![[Uncaptioned image]](logo.png) XNLP:通用结构化NLP的交互式演示系统
XNLP:通用结构化NLP的交互式演示系统
摘要
结构化自然语言处理 (XNLP) 是 NLP 的一个重要子集,需要理解文本的底层语义或句法结构,这是许多下游应用程序的基础组件。 尽管最近做出了一些努力来探索针对特定类别的 XNLP 任务的通用解决方案,但长期以来,统一所有 XNLP 任务的全面有效的方法仍然不足。 与此同时,虽然 XNLP 演示系统对于研究人员探索各种 XNLP 任务至关重要,但现有平台可能仅限于支持少数 XNLP 任务,缺乏交互性和通用性。 为此,我们提出了一个先进的XNLP演示平台,我们建议利用大语言模型来实现通用的XNLP,一个模型适用于所有,具有很高的通用性。 总体而言,我们的系统在通用 XNLP 建模、高性能、可解释性、可扩展性和交互性等多个方面取得了进步,为探索社区中的各种 XNLP 任务提供了统一的平台。111XNLP上线:https://xnlp.haofei.vip/,视频演示在https://youtu.be/bOc-9HELEVw。
1简介
XNLP 被称为 NLP 任务的一种特殊形式,涉及整体分析和解释文本中的底层语义或句法结构,例如句法依存解析 Nivre (2003)、信息提取 Wang and Cohen (2015)、共指消解Lee 等人(2017)、意见提取Pontiki 等人(2016)等。 图1(上半部分)说明了不同类别下的一些代表性 XNLP 任务。 XNLP 已经为广泛的下游 NLP 应用提供了基础设施,例如知识图谱构建 Bosselut 等人 (2019)、Empathetic Dialogue Rashkin 等人 (2019) 等新兴应用和技术Tang 等人 (2020)。
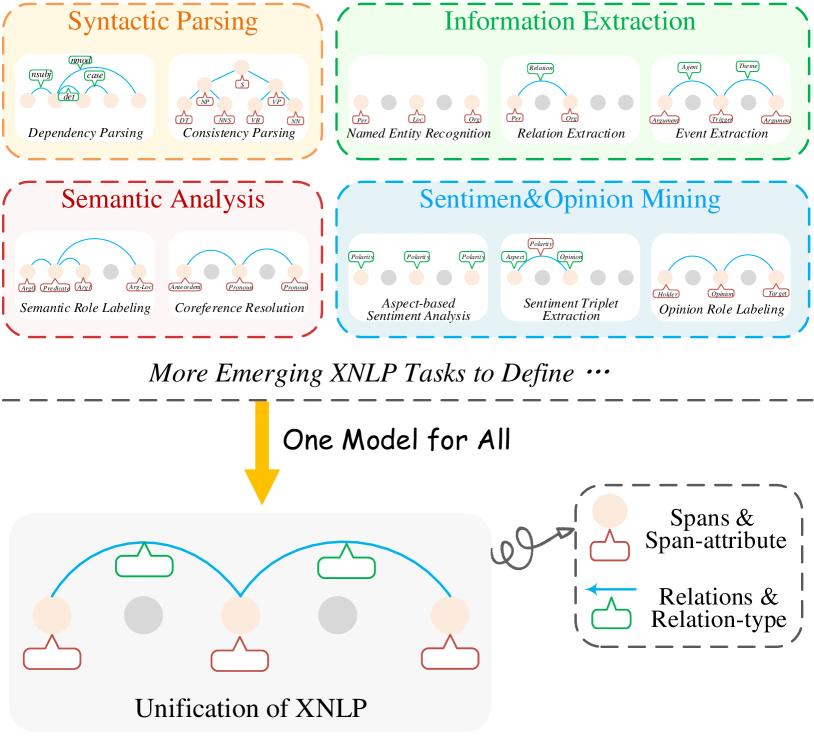
作为关键的共同特征,所有 XNLP 任务都围绕着根据输入预测两个关键元素:1)文本跨度 和 2)跨度之间的关系 Fei 等人(2022b),如图1(下半部分)所示。 XNLP 的传统工作是独立处理每个任务,这导致 XNLP 任务之间共享特征的利用有限 He 等人 (2019),以及跨不同数据集 Chauhan 等的次优模型泛化人(2020),比如跨语言、跨域场景。 在本文中,我们强调模型统一作为 NLP 关键主题的重要性。 通过将各种 NLP 任务统一在 XNLP 框架下,我们可以利用任务之间的共享特性,从而在产品部署的实际场景中获得更好的模型泛化和性能提升。
尽管最近在探索某些类别的 XNLP 任务的通用解决方案方面做出了一定的努力,例如统一情感分析Chen 和Qian (2020); Fei 等人 (2022a) 和通用信息提取 (UIE; Lu 等人, 2022; Fei 等人, 2022b),一种全面有效的统一所有 XNLP 任务的方法尚未出现已完全成立。 幸运的是,Large Language Models (大语言模型) Vaswani 等人 (2017); Raffel 等人 (2020) 提出了一种统一所有 XNLP 任务的潜在解决方案。 最近有大语言模型形式的发展,例如 ChatGPT Ouyang 等人 (2022)、LLaMA Touvron 等人 (2023) 和 Vicuna Peng等人 (2023),在 NLP 和其他领域显示出有希望的进展。 大语言模型拥有足够规模的模型和数据,表现出了令人印象深刻的泛化能力,很好地支持了“一个模型为所有人”OpenAI(2023)的思想。 在这项工作中,我们建议利用大语言模型来实现通用的 XNLP,解决缺乏明确定义和整体方法的问题。
另一方面,演示系统对于研究人员(尤其是初学者)探索各种 XNLP 任务发挥着至关重要的作用,为分析和理解不同 NLP 组件的功能及其应用提供了平台。 虽然现有广泛使用的 XNLP 演示系统,例如 CoreNLP、AllenNLP,但我们观察到它们的几个关键问题:1)仅限于少数特定任务; 2)缺乏交互性和可扩展性,使得支持新的XNLP任务的动态增长具有挑战性; 3)不是通用系统,每个任务需要单独的模型,这可能导致开销增加。 为了解决这些限制,这项工作旨在构建一个先进的平台,提供卓越的 XNLP 演示并造福更广泛的 NLP 社区。 概括起来,我们的系统在以下几个方面取得了进步。
-
1)
普遍性
-
•
我们的XNLP系统以现有的开源大语言模型为骨干引擎,具有出色的泛化能力,能够对各种XNLP任务进行统一预测,从而形成一个精简且有凝聚力的XNLP生态系统。
-
•
基于LLM的系统支持复杂结构化任务的端到端预测,无论跨度是嵌套的还是不连续的,使其具有多功能性并适应不同的语言结构。
-
•
-
2)
高性能
-
•
我们的系统能够进行少样本或弱监督学习。 经过大量的预训练,大语言模型不需要对特定任务数据进行域内微调。
-
•
我们的系统支持开放标签和词汇预测,利用大语言模型的泛化能力来发现具有卓越域外泛化能力的新标签和词汇。
-
•
我们的方法自然适合跨语言、代码转换和跨域设置。
-
•
-
3)
可扩展性&可解释性&交互性
-
•
系统允许动态添加和定义新任务,只需要用户提供新任务的演示即可。
-
•
我们的系统生成的预测是可解释的,因为大语言模型能够为他们的决策提供基本原理,解释为什么会产生特定的结果。
-
•
该系统支持人机交互,使用户能够提供反馈,从而使系统能够根据用户输入完善其预测。
-
•
2相关工作
2.1结构化自然语言处理
在过去的几十年里,XNLP 引起了广泛的研究关注,有几项工作解决了 XNLP 任务的特定方面,从语言/句法解析 Kitaev 和 Klein (2018) 到信息提取 Mikheev等人 (1999),语义分析 He 等人 (2017) 以及情感分析和观点挖掘 Wu 等人 (2021)。 之前的研究和努力已经为每个 XNLP 任务付出了显着的进展,例如句法依存解析 Nivre (2003)、信息提取 Wang 和 Cohen (2015) 、共指解析Lee 等人(2017)、意见提取Pontiki 等人(2016)等。 不同的XNLP任务可能有不同的具体任务定义,而所有XNLP任务的预测格式可以简化为相同的原型:术语提取和关系检测Lu等人(2022); Fei 等人 (2022b).
XNLP 演示。
演示平台的开发对于教育和学术目的至关重要,例如帮助研究人员探索各种任务并获得实践经验。 现有广泛使用的 XNLP 开放演示系统包括 CoreNLP222http://corenlp.run/,AllenNLP30>33https://demo.allennlp.org/ 和 Explosion.ai6>48>44https://explosion.ai/ 虽然为用户提供用户友好的 Web 界面来访问一组 XNLP 功能,但仍然存在一定的局限性,例如缺乏合并新任务的灵活性、模型的非通用性和跨域泛化。
2.2模型统一
人们在探索一类 NLP 任务的通用建模方面做出了显着的努力Chen 和Qian (2020); Fei 等人 (2022a);卢等人 (2022); Fei等人(2022b),展示了模型统一的好处和潜力,例如,更好地利用跨任务的共享特征和知识、简化模型维护和提高系统效率。 然而,统一所有 XNLP 任务的全面有效的方法仍未得到充分研究。 在这项工作中,通过利用大语言模型的稳健性和广泛的适用性,我们的目标是为能够有效处理各种 XNLP 任务的先进统一框架铺平道路。
3系统设计
架构概述。
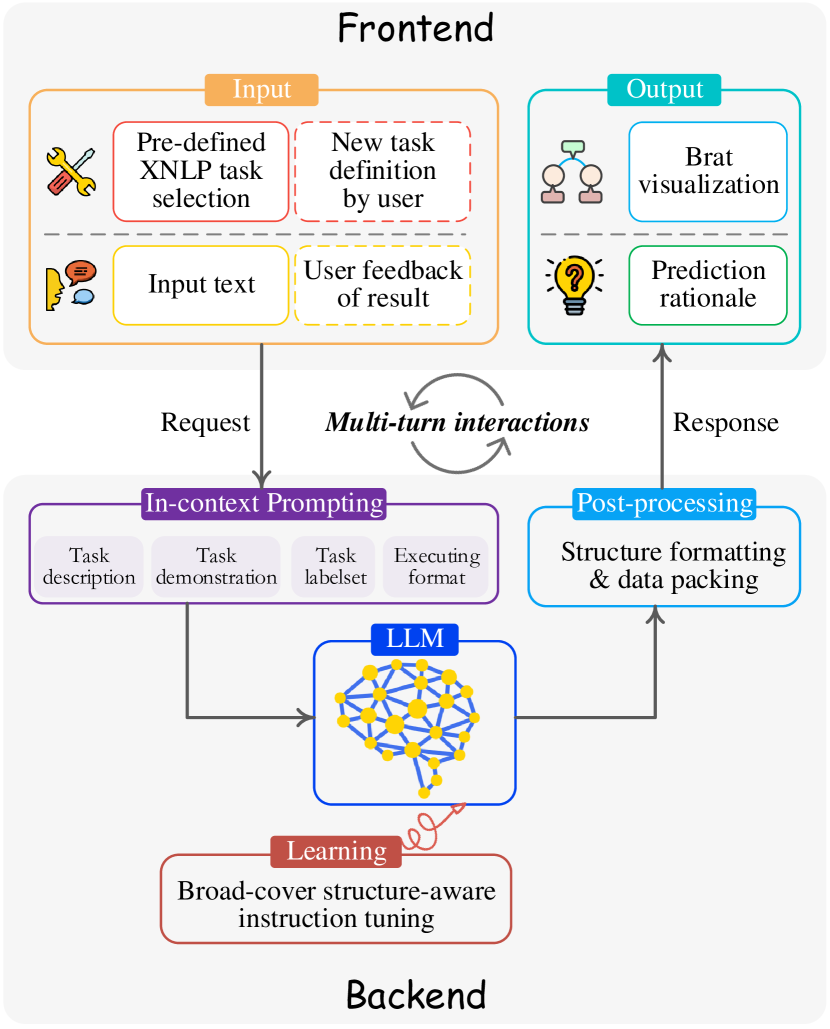
我们将XNLP演示系统设计成Web界面形式。 基于 Django555https://www.djangoproject.com/, v4.2.4框架,XNLP将功能分为前端模块和后端模块。 如图2所示,前端接受用户输入并显示输出的可视化,后端基于上下文学习范式,以大语言模型为核心引擎提供任务预测服务。 此外,前端和后端之间可以进行多轮交互。
3.1后端
骨干大语言模型。
在开源大语言模型列表中,我们考虑的是Vicuna-13B666https://github.com/lm-sys/FastChat 作为我们的骨干。 通过对从 ShareGPT 收集的用户共享对话进行微调 LLaMA Touvron 等人 (2023) 进行训练,Vicuna 的成绩达到了 OpenAI ChatGPT Peng 等人 (2023) 的 90% 以上> 用户偏好测试的质量。
情境学习。
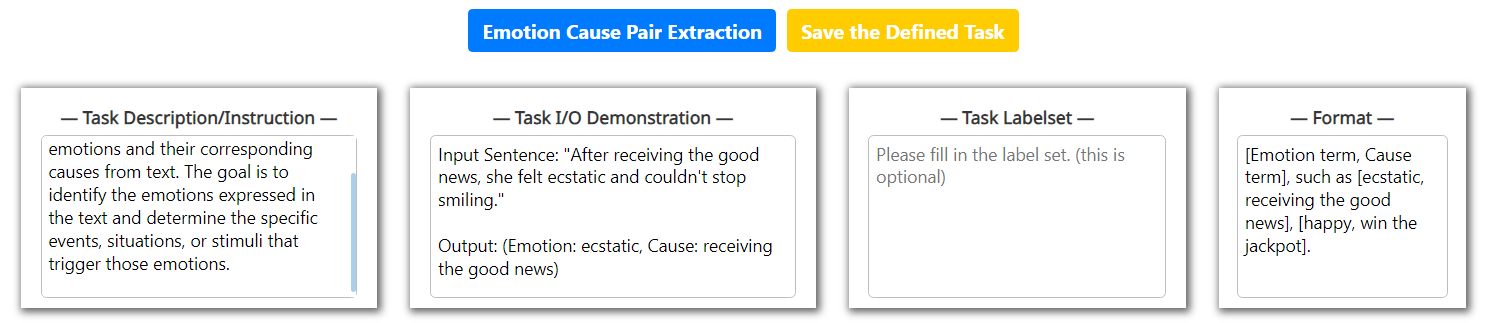
为了引发大语言模型来诱导任务预测,我们构建了上下文提示。 我们注意到,为了确保通用 XNLP 支持任何潜在的任务和输入,提示模板应该涵盖来自用户端的丰富且信息丰富的信息。 因此,我们设计提示时主要涵盖任务名称、任务描述、任务演示、任务标签集 、执行格式、输入文本、语言和域。
根据上述提示,大语言模型预计会以提供的格式(执行格式)输出预测,后处理程序将进一步对结构结果进行解析和完善,并对数据进行打包返回到前端。
广泛的结构感知指令调整。
大语言模型的输出是顺序的,而 XNLP 任务是高度结构化的。 因此,我们期望大语言模型能够生成以序列输入为条件的严格结构结果。 我们考虑通过广泛的结构感知指令调优机制进一步调优大语言模型。 指令调优是大语言模型微调的一种新兴范式,其中自然语言指令与大语言模型相结合,可以更准确地得出所需的结果。 我们通过将预测格式化为与任务无关(即任务广泛覆盖)的格式良好的结构表示形式来编写任何输入提示的 XNLP 预测(输出),如 Fei 等人 (2022b) 中所示。
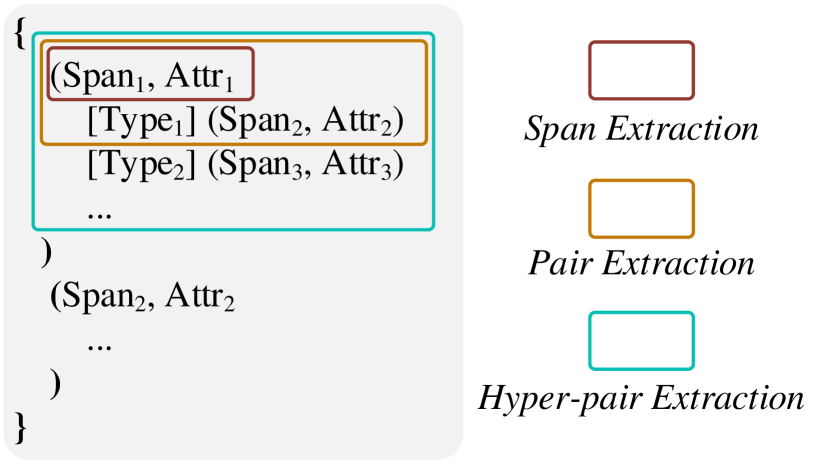
结构格式化。
3.2前端
如图2(上半部分)所示,XNLP的前端接收1)文本或用户反馈或2)任务元数据(预定义或用户定义)的输入),并展示大语言模型的输出。 下面我们主要描述前端模块的以下几个关键特性。
预定义的 XNLP 任务。
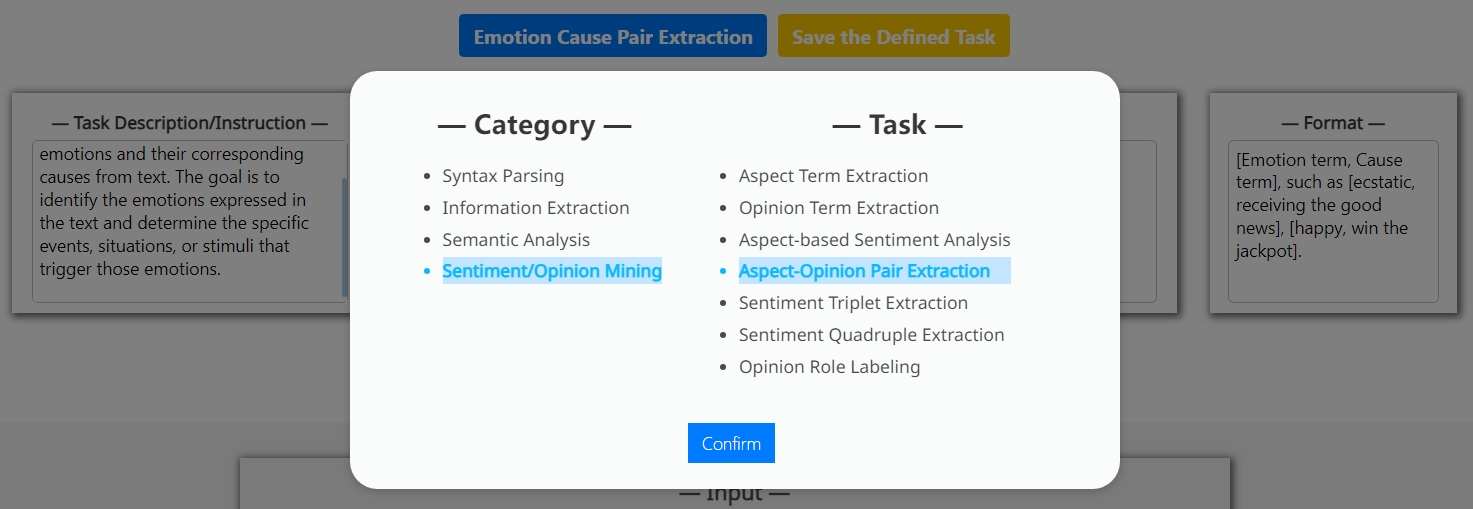
为了方便用户操作,我们预定义了总共22个XNLP任务,涵盖四个常见类别,包括语法解析、信息提取、语义分析和情感/意见挖掘。
新任务定义。
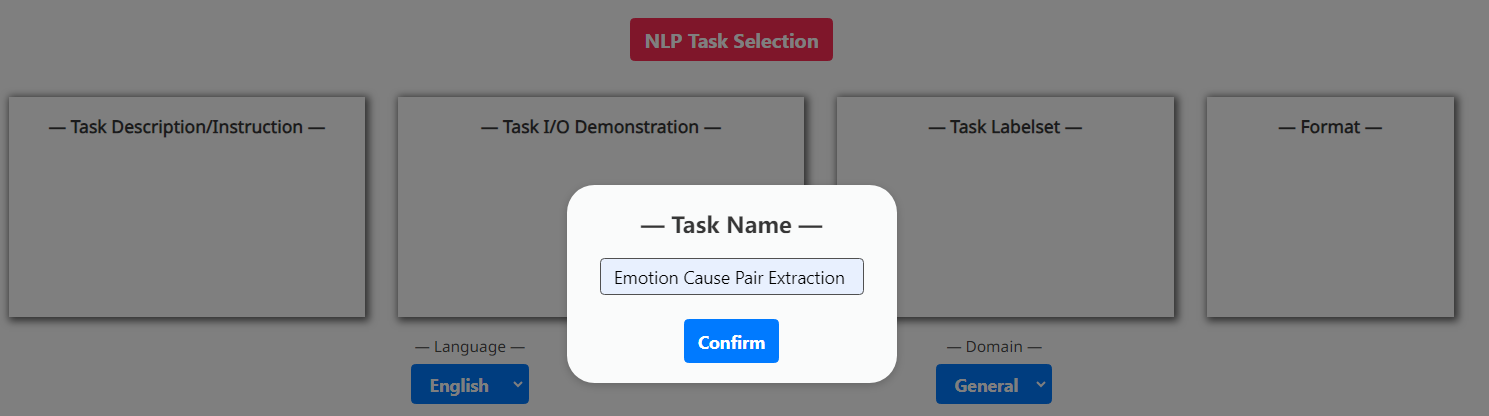
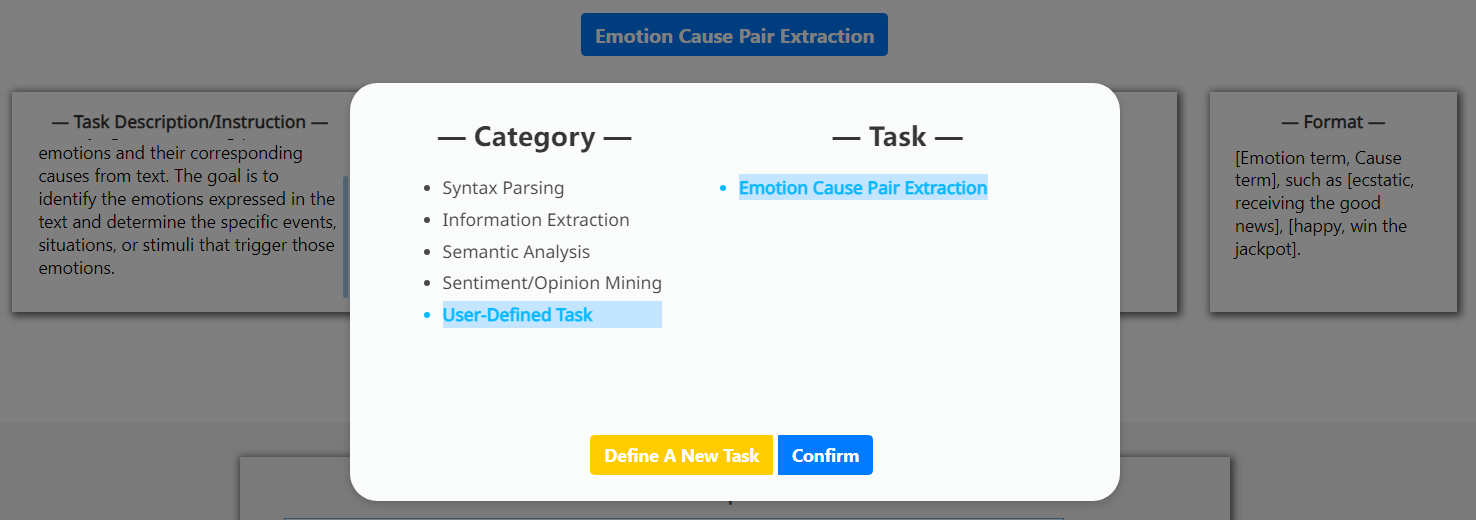
由于NLP社区中快速出现的XNLP任务,不可能在预定义中涵盖所有内容。 因此,我们允许用户定义自己的 XNLP 任务。 这可以在我们的系统中轻松完成,无需太多努力,因为大语言模型具有出色的零样本性能和理解能力。 我们只需要用户提供任务名称、任务描述、任务演示、任务标签集、执行格式。
XNLP 结构可视化。
XNLP系统的关键作用是任务输出结构的可视化。 我们采用开源 brat 系统777https://brat.nlplab.org/ 来实现这一点。 brat 在渲染结构化数据方面已被证明非常流行和有效,具有漂亮的可视化和稳定的功能。
可解释的任务预测的基本原理。
除了直接任务结果的可视化之外,我们还显示每个预测的基本原理,允许看到什么并知道为什么。 这对于 XNLP 任务的研究者的初学者来说尤其有意义。 为了实现这一点,我们只需在每次任务预测后询问大语言模型“你如何以及为什么做出决定?”。
通过用户交互增强预测。
为了充分利用大语言模型,我们进一步允许用户通过提供任何反馈来与我们的系统进行交互,以便用户在感觉结果不正确或与自己的想法不符时可以修改任务预测。 为了达到这个目的,我们还向大语言模型添加了另一轮查询,通过询问 “上面的预测并不全对,因为反馈。 请仔细阅读此处的反馈,再次执行任务”.
4系统演练
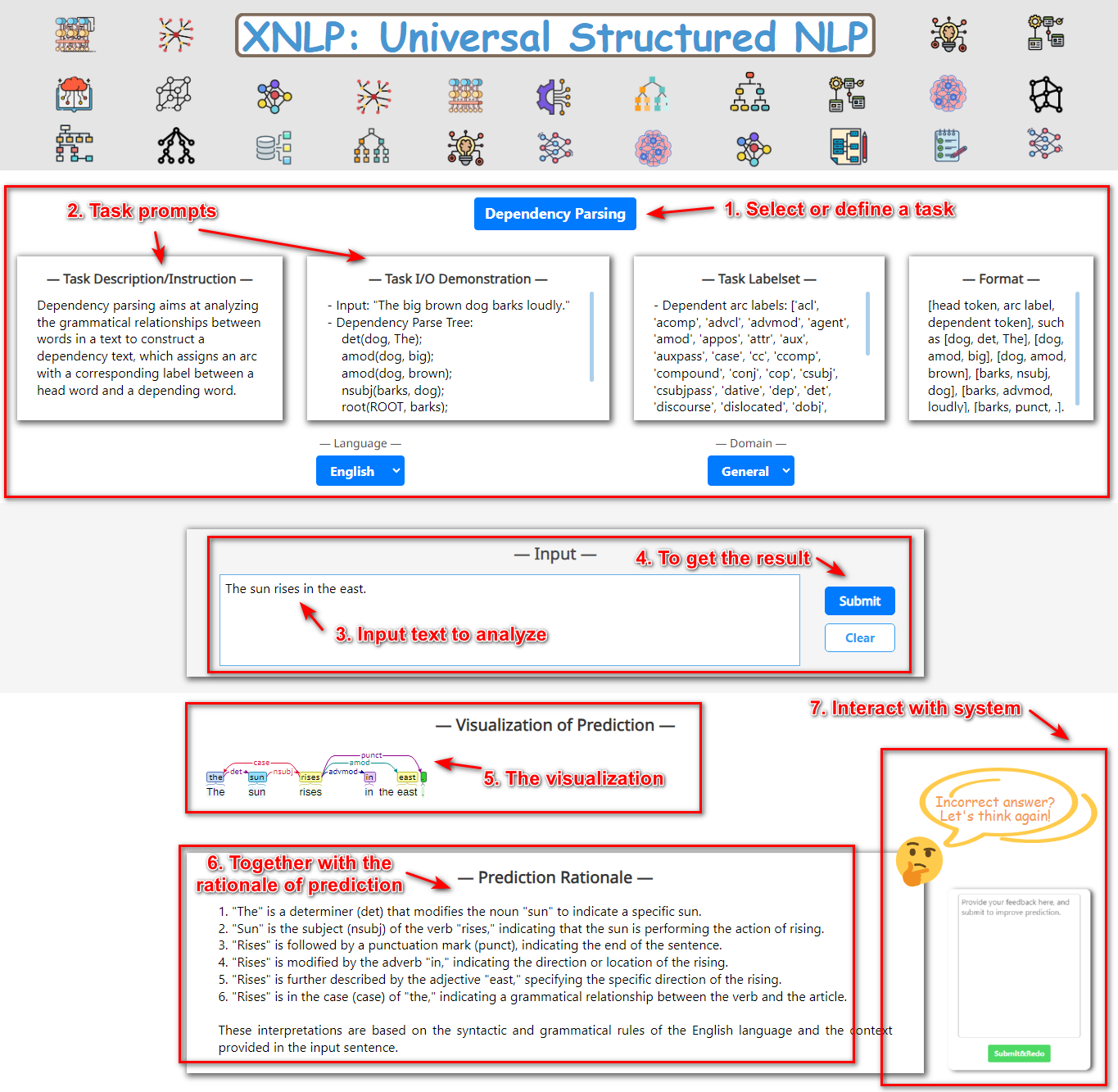
图3全面介绍了用户如何操作系统。
-
第 1 步。
用户选择或定义任务;
-
步骤 2。
用户浏览(对于预定义)或填写(对于用户定义)任务提示;
-
步骤 3。
用户键入要分析的文本;
-
步骤 4。
用户提交文本和元数据并请求结果;
-
第 5 步。
用户可以浏览任务输出的可视化;
-
步骤 6。
用户观察这个结果的基本原理;
-
步骤 7。
用户可以进一步向系统提供反馈,以便重新生成结果;
接下来,我们将通过引导读者完成几个重要功能来演示 XNLP 系统。
4.1 用户允许的操作
预定义的 XNLP 任务选择。
新任务定义。
语言和域通知。
根据用户反馈改进/修改预测
4.2 任务可视化
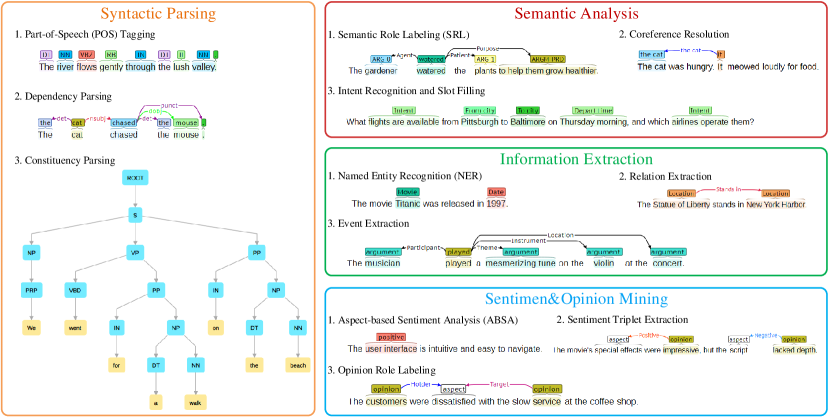
在这里,我们通过我们的系统展示了真实示例的 XNLP 任务可视化。 图5呈现了四个任务集群的输出,每个集群显示了三个代表性任务结果,例如:
语法分析,
包括词性(POS)标记、依存分析和选区分析。
语义分析,
包括语义角色标签 (SRL)、共指解析、意图识别和槽位填充。
信息提取,
包括命名实体识别(NER)、关系提取和事件提取。
情绪/意见挖掘,
包括基于方面的情感分析(ABSA)、情感三元组提取和意见角色标记。
我们可以从可视化中观察到,1)由于使用了brat系统,结构可视化很漂亮; 2)任务结果正确,这归功于大语言模型的集成,以及广覆盖的结构感知指令调优机制。
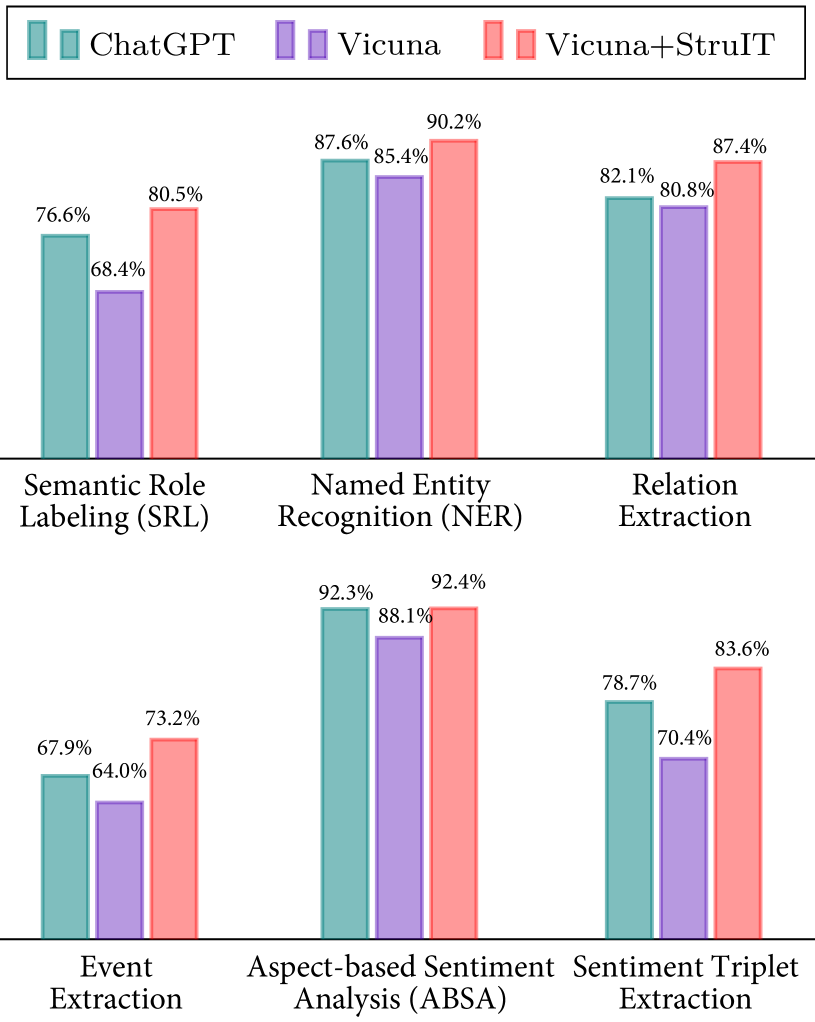
5绩效评估
为了定量验证主干大语言模型在 XNLP 任务上的性能,我们现在进行评估。 我们在 6 个 XNLP 任务的 100 多个随机选择的测试实例中将 Vicuna (13B) 与 ChatGPT 进行比较。 这些实验基于一次性上下文学习,即以一次演示作为输入。 图6显示了比较。 我们看到 Vicuna 的性能略低于 ChatGPT,而经过广泛覆盖的结构感知指令调优(Vicuna+StruIT)后的 Vicuna 显示的结果甚至比 ChatGPT 好得多,模型尺寸更小(13B 与 175B)。
6结论
我们推出了XNLP,这是一个用于 XNLP 任务交互和可视化的先进在线演示系统。 XNLP基于大语言模型,有效地对所有XNLP任务进行通用建模,在零样本或弱监督下实现了一个模型。 XNLP 不仅以精致的可视化效果呈现输出结构,而且还提供可解释预测的基本原理。 此外,XNLP允许用户定义新出现的XNLP任务;并使用户能够通过多轮交互动态修改输出。 我们的 XNLP 通过为统一、可扩展和交互式演示平台铺平道路,为社区做出贡献。
局限性
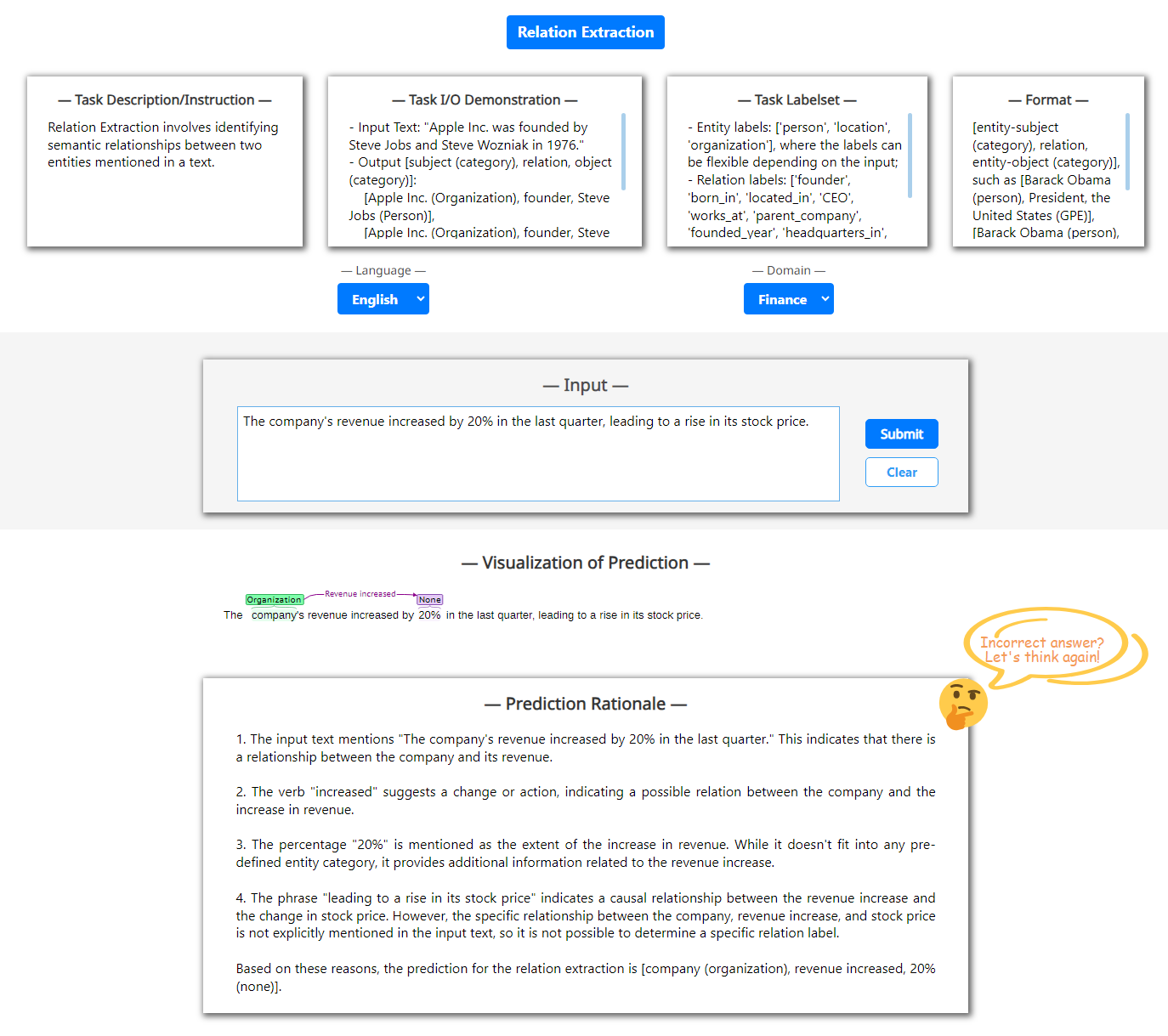
本文的重点是介绍一个开放的在线 Web 应用程序(演示系统),以使尽可能多的从业者可以使用 XNLP 任务的交互,但该系统和我们提出的模型存在一些限制。 首先,我们的系统是基于Web服务形式,后端运行的大语言模型部署在在线服务器上,有时当网络流量不好时,用户可能会等待太长时间才能得到响应。 其次,由于大语言模型本质上生成任何输入的顺序文本,因此输出文本有可能包含有问题的结构化格式化程序(即结构表示,参见 图4)。 对于格式不正确的结构表示,将它们解析为用于渲染为小孩子可视化的正确数据是有问题的,即导致失败预测。 第三,作为自然特征之一,大语言模型有时会产生错误的输出,或者不服从输入指令,这被称为幻觉现象Varshney 等人 (2023). 这样的话,用户体验就会受到影响。
道德声明
我们的XNLP系统使用大语言模型作为骨干。 虽然 Vacuna 模型是在预训练的 LLaMA 模型上进行微调的,已知该模型含有一些有毒内容Schick 等人 (2021),但内部检查并未发现任何有毒物质的产生。 然而,由于底层的黑盒大语言模型,Vacuna 存在可能为用户生成有毒文本的潜在风险。
参考
- Bosselut et al. (2019) Antoine Bosselut, Hannah Rashkin, Maarten Sap, Chaitanya Malaviya, Asli Celikyilmaz, and Yejin Choi. 2019. COMET: Commonsense transformers for automatic knowledge graph construction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4762–4779.
- Chauhan et al. (2020) Dushyant Singh Chauhan, Dhanush S R, Asif Ekbal, and Pushpak Bhattacharyya. 2020. Sentiment and emotion help sarcasm? a multi-task learning framework for multi-modal sarcasm, sentiment and emotion analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4351–4360.
- Chen and Qian (2020) Zhuang Chen and Tieyun Qian. 2020. Relation-aware collaborative learning for unified aspect-based sentiment analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3685–3694.
- Fei et al. (2022a) Hao Fei, Fei Li, Chenliang Li, Shengqiong Wu, Jingye Li, and Donghong Ji. 2022a. Inheriting the wisdom of predecessors: A multiplex cascade framework for unified aspect-based sentiment analysis. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI, pages 4121–4128.
- Fei et al. (2022b) Hao Fei, Shengqiong Wu, Jingye Li, Bobo Li, Fei Li, Libo Qin, Meishan Zhang, Min Zhang, and Tat-Seng Chua. 2022b. Lasuie: Unifying information extraction with latent adaptive structure-aware generative language model. In Proceedings of the Advances in Neural Information Processing Systems, NeurIPS 2022, pages 15460–15475.
- He et al. (2017) Luheng He, Kenton Lee, Mike Lewis, and Luke Zettlemoyer. 2017. Deep semantic role labeling: What works and what’s next. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 473–483.
- He et al. (2019) Ruidan He, Wee Sun Lee, Hwee Tou Ng, and Daniel Dahlmeier. 2019. An interactive multi-task learning network for end-to-end aspect-based sentiment analysis. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 504–515.
- Kitaev and Klein (2018) Nikita Kitaev and Dan Klein. 2018. Constituency parsing with a self-attentive encoder. pages 2676–2686.
- Lee et al. (2017) Kenton Lee, Luheng He, Mike Lewis, and Luke Zettlemoyer. 2017. End-to-end neural coreference resolution. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 188–197.
- Lu et al. (2022) Yaojie Lu, Qing Liu, Dai Dai, Xinyan Xiao, Hongyu Lin, Xianpei Han, Le Sun, and Hua Wu. 2022. Unified structure generation for universal information extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5755–5772.
- Mikheev et al. (1999) Andrei Mikheev, Marc Moens, and Claire Grover. 1999. Named entity recognition without gazetteers. In Proceedings of the Ninth Conference of the European Chapter of the Association for Computational Linguistics, pages 1–8.
- Nivre (2003) Joakim Nivre. 2003. An efficient algorithm for projective dependency parsing. In Proceedings of the Eighth International Conference on Parsing Technologies, pages 149–160.
- OpenAI (2023) OpenAI. 2023. GPT-4 technical report. CoRR, abs/2303.08774.
- Ouyang et al. (2022) Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155.
- Peng et al. (2023) Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. 2023. Instruction tuning with GPT-4. CoRR, abs/2304.03277.
- Pontiki et al. (2016) Maria Pontiki, Dimitris Galanis, Haris Papageorgiou, Ion Androutsopoulos, Suresh Manandhar, Mohammad AL-Smadi, Mahmoud Al-Ayyoub, Yanyan Zhao, Bing Qin, Orphée De Clercq, Véronique Hoste, Marianna Apidianaki, Xavier Tannier, Natalia Loukachevitch, Evgeniy Kotelnikov, Nuria Bel, Salud María Jiménez-Zafra, and Gülşen Eryiğit. 2016. SemEval-2016 task 5: Aspect based sentiment analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), pages 19–30.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21:140:1–140:67.
- Rashkin et al. (2019) Hannah Rashkin, Eric Michael Smith, Margaret Li, and Y-Lan Boureau. 2019. Towards empathetic open-domain conversation models: A new benchmark and dataset. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5370–5381.
- Schick et al. (2021) Timo Schick, Sahana Udupa, and Hinrich Schütze. 2021. Self-diagnosis and self-debiasing: A proposal for reducing corpus-based bias in NLP. Trans. Assoc. Comput. Linguistics, 9:1408–1424.
- Tang et al. (2020) Hao Tang, Donghong Ji, Chenliang Li, and Qiji Zhou. 2020. Dependency graph enhanced dual-transformer structure for aspect-based sentiment classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6578–6588.
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurélien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. Llama: Open and efficient foundation language models. CoRR, abs/2302.13971.
- Varshney et al. (2023) Neeraj Varshney, Wenlin Yao, Hongming Zhang, Jianshu Chen, and Dong Yu. 2023. A stitch in time saves nine: Detecting and mitigating hallucinations of llms by validating low-confidence generation. CoRR, abs/2307.03987.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, pages 5998–6008.
- Wang and Cohen (2015) William Yang Wang and William W. Cohen. 2015. Joint information extraction and reasoning: A scalable statistical relational learning approach. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 355–364.
- Wu et al. (2021) Shengqiong Wu, Hao Fei, Yafeng Ren, Donghong Ji, and Jingye Li. 2021. Learn from syntax: Improving pair-wise aspect and opinion terms extraction with rich syntactic knowledge. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, pages 3957–3963.
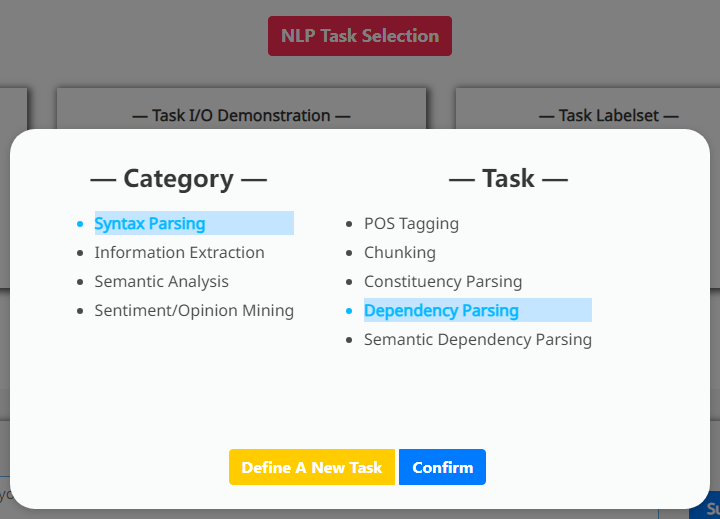
附录A预定义XNLP任务的选择
参见图7。
附录 B新的 XNLP 任务定义
参见图8。
附录C与用户反馈的多轮交互
参见图9。

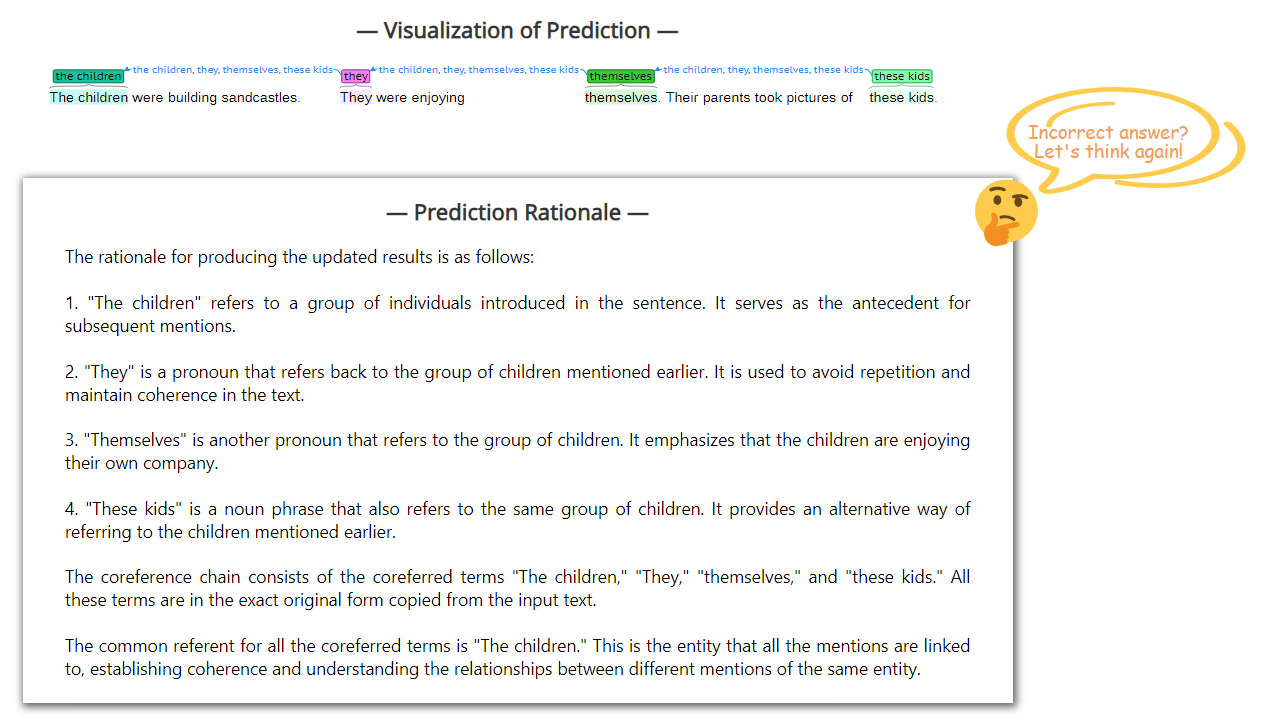
附录D不同语言的文本
参见图10。
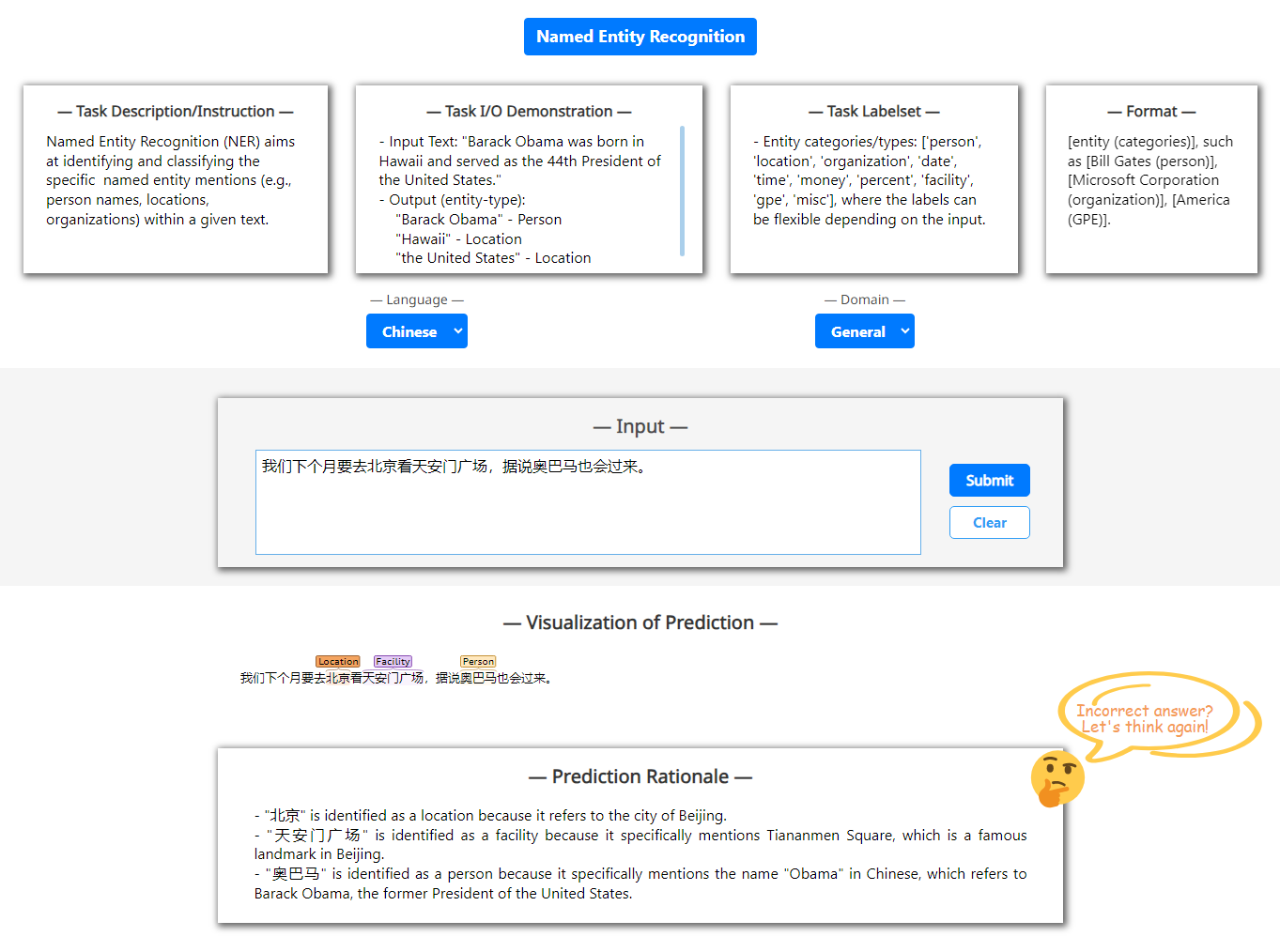
附录E不同域中的文本
参见图11。