SeACo-Paraformer:具有灵活有效的热词定制能力的非自回归ASR系统
摘要
热词定制是ASR领域仍然关注的问题之一——让ASR系统的用户能够定制实体、人名和其他短语以获得更好的体验是有价值的。 在过去的几年里,我们已经开发出有效的 ASR 情境化建模策略,但它们在训练稳定性和隐形激活过程方面仍然存在改进空间。 在本文中,我们提出了语义增强上下文参数化器(SeACo-Paraformer),一种新颖的基于 NAR 的 ASR 系统,具有灵活有效的热词定制能力。 它具有基于AED的模型的准确性、NAR模型的效率以及性能卓越的显式定制能力的优点。 通过对 50,000 小时工业大数据的广泛实验,我们提出的模型在定制方面优于强大的基线。 此外,我们探索了一种有效的方法来过滤大规模传入的热词以进一步改进。 所比较的工业模型、源代码和两个热词测试集都是开源的。
索引术语— 端到端 ASR、非自回归 ASR、情境化 ASR、热词定制
1简介
端到端语音识别在过去十年中取得了重大进展,出现了几种经典的高性能 ASR 主干模型,包括 Transducer [1]、listen-attend-and-spell (LAS) [2] 和 Transformer [3] 受到相当多的关注,并产生了许多变体来解决 ASR 领域的各种问题,例如流式 ASR [4, 5, 6] 、多语言 ASR [7, 8] 和非自回归 ASR [9, 10] 等。 在商业ASR系统中,特别是应用于垂直领域的系统中,用户可以输入人名、地名、命名实体等词语作为热词来获得个性化的识别结果,简而言之就是支持 热词定制,是一个兼具学术价值和商业价值的问题。
在传统 ASR 系统时代,由于声学模型和语言模型分别关注语音和语言信息,因此通过调整加权有限状态换能器(WFST)解码器中的权重来引入个性化和偏差信息[11, 12]。 对于没有 WFST 解码器的 E2E ASR 系统,人们探索了一些工作来使用户能够自定义自己的热词[13,14,15]。 上下文聆听、出席和拼写(CLAS)[13]是Golan Pundak等人提出的一种端到端上下文ASR建模方法 他们首先提出引入多头注意力(MHA),它与 LAS 模型中的随机采样短语联合训练。 直观地说,MHA 被训练来捕获每个步骤中热词嵌入和解码器输出之间的关系。 一旦匹配,就会导致解码器生成有偏差的概率。 这种策略被证明是一种在不损害识别性能的情况下向 ASR 模型引入偏差信息的有效方法,从而成为广泛采用的上下文 ASR 解决方案。
基于 CLAS 的基本策略:随机热词采样和 MHA,探索了多种扩展来实现热词定制[14,15,16,17,18,19]。 这些方法可以分类为 显式和隐式 那些。 Huang等人最近提出了上下文短语预测网络(CPP Network)[15],它与CLAS类似(都是 隐含的)。 引入了额外的 CTC [20] 头来预测热词。 通过联合优化CTC模块,引导编码器输出获取热词信息,从而使ASR结果在推理阶段对给定的热词产生偏差。 CPP网络可以在CTC、Transducer和Transformer模型中采用。 Han等人提出了基于连续集成和激发(CIF)的协作解码(ColDec)[14]。 它是一个 明确的 基于CIF模型的方法实现热词定制,预测与ASR预测同步的外部热词概率。 在训练阶段,MHA在CIF输出之间进行 和热词嵌入。 MHA输出的每一步都携带热词参与的语义信息 ,然后前馈层将其转换为概率,用于计算与热词位置感知目标的交叉熵 (CE) 损失(例如 'A B C D E F' 表示 ASR 目标,'A B # # # #' 表示偏差目标当“A B”被采样为热词并且“#0>”时’用于无偏见标签)。 引入的模块实际上作为一个热词检测器来生成与 ASR 预测同步的偏差概率。 在推理阶段,ASR 概率和有偏概率被合并。 在[19]中,作者提出使用注意力权重来过滤传入的热词列表,这被证明是进一步改进的有效方法。
然而,上述每种方法都有其各自的缺点。 普通的 CLAS 并没有表现出一致的有效性——[13]中提出的标签插入策略并不适用于所有 E2E 系统。 此外,当系统遇到不良情况时,隐式建模使得一般 ASR 建模和上下文建模很难解耦。 显然,与CLAS及其扩展相比,CIF ColDec具有更直观、可控的热词预测过程,并且外部参数的训练与ASR模型解耦。 另一方面,它采用的 ASR 主干网并没有达到注意力编码器解码器 (AED) 模型的高精度。 这些因素促使我们提出一种新颖的启用热词定制的 ASR 系统: 语义mantic-增强增强上下文文本参数化器 (SeACo-Paraformer)。 我们采用 Paraformer [10] 作为我们的骨干模型,它是一个高效的 NAR 模型,同时也保持了主流 AED 模型的高精度。 Paraformer 内部的并行解码器允许我们基于 CIF ColDec 部署更复杂的定制建模策略。 为了解决由于热词列表不断扩大而导致性能下降的问题,我们使用注意力分数过滤(ASF)来过滤大规模传入的热词。 我们对大规模工业数据进行了一系列实验,以验证 SeACo-Paraformer 和 ASF 的性能。 本文的结构如下:第 2 节简要介绍了所采用的 CIF 和 Paraformer。 第 3 节详细介绍了 SeACo-Paraformer,包括训练、推理和其他技术。 第 4 节介绍了实验设置和结果,第 5 节分析了模型的性能。 最后,第 6 节总结了本文。
2 预备知识
2.1 持续集成和激发
连续集成和激发(CIF)是一种对齐机制,利用 ASR 任务的单调特性来预测输出标记的数量并获得与编码器输出的声学嵌入。 CIF 预测每一帧的权重并从头到尾累加它们。 一旦权重加起来达到 1.0,对前一周期的编码器输出进行积分(加权和)以生成声学嵌入步骤。 考虑编码器输出 具有预测权重 ,集成声学嵌入 ,。权重之和为 - 输出序列的词符编号。 CIF 最重要的特征是它生成的嵌入与目标序列具有相同的长度,这意味着它是完全基于声学的表示,但与预测同步。
2.2参数化器
在这项工作中,我们采用 Paraformer [10],一种新颖的 NAR ASR 模型作为我们的骨干。 Paraformer 代表 副内转前 其中包含在训练中同时接收声学嵌入或语义嵌入的解码器。 简而言之,Paraformer 通过利用 CIF [21] 和两遍训练策略实现非自回归解码能力,如图 1 所示。 1 (下方虚线框)。 CIF 预测器经过训练来预测标记数量并生成声学嵌入 对于并行解码器,它构成了训练中的 Pass1(无梯度)。 字符嵌入的步骤 随着 Pass1 准确率的提高和所谓的语义嵌入, 将逐渐被 取代 根据正确识别的位置生成。 Paraformer 摆脱了自回归解码和波束搜索带来的大量计算开销,获得了超过 10 倍的加速,并且错误率更低。 更多实现细节和实验结果可以在[10, 22]中找到。
3 SeACo-Paraformer
3.1 架构和训练
考虑到第 1 节中讨论的先前工作的优点和缺点,我们提出了一种新颖的热词定制系统,称为语义增强上下文参数化器(SeACo-Paraformer)。 基于Paraformer这个强大的ASR骨干,引入了3个模块,如图所示 1. 直观上,SeACo-Paraformer利用CIF预测器的建模特性进行热词预测,而CIF输出和并行解码器输出分别发送到偏置解码器。
形式上,考虑语音特征和相应的文本,我们保留CIF输出 和并行解码器隐藏状态(输出层之前) 在 Paraformer 推理中:
| (1) | ||||
然后从批次中随机抽取热词,批次大小为,表示为。. 我们这里使用4个超参数来控制采样过程: 为进行抽样的批次比例,其他批次的转发将使用默认热词进行;与类似,但在活动批次内部的话语级别中,活动批次的平均热词抽样数为(默认热词为一个);和 采样热词的最小和最大长度。
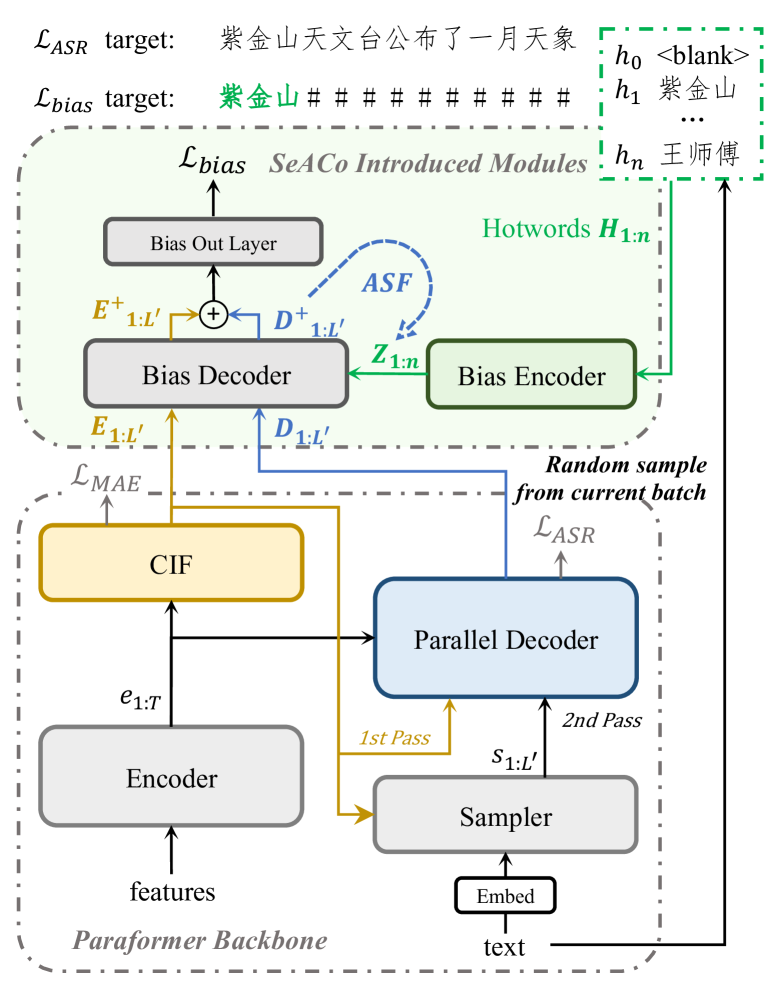
然后使用偏置编码器嵌入热词列表中的字符序列,该编码器包含嵌入层(与 ASR 嵌入共享参数)和 LSTM 层:
| (2) |
未压缩并在第 0 维上重复进行批量计算。 接下来是SeACo-Paraformer的主体部分。 在偏差解码器内部,将热词的偏差信息引入到声学嵌入中 和解码器隐藏状态 通过注意力机制:
| (3) | ||||
偏差解码器由多个多头注意力和前馈层组成。 通过有偏差的声学嵌入和有偏差的解码器隐藏状态,有偏差的概率 可以通过输出层获得。 请注意,ASR 输出词汇表中会附加一个额外的词符(计为#,表示无偏差),以标记非热词位置输出。
| (4) |
给定有偏差的概率,可以使用热词位置感知标准来更新与偏差相关的参数,其中非热词位置中的标签被 # 替换(如图1中)。
通过训练有素的 Paraformer 模型冻结,我们通过引入偏差输出层、偏差解码器和偏差编码器来实现 ASR 系统的热词语境化,并使用随机采样的热词及其相应的目标对其进行训练。 值得注意的是,偏差相关参数的训练与 ASR 训练是分开的,从而允许使用专门的热词数据(例如低频语言短语)和训练策略,而不会影响一般 ASR 性能。
3.2 推理及辅助技术
对于给定热词列表的 SeACo-Paraformer 推理中的 第一步,我们得到上下文化 ASR 的最终合并概率为
| (5) |
当没有传入热词或未检测到热词时,SeACo-Paraformer 仅使用。 是一个可调参数,用于调整解码器输出的信任偏差程度。
在实际应用中,随着传入热词数量的增加,热词激活的性能相应下降 - 偏置解码器内部的交叉注意力很难在 ASR 解码器输出之间建立正确的连接 和大规模稀疏热词嵌入 . 为了使 SeACo-Paraformer 能够利用大规模的热词列表进行热词定制,我们提出了注意力评分过滤(ASF)策略。 首先使用完整的热词列表进行偏差解码器推理以获得注意力得分矩阵 ,其中是输出标记的长度, 是热词的数量。 然后我们总结步骤的分数 并获取每个热词的注意力分数。 根据注意力分数,我们可以选择最活跃的 热词来进行真正有效的偏差解码器推理。 相比 细粒度的上下文知识选择 [19],我们的偏差解码器由多个交叉注意层组成,我们发现最后一层的分数对于过滤最有效。
4实验
4.1数据介绍
我们利用大规模的内部工业数据进行了一系列的实验——基于随机抽样的热词建模策略需要足够的数据多样性,否则很容易对有限的语义信息过度拟合。 我们使用的训练数据总量约为 50,000 小时。 为了评估模型在热词定制和一般 ASR 中的性能,我们使用不同领域的测试集,如表所示1。对于所有热词测试集,我们将部分热词区分为R1-hotwords,这意味着他们在基本ASR模型的识别中统计的召回率低于40%。 这些热词表现出较高的召回难度,从而有效地展示了模型的定制能力。 通用测试 是多个通用 ASR 测试集的大集合,涵盖各个领域和场景。 测试商业、测试期限和测试实体 是不同领域的三个热词测试集。
为了展示可重复实验结果和模型比较,我们构建并开源 基于开源Aishell-1数据集[23],用于测试热词定制的两个数据集。 首先,我们使用词性标记 [24] 从 Aishell-1 测试和开发集的转录中生成名称实体列表。 然后将名称实体视为热词,我们使用所有 R1 热词和其余热词的随机部分组成两个热词列表。 最后, 根据热词列表过滤掉 Test-Aishell1-NE 和 Dev-Aishell1-NE 111Find the open source data sets, source codes, detailed experiment results and models at https://github.com/R1ckShi/SeACo-Paraformer。 0>
| #utt | #hotword | #R1-hotword | |
|---|---|---|---|
| Test-Gerneral | 40603 | - | - |
| Test-Commercial | 2000 | 693 | 72 |
| Test-Term | 1639 | 969 | 258 |
| Test-Entity | 1308 | 231 | 54 |
| Test-Aishell1-NE | 808 | 400 | 226 |
| Dev-Aishell1-NE | 1334 | 600 | 371 |
4.2实验设置和评估指标
我们使用FunASR实现模型222https://github.com/alibaba-damo-academy/FunASR。 Paraformer模型、Paraformer-CLAS模型和提出的SeACo-Paraformer模型完全开源10>1footnotemark: 1 包括源代码、配置文件和用工业数据训练的模型。 Paraformer基础模型由50层SAN-M [25]编码器和16层NAR Transformer解码器组成,具有2048个隐藏单元。 与[22]中讨论的模型相比,本文提出的Paraformer-CLAS进行了升级,并保证拥有强大且微调的定制基线。 至于 SeACo-Paraformer,该模型使用 ASR 主干冻结进行训练,使用 6 个 epoch 的相同 50,000 小时训练数据。 我们设置采样率 和至0.75,和. 引入的模块具有以下架构:偏置编码器是具有 512 个隐藏单元的 2 层 LSTM,偏置解码器是具有 1024 个隐藏单元的 4 层 Transformer 解码器。 每个训练批次有 6,000 个语音帧(GPU)。
![[Uncaptioned image]](x2.png)
根据 3 个指标对模型进行比较:总测试集的字符错误率 (CER)、所有热词的平均召回率/精度/F1 分数 (R/P/F) 以及 R1 热词的 R/P/F平均的。 为了更严格的评估,我们只考虑在预测完整时成功召回一个热词,因此我们排除了热词位置错误率的计算。
4.3结果
表2 显示了四个模型的所有测试集的实验结果。 请注意,我们使用 用于推理中的方程(5)和 对于非洲猪瘟。 在一般测试中,Paraformer-CLAS 表现出与 Paraformer-Base 模型相似的 CER。 由于 SeACo-Paraformer 使用冻结的 ASR 主干进行训练,因此四个模型在一般 ASR 性能方面表现出最小的差异。 在内部热词定制测试中,CLAS被证明是一种有效的方法,R1热词的平均召回率从12%提高到51%。 然而,SeACo-Paraformer 的召回率仍优于 CLAS,召回率为 60%。 ASF的加入效果进一步增强,召回率提高到65%。 与 Paraformer-CLAS 相比,SeACo-Paraformer 的 CER 相对降低了 5%。 我们在开源测试集中得到了类似的结果,而 Paraformer-CLAS、SeACo-Paraformer 和 SeACo-Paraformer+ASF 的召回率分别为 69%、79% 和 87%。 与 Paraformer-CLAS 相比,该方法实现了相对 30.2% 的 CER 降低和 26.1% 的召回率提高。
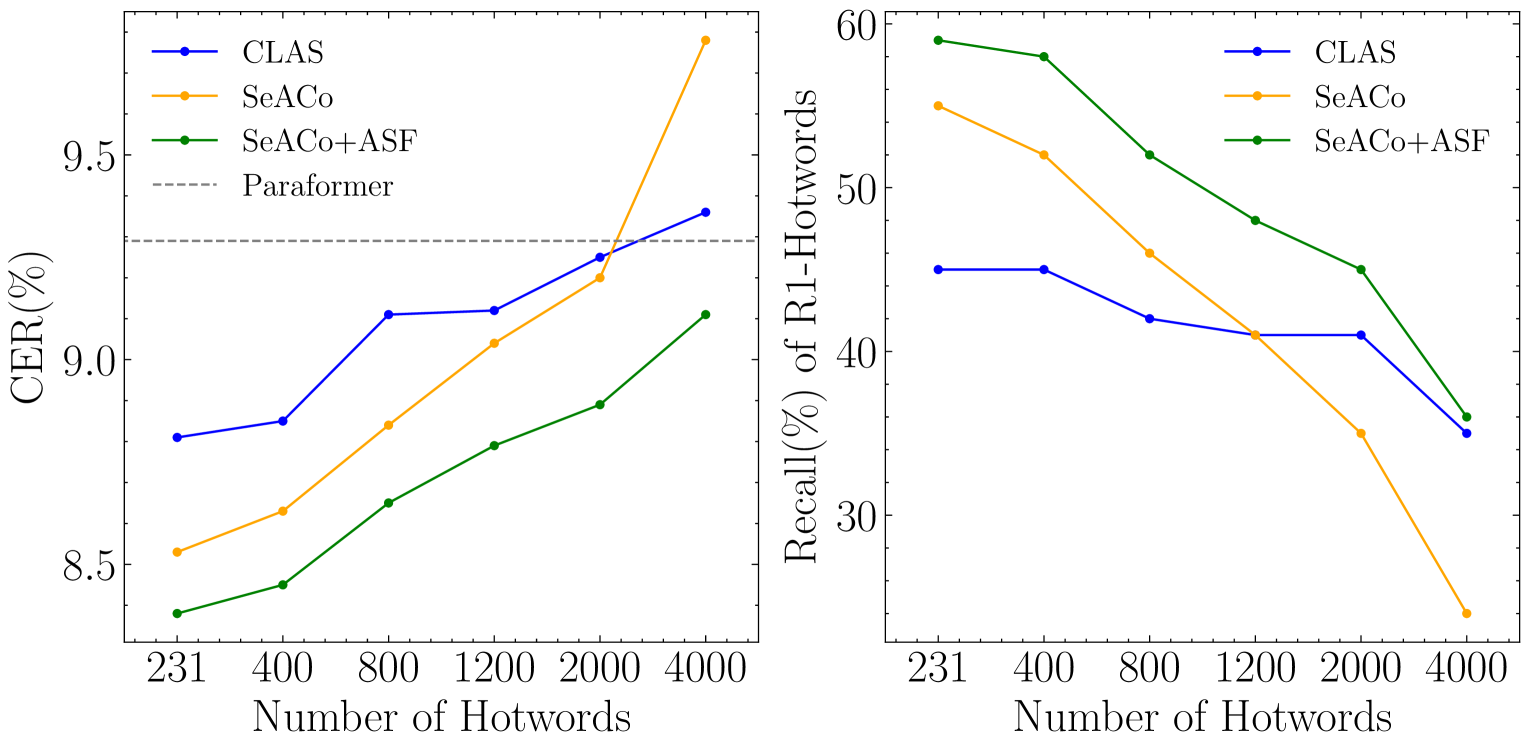
增加热词数量的实验结果如图 2 所示。 2. 测试实体 总共有 231 个热词,我们用不相关的热词将其扩大到 400、800、1200、2000 和 4,000。 图中的曲线表明,随着热词列表的扩展,所有三个模型的性能都会恶化。 在CER方面,当列表扩展到4000个热词时,只有SeACo-Paraformer+ASF实现了CER的降低。 从召回率来看,当热词数量达到 1200 时,SeACo-Paraformer 模型的表现与 CLAS 相当。 然而,通过采用 ASF,所提出的模型保持了其相对于 CLAS 的优势。
| Test -C | Test -T | Test-E | Avg. | |
|---|---|---|---|---|
| Seaco-Paraformer | 3.16/67 | 4.51/59 | 8.53/55 | 5.40/60 |
| A1: merge first | 3.28/65 | 4.72/61 | 8.67/53 | 5.56/60 |
| A2: only | 3.86/64 | 5.29/62 | 8.66/58 | 5.94/61 |
| A3: only | 3.25/63 | 4.59/50 | 8.60/51 | 5.49/55 |
表3 显示了偏置解码器计算的消融研究结果。 重点关注式(3),在偏置输出层之前引入偏置信息有几种方式,合并 和 在 MHA 之前而不是之后也有意义 (A1)。 此外,使用时必须进行消融实验 或 仅(A2 和 A3)。 结果表明,单独使用 CIF 输出来计算热词损失会导致较高的召回率,但 CER 较差,这意味着仅使用声学嵌入来预测热词并不是一种稳定的方法,解码器输出是必不可少的。 另一方面,进行 MHA 和 两次单独比先合并要好。
5分析
偏差解码器中的注意力在热词定制中起着最关键的作用,在本节中我们将深入研究注意力得分矩阵。 数字 3 揭示了偏差解码器如何建立热词和语义信息(偏差解码器最后一层的注意力得分矩阵)之间的联系,但这种现象与我们最初的假设相矛盾。 在这种情况下,SeACo-Paraformer 正确预测了两个热词。 两个黄色虚线框描绘了成功匹配时的注意模式,表明语义信息仅在相关热词开始和结束时才选择性地关注非空白短语(由黄色箭头表示)。 这种现象几乎出现在所有的话语中,而且并非孤例。 此外,我们发现注意力分数 每一步都表示热词出现的概率,与[14]不同。 每个热词在所有步骤中的累积分数反映了其出现的可能性,这构成了 ASF 的基本概念。

6结论
在本文中,我们提出了一种基于 NAR ASR 主干的灵活有效的热词定制模型,称为 SeACo-Paraformer。 一系列工业数据实验证明,该模型优于经典的热词定制解决方案CLAS,并且ASF推理策略被证明是提高ASR准确率和热词召回率的有效方法。 此外,我们还进一步分析了随着热词数量增加的性能,偏差解码器计算和注意力得分矩阵的消融研究。 未来,我们将重点关注大规模传入的热词列表和不同的偏置编码器结构。
参考
- [1] Alex Graves, Abdel-rahman Mohamed, and Geoffrey Hinton, “Speech recognition with deep recurrent neural networks,” in 2013 IEEE international conference on acoustics, speech and signal processing. IEEE, 2013, pp. 6645–6649.
- [2] William Chan, Navdeep Jaitly, Quoc Le, and Oriol Vinyals, “Listen, attend and spell: A neural network for large vocabulary conversational speech recognition,” in 2016 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2016, pp. 4960–4964.
- [3] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [4] Kanishka Rao, Haşim Sak, and Rohit Prabhavalkar, “Exploring architectures, data and units for streaming end-to-end speech recognition with rnn-transducer,” in 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2017, pp. 193–199.
- [5] Niko Moritz, Takaaki Hori, and Jonathan Le, “Streaming automatic speech recognition with the transformer model,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6074–6078.
- [6] Zhifu Gao, Shiliang Zhang, Ming Lei, and Ian McLoughlin, “Universal asr: Unifying streaming and non-streaming asr using a single encoder-decoder model,” arXiv preprint arXiv:2010.14099, 2020.
- [7] Shiyu Zhou, Shuang Xu, and Bo Xu, “Multilingual end-to-end speech recognition with a single transformer on low-resource languages,” arXiv preprint arXiv:1806.05059, 2018.
- [8] Shigeki Karita, Nanxin Chen, Tomoki Hayashi, Takaaki Hori, Hirofumi Inaguma, Ziyan Jiang, Masao Someki, Nelson Enrique Yalta Soplin, Ryuichi Yamamoto, Xiaofei Wang, et al., “A comparative study on transformer vs rnn in speech applications,” in 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2019, pp. 449–456.
- [9] Fan Yu, Haoneng Luo, Pengcheng Guo, Yuhao Liang, Zhuoyuan Yao, Lei Xie, Yingying Gao, Leijing Hou, and Shilei Zhang, “Boundary and context aware training for cif-based non-autoregressive end-to-end asr,” in 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2021, pp. 328–334.
- [10] Zhifu Gao, Shiliang Zhang, Ian McLoughlin, and Zhijie Yan, “Paraformer: Fast and accurate parallel transformer for non-autoregressive end-to-end speech recognition,” INTERSPEECH, 2022.
- [11] Petar Aleksic, Cyril Allauzen, David Elson, Aleksandar Kracun, Diego Melendo Casado, and Pedro J Moreno, “Improved recognition of contact names in voice commands,” in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2015, pp. 5172–5175.
- [12] Keith Hall, Eunjoon Cho, Cyril Allauzen, Francoise Beaufays, Noah Coccaro, Kaisuke Nakajima, Michael Riley, Brian Roark, David Rybach, and Linda Zhang, “Composition-based on-the-fly rescoring for salient n-gram biasing,” 2015.
- [13] Golan Pundak, Tara N Sainath, Rohit Prabhavalkar, Anjuli Kannan, and Ding Zhao, “Deep context: end-to-end contextual speech recognition,” in 2018 IEEE spoken language technology workshop (SLT). IEEE, 2018, pp. 418–425.
- [14] Minglun Han, Linhao Dong, Shiyu Zhou, and Bo Xu, “Cif-based collaborative decoding for end-to-end contextual speech recognition,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6528–6532.
- [15] Kaixun Huang, Ao Zhang, Zhanheng Yang, Pengcheng Guo, Bingshen Mu, Tianyi Xu, and Lei Xie, “Contextualized end-to-end speech recognition with contextual phrase prediction network,” arXiv preprint arXiv:2305.12493, 2023.
- [16] Ke Hu, Antoine Bruguier, Tara N Sainath, Rohit Prabhavalkar, and Golan Pundak, “Phoneme-based contextualization for cross-lingual speech recognition in end-to-end models,” arXiv preprint arXiv:1906.09292, 2019.
- [17] Mahaveer Jain, Gil Keren, Jay Mahadeokar, Geoffrey Zweig, Florian Metze, and Yatharth Saraf, “Contextual rnn-t for open domain asr,” arXiv preprint arXiv:2006.03411, 2020.
- [18] Kanthashree Mysore Sathyendra, Thejaswi Muniyappa, Feng-Ju Chang, Jing Liu, Jinru Su, Grant P Strimel, Athanasios Mouchtaris, and Siegfried Kunzmann, “Contextual adapters for personalized speech recognition in neural transducers,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 8537–8541.
- [19] Minglun Han, Linhao Dong, Zhenlin Liang, Meng Cai, Shiyu Zhou, Zejun Ma, and Bo Xu, “Improving end-to-end contextual speech recognition with fine-grained contextual knowledge selection,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 8532–8536.
- [20] Alex Graves, Santiago Fernández, Faustino Gomez, and Jürgen Schmidhuber, “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” in Proceedings of the 23rd international conference on Machine learning, 2006, pp. 369–376.
- [21] Linhao Dong and Bo Xu, “Cif: Continuous integrate-and-fire for end-to-end speech recognition,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6079–6083.
- [22] Zhifu Gao, Zerui Li, Jiaming Wang, Haoneng Luo, Xian Shi, Mengzhe Chen, Yabin Li, Lingyun Zuo, Zhihao Du, Zhangyu Xiao, et al., “Funasr: A fundamental end-to-end speech recognition toolkit,” arXiv preprint arXiv:2305.11013, 2023.
- [23] Hui Bu, Jiayu Du, Xingyu Na, Bengu Wu, and Hao Zheng, “Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline,” in 2017 20th conference of the oriental chapter of the international coordinating committee on speech databases and speech I/O systems and assessment (O-COCOSDA). IEEE, 2017, pp. 1–5.
- [24] Zhenyu Jiao, Shuqi Sun, and Ke Sun, “Chinese lexical analysis with deep bi-gru-crf network,” arXiv preprint arXiv:1807.01882, 2018.
- [25] Zhifu Gao, Shiliang Zhang, Ming Lei, and Ian McLoughlin, “San-m: Memory equipped self-attention for end-to-end speech recognition,” arXiv preprint arXiv:2006.01713, 2020.