告诉我们事实:利用知识图增强大型语言模型以实现事实感知语言建模
摘要
近年来,具有代表性的大语言模型ChatGPT受到了广泛关注。 由于其强大的涌现能力,最近的大语言模型被认为是知识图谱(KG)等结构化知识库的可能替代品。 然而,尽管大语言模型擅长学习概率语言模式并与人类进行对话,但它们与之前较小的预训练语言模型(PLM)一样,在生成基于知识的内容时仍然难以回忆事实。 为了克服这些限制,研究人员建议使用基于知识的 KG 来增强数据驱动的 PLM,将明确的事实知识纳入 PLM,从而提高其生成需要事实知识的文本并为用户查询提供更明智的响应的性能。 本文回顾了利用 KG 增强 PLM 的研究,详细介绍了现有的知识图增强预训练语言模型(KGPLM)及其应用。 受 KGPLM 现有研究的启发,本文提出通过开发知识图增强型大语言模型(KGLLM)来利用知识图谱增强大语言模型。 KGLLM提供了增强大语言模型事实推理能力的解决方案,为大语言模型研究开辟了新途径。
索引术语:
大语言模型、知识图谱、ChatGPT、知识推理、知识管理。我简介
近年来,大数据[1,2,3]和高速计算的快速发展导致了预训练语言模型(PLM)的出现。 人们提出了很多PLM,例如BERT [4]、GPT [5]和T5 [6],极大地提高了PLM的性能。各种自然语言处理(NLP)任务的性能。 最近,研究人员发现,缩放模型大小或数据大小可以提高下游任务的模型能力。 此外,他们发现,当参数大小超过一定规模[7]时,这些 PLM 表现出一些令人惊讶的涌现能力。 涌现能力是指小模型中不存在但在大模型中出现的能力[7],用于区分大语言模型(大语言模型)和PLM。
2022年11月30日,OpenAI发布了基于大语言模型GPT-3.5开发的聊天机器人程序ChatGPT。 通过监督学习对 GPT 进行微调,并使用人类反馈的强化学习 (RLHF) 进一步优化模型,ChatGPT 能够根据聊天上下文与人类进行持续对话。 它甚至可以完成编码、论文写作等复杂任务,展示了其强大的突发能力[7]。 因此,一些研究人员[8,9,10,11]探索大语言模型是否可以作为参数化知识库来替代知识图谱(KG)等结构化知识库,因为它们也存储了大量数据的事实。
然而,现有研究[12,13,14,15]发现大语言模型生成事实正确文本的能力仍然有限。 他们只有在训练时才能记住事实。 因此,这些模型在尝试回忆相关知识并应用正确的知识来生成基于知识的内容时常常面临挑战。 另一方面,知识图谱作为人工构建的结构化知识库,以可读的格式存储了大量与现实世界事实密切相关的知识。 它们明确地表达实体之间的关系,直观地展示知识和推理链的整体结构,使其成为知识建模的理想选择。 因此,大语言模型与知识图谱之间既存在竞争关系,又存在互补关系。 大语言模型能够提高知识抽取的准确性,提高知识图谱的质量[16],而知识图谱可以利用显性知识指导大语言模型的训练,提高大语言模型的回忆和应用能力知识。
到目前为止,已经提出了许多利用 KG 增强 PLM 的方法,这些方法可以分为三种类型:训练前增强、训练期间增强和训练后增强。 尽管存在一些关于知识增强型PLM的调查[17,18,19],但它们关注的是各种形式的知识,缺乏对知识图增强型预训练语言模型(KGPLM)的系统回顾方法。 例如,Wei等人[17]对基于不同知识源的知识增强PLM进行了审查,但仅涵盖了一小部分KGPLM。 同样,Yang 等人 [18]涵盖了各种形式的知识增强PLM,但仅提供了对KGPLM的部分回顾,而没有进行技术分类。 在另一项研究中,Zhen 等人 [19]将知识增强 PLM 分为隐式合并和显式合并方法,但他们的评论仅涵盖 KGPLM 的一小部分。 此外,该领域正在迅速发展,不断引入大量新技术。 因此,针对是否还有必要构建知识图谱以及如何提高大语言模型的知识建模能力等问题,我们对相关研究进行了系统回顾。 我们对与关键词“语言模型”和“知识图谱”相关的论文进行了彻底的搜索。 随后,与 KGPLM 最相关的论文被仔细提炼和分类。 与现有的调查相比,本文特别关注 KGPLM,并涵盖了更广泛的最新论文。 此外,我们建议开发知识图增强型大语言模型(KGLLM)来解决大语言模型中的知识建模挑战。 本文的主要贡献总结如下:
-
•
我们对 KGPLM 进行了全面的综述,这有助于研究人员深入了解该领域。
-
•
我们综述了大语言模型的评价研究,并对大语言模型和知识图谱进行了比较。
-
•
我们建议用知识图谱来增强大语言模型,并提出一些未来可能的研究方向,这可能会使大语言模型领域的研究人员受益。
本文的其余部分安排如下。 第二节概述了大语言模型的背景。 第三节对 KGPLM 的现有方法进行了分类,并介绍了每个组的代表。 第四节介绍了 KGPLM 的应用。 第五节结合现有研究的证据讨论大语言模型是否可以取代知识图谱。 第六节提出通过开发 KGLLM 来增强大语言模型学习事实知识的能力,并提出了一些未来的研究方向。 第七节得出结论。
二背景
PLM 学习单词的密集且连续的表示,解决传统编码方法中遇到的特征稀疏问题,并显着提高各种 NLP 任务的性能。 因此,基于 PLM 的方法得到了重视,从而导致了各种类型的 PLM 的发展。 最近,PLM 已扩展到大语言模型,以获得更好的性能。 在本节中,我们将提供 PLM 的全面背景并概述其历史发展。
II-A PLM 的背景
PLM 是通过在大型语料库上进行无监督学习[20]获得的一种语言模型。 它们能够捕获语言的结构和特征并生成单词的通用表示。 经过预训练后,可以针对特定的下游任务(例如文本摘要、文本分类和文本生成)对 PLM 进行微调。
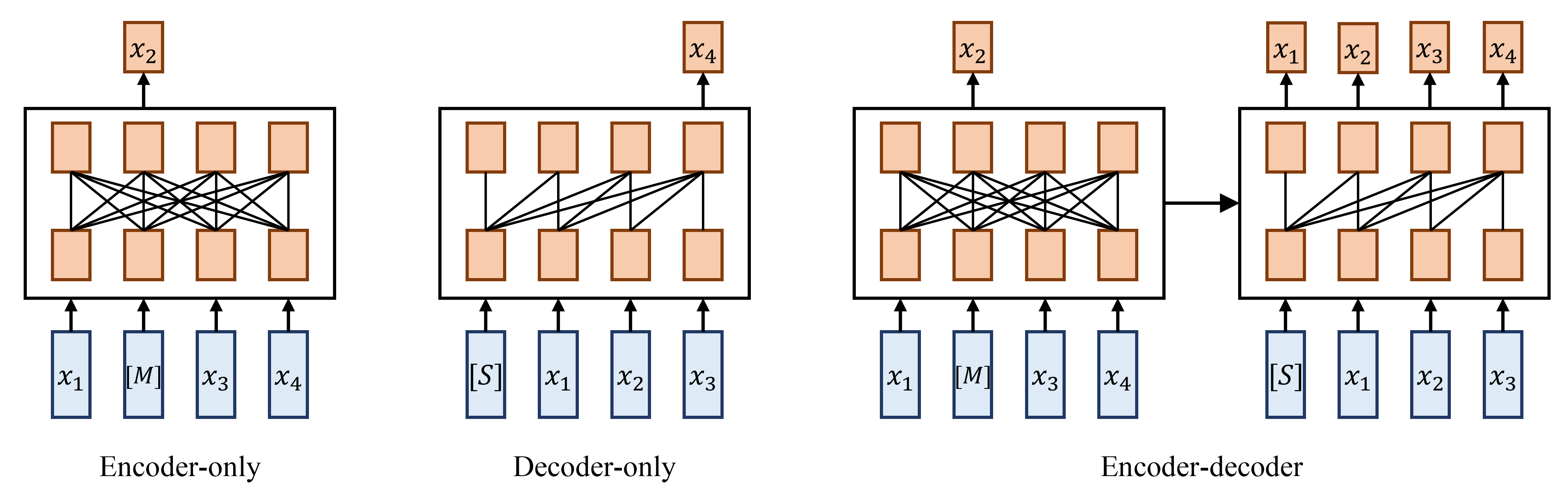
现有PLM使用的模型框架可分为三类,如图1所示:仅编码器、仅解码器和编码器-解码器[21] 。 仅编码器框架利用双向 Transformer 根据输入句子恢复屏蔽标记,从而有效地利用上下文信息来学习更好的文本表示。 更具体地说,给定一个输入词符序列 和一些屏蔽标记 ,它将屏蔽标记的可能性建模为 。 然而,由于缺乏解码器,它不能直接应用于文本生成任务。 BERT 及其改进模型大多采用仅编码器框架。 仅解码器框架利用单向 Transformer 以自回归方式预测标记,使其适合文本生成任务。 也就是说,给定文本序列,该框架将输入词符序列的可能性建模为。 GPT系列及其改进型号大多采用该框架。 然而,与其他两个框架相比,仅解码器框架无法利用上下文信息,并且不能很好地推广到其他任务。 编码器-解码器框架构建了一个序列到序列模型,以基于具有屏蔽标记的历史上下文来预测当前词符。 其目标可以描述为。 该框架擅长需要根据给定输入生成输出的任务,但与其他两个框架相比,其编码和解码速度较慢。
设计了多种 PLM 预训练任务,可分为单词级、短语级和句子级任务。 典型的词级预训练任务包括掩码语言建模(MLM)[4]和替换词符检测(RTD)[22]。 MLM 随机屏蔽输入序列中的一些 token,并训练 PLM 基于上下文重建屏蔽的 token,其损失函数为:
| (1) |
它可以促进上下文信息的学习,从而在语言理解和语言建模任务中取得更好的结果。 RTD 的操作与 MLM 类似,但通过用替代 Token 替换一些 Token 并训练模型来预测原始 Token ,引入了更大的随机性,其损失函数定义为:
| (2) |
这里,是的损坏词符,而如果则为1,否则为0。 与 MLM 相比,RTD 可以更真实地反映真实文本中词汇的变化,并使 PLM 能够处理未知单词和拼写错误的单词。 短语级预训练任务的代表是跨度边界目标(SBO)[23, 24],它迫使 PLM 仅依赖于可见跨度的表示来预测屏蔽跨度的每个词符。边界处的标记,增强PLM的句法结构分析能力,提高其在命名实体识别和情感分析方面的性能。 SBO任务的训练目标可以表示为:
| (3) |
其中是词符在span中的表示。 句子级预训练任务的代表包括下一句预测(NSP)[4]和句子顺序预测(SOP)[25]。 NSP 训练 PLM 来区分两个给定句子是否连续,从而提高 PLM 在自然语言推理和文本分类等基于上下文的任务中的性能。 同样,SOP 训练 PLM 来确定两个随机采样和打乱的句子的顺序,这提高了它们捕获句子顺序信息的能力。 NSP和SOP的训练目标如下:
| (4) |
其中 如果 和 是从语料库中提取的两个连续片段。 一些PLM[26]还利用了其他任务,例如删除词符检测(DTD)、文本填充、句子重新排序(SR)和文档重新排序(DR),从而提高了它们在某些特殊情况下的性能任务。
II-B 里程碑
作为早期尝试,Elmo [27] 采用双向长短期记忆 (LSTM) 网络来学习捕获上下文的单词表示。 该模型使用双向自回归语言建模目标进行训练,其中涉及最大化以下对数似然:
| (5) | ||||
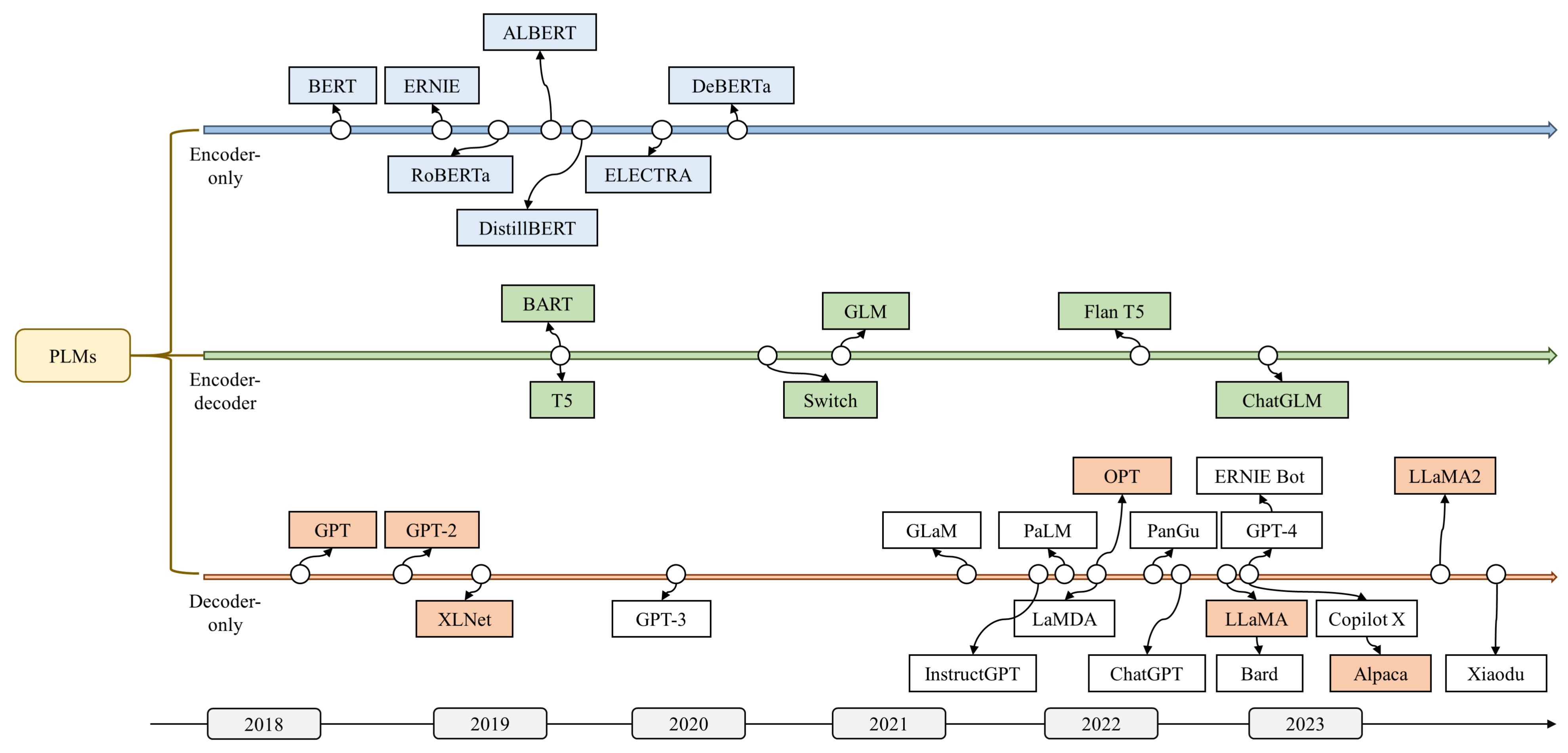
其中对给定历史上下文或未来上下文的词符的概率进行建模。 表示词符表示。 和分别表示前向和后向的LSTM编码器。 通过学习上下文感知的单词表示,Elmo 极大地提高了 NLP 任务的性能标准。 然而,由于 LSTM 难以处理长序列,其特征提取能力受到限制。 随着高度并行化 Transformer [28] 的出现,更强大的情境化 PLM 被开发出来。 具有不同框架的著名 PLM 如图2所示。
Transformer 采用自注意力机制来捕获输入序列之间的依赖性,从而允许并行处理 Token 并提高效率。 具体来说,自注意力机制的输出为:
| (6) |
其中 、 和 是查询矩阵、键矩阵和值矩阵。 是键向量和查询向量的维度。
仅编码器 PLM 使用双向 Transformer 作为编码器,并使用 MLM 和 NSP 任务进行自监督训练。 RoBERTa [29] 引入了一组设计选择和训练策略,可以带来更好的性能,显着提高 BERT 在各种基准上的性能。 DistilBERT [30] 将知识蒸馏融入到预训练中,将 BERT 模型的大小减少了 40%。 其他著名的仅编码器 PLM 包括 ERNIE [31]、ALBERT [25]、ELECTRA [22] 和 DeBERTa [32 ]。
相比之下,在仅解码器的 PLM 中,使用单向 Transformer 作为解码器,并训练模型根据前面的序列预测下一个词符。 这种训练方法提高了他们的语言理解和文本生成能力。 给定一个无监督语料库,GPT 使用单向语言建模目标来优化模型,最大化以下对数似然:
| (7) |
这里,表示Transformer模型的参数。 GPT-2 [33]训练训练 通过增加模型大小和语料库并使模型能够自动识别无监督任务类型来改进 GPT。 XLNet [34] 提出了一种广义自回归预训练方法,可以学习双向上下文。
在编码器-解码器 PLM 中,Transformer 既充当编码器又充当解码器。 编码器生成输入序列的潜在表示,而解码器生成目标输出文本。 T5 [6] 开发了一个统一的框架,将所有 NLP 任务转换为文本到文本的格式,从而在众多基准测试中获得出色的性能。 为了有效地预训练序列到序列模型,BART[26]采用标准神经机器翻译架构,并开发了去噪自动编码器。
| Model framework | PLM | Year | Base model | Pre-training tasks | Pre-training data size | model size |
| Encoder-only | BERT | 2018 | Transformer | MLM, NSP | 3300M words | 340M |
| ERNIE | 2019 | Transformer | MLM, NSP | 4500M subwords | 114M | |
| RoBERTa | 2019 | BERT | MLM | 160GB of text | 335M | |
| ALBERT | 2019 | BERT | SOP | 16GB of text | 233M | |
| DistillBERT | 2019 | BERT | MLM | 3300M words | 66M | |
| ELECTRA | 2020 | Transformer | RTD | 126GB of text | 110M | |
| DeBERTa | 2020 | Transformer | MLM | 78GB of text | 1.5B | |
| Encoder-decoder | BART | 2019 | Transformer | MLM, DTD, text infilling, SR, DR | 160GB of text | 406M |
| T5 | 2019 | Transformer | MLM | 20TB of text | 11B | |
| Switch | 2021 | Transformer | MLM | 180B tokens | 1.6T | |
| GLM | 2021 | Transformer | Blank infilling | 400B tokens | 130B | |
| Flan T5 | 2022 | T5 | 1800 fine-tuning tasks | - | 11B | |
| ChatGLM | 2023 | GLM | Blank infilling | 1T tokens | 6B | |
| Decoder-only | GPT | 2018 | Transformer | Autoregressive language modeling | 800M words | 117M |
| GPT-2 | 2019 | Transformer | Autoregressive language modeling | 40GB of text | 1.5B | |
| XLNet | 2019 | Transformer | Autoregressive language modeling | 33B tokens | 340M | |
| GPT-3 | 2020 | Transformer | Autoregressive language modeling | 45TB of text | 175B | |
| GLaM | 2021 | Transformer | Autoregressive language modeling | 1.6T tokens | 1.2T | |
| InstructGPT | 2022 | GPT-3 | Autoregressive language modeling | - | 175B | |
| PaLM | 2022 | Transformer | Autoregressive language modeling | 780B tokens | 540B | |
| LaMDA | 2022 | Transformer | Autoregressive language modeling | 768B tokens | 137B | |
| OPT | 2022 | Transformer | Autoregressive language modeling | 180B tokens | 175B | |
| ChatGPT | 2022 | GPT-3.5 | Autoregressive language modeling | - | - | |
| LLaMA | 2023 | Transformer | Autoregressive language modeling | 1.4T tokens | 65B | |
| GPT-4 | 2023 | Transformer | Autoregressive language modeling | 13T tokens | 1.8T | |
| Alpaca | 2023 | LLaMA | Autoregressive language modeling | 52K data | 7B | |
| LLaMA2 | 2023 | Transformer | Autoregressive language modeling | 2T tokens | 70B |
II-C 将 PLM 扩展到大语言模型
随着越来越多的 PLM 的出现,人们发现模型扩展可以提高性能。 通过将参数规模和数据规模增加到足够大的规模,我们发现这些放大的模型表现出了一些小规模PLM所不具备的特殊能力。 因此,最近致力于将 PLM 扩展到大语言模型,以赋予其新兴能力。 通常,大语言模型是指由数千亿个参数组成的PLM,例如GLM [35]、Switch [36]、Flan T5 [37 ],以及编码器-解码器框架的 ChatGLM [38]。 此外,现有的大语言模型大多采用仅解码器的框架。 仅限解码器的大语言模型的著名示例包括 GPT-3 [39]、GLaM [40]、InstructGPT [41]、PaLM [42]、LaMDA [43]、OPT [44]、LLaMA [45]、羊驼毛 [46]、GPT-4 [47] 和 LLaMA2 [48]。 GPT-3 [39]进一步增加了GPT-2的参数和数据量,并采用零样本训练和多样性生成技术,使得无需注释数据即可学习和执行新任务并生成文本风格多样。 GPT-3.5不仅增加了模型大小,还应用了基于提示的模板提取(PET)等新颖的预训练方法,进一步提高了生成文本的准确性和流畅性。 大语言模型比小型 PLM 具有更强的理解自然语言和解决复杂 NLP 任务的能力。 例如,GPT-3 就表现出了卓越的情境学习能力。 它可以通过填充输入文本的单词序列来生成测试用例的预期输出,仅依靠自然语言指令或演示,而不需要额外的训练。 相反,GPT-2 缺乏这种能力[49]。
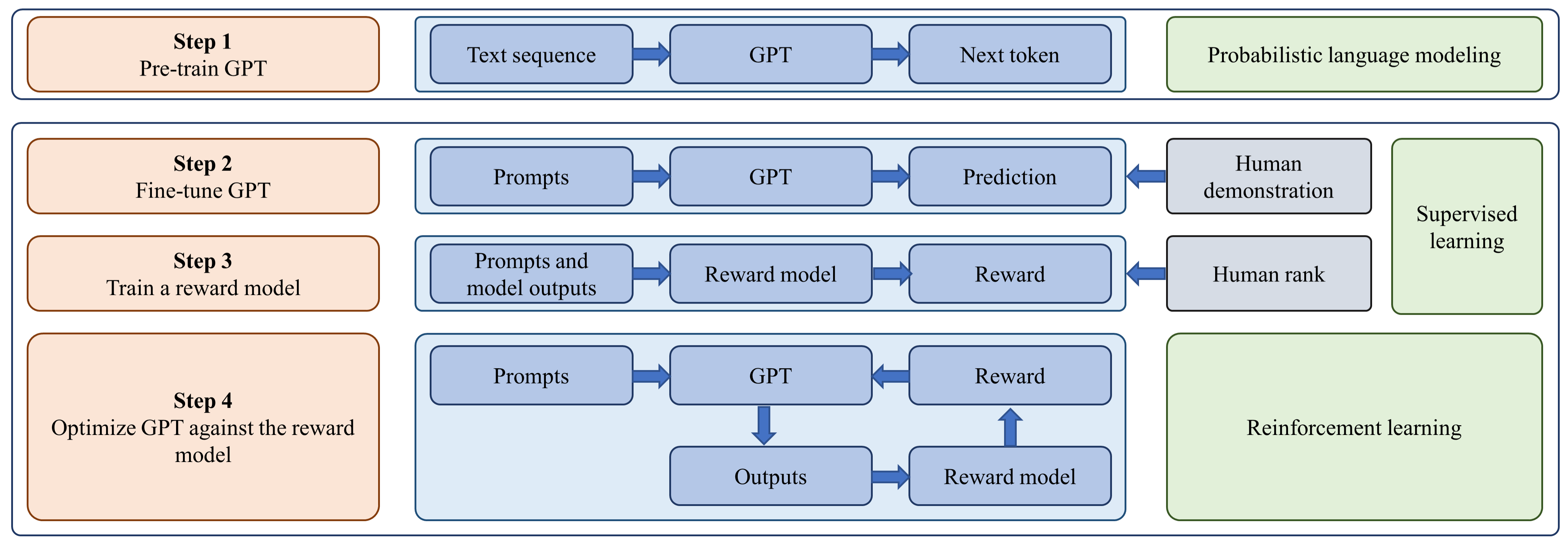
大语言模型最引人注目的应用是ChatGPT,它采用GPT-3.5进行对话,展示了惊人的对话能力。 ChatGPT的实现流程如图3[50]所示。 它首先在大规模语料库上训练 GPT,然后在贴标机演示数据集上对其进行微调。 之后,它使用 RLHF [51] 优化模型,该模型训练奖励模型以从人类评估者提供的直接反馈中学习,并通过将其表述为强化学习问题来优化 GPT 模型。 在此设置中,预训练的 GPT 模型充当策略模型,将小段提示 [52] 作为输入并返回输出文本。 然后使用近端策略优化 (PPO) 算法[53]针对奖励模型优化 GPT 策略模型。 ChatGPT基于RLHF方法,使GPT能够遵循人类预期的指令,减少有毒、偏见和有害内容的产生。 此外,ChatGPT 采用思想链策略[54],并额外接受代码数据训练,使其能够解决需要中间逻辑步骤的任务。
另一个值得注意的进步是 GPT-4 [47],该模型将文本输入扩展到多模态信号,并在解决任务 [55] 方面表现出更高的熟练程度。 此外,GPT-4 训练经历了六个月的迭代调整,在 RLHF 中添加了额外的安全奖励,这使其更擅长生成有用、诚实且无害的内容。 此外,GPT-4 还实现了一些增强的优化方法,例如可预测的缩放,可以通过使用较少计算训练的较小模型准确预测 GPT-4 的最终性能。
表I总结了上述基于上下文的PLM和大语言模型的特征。 据观察,最大模型的参数大小逐年增加。
II-D 大语言模型的优缺点
利用大量基准和任务来评估大语言模型的有效性和优越性。 相应的实验结果表明,大语言模型在各种 NLP 任务上比以前的深度学习模型和较小的 PLM 取得了更好的性能。 此外,大语言模型表现出一些新兴能力,能够解决传统模型和小型PLM无法解决的一些复杂任务。 综上所述,大语言模型具有以下优越特点。
零样本学习。 大语言模型在大多数任务上都优于其他具有零样本学习的模型,甚至在某些任务上比微调模型表现得更好。 一项实证研究[15]表明,ChatGPT 在 13 个数据集中的 9 个上优于以前的零样本学习模型,甚至在 4 个任务上优于完全微调的特定任务模型。 这种优越的性能归功于丰富多样的输入数据以及大语言模型的大参数规模,这使得它们能够高保真地捕获自然语言的潜在模式,从而产生更稳健和准确的推理。
情境学习。 上下文学习(ICL)是一种范式,允许大语言模型以演示的形式仅从少数实例中学习任务[56]。 ICL首次在GPT-3上展出,已成为大语言模型的通用使用方法。 ICL 采用格式化的自然语言提示,其中包括任务描述和一些示例来说明完成任务的方法。 ICL能力还得益于大语言模型强大的序列处理能力和丰富的知识储备。
逐步推理。 利用思维链提示策略,大语言模型可以顺利完成一些复杂的任务,包括算术推理、常识推理和符号推理。 此类任务通常超出小型 PLM 的能力。 思维链是一种改进的提示策略,它将中间推理步骤整合到提示中,以提高大语言模型在复杂推理任务上的性能。 此外,逐步推理能力被认为可以通过大语言模型在结构良好的代码数据[54]上的训练来获得。
遵循说明。 指令调优是一种独特的微调方法,可在自然语言格式化实例的集合上微调大语言模型。 通过这种方法,大语言模型能够在通过自然语言指令描述的以前未见过的任务上表现良好,而无需依赖显式示例[49]。 例如,Wei 等人 [57]基于指令调优,在60多个数据集上微调了137B参数的大语言模型,并在未见过的任务类型上进行了测试。 实验结果表明,指令调整模型的性能显着优于未修改的模型和零样本 GPT-3。
人类对齐。 通过 RLHF 技术,可以训练大语言模型生成符合人类价值观的高质量、无害的响应,其中涉及使用精心设计的标签策略将人类纳入训练循环。 RLHF 包括三个步骤:1)以有监督的方式收集由输入提示和目标输出组成的标记数据集到大语言模型; 2)在组装数据上训练奖励模型,3)通过将其优化表述为强化学习问题来优化大语言模型。 通过这种方法,大语言模型能够生成符合人类期望的适当输出。
工具操纵。 传统的 PLM 是基于纯文本数据进行训练的,这限制了它们解决非文本任务的能力。 此外,它们的能力受到预训练语料库的限制,无法有效解决需要实时知识的任务。 针对这些限制,最近开发的大语言模型能够操作搜索引擎、计算器和编译器等外部工具,以增强其在专业领域的性能[58]。 最近,大语言模型支持了插件机制,为实现新功能提供了途径。 这一机制极大地拓宽了大语言模型的能力范围,使其更加灵活,能够适应不同的任务。
尽管大语言模型在自然语言理解和类人内容生成方面取得了重大进展,但仍然存在以下局限性和挑战[49]。
无组织的一代。 大语言模型通常依靠自然语言提示或指令在特定条件下生成文本。 这种机制对根据细粒度或结构标准精确约束生成的输出提出了挑战。 确保特定的文本结构(例如整个文本中概念的逻辑顺序)可能很困难。 对于需要正式规则或语法的任务来说,这种难度会更大。 这是因为大语言模型在预训练时主要关注单词和句子的局部上下文信息,而忽略了全局句法和结构知识。 解决这个问题的一个建议是采用迭代提示的方法来生成文本[59],模仿人类书写的过程。 相比之下,当涉及同一实体的复杂事件跨越多个句子[60]时,知识图谱提供了结构化摘要并强调相关概念的相关性,从而增强了结构化文本生成的过程。
幻觉。 在生成事实或基于知识的文本时,大语言模型可能会生成与现有来源相矛盾或缺乏支持证据的内容。 这一挑战在现有的大语言模型中广泛存在,被称为幻觉问题,这会导致其性能下降,并在将其部署到实际应用中时带来风险。 造成这个问题的原因与大语言模型在解决任务时利用正确的内部和外部知识的能力有限有关。 为了缓解这个问题,现有的研究采用了对齐调整策略,其中将人类反馈融入到大语言模型中。 知识图谱提供了结构化和明确的知识表示,可以动态地将其合并以增强大语言模型,从而在[61]一代中产生更多事实依据并减少幻觉。
不一致。 借助思维链策略,大语言模型能够基于分步推理来解决一些复杂的推理任务。 尽管性能优越,大语言模型有时可能会基于无效的推理路径得出所需的答案,或者尽管遵循正确的推理过程却会产生错误的答案。 结果,得出的答案和潜在的推理过程之间出现不一致。 此外,研究[62]表明,大语言模型预测事实和回答查询的能力很大程度上受到特定提示模板和相关实体的影响。 这是因为大语言模型很大程度上依靠简单的启发式进行预测,它们的生成与目标词和提示中的词的共现频率相关。 此外,虽然大语言模型的预训练过程可以帮助他们记忆事实,但未能赋予他们概括观察到的事实的能力,从而导致推断不佳。 通过在大语言模型推理中引入外部知识图谱可以部分解决这个问题。 通过交互地探索知识图谱上的相关实体和关系,并根据检索到的知识进行推理,大语言模型可以具有更好的知识追溯和知识纠正能力[63]。
推理能力有限。 当提供问答示例时,大语言模型在一些基本逻辑推理任务上表现出了良好的性能。 然而,他们在需要理解和利用支持证据来得出结论的任务中表现不佳。 虽然大语言模型通常会生成有效的推理步骤,但当多个候选步骤被视为有效时,它们会面临挑战[64]。 这是因为大语言模型只选择与输入问题重叠的最高单词的答案。 此外,大语言模型由于强调单词的浅层共现和序列模式而难以预测实体关系。 此外,尽管大语言模型表现出一些基本的数值和符号推理能力[65],但在数值计算方面仍面临困难,特别是对于预训练期间不常遇到的符号。 知识图谱明确地捕捉了概念之间的关系,这对于推理至关重要,可用于增强大语言模型的结构推理能力。 已有研究表明,文本语义与结构推理的融合可以显着提高大语言模型[66, 67]的推理能力。
领域知识不足。 由于特定领域语料库的可用性有限,大语言模型在特定领域任务上的表现可能不如一般任务。 例如,虽然此类模型通常会捕获一般文本中的频繁模式,但生成涉及大量技术术语的医疗报告可能对大语言模型构成巨大挑战。 这种局限性表明,在预训练过程中,大语言模型很难获得足够的领域知识,考虑到灾难性遗忘的问题,注入额外的专业知识可能会以丢失先前学到的信息为代价。 因此,开发有效的知识注入技术对于提高大语言模型在专业领域的性能至关重要。 领域知识图谱是特定领域有效、标准化的知识库,为统一领域知识提供了可行的来源。 例如,丁等人[68]提出了统一领域大语言模型开发服务,利用领域知识图谱增强训练过程,有效提高了大语言模型'特定领域任务的表现。
知识过时。 大语言模型是根据先前的文本进行预训练的,因此限制了它们在训练语料库之外学习的能力。 在处理需要最新知识的任务时,这通常会导致性能不佳。 解决此限制的一个简单解决方案是根据新数据定期重新训练大语言模型。 然而,这种再培训的成本普遍较高。 因此,设计有效且高效的方法将当前知识纳入大语言模型至关重要。 先前的研究建议使用插件作为搜索引擎来访问最新信息。 然而,由于难以将特定知识直接整合到大语言模型中,这些方法似乎不够充分。 与大语言模型相比,知识图谱提供了更直接的更新过程,不需要额外的训练。 更新的知识可以以提示的形式纳入输入中,随后由大语言模型利用来生成准确的响应[69]。
偏见、隐私和毒性。 尽管大语言模型经过训练以符合人类的期望,但它们有时会产生有害的、完全有偏见的、冒犯性的和私人的内容。 当用户与大语言模型交互时,即使没有事先提示或提示安全文本,也可以诱导模型生成此类文本。 事实上,据观察,大语言模型在短短 25 代内就倾向于退化为生成有毒文本[70]。 此外,尽管大语言模型的文本看似令人信服,但它们通常倾向于提供无益且有时不安全的建议。 例如,据透露,在 Reddit [71] 上描述的超过 95% 的情况下,GPT-3 给出的建议比人类给出的建议更糟糕。 原因是这种有偏见的、私人的、有毒的文本广泛存在于预训练语料库中,而大语言模型往往会生成与输入文本相似的记忆文本或新文本。 知识图谱通常由权威可靠的数据源构建,能够生成符合人类价值观的高质量训练数据,有望提高大语言模型的安全性和可靠性。
计算密集型。 训练大语言模型的计算成本很高,因此很难使用不同的技术来研究其有效性。 训练过程通常需要数千个 GPU 和几周的时间才能完成。 此外,大语言模型的计算量和数据量非常大,这使得它们难以部署,特别是在数据和计算资源有限的实际应用中。 通过知识图谱的整合,较小的大语言模型有可能超越较大的大语言模型,从而降低大语言模型部署和应用的成本[63]。
可解释性不足。 可解释性是指人类理解模型预测的难易程度,是衡量模型可信度的重要指标。 大语言模型被广泛认为是具有不透明决策过程的黑匣子,这使得它们难以解释。 KG可以用来理解大语言模型所学到的知识,解释大语言模型的推理过程,从而增强大语言模型[72]的可解释性。
总体而言,大语言模型取得了显着的进步,被认为是早期阶段的通用人工智能系统的原型。 然而,尽管他们能够生成流畅连贯的文本,但他们仍然遇到许多障碍。 在这些障碍中,他们在回忆和准确应用事实知识方面的努力是主要挑战,并削弱了他们熟练地推理和完成基于知识的任务的能力。
III KGPLM
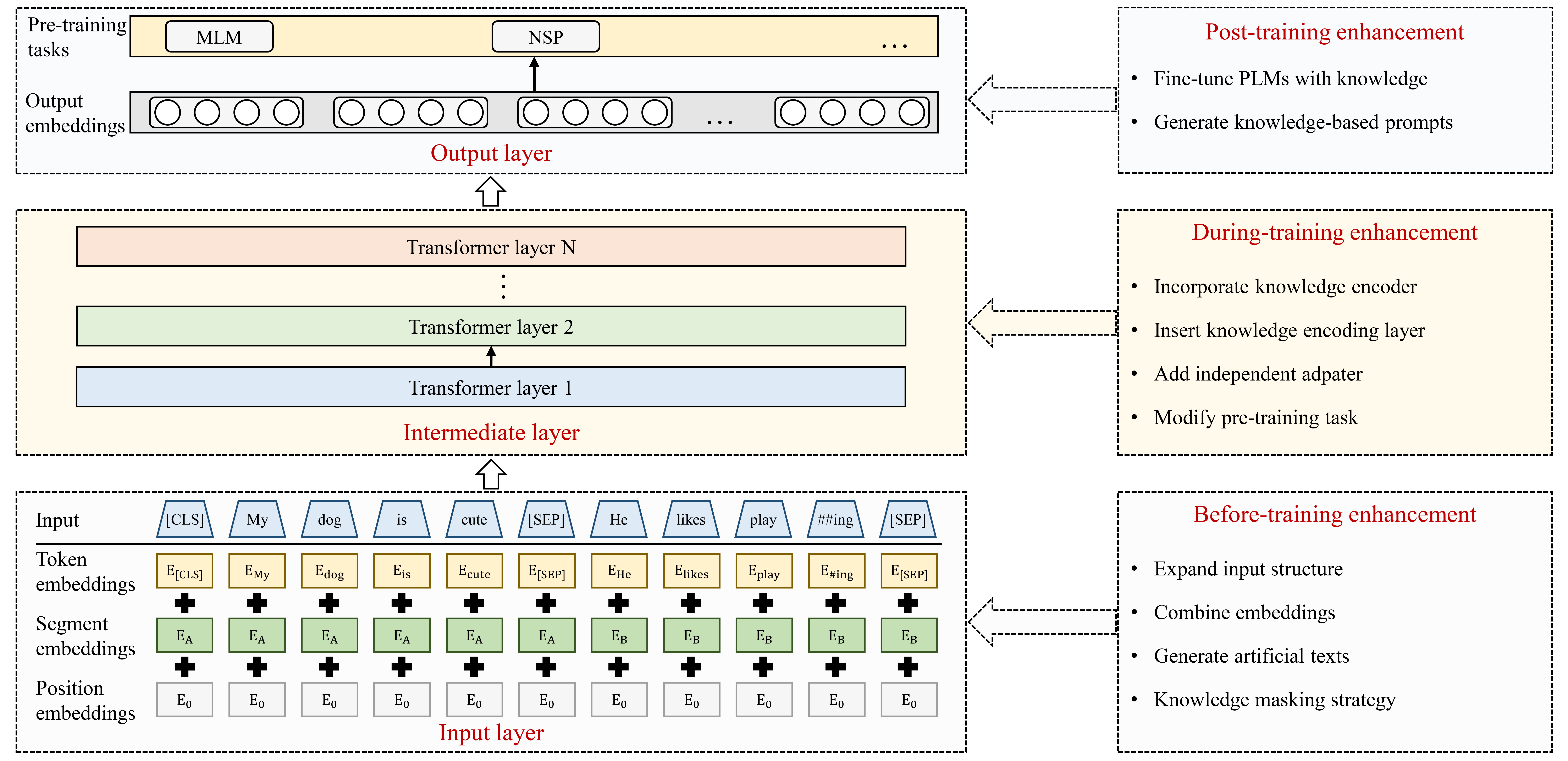
鉴于事实知识建模能力较差所带来的局限性,研究人员提出将知识纳入 PLM 中以提高其性能。 近年来,人们提出了多种 KGPLM,按照 KG 参与预训练的阶段,可分为训练前增强、训练中增强和训练后增强方法,如图4所示。
| Method | KGPLM | |
| Before-training enhancement | Expand input structures | K-BERT [73], CoLAKE [74], Zhang et al. [75] |
| Enrich input information | LUKE [76], E-BERT [77], KALM [78], OAG-BERT [79], DKPLM [80] | |
| Generate new data | AMS [81], KGPT [82], KGLM [83], ATOMIC [84], KEPLER [85] | |
| Optimize word masks | ERNIE [31], WKLM [86], GLM [35] | |
| During-training enhancement | Incorporate knowledge encoders | ERNIE [31], ERNIE 3.0 [87], BERT-MK [88], CokeBERT [89], JointLK [90], |
| KET [91], Liu et al. [92], QA-GNN [93], GreaseLM [67], KLMo [94] | ||
| Insert knowledge encoding layers | KnowBERT [95], K-BERT [73], CoLAKE [74], JAKET [96], KGBART [97] | |
| Add independent adapters | K-Adapter [98], OM-ADAPT [99], DAKI-ALBERT [100], CKGA [101] | |
| Modify the pre-training task | ERNIE [31], LUKE [76], OAG-BERT [79], WKLM [86], SenseBERT [102], | |
| ERICA [103], SentiLARE [104], GLM [35], KEPLER [85], JAKET [96], | ||
| ERNIE 2.0 [105], ERNIE 3.0 [87], DRAGON [106], LRLM [107] | ||
| Post-training enhancement | Fine-tune PLMs with knowledge | KALA [108], KeBioSum [109], KagNet [110], BioKGLM [111], |
| Chang et al. [112] | ||
| Generate knowledge-based prompts | Chang et al. [112], Andrus et al. [113], KP-PLM [114] | |
III-A 训练前增强 KGPLM
将知识图谱中的知识集成到 PLM 中时存在两个挑战:异构嵌入空间和知识噪声。 第一个挑战来自文本和知识图谱之间的异构性。 当不相关的知识使句子偏离其正确含义时,就会出现第二个挑战。 训练前增强方法通过将文本和 KG 三元组统一为相同的输入格式来解决这些问题,其框架如图5所示。 现有研究提出了多种方法来实现这一目标,包括扩展输入结构、丰富输入信息、生成新数据和优化词掩码。
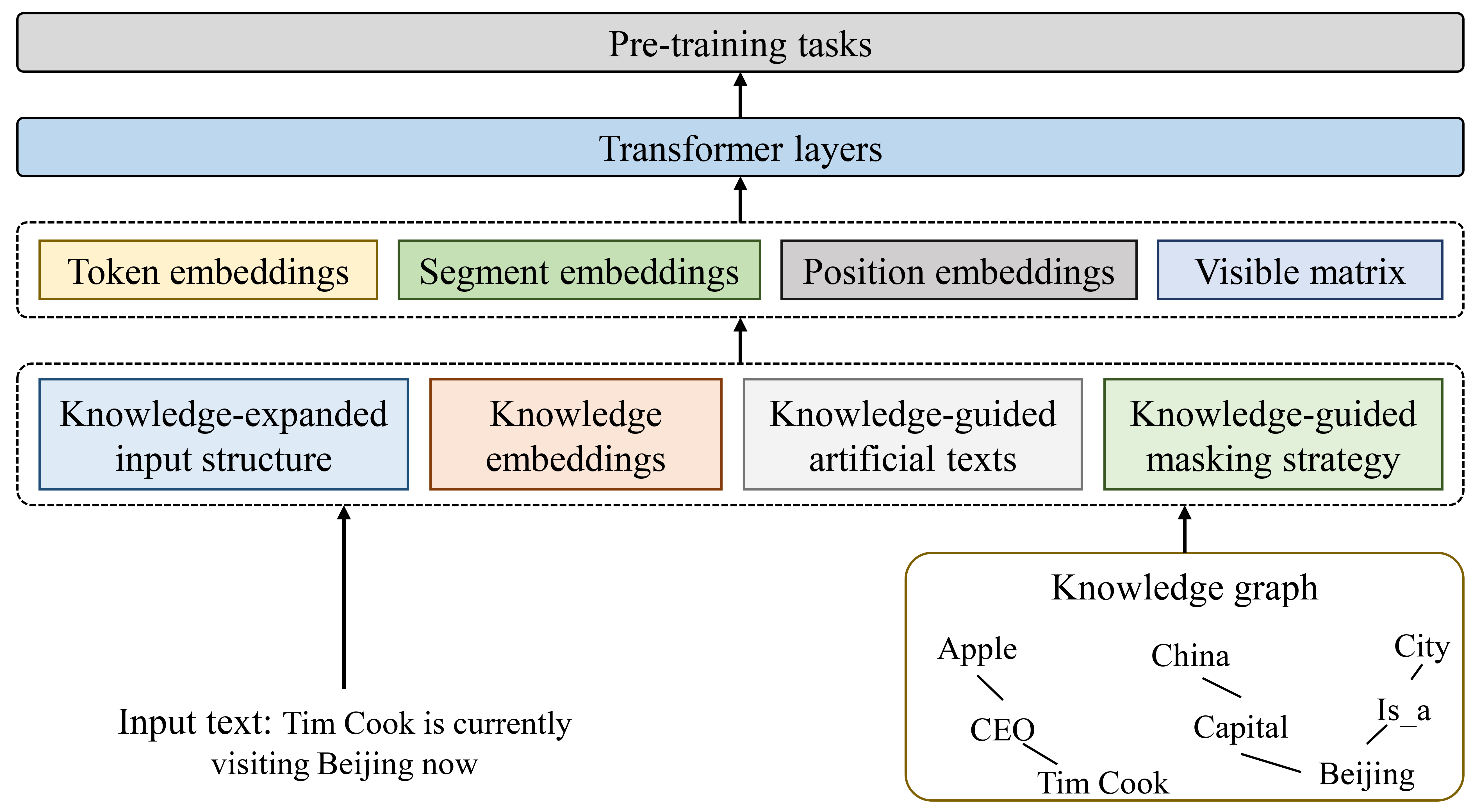
展开输入结构。 一些方法将输入文本扩展为图结构,以合并知识图谱的结构化知识,然后将合并的图转换为文本以供 PLM 训练。 例如,K-BERT [73]将文本转换为句子树,通过与KG子图融合来注入相关三元组,并引入软位置和可见矩阵来克服知识噪声问题。 此外,它提出了 mask-self-attention,这是 self-attention 的扩展,通过利用句子结构信息来防止错误的语义改变。 形式上,mask-self-attention 的输出计算如下:
| (8) |
其中 是可见矩阵。 CoLAKE [74] 通过将知识上下文和语言上下文组合成统一的单词知识图来解决异构嵌入空间挑战。 张等人[75]采用ConceptNet作为知识源,并改进可见矩阵来控制信息流,进一步提高了K-BERT的性能。
丰富输入信息。 一些研究不是合并来自文本和知识图谱的数据,而是通过将实体的嵌入与文本嵌入相结合来将实体作为辅助信息。 LUKE [76]引入实体类型嵌入来指示句子中对应的词符是一个实体,并除了MLM任务之外还使用屏蔽实体预测任务来训练模型。 此外,它使用实体感知的自注意力机制来扩展 Transformer 编码器,以同时处理两种类型的 Token 。 E-BERT [77] 通过无约束的线性映射矩阵将实体嵌入与单词向量对齐,并将对齐的表示输入到 BERT 中,就像它们是单词向量一样。 KALM [78]训练 在预训练中使用实体扩展标记器向编码器的输入发出实体存在的信号,并向模型添加实体预测任务。 Liu等人[79]提出了OAG-BERT,一种学术知识服务的统一骨干语言模型,它将异构实体知识和科学语料库集成在开放的学术图谱中。 他们设计了一种实体类型嵌入来区分各种实体类型,并针对不同长度的实体名称使用跨度感知实体屏蔽策略进行 MLM。 此外,他们设计了实体感知的二维位置编码来合并实体跨度和序列顺序信息。 张等人 [80]将PLM的知识注入过程分解为预训练、微调和推理阶段,并提出了DKPLM,仅在预训练。 具体来说,DKPLM 根据文本和知识图谱中的语义重要性来检测长尾实体,并将检测到的长尾实体的表示替换为共享 PLM 编码器生成的相应知识三元组的表示。 最常用的知识嵌入模型是 TransE [115],它通过最小化以下损失函数来学习实体和关系表示:
| (9) |
其中 和 是头实体和尾实体的嵌入,而 是关系的表示。
生成新数据。 也有一些研究通过基于 KG 生成人工文本来将知识注入到 PLM 中。 例如,AMS [81]基于align-mask-select方法为训练PLM构建了一个常识相关的问答数据集。 具体来说,它将句子与常识知识三元组对齐,屏蔽句子中对齐的实体,并将屏蔽的句子视为问题。 最后,它从知识图谱中选择几个实体作为干扰项选择,并训练模型以确定正确答案。 KGPT [82] 从维基百科中抓取带有超链接的句子,并将超链接实体与 KG 维基数据对齐,以构建基于知识的语料库 KGText。 KGLM [83] 通过对齐 WikiText-2 中的文本和 Wikidata 中的实体来构建链接的 WikiText-2 数据集。 ATOMIC [84] 将 877K 文本描述中的推理知识组织到 KG 中,并通过条件序列生成问题训练 PLM,该问题鼓励模型在给定事件短语和推理维度的情况下生成目标序列。 KEPLER [85] 构建一个大规模 KG 数据集,其中包含来自相应维基百科页面的对齐实体描述,用于训练 KGPLM。
优化文字掩码。 MLM 是 PLM 中最常用的预训练任务,掩模的数量和分布对 PLM 的性能有很大影响[116]。 然而,随机掩码方法可能会破坏连续单词之间的相关性,使得PLM难以学习语义信息。 为了解决这个问题,一些研究提出用知识屏蔽策略取代随机屏蔽策略,知识屏蔽策略根据知识图谱的知识选择屏蔽目标,迫使模型学习足够的知识来准确预测屏蔽内容。 例如,ERNIE [31] 识别文本中的命名实体并将它们与知识图谱中相应的实体对齐。 然后,它随机屏蔽输入文本中的实体并训练模型以选择知识图谱中的对应实体。 在WKLM [86]中,原始文本中的实体提及被相同类型的实体替换,并且训练模型以区分准确的实体提及和损坏的实体提及,这有效地提高了其事实完成性能。 GLM [35] 将 MLM 目标重新表述为实体级屏蔽策略,该策略通过考虑文本中检测到的实体的文档频率和相互可达性来识别实体并选择信息丰富的实体。
训练前增强方法可以提高语料库的语义标准化和结构水平,有助于在不提高模型大小和训练时间的情况下提高PLM[117]的推理能力。 此外,知识图谱增强的训练数据可以更好地描述常识知识,有助于提高大语言模型的常识知识建模能力。 这些方法更适合那些训练语料不足的领域,可以有效提高大语言模型在此类领域的性能和泛化能力。 然而,训练前增强处理需要额外的计算资源和时间,使得预训练过程更加复杂和繁琐。 此外,它可能会引入噪音,对大语言模型的训练产生负面影响。
III-B 培训期间增强 KGPLM
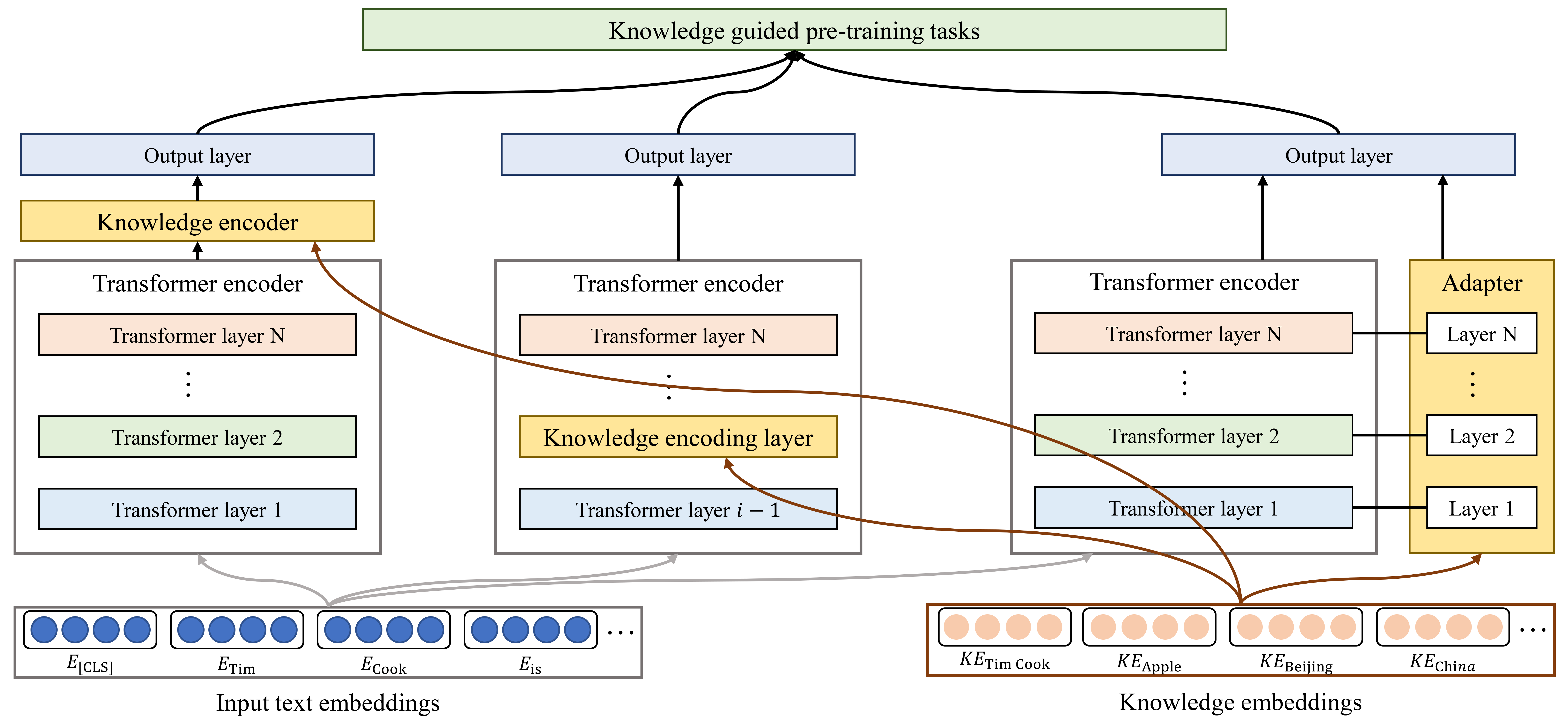
训练期间增强方法使 PLM 能够通过改进其编码器和训练任务来在训练期间直接学习知识。 由于普通 PLM 无法同时处理文本序列和结构化知识图谱,因此一些研究提出结合知识编码器或外部知识模块,以实现同时从文本和知识图谱学习。 现有的训练期间增强KGPLM可分为合并知识编码器、插入知识编码层、添加独立适配器和修改预训练任务,如图6所示。
合并知识编码器。 ERNIE [31]集成了一个知识编码器来合并KG信息,它采用两种类型的输入:词符嵌入以及词符和实体嵌入的串联。 ERNIE 3.0 [87] 以 ERNIE 为基础,在通用表示模块上构建了一些特定于任务的模块,以便轻松定制自然语言理解和生成任务的模型。 BERT-MK [88]利用图上下文知识嵌入模块来学习子图中的知识,并将学习到的知识合并到语言模型中以进行知识泛化。 CokeBERT [89]利用三个模块来选择上下文知识并嵌入知识上下文,其中文本编码器计算输入文本的嵌入,知识上下文编码器根据文本上下文动态选择知识上下文并计算知识嵌入,而知识融合编码器融合文本上下文和知识上下文嵌入,以实现更好的语言理解。 JointLK [90] 通过密集的双向注意力模块在 PLM 和图神经网络(GNN)之间进行联合推理,以有效地融合和推理问题和 KG 表示。 KET [91] 使用分层自注意力来解释上下文话语,并使用上下文感知情感图注意力机制动态利用外部常识知识来检测文本对话中的情绪。 Liu 等人 [92]提出了一种记忆增强方法,以 KG 为条件来调节 PLM,该方法将 KG 表示为一组关系三元组,并检索相关关系给定的上下文来增强文本生成。 QA-GNN[93]使用PLM来估计节点的重要性,以从大型KG中识别相关知识,并将QA上下文和KG结合起来形成联合图。 然后,它通过基于图的消息传递相互更新QA上下文和KG的表示以执行联合推理。 GreaseLM [67] 通过多层模态交互操作集成了 PLM 和 GNN 的嵌入。 KLMo [94] 使用新颖的知识聚合器显式地模拟文本中的实体跨度与上下文 KG 中的所有实体和关系之间的交互。
插入知识编码层。 一些方法在PLM中间插入额外的知识编码层或调整编码机制以使PLM能够处理知识。 例如,KnowBERT [95] 结合了知识注意力重构模块,将多个知识图谱集成到 PLM 中。 它显式地对输入文本中的实体跨度进行建模,并使用实体链接器从知识图谱中检索相关实体嵌入。 然后利用这些检索到的嵌入来创建知识增强的实体跨度嵌入。 K-BERT[73]将Transformer编码器改为mask-Transformer,以软位置和可见矩阵作为输入来控制知识的影响,避免知识噪声问题。 CoLAKE [74]稍微修改了Transformer的嵌入层和编码器层以适应单词知识图形式的输入。 该图将知识上下文和语言上下文组合成统一的数据结构。 JAKET [96] 将 PLM 的编码器分解为两个模块,第一个模块为第二个模块和 KG 提供嵌入,而第二个模块采用文本和实体嵌入来生成最终表示。 KGBART [97] 遵循 BART 架构,但用有效的知识图增强 Transformer 取代了传统 Transformer,以捕获概念集之间的关系,其中 KG 作为图注意力机制的额外输入。
添加独立适配器。 有些方法在过程知识中添加独立的适配器,易于训练,并且训练过程不影响原始PLM的参数。 例如,K-Adapter [98] 允许适配器在不同的任务上独立注入各种类型的知识。 这种方法有利于知识的不断融合。 OM-ADAPT [99训练] 通过适配器整合来自 ConceptNet 的概念知识和相应的 Open Mind Common Sense 语料库,补充了 BERT 的分布式知识。 这种方法避免了联合预训练昂贵的计算开销,以及与事后微调相关的灾难性遗忘问题。 DAKI-ALBERT [100]提出针对特定领域知识源的预训练知识适配器,并通过基于注意力的知识控制器将它们集成,以通过丰富的知识来增强PLM。 CKGA [101] 为情感分类任务引入了一种新颖的基于知识图谱的常识性适配器,它利用 PLM 来编码常识知识并使用 GNN 提取相应的知识。
修改预训练任务。 一些研究尝试通过修改预训练任务将知识纳入 PLM。 最常用的方法是将MLM更改为基于文本中标记的实体的掩码实体建模(MEM)。 此类方法的示例包括 ERNIE [31]、LUKE [76]、OAG-BERT [79]、WKLM [86] SenseBERT [102] 直接在词义级别应用弱监督,训练 PLM 不仅可以预测屏蔽词,还可以预测它们的 WordNet 超义。 ERICA [103]定义了两个新颖的预训练任务,通过对比学习显式地建模文本中的关系事实,其中实体辨别任务训练模型区分尾部实体,而关系辨别任务旨在训练模型区分尾部实体。训练模型来区分两个关系之间的接近程度。 SentiLARE [104]引入了上下文感知的情感注意机制,通过查询SentiWordNet,根据词性标签确定每个单词的情感极性。 它还提出了一种新颖的预训练任务,称为标签感知掩码语言模型,以构建知识感知语言表示。 GLM [35]引入了KG引导的屏蔽方案,然后使用KG来获取屏蔽实体的干扰项,并使用新颖的干扰项抑制排序目标来优化模型。
其他方法利用多任务学习机制将知识表示学习与 PLM 的训练相结合,同时优化知识表示和模型参数。 KEPLER [85] 采用共享编码器将文本和实体编码到统一的语义空间中,同时优化知识嵌入和 MLM 目标。 JAKET[96]使用两个模块联合建模KG和语言,其中语言模块和知识模块通过嵌入相互协助。 ERNIE 2.0 [105] 在 ERNIE 的基础上提出了一个持续的多任务学习框架,可以提取有价值的词汇、句法和语义信息。 ERNIE 3.0 [87] 结合自回归和自动编码网络来处理语言和知识层面的多个预训练任务。 DRAGON [106] 使用跨模式编码器在文本标记和 KG 节点之间双向交换信息以生成融合表示,并通过统一两个自监督推理任务:MLM 和 KG 链接预测来训练该编码器。 LRLM [107] 参数化文本中单词及其实体的联合分布,在建模文本时通过关系利用知识图谱。
训练期间的增强方法可以在学习参数时自适应地结合外部知识,通常可以提高各种下游任务的性能。 此外,它们允许通过引入特殊信息或模块来定制特定领域或任务。 然而,它们可能会增加训练时间,因为它们通常会提高参数大小,并且可能受到数据中包含的知识范围的限制。 此外,由于架构更复杂、参数更多,大语言模型更容易出现过拟合,需要更多的训练来维持泛化能力。 训练期间增强方法更适合那些需要处理多个复杂任务的场景,并且它们在基于知识的任务上通常比其他方法表现更好。
III-C 培训后增强 KGPLM
训练后增强方法通常通过对附加数据和任务进行微调,将特定领域的知识注入 PLM,从而提高模型在特定领域任务上的性能。 此外,随着提示学习的快速发展[118],最近的一些研究提出自动生成提示以提高 PLM 的输出。 训练后增强KGPLMs的主要框架如图7所示。
具有知识的 PLM。 KALA [108] 使用领域知识调节 PLM 的中间隐藏表示,其性能在很大程度上优于自适应预训练模型,同时仍然具有计算效率。 KeBioSum [109] 研究生成性和判别性训练技术的整合,以将知识融合到知识适配器中。 它应用适配器融合来有效地将这些知识适配器合并到 PLM 中,以微调生物医学文本摘要任务。 KagNet [110]提出了一种用于回答常识问题的文本推理框架,该框架有效地利用知识图谱通过中间注意力分数提供人类可读的结果。 BioKGLM [111]提出了一种介于预训练和微调之间的后训练过程,并使用不同的知识融合策略来促进KG的注入。 Chang 等人 [112]提出在微调过程中仔细合并从知识图谱中检索到的元组,以纳入常识知识。
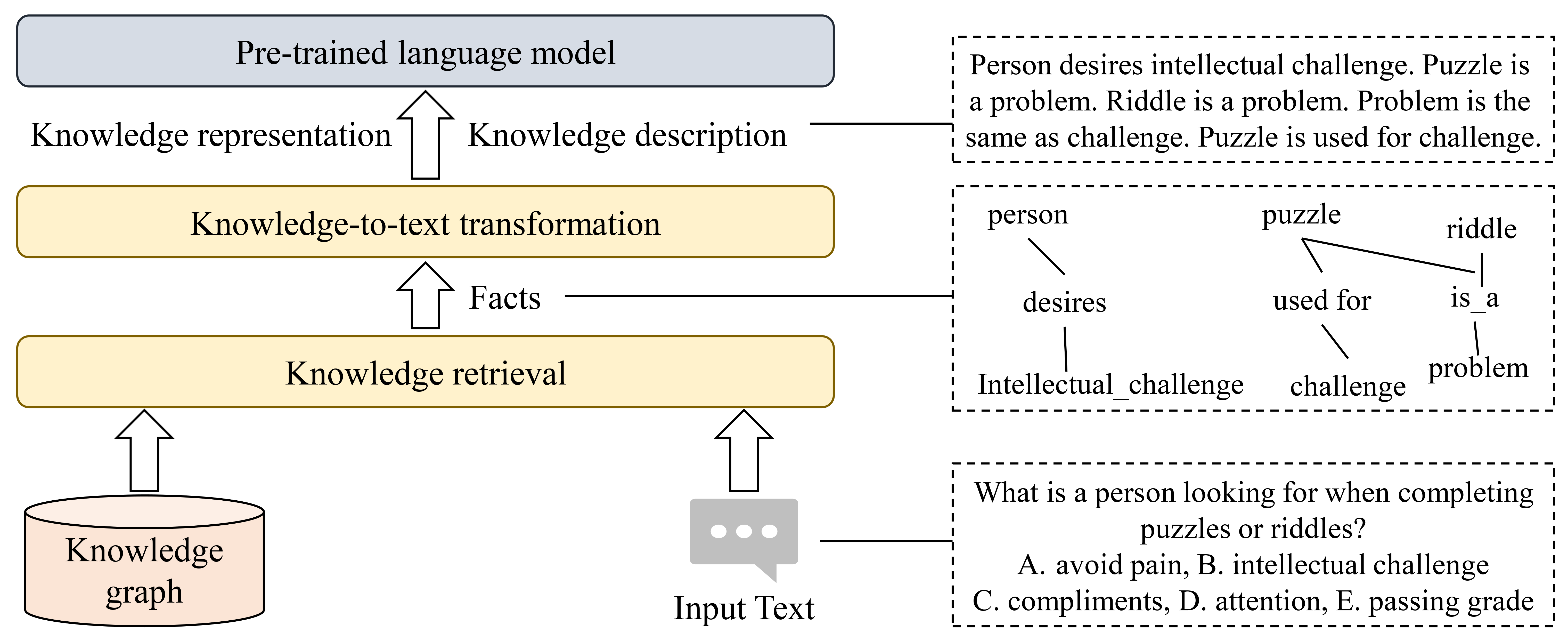
生成基于知识的提示。 Bian 等人 [119]提出了一种用于知识增强常识问答的知识到文本框架。 它将结构化知识转化为文本描述,并利用机器阅读理解模型通过利用原始问题和文本知识描述来预测答案。 Andrus 等人 [113]提出使用开放信息提取模型和基于规则的后处理来构建自定义动态知识图谱。 他们进一步建议利用 GPT-3 的少样本学习,将从 KG 中提取的事实表述为自然语言,并将其合并到提示中。 KP-PLM[114]针对每个上下文从KG构建知识子图,并采用多个连续提示规则将知识子图转换为自然语言提示。 此外,它利用两个新颖的知识感知自我监督任务:提示相关性检查和屏蔽提示建模来优化模型。
| KGPLM | Entity typing | Relation classification | Question answering |
| CoLAKE | 2.8 | 5.6 | — |
| LUKE | 4.6 | 6.7 | 19.2 |
| KEPLER | 2.6 | 6 | — |
| ERNIE | 2 | 3.4 | — |
| CokeBERT | 1.3 | 2.7 | — |
| K-Adapter | 4.1 | 1.9 | 5.4 |
| ERICA | 4.4 | 2.2 | 1.5 |
| KP-PLM | 4.6 | 3.8 | — |
训练后增强方法成本低、易于实施,可以有效提高大语言模型在特定任务上的性能。 此外,这些方法可以指导大语言模型生成特定风格的文本,提高大语言模型输出的质量和安全性。 因此,训练后增强方法更适合特定领域的任务和需要敏感信息过滤和风险控制的文本生成场景。 然而,微调数据的标记和提示的设计依赖于先验知识和外部资源。 如果缺乏相关先验知识,优化效果可能会受到限制。 此外,这些方法可能会对大语言模型生成的灵活性造成一定的限制。 生成的文本可能会受到提示的限制,可能无法完全自由地创建。
III-D KGPLM 的有效性和效率
大多数 KGPLM 都是为知识基础任务而设计的。 为了评估它们在知识建模方面的有效性,我们报告了它们在三个基于知识的任务上的表现:实体类型、关系分类和问题回答。 表III总结了 KGPLM 及其相对于未增强 BERT 的各自改进。 报告的指标是 F1 分数。 在表III中,这些模型在所有任务上的性能均高于BERT,表明KG增强了其知识建模能力。
| Model | Pre-training | Fine-tuning | Inference |
| BERT | 8.46 | 6.76 | 0.97 |
| RoBERTa | 9.60 | 7.09 | 1.55 |
| ERNIE | 14.71 | 8.19 | 1.95 |
| KEPLER | 18.12 | 7.53 | 1.86 |
| CoLAKE | 12.46 | 8.02 | 1.91 |
| DKPLM | 10.02 | 7.16 | 1.61 |
通常,与基础 PLM 相比,结合知识图谱知识会导致参数大小更大。 因此,普通 PLM 的预训练、微调和推理时间始终比 KGPLM 短。 如表IV中的统计数据所示,由于这些KGPLM将知识编码器模块注入到PLM中,因此它们三个阶段的运行时间始终比BERT长。 然而,随着外部知识的结合,KGPLM 更容易被训练并具有更高的性能。 例如,具有775M参数的KALM在一些参数大小为1.5B的下游任务[78]上甚至比GPT-2表现更好。 这意味着我们可以获得一个具有较小参数大小和较少训练资源的令人满意的模型。
IV KGPLM的应用
KGPLM 在捕获事实和关系信息方面优于传统 PLM,表现出更强的语言理解和生成能力。 这些优势提高了一系列下游应用的性能。 如图8所示,通过采用不同的预训练任务并针对特定应用微调 PLM,KGPLM 已成功用于多种任务。
命名实体识别。 命名实体识别(NER)旨在从文本中识别具有特定含义的实体,例如人名、地名和组织名称。 PLM 已成功改进了最先进的单词表示,并通过对上下文信息进行建模[120],展示了 NER 任务的有效性。 然而,这些模型经过训练来预测标记之间的相关性,忽略了它们背后的潜在含义以及由多个标记组成的实体的完整语义[121]。 先前的工作已经将NER视为知识密集型任务,并通过将外部知识融入PLM中来提高PLM的NER性能[122]。 因此,研究人员开发了用于 NER 的 KGPLM,它可以利用训练语料库之外的附加信息来获得更好的性能,特别是在训练样本通常不足的特定领域任务中。 例如,He 等人 [123]将外部知识库中实体的先验知识融入到单词表示中,并为NER引入了KG增强单词表示框架。 其他一些 KGPLM,如 K-BERT [73] 和 ERNIE [31] 也展示了它们在不同 NER 数据集上的优越性。
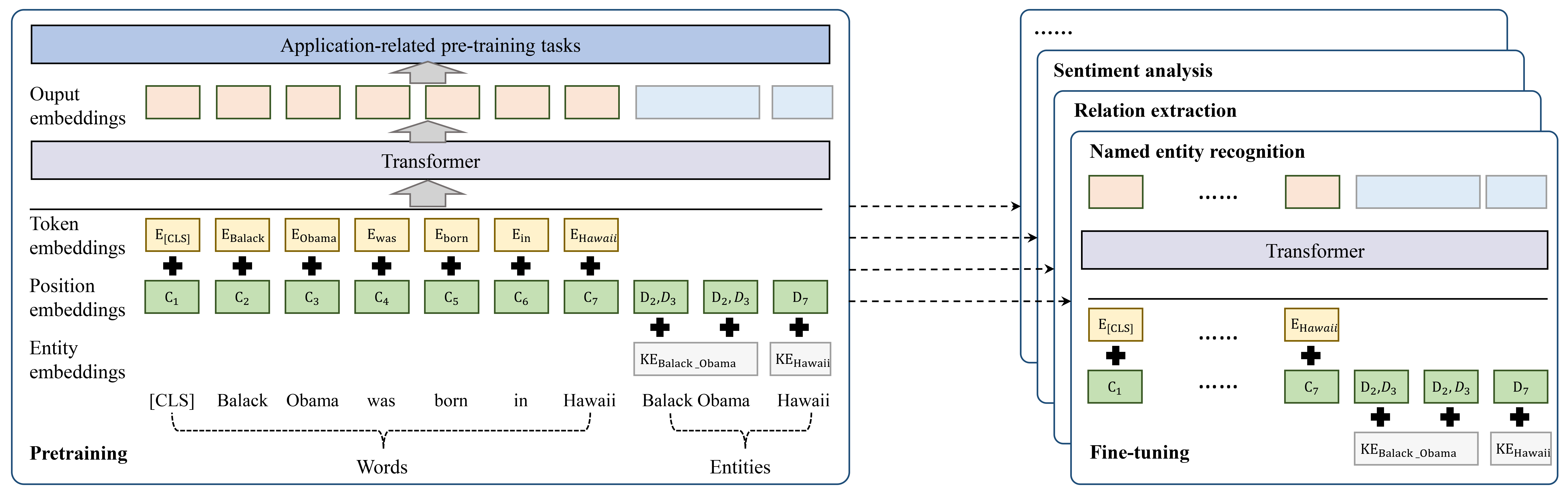
关系提取。 关系提取涉及区分实体之间的语义关系并将它们分类为预定义的关系类型。 尽管PLM在一定程度上提高了关系抽取的效率,但应用于小规模和特定领域的文本时,仍然缺乏信息学习[124]。 为了解决这一限制,一些研究建议将 KG 中的先验知识注入到 PLM 中。 KGPLM 已被证明在关系提取方面比普通 PLM 更有效[125]。 例如,Roy 等人 [126]提出将KG嵌入与BERT合并以提高其在临床关系提取方面的性能。 BERT-MK [88] 还证明了 KGPLM 在生物医学关系提取方面的有效性。 除了生物医学领域之外,KEPLER[85]和JAKET[96]等KGPLM也常应用于公共领域关系抽取任务。
情绪分析。 情感分析旨在分析文本中表达的情感是积极的、消极的还是中性的。 最近,情感分析在 PLM 的帮助下取得了显着的进步,在不同的基准上实现了最先进的性能。 然而,当前的 PLM 侧重于通过自我监督技术获取语义信息,在整个预训练过程中忽略了情感相关知识[127]。 通过将不同类型的情感知识整合到预训练过程中,学习到的语义表示将更加合适。 因此,一些KGPLM被应用于情感分析,包括SentiLARE [104]、KCF-PLM [128]和KET [91],证明了将 KG 注入到 PLM 中进行情感分析的有效性。
知识图谱补全。 由于数据质量和自动提取技术的限制,知识图谱往往不完整,实体之间的一些关系缺失[129]。 因此,旨在推断缺失关系并提高知识图谱完整性的知识图谱补全任务得到了广泛的研究。 鉴于 PLM 的胜利,人们提出了一些基于 PLM 的方法来完成知识图谱任务。 尽管如此,这些方法大多数都集中于对事实三元组的文本表示进行建模,而忽略了知识图谱建模所必需的底层拓扑上下文和逻辑规则[130, 131]。 为了应对这一挑战,一些研究建议将知识图谱中的拓扑上下文和逻辑规则与 PLM 中的文本语义相结合来完成知识图谱。 通过整合知识图谱的结构信息和文本的上下文信息,KGPLM 的性能优于那些专门为知识图谱完成任务[35]设计的 PLM。 我们还可以提取知识增强的嵌入来预测给定三元组[85]的合理性。
问答。 问答系统需要为给定的问题选择正确的答案,这必须能够访问相关知识并对其进行推理。 尽管 PLM 在许多问答任务上取得了显着的成就[132],但从经验上看,它们在结构化推理方面表现不佳。 另一方面,KG 更适合结构化推理并实现可解释的预测。 因此,一些研究提出将 PLM 与知识图谱相集成,以进行结构化推理并实现可解释的预测。 一些方法在训练 PLM 时将 KG 合并到 PLM 中,例如 QA-GNN [93] 和 WKLM [86]。 另一项研究使用 KG 在答案推理过程中增强 PLM。 例如,OreoLM [133] 将新颖的知识交互层合并到 PLM 中,与可微知识图推理模块交互以进行协作推理。 在这里,PLM 引导 KG 走向所需的答案,而检索的知识则增强 PLM。 常见基准测试的实验表明,在 KG 合并后,KGPLM 的性能优于传统 PLM。
自然语言生成。 自然语言生成 (NLG) 是 NLP 中各种应用(例如对话系统、神经机器翻译和故事生成)的基本构建块,并且已经进行了大量研究。 在大型语料库上预训练的深度神经语言模型在多个 NLG 基准测试中带来了显着的改进。 然而,即使他们在预训练期间可以记住足够的语言模式,他们也只是捕获数据的平均语义,并且大多数人并没有明确意识到特定领域的知识。 因此,当需要特定知识时,PLM 生成的内容可能不合适。 KG 存储实体属性及其关系,包含丰富的语义上下文信息。 因此,一些研究建议将 KG 纳入 PLM 中,以提高其 NLG 性能。 例如,Guan 等人 [134]提出通过使用来自知识图谱的知识示例对模型进行后训练,用结构化知识改进 GPT-2。 他们的目的是为故事生成提供额外的关键信息。 Ji 等人 [135]提出了GRF,一种对外部KG进行多跳推理的生成模型,利用KG衍生的数据丰富了语言生成。 实验结果表明,KGPLM 在故事结局生成[136]、溯因推理[137]和问题回答[93]方面优于PLM。
工业应用。 KGPLM 已应用于许多实际应用中。 典型应用包括聊天机器人,如ERNIE Bot111https://yiyan.baidu.com/ 来自百度,钱文222https://qianwen.aliyun.com/ 来自阿里巴巴,巴德33>33https://bard.google.com/ 此类应用表明 KGPLM 可以提供出色的语言理解和知识建模能力。 PLM 还成功应用于编程助手,可以根据上下文或自然语言提示轻松生成代码。 然而,基于PLM的编程助手仍然遇到一些问题,例如代码推荐不正确、过度依赖代码库等。 为了应对这些挑战,GitHub 和 OpenAI 发布了 Copilot X444https://github.com/features/preview/copilot-x,将KG纳入编程助手中,用于分析代码的逻辑依赖关系并生成合适的代码建议。 除了上述应用之外,KGPLM 还广泛应用于各种虚拟助手和搜索引擎。 这些应用的代表包括小度555https://dueros.baidu.com/en/index.html 来自百度和盘古666https://www.huaweicloud.com/product/pangu.html,可以响应天气预报、唱歌、导航等广泛的查询。
V 大语言模型可以取代KG吗?
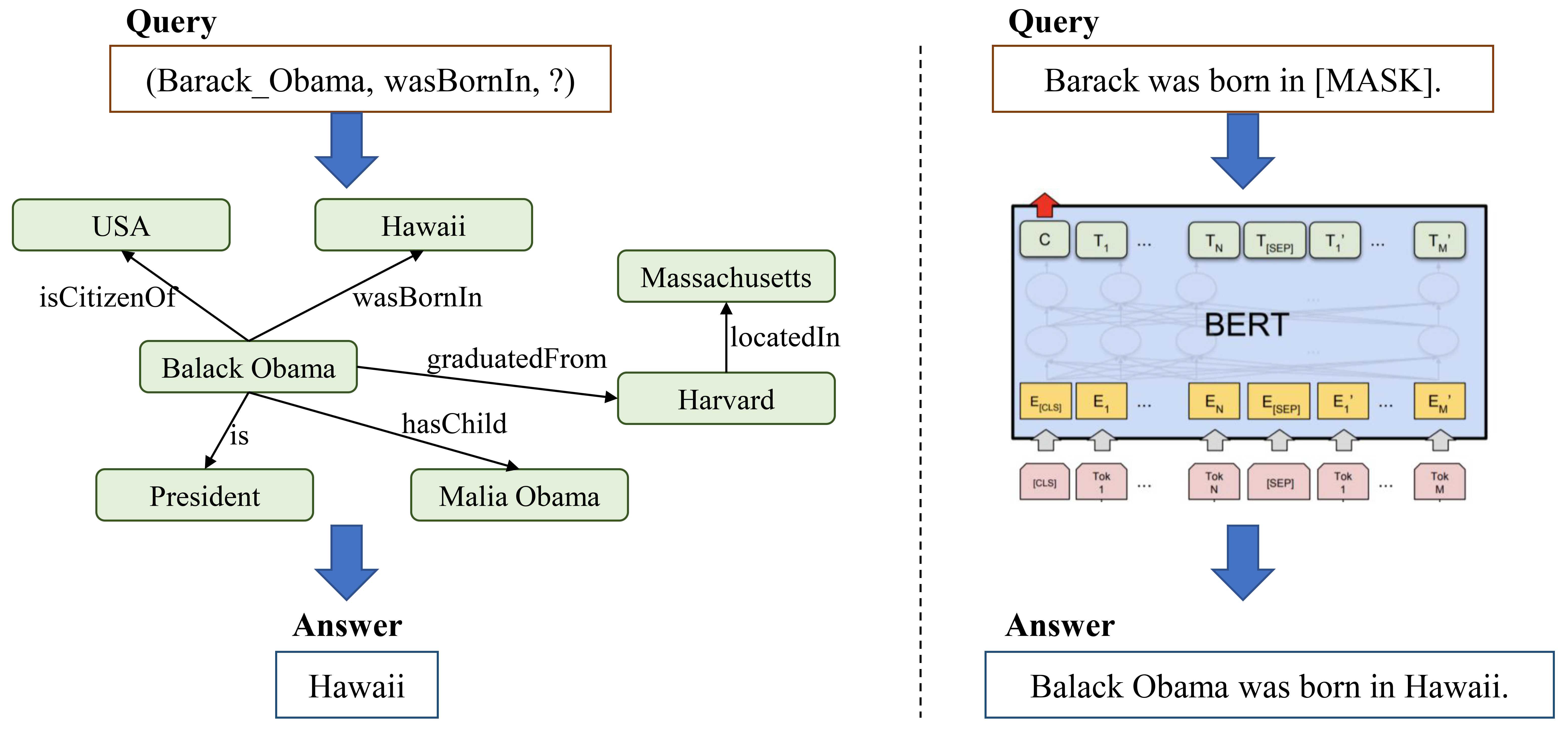
最近在大型语料库上训练 PLM 的进展导致了下游 NLP 任务的大幅改进。 在主要学习语言知识的同时,PLM 还可以存储数据中存在的一些训练相关知识,使它们能够回答复杂的查询。 虽然它们的知识不能像知识图谱那样直接查询,但我们可以尝试通过要求它们按顺序填写屏蔽标记来查询它们的事实知识,如图9所示。 因此,一些研究人员认为参数化 PLM 可以取代符号 KG 作为知识库[138]。 例如,Petroni 等人 [8]提出了LAMA,一种由完形填空式查询组成的知识探针,用于测量PLM中包含的关系知识。 他们的结果表明,PLM 包含相关知识,并且无需微调即可调用存储的事实。 Talmor 等人 [139]开发了八个完形填空式推理任务来测试 BERT 和 RoBERTa 中捕获的知识。 他们发现不同的 PLM 表现出本质上不同的推理能力,并且不是以摘要方式推理,而是依赖于上下文。 Heinzerling 和 Inui [10] 评估了 PLM 存储数百万个实体事实并通过使用三种实体表示的实验测试查询这些事实的能力。 他们的实验结果为 PLM 作为知识库提供了概念验证。
然而,在对 PLM 进行广泛的实验分析后,一些研究报告称 PLM 难以准确回忆相关事实,这引发了对其作为知识库的可行性的怀疑。 人们提出了大量的基准数据集和任务来检查 PLM 中包含的知识。 例如,Wang 等人 [140]发布了一个基准测试来直接测试系统区分有意义和无意义的自然语言语句的能力。 通过将他们的表现与人类进行比较,他们发现理解意义仍然是 PLM 的一个技术挑战。 Sung 等人 [141] 创建了 BioLAMA 基准,该基准由 49K 个生物医学事实知识三元组组成,用于探索生物医学 PLM。 他们的详细分析表明,大多数 PLM 的预测与没有任何主题的提示模板高度相关,因此在每个关系上产生相似的结果,并阻碍了它们用作生物医学知识库的能力。 Wang 等人 [12]构建了一个新的闭卷问答数据集,并测试了 BART [26]回答这些问题的能力。 实验结果表明,BART 无法高精度记住训练事实,因此回答闭卷问题具有挑战性。 赵等人[142]介绍了LAMA-TK,一个旨在探索时间范围知识的数据集。 他们研究了 PLM 存储包含冲突信息的时态知识的能力,以及使用存储的知识进行时态范围的知识查询的能力。 他们的实验结果表明,冲突的信息给 PLM 带来了巨大的挑战,这会降低其存储准确性并阻碍其对多个答案的记忆。 Kassner 等人 [143]将两个已建立的基准翻译成 53 种语言,以研究多语言 PLM mBERT [144] 中包含的知识。 他们发现 mBERT 在不同语言中产生不同的性能。 上述研究证明PLM在准确存储知识、处理知识多样性以及检索正确知识来解决相应任务方面仍然面临挑战。 此外,Cao 等人 [13]对不同提取范式的 PLM 预测机制进行了全面研究。 他们发现 PLM 之前良好的性能主要归功于过度拟合数据集工件的有偏差的提示。 AlKhamassi 等人 [138]提出了 PLM 应该满足五个基本标准才能被视为熟练的知识库:访问、编辑、一致性、推理以及可解释性和可解释性,并发现 PLM 在一致性、推理和可解释性方面的表现不如 KG。 他们还回顾了这五个方面的文献,并揭示尽管最近取得了一些突破,但社区在使 PLM 成为知识库方面仍有很长的路要走。 这些研究对 PLM 作为知识库的潜力提出了质疑,并强调了在该领域进行进一步研究的必要性。
尽管规模更大的大语言模型似乎拥有更基础的世界知识,但它们学到的百科全书式事实和物体的常识属性仍然不可靠。 此外,它们推断动作和事件之间关系的能力有限[65]。 大语言模型预测事实的能力也很大程度上依赖于特定的提示模板和包含的实体[145]。 这是因为大语言模型主要依赖于简单的启发式方法,大多数预测与目标词和提示中的词的共现频率相关。 此外,他们预测的准确性高度依赖于预训练语料库中事实的频率[146]。
综上所述,大语言模型和知识图谱各有优缺点。 知识图谱缺乏大语言模型所提供的灵活性,因为知识图谱需要大量的人力来构建和维护,而大语言模型通过在大型语料库上进行无监督训练来提供更大的灵活性。 然而,知识图谱更容易访问和编辑,并且具有更好的一致性、推理能力和可解释性。 首先,知识图谱中的事实知识通常可以通过手动查询指令轻松访问。 相反,大语言模型无法显式查询,因为知识隐式编码在其参数中。 其次,KG中的三元组可以直接添加、修改和删除。 然而,编辑大语言模型中的特定事实并不简单,因为大语言模型中的事实无法直接访问。 为了使大语言模型能够学习到最新的、正确的、公正的知识,整个模型需要根据更新的数据进行重新训练,这是昂贵且不灵活的。 第三,知识图谱的构建考虑到了一致性,并且已经提出了各种算法来消除知识图谱中出现的冲突。 另一方面,大语言模型可能不一致,因为它们可能对相同的基本事实问题产生不同的答案。 第四,知识图谱的推理路径很简单,而大语言模型在关系推理任务上表现不佳。 最后,知识图谱有清晰的推理路径,因此它们的输出很容易解释。 然而,作为典型的黑盒模型,知识很难仅通过查看大语言模型的输出来识别。
尽管当前的大语言模型在直接作为知识库方面面临局限性,但它们有助于构建明确表达其存储知识的知识图谱。 一种方法是利用大语言模型作为信息抽取工具来提高NER和关系抽取的准确性。 另一种方法是使用提示从大语言模型中提取符号知识图谱。 例如,Hao 等人 [147]提出了一种新颖的框架,可以从大语言模型自动构建知识图谱,生成多样化的提示,搜索一致的输出,并执行有效的知识搜索。 Bosselut 等人 [148]提出了一种微调的生成大语言模型,用于自动构建常识知识图谱,根据给定的头部实体和关系生成尾部实体。 这些方法展示了利用大语言模型进行有效知识图谱构建的潜力。
综上所述,大语言模型在记忆大量复杂知识和准确检索所需信息方面仍然面临挑战。 大语言模型需要在多个方面表现出色,才能成为综合知识库。 另一方面,知识图谱和大语言模型相辅相成,提高了整体表现。 因此,利用知识图谱增强大语言模型可以显着提高其在知识基础任务上的表现。
VI 利用知识图谱强化大语言模型
在前面的章节中,我们分析和比较了现有的 KGPLM。 尽管 KGPLM 表现出了对各种 NLP 任务的熟练程度,但知识和语言的复杂性仍然给 KGPLM 带来了未解决的挑战。 此外,尽管生成的文本质量和学习事实的模型超过 100B 参数,大语言模型仍然容易出现不事实的响应和常识性错误。 他们的预测高度依赖于输入文本,措辞和单词选择的微小变化都可能导致此类错误。 一个潜在的解决方案是通过知识图谱增强大语言模型,以提高他们对事实知识的学习,这是一个尚未得到彻底研究的课题。 因此,我们建议使用 KGPLM 所利用的技术来增强 KG 的大语言模型,以实现事实感知的语言建模。
VI-A 总体框架
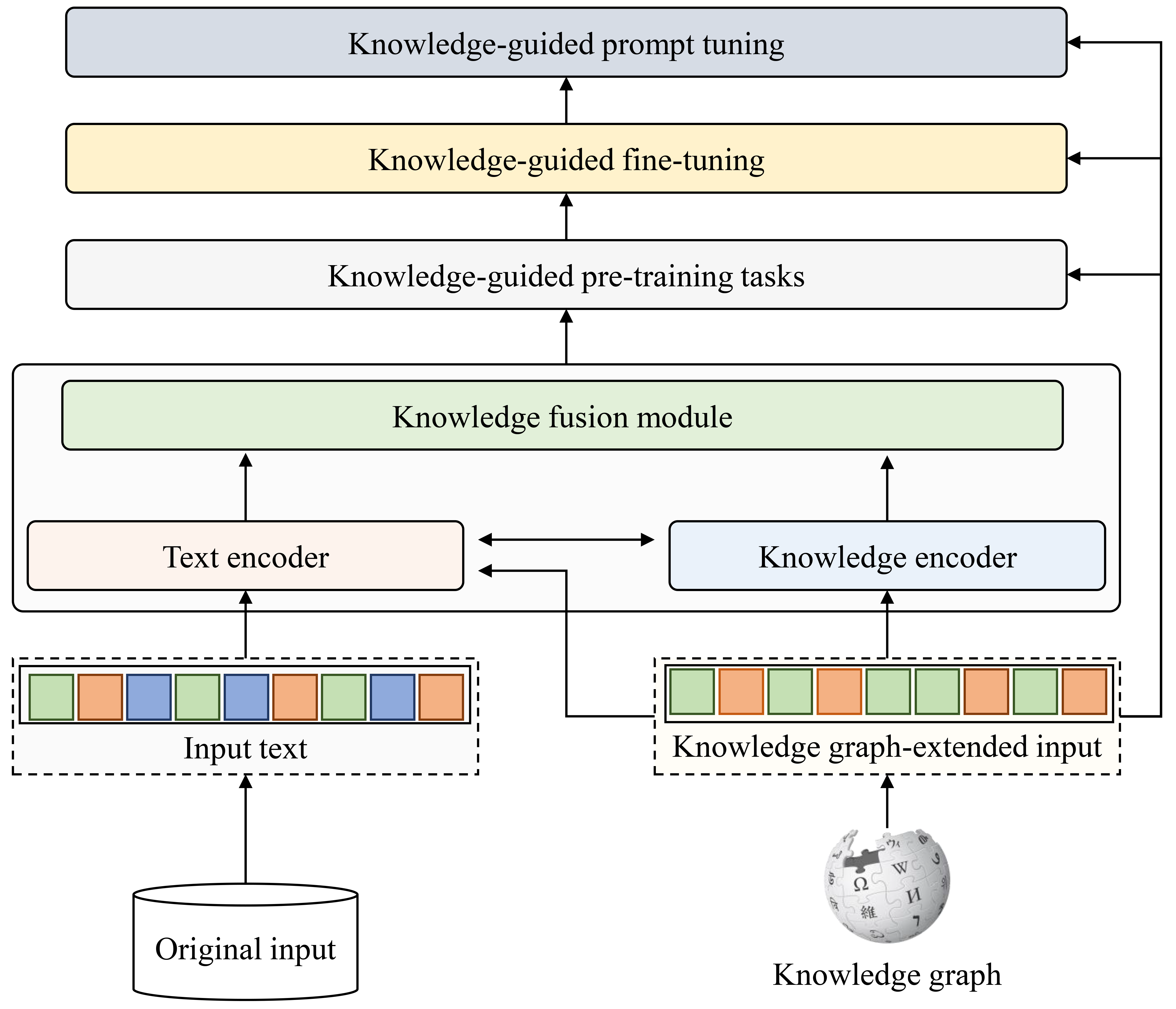
基于现有技术的KGLLMs开发框架如图10所示。 由于大语言模型主要缩放来自 PLM 的参数和训练数据的大小,因此它们的模型架构和训练方法基本保持不变。 因此,之前介绍的所有三种类型的 KGPLM 方法都可以应用于开发 KGLLM。 训练前增强方法可用于构建 KG 扩展文本,提高输入质量并将事实信息集成到输入中。 训练期间增强方法可用于自适应地融合文本知识和结构知识,以学习知识增强的单词表示。 图编码器,例如GNN,可以作为知识编码器,而注意力机制可以用来设计知识融合模块。 多任务学习,包括知识引导的预训练任务,有助于提高大语言模型对事实知识的学习。 训练后增强方法可以通过在知识扩展数据或知识基础任务上进行微调,进一步提高大语言模型在某些特定领域任务上的性能。 此外,大语言模型最近最重要的进步之一是即时学习,它通过在输入中插入文本片段,有效提高了生成文本的质量并增强了大语言模型的泛化能力。 在提示学习中,为特定任务选择合适的提示模板对于增强模型性能至关重要,需要领域专业知识。 因此,可以将知识图谱融入构建提示模板中,利用领域知识,通过知识提示指导大语言模型,有望提高模型对领域事实知识的理解。
VI-B 讨论和未来方向
除了知识图谱增强方法之外,还有其他增强方法可以用来提高大语言模型的事实语言建模能力。 通常,这些方法包括数据增强和检索增强。 数据增强涉及在预训练期间细化训练数据并强调信息性词语,强调训练语料库在为模型配备事实知识方面的重要性。 与知识图增强方法相比,这些方法利用隐式知识对文本中的事实知识进行建模,并忽略实体之间的关系。 检索增强已成为一种广泛采用的方法,允许大语言模型从数据库[149]或工具中检索外部数据,并以提示或嵌入的形式将其传递给大语言模型,以改进大语言模型模型'一代。 这些方法可以解决普通大语言模型面临的一些挑战,例如信息过时和无法记忆。 然而,由于它们并没有改变大语言模型的参数,因此并不能从根本上提高大语言模型的知识建模能力。
此外,还开发了一些插件来增强大语言模型在知识库背景下的功能。 例如,浏览插件可以调用搜索引擎来访问网站的实时信息;检索插件777https://github.com/openai/chatgpt-retrieval-plugin 使用 OpenAI 嵌入来索引和搜索矢量数据库中的文档; Wolfram888https://www.wolfram.com/wolfram-plugin-chatgpt/ 插件通过允许 ChatGPT 访问 Wolfram Alpha 知识库,使其能够提供更全面、更准确的答案; Expedia 插件93>99https://chatonai.org/expedia-chatgpt-plugin
尽管 KGLLM 取得了一些成功,但仍然存在许多尚未解决的挑战。 在这里,我们概述并讨论了 KGLLM 的一些有前景的研究方向。
提高 KGLLM 的效率。 由于需要对 KG 中的知识进行预处理和编码,与普通大语言模型相比,开发 KGLLM 通常需要更多的计算资源和时间。 然而,KGLLM 的标度法则可能与普通大语言模型不同。 先前对 KGPLM 的研究表明,较小的 KGPLM 甚至可以胜过较大的 PLM。 因此,有必要对 KGLLM 的标度规律进行全面研究,以确定其开发的最佳参数大小。 基于此,我们有可能实现一个满足性能要求的更小的模型,从而减少计算资源和时间。
以不同的方式融合不同的知识。 一些常见且定义明确的知识可以存储在知识图谱中以便于访问,而很少使用或无法通过三元组表达的隐性知识应纳入大语言模型的参数中。 特别是,特定领域的知识虽然很少被访问,但由于其相关语料库的稀疏性,可能仍然需要大量的人力来构建相关的知识图谱。
融入更多类型的知识。 正如III节中所介绍的,大多数现有的KGPLM仅使用单一模态和静态KG。 然而,存在包含多模态和时间知识的多模态和时间知识图谱。 这些类型的知识可以补充文本和结构知识,使大语言模型能够随着时间的推移学习实体之间的关系。 此外,多模态预训练模型已经受到欢迎,因为它们已被证明可以提高预训练模型在多模态任务上的性能[150]并增强其认知能力。 因此,将多模态和时间知识图谱纳入大语言模型有可能提高其性能,值得研究。 为了实现这一目标,我们需要对齐多模态实体,设计能够处理和融合多模态时态数据的编码器,并建立多模态时态学习任务来提取有用的信息。
提高知识整合的有效性。 通过修改输入、模型架构和微调过程,人们提出了多种方法将关系三元组合并到 PLM 中。 然而,每种方法都有其自身的优点和缺点,有些方法在特定任务上表现良好,但在其他任务上表现不佳。 例如,在大多数实体类型和关系分类任务中,LUKE [76] 表现出优于 KEPLER [85] 的性能,但在其他一些任务中表现较差 [89 ]。 此外,最近的实验分析[151]表明现有的KGPLM仅集成了一小部分事实知识。 因此,有效的知识整合方法还有很大的研究空间。 需要进一步研究如何选择有价值的知识,并在面对海量且相互冲突的知识时避免灾难性遗忘。
增强 KGLLM 的可解释性。 尽管人们普遍认为知识图谱可以增强大语言模型的可解释性,但相应的方法尚未得到深入研究。 Schuff 等人 [152]通过评估在域内数据和特殊传输数据集上生成的解释的分数,研究了整合外部知识是否可以提高自然语言推理模型的可解释性。 然而,他们发现最常用的指标与人类对解释准确性、常识整合以及语法和标签正确性的评估不一致。 为了给大语言模型提供人类可理解的解释,Chen 等人 [153]提出了一种知识增强解释模块,利用 KG 和 GNN 来提取关键决策大语言模型的信号。 尽管有一些研究试图提高 PLM 的可解释性,但仍不清楚如何利用 KG 来提高 KGPLM 的可解释性。 一种可行的方法可能是根据生成的内容在知识图谱中搜索相关推理路径,然后根据推理路径生成解释文本。
探索特定领域的 KGLLM。 尽管已经有大量研究将标准 KG 与通用 PLM 相结合,但有限的工作集中在特定领域的 KGLLM 上。 然而,科学人工智能的兴起将导致对特定领域 KGLLM 的需求不断增加。 与一般大语言模型相比,特定领域大语言模型在整合领域知识时需要更高的精度和特异性。 因此,构建准确的特定领域知识图谱并将其与大语言模型集成值得进一步探索。 为了开发特定领域的KGLLM,必须首先构建领域知识图谱并在领域专家的帮助下收集相关语料数据。 考虑到语言模式的通用性,建议将通用知识图谱与特定领域的知识图谱混合起来进行增强。
七结论
ChatGPT的巨大成功带动了大语言模型的快速发展。 鉴于大语言模型在各种 NLP 任务上的出色表现,一些研究人员想知道它们是否可以被视为一种参数化知识库并取代 KG。 然而,大语言模型在生成基于知识的文本时,在回忆和正确使用事实知识方面仍然存在不足。 为了阐明KG在大语言模型时代的价值,本文对KGPLM进行了全面的调查。 我们首先研究了 PLM 的背景以及将 KG 纳入 PLM 的动机。 接下来,我们将现有的 KGPLM 分为三类,并提供了每个类别的详细信息。 我们还回顾了 KGPLM 的应用。 之后,我们根据现有研究分析了PLM和最近的大语言模型是否可以取代KG。 最后,我们建议利用知识图谱增强大语言模型,进行事实感知语言建模,以提高他们对事实知识的学习。 本文讨论了三个问题:(1)知识图谱在大语言模型时代的价值是什么? (2)如何将知识图谱纳入大语言模型以提高其性能? (3)KGLLM未来的发展需要做什么? 我们希望这项工作能够促进大语言模型和知识图谱的进一步研究进展。
参考
- [1] X. Zhou, C. Chai, G. Li, and J. Sun, “Database meets artificial intelligence: A survey,” IEEE Trans. Knowl. Data Eng., vol. 34, no. 3, pp. 1096–1116, 2022.
- [2] Q. Wang, Y. Li, R. Zhang, K. Shu, Z. Zhang, and A. Zhou, “A scalable query-aware enormous database generator for database evaluation,” IEEE Trans. Knowl. Data Eng., vol. 35, no. 5, pp. 4395–4410, 2023.
- [3] R. Lu, X. Jin, S. Zhang, M. Qiu, and X. Wu, “A study on big knowledge and its engineering issues,” IEEE Trans. Knowl. Data Eng., vol. 31, no. 9, pp. 1630–1644, 2019.
- [4] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” in Proc. of the 17th Annu. Conf. of the North Amer. Chapter of the Assoc. for Comput. Linguistics: Hum. Lang. Technol., 2019, pp. 4171–4186.
- [5] A. Radford, K. Narasimhan, T. Salimans, I. Sutskever et al., “Improving language understanding by generative pre-training,” 2018.
- [6] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” J. of Mach. Learn. Res., vol. 21, no. 140, pp. 1–67, 2020.
- [7] J. Wei, Y. Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzler et al., “Emergent abilities of large language models,” arXiv:2206.07682, 2022.
- [8] F. Petroni, T. Rocktäschel, P. Lewis, A. Bakhtin, Y. Wu, A. H. Miller, and S. Riedel, “Language models as knowledge bases?” in Proc. 2019 Conf. Empirical Methods Nat. Lang. Process. and 9th Int. Joint Conf. Nat. Lang. Process., 2019, pp. 2463–2473.
- [9] C. Wang, X. Liu, and D. Song, “Language models are open knowledge graphs,” arXiv:2010.11967, 2020.
- [10] B. Heinzerling and K. Inui, “Language models as knowledge bases: On entity representations, storage capacity, and paraphrased queries,” in Proc. 16th Conf. Eur. Chapter Assoc. Comput. Linguist., 2021, pp. 1772–1791.
- [11] N. Bian, X. Han, L. Sun, H. Lin, Y. Lu, and B. He, “Chatgpt is a knowledgeable but inexperienced solver: An investigation of commonsense problem in large language models,” arXiv:2303.16421, 2023.
- [12] C. Wang, P. Liu, and Y. Zhang, “Can generative pre-trained language models serve as knowledge bases for closed-book qa?” in Proc. 59th Annu. Meet. Assoc. Comput. Linguist. and 11th Int. Joint Conf. Nat. Lang. Process., 2021, pp. 3241–3251.
- [13] B. Cao, H. Lin, X. Han, L. Sun, L. Yan, M. Liao, T. Xue, and J. Xu, “Knowledgeable or educated guess? revisiting language models as knowledge bases,” in Proc. 59th Annu. Meet. Assoc. Comput. Linguist. and 11th Int. Joint Conf. Nat. Lang. Process., 2021, pp. 1860–1874.
- [14] H. Liu, R. Ning, Z. Teng, J. Liu, Q. Zhou, and Y. Zhang, “Evaluating the logical reasoning ability of chatgpt and gpt-4,” arXiv:2304.03439, 2023.
- [15] Y. Bang, S. Cahyawijaya, N. Lee, W. Dai, D. Su, B. Wilie, H. Lovenia, Z. Ji, T. Yu, W. Chung et al., “A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity,” arXiv:2302.04023, 2023.
- [16] H. M. Yohannes and T. Amagasa, “Named-entity recognition for a low-resource language using pre-trained language model,” in Proc. 37th ACM/SIGAPP Symp. Appl. Comput., 2022, p. 837–844.
- [17] X. Wei, S. Wang, D. Zhang, P. Bhatia, and A. Arnold, “Knowledge enhanced pretrained language models: A compreshensive survey,” arXiv:2110.08455, 2021.
- [18] L. Hu, Z. Liu, Z. Zhao, L. Hou, L. Nie, and J. Li, “A survey of knowledge enhanced pre-trained language models,” IEEE Trans. Knowl. Data Eng., pp. 1–19, 2023.
- [19] C. Zhen, Y. Shang, X. Liu, Y. Li, Y. Chen, and D. Zhang, “A survey on knowledge-enhanced pre-trained language models,” arXiv:2212.13428, 2022.
- [20] X. Liu, F. Zhang, Z. Hou, L. Mian, Z. Wang, J. Zhang, and J. Tang, “Self-supervised learning: Generative or contrastive,” IEEE Trans. on Knowl. Data Eng., vol. 35, no. 1, pp. 857–876, 2023.
- [21] H. Wang, J. Li, H. Wu, E. Hovy, and Y. Sun, “Pre-trained language models and their applications,” Eng., 2022.
- [22] K. Clark, M.-T. Luong, Q. V. Le, and C. D. Manning, “ELECTRA: Pre-training text encoders as discriminators rather than generators,” in Proc. 8th Int. Conf. Learn. Representations, 2020.
- [23] M. Joshi, D. Chen, Y. Liu, D. S. Weld, L. Zettlemoyer, and O. Levy, “SpanBERT: Improving pre-training by representing and predicting spans,” Trans. Assoc. Comput. Linguist., vol. 8, pp. 64–77, 2020.
- [24] Y. Wang, C. Sun, Y. Wu, J. Yan, P. Gao, and G. Xie, “Pre-training entity relation encoder with intra-span and inter-span information,” in Proc. 2020 Conf. Empirical Methods Nat. Lang. Process., 2020, pp. 1692–1705.
- [25] Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut, “Albert: A lite bert for self-supervised learning of language representations,” arXiv:1909.11942, 2019.
- [26] M. Lewis, Y. Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V. Stoyanov, and L. Zettlemoyer, “BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension,” in Proc. 58th Ann. Meet. Assoc. Comput. Linguistics., 2020, pp. 7871–7880.
- [27] M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer, “Deep contextualized word representations,” arXiv:1802.05365, 2018.
- [28] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. 31st Conf. Neural Inform. Process. Syst., 2017.
- [29] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” arXiv:1907.11692, 2019.
- [30] V. Sanh, L. Debut, J. Chaumond, and T. Wolf, “Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter,” arXiv:1910.01108, 2019.
- [31] Z. Zhang, X. Han, Z. Liu, X. Jiang, M. Sun, and Q. Liu, “ERNIE: Enhanced language representation with informative entities,” in Proc. 57th Ann. Meet. Assoc. Comput. Linguistics., 2019, pp. 1441–1451.
- [32] P. He, X. Liu, J. Gao, and W. Chen, “Deberta: Decoding-enhanced bert with disentangled attention,” in International Conference on Learning Representations, 2021.
- [33] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever et al., “Language models are unsupervised multitask learners,” OpenAI blog, vol. 1, no. 8, pp. 1–9, 2019.
- [34] Z. Yang, Z. Dai, Y. Yang, J. Carbonell, R. R. Salakhutdinov, and Q. V. Le, “Xlnet: Generalized autoregressive pretraining for language understanding,” in Advances in neural information processing systems, 2019.
- [35] T. Shen, Y. Mao, P. He, G. Long, A. Trischler, and W. Chen, “Exploiting structured knowledge in text via graph-guided representation learning,” in Proc. 2020 Conf. Empirical Methods Nat. Lang. Process., 2020, p. 8980–8994.
- [36] W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,” The Journal of Machine Learning Research, vol. 23, no. 1, pp. 5232–5270, 2022.
- [37] H. W. Chung, L. Hou, S. Longpre, B. Zoph, Y. Tay, W. Fedus, E. Li, X. Wang, M. Dehghani, S. Brahma et al., “Scaling instruction-finetuned language models,” arXiv:2210.11416, 2022.
- [38] A. Zeng, X. Liu, Z. Du, Z. Wang, H. Lai, M. Ding, Z. Yang, Y. Xu, W. Zheng, X. Xia et al., “Glm-130b: An open bilingual pre-trained model,” arXiv:2210.02414, 2022.
- [39] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, and A. Askell, “Language models are few-shot learners,” in Adv. Neural Inform. Process. Syst., 2020, pp. 1877–1901.
- [40] N. Du, Y. Huang, A. M. Dai, S. Tong, D. Lepikhin, Y. Xu, M. Krikun, Y. Zhou, A. W. Yu, O. Firat, B. Zoph, L. Fedus, M. P. Bosma, Z. Zhou, T. Wang, E. Wang, K. Webster, M. Pellat, K. Robinson, K. Meier-Hellstern, T. Duke, L. Dixon, K. Zhang, Q. Le, Y. Wu, Z. Chen, and C. Cui, “GLaM: Efficient scaling of language models with mixture-of-experts,” in Proc. 39th Int. Conf. Machine Learning, 2022, pp. 5547–5569.
- [41] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, and A. Ray, “Training language models to follow instructions with human feedback,” in Adv. Neural Inform. Process. Syst., 2022, pp. 27 730–27 744.
- [42] A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann et al., “Palm: Scaling language modeling with pathways,” arXiv:2204.02311, 2022.
- [43] R. Thoppilan, D. De Freitas, J. Hall, N. Shazeer, A. Kulshreshtha, H.-T. Cheng, A. Jin, T. Bos, L. Baker, and Y. Du, “Lamda: Language models for dialog applications,” arXiv:2201.08239, 2022.
- [44] S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. Diab, X. Li, X. V. Lin et al., “Opt: Open pre-trained transformer language models,” arXiv:2205.01068, 2022.
- [45] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar et al., “Llama: Open and efficient foundation language models,” arXiv:2302.13971, 2023.
- [46] R. Taori, I. Gulrajani, T. Zhang, Y. Dubois, X. Li, C. Guestrin, P. Liang, and T. B. Hashimoto, “Stanford alpaca: An instruction-following llama model,” 2023.
- [47] OpenAI, “Gpt-4 technical report,” arXiv:2303.08774, 2023.
- [48] H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale et al., “Llama 2: Open foundation and fine-tuned chat models,” arXiv:2307.09288, 2023.
- [49] W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong et al., “A survey of large language models,” arXiv:2303.18223, 2023.
- [50] J.-W. Lu, C. Guo, X.-Y. Dai, Q.-H. Miao, X.-X. Wang, J. Yang, and F.-Y. Wang, “The chatgpt after: Opportunities and challenges of very large scale pre-trained models,” Acta Autom. Sin., vol. 49, no. 4, pp. 705–717, 2023.
- [51] P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,” in Adv. Neural Inf. Process. Syst., 2017.
- [52] P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashi, and G. Neubig, “Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing,” ACM Comput. Surv., vol. 55, no. 9, pp. 1–35, 2023.
- [53] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv:1707.06347, 2017.
- [54] J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. Chi, Q. Le, and D. Zhou, “Chain of thought prompting elicits reasoning in large language models,” arXiv:2201.11903, 2022.
- [55] S. Bubeck, V. Chandrasekaran, R. Eldan, J. Gehrke, E. Horvitz, E. Kamar, P. Lee, Y. T. Lee, Y. Li, S. Lundberg et al., “Sparks of artificial general intelligence: Early experiments with gpt-4,” arXiv:2303.12712, 2023.
- [56] Q. Dong, L. Li, D. Dai, C. Zheng, Z. Wu, B. Chang, X. Sun, J. Xu, and Z. Sui, “A survey for in-context learning,” arXiv:2301.00234, 2022.
- [57] J. Wei, M. Bosma, V. Y. Zhao, K. Guu, A. W. Yu, B. Lester, N. Du, A. M. Dai, and Q. V. Le, “Finetuned language models are zero-shot learners,” arXiv:2109.01652, 2021.
- [58] Y. Qin, S. Hu, Y. Lin, W. Chen, N. Ding, G. Cui, Z. Zeng, Y. Huang, C. Xiao, and C. Han, “Tool learning with foundation models,” arXiv:2304.08354, 2023.
- [59] K. Yang, Y. Tian, N. Peng, and K. Dan, “Re3: Generating longer stories with recursive reprompting and revision,” in Proc. 2022 Conf. Empir. Methods Nat. Lang. Process., 2022, p. 4393–4479.
- [60] W. Yu, C. Zhu, Z. Li, Z. Hu, Q. Wang, H. Ji, and M. Jiang, “A survey of knowledge-enhanced text generation,” ACM Comput. Surv., vol. 54, no. 11, pp. 1–18, 2022.
- [61] X. Li, R. Zhao, Y. K. Chia, B. Ding, L. Bing, S. Joty, and S. Poria, “Chain of knowledge: A framework for grounding large language models with structured knowledge bases,” arXiv:2305.13269, 2023.
- [62] E. Yanai, K. Nora, R. Shauli, F. Amir, R. Abhilasha, M. Marius, B. Yonatan, S. Hinrich, and G. Yoav, “Measuring causal effects of data statistics on language model’s ‘factual’ predictions,” arXiv:2207.14251, 2022.
- [63] J. Sun, C. Xu, L. Tang, S. Wang, C. Lin, Y. Gong, H.-Y. Shum, and J. Guo, “Think-on-graph: Deep and responsible reasoning of large language model with knowledge graph,” arXiv:2307.07697, 2023.
- [64] S. Abulhair and H. He, “Language models are greedy reasoners: A systematic formal analysis of chain-of-thought,” arXiv:2210.01240, 2022.
- [65] T. A. Chang and B. K. Bergen, “Language model behavior: A comprehensive survey,” arXiv:2303.11504, 2023.
- [66] S. Wang, Z. Wei, J. Xu, and Z. Fan, “Unifying structure reasoning and language model pre-training for complex reasoning,” arXiv:2301.08913, 2023.
- [67] X. Zhang, A. Bosselut, M. Yasunaga, H. Ren, P. Liang, C. D. Manning, and J. Leskovec, “Greaselm: Graph reasoning enhanced language models for question answering,” arXiv:2201.08860, 2022.
- [68] R. Ding, X. Han, and L. Wang, “A unified knowledge graph augmentation service for boosting domain-specific nlp tasks,” in Find. Assoc. Comput. Linguist.: ACL 2023, 2023, pp. 353–369.
- [69] J. Baek, A. F. Aji, and A. Saffari, “Knowledge-augmented language model prompting for zero-shot knowledge graph question answering,” in Proc. 1st Workshop Nat. Lang. Reasoning Struct. Expl., 2023, pp. 78–106.
- [70] S. Gehman, S. Gururangan, M. Sap, Y. Choi, and N. A. Smith, “RealToxicityPrompts: Evaluating neural toxic degeneration in language models,” in Find. Assoc. Comput. Linguist.: EMNLP 2020, 2020, pp. 3356–3369.
- [71] R. Zellers, A. Holtzman, E. Clark, L. Qin, A. Farhadi, and Y. Choi, “TuringAdvice: A generative and dynamic evaluation of language use,” in Proc. 2021 Conf. North Am. Chapter Assoc. Comput. Linguist.: Hum. Lang. Technol., 2021, pp. 4856–4880.
- [72] V. Swamy, A. Romanou, and M. Jaggi, “Interpreting language models through knowledge graph extraction,” arXiv:2111.08546, 2021.
- [73] W. Liu, P. Zhou, Z. Zhao, Z. Wang, Q. Ju, H. Deng, and P. Wang, “K-bert: Enabling language representation with knowledge graph,” in Proc. AAAI Conf. Artif. Intell., 2020, pp. 2901–2908.
- [74] T. Sun, Y. Shao, X. Qiu, Q. Guo, Y. Hu, X. Huang, and Z. Zhang, “CoLAKE: Contextualized language and knowledge embedding,” in Proc. 28th Int. Conf. Comput. Linguistics, 2020, pp. 3660–3670.
- [75] Y. Zhang, J. Lin, Y. Fan, P. Jin, Y. Liu, and B. Liu, “Cn-hit-it. nlp at semeval-2020 task 4: Enhanced language representation with multiple knowledge triples,” in Proc. 14th Workshop Semant. Eval., 2020, pp. 494–500.
- [76] I. Yamada, A. Asai, H. Shindo, H. Takeda, and Y. Matsumoto, “LUKE: Deep contextualized entity representations with entity-aware self-attention,” in Proc. 2020 Conf. Empir. Methods Nat. Lang. Process., 2020, pp. 6442–6454.
- [77] N. Poerner, U. Waltinger, and H. Schütze, “E-BERT: Efficient-yet-effective entity embeddings for BERT,” in Find. Assoc. Comput. Linguist.: EMNLP 2020, 2020, pp. 803–818.
- [78] C. Rosset, C. Xiong, M. Phan, X. Song, P. Bennett, and S. Tiwary, “Knowledge-aware language model pretraining,” arXiv:2007.00655, 2020.
- [79] X. Liu, D. Yin, J. Zheng, X. Zhang, P. Zhang, H. Yang, Y. Dong, and J. Tang, “Oag-bert: Towards a unified backbone language model for academic knowledge services,” in Proc. 28th ACM SIGKDD Conf. Knowl. Discov. Data Min., 2022, p. 3418–3428.
- [80] T. Zhang, C. Wang, N. Hu, M. Qiu, C. Tang, X. He, and J. Huang, “Dkplm: Decomposable knowledge-enhanced pre-trained language model for natural language understanding,” in Proc. AAAI Conf. Artif. Intell., 2022, pp. 11 703–11 711.
- [81] Z.-X. Ye, Q. Chen, W. Wang, and Z.-H. Ling, “Align, mask and select: A simple method for incorporating commonsense knowledge into language representation models,” arXiv:1908.06725, 2019.
- [82] W. Chen, Y. Su, X. Yan, and W. Y. Wang, “KGPT: Knowledge-grounded pre-training for data-to-text generation,” in Proc. 2020 Conf. Empir. Methods Nat. Lang. Process., 2020, pp. 8635–8648.
- [83] R. Logan, N. F. Liu, M. E. Peters, M. Gardner, and S. Singh, “Barack’s wife hillary: Using knowledge graphs for fact-aware language modeling,” in Proc. 57th Annu. Meet. Assoc. Comput. Linguist., 2019, pp. 5962–5971.
- [84] M. Sap, R. Le Bras, E. Allaway, C. Bhagavatula, N. Lourie, H. Rashkin, B. Roof, N. A. Smith, and Y. Choi, “Atomic: An atlas of machine commonsense for if-then reasoning,” in Proc. 33rd AAAI Conf. Artif. Intell. & 31st Innov. Appl. Artif. Intell. Conf. & 9th AAAI Symp. Educ. Adv. Artif. Intell., 2019, p. 3027–3035.
- [85] X. Wang, T. Gao, Z. Zhu, Z. Zhang, Z. Liu, J. Li, and J. Tang, “Kepler: A unified model for knowledge embedding and pre-trained language representation,” Trans. Assoc. Comput. Linguist., vol. 9, pp. 176–194, 2021.
- [86] W. Xiong, J. Du, W. Y. Wang, and V. Stoyanov, “Pretrained encyclopedia: Weakly supervised knowledge-pretrained language model,” arXiv:1912.09637, 2019.
- [87] Y. Sun, S. Wang, S. Feng, S. Ding, C. Pang, J. Shang, J. Liu, X. Chen, Y. Zhao, Y. Lu et al., “Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation,” arXiv:2107.02137, 2021.
- [88] B. He, D. Zhou, J. Xiao, X. Jiang, Q. Liu, N. J. Yuan, and T. Xu, “BERT-MK: Integrating graph contextualized knowledge into pre-trained language models,” in Find. Assoc. Comput. Linguist.: EMNLP 2020, 2020, pp. 2281–2290.
- [89] Y. Su, X. Han, Z. Zhang, Y. Lin, P. Li, Z. Liu, J. Zhou, and M. Sun, “Cokebert: Contextual knowledge selection and embedding towards enhanced pre-trained language models,” AI Open, vol. 2, pp. 127–134, 2021.
- [90] Y. Sun, Q. Shi, L. Qi, and Y. Zhang, “JointLK: Joint reasoning with language models and knowledge graphs for commonsense question answering,” in Proc. 2022 Conf. North Am. Chapter Assoc. Comput. Linguist.: Hum. Lang. Technol., 2022, pp. 5049–5060.
- [91] P. Zhong, D. Wang, and C. Miao, “Knowledge-enriched transformer for emotion detection in textual conversations,” in Proc. 2019 Conf. Empir. Methods Nat. Lang. Process. & 9th Int. Joint Conf. Nat. Lang. Process., 2019, pp. 165–176.
- [92] Q. Liu, D. Yogatama, and P. Blunsom, “Relational memory-augmented language models,” Trans. Assoc. Comput. Linguist., vol. 10, pp. 555–572, 2022.
- [93] M. Yasunaga, H. Ren, A. Bosselut, P. Liang, and J. Leskovec, “QA-GNN: Reasoning with language models and knowledge graphs for question answering,” in Proc. 2021 Conf. North Am. Chapter Assoc. Comput. Linguist.: Hum. Lang. Technol., Online, 2021, pp. 535–546.
- [94] L. He, S. Zheng, T. Yang, and F. Zhang, “KLMo: Knowledge graph enhanced pretrained language model with fine-grained relationships,” in Find. Assoc. Comput. Linguist.: EMNLP 2021, 2021, pp. 4536–4542.
- [95] M. E. Peters, M. Neumann, R. Logan, R. Schwartz, V. Joshi, S. Singh, and N. A. Smith, “Knowledge enhanced contextual word representations,” in Proc. 2019 Conf. Empir. Methods Nat. Lang. Process. & 9th Int. Joint Conf. Nat. Lang. Process., 2019, pp. 43–54.
- [96] D. Yu, C. Zhu, Y. Yang, and M. Zeng, “Jaket: Joint pre-training of knowledge graph and language understanding,” in Proc. AAAI Conf. Artif. Intell., 2022, pp. 11 630–11 638.
- [97] Y. Liu, Y. Wan, L. He, H. Peng, and S. Y. Philip, “Kg-bart: Knowledge graph-augmented bart for generative commonsense reasoning,” in Proc. AAAI Conf. Artif. Intell., 2021, pp. 6418–6425.
- [98] R. Wang, D. Tang, N. Duan, Z. Wei, X. Huang, G. Cao, D. Jiang, and M. Zhou, “K-adapter: Infusing knowledge into pre-trained models with adapters,” in Proc. Joint Conf. 59th Annu. Meet. Assoc. Comput. Linguist. and 11th Int. Joint Conf. Nat. Lang. Process., 2021, p. 1405–1418.
- [99] A. Lauscher, O. Majewska, L. F. R. Ribeiro, I. Gurevych, N. Rozanov, and G. Glavaš, “Common sense or world knowledge? investigating adapter-based knowledge injection into pretrained transformers,” in Proc. DeeLIO: 1st Workshop Knowl. Extract. Integr. Deep Learn. Archit., 2020, pp. 43–49.
- [100] Q. Lu, D. Dou, and T. H. Nguyen, “Parameter-efficient domain knowledge integration from multiple sources for biomedical pre-trained language models,” in Find. Assoc. Comput. Linguist.: EMNLP 2021, 2021, pp. 3855–3865.
- [101] G. Lu, H. Yu, Z. Yan, and Y. Xue, “Commonsense knowledge graph-based adapter for aspect-level sentiment classification,” Neurocomput., vol. 534, pp. 67–76, 2023.
- [102] Y. Levine, B. Lenz, O. Dagan, O. Ram, D. Padnos, O. Sharir, S. Shalev-Shwartz, A. Shashua, and Y. Shoham, “SenseBERT: Driving some sense into BERT,” in Proc. 58th Annu. Meet. Assoc. Comput. Linguist., 2020, pp. 4656–4667.
- [103] Y. Qin, Y. Lin, R. Takanobu, Z. Liu, P. Li, H. Ji, M. Huang, M. Sun, and J. Zhou, “ERICA: Improving entity and relation understanding for pre-trained language models via contrastive learning,” in Proc. 59th Ann. Meet. Assoc. Comput. Ling. Int. Jt. Conf. Nat. Lang. Process., 2021, pp. 3350–3363.
- [104] P. Ke, H. Ji, S. Liu, X. Zhu, and M. Huang, “SentiLARE: Sentiment-aware language representation learning with linguistic knowledge,” in Proc. 2020 Conf. Empir. Methods Nat. Lang. Process., Online, 2020, pp. 6975–6988.
- [105] Y. Sun, S. Wang, Y. Li, S. Feng, H. Tian, H. Wu, and H. Wang, “Ernie 2.0: A continual pre-training framework for language understanding,” in Proc. AAAI Conf. Artif. Intell., 2020, pp. 8968–8975.
- [106] M. Yasunaga, A. Bosselut, H. Ren, X. Zhang, C. D. Manning, P. S. Liang, and J. Leskovec, “Deep bidirectional language-knowledge graph pretraining,” in Adv. Neural Inform. Process. Syst., 2022, pp. 37 309–37 323.
- [107] H. Hayashi, Z. Hu, C. Xiong, and G. Neubig, “Latent relation language models,” in Proc. AAAI Conf. Artif. Intell., 2020, pp. 7911–7918.
- [108] M. Kang, J. Baek, and S. J. Hwang, “KALA: knowledge-augmented language model adaptation,” in Proc. 2022 Conf. North Am. Chapter Assoc. Comput. Linguist.: Hum. Lang. Technol., 2022, pp. 5144–5167.
- [109] Q. Xie, J. A. Bishop, P. Tiwari, and S. Ananiadou, “Pre-trained language models with domain knowledge for biomedical extractive summarization,” Knowl. Based Syst., vol. 252, p. 109460, 2022.
- [110] B. Y. Lin, X. Chen, J. Chen, and X. Ren, “KagNet: Knowledge-aware graph networks for commonsense reasoning,” in Proc. 2019 Conf. Empir. Methods Nat. Lang. Process. & 9th Int. Joint Conf. Nat. Lang. Process., 2019, pp. 2829–2839.
- [111] H. Fei, Y. Ren, Y. Zhang, D. Ji, and X. Liang, “Enriching contextualized language model from knowledge graph for biomedical information extraction,” Brief. Bioinform., vol. 22, no. 3, p. bbaa110, 2021.
- [112] T.-Y. Chang, Y. Liu, K. Gopalakrishnan, B. Hedayatnia, P. Zhou, and D. Hakkani-Tur, “Incorporating commonsense knowledge graph in pretrained models for social commonsense tasks,” in Proc. DeeLIO: 1st Workshop Knowl. Extract. Integr. Deep Learn. Archit., Nov. 2020, pp. 74–79.
- [113] B. R. Andrus, Y. Nasiri, S. Cui, B. Cullen, and N. Fulda, “Enhanced story comprehension for large language models through dynamic document-based knowledge graphs,” in Proc. AAAI Conf. Artif. Intell., 2022, pp. 10 436–10 444.
- [114] J. Wang, W. Huang, Q. Shi, H. Wang, M. Qiu, X. Li, and M. Gao, “Knowledge prompting in pre-trained language model for natural language understanding,” in Proc. 2022 Conf. Empir. Methods Nat. Lang. Process., 2022, pp. 3164–3177.
- [115] A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, and O. Yakhnenko, “Translating embeddings for modeling multi-relational data,” in Adv. Neural Inf. Process. Syst., 2013.
- [116] A. Wettig, T. Gao, Z. Zhong, and D. Chen, “Should you mask 15% in masked language modeling?” arXiv:2202.08005, 2022.
- [117] Z. Bi, N. Zhang, Y. Jiang, S. Deng, G. Zheng, and H. Chen, “When do program-of-thoughts work for reasoning?” arXiv:2308.15452, 2023.
- [118] T. Schick and H. Schütze, “Exploiting cloze-questions for few-shot text classification and natural language inference,” in Proc. 16th Conf. Eur. Chapter Assoc. Comput. Linguist., 2021, pp. 255–269.
- [119] N. Bian, X. Han, B. Chen, and L. Sun, “Benchmarking knowledge-enhanced commonsense question answering via knowledge-to-text transformation,” in Proc. AAAI Conf. Artif. Intell., 2021, pp. 12 574–12 582.
- [120] J. Giorgi, X. Wang, N. Sahar, W. Y. Shin, G. D. Bader, and B. Wang, “End-to-end named entity recognition and relation extraction using pre-trained language models,” arXiv:1912.13415, 2019.
- [121] Z. Yuan, Y. Liu, C. Tan, S. Huang, and F. Huang, “Improving biomedical pretrained language models with knowledge,” in Proc. BioNLP 2021 workshop, 2021, pp. 180–190.
- [122] D. Seyler, T. Dembelova, L. Del Corro, J. Hoffart, and G. Weikum, “A study of the importance of external knowledge in the named entity recognition task,” in Proc. 56th Ann. Meet. Assoc. Comput. Linguistics., 2018, pp. 241–246.
- [123] Q. He, L. Wu, Y. Yin, and H. Cai, “Knowledge-graph augmented word representations for named entity recognition,” in Proc. AAAI Conf. Artif. Intell., 2020, pp. 7919–7926.
- [124] Y. Song, W. Zhang, Y. Ye, C. Zhang, and K. Zhang, “Knowledge-enhanced relation extraction in chinese emrs,” in Proc. 2022 5th Int. Conf. Mach. Learn. Nat. Lang. Process., 2023, p. 196–201.
- [125] J. Li, Y. Katsis, T. Baldwin, H.-C. Kim, A. Bartko, J. McAuley, and C.-N. Hsu, “Spot: Knowledge-enhanced language representations for information extraction,” in Proc. 31st ACM Int. Conf. Inf. Knowl. Manage., 2022, p. 1124–1134.
- [126] A. Roy and S. Pan, “Incorporating medical knowledge in BERT for clinical relation extraction,” in Proc. 2021 Conf. Empir. Methods Nat. Lang. Process., 2021, pp. 5357–5366.
- [127] J. Zhou, J. Tian, R. Wang, Y. Wu, W. Xiao, and L. He, “SentiX: A sentiment-aware pre-trained model for cross-domain sentiment analysis,” in Proc. 28th Int. Conf. Comput. Linguist., 2020, pp. 568–579.
- [128] Q. Wang, X. Cao, J. Wang, and W. Zhang, “Knowledge-aware collaborative filtering with pre-trained language model for personalized review-based rating prediction,” IEEE Trans. Knowl. Data Eng., pp. 1–13, 2023.
- [129] S. Liang, J. Shao, D. Zhang, J. Zhang, and B. Cui, “Drgi: Deep relational graph infomax for knowledge graph completion,” IEEE Trans. Knowl. Data Eng., vol. 35, no. 3, pp. 2486–2499, 2023.
- [130] Q. Lin, R. Mao, J. Liu, F. Xu, and E. Cambria, “Fusing topology contexts and logical rules in language models for knowledge graph completion,” Inf. Fusion, vol. 90, pp. 253–264, 2023.
- [131] W. Li, R. Peng, and Z. Li, “Knowledge graph completion by jointly learning structural features and soft logical rules,” IEEE Trans. Knowl. Data Eng., vol. 35, no. 3, pp. 2724–2735, 2023.
- [132] A. Ghanbarpour and H. Naderi, “An attribute-specific ranking method based on language models for keyword search over graphs,” IEEE Trans. Knowl. Data Eng., vol. 32, no. 1, pp. 12–25, 2020.
- [133] Z. Hu, Y. Xu, W. Yu, S. Wang, Z. Yang, C. Zhu, K.-W. Chang, and Y. Sun, “Empowering language models with knowledge graph reasoning for open-domain question answering,” in Proc. 2022 Conf. Empir. Methods Nat. Lang. Process., 2022, pp. 9562–9581.
- [134] J. Guan, F. Huang, Z. Zhao, X. Zhu, and M. Huang, “A knowledge-enhanced pretraining model for commonsense story generation,” Trans. Assoc. Comput. Linguist., vol. 8, pp. 93–108, 2020.
- [135] H. Ji, P. Ke, S. Huang, F. Wei, X. Zhu, and M. Huang, “Language generation with multi-hop reasoning on commonsense knowledge graph,” in Proc. 2020 Conf. Empir. Methods Nat. Lang. Process., 2020, pp. 725–736.
- [136] X. Yang and I. Tiddi, “Creative storytelling with language models and knowledge graphs,” in Proc. CIKM 2020 Workshops, 2020.
- [137] L. Du, X. Ding, T. Liu, and B. Qin, “Learning event graph knowledge for abductive reasoning,” in Proc. 59th Annu. Meet. Assoc. Comput. Linguist. and 11th Int. Joint Conf. Nat. Lang. Process., 2021, pp. 5181–5190.
- [138] B. AlKhamissi, M. Li, A. Celikyilmaz, M. Diab, and M. Ghazvininejad, “A review on language models as knowledge bases,” arXiv:2204.06031, 2022.
- [139] A. Talmor, Y. Elazar, Y. Goldberg, and J. Berant, “olmpics-on what language model pre-training captures,” Trans. Assoc. Comput. Linguist., vol. 8, pp. 743–758, 2020.
- [140] C. Wang, S. Liang, Y. Zhang, X. Li, and T. Gao, “Does it make sense? and why? a pilot study for sense making and explanation,” in Proc. 57th Ann. Meet. Assoc. Comput. Linguistics., 2019, pp. 4020–4026.
- [141] M. Sung, J. Lee, S. Yi, M. Jeon, S. Kim, and J. Kang, “Can language models be biomedical knowledge bases?” in Proc. 2021 Conf. Empir. Methods Nat. Lang. Process., 2021, pp. 4723–4734.
- [142] R. Zhao, F. Zhao, G. Xu, S. Zhang, and H. Jin, “Can language models serve as temporal knowledge bases?” in Find. Assoc. Comput. Linguist.: EMNLP 2022, 2022, pp. 2024–2037.
- [143] N. Kassner, P. Dufter, and H. Schütze, “Multilingual lama: Investigating knowledge in multilingual pretrained language models,” arXiv:2102.00894, 2021.
- [144] T. Pires, E. Schlinger, and D. Garrette, “How multilingual is multilingual BERT?” in Proc. 57th Ann. Meet. Assoc. Comput. Linguistics., 2019, pp. 4996–5001.
- [145] B. Cao, H. Lin, X. Han, F. Liu, and L. Sun, “Can prompt probe pretrained language models? understanding the invisible risks from a causal view,” arXiv:2203.12258, 2022.
- [146] N. Kandpal, H. Deng, A. Roberts, E. Wallace, and C. Raffel, “Large language models struggle to learn long-tail knowledge,” arXiv:2211.08411, 2022.
- [147] S. Hao, B. Tan, K. Tang, H. Zhang, E. P. Xing, and Z. Hu, “Bertnet: Harvesting knowledge graphs from pretrained language models,” arXiv:2206.14268, 2022.
- [148] A. Bosselut, H. Rashkin, M. Sap, C. Malaviya, A. Celikyilmaz, and Y. Choi, “COMET: Commonsense transformers for automatic knowledge graph construction,” in Proc. 57th Ann. Meet. Assoc. Comput. Linguistics., 2019, pp. 4762–4779.
- [149] O. Ram, Y. Levine, I. Dalmedigos, D. Muhlgay, A. Shashua, K. Leyton-Brown, and Y. Shoham, “In-context retrieval-augmented language models,” arXiv:2302.00083, 2023.
- [150] D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu et al., “Palm-e: An embodied multimodal language model,” arXiv:2303.03378, 2023.
- [151] Y. Hou, G. Fu, and M. Sachan, “Understanding the integration of knowledge in language models with graph convolutions,” arXiv:2202.00964, 2022.
- [152] H. Schuff, H.-Y. Yang, H. Adel, and N. T. Vu, “Does external knowledge help explainable natural language inference? automatic evaluation vs. human ratings,” in Proc. 4th BlackboxNLP Workshop on Analyz. Interpr. Neural Networks NLP, 2021, pp. 26–41.
- [153] Z. Chen, A. K. Singh, and M. Sra, “Lmexplainer: a knowledge-enhanced explainer for language models,” arXiv:2303.16537, 2023.