卷起袖子:使用协作且参与的
面向任务的对话系统
摘要
我们推出了 TacoBot,这是一种以用户为中心、面向任务的数字助理,旨在引导用户通过多个步骤完成复杂的现实任务。 我们涵盖广泛的烹饪和操作方法任务,旨在提供协作且引人入胜的对话体验。 TacoBot 配备了由强大的搜索引擎支持的语言理解、对话管理和响应生成组件,可确保高效的任务协助。 为了增强对话体验,我们探索了一系列使用大语言模型的数据增强策略来不断训练高级神经模型。 TacoBot 建立在我们成功参加首届 Alexa 奖 TaskBot 挑战赛的基础上,我们的团队在十个参赛团队中获得了第三名。 我们提供 TacoBot 作为开源框架,作为部署面向任务的对话系统的实际示例。111代码和数据集可从 OSU-NLP/TacoBot 获取。
1简介
面向任务的对话(TOD)系统在通过对话交互实现用户目标方面表现出了良好的前景(Semantic Machines 等人,2020;Su 等人,2022;Mo 等人,2022)。 然而,现有的 TOD 系统侧重于用户在系统执行任务时提供信息。 相比之下,我们的任务机器人通过提供准确的信息和指导来帮助用户自行执行任务。
然而,我们面临着一些挑战,包括:(1)现有的TOD系统以牺牲用户体验为代价优先考虑功能目标。 (2)领域内训练数据不足,现代神经模型需要大量数据,通过众包获取注释成本高昂。 在本文中,我们提出了TacoBot,这是一种面向任务的对话系统,旨在帮助用户完成多步骤烹饪和指导任务。 TacoBot 的目标是基于我们之前在 Alexa 奖 TaskBot 挑战赛中部署的机器人 (Chen 等人,2022)(Gottardi 等人,2022)提供协作且引人入胜的用户体验。 图1展示了部分示例对话。
我们的贡献包括:(1)开发模块化的 TOD 框架,具有准确的语言理解、灵活的对话管理和参与式响应生成。 (2)探索数据增强策略,例如利用GPT-3来合成大规模训练数据。 (3)在烹饪任务中引入有关营养的澄清问题,以个性化搜索并更好地满足用户需求。 (4) 结合闲聊功能,允许用户讨论手头任务之外感兴趣的开放话题。

2系统设计
2.1系统概述
TacoBot 遵循 TOD 系统的规范管道方法。 该系统由三个主要模块组成:自然语言理解(NLU)、对话管理(DM)和响应生成(RG)。 NLU 模块预处理用户的话语以确定他们的意图。 DM模块采用分层有限状态机设计,控制对话流程,处理异常,并引导对话完成任务。 RG 模块使用相关知识和附加模式生成响应,以增强用户参与度。 每个模块都由组织良好的知识后端和搜索引擎支持,能够连接各种来源以提供最佳的用户帮助。
2.2 自然语言理解
| Category | Description |
|---|---|
| Sentiment | The user can confirm or reject the bot’s response on each turn, leading to three labels: Affirm, Negate, and Neutral, indicating the user utterance’s polarity. |
| Commands | The user can drive the conversation using these commands: Task Request, Navigation (to view candidate tasks or walk through the steps), Detail Request, PAK Request, Task Complete, and Stop to terminate the conversation at any time. |
| Utilities | We use a Question intent to capture user questions and a Chat intent for casual talk. |
| Exception | To avoid unintentional changes in dialogue states, we have one additional intent for out-of-domain inputs, such as incomplete utterances and greetings. |
我们的机器人采用强大的 NLU 管道,它将预训练语言模型的优势与基于规则的方法融合在一起。 关键组件是意图识别,我们将多个意图组织为四个类别,以适应广泛的用户计划,如表1中详述。 现实世界的用户计划通常在一篇文章中包含多个意图。 因此,我们将意图识别视为多标签分类问题,并根据对话状态过滤模型预测。
为了在数据有限的情况下开发高质量的多标签分类模型,我们采用了数据增强和领域适应技术。 我们利用现有数据集(Rastogi等人,2019)来实现情感和问题等常见意图,同时利用GPT的上下文学习功能-3 表示其他意图。 通过综合初始话语与意图描述和少量样本示例,我们为训练数据奠定了基础。 为了扩展数据集,我们将合成话语转换为模板,用占位符替换槽值,并用采样值填充它们以生成实际的训练话语。 此外,我们还结合了语言规则、神经释义模型和用户噪声(例如填充词),以增强数据多样性并提高意图识别模块的稳健性。
2.3对话管理
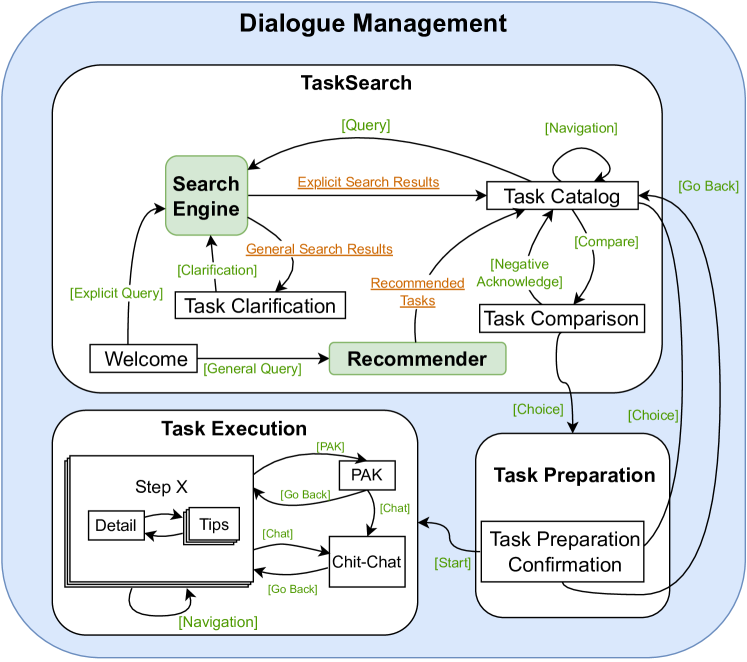
我们为 DM 组件设计了一个分层有限状态机,由三个阶段组成:任务搜索、任务准备和任务执行。 每个阶段都包含多个细粒度的对话状态,如图2所示。
在任务搜索阶段,用户可以通过发出查询或要求任务推荐来直接搜索操作方法任务或食谱。 TacoBot从后端搜索引擎检索搜索结果(第2.4节)并呈现候选任务供用户比较和选择。 用户选择一个选项后,就会进入任务准备阶段。 在此阶段,用户查看有关所选任务的详细信息,并决定是否继续或搜索另一个任务。 如果用户改变主意,他们可以返回任务搜索并查找替代任务。 如果他们提交了所选任务,他们就会进入任务执行阶段。 在最后一个阶段,用户按照 TacoBot 提供的分步说明来完成任务。 实用程序模块(例如 QA 模块)在整个阶段为用户提供帮助。 任务的每个步骤都有自己的状态,对于操作方法任务,我们将冗长的步骤分解为较短的说明、细节和提示,以便用户更好地理解。
DM 根据用户输入执行状态转换并选择响应生成器(第 2.5 节)。 对话状态的分层设计允许不同级别的可扩展和灵活的转换。 维护对话状态历史堆栈以便于轻松导航到之前的状态。 不触发有效转换的用户意图会提供上下文帮助信息来指导用户完成对话。 这些设计选择确保了用户稳定而灵活的对话体验。
2.4搜索引擎
TacoBot可以支持大规模语料库支持的多种任务。 对于烹饪领域,我们基于Recipe1M+数据集(Marın等人,2019)构建了一个食谱语料库,其中包含1.02M食谱。 同时,我们构建了一个 wikiHow 语料库,其中包括从 wikiHow 网站收集的 93.1K 操作任务222https://www.wikihow.com。 最重要的是,我们基于弹性搜索构建了两个领域的搜索引擎。
2.4.1 排名策略
为了提高搜索结果的相关性并缓解弹性搜索中的词汇相似性问题,我们采用了查询扩展技术,通过合并任务名称中的相关单词(例如词形还原的动词、名词和分解的复合名词)来扩展用户查询。 此外,我们通过实施基于 BERT 的神经重新排序模型来增强搜索性能。 该模型通过将任务请求和检索到的任务标题作为输入来为每个任务分配分数。 训练重新排序器涉及采用弱监督的列表排序损失并通过 GPT-3 查询模拟利用合成任务查询。 我们还建议从谷歌搜索引擎收集弱监督信号,以避免需要人类标注。
2.4.2 个性化搜索
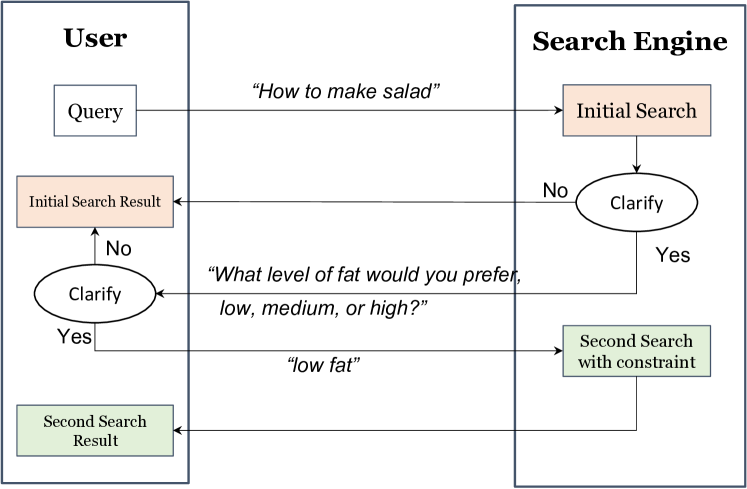
除了实施准确搜索结果的排名策略外,我们的目标是将个性化注入搜索引擎,确保更精细地匹配用户的需求。 为了实现这一目标,我们提出了一种在食谱搜索过程中提出澄清问题的方法,与用户密切合作以了解他们对营养的偏好。 该过程的逻辑流程如图3所示。 具体来说,当用户提供感兴趣的烹饪任务时,我们会主动与他们进行澄清讨论,讨论所需的营养水平,包括糖、脂肪、饱和度和盐,使用食品标准局 (FSA) 制定的交通灯定义。
2.5 响应生成
我们的响应生成模块融合了基于填充的方法和神经模型。 我们利用手工制作的条件规则根据分层有限状态机中的高级状态来组织策划的模板及其组合策略。 同时,我们构建了一个 QA 系统来响应不同的用户查询。
2.5.1 问题类型分类器
我们的 QA 系统涵盖各种问题类型,包括针对上下文相关问题的上下文机器阅读理解 (MRC)、针对开放域问题的脱离上下文 (OOC) QA、针对操作方法的常见问题 (FAQ) 检索任务,以及基于规则的烹饪任务的配料和替代品 QA。
然后,我们开发了一个问题类型分类器,将用户问题分类为烹饪任务的五种类型(MRC、OOC、FAQ、配料、替代品)和操作方法任务的三种类型(MRC、OOC、FAQ)。 为了提高分类准确性,我们将当前步骤的指令(如果可用)作为上下文与输入问题连接起来。 然后将这个组合序列输入到 Roberta 基分类器中。 我们的训练集包含每种问题类型 5,000 个问题,可以有效区分不同类型的问题。
2.5.2 上下文相关的质量检查
我们首先注释一个包含 5,183 个 QA 对的上下文 QA 数据集,其中 752 个是无法回答的问题。 为了确保可靠的响应,我们采用 Roberta-base 分两个阶段构建提取式 QA 模型。 最初,我们在 SQuAD 2.0 上预训练模型,然后对带注释的 QA 数据集进行微调。 认识到用户可能会查询之前显示的步骤,我们通过在训练和推理过程中将当前步骤与前面的 步骤 () 连接来增强上下文,以防止信息差距和幻觉。
2.5.3 上下文无关的 QA
TacoBot 支持上下文中和上下文无关的问题。 对于断章取义的QA,我们利用FLAN-T5-XXL (Chung 等人, 2022),一种指令微调语言模型具有 11B 参数。 在零样本提示设置下,我们的机器人能够处理开放域质量检查并演示常识推理。
此外,常见问题解答模块利用 wikiHow 社区问答部分的常见问题,提供来自真实用户问题和专家回复的答案。 我们使用基于余弦相似度的检索模块,并使用句子 BERT 编码器生成的问题嵌入。 对于与成分相关的查询,我们针对配方的成分列表采用了高召回率字符串匹配机制。 如果用户缺少特定成分,我们会利用涵盖 200 种常用成分的数据集建议替代方案。
2.6用户参与度
我们在以下部分中制定了几种策略来追求引人入胜的对话体验。
2.6.1 闲聊
在现实世界的对话中,用户通常希望在执行任务的同时进行随意的交谈。 为了增强用户体验,TacoBot提供闲聊功能,实现灵活多样的对话。 受到 Chirpy Cardinal (Chi 等人, 2022) 的启发,我们将闲聊模块集成到我们的 TOD 系统中。 采用基于模板的策略来识别进入和退出聊天时的用户意图。 闲聊过程由三个部分组成。
首先,Entity Tracker 监控整个对话过程中的实体,根据用户意图调整响应并关注当前主题。 认可的实体允许 TacoBot 访问网络资源(维基百科和 Google)并提供有趣的信息。 其次,Chit-Chat Response Generator 包含各种响应生成器:Neural Chat、Categories、Food、Aliens、Wiki 和 Transition。 神经聊天使用 BlenderBot-3B 生成开放域响应。 类别和食物生成器使用模板引发与实体相关的响应。 过渡有利于实体之间的平稳转移。 Wiki 使用户能够以对话方式发现引人入胜的信息。 《外星人》呈现了一个关于外星存在的五部分独白系列。 最后,意图识别模型确定用户是否想要继续或转移主题。 TacoBot 在闲聊后主动提示用户返回任务。 实现闲聊和任务导向对话之间的自然过渡需要持续的努力。
2.6.2 人们还问
此外,TacoBot 旨在通过提供引人入胜的内容来增强对话体验。 我们利用 Google 的“People Also Ask”(PAK)功能,该功能提供相关问题的列表以及网页上的总结答案。 此功能揭示了人们感兴趣的热门话题。 为了收集 PAK 数据,我们从配方和 wikiHow 语料库中的任务标题中提取了 30k 个常见关键字,总共产生了 494k 个 PAK QA 对。
在任务执行期间,PAK 作为附加信息呈现。 为了避免干扰用户注意力,我们限制了显示频率,目前每 3 步显示一次。 我们没有直接显示 PAK QA 对,而是通过首先提出问题来提供交互式体验,让用户决定是否要查看相应的答案。 如果用户选择查看 PAK,我们还为他们提供参与闲聊的选项。
3结论
在本文中,我们介绍了TacoBot,这是一种模块化的面向任务的对话系统,可帮助用户完成复杂的日常任务。 我们提出了一套全面的模块和方法来创建协作且引人入胜的任务机器人。 为了确保坚实的基础,我们利用大语言模型采用了多种数据增强技术。 此外,我们开源了框架和数据集,提供了宝贵的资源,并激励未来加强用户与机器人协作的努力。
道德声明
我们提出了一个任务机器人,它能够与用户对话以完成现实世界的任务。 整个对话过程中不包含任何个人或身份信息。 此外,我们的机器人还包括安全检查,以确保安全对话。 我们拒绝不适当的任务请求,并防止显示危险任务,因为用户及其财产可能会受到伤害。 为此,我们对关键字黑名单进行基于规则的匹配,以过滤掉不适当的任务。 同时,对于回复生成,我们不直接使用大语言模型(例如ChatGPT)来生成用户问题的答案,这将存在将用户数据泄露给第三方API的风险。 相反,我们利用大语言模型进行数据增强和领域适应,并在本地训练模型以保护隐私。
作者贡献
在这项工作中,每位作者都做出了重大贡献,共同提高了最终结果。 莫凌波在构建和组织代码库以及为演示构建交互界面方面发挥了至关重要的作用。 陈士杰和陈自如在挑战赛中共同领导了团队,为机器人的开发奠定了基础。 邓翔和张天舒负责 NLU 流程。 向悦主要开发QA模块。 凌波莫和王臻共同构建了后台知识库和搜索引擎。 Samuel Stevens 为构建自动化测试套件提供了工程支持。 Ashley Lewis 专注于提高用户参与度。 Chang-You Tai 为闲聊和 PAK 功能做出了贡献,而 Sunit Singh 则协助设计了演示界面。 孙焕和苏宇是教师顾问,提供了宝贵的指导和反馈。
致谢
我们感谢 OSU NLP 小组和 Amazon 的同事提供的宝贵反馈。 部分工作是在首届 Alexa 奖 TaskBot 挑战赛期间完成的,并得到了 Amazon.com, Inc. 的支持。 这项工作也得到了 NSF CAREER #1942980 的部分支持。
参考
- Chen et al. (2022) Shijie Chen, Ziru Chen, Xiang Deng, Ashley Lewis, Lingbo Mo, Samuel Stevens, Zhen Wang, Xiang Yue, Tianshu Zhang, Yu Su, et al. 2022. Bootstrapping a user-centered task-oriented dialogue system. arXiv preprint arXiv:2207.05223.
- Chi et al. (2022) Ethan A Chi, Ashwin Paranjape, Abigail See, Caleb Chiam, Kathleen Kenealy, Swee Kiat Lim, Amelia Hardy, Chetanya Rastogi, Haojun Li, Alexander Iyabor, et al. 2022. Neural generation meets real people: Building a social, informative open-domain dialogue agent. arXiv preprint arXiv:2207.12021.
- Chung et al. (2022) Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. 2022. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
- Gottardi et al. (2022) Anna Gottardi, Osman Ipek, Giuseppe Castellucci, Shui Hu, Lavina Vaz, Yao Lu, Anju Khatri, Anjali Chadha, Desheng Zhang, Sattvik Sahai, et al. 2022. Alexa, let’s work together: Introducing the first alexa prize taskbot challenge on conversational task assistance. arXiv preprint arXiv:2209.06321.
- Marın et al. (2019) Javier Marın, Aritro Biswas, Ferda Ofli, Nicholas Hynes, Amaia Salvador, Yusuf Aytar, Ingmar Weber, and Antonio Torralba. 2019. Recipe1m+: A dataset for learning cross-modal embeddings for cooking recipes and food images.
- Mo et al. (2022) Lingbo Mo, Ashley Lewis, Huan Sun, and Michael White. 2022. Towards transparent interactive semantic parsing via step-by-step correction. In Findings of the Association for Computational Linguistics: ACL 2022, pages 322–342.
- Rastogi et al. (2019) Abhinav Rastogi, Xiaoxue Zang, Srinivas Sunkara, Raghav Gupta, and Pranav Khaitan. 2019. Towards scalable multi-domain conversational agents: The schema-guided dialogue dataset. CoRR, abs/1909.05855.
- Semantic Machines et al. (2020) Semantic Machines, Jacob Andreas, John Bufe, David Burkett, Charles Chen, Josh Clausman, Jean Crawford, Kate Crim, Jordan DeLoach, Leah Dorner, Jason Eisner, Hao Fang, Alan Guo, David Hall, Kristin Hayes, Kellie Hill, Diana Ho, Wendy Iwaszuk, Smriti Jha, Dan Klein, Jayant Krishnamurthy, Theo Lanman, Percy Liang, Christopher H. Lin, Ilya Lintsbakh, Andy McGovern, Aleksandr Nisnevich, Adam Pauls, Dmitrij Petters, Brent Read, Dan Roth, Subhro Roy, Jesse Rusak, Beth Short, Div Slomin, Ben Snyder, Stephon Striplin, Yu Su, Zachary Tellman, Sam Thomson, Andrei Vorobev, Izabela Witoszko, Jason Wolfe, Abby Wray, Yuchen Zhang, and Alexander Zotov. 2020. Task-oriented dialogue as dataflow synthesis. Transactions of the Association for Computational Linguistics, 8:556–571.
- Su et al. (2022) Yixuan Su, Lei Shu, Elman Mansimov, Arshit Gupta, Deng Cai, Yi-An Lai, and Yi Zhang. 2022. Multi-task pre-training for plug-and-play task-oriented dialogue system. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4661–4676.