统计物理中的机器学习重整化群
摘要
我们开发了一种机器学习重整化群 (MLRG) 算法来探索和分析统计物理中的多体晶格模型。 利用生成式建模的表征学习能力,MLRG 自动学习最优重整化群 (RG) 变换,这些变换来自自生成的自旋构型,并在没有人工监督的情况下制定 RG 方程。 该算法不专注于模拟任何特定的晶格模型,而是广泛地探索所有与内部和晶格对称性兼容的可能模型,前提是给定现场对称性表示。 它可以发现控制 RG 流的 RG 单调,假设 -定理的强形式。 这使得一些下游任务成为可能,包括相的无监督分类、相变或临界点的自动定位、临界指数和算子尺度维度的受控估计。 我们在具有伊辛对称性的二维晶格模型中演示了 MLRG 方法,并表明该算法正确地识别并表征了伊辛临界性。
I 引言
重整化群 (RG) 是统计物理和量子场论中一个优雅的概念框架和强大的计算方法。 RG 通过分层地逐步粗化物理系统中的自由度来提取每个给定尺度上的相关特征。 通常,实空间 RG 依赖于人类物理学家根据他们对物理系统的直觉来设计粗粒化变换。 在这项研究中,我们旨在探索人工智能 (AI) 从能量模型中自动学习最优 RG 变换的潜力。 无监督机器学习特别适合这项任务,因为它能够从数据中学习低维表示或相关特征,并在没有监督的情况下去除噪声和无关特征。 这种方法与学习 RG 变换的目标一致,RG 变换旨在通过将细粒度配置转换为粗粒度配置来提取物理系统的相关特征,同时保留必要的信息和相关性。
先前的研究表明,神经网络可以学习在配置级别执行分层特征提取 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]。 然而,RG 更令人着迷的一方面是它能够在模型层面上定量分析物理理论在参数空间中的流动 [12, 13]. 因此,本研究旨在开发一种新颖的机器学习重整化群 (MLRG) 方法,该方法能够自动推导出 RG 流方程,发现 RG 单调函数,提出有效理论,识别临界点并估计临界指数,所有这些都从物理系统的对称性和维度开始。
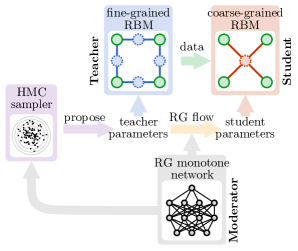
在本研究中,我们将重点关注定义在规则格上的统计力学模型,并开发机器学习算法,以在实空间 RG 框架内分析这些模型。 我们提出的 MLRG 算法如图 1 所示。 我们引入了两个受限玻尔兹曼机 (RBM) [14, 15, 16, 17],分别对细粒度和粗粒度格上的不同尺度上的局部能量模型进行建模。 细粒度模型充当教师,通过生成可见配置样本,这些样本随后用于训练粗粒度模型。 粗粒度模型充当学生,并学习其能量模型来描述教师提供的训练数据。 我们还引入了一个第三个模型,RG 单调网络,作为观察师生学习过程并学习预测粗粒度模型的模型参数如何与细粒度模型的模型参数相关的调节器。 这使得调节器模型能够学习 RG 流动并利用其知识来指导哈密顿蒙特卡罗 (HMC) [18, 19, 20] 采样器提出最值得训练的新模型参数。 训练后,我们可以使用机器学习的 RG 流动来识别参数空间中的 RG 固定点,并自动分析这些固定点处的物理性质。
本文将按以下顺序组织。 我们将在 Sec. II 中首先介绍 MLRG 算法,其中包括 (i) 师生学习系统 Sec. II.2 来模拟 RG 流动,以及 (ii) 调节器 Sec. II.4 和 HMC 采样系统 Sec. II.5 用于提取 RG 单调并用它来指导训练。 教师和学生由等变 RBM 建模,如 Sec. II.1 中所述,其点群表示选择在 Sec. II.3 中详细说明。 然后我们在 Sec. III 中演示了 MLRG 在二维 Ising 模型上的应用。 Sec. III.1 描述了问题设置。 Sec. III.2 展示了机器学习的 RG 单调和 RG 流动图。 然后给出了一些定量结果,包括临界点 Sec. III.3、基态简并度 Sec. III.4 和标度维 Sec. III.6。 Sec. III.5 解释了如何使用牛顿法来定位 RG 固定点。 我们在 Sec. IV 中总结了 MLRG 的优势和局限性,并评论了它与相关工作的联系。
II 方法论
II.1 统计力学模型
我们从晶格上统计力学系统的通用定义开始。 令晶格由图 描述,其中 表示顶点(位点)集,而 表示边(键)集。 在每个位置 上,我们引入一个向量 来表征该位置上的自由度,通常被称为 自旋。 格子上的整个自旋构型 可以被视为一个映射 。 平衡统计物理学的一个核心主题是使用局部能量函数 对概率分布 进行建模,例如
| (1) |
其中 是一个标量函数,描述了每对自旋 在边 上的能量。 下标 表示参数化能量模型的参数集合。
对称性在定义自旋自由度和约束能量函数方面起着重要作用。 令 为内部对称群, 为格子的点群。 假设 和 可交换,并形成一个直积群 ,则该位置上的自旋 应构成 对称性的 维线性表示。 在对称性作用 和 下,自旋 变换为
| (2) |
其中 和 分别是内部 和点群 对称性变换的矩阵表示。 表示通过应用点群变换 从原始位置 获得的结果位置。
能量函数 必须在内部对称性和格子对称性(包括点群和平移对称性)下保持不变。 这要求 满足以下对称性约束:
| (3) |
对于所有 。 这意味着,在代表性键上定义能量函数 就足够了,并使用格子对称性将其传递到格子上所有其他键(假设格子上所有键都通过格子对称性变换相关联)。
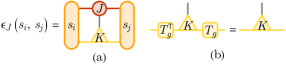
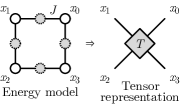
更明确地说,假设自旋分量 由两个索引 和 标记,分别索引点群和内部对称性的表示空间基。 在代表性键上,等变键能函数 的一种可能设计是使用张量网络:
| (4) |
其中重复的索引自动累加,如图 2(a) 所示。 是一个 不变张量,满足对称性约束 (),如图 2(b) 所示。 张量 包含所有决定能量函数的参数。 它们可以被视为不同对称表示之间的耦合常数。 虽然等式 (4) 还没有代表最一般的等变能量模型,但如果表示空间维度 足够大,它已经足够表达。 所以我们不会深入研究更复杂的等变神经网络模型 [21, 22, 23, 24, 25, 26],而是采用这种张量网络设计来构建等变受限玻尔兹曼机。
总之,给定内部对称群 和晶格图 (晶格对称性由 的自同构群给出),可以通过其在内部和点群对称性下的表示来指定现场自旋 。 统计力学模型通常由对称能量函数 定义,由 参数化,如等式 (1) 所示。 RG 分析旨在确定模型参数 如何在不同尺度上有效地变化。
II.2 实空间重整化群
为具体起见,我们将重点关注二维晶格模型。 特别地,我们将考虑如图 3(a,b) 所示的 Lieb 晶格 [27](键插入方形晶格)。 在 Lieb 格子上定义的 Ising 模型在物理上等效于简单的方格,但 Lieb 格子更便于描述实空间 RG 方案。 一般来说,将我们的方法扩展到其他格子和更高维度是可能的。
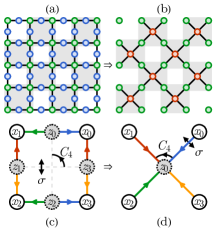
从在 Lieb 格子上定义的能量模型开始,我们的 RG 方案可以描述如下:(i) 将格子划分为重叠的 块,如图 3(a) 所示。 (ii) 在每个块中,用方形图 3(c) 上的局部能量模型替换十字图 3(d) 上的新模型,使得它们在角自旋上的边缘分布尽可能匹配。 (iii) 将新的局部能量模型嵌入回原始格子中。 新格子 3(b) 成为粗粒度 Lieb 格子,晶格常数增大为 。 递归地重复该过程,能量模型参数将被重新归一化到越来越大的格子尺度。
此 RG 方案的主要目标是学习新的局部能量模型。 为此,我们将方形和十字图局部能量模型视为两个受限玻尔兹曼机 (RBM) [14, 15, 16, 17]。 我们将细粒度方形图上的 RBM 称为 教师 机,其中角自旋 是可见变量,装饰自旋 是隐藏变量,参见图 3(c)。 它的能量模型如下:
| (5) |
在粗粒度交叉图上的 RBM 将被称为 学生 机,其中角自旋 仍然是可见变量,但中心只有一个隐藏自旋 ,见图 3(d)。 它的能量模型是:
| (6) |
教师和学生 RBM 分别由 和 参数化。 在等式 (5) 和等式 (6) 中,键能函数 在沿 方向的代表性键上定义,使用张量网络模型等式 (4)。 在图 3(c,d) 中,代表性键用蓝色着色,箭头表示键方向。
正方形和交叉图都符合 点群对称性,该对称性由四重旋转 和镜像反射 生成,见图 3(c,d)。 镜像反射 始终被分配以保留代表性键(蓝色)。 它仅根据等式 (3) 的要求对键能模型 强加对称性约束。 四重旋转 进一步将代表性键带到其他键(其他颜色),在该键下,键能模型将根据等式 (3) 等变地变化。 这样,RBM 将根据设计尊重内部 和点群 对称性。
目标是训练学生 RBM 从教师 RBM 生成的可见自旋配置中学习粗粒度局部能量模型。 给定教师模型参数 ,我们通过最小化两个模型的可见变量分布之间的 Kullback-Leibler (KL) 散度来优化学生模型参数 ,
| (7) |
其中边缘分布 和 是通过消去隐藏自旋来定义的:
| (8) |
虽然直接评估等式 (7) 中的 KL 散度是不可行的,但优化可以通过遵循 RBM 的标准对比发散 (CD) [15] 训练技术的随机梯度下降来执行。
通过这种方式,学生机器会自动学习粗粒度模型参数 ,这些参数由教师机器的细粒度模型参数 给定。 这与传统的真实空间 RG 方法形成对比,在传统的真实空间 RG 方法中,人类物理学家必须设计粗粒化规则,将可见自旋配置 映射到每个块中的隐藏自旋 。 我们的方法在两个方面有所不同:(i)粗粒化变量 不再是 的确定性映射,而是通过学生机器给出的条件分布 以概率方式定义的。 (ii)条件分布 不是由人类指定的,而是从数据中学习的。 这使学生机器能够在其可用的表示空间维度内开发最佳的 RG 变换,从可见配置 中提取最相关的特征 ,而无需监督。
训练完成后,我们可以用学生模型参数 替换教师模型参数 ,并继续训练下一代学生。 因此,一代一代地,师生学习迭代将追踪参数空间中 的 RG 流。
II.3 选择点群表示
为了证明学生 RBM 可以很好地逼近教师 RBM,我们考虑一个基于二维 Ising 模型在方形格子上具体例子。 在这种情况下,内部对称性是 ,点群对称性是 。 然后,两个 RBM 中的每个自旋变量(无论可见还是隐藏)都将被指定为 的表示。 群只有一个非平凡表示,即奇(带符号)表示,变换为 。 因此,我们将假设自旋的每个分量在 Ising 对称性下变换为该奇表示。 点群具有更丰富的不可约表示,总结在表 1 中。 RBM 的表达能力取决于为每个自旋选择的 点群表示,这将在下面详细说明。
| irrep | dim | transforms as | ||
在传统的 Ising 模型中,单个 Ising 自旋对应于一个 奇数变量,该变量携带 表示,它在点群对称性下根本不发生变换。 然而,在 RG 下,粗粒度自旋(例如学生 RBM 中的 自旋)可以携带扩大的点群表示。 从图 3(c,d) 可以清楚地看到,RG 过程实际上是将教师模型中的四个隐藏自旋(方图)合并为学生模型中的一个隐藏自旋(十字图)。 因此,学生模型中的隐藏自旋 必须包含更多内部结构并携带轨道角动量(即 的非平凡表示)以解决教师模型中不均匀隐藏自旋配置的复杂性。
例如,通过说一个 自旋变量 携带 表示,我们隐含地认为 是一个三维向量,由三个 Ising 变量组成:一个 Ising 变量形成 表示,在晶格旋转下保持不变,两个 Ising 变量形成二维 表示,可以像向量一样旋转。 然后, 和 变换表示为
| (9) |
根据表 1 中列出的变换矩阵。
假设我们从一个细粒度的教师模型开始,该模型的可见自旋和隐藏自旋都是 表示中的普通 Ising 自旋,即 。 考虑到对称性约束,参数张量 将只包含一个分量。 根据图 3(c) 中的方图,教师模型由以下能量函数描述
| (10) |
隐藏自旋 可以立即在配分函数中被迹出(边缘化),留下我们一个针对可见自旋 的有效模型,其描述如下
| (11) |
其中 是一个取决于 的有效耦合。 相应地,可见自旋分布为 。
要构建一个粗粒度的学生模型来近似 ,第一步是指定学生 RBM 中粗粒度变量 的点群表示的选择。 例如,如果选择 来携带 表示,该表示具有总共三个分量作为 ,其中每个分量都是一个 Ising 变量,该变量 ,那么学生模型可以写成(见图 3(d) 了解这些变量的连通性)
| (12) |
表示的波动在每对可见自旋之间介导等量的正相关,这确实是铁磁中的主要相关模式伊辛模型。 然而,为了更好地匹配教师模型 , 和 应该相对于其他相关性进一步减弱,因为在原始教师模型等式 11 中,这些对角自旋之间没有直接耦合。 这就是 表示发挥作用的地方,因为 和 的波动将在 和 中介导一些负相关,这是由于等式 12 中的负号,这有助于使学生模型的可见分布 更接近教师模型 的分布。 这种论点解释了为什么在学生模型中将更多点群表示包含到隐藏自旋中通常有助于提高其表达能力。
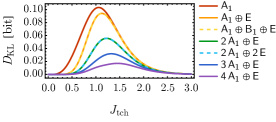
在这种设置下,我们测试了一系列学生 RBM 的性能,这些 RBM 是用不同的隐藏自旋 点群表示选择构建的。 性能通过优化学生机器后实现的最小 KL 散度 来评估。 在图 4 中,我们展示了在 的不同表示选择下,教师模型参数 的一个较大范围内,最小 KL 散度的值。 一般表示是通过组合不可约表示 、 和 来构建的。 其他两个不可约表示 和 未在本特定计算中使用,因为由于镜像反射对称性 的约束,它们不会与 中的 耦合。 但在更一般的情况下,当 的表示更大时,原则上所有不可约表示都可能出现在 上。 此计算定量地证明了学生 RBM 可以学习从教师 RBM 逼近可见自旋分布。 通过在隐藏自旋 上引入更大的表示,逼近可以逐步改进,即使精确匹配可能只在较大表示维数限制 下才能实现。
在实践中,RBM 只能处理有限的表示空间维数 。因此,我们必须在最大维数 处截断表示空间。 这将在每个 RG 步中引入不精确性,但希望是截断引入的误差在 RG 流下变得无关紧要,这样截断只以可控的方式影响 RG 固定点行为。 这也是许多真实空间 RG 方案的潜在假设,其中每个 RG 步不需要精确地保留配分函数。
当我们通过递归地用教师 RBM 训练学生 RBM 并用训练好的学生替换教师来执行 MLRG 程序时,RG 流应该将我们(接近)带到某个固定点 RBM 模型,在这个模型中,我们可以进一步研究 RG 固定点的普适性质(如临界指数和算符尺度维数)。 我们将提供数值证据来表明,当表示维度 变大时,MLRG 算法可以更准确地定位 RG 固定点并估计其普适性质,因此它可以提供一种有用且可控的数值方法,在没有人工监督的情况下自动绘制相图并研究统计物理模型中的临界现象。
II.4 学习 RG 单调性
虽然上述用于真实空间 RG 的师生学习方法很有吸引力,但它在实际训练中面临着严峻的挑战。 这种挑战来自 RBM 训练的随机性,因此学生 RBM 参数 将在每个 RG 步的最佳值附近波动。 这不可避免地将随机噪声注入整个 RG 流,导致模型在参数空间中进行随机游走。 由于临界点(即不稳定 RG 固定点)附近的 RG 流对微小扰动特别敏感,因此随机 RG 流几乎总是会错过临界点。 因此,如果不解决参数空间随机游走的问题,上述简单的 MLRG 算法对于研究任何临界现象都是无用的。
为了应对这一挑战,我们引入了第三个 AI 系统,称为 主持人,它在师生系统之外运行。 主持人的目标是在许多不同的场景下监控随机 RG 流随时间的变化,并学习整个参数空间的潜在确定性 RG 流。 这里的主要思想是假设存在一个 RG 单调性 ,它是一个关于 RBM 模型参数 的实标量函数,这样 RG 流就可以被表述为 RG 单调性 的梯度流,其中 参数化了 RG 步。 这是 -定理 [28, 29, 30, 31] 的最强形式。 我们没有试图用人工来构建这种 RG 单调性,而是引入了一个前馈神经网络 ,称为 RG 单调性网络,来建模函数 并与 RG 流中的 RBM 联合训练。 这里 表示神经网络中所有参数的集合。
训练从参数空间中教师模型参数 的随机选择开始。 调节器采用初始条件 并通过求解 RG 方程将 从 进化到
| (13) |
遵循 RG 单调网络 提供的梯度信号。 这里采用神经常微分方程 (neuralODE) 技术 [32, 33] 来实现通过 ODE 求解器的梯度反向传播。 然后,调节器将解传递给学生 RBM 作为其模型参数 。 然后,教师 RBM 开始采样可见自旋配置并将它们发送给学生 RBM。 学生 RBM 接收训练数据并评估等式 ( 7 ) 中的 KL 散度作为总损失函数。 所有模型通过使用 CD 训练技术最小化 KL 散度来联合训练。 损失函数梯度最终将反向传播到 以更新 RG 单调网络。 训练在许多随机选择的初始参数 上进行,这样可以聚合大量训练数据以优化整个参数空间的 RG 单调性。
尽管训练的本质仍然是随机的,但随机噪声将在拟合 RG 单调性时被平均掉,这样在训练之后,最佳拟合 可用于生成遵循等式 ( 13 ) 的确定性 RG 流。 通过这种方式,可以避免参数空间中的随机游走行为,从而使 MLRG 算法能够准确地定位 RG 不动点。
II.5 参数空间采样
接下来,我们将讨论如何更有效地对 进行采样以加快训练速度。 由于 RBM 模型参数 存在于高维参数空间中,均匀采样可能不是一种有效的策略。 我们提出了一种重要性采样策略,该策略专注于 RG 不动点。
采样器利用有关 RG 单调性的知识从以下概率分布中对参数 进行采样
| (14) |
作为超参数,使用一些反温度 。 我们最初设置 ,使得采样器将在参数空间中均匀地提出模型参数 。 随着训练的进行,RG 单调网络逐渐积累了关于 RG 流的知识。 RG 固定点作为梯度 消失的局部鞍点出现。 然后,我们逐渐增加 ,因此采样器将被偏向于更多地围绕 RG 固定点(包括稳定和不稳定)进行采样。 这种设计鼓励 RG 单调网络在 RG 固定点附近接受更密集的训练,以便可以更准确地估计固定点位置,这是统计力学系统中自动发现临界点(相变)的理想特征。
由于 连续变化,哈密顿蒙特卡罗 (HMC) 方法 [18, 19, 20] 成为采样方法的自然选择。 HMC 是一种马尔可夫链蒙特卡罗算法,它使用哈密顿动力学来有效地提出目标分布 参数空间中的移动。 它是用于对高维空间中连续变量的复杂分布进行采样的强大方法。 我们使用多个具有副本交换的 HMC 采样器来实现该方法,以减轻陷入单个固定点的可能性。
III 结果与分析
III.1 对称赋值和耦合参数
为了应用 MLRG 方法,我们专注于具有 Ising 对称性的二维晶格模型。 我们不需要指定任何特定的 Ising 模型哈密顿量,因为 MLRG 可以自动探索所有与内部和晶格对称性一致的模型,前提是给定了现场对称性表示。
以下,我们将始终采用 内部对称性和 点群对称性。 关于现场自旋的对称性表示,我们认为每个自旋(无论可见还是隐藏)在 下都是奇数,并且在 下具有 或 或 表示。 这些点群表示的选择基于我们的经验,即它们是各自表示维度中最有效的表示,可以最小化教师和学生 RBM 之间的 KL 散度,如图 4 所示。 上述对称性赋值总结在表 2 中,这是我们设置等变 RBM 并准备 MLRG 模型进行训练所需的全部信息。
| symmetry | representation | |
对于 自旋,Eq. (4) 中的(代表性的)键能函数简化为以下形式
| (15) |
其中 标注 对称性表示的基础。 Eq. (4) 中的内部对称性表示标签 被省略,因为 群只有一个非平凡的不可约表示。 耦合 是一个矩阵,它可以在不同点群表示的选择下参数化如下:
-
•
表示(一维,1 个耦合参数)
(16) -
•
表示(三维,5 个耦合参数)
(17) -
•
(4 维,10 个耦合参数)
(18)
在上述矩阵中,我们使用线条将 对称性的不同不可约表示分开。 一些矩阵元素为零,因为镜面反射对称性 施加了限制,正如方程式 ( 3 ) 在一般情况下所要求的那样。 在所有情况下,参数 始终表示第一个 之间的伊辛耦合,直接连接到晶格模型中的裸伊辛耦合。
III.2 RG 单调性和 RG 流
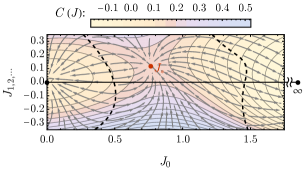
选择最小的点群表示 ,耦合矩阵 由单个变量 参数化。 在这种情况下,RG 流在单维参数空间中简单地定义。 通过 MLRG 方法确定的 RG 单调性 如图 5 (a) 所示。 在 处观察到 RG 单调性的局部最大值。 由于 RG 流旨在遵循 RG 单调性的梯度下降轨迹,如方程式 (13 ) 所示,这意味着参数 将从不稳定的固定点 出发,并流向两个稳定固定点之一,即 或 。 RG 流也可以从图 5 (b) 中 的图中理解,该图对应于 RG 理论背景下的 β 函数。
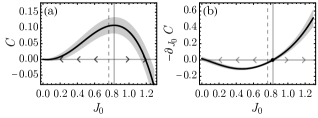
RG 单调 的最大位置 提供了分离顺磁相 () 和铁磁相 ()。 Lieb 格子模型的精确伊辛临界点位于
| (19) |
估计值 接近但仍偏离精确值 。 这是因为 表示的维度很小,这限制了学生 RBM 在 MLRG 算法中逼近教师 RBM 的能力。 我们应该期望当现场自旋涉及点群的更大表示时,估计值会得到改进。
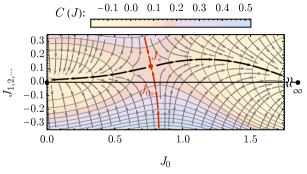
超越 表示,RG 流将在高维参数空间中定义。 为了可视化 RG 单调函数 ,我们将参数 与耦合矩阵 中的剩余参数 分开。 我们始终通过将 设置为格子模型的裸伊辛耦合并允许 在 RG 流下生成来初始化 RG 流。 在由 和 的最相关流方向(表示 参数的特定线性组合,其中 RG 单调函数的梯度最大)所跨越的子流形上,我们可以绘制由 MLRG 方法获得的 RG 单调函数 ,以及其梯度方向(RG 流方向)。 一个例子如图 6 所示,该图是通过使用 现场表示进行训练得到的。
MLRG 算法在整个参数空间中学习 RG 单调 ,在此基础上可以获得 RG 流图。 当我们沿着水平轴将裸耦合 调到临界点 时,RG 流将我们带到远离水平轴的真实 RG 固定点 。 参数 定义了一个统计力学模型,该模型近似于 Ising 共形场理论 (CFT)。 预计随着现场点群表示的增大,近似效果会更好。
III.3 确定临界点
为了估计 Ising 临界点 ,我们首先用给定的 和 初始化耦合矩阵 ,记为
| (20) |
然后,我们通过从 到某个较大的 求解 RG 方程 来使耦合矩阵 流动。 我们将该解记为 ,因为它取决于初始条件 和 RG 尺度 。 在我们的 RG 方案中,线性系统大小将在 RG 尺度 上有效地放大 。 图 7 显示了 RG 单调 作为不同 RG 尺度 下 不同初始值的函数。
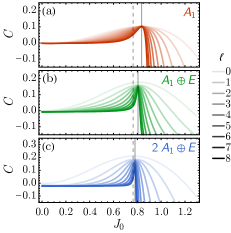
可以看到,RG 单调在临界点处达到峰值,并且随着 RG 流动 的延长,峰值变得更尖锐。 对于足够大的 ,我们可以通过找到 RG 单调的局部最大值来估计临界点 。
| (21) |
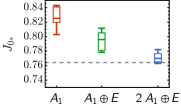
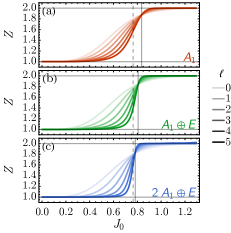
只要 RG 规模足够大以致 RG 流收敛,结果 对 RG 规模 不敏感。 我们为每个现场点群表示选择训练了几个不同的MLRG模型,并使用上述方法估计了伊辛临界点 我们的结果如图 8 所示。 我们可以看到一个明显的趋势,即估计的临界点 更大的点群表示(因此更强的RBM模型)而收敛到其精确值。
III.4 玻尔兹曼权重张量
为了进一步分析不同RG不动点的物理性质,我们根据耦合参数 从RBM能量模型中定义了玻尔兹曼权重张量 张量元素被指定为
| (22) |
其中 可见自旋共同, 隐藏自旋共同。 一个秩4张量,每个张量元素编码可见自旋 特定配置的玻尔兹曼权重,如图 9 所示。 我们可以使用教师RBM(如公式 5)或学生RBM(如公式 6)作为能量模型 只要模型参数 收敛到一个RG不动点,教师和学生在理想极限情况下应该表现相同,它们应该没有太大差异。 然而,在以下分析中,我们将始终采用教师模型,因为我们发现它比学生模型更准确一些。
玻尔兹曼权重张量 使我们能够方便地定义统计力学模型的各种物理性质。 例如,基态简并度 (正则化配分函数)[34, 35] 可以定义为以下张量收缩的比率(重复索引自动求和)
| (23) |
对于 Ising 模型,基态简并度表征了破缺对称群的阶数: 在顺磁(无序)不动点,其中内部 对称性保持,以及 在铁磁(有序)不动点,其中内部 对称性被破坏。
遵循 Sec. III.3 中描述的方法,我们从用单个参数 初始化耦合矩阵 开始,如等式 ( 20 ) 中,并遵循 RG 流获得 。 在不同的 RG 尺度 ,我们绘制基态简并度 作为初始参数 的函数,结果显示在图 10 中。 当 穿过临界值 时,基态简并度从 (顺磁体)过渡到 (铁磁体)。 沿 RG 流动,过渡随着 的增加变得更尖锐。 可以使用不同 RG 尺度下基态简并度曲线的交点来推断 Ising 临界点 。 当我们扩大点群表示时, 逐渐接近图 8 中所示的 处的精确 Ising 临界点。
MLRG 可以使用此分析自动通过其基态简并度标记不同的对称性破缺相。 这可以被视为一种无监督相分类方法。 基态简并曲线 也提供了一种通过寻找其交点来估计临界点 的方法。
III.5 定位单调鞍点
我们的目标是估计临界点的通用性质。 这要求我们在高维参数空间中准确地定位 RG 固定点参数 ,如 Fig. 6 所示。
但是,如果我们只是沿着 RG 流动来逼近 ,我们几乎不可避免地会错过它。 这是由于 RG 流动有偏离不稳定固定点的趋势。 幸运的是,MLRG 算法已被训练来学习 RG 单调函数 。 此功能使我们能够通过牛顿法定位 RG 单调的鞍点来找到 RG 固定点。 通过这样做,我们可以有效地规避参数空间中微调参数的复杂性。
给定 RG 单调函数 并从 RG 固定点附近的初始猜测 开始,牛顿法通过以下更新递归地改进近似值
| (24) |
其中 表示梯度向量, 表示 在 处的 Hessian 矩阵。 Fig. 11 展示了 沿着 的向量场流动。 与 Fig. 6 中的 RG 流动不同,牛顿法从各个方向收敛到 RG 固定点的邻域,无论 RG 固定点是稳定还是不稳定。 这使我们能够从附近的初始猜测中精确定位 RG 固定点。
III.6 计算标度维数
一旦我们通过 Eq. (24) 中的迭代找到 RG 不动点 ,就可以将其代入 Eq. (22) 来构建不动点玻尔兹曼权重张量 。 然后可以使用该张量来计算传递矩阵 ,其矩阵元素如下:
| (25) |
传递矩阵 的特征值与 CFT [34, 35, 36, 13, 37] 中算子的标度维数 () 相关,
| (26) |
其中 是中心电荷。 比例因子可以通过要求恒等算子(即真空态)具有零标度维数 来确定。 这使得我们可以提取与最相关算子相关的最低几个标度维数。
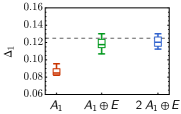
图 12 显示了使用不同点群表示选择进行 Ising MLRG 对最低标度维数 的估计。 这是 奇数伊辛序参数的缩放维度,其确切值为 。 我们可以看到,MLRG 可以通过更大的点群表示来逼近精确值。
IV 摘要和讨论
在这项研究中,我们提出了 MLRG 算法,并用它来分析统计物理学中的多体晶格模型。 我们的方法结合了多种现代机器学习技术,包括使用等变神经网络 [21, 22, 23, 24, 25, 26] 用于 RBM 和神经常微分方程 [32, 33] 用于模拟 RG 流。 源代码和原始数据可在 MLRG GitHub 仓库中获取 [38]。
MLRG 算法展示了机器学习在自动化和增强统计物理系统研究方面的强大功能。 我们利用生成式建模提供的表示学习能力,直接从数据中学习最佳的 RG 变换,而无需直接的人为干预或关于系统先验知识(除了对称性和维度)。
MLRG 算法的设计体现了 内省学习 [39] 的范式,这是机器学习中用于科学发现的一种有效方法。 它指的是算法在学习过程中能够自我分析和自我适应的能力,利用多个层次的学习和分析来生成对当前问题的更全面、更深入的理解。 MLRG 的设计通过其多级、多模型架构体现了这种内省性质。 它使用两个“低级”机器,教师和学生模型,来模拟通过表示学习提取相关特征的重整化群过程。 它还包含一个“高级”机器,调节器模型,它学习 RG 流并利用其知识来指导对最值得训练的新模型参数进行采样。 这种多级、多模型设计允许在 任务执行(由教师和学生模型执行)和 知识提取(由调节器模型执行)之间进行清晰的区分。 这种分离赋予了高级模型错误校正能力,使其能够抵抗 RBM 训练中噪声对学习 RG 流的影响。 这种压缩知识和纠正错误的能力对于 AI 进行科学发现至关重要 [40]。
MLRG 方法与现有工作(并与之区别)在以下方面相关:
-
•
蒙特卡洛重整化群 (MCRG): MCRG [41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54] 使用蒙特卡罗采样来促进非微扰 RG 技术。 此过程从给定模型参数的细粒度模型中采样配置开始。 然后,它采用局部 RG 变换来生成粗粒度配置,并相应地估计新模型参数。 此方法与我们从教师 RBM 训练学生 RBM 的方法一致。 特别是,最近的进展 [4, 7, 8] 引入了生成模型来学习最佳 RG 变换,这是一个与我们目标一致的目标。
然而,我们的方法利用特定晶格结构,如 Lieb 晶格,将 RG 操作限制在小的自旋簇内。 在缺乏这种设计的情况下,MCRG 必须在更大的晶格上执行采样,并对许多长程多自旋耦合进行建模,这会增加计算复杂性。 此外,MCRG 不会学习 RG 单调性,也不能自动找到 RG 固定点,因此在研究临界点性质时需要微调模型参数,从而增加了计算负担。
-
•
深度学习与 RG: 多项研究 [55, 56, 57, 58, 59] 在深度神经网络和 RG 之间发现了平行关系。 值得注意的是,他们认识到生成是重整化的逆过程 [6, 11]。 因此,生成模型可用于实现数据驱动的 RG。 这些讨论侧重于使用深度学习优化 RG 变换,这通常依赖于蒙特卡罗模拟的自旋配置进行分层特征提取。 尽管它们在提取稳定相的特征方面非常有效,但它们在预测相变的普适性质方面缺乏可控精度,因为它们没有学习 RG 方程或 RG 单调性。
-
•
基于 RG 流的生成模型: 神经 RG [2, 6] 和 RG 流 [10, 11] 等技术将 RG 变换嵌入到多级基于流的生成模型 [60, 61, 62] 中,通过最小化自由能应用深度学习方法来学习模型哈密顿量中的最佳 RG 变换。 这些方法基于 可逆 RG 框架,该框架将局部 RG 变换设计为从自旋配置到相关和不相关特征的双射(可逆)确定性映射。
然而,双射的要求限制了 RG 变换的可能性。 此外,基于流的模型难以对离散变量概率分布进行建模,限制了它们在各种统计力学问题中的应用。 它们也缺乏渐近精确极限,这意味着它们通常只能用作配置更新提议者来加速蒙特卡罗计算,而不是取代蒙特卡罗作为无偏模拟方法。
相反,MLRG 适用于离散变量和连续变量,提供更灵活的 RG 变换,具有随机粗粒度映射,允许扩展现场自由度,并且在现场自由度趋于无穷大时是精确的。 这些特性使 MLRG 成为研究统计物理学的宝贵方法。
-
•
信息论方法 RG:一些研究探索了最佳 RG 的信息论标准,表明 RG 变换应该最大化相关特征与环境的互信息 [1, 5, 63, 64, 65, 66] 或最小化无关特征之间的互信息 [6]。 虽然 MLRG 不与这些原则冲突,但它没有明确地将它们用作优化标准。 相反,它使用教师模型和学生模型在其共同自旋上的边际分布的匹配来定义最佳 RG 变换,这种方法更直接且更容易优化。
作为一种解决统计力学问题的数值算法,MLRG 展示了几个优势:
-
•
小簇抽样效率:与传统的蒙特卡罗 (MC) 模拟相比,MLRG 算法在更小、更轻量级的规模上运行。 它只需要对一小簇自旋(在晶胞内)内的自旋配置进行采样。 此外,不同自旋簇中的吉布斯抽样可以在现代计算设备上有效地并行化。 这种紧凑的操作允许该算法比更大规模的模拟更有效地执行。
-
•
探索完整的参数空间:MLRG 算法旨在在一个训练过程中有效地遍历整个参数空间。 这与 MC 模拟和张量网络重整化群 (TNRG) [67, 68, 34, 69, 70, 35] 存在很大差异,后者必须在不同参数下多次求解哈密顿量。 MLRG 算法能够探索完整的参数空间,降低了计算成本和扫描相图所花费的时间,这在参数空间维数很大时可能是有益的。
-
•
关键点的发现和分析:MLRG 利用关于 RG 单调性的知识来识别关键点(即不稳定的 RG 固定点)。 它使用机器学习的 RG 流来计算固定点属性,从而消除了对有限尺寸缩放的需要。 这种自动发现和分析过程增强了算法分析复杂物理系统中关键属性的能力,尤其是在具有多个不稳定方向的多临界点的情况下。
-
•
算法的受控收敛:与张量网络方法类似,MLRG 算法对物理属性的估计随着潜在空间维度的增加而收敛。 这种行为确保随着更多计算资源的投入,算法的预测变得越来越准确和可靠。
-
•
可解释性:与其他用于 RG 的机器学习方法相比,MLRG 方法通过使用对称表示对模型中的隐藏自旋进行标记,从而提供更好的可解释性,从而得出物理上有意义的耦合参数和 RG 规则。 在物理科学中,这一特性尤其宝贵,因为目标不仅是准确预测,还要获得物理见解。
目前用于对 MLRG 中局部能量进行建模的 RBM 训练是一个随机过程。 这会导致波动和噪声,从而导致 RG 单调性网络不稳定。 RG 单调性网络的稳定性直接影响关键属性预测的可靠性。 提高这种稳定性的一个潜在方法是用张量网络替换 RBM,如 Fig. 9 所示。 这将允许基于张量网络优化的确定性训练方法,从而减少噪声并提高 RG 单调性网络的稳定性。 随着稳定性和可靠性的提高,MLRG 可以扩展到处理更复杂的自旋模型。 这些模型涉及更大的内部对称群,例如 群,这对研究分类对称 [71, 72] 和纠缠跃迁 [73, 74, 75, 76, 77, 78] 至关重要。
致谢。
我们感谢 Rokas Veitas、John McGreevy、Roger Melko、Han Ma 和 Lei Wang 的讨论。 WH 和 YZY 由加州大学圣地亚哥分校的创业基金和美国国家科学基金会 (NSF) 资助,资助编号为: DMR-2238360。 该研究最初于 2021 年夏季在 Swarma Club 的因果涌现阅读小组中发表,并受益于活动期间与观众的互动。 我们感谢 OpenAI GPT4 模型在撰写本文的过程中提供了编辑建议。参考文献
- Koch-Janusz and Ringel [2018] M. Koch-Janusz and Z. Ringel, Nature Physics 14, 578 (2018), arXiv:1704.06279 [cond-mat.dis-nn] .
- Li and Wang [2018] S.-H. Li and L. Wang, Phys. Rev. Lett. 121, 260601 (2018), arXiv:1802.02840 [cond-mat.stat-mech] .
- Efthymiou et al. [2018] S. Efthymiou, M. J. S. Beach, and R. G. Melko, arXiv e-prints , arXiv:1810.02372 (2018), arXiv:1810.02372 [cond-mat.stat-mech] .
- Chung and Kao [2019] J.-H. Chung and Y.-J. Kao, arXiv e-prints , arXiv:1912.09005 (2019), arXiv:1912.09005 [cond-mat.stat-mech] .
- Lenggenhager et al. [2020] P. M. Lenggenhager, D. E. Gökmen, Z. Ringel, S. D. Huber, and M. Koch-Janusz, Physical Review X 10, 011037 (2020), arXiv:1809.09632 [cond-mat.stat-mech] .
- Hu et al. [2020] H.-Y. Hu, S.-H. Li, L. Wang, and Y.-Z. You, Physical Review Research 2, 023369 (2020), arXiv:1903.00804 [cond-mat.dis-nn] .
- Chung and Kao [2021] J.-H. Chung and Y.-J. Kao, Physical Review Research 3, 023230 (2021), arXiv:2010.05703 [cond-mat.dis-nn] .
- Ron et al. [2021] D. Ron, A. Brandt, and R. H. Swendsen, Phys. Rev. E 104, 025311 (2021), arXiv:2011.05567 [cond-mat.stat-mech] .
- Giataganas et al. [2022] D. Giataganas, C.-Y. Huang, and F.-L. Lin, New Journal of Physics 24, 043040 (2022), arXiv:2102.05219 [cond-mat.dis-nn] .
- Hu et al. [2022] H.-Y. Hu, D. Wu, Y.-Z. You, B. Olshausen, and Y. Chen, Machine Learning: Science and Technology 3, 035009 (2022), arXiv:2010.00029 [cs.LG] .
- Sheshmani et al. [2023] A. Sheshmani, Y.-Z. You, W. Fu, and A. Azizi, Machine Learning: Science and Technology 4, 015012 (2023), arXiv:2203.07975 [cs.LG] .
- Di Sante et al. [2022] D. Di Sante, M. Medvidović, A. Toschi, G. Sangiovanni, C. Franchini, A. M. Sengupta, and A. J. Millis, Phys. Rev. Lett. 129, 136402 (2022), arXiv:2202.13268 [cond-mat.str-el] .
- Ueda and Oshikawa [2023] A. Ueda and M. Oshikawa, Phys. Rev. B 108, 024413 (2023), arXiv:2302.06632 [cond-mat.stat-mech] .
- Hinton and Sejnowski [1983] G. E. Hinton and T. J. Sejnowski, in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Vol. 448 (Citeseer, 1983) pp. 448–453.
- Hinton [2002] G. E. Hinton, Neural computation 14, 1771 (2002).
- Welling et al. [2004] M. Welling, M. Rosen-zvi, and G. E. Hinton, in Advances in Neural Information Processing Systems, Vol. 17, edited by L. Saul, Y. Weiss, and L. Bottou (MIT Press, 2004).
- Hinton [2012] G. E. Hinton, Neural Networks: Tricks of the Trade: Second Edition , 599 (2012).
- Duane et al. [1987] S. Duane, A. Kennedy, B. J. Pendleton, and D. Roweth, Physics Letters B 195, 216 (1987).
- Neal [2011] R. Neal, in Handbook of Markov Chain Monte Carlo (2011) pp. 113–162.
- Betancourt [2017] M. Betancourt, arXiv e-prints , arXiv:1701.02434 (2017), arXiv:1701.02434 [stat.ME] .
- Cohen and Welling [2016] T. S. Cohen and M. Welling, arXiv e-prints , arXiv:1602.07576 (2016), arXiv:1602.07576 [cs.LG] .
- Kondor and Trivedi [2018] R. Kondor and S. Trivedi, arXiv e-prints , arXiv:1802.03690 (2018), arXiv:1802.03690 [stat.ML] .
- Weiler et al. [2018] M. Weiler, M. Geiger, M. Welling, W. Boomsma, and T. Cohen, arXiv e-prints , arXiv:1807.02547 (2018), arXiv:1807.02547 [cs.LG] .
- Cohen et al. [2018] T. Cohen, M. Geiger, and M. Weiler, arXiv e-prints , arXiv:1811.02017 (2018), arXiv:1811.02017 [cs.LG] .
- Finzi et al. [2021] M. Finzi, M. Welling, and A. G. Wilson, arXiv e-prints , arXiv:2104.09459 (2021), arXiv:2104.09459 [cs.LG] .
- Lim and Nelson [2022] L.-H. Lim and B. J. Nelson, arXiv e-prints , arXiv:2205.07362 (2022), arXiv:2205.07362 [cs.LG] .
- Lieb [1989] E. H. Lieb, Phys. Rev. Lett. 62, 1201 (1989).
- Zomolodchikov [1986] A. B. Zomolodchikov, Soviet Journal of Experimental and Theoretical Physics Letters 43, 730 (1986).
- Barnes et al. [2004] E. Barnes, K. Intriligator, B. Wecht, and J. Wright, Nuclear Physics B 702, 131 (2004), arXiv:hep-th/0408156 [hep-th] .
- Friedan and Konechny [2010] D. Friedan and A. Konechny, Journal of Physics A Mathematical General 43, 215401 (2010), arXiv:0910.3109 [hep-th] .
- Komargodski and Schwimmer [2011] Z. Komargodski and A. Schwimmer, Journal of High Energy Physics 2011, 99 (2011), arXiv:1107.3987 [hep-th] .
- Chen et al. [2018] R. T. Q. Chen, Y. Rubanova, J. Bettencourt, and D. Duvenaud, arXiv e-prints , arXiv:1806.07366 (2018), arXiv:1806.07366 [cs.LG] .
- Grathwohl et al. [2018] W. Grathwohl, R. T. Q. Chen, J. Bettencourt, I. Sutskever, and D. Duvenaud, arXiv e-prints , arXiv:1810.01367 (2018), arXiv:1810.01367 [cs.LG] .
- Gu and Wen [2009] Z.-C. Gu and X.-G. Wen, Phys. Rev. B 80, 155131 (2009), arXiv:0903.1069 [cond-mat.str-el] .
- Yang et al. [2015] S. Yang, Z.-C. Gu, and X.-G. Wen, arXiv e-prints , arXiv:1512.04938 (2015), arXiv:1512.04938 [cond-mat.str-el] .
- Huang et al. [2023] C.-Y. Huang, S.-H. Chan, Y.-J. Kao, and P. Chen, Phys. Rev. B 107, 205123 (2023), arXiv:2302.02585 [cond-mat.stat-mech] .
- Lyu et al. [2021] X. Lyu, R. G. Xu, and N. Kawashima, Physical Review Research 3, 023048 (2021), arXiv:2102.08136 [cond-mat.stat-mech] .
- Hou and You [2023] W. Hou and Y.-Z. You, MLRG GitHub repository (2023).
- Wang et al. [2019] C. Wang, H. Zhai, and Y.-Z. You, Science Bulletin 64, 1228 (2019), arXiv:1901.11103 [cond-mat.dis-nn] .
- Raghu and Schmidt [2020] M. Raghu and E. Schmidt, arXiv e-prints , arXiv:2003.11755 (2020), arXiv:2003.11755 [cs.LG] .
- Ma [1976] S.-k. Ma, Phys. Rev. Lett. 37, 461 (1976).
- Swendsen [1984a] R. H. Swendsen, Journal of Statistical Physics 34, 963 (1984a).
- Pawley et al. [1984] G. S. Pawley, R. H. Swendsen, D. J. Wallace, and K. G. Wilson, Phys. Rev. B 29, 4030 (1984).
- Gupta et al. [1984] R. Gupta, G. Guralnik, A. Patel, T. Warnock, and C. Zemach, Phys. Rev. Lett. 53, 1721 (1984).
- Swendsen [1984b] R. H. Swendsen, Phys. Rev. B 30, 3866 (1984b).
- Swendsen [1984c] R. H. Swendsen, Phys. Rev. B 30, 3875 (1984c).
- Baillie et al. [1992] C. F. Baillie, R. Gupta, K. A. Hawick, and G. S. Pawley, Phys. Rev. B 45, 10438 (1992).
- Blöte et al. [1996] H. W. J. Blöte, J. R. Heringa, A. Hoogland, E. W. Meyer, and T. S. Smit, Phys. Rev. Lett. 76, 2613 (1996), arXiv:cond-mat/9602020 [cond-mat] .
- Ron and Swendsen [2002] D. Ron and R. H. Swendsen, Phys. Rev. E 66, 056106 (2002).
- Ron et al. [2002] D. Ron, R. H. Swendsen, and A. Brandt, Phys. Rev. Lett. 89, 275701 (2002).
- Ron et al. [2017] D. Ron, A. Brandt, and R. H. Swendsen, Phys. Rev. E 95, 053305 (2017), arXiv:1703.02430 [cond-mat.stat-mech] .
- Wu and Car [2017] Y. Wu and R. Car, Phys. Rev. Lett. 119, 220602 (2017), arXiv:1707.08683 [cond-mat.stat-mech] .
- Wu and Car [2019] Y. Wu and R. Car, Phys. Rev. E 100, 022138 (2019), arXiv:1903.08231 [cond-mat.stat-mech] .
- Wu [2019] Y. Wu, Phys. Rev. E 100, 023306 (2019), arXiv:1903.12137 [cond-mat.stat-mech] .
- Bény [2013] C. Bény, arXiv e-prints , arXiv:1301.3124 (2013), arXiv:1301.3124 [quant-ph] .
- Mehta and Schwab [2014] P. Mehta and D. J. Schwab, arXiv e-prints , arXiv:1410.3831 (2014), arXiv:1410.3831 [stat.ML] .
- Bény and Osborne [2015] C. Bény and T. J. Osborne, New Journal of Physics 17, 083005 (2015), arXiv:1402.4949 [quant-ph] .
- Lin et al. [2017] H. W. Lin, M. Tegmark, and D. Rolnick, Journal of Statistical Physics 168, 1223 (2017), arXiv:1608.08225 [cond-mat.dis-nn] .
- Shiba Funai and Giataganas [2018] S. Shiba Funai and D. Giataganas, arXiv e-prints , arXiv:1810.08179 (2018), arXiv:1810.08179 [cond-mat.stat-mech] .
- Kingma and Dhariwal [2018] D. P. Kingma and P. Dhariwal, arXiv e-prints , arXiv:1807.03039 (2018), arXiv:1807.03039 [stat.ML] .
- Kobyzev et al. [2019] I. Kobyzev, S. J. D. Prince, and M. A. Brubaker, arXiv e-prints , arXiv:1908.09257 (2019), arXiv:1908.09257 [stat.ML] .
- Papamakarios et al. [2019] G. Papamakarios, E. Nalisnick, D. Jimenez Rezende, S. Mohamed, and B. Lakshminarayanan, arXiv e-prints , arXiv:1912.02762 (2019), arXiv:1912.02762 [stat.ML] .
- Gordon et al. [2021] A. Gordon, A. Banerjee, M. Koch-Janusz, and Z. Ringel, Phys. Rev. Lett. 126, 240601 (2021), arXiv:2012.01447 [cond-mat.stat-mech] .
- Gökmen et al. [2021a] D. E. Gökmen, Z. Ringel, S. D. Huber, and M. Koch-Janusz, Phys. Rev. Lett. 127, 240603 (2021a), arXiv:2101.11633 [cond-mat.stat-mech] .
- Gökmen et al. [2021b] D. E. Gökmen, Z. Ringel, S. D. Huber, and M. Koch-Janusz, Phys. Rev. E 104, 064106 (2021b), arXiv:2103.16887 [cond-mat.stat-mech] .
- Gökmen et al. [2023] D. E. Gökmen, S. Biswas, S. D. Huber, Z. Ringel, F. Flicker, and M. Koch-Janusz, arXiv e-prints , arXiv:2301.11934 (2023), arXiv:2301.11934 [cond-mat.stat-mech] .
- Levin and Nave [2007] M. Levin and C. P. Nave, Phys. Rev. Lett. 99, 120601 (2007), arXiv:cond-mat/0611687 [cond-mat.stat-mech] .
- Gu et al. [2008] Z.-C. Gu, M. Levin, and X.-G. Wen, arXiv e-prints , arXiv:0807.2010 (2008), arXiv:0807.2010 [cond-mat.str-el] .
- Evenbly [2015] G. Evenbly, arXiv e-prints , arXiv:1509.07484 (2015), arXiv:1509.07484 [cond-mat.str-el] .
- Evenbly and Vidal [2015] G. Evenbly and G. Vidal, Phys. Rev. Lett. 115, 180405 (2015), arXiv:1412.0732 [cond-mat.str-el] .
- Ji and Wen [2019] W. Ji and X.-G. Wen, arXiv e-prints , arXiv:1912.13492 (2019), arXiv:1912.13492 [cond-mat.str-el] .
- Chatterjee et al. [2022] A. Chatterjee, W. Ji, and X.-G. Wen, arXiv e-prints , arXiv:2212.14432 (2022), arXiv:2212.14432 [cond-mat.str-el] .
- Vasseur et al. [2019] R. Vasseur, A. C. Potter, Y.-Z. You, and A. W. W. Ludwig, Phys. Rev. B 100, 134203 (2019), arXiv:1807.07082 [cond-mat.stat-mech] .
- Li et al. [2018] Y. Li, X. Chen, and M. P. A. Fisher, Phys. Rev. B 98, 205136 (2018), arXiv:1808.06134 [quant-ph] .
- Skinner et al. [2019] B. Skinner, J. Ruhman, and A. Nahum, Physical Review X 9, 031009 (2019), arXiv:1808.05953 [cond-mat.stat-mech] .
- Gullans and Huse [2020] M. J. Gullans and D. A. Huse, Physical Review X 10, 041020 (2020), arXiv:1905.05195 [quant-ph] .
- Bao et al. [2020] Y. Bao, S. Choi, and E. Altman, Phys. Rev. B 101, 104301 (2020), arXiv:1908.04305 [cond-mat.stat-mech] .
- Jian et al. [2020] C.-M. Jian, Y.-Z. You, R. Vasseur, and A. W. W. Ludwig, Phys. Rev. B 101, 104302 (2020), arXiv:1908.08051 [cond-mat.stat-mech] .