MM-Vet:评估大型多模式模型
的集成功能
摘要
我们建议 MM-Vet-1-1-1Short for “Multimodal Veterinarian.”,一个评估基准,用于检查复杂多模态任务的大型多模态模型 (LMM)。 最近的 LMM 表现出了各种有趣的能力,例如解决黑板上写的数学问题、推理新闻图像中的事件和名人以及解释视觉笑话。 模型的快速进步给评估基准的开发带来了挑战。 问题包括:(1)如何系统地构建和评估复杂的多模态任务; (2)如何设计适用于各种问答类型的评估指标; (3) 如何在简单的性能排名之外提供模型见解。 为此,我们提出了 MM-Vet,其设计基于这样的见解:解决复杂任务的有趣能力通常是通过能够集成不同核心视觉语言 (VL) 功能的通才模型来实现的。 MM-Vet 定义了 核心VL 功能,并检查从功能组合中得出的感兴趣的 集成。 对于评估指标,我们提出了一个基于 LLM 的开放式输出评估器。 评估器可以对不同的问题类型和答案风格进行评估,从而产生统一的评分指标。 我们评估 MM-Vet 上的代表性 LMM,提供对不同 LMM 系统范式和模型功能的见解。 代码和数据可在https://github.com/yuweihao/MM-Vet获取。
1简介

大语言模型的突破gpt3; openai2023gpt4; chowdhery2022棕榈; anil2023棕榈; touvron2023美洲驼 ; hoffmann2022training 带来了通用人工智能模型,可以解决各种复杂的自然语言任务,许多接近人类专家级别的性能openai2023gpt4; bubeck2023sparks 。 大型多模态模型(LMM)旨在通过使用多模态输入扩展大语言模型来实现更强大的通用智能。 由于我们人类80%以上的感知、学习、认知和活动都是通过视觉vision80来调节的,所以很自然地为大语言模型配备“眼睛”来开始探索。 LMM作品的一条主线,以Frozen tsimpoukelli2021multimodal 、 Flamingo alayrac2022flamingo 、 PaLM-E driess2023palme 、 GPT-4 openai2023gpt4 为代表t4> ,通过端到端调优扩展大语言模型的视觉理解能力。 还有探索yang2022经验;曾2022苏格拉底式;阳2023mm;沉2023拥抱gpt ; gao2023assistgpt研究大语言模型和图像到文本视觉语言模型的模块化组合。 最近,得益于 LLaMA touvron2023llama 等强大的大语言模型的开源,更多开源的 LMM 也随之诞生,包括 OpenFlamingo anas_awadalla_2023_7733589 、 LLaVA llava 等t2> 、 MiniGPT-4 zhu2023minigpt 、 Otter li2023otter 、 InstructBLIP dai2023instructblip ,以及更多 gong2023multimodalgpt ;刘2023视觉; ye2023mplug 。 这些研究展示了解决各种复杂多模态任务的有趣能力,例如开放世界识别、多模态知识和常识、场景文本理解等。
尽管 LMM 的能力取得了有希望的定性结果,但仍不清楚如何系统地评估那些展示的复杂多模态任务以及评估的任务之间的关系是什么,这是开发定量评估基准的第一步。 如图1所示,现有视觉语言基准VQA_15;陈2015微软; textvqa 专注于需要特定一两种功能(例如识别、语言生成或 OCR)的简单视觉语言 (VL) 任务,但在对更复杂的任务进行基准测试方面存在不足。 或者,我们研究了复杂任务的核心 VL 功能的任意集成,并认识到解决复杂多模态任务的有趣能力可以通过掌握和集成不同核心功能的通才模型来实现。 根据这一见解,我们提出了一个评估 LMM 的新基准,即 MM-Vet。 MM-Vet定义了六大核心VL能力,包括识别、OCR、知识、语言生成、空间感知和数学,它们集成起来解决各种复杂的多模态任务。 MM-Vet 包含 16 项定量评估任务。 例如,在图1(d)中,回答问题“右边的女孩会在黑板上写什么?MM-Vet 中需要识别三个孩子的性别,在空间上定位被查询的女孩,识别女孩写的场景文本,最后计算结果。
除了评估类别定义之外,考虑到不同的答案风格和问题类型,评估指标是基准开发中的另一个挑战。 具体来说:(1)不同多模态任务中所需的输出具有不同的格式,例如,图1(d)的数学问题可以是用一个词回答,而论文写作问题的输出是一百个字长; (2)不同任务中评估的核心方面有所不同,例如,文本生成更注重文本质量,识别可以认为识别出关键概念是正确的。 大多数综合任务都需要从多个维度进行综合评估。 受到最近 NLP 研究 chiang2023can 的启发;刘2023gpteval ; fu2023gptscore使用大语言模型进行模型评估,我们提出了一种基于LLM的评估器作为开放式模型输出的评估指标。 如表1所示,我们用少样本评估提示提示GPT-4 openai2023gpt4,获得从到 我们没有手动定义可能的答案风格和问题类型,而是将不同的样本类型作为少样本示例,并让大语言模型自动推断评分标准。 这种度量设计方便了未来扩展到更多问题类型,例如框定位 chen2021pix2seq ; yang2022unitab ; wang2023visionllm 。
MM-Vet的评估类别和指标设计使用户能够获得不同LMM的能力洞察。 此类模型分析比单一总体排名提供更多信息,后者高度依赖于数据集样本组成,并且可能存在偏差。 我们评估了两套多模态系统,即, 端到端调整的 LMM 包括 OpenFlamingo anas_awadalla_2023_7733589, LLaVA llava, MiniGPT-4 zhu2023minigpt、Otter li2023otter , InstructBLIP dai2023instructblip , etc, 以及使用大语言模型的系统 yang2023mm ;shen2023hugginggpt ; gao2023assistgpt ; transformers_agent 如 MM-ReAct yang2023mm 。 尽管不了解模型详细信息,我们也评估了 Bard bard 等行业解决方案。 我们首先讨论这两种系统范式和代表性模型的能力分析。 然后,我们深入研究开源 LMM,并研究训练数据、视觉编码器和大语言模型选择如何影响不同功能的性能。
我们的贡献总结如下。
-
•
我们提出 MM-Vet 来评估 LMM 在复杂多模态任务上的能力。 MM-Vet 定义了 16 个感兴趣的紧急任务,集成了六个定义的核心 VL 功能。
-
•
我们提出了一个基于 LLM 的评估器,用于 LMM 的开放式输出,它统一了不同答案风格和问题类型的评估。 评估指标确保对答复的事实正确性和文本质量进行彻底评估。
-
•
我们在 MM-Vet 上对代表性 LMM 进行基准测试,揭示不同系统范式和模型的相对优势和劣势,如 4.5 节中总结的那样。
2相关工作
多式联运模型。 视觉语言模型 chen2015microsoft ; vqav2; lu2019维尔伯特;陈2019单位; li2020奥斯卡;金2021维尔特;王2021simvlm;王2022git; yang2022unitab ; gan2022vision方法联合理解和生成视觉和语言信号的多模态智能。 受到最近大型语言模型(大语言模型)令人印象深刻的质量和通用性的启发 brown2020language ; openai2023gpt4; chowdhery2022棕榈; touvron2023llama,研究人员探索大型多模态模型(LMM),无缝集成不同的视觉语言功能来解决复杂的多模态任务。 在处理此类多模态通才系统时,一个方向是扩展具有多感官能力的大语言模型,例如先驱作品《冰雪奇缘》tsimpoukelli2021multimodal、Flamingoalayrac2022flamingo、PaLM-Edriess2023palme ,GPT-4 openai2023gpt4 。 最近开源的大语言模型 zhang2022opt ; touvron2023美洲驼 ; peng2023instruction 还促进了各种研究,包括 OpenFlamingo anas_awadalla_2023_7733589 、 LLaVA llava 、 MiniGPT-4 zhu2023minigpt 、 Otter li2023otter 、 InstructBLIP dai2023instructblip 等 gong2023multimodalgpt ;刘2023视觉; ye2023mplug 。 另一方面,多式联运代理人yang2023mm;沉2023拥抱gpt ; Transformer _代理; gao2023assistgpt 探索与大语言模型链接不同的视觉工具 brown2020language ; openai2023gpt4 实现集成视觉语言功能。
VL 基准。 经典的 VL 基准测试专注于感兴趣的特定功能,例如视觉识别 vqav2 、图像描述 chen2015microsoft ; agrawal2019nocaps ,以及其他专业功能基准测试,例如场景文本理解 textvqa ; sidorov2020textcaps ; yang2021tap ,常识推理zellers2019recognition ,外部知识marino2019ok 。 通用 LMM 的最新发展强烈需要现代化的 VL 基准,其中包含需要集成 VL 功能的复杂多模式任务。
我们的 MM-Vet 与并行评估研究最相关fu2023mme;刘2023mm长凳; li2023seedbench ; xu2023lvlm如MME和MMBench,设计综合评估样本以方便LMM评估。 一个主要区别是 MM-Vet 定义并研究了集成的 VL 功能,从而使评估能够提供超出总体模型排名的见解。
基于LLM的评估。 MM-Vet 采用基于 LLM 的开放式评估器,允许跨答案风格和问题类型进行评估,而不需要二元或多答案选择。 提示大语言模型进行模型评估的技术与NLPchiang2023can的探索有关;刘2023gpteval ; fu2023gptscore 。 我们证明该技术可以很好地扩展到多模式任务,并提供统一的提示来评估具有不同答案风格和问题类型的样本。
3 MM-兽医
3.1数据收集
我们的目标是开发一个需要综合能力的多模式基准,与人工智能代理可能遇到的现实场景相对应。 例如,考虑以下场景:从睡眠中醒来,您伸出智能手机(识别功能)来检查当前时间(OCR 功能)。 今天,您的计划是去一家您从未去过的新杂货店。 根据杂货店位于体育场正对面、电影院旁边的信息(空间感知),您成功找到了它。 牢记医生关于减肥的建议,您有意识地避开高热量食物,选择牛奶、蔬菜和水果(知识能力)。 在乳制品货架上,您面临着两种纯牛奶的选择。 第一种是4美元一升,有20%的折扣,第二种是7美元1.5升,有25%的折扣。 经过一些快速算术后,您发现前者更便宜(数学能力),并选择一升包装。 购物后,你走过电影院,发现一个人指着海报介绍一部新电影(语言生成)。
从感兴趣的场景中,我们总结了以下六种核心VL能力进行评估,相应的MM-Vet示例如表8-13所示。
-
•
认可(Rec)。 识别是指一般的视觉识别能力,包括识别场景、物体、物体属性(颜色、材质、形状等等)、计数以及计算机视觉中的各种其他高级视觉识别任务。
-
•
知识(知道)。 知识范畴涵盖各种与知识相关的能力,包括社会性和视觉常识性知识、百科知识以及新闻等时效性知识。 这种能力要求模型不仅拥有这些知识,而且能够根据需要有效地利用它来解决复杂的任务。
-
•
OCR。 光学字符识别(OCR)是指对场景文本的理解和推理能力。 这些模型经过测试可以读取图像中的场景文本,并对文本进行推理以解决各种任务。
-
•
空间意识(Spat)。 空间意识体现了与理解空间相关的多种能力,包括理解对象和场景文本区域之间的空间关系。
-
•
语言生成(Gen)。 语言生成是一种至关重要的能力,它使模型能够以清晰、引人入胜且信息丰富的方式表达他们的反应。 我们使用需要更多扩展答案的问题来评估语言生成能力。
-
•
数学。 数学评估模型解决书面方程或实际问题的算术能力。
在现实场景中,各种复杂的多模式任务需要集成不同的核心 VL 功能。 例如,解释表8(a)所示的视觉笑话需要识别、幽默知识和语言生成;阅读文档并解决表9(a)所示的数学问题需要OCR、空间意识和数学;根据表12(b)所示的图像回答考试问题需要OCR、知识、空间意识。 为了解决这些复杂的任务,LMM 需要无缝集成不同的 VL 功能。 因此,建立一个评估 LMM 内这些综合能力表现的基准至关重要。
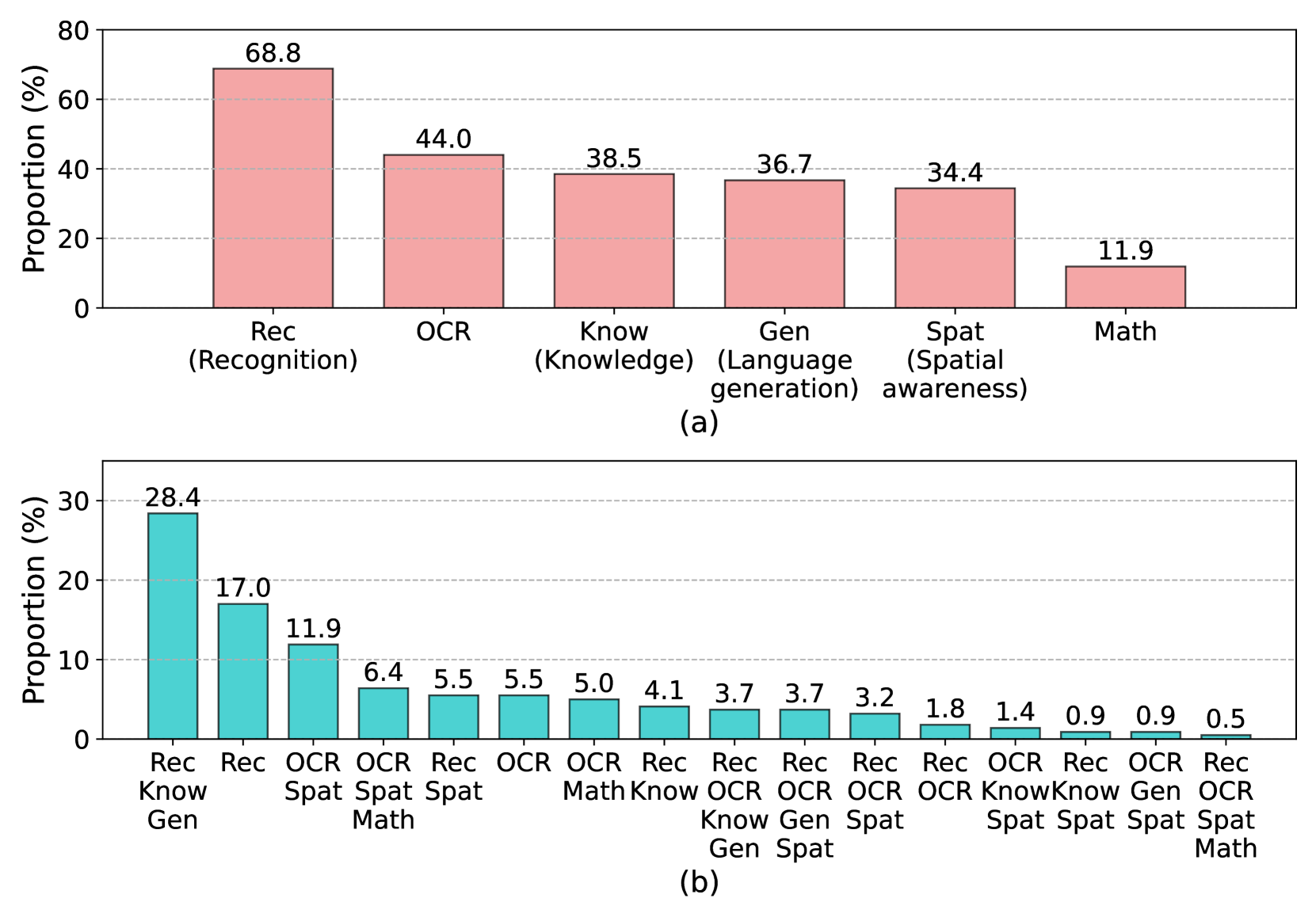
为了构建基准,我们从各种在线来源收集了 187 张图像,并提出了 205 个问题,每个问题都需要一种或多种能力来回答。 如表8-13所示,这些问题的类型各不相同,并且需要不同长度的开放式回答。 155 个问题的基本事实是人工注释的,而 50 个问题的其余答案是从互联网收集的。 除了这 187 张图片之外,还从 VCR zellers2019recognition 中额外收集了 10 张带有高质量问题的图片,并将问题和答案修改为开放式回答格式。 另外三幅图像来自ChestX-ray14 wang2017chestx,以获得相应的医学专家知识。 我们的 MM-Vet 总共包含 200 张图像和 218 个问题(样本),所有这些都与各自的基本事实配对。 对于每个问题,我们还确定了回答这些问题所需的能力,并在图 2 中以统计方式显示了此信息。
3.2 基于 LLM 的开放式模型输出评估器
MM-Vet 中的问题和预期答复被设计为开放式的,以涵盖不同的现实世界场景。 这自然对模型评估和指标设计提出了巨大的挑战。 从最近的 NLP 研究中汲取灵感 chiang2023can ; zheng2023判断利用大语言模型进行开放式评估,我们利用GPT-4来辅助评估。 如表1所示,我们制作了一个用于模型评估的少样本提示。 少样本设计使我们能够通过上下文示例定义评分指标,并支持轻松扩展到新的问题集。 具体来说,我们实现的提示包含五个带有开放式简短答案的上下文示例和两个带有长答案的示例。 我们涵盖完全正确(即,1.0)或不正确(即,0.0)的示例,以及用于定义不同类型的“部分正确”响应的示例。 基于 LLM 的评估器允许使用统一一致的指标评估任何类型的模型输出。 此外,它还支持通过简单地修改评估示例来轻松适应不同的问题类型和答案风格。
通过输入提示,GPT-4 根据每个样本的输入问题、基本事实和模型输出自动生成每个样本的分数。 每个样本的得分范围为 0 到 1。 总分由下式计算
| (1) |
其中是样本的分数,是样本编号。 关于每个能力或能力集成的分数可以类似地通过以下方式获得
| (2) |
其中,是需要特定能力或能力集成的样本集合,是该集合的样本编号。
4评估结果
4.1 实验设置
我们利用 MM-Vet 来评估两种类型的 LMM,即,(1) 端到端调整的 LMM(OpenFlamingo alayrac2022flamingo ; anas_awadalla_2023_7733589 、BLIP-2 li2023blip 、 LLaVA llava 、 MiniGPT-4 zhu2023minigpt 、 Otter li2023otter 和 InstructBLIP dai2023instructblip ); (2)LLM工具使用方法(MM-ReAct yang2023mm 和 Transformers Agent transformers_agent )。 这些方法的总结如表2所示。 如表 1 所示,对于每个样本,我们用其问题、基本事实和特定 LMM 的输出填充提示模板。 通过将填写的提示带入 GPT-4,GPT-4 将为样本生成从 0 到 1 的分数。 发现虽然温度设置为0,GPT-4的输出仍然存在方差。 因此,我们利用GPT-4对大语言模型的输出进行了5次评估。 由于篇幅限制,我们报告了功能/功能集成的平均分数,以及总分数的平均值和方差。
| Method | Initial models | Tuning data | Total params | ||
| Vision | Language | Other | |||
| OpenFlamingo-9B alayrac2022flamingo ; anas_awadalla_2023_7733589 | CLIP ViT-L/14 radford2021learning | LLaMA-7B touvron2023llama | – | Multimodal C4 zhu2023multimodal | 9B |
| BLIP-2-12B li2023blip | EVA-ViT-G fang2023eva | Flan-T5-XXL chung2022scaling | – | 1. COCO lin2014microsoft ; 2. Visual Genome krishna2017visual ; 3. CC3M sharma2018conceptual ; 4. CC12M changpinyo2021conceptual ; 5. SBU ordonez2011im2text ; 6. 115M images from the LAION-400M schuhmann2021laion . (CapFilt li2022blip is used to create synthetic captions for the web images) | 12B |
| LLaVA-7B llava | CLIP ViT-L/14 radford2021learning | Vicuna-7B zheng2023judging | – | 1. CC3M sharma2018conceptual Concept-balanced 595K llava ; 2. LLaVA-Instruct-158K llava . | 7B |
| LLaVA-13B llava | Vicuna-13B zheng2023judging | 13B | |||
| LLaVA-7B (LLaMA-2) llava | CLIP ViT-L/14 radford2021learning | LLaMA-2-7B-Chat touvron2023llama2 | – | 1. LAION /CC/SBU BLIP-Caption Concept-balanced 558K llava ; 2. LLaVA-Instruct-80K llava . | 7B |
| LLaVA-13B (LLaMA-2) llava | LLaMA-2-13B-Chat touvron2023llama2 | 13B | |||
| LLaVA-13B (V1.3, 336px) llava | CLIP ViT-L/336px radford2021learning | Vicuna-13B-v1.3 zheng2023judging | 13B | ||
| MiniGPT-4-8B zhu2023minigpt | EVA-ViT-G fang2023eva | Vicuna-7B zheng2023judging | BLIP-2’s Q-Former li2023blip | 1. CC3M sharma2018conceptual ; 2. CC12M changpinyo2021conceptual ; 3. SBU ordonez2011im2text ; 4. LAION-400M schuhmann2021laion 5. Proposed 3,500 aligned image-text pairs zhu2023minigpt . | 8B |
| MiniGPT-4-14B zhu2023minigpt | Vicuna-13B zheng2023judging | 14B | |||
| LLaMA-Adapter v2-7B gao2023llama | CLIP ViT-L/14 radford2021learning | LLaMA-7B touvron2023llama | – | 1. GPT-4-LLM peng2023instruction ; 2. COCO lin2014microsoft | 7B |
| Otter-9B li2023otter | CLIP ViT-L/14 radford2021learning | LLaMA-7B touvron2023llama | OpenFlamingo-9B’s alayrac2022flamingo ; anas_awadalla_2023_7733589 1. Perceiver Resampler; 2. GATED XATTN-DENSE | MIMIC-IT li2023mimic | 9B |
| InstructBLIP-8B dai2023instructblip | EVA-ViT-G fang2023eva | Vicuna-7B zheng2023judging | BLIP-2’s Q-Former li2023blip | 1. Tuning data of BLIP-2 li2023blip ; 2. 26 publicly available datasets (transformed into instruction tuning format). | 8B |
| InstructBLIP-14B dai2023instructblip | Vicuna-13B zheng2023judging | 14B | |||
| Transformers Agent (GPT-4 as agent) transformers_agent | – | 1. GPT-4 openai2023gpt4 ; 2. Flan-T5 chung2022scaling ; 3. BART lewis2019bart | 1. Donut kim2022ocr ; 2. BLIP li2022blip ; 3. ViLT kim2021vilt ; 4. CLIPSeg luddecke2022image 5. Whisper radford2023robust ; 6. SpeechT5 ao2021speecht5 ; 7. NLLB costa2022no | None | Not clear |
| MM-ReAct-GPT-3.5 yang2023mm MM-ReAct-GPT-4 yang2023mm | – | GPT-3.5 ouyang2022training GPT-4 openai2023gpt4 | 1. Azure Cognitive Services APIs azure_cognition_api for image captioning, image tagging, dense captioning, OCR and specialized recognition on celebrities, receipts, etc 2. Bing search; 3. PAL gao2022pal | None | Not clear |
4.2结果分析
4.2.1 关于各项能力
认可。 “识别”类别包含需要识别能力来回答的问题。 示例如表8(a, b)、9(b)、10(a, b)、11(a,b),12(a,c)和13 表3中的“Rec”列比较了“Recognition”上的性能。 在评估的模型中,LLaVA-13B(LLaMA-2)是最好的模型,获得了39.2%。 可能有两个原因。 首先,LLaVA-13B(LLaMA-2)采用来自CLIPradford2021learning的ViT-L/14dosovitskiy2020image作为视觉模型,经过大量数据训练,400百万图像文本对; 2)其次,令人惊讶的是,更强的语言模型可以很大程度上提高识别性能。 LLaVA-13B (LLaMA-2) 的重要性比 LLaVA-13B (Vicuna-13B) 高出 8.3%。 更强的大语言模型可能有助于更好地理解问题并从视觉输入中识别关键信息。
此外,对于低于 10B 的模型参数,InstructBLIP-8B dai2023instructblip 获得了最佳性能(MM-Vet 中为 32.4%)。 如表2所示,InstructBLIP的调优数据包括26个公开的数据集,其中包含识别重度数据集,例如VQA v2 vqav2和GQA hudson2019gqa . InstructBLIP 在识别方面的有前景的能力可能会受益于这些数据集。
OCR。 OCR 评估模型识别图像中的场景文本以及执行各种类型推理(包括数学、空间、识别等)的能力。等。 示例如表8(c)、9(a、c、d)、10(b)、11(a,b),12(a,b),13 如表2的“OCR”列所示,MMReAct-GPT4 yang2023mm 在外部 OCR 模型的帮助下,在 OCR 能力方面表现最好(65.7%)。工具。 在端到端调整的模型中,LLaVA-13B (LLaMA-2) llava 实现了最高的性能 (22.7%)。 这种卓越的性能可能归功于 LLaVA 采用 CLIP radford2021learning ViT-L/14 dosovitskiy2020image 作为其视觉模型,并在其中包含大量图像-OCR 配对训练数据 liu2023hidden 。
知识。 如表8(a)、10(a, b)和12(b, c)所示,“知识”类别涵盖与知识相关的问题范围广泛,从笑话理解到百科全书知识。 MMReAct-GPT4 yang2023mm 在该能力上取得了最好的分数,如表 3 所示,因为其强大的大语言模型骨干 openai2023gpt4 ,再加上用于获取知识的外部工具,例如 Bing 搜索。
语言的产生。 “语言生成”是指生成流畅且内容丰富的文本输出的能力,如表8(a)、10(b)、11所示>(a) 和 13(a)。 该类别中的性能与语言建模的功效高度相关。 结果,MMReAct-GPT4 yang2023mm 和 LLaVA-13B (LlaMA-2) 脱颖而出,成为前两名模型。 他们的成功可以归功于构建这些系统的 GPT-4 和 LlaMA-2 语言模型。
空间意识。 “空间意识”涉及对视觉对象区域(例如,表8(c))和场景文本区域(例如)之间空间关系的理解>,表11(a,b))。 MMReAct-GPT4 yang2023mm 在此能力上显着领先(56.8%),因为采用的密集字幕和 OCR 等工具以坐标的形式提供了详细的对象和场景文本位置信息,可以被 GPT-4 理解和处理。
在端到端调整模型方面,LLaVA-13B(V1.3,336px)表现出最佳性能,达到 31.3%。 LLaVA 的调整数据部分源自捕获对象名称及其相应的坐标作为输入。 此过程确保生成充满空间信息的数据,可能有助于模型开发和增强其空间感知能力。
数学。 “数学”衡量书面方程(例如,表13(b))或实际问题(例如,表)的算术能力9(d))。 值得注意的是,MMReAct-GPT4 yang2023mm 始终优于其他模型。 这种优越的性能可能要归功于采用的 PAL 数学工具(程序辅助语言模型)gao2022pal。
| Model | Rec | OCR | Know | Gen | Spat | Math | Total |
| Transformers Agent (GPT-4) transformers_agent | 18.2 | 3.9 | 2.2 | 3.2 | 12.4 | 4.0 | 13.40.5 |
| LLaMA-Adapter v2-7B gao2023llama | 16.8 | 7.8 | 2.5 | 3.0 | 16.6 | 4.4 | 13.60.2 |
| OpenFlamingo-9B alayrac2022flamingo ; anas_awadalla_2023_7733589 | 24.6 | 14.4 | 13.0 | 12.3 | 18.0 | 15.0 | 21.80.1 |
| MiniGPT-4-8B zhu2023minigpt | 27.4 | 15.0 | 12.8 | 13.9 | 20.3 | 7.7 | 22.10.1 |
| BLIP-2-12B li2023blip | 27.5 | 11.1 | 11.8 | 7.0 | 16.2 | 5.8 | 22.40.2 |
| LLaVA-7B llava | 28.0 | 17.1 | 16.3 | 18.9 | 21.2 | 11.5 | 23.80.6 |
| MiniGPT-4-14B zhu2023minigpt | 29.9 | 16.1 | 20.4 | 22.1 | 22.2 | 3.8 | 24.40.4 |
| Otter-9B li2023otter | 28.4 | 16.4 | 19.4 | 20.7 | 19.3 | 15.0 | 24.60.2 |
| InstructBLIP-14B dai2023instructblip | 30.8 | 16.0 | 9.8 | 9.0 | 21.1 | 10.5 | 25.60.3 |
| InstructBLIP-8B dai2023instructblip | 32.4 | 14.6 | 16.5 | 18.2 | 18.6 | 7.7 | 26.20.2 |
| LLaVA-13B llava | 30.9 | 20.1 | 23.5 | 26.4 | 24.3 | 7.7 | 26.40.1 |
| MM-ReAct-GPT-3.5 yang2023mm | 24.2 | 31.5 | 21.5 | 20.7 | 32.3 | 26.2 | 27.90.1 |
| LLaVA-7B (LLaMA-2) llava | 32.9 | 20.1 | 19.0 | 20.1 | 25.7 | 5.2 | 28.10.4 |
| LLaVA-13B (V1.3, 336px) llava | 38.1 | 22.3 | 25.2 | 25.8 | 31.3 | 11.2 | 32.50.1 |
| LLaVA-13B (LLaMA-2) llava | 39.2 | 22.7 | 26.5 | 29.3 | 29.6 | 7.7 | 32.90.1 |
| MM-ReAct-GPT-4 yang2023mm | 33.1 | 65.7 | 29.0 | 35.0 | 56.8 | 69.2 | 44.60.2 |
| Model | Rec Know Gen | Rec | OCR Spat | OCR Spat Math | Rec Spat | OCR | OCR Math | Rec Know | Rec OCR Know Gen | Rec OCR Gen Spat | Rec OCR Spat | Rec OCR | OCR Know Spat | Rec Know Spat | OCR Gen Spat | Rec OCR Spat Math | Total |
| Transformers Agent (GPT-4) transformers_agent | 1.3 | 49.1 | 0.0 | 7.4 | 45.8 | 0.0 | 0.0 | 0.0 | 0.0 | 9.5 | 0.0 | 25.0 | 0.0 | 50.0 | 49.0 | 0.0 | 13.40.5 |
| LLaMA-Adapter v2-7B gao2023llama | 0.2 | 43.2 | 7.9 | 8.1 | 41.7 | 0.0 | 0.0 | 0.0 | 0.0 | 26.8 | 0.0 | 25.0 | 33.3 | 50.0 | 6.0 | 0.0 | 13.60.2 |
| OpenFlamingo-9B alayrac2022flamingo ; anas_awadalla_2023_7733589 | 15.6 | 48.6 | 17.3 | 21.4 | 41.7 | 18.3 | 8.2 | 11.1 | 2.5 | 0.0 | 14.3 | 50.0 | 0.0 | 0.0 | 0.0 | 0.0 | 21.80.1 |
| MiniGPT-4-8B zhu2023minigpt | 14.2 | 47.9 | 9.6 | 14.3 | 50.0 | 20.8 | 0.0 | 14.4 | 8.0 | 21.2 | 42.9 | 50.0 | 0.7 | 0.0 | 0.0 | 0.0 | 22.10.1 |
| BLIP-2-12B li2023blip | 7.3 | 65.1 | 11.5 | 7.1 | 41.7 | 21.2 | 4.5 | 38.9 | 5.2 | 8.5 | 14.3 | 25.0 | 16.7 | 50.0 | 0.0 | 0.0 | 22.40.2 |
| LLaVA-7B llava | 17.1 | 46.6 | 13.3 | 21.4 | 41.7 | 24.8 | 0.0 | 28.9 | 6.2 | 45.2 | 6.6 | 50.0 | 0.0 | 0.0 | 19.0 | 0.0 | 23.80.6 |
| MiniGPT-4-14B zhu2023minigpt | 21.1 | 47.5 | 14.6 | 7.1 | 50.0 | 16.7 | 0.0 | 11.1 | 18.7 | 38.5 | 18.3 | 32.5 | 50.0 | 0.0 | 0.0 | 0.0 | 24.40.4 |
| Otter-9B li2023otter | 22.5 | 50.0 | 18.1 | 21.4 | 33.3 | 16.7 | 8.2 | 16.7 | 5.0 | 28.5 | 0.0 | 50.0 | 16.7 | 0.0 | 0.0 | 0.0 | 24.60.2 |
| InstructBLIP-14B dai2023instructblip | 8.1 | 74.3 | 14.6 | 14.3 | 50.0 | 19.2 | 6.5 | 11.1 | 8.8 | 15.2 | 14.3 | 70.0 | 16.7 | 50.0 | 15.0 | 0.0 | 25.60.3 |
| InstructBLIP-8B dai2023instructblip | 18.0 | 69.9 | 15.4 | 14.3 | 33.3 | 20.8 | 0.0 | 23.3 | 7.8 | 35.2 | 15.7 | 25.0 | 0.0 | 0.0 | 0.0 | 0.0 | 26.20.2 |
| LLaVA-13B llava | 25.2 | 41.1 | 17.3 | 7.1 | 47.5 | 23.3 | 9.1 | 18.0 | 12.5 | 53.8 | 14.3 | 50.0 | 50.0 | 0.0 | 12.0 | 0.0 | 26.40.1 |
| MM-ReAct-GPT-3.5 yang2023mm | 19.1 | 33.1 | 28.8 | 35.7 | 28.3 | 60.0 | 9.1 | 33.3 | 2.5 | 47.8 | 0.0 | 25.0 | 100.0 | 0.0 | 35.0 | 80.0 | 27.90.1 |
| LLaVA-7B (LLaMA-2) llava | 18.8 | 57.0 | 26.9 | 9.7 | 50.0 | 26.7 | 0.0 | 34.7 | 10.2 | 44.8 | 14.3 | 50.0 | 11.3 | 0.0 | 0.0 | 0.0 | 28.10.4 |
| LLaVA-13B (V1.3, 336px) llava | 25.5 | 59.7 | 25.0 | 14.3 | 66.7 | 25.8 | 8.2 | 27.8 | 11.2 | 49.3 | 14.3 | 50.0 | 33.3 | 50.0 | 2.0 | 0.0 | 32.50.1 |
| LLaVA-13B (LLaMA-2) llava | 29.8 | 59.5 | 21.2 | 14.3 | 58.3 | 36.2 | 0.0 | 27.8 | 3.5 | 56.8 | 28.6 | 50.0 | 33.3 | 0.0 | 8.0 | 0.0 | 32.90.1 |
| MM-ReAct-GPT-4 yang2023mm | 22.5 | 33.0 | 69.2 | 78.6 | 25.0 | 83.0 | 63.6 | 44.4 | 68.2 | 88.0 | 14.3 | 50.0 | 0.0 | 50.0 | 80.0 | 0.0 | 44.60.2 |
4.2.2 关于各个能力集成
识别、知识和语言生成。. 如表8(a)所示,这种能力集成可以使模型能够解释视觉笑话。 LLaVA-13B (LLaMA-2) 和 LLaVA-13B (V1.3, 336px) llava 是这种能力集成中最好的型号。 采用 CLIP radford2021learning 和更强大的语言模型可能就是原因。 表2所示的LLaVA调优数据也不容忽视。
认可(唯一)。 该类别包含仅需要识别的样本,如表8(b)所示。 InstructBLIP-14B 和 InstructBLIP-8B dai2023instructblip 实现了最佳性能,这可能是由于包括识别数据集在内的调优数据造成的,例如 VQA v2 vqav2 和 GQA hudson2019gqa .
OCR 和空间意识。 对于此集成,表8(c) 中显示了一个示例。 MM-ReAct-GPT-4 yang2023mm 是这种集成的最佳方法。 值得注意的是,与MM-ReAct-GPT-3.5相比,MM-ReAct-GPT-4有显着的改进,超过40%,表明大语言模型对于整合OCR和位置信息的重要性。
OCR、空间意识和数学。 这种集成的一个例子如表9(a)所示,它需要读取平面图并进行算术。 与上述整合相比,这种结合又多了一项数学能力。 观察类似于OCR和空间感知的整合。 MM-ReAct-GPT-4 yang2023mm 仍然达到了最佳性能。
识别和空间意识。 表9(b) 显示了此集成的示例。 LLaVA-13B(V1.3,336px)llava 在该类别中表现最佳。 与LLaVA-13B(LLaMA-2)相比,LLaVA-13B(V1.3,336px)获得了8.4%的改进,表明图像分辨率的显着贡献。
OCR(唯一)。 此任务仅需要 OCR,如表9(c) 所示。 由于 Azure API 的 OCR 工具,MM-ReAct-GPT-4 yang2023mm 对于单独的 OCR 具有最佳结果。 值得注意的是,MM-ReAct-GPT-4 比 MM-ReAct-GPT-3.5 好得多,提高了 23.0%,这证明了语言模型在 OCR 中的重要性。
OCR 和数学。 通过这种集成,可以读取现实场景中的文本并解决数学问题,如表 9(d) 所示。 MM-ReAct-GPT-4yang2023mm在此项能力集成中获得了最佳表现,遥遥领先于其他模型。 我们强烈建议使用 MM-ReAct-GPT-4 来完成与此功能集成相关的任务。
4.3结果讨论
4.3.1 基础模型和调优数据
在本小节中,我们讨论 LMM 中的模块,并推测每个组件如何影响由 MM-Vet 评估的 LMM 不同方面的能力。 我们主要考虑基于开源大语言模型的模型,即、Flan-T5 chung2022scaling、LLaMA touvron2023llama、Vicuna zheng2023judging 和 LLaMA-2 touvron2023llama2 。
愿景。 对于视觉组件,我们评估的端到端 LMM 中采用了两种模型,即 CLIP-ViT/L14 radford2021learning (428M) 和 EVA-ViT-G (1.13B)。 由于缺乏全面的消融研究zeng2023matters,目前不可能确定更好的模型。 然而,值得注意的是,当与相同的语言模型 Vicuna-7B 搭配使用时,InstructBLIP-8B 在识别任务中表现出色,而 LLaVA-7B 在 OCR 方面效果尤其出色。
语言。 有一个显着的趋势表明,高级语言模型(大语言模型)通常会产生更好的性能,例如比较不同模型的 7B 和 13B 变体,但 InstructBLIP 的异常值除外,其中 8B 版本的性能优于 14B 版本。
调整数据。 首先,增加数据量可以显着提高性能。 例如,Otter li2023otter 基于 OpenFlamingo anas_awadalla_2023_7733589 配合 MIMIC-IT li2023mimic 进一步调优,Otter 获得的效果明显优于 OpenFlaminigo。 另一个例子是 InstructBLIP-8B dai2023instructblip ,它利用来自 26 个公开数据集的更多数据来调整模型并获得比 BLIP-2-12B 更高的分数。 鉴于 InstructBLIP 和 LLaVA 令人印象深刻的性能(如表3所示),我们期望通过结合这两种方法的调优数据来进一步改进。
| Model | Rec | OCR | Know | Gen | Spat | Math | Total |
| LLaVA-13B (LLaMA-2) llava | 37.8 | 22.9 | 22.4 | 27.6 | 27.2 | 8.0 | 30.30.1 |
| LLaVA-13B (V1.3, 336px) llava | 39.4 | 22.3 | 22.7 | 24.6 | 30.6 | 11.6 | 31.50.1 |
| MM-ReAct-GPT-3.5 yang2023mm | 22.3 | 31.4 | 15.6 | 16.6 | 32.9 | 24.0 | 27.60.2 |
| MM-ReAct-GPT-4 yang2023mm | 34.3 | 66.3 | 25.6 | 36.6 | 60.6 | 72.0 | 48.10.2 |
| Bard bard | 56.2 | 52.5 | 50.9 | 61.0 | 52.0 | 39.6 | 53.50.2 |
| Model | Rec Know Gen | Rec | OCR Spat | OCR Spat Math | Rec Spat | OCR | OCR Math | Rec Know | Rec OCR Know Gen | Rec OCR Gen Spat | Rec OCR Spat | Rec OCR | OCR Know Spat | Rec Know Spat | OCR Gen Spat | Rec OCR Spat Math | Total |
| Vicuna-13B (LLaMA-2) llava | 26.6 | 55.2 | 18.8 | 14.3 | 57.1 | 39.5 | 0.0 | 20.0 | 1.3 | 56.8 | 28.6 | 50.0 | 33.3 | 0.0 | 8.0 | – | 30.30.1 |
| Vicuna-13B (V1.3, 336px) llava | 21.9 | 59.0 | 22.9 | 14.3 | 85.7 | 25.5 | 8.2 | 20.0 | 15.0 | 49.3 | 14.3 | 50.0 | 33.3 | 50.0 | 2.0 | – | 31.50.1 |
| MM-ReAct-GPT-3.5 yang2023mm | 11.3 | 38.8 | 31.2 | 35.7 | 28.6 | 56.4 | 9.1 | 20.0 | 0.0 | 47.8 | 0.0 | 25.0 | 100.0 | 0.0 | 35.0 | – | 27.60.2 |
| MM-ReAct-GPT-4 yang2023mm | 17.0 | 35.2 | 70.8 | 78.6 | 28.6 | 81.5 | 63.6 | 40.0 | 68.3 | 88.0 | 14.3 | 50.0 | 0.0 | 50.0 | 80.0 | – | 48.10.2 |
| Bard bard | 52.3 | 70.3 | 45.2 | 56.4 | 42.9 | 70.2 | 18.2 | 0.0 | 77.7 | 81.5 | 28.6 | 50.0 | 66.7 | 50.0 | 80.0 | – | 53.50.2 |
4.3.2 与巴德的比较
Bard bard 是一种流行的闭源商业 LMM 系统。 评估中的一个问题是巴德拒绝包含人物的图像,而是输出“抱歉,我还无法帮助处理人物图像。”为了与其他模型进行公平的比较,我们构建了 MM-Vet 的子集,其中包含 Bard 可以处理的 168 个样本,以下称为 Bard 集。 Bard 集上的结果如表5和6所示。
巴德在六项能力中的三项中获得最高分,在十五项能力集成中的七项中获得最高分,并拥有最高的总分(53.5%)。 MM-ReAct-GPT-4 yang2023mm 在六项功能中的其余三项中表现出色,并在十五项功能集成中的九项中名列前茅。 特别是,MM-ReAct 在 OCR、空间感知和数学能力方面表现更好,这表明即使在使用最先进的 LMM 时,拥有专门的外部工具也具有潜在的好处。
在考虑端到端模型时,与巴德还有很大差距。 例如,Vicuna-13B (V1.3, 336px) llava 获得 31.5%,比 Bard 低了 22.0%。 未来更强大的开源大语言模型和多模式训练的进步有可能进一步缩小这一差距。
4.4LLM评估效果分析
为了验证基于 LLM 的 LMM 预测评估的有效性,我们选择了 MMReAct-GPT-4 对 138 个客观问题的输出,这些问题可以由人类客观地注释。 我们计算评估者的输出分数与每个样本的人工注释分数之间差异的绝对值。 然后计算这些绝对值的平均值以获得最终结果,表示为。
最大潜在差异为 1.0。 基线评估方法,关键词匹配,产生0.273的高差异。 这说明了 MM-Vet 在处理开放式答案时不适合进行关键字匹配。 令人惊讶的是,LLaMA-2-7B touvron2023llama2 的 甚至高于关键字匹配,而 LLaMA-2-13B 仅略低于关键字匹配比关键字匹配。 这表明评估模型的开放式输出远非直截了当。 对于OpenAI的模型,GPT-3.5(turbo-0613)获得的0.178,而GPT-4(0613)获得最低的0.042的差异。 在本文中,我们利用 GPT-4 (0613) 来评估 LMM 的输出。
| Model | Keyword matching | LLM-based evaluation | |||
| LLaMA-2-7B | LLaMA-2-13B | GPT-3.5 (turbo-0613) | GPT-4 (0613) | ||
| 0.273 | 0.307 | 0.254 | 0.178 | 0.042 | |
4.5要点
我们将以上分析和讨论总结如下:
- •
-
•
根据当前模型比较,对开源 LMM 的分析(第 4.3.1 节)对于 LMM 的高级视觉编码器留下了模糊的空间。 然而,很明显更强的大语言模型可以提高 LMM 的性能。
-
•
对于开放式评估(第 4.4 节),使用 GPT-4 来评估 LMM 的开放式输出是有效的。 使用功能较弱的大语言模型可能会导致与人类评估结果的黄金标准产生更显着的偏差。
-
•
目前表现最好的方法,例如 Bard bard 和 MM-ReAct-GPT-4 yang2023mm ,在 MM-Vet 上仅获得 50% 左右的分数(其中满分为100%)。 这一差距表明,有必要通过开发更强大的 LMM 或利用外部工具扩展 LMM,进一步努力提高 LMM 在综合能力方面的性能,例如。
5结论
在本文中,我们引入了 MM-Vet 基准来评估 LMM 的集成视觉语言能力。 我们组装了一个新的多模态数据集,这需要集成多种视觉语言功能。 为了促进开放式评估,我们采用基于 LLM 的评估器对 LMM 的开放式输出进行评分。 然后,我们在 MM-Vet 上评估各种 LMM,分析其结果,以深入了解不同的 LMM 系统范例和模块选择。 我们观察到,目前最好的 LMM 在 MM-Vet 上仅取得 50% 左右的分数(满分 100%),这表明需要努力进一步提高 LMM 的综合能力。
附录A能力集成示例
| (a) | |
|
|
|
| Q: |
What occasions would someone use this meme? |
| GT: |
This meme, commonly known as "Screaming Panda," is typically used to express shock, surprise, or fear. It could be used in response to a startling or unexpected event, or to convey a sense of panic or alarm. Some possible occasions where someone might use this meme include: |
|
- Reacting to a jump scare in a horror movie |
|
|
- Responding to a surprising plot twist in a TV show or book |
|
|
- Expressing shock at a news headline or current event |
|
|
- Conveying fear or anxiety about an upcoming deadline or exam |
|
|
- Showing surprise at an unexpected outcome in a sports game or other competition. |
|
| Required capabilities: |
Recognition, knowledge, language generation |
| (b) | |
|
|
|
| Q: |
How many tomatoes are there? |
| GT: |
5 |
| Required capabilities: |
Recognition |
| (c) | |
|
|
|
| Q: |
What is located to the right of the shampoo? |
| GT: |
conditioner |
| Required capabilities: |
OCR, spatial awareness |
![[Uncaptioned image]](joke_8.jpg)
![[Uncaptioned image]](recognition_22.jpg)
![[Uncaptioned image]](spatial_1.jpg)
| (a) | |
|
|
|
| Q: |
Which room is bigger, the double garage or the living room? |
| GT: |
double garage |
| Required capabilities: |
OCR, spatial awareness, math |
| (b) | |
|
|
|
| Q: |
On the right desk, what is to the left of the laptop? |
| GT: |
table lamp <OR> desk lamp |
| Required capabilities: |
Recognition, spatial awareness |
| (c) | |
|
|
|
| Q: |
What are all the scene text in the image? |
| GT: |
5:30PM <AND> 88% <AND> Mario Kart 8 Deluxe <AND> MARIO KART 8 DELUXE <AND> SUPER MARIO ODYSSEY <AND> THE LEGEND OF ZELDA <AND> BREATH OF WILD <AND> Options <AND> Start |
| Required capabilities: |
OCR |
| (d) | |
|
|
|
| Q: |
How many gallons of supreme gasoline can I get with $50? |
| GT: |
13.6 <OR> 13.7 |
| Required capabilities: |
OCR, math |
![[Uncaptioned image]](document_5.jpg)
![[Uncaptioned image]](reg_spat.jpg)
![[Uncaptioned image]](ocr_3.jpg)
![[Uncaptioned image]](math_6.png)
| (a) | |
|
|
|
| Q: |
In which country was this photo taken? |
| GT: |
Australia |
| Required capabilities: |
Recognition, knowledge |
| (b) | |
|
|
|
| Q: |
Can you explain this meme? |
| GT: |
This meme is a humorous take on procrastination and the tendency to delay tasks until a specific time. The person in the meme plans to do something at 8 o’clock, but when they miss that deadline by a few minutes, they decide to wait until 9 o’clock instead. The image of Kermit the Frog lying in bed represents the person’s laziness and lack of motivation to complete the task. |
| Required capabilities: |
Recognition, OCR, knowledge, language generation |
![[Uncaptioned image]](news_3.png)
![[Uncaptioned image]](joke_0.jpg)
| (a) | |
|
|
|
| Q: |
The graph below shows the long-term international migration, UK, 1999-2008. |
|
Summarize the information by selecting and reporting the main features, and make comparisons where relevant. |
|
|
You should write at least 150 words. |
|
| GT: |
The chart gives information about UK immigration, emigration and net migration between 1999 and 2008. |
|
Both immigration and emigration rates rose over the period shown, but the figures for immigration were significantly higher. Net migration peaked in 2004 and 2007. |
|
|
In 1999, over 450,000 people came to live in the UK, while the number of people who emigrated stood at just under 300,000. The figure for net migration was around 160,000, and it remained at a similar level until 2003. From 1999 to 2004, the immigration rate rose by nearly 150,000 people, but there was a much smaller rise in emigration. Net migration peaked at almost 250,000 people in 2004. |
|
|
After 2004, the rate of immigration remained high, but the number of people emigrating fluctuated. Emigration fell suddenly in 2007, before peaking at about 420,000 people in 2008. As a result, the net migration figure rose to around 240,000 in 2007, but fell back to around 160,000 in 2008. |
|
| Required capabilities: |
Recognition, OCR, language generation, spatial awareness |
| (b) | |
|
|
|
| Q: |
Which car is on the parking spot 33? |
| GT: |
no <OR> empty |
| Required capabilities: |
Recognition, OCR, spatial awareness |
![[Uncaptioned image]](ielts_0.png)
![[Uncaptioned image]](spatial_3.jpg)
| (a) | |
|
|
|
| Q: |
Is this apple organic? |
| GT: |
yes |
| Required capabilities: |
Recognition, OCR |
| (b) | |
|
|
|
| Q: |
Which are producers in this food web? |
| GT: |
Phytoplankton <AND> Seaweed |
| Required capabilities: |
OCR, knowledge, spatial awareness |
| (c) | |
|
|
|
| Q: |
Does the person bigger than the car? |
| GT: |
no |
| Required capabilities: |
Recognition, knowledge, spatial awareness |
![[Uncaptioned image]](recognition_4.png)
![[Uncaptioned image]](science_1.png)
![[Uncaptioned image]](spatial_9.png)
| (a) | |
|
|
|
| Q: |
The table below gives information about the underground railway systems in six cities. |
|
Summarise the information by selecting and reporting the main features, and make comparisons where relevant. |
|
|
You should write at least 150 words. |
|
| GT: |
The table shows data about the underground rail networks in six major cities. |
|
The table compares the six networks in terms of their age, size and the number of people who use them each year. It is clear that the three oldest underground systems are larger and serve significantly more passengers than the newer systems. |
|
|
The London underground is the oldest system, having opened in 1863. It is also the largest system, with 394 kilometres of route. The second largest system, in Paris, is only about half the size of the London underground, with 199 kilometres of route. However, it serves more people per year. While only third in terms of size, the Tokyo system is easily the most used, with 1927 million passengers per year. |
|
|
Of the three newer networks, the Washington DC underground is the most extensive, with 126 kilometres of route, compared to only 11 kilometres and 28 kilometres for the Kyoto and Los Angeles systems. The Los Angeles network is the newest, having opened in 2001, while the Kyoto network is the smallest and serves only 45 million passengers per year. |
|
| Required capabilities: |
OCR, language generation, spatial awareness |
| (b) | |
|
|
|
| Q: |
What will the girl on the right write on the board? |
| GT: |
14 |
| Required capabilities: |
Recognition, OCR, spatial awareness, math |
![[Uncaptioned image]](ielts_4.png)
![[Uncaptioned image]](math_5.png)
参考
- [1] Harsh Agrawal, Karan Desai, Yufei Wang, Xinlei Chen, Rishabh Jain, Mark Johnson, Dhruv Batra, Devi Parikh, Stefan Lee, and Peter Anderson. Nocaps: Novel object captioning at scale. In Proceedings of the IEEE/CVF international conference on computer vision, pages 8948–8957, 2019.
- [2] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems, 35:23716–23736, 2022.
- [3] Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
- [4] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. VQA: Visual Question Answering. In ICCV, 2015.
- [5] Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, et al. Speecht5: Unified-modal encoder-decoder pre-training for spoken language processing. arXiv preprint arXiv:2110.07205, 2021.
- [6] Anas Awadalla, Irena Gao, Joshua Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Jenia Jitsev, Simon Kornblith, Pang Wei Koh, Gabriel Ilharco, Mitchell Wortsman, and Ludwig Schmidt. Openflamingo, March 2023.
- [7] Microsoft Azure. Azure cognitive services apis. https://azure.microsoft.com/en-us/products/ai-services/ai-vision, 2023. Accessed: 2023-06-20.
- [8] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [9] Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. In NeurIPS, 2020.
- [10] Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- [11] Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3558–3568, 2021.
- [12] Ting Chen, Saurabh Saxena, Lala Li, David J Fleet, and Geoffrey Hinton. Pix2seq: A language modeling framework for object detection. In ICLR, 2022.
- [13] Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server. arXiv preprint arXiv:1504.00325, 2015.
- [14] Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. Uniter: Learning universal image-text representations. In ECCV, 2020.
- [15] Cheng-Han Chiang and Hung-yi Lee. Can large language models be an alternative to human evaluations? arXiv preprint arXiv:2305.01937, 2023.
- [16] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- [17] Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
- [18] Marta R Costa-jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, et al. No language left behind: Scaling human-centered machine translation. arXiv preprint arXiv:2207.04672, 2022.
- [19] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. arXiv preprint arXiv:2305.06500, 2023.
- [20] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- [21] Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, and Pete Florence. Palm-e: An embodied multimodal language model. In arXiv preprint arXiv:2303.03378, 2023.
- [22] Yuxin Fang, Wen Wang, Binhui Xie, Quan Sun, Ledell Wu, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. Eva: Exploring the limits of masked visual representation learning at scale. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19358–19369, 2023.
- [23] Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Zhenyu Qiu, Wei Lin, Jinrui Yang, Xiawu Zheng, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394, 2023.
- [24] Jinlan Fu, See-Kiong Ng, Zhengbao Jiang, and Pengfei Liu. Gptscore: Evaluate as you desire. arXiv preprint arXiv:2302.04166, 2023.
- [25] Zhe Gan, Linjie Li, Chunyuan Li, Lijuan Wang, Zicheng Liu, and Jianfeng Gao. Vision-language pre-training: Basics, recent advances, and future trends. arXiv preprint arXiv:2210.09263, 2022.
- [26] Difei Gao, Lei Ji, Luowei Zhou, Kevin Qinghong Lin, Joya Chen, Zihan Fan, and Mike Zheng Shou. Assistgpt: A general multi-modal assistant that can plan, execute, inspect, and learn. arXiv preprint arXiv:2306.08640, 2023.
- [27] Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. Pal: Program-aided language models. arXiv preprint arXiv:2211.10435, 2022.
- [28] Peng Gao, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xiangyu Yue, et al. Llama-adapter v2: Parameter-efficient visual instruction model. arXiv preprint arXiv:2304.15010, 2023.
- [29] Tao Gong, Chengqi Lyu, Shilong Zhang, Yudong Wang, Miao Zheng, Qian Zhao, Kuikun Liu, Wenwei Zhang, Ping Luo, and Kai Chen. Multimodal-gpt: A vision and language model for dialogue with humans, 2023.
- [30] Google. Bard. https://bard.google.com, 2023. Accessed: 2023-07-17.
- [31] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017.
- [32] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- [33] Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In CVPR, 2019.
- [34] Huggingface. Transformers agent. https://huggingface.co/docs/transformers/transformers_agents, 2023. Accessed: 2023-07-20.
- [35] Geewook Kim, Teakgyu Hong, Moonbin Yim, JeongYeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, and Seunghyun Park. Ocr-free document understanding transformer. In European Conference on Computer Vision, pages 498–517. Springer, 2022.
- [36] Wonjae Kim, Bokyung Son, and Ildoo Kim. Vilt: Vision-and-language transformer without convolution or region supervision. In ICML, 2021.
- [37] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. IJCV, 2017.
- [38] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461, 2019.
- [39] Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Fanyi Pu, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Mimic-it: Multi-modal in-context instruction tuning. arXiv preprint arXiv:2306.05425, 2023.
- [40] Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang, and Ziwei Liu. Otter: A multi-modal model with in-context instruction tuning. arXiv preprint arXiv:2305.03726, 2023.
- [41] Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed-bench: Benchmarking multimodal llms with generative comprehension, 2023.
- [42] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023.
- [43] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, pages 12888–12900. PMLR, 2022.
- [44] Xiujun Li, Xi Yin, Chunyuan Li, Xiaowei Hu, Pengchuan Zhang, Lei Zhang, Lijuan Wang, Houdong Hu, Li Dong, Furu Wei, et al. Oscar: Object-semantics aligned pre-training for vision-language tasks. In ECCV, 2020.
- [45] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014.
- [46] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023.
- [47] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023.
- [48] Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. Gpteval: Nlg evaluation using gpt-4 with better human alignment. arXiv preprint arXiv:2303.16634, 2023.
- [49] Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? arXiv preprint arXiv:2307.06281, 2023.
- [50] Yuliang Liu, Zhang Li, Hongliang Li, Wenwen Yu, Mingxin Huang, Dezhi Peng, Mingyu Liu, Mingrui Chen, Chunyuan Li, Lianwen Jin, et al. On the hidden mystery of ocr in large multimodal models. arXiv preprint arXiv:2305.07895, 2023.
- [51] Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In NeurIPS, 2019.
- [52] Timo Lüddecke and Alexander Ecker. Image segmentation using text and image prompts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7086–7096, 2022.
- [53] Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge. In CVPR, pages 3195–3204, 2019.
- [54] OpenAI. Gpt-4 technical report, 2023.
- [55] Vicente Ordonez, Girish Kulkarni, and Tamara L Berg. Im2text: Describing images using 1 million captioned photographs. In NeurIPS, 2011.
- [56] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- [57] Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction tuning with gpt-4. arXiv preprint arXiv:2304.03277, 2023.
- [58] Thomas Politzer. Vision is our dominant sense. https://www.brainline.org/article/vision-our-dominant-sense. Accessed: 2023-05-20.
- [59] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021.
- [60] Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In International Conference on Machine Learning, pages 28492–28518. PMLR, 2023.
- [61] Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114, 2021.
- [62] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In ACL, 2018.
- [63] Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in huggingface. arXiv preprint arXiv:2303.17580, 2023.
- [64] Oleksii Sidorov, Ronghang Hu, Marcus Rohrbach, and Amanpreet Singh. Textcaps: a dataset for image captioning with reading comprehension. In ECCV, pages 742–758, 2020.
- [65] Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317–8326, 2019.
- [66] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [67] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [68] Maria Tsimpoukelli, Jacob Menick, Serkan Cabi, SM Eslami, Oriol Vinyals, and Felix Hill. Multimodal few-shot learning with frozen language models. arXiv preprint arXiv:2106.13884, 2021.
- [69] Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, and Lijuan Wang. Git: A generative image-to-text transformer for vision and language. arXiv preprint arXiv:2205.14100, 2022.
- [70] Wenhai Wang, Zhe Chen, Xiaokang Chen, Jiannan Wu, Xizhou Zhu, Gang Zeng, Ping Luo, Tong Lu, Jie Zhou, Yu Qiao, et al. Visionllm: Large language model is also an open-ended decoder for vision-centric tasks. arXiv preprint arXiv:2305.11175, 2023.
- [71] Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, and Ronald M Summers. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2097–2106, 2017.
- [72] Zirui Wang, Jiahui Yu, Adams Wei Yu, Zihang Dai, Yulia Tsvetkov, and Yuan Cao. Simvlm: Simple visual language model pretraining with weak supervision. In ICLR, 2022.
- [73] Peng Xu, Wenqi Shao, Kaipeng Zhang, Peng Gao, Shuo Liu, Meng Lei, Fanqing Meng, Siyuan Huang, Yu Qiao, and Ping Luo. Lvlm-ehub: A comprehensive evaluation benchmark for large vision-language models. arXiv preprint arXiv:2306.09265, 2023.
- [74] Zhengyuan Yang, Zhe Gan, Jianfeng Wang, Xiaowei Hu, Faisal Ahmed, Zicheng Liu, Yumao Lu, and Lijuan Wang. Unitab: Unifying text and box outputs for grounded vision-language modeling. In European Conference on Computer Vision, pages 521–539. Springer, 2022.
- [75] Zhengyuan Yang, Zhe Gan, Jianfeng Wang, Xiaowei Hu, Yumao Lu, Zicheng Liu, and Lijuan Wang. An empirical study of gpt-3 for few-shot knowledge-based vqa. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 3081–3089, 2022.
- [76] Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. Mm-react: Prompting chatgpt for multimodal reasoning and action. arXiv preprint arXiv:2303.11381, 2023.
- [77] Zhengyuan Yang, Yijuan Lu, Jianfeng Wang, Xi Yin, Dinei Florencio, Lijuan Wang, Cha Zhang, Lei Zhang, and Jiebo Luo. Tap: Text-aware pre-training for text-vqa and text-caption. In CVPR, pages 8751–8761, 2021.
- [78] Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. mplug-owl: Modularization empowers large language models with multimodality. arXiv preprint arXiv:2304.14178, 2023.
- [79] Rowan Zellers, Yonatan Bisk, Ali Farhadi, and Yejin Choi. From recognition to cognition: Visual commonsense reasoning. In CVPR, pages 6720–6731, 2019.
- [80] Andy Zeng, Adrian Wong, Stefan Welker, Krzysztof Choromanski, Federico Tombari, Aveek Purohit, Michael Ryoo, Vikas Sindhwani, Johnny Lee, Vincent Vanhoucke, et al. Socratic models: Composing zero-shot multimodal reasoning with language. arXiv preprint arXiv:2204.00598, 2022.
- [81] Yan Zeng, Hanbo Zhang, Jiani Zheng, Jiangnan Xia, Guoqiang Wei, Yang Wei, Yuchen Zhang, and Tao Kong. What matters in training a gpt4-style language model with multimodal inputs? arXiv preprint arXiv:2307.02469, 2023.
- [82] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- [83] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric. P Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023.
- [84] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.
- [85] Wanrong Zhu, Jack Hessel, Anas Awadalla, Samir Yitzhak Gadre, Jesse Dodge, Alex Fang, Youngjae Yu, Ludwig Schmidt, William Yang Wang, and Yejin Choi. Multimodal c4: An open, billion-scale corpus of images interleaved with text. arXiv preprint arXiv:2304.06939, 2023.