 89.26 90.27 89.77 87.59 90.23 88.91 NAC-UE 96.52 93.72 95.12 91.45 91.58 91.52 97.9 94.17 96.04
附录 K 完整 DomainBed 结果
Method Caltech101 LabelMe SUN09 VOC2007 Average RC ACC RC ACC RC ACC RC ACC RC ACC Oracle - 97.000.6 - 65.600.3 - 71.440.8 - 76.640.5 - 77.67 Validation 36.0317.3 95.380.9 17.5713.2 63.621.1 50.3313.6 67.730.6 33.1715.7 73.750.7 34.27 75.12 NAC-ME 67.733.0 96.410.5 7.523.4 63.720.8 64.227.2 70.891.1 61.6810.2 72.290.5 50.29 75.83 RN18 Oracle - 98.530.3 - 68.690.8 - 73.880.5 - 78.070.3 - 79.79 Validation 20.7517.0 98.000.2 35.2913.2 65.161.4 33.013.1 70.370.6 36.684.3 77.280.3 31.43 77.70 NAC-ME 54.902.6 98.500.3 -2.042.7 60.270.6 28.2714.0 70.882.1 33.588.9 76.001.0 28.68 76.41 RN50 Oracle - 98.880.1 - 66.650.3 - 74.780.2 - 76.140.3 - 79.11 Validation 25.578.8 98.320.3 41.014.6 63.870.6 47.142.7 72.440.1 38.0712.3 75.080.6 37.95 77.43 NAC-ME 24.020.2 98.260.1 69.693.6 64.300.2 49.516.2 74.360.4 55.159.0 74.950.3 49.59 77.97 Vit-t16 Oracle - 98.650.1 - 67.180.5 - 78.240.4 - 79.770.5 - 80.96 Validation -6.4510.2 95.490.7 43.3014.1 64.670.6 12.8312.2 76.680.9 25.5726.9 77.960.9 18.81 78.70 Vit-b16 NAC-ME 47.792.2 97.440.1 38.4810.4 64.301.4 30.0711.6 77.220.4 33.334.1 77.850.4 37.42 79.20
Method Art Cartoon Photo Sketch Average RC ACC RC ACC RC ACC RC ACC RC ACC Oracle - 78.520.2 - 75.090.8 - 94.960.3 - 73.471.5 - 80.51 Validation 72.225.1 77.320.7 65.206.6 71.910.7 60.877.1 94.440.2 76.551.2 72.361.1 68.71 79.01 NAC-ME 75.495.8 77.890.3 74.841.3 71.540.8 65.366.0 94.640.2 80.961.9 71.342.4 74.16 78.85 RN18 Oracle - 86.780.5 - 81.310.5 - 98.430.0 - 77.870.4 - 86.10 Validation 70.269.1 86.720.5 65.9310.3 78.861.3 38.7312.3 97.830.1 59.2311.4 74.871.1 58.54 84.57 NAC-ME 73.611.4 86.560.4 76.145.0 80.221.1 30.1515.3 97.680.1 68.388.8 76.661.2 62.07 85.28 RN50 Oracle - 75.840.1 - 66.010.7 - 96.310.2 - 49.791.6 - 71.99 Validation 88.973.7 75.660.2 92.321.6 65.410.4 93.791.8 96.160.2 82.273.7 42.102.2 89.34 69.83 NAC-ME 88.153.8 75.640.2 92.570.5 64.040.6 95.022.0 96.110.2 86.932.4 48.201.9 90.67 70.99 Vit-t16 Oracle - 94.810.3 - 86.570.2 - 99.650.0 - 79.890.6 - 90.23 Validation 22.967.7 92.580.2 47.964.3 84.540.3 55.645.2 99.430.0 38.973.1 74.662.8 41.38 87.80 Vit-b16 NAC-ME 17.733.9 93.250.5 63.243.1 85.091.1 37.177.7 99.330.1 62.016.0 77.660.4 45.04 88.83
Method Art Clipart Product Real Average RC ACC RC ACC RC ACC RC ACC RC ACC Oracle - 48.040.2 - 41.990.2 - 66.260.2 - 68.410.2 - 56.18 Validation 86.361.9 47.680.3 75.333.2 41.160.6 88.733.3 65.820.1 83.583.1 67.730.4 83.50 55.60 NAC-ME 86.192.5 47.680.1 77.455.8 41.160.6 91.831.2 66.150.2 84.154.5 68.040.3 84.91 55.76 RN18 Oracle - 60.200.3 - 51.760.2 - 75.490.1 - 76.370.3 - 65.95 Validation 71.324.2 59.010.5 53.436.5 50.290.4 81.215.7 74.960.5 65.777.0 75.880.2 67.93 65.04 NAC-ME 78.687.0 60.200.3 59.153.1 50.190.4 78.685.3 74.660.4 60.137.3 75.860.1 69.16 65.23 RN50 Oracle - 56.970.1 - 43.580.4 - 71.820.1 - 73.410.1 - 61.44 Validation 98.770.3 56.390.4 98.450.1 43.470.5 98.280.6 71.620.2 99.350.3 73.410.1 98.71 61.22 NAC-ME 98.770.5 56.390.4 98.860.4 43.550.4 99.350.3 71.730.1 99.590.1 73.390.1 99.14 61.26 Vit-t16 Oracle - 78.940.2 - 68.120.3 - 87.930.1 - 89.910.0 - 81.23 Validation 54.664.7 77.770.3 56.702.4 66.490.3 61.035.9 87.190.0 60.789.2 88.990.1 58.29 80.11 Vit-b16 NAC-ME 70.831.0 78.030.3 65.032.3 67.520.7 56.133.6 87.430.3 60.703.2 89.120.2 63.17 80.52
Method Loc100 Loc38 Loc43 Loc46 Average RC ACC RC ACC RC ACC RC ACC RC ACC Oracle - 54.941.3 - 35.640.7 - 52.320.1 - 35.140.6 - 44.51 Validation 12.0111.9 40.602.5 49.7510.9 28.412.9 58.1712.8 48.311.5 38.4010.3 32.120.8 39.58 37.36 NAC-ME 10.2913.2 41.312.5 53.199.4 33.230.7 54.498.2 50.260.5 43.7110.6 33.010.2 40.42 39.45 RN18 Oracle - 55.620.5 - 45.121.1 - 58.750.3 - 43.550.8 - 50.76 Validation 43.957.6 49.083.5 36.6013.6 37.442.3 28.028.6 56.120.3 39.7115.0 41.630.5 37.07 46.07 NAC-ME 48.287.0 50.942.5 34.0715.4 40.932.0 26.068.4 55.950.6 52.2115.1 40.590.9 40.16 47.10 RN50 Oracle - 52.030.3 - 27.383.0 - 49.610.4 - 36.140.1 - 41.29 Validation 21.2411.8 43.512.8 13.154.0 20.852.1 20.0218.6 46.550.1 36.4414.2 34.200.7 22.71 36.28 NAC-ME 21.6512.1 44.373.3 15.771.5 20.230.7 18.3017.9 46.770.2 37.3413.9 35.390.5 23.26 36.69 Vit-t16 Oracle - 62.230.4 - 46.941.7 - 57.450.5 - 42.290.1 - 52.23 Validation -1.313.1 53.132.0 -16.9113.4 36.782.2 -3.279.5 54.190.2 25.167.0 37.840.4 0.92 45.49 Vit-b16 NAC-ME 32.6011.5 58.980.7 11.4419.7 40.482.6 15.6019.7 53.630.6 21.242.7 38.350.4 20.22 47.86