ChatGPT 与 SBST:单元测试套件生成的比较评估
摘要
大型语言模型(大语言模型)的最新进展在广泛的一般领域任务(例如回答问题和遵循指令)中表现出了非凡的成功。 此外,大语言模型在各种软件工程应用中都显示出了潜力。 在这项研究中,我们对 ChatGPT 大语言模型和最先进的 SBST 工具 EvoSuite 生成的测试套件进行了系统比较。 我们的比较基于几个关键因素,包括正确性、可读性、代码覆盖率和错误检测能力。 通过强调大语言模型(特别是 ChatGPT)与 EvoSuite 相比在生成单元测试用例方面的优势和劣势,这项工作为大语言模型在解决软件工程问题方面的性能提供了有价值的见解。 总的来说,我们的研究结果强调了大语言模型在软件工程中的潜力,并为该领域的进一步研究铺平了道路。
索引术语:
ChatGPT、基于搜索的软件测试、大型语言模型1 简介
单元测试是一种广泛接受的软件测试方法,旨在验证应用程序中各个单元的功能。 通过使用单元测试,开发人员可以在软件开发生命周期的早期阶段检测代码中的错误,并防止代码更改破坏现有功能,这称为回归[1]。 单元测试的主要目标是确认软件应用程序的每个单元都按预期运行。 这种测试方法有助于通过尽早识别和解决问题来提高软件的质量和可靠性。
SBST。 单元测试在软件开发和软件开发生命周期中的重要性怎么强调都不为过。 为了生成单元测试用例,广泛采用基于搜索的软件测试 (SBST)[2] 技术。 SBST 是一种采用遗传算法和模拟退火等搜索算法来创建测试用例的技术。 SBST 的目标是利用此类算法来优化测试套件,从而产生一组测试用例,提供广泛的代码覆盖率并有效检测程序缺陷。 与其他测试技术相比,SBST 在减少测试用例数量的同时保持相同水平的缺陷检测能力方面表现出了可喜的结果[3, 4]。 SBST 已成为提高软件测试质量和效率的有效方法,为软件开发人员简化测试过程提供了宝贵的工具。
大型语言模型和 ChatGPT。 最近,大型语言模型(大语言模型)在处理和执行机器翻译、问答、摘要和文本生成等日常任务方面表现出了惊人的熟练程度,准确率令人印象深刻[5,6,7] 。 这些模型具有与人类几乎相同的理解和生成类人文本的能力。 现实世界的大语言模型应用程序的一个例子是 OpenAI 的 GPT-3(生成式预训练 Transformer 3),它已经过来自互联网的大量文本数据的训练。 其实际实现,ChatGPT 111CharGPT: The version used in this study is GPT-3 instead of GPT-4,广泛应用于各种日常活动,包括文本生成、语言翻译、问答和自动化客户支持。 ChatGPT 已成为许多人的必备工具,可以简化各种任务并提高整体效率。
基于深度学习的测试用例生成。 除了完成文本生成、语言翻译和问答等日常任务外,还采用大型语言模型来处理软件工程(SE)任务,例如代码生成[8,9,10 ]、代码摘要[11, 12, 13]、文档和注释生成[14, 15]等等。 这些模型可用于在开发人员/测试人员编写的大量实际测试用例的帮助下为程序生成单元测试用例。 这允许验证软件应用程序内各个单元的预期功能。 大语言模型在SE任务中的集成展示了其多功能性和改进软件开发流程的潜力。
动机。 尽管SBST在生成单元测试方面表现良好,但对于经验有限的测试人员来说仍然存在学习成本。 因此,它可能成为采用 SBST 技术的障碍,特别是对于新测试人员而言。 然而,基于大型语言模型的应用程序可以完成相同的任务(即生成测试套件),而几乎不需要学习成本。 然而,SBST生成的单元测试能否与先进的人工智能模型和技术进行比较仍是未知数。 例如,LLM生成的测试用例是否可读、可理解、可靠、可以在实践中使用。 在本文中,我们有兴趣了解大语言模型生成的测试套件的优点和缺点。 具体来说,我们利用最先进的 GPT-3 [16] 模型的产品 ChatGTP [17, 16] 作为大语言模型的代表进行比较。 更重要的是,本文旨在从两个方面获得见解:(1)我们热衷于从大型语言模型中学习知识以改进最先进的 SBST 技术,(2)我们也有兴趣揭示现有大型语言模型在生成测试套件方面的潜在局限性。
我们的研究。 为了应对上述挑战并实现目标,在本文中,我们打算回答以下研究问题(RQ):
RQ1(正确性): ChatGPT 的单元测试套件建议是否正确?
RQ2(可读性): ChatGPT 提供的测试套件易于理解吗?
RQ3(代码覆盖率): ChatGPT 与 SBST 的代码覆盖率表现如何?
RQ4(错误检测): ChatGPT 和 SBST 在生成检测错误的测试套件方面有多有效?
贡献。 总之,我们在本文中做出了以下贡献:
本文对大语言模型和SBST在Java编程语言程序生成单元测试套件方面进行了第一次对比评估;
我们从正确性、可读性、代码覆盖率、bug检测能力等多个方面系统地评估ChatGPT生成的测试套件;和
我们的研究结果有助于更好地理解大语言模型改进软件工程实践的潜力,特别是在单元测试生成领域。
2 背景
SBST 和 Evosuite。 基于搜索的软件测试(SBST)是一种将单元测试生成表述为优化问题[18]的技术。 SBST 将代码覆盖率视为测试生成的目标(例如分支覆盖率),并将其描述为指导遗传算法的适应度函数[3,19,20]。 遗传算法通过迭代来进化测试:(1) 将突变和交叉算子应用于现有测试(即当前一代)以进行新的后代测试,以及 (2) 通过从当前一代中选择具有更好适应度分数的测试来形成新一代,后代。 在我们的工作中,我们选择了 Java 中最成熟的 SBST 工具 Evosuite [21]。
大语言模型和ChatGPT。 大语言模型是参数数量最大的模型类型,在大量文本数据(例如,类人文本、代码等)上进行训练[22, 23, 24, 16, 25, 17]。 它旨在处理和理解输入的自然语言文本并生成与输入一致的文本,在机器翻译、问答、文本生成等自然语言处理(NLP)任务中表现出强大的能力。 ChatGPT [17] 是目前最理想的大语言模型(即通过 Instruct 来适应人类表达)[26, 25] 在 GPT-3 之上实现。 GPT-3 [16] 是在多层 Transformer 解码器 [22, 27, 28] 上构建的,具有 1750 亿个参数,使用少样本学习(即多个示例和迅速的)。 它在许多任务中表现出与最先进的微调系统类似的性能。 图1显示了使用GPT-3的一个示例。 GPT-3 接收输入文本并根据输入中的任务描述、示例和提示推断答案。 为了使大语言模型进一步与用户(人类)保持一致,InstructGPT [25]利用人类反馈的额外监督学习和强化学习来对 GPT-3 进行处理。 ChatGPT[17]使用与InstructGPT相同的方法,并且具有回答后续问题的能力。
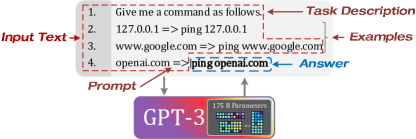
为了生成单元测试用例,可以利用 GPT-3 等大型语言模型。 为了生成给定代码片段作为输入的新测试用例,可以在代码片段及其附带测试用例的数据集上微调模型。 人们还可以利用 ChatGPT 回答后续问题的优势,为给定的代码片段生成更多样化的测试套件。
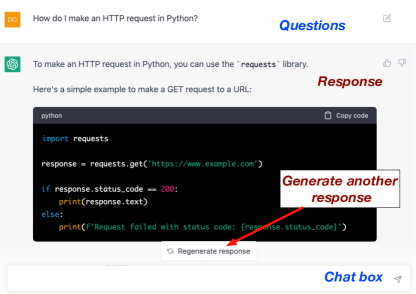
ChatGPT 的使用。 ChatGPT [17, 16] 可以按如下方式使用。 软件开发人员/测试人员(用户)注册 ChatGPT 帐户。 然后,用户向 ChatGPT 发送提示(文本或问题)。 然后,ChatGPT 将根据从训练数据中学到的信息做出响应。 此外,ChatGPT 可用于大多数软件工程相关任务,例如生成代码、生成注释和生成测试用例。 例如,如图2所示,ChatGPT提供了一个类似于Chatbot的基本用户界面,用户可以在其中用自然语言提出任何问题。 如图2所示,我们向ChatGPT询问如何用Python发出HTTP请求,ChatGPT展示了用Python编写的示例代码以及相应的解释。 如果用户对生成的响应不满意,他可以通过单击页面底部的“重新生成响应”按钮来要求 ChatGPT 重新生成响应。
3 比较评估设置
3.1 数据收集
对于RQ1-3,为了减少选择用于生成测试用例的主题代码的偏差,我们重用现有研究中使用的现有基准来评估 Evosuite 的性能。 在这里,我们使用 DynaMOSA(又名动态多目标排序算法)[20] 中提供的基准。 该基准测试包含来自 117 个项目的 346 个 Java 类。 详细的类信息可以在[20]和我们的工件存储库(第8)中找到。 然而,根据其他作品[4, 29]报告的事实,SF100数据集中的一些项目可能已过时并且不再维护。 由于 DynaMOSA 数据集中所需的某些类丢失或未公开,某些项目无法构建和编译。 结果,我们删除了 38 个项目,保留了 79 个项目,其中包含 248 个 Java 类。 对于RQ4,我们使用最先进的缺陷数据库进行Java相关研究,即Defects4J [30]。 它包含来自 17 个开源项目的 835 个错误。
3.2 使用ChatGPT生成单元测试用例
借助ChatGPT,我们能够自动生成程序的单元测试用例。 不幸的是,没有关于如何使用 ChatGPT 自动生成单元测试用例的标准或预言。 因此,我们采取以下步骤来学习使用ChatGPT生成单元测试用例的合理实践:
步骤1。 收集利用大语言模型(例如ChatGPT)从各种来源(包括Google、Google Scholar、GitHub和技术博客)自动生成单元测试用例的现有工具;
第2步。 分析这些工具中使用的短语和描述,以提示大语言模型生成测试用例。 这部分涉及分析源码、阅读块、学习技术文档;和
步骤 3. 使用 ChatGPT 验证步骤 2 中收集的短语和描述,以排除无效的短语和描述;
通过步骤1-3,我们得到以下能够为代码段生成单元测试用例的代表性表达式:
表达式1: “为${input}编写一个单元测试”,将被测代码段作为输入;
表达式2: “您可以使用 JUnit 为 ${input} 创建单元测试吗?”以被测代码段作为输入;
表达式3: “使用以下 Java 代码的测试用例创建完整的测试:${input}?”以被测代码段作为输入;
基于以上发现,我们将提示总结为:“编写一个 JUnit 测试用例来覆盖以下代码中的方法(每个方法一个测试用例):${input}?”将被测试的代码段作为输入。 请注意,为了模仿现实世界的实践,我们并不打算比较和评估 ChatGPT 提示来构建性能最佳的提示。 相反,我们只打算为 ChatGPT 建立一个合理的提示,以激励开发人员在现实环境中使用 ChatGPT。
3.3 研究的其他设置
EvoSuite 的设置。 EvoSuite 提供了许多参数(例如,交叉概率、群体大小[31])来运行算法。 在本文中,为了评估和比较 Evosuite 和 ChatGPT 之间的性能,我们保留 Evosuite 中的默认设置。 由于 Evosuite 利用遗传算法来选择和生成测试用例,为了减少随机性引入的偏差,我们为每个类别运行 30 次。
ChatGPT 的长输入。 ChatGPT 的最大输入长度为 2,048 个 Token ,大致相当于 340-350 个单词。 如果提交的输入太长,ChatGPT 会报告错误消息并且不给出任何响应。 在这种情况下,我们尝试按方法拆分整个类,并要求 ChatGPT 生成方法的单元测试用例。 然而,通过方法分割整个类来生成测试用例并不是一个好的做法,因为有关整个类的一些信息无法被 ChatGPT 感知。 结果,它损害了生成的测试用例的质量。 在这里,我们将最大长度设置为 4,096 个标记。 也就是说,如果一个类的长度大于 4,096 个标记,我们就会丢弃它。
环境。 EvoSuite 的实验是在配备 Intel(R) Core(TM) i9-10900 CPU @ 2.80GHz 和 128 GB RAM 的机器上进行的。
4 实验与评估
4.1 正确性
RQ1:ChatGPT 的单元测试套件建议是否正确?
动机。 我们首先需要检查的是 ChatGPT 是否可以正确返回测试用例来测试给定的程序/代码段。
方法论。 测试生成的测试用例是否正确。 我们需要从三个方面来评估它们:(1)ChatGPT 是否成功返回每个被测输入的测试用例; (2)这些测试用例是否可以编译并执行; (3) 这些测试用例是否包含潜在的错误。 具体来说,对于(2),可以借助Java虚拟机(JVM)来检查。 我们编译并执行测试用例来查看 JVM 是否报告错误。 对于(3),我们依靠最先进的静态分析器SpotBugs [32, 33, 34]来扫描ChatGPT生成的测试用例,以找出这些测试用例是否包含潜在的错误或漏洞。 SpotBugs [32] 是 FindBugs [33, 34](废弃项目)的后继者,是一个开源静态软件分析器,可用于捕获 bug在Java程序中。 它支持 400 多种错误模式和不良编程实践。
结果。 根据第 2 节中的长输入设置。 3.3,我们从 75 个项目中删除了 41 个类,并保留了 207 个 Java 类。
我们发现 ChatGPT 可以成功为所有 207 个 Java 类生成单元测试用例,并且不会报告任何错误。 在这些测试用例中,有144个(69.6%)测试用例可以在不需要额外人力的情况下成功编译和执行。 接下来,我们请两名有 Java 编程基础的本科生尝试借助 IntelliJ IDE [35] 修复错误。 其余64个测试用例中,有3个测试用例在没有目标程序背景知识的情况下无法直接修复,而60个测试用例可以借助IDE进行修复。 具体来说,3个测试用例中的错误分为3类:a)未能实现接口; b) 无法启动 Abstract 类实例; c) 尝试启动内部类的实例。
| Type of Errors | Frequency |
| Access Private/Protected Field | 31 |
| Access Private/protected Methods | 20 |
| Invoke undefined methods | 11 |
| Fail to initiate an instance for an interface | 10 |
| Incorrect parameter type | 2 |
| Fail to initiate an instance | 2 |
| Access undefined field | 1 |
其他 60 个测试用例的错误分为 7 类,如表所示。 I。 这里,invoke undefinedmethods表示调用目标类中未定义的方法。 桌子。 II 显示了一些调用未定义方法错误的示例。 调用未定义方法的根本原因是ChatGPT只给出了被测类而不是整个项目。 因此,ChatGPT 必须在需要时预测被调用者的名称。 当 ChatGPT 尝试生成一些断言时尤其如此。 但结果见表。 II 还让我们惊讶的是,即使 ChatGPT 未能调用正确的被调用者,它的预测也为找到正确的被调用者名称提供了强有力的线索。 这就是为什么我们不需要这些目标项目的领域知识就可以修复这些错误。 无法启动接口实例表示ChatGPT创建接口实例,但无法覆盖方法,类型错误表示调用点中的参数类型为不正确。
| Project | Classes | ChatGPT’s CallSite | Correct CallSite |
| trove | TFloatDoubleHash | hash.get(val) | hash.index(val) |
| trove | TFloatDoubleHash | hash.put(3, 4.0f) | hash.insertKeyAt(3, 4.0f) |
| 24_saxpath | XPathLexer | token.getStart() | token.getTokenBegin() |
| 24_saxpath | XPathLexer | token.getType() | token.getTokenType() |
| 73_fim1 | UpdateUserPanel | user.setUsername | user.setName() |
总而言之,ChatGPT 的编译错误主要是因为它无法概览整个项目。 因此,ChatGPT 尝试预测被调用者的名称、参数、参数类型等。 结果,引入了编译错误。
对于 (3),我们利用最先进的静态分析器 SpotBugs 来扫描 ChatGPT 生成的测试用例。 结果,SpotBugs 报告了 204 个测试用例中的 403 个潜在错误(3 个测试用例无法编译)。 总体分布情况如表所示。 III。 平均每个案例包含 1.97 个错误。
| Num. of Potential Bugs | Num. of Class |
| Over 20 | 3 (1.47%) |
| 10 - 20 | 7 (3.43%) |
| 1 - 9 | 69 (33.8%) |
| 0 | 125 (61.2%) |
| Priority Level | # Bugs | # Related Test Cases | Average |
| Scariest | 15 | 8 (3.9%) | 1.87 |
| Scary | 35 | 12 (5.8%) | 2.91 |
| Troubling | 10 | 7 (3.4%) | 1.42 |
| Of Concern | 343 | 70 (34.3%) | 4.9 |
| Bug Patterns | # Bugs | # Related Test Cases | Average |
| Bad Practice | 65 | 20 (9.8%) | 3.25 |
| Performance | 36 | 19 (9.4%) | 1.89 |
| Correctness | 52 | 20 (9.8%) | 2.6 |
| Multi-thread Correctness | 1 | 1 (0.49% | 1 |
| Dodgy Code | 199 | 45 (22.2%) | 4.42 |
| Internationalization | 47 | 10 (4.9%) | 4.7 |
| Experimental | 3 | 2 (0.98%) | 1.5 |
从bug优先级的角度来看,SpotBugs将bug的优先级分为最可怕、最可怕、麻烦和令人担忧。 最可怕级别表示错误被认为是最严重的,并且对代码的整体功能和安全性有潜在危害; 可怕级别表示错误被认为是重大的,如果不修复可能会导致问题; Troubling 级别表示错误被归类为次要错误,但如果不解决,仍然可能导致问题;和关注级别表示错误被认为是信息性的,通常对代码的功能或安全性构成最小甚至没有风险。 如表所示。 IV,大多数错误 (85.11%) 属于 Of Concern 类型。 只有 8 个测试用例 (3.9%) 存在 最可怕 级别的错误。
从错误模式的角度来看,已发现的错误分为七类:(1)不良实践; (2) 表现; (3) 正确性; (4)多线程正确性; (5) 狡猾的代码; (6)国际化; (7) 实验性的。 每个错误模式的详细描述可以在官方文档[36]中找到。 如表所示。 V,有21个测试用例涉及正确性错误或多线程正确性错误。 这些类型的错误代表出现的编码错误,通常属于最可怕或最可怕的优先级。 至于 Dodgy Code Pattern 所占比例最大,它代表代码混乱、异常或编写方式会导致错误。 示例案例可以是本地商店失效、交换机失败以及未经确认的演员阵容。 至于正确性/多线程正确性错误,根据我们的结果,主要指以下3种情况:空取消引用、越界数组访问和未使用的变量。
总之,从错误优先级和错误模式来看,我们可以得出结论,大多数(61.2%)ChatGPT 生成的测试用例没有错误。 只有 20 个 (9.8%) 测试用例来自最可怕和最可怕的级别。
4.2 可读性
RQ2:ChatGPT 提供的测试套件易于理解吗?
动机。 分析 ChatGPT 生成的代码的可读性是为了确保人类开发人员可以轻松维护、理解和修改它。 当其他开发人员随着时间的推移维护和更改 ChatGPT 生成的代码或将其合并到现有代码库时,这一点至关重要。
方法论。 对于这个RQ,我们设置了两个子任务:(1)代码风格检查; (2) 代码的可理解性。
为了检查生成的测试用例的代码风格,我们依靠支持 Java 的最先进的软件质量工具:Checkstyle [37],它是一个开发工具,用于检查生成的测试用例的代码风格。检查 Java 代码是否遵循编码标准。 它自动执行检查 Java 代码的过程。 在这里,我们利用两个标准(即 Sun Code Conventions [38]、Google Java Style [39])和 Checkstyle 来检查 ChatGPT 生成的测试套件是否遵循这些标准标准。
Dantas等人[40]提出了认知复杂度和圈复杂度指标来衡量代码片段的可理解性。 循环复杂度通过计算源代码中的独立路径来衡量程序复杂度。 它指示代码大小、结构和复杂性,并帮助找到容易出错的区域。 认知复杂性是从人类角度评估代码复杂性的指标。 它考虑代码结构、命名和缩进等因素来确定代码的难懂程度。 它可以帮助开发人员衡量可维护性和修改难度,并识别复杂或令人困惑的代码部分。 循环复杂度和认知复杂度可以使用 PMD IntelliJ 插件[41]来测量。 详细信息可以在项目存储库中找到(第 8 节)。
结果。 根据第 2 节中的长输入设置。 3.3,我们从 75 个项目中删除了 41 个类,保留了 204 个 Java 类。
代码风格检查结果。
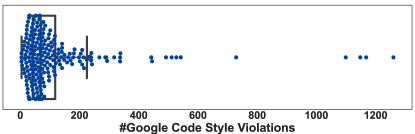
Checkstyle-Google: 图 3 显示了每个类的 Google Codestyle 违规情况的箱线图。 它表明数据集有几个较高的异常值,中值约为 70。 四分位距 (IQR) 介于 30 到 175 之间,表明大多数数据都在此范围内。 然而,数据严重向右倾斜,有一些极端数据点位于较高的一侧,表明分布不正常。 最小值为 4,最大值为 1260,这表明数据集中的值范围很广。
缩进是最常见的代码风格违规,这表明ChatGPT可能需要致力于一致地格式化其代码以提高可读性和可维护性;
FileTabCharacter 和 CustomImportOrder 似乎也经常违规,这凸显了正确配置和代码结构一致性的重要性;和
与代码易读性和易读性相关的违规行为(例如 LineLength 和 AvoidStarImport)不应被忽视,以保持高标准的代码质量。
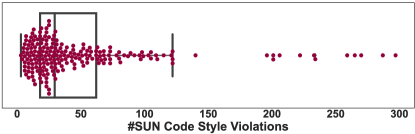
Checkstyle-SUN: 图5显示了箱线图。 数据中值在28左右,其中25%的数据低于15,75%的数据低于55。 上四分位上方有多个值,表示潜在的异常值或极值。 数据中的最小值为 3,最大值为 297。 该数据集的 IQR 为 40,表明数据集中的大多数值都在此范围内。
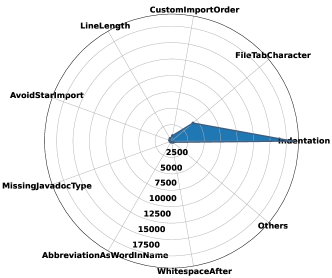
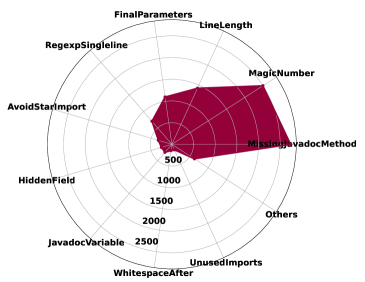
接下来,图6中的雷达图按类型细分违规问题以显示详细信息。 如图6所示,最常见的两种编码问题类型是MissingJavadocMethod和MagicNumber,分别出现了2742次和2498次。 MissingJavadocMethod 问题表明 ChatGPT 需要更多文档和解释。 此外,ChatGPT 生成的测试用例中的幻数主要用在断言中。 另外,从图中可以看出,FinalParameters、RegexpSingleline、AvoidStarImport也出现频率很高,说明这些地方也应该引起重视。 一些不太常见的问题,例如 HiddenField 和 UnusedImports,可能不太紧急,但仍然值得解决,以提高 ChatGPT 的整体代码质量。
综上所述,作为一种 AI 语言模型,ChatGPT 在生成测试用例时可能没有遵循特定的代码风格。 但是,测试用例的代码风格可能会受到为生成过程设置的参数和规则或为模型提供的输入的影响。 它还建议程序员在使用ChatGPT生成的测试用例时应注意代码风格。
代码理解。 PMD 中默认的圈复杂度和认知复杂度阈值是 10 和 15,这意味着如果类/方法的圈复杂度和认知复杂度低于这些值,系统不会报告该问题。 因此,我们构建了一系列定制规则来衡量复杂性。 规则集可以从我们的在线存储库下载。 请注意,复杂性是基于方法来测量的。
认知复杂性: 根据 SonarSource [42] 的技术报告,认知复杂度可分为四类:低(5 认知复杂度)、中度(6-10)、高( 11-20),并且复杂性非常高(21+)。 结果如表所示。 VI,所有方法复杂度较低。
| Cognitive Complexity Level | Num. of Class | Num. of Methods |
| Low complexity (5) | 204 | 3302 |
| Moderate complexity (6-10) | 0 | 0 |
| High complexity (11-20) | 0 | 0 |
| Very High complexity (21+) | 0 | 0 |
| Cyclomatic Complexity Level | Num. of Class | Num. of Methods |
| Low complexity (1-4) | 204 | 3300 |
| Moderate complexity (5-7) | 2 | 2 |
| High complexity (8-10) | 0 | 0 |
| Very High complexity (11+) | 0 | 0 |
圈复杂度: 根据PMD的官方文档[41],认知复杂度可以分为四类:低(1-4认知复杂度)、中(5-7)、高(8-10)、并且复杂性非常高(11+)。 结果如表所示。 VII,有204个低复杂度类的3300个方法和2个中等复杂度类的2个方法。
因此,根据上述结果,我们可以得出结论,ChatGPT 生成的测试用例非常容易遵循且复杂度较低。
4.3 代码覆盖率
RQ3:ChatGPT 与 SBST 的代码覆盖率表现如何?
动机。 虽然低覆盖率意味着代码的某些部分尚未经过检查,但高覆盖率表明生成的测试已经彻底评估了代码。 比较 ChatGPT 和 SBST 生成的测试套件之间的代码覆盖率使我们能够评估和评估 ChatGPT 生成的测试套件。
方法论。 JaCoCo [43] 测量指令和分支覆盖率。 指令覆盖率与 Java 字节码指令相关,因此类似于源代码上的语句覆盖率。 我们仅使用指令覆盖率(即语句覆盖率 (SC))来评估代码覆盖率,因为 JaCoCo 的分支覆盖率定义仅计算条件语句的分支,也不计算控制流图中的边缘。
结果。 根据第 2 节中的长输入设置。 3.3,我们从 75 个项目中删除了 41 个类,并保留了 207 个 Java 类。
| Projects | (A)Max | (A)Min | (A)SDEV. | (A)Avg. | (A)ChatGPT |
| 1_tullibee | 100% | 100% | 0.00 | 100% | 93% |
| 100_jgaap | 95.0% | 95.0% | 0.00 | 95.0% | 83% |
| 105_freemind | 71.5% | 64.5% | 1.56 | 69.1% | 52% |
| 107_weka | 87.0% | 79.0% | 2.95 | 83.0% | 37% |
| 11_imsmart | 100% | 100% | 0.00 | 100% | 100% |
| 12_dsachat | 35.5% | 35.5% | 0.00 | 35.5% | 34% |
| 14_omjstate | 67.0% | 67.0% | 0.00 | 67.0% | 55% |
| 15_beanbin | 80.5% | 80.5% | 0.00 | 80.5% | 46% |
| 17_inspirento | 94.0% | 92.5% | 0.33 | 94.0% | 87.5% |
| 2_a4j | 50.5% | 44.0% | 1.54 | 48.5% | 31% |
| 21_geo-google | 54.0% | 54.0% | 0.00 | 54.0% | 67% |
| 24_saxpath | 97.0% | 96.0% | 0.34 | 96.5% | 95% |
| 26_jipa | 88.0% | 73.5% | 3.63 | 83.50% | 97% |
| 29_apbsmem | 98.0% | 98.0% | 0.00 | 98.0% | 80% |
| 31_xisemele | 71.0% | 71.0% | 0.00 | 71.0% | 75% |
| 33_javaviewcontrol | 82.0% | 62.5% | 6.13 | 76.0% | 46% |
| 35_corina | 85.0% | 75.0% | 3.69 | 78.0% | 65% |
| 36_schemaspy | 100.0% | 100.0% | 0.00 | 100.0% | 67% |
| 39_diffi | 99.0% | 93.0% | 3.02 | 95.5% | 69.5% |
| 4_rif | 100.0% | 100.0% | 0.00 | 100.00% | 96% |
| 40_glengineer | 97.0% | 86.5% | 3.37 | 95.0% | 73% |
| 41_follow | 92.5% | 71.0% | 5.73 | 82.0% | 38% |
| 43_lilith | 100.0% | 100.0% | 0.00 | 100.0% | 95% |
| 45_lotus | 70.5% | 70.5% | 0.00 | 70.5% | 75% |
| 47_dvd-homevideo | 13.3% | 13.3% | 0.00 | 13.3% | 0.7% |
| 51_jiprof | 96.5% | 78.0% | 3.76 | 93.0% | 44.5% |
| 52_lagoon | 19.5% | 14.0% | 1.15 | 18.0% | 27% |
| 55_lavalamp | 100.0% | 100.0% | 0.00 | 100.0% | 100% |
| 60_sugar | 96.0% | 87.5% | 2.47 | 90.0% | 79% |
| 61_noen | 82.5% | 81.5% | 0.18 | 81.5% | 60% |
| 63_objectexplorer | 51.5% | 51.5% | 0.00 | 51.5% | 47% |
| 64_jtailgui | 76.5% | 17.0% | 16.41 | 70.0% | 0% |
| 68_biblestudy | 81.5% | 81.5% | 0.00 | 81.5% | 57% |
| 69_lhamacaw | 43.5% | 43.5% | 0.00 | 43.5% | 6% |
| 7_sfmis | 100.0% | 100.0% | 0.00 | 100.0% | 87% |
| 72_battlecry | 1.0% | 1.0% | 0.00 | 1.0% | 57% |
| 73_fim1 | 24.0% | 24.0% | 0.00 | 24.0% | 44.5% |
| 74_fixsuite | 67.5% | 50.0% | 6.43 | 54.5% | 40% |
| 77_io-project | 100.0% | 100.0% | 0.00 | 100.0% | 71% |
| 78_caloriecount | 92.7% | 88.3% | 1.24 | 89.7% | 46.7% |
| 79_twfbplayer | 97.5% | 95.5% | 0.53 | 96.5% | 69.5% |
| 8_gfarcegestionfa | 68.0% | 62.5% | 1.31 | 65.0% | 55% |
| 80_wheelwebtool | 84.3% | 83.0% | 0.31 | 83.3% | 36% |
| 82_ipcalculator | 91.5% | 81.0% | 4.07 | 85.0% | 73% |
| 83_xbus | 34.0% | 19.0% | 6.75 | 23.00% | 33% |
| 84_ifx-framework | 55.0% | 55.0% | 0.00 | 55.0% | 32% |
| 85_shop | 71.5% | 55.8% | 4.22 | 63.8% | 24.8% |
| 86_at-robots2-j | 86.0% | 48.0% | 15.02 | 58.0% | 45% |
| 87_jaw-br | 32.0% | 31.0% | 0.18 | 32.0% | 17.5% |
| 88_jopenchart | 99.5% | 72.0% | 10.87 | 78.5% | 52% |
| 89_jiggler | 91.0% | 81.7% | 2.10 | 89.7% | 30.3% |
| 90_dcparseargs | 100.0% | 94.0% | 1.22 | 99.0% | 75% |
| 91_classviewer | 93.0% | 91.0% | 0.29 | 92.5% | 73% |
| 92_jcvi-javacommon | 100.0% | 100.0% | 0.00 | 100.0% | 74% |
| 94_jclo | 82.0% | 68.0% | 4.31 | 74.0% | 11% |
| 95_celwars2009 | 47.0% | 47.0% | 0.00 | 47.0% | 46% |
| 97_feudalismgame | 25.0% | 19.5% | 2.06 | 21.1% | 15% |
| 98_trans-locator | 50.0% | 47.0% | 0.57 | 50.0% | 15% |
| 99_newzgrabber | 20.7% | 17.7% | 0.76 | 20.3% | 10.7% |
| Projects | (A)Max | (A)Min | (A)SDEV. | (A)Avg. | (A)ChatGPT |
| checkstyle | 87.5% | 79.3% | 3.28 | 84.7% | 65.2% |
| commons-cli | 98.5% | 95.0% | 1.09 | 98.1% | 69% |
| commons-collections | 94.3% | 89.3% | 0.91 | 94.1% | 68% |
| commons-lang | 94.0% | 86.0% | 2.36 | 90.1% | 73.1% |
| commons-math | 72.7% | 64.1% | 3.17 | 69.0% | 45.6% |
| compiler | 67.7% | 36.9% | 9.48 | 53.9% | 6.29% |
| guava | 75.0% | 70.1% | 1.28 | 72.9% | 63.1% |
| javaml | 97.1% | 87.3% | 2.46 | 96.4% | 76.1% |
| javex | 94.0% | 67.0% | 12.59 | 81.2% | 63% |
| jdom | 80.7% | 80.5% | 0.06 | 80.7% | 31.3% |
| joda | 94.9% | 92.4% | 0.64 | 93.9% | 71.6% |
| jsci | 97.0% | 86.0% | 2.62 | 92.4% | 50% |
| scribe | 95.3% | 95.3% | 0.00 | 95.3% | 91.2% |
| trove | 81.0% | 76.7% | 1.26 | 79.3% | 45.3% |
| twitter4j | 92.2% | 89.7% | 0.67 | 91.3% | 70.7% |
| xmlenc | 97.0% | 94.0% | 0.61 | 95.1% | 54% |
| Overall Avg. (Project) | 77.4% | 70.6% | - | 74.5% | 55.4% |
语句覆盖率 (SC) 比较。 当我们运行 EvoSuite 30 次时,我们计算最大、最小、平均值和平均标准差。 回想一下 RQ1 中的结果,对于 3 个 ChatGPT 生成的测试用例,在没有背景知识的情况下无法修复,我们将其代码覆盖率视为 0 222与其他 RQ 中的 204 个测试用例不同,我们在本 RQ 中考虑了 207 个测试用例。.
如表VIII和IX所示,对于Evosuite,所有项目平均最大SC可达77.4%;所有项目最低SC可达70.6%;所有项目的平均SC可达74.2%。 相比之下,对于 ChatGPT,所有项目的平均 SC 可以达到 55.4%。 总体而言,Evosuite 在 SC 方面的表现优于 ChatGPT 19.1%。 此外,ChatGPT 在 75 个项目中的 10 个(13.33%)中优于 Evosuite,这些项目在表中突出显示。 VIII 和 IX。 从类别角度来看,ChatGPT 在 207 个类别中的 37 个类别(17.87%)中优于 EvoSuite。
此外,通过投资 ChatGPT 优于 EvoSuite 的 37 个案例,我们发现 ChatGPT 非常擅长生成测试用例,原因如下:
1. 与 Evosuite 相比,ChatGPT 可以生成不同的字符串对象/整数/双精度值以供使用(例如比较),具有高度多样性(参考:guava::Objects、math::SimplexTableu );
2. ChatGPT 可以为 FontChooser 生成 Font 实例,但不适用于 Evosuite(参考:71_film2::FontChooserDialog);
3. 与 Evosuite 相比,ChatGPT 可以生成更合理且可用的 UI 操作(即 ActionEvents)来测试 UI(参考:72_bcry::battlecryGUI);
4. ChatGPT 可以根据被测类的现有信息生成测试用例或实例(参考:45_lotus::Phase)。 图7显示了45-lotus::Phase.java中的代码段。 这段代码还表明,某些实例(例如 UpkeepPhase()、DrawPhase()、Main1Phase())与
Game.currentPhase 的类型兼容。 ChatGPT 可以正确捕获此类信息,并用于生成各种 Phase 实例。 因此,它可以达到比EvoSuite更高的覆盖率;

5. 与 EvoSuite 相比,ChatGPT 可以根据从被测类收集的语义信息生成更复杂的调用链进行测试(参考 guava::Monitor)。 例如图8中的代码段,ChatGPT可以生成更复杂的调用链,而不是一次调用单个方法。 更重要的是,它的调用链逻辑上是正确的。 也就是说,方法enter必须在leave之前调用。 这得益于大语言模型可以从代码或标识符中感知语义上下文。

6. ChatGPT 可以生成适合目标的语义上下文测试数据。 例如,调用方法 setCountry
(Ref: 21_geo-google::GeoStatusCode) 的输入参数可以是任何字符串。 但是,与随机字符串相比,真实的国家/地区名称(例如,美国)可能更适合测试方法 setCountry。
此外,随着代码复杂性的增加,用于识别适当测试用例的搜索空间也随之增加,导致 SBST 技术的执行时间更长,计算开销更大。 因此,这可能对发现有效的测试用例构成重大挑战,这些测试用例可以确保最佳的代码覆盖率并暴露任何缺陷。
继之前的研究工作[4,44,45]之后,我们采用Vargha-Delaney来评估特定方法()是否优于另一种( )。 根据 Vargha 和 Delaney [45],A12 分别超过 0.56、0.64、0.71 和 0.8 表示可忽略、小、中等和大的差异。
所有类别的比较。 如表所示。 X,有193个测试用例属于大组,14个测试用例属于忽略组。 这表明在大多数情况下,EvoSuite 在达到更高的代码覆盖率方面明显优于 ChatGPT。 所有类别的总体 Vargha-Delaney 测量值为 0.71(中)。
| Large | Medium | Small | Negligible | |
| Num. of Classes | 193 | 0 | 0 | 14 |
| Overall V.D. | 0.71 (Medium) | |||
小班/大班比较。 这里,小班被定义为分支少于50个的班。 超过50个分校的班级被视为大班。
| Large | Medium | Small | Negligible | |
| Num. of Big Classes | 121 | 0 | 0 | 5 |
| Overall V.D. | 0.764 (Large) | |||
| Large | Medium | Small | Negligible | |
| Num. of Small Classes | 70 | 0 | 0 | 11 |
| Overall V.D. | 0.63 (Small) | |||
大班比较。 桌子。 XI 显示大类的比较。 有121个测试用例属于大组,5个测试用例属于忽略组。 这表明 EvoSuite 在大类情况下达到更高的代码覆盖率方面明显优于 ChatGPT。 所有类别的总体 Vargha-Delaney 度量为 0.764(大)。
小班比较。 桌子。 XII 显示了小班的比较。 有 70 个测试用例属于大组,11 个测试用例属于可忽略组。 这表明 EvoSuite 在大类情况下达到更高的代码覆盖率方面明显优于 ChatGPT。 所有类别的总体 Vargha-Delaney 度量为 0.63(小)。
不幸的是,即使在大型课程中,我们也没有看到 ChatGPT 的表现优于 EvoSuite。 这表明无论是大类还是小类,都建议开发人员转向EvoSuite以获得更高的代码覆盖率。 潜在的原因可能多种多样。 一些可能的原因可能是:(1) 规格不齐全: ChatGPT 仅提供被测试的类,而不是整个项目。 因此,如果没有整个项目的信息,ChatGPT 就很难生成更有价值的测试用例; (2) 缺乏反馈机制: 与可以从反馈训练(即覆盖数据)中学习的 Evosuit 不同,ChatGPT 仅依赖于数据。 这使得 ChatGPT 很难通过迭代过程来理解测试结果的反馈,从而导致测试覆盖率较低。
然而,结果也提出了两个见解:
见解一: 作为人工智能助手,ChatGPT 具有很强的能力,可以从被测代码中理解规则语义和上下文。 这意味着ChatGPT可以帮助有效生成测试数据。 通过在SBST(基于搜索的软件测试)工具中嵌入AI模型或NLP(自然语言处理)模块,ChatGPT可以极大地提高SBST工具的性能。 这是因为该工具将能够理解和解释复杂的代码结构,并基于它们以更高的准确性和效率生成测试用例。 因此,开发人员可以受益于更快、更高效的测试和更可靠的软件产品;和
见解2: 尽管无法与EvoSuite相比,ChatGPT仍然可以达到较高的代码覆盖率(55.4%)。 因此,ChatGPT 仍然可以作为测试新人的入门级工具或作为备用选项。
4.4 错误检测
RQ4:ChatGPT 和 SBST 在生成检测错误的测试套件方面有多有效?
动机。 生成的测试套件的主要用途是在程序中查找伙伴代码。 因此,在此 RQ 中,我们评估生成的测试套件在检测错误方面的有效性。
方法论。 为了评估生成的测试套件在检测错误方面的有效性,我们首先为目标类生成单元测试套件,并检查测试套件是否能够在 Defects4J 基准测试中成功捕获错误。 请注意,在此 RQ 中,为了公平起见,我们仅运行 EvoSuite 一次来生成测试用例。

结果。 Defects4J 中的一些错误是逻辑错误,由 断言 触发。 不幸的是,我们发现有时 ChatGPT 生成的 断言 并不可靠。 例如,图9说明了Time项目中Period的测试用例。 断言语句 assertEquals(1000, p.getMillis(); 不正确。 然而,被测试的代码段没有错误,预期值应该是 0 而不是 1000。 ChatGPT 对于这种情况做出了错误的断言。 这意味着我们不能完全依赖 ChatGPT 生成的测试用例中的断言来确定错误是否被成功触发。 然而,手动检查 ChatGPT 生成的测试用例中的断言可能非常耗时且容易出错[46,47,48]。 因此,在此 RQ 中,我们重点关注与 Java 异常相关的错误,例如 NullPointerException、UnsupportedOperationException。
| ChatGPT | Evosuite | ||||
| Project | # All/ # Exce. Bugs | Detected | Coverage | Detected | Coverage |
| Chart | 26 / 8 | 4 (50%) | 62% | 3 (38%) | 85% |
| Cli | 39 / 8 | 1 (13%) | 70% | 2 (25%) | 88% |
| Closure | 174 / 9 | 1 (11%) | 14% | 0 (0%) | 4% |
| Codec | 18 / 7 | 0 (0%) | 60% | 2 (29%) | 94% |
| Collections | 4 / 2 | 0 (0%) | 87% | 0 (0%) | 67% |
| Compress | 47 / 19 | 6 (32%) | 42% | 3 (16%) | 57% |
| Csv | 16 / 7 | 2 (29%) | 80% | 5 (71%) | 90% |
| Gson | 18 /12 | 2 (17%) | 59% | 6 (50%) | 55% |
| JacksonCore | 26 / 8 | 2 (25%) | 38% | 2 (25%) | 64% |
| JacksonDatabind | 112 / 53 | 9 (17%) | 30% | 4 (8%) | 56% |
| JacksonXml | 6 / 1 | 0 (0%) | 29% | 0 (0%) | 49% |
| Jsoup | 93 / 22 | 4 (18%) | 63% | 10 (45%) | 86% |
| JxPath | 22 / 1 | 1 (100%) | 40% | 1 (100%) | 88% |
| Lang | 64 / 20 | 6 (30%) | 68% | 3 (15%) | 55% |
| Math | 106 / 28 | 5 (18%) | 64% | 12 (43%) | 84% |
| Time | 26 / 7 | 1 (14%) | 56% | 2 (29%) | 88% |
| Total | 796 / 212 | 44 (21%) | 50% | 55 (26%) | 67% |
桌子。 XIII显示了实验结果。 在表中,对于每个项目,在两种方法之间的比较中突出显示了较高的值(例如,较高的代码覆盖率)。 此外,在 212 个错误中,ChatGPT 生成的测试用例成功检测到了 44 个错误,平均语句代码覆盖率为 50%。 相比之下,EvoSuite 生成的测试用例成功检测到 55 个错误,平均语句代码覆盖率为 67%。 从比较中我们还可以看到,在某些情况下,EvoSuite 比 ChatGPT 检测到更多的 bug,而在其他情况下,ChatGPT 比 EvoSuite 检测到更多的 bug。 例如,在 Chart 项目中,EvoSuite 的 bug 检测覆盖率高于 ChatGPT,但在某些情况下,ChatGPT 检测到的 bug 数量比 EvoSuite 更多。 值得注意的是,这两种工具的覆盖率在不同的项目中差异很大,这表明每种工具的有效性可能取决于所测试项目的具体特征。 有趣的是,ChatGPT 能够在某些情况下检测到 EvoSuite 无法检测到的错误,这表明这两个工具可以相互补充,并且可以一起使用来改进错误检测。
通过比较 ChatGPT 和 EvoSuite 生成的测试用例,我们发现大语言模型(例如 ChatGPT)可能无法优于 Evosuite 的几个可能原因:
由于ChatGPT的输入只能是被测类,而不是整个项目(例如jar文件),因此ChatGPT很难生成复杂的实例,这会使测试用例生成极端情况探索错误;
作为一个大型语言模型,ChatGPT 生成/预测内容,以提示或起始文本作为输入,并使用其学到的语言理解来预测接下来应该出现什么单词或短语。 该预测基于特定单词序列出现在数据集中的概率。 与边缘情况相比,常用案例(即我们上下文中的测试案例/数据)很有可能拥有更高的概率;和
通过采用遗传算法来探索能够实现更高代码覆盖率的潜在测试套件,Evosuite 理论上可能拥有更大的发现 bug 的概率。 值得注意的是,这样的反馈机制目前在大语言模型(例如 ChatGPT)中并不存在,这凸显了将 SBST 技术与大语言模型相结合进行程序测试和错误检测的潜在好处。
还值得一提的是,给出的结果并不能反映ChatGPT发现或定位Bug的能力。 它仅涉及 ChatGPT 生成的测试用例的错误检测能力。
5 限制和有效性威胁
5.1 限制
本研究的结果和实验仅限于两部分:(1)考虑到手动查询ChatGPT的需要,我们的研究仅限于为本研究所做的查询。 由于 ChatGPT 是闭源的,我们无法将我们的结果映射到 ChatGPT 内部模型的细节或特征。 我们也不知道 ChatGPT 的确切训练数据,这意味着我们无法确定对我们查询的确切响应是否是训练数据的成员; (2) 由于 ChatGPT 正在不断更新和训练,ChatGPT 的响应只能反映我们进行工作时 ChatGPT 的性能(即 ChatGPT Jan 30 (2023) 版本)。
5.2 有效性威胁
为了通过手动选择测试主题程序来减少偏差,我们重用了现有研究中已使用和研究的基准(即 Defects4J、DyanMOSA 数据集)。 此外,我们还重用现有研究工作中提出的指标来计算代码覆盖率、代码可读性等。 对内部有效性的另一个威胁来自遗传算法的随机性。 为了降低风险,我们每堂课重复 EvoSuite 30 次。 至于外部有效性,由于基准的规模,我们并不试图概括我们的结果和结论。
6 相关工作
语言模型。 语言模型在 NLP 中用于许多任务,例如机器翻译、问答、摘要、文本生成等[5, 7, 49, 50, 51, 52, 53, 54, 55, 56] 。 为了更好地理解语言,具有大量参数的模型在非常大的语料库(即大语言模型)上进行训练。 Transformer [22] 是在堆叠的编码器和解码器上构建的。 它利用自注意力机制来权衡输入文本中单词的重要性,捕获输入中单词之间的远程依赖性和关系。 它是许多大语言模型的基础。 ELMo [57] 利用多层双向 LSTM 并提供高质量的单词表示。 GPT [28]和BERT [23]分别基于Transformer的解码器(单向)和编码器(双向)构建,使用预训练和微调技术。 GPT-2 [27] 和 GPT-3 [16] 是 GPT 的后代。 GPT-2的模型尺寸比GPT大,GPT-3比GPT-2大。 此外,在语料库更大的情况下,GPT-2和GPT-3引入了零样本和少样本学习,使模型适应多任务。 Codex [55] 是使用 Github 代码数据训练 GPT-3 获得的。 它是为 GitHub Copilot [58] 提供支持的模型,这是一个自动生成计算机代码的工具。 InstructGPT [25] 利用来自人类反馈的额外监督学习和强化学习来调整 GPT-3,使大语言模型与用户保持一致。 ChatGPT[17]使用与InstructGPT相同的方法,并且具有回答后续问题的能力。
基于搜索的软件测试。 SBST 将测试用例生成视为优化问题。 Miller 等人[59]提出了第一个为具有浮点类型输入的函数生成测试数据的SBST方法。 许多软件测试方法[60,61,62]都广泛使用了 SBST 方法。 大多数研究集中在 (1) 搜索算法上:Tonella [18] 建议迭代为每个分支生成一个测试用例。 Fraser 等人[3]建议为所有分支建立一个测试套件。 Panichella 等人[19, 20]提出了多目标优化技术。 为了降低计算成本,Grano等人[63]开发了DynaMOSA的变体; (2)增强适应度梯度:Arcuri等人将可测试性转换引入API测试中[64]对于具有复杂输入的程序。 Lin等人[65]提出了一种处理过程间标志问题的方法。 Lin 等人提出了一种测试种子合成方法来产生复杂的测试输入[29]。 Braione 等人 [66] 耦合符号执行和 SBST; (3)适应度函数的设计:徐等人[67]提出了一种增强SBST的自适应适应度函数; Rojas等人[68]建议结合多种覆盖标准,以满足开发者更多的需求。 Gregory Gay 尝试了各种标准组合[69],以比较多标准套件在发现实际缺陷方面的有用性。 Zhou等人[4]提出了一种从多个标准中选择覆盖目标而不是组合所有目标的方法; (4)创建的测试的可读性:Daka等人[70]建议通过陈述覆盖的目标来命名测试。 深度学习技术由Roy等人[71]介绍; (5) 将SBST应用于更多软件领域,例如机器学习库[72]、Android应用程序[73]、Web API [74]和深度神经网络[75]。
7 结论
在本文中,我们对由两种最先进的技术生成的单元测试套件进行了系统评估:ChatGPT 和 SBST。 我们从多个关键角度全面评估 ChatGPT 生成的测试套件,包括正确性、可读性、代码覆盖率和错误检测能力。 我们的实验结果表明(1)ChatGPT 生成的测试用例中有 69.6% 可以成功编译和执行; (2) 我们还观察到,生成的代码风格中最常见的违规行为是 Indentation(针对 Google 风格)和 MissingJavadocMethod(针对 SUN 风格),而大多数测试用例的复杂性较低; (3) 此外,我们的评估显示,EvoSuite 在代码覆盖率方面优于 ChatGPT 19%; (4) EvoSuite 在代码覆盖率方面优于 ChatGPT 5%。
8 数据可用性
实验结果和原始数据可访问:https://sites.google.com/view/chatgpt-sbst
参考
- [1] H. Zhu, P. A. V. Hall, and J. H. R. May, “Software unit test coverage and adequacy,” ACM Comput. Surv., vol. 29, no. 4, p. 366–427, 1997.
- [2] M. Harman, S. A. Mansouri, and Y. Zhang, “Search-based software engineering: Trends, techniques and applications,” ACM Computing Surveys (CSUR), vol. 45, no. 1, pp. 1–61, 2012.
- [3] G. Fraser and A. Arcuri, “Whole test suite generation,” IEEE Transactions on Software Engineering, vol. 39, no. 2, pp. 276–291, 2013.
- [4] Z. Zhou, Y. Zhou, C. Fang, Z. Chen, and Y. Tang, “Selectively combining multiple coverage goals in search-based unit test generation,” in 37th IEEE/ACM International Conference on Automated Software Engineering, 2022, pp. 1–12.
- [5] N. Carlini, F. Tramer, E. Wallace, M. Jagielski, A. Herbert-Voss, K. Lee, A. Roberts, T. B. Brown, D. Song, U. Erlingsson et al., “Extracting training data from large language models.” in USENIX Security Symposium, vol. 6, 2021.
- [6] T. Brants, A. C. Popat, P. Xu, F. J. Och, and J. Dean, “Large language models in machine translation,” 2007.
- [7] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” J. Mach. Learn. Res., vol. 21, no. 1, 2022.
- [8] A. Svyatkovskiy, S. K. Deng, S. Fu, and N. Sundaresan, “Intellicode compose: Code generation using transformer,” in Proc. of ESEC/FSE, 2020, p. 1433–1443.
- [9] U. Alon, R. Sadaka, O. Levy, and E. Yahav, “Structural language models for any-code generation,” 2019.
- [10] G. Poesia, A. Polozov, V. Le, A. Tiwari, G. Soares, C. Meek, and S. Gulwani, “Synchromesh: Reliable code generation from pre-trained language models,” in Proc. of ICLR, 2022.
- [11] P. W. McBurney and C. McMillan, “Automatic source code summarization of context for java methods,” IEEE Transactions on Software Engineering, vol. 42, no. 2, pp. 103–119, 2016.
- [12] S. Haiduc, J. Aponte, and A. Marcus, “Supporting program comprehension with source code summarization,” in Proc. of ICSE, 2010, p. 223–226.
- [13] J. Zhang, X. Wang, H. Zhang, H. Sun, and X. Liu, “Retrieval-based neural source code summarization,” in Proc. of ICSE, 2020, p. 1385–1397.
- [14] P. W. McBurney and C. McMillan, “Automatic documentation generation via source code summarization of method context,” in Proc. of ICPC, 2014, p. 279–290.
- [15] X. Hu, G. Li, X. Xia, D. Lo, and Z. Jin, “Deep code comment generation,” in Proc. of ICPC, 2018, p. 200–210.
- [16] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are few-shot learners,” in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 1877–1901.
- [17] OpenAI, “Chatgpt: Optimizing language models for dialogue,” 2023, https://openai.com/blog/chatgpt/.
- [18] P. Tonella, “Evolutionary testing of classes,” in Proc. of ISSTA, 2004, p. 119–128.
- [19] A. Panichella, F. M. Kifetew, and P. Tonella, “Reformulating branch coverage as a many-objective optimization problem,” in Proc. of ICST, 2015, pp. 1–10.
- [20] ——, “Automated test case generation as a many-objective optimisation problem with dynamic selection of the targets,” IEEE Transactions on Software Engineering, vol. 44, no. 2, pp. 122–158, 2018.
- [21] G. Fraser and A. Arcuri, “Evosuite: Automatic test suite generation for object-oriented software,” in Proc. of ESEC/FSE, 2011, p. 416–419.
- [22] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [23] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [24] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” The Journal of Machine Learning Research, vol. 21, no. 1, pp. 5485–5551, 2020.
- [25] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray et al., “Training language models to follow instructions with human feedback,” arXiv preprint arXiv:2203.02155, 2022.
- [26] M. Artetxe, J. Du, N. Goyal, L. Zettlemoyer, and V. Stoyanov, “On the role of bidirectionality in language model pre-training,” arXiv preprint arXiv:2205.11726, 2022.
- [27] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever et al., “Language models are unsupervised multitask learners,” OpenAI blog, vol. 1, no. 8, p. 9, 2019.
- [28] A. Radford, K. Narasimhan, T. Salimans, I. Sutskever et al., “Improving language understanding by generative pre-training,” 2018.
- [29] Y. Lin, Y. S. Ong, J. Sun, G. Fraser, and J. S. Dong, “Graph-based seed object synthesis for search-based unit testing,” in Proc. of ESEC/FSE, 2021, p. 1068–1080.
- [30] Defects4J, “Defects4j: A database of real faults and an experimental infrastructure to enable controlled experiments in software engineering research,” 2023, https://github.com/rjust/defects4j.
- [31] Evosuite, “Evosuite: Automatic test suite generation for java,” 2023, https://www.evosuite.org/.
- [32] SpotBugs, “Spotbugs,” 2023, https://spotbugs.github.io/index.html.
- [33] B. Pugh and D. Hovemeyer, “Findbugs,” 2023, https://findbugs.sourceforge.net/.
- [34] N. Ayewah, W. Pugh, D. Hovemeyer, J. D. Morgenthaler, and J. Penix, “Using static analysis to find bugs,” IEEE Software, vol. 25, no. 5, pp. 22–29, 2008.
- [35] JetBrain, “Intellij idea – the leading java and kotlin ide,” 2023, https://www.jetbrains.com/idea/.
- [36] Spotbugs, “Spotbug bug descriptions,” 2023, https://spotbugs.readthedocs.io/en/stable/bugDescriptions.html.
- [37] CheckStyle, “Checkstyle,” 2023, https://checkstyle.sourceforge.io/.
- [38] Oracle, “Code conventions for the java programming language,” 1999, https://www.oracle.com/java/technologies/javase/codeconventions-contents.html.
- [39] Google, “Google java style guide,” 2023, https://google.github.io/styleguide/javaguide.html.
- [40] C. E. C. Dantas and M. A. Maia, “Readability and understandability scores for snippet assessment: an exploratory study,” arXiv preprint arXiv:2108.09181, 2021.
- [41] P. S. C. Analyzer, “Pmd,” 2023, https://pmd.github.io/.
- [42] sonarsource, “Cognitive computing: A new way of measuring understandability,” 2021, https://www.sonarsource.com/docs/CognitiveComplexity.pdf.
- [43] M. G. . C. KG, “Jacoco java code coverage library,” 2023, https://www.jacoco.org/jacoco/.
- [44] A. Vargha and H. D. Delaney, “A critique and improvement of the cl common language effect size statistics of mcgraw and wong,” Journal of Educational and Behavioral Statistics, vol. 25, no. 2, pp. 101–132, 2000.
- [45] J. M. Rojas, J. Campos, M. Vivanti, G. Fraser, and A. Arcuri, “Combining multiple coverage criteria in search-based unit test generation,” in Search-Based Software Engineering: 7th International Symposium, 2015, pp. 93–108.
- [46] K. Shrestha and M. J. Rutherford, “An empirical evaluation of assertions as oracles,” in 2011 Fourth IEEE International Conference on Software Testing, Verification and Validation, 2011, pp. 110–119.
- [47] G. Jahangirova, D. Clark, M. Harman, and P. Tonella, “An empirical validation of oracle improvement,” IEEE Transactions on Software Engineering, vol. 47, no. 8, pp. 1708–1728, 2021.
- [48] V. Terragni, G. Jahangirova, P. Tonella, and M. Pezzè, “Gassert: A fully automated tool to improve assertion oracles,” in 2021 IEEE/ACM 43rd International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), 2021, pp. 85–88.
- [49] Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut, “Albert: A lite bert for self-supervised learning of language representations,” arXiv preprint arXiv:1909.11942, 2019.
- [50] Y. Zhang, S. Sun, M. Galley, Y.-C. Chen, C. Brockett, X. Gao, J. Gao, J. Liu, and B. Dolan, “DIALOGPT : Large-scale generative pre-training for conversational response generation,” in Proc. of ACL, 2020.
- [51] J. Pilault, R. Li, S. Subramanian, and C. Pal, “On extractive and abstractive neural document summarization with transformer language models,” in Proc. of EMNLP, 2020, pp. 9308–9319.
- [52] X. Cai, S. Liu, J. Han, L. Yang, Z. Liu, and T. Liu, “Chestxraybert: A pretrained language model for chest radiology report summarization,” IEEE Transactions on Multimedia, pp. 845 – 855, 2021.
- [53] D. Khashabi, S. Min, T. Khot, A. Sabharwal, O. Tafjord, P. Clark, and H. Hajishirzi, “Unifiedqa: Crossing format boundaries with a single qa system,” arXiv preprint arXiv:2005.00700, 2020.
- [54] K. Cho, B. Van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y. Bengio, “Learning phrase representations using rnn encoder-decoder for statistical machine translation,” arXiv preprint arXiv:1406.1078, 2014.
- [55] M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman et al., “Evaluating large language models trained on code,” arXiv preprint arXiv:2107.03374, 2021.
- [56] N. D. Bui, Y. Yu, and L. Jiang, “Infercode: Self-supervised learning of code representations by predicting subtrees,” in Proc. of ICSE. IEEE, 2021, pp. 1186–1197.
- [57] M. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer, “Deep contextualized word representations. arxiv 2018,” arXiv preprint arXiv:1802.05365, vol. 12, 2018.
- [58] G. Copilot, “Your ai pair programmer,” 2023, https://github.com/features/copilot/.
- [59] W. Miller and D. L. Spooner, “Automatic generation of floating-point test data,” IEEE Transactions on Software Engineering, no. 3, pp. 223–226, 1976.
- [60] Z. Li, M. Harman, and R. M. Hierons, “Search algorithms for regression test case prioritization,” IEEE Transactions on Software Engineering, vol. 33, no. 4, pp. 225–237, 2007.
- [61] R. A. Silva, S. d. R. S. de Souza, and P. S. L. de Souza, “A systematic review on search based mutation testing,” Information and Software Technology, vol. 81, pp. 19–35, 2017.
- [62] K. R. Walcott, M. L. Soffa, G. M. Kapfhammer, and R. S. Roos, “Time-aware test suite prioritization,” in Proc. of ISSTA, 2006, pp. 1–12.
- [63] G. Grano, C. Laaber, A. Panichella, and S. Panichella, “Testing with fewer resources: An adaptive approach to performance-aware test case generation,” IEEE Transactions on Software Engineering, vol. 47, no. 11, pp. 2332–2347, 2019.
- [64] A. Arcuri and J. P. Galeotti, “Enhancing search-based testing with testability transformations for existing apis,” ACM Transactions on Software Engineering and Methodology, vol. 31, no. 1, pp. 1–34, 2021.
- [65] Y. Lin, J. Sun, G. Fraser, Z. Xiu, T. Liu, and J. S. Dong, “Recovering fitness gradients for interprocedural boolean flags in search-based testing,” in Proc. of ISSTA, 2020, pp. 440–451.
- [66] P. Braione, G. Denaro, A. Mattavelli, and M. Pezzè, “Combining symbolic execution and search-based testing for programs with complex heap inputs,” in Proc. of ISSTA, 2017, pp. 90–101.
- [67] X. Xu, Z. Zhu, and L. Jiao, “An adaptive fitness function based on branch hardness for search based testing,” in Proc. of GECCO, 2017, pp. 1335–1342.
- [68] J. M. Rojas, J. Campos, M. Vivanti, G. Fraser, and A. Arcuri, “Combining multiple coverage criteria in search-based unit test generation,” in Search-Based Software Engineering, M. Barros and Y. Labiche, Eds., 2015, pp. 93–108.
- [69] G. Gay, “Generating effective test suites by combining coverage criteria,” in Search Based Software Engineering, 2017, pp. 65–82.
- [70] E. Daka, J. M. Rojas, and G. Fraser, “Generating unit tests with descriptive names or: Would you name your children thing1 and thing2?” in Proc. of ISSTA, 2017, pp. 57–67.
- [71] D. Roy, Z. Zhang, M. Ma, V. Arnaoudova, A. Panichella, S. Panichella, D. Gonzalez, and M. Mirakhorli, “Deeptc-enhancer: Improving the readability of automatically generated tests,” in Proc. of ASE, 2020, pp. 287–298.
- [72] S. Wang, N. Shrestha, A. K. Subburaman, J. Wang, M. Wei, and N. Nagappan, “Automatic unit test generation for machine learning libraries: How far are we?” in Proc. of ICSE, 2021, pp. 1548–1560.
- [73] Z. Dong, M. Böhme, L. Cojocaru, and A. Roychoudhury, “Time-travel testing of android apps,” in Proc. of ICSE, 2020, pp. 481–492.
- [74] A. Martin-Lopez, S. Segura, and A. Ruiz-Cortés, “Restest: automated black-box testing of restful web apis,” in Proc. of ISSTA, 2021, pp. 682–685.
- [75] F. U. Haq, D. Shin, L. C. Briand, T. Stifter, and J. Wang, “Automatic test suite generation for key-points detection dnns using many-objective search (experience paper),” in Proc. of ISSTA, 2021, pp. 91–102.