用于属性网络嵌入的协作图神经网络
摘要
图神经网络(GNN)在归因网络嵌入方面表现出了突出的性能。 然而,现有的工作主要集中在利用网络结构,而对节点属性的利用相当有限,因为它们仅充当初始层的节点特征。 这种简单的策略阻碍了节点属性在增强节点连接方面的潜力,导致邻居很少甚至没有邻居的非活动节点的感受野有限。 此外,大多数 GNN 的训练目标(即重建网络结构)也不包括节点属性,尽管研究表明重建节点属性是有益的。 因此,令人鼓舞的是,将节点属性深入涉及 GNN 的关键组件,包括图卷积操作和训练目标。 然而,这是一项不平凡的任务,因为需要适当的集成方式来保持 GNN 的优点。 为了弥补这一差距,在本文中,我们提出了协作图神经网络 - CONN,这是一种用于属性网络嵌入的定制 GNN 架构。 它通过以下方式提高模型容量:1)有选择地扩散来自相邻节点和涉及的属性类别的消息,2)通过互相关联合重建节点到节点和节点到属性类别的交互。 现实网络上的实验表明,CONN 远远优于最先进的嵌入算法。
索引术语:
属性网络嵌入、图神经网络、协作聚合、互相关1 简介
属性网络[1,2,3,4]在无数现实世界的信息系统中无处不在,例如学术网络和社交媒体系统。 与仅提供节点到节点交互的普通网络不同,属性网络中的每个节点都与一组丰富的属性相关联,描述其独特的特征。 例如,在社交网络中,用户以朋友的身份与他人联系、分享观点并以属性的形式发表评论。 在学术引文网络中,不同的文章通过引文链接连接起来,每篇文章都有大量的文本信息,比如一个摘要句子来描述自己的主题。 社会科学领域的多项研究[5, 6]表明节点的属性在实践中可以反映并影响其社区结构[7]。 因此,研究归因网络是令人鼓舞且重要的。 为此,属性网络嵌入[8,1,9],旨在利用网络邻近度和节点属性亲和力来学习低维节点表示,近年来引起了极大的关注,许多人学术界和工业界都付出了努力[10,11,12,13,14,15,16]。
其中,基于图神经网络(GNN)的嵌入范式[17, 15, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 18] 在多种下游图分析任务上取得了显着的成功,包括节点分类[31, 32, 33]、图分类[34, 35]、链接预测[36, 37, 38, 39],节点聚类[40, 41],异常检测[42, 43, 44, 45]. 基于 GNN 的方法的设计方案包括两个主要组成部分:1)GNN 编码器,将节点属性和节点到节点交互网络作为输入并输出低维节点表示; 2)训练目标,是为了重建输入数据(例如网络结构)而导出的,以便在无监督的情况下训练模型。 由于 GNN 中关键的消息传播机制,GNN 编码器自然适用于属性网络。 因此,现有的基于 GNN 的嵌入工作主要集中在通过更具表现力的消息传递模式来提高模型性能,例如通过注意力层自适应聚合来自邻居的消息[46,47,48]
尽管它们很受欢迎,并且最近在改进 GNN 架构以有效建模拓扑结构方面取得了进展[49,50,51,52,53],但很少有人关注节点属性。 先前的 GNN 研究重点是通过递归聚合自身及其邻居 [54] 的表示来更新每个节点的表示。 在这个学习过程中,节点属性仅用作初始层[55]中节点的表示。 如果网络结构不完整或缺失,它们将被阻止消息传播,这在现实应用中很常见,其中图表现出长尾节点度分布[56, 57]。 此外,即使我们设计 GNN 的训练目标时,也很少使用节点属性。 例如,训练基于 GNN 的嵌入算法进行属性网络嵌入的常见做法是通过采用基于负采样的目标或直接恢复整个输入网络结构来重建观察到的节点交互 [15] [14]。 总而言之,现有的工作中没有很好地利用节点属性。
最近,发生了一场重新思考基于随机游走的嵌入方法中节点属性的价值的革命[58, 59]。 核心思想是以属性感知的方式重新设计关键组件——随机游走。 具体来说,ANRL [60]利用节点属性细化了估计锚节点与其上下文之间的倾向得分的条件概率。 FeatWalk [59] 进行属性感知联合随机游走,以增加生成游走的多样性。 根据他们的实证实验,与普通的同行相比,它们都显示出显着的性能提升。 然而,它们是为基于随机游走的方法量身定制的,无法直接应用于 GNN 模型。 受此启发,在本文中,我们建议探索是否可以有效地利用节点属性来推进 GNN 架构的基本构建块(即消息聚合机制和训练目标)。
然而,将节点属性集成到 GNN 架构中是一项不平凡且具有挑战性的任务,主要是因为两个原因:(i)GNN 通过集成节点属性作为初始节点表示已经显示出有希望的结果。 很难将节点属性进一步纳入 GNN 的关键组件,同时保持现有的优势和突出的性能[54, 61]; (ii) 现实世界的节点属性,例如用户评论、论文摘要和产品描述,与网络拓扑结构不同,不符合 GNN 中的图卷积运算。 具体来说,节点属性中的值通常是多类别或连续变量,而网络结构中的值是二元的。 它们彼此不兼容。 因此需要量身定制的操作来共同向他们学习。 例如,采用自动编码器作为 GNN 的训练目标将实现次优性能[14, 62]。
为了解决上述挑战,我们提出了一种新颖的无监督表示学习模型,称为COllaborative Graph Neural N网络(CONN)。 它旨在为属性网络开发定制的 GNN 架构,以便节点属性可以明确地融合到消息聚合过程和训练目标中。 具体来说,我们的目标是调查两个重要的研究问题。 (i) 如何利用节点属性显式引导 vanilla GNN 的消息传播,并进行协作聚合机制? (ii)在训练目标中,如何有效地对异构交互进行建模,从而共同重建网络结构和节点属性? 我们将我们的主要贡献总结如下。
-
•
我们专注于属性网络上的无监督表示学习,并提出了一种有效的 GNN 框架 - CONN,以利用上述普通 GNN 的两个关键组件中的节点属性。
-
•
通过对节点属性进行二分图,我们开发了一种用于节点嵌入的协作聚合机制。 它不仅有助于通过属性类别丰富或重建节点连接,而且还提供了一种从相邻节点和涉及的属性类别更新节点表示的原则方法。
-
•
基于节点和属性类别表示,我们设计了一种新颖的互相关层来有效地建模复杂的节点或节点属性类别交互。 它从多粒度特征中突出了两个锚节点的相似性,并显着提高了普通 GNN 的重建能力。
-
•
我们在节点分类和链接预测任务上评估 CONN。 基准数据集的实证结果表明,CONN 的性能始终优于其他最先进的嵌入方法。 此外,我们还在5.8节中分析了CONN的鲁棒性和收敛速度。
2 相关工作
根据节点属性是否针对网络嵌入进行建模,相关工作分为三种类型。 在本节中,我们简要回顾这两个领域的一些相关工作。 请参阅[63,64,65,66,67]进行全面审查。
2.1 网络嵌入
第一类方法可以追溯到传统的图机器学习问题,其目的是在保留局部流形结构的同时学习节点嵌入,例如LPP [68]和拉普拉斯特征图[ 69]。 然而,由于邻接矩阵上的特征分解操作耗时,这些方法面临着大规模网络的可扩展性挑战,其时间复杂度为,其中是节点。 受最近自然语言处理中分布式表示学习[70]突破的启发,出现了很多可扩展的网络嵌入方法[58,71,72,73,74,75,76,77 ] 已经开发出来。 例如,DeepWalk [58] 和 Node2vec [73] 在网络上进行截断随机游走,生成节点序列,然后将其输入 Skip-Gram 算法[70] 用于节点嵌入。 LINE [71] 优化一阶和二阶邻域关联来学习表示。 GraRep [72] 扩展了 LINE 以捕获高阶邻域关系。 SDNE [74]将深度学习应用于节点嵌入和目标,以捕获非线性图结构并保留图的全局和局部结构。 [78]尝试将图的社区结构纳入表示学习。 其他一些研究旨在处理大规模图[79,80,81]。 尽管它们很简单,但上述方法在实践中可能受到限制,因为它们无法利用辅助信息,例如用户个人资料、帖子中的世界以及社交媒体上照片中的上下文。
2.2 属性网络嵌入
与传统网络嵌入不同,属性网络嵌入[82,31,83,84,85,86,87,88],旨在通过利用网络结构和节点属性来学习节点表示,近年来引起了广泛关注。 例如,ANRL [60] 将节点属性合并到 Skip-gram 的条件概率函数中,该函数预测锚节点与其上下文之间的倾向得分,以捕获结构相关性。 MUSAE[13]通过考虑基于节点属性的多尺度邻域关系来改进Skip-gram模型。 FeatWalk [59] 旨在进行属性感知随机游走,以增加生成游走的多样性,从而增强 Skip-gram 模型。 PANE [89] 是另一种基于随机游走的可扩展训练方法。 TADW[83]将节点属性合并到矩阵分解框架下的DeepWalk中。 PTE [90]采用不同顺序的世界共现关系和节点标签来生成预测文本表示。 ProGAN [91] 旨在基于生成对抗网络保留隐藏空间中的潜在邻近性。 尽管上述方法能够利用网络结构和节点属性进行联合表示学习,但它们在捕获结构信息方面受到限制。
最近,基于图神经网络[23]的属性网络嵌入由于其捕获结构信息、合并节点属性和建模非线性关系的能力而引起了越来越多的关注。 作为GNN的开创性工作,GCN[23]正式提出通过递归聚合相邻邻居的表示来更新节点表示,并在半监督分类任务上实现了显着的性能提升。 接下来,GAE [14] 首次努力将 GCN 扩展到自动编码器框架,以无监督地学习节点表示。 同时,GraphSage [15] 通过采样和聚合节点本地邻域的特征来提高 GCN 的可扩展性。 他们的结果表明,GCN 天然适合属性网络,因为它可以直接利用节点属性作为第一层的初始节点特征进行训练。 受此推动,许多后续研究[46,50,92]被提出,通过开发更具表现力的 GNN 架构来提高模型能力。 最近,人们还致力于重新定义 GCN 的训练目标,以学习更有效的节点表示。 CAN[62]和[93]主张在变分自动编码器框架下联合重构网络结构和节点属性。 DGI [94] 和 GIC [95] 建议通过最大化本地节点表示和图摘要表示之间的互信息来学习节点表示。 GCA [96] 和 MVGRL [97] 寻求通过最大化数据增强生成的不同视图之间表示的一致性来更新节点表示。 然而,他们只能在 GNN 的消息传播过程中隐式地探索节点属性。 在本文中,我们提出了一种用于属性网络嵌入的有原则的 GNN 变体,它允许节点属性明确地指导消息传播和训练目标。
2.3 具有额外知识的属性网络嵌入
除了简单的属性网络(包括节点特征和同构图结构)之外,一些研究还利用额外的知识,例如知识图(KG)[98,99,100,101],来提高模型的性能。 例如,PGE [102] 研究如何合并额外的边缘特征。 KGCN [103] 和 KGAT [104] 研究如何利用外部知识图(例如项目知识图)来提高推荐质量。 然而,这些方法需要额外的努力来生成高质量的信息源,例如边缘特征和知识图。 相比之下,在这项工作中,我们专注于标准属性网络嵌入,对具有纯节点属性的同构图进行建模,例如连续特征和分类特征。
3 问题陈述
我们假设给出了一个由 表示的属性网络。 它在集合 中收集了 个顶点。 这些节点通过无向网络连接,其邻接矩阵表示为。 如果节点和之间有边,则;否则,。 除了网络之外,每个节点还有一个描述性特征向量,称为节点属性,其中是总的属性类别的数量。 我们将节点的邻居集表示为,将属性类别的邻居集表示为,即。 我们使用对角矩阵来表示度矩阵,其中。 主要符号列于表I中。 为了在无监督环境中研究 GNN,我们遵循文献 [23, 105] 并在定义 1 中正式定义了属性网络嵌入问题。
| Notation | Description |
|---|---|
| adjacency matrix | |
| a matrix collects all node attributes | |
| a set collects all nodes | |
| a set collects all attribute categories | |
| the node attribute category | |
| a set collects adjacent neighbors of | |
| the number of graph convolutional layers | |
| adjacency matrix of augmented network | |
| representation of node at the layer | |
| representation of at the layer |
定义1
归因网络嵌入。 给定一个属性网络,目标是为每个节点学习一个维连续向量,使得 中的拓扑结构和以 为特征的辅助信息可以保留在嵌入表示 中。 通过将 应用于各种下游任务(例如节点分类和链路预测)来评估此学习任务的性能。
为了执行属性网络嵌入,GNN 模型 [23, 15] 通过聚合自身及其邻居 的表示来学习每个节点 的嵌入表示在上一层中。 典型的邻域聚合机制[23]表示如下:
| (1) |
其中表示节点在GNN的层的隐藏表示,表示。 最终输出为 ,其中 是考虑的最大层数。 图 1 中的顶部子图通过使用玩具示例说明了这种传统的邻域聚合。 我们可以看到,通过堆叠两层,两跳邻居 和 的表示可以被节点 访问。 为了以无监督的方式训练这一模型,一个被广泛采用的基于图形的损失函数被定义为:[15]、
| (2) |
是相似函数,例如内积。 目标是使连接节点的表示彼此相似,同时强制未连接节点的表示不同。 我们观察到,节点属性仅用作初始表示。 它们还没有被进一步利用,特别是没有被整合到 GNN 的核心机制中。
4 协作图卷积
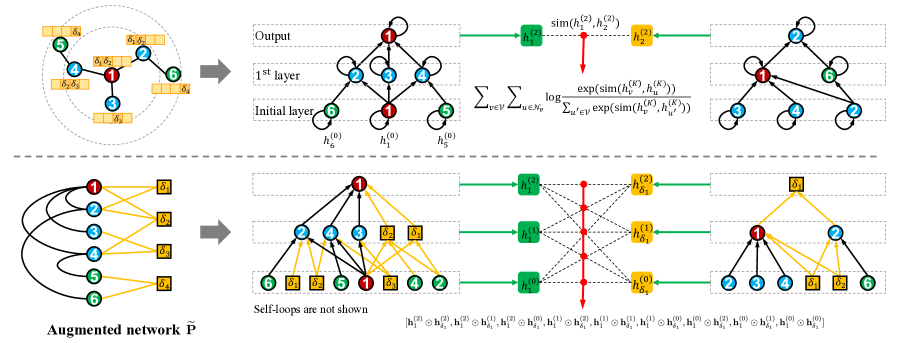
节点属性信息丰富,与网络[60,106,107,108,109]显着相关和互补。 由于它们在 GNN 中尚未得到充分利用,我们探索将节点属性深度集成到 GNN 的核心机制中,并开发了一种名为协作图神经网络(CONN)的新颖框架。 图1描述了CONN的两个主要组成部分,即协作邻域聚合和协作训练目标。 首先,我们通过将节点属性类别 视为另一组节点来重新定义图卷积。 如图1所示,我们将原始网络增强为具有节点的新网络。 它保留 中的所有边,并且如果 的值非零,则包含从节点 到 的链接。节点属性。 请注意, 可以为正值,也可以为负值,其中负值表示邻居对锚节点有负面影响。 基于,我们进行邻域聚合。 例如,节点的一阶邻居已从增强到,而节点的二阶邻居t3> 已从 扩充到 。 我们观察到,我们的协作邻域聚合不仅可以捕获节点到节点的交互,还可以捕获节点到属性类别的交互。 其次,为了训练我们的模型,我们设计了一个协作损失。 我们的目标是协同预测增强网络 中的所有链接,该网络包含 和 X 。此外,我们还设计了一种新颖的交叉相关机制,以模拟 中任意一对节点之间的复杂交互(例如,图 1 中的 和 )。 它不仅使用最后一层中的节点表示,还使用所有剩余的。 我们现在在以下小节中介绍详细信息。
4.1 协作邻域聚合
给定一个属性图,现有的GCN架构主要纯粹基于网络结构来定义节点的多跳邻居。 节点的一阶邻居用表示,而二阶邻居用表示,依此类推。 表示的幂。 因此,除了作为初始节点表示(即 )之外,节点属性被排除在图卷积(即 GNN 的核心操作)之外。 正如简介部分中所讨论的,这对于实践中邻居很少或没有的非活动节点来说可能不是最理想的,因为它们没有足够的邻域信息供 GNN 有效地学习其嵌入表示[56]。
4.1.1 增强网络
为了解决上述问题,我们建议利用节点属性的几何属性。 我们将每个节点属性类别视为一个新节点,将节点属性视为加权二分图。 通过将其添加到原始网络中,我们将得到一个增强网络,表示为。 从数学上来说,它的邻接矩阵可以写成:
| (3) |
方程(9)适用于分类和连续节点属性。 然而,对于连续特征,它会生成基于的密集二分图,这可能会显着增加对其进行卷积时的计算成本。 为了节省计算量,我们通过仅保留 每一行中的 top- 值,根据经验将稠密二分图简化为稀疏二分图。 适当的值可以在效率和准确性之间进行权衡,我们在5.8节中分析其影响。 综上所述,我们直接使用分类属性的特征矩阵来构造增强图,同时采用每行中的top-值来生成连续特征的稀疏图。
4.1.2 增强的多跳邻居
通过使用,节点的一阶和二阶邻居可以展开为:
| (4) | ||||
其中 收集共享至少一个节点属性类别的所有节点对,即所有 路径。 表示由 路径反映的节点到属性类别的交互。 与传统的 GNN 相比,我们对 跳内的节点到属性类别的交互进行了显式建模。 通过的路径丰富了原始节点到节点的交互。 类似地, 的一阶和二阶邻居可以计算为:
| (5) | ||||
其中表示由公共节点估计的属性类别相关性。 它收集 路径。 我们使 中的节点能够将消息传播到属性类别,以及属性类别之间的相关性来影响图卷积。 基于此,我们不仅可以利用属性类别作为中介丰富节点交互来提高模型性能(见表III和IV),而且可以增强模型的鲁棒性w.r.t. 缺少边缘,如第 5.8 节所示。
我们要指出的另一件事是,与之前基于特征距离定义节点到节点相似性网络的工作[110, 111]不同,我们直接构建节点到属性类别使用属性值作为边权重的特征矩阵上的二部图。 如前所述,节点和属性类别之间的二分图不仅可以以属性为媒介丰富或重建节点交互,而且可以尽可能保留特征信息。
4.1.3 协作聚合
我们现在说明如何基于增强网络学习节点表示。 鉴于异构图嵌入 [112, 112, 113] 的最新进展,直观的解决方案是应用这些完善的异构 GNN 来学习 的嵌入(它包括两个对象(节点和属性类别)和两个关系(节点到节点和节点到属性类别)。 然而,我们的基础知识实验表明,这些方法在我们的合成异构图上表现不佳(参见5.8.4中的讨论),因为它们可能过度强调之间的异构性节点及其属性,使得学习过程变得相当复杂。 由于标准 GNN 架构 [46, 50, 92, 62] 已经可以通过将属性网络视为同构图来实现高性能,因此我们建议遵循传统并考虑增强网络 作为具有简单权重模式的同质资源。 我们将异构 GNN 角度的归因网络嵌入作为我们未来的工作。
具体来说,我们的基本思想是将节点顶点和属性类别顶点视为相同的顶点,但提供权重超参数来控制网络和节点属性<之间的信息扩散。 这是因为节点到节点交互的重要性和节点属性没有明确可用。 在我们的设置中,中的二进制值可能与中的特征值(例如,连续特征)不兼容,我们定义了一个精炼的转移概率矩阵如下。
| (6) |
其中 和 分别表示应用 范数对每一行进行归一化后的 和 的归一化。 是一个权衡超参数,用于对网络结构和节点属性的重要性施加我们的归纳偏差。 具体来说,当 时,它产生纯粹基于网络结构的普通图卷积运算。 随着 的增加,节点表示将更加依赖于节点属性,节点到属性类别的交互和属性类别的相关性将逐渐纳入图卷积过程中。
基于,标准图卷积层可以直接应用于更新节点表示。 我们遵循简单的 GNN 模型[54],并通过简单的稀疏矩阵乘法更新相应的嵌入矩阵。 我们使用来表示层中所有节点的中间表示。 从数学上来说,它可以写成,
| (7) |
我们的初始节点表示 并不基于 。 相反, 是一个可训练的嵌入矩阵,按照通用协议 [58, 114] 随机初始化。 为了进一步说明和之间的相关性,我们将相应的更新规则重写如下:
| (8) | ||||
等式。 (8) 提供了利用和控制节点属性的原则性解决方案。 一方面,它可以通过将属性类别视为附加节点来显式丰富或补充节点交互。 另一方面,来自节点和属性类别的邻域信息通过权衡参数有选择地组合。
4.2 协作训练目标
给定 的更新表示 ,我们需要一个无监督目标来训练 GNN 模型。 一种广泛采用的方法[14,15,62]是利用最后一层的节点表示来重建所有边。 如方程式所示。 (2),它根据两个节点 和 的向量 和 之间的相似度来估计它们连接的概率。 这种方法已被证明在普通网络中是有效的,但节点属性在实践中通常是可用的。 等式。 (2) 无法直接合并节点属性。 另一个直观的解决方案[14]是使用自动编码器来重建和。 它将实现次优性能,因为拓扑结构 与节点属性 是异构的。
4.2.1 互相关机制
为了解决上述问题,我们提出了一种新颖的互相关机制来建模和预测复杂的节点到节点和节点到属性类别的交互。 它有两个主要步骤。 首先,我们删除中的所有权重并将其转换为二进制矩阵。 我们的目标是将网络和节点属性集成到我们的训练目标中。 为了使它们彼此兼容,我们将二进制邻接矩阵定义为:
| (9) |
其中 如果 。 我们的目标是恢复 中节点到节点和节点到属性类别的交互。 其次,所有层的节点表示是根据邻居的不同顺序学习的。 我们模型的一个优点是我们将节点属性 集成到协作邻域聚合中,不再需要使用 作为初始节点表示 。 由于我们可以灵活地定义,因此我们可以使所有的尺寸相同。 通过这种方式,我们可以轻松地充分利用它们,并建模从节点 到节点 或节点 到节点属性类别的复杂交互 作为,
| (10) | |||
其中表示串联操作。 表示节点的下阶邻域与节点下阶邻域之间的相关性特征。 表示逐元素乘法。 和 分别是对 和 的预测分数。 MLP 表示具有 Relu 激活函数的三层多层感知器。
值得注意的是,KGAT [104] 和 NGCF [115] 中已经探索了节点表示之间的逐元素操作以进行推荐。 我们的方法有两个不同之处。 首先,KGAT 和 NGCF 利用这种技术来促进每个 GNN 层中的消息传播(用于节点级嵌入)。 然而,CONN 应用它来生成不同粒度的两个端节点的边表示。 其次,所提出的互相关机制更加注重元素。 它的新颖之处在于提出通过整合 GNN 层不同组合的互相关来获得终端节点的信息丰富的边缘表示。 因此,所提出的互相关层与 KGAT 和 NGCF 不同,因为它的目的是提高边缘表示的质量,而参考的方法致力于增强每个 GNN 层每个节点的表示,从中它们与我们正交并且可以作为基础 GNN 主干网。
4.2.2分析
4.2.3 优化和最终表示
在我们的协作训练目标中,目标是通过使用 重建 中节点与节点之间的交互,并通过使用 重建 中节点与属性类别之间的交互。 相应的目标函数定义如下。
| (11) | ||||
等式。 (11) 在实践中通常很棘手,因为分母的求和运算在计算上是令人望而却步的。 因此,我们采用负采样[71, 15]策略来加速优化。
在我们使用等式中的协作目标训练模型 CONN 后, (11),我们需要定义节点的最终嵌入表示来执行下游任务。 对于链接预测任务,我们直接根据节点对的预测链接概率。 对于节点分类,我们采用最后一层的输出作为节点嵌入,其中现成的分类算法可以直接使用它进行分类。
4.3 与之前的工作比较
据我们所知,很少有人致力于利用节点属性来重新定义图嵌入方法的核心组件。 我们大致将其分为两类,下面分析一下它们的区别。
基于随机游走的方法。 基于随机游走的方法侧重于进行截断随机游走来生成节点序列,然后应用 Skip-gram 算法来学习基于序列的节点表示。 这种方法最初不适用于节点属性。 ANRL [60] 通过修改 Skip-gram 的损失函数以依赖于节点属性来解决此问题。 Featwalk [59] 建议进行属性感知随机游走,以在随机游走生成过程中注入节点属性。 与这些方法相比,我们的模型属于图神经网络方法,利用图卷积网络对局部图结构进行显式建模。
基于图神经网络的方法。 这一系列方法侧重于利用图卷积网络[23]对锚节点的局部子图进行建模以进行节点表示。 通过使用节点属性作为第一层的初始节点特征来处理属性图是很自然的。 然而,这种方法在利用节点属性方面相当有限,因为它们被排除在 GCN 的两个关键组成部分(即邻域消息传播和训练目标)之外。 CAN[62]试图通过在变分自动编码器下联合重建节点属性和网络结构来缓解这一问题。 相比之下,我们的模型侧重于利用节点属性来共同影响两个构建块。
此外,我们还想指出的是,我们工作中节点属性的使用与跳过连接技巧[117]不同。 跳过连接目标是通过回顾初始特征来跳过更深层中的一些高阶邻居,但我们的重点是通过将属性类别视为“邻居”来重新定义不同顺序的节点的邻域集。 也就是说,我们的模型在每层的消息聚合过程中引入了额外的节点到属性类别的关系。 总而言之,跳跃连接与我们的模型是互补的,并且可以添加到我们的 GNN 主干中以避免过度平滑。
异构网络嵌入。 感谢我们在4.1.1节中提出的在节点和属性类别之间构建增强网络的建议,我们还可以将由此产生的嵌入任务视为特殊的异构网络嵌入(HNE)问题[118 , 112, 119, 113],其中我们有两种对象类型(节点和属性类别)和两种关系类型(节点到节点和节点到属性类别)。 根据这一原则,可以应用最先进的异构模型。 然而,我们发现这种方法可能会使学习任务变得不必要的复杂,因为 HNE 会过分强调归因网络的异质性。 这可能不是最理想的,因为归因网络并不是真正的“异构”图。 此外,训练好模型也很重要,因为没有可用于第二个对象(属性类别)的特征。 此外,很难以混合方式控制两种关系或节点类型的重要性,例如混合随机游走[112]。 相比之下,通过在我们的设置中将增强网络视为同构图,问题本身得到了极大的简化,并且可以以即插即用的方式使用任意标准的 GNN 架构,从而使我们的建议具有更广泛的适用性和实用性。
总而言之,我们提出了一种基于 GNN 的属性网络嵌入的新替代方法,将属性类别视为附加节点并将属性网络转换为增强图。 增强图在节点和属性类别之间提供灵活的信息扩散,而不会造成信息损失。 为了有效地从新图中学习节点表示,我们开发了两种定制设计:协作聚合和互相关机制,其中前者有助于显式控制卷积中节点和节点属性之间的信息传播,而后者通过使用多粒度特征。 尽管我们的建议看起来很通用并且适用于同构 GNN 和异构 GNN,但我们凭经验发现基于异构 GNN 学习节点表示并不简单(请参阅 5.8.4 中的讨论)。 因此,我们关注简单的情况,并将基于异构 GNN 的属性网络嵌入作为未来的工作。
5 实验
我们分析了 CONN 在不同规模和类型的多个真实数据集上的有效性。 具体来说,我们的评估围绕三个问题。
-
•
Q1:与最先进的嵌入方法相比,CONN 在节点分类和链路预测任务方面能否取得更好的性能?
-
•
Q2:CONN中有图混合卷积层、图相关层、协同优化三个关键组件,每个组件贡献多少?
-
•
Q3:超参数:权衡参数和嵌入维度对CONN有何影响?
| # Edge | ||||
|---|---|---|---|---|
| Pubmed | , | , | ||
| ACM | , | , | , | |
| BlogCatalog | , | , | , | |
| ogbn-arxiv | 169,343 | 1,166,243 | 128 | 40 |
| , | ,, | |||
| ogbl-collab |
5.1 数据集
我们在六个不同规模和类型的公开归因网络上进行了实验。 他们的统计信息总结在表II中。
泵送 [120]。 它是[23]中使用的最大基准引用网络。 节点对应于文档,边对应于引文。 根据论文摘要,每个节点都有一个词袋特征向量。 标签被定义为学术主题。
| Method | Pubmed | ACM | BlogCatalog | ogbn-arxiv | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| F1-micro | F1-macro | F1-micro | F1-macro | F1-micro | F1-macro | F1-micro | F1-macro | F1-micro | F1-macro | |
| GAE | ||||||||||
| ARGE | ||||||||||
| DSGC | ||||||||||
| DGI | ||||||||||
| GIC | ||||||||||
| GCA | ||||||||||
| FeatWalk | ||||||||||
| CAN | ||||||||||
| CONN | ||||||||||
ACM [121]。 它是一个由 ACM 发表的 48,579 篇论文组成的大规模引用网络。 基于词袋模型,采用论文摘要中的单词作为节点属性。 引文链接被视为边缘。 每篇论文都在特定领域发表,作为分类标签。
博客目录 [1]。 它是从博客社区收集的社交网络。 节点是网络用户,边表示用户交互。 节点属性表示博客的关键字。 每个用户可以将他/她的博客注册到六个不同的预定义类别中,这些类别被视为节点分类的类别标签。
Reddit[15]。 这是从在线讨论论坛 Reddit 收集的另一个社交网络数据集。 节点对应于 Reddit 帖子,边代表共同评论关系。 这些帖子通过 Glove CommonCrawl 世界嵌入 [122] 预处理为 602 维特征向量。 因此,节点属性指的是602个潜在维度。 我们使用帖子所属的社区或“subreddit”作为目标标签。
ogbl-collab [123]。 这是来自 KDD Cup 2021 的具有挑战性的作者协作网络。 每个节点都是一个作者,边表示作者之间的协作。 所有节点都具有 128 维特征,这些特征是通过对作者发表的论文的词嵌入进行平均而获得的。 它被广泛用于进行链接预测任务。
ogbn-arxiv [123]。 它是 KDD Cup 2021 的 arXiv 论文的大规模论文引用网络。 每个节点都是一篇 arXiv 论文,边表示一篇论文引用了另一篇论文。 每篇论文都由一个 128 维的特征向量表示,该特征向量是通过对标题和摘要中单词的嵌入进行平均而获得的。 目标是预测 40 个主题领域。
5.2 基线方法
为了验证 CONN 的有效性,我们包括以下四类无监督基线。 首先,为了研究为什么我们需要定制框架将节点属性合并到 GCN 架构中,我们与普通的 GCN 方法 GAE [14] 进行比较。 其次,为了研究 CONN 与其他定制解决方案相比的有效性,我们包括两个最近的工作,即 CAN [62] 和 FeatWalk [59]。 第三,为了对最先进的无监督模型进行综合评估,我们引入了三种流行的基于自监督学习的 GNN 方法,DGI [94]、GIC [95] 和 GCA [96]。 请注意,不包括其他基于非 GCN 的嵌入方法,即 DeepWalk [58]、LINE [71] 和 ANRL [60],因为它们在实验中优于 CAN 和 FeatWalk [62, 59]。 此外,其他经典的 GNN 架构,即 GAT [46]、SGC [54] 和 APPNP [61] 不包括在内比较,因为它们最初致力于监督学习,而我们专注于无监督表示学习。
-
•
GAE [14]。 它通过在自动编码器方法下重建网络结构来学习节点嵌入。 具体来说,它采用图卷积网络将子图编码到潜在空间中。
-
•
ARGE [124]。它是一个对抗性正则化 GAE。 我们不考虑变体版本,因为这两种变体在大多数情况下表现得很快相似。
-
•
DGI[94]。 它通过最大化局部补丁表示和全局图表示之间的互信息来学习节点嵌入。
-
•
GIC [95]。 它通过利用集群级节点表示进行无监督表示学习来更新 DGI。
-
•
GCA [96]。 它通过最小化原始图与其增强形式之间的对比损失来学习节点表示。
-
•
CAN[62]。 它通过在变分自动编码器框架下重建网络结构和属性矩阵来学习节点嵌入。
-
•
FeatWalk [59]。 它通过引入属性增强的随机游走策略来改进基于普通随机游走的方法,这有助于生成用于表示学习的多样化随机游走。
-
•
DSGC [125]。 它根据节点特征定义一个-NN图,然后将其用作网络嵌入的属性感知图过滤器。
此外,我们还引入了三个变体来验证 CONN 中核心组件的有效性。
-
•
CONN-gcn。 它将图混合卷积层替换为普通图卷积层,以验证建模混合邻居(即节点和属性)的有效性。
-
•
CONN-内部。 它排除了图相关层,并利用内积来基于两个节点的最后一层表示来估计两个节点之间的相似性,类似于 [15, 14]。 我们用它来验证所提出的相关层的有用性。
-
•
CONN-ncoll。 它只考虑目标函数中节点到节点的交互。 该变体用于证明联合优化节点到节点和节点到属性交互的贡献。
5.3 实验设置
我们遵循通用协议[14, 62]来评估CONN的性能。 学习到的潜在表示的有效性是通过两个流行的下游任务(即链路预测和节点分类)进行评估的。 对于链接预测任务,我们随机分割网络中 85%、10% 和 5% 的边,形成类似于 [14] 的训练集、测试集和验证集。 链接预测任务旨在根据其嵌入表示来估计网络中缺失的边是否应该连接。 性能通过两个标准指标来衡量,即 ROC 曲线下面积 (AUC) 和平均精度 (AP) 分数。
对于节点分类任务,其目标是根据获得的节点表示和训练的分类器将新实例分类为一个或多个类别。 具体来说,我们对所有数据集应用 5 倍交叉验证来构建训练集和测试集。 为了执行分类,我们基于 scikit-learn 包构建了一个 SVM 分类器,并根据训练组中的节点和相应的标签来训练分类器。 然后我们应用学习到的分类器来预测测试组中实例的标签。 报告了五倍的平均结果。
我们使用官方发布的基线代码进行实验,并使用验证集来调整其参数。 对于我们的方法,我们使用 Adam 优化器以 0.01 的学习率训练 CONN 100 个时期,并以 20 个时期的耐心提前停止。 如果不指定,对于节点分类和链路预测任务,设置为128,和分别等于0.2和0.8。 对于连续数据集(Reddit、ogbn-arxiv 和 ogbl-collab),我们默认使用 每一行中的 top- 值来构造二分图。 CONN的源代码可以在https://github.com/Qiaoyut/CONN获取。
| Pubmed | ACM | BlogCatalog | ogbl-collab | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AUC | AP | AUC | AP | AUC | AP | AUC | AP | AUC | AP | |
| GAE | ||||||||||
| ARGE | ||||||||||
| DSGC | ||||||||||
| DGI | ||||||||||
| GIC | ||||||||||
| GCA | ||||||||||
| FeatWalk | ||||||||||
| CAN | ||||||||||
| CONN | ||||||||||
| CONN-gcn | CONN-inner | CONN-ncoll | CONN | ||
|---|---|---|---|---|---|
| F1-micro | Pubmed | ||||
| ACM | |||||
| BlogCatalog | |||||
| ogbn-arxiv | |||||
| F1-macro | Pubmed | ||||
| ACM | |||||
| BlogCatalog | |||||
| ogbn-arxiv |
5.4 节点分类
我们开始评估 CONN 在节点分类任务(Q1)中的性能。 表III总结了五个数据集的微观平均和宏观平均得分的结果。
从表III中,我们观察到,在具有分类属性(PubMed、ACM 和 BlogCatalog)和连续特征嵌入(Reddit 和 ogbn-arxiv)的数据集上的两个评估指标上,CONN 的表现始终优于其他基线。 它证明了 CONN 的有效性。具体来说,与普通的 GCN 变体相比,CONN 在 BlogCatalog 和 ogbn-arxiv 数据集上的微平均得分分别比 GAE 提高了 48.6% 和 9.8%。 在宏观平均得分下,CONN 在 BlogCatalog 和 ogbn-arxiv 数据集上分别比 ARGE 提高了 46.7% 和 4.8%。 这一改进验证了为属性网络设计定制 GCN 架构的必要性。 CAN 也被提出对节点属性进行建模,但在五个场景中它明显输给了 CONN。 它们之间的主要区别在于CAN的目标是在自动编码器框架下联合重建节点属性和网络,而CONN的目标是通过明确地利用节点属性来指导消息传播来修改GCN架构。 这一比较证明,为归因网络量身定制的 GCN 解决方案更有前景、更有效。 FeatWalk 将节点属性合并到基于随机游走的模型中,但在所有情况下它的性能都优于 CONN。 以 Reddit 数据集为例,CONN 将 FeatWalk 提升了 37.7% 以上。 这是合理的,因为我们的模型可以利用结构信息进行节点嵌入,而基于随机游走的方法无法使用它。 虽然 DSGC 也为网络嵌入构建了属性感知图,但几乎在所有情况下都输给了 CONN。 这是因为DSGC需要根据节点特征构建-NN图,这可能会删除很多重要的属性信息。
另一个有希望的观察结果是,CONN 的表现总体上明显优于最先进的自我监督竞争对手(DGI、GIC 和 GCA)。 这一结果表明了重构原始网络结构对于无监督表示学习的有效性。 此外,CONN 和 FeatWalk 之间的性能差距在连续值数据集(reddit 和 orgn-arxiv)上增加。 这主要是因为FeatWalk由于采样图是全连接的,降低了所有属性类别之间的随机选择,这损害了随机游走的质量。
5.5 链接预测
我们现在根据链接预测任务(Q1)评估 CONN 的性能。 由于 DGI、GIC、GCA 和 FeatWalk 最初并未在此任务上进行测试,因此我们从相邻矩阵中删除测试边,并使用生成的相邻矩阵来训练它们。 然后,我们根据类似于 [62] 的相应节点表示的内积来估计测试边的相似度分数。 表 IV 报告了三个中位数大小(PubMed、ACM 和 BlogCatalog)和两个大型数据集(Reddit 和 ogbl-collab)的 AUC 和 AP 分数结果。
从表中我们可以看到 CONN 的表现明显优于其他基线。 具体来说,它在 BlogCatalog 上比 GAE、ARGE、DSGC、DGI、GIC、GCA、FeatWalk 和 CAN 提高了 11.4%、21.5%、16.5%、25.2%、22.7%、11.1%、48.8% 和 9.7%分别为AUC值。 大多数情况下,CAN 在节点分类任务上输给 FeatWalk,但在预测缺失边方面优于 FeatWalk。 它表明捕获结构信息对于链接预测的重要性。 CAN 和 CONN 的目标都是利用节点属性进行节点嵌入,但 CONN 在所有情况下都远远优于 CAN。 主要区别在于CAN侧重于利用节点属性来丰富目标函数,希望增强GCN编码器的优化。 相比之下,我们的模型直接将有用的节点属性合并到 GCN 构建块中,从而可以显式地实现更强大的 GCN 编码器。 尽管 DGI、GIC 和 GCA 是基于高级对比损失函数进行训练的,但我们的模型的性能明显优于它们,并且有很大优势。 这些结果表明现有的基于 GCN 的架构在利用有用的节点属性方面存在不足。 基于这些观察,我们相信我们提出的框架更适合链接预测任务。
5.6 消融研究
我们现在研究第二个问题(Q2),即CONN的三个主要组成部分,即图混合卷积层、图相关层和协同优化能贡献多少? 本消融研究使用了开头介绍的三种变体,即 CONN-gcn、CONN-inner 和 CONN-ncoll。 表V记录了五个数据集上节点分类性能的微观和宏观平均得分。
根据表V,我们有三个主要观察结果。 首先,在图卷积过程中没有节点属性来指导消息传播,CONN-gcn的性能会下降。 它验证了将节点属性显式合并到 GCN 架构中的有效性。 其次,没有图相关层,CONN-inner 大幅输给 CONN。 例如,在微观平均方面,CONN 在 Pubmed 上比 CONN-inner 提高了 23.5%。 CONN-inner和CONN的主要区别在于,前者采用简单的内积来估计边缘相似度,而CONN设计了深层相关层,能够捕获两个节点之间的复杂相关性。 这一比较验证了所提出的图相关层的有效性。 第三,CONN 在五个数据集上的表现略好于 CONN-ncoll。 这表明联合优化节点到节点和节点到属性的交互是有益的。 鉴于 CONN 优于三个变体,它验证了我们提出了一个原则框架来加强三个组件之间的相互影响。
5.7 参数敏感性分析
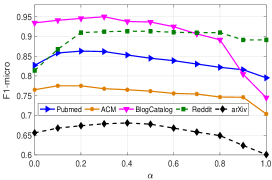
我们现在研究 CONN 上的参数 和嵌入维度 对 BlogCatalog 的影响(Q3)。 控制节点到节点交互和节点到属性交互对于消息传递的重要性。 我们在图2-a上绘制了当从变化到时CONN的性能,步长大小为0.1。 从结果中,我们观察到 CONN 的性能随着 在五个数据集上从 0.0 增加到 0.2 而增加。 一般来说,CONN在时获得最好的结果。 请注意,当时,CONN仅利用节点属性交互进行图卷积,而排除网络结构。 当时,不考虑节点到属性的交互。 CONN 简化为普通 GCN,只不过节点属性和节点交互都是联合优化的。
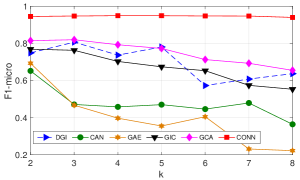
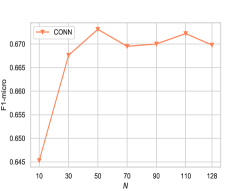
是 GCN 主干的层数。 大的 意味着包含高阶邻居。 由于FeatWalk没有这个参数,所以我们省略它来进行比较。 我们将从2更改为8,BlogCatalog上的性能如图2-b所示。 从结果中,我们观察到我们的模型 CONN 在不同层数上始终优于所有基线。 另一个有趣的观察是,当从2变化到8时,CAN、GAE、GIC、GCA和DGI的性能下降,而CONN表现稳定。 它验证了我们的模型在捕获高阶依赖关系方面的优越性。 值得注意的是,尽管当 K 较小(例如 8)时,CONN 比图 2(b)中的标准 GNN 模型取得了相对稳定的结果,但当 K 较大(即 15)时,我们确实观察到明显的性能下降。 因此,通过对属性感知关系进行建模,我们的方法可以在一定程度上缓解 GNN 模型相对较浅时的过度平滑问题。 尽管如此,仍需要采取针对性的措施来彻底解决[52]中所做的过度平滑问题。
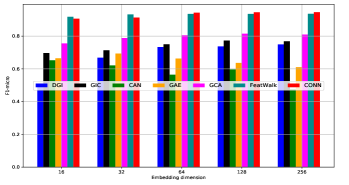
在CONN中,维度表示下游应用程序的输出潜在空间,即节点分类和链路预测。 我们从开始搜索,所有方法的性能如图2-c所示。我们观察到不同的方法有不同的最佳,并且我们的模型CONN在时可以获得令人满意的性能。 对其他数据集也进行了类似的观察。 为了公平起见,我们调整了所有方法的最佳嵌入维度并报告了它们的最佳结果。
5.8 进一步分析
与 SOTA 方法的性能比较完成后,我们深入研究我们的提案以获得更多见解。
5.8.1 从连续特征构建稀疏二部图是一个很好的权衡。
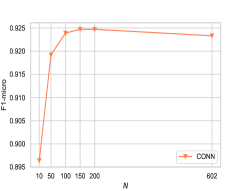
我们要回答的第一个问题是:top- 值对于具有连续特征的图有什么影响? 图3显示了我们的模型w.r.t.的结果 两个图(Reddit 和 ogbl-collab)上的不同 值,其中嵌入向量(例如,连续值)作为节点属性。 从图中我们可以看出,CONN的性能随着值的增加而提高,并且当等于节点属性的维度,即128和602 分别用于协作和 Reddit。
这一观察揭示了以下见解。 (i) Top- 策略是在我们的模型中处理连续特征向量的好方法,因为 在这两种情况下都已经取得了令人满意的结果。 (ii)此外,这表明我们的模型可以用于高维数据,因为我们可以首先采用经典的降维技术来降低维度。
为了检查我们的模型在高维数据上的可扩展性,我们首先采用 Deepwalk 获取 ACM 和 BlogCataglog 中节点的 128 维嵌入向量,然后使用得到的节点特征作为训练我们模型的输入。 我们在两个下游任务中观察到可比较的结果。 具体来说,ACM和BlogCatalog在链接预测上的AUC结果分别是0.987和0.916;而节点分类的微观平均结果为0.769和0.941。
5.8.2 将节点属性建模为二分图增强了 GNN 用于表示学习的鲁棒性。
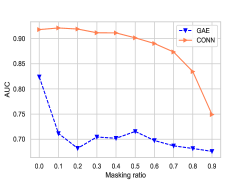
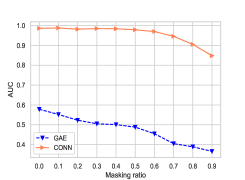
接下来,我们探讨将节点属性建模为增强图是否可以提高模型对噪声(即缺失链接)的鲁棒性。 我们分析了我们的模型和普通 GNN 竞争对手 (GAE) 对边缘扰动的鲁棒性,即用范围从 0.0 到 0.9 的比率随机屏蔽一些边缘,步长大小为 0.1。 我们在图 4 中显示了链接预测的结果。 在其他数据集中也观察到类似的敏感趋势。
两张图的结果表明,当两个数据集的掩蔽率小于 50% 时,我们的模型表现相对稳定,而当掩蔽率增加时,GAE 的性能普遍下降。 我们认为这种稳定的优点归功于所提出的增强二部图,因为它可以通过使用节点类别作为中介来补充节点之间缺失的连接。
5.8.3 联合重建节点属性和节点交互不会影响收敛速度。
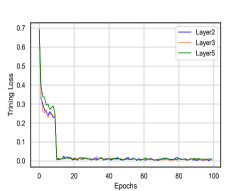
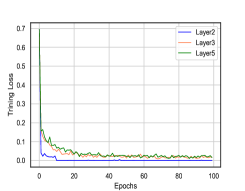
此外,我们想检查我们模型的经验收敛性。 我们在图 5 中展示了两个代表性数据集(分别用于分类和连续属性的 BlogCatalog 和 Reddit)上不同 GNN 层下 CONN 的训练曲线。 我们可以观察到,训练损失在前 10 个 epoch 中下降得非常快,并且我们的模型一般倾向于在 50 个 epoch 内收敛。
| HetGNN | MAGNN | CONN | ||
|---|---|---|---|---|
| NC | Pubmed | |||
| ACM | ||||
| BlogCatalog | ||||
| ogbn-arxiv | ||||
| LP | Pubmed | |||
| ACM | ||||
| BlogCatalog | ||||
| ogbn-collab |
5.8.4 将增强网络视为异构图是次优的。
最后,我们研究了我们的提案在异构 GNN 方面的泛化。 特别是,我们想探索成熟的异构 GNN 成果是否可以通过使用我们提出的增强网络直接应用于属性网络嵌入。 为此,我们选择两种流行的无监督异构 GNN 嵌入方法作为骨干:HetGNN [112] 和 MAGNN [126]。 为了公平比较,我们初始化与我们的模型类似的节点和属性类别的可学习嵌入。 表VI报告了节点分类和链路预测任务的结果。
我们观察到我们的 CONN 和两种异构 GNN 方法(HetGNN 和 MAGNN)在所有评估场景上都存在明显的性能差距。 综合考虑表III和IV中的结果,两种异构变体的性能相对于所有基线排名居中。 可能的解释是,将增强网络视为异构图可能会过分强调节点交互和节点属性之间的异构性。 通过随机游走[112]或元路径[126]很难控制它们之间的重要性。 这些比较证明了我们将增强网络视为同构图的动机。 我们认为,需要付出巨大的努力来释放异构 GNN 在属性网络嵌入方面的力量。
6 结论
在本文中,我们研究了图神经网络(GNN)下属性图的无监督节点表示学习问题。 现有的 GNN 工作主要集中在利用拓扑结构,而仅使用节点属性作为第一层的初始节点表示。 在这里,我们认为这种 GNN 架构对于建模现实世界的属性图来说并不是最优的,因为节点属性完全被排除在 GNN 的关键因素之外,即消息聚合机制和训练目标。 为了解决这个问题,我们提出了一种新颖的协作图神经网络,称为 CONN。 它允许节点属性确定邻域聚合的消息传递过程,并使节点到节点和节点到属性类别的交互能够被联合恢复。 社交和引文图上的节点分类和链接预测任务的实证结果证明了 CONN 相对于最先进的嵌入方法的优越性。 我们未来的工作是探索其对动态图的适用性,并通过集成对抗性训练进一步提高模型的鲁棒性。 此外,我们有兴趣在推荐场景[127]中探索类似的想法,例如顺序推荐[128, 129]和会话推荐[130, 131] 。
7 致谢
我们感谢异常审稿人的反馈。 这项工作得到了 NSF 的部分支持(IIS-2224843 和 IIS-1849085)。
参考
- [1] X. Huang, J. Li, and X. Hu, “Label informed attributed network embedding,” in Proceedings of the tenth ACM international conference on web search and data mining, 2017, pp. 731–739.
- [2] H. Gao and H. Huang, “Deep attributed network embedding.” in International Joint Conference on Artificial Intelligence, vol. 18. New York, NY, 2018, pp. 3364–3370.
- [3] R. Hong, Y. He, L. Wu, Y. Ge, and X. Wu, “Deep attributed network embedding by preserving structure and attribute information,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 51, no. 3, pp. 1434–1445, 2019.
- [4] H. Wang, D. Lian, H. Tong, Q. Liu, Z. Huang, and E. Chen, “Decoupled representation learning for attributed networks,” IEEE Transactions on Knowledge and Data Engineering, 2021.
- [5] M. McPherson, L. Smith-Lovin, and J. M. Cook, “Birds of a feather: Homophily in social networks,” Annual review of sociology, pp. 415–444, 2001.
- [6] P. V. Marsden and N. E. Friedkin, “Network studies of social influence,” Sociological Methods & Research, vol. 22, no. 1, pp. 127–151, 1993.
- [7] Z. Yang, J. Guo, K. Cai, J. Tang, J. Li, L. Zhang, and Z. Su, “Understanding retweeting behaviors in social networks,” in Proceedings of the 19th ACM international conference on Information and knowledge management, 2010, pp. 1633–1636.
- [8] L. Liao, X. He, H. Zhang, and T.-S. Chua, “Attributed social network embedding,” IEEE Transactions on Knowledge and Data Engineering, vol. 30, no. 12, pp. 2257–2270, 2018.
- [9] S. Wang, C. Aggarwal, J. Tang, and H. Liu, “Attributed signed network embedding,” in Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, 2017, pp. 137–146.
- [10] H. Wang, J. Wang, J. Wang, M. Zhao, W. Zhang, F. Zhang, W. Li, X. Xie, and M. Guo, “Learning graph representation with generative adversarial nets,” IEEE Transactions on Knowledge and Data Engineering, vol. 33, no. 8, pp. 3090–3103, 2019.
- [11] H. Yang, S. Pan, P. Zhang, L. Chen, D. Lian, and C. Zhang, “Binarized attributed network embedding,” in 2018 IEEE International Conference on Data Mining (ICDM). IEEE, 2018, pp. 1476–1481.
- [12] Y. Gao, M. Gong, Y. Xie, and H. Zhong, “Community-oriented attributed network embedding,” Knowledge-Based Systems, vol. 193, p. 105418, 2020.
- [13] B. Rozemberczki, C. Allen, and R. Sarkar, “Multi-scale attributed node embedding,” Journal of Complex Networks, vol. 9, no. 2, p. cnab014, 2021.
- [14] T. N. Kipf and M. Welling, “Variational graph auto-encoders,” arXiv preprint arXiv:1611.07308, 2016.
- [15] W. Hamilton, Z. Ying, and J. Leskovec, “Inductive representation learning on large graphs,” in Advances in Neural Information Processing Systems, 2017, pp. 1024–1034.
- [16] J. Li, H. Dani, X. Hu, J. Tang, Y. Chang, and H. Liu, “Attributed network embedding for learning in a dynamic environment,” in International Conference on Information and Knowledge Management, 2017, pp. 387–396.
- [17] J. Gilmer, S. S. Schoenholz, P. F. Riley, O. Vinyals, and G. E. Dahl, “Neural message passing for quantum chemistry,” in International Conference on Machine Learning, 2017, pp. 1263–1272.
- [18] X. Han, Z. Jiang, N. Liu, Q. Song, J. Li, and X. Hu, “Geometric graph representation learning via maximizing rate reduction,” in Proceedings of the ACM Web Conference 2022, 2022, pp. 1226–1237.
- [19] H. Gao, Z. Wang, and S. Ji, “Large-scale learnable graph convolutional networks,” in ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2018, pp. 1416–1424.
- [20] Z. Jiang, X. Han, C. Fan, Z. Liu, N. Zou, A. Mostafavi, and X. Hu, “Fmp: Toward fair graph message passing against topology bias,” arXiv preprint arXiv:2202.04187, 2022.
- [21] X. Li and Y. Cheng, “Understanding the message passing in graph neural networks via power iteration clustering,” Neural Networks, vol. 140, pp. 130–135, 2021.
- [22] Z. Jiang, X. Han, C. Fan, Z. Liu, X. Huang, N. Zou, A. Mostafavi, and X. Hu, “Topology matters in fair graph learning: a theoretical pilot study,” 2022.
- [23] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” in International Conference on Learning Representations, 2017.
- [24] Q. Tan, N. Liu, X. Huang, S.-H. Choi, L. Li, R. Chen, and X. Hu, “S2gae: Self-supervised graph autoencoders are generalizable learners with graph masking,” in ACM International Conference on Web Search and Data Mining, 2023, pp. 787–795.
- [25] Z. Jiang, X. Han, C. Fan, Z. Liu, N. Zou, A. Mostafavi, and X. Hu, “Fair graph message passing with transparency,” 2022.
- [26] Q. Li, Z. Han, and X.-M. Wu, “Deeper insights into graph convolutional networks for semi-supervised learning,” in AAAI Conference on Artificial Intelligence, vol. 32, no. 1, 2018.
- [27] L. Yu, L. Sun, B. Du, C. Liu, W. Lv, and H. Xiong, “Heterogeneous graph representation learning with relation awareness,” IEEE Transactions on Knowledge and Data Engineering, 2022.
- [28] Q. Tan, D. Zha, S.-H. Choi, L. Li, R. Chen, and X. Hu, “Double wins: Boosting accuracy and efficiency of graph neural networks by reliable knowledge distillation,” 2022.
- [29] X. Miao, W. Zhang, Y. Shao, B. Cui, L. Chen, C. Zhang, and J. Jiang, “Lasagne: A multi-layer graph convolutional network framework via node-aware deep architecture,” IEEE Transactions on Knowledge and Data Engineering, 2021.
- [30] Q. Tan, N. Liu, and X. Hu, “Deep representation learning for social network analysis,” Frontiers in Big Data, vol. 2, p. 2, 2019.
- [31] X. Huang, J. Li, and X. Hu, “Accelerated attributed network embedding,” in Proceedings of the 2017 SIAM international conference on data mining. SIAM, 2017, pp. 633–641.
- [32] Q. Tan, S. Ding, N. Liu, S.-H. Choi, L. Li, R. Chen, and X. Hu, “Graph contrastive learning with model perturbation,” 2022.
- [33] X. Gao, W. Hu, and G.-J. Qi, “Self-supervised graph representation learning via topology transformations,” IEEE Transactions on Knowledge and Data Engineering, 2021.
- [34] X. Han, Z. Jiang, N. Liu, and X. Hu, “G-mixup: Graph data augmentation for graph classification,” in International Conference on Machine Learning. PMLR, 2022, pp. 8230–8248.
- [35] X. Zhang, Q. Tan, X. Huang, and B. Li, “Graph contrastive learning with personalized augmentation,” arXiv preprint arXiv:2209.06560, 2022.
- [36] Q. Tan, X. Zhang, N. Liu, D. Zha, L. Li, R. Chen, S.-H. Choi, and X. Hu, “Bring your own view: Graph neural networks for link prediction with personalized subgraph selection,” in ACM International Conference on Web Search and Data Mining, 2023, pp. 625–633.
- [37] M. Zhang and Y. Chen, “Link prediction based on graph neural networks,” in Advances in Neural Information Processing Systems, 2018, pp. 5165–5175.
- [38] M. Zhang, P. Li, Y. Xia, K. Wang, and L. Jin, “Labeling trick: A theory of using graph neural networks for multi-node representation learning,” Advances in Neural Information Processing Systems, vol. 34, pp. 9061–9073, 2021.
- [39] Q. Tan, N. Liu, X. Zhao, H. Yang, J. Zhou, and X. Hu, “Learning to hash with graph neural networks for recommender systems,” in International Conference on World Wide Web, 2020, pp. 1988–1998.
- [40] Y. He, “Gnns for node clustering in signed and directed networks,” in Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, 2022, pp. 1547–1548.
- [41] C. Fettal, L. Labiod, and M. Nadif, “Efficient graph convolution for joint node representation learning and clustering,” in Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, 2022, pp. 289–297.
- [42] S. Zhou, Q. Tan, Z. Xu, X. Huang, and F.-l. Chung, “Subtractive aggregation for attributed network anomaly detection,” in ACM International Conference on Information & Knowledge Management, 2021, pp. 3672–3676.
- [43] S. Zhou, X. Huang, N. Liu, Q. Tan, and F.-L. Chung, “Unseen anomaly detection on networks via multi-hypersphere learning,” in SIAM International Conference on Data Mining. SIAM, 2022, pp. 262–270.
- [44] Q. Zhang, J. Dong, Q. Tan, and X. Huang, “Integrating entity attributes for error-aware knowledge graph embedding,” IEEE Transactions on Knowledge and Data Engineering, 2023.
- [45] J. Dong, Q. Zhang, X. Huang, Q. Tan, D. Zha, and Z. Zihao, “Active ensemble learning for knowledge graph error detection,” in ACM International Conference on Web Search and Data Mining, 2023, pp. 877–885.
- [46] P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y. Bengio, “Graph attention networks,” arXiv preprint arXiv:1710.10903, 2017.
- [47] J. Gao, J. Gao, X. Ying, M. Lu, and J. Wang, “Higher-order interaction goes neural: a substructure assembling graph attention network for graph classification,” IEEE Transactions on Knowledge and Data Engineering, 2021.
- [48] Z. Luo, Y. Cui, S. Zhao, and J. Yin, “g-inspector: Recurrent attention model on graph,” IEEE Transactions on Knowledge and Data Engineering, 2020.
- [49] K. Xu, W. Hu, J. Leskovec, and S. Jegelka, “How powerful are graph neural networks?” arXiv preprint arXiv:1810.00826, 2018.
- [50] H. Gao and S. Ji, “Graph representation learning via hard and channel-wise attention networks,” in ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2019, pp. 741–749.
- [51] W. Feng, J. Zhang, Y. Dong, Y. Han, H. Luan, Q. Xu, Q. Yang, E. Kharlamov, and J. Tang, “Graph random neural networks for semi-supervised learning on graphs,” Advances in Neural Information Processing Systems, vol. 33, 2020.
- [52] M. Chen, Z. Wei, Z. Huang, B. Ding, and Y. Li, “Simple and deep graph convolutional networks,” in International conference on machine learning. PMLR, 2020, pp. 1725–1735.
- [53] K. Stachenfeld, J. Godwin, and P. Battaglia, “Graph networks with spectral message passing,” arXiv preprint arXiv:2101.00079, 2020.
- [54] F. Wu, A. Souza, T. Zhang, C. Fifty, T. Yu, and K. Weinberger, “Simplifying graph convolutional networks,” in International conference on machine learning, 2019, pp. 6861–6871.
- [55] V. P. Dwivedi, C. K. Joshi, T. Laurent, Y. Bengio, and X. Bresson, “Benchmarking graph neural networks,” arXiv preprint arXiv:2003.00982, 2020.
- [56] Z. Liu, T.-K. Nguyen, and Y. Fang, “Tail-gnn: Tail-node graph neural networks,” in Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, 2021, pp. 1109–1119.
- [57] W. Zheng, E. W. Huang, N. Rao, S. Katariya, Z. Wang, and K. Subbian, “Cold brew: Distilling graph node representations with incomplete or missing neighborhoods,” arXiv preprint arXiv:2111.04840, 2021.
- [58] B. Perozzi, R. Al-Rfou, and S. Skiena, “Deepwalk: Online learning of social representations,” in ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2014, pp. 701–710.
- [59] X. Huang, Q. Song, F. Yang, and X. Hu, “Large-scale heterogeneous feature embedding,” in AAAI Conference on Artificial Intelligence, vol. 33, 2019, pp. 3878–3885.
- [60] Z. Zhang, H. Yang, J. Bu, S. Zhou, P. Yu, J. Zhang, M. Ester, and C. Wang, “Anrl: Attributed network representation learning via deep neural networks.” in International Joint Conference on Artificial Intelligence, vol. 18, 2018, pp. 3155–3161.
- [61] J. Klicpera, A. Bojchevski, and S. Günnemann, “Predict then propagate: Graph neural networks meet personalized pagerank,” International Conference on Learning Representations, 2019.
- [62] Z. Meng, S. Liang, H. Bao, and X. Zhang, “Co-embedding attributed networks,” in ACM International Conference on Web Searching and Data Mining, 2019, pp. 393–401.
- [63] Z. Zhang, P. Cui, and W. Zhu, “Deep learning on graphs: A survey,” IEEE Transactions on Knowledge and Data Engineering, 2020.
- [64] J. Zhou, G. Cui, Z. Zhang, C. Yang, Z. Liu, L. Wang, C. Li, and M. Sun, “Graph neural networks: A review of methods and applications,” arXiv preprint arXiv:1812.08434, 2018.
- [65] Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and S. Y. Philip, “A comprehensive survey on graph neural networks,” IEEE Transactions on Neural Networks and Learning Systems, 2020.
- [66] I. Makarov, D. Kiselev, N. Nikitinsky, and L. Subelj, “Survey on graph embeddings and their applications to machine learning problems on graphs,” PeerJ Computer Science, vol. 7, p. e357, 2021.
- [67] D. Zhang, J. Yin, X. Zhu, and C. Zhang, “Network representation learning: A survey,” IEEE transactions on Big Data, vol. 6, no. 1, pp. 3–28, 2018.
- [68] X. He and P. Niyogi, “Locality preserving projections,” Advances in neural information processing systems, vol. 16, 2003.
- [69] M. Belkin and P. Niyogi, “Laplacian eigenmaps and spectral techniques for embedding and clustering,” Advances in Neural Information Processing Systems, vol. 14, pp. 585–591, 2001.
- [70] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” in Advances in Neural Information Processing Systems, 2013, pp. 3111–3119.
- [71] J. Tang, M. Qu, M. Wang, M. Zhang, J. Yan, and Q. Mei, “Line: Large-scale information network embedding,” in International World Wide Web Conference, 2015, pp. 1067–1077.
- [72] S. Cao, W. Lu, and Q. Xu, “Grarep: Learning graph representations with global structural information,” in International Conference on Information and Knowledge Management, 2015, pp. 891–900.
- [73] A. Grover and J. Leskovec, “node2vec: Scalable feature learning for networks,” in ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2016, pp. 855–864.
- [74] D. Wang, P. Cui, and W. Zhu, “Structural deep network embedding,” in ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2016, pp. 1225–1234.
- [75] R. A. Rossi, R. Zhou, and N. K. Ahmed, “Deep inductive graph representation learning,” IEEE transactions on knowledge and data engineering, vol. 32, no. 3, pp. 438–452, 2018.
- [76] C. Tu, X. Zeng, H. Wang, Z. Zhang, Z. Liu, M. Sun, B. Zhang, and L. Lin, “A unified framework for community detection and network representation learning,” IEEE Transactions on Knowledge and Data Engineering, vol. 31, no. 6, pp. 1051–1065, 2018.
- [77] N. Liu, Q. Tan, Y. Li, H. Yang, J. Zhou, and X. Hu, “Is a single vector enough? exploring node polysemy for network embedding,” in ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2019, pp. 932–940.
- [78] X. Wang, P. Cui, J. Wang, J. Pei, W. Zhu, and S. Yang, “Community preserving network embedding,” in AAAI Conference on Artificial Intelligence, vol. 31, no. 1, 2017.
- [79] R. Yang, J. Shi, X. Xiao, Y. Yang, and S. S. Bhowmick, “Homogeneous network embedding for massive graphs via reweighted personalized pagerank,” arXiv preprint arXiv:1906.06826, 2019.
- [80] J. Qiu, Y. Dong, H. Ma, J. Li, C. Wang, K. Wang, and J. Tang, “Netsmf: Large-scale network embedding as sparse matrix factorization,” in The World Wide Web Conference, 2019, pp. 1509–1520.
- [81] W. Lin, “Large-scale network embedding in apache spark,” in Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, 2021, pp. 3271–3279.
- [82] S. Zhao, Z. Du, J. Chen, Y. Zhang, J. Tang, and P. Yu, “Hierarchical representation learning for attributed networks,” IEEE Transactions on Knowledge and Data Engineering, 2021.
- [83] C. Yang, Z. Liu, D. Zhao, M. Sun, and E. Y. Chang, “Network representation learning with rich text information.” in International Joint Conference on Artificial Intelligence, vol. 2015, 2015, pp. 2111–2117.
- [84] W. Wang, X. Wei, X. Suo, B. Wang, H. Wang, H.-N. Dai, and X. Zhang, “Hgate: heterogeneous graph attention auto-encoders,” IEEE Transactions on Knowledge and Data Engineering, 2021.
- [85] X. Zhao, Q. Dai, J. Wu, H. Peng, M. Liu, X. Bai, J. Tan, S. Wang, and P. Yu, “Multi-view tensor graph neural networks through reinforced aggregation,” IEEE Transactions on Knowledge and Data Engineering, 2022.
- [86] X. Zhang, H. Liu, Q. Li, and X.-M. Wu, “Attributed graph clustering via adaptive graph convolution,” arXiv preprint arXiv:1906.01210, 2019.
- [87] Z. Liu, C. Huang, Y. Yu, and J. Dong, “Motif-preserving dynamic attributed network embedding,” in Proceedings of the Web Conference 2021, 2021, pp. 1629–1638.
- [88] W. Huang, Y. Li, Y. Fang, J. Fan, and H. Yang, “Biane: Bipartite attributed network embedding,” in Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval, 2020, pp. 149–158.
- [89] R. Yang, J. Shi, X. Xiao, Y. Yang, J. Liu, and S. S. Bhowmick, “Scaling attributed network embedding to massive graphs,” arXiv preprint arXiv:2009.00826, 2020.
- [90] J. Tang, M. Qu, and Q. Mei, “Pte: Predictive text embedding through large-scale heterogeneous text networks,” in ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2015, pp. 1165–1174.
- [91] H. Gao, J. Pei, and H. Huang, “Progan: Network embedding via proximity generative adversarial network,” in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2019, pp. 1308–1316.
- [92] M. Liu, H. Gao, and S. Ji, “Towards deeper graph neural networks,” in Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, 2020, pp. 338–348.
- [93] J. Fang, S. Liang, Z. Meng, and M. De Rijke, “Hyperspherical variational co-embedding for attributed networks,” ACM Transactions on Information Systems (TOIS), vol. 40, no. 3, pp. 1–36, 2021.
- [94] P. Velickovic, W. Fedus, W. L. Hamilton, P. Liò, Y. Bengio, and R. D. Hjelm, “Deep graph infomax.” in International Conference on Learning Representations, 2019.
- [95] C. Mavromatis and G. Karypis, “Graph infoclust: Maximizing coarse-grain mutual information in graphs,” in Pacific-Asia Conference on Knowledge Discovery and Data Mining. Springer, 2021, pp. 541–553.
- [96] Y. Zhu, Y. Xu, F. Yu, Q. Liu, S. Wu, and L. Wang, “Graph contrastive learning with adaptive augmentation,” in Proceedings of the Web Conference 2021, 2021, pp. 2069–2080.
- [97] K. Hassani and A. H. Khasahmadi, “Contrastive multi-view representation learning on graphs,” in International Conference on Machine Learning. PMLR, 2020, pp. 4116–4126.
- [98] N. Park, A. Kan, X. L. Dong, T. Zhao, and C. Faloutsos, “Estimating node importance in knowledge graphs using graph neural networks,” in Proceedings of the ACM SIGKDD international conference on knowledge discovery & data mining, 2019, pp. 596–606.
- [99] Z. Zhang, F. Zhuang, H. Zhu, Z. Shi, H. Xiong, and Q. He, “Relational graph neural network with hierarchical attention for knowledge graph completion,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 05, 2020, pp. 9612–9619.
- [100] M. Yasunaga, H. Ren, A. Bosselut, P. Liang, and J. Leskovec, “Qa-gnn: Reasoning with language models and knowledge graphs for question answering,” in Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021, pp. 535–546.
- [101] J. Dong, Q. Zhang, X. Huang, K. Duan, Q. Tan, and Z. Jiang, “Hierarchy-aware multi-hop question answering over knowledge graphs,” in International World Wide Web Conference, 2023, pp. 2519–2527.
- [102] Y. Hou, H. Chen, C. Li, J. Cheng, and M.-C. Yang, “A representation learning framework for property graphs,” in Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 2019, pp. 65–73.
- [103] H. Wang, M. Zhao, X. Xie, W. Li, and M. Guo, “Knowledge graph convolutional networks for recommender systems,” in The world wide web conference, 2019, pp. 3307–3313.
- [104] X. Wang, X. He, Y. Cao, M. Liu, and T.-S. Chua, “Kgat: Knowledge graph attention network for recommendation,” in Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 2019, pp. 950–958.
- [105] L. Yao, C. Mao, and Y. Luo, “Graph convolutional networks for text classification,” in AAAI Conference on Artificial Intelligence, vol. 33, 2019, pp. 7370–7377.
- [106] C. Park, D. Kim, J. Han, and H. Yu, “Unsupervised attributed multiplex network embedding,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 04, 2020, pp. 5371–5378.
- [107] G. Cui, J. Zhou, C. Yang, and Z. Liu, “Adaptive graph encoder for attributed graph embedding,” in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2020, pp. 976–985.
- [108] J. Chen, S. Zheng, Y. Song, J. Rao, and Y. Yang, “Learning attributed graph representations with communicative message passing transformer,” arXiv preprint arXiv:2107.08773, 2021.
- [109] Z. Zhou, S. Zhou, B. Mao, X. Zhou, J. Chen, Q. Tan, D. Zha, C. Wang, Y. Feng, and C. Chen, “Opengsl: benchmarking graph structure learning,” in arxiv, 2023.
- [110] X. Wang, M. Zhu, D. Bo, P. Cui, C. Shi, and J. Pei, “Am-gcn: Adaptive multi-channel graph convolutional networks,” in Proceedings of the 26th ACM SIGKDD International conference on knowledge discovery & data mining, 2020, pp. 1243–1253.
- [111] C. Liu, L. Wen, Z. Kang, G. Luo, and L. Tian, “Self-supervised consensus representation learning for attributed graph,” in Proceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 2654–2662.
- [112] C. Zhang, D. Song, C. Huang, A. Swami, and N. V. Chawla, “Heterogeneous graph neural network,” in Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 2019, pp. 793–803.
- [113] D. Jin, C. Huo, C. Liang, and L. Yang, “Heterogeneous graph neural network via attribute completion,” in Proceedings of the Web Conference 2021, 2021, pp. 391–400.
- [114] J. Qiu, Y. Dong, H. Ma, J. Li, K. Wang, and J. Tang, “Network embedding as matrix factorization: Unifying deepwalk, line, pte, and node2vec,” in ACM International Conference on Web Searching and Data Mining, 2018, pp. 459–467.
- [115] X. Wang, X. He, M. Wang, F. Feng, and T.-S. Chua, “Neural graph collaborative filtering,” in Proceedings of the 42nd international ACM SIGIR conference on Research and development in Information Retrieval, 2019, pp. 165–174.
- [116] H. Zhu, F. Feng, X. He, X. Wang, Y. Li, K. Zheng, and Y. Zhang, “Bilinear graph neural network with neighbor interactions,” in International Joint Conference on Artificial Intelligence, vol. 5, 2020.
- [117] Y. Li and I. King, “Autograph: Automated graph neural network,” in International Conference on Neural Information Processing. Springer, 2020, pp. 189–201.
- [118] C. Yang, Y. Xiao, Y. Zhang, Y. Sun, and J. Han, “Heterogeneous network representation learning: A unified framework with survey and benchmark,” IEEE Transactions on Knowledge and Data Engineering, 2020.
- [119] X. Wang, H. Ji, C. Shi, B. Wang, Y. Ye, P. Cui, and P. S. Yu, “Heterogeneous graph attention network,” in The world wide web conference, 2019, pp. 2022–2032.
- [120] P. Sen, G. Namata, M. Bilgic, L. Getoor, B. Galligher, and T. Eliassi-Rad, “Collective classification in network data,” AI magazine, vol. 29, no. 3, pp. 93–93, 2008.
- [121] J. Tang, J. Zhang, L. Yao, J. Li, L. Zhang, and Z. Su, “Arnetminer: extraction and mining of academic social networks,” in ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2008, pp. 990–998.
- [122] J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors for word representation,” in EMNLP, 2014, pp. 1532–1543.
- [123] K. Wang, Z. Shen, C. Huang, C.-H. Wu, Y. Dong, and A. Kanakia, “Microsoft academic graph: When experts are not enough,” Quantitative Science Studies, vol. 1, no. 1, pp. 396–413, 2020.
- [124] S. Pan, R. Hu, G. Long, J. Jiang, L. Yao, and C. Zhang, “Adversarially regularized graph autoencoder for graph embedding,” arXiv preprint arXiv:1802.04407, 2018.
- [125] Q. Li, X. Zhang, H. Liu, Q. Dai, and X.-M. Wu, “Dimensionwise separable 2-d graph convolution for unsupervised and semi-supervised learning on graphs,” in Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, 2021, pp. 953–963.
- [126] X. Fu, J. Zhang, Z. Meng, and I. King, “Magnn: Metapath aggregated graph neural network for heterogeneous graph embedding,” in Proceedings of The Web Conference 2020, 2020, pp. 2331–2341.
- [127] D. Zha, L. Feng, Q. Tan, Z. Liu, K.-H. Lai, B. Bhushanam, Y. Tian, A. Kejariwal, and X. Hu, “Dreamshard: Generalizable embedding table placement for recommender systems,” in Advances in Neural Information Processing Systems, 2022.
- [128] Q. Tan, J. Zhang, J. Yao, N. Liu, J. Zhou, H. Yang, and X. Hu, “Sparse-interest network for sequential recommendation,” in ACM International Conference on Web Search and Data Mining, 2021, pp. 598–606.
- [129] Q. Tan, J. Zhang, N. Liu, X. Huang, H. Yang, J. Zhou, and X. Hu, “Dynamic memory based attention network for sequential recommendation,” in AAAI Conference on Artificial Intelligence, vol. 35, no. 5, 2021, pp. 4384–4392.
- [130] H. Zhou, Q. Tan, X. Huang, K. Zhou, and X. Wang, “Temporal augmented graph neural networks for session-based recommendations,” in International ACM SIGIR Conference on Research and Development in Information Retrieval, 2021, pp. 1798–1802.
- [131] H. Zhou, S. Zhou, K. Duan, X. Huang, Q. Tan, and Z. Yu, “Interest driven graph structure learning for session-based recommendation,” in Pacific-Asia Conference on Knowledge Discovery and Data Mining. Springer, 2023, pp. 284–296.