GridMM:用于视觉和语言导航的网格内存映射
摘要
视觉和语言导航 (VLN) 使代理能够按照 3D 环境中的自然语言指令导航到远程位置。 为了表示先前访问的环境,大多数 VLN 方法使用循环状态、拓扑图或自上而下的语义图来实现内存。 与这些方法相反,我们构建自上而下的以自我为中心且动态增长的网格内存映射(即,GridMM)来构建访问的环境。 从全局角度来看,历史观测结果以自上而下的方式投影到统一的网格地图上,可以更好地表征环境的空间关系。 从局部角度来看,我们进一步提出了一种指令相关性聚合方法来捕获每个网格区域中的细粒度视觉线索。 在离散环境中的 REVERIE、R2R、SOON 数据集和连续环境中的 R2R-CE 数据集上进行了大量的实验,显示了我们提出的方法的优越性。 源代码可在 https://github.com/MrZihan/GridMM 获取。
1简介
视觉和语言导航 (VLN) 任务[4,35,42]要求代理理解自然语言指令并根据指令采取行动。 已经提出了两种不同的 VLN 场景,即离散环境中的导航(例如、R2R [4]、REVERIE [42]、SOON [65])和连续环境(例如、R2R-CE [34]、RxR-CE [35] )。 VLN中的离散环境被抽象为互连的可导航节点的拓扑结构。 通过连接图,代理可以通过从可导航方向中选择方向来移动到图上的相邻节点。 与离散环境不同,连续环境中的 VLN 要求智能体通过低级控制移动(即左转 15 度、右转 15 度或向前移动 0.25 米),更加接近使现实世界的机器人导航更具挑战性。
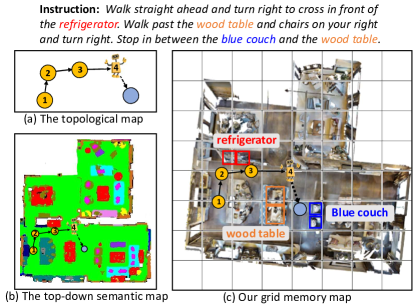
无论是在离散环境还是连续环境中,导航过程中的历史信息对于环境理解和指令落地都起着重要作用。 在之前的工作[4,19,52,58,27]中,循环状态最常用作VLN的历史信息,它在固定大小的状态向量内编码历史观察和动作。 然而,这种压缩状态可能不足以捕获轨迹历史中的基本信息。 因此,Episodic Transformer [41] 和 HAMT [12] 建议将轨迹历史和动作直接编码为先前观察的序列,而不是使用循环状态。 此外,为了构建访问环境并进行全局规划,最近的一些方法[10,14,36]构建了拓扑图,如图1所示(A)。 然而,这些方法很难表示历史观测中物体和场景之间的空间关系,从而丢失了大量的详细信息。 如图1(b)所示,最近的工作[29,20,11,28]使用自上而下的语义图对导航环境进行建模,它表示空间关系更加精确。 但由于预定义的语义标签,语义概念极其有限。 因此,未包含在先验语义标签中的物体或场景无法表示,例如图1(b)中的“冰箱”。 此外,如图1(b)所示,具有多种属性的对象(例如“木桌”和“蓝色沙发”)无法通过缺少对象属性的语义图来完整表达。
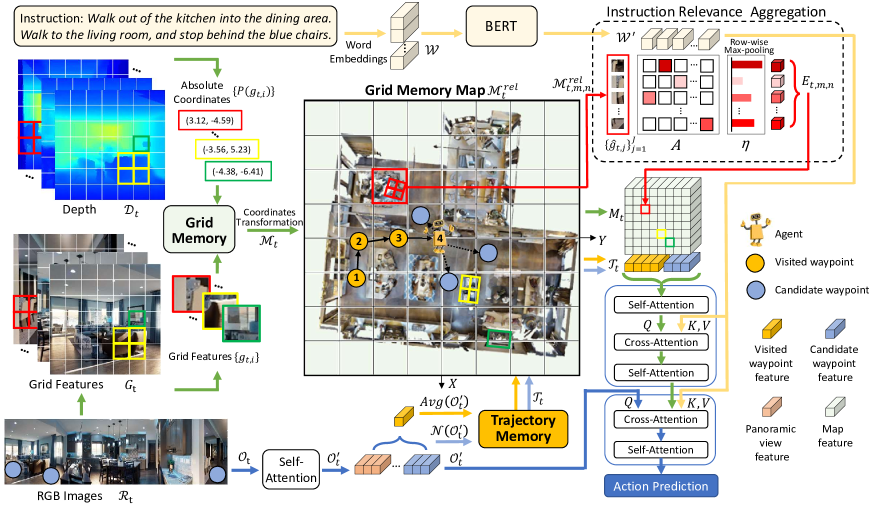
与上述工作[10,14,20,28]相比,我们提出了网格内存映射(即,GridMM),一种用于建模全球历史的可视化表示结构航行期间的观察。 与 BEVbert [1] 应用局部混合度量图进行短期推理不同,我们的 GridMM 利用时间和空间信息来描述全局访问的环境。 具体来说,网格地图将访问的环境划分为许多同样大的网格区域,每个网格区域包含许多细粒度的视觉特征。 我们动态构建网格存储库以在导航过程中更新网格地图。 在导航的每一步中,预先训练的 CLIP [45] 模型的视觉特征都会保存到内存库中,并且所有这些特征都根据通过计算得出的坐标被分类到网格地图区域中深度信息。 为了获得每个区域的表示,我们设计了一种指令相关性聚合方法来捕获与指令最相关的视觉特征并将它们聚合成一个整体特征。 借助聚合的地图特征,智能体能够准确地进行下一步的行动规划。 大量的实验说明了我们的 GridMM 与以前的方法相比的有效性。
总之,我们做出以下贡献:
-
•
我们提出了 VLN 的网格内存映射来构建访问环境的全局时空关系,并采用指令相关性聚合来捕获与指令相关的视觉线索。
-
•
我们全面比较了 VLN 中代表访问环境的不同地图,并分析了我们提出的 GridMM 的特征,它描述了更细粒度的信息,并为 VLN 中的未来工作提供了一些见解。
-
•
进行了大量的实验来验证我们的方法在离散环境和连续环境中的有效性,这表明我们的方法在许多基准数据集上优于现有方法。
2相关工作
视觉和语言导航(VLN)。 VLN[4,58,25,56,43,14,13]近年来随着不断改进而受到广泛关注。 VLN 任务包括分步说明(例如 R2R [4] 和 RxR [35])、对话框导航(例如 CVDN [55]) t2>,以及远程对象接地导航,例如 REVERIE [42] 和 SOON [65]。 所有任务都要求代理能够使用与时间相关的视觉观察来做出决策。 由于在连续环境中探索大动作空间需要大量计算,早期的工作主要集中在离散环境上。 其中,循环单元通常用于在固定大小的状态向量[4,19,52,58,27]内对历史观察和动作进行编码。 HAMT [12] 不依赖循环状态,而是显式编码全景观测历史以捕获长程依赖性,而 DUET [14] 提出对拓扑图进行编码进行有效的全球规划。 受视觉和语言预训练 [51, 45] 成功的启发,HOP [43, 44] 利用精心设计的代理任务进行预训练增强视觉和语言模式之间的互动。 ADAPT [40]采用动作提示来提高跨模态对齐能力。 基于数据增强方法,一些方法根据现有的 VLN 数据集放大视觉模态 [30] 和语言模态 [19, 39, 18, 31] 的训练数据。 此外,AirBERT [21] 和 HM3D-AutoVLN [13] 通过创建大规模数据集来提高性能。 KERM [38] 利用大型知识库来描述导航视图,以获得更好的泛化能力。 在这项工作中,我们提出了一种动态增长的网格内存映射,用于构建访问环境并制定长期规划,这有助于环境理解和指令基础。
连续环境中的 VLN (VLN-CE)。 VLN-CE [34]将拓扑定义的VLN任务(例如R2R [4])转换为连续环境任务,更接近现实世界的导航。 与离散环境不同,VLN-CE中的智能体必须通过选择低级动作来导航到目的地,类似于一些视觉导航任务[62,61,37,63,53,54,66]. 一些方法[20, 11]应用自上而下的语义图来理解环境,并使用语言对齐的路点监督[29]来进行动作预测。 最近,用于将预训练的 VLN 智能体转移到连续环境的 Bridging [26] 和 Sim-2-Sim [33] 取得了可观的成果。 与VLN-CE中从头开始训练智能体相比,该策略可以减少预训练的计算成本并加速模型收敛。 在这项工作中,我们基于提出的 GridMM 在离散环境中预训练我们的模型,然后将模型转移到连续环境中。 离散环境和连续环境中的实验说明了我们方法的有效性。
导航地图。 视觉导航[22,8,59]和其他3D室内场景理解任务[24,5,6,15]的工作具有构建地图的悠久传统。 一些作品将地图表示为拓扑结构,用于回溯到其他位置[10]或支持全球行动规划[14]。 此外,一些方法[20, 28]构建了自上而下的语义图来更精确地表示环境的空间关系。 最近,BEVbert[1]将机器人技术中的拓扑度量图引入到VLN中,VLN使用拓扑图进行长期规划,并应用混合度量图进行短期推理。 它的度量地图将代理周围的局部环境划分为 个单元,每个单元代表边长为 的正方形区域。 此外,两个步骤内的短期视觉观察被映射到这些单元格中。 然而,我们的 GridMM 在以下方面完全不同: (1) BEVbert 通过网格特征丰富了局部观测的表示。 我们的 GridMM 旨在通过动态增长的网格地图感知更多的时空关系,利用时间和空间信息来描述全球访问的环境。 (2) BEVbert 中基于网格的度量地图仅用于局部动作预测。 我们的 GridMM 随着访问环境的扩展而扩展,为局部和全局动作预测提供空间增强表示。 (3) BEVbert 的度量图表示只是视觉特征。 GridMM 中每个单元格的表示都会根据指令进行自适应,其中包含视觉和语言信息。
3方法
3.1 导航设置
对于离散环境中的 VLN,Matterport3D 模拟器 [7] 中提供了导航连接图 ,其中 表示可导航节点, 表示边缘。 代理配备 RGB 和深度摄像头以及 GPS 传感器。 在起始节点初始化并给出自然语言指令,代理需要探索导航连接图并到达目标节点。 表示带有 个词的指令的词嵌入。 在每个时间步,代理观察其当前节点的全景RGB图像和深度图像,其中包含 单视图图像。 代理知道一些与其相邻节点及其坐标相对应的可导航视图。
连续环境中的 VLN 是在栖息地 [50] 上建立的,其中智能体的位置 可以是开放空间中的任意点。 在每个导航步骤中,我们使用预先训练的航路点预测器[26]在连续环境中生成可导航航路点,这将任务与离散环境中的VLN同化。
3.2 网格内存映射
如图2所示,我们展示了我们的网格内存映射管道。 在每个导航步骤,我们首先将细粒度的视觉特征及其相应的坐标存储在网格内存中。 对于全景RGB图像,我们使用预训练的CLIP-ViT-B/32[45]模型来提取网格特征,并且行列的网格特征表示为。 对应的深度图像被缩小到与相同的比例,行列的深度值表示为。 为了方便起见,我们将所有下标表示为,其中范围从1到,。 因此表示为,表示为。 与[3, 28]类似,我们可以计算出的绝对坐标:
| (1) | |||
其中表示代理的当前坐标,表示与代理当前方向之间的航向角,表示欧几里德与代理之间的距离,可以通过和计算出来。 我们将所有这些网格特征及其绝对坐标存储在网格内存中:
| (2) |
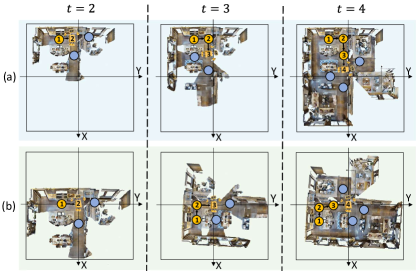
然后,我们提出了一种使用网格存储器中的视觉特征构建网格存储器映射的动态坐标变换方法。 直观上,我们可以构建如图3(a)所示的地图。 通过根据绝对坐标将所有历史观测投影到统一地图中来表示访问的环境。 然而,这样的地图有两个缺点。 首先,将候选观察值和指令与绝对坐标对齐不够有效。 其次,在没有有关环境的先验信息的情况下很难确定地图的比例和范围[64]。
为了解决这些缺陷,我们提出了一种新的映射方法来构建自上而下的以自我为中心且动态增长的映射,如图3(b)所示。 在每一步中,我们通过将网格内存 的所有特征投影到新的平面笛卡尔坐标系中,以自我为中心的视图构建网格地图,以代理的位置为坐标原点,以代理的当前方向为坐标原点。 y 轴正方向。 在这个新的坐标系中,对于中的每个网格特征(其中范围从1到),我们可以计算时间步中的新相对坐标:
| (3) |
其中表示新坐标系和旧坐标系之间的航向角。
此外,我们通过网格特征及其新坐标构建网格内存映射(即,GridMM)。 在步骤,网格内存映射将作为边长:
| (4) | |||
使得GridMM的大小随着访问环境的扩大而增大。 代理始终位于该地图的中心,并且该地图与以自我为中心的视图中当前的全景观察对齐。 然后将地图分为 个单元格,并且 的所有要素根据新的相对坐标投影到这些单元格中。 最后,我们用单元构建网格内存映射,每个单元包含多个细粒度的视觉特征。 将每个单元格中的所有视觉特征聚合到一个嵌入向量后,就得到了地图特征。 详细的聚合方法在第 2 节中描述。 3.3.2。
3.3模型架构
3.3.1 指令和观察编码
对于指令编码,中的每个词嵌入都添加了位置嵌入和词符类型嵌入。 然后将所有标记输入多层 Transformer 以获得单词表示,表示为 。
对于全景观测的视图图像,我们使用在ImageNet上预训练的ViT-B/16[17]来提取视觉特征。 然后我们将它们的相对角度表示为 ,其中 和 是相对于代理方向的相对航向角和仰角。 候选路径点表示为,路径点与当前代理之间的直线距离表示为。 类似地,我们将代理与起始航路点之间的相对角度表示为。 然后我们将代理与起始航路点之间的直线距离、导航轨迹长度和动作步骤连接起来以获得 。 最后,观察嵌入如下:
| (5) |
其中表示层归一化,和是可学习参数。 在上添加一个特殊的“停止”词符来表示停止动作。 我们使用两层 Transformer 来对观察嵌入和输出 之间的关系进行建模。
3.3.2 网格内存编码
如第 2 节所述。 3.2,我们需要将每个单元格中的多个网格特征聚合成一个嵌入向量。 由于导航环境的复杂性,智能体并不需要每个单元区域内的大量网格特征来完成导航。 代理需要更关键且与当前指令高度相关的信息来了解环境。 因此,我们提出了一种指令相关性方法来聚合每个单元中的特征。 具体来说,对于每个单元格中的网格要素,其对应的坐标均位于行列的单元格内,该单元格中的特征数量为。 我们通过计算相关性矩阵来评估每个网格特征与导航指令的每个词符的相关性:
| (6) |
其中 和 是可学习的参数。 之后,我们计算 上的行最大池化,以评估每个网格特征与指令的相关性:
| (7) |
最后,我们将每个单元内的网格特征聚合成一个嵌入向量:
| (8) |
| (9) |
其中 是可学习的参数。 为了表示空间关系,我们将位置信息引入网格内存映射中。 具体来说,在每个单元中心和代理之间,我们将线距离表示为,并将相对航向角度表示为。 则可以得到地图特征:
| (10) |
其中 是可学习的参数。
3.3.3 导航轨迹编码
为了实施全局行动规划,我们进一步将导航轨迹引入到 GridMM 中。 如第 2 节所示。 3.3.1,在时间步,代理接收路点的全景特征。 然后我们可以通过的平均池化获得当前路点的视觉表示。 由于代理还部分观察候选航路点,因此我们使用包含这些可导航航路点的视图图像特征 作为其视觉表示。 在路径点和当前代理之间,我们将线距离表示为 ,将相对航向角度表示为 ,将动作步骤嵌入表示为 。 所有历史航点特征、当前航点特征和候选航点特征构成导航轨迹:
| (11) |
其中和是可学习的参数,在中添加了一个特殊的“stop”词符来执行停止操作。
3.3.4 跨模态推理
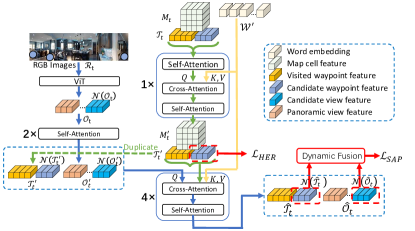
随后,我们使用另一个 4 层的跨模态 Transformer 来建模视觉语言关系和时空关系。 具体来说,每个 Transformer 层都由交叉注意力层和自注意力层组成。 对于交叉注意力层,我们输入全景观察和导航轨迹作为查询,这些查询关注编码指令标记、导航轨迹和地图特征。 然后,自注意力层将编码的全景观察和导航轨迹作为动作推理的输入,其中输出表示为。
3.3.5 动作预测
我们预测候选视图 的本地导航分数如下:
| (12) |
并预测候选可导航航路点的全局导航分数,如下所示:
| (13) |
其中表示两层前馈网络。 需要注意的是,和是停止分数。 两个独立的 FFN 用于预测局部动作分数和全局动作分数,我们对以下分数进行门控融合:[14]:
| (14) |
其中。
3.4预训练和微调
预训练。
我们利用四个任务来预训练我们的模型。
1)掩码语言建模(MLM)。 我们以 15% 的概率随机屏蔽指令中的单词,然后预测屏蔽的单词 。
2)屏蔽视图建模(MVM)。 我们以 15% 的概率随机屏蔽视图图像,并预测屏蔽视图图像的语义标签。 与[14]类似,视图图像的目标标签是通过在ImageNet上预训练的图像分类模型[17]获得的。
3)单步动作预测(SAP)。 给定真实值动作 ,SAP 损失定义如下:
| (15) |
4)历史环境推理(HER)。 HER要求智能体仅根据地图特征和导航轨迹来预测下一步动作,而不需要全景观察:
| (16) |
| (17) |
微调。
为了进行微调,我们按照现有作品[14, 26]使用Dagger [49]训练技术。 与使用演示路径的预训练过程不同,微调的监督来自于伪交互式演示器,它选择一个可导航的航路点作为下一个目标,并且从当前航路点到目的地的整体最短距离。
4实验
4.1 数据集和评估指标
我们在离散环境中的 REVERIE [42]、R2R [4]、SOON [65] 数据集和 R2R-CE [34] 在连续环境中。
REVERIE包含高级指令,平均包含21个字,路径长度在4到7步之间。 为每个全景图提供了预定义的对象边界框,代理应从导航路径末尾的候选对象中选择正确的对象边界框。
R2R 提供分步说明。 指令的平均长度为32个字,平均路径长度为6步。
很快还提供描述目标位置和目标对象的说明。 指令的平均长度为47个字,路径长度在2到21步之间。 然而,没有提供对象边界框,代理需要预测目标对象的中心位置。 与[14]中的设置类似,我们使用对象检测器[2]来获取候选对象框。
R2R-CE是基于离散Matterport3D环境[7]收集的,但使用Habitat模拟器[46]在连续环境中导航。
VLN中有几个标准指标[4, 42]用于评估代理的性能,包括轨迹长度(TL)、导航错误(NE)、成功率(SR)、给定Oracle停止策略的SR (OSR)、路径长度的归一化倒数 (SPL)、远程接地成功 (RGS) 和受路径长度惩罚的 RGS (RGSPL)。
4.2实现细节
我们采用预训练的 CLIP-ViT-B/32 [45] 在所有数据集上提取网格特征 。 我们使用在 ImageNet 上预训练的 ViT-B/16 [17] 来提取所有数据集上的全景视图特征 并提取 REVERIE 数据集上的对象特征,因为它提供了边界盒子。 BUTD 对象检测器 [2] 用于 SOON 数据集来提取对象边界框。 语言编码器、全景编码器、地图和轨迹编码器、跨模态推理编码器的层数分别设置为9、2、1和4,如图2所示,全部隐藏尺寸为 768。 所有 Transformer 层的参数均使用预训练的 LXMERT [51] 进行初始化。
4.3与最先进方法的比较
表 1、2、3 将我们的方法与之前在 REVERIE、R2R 和 SOON 基准测试上的 VLN 方法进行比较。 表 4 将我们的方法与之前在 R2R-CE 基准上的 VLN-CE 方法进行了比较。 我们的方法在大多数指标上实现了最先进的性能,证明了所提出方法的有效性。 对于表1中 REVERIE 数据集的未见值拆分,我们的模型在 SR 方面比之前的 DUET [14] 高出 4.39%,在 SPL 方面比之前的 DUET 高出 2.74%。 如表 2 和 3 所示,它还显示了与 DUET 相比,R2R 和 SOON 数据集的性能提升。 特别是,我们的方法在表 4 中的 R2R-CE 数据集上显着优于以前的所有方法,证明了我们的 GridMM 对于 VLN-CE 的有效性。
| Methods | Val Unseen | Test Unseen | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Navigation | Grounding | Navigation | Grounding | |||||||||
| TL↓ | OSR↑ | SR↑ | SPL↑ | RGS↑ | RGSPL↑ | TL↓ | OSR↑ | SR↑ | SPL↑ | RGS↑ | RGSPL↑ | |
| VLNBERT [27] | 16.78 | 35.02 | 30.67 | 24.90 | 18.77 | 15.27 | 15.68 | 32.91 | 29.61 | 23.99 | 16.50 | 13.51 |
| AirBERT [21] | 18.71 | 34.51 | 27.89 | 21.88 | 18.23 | 14.18 | 17.91 | 34.20 | 30.28 | 23.61 | 16.83 | 13.28 |
| HOP [43] | 16.46 | 36.24 | 31.78 | 26.11 | 18.85 | 15.73 | 16.38 | 33.06 | 30.17 | 24.34 | 17.69 | 14.34 |
| HAMT [12] | 14.08 | 36.84 | 32.95 | 30.20 | 18.92 | 17.28 | 13.62 | 33.41 | 30.40 | 26.67 | 14.88 | 13.08 |
| TD-STP [64] | - | 39.48 | 34.88 | 27.32 | 21.16 | 16.56 | - | 40.26 | 35.89 | 27.51 | 19.88 | 15.40 |
| DUET [14] | 22.11 | 51.07 | 46.98 | 33.73 | 32.15 | 23.03 | 21.30 | 56.91 | 52.51 | 36.06 | 31.88 | 22.06 |
| BEVBert [1] | - | 56.40 | 51.78 | 36.37 | 34.71 | 24.44 | - | 57.26 | 52.81 | 36.41 | 32.06 | 22.09 |
| GridMM (Ours) | 23.20 | 57.48 | 51.37 | 36.47 | 34.57 | 24.56 | 19.97 | 59.55 | 53.13 | 36.60 | 34.87 | 23.45 |
| Methods | Val Unseen | Test Unseen | ||||||
|---|---|---|---|---|---|---|---|---|
| TL↓ | NE↓ | SR↑ | SPL↑ | TL↓ | NE↓ | SR↑ | SPL↑ | |
| VLNBERT [27] | 12.01 | 3.93 | 63 | 57 | 12.35 | 4.09 | 63 | 57 |
| AirBERT [21] | 11.78 | 4.01 | 62 | 56 | 12.41 | 4.13 | 62 | 57 |
| SEvol [9] | 12.26 | 3.99 | 62 | 57 | 13.40 | 4.13 | 62 | 57 |
| HOP [43] | 12.27 | 3.80 | 64 | 57 | 12.68 | 3.83 | 64 | 59 |
| HAMT [12] | 11.46 | 2.29 | 66 | 61 | 12.27 | 3.93 | 65 | 60 |
| TD-STP [64] | - | 3.22 | 70 | 63 | - | 3.73 | 67 | 61 |
| DUET [14] | 13.94 | 3.31 | 72 | 60 | 14.73 | 3.65 | 69 | 59 |
| BEVBert [1] | 14.55 | 2.81 | 75 | 64 | 15.87 | 3.13 | 73 | 62 |
| GridMM (Ours) | 13.27 | 2.83 | 75 | 64 | 14.43 | 3.35 | 73 | 62 |
| Split | Method | TL↓ | OSR↑ | SR↑ | SPL↑ | RGSPL↑ |
|---|---|---|---|---|---|---|
| Val Unseen | GBE [65] | 28.96 | 28.54 | 19.52 | 13.34 | 1.16 |
| DUET [14] | 36.20 | 50.91 | 36.28 | 22.58 | 3.75 | |
| GridMM (Ours) | 38.92 | 53.39 | 37.46 | 24.81 | 3.91 | |
| Test Unseen | GBE [65] | 27.88 | 21.45 | 12.90 | 9.23 | 0.45 |
| DUET [14] | 41.83 | 43.00 | 33.44 | 21.42 | 4.17 | |
| GridMM (Ours) | 46.20 | 48.02 | 36.27 | 21.25 | 4.15 |
| Methods | Val Seen | Val Unseen | Test Unseen | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TL↓ | NE↓ | OSR↑ | SR↑ | SPL↑ | TL↓ | NE↓ | OSR↑ | SR↑ | SPL↑ | TL↓ | NE↓ | OSR↑ | SR↑ | SPL↑ | |
| VLN-CE∗ [34] | 9.26 | 7.12 | 46 | 37 | 35 | 8.64 | 7.37 | 40 | 32 | 30 | 8.85 | 7.91 | 36 | 28 | 25 |
| AG-CMTP [10] | - | 6.60 | 56.2 | 35.9 | 30.5 | - | 7.9 | 39.2 | 23.1 | 19.1 | - | - | - | - | - |
| R2R-CMTP [10] | - | 7.10 | 45.4 | 36.1 | 31.2 | - | 7.9 | 38.0 | 26.4 | 22.7 | - | - | - | - | - |
| WPN [32] | 8.54 | 5.48 | 53 | 46 | 43 | 7.62 | 6.31 | 40 | 36 | 34 | 8.02 | 6.65 | 37 | 32 | 30 |
| LAW∗ [47] | 9.34 | 6.35 | 49 | 40 | 37 | 8.89 | 6.83 | 44 | 35 | 31 | - | - | - | - | - |
| CM2∗ [20] | 12.05 | 6.10 | 50.7 | 42.9 | 34.8 | 11.54 | 7.02 | 41.5 | 34.3 | 27.6 | 13.9 | 7.7 | 39 | 31 | 24 |
| CM2-GT∗ [20] | 12.60 | 4.81 | 58.3 | 52.8 | 41.8 | 10.68 | 6.23 | 41.3 | 37.0 | 30.6 | - | - | - | - | - |
| WS-MGMap∗ [11] | 10.12 | 5.65 | 51.7 | 46.9 | 43.4 | 10.00 | 6.28 | 47.6 | 38.9 | 34.3 | 12.30 | 7.11 | 45 | 35 | 28 |
| Sim-2-Sim [33] | 11.18 | 4.67 | 61 | 52 | 44 | 10.69 | 6.07 | 52 | 43 | 36 | 11.43 | 6.17 | 52 | 44 | 37 |
| ERG† [57] | 11.8 | 5.04 | 61 | 46 | 42 | 9.96 | 6.20 | 48 | 39 | 35 | - | - | - | - | - |
| CMA† [26] | 11.47 | 5.20 | 61 | 51 | 45 | 10.90 | 6.20 | 52 | 41 | 36 | 11.85 | 6.30 | 49 | 38 | 33 |
| VLNBERT† [26] | 12.50 | 5.02 | 59 | 50 | 44 | 12.23 | 5.74 | 53 | 44 | 39 | 13.31 | 5.89 | 51 | 42 | 36 |
| DUET† (Ours) [14] | 12.62 | 4.13 | 67 | 57 | 49 | 13.04 | 5.26 | 58 | 47 | 39 | 13.13 | 5.82 | 50 | 42 | 36 |
| GridMM† (Ours) | 12.69 | 4.21 | 69 | 59 | 51 | 13.36 | 5.11 | 61 | 49 | 41 | 13.31 | 5.64 | 56 | 46 | 39 |
| Mapping methods | TL↓ | NE↓ | OSR↑ | SR↑ | SPL↑ |
|---|---|---|---|---|---|
| No Map | 14.61 | 5.64 | 57.24 | 45.19 | 37.82 |
| DUET (topological map) | 13.04 | 5.26 | 57.91 | 47.02 | 38.86 |
| Top-down semantic map | 13.78 | 5.33 | 57.46 | 46.36 | 38.41 |
| Map with object features | 13.15 | 5.39 | 59.12 | 47.61 | 40.13 |
| Our GridMM | 13.36 | 5.11 | 60.90 | 49.05 | 40.99 |
| GridMM | Ego. | Traj. | Instr. | TL↓ | NE↓ | OSR↑ | SR↑ | SPL↑ |
|---|---|---|---|---|---|---|---|---|
| 14.61 | 5.64 | 57.24 | 45.19 | 37.82 | ||||
| 13.24 | 5.23 | 59.11 | 48.72 | 40.14 | ||||
| 13.14 | 5.24 | 58.35 | 47.42 | 39.41 | ||||
| 13.22 | 5.39 | 59.75 | 48.63 | 39.83 | ||||
| 13.36 | 5.11 | 60.90 | 49.05 | 40.99 |
| Map scale | TL↓ | NE↓ | OSR↑ | SR↑ | SPL↑ |
|---|---|---|---|---|---|
| 88 | 13.42 | 5.23 | 58.58 | 47.07 | 39.49 |
| 1414 | 13.36 | 5.11 | 60.90 | 49.05 | 40.99 |
| 2020 | 12.59 | 4.95 | 57.86 | 49.86 | 42.52 |
4.4消融研究
我们比较了代表访问环境的不同地图在 R2R-CE 数据集的未见分割上的性能。
1) 网格内存映射与其他映射。
如表5所示,我们比较了三种不同图谱在R2R-CE数据集上的效果。 对于第 2 行,我们遵循与 [14] 相同的模型结构。 对于第 3 行,我们采用自上而下的语义图作为网格特征的替代。 具体来说,我们按照 CM2 [20] 获得以自我为中心的自顶向下语义图,并使用卷积层提取每个单元中的语义特征而不是网格特征。 第 4 行使用预训练的对象检测模型 VinVL [60] 来检测多个对象并提取它们的特征作为网格特征的替代。 更详细的实验设置可以在补充材料中找到。
2)网格特征与对象特征。
通过比较表5中第4行和第5行的结果,我们可以发现使用网格特征的网格地图比使用对象特征的网格地图效果更好。 这主要是因为以下原因:(i)目标检测模型[60]中的目标特征不足以表示所有视觉信息,例如房屋结构和背景。 (ii) CLIP[45]的网格特征具有更大的语义空间和更好的泛化能力。 与以往基于对象获取环境表示的方法[9][57]不同,网格特征对于表示环境非常重要。
3)是否有必要以自我为中心的观点来绘制地图?
4)导航轨迹信息的影响。
5)指令相关性聚合方法的效果。
如表6所示,具有指令相关性聚合的第5行比第4行具有更好的性能。 第 4 行只是通过平均池化来聚合每个地图单元中的特征,这使得挖掘关键视觉线索变得困难。 我们的聚合方法评估每个网格特征与导航指令的相关性,并使用注意机制过滤掉不相关的特征并捕获关键线索。
6)地图比例尺的影响。
如表7所示,我们评估了GridMM的规模。 我们观察到随着地图比例的增加,导航性能呈上升趋势。 这主要是因为比例尺越大的地图可以容纳更多的环境细节,更准确地表达空间关系。 然而,增加地图比例会导致大量的计算成本,但收益却很小。 所以我们选择一个相对平衡的尺度(即,1414)。
4.5统计分析
GridMM 的边长。
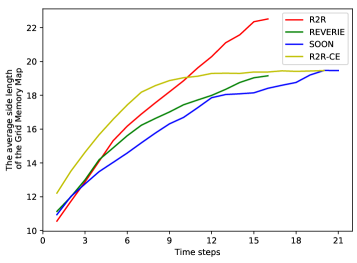
如图5所示,GridMM的边长随着访问环境的扩大而增加。 对于所有数据集,在导航过程中边长从约 10 米逐渐增加到约 20 米。 显然,固定大小的地图很难适应不断扩展的访问环境,因此我们具有动态相对坐标系的GridMM效果更好。 与其他数据集相比,R2R 在导航结束时的地图尺寸更大。 它表明代理可以在 R2R 数据集上更多地探索新的未访问环境。
每个单元区域内网格要素的数量。
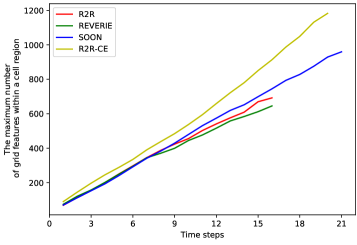
如图6所示,在所有数据集上导航结束时,单元格区域内的网格特征的最大数量超过600。 单元区域内的大量网格特征包含噪声并且是冗余的。 这么多特征的平均池化效率不够高,导致关键线索被噪音淹没。 相比之下,指令相关性聚合方法比平均池化效果更好,它可以过滤掉不相关的特征并捕获关键线索。
5结论
在本文中,我们提出了一种自上而下的以自我为中心且动态增长的网格内存映射(即,GridMM)来构建 VLN 的访问环境。 此外,提出了指令相关性聚合模块来捕获与指令相关的细粒度视觉线索。 我们全面分析我们模型的有效性,并将其与其他方法进行比较。 我们的GridMM既提供全局时空感知,又提供局部详细线索,从而实现更准确的导航结果。 然而,我们的方法仍然存在一些限制,关于如何处理多层环境仍然悬而未决。 未来,我们将不断探索如何更好地为VLN和Embodied AI表示室内环境。
致谢。
这项工作得到了国家自然科学基金项目62125207、62102400、62272436和U1936203的部分支持,以及国家博士后创新人才计划BX20200338的部分支持。
参考
- [1] Dong An, Yuankai Qi, Yangguang Li, Yan Huang, Liang Wang, Tieniu Tan, and Jing Shao. Bevbert: Topo-metric map pre-training for language-guided navigation. arXiv preprint arXiv:2212.04385, 2022.
- [2] Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. Bottom-up and top-down attention for image captioning and visual question answering. In CVPR, pages 6077–6086, 2018.
- [3] Peter Anderson, Ayush Shrivastava, Joanne Truong, Arjun Majumdar, Devi Parikh, Dhruv Batra, and Stefan Lee. Sim-to-real transfer for vision-and-language navigation. In Conference on Robot Learning (CoRL), 2020.
- [4] Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünderhauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In CVPR, pages 3674–3683, 2018.
- [5] Edward Beeching, Jilles Dibangoye, Olivier Simonin, and Christian Wolf. Egomap: Projective mapping and structured egocentric memory for deep rl. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 525–540. Springer, 2020.
- [6] Vincent Cartillier, Zhile Ren, Neha Jain, Stefan Lee, Irfan Essa, and Dhruv Batra. Semantic mapnet: Building allocentric semantic maps and representations from egocentric views. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 964–972, 2021.
- [7] Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments. In 3DV, pages 667–676, 2017.
- [8] Devendra Singh Chaplot, Dhiraj Prakashchand Gandhi, Abhinav Gupta, and Russ R Salakhutdinov. Object goal navigation using goal-oriented semantic exploration. Advances in Neural Information Processing Systems, 33:4247–4258, 2020.
- [9] Jinyu Chen, Chen Gao, Erli Meng, Qiong Zhang, and Si Liu. Reinforced structured state-evolution for vision-language navigation. In CVPR, pages 15450–15459, June 2022.
- [10] Kevin Chen, Junshen K. Chen, Jo Chuang, Marynel Vázquez, and Silvio Savarese. Topological planning with transformers for vision-and-language navigation. In CVPR, 2021.
- [11] Peihao Chen, Dongyu Ji, Kunyang Lin, Runhao Zeng, Thomas H Li, Mingkui Tan, and Chuang Gan. Weakly-supervised multi-granularity map learning for vision-and-language navigation. In NeurIPS, 2022.
- [12] Shizhe Chen, Pierre-Louis Guhur, Cordelia Schmid, and Ivan Laptev. History aware multimodal transformer for vision-and-language navigation. In NeurIPS, volume 34, pages 5834–5847, 2021.
- [13] Shizhe Chen, Pierre-Louis Guhur, Makarand Tapaswi, Cordelia Schmid, and Ivan Laptev. Learning from unlabeled 3d environments for vision-and-language navigation. In ECCV, pages 638–655, 2022.
- [14] Shizhe Chen, Pierre-Louis Guhur, Makarand Tapaswi, Cordelia Schmid, and Ivan Laptev. Think global, act local: Dual-scale graph transformer for vision-and-language navigation. In CVPR, pages 16537–16547, 2022.
- [15] Samyak Datta, Sameer Dharur, Vincent Cartillier, Ruta Desai, Mukul Khanna, Dhruv Batra, and Devi Parikh. Episodic memory question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19119–19128, 2022.
- [16] Narayanan Deepak, Shoeybi Mohammad, Casper Jared, LeGresley Patrick, Patwary Mostofa, Korthikanti Vijay, Vainbrand Dmitri, Kashinkunti Prethvi, Bernauer Julie, Catanzaro Bryan, Phanishayee Amar, and Zaharia Matei. Efficient large-scale language model training on gpu clusters using megatron-lm. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2021.
- [17] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2020.
- [18] Zi-Yi Dou and Nanyun Peng. Foam: A follower-aware speaker model for vision-and-language navigation. In NAACL, 2022.
- [19] Daniel Fried, Ronghang Hu, Volkan Cirik, Anna Rohrbach, Jacob Andreas, Louis-Philippe Morency, Taylor Berg-Kirkpatrick, Kate Saenko, Dan Klein, and Trevor Darrell. Speaker-follower models for vision-and-language navigation. In NeurIPS, volume 31, 2018.
- [20] Georgios Georgakis, Karl Schmeckpeper, Karan Wanchoo, Soham Dan, Eleni Miltsakaki, Dan Roth, and Kostas Daniilidis. Cross-modal map learning for vision and language navigation. In CVPR, 2022.
- [21] Pierre-Louis Guhur, Makarand Tapaswi, Shizhe Chen, Ivan Laptev, and Cordelia Schmid. Airbert: In-domain pretraining for vision-and-language navigation. In CVPR, pages 1634–1643, 2021.
- [22] Saurabh Gupta, James Davidson, Sergey Levine, Rahul Sukthankar, and Jitendra Malik. Cognitive mapping and planning for visual navigation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2616–2625, 2017.
- [23] Weituo Hao, Chunyuan Li, Xiujun Li, Lawrence Carin, and Jianfeng Gao. Towards learning a generic agent for vision-and-language navigation via pre-training. In CVPR, pages 13137–13146, 2020.
- [24] Joao F Henriques and Andrea Vedaldi. Mapnet: An allocentric spatial memory for mapping environments. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8476–8484, 2018.
- [25] Yicong Hong, Cristian Rodriguez, Yuankai Qi, Qi Wu, and Stephen Gould. Language and visual entity relationship graph for agent navigation. In NeurIPS, volume 33, pages 7685–7696, 2020.
- [26] Yicong Hong, Zun Wang, Qi Wu, and Stephen Gould. Bridging the gap between learning in discrete and continuous environments for vision-and-language navigation. In CVPR, June 2022.
- [27] Yicong Hong, Qi Wu, Yuankai Qi, Cristian Rodriguez-Opazo, and Stephen Gould. Vln bert: A recurrent vision-and-language bert for navigation. In CVPR, pages 1643–1653, 2021.
- [28] Chenguang Huang, Oier Mees, Andy Zeng, and Wolfram Burgard. Visual language maps for robot navigation. In ICRA, London, UK, 2023.
- [29] Muhammad Zubair Irshad, Niluthpol Chowdhury Mithun, Zachary Seymour, Han-Pang Chiu, Supun Samarasekera, and Rakesh Kumar. Sasra: Semantically-aware spatio-temporal reasoning agent for vision-and-language navigation in continuous environments. arXiv preprint arXiv:2108.11945, 2021.
- [30] Mohit Bansal Jialu Li, Hao Tan. Envedit: Environment editing for vision-and-language navigation. In CVPR, 2022.
- [31] Aishwarya Kamath, Peter Anderson, Su Wang, Jing Yu Koh, Alexander Ku, Austin Waters, Yinfei Yang, Jason Baldridge, and Zarana Parekh. A new path: Scaling vision-and-language navigation with synthetic instructions and imitation learning. arXiv preprint arXiv:2210.03112, 2022.
- [32] Jacob Krantz, Aaron Gokaslan, Dhruv Batra, Stefan Lee, and Oleksandr Maksymets. Waypoint models for instruction guided navigation in continuous environment. In ICCV, 2021.
- [33] Jacob Krantz and Stefan Lee. Sim-2-sim transfer for vision-and-language navigation in continuous environments. In ECCV, 2022.
- [34] Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. Beyond the nav-graph: Vision-and-language navigation in continuous environments. In ECCV, 2020.
- [35] Alexander Ku, Peter Anderson, Roma Patel, Eugene Ie, and Jason Baldridge. Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding. In EMNLP, pages 4392–4412, 2020.
- [36] Mingxiao Li, Zehao Wang, Tinne Tuytelaars, and Marie-Francine Moens. Layout-aware dreamer for embodied referring expression grounding. In AAAI, 2023.
- [37] Weijie Li, Xinhang Song, Yubing Bai, Sixian Zhang, and Shuqiang Jiang. ION: instance-level object navigation. In ACM MM, pages 4343–4352, 2021.
- [38] Xiangyang Li, Zihan Wang, Jiahao Yang, Yaowei Wang, and Shuqiang Jiang. KERM: Knowledge enhanced reasoning for vision-and-language navigation. In CVPR, pages 2583–2592, 2023.
- [39] Xiwen Liang, Fengda Zhu, Lingling Li, Hang Xu, and Xiaodan Liang. Visual-language navigation pretraining via prompt-based environmental self-exploration. In ACL, pages 4837–4851, 2022.
- [40] Bingqian Lin, Yi Zhu, Zicong Chen, Xiwen Liang, Jianzhuang Liu, and Xiaodan Liang. Adapt: Vision-language navigation with modality-aligned action prompts. In CVPR, pages 15396–15406, 2022.
- [41] Alexander Pashevich, Cordelia Schmid, and Chen Sun. Episodic transformer for vision-and-language navigation. In ICCV, 2021.
- [42] Yuankai Qi, Qi Wu, Peter Anderson, Xin Wang, William Yang Wang, Chunhua Shen, and Anton van den Hengel. Reverie: Remote embodied visual referring expression in real indoor environments. In CVPR, pages 9982–9991, 2020.
- [43] Yanyuan Qiao, Yuankai Qi, Yicong Hong, Zheng Yu, Peng Wang, and Qi Wu. HOP: History-and-order aware pre-training for vision-and-language navigation. In CVPR, pages 15418–15427, 2022.
- [44] Yanyuan Qiao, Yuankai Qi, Yicong Hong, Zheng Yu, Peng Wang, and Qi Wu. Hop+: History-enhanced and order-aware pre-training for vision-and-language navigation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- [45] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, pages 8748–8763, 2021.
- [46] Santhosh K Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alex Clegg, John Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X Chang, et al. Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai. arXiv preprint arXiv:2109.08238, 2021.
- [47] Sonia Raychaudhuri, Saim Wani, Shivansh Patel, Unnat Jain, and Angel Chang. Language-aligned waypoint (law) supervision for vision-and-language navigation in continuous environments. In EMNLP, 2021.
- [48] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In MICCAI, page 234–241, 2015.
- [49] Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. In AISTATS, pages 627–635. JMLR Workshop and Conference Proceedings, 2011.
- [50] Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. In ICCV, pages 9339–9347, 2019.
- [51] Hao Tan and Mohit Bansal. Lxmert: Learning cross-modality encoder representations from transformers. In EMNLP, pages 5103–5114, 2019.
- [52] Hao Tan, Licheng Yu, and Mohit Bansal. Learning to navigate unseen environments: Back translation with environmental dropout. In NAACL, pages 2610–2621, 2019.
- [53] Tianqi Tang, Heming Du, Xin Yu, and Yi Yang. Monocular camera-based point-goal navigation by learning depth channel and cross-modality pyramid fusion. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 5422–5430, 2022.
- [54] Tianqi Tang, Xin Yu, Xuanyi Dong, and Yi Yang. Auto-navigator: Decoupled neural architecture search for visual navigation. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 3743–3752, 2021.
- [55] Jesse Thomason, Michael Murray, Maya Cakmak, and Luke Zettlemoyer. Vision-and-dialog navigation. In PMLR, 2020.
- [56] Hanqing Wang, Wenguan Wang, Wei Liang, Caiming Xiong, and Jianbing Shen. Structured scene memory for vision-language navigation. In CVPR, pages 8455–8464, 2021.
- [57] Ting Wang, Zongkai Wu, Feiyu Yao, and Donglin Wang. Graph based environment representation for vision-and-language navigation in continuous environments. arXiv preprint arXiv:2301.04352, 2023.
- [58] Xin Wang, Qiuyuan Huang, Asli Celikyilmaz, Jianfeng Gao, Dinghan Shen, Yuan-Fang Wang, William Yang Wang, and Lei Zhang. Reinforced cross-modal matching and self-supervised imitation learning for vision-language navigation. In CVPR, pages 6629–6638, 2019.
- [59] Saim Wani, Shivansh Patel, Unnat Jain, Angel Chang, and Manolis Savva. Multion: Benchmarking semantic map memory using multi-object navigation. Advances in Neural Information Processing Systems, 33:9700–9712, 2020.
- [60] Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, and Jianfeng Gao. Vinvl: Revisiting visual representations in vision-language models. In CVPR, pages 5579–5588, 2021.
- [61] Sixian Zhang, Weijie Li, Xinhang Song, Yubing Bai, and Shuqiang Jiang. Generative meta-adversarial network for unseen object navigation. In ECCV, volume 13699, pages 301–320.
- [62] Sixian Zhang, Xinhang Song, Yubing Bai, Weijie Li, Yakui Chu, and Shuqiang Jiang. Hierarchical object-to-zone graph for object navigation. In ICCV, pages 15110–15120, 2021.
- [63] Sixian Zhang, Xinhang Song, Weijie Li, Yubing Bai, Xinyao Yu, and Shuqiang Jiang. Layout-based causal inference for object navigation. In CVPR, pages 10792–10802, 2023.
- [64] Yusheng Zhao, Jinyu Chen, Chen Gao, Wenguan Wang, Lirong Yang, Haibing Ren, Huaxia Xia, and Si Liu. Target-driven structured transformer planner for vision-language navigation. In ACM MM, pages 4194–4203, 2022.
- [65] Fengda Zhu, Xiwen Liang, Yi Zhu, Qizhi Yu, Xiaojun Chang, and Xiaodan Liang. Soon: Scenario oriented object navigation with graph-based exploration. In CVPR, pages 12689–12699, 2021.
- [66] Fengda Zhu, Linchao Zhu, and Yi Yang. Sim-real joint reinforcement transfer for 3d indoor navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11388–11397, 2019.
附录
附录A数据集
我们在离散环境中评估我们的方法(例如、R2R [4]、REVERIE [42] 和 SOON [65]),并进一步分析我们的方法在连续环境中的许多特征(例如、R2R-CE [34]和RxR-CE [35])。
离散环境中的所有基准测试均基于 Matterport3D 环境[7] 构建,并包含 90 个逼真的房屋。 每个房屋都包含一组可导航位置,每个位置都由相应的全景图像和 GPS 坐标表示。 我们采用标准的房屋划分为训练、已见、未见和测试划分。 val saw split 中的房屋与训练中的相同,而 val unseen 和 test split 中的房屋则与训练中不同。 离散环境中的所有分割与 Chen 等人 [14] 一致。
R2R-CE [34] 将 R2R 数据集中的离散路径转换为 Habitat 模拟器 [50] 上的连续轨迹。 RxR-CE [35] 将 RxR 数据集中的离散路径转换为 Habitat 模拟器 [50] 上的连续轨迹。
附录 BRxR-CE 中的性能
| Method | TL | NE↓ | SR↑ | SPL↑ | nDTW↑ | SDTW↑ |
|---|---|---|---|---|---|---|
| VLN-CE [34] | 7.33 | 12.1 | 13.93 | 11.96 | 30.86 | 11.01 |
| CMA [26] | 20.04 | 10.4 | 24.08 | 19.07 | 37.39 | 18.65 |
| VLNBERT [26] | 20.09 | 10.4 | 24.85 | 19.61 | 37.30 | 19.05 |
| DUET [14](Ours) | 21.48 | 9.78 | 29.93 | 23.12 | 42.46 | 25.39 |
| GridMM (Ours) | 21.13 | 8.42 | 36.26 | 30.14 | 48.17 | 33.65 |
如表8所示,我们的GridMM在较长轨迹导航(例如RxR-CE)上取得了有竞争力的结果。
附录C实验细节
C.1 培训详细信息
对于 REVERIE 数据集,我们将原始数据集与 DUET [14] 合成的增强数据相结合,以批量大小为 32、学习率为 5e-5 的模型进行 100k 次迭代的预训练,使用 3 个 NVIDIA RTX3090 GPU。 然后我们使用 4 的批量大小和 1e-5 的学习率在 3 个 GPU 上进行 50k 次迭代。
对于 SOON 数据集,我们仅使用具有自动清理对象边界框的原始数据,与 DUET [14] 共享相同的设置。 我们使用 3 个 GPU 预训练模型,批量大小为 16,学习率为 5e-5,进行 40k 次迭代,然后在 3 上使用批量大小为 2,学习率为 5e-5,进行 20k 次迭代进行调整。 GPU。
对于 R2R 数据集,[23] 中的附加增强数据用于 DUET [14] 之后的预训练。 我们使用 3 个 GPU 预训练模型,批量大小为 32,学习率为 5e-5,迭代次数为 100k。 然后我们使用 4 的批量大小和 1e-5 的学习率在 3 个 GPU 上进行 50k 次迭代。
对于 R2R-CE 数据集,我们将在 R2R 数据集上预训练的模型转移到连续环境中,并使用 3 个 RTX3090 GPU,以 8 的批量大小和 1e-5 的学习率进行 30 个周期的调整。
对于所有数据集,SPL 在未见过的分割上选择最佳模型。
C.2 消融详细信息
自上而下的语义图。
对于表5中的第3行,我们按照CM2[20]得到 自上而下的语义图。 具体来说,我们使用来自 CM2 [20] 的预训练 UNet [48] 来生成观察图像的语义分割,然后投影将像素转化为统一的自上而下的语义图。 将自上而下的语义图划分为尺度为 3232 的多个 patch 后,使用卷积层将这些 patch 编码为隐藏大小为 768 的嵌入。 我们将这些语义嵌入作为地图特征。
具有对象特征的地图。
对于表5中的第4行,利用预训练的检测模型VinVL[60]来检测每个视图图像中的多个对象,然后我们采用10个对象特征作为网格特征替代品的最高置信度得分。 对于每个对象的坐标,是通过边界框的中心点获得的。
附录D计算成本分析
参考[16],我们描述了如何计算 VLN 模型中的浮点运算(FLOP)数量,如下所示:
1)矩阵乘法():
次失败
2)2层MLP(序列长度,将隐藏大小增加到,然后减少回):
次失败
3)自注意力块(序列长度,隐藏大小):
次失败
4)交叉注意块(查询序列长度,键值序列长度,隐藏大小):
次失败
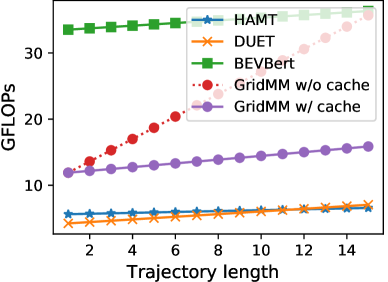
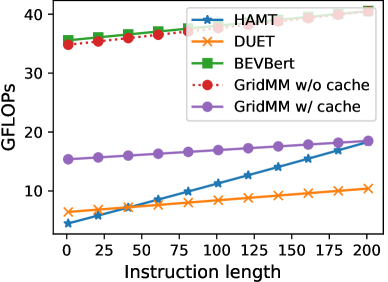
我们在 R2R 数据集上计算 GFLOP(千兆浮点运算),如图 7 和图 8 所示。 “GridMM w/o 缓存”表示我们的 GridMM 在所有导航步骤中更新网格地图的每个单元格,而无需任何缓存。 通过使用缓存(存储以前的结果以供以后使用),计算成本显着降低。 对于所有导航步骤中相同的网格特征,在更新网格地图的单元格时,我们只需要重新计算网格特征的位置,而不用指令重新计算它们在相关矩阵中的相关值。 原因是,对于方程(6)和(9),(其中是的一部分)的输出, 和 在所有导航步骤中都是相同的,并且可以缓存以供重用。 “GridMM w/ 缓存”的 GFLOP 明显低于 BEVbert [1]。 在注意力计算过程中,BEVbert 中的度量图特征数量超过 400 个,引入了巨大的计算成本。 然而,GridMM中的地图特征数量不到200个,并且它们仅用作交叉注意力计算中的键和值标记,这大大降低了计算成本。