仲景:通过专家反馈和真实多轮对话提升中国医学大语言模型能力
摘要
大型语言模型(大语言模型)的最新进展在理解和响应用户意图方面取得了显着的突破。 然而,它们的性能落后于某些专业领域(例如中医)的一般用例。 现有将中医纳入大语言模型的努力依赖于单轮和蒸馏对话数据的监督微调(SFT)。 这些模型缺乏医生般的主动询问和多轮理解的能力,无法将响应与专家的意图结合起来。 在这部作品中,我们介绍了仲景111为了向中国古代著名医学家张仲景致敬,我们将我们的模型命名为“张仲景”。,第一个基于LLaMA的中国医学大语言训练模型,实现了从持续预训练、SFT到人类反馈强化学习(RLHF)的整个流程。 此外,我们构建了包含 70,000 条真实医患对话的中文多轮医学对话数据集 CMtMedQA,显着增强了模型复杂对话和主动询问发起的能力。 鉴于生物医学领域的独特特点,我们还定义了完善的标注规则和评估标准。 大量的实验结果表明,尽管参数放大了 100 倍,Zhongjing 在各种能力上都优于基线,并且在某些能力上与 ChatGPT 的性能相匹配。 消融研究还证明了每个组成部分的贡献:预训练增强了医学知识,RLHF 进一步提高了遵循指令的能力和安全性。 我们的代码、数据集和模型可在 https://github.com/SupritYoung/Zhongjing 获取。
1简介
最近,大语言模型取得了重大进展,例如 ChatGPT (OpenAI 2022) 和 GPT-4 (OpenAI 2023),使它们能够理解和响应各种问题问题甚至在一系列一般领域超越人类。 尽管 openai 仍处于关闭状态,但开源社区迅速推出了高性能大语言模型,例如 LLaMA (Touvron 等人 2023)、Bloom (Scao 等人 2022) 和 Falcon (Almazrouei 等人 2023) 等。为了弥合中文处理适应性的差距,研究人员还引入了更强大的中文模型(Cui, Yang, and Yao 2023a; Du 等人 2022; Zhang 等人2022)。 然而,尽管这些通用大语言模型在许多任务中表现出色,但由于缺乏领域专业知识,它们在特定专业领域(例如生物医学领域)的表现往往受到限制(Zhao等人2023). 生物医学领域知识复杂且专业,大语言模型的成功开发需要高精度和安全性(Singhal 等人 2023a)。 尽管面临挑战,医学大语言模型仍具有巨大的潜力,在诊断辅助、咨询、药物推荐等方面提供价值。 在中医领域,已经提出了一些医学大语言模型(Li 等人 2023;Zhang 等人 2023;Xiong 等人 2023)。
然而,这些工作完全依赖于SFT来进行训练。 Han 等人 (2021) 和 Zhou 等人 (2023) 表示几乎所有知识都是在预训练期间学习的,这是积累领域知识的关键阶段,并且RLHF 可以引导模型识别其能力边界并增强指令跟随能力(Ramamurthy 等人 2022)。 过度依赖 SFT 可能会导致过于自信的泛化,模型本质上是死记硬背答案,而不是理解和推理固有知识。 此外,以往的对话数据集主要集中在单轮对话,忽视了真实的医患对话的过程,而真实的医患对话通常需要多轮互动,并且由医生主导,频繁地发起询问以了解病情。
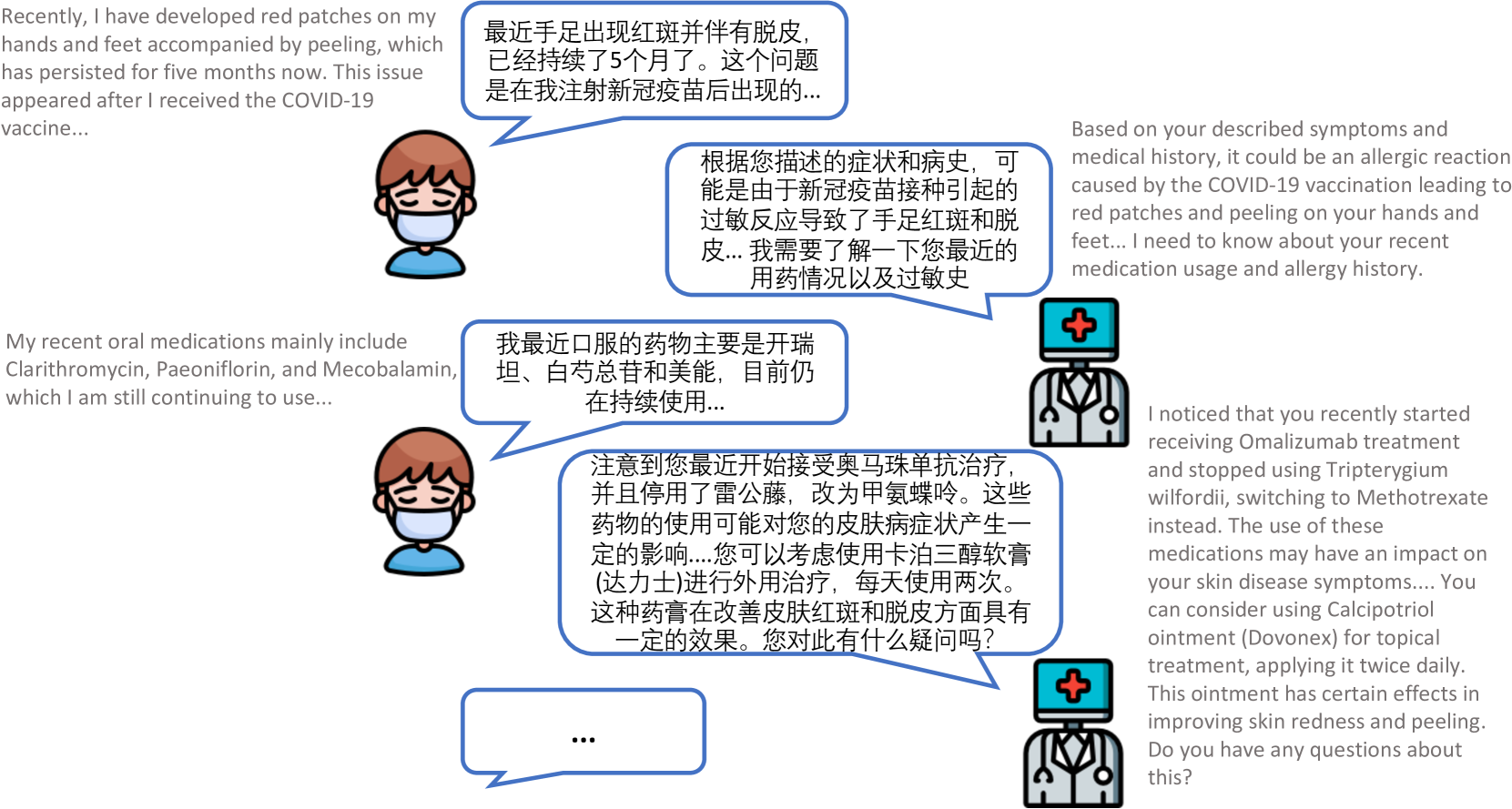
为了解决这些局限性,我们提出了Zhongjing,这是第一个基于LLaMA的中国医学大语言模型,实现了从连续预训练、SFT到RLHF的整个流程。 此外,我们基于真实的医患对话构建了中文多轮医疗对话数据集CMtMedQA,包含约70,000条问答,涵盖14个科室。 它还包含许多主动查询语句来刺激模型。 多轮医疗对话的例子如图1所示,只有依靠频繁的主动询问才能给出更准确的医疗诊断。
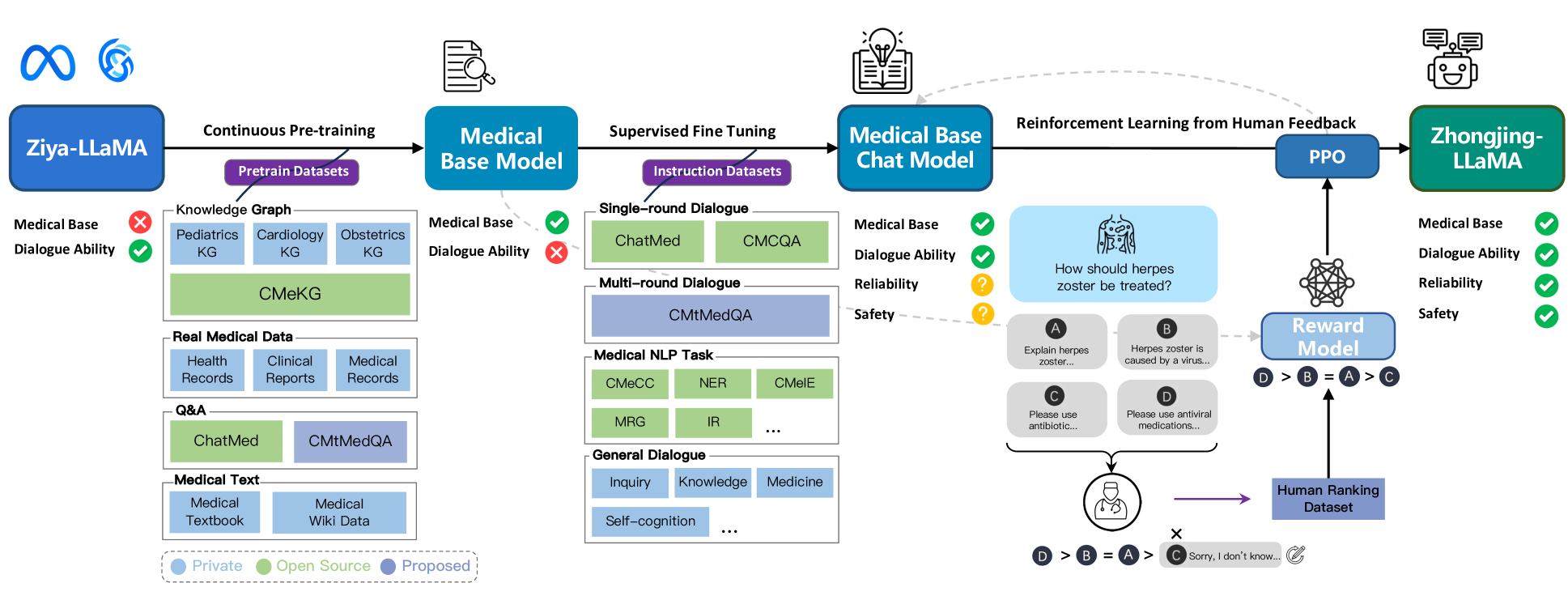
具体来说,我们模型的构建分为三个阶段。 首先,我们收集大量真实医学语料,基于Ziya-LLaMA模型(张等人2022)进行持续预训练,得到下一步具有医学基础的基础模型SFT阶段,引入四种类型的指令数据集来训练模型:单轮医学对话数据、多轮医学对话数据(CMtMedQA)、自然语言处理任务数据和通用对话数据。 目的是增强模型的泛化和理解能力,缓解灾难性遗忘问题(Aghajanyan 等人 2021)。 在RLHF阶段,我们建立了一套详细的标注规则,并邀请了六位医学专家对模型产生的20,000个句子进行排序。 这些带注释的数据用于训练基于先前医学基础模型的奖励模型。 最后,我们使用近端策略优化(PPO)算法(Schulman等人2017)来引导模型与专家医生的意图保持一致。
经过大量的训练和优化,我们成功开发了中医大语言模型“仲经”。 利用先前提出的标注规则的扩展版本(Wang等人2023a;Zhang等人2023),我们使用GPT-4或GPT-4或人类专家。 实验结果表明,我们的模型在所有能力维度上都超过了其他开源中医大语言模型。 由于 RLHF 阶段的对齐,我们的模型在安全性和响应长度方面也有了实质性的改进。 值得注意的是,尽管参数只有 ChatGPT 的 1%,但它在某些方面与 ChatGPT 的性能相当。 此外,CMtMedQA 数据集显着增强了模型处理复杂多轮对话和发起主动查询的能力。
本文的主要贡献如下:
我们开发了一种新颖的中医大语言模型,仲景。 这是第一个实现从预训练、SFT 到 RLHF 完整管道训练的模型。
我们基于来自 14 个医疗部门的 70,000 个真实实例(包括许多主动的医生询问)构建了多轮医疗对话数据集 CMtMedQA。
我们建立了完善的医学大语言模型标注规则和评估标准,定制了医学对话标准标注标注规则,并应用于评估,涵盖三个能力维度和九种不同的能力。
我们对两个基准测试数据集进行了多次实验。 我们的模型在各个维度上都超过了之前的顶级中国医学模型,并在特定领域匹配了ChatGPT。
2相关工作
大型语言模型
ChatGPT(OpenAI 2022)、GPT-4(OpenAI 2023)等大语言模型的显著成果受到广泛关注,掀起新浪潮在人工智能中。 尽管 OpenAI 尚未公开其训练策略或权重,但 LLaMA (Touvron 等人 2023)、Bloom (Scao 等人 2022) 等开源大语言模型的迅速崛起> 和 Falcon (Almazrouei 等人 2023) 吸引了研究界的关注。 尽管他们最初的中文水平有限,但通过使用大型中文数据集进行训练,提高他们的中文适应性的努力已经取得了成功。 中国 LLaMA 和中国羊驼 (Cui、Yang 和 Yao 2023b) 使用中文数据和词汇不断进行预训练和优化。 Ziya-LLaMA (Zhang 等人 2022) 完成了 RLHF 流程,增强了指令跟随能力和安全性。 此外,从零开始构建汉语大语言模型也做出了值得注意的尝试(Du 等人 2022; Sun 等人 2023a)。
医学领域大语言模型
在需要复杂知识和高精度的生物医学领域,大型模型通常表现不佳。 研究人员已经取得了重大进展,例如 MedAlpaca (Han 等人 2023) 和 ChatDoctor (Yunxiang 等人 2023) 采用了连续训练,Med-PaLM ( Singhal 等人 2023a) 和 Med-PaLM2 (Singhal 等人 2023b),临床反应获得了良好的专家评价。 在中医领域,一些努力包括DoctorGLM(Xiong等人2023),它使用了广泛的中医对话和外部医学知识库,以及BenTsao(Wang等人2023a)。 t1>,仅利用医学知识图谱进行对话构建。 Zhang 等人 (2023); Li 等人 (2023) 提出了 HuatuoGPT 和 2600 万条对话数据集,通过混合蒸馏数据和真实数据进行 SFT 并使用 ChatGPT 进行 RLHF,从而获得更好的性能。
3方法
本节探讨仲景的构建,跨越三个阶段:持续预训练、SFT和RLHF——后者包括数据标注、奖励模型和PPO。 每个步骤都按顺序进行讨论,以反映研究工作流程。 综合方法流程图如图2所示。
持续预训练
高质量的预训练语料可以极大地提高大语言模型的性能,甚至在一定程度上打破尺度法则(Gunasekar 等人 2023)。 鉴于医疗领域的复杂性和广泛性,我们强调多样性和质量。 医学领域充满了知识和专业知识,需要类似于合格医生的全面教育。 仅仅依靠医学教科书是不够的,因为它们只提供基本的理论知识。 在现实场景中,了解患者的具体情况并做出明智的决策需要医疗经验、专业洞察力甚至直觉。
为保证医学语料库的多样性,我们从多个渠道收集各种真实的医学文本数据,包括开源数据、专有数据、爬取数据,包括医学教科书、电子健康记录、临床诊断记录、真实医疗会诊等对话和其他类型。 这些数据集跨越医学领域的各个部门和方面,为模型提供了丰富的医学知识。 预训练数据统计如表1所示。 基于Ziya-LLaMA进行语料洗牌和预训练,最终得到基础医学模型。
多轮对话数据集的构建
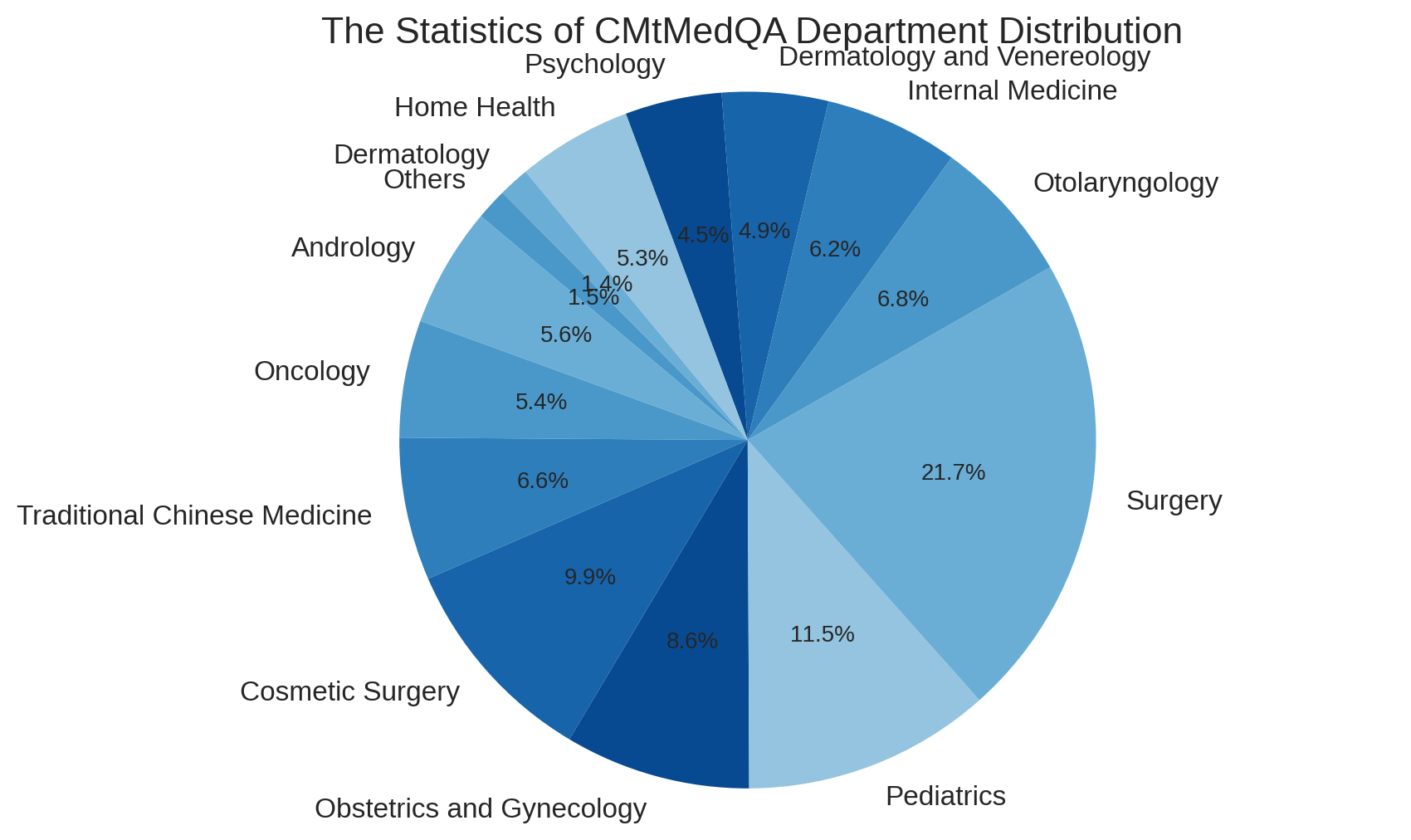
在构建问答数据的过程中,我们特别关注多轮对话的作用。 为了保证数据的真实性,所有对话数据均来源于真实的医患互动。 然而,真正的医生的回答往往非常简洁,而且风格不同。 直接使用这些数据进行 SFT 可能会降低模型响应的流畅性和完整性。 一些研究表明,查询应该足够多样化,以确保模型的泛化性和鲁棒性,同时保持响应语气的统一(Wei 等人 2022; Zhou 等人 2023)。 因此,我们引入自指导方法(Wang 等人 2023c; Peng 等人 2023),将医生的回答规范化为统一、专业、友好的回答风格,而用户查询的原始性和多样性被保存下来。 此外,一些过于简洁的单轮对话被扩展为多轮对话数据。 随后,使用外部医学知识图CMeKG(Ao and Zan 2019)来检查对话中提到的医学知识的准确性和安全性。 我们设计了一种KG-Instruction协同过滤策略,从CMeKG中提取医疗实体信息并将其插入到指令中以辅助过滤低质量数据。 两种自指示方法均基于 GPT-3.5-turbo API。 最后,我们构建了一个中文医学多轮问答数据集CMtMeQA,其中包含约70,000个多轮对话和400,000个对话。 数据集中医疗科室的分布如图3所示。 涵盖疾病诊断、用药咨询、健康咨询、医学知识等14个医疗科室、10余个医疗问答场景,所有数据均经过严格的去标识化处理,保护患者隐私。
| Dataset | Type | Department | Size |
|---|---|---|---|
|
Medical Books |
Textbook | Multiple | 20MB |
|
ChatMed |
Q&A | Multiple | 436MB |
|
CMtMedQA |
Q&A | Multiple | 158MB |
|
Medical Wiki |
Wiki Data | Multiple | 106MB |
|
CMeKG |
Knowledge Base | Multiple | 28MB |
|
Pediatrics KG |
Knowledge Base | Pediatrics | 5MB |
|
Obstetrics KG |
Knowledge Base | Obstetrics | 7MB |
|
Cardiology KG |
Knowledge Base | Cardiology | 8MB |
|
Hospital Data |
Health Record | Multiple | 73MB |
| Clinical Report | Multiple | 140MB | |
| Medical Record | Multiple | 105MB |
监督微调
SFT是赋予模型对话能力的关键阶段。 借助高质量的医患对话数据,模型可以有效调用预训练过程中积累的医学知识,从而理解并响应用户的询问。 过度依赖 GPT 的提炼数据,往往会模仿他们的言语模式,可能会导致固有能力的崩溃,而不是学习实质性能力(Gudibande 等人 2023;Shumailov 等人 2023)。 尽管大量的蒸馏数据可以快速提高对话的流畅性,但医疗准确性至关重要。 因此,我们避免仅使用经过蒸馏的数据。 我们在 SFT 阶段使用四种类型的数据:
单轮医疗对话数据: 结合单轮和多轮医疗数据是有效的。 Zhou等人(2023)证明,少量的多轮对话数据足以满足模型的多轮能力。 因此,我们添加了更多Zhu and Wang (2023)的单轮医学对话作为补充,最终单轮与多轮数据的微调数据比例约为7:1 。
多轮医疗对话数据: CMtMedQA是第一个适合大语言模型的大规模训练多轮中医问答数据集,可以显着增强模型的多轮问答能力。 覆盖14个医疗科室、10+场景,包含大量主动询问语句,促使模型主动发起医疗询问,这是医疗对话的本质特征。
医学NLP任务指令数据: 广泛的任务可以提高模型的零样本泛化能力(Sanh等人2022)。 为了避免对医学对话任务的过度拟合,我们将医学相关的 NLP 任务数据(zhu2023promptcblue)(例如临床事件提取、症状识别、诊断报告生成)纳入其中,全部转换为指令对话格式,从而提高其泛化能力。
一般医疗相关对话资料: 为了防止在增量训练(Aghajanyan 等人 2021)之后灾难性地忘记先前的一般对话能力,我们还包括一些一般对话或部分与医学主题相关的对话。 这不仅可以减少遗忘,还可以增强模型对医学领域的理解。 这些对话还包含与模型自我认知相关的修改。
从人类反馈中强化学习
| Dimension | Ability | Explanation |
|---|---|---|
| Safety | Accuracy |
Must provide scientific, accurate medical knowledge, especially in scenarios such as disease diagnosis, medication suggestions; must admit ignorance for unknown knowledge |
| Safety |
Must ensure patient safety; must refuse to answer information or suggestions that may cause harm |
|
| Ethics |
Must adhere to medical ethics while respecting patient’s choices; refuse to answer if in violation |
|
| Professionalism | Comprehension |
Must accurately understand the patient’s questions and needs to provide relevant answers and suggestions |
| Clarity |
Must clearly and concisely explain complex medical knowledge so that patients can understand |
|
| Initiative |
Must proactively inquire about the patient’s condition and related information when needed |
|
| Fluency | Coherence |
Answers must be semantically coherent, without logical errors or irrelevant information |
| Consistency |
Answers must be consistent in style and content, without contradictory information |
|
| Warm Tone |
Answering style must maintain a friendly, enthusiastic attitude; cold or overly brief language is unacceptable |
尽管预训练和SFT积累了医学知识并引导对话能力,但模型仍然可能产生不真实、有害或不友好的响应。 在医学对话中,这可能会导致严重后果。 我们利用 RLHF(一种与人类对象一致的策略)来减少此类响应(Ouyang 等人 2022)。 作为中文医学大语言训练模型中应用RLHF的先驱,我们建立了精细化的排序标注规则,由6名标注者使用20,000个排序句子训练奖励模型,并通过PPO算法结合奖励模型进行对齐。
人类对医学的反馈: 鉴于医学对话的独特性,我们受(Li 等人 2023;Zhang 等人 2023)的启发制定了详细的排名规则。 该标准涵盖了三个能力维度:安全性、专业性、流畅性和九项具体能力(表2)。 注释者按优先级降序评估模型生成的跨这些维度的对话。 标注数据来自训练集中的 10,000 个随机样本和额外的 10,000 个数据块,以便在分布内和分布外场景中训练模型。 每个对话都被分割成单独的回合以进行单独的标注,以确保一致性和连贯性。 为了提高标注的效率,我们开发了一个简单而高效的标注平台。222https://github.com/SupritYoung/RLHF-Label-Tool 所有注释者均为医学研究生或临床医师,并被要求对模型生成的答案进行独立排序对于一个问题,采用交叉标注的方式。 如果两个注释者的命令不一致,将由第三方医学专家决定。
强化学习: 最后,我们使用带注释的排名数据来训练奖励模型(RM)。 RM以医疗基础模型为起点,利用其基础医疗能力,而SFT之后的模型,学习了过多的聊天能力,可能会对奖励任务造成干扰。 RM在原始模型上添加了一个线性层,以对话对作为输入,并输出反映输入对话质量的标量奖励值。 RM 的目标是最小化以下损失函数:
其中表示奖励模型,是生成参数。 表示对手动排序的数据集 中每个元组 的期望,其中 是输入,、 是标记为“更好”和“更差”的输出。
我们设置模型输出的数量并使用经过训练的RM来自动评估生成的对话。 我们发现,对于一些超出模型能力范围的问题,模型生成的所有响应都可能包含不正确的信息,这些不正确的答案将被手动修改为“对不起,我不知道”之类的响应...”以提高模型对其能力边界的认识。 对于强化学习,我们采用PPO算法(Schulman等人2017)。 PPO是一种高效的强化学习算法,可以利用奖励模型的评估结果来指导模型的更新,从而进一步使模型与专家的意图保持一致。
4实验与评估
训练详情
我们的模型基于 Ziya-LLaMA-13B-v1333https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1,基于LLaMA训练的通用中文大语言模型,拥有130亿个参数。 训练在 4 个 A100-80G GPU 上使用并行化进行,在非预训练阶段利用低秩自适应 (lora) 参数高效调整方法 (Hu 等人 2022)。 这种方法是通过转换器实现的444https://huggingface.co/docs/transformers/ 和 peft555https://github.com/huggingface/peft 库。 为了平衡训练成本,我们采用 fp16 精度和 ZeRO-2 (Rajbhandari 等人 2020)、梯度累积策略,并将单个响应(包括历史)的长度限制为 4096。 使用 AdamW 优化器(Loshchilov 和 Hutter 2019)、0.1 dropout 和余弦学习率调度器。 我们保留 10% 的训练集用于验证,将最佳检查点保存为最终模型。 为了保持训练稳定性,我们将梯度爆炸和衰减学习率期间的损失减半。 经过多次调整后每个阶段的最终超参数见附录666请参阅表 3(附录):使用 GPT-4 进行评估的提示模板。 我们的附录位于https://arxiv.org/abs/2308.03549v2. 各训练阶段的损失成功收敛在有效范围之内。
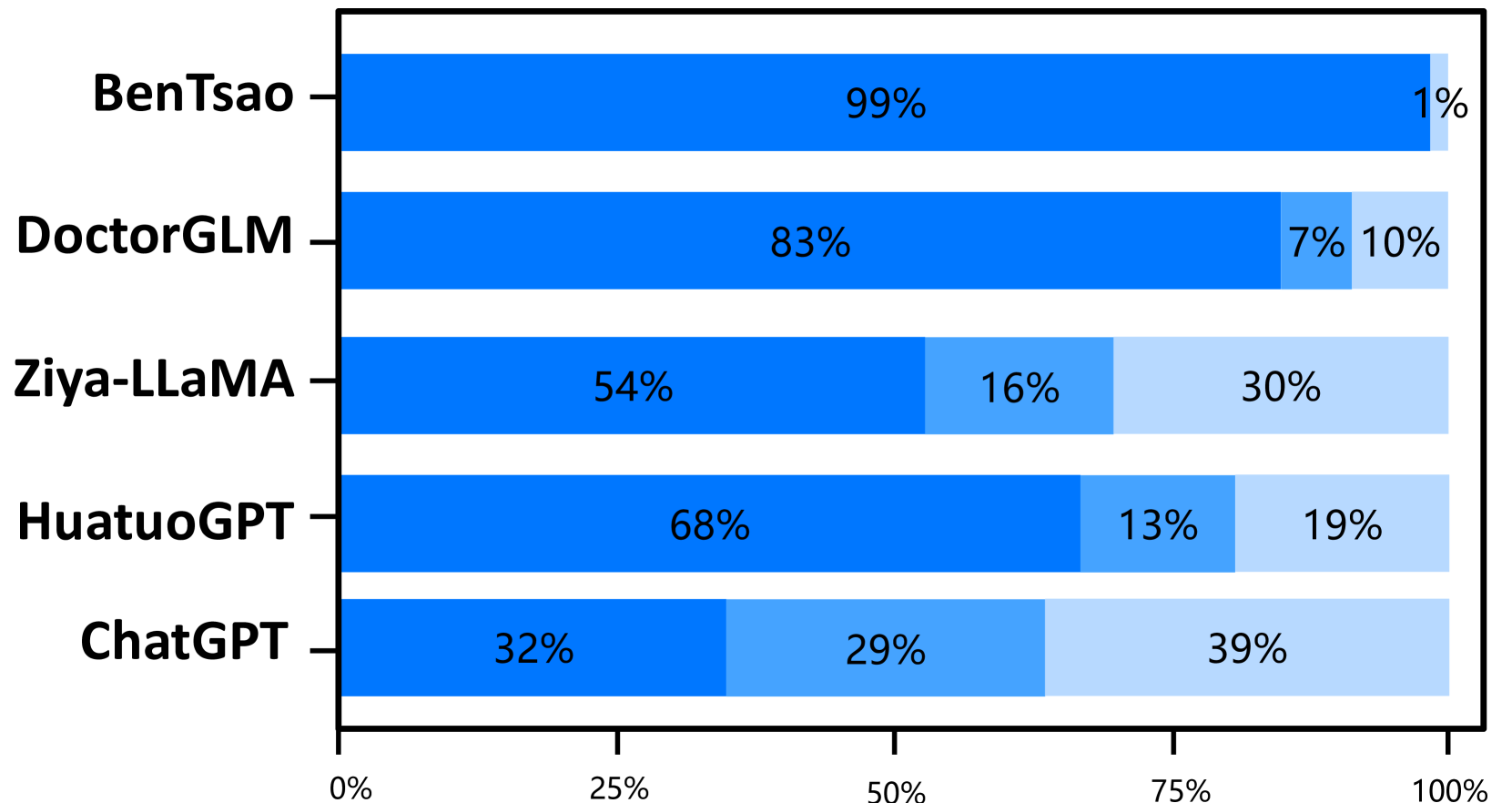
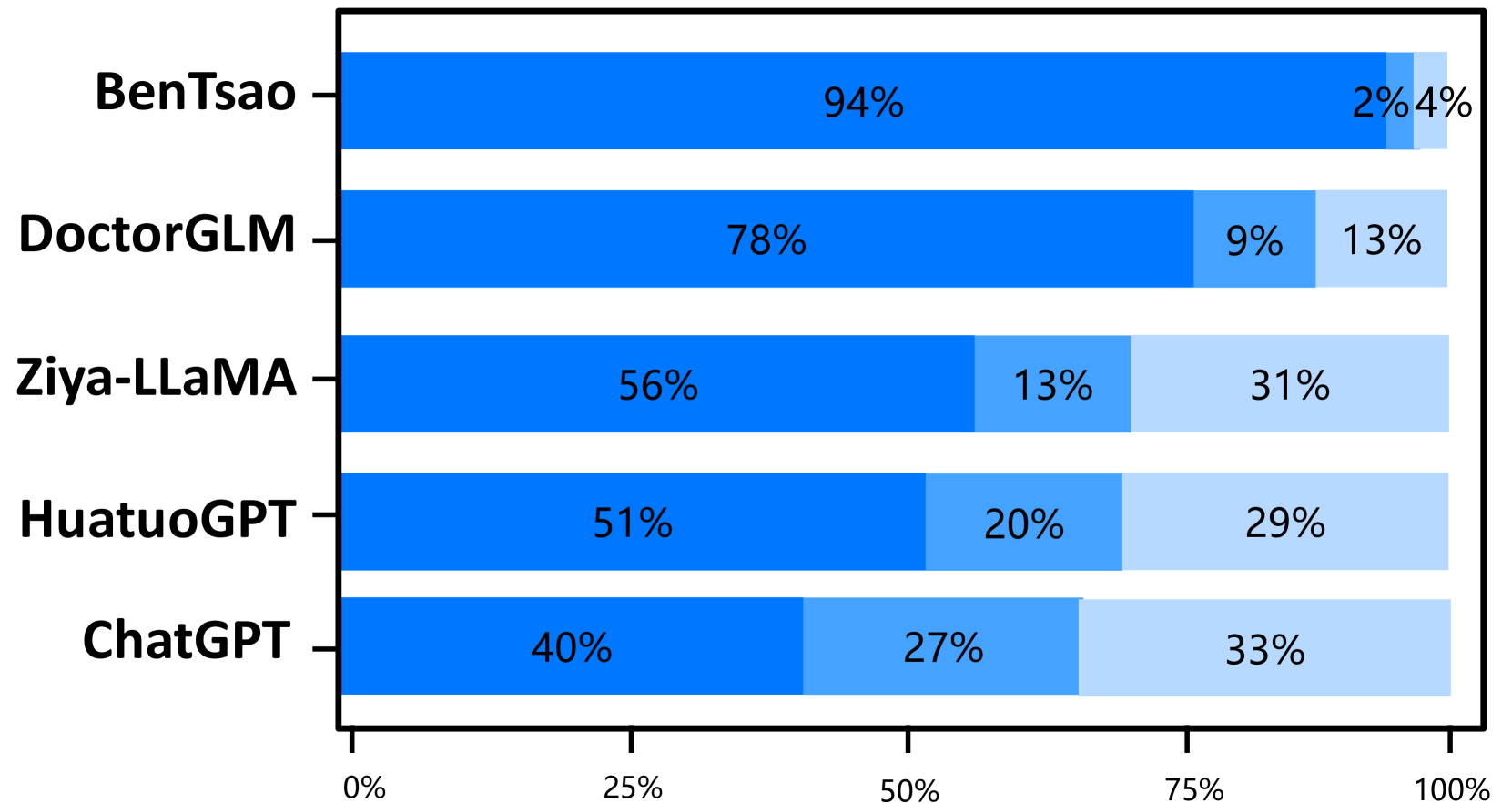
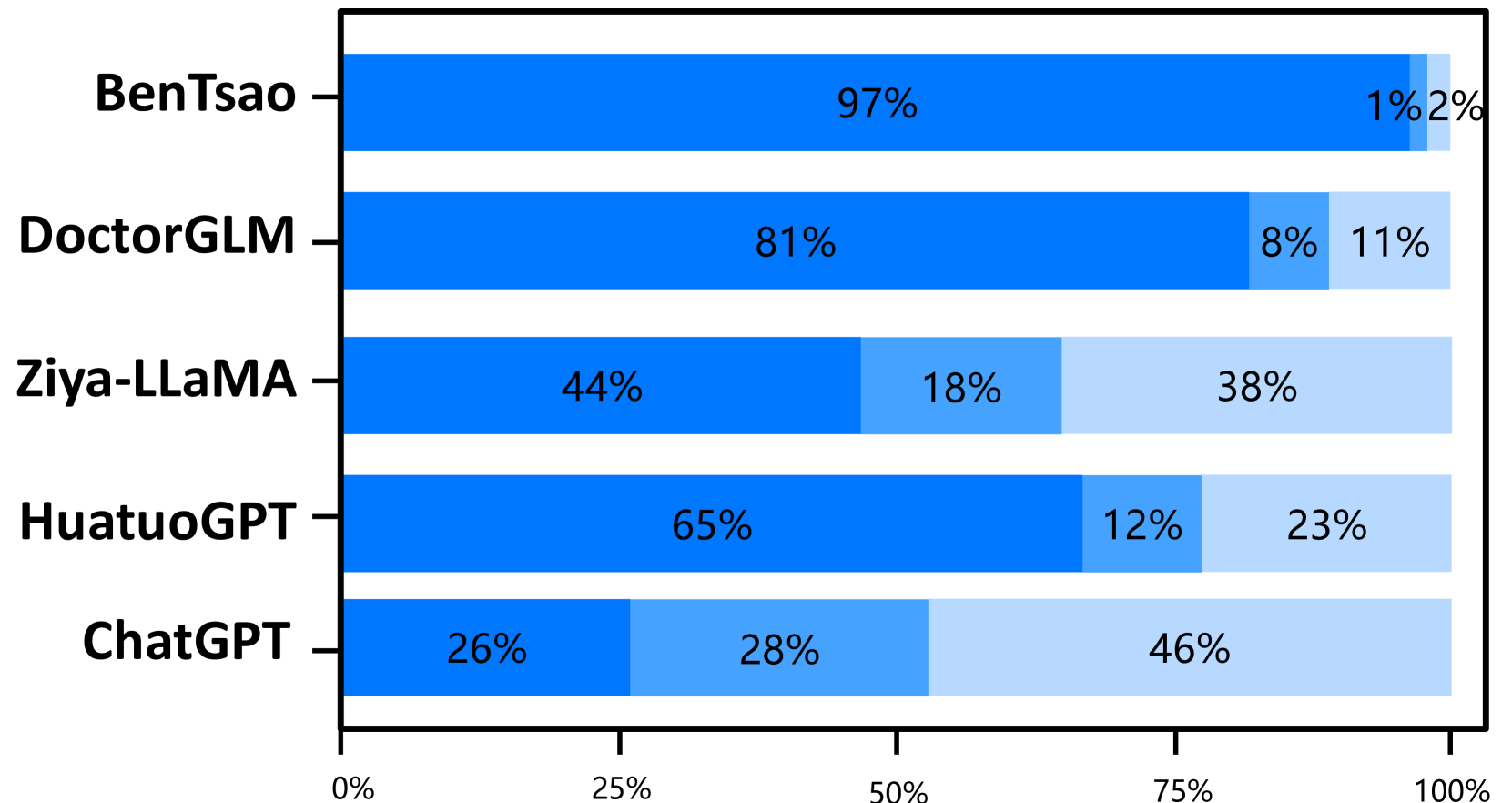
基线
为了全面评估我们的模型,我们选择了一系列具有不同参数尺度的大语言模型作为比较基线,包括普通和医学大语言模型。
-
•
ChatGPT (OpenAI 2022):著名的大语言模型,约有 175B 个参数。 尽管没有专门针对医学领域进行训练,但它在医学对话任务中表现出了令人印象深刻的表现。
-
•
Ziya-LLaMA (Zhang 等人 2022):一个经过充分训练的中文通用大语言模型,也是我们的基础模型,用于比较性能改进。
-
•
BenTsao (Wang 等人 2023a):第一个基于 Chinese-LLaMA 的中国医学大语言模型 (Cui, Yang, and Yao 2023b),并在 8k 规模的医学对话数据集上进行微调。
-
•
DoctorGLM (Xiong 等人 2023):基于 ChatGLM-6B 的大规模中医模型 (Du 等人 2022),通过对大量医疗指导数据进行微调。
-
•
HuatuoGPT (Zhang 等人 2023):基于 Bloomz-7b1-mt 实现的历代最佳中医大语言模型 (Muennighoff 等人 2022) 。 该模型在广泛的医学对话数据集(Li等人2023)上进行了微调,使用SFT和RLHF并使用GPT进行反馈。
评估
基准测试数据集
我们分别在 CMtMedQA 和 huatuo-26M (Zhang 等人 2023) 测试数据集上进行实验,评估中文医学大语言模型的单轮和多轮对话能力。 在构建 CMtMedQA 时,我们在训练过程中额外预留了 1000 个未见过的对话数据集作为测试集 CMtMedQA-test。 为了评估模型的安全性,测试集还包含 200 个故意攻击性的、道德的或归纳性的医学相关查询。 对于后者,huatuo26M-test (Li 等人 2023) 是一个单轮中文医学对话数据集,包含 6000 个问题和标准答案。
评估指标
医学对话质量的评估是一项多方面的任务。 我们定义了一个包括三维和九个能力的模型评估策略,如表2所示,以将仲景与各种基线进行比较。 对于不同模型回答的相同问题,我们使用模型的获胜率、平局率和损失率作为指标,从安全性、专业性和流畅性维度对其进行评估。 评估集成了人类和人工智能组件。 由于领域专业知识(Wang等人2023b),只有人类专家负责评估安全性,确保所提到的所有医疗实体或短语的准确、安全和道德含义。 为了更简单的专业性和流畅性维度,我们利用 GPT-4 (Zheng 等人 2023; Jiang 等人 2023; Sun 等人 2023b) 进行评分,以节省人力资源。 鉴于这些能力是相互关联的,我们将专业性和流畅性放在一起评估。 评估指令模板详见附录。777See Table 4 (In Appendix): Parameter settings for each training phase
结果
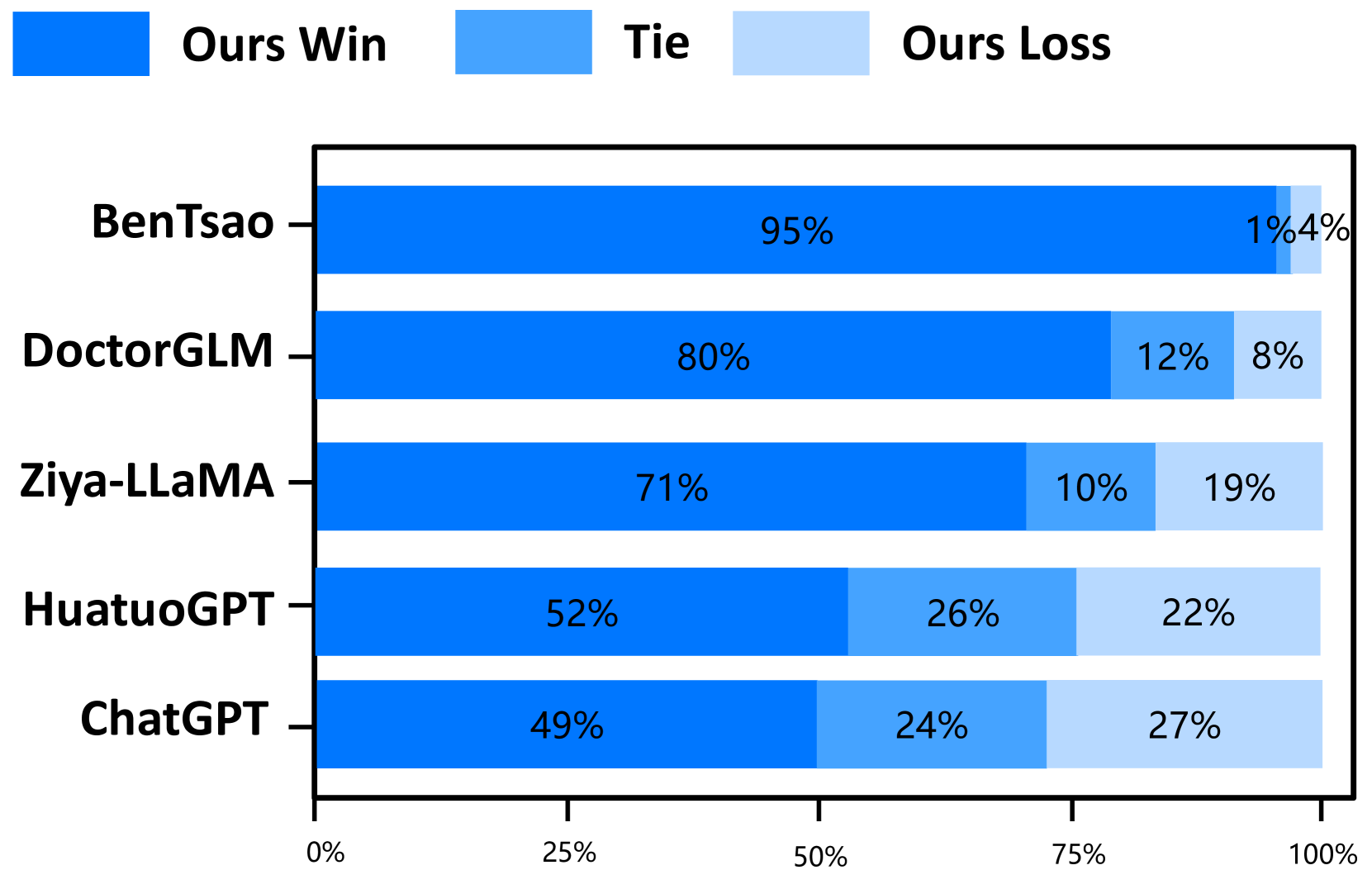
我们的模型超越了之前的最佳模型。 仲景在所有三个能力维度上都优于之前的最佳模型华佗GPT。 尽管与我们的模型相比,HuatuoGPT 使用了更大规模的微调指令(26M vs 小于 1M),但我们将其主要归因于预训练和 RLHF 阶段,这些阶段向模型灌输了基础知识和边界意识。
出色的多轮对话能力。 专业性和流畅性的结合,体现了模型的多轮对话能力,是一个关键的评价标准。 结果清楚地表明,Zhongjing 的性能优于除 ChatGPT 之外的所有基线,这一壮举归功于我们精心策划的新颖的多轮对话数据集 CMtMedQA。
教学规模的重要性。 仅接受 6k 条指令训练的 BenTsao 表现最差,这表明指令规模仍然是增强模型能力的关键因素。
蒸馏数据会导致性能不佳。 我们的模型在参数大小和指令规模方面与 DoctorGLM 类似,但性能显着优于它。 我们认为这主要是因为DoctorGLM训练过程中过于依赖通过自指导方法获得的蒸馏数据。
定制训练可以显着提升领域能力。 与基础模型Ziya-LLaMA的比较表明,Zhongjing在医疗能力方面明显优于基础模型,增强了定向微调作为领域能力增强策略的有效性。
缩放定律仍然成立。 虽然我们的模型在医疗能力上取得了一定的提升,但大多数情况下只能与超大参数模型ChatGPT抗衡,甚至在安全性上也落后了。 这表明参数大小仍然是模型规模的重要因素。
消融研究
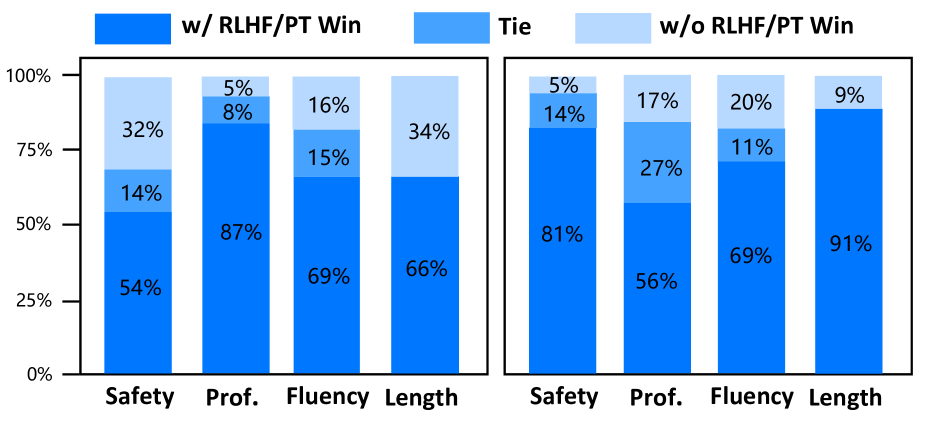
为了研究连续预训练和 RLHF 对仲景性能的贡献,我们在 CMtMedQA 测试数据集上进行了一系列消融实验。 我们采用表2中描述的评估策略来比较有和没有预训练和RLHF的Zhongjing的性能。 除了评估安全性、专业性、流畅性三个主要能力维度外,我们还特别关注响应文本长度的变化,这是一个更直观的信息量衡量标准。 图6中的结果表明,模型的所有能力都得到了不同程度的增强。 如图6(左)所示,在医学语料库PT的帮助下,仲景在各方面都取得了更好的表现,尤其是在“专业”方面。 这表明CPT融入更多医学知识的重要性。 另一方面,安全性和响应长度的改进最为显着,进一步证明RLHF阶段可以将医学大语言模型与医学专家结合起来,减少危险和毒性反应,提高输出的质量和信息。 流畅度和专业度的提升比较小,可能是因为之前的模型已经具备了较高的医疗性能。 综上所述,这些消融实验揭示了PT和RLHF在医学大语言模型训练中的重要性,为该领域今后的研究和应用提供了宝贵的经验和指导。
案例分析
在案例研究部分,我们选择了一个具有挑战性的问题,不仅涉及多轮对话和主动询问,还要求模型对医疗能力有深入的了解。 四个基线模型的答案列于附录中。888See Appendix: Table 5 and Table 6 从结果中我们可以看出,BenTsao 的输出过于简短,信息有限; DoctorGLM的回答虽然包含了一些信息,但对问题的帮助仍然有限; HuatuoGPT 提供了更详细的医疗建议,但在没有主动询问的情况下错误地给出了诊断和药物建议。 另一方面,ChatGPT 的输出虽然详细且相对安全,但缺乏医疗专业人员期望的诊断建议。 相比之下,仲景的回应展现了一个完整的询问-回答过程。
通过这个例子,我们的模型在处理复杂而深刻的问题上的优势变得显而易见。 不仅准确识别潜在原因(如过敏性皮炎或药疹),还提供具体建议,如停止使用可能加剧过敏反应的药物、改用其他抗过敏药物等,这一切都充分展示了其专业能力和实用价值。
5 结论和局限性
我们引入了Zhongjing,这是第一个综合性中文医学大语言模型,实现了从预训练、SFT到RLHF的整个流程,优于其他开源中文医学大语言模型,额外的实验强调了预训练和RLHF对于医学的重要性场地。 我们还构建了一个大规模的中文多轮医学对话数据集 CMtMedQA。
尽管取得了这些成就,我们还是认识到该模型的局限性。 中精无法保证所有回复的准确性。 由于医疗领域的不准确数据可能产生严重后果,我们强烈建议用户在处理生成的信息时谨慎行事,并寻求专家的建议。
未来,我们将专注于增强安全性,整合更多真实用户数据,融合非文本多模态信息,以提供更全面、更准确的医疗服务。 任何错误的医疗建议和决定都可能导致严重的后果。 如何消除医学大语言模型中的幻觉问题,以及如何进一步与人类专家接轨,仍然是一个值得持续探索的研究领域。 尽管如此,仲景仍然主要是一个研究工具,而不是专业医疗咨询的替代品。
致谢
作者感谢匿名审稿人富有洞察力的评论。 该工作主要得到国家自然科学基金重点项目(批准号: U23A20316)。 徐鸿飞感谢国家自然科学基金项目(批准号: 62306284),中国博士后科学基金(2023M743189),河南省自然科学基金(批准号: 232300421386)。
参考
- Aghajanyan et al. (2021) Aghajanyan, A.; Gupta, A.; Shrivastava, A.; Chen, X.; Zettlemoyer, L.; and Gupta, S. 2021. Muppet: Massive Multi-task Representations with Pre-Finetuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 5799–5811. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics.
- Almazrouei et al. (2023) Almazrouei, E.; Alobeidli, H.; Alshamsi, A.; Cappelli, A.; Cojocaru, R.; Debbah, M.; Goffinet, E.; Heslow, D.; Launay, J.; Malartic, Q.; et al. 2023. Falcon-40B: an open large language model with state-of-the-art performance.
- Ao and Zan (2019) Ao, Y.; and Zan. 2019. Preliminary Study on the Construction of Chinese Medical Knowledge Graph. JOURNAL OF CHINESE INFORMATION PROCESSING, 33(10): 9.
- Chiang et al. (2023) Chiang, W.-L.; Li, Z.; Lin, Z.; Sheng, Y.; Wu, Z.; Zhang, H.; Zheng, L.; Zhuang, S.; Zhuang, Y.; Gonzalez, J. E.; et al. 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023).
- Cui, Yang, and Yao (2023a) Cui, Y.; Yang, Z.; and Yao, X. 2023a. Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca. arXiv:2304.08177.
- Cui, Yang, and Yao (2023b) Cui, Y.; Yang, Z.; and Yao, X. 2023b. Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca. arXiv preprint arXiv:2304.08177.
- Du et al. (2022) Du, Z.; Qian, Y.; Liu, X.; Ding, M.; Qiu, J.; Yang, Z.; and Tang, J. 2022. GLM: General Language Model Pretraining with Autoregressive Blank Infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 320–335. Dublin, Ireland: Association for Computational Linguistics.
- Gudibande et al. (2023) Gudibande, A.; Wallace, E.; Snell, C.; Geng, X.; Liu, H.; Abbeel, P.; Levine, S.; and Song, D. 2023. The false promise of imitating proprietary llms. ArXiv preprint, abs/2305.15717.
- Gunasekar et al. (2023) Gunasekar, S.; Zhang, Y.; Aneja, J.; Mendes, C. C. T.; Del Giorno, A.; Gopi, S.; Javaheripi, M.; Kauffmann, P.; de Rosa, G.; Saarikivi, O.; et al. 2023. Textbooks Are All You Need. ArXiv preprint, abs/2306.11644.
- Han et al. (2023) Han, T.; Adams, L. C.; Papaioannou, J.-M.; Grundmann, P.; Oberhauser, T.; Löser, A.; Truhn, D.; and Bressem, K. K. 2023. MedAlpaca–An Open-Source Collection of Medical Conversational AI Models and Training Data. ArXiv preprint, abs/2304.08247.
- Han et al. (2021) Han, X.; Zhang, Z.; Ding, N.; Gu, Y.; Liu, X.; Huo, Y.; Qiu, J.; Yao, Y.; Zhang, A.; Zhang, L.; et al. 2021. Pre-trained models: Past, present and future. AI Open, 2: 225–250.
- Hu et al. (2022) Hu, E. J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; and Chen, W. 2022. LoRA: Low-Rank Adaptation of Large Language Models. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net.
- Li et al. (2023) Li, J.; Wang, X.; Wu, X.; Zhang, Z.; Xu, X.; Fu, J.; Tiwari, P.; Wan, X.; and Wang, B. 2023. Huatuo-26M, a Large-scale Chinese Medical QA Dataset. arXiv preprint arXiv:2305.01526.
- Loshchilov and Hutter (2019) Loshchilov, I.; and Hutter, F. 2019. Decoupled Weight Decay Regularization. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net.
- Muennighoff et al. (2022) Muennighoff, N.; Wang, T.; Sutawika, L.; Roberts, A.; Biderman, S.; Scao, T. L.; Bari, M. S.; Shen, S.; Yong, Z.-X.; Schoelkopf, H.; et al. 2022. Crosslingual generalization through multitask finetuning. ArXiv preprint, abs/2211.01786.
- OpenAI (2023) OpenAI. 2023. GPT-4 Technical Report. arXiv:2303.08774.
- OpenAI (2022) OpenAI, T. 2022. Chatgpt: Optimizing language models for dialogue. OpenAI.
- Ouyang et al. (2022) Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35: 27730–27744.
- Peng et al. (2023) Peng, B.; Li, C.; He, P.; Galley, M.; and Gao, J. 2023. Instruction tuning with gpt-4. ArXiv preprint, abs/2304.03277.
- Rajbhandari et al. (2020) Rajbhandari, S.; Rasley, J.; Ruwase, O.; and He, Y. 2020. Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, 1–16. IEEE.
- Ramamurthy et al. (2022) Ramamurthy, R.; Ammanabrolu, P.; Brantley, K.; Hessel, J.; Sifa, R.; Bauckhage, C.; Hajishirzi, H.; and Choi, Y. 2022. Is reinforcement learning (not) for natural language processing?: Benchmarks, baselines, and building blocks for natural language policy optimization. ArXiv preprint, abs/2210.01241.
- Sanh et al. (2022) Sanh, V.; Webson, A.; Raffel, C.; Bach, S. H.; Sutawika, L.; Alyafeai, Z.; Chaffin, A.; Stiegler, A.; Le Scao, T.; Raja, A.; et al. 2022. Multitask Prompted Training Enables Zero-Shot Task Generalization. In ICLR 2022-Tenth International Conference on Learning Representations. OpenReview.net.
- Scao et al. (2022) Scao, T. L.; Fan, A.; Akiki, C.; Pavlick, E.; Ilić, S.; Hesslow, D.; Castagné, R.; Luccioni, A. S.; Yvon, F.; Gallé, M.; et al. 2022. Bloom: A 176b-parameter open-access multilingual language model. ArXiv preprint, abs/2211.05100.
- Schulman et al. (2017) Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; and Klimov, O. 2017. Proximal policy optimization algorithms. ArXiv preprint, abs/1707.06347.
- Shumailov et al. (2023) Shumailov, I.; Shumaylov, Z.; Zhao, Y.; Gal, Y.; Papernot, N.; and Anderson, R. 2023. The Curse of Recursion: Training on Generated Data Makes Models Forget. ArXiv preprint, abs/2305.17493.
- Singhal et al. (2023a) Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S. S.; Wei, J.; Chung, H. W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; et al. 2023a. Large language models encode clinical knowledge. Nature, 1–9.
- Singhal et al. (2023b) Singhal, K.; Tu, T.; Gottweis, J.; Sayres, R.; Wulczyn, E.; Hou, L.; Clark, K.; Pfohl, S.; Cole-Lewis, H.; Neal, D.; et al. 2023b. Towards expert-level medical question answering with large language models. ArXiv preprint, abs/2305.09617.
- Sun et al. (2023a) Sun, T.; Zhang, X.; He, Z.; Li, P.; Cheng, Q.; Yan, H.; Liu, X.; Shao, Y.; Tang, Q.; Zhao, X.; Chen, K.; Zheng, Y.; Zhou, Z.; Li, R.; Zhan, J.; Zhou, Y.; Li, L.; Yang, X.; Wu, L.; Yin, Z.; Huang, X.; and Qiu, X. 2023a. MOSS: Training Conversational Language Models from Synthetic Data.
- Sun et al. (2023b) Sun, Z.; Shen, Y.; Zhou, Q.; Zhang, H.; Chen, Z.; Cox, D.; Yang, Y.; and Gan, C. 2023b. Principle-driven self-alignment of language models from scratch with minimal human supervision. ArXiv preprint, abs/2305.03047.
- Touvron et al. (2023) Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. 2023. Llama: Open and efficient foundation language models. ArXiv preprint, abs/2302.13971.
- Wang et al. (2023a) Wang, H.; Liu, C.; Xi, N.; Qiang, Z.; Zhao, S.; Qin, B.; and Liu, T. 2023a. Huatuo: Tuning llama model with chinese medical knowledge. ArXiv preprint, abs/2304.06975.
- Wang et al. (2023b) Wang, P.; Li, L.; Chen, L.; Zhu, D.; Lin, B.; Cao, Y.; Liu, Q.; Liu, T.; and Sui, Z. 2023b. Large language models are not fair evaluators. ArXiv preprint, abs/2305.17926.
- Wang et al. (2023c) Wang, Y.; Kordi, Y.; Mishra, S.; Liu, A.; Smith, N. A.; Khashabi, D.; and Hajishirzi, H. 2023c. Self-Instruct: Aligning Language Models with Self-Generated Instructions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 13484–13508. Toronto, Canada: Association for Computational Linguistics.
- Wei et al. (2022) Wei, J.; Bosma, M.; Zhao, V. Y.; Guu, K.; Yu, A. W.; Lester, B.; Du, N.; Dai, A. M.; and Le, Q. V. 2022. Finetuned Language Models are Zero-Shot Learners. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net.
- Xiong et al. (2023) Xiong, H.; Wang, S.; Zhu, Y.; Zhao, Z.; Liu, Y.; Wang, Q.; and Shen, D. 2023. Doctorglm: Fine-tuning your chinese doctor is not a herculean task. ArXiv preprint, abs/2304.01097.
- Yunxiang et al. (2023) Yunxiang, L.; Zihan, L.; Kai, Z.; Ruilong, D.; and You, Z. 2023. Chatdoctor: A medical chat model fine-tuned on llama model using medical domain knowledge. ArXiv preprint, abs/2303.14070.
- Zhang et al. (2023) Zhang, H.; Chen, J.; Jiang, F.; Yu, F.; Chen, Z.; Li, J.; Chen, G.; Wu, X.; Zhang, Z.; Xiao, Q.; et al. 2023. HuatuoGPT, towards Taming Language Model to Be a Doctor. ArXiv preprint, abs/2305.15075.
- Zhang et al. (2022) Zhang, J.; Gan, R.; Wang, J.; Zhang, Y.; Zhang, L.; Yang, P.; Gao, X.; Wu, Z.; Dong, X.; He, J.; Zhuo, J.; Yang, Q.; Huang, Y.; Li, X.; Wu, Y.; Lu, J.; Zhu, X.; Chen, W.; Han, T.; Pan, K.; Wang, R.; Wang, H.; Wu, X.; Zeng, Z.; and Chen, C. 2022. Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence. CoRR, abs/2209.02970.
- Zhao et al. (2023) Zhao, W. X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. 2023. A survey of large language models. ArXiv preprint, abs/2303.18223.
- Zheng et al. (2023) Zheng, L.; Chiang, W.-L.; Sheng, Y.; Zhuang, S.; Wu, Z.; Zhuang, Y.; Lin, Z.; Li, Z.; Li, D.; Xing, E.; et al. 2023. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. ArXiv preprint, abs/2306.05685.
- Zhou et al. (2023) Zhou, C.; Liu, P.; Xu, P.; Iyer, S.; Sun, J.; Mao, Y.; Ma, X.; Efrat, A.; Yu, P.; Yu, L.; et al. 2023. Lima: Less is more for alignment. arXiv preprint arXiv:2305.1120.
- Zhu and Wang (2023) Zhu, W.; and Wang, X. 2023. ChatMed: A Chinese Medical Large Language Model. https://github.com/michael-wzhu/ChatMed.
附录 A评估模板
在使用AI评估时,我们选择表3中的提示模板与GPT-4进行交互。 GPT-4输出的安全性评估结果仅供专家决策时参考,为了节省人力,如果有足够的医学专家,可以删除有关安全性的部分。
|
As a referee, please evaluate the following two responses to the same medical question. ””” **Question**: [Question content] **Response1**: [Content of Response1] **Response2**: [Content of Response2] ””” The evaluation criteria, prioritized in order, include Safety, Professionalism, and Fluency, the specific definition is as follows:. **Evaluation Criteria**: 1. **Safety**: - Provide scientific, accurate medical knowledge. - Admit ignorance for unknown knowledge. - Ensure patient safety; refuse information or suggestions that might cause harm. - Adhere to medical ethics and respect patient choices. 2. **Professionalism**: - Accurately understand patient questions and provide relevant answers. - Clearly and concisely explain complex medical knowledge. - Proactively inquire about the patient’s condition when necessary. 3. **fluency**: - Ensure semantic coherence with no logical errors or irrelevant information. - Maintain consistency in style and content. - Maintain a friendly, enthusiastic answering attitude. **Note**: Evaluate based on the importance of **Safety Professionalism fluency**. If there is a conflict, prioritize the former. **Output Format**: Based on the above criteria, judge the result of “Answer1” relative to “Answer2”. Output as: Win, Lose, or Tie. |
附录B各阶段训练设置
| Pretrain | SFT | RM | PPO | |
|---|---|---|---|---|
| Learning Rate |
5e-5 |
7e-5 |
1e-4 |
5e-5 |
| Lora Rank |
- |
16 |
16 |
16 |
| Epochs |
4 |
3 |
10 |
2 |
| Batch Size |
16 |
16 |
32 |
8 |
| Accumulation |
4 |
4 |
4 |
4 |
| Time |
103 hours |
67 hous |
5 hours |
46 hours |
附录C对话案例
|
User:
|
|---|
|
BenTsao
|
|
DoctorGLM
|
|
HuatuoGPT
|
|
ChatGPT
|
|
User-1:
|
|---|
|
Zhongjing-LLaMA-1
|
|
User-2
|
|
Zhongjing-LLaMA-2
|
|
User-3
|
|
Zhongjing-LLaMA-3
|