PanGu-Coder2:通过排名反馈提升代码的大型语言模型
摘要
大型代码语言模型(Code大语言模型)正在蓬勃发展。 每周都会发布新的强大模型,在代码生成任务上展示出卓越的性能。 人们提出了各种方法来提高预训练代码大语言模型的代码生成性能,例如监督微调、指令调优、强化学习等。 在本文中,我们提出了一种新颖的RRTF(Rank R响应来对齐Test&T eacher Feedback)框架,可以有效且高效地提升用于代码生成的预训练大型语言模型。 在此框架下,我们提出了 PanGu-Coder2,它在 OpenAI HumanEval 基准测试中达到了 62.20% pass@1。 此外,通过对 CoderEval 和 LeetCode 基准测试的广泛评估,我们表明 PanGu-Coder2 始终优于所有以前的 Code 大语言模型。
关键字大型语言模型代码生成强化学习指令指令
1简介
作为大语言模型最有前景的应用之一,代码大语言模型因其在代码相关任务中的卓越能力而引起了学术界和工业界的广泛关注Zan等人(2023). 自OpenAI发布Codex Chen 等人 (2021)、AlphaCode Li 等人 (2022)、PaLM-Coder Chowdhery 等人 (2022)、和 PanGu-Coder Christopoulou 等人 (2022) 随后以闭源方式发布。 研究人员开源了 CodeParrot Huggingface (2021)、PolyCoder Xu 等人 (2022)、PyCodeGPT Zan 等人 (2022a) 和 SantaCoder Allal等人(2023),但在模型规模、能力和性能方面远远落后于商业模型。 Hugging Face改变了这种情况111https://huggingface.co,BigCode 社区发布 StarCoder Li 等人 (2023):具有 8K 窗口大小和 FIM(Fill In the Middle,或填充)功能的 15B 参数模型。 StarCoder 优于之前许多支持从自然语言描述生成代码的开源大语言模型,甚至在 HumanEval Chen 等人 (2021) 和 MBPP 基准测试上匹配 OpenAI code-cushman-001 模型奥斯汀等人 (2021)。
然而,大多数大型代码语言模型仍然落后于 OpenAI OpenAI (2023) 的 GPT-3.5 和 GPT-4 等最新商业模型; Bubeck 等人 (2023)。 我们使用Code大语言模型来表示主要在代码语料库上预训练的大型语言模型,例如PanGu-Coder Christopoulou 等人 (2022)、Replit 2 22https://github.com/replit/ReplitLM 和 StarCoder 李等人(2023)。 与开源的Code大语言模型相比,OpenAI GPT系列模型通常规模更大,并且主要在自然语言语料库上进行预训练(带有少量代码相关数据命题),这有助于其优于自然语言理解和遵循指令的能力。 我们在代码大语言模型方面做出了一些努力,如数据工程(phi-1 Gunasekar 等人 (2023))、指令调优(WizardCoder Luo 等人 (2023))、检索增强生成(ReAcc Lu 等人 (2022)、RepoCoder Zhang 等人 (2023) 等)和强化学习(RLTF Liu 等人 (2023)、CodeRL Le 等人 (2022)、PPOCoder Shojaee 等人 (2023) 等)。
尽管强化学习 (RL) 似乎是一个有前途的方向,因为编程本质上是一个试错过程,但现有的基于 RL 的方法面临几个主要限制。 动机很直观和直接:由于我们期望模型能够根据人类的意图和要求生成代码,所以对Code大语言模型的强化学习可以帮助模型增强解释和响应代码生成指令的能力,从而增加生成代码以成功解决给定问题。 通常,现有的基于强化学习的方法根据来自代码处理器(如编译器、调试器、执行器和测试用例)的反馈信号来设计价值/奖励函数。 然而,这导致了三个限制:首先,将测试结果作为奖励直接对基础模型提供有限的改进。 其次,所采用的强化学习算法(如 PPO)实现起来很复杂,并且很难在大型语言模型上训练Liu 等人 (2023)。 此外,在训练模型时运行测试非常耗时。 于是,之前的作品乐等人(2022); Liu等人(2023)仅在中等大小的模型上进行实验,并且改进相当有限。
为了解决现有基于强化学习的方法的问题并进一步挖掘代码大语言模型的潜力,我们提出了 RRTF (Rank R esponses toalign Test&TeacherFeedback)框架,是成功地将自然语言大语言模型对齐技术应用于Code上的新颖作品大语言模型. 与之前的CodeRL Le 等人 (2022) 和 RLTF Liu 等人 (2023) 等作品不同,我们遵循 RLHF(Reinforcement Learning from Human Feedback)的思想, InstructGPT/ChatGPT Ouyang 等人 (2022a),但使用排名响应作为反馈而不是奖励模型的绝对值来实现更简单、更高效的训练方法。
作为概念验证,我们在 StarCoder 15B 上应用 RRTF,并提出了一个在所有已发布的代码大语言模型中实现最佳性能的模型,即 PanGu-Coder2。 通过对 HumanEval、CoderEval 和 LeetCode 三个基准的广泛评估,我们推测 Code 大语言模型在代码生成任务上确实有潜力超越相同或更大规模的自然语言模型。 此外,通过分析训练过程和手动检查生成代码样本,我们强调了高质量数据对于提高模型指令跟随和代码编写能力的重要性。
简而言之,我们做出以下贡献:
-
•
我们引入了一种名为 RRTF 的新优化范式,它是一个数据高效、易于实现且与模型无关的框架,可以有效提高预训练代码大语言模型的代码生成性能。
-
•
我们推出了 PanGu-Coder2,该模型比其基本模型提高了近 30%,并在 HumanEval、CoderEval 和 LeetCode 基准测试中实现了新的最先进性能,超越了之前发布的所有 Code 大语言模型。
-
•
我们分享在构建有效的训练数据、使用 RRTF 训练模型以及优化此类模型以实现快速推理方面的经验和发现。
2相关工作
2.1代码大语言模型(Code大语言模型)
作为一个重要的里程碑,Codex Chen 等人 (2021) 拥有 十亿参数模型,展示了处理多达 个 Python 的非凡能力编程问题。 随后,出现了新一波的代码生成模型,如 AlphaCode Li 等人 (2022)、PaLM-Coder Chowdhery 等人 (2022)、PanGu-Coder Christopoulou 等人 (2022),也被提出。 尽管上述模型表现出了非凡的能力,但令人沮丧的是它们无法作为开源项目使用。 因此,一些开源代码生成模型,包括 CodeParrot Huggingface (2021)、PolyCoder Xu 等人 (2022)、PyCodeGPT Zan 等人 (2022a)、SantaCoder Allal 等人 (2023) 和 StarCoder Li 等人 (2023) 发布,为代码生成领域注入新的活力陈等人 (2022). 同时,代码生成模型也被应用到更广泛的实际编码场景中。 例如,CodeGeeX Zheng 等人 (2023)、BLOOM Scao 等人 (2022) 和 ERNIE-Code Chai 等人 (2022) 有被提议促进多语言建模; JuPyT5 Chandel 等人 (2022) 在 Jupyter Notebook 的大型语料库上进行训练,旨在提升交互式编程的体验; DocCoder Zhou 等人 (2023a) 和 APICoder Zan 等人 (2022b) 被提出,赋予语言模型调用 API 的能力;部分模型如InCoder Fried 等人 (2023)、FIM Bavarian 等人 (2022)、MIM Nguyen 等人 (2023)、SantaCoder Allal 等人 (2023) 和 StarCoder Li 等人 (2023)0> 支持任意位置的代码生成。
最近,一些努力 Zhou 等人 (2023b); Peng 等人 (2023) 使用指令调优技术,通过对精心策划的高质量指令数据集进行微调,解锁大型语言模型中存储的潜在有价值的知识。 在代码生成领域,WizardCoder B Luo 等人 (2023) 和 phi-1 B Gunasekar 等人 (2023) 通过对 OpenAI 的 GPT-3.5 或 GPT-4 生成的数据进行微调,实现卓越的代码生成性能。
2.2 大语言模型上的强化学习
从人类反馈中强化学习
大型语言模型可能会生成不真实、意外且无用的输出,这与最终用户的意图不一致。 为了使大型语言模型的行为与人类意图保持一致,Ouyang 等人(2022b)最近提出了人类反馈强化学习(RLHF)。 基本思想是利用人类对给定任务的偏好来改进语言模型的行为。 典型的 RLHF 过程由三个步骤组成,包括训练监督微调(SFT)和奖励模型(RM),训练监督微调(SFT)收集期望模型行为的人类演示并微调语言模型,奖励模型(RM)利用人类来标记各种模型中的首选输出基于标记数据输出并训练奖励模型,并通过近端策略优化(PPO)进行强化学习,根据奖励模型优化语言模型。 OpenAI 的 GPT-3.5 和 GPT-4 使用 RLHF 进行训练,它们的成功证明了 RLHF 使语言模型的行为与人类偏好保持一致的有效性。 然而,实现 RLHF 需要大量的训练资源和复杂的参数调整,这使得该技术难以在实践中轻松应用。 此外,强化学习算法的低效和不稳定会给语言模型的对齐带来挑战。 考虑到训练资源繁重和参数调整复杂的局限性,Yuan 等人 (2023) 提出了 RRHF 范式,该范式利用从各种资源收集的具有人类偏好的输出来训练符合人类偏好的模型。 其使模型行为与人类一致的原则是训练一个模型,根据人类对一组输出的偏好来学习具有更好奖励的输出。 与 RLHF 相比,RRHF 在资源受限的情况下可以轻松扩展到更大尺寸的大语言模型。 针对语言模型效率低下和不稳定的问题,Dong等人(2023)提出了语言模型的奖励排名微调(RAFT)技术。 他们的基本思想是首先根据奖励模型估计的输出排名选择模型的高质量输出,然后利用所选的输出来训练符合人类偏好的模型。 与 RLHF 相比,SFT 式 RAFT 通常比 RLHF 中使用的 PPO 收敛得更快,同时利用更简单的参数配置和更少的计算资源。
代码强化学习
RLHF的成功实践启发了研究人员通过强化学习来提高Code大语言模型的能力。 例如,CodeRL Le 等人 (2022) 将 actor-critic RL 框架与单元测试信号集成到了模型中。 继 CodeRL 之后,PPOCoder Shojaee 等人 (2023) 使用了近端策略优化 (PPO) 算法,但在 MBPP 基准上几乎没有什么改进。 最近,RLTF Liu 等人 (2023) 又向前迈进了一步,采用了具有多粒度单元测试反馈的在线强化学习框架,克服了 CodeRL 和 PPOCoder 采用的离线强化学习的局限性。
2.3 代码微调大语言模型
对预训练语言模型进行微调是一种主流建模范式,可以最大限度地提高下游任务的性能。 在代码领域,一些工作也采用该范式来解决与代码相关的场景。 例如,CodeGen Nijkamp 等人 (2022) 和 StarCoder Li 等人 (2023) 首先对多语言代码语料库进行预训练,然后对单语代码语料库进行微调数据,从而在单语任务上取得优异的性能。 Codex-S Chen 等人 (2021) 和 PanGu-Coder-FT Christopoulou 等人 (2022) 通过对竞争性编程问题进行微调来提升代码生成能力。 最近,指令调优Ouyang等人(2022a); OpenAI(2023)作为监督微调(SFT)的一种形式,提出通过学习丰富的高质量指令语料库来使模型与人类行为保持一致。 对此,WizardCoder Luo 等人(2023)对教师模型衍生的一系列指令语料库进行了微调,以相对有限的参数有效地最大化了其代码知识。 在这份技术报告中,PanGu-Coder2在微调过程中采用了排序反馈策略Yuan等人(2023),并取得了令人惊讶的代码生成性能。
3方法
3.1概述
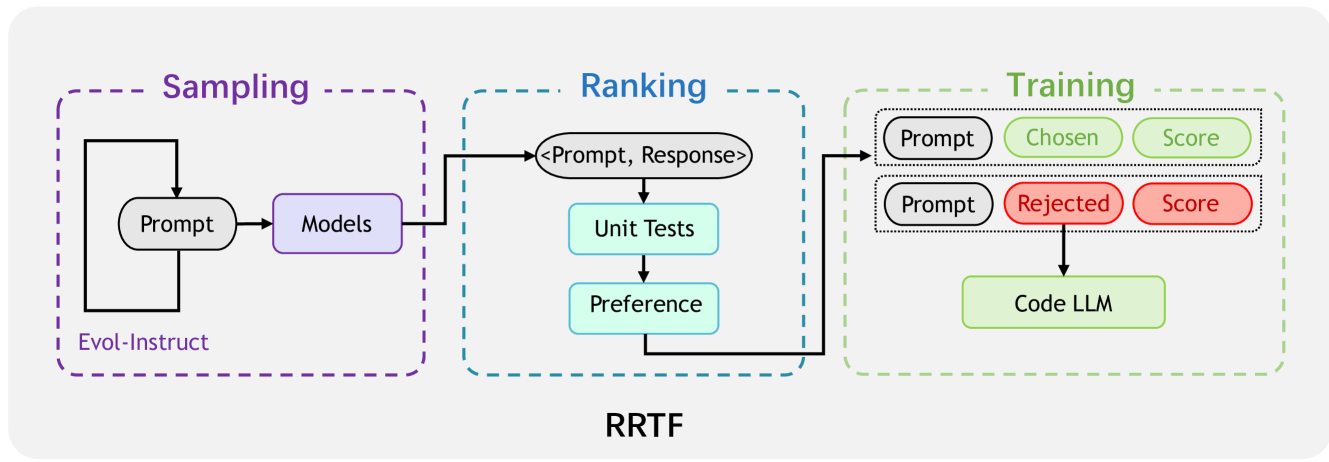
在这份技术报告中,我们提出了一个更简单但功能强大的框架RRTF,它无缝地结合了多种前沿技术,包括指令调优Peng等人(2023)、Evol-Instruct method Xu 等人 (2023); Luo 等人 (2023) 和强化学习 Yuan 等人 (2023)。 我们方法的核心思想是通过联合利用测试信号和人类偏好作为对响应进行排名的反馈,引导模型生成更高质量的代码。 受到大型自然语言模型强化学习和指令微调方面最新进展的启发,特别是 RLHF Ouyang 等人 (2022a)、RRHF Yuan 等人 (2023) 和 RLTF Liu 等人 (2023),我们提出了一种新的训练范式,即 RRTF 框架。 图1展示了RRTF框架的概述,它包括三个步骤:采样、排序和训练。 在采样阶段,根据 Evol-Instruct 生成的提示对响应进行采样。 在排名阶段,根据单元测试和启发式偏好对来自不同来源的响应进行排名。 在训练阶段,使用三重提示和相应分数的选择/拒绝响应来训练代码大语言模型。
3.2模型架构
在这项工作中,我们基于具有 Multi-Query-AttentionShazeer (2019) 的仅解码器 Transformer 训练了 B 参数模型,并学习了绝对位置嵌入。 同时利用FlashAttention来减少计算量和内存占用。 因此,模型的最大长度可以扩展到 8192。 表 1 显示了我们模型的详细超参数。
| Hyper-Parameters | Value |
| Hidden size | 6144 |
| Max Length | 8192 |
| Num of attention heads | 48 |
| Num of transformer hidden layers | 40 |
3.3训练语料库
我们遵循 Evol-Instruct 技术 Xu 等人 (2023); Luo 等人 (2023) 来构建我们的训练语料库,因为手动收集高质量的语料库既费力又耗时。 具体来说,我们从 Alpaca 20K 数据集333https://huggingface.co/datasets/sahil2801/CodeAlpaca-20k,通过深度进化迭代进化该数据集中的编程问题,得到新的编程问题(提示如图2)。 针对这些问题,我们从不同的模型中抽取了答案。 总的来说,我们收集了一个包含 K 个编程问题及其答案的初始语料库,我们将其称为指令和解决方案对。 此外,我们使用一些手动定义的规则对初始语料库进行了数据预处理,并将语料库的大小减少到K。更重要的是,为了防止数据泄露,我们投入了大量精力来调查收集的 K 数据集和 HumanEval 基准之间的潜在重叠。 经过细致的勘察,我们确认实验中没有数据泄露,进一步验证了PanGu-Coder2的有效性。
3.4RRTF框架
受 RRHF Yuan 等人 (2023) 的启发,我们提出 RRTF (Rank Responses toalign Test&TeacherF反馈)代码大语言模型框架。 RRHF 444https://github.com/GanjinZero/RRHF 被提出作为 RLHF 的简化训练范例,它根据人类偏好对来自不同来源的响应进行排名,并通过排名损失函数来调整模型。 与 RLHF 相比,RRHF 可以有效地将语言模型的输出概率与人类偏好对齐,调优期间只需要 1-2 个模型,并且在实现、超参数调优和训练方面比 PPO 更简单。
代码生成的目的不是使模型与人类意图保持一致,而是提高生成的正确性,因此我们将 H(人类)替换为 T,它可以是组合测试和教师(更强大的模型或人类专家)的共同组成反馈信号来指导代码大语言模型的生成,并且大部分反馈可以以更快的方式全自动或半自动获得。 RRTF的训练过程可以分为3步:
-
1.
第1步:采样 在采样阶段,根据提示对响应进行采样。 根据 Evol-Instruct 生成的提示(参见第 3.3 节),我们对学生模型(模型到训练)和教师模型在不同温度下的响应进行采样。 该过程是离线且并行的,因此我们可以有效地获得足够的样本用于训练。
-
2.
第二步:排名 在排名阶段,根据单元测试和启发式偏好对不同来源的响应进行排名。 获得所有响应后,我们从响应中提取程序并在支持大规模并行执行的运行环境中执行它们。 根据测试结果,有4种情况,分别是编译错误、运行时错误、部分测试通过、全部通过. 对于每个数据,我们根据上述情况从低到高分配不同的分数。 同时,我们过滤掉教师分数低于学生模型的数据。 对于处于相同情况的两个样本,我们总是为来自教师的样本分配更高的排名,因为我们更喜欢学生向老师学习。
-
3.
Step3:训练 在训练阶段,使用三重提示和相应分数的选择/拒绝响应来训练代码大语言模型。 在训练过程中,对于每个提示,我们都有一对响应,其中是老师生成的响应, 是学生模型生成的响应。 因此我们可以通过以下方式表示条件对数概率(长度归一化):
其中 是模型,, 是时间步长。 等级损失可以表示为:
其中和是排名阶段给出的分数。 还有一个类似于监督微调的交叉熵损失,它让模型学习老师生成的响应:
最后,总损失就是上述两个损失之和:
3.5实施细节
我们选择 StarCoder 15B Li 等人 (2023) 作为基础模型,并以 512 的全局批量大小对其进行 6 个 epoch 的训练。
图3显示了单个训练样本的格式。 除了在提示上添加一对三引号之外,我们仅使用从响应中提取的代码片段进行训练。

4评估
我们进行了广泛的评估来研究我们方法的性能。 本节描述了我们的评估设置并报告了实验结果以及我们的发现。
4.1 评估设置
4.1.1 主要评估模型
-
•
CodeGen-mono 16B Nijkamp 等人 (2022) 是 CodeGen-Multi B 的变体,专门使用来自 GitHub 的额外 Python 代码进行了微调。
-
•
CodeGeeX 13B Zheng 等人 (2023) 是参数数量为 B 的代码多语言语言模型,大约在 来自 编程语言的 B Token 。
-
•
StarCoder 15B Li 等人 (2023) 是一个代码大语言模型,具有 B 参数和上下文大小 K,支持填充能力和快速推理。
-
•
CodeT5+ 16B Wang 等人 (2023) 是一个编码器-解码器代码大语言模型,具有模块化灵活性,可容纳各种与代码相关的下游任务。
-
•
WizardCoder 15B Luo 等人 (2023) 是先于 PanGu-Coder2 的最先进的 Code 大语言模型,并使用 Evol-Instruct 技术进行训练。
4.1.2基准
-
•
HumanEval:555https://github.com/openai/human-eval 由 OpenAI Chen 等人 (2021) 与 Codex 一起发布,这是最广泛采用的比较大语言模型代码生成性能的基准。 HumanEval 由 164 个手动编写的编程任务组成。
-
•
CoderEval Yu 等人 (2023):一个实用的代码生成基准,用于评估真实软件开发场景下的模型,包括 230 个函数以及来自 43 个开源 Python 项目的测试。
-
•
LeetCode(2022.7之后):我们从leetcode中收集了满足以下条件的问题:
-
–
公开且可免费访问的问题。
-
–
2022 年 7 月 1 日之后创建的问题,确保此基准测试中的任何数据不会与 StarCoder 的训练数据重叠,后者仅包含 2022 年 6 月之前的代码。
除了问题描述之外,我们还收集了 Python 编辑器提示,包括方法名称和签名。 我们将编辑器提示作为提示输入,并使用公共测试来测试模型的输出。 结果,本次基准测试共包含 300 个问题(问题 ID 2325),其中简单问题 79 个问题,中等问题 150 个问题,困难问题 71 个问题。
-
–
4.1.3公制
通过@k
与相关工作相同,我们也采用 OpenAI Chen 等人 (2021) 实现的 pass@k 指标来评估生成代码的功能正确性,其中 为每个问题生成代码样本,并统计正确样本的数量。 代码示例的功能正确性是通过执行相应的单元测试并检查它是否通过所有测试用例来确定的。 给定总代数、正确样本数和采样预算,pass@k为通过无偏估计量计算:
4.1.4解码策略
对于通过估计 pass@k 来评估代码生成模型性能的实验,我们使用 0.2 的温度来生成 pass@1 的响应,并使用 1.2 的温度来生成 pass@10 和 pass@100 的响应以获得更多多样性。 对于闭源模型,我们从以前的论文中检索了数据。 对于可用模型,我们生成了 200 个样本,以尽可能保证统计上可靠的结果。 此外,我们使用 0.95 的 top_p 进行核采样。 为了在三个基准上将 PanGu-Coder2 与其他最新开源模型进行比较,我们使用了贪婪解码策略。
4.1.5提示
我们注意到,代码大语言模型的性能很大程度上受到用于生成编程问题解决方案的提示的影响。 为了与现有研究保持一致,对于给定的代码大语言模型,我们利用相应论文中报告的提示进行评估。 PanGu-Coder2等型号的详细代码生成提示如下:
4.2评估结果
4.2.1性能
我们将 PanGu-Coder2 与现有的 Code 大语言模型在 Python 代码生成性能方面进行了比较。 表2显示了pass@k在HumanEval基准上的比较结果。 在所有开源模型中,PanGu-Coder2 在所有 值(pass@1=61.64、pass@10=79.55、pass@100=91.76)上均取得了最佳结果。 与 HumanEval 基准测试中最先进的代码大语言模型 WizardCoder 相比,我们可以观察到 PanGu-Coder2 的性能优于 WizardCoder 4.34%。 对于 StarCoder,我们可以观察到 pass@1 分数绝对提高了 28%(从 33.6% 提高到 61.6%)。 此外,对于pass@10和pass@100,PanGu-Coder2的性能始终优于StarCoder。
在所有闭源模型中,PanGu-Coder2 排名第二。 与 PaLM-Coder 和 LaMDA 等较大模型相比,PanGu-Coder2 尽管规模较小,但性能更好。 另一个有希望的观察结果是 PanGu-Coder2 优于 OpenAI 的 GPT-3.5。 然而,我们的模型与 OpenAI 的 GPT-4(OpenAI 报告 OpenAI (2023) 中报告的版本)仍然存在差距。
表3显示了贪婪解码pass@1的比较结果。 在所有基准测试中,我们可以观察到 PanGu-Coder2 在所有模型中取得了最好的结果,在 HumanEval 上的 pass@1 值为 62.20%,在 CoderEval 上为 38.26%,在 LeetCode 上为 32/30/10。 一个有希望的观察结果是,PanGu-Coder2 不仅在 HumanEval 上超越了 WizardCoder 和 StarCoder,而且在 CoderEval 和 LeetCode 上也优于这两个模型。 这表明PanGu-Coder2不仅擅长简单的编程任务,而且在上下文感知开发任务和编程竞赛问题上也表现出色。
-
•
PanGu-Coder2 在开源模型中的 HumanEval 上实现了最先进的 61.64% pass@1。
-
•
尽管规模较小,但 PanGu-Coder2 的性能优于较大规模的模型,包括 PaLM-Coder 和 LaMDA。
-
•
PanGu-Coder2 是我们测试的唯一在 HumanEval、CoderEval 和 LeetCode 上同时达到最佳性能的模型。
| Model | Params | Pass@k (%) | ||
| k=1 | k=10 | k=100 | ||
| Closed-source Models | ||||
| AlphaCode Li et al. (2022) | 1.1B | 17.1 | 28.2 | 45.3 |
| Phi-1 Gunasekar et al. (2023) | 1.3B | 50.6 | - | - |
| Codex Chen et al. (2021) | 12B | 28.81 | 46.81 | 72.31 |
| LaMDA Thoppilan et al. (2022) | 137B | 14.0 | - | 47.3 |
| PaLM-Coder Chowdhery et al. (2022) | 540B | 36.0 | - | 88.4 |
| GPT-3.5 OpenAI (2023) | - | 48.1 | - | - |
| GPT-3.5 Luo et al. (2023) | - | 68.9 | - | - |
| GPT-4 OpenAI (2023) | - | 67.0 | - | - |
| GPT-4 Bubeck et al. (2023) | - | 82.0 | - | - |
| Open-source Models | ||||
| CodeGen-mono Nijkamp et al. (2022) | 16B | 29.28 | 49.86 | 75.00 |
| CodeGeeX Zheng et al. (2023) | 13B | 22.89 | 39.57 | 60.92 |
| StarCoder Li et al. (2023)* | 15B | 33.60 | 45.78 | 79.82 |
| CodeT5+ Wang et al. (2023) | 16B | 30.9 | 51.6 | 76.7 |
| WizardCoder Luo et al. (2023)* | 15B | 57.30 | 73.32 | 90.46 |
| PanGu-Coder2* | 15B | 61.64 | 79.55 | 91.76 |
| Model | Params | HumanEval (text2code) | CoderEval (context2code) | LeetCode (easy/medium/hard) |
| PanGu-Coder | 2.6B | 23.78 | 15.21 | 6/3/0 |
| Replit-code-instruct-glaive666https://huggingface.co/sahil2801/replit-code-instruct-glaive | 2.7B | 56.10 | 27.39 | 3/5/2 |
| StarCoder | 15B | 32.93 | 37.82 | 18/13/2 |
| WizardCoder | 15B | 59.80 | 33.48 | 29/22/7 |
| PanGu-Coder2 | 15B | 62.20 | 38.26 | 32/30/10 |
4.2.2调查结果
为了分析 PanGu-Coder2 的训练过程,我们关注影响大型语言模型性能的两个关键因素:数据集大小和训练计算。
数据集大小
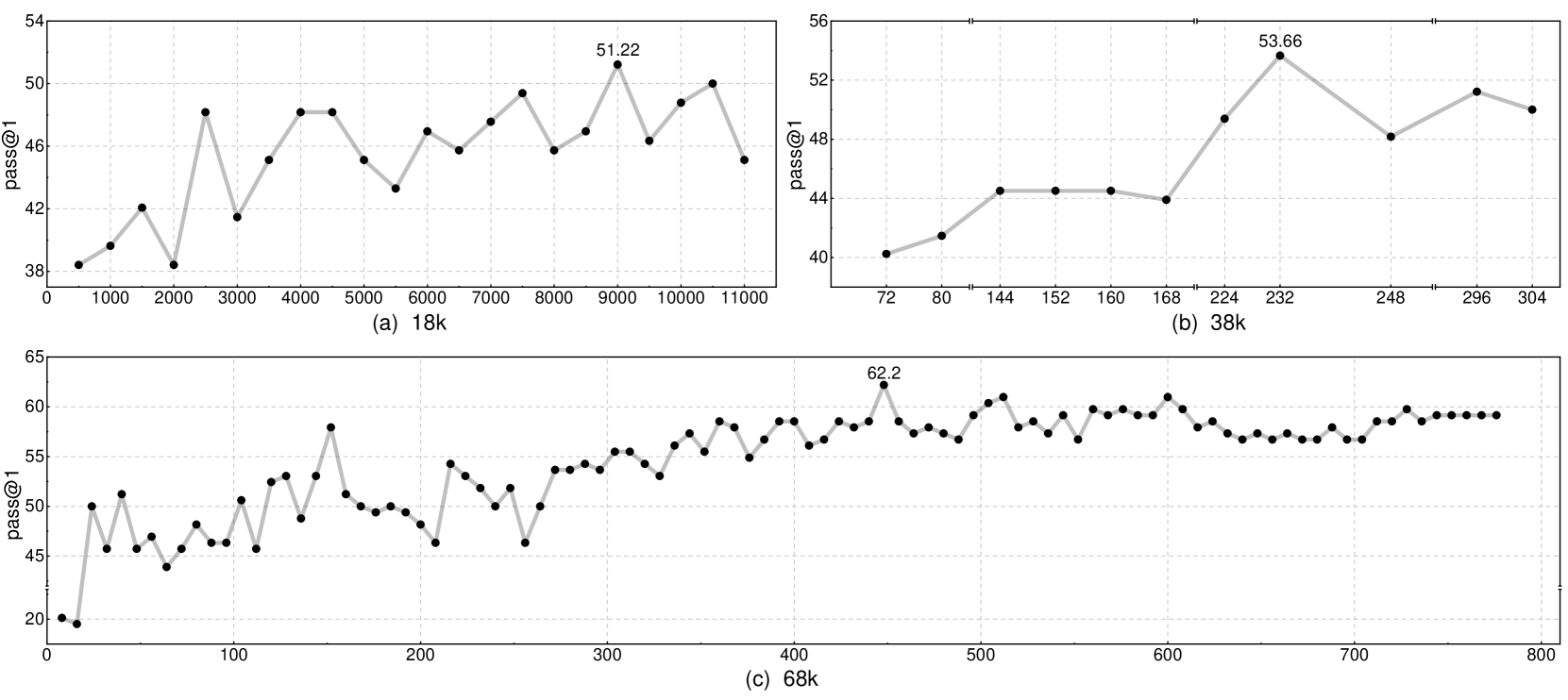
总体准确率(通过贪婪解码 pass@1 估计)随着数据集大小的增长而增加,如图4所示。 此外,随着数据集大小的增长,训练曲线变得更加稳定,在 38k/68k 数据集上大约为 2-3 个 epoch。 对于 18k 数据集,3 个 epoch 后性能仍然剧烈波动。 这表明更多和变体的语料库可以带来更好的性能,而训练成本仍然可以接受,因为达到最佳性能所需的时期不会随着语料库的规模而增加。
训练计算
无论数据集大小如何,准确性可能会急剧下降或在训练开始时保持不变。 大约 2 个 epoch 后,训练曲线变得更加稳定,并且随着损失的减少,准确率持续增加。 3 个 epoch 后达到最佳性能,而 4 个 epoch 后精度变得更加稳定,显示出收敛的迹象。 这表明模型需要大约 3-4 个 epoch 才能完全捕获数据集中的知识,而此后的训练步骤可能对提高模型的能力几乎没有帮助。
4.2.3案例研究
为了对模型进行实证研究并为未来的工作提供启示,我们比较和分析了三个模型的成功和失败案例:基础模型 StarCoder、指令调整模型 WizardCoder 和 PanGu-Coder2 模型。
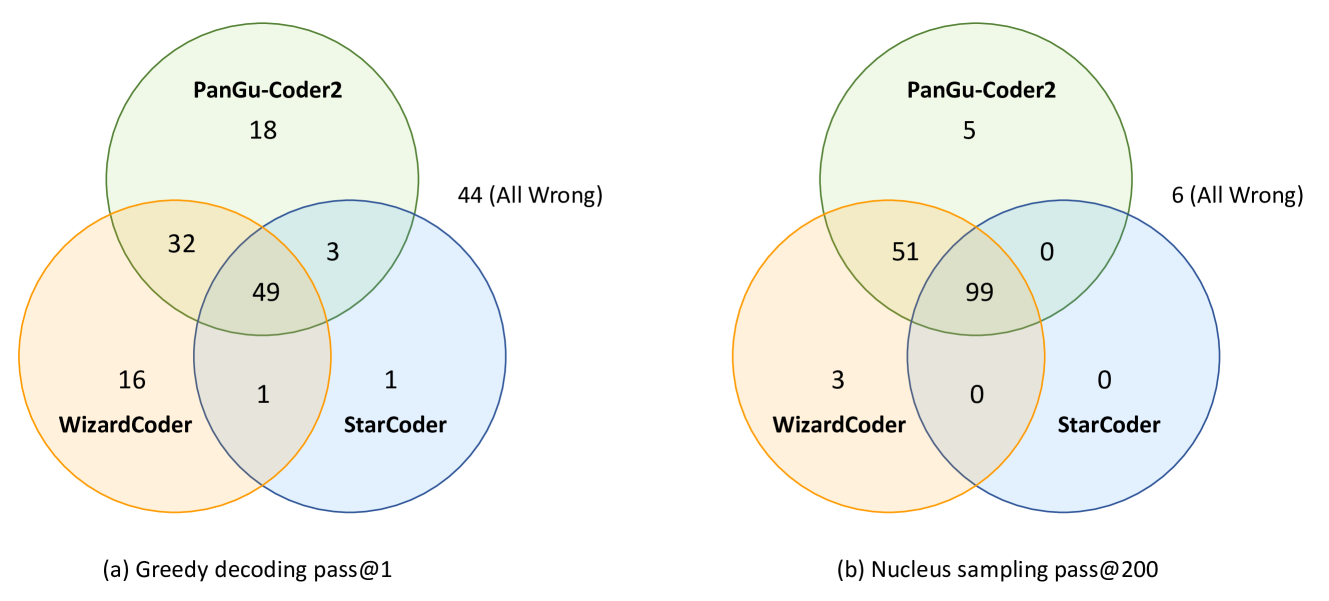
图5展示了三种模型在贪婪解码和核采样方面解决问题的差异和交集。 从图中我们发现PanGu-Coder2和WizardCoder可以互补:虽然PanGu-Coder2解决了大部分问题,并且其中一些问题是WizardCoder无法解决的,但也有一些问题只能通过WizardCoder解决,从而提高了StarCoder的性能指示调整方式。 此外,还有一些问题是这些模型即使采样200次也无法解决的。
我们选择StarCoder、WizardCoder和PanGu-Coder2生成的几个具有代表性的示例代码作为案例研究,对PanGu-Coder2的优缺点进行批判性评估。 如图6所示,PanGu-Coder2 能够熟练地理解编程问题的逻辑方面,而 WizardCoder 和 StarCoder 在这方面则有所欠缺。 这一观察结果表明,PanGu-Coder2 通过我们提出的排名反馈,有效地在编程问题陈述和代码解决方案之间建立了细致的映射。 根据图7的描述,在某些情况下,PanGu-Coder2和StarCoder的性能优于WizardCoder,WizardCoder可能受益于大量丰富注释代码指令的训练。 在某种程度上,这一观察表明,在训练过程中纳入分步评论数据可能会产生积极的效果。 此外,图8显示了StarCoder、WizardCoder和PanGu-Coder2由于编程问题所带来的复杂性和挑战而都给出了错误的代码解决方案的情况。 这一观察结果表明,目前的代码大语言模型在处理复杂编程要求方面仍达不到类似人类的熟练程度,还有一些改进的空间。



4.3 推理优化
由于GPU内存消耗和推理速度是实际中模型部署和使用的关键因素,我们进行了涉及以下量化技术的实验来研究模型推理的优化策略:
-
•
CTranslate2:777https://github.com/OpenNMT/CTranslate2 CTranslate2是OpenNMT开发的一个用于加速Transformer模型推理的库。
-
•
GPTQ:888https://github.com/PanQiWei/AutoGPTQ 基于GPTQ算法的大语言模型量化包。
表4显示了使用不同量化技术优化的模型的GPU内存消耗、推理速度和HumanEval性能。 我们在推理阶段使用8位(4位)量化和以下解码参数:top_p=0.95,tempreture=0.2,max_new_tokens=512。 在所有量化技术中,我们可以观察到内存使用量显着减少,推理速度显着增加。 令人难以置信的是,在使用 CTranslate2 量化后,我们的模型在 HumanEval 上的性能有了轻微的提升。 造成这种现象的一个可能原因是 PanGu-Coder2 本身的稳健性。 我们计划在进一步的工作中对这一有趣的结果进行深入研究。
| Model | Precision | GPU Memory Consumption (GB) | Inference Speed (ms/token) | HumanEval (greedy decoding) |
| PanGu-Coder2 | float16 | 32.36 | 75 | |
| PanGu-Coder2-CTranslate2 | int8 | 16.29 | 33 | 64.63 |
| PanGu-Coder2-GPTQ | int8 | 16.92 | 51 | 51.22 |
| PanGu-Coder2-GPTQ | int4 | 9.82 | 42 | 51.83 |
5结论
在本文中,我们介绍了一种新颖的框架,即RRTF,并提出了一种新的代码大语言模型,即PanGu-Coder2。 首先,我们采用Evol-Instruct技术获得大量高质量的自然语言指令和代码解决方案数据对。 然后,我们通过使用测试用例的反馈和启发式偏好对候选代码解决方案进行排名来训练基本模型。 通过对HumanEval、CodeEval和LeetCode基准的综合评估,PanGu-Coder2在十亿参数级代码大语言模型中取得了新的state-of-the-art性能,大幅超越了所有现有模型。 在未来的工作中,我们将深入研究RRTF的结合和指导调优,以提高Code大语言模型的性能。
参考
- Zan et al. [2023] Daoguang Zan, Bei Chen, Fengji Zhang, Dianjie Lu, Bingchao Wu, Bei Guan, Wang Yongji, and Jian-Guang Lou. Large language models meet NL2Code: A survey. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7443–7464, Toronto, Canada, July 2023. Association for Computational Linguistics. URL https://aclanthology.org/2023.acl-long.411.
- Chen et al. [2021] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- Li et al. [2022] Yujia Li, David H. Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom, Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de, Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey, Cherepanov, James Molloy, Daniel Jaymin Mankowitz, Esme Sutherland Robson, Pushmeet Kohli, Nando de, Freitas, Koray Kavukcuoglu, and Oriol Vinyals. Competition-level code generation with alphacode. Science, 378:1092 – 1097, 2022.
- Chowdhery et al. [2022] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam M. Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Benton C. Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier García, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Díaz, Orhan Firat, Michele Catasta, Jason Wei, Kathleen S. Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. PaLM: Scaling language modeling with pathways. ArXiv, abs/2204.02311, 2022.
- Christopoulou et al. [2022] Fenia Christopoulou, Gerasimos Lampouras, Milan Gritta, Guchun Zhang, Yinpeng Guo, Zhong-Yi Li, Qi Zhang, Meng Xiao, Bo Shen, Lin Li, Hao Yu, Li yu Yan, Pingyi Zhou, Xin Wang, Yu Ma, Ignacio Iacobacci, Yasheng Wang, Guangtai Liang, Jia Wei, Xin Jiang, Qianxiang Wang, and Qun Liu. PanGu-Coder: Program synthesis with function-level language modeling. ArXiv, abs/2207.11280, 2022.
- Huggingface [2021] Huggingface. Training CodeParrot from Scratch, 2021. https://huggingface.co/blog/codeparrot.
- Xu et al. [2022] Frank F. Xu, Uri Alon, Graham Neubig, and Vincent J. Hellendoorn. A systematic evaluation of large language models of code. Proceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming, 2022.
- Zan et al. [2022a] Daoguang Zan, Bei Chen, Dejian Yang, Zeqi Lin, Minsu Kim, Bei Guan, Yongji Wang, Weizhu Chen, and Jian-Guang Lou. CERT: Continual pre-training on sketches for library-oriented code generation. In International Joint Conference on Artificial Intelligence, 2022a.
- Allal et al. [2023] Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Muñoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alexander Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, J. Poirier, Hailey Schoelkopf, Sergey Mikhailovich Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Franz Lappert, Francesco De Toni, Bernardo Garc’ia del R’io, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luisa Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Christopher Hughes, Daniel Fried, Arjun Guha, Harm de Vries, and Leandro von Werra. SantaCoder: don’t reach for the stars! ArXiv, abs/2301.03988, 2023.
- Li et al. [2023] Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161, 2023.
- Austin et al. [2021] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
- OpenAI [2023] OpenAI. GPT-4 technical report. CoRR, abs/2303.08774, 2023. doi:10.48550/arXiv.2303.08774. URL https://doi.org/10.48550/arXiv.2303.08774.
- Bubeck et al. [2023] Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- Gunasekar et al. [2023] Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, et al. Textbooks are all you need. arXiv preprint arXiv:2306.11644, 2023.
- Luo et al. [2023] Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. WizardCoder: Empowering code large language models with evol-instruct. arXiv preprint arXiv:2306.08568, 2023.
- Lu et al. [2022] Shuai Lu, Nan Duan, Hojae Han, Daya Guo, Seung-won Hwang, and Alexey Svyatkovskiy. Reacc: A retrieval-augmented code completion framework. arXiv preprint arXiv:2203.07722, 2022.
- Zhang et al. [2023] Fengji Zhang, Bei Chen, Yue Zhang, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. Repocoder: Repository-level code completion through iterative retrieval and generation. arXiv preprint arXiv:2303.12570, 2023.
- Liu et al. [2023] Jiate Liu, Yiqin Zhu, Kaiwen Xiao, Qiang Fu, Xiao Han, Wei Yang, and Deheng Ye. Rltf: Reinforcement learning from unit test feedback, 2023.
- Le et al. [2022] Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven CH Hoi. CodeRL: Mastering code generation through pretrained models and deep reinforcement learning. arXiv preprint arXiv:2207.01780, abs/2207.01780, 2022.
- Shojaee et al. [2023] Parshin Shojaee, Aneesh Jain, Sindhu Tipirneni, and Chandan K Reddy. Execution-based code generation using deep reinforcement learning. arXiv preprint arXiv:2301.13816, 2023.
- Ouyang et al. [2022a] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022a.
- Chen et al. [2022] Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. Codet: Code generation with generated tests. arXiv preprint arXiv:2207.10397, 2022.
- Zheng et al. [2023] Qinkai Zheng, Xiao Xia, Xu Zou, Yuxiao Dong, Shanshan Wang, Yufei Xue, Zi-Yuan Wang, Lei Shen, Andi Wang, Yang Li, Teng Su, Zhilin Yang, and Jie Tang. CodeGeeX: A pre-trained model for code generation with multilingual evaluations on humaneval-x. ArXiv, abs/2303.17568, 2023.
- Scao et al. [2022] Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilić, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, et al. BLOOM: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100, 2022.
- Chai et al. [2022] Yekun Chai, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, and Hua Wu. ERNIE-Code: Beyond english-centric cross-lingual pretraining for programming languages. arXiv preprint arXiv:2212.06742, 2022.
- Chandel et al. [2022] Shubham Chandel, Colin B. Clement, Guillermo Serrato, and Neel Sundaresan. Training and evaluating a jupyter notebook data science assistant. ArXiv, abs/2201.12901, 2022.
- Zhou et al. [2023a] Shuyan Zhou, Uri Alon, Frank F Xu, Zhengbao JIang, and Graham Neubig. DocCoder: Generating code by retrieving and reading docs. In The Eleventh International Conference on Learning Representations, 2023a.
- Zan et al. [2022b] Daoguang Zan, Bei Chen, Zeqi Lin, Bei Guan, Yongji Wang, and Jian-Guang Lou. When language model meets private library. In Conference on Empirical Methods in Natural Language Processing, 2022b.
- Fried et al. [2023] Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Scott Yih, Luke Zettlemoyer, and Mike Lewis. InCoder: A generative model for code infilling and synthesis. In The Eleventh International Conference on Learning Representations, 2023.
- Bavarian et al. [2022] Mohammad Bavarian, Heewoo Jun, Nikolas A. Tezak, John Schulman, Christine McLeavey, Jerry Tworek, and Mark Chen. Efficient training of language models to fill in the middle. ArXiv, abs/2207.14255, 2022.
- Nguyen et al. [2023] Anh Nguyen, Nikos Karampatziakis, and Weizhu Chen. Meet in the Middle: A new pre-training paradigm. arXiv preprint arXiv:2303.07295, 2023.
- Zhou et al. [2023b] Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. Lima: Less is more for alignment. arXiv preprint arXiv:2305.11206, 2023b.
- Peng et al. [2023] Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction tuning with gpt-4. arXiv preprint arXiv:2304.03277, 2023.
- Ouyang et al. [2022b] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. In NeurIPS, 2022b. URL http://papers.nips.cc/paper_files/paper/2022/hash/b1efde53be364a73914f58805a001731-Abstract-Conference.html.
- Yuan et al. [2023] Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. Rrhf: Rank responses to align language models with human feedback without tears. arXiv preprint arXiv:2304.05302, 2023.
- Dong et al. [2023] Hanze Dong, Wei Xiong, Deepanshu Goyal, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, and Tong Zhang. RAFT: Reward ranked finetuning for generative foundation model alignment. arXiv preprint arXiv:2304.06767, 2023.
- Nijkamp et al. [2022] Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. CodeGen: An open large language model for code with multi-turn program synthesis. arXiv preprint arXiv:2203.13474, 2022.
- Xu et al. [2023] Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244, 2023.
- Shazeer [2019] Noam Shazeer. Fast transformer decoding: One write-head is all you need. CoRR, abs/1911.02150, 2019. URL http://arxiv.org/abs/1911.02150.
- Wang et al. [2023] Yue Wang, Hung Le, Akhilesh Deepak Gotmare, Nghi DQ Bui, Junnan Li, and Steven CH Hoi. Codet5+: Open code large language models for code understanding and generation. arXiv preprint arXiv:2305.07922, 2023.
- Yu et al. [2023] Hao Yu, Bo Shen, Dezhi Ran, Jiaxin Zhang, Qi Zhang, Yuchi Ma, Guangtai Liang, Ying Li, Tao Xie, and Qianxiang Wang. Codereval: A benchmark of pragmatic code generation with generative pre-trained models. arXiv preprint arXiv:2302.00288, 2023.
- Thoppilan et al. [2022] Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239, 2022.