用于高效视频理解的时间自适应模型
摘要
空间卷积111在这项工作中,我们交替使用空间卷积和二维卷积。 广泛应用于众多深度视频模型中。 它从根本上假设时空不变性,即,对不同帧中的每个位置使用共享权重。 这项工作提出了用于视频理解的时间自适应卷积(TAdaConv),这表明沿时间维度的自适应权重校准是促进视频中复杂时间动态建模的有效方法。 具体来说,TAdaConv 通过根据局部和全局时间上下文校准每个帧的卷积权重,为空间卷积提供时间建模能力。 与现有的时间建模操作相比,TAdaConv 更高效,因为它对卷积核而不是特征进行操作,特征的维度比空间分辨率小一个数量级。 此外,内核校准带来了模型容量的增加。 基于这种易于插入的操作TAdaConv及其扩展即TAdaConvV2,我们构建了TAdaBlocks,使ConvNeXt和Vision Transformer具有强大的时间建模能力。 实证结果表明,在各种视频理解基准测试中,TAdaConvNeXtV2 和 TAdaFormer 的表现与最先进的卷积和基于 Transformer 的模型相比具有竞争力。 我们的代码和模型发布于:https://github.com/alibaba-mmai-research/TAdaConv。
索引术语:
动态网络、高效视频理解、动作识别、时间自适应卷积、时间自适应 Transformer
1 简介
卷积是现代深度视觉模型中不可或缺的操作[1,2,3,4],其不同的变体推动了卷积神经网络(CNN)在许多领域的最先进性能视觉任务[5,6,7,8,9]和应用场景[10,11]。 在视频范式中,与 3D 卷积[12]相比,2D 空间卷积和 1D 时间卷积的组合由于其效率[13, 14]而受到更广泛的青睐>。 然而,一维时间卷积在空间卷积之上引入了不可忽略的计算开销。 因此,我们寻求直接为空间卷积配备时间建模能力。
卷积的一个基本属性是平移不变性 [15, 16],这是由其局部连通性和共享权重产生的。 然而,动态过滤方面的最新研究表明,对于对各种空间内容进行建模,所有像素的严格分片权重可能不是最佳的[17, 18]。
鉴于视频中时间动态的多样性,我们假设时间建模可以受益于沿时间维度的宽松不变性。 这意味着不同时间步长的卷积权重不再严格共享。 现有的动态滤波器网络可以实现这一点,但有两个缺点。 (i) 对于大多数人来说[17, 11]很难利用预训练的权重,这在视频应用中至关重要,因为从头开始训练视频模型非常困难资源要求高[19, 20]并且容易在小数据集上过度拟合。 (ii) 对于大多数动态滤波器,权重是根据其空间上下文 [17, 21] 或全局描述符 [22, 11]< 生成的/t2>,它无法捕获帧之间的细粒度时间变化。
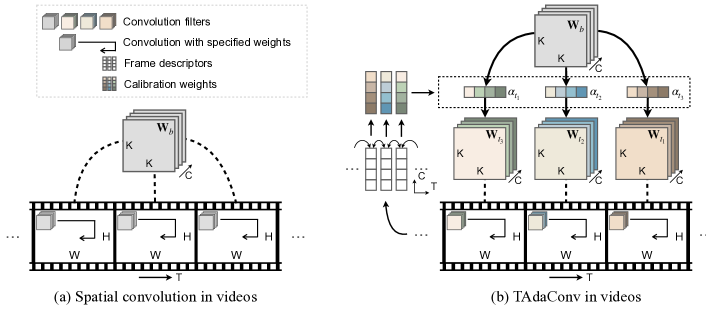
受此启发,我们提出了用于视频理解的时间自适应卷积(TAdaConv),其中卷积权重在不同帧之间不再固定。 具体来说,第帧的卷积核被分解为基本权重和校准权重的乘积:,其中基本权重是可学习的,校准权重是根据基本权重中的输入数据自适应生成的。 对于每一帧,我们根据其相邻时间步的帧描述符以及全局描述符生成校准权重,这有效地对视频中的局部和全局时间动态进行编码。 TAdaConv 和标准卷积之间的差异如图 1 所示。
这种分解的主要优点有三个:(i) TAdaConv 可以轻松插入任何现有模型以增强时间建模,并且仍然可以利用它们的预训练权重; (ii)借助时间自适应权重可以极大地提高时间建模能力; (iii) 与通常在学习到的 2D 特征图上操作的时间卷积相比,TAdaConv 通过直接在卷积核上操作,效率更高。
TAdaConv 被提议作为现有模型中卷积的直接替代品。 这项工作的预备知识版本[23]发布在 ICLR 2022 上,其中 TAdaConv 展示了强大的时间建模能力,为基于图像的模型以及现有视频模型带来了显着的性能提升。 在这项工作中,我们遵循 TAdaConv 的概念思想,并在结构设计以及模型和数据缩放方面对基本知识版本进行了改进。 在结构设计方面,我们对TAdaConv进行了以下几个方面的优化:(i)在操作层面,优化了TAdaConv的校准因子生成过程,其中多头自注意力[ 24]被引入用于对视频的全局信息进行建模。 (ii) 在块级别,我们通过引入高效的时间特征聚合来构建更强大的 TAdaBlocks,我们用它来构建我们的卷积模型 TAdaConvNeXtV2 和 Transformer TAdaFormer。 我们的实证结果表明,我们对以场景和运动为中心的基准的修改带来了显着的改进。 基于 TAdaConvNeXtV2 和 TAdaFormer,我们进一步扩大了模型和数据规模,这使得性能与现有最先进的方法相比具有竞争力。
2 相关工作
用于视频理解的卷积模型。 早期的卷积模型通过3D卷积[25,12,20,26]或双流网络[27]获得时空表示。 为了提高效率,最近的网络建立在 2D 网络的基础上,并设计了用于时间建模的附加操作[28,29,30,13,31,32,33,34,35],其中 2D 卷积的权重在不同的时间戳之间共享。 我们的预备知识版本[23]发现消除这个约束会带来更强的时间建模能力。 在这项工作中,我们根据 ConvNeXt [36] 对卷积模型进行现代化改造,并构建了一个更强的用于视频理解的卷积模型。
用于视频理解的 Vision Transformer。 随着 Transformers 在自然语言处理方面取得的巨大成功[24,37,38],Vision Transformers (ViT)[39]在各种视觉任务中展现出强劲的表现[40, 41, 42, 43, 44, 45, 46] 包括视频理解[47, 48, 49, 50, 51, 52, 53]。 当 ViT 在图像 [54, 55]、视频 [56, 57, 58] 或多语料库上进行预训练时,其能力得到进一步增强。模态数据[59, 60],或当模型尺寸增加时[61, 62],或两者[63, 64]。 由于直接使用视频数据进行预训练既耗时又耗资源,因此另一种方法是利用在大规模图像数据上预训练的模型,并为模型提供用于时间建模的彻底附加结构,例如时间 [50]或3D窗口自注意力[48],时空适配器[65],等。 在我们的工作中,我们利用在大型图像文本数据集[59]上预训练的普通 Vision Transformer,并通过我们的 TAdaBlock 为其配备强大的时间建模能力。
动态网络。 动态网络是指具有内容自适应权重或模块的网络,例如动态滤波器/卷积[21, 11, 66, 17],动态激活[67, 68] ,以及动态路由[69, 70],等。 与静态任务相比,它们在各种任务[71,72,73,74]以及视频理解[31,75,76,77]. 最近的一些空间自适应卷积[78, 79]显示放松的空间不变性可以帮助建模不同的视觉内容,我们的预备知识版本[23]显示视频理解可以受益于放松时间不变性。 这项工作通过引入多头自注意力进行全局时间建模,进一步利用了这个想法并增强了 TAdaConv 的时间建模能力。
3 时间自适应卷积
3.1 重新审视时间卷积
我们首先回顾时间卷积以显示底层过程及其与动态滤波器的关系。 为简单起见,我们考虑深度时间卷积,由于其效率[31, 30]而得到更广泛的使用。 形式上,对于由 参数化的 311 时间卷积滤波器,并放置(忽略归一化)在由 参数化的 2D 卷积之后t3>,第帧的输出特征可以通过以下方式获得:
| (1) |
其中表示逐元素乘法,表示空间维度上的卷积,表示ReLU激活[80]。 可以重写如下:
| (2) |
其中和是时空位置自适应卷积权重。 是一个动态张量,其值取决于空间卷积的结果(详细信息请参见附录)。 因此,(2+1)D卷积中的时间卷积本质上是对空间卷积进行(i)权重校准以及相邻帧之间的(ii)特征聚合。 然而,如果通过将时间卷积与空间卷积耦合来实现时间建模,仍然会引入不可忽略的计算开销(见表I)。
3.2 TAdaConv和TAdaConvV2的制定
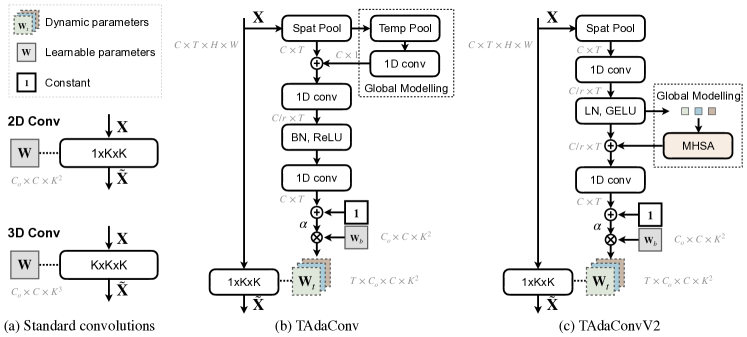
为了提高效率,我们开始直接为空间卷积提供时间建模能力。 受最近发现空间不变性的放松可以增强空间建模[17, 78]的启发,我们假设时间自适应权重也可以帮助时间建模。 因此,TAdaConv 层中的卷积权重逐帧变化。 由于我们观察到以前的动态滤波器很难利用预训练的权重,因此我们从时间卷积中的观察中获得灵感,并将第 帧 的权重分解为乘法为所有帧共享的基本权重 以及每个时间步长不同的校准权重 :
| (3) |
3.3 校准重量生成。
为了让 TAdaConv 能够对时间动态进行建模,至关重要的是第 帧的校准权重 不仅要考虑当前帧,而且更重要的是,它的时间上下文,即 。 否则,TAdaConv 将退化为一组不相关的空间卷积,并在不同帧上应用不同的权重。 实际上,校准生成函数可以有多种结构设计。 在图2(b)和(c)中,我们展示了校准生成函数的两个实例,分别对应于TAdaConv和TAdaConvV2。
TAdaConv。 在我们的设计中,我们的目标是效率和捕获帧间时间动态的能力。 为了提高效率,我们对每个帧在空间维度上通过全局平均池化获得的帧描述向量进行操作,即 。 对于时间建模,我们在局部时间上下文 上应用降维率为 的两层一维卷积 :
| (4) |
我们使用 ReLU [80] 和批标准化 [81] 进行激活和标准化。 表示一维卷积。
为了获得更大的帧间视场以补充局部一维卷积,我们进一步将全局时间信息合并到校准权重生成过程中。 对于TAdaConv,我们通过线性映射函数FC在权重生成过程中添加一个全局描述符:
| (5) |
其中 表示帧描述符 上时间维度上的全局平均池化。 这相当于原始输入 上所有时空维度的全局平均池化。 因此, 包含输入视频中的全局时间上下文。
TAdaConvV2。 TAdaConvV2 的实例化总体上与 TAdaConv 类似,但有两处改进。 (i) 我们将 ReLU 和批量归一化的组合更改为 GELU 和层归一化,以符合 ConvNeXt 模型中的结构。 (ii) 对于全局时间上下文建模,我们利用自注意力强大的全局建模能力[24]。 具体地,校准权重生成函数可以表示为:
| (6) |
其中 MHSA 表示多头自注意力[24]。 由于 MHSA 之前的 1D 卷积实质上为帧描述符 提供了动态位置嵌入,因此我们不会在 MHSA 操作之前添加额外的位置嵌入。
| (2+1)D Conv | TAdaConv | |
| FLOPs | ||
| E.G. Op | 1.2331 (+0.308, 33) | 0.9268 (+0.002, 0.2) |
| E.G. Net | 37.94 (+4.94, 15) | 33.02 (+0.02, 0.06) |
| Params. | ||
| E.G. Op. | 49,152 (+12,288, 33) | 43,008 (+6,144, 17) |
| E.G. Net | 28.1M (+3.8M, 15.6) | 27.5M (+3.2M, 13.1) |
初始化。 TAdaConv 的设计目的是通过简单地替换 2D 卷积即可轻松插入现有模型。 为了有效使用预训练权重,TAdaConv 被初始化为与标准卷积完全相同的行为。 这是通过将 中最后一个卷积的权重初始化为零并向公式中添加常数向量 来实现的:
| (7) |
这样,在初始状态,我们用预训练的权重加载。
校准尺寸。 基础重量可以在不同维度进行校准。 对于标准卷积,我们在 维度 () 上实例化校准,因为基于输入特征的权重生成可以比输出通道或空间结构(表LABEL:tab:calibrationdim中的经验分析)。 对于深度卷积,由于卷积核没有维度,因此校准直接应用于卷积核的维度。
与时间卷积的比较。 表I比较了TAdaConv与R(2+1)D的参数和FLOPs,这表明我们在空间卷积之上的大部分额外计算开销比时间卷积小一个数量级。
| Temporal | Location | Pretrained | |
| Operations | modeling | adaptive | weights |
| CondConv [11] | ✗ | ✗ | ✗ |
| DynamicFilter [21] | ✗ | ✗ | ✗ |
| DDF [17] | ✗ | ✓ | ✗ |
| TAM [31] | ✓ | ✗ | ✗ |
| TAdaConv(V2) | ✓ | ✓ | ✓ |
与现有动态滤波器的比较。 表II将TAdaConv与现有动态滤波器进行了比较。 不同动态过滤方法之间的主要区别在于动态权重的生成方式。 基于专家混合的动态滤波器[11]生成内容相关的权重来动态聚合可学习的卷积权重。 其他类型的动态过滤器[21,17,31]完全基于输入内容生成动态权重。 我们的 TAdaConv 与现有的动态滤波器在以下三个方面有所不同: (i) 与基于图像的动态滤波器 [21, 17, 11] 相比,TAdaConv 实现了时间建模通过根据局部和全局上下文生成权重。 (ii) 与视频范式中的 TANet [31] 相比,由于时间自适应权重,TAdaConv 可以建模更复杂的时间动态。 (iii) 大多数现有动态滤波器无法利用现有的预训练权重,而 TAdaConv 可以初始化以生成与预训练权重相同的动态权重。 这降低了视频应用中的训练难度。 附录中包含动态滤波器的更详细比较。
4 TAdaBlocks
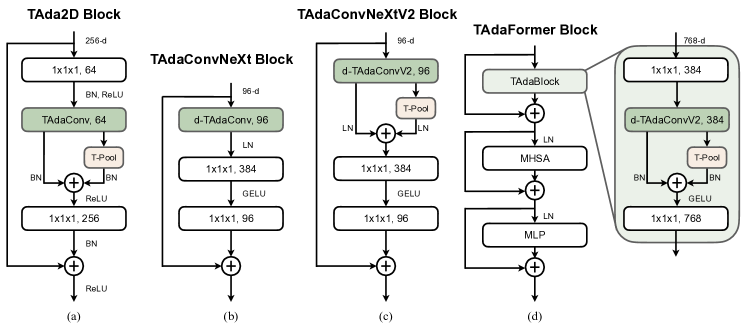
基于 TAdaConv 和 TAdaConvV2,我们可以为各种模型构造一系列 TAdaBlock,包括卷积模型和基于 Transformer 的模型。 在图3中,我们分别为ResNet [1]、ConvNeXt [36]构造TAda2D块、TAdaConvNeXt(V2)块和TAdaFormer块。 t3> 和 ViT [39]。
除了 TAdaConv 和 TAdaConvV2 之外,TAdaBlocks 的一个重要组成部分是高效的时间特征聚合方案。 这对应于时间卷积的第二个基本步骤。 形式上,给定 TAdaConv 的输出,可以按如下方式获得聚合特征:
| (8) |
其中 表示内核大小为 的跨步时间池操作。我们对 TAdaConv 提取的特征和通过跨步平均池 聚合的特征使用不同的归一化参数,因为它们的分布本质上是不同的。
在初始化过程中,我们将预训练的权重(如果有)加载到中,并将的参数初始化为零。 再加上TAdaConv的初始化,TAdaBlocks的初始状态与基础模型完全相同,而校准和聚合通过训练显着提高了模型容量(参见附录)。 在实验中,我们将此结构称为快捷方式(Sc.) 分行和独立国阵 (SepBN.) 分支。
在我们的预备知识版本[23]中,我们探索了 TAda2D 块和 TAdaConvNeXt 块。 受时间特征聚合带来的改进的启发,我们在图3(c)中提出了TAdaConvNeXt块的改进版本,即TAdaConvNeXtV2块。 为了适应现代化的卷积块[36],TAdaConvNeXtV2块中聚合方案的结构进行了相应修改,其中激活函数被删除,归一化切换为LayerNorm[82] 。
5 视频分类评估
型号。 我们按照各自基础模型 ResNet [1]、ConvNeXt [36] 和 Vision Transformer 的结构,为 TAda2D、TAdaConvNeXtV2 和 TAdaFormer 构建了不同的变体[39]。 我们的模型变体是通过用我们的 TAdaBlock 替换原始模型中的残差块或 Transformer 块来获得的。 此外,对于 TAdaConvNeXtV2 和 TAdaFormer,我们遵循最近的工作[48, 49]并使用小管嵌入茎。 有关模型结构的更多详细信息包含在附录中。
数据集。 对于视频分类,我们使用 Kinetics-400 [83] (K400)、Something-Something-V1 和 V2 [84] (SSV1 和 SSV2)、Epic-Kitchens-100 [85] (EK100) 和 HACS [86 ]。 此外,我们采用 UCF101 [87] 和 HMDB51 [88] 进行多模式零样本评估。 K400 是一个广泛使用的动作分类数据集,包含 300K 视频涵盖的 400 个类别。 SSV1 和 SSV2 包括 108K 和 220K 视频,在 174 个类别中具有挑战性的时空交互。 EK100 包括由 97 个动词和 300 个名词类标记的 90K 段,其动作由名词和动词的组合定义。 HACS 包含 504K 视频,分类为 200 个动作类别。 后两个数据集也用于动作定位的评估。
此外,我们还结合 Kinetics-400 [83]、Kinetics-600 [89] 和 Kinetics-700 [ 90] 用于预训练我们的视频模型,遵循 [91, 64]。 这会产生一个包含超过 710 个动作类别的约 660K 视频的数据集,在以下部分中称为 K710。
| Temporally | SSV2 | SSV2 | |
| Calibration | Varying | Top-1 | Top-1* |
| None | ✗ | - | 32.0 |
| Learnable | ✗ | 34.3 | 32.6 |
| ✓ | 45.4 | 43.8 | |
| Dynamic | ✗ | 51.2 | 41.7 |
| ✓ | 53.8 | 49.8 | |
| TAda | ✓ | 59.2 | 47.8 |
| Cal. dim. | Top-1 | ||
| 3.16M | 0.016 | 63.8 | |
| 3.16M | 0.016 | 63.4 | |
| 4.10M | 0.024 | 63.7 | |
| 2.24M | 0.009 | 62.7 |
| TAda | |||||
| Base Model | Conv | #params. | GFLOPs | K400 | SSV2 |
| SlowOnly 88⋆ [19] | ✗ | 32.5M | 54.52 | 74.6 | 60.3 |
| ✓ | 35.6M | 54.53 | 75.9 (+1.3) | 63.3 (+3.0) | |
| SlowFast 416⋆ [19] | ✗ | 34.5M | 36.10 | 75.0 | 56.7 |
| ✓ | 37.7M | 36.11 | 76.5 (+1.5) | 59.8 (+3.1) | |
| SlowFast 88⋆ [19] | ✗ | 34.5M | 65.71 | 76.2 | 61.5 |
| ✓ | 37.7M | 65.73 | 77.4 (+1.2) | 63.9 (+2.4) | |
| R(2+1)D⋆ [13] | ✗ | 28.1M | 49.55 | 73.6 | 61.1 |
| ✓2d | 31.2M | 49.57 | 75.2 (+1.6) | 62.9 (+1.8) | |
| ✓(2+1)d | 34.4M | 49.58 | 75.4 (+1.8) | 63.8 (+2.7) | |
| R3D⋆ [13] | ✗ | 47.0M | 84.23 | 73.8 | 59.9 |
| ✓3d | 50.1M | 84.24 | 74.9 (+1.1) | 62.9 (+3.0) | |
| Notation indicates our own implementation. | |||||
| See Appendix for details on the model structure. | |||||
| Model | TAdaConv | K. | G. | Top-1 |
| TSN⋆ | - | - | - | 32.0 |
| Ours | Lin. | 1 | ✗ | 37.5 |
| Lin. | 3 | ✗ | 56.5 | |
| Non-Lin. | (1, 1) | ✗ | 36.8 | |
| Non-Lin. | (3, 1) | ✗ | 57.1 | |
| Non-Lin. | (1, 3) | ✗ | 57.3 | |
| Non-Lin. | (3, 3) | ✗ | 57.8 | |
| Lin. | 1 | ✓ | 53.4 | |
| Non-Lin. | (1, 1) | ✓ | 54.4 | |
| Non-Lin. | (3, 3) | ✓ | 59.2 |
| TAdaConv | FA. | Sc. | SepBN. | Top-1 | |
| ✗ | - | - | - | 32.0 | - |
| ✓ | - | - | - | 59.2 | +27.2 |
| ✗ | Avg. | ✗ | - | 47.9 | +15.9 |
| ✗ | Avg. | ✓ | ✗ | 49.0 | +17.0 |
| ✗ | Avg. | ✓ | ✓ | 57.0 | +25.0 |
| ✓ | Avg. | ✗ | - | 60.1 | +28.1 |
| ✓ | Avg. | ✓ | ✗ | 61.5 | +29.5 |
| ✓ | Avg. | ✓ | ✓ | 63.8 | +31.8 |
| ✓ | Max. | ✓ | ✓ | 63.5 | +31.5 |
| ✓ | Mix. | ✓ | ✓ | 63.7 | +31.7 |
训练。 我们使用 AdamW [92] 在 K400, SSV1/SSV2 和 EK100 上分别进行 100/64/50 epochs 的 ImageNet 预训练来初始化训练模型。 我们采用 RandAugment [93] 进行数据增强,采用随机深度 [94] 和标签平滑 [95] 进行模型正则化。 对于这两个模型,我们不使用 Mixup [96] 或 Cutmix [97]。 指数移动平均线 (EMA) [98] 用于减少训练期间的过度拟合。 对于具有 CLIP 预训练权重 [59] 的 TAdaFormer,我们将时间表分别缩短到 30/24/24 epoch。 请参阅附录了解更多详情。
5.1 假设验证
我们通过验证我们的假设开始我们的实验 放宽时间不变性可能会导致视频模型的时间建模能力更强。 为此,我们选择了几个校准权重源,并比较了在放松时间不变性和不放松时间不变性的情况下 SSV2 上的动作分类性能。 结果如表III(b)所示。 可以看出,可学习校准和动态校准都可以给无校准基线(TSN [99])带来显着的改善,其中动态校准的性能比可学习校准更强。 在校准模型之上,使权重沿时间维度变化可以进一步提高分类精度,这意味着当时间方差放松时,模型显示出更好的时间建模能力。
5.2 现有视频主干上的 TAdaConv
TAdaConv 被设计为视频模型中空间卷积的插件替代品。 如表III(c)所示,TAdaConv 在多种视频模型上以可忽略的计算开销提高了分类性能,包括 SlowFast [19]、R3D [ 100] 和 R(2+1)D [13],在 K400 和 SSV2 上平均分别提高了 1.3% 和 2.8%,额外计算成本低于 0.02 GFlops。 此外,TAdaConv 不仅可以改善空间卷积,还可以显着改善 3D 和 1D 卷积。 为了公平比较,所有模型都使用相同的训练策略进行训练。 附录中介绍了针对动作分类的进一步插件评估。
5.3 TAdaConv 的烧蚀分析
在本节中,我们将彻底分析我们的设计选择以及 TAdaConv 和 TAdaConvV2 在建模时间动态方面的有效性。 我们从 TAdaConv 开始,选择 SSV2 作为我们的主要评估基准,因为它的时空关系更复杂。
校准砝码初始化。 在表III(b)中,我们表明我们的校准权重生成初始化策略在动态权重校准中起着至关重要的作用。 如表III(b)所示,随机初始化可学习权重会略微降低性能,而随机初始化动态校准权重(通过随机初始化权重生成函数的最后一层)会显着降低性能。 随机初始化的动态校准权重可能比可学习权重更严重地干扰预训练权重,因为它依赖于输入。 附录中显示了初始化的进一步比较。
校准重量生成功能。 确定具有适当初始化的时间自适应动态校准可以成为时间建模的理想策略后,我们进一步消除了表 LABEL:tab:calibrationweightgen 中生成校准权重的不同方法。 线性权重生成函数 (Lin.) 应用单个一维卷积来生成校准权重,而非线性权重生成函数 (Non-Lin.) 使用两个堆叠的一维卷积批量归一化和 ReLU 激活介于两者之间。 当不考虑时间上下文时(K.=1 或 (1,1)),TAdaConv 仍然可以改善基线,但差距有限。 扩大内核大小以覆盖时间上下文 (K.=3, (1,3), (3,1) 或 (3,3)) 可以有效地将准确度提高 20% 以上,其中 K.=( 3,3) 具有最强的性能。 这显示了校准权重生成期间局部时间上下文的重要性。 最后,对于时间上下文的范围,将全局上下文引入帧描述符与仅在全局上下文上生成时间自适应校准权重类似(在表III(b)中)。 全局和时间上下文的结合为这两种变体带来了更好的性能。 在附录中,我们还表明,与现有动态滤波器相比,TAdaConv 中的此函数可以对基本权重进行更好的校准。
特征聚合。 我们在表III(e)中消除了TAda2D中的聚合方案。 普通聚合 和快捷方式聚合的性能相似 (Sc.) 分支 ,带有 Sc。 稍微好一点。 将快捷方式和聚合分支的批归一化(等式8)分开带来了显着的改进。 跨步最大和混合(平均+最大)池的表现略低于平均池变体。 总体而言,TAdaConv 和我们的特征聚合方案的组合比 TSN 基线有 31.8% 的优势。
校准尺寸。 可以在基本重量中校准多个尺寸。 表LABEL:tab:calibrationdim表明,校准通道维度比空间维度更合适,这意味着应保留原始卷积核的空间结构。 在通道内, 上的校准效果优于 或两者的组合。 这可能是因为输入特征生成的校准权重能够更好地适应自身。
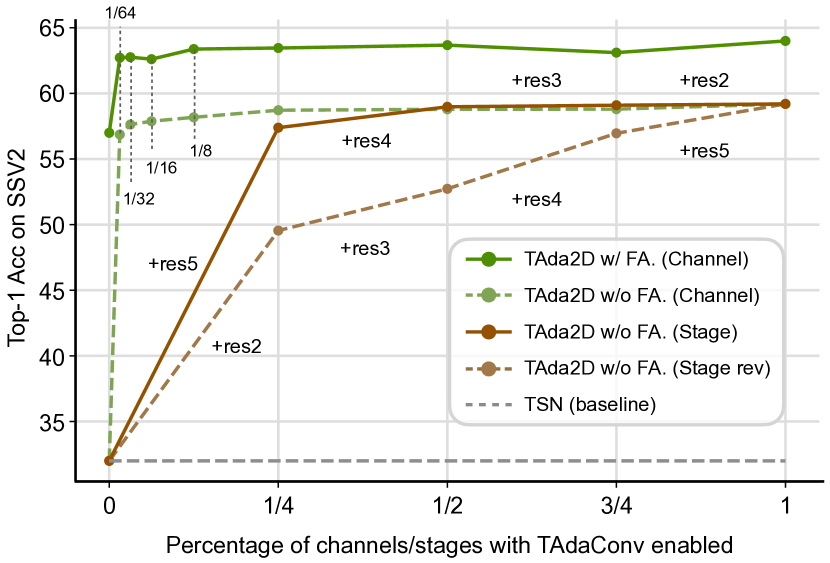
使用 TAdaConv 的不同阶段。 图4显示了ResNet中用TAdaConv逐步替换空间卷积的过程。 当在 Res2 中使用 TAdaConv 时,观察到的最小改进为 17.55%。 与早期阶段相比,后期阶段对最终性能的贡献更大,因为后期阶段由于其丰富的语义而提供了更准确的校准。 总体而言,TAdaConv 在所有阶段都使用以获得最高精度。
校准的通道比例不同。 在这里,我们仅使用 TAdaConv 校准一部分通道,而其他通道不校准。 结果如图4所示。 我们发现,即使只校准 1/64 个通道,TAdaConv 也可以大幅提高基线,并且比例越大,改善效果就越大。
| Model | Variant | K400 | SSV2 |
| ResNet2D | Baseline | 70.4 | 32.0 |
| + TAdaConv | 73.9 | 59.2 | |
| TAda2D | + T-Pool | 76.7 | 64.0 |
| ConvNeXt | Baseline | 76.0 | 41.4 |
| + TAdaConv | 76.9 | 59.0 | |
| TAdaConvNeXt-T | + T-Down | 78.4 | 64.8 |
| + TAdaConvV2 | 78.9 | 66.0 | |
| + T-Pool | 79.3 | 66.8 | |
| TAdaConvNeXtV2-T | + Stronger Aug | 79.6 | 67.2 |
5.4 现代化和改进 TAdaBlocks
我们按照 [36] 对 TAdaBlock 进行现代化改造,并使用 TAdaConvV2 和表 IV 中的时间聚合对其进行改进。 当我们将基础模型从 ResNet [1] 切换到 ConvNeXt [36] 时,我们观察到 K400 和 SSV2 的分类精度分别提高了 5.6% 和 9.4% 。 用深度卷积替代 TAdaConv 进一步带来了 0.9% 和 17.6% 的提升。 继[49, 48]之后,我们在 TAdaConvNeXt 中采用了 tubelet 嵌入茎(T-Down),实例化为具有时间下采样和增加帧数的 3D 卷积,以保持整体计算不变。
在 TAdaConvNeXt 模型之上,我们通过用 TAdaConvV2 替换 TAdaConv 并引入时间聚合方案(T-Pool)来改进 TAdaBlock。 结构修改进一步导致 K400 和 SSV2 的性能分别提高了 0.9% 和 2.0%。 最后,通过更强的增强(RandAugment [93] 的 m7 到 m9),我们使用微型模型在两个基准上实现了 79.6% 和 67.2% 的准确率。
5.5 TAdaConvV2和TAdaBlocks的烧蚀分析
TAdaBlocks 中的 TAdaConvV2 和 T-Pool。 表V展示了TAdaFormer和TAdaConvNeXtV2中TAdaBlock的烧蚀分析,特别是关于TAdaConvV2和时间聚合策略。
通过CLIP[59]预训练的TAdaFormer基线表现出强大的空间建模能力,在K400上达到了令人印象深刻的83.6%的准确率。 然而,它缺乏对复杂动态进行建模的能力。 引入TAdaBlock,其间具有简单的空间卷积并且没有时间聚合带来的影响可以忽略不计。 除此之外,TAdaConvV2 在时间建模方面显着改进了模型,在场景相关基准 K400 上的性能提高了 0.9%,同时在时间相关基准 SSV2 上带来了 20% 的性能增益。 除此之外,采用时间聚合(T-Pool)和小管嵌入(Temp. 向下。) 进一步增强了模型模拟复杂时间动态的能力。
与 TAdaFormer 相比,由于 TAdaConvNeXtV2 是在 ImageNet 上预训练的,因此基线性能略低。 所有这三种策略都给以场景和时间为中心的基准带来了显着的改进。
预训练。 我们在表 VI 中探索了不同的预训练权重作为 TAdaConvNeXt 和 TAdaFormer 的初始化。 对于 TAdaConvNeXtV2,K400 上的预训练有利于 SSV2 性能。 对于 TAdaFormer,使用 CLIP [59] 预训练权重在 K400 和 SSV2 上的性能均优于 ImageNet 预训练权重。 CLIP+K710 初始化在 K400 上进一步将 CLIP 预训练变体提高了 2.1%,但对 SSV2 的影响不太显着(0.1%)。 为了与最先进的技术进行比较,我们分别使用 ImageNet 和 CLIP 作为 TAdaConvNeXtV2 和 TAdaFormer 的默认预训练源。
| TAdaBlock | Temp. | ||||
| Model | TAdaConvV2 | T-Pool | Down. | K400 | SSV2 |
| ViT-B/16 | N/A | N/A | ✗ | 83.6 | 48.1 |
| TAdaFormer-B/16 | ✗ | ✗ | ✗ | 83.6 | 48.2 |
| TAdaFormer-B/16 | ✓ | ✗ | ✗ | 84.5 | 68.6 |
| TAdaFormer-B/16 | ✓ | ✓ | ✗ | 84.5 | 69.2 |
| TAdaFormer-B/16 | ✓ | ✓ | ✓ | 84.5 | 70.4 |
| ConvNeXt-T | ✗ | ✗ | ✗ | 77.2 | 46.2 |
| TAdaConvNeXtV2-T | ✓ | ✗ | ✗ | 78.0 | 63.3 |
| TAdaConvNeXtV2-T | ✓ | ✓ | ✗ | 79.3 | 66.3 |
| TAdaConvNeXtV2-T | ✓ | ✓ | ✓ | 79.6 | 67.2 |
| Model | Pretrain | K400 | SSV2 |
| TAdaConvNeXtV2-T | IN1K | 79.6 | 65.2 |
| IN1K+K400 | - | 67.2 | |
| TAdaFormer-B/16 | IN1K | 76.3 | 63.9 |
| IN21K | 81.8 | 67.5 | |
| CLIP | 84.5 | 70.4 | |
| CLIP+K710 | 86.6 | 70.5 | |
| TimeSformer [50] | IN21K | 78.7 | 59.5 |
| UniFormerV2-B/16 [91] | IN21K | 81.6 | 67.5 |
| CLIP | 84.4 | 69.5 | |
| CLIP+K710 | 85.6 | - |
| Model | #frames | #param. | GFLOPsviews | Top-1 |
| Models without pretraining | ||||
| SlowFast 88 [19] | 8+32 | 34.5M | 66310 | 77.0 |
| MViTv2-B [101] | 32 | 51.2M | 22515 | 82.9 |
| ImageNet-1K pretrained models | ||||
| TSM [28] | 8 | 24.3M | 43310 | 74.1 |
| TAda2D [23] | 16 | 27.5M | 86310 | 77.4 |
| TAdaConvNeXt-T [23] | 32 | 38.6M | 9434 | 79.1 |
| TANet [31] | 16 | 25.6M | 24234 | 79.3 |
| TDN-R101 [29] | 8+16 | - | 258310 | 79.4 |
| X3D-XXL [20] | - | 20.3M | 194310 | 80.4 |
| Swin-T [48] | 32 | 28.2M | 8834 | 78.8 |
| Swin-S [48] | 32 | 49.8M | 16634 | 80.6 |
| Swin-B [48] | 32 | 88.1M | 28234 | 80.6 |
| MoViNet-A6 [102] | 120 | 31.4M | 38611 | 81.5 |
| TAdaConvNeXtV2-T | 16 | 45.9M | 4734 | 79.6 |
| TAdaConvNeXtV2-T | 32 | 45.9M | 9434 | 80.8 |
| TAdaConvNeXtV2-S | 16 | 82.2M | 9134 | 80.8 |
| TAdaConvNeXtV2-S | 32 | 82.2M | 18334 | 81.9 |
| TAdaConvNeXtV2-B | 16 | 145.7M | 16234 | 81.4 |
| TAdaConvNeXtV2-B | 32 | 145.7M | 32434 | 82.3 |
| ImageNet-21K pretrained models | ||||
| X-ViT [103] | 16 | - | 28331 | 80.2 |
| TimeSformer [50] | 96 | 121.4M | 238031 | 80.7 |
| ViViT-L [49] | 16 | 310.8M | 144634 | 80.6 |
| MTV-B [104] | 32 | 310M | 93034 | 82.4 |
| Swin-B [48] | 32 | 88.1M | 28234 | 82.7 |
| Swin-L [48] | 32 | 197.0M | 60434 | 83.1 |
| MViT-v2-L [101] | 40 | 217.6M | 282835 | 86.1 |
| TAdaConvNeXtV2-S | 32 | 82.2M | 18334 | 82.9 |
| TAdaConvNeXtV2-B | 32 | 145.7M | 32434 | 83.7 |
| Model | #frames | #param. | GFLOPsviews | Top-1 |
| Other large-scale pretrained models | ||||
| MAE-ST [57] | 16 | 632M | 119337 | 85.1 |
| MAR [105] | 16 | 311M | 27635 | 85.3 |
| MaskFeat [106] | 40 | 218M | 379034 | 87.0 |
| CoVeR [107] (JFT-3B) | 16 | - | - | 87.2 |
| MTV-H(WTS) [104] | 32 | - | 613034 | 89.9 |
| VideoMAE V2-g [64] | 64 | - | 2671632 | 90.0 |
| CLIP pretrained models | ||||
| UniFormerV2-B/16 [91] | 8 | 115M | 15034 | 84.4 |
| ST-Adapter-B/16 [65] | 32 | 93M | 60731 | 82.0 |
| EVL ViT-B/16 [108] | 32 | 115M | 59231 | 84.2 |
| X-CLIP-B/16 [109] | 16 | - | 28734 | 84.7 |
| ViFi-CLIP [110] | 16 | 124.7M | 28143 | 83.9 |
| TAdaFormer-B/16 | 16 | 104.1M | 15334 | 84.5 |
| ST-Adapter-L/14 [65] | 32 | 347M | 274931 | 87.2 |
| EVL ViT-L/14 [108] | 32 | 363M | 269631 | 87.3 |
| X-CLIP-L/14 [109] | 8 | - | 65834 | 87.1 |
| TAdaFormer-L/14 | 16 | 364M | 70334 | 87.6 |
| CLIP+K710 post-pretrained models | ||||
| UniFormerV2-B/16 [91] | 8 | 115M | 15034 | 85.6 |
| TAdaConvNeXtV2-S | 32 | 82.2M | 18334 | 86.1 |
| TAdaConvNeXtV2-B | 32 | 145.7M | 32434 | 86.4 |
| TAdaFormer-B/16 | 16 | 104.1M | 15334 | 86.6 |
| UniFormerV2-L/14 [91] | 8 | 354M | 66734 | 88.8 |
| UniFormerV2-L/14 [91] | 16 | 354M | 133434 | 89.1 |
| UniFormerV2-L/14 [91] | 32 | 354M | 266734 | 89.5 |
| TAdaFormer-L/14 | 16 | 364M | 70334 | 88.9 |
| TAdaFormer-L/14 | 32 | 364M | 140634 | 89.5 |
| TAdaFormer-L/14 | 64 | 364M | 281234 | 89.9 |
| Model | #frames | GFLOPsviews | SSV1 | SSV2 |
| TSM [28] | 16 | 8632 | 47.2 | 63.4 |
| MoViNet-A3 [102] | 50 | 2411 | - | 64.1 |
| TANet [31] | 16 | 8632 | 47.6 | 64.6 |
| TEANet [111] | 16 | 8611 | 48.9 | - |
| TEANet [111] | 16 | 86310 | - | 65.1 |
| TAda2D [23] | 16 | 8632 | - | 65.6 |
| TAdaConvNeXt-T [23] | 32 | 9432 | - | 67.1 |
| TDN-R101 [29] | 8+16 | 25811 | 56.8 | 68.2 |
| TAdaConvNeXtV2-T | 16 | 4732 | 54.1 | 67.2 |
| TAdaConvNeXtV2-T | 32 | 9432 | 56.4 | 69.8 |
| TAdaConvNeXtV2-S | 16 | 9132 | 55.6 | 68.4 |
| TAdaConvNeXtV2-S | 32 | 18332 | 58.5 | 70.0 |
| TAdaConvNeXtV2-S† | 32 | 18332 | 59.7 | 70.6 |
| TAdaConvNeXtV2-B† | 32 | 32432 | 60.7 | 71.1 |
| ViViT-L/16x2 FE [49] | 32 | 90334 | - | 65.4 |
| X-ViT [103] | 16 | 28331 | - | 67.2 |
| MTV-B [104] | 32 | 93034 | - | 68.5 |
| Swin-B†[48] | 32 | 32131 | - | 69.6 |
| MViTv2-B [101] | 32 | 22531 | - | 70.5 |
| ST-Adapter-B/16⋆ [65] | 32 | 65131 | - | 69.5 |
| ST-Adapter-L/14⋆ [65] | 32 | 274931 | - | 72.3 |
| UniFormerV2-B/16⋆ [91] | 32 | 37032 | 59.5 | 71.0 |
| UniFormerV2-L/14⋆ [91] | 32 | 171632 | 62.9 | 73.1 |
| MViTv2-L [101] | 40 | 282831 | - | 73.3 |
| TAdaFormer-B/16⋆ | 16 | 18732 | 59.2 | 70.4 |
| TAdaFormer-B/16⋆ | 32 | 37432 | 61.2 | 71.3 |
| TAdaFormer-L/14⋆ | 16 | 85832 | 62.0 | 72.4 |
| TAdaFormer-L/14⋆ | 32 | 171632 | 63.7 | 73.6 |
| † indicates initialization with ImageNet21K+K400 pre-training. | ||||
| ⋆ indicates initialization with CLIP-400M pre-training. | ||||
5.6 主要结果
| Model | Act. | Verb | Noun |
| TSN [99] | 33.2 | 60.2 | 46.0 |
| TRN [112] | 35.3 | 65.9 | 45.4 |
| TSM [28] | 38.3 | 67.9 | 49.0 |
| SlowFast [19] | 38.5 | 65.6 | 50.0 |
| TAda2D [23] | 41.6 | 65.1 | 52.4 |
| ir-CSN-152 [113] | 44.5 | 68.4 | 55.9 |
| MoViNet-A6 [102] | 47.7 | 72.2 | 57.3 |
| TAdaConvNeXtV2-T (IN1K) | 42.4 | 67.1 | 53.7 |
| TAdaConvNeXtV2-T (K710) | 47.4 | 70.4 | 58.6 |
| TAdaConvNeXtV2-S (K710) | 48.9 | 71.0 | 60.2 |
| ViViT-L/16x2 FE [49] | 44.0 | 66.4 | 56.8 |
| X-ViT [103] | 44.3 | 68.7 | 56.4 |
| ViViT-B/16x2 FE [113] | 47.0 | 67.2 | 59.0 |
| ST-Adapter-B/16 [65] | - | 67.6 | 55.0 |
| MeMViT [114] | 48.4 | 71.4 | 60.3 |
| MTV-B [104] | 48.6 | 68.0 | 63.1 |
| MTV-B(WTS) [104] | 50.5 | 69.9 | 63.9 |
| TAdaFormer-B/16 (K710) | 49.1 | 71.0 | 60.5 |
| TAdaFormer-L/14 (K710) | 51.8 | 71.7 | 64.1 |
| Model | HMDB-51 | UCF-101 |
| MTE [115] | 19.7 1.6 | 15.8 1.3 |
| ASR [116] | 21.8 0.9 | 24.4 1.0 |
| ER-ZSAR [117] | 35.3 4.6 | 51.8 2.9 |
| CLIP [59] | 40.8 0.3 | 63.2 0.2 |
| ActionCLIP [118] | 40.8 5.4 | 58.3 3.4 |
| X-CLIP-B/16 [109] | 44.6 5.2 | 72.0 2.3 |
| A5 [119] | 44.3 2.2 | 69.3 4.2 |
| ViFi-CLIP [110] | 51.3 0.6 | 76.8 0.7 |
| TAdaFormer-B/16 | 52.1 1.4 | 78.5 1.2 |
| TAdaFormer-L/14 | 57.2 0.7 | 81.1 0.9 |
| TAdaFormer-B/16 (K710) | 55.9 0.4 | 79.5 0.7 |
| TAdaFormer-L/14 (K710) | 59.7 0.5 | 83.0 0.7 |
| HACS | ||||||
| Model | @0.5 | @0.6 | @0.7 | @0.8 | @0.9 | Avg. |
| SSN [120] | 28.8 | - | - | - | - | 19.0 |
| G-TAD [121] | 41.1 | - | - | - | - | 27.5 |
| TadTR [51] | 47.1 | - | - | - | - | 32.1 |
| BMN [122]+ | ||||||
| TSN [23] | 43.6 | 37.7 | 31.9 | 24.6 | 15.0 | 28.6 |
| TAda2D [23] | 48.7 | 42.7 | 36.2 | 28.1 | 17.3 | 32.3 |
| TAdaFormer-L/14 | 51.3 | 44.8 | 38.0 | 30.0 | 18.6 | 34.1 |
| TAdaConvNeXt-S | 53.3 | 47.0 | 40.2 | 32.0 | 20.2 | 36.1 |
| Epic-Kitchens-100 | |||||||
| Model | Task | @0.1 | @0.2 | @0.3 | @0.4 | @0.5 | Avg. |
| BMN [122] +TSN | Verb | 15.98 | 15.01 | 14.09 | 12.25 | 10.01 | 13.47 |
| Noun | 15.11 | 14.15 | 12.78 | 10.94 | 8.89 | 12.37 | |
| Act. | 10.24 | 9.61 | 8.94 | 7.96 | 6.79 | 8.71 | |
| BMN [122] +TAda2D [23] | Verb | 19.70 | 18.49 | 17.41 | 15.50 | 12.78 | 16.78 |
| Noun | 20.54 | 19.32 | 17.94 | 15.77 | 13.39 | 17.39 | |
| Act. | 15.15 | 14.32 | 13.59 | 12.18 | 10.65 | 13.18 | |
| BMN [122] +TAdaFormer-L/14 | Verb | 20.87 | 20.09 | 18.99 | 16.42 | 13.81 | 18.03 |
| Noun | 27.75 | 26.28 | 24.51 | 21.86 | 17.97 | 23.67 | |
| Act. | 20.39 | 19.35 | 18.28 | 16.35 | 14.51 | 17.85 | |
| BMN [122] +TAdaConvNeXt-S | Verb | 17.81 | 16.94 | 16.05 | 14.25 | 11.89 | 15.39 |
| Noun | 21.90 | 20.92 | 19.33 | 17.22 | 14.68 | 18.81 | |
| Act. | 15.61 | 14.80 | 13.73 | 12.35 | 10.90 | 13.47 | |
| ActionFormer [123] +SlowFast | Verb | 26.58 | 25.42 | 24.15 | 22.29 | 19.09 | 23.51 |
| Noun | 25.21 | 24.11 | 22.66 | 20.47 | 16.97 | 21.88 | |
| Act. | 18.40 | 17.71 | 16.80 | 15.65 | 13.52 | 16.42 | |
| ActionFormer [124] +SlowFast&ViViT | Verb | 26.97 | 25.90 | 24.21 | 21.77 | 18.47 | 23.46 |
| Noun | 28.61 | 27.14 | 24.92 | 22.13 | 18.69 | 24.30 | |
| Act. | 23.90 | 22.98 | 21.37 | 19.57 | 16.94 | 20.95 | |
| ActionFormer +TAdaConvNeXt-S | Verb | 29.11 | 28.37 | 26.99 | 24.22 | 20.64 | 25.86 |
| Noun | 29.21 | 27.94 | 26.22 | 23.54 | 18.73 | 25.13 | |
| Act. | 20.78 | 19.75 | 18.56 | 17.07 | 14.54 | 18.14 | |
| ActionFormer +TAdaFormer-L/14 | Verb | 32.08 | 31.09 | 29.40 | 26.64 | 22.71 | 28.38 |
| Noun | 35.00 | 33.42 | 30.98 | 27.32 | 22.36 | 29.82 | |
| Act. | 24.92 | 23.68 | 22.33 | 20.61 | 18.29 | 21.97 | |
动力学-400。 表VII显示了在没有大规模预训练的Kinetics-400上的结果。 在 ImageNet-1K 和 ImageNet-21K 上进行预训练时,TAdaConvNeXtV2 以相似的计算预算超越了大多数现有方法。 值得注意的是,我们的 32 帧 TAdaConvNeXtV2-S 仅使用 57% 的计算量,性能就比 Swin-B 高 1.3。
表VIII展示了大规模预训练模型的比较。 与现有的 CLIP 预训练模型相比,TAdaFormer 实现了具有竞争力的性能。 在 K710 上进行后预训练时,在类似的计算预算下,TAdaFormer 的性能明显优于 UniFormerV2。 与 TAdaConvNeXtV2 相比,我们还观察到 TAdaFormer 具有更好的可扩展性。
某事-某事-V1 和 V2。 我们在表IX中展示了时间相关数据集即SSV1和SSV2的性能比较。 TAdaConvNeXt 和 TAdaFormer 分别针对具有相同或相似预训练源的现有卷积模型和基于 Transformer 的模型实现了良好的性能。 与最好的卷积模型 TDN-R101 相比,TAdaConvNeXt-B 在 SSV1 和 SSV2 上的表现分别比它高出 3.9 和 2.9。 与 CLIP 预训练的 UniFormerV2-L/14 相比,TAdaFormer-L/14 在两个数据集上实现了 0.8 和 0.5 的改进。
史诗厨房-100。 我们在表X中比较了以自我为中心的动作识别的性能。 与现有的卷积模型相比,我们的 TAdaConvNeXtV2-S 取得了良好的性能。 值得注意的是,我们观察到 TAdaConvNeXt 模型在以自我为中心的视频中的名词识别方面具有更高的准确性。 基于 Transformer 的模型通常比 EK100 上的卷积模型更强,我们的 TAdaFormer 在视频理解方面与现有 Transformer 的性能具有竞争力。
UCF101 和 HMDB51 的零样本分类。 为了更全面地评估我们的 TAdaFormer,我们将零样本分类的结果包含在表XI中。 在这里,我们使用 CLIP 预训练权重初始化模型,并使用相应的语言模型 [59] 训练我们的 TAdaFormer。 与微调的 CLIP ViFi-CLIP [110] 相比,我们观察到 TAdaFormer-B/16 在两个数据集上都有显着的改进。 最重要的是,我们发现扩大模型和预训练可以进一步提高零样本的性能。
6 动作本地化评估
数据集、管道和评估。 动作定位是理解未修剪视频的一项重要任务,其当前的流程使其严重依赖于视频表示的质量。 我们在两个大型动作本地化数据集 HACS [86] 和 Epic-Kitchens-100 [85] 上评估 TAdaConvNeXtV2 和 TAdaFormer。 一般管道遵循[85, 125, 126],它使用边界匹配网络(BMN)[122]来生成动作边界。 为了进行评估,我们使用 HACS 的 IoU [0.5:0.05:0.95] 和 EK100 的 IoU [0.1:0.1:0.5] 的平均平均精度(平均 mAP),遵循标准协议。 更多详细信息包含在附录中。
7 结论
基于我们的基础知识工作[23],这项工作提出了 TAdaConvV2 来替代现有视频理解模型中的卷积运算,以及两个强大的视频模型,即 TAdaConvNeXtV2和塔达前任。 通过大规模的预训练和后预训练,我们的视频模型在动作识别和定位任务中都表现出了与最先进方法相比的竞争性能。 我们希望我们的工作能够促进视频理解方面的进一步研究。
致谢
这项研究得到了科学技术研究局 (A*STAR) 的 AME 计划资助计划(项目 #A18A2b0046)、RIE2020 产业协调基金 – 产业合作项目 (IAF-ICP) 资助计划的支持行业合作伙伴以及阿里巴巴集团通过阿里巴巴研究院实习生计划提供的现金和实物捐助。
参考
- [1] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016, pp. 770–778.
- [2] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in CVPR, 2015, pp. 1–9.
- [3] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” NeurIPS, vol. 25, pp. 1097–1105, 2012.
- [4] Z. Dai, H. Liu, Q. V. Le, and M. Tan, “Coatnet: Marrying convolution and attention for all data sizes,” NeurIPS, vol. 34, pp. 3965–3977, 2021.
- [5] S. Xie, R. Girshick, P. Dollár, Z. Tu, and K. He, “Aggregated residual transformations for deep neural networks,” in CVPR, 2017, pp. 1492–1500.
- [6] J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y. Wei, “Deformable convolutional networks,” in ICCV, 2017, pp. 764–773.
- [7] D. Zhou, X. Jin, Q. Hou, K. Wang, J. Yang, and J. Feng, “Neural epitome search for architecture-agnostic network compression,” arXiv preprint arXiv:1907.05642, 2019.
- [8] H. Zhang, C. Wu, Z. Zhang, Y. Zhu, H. Lin, Z. Zhang, Y. Sun, T. He, J. Mueller, R. Manmatha et al., “Resnest: Split-attention networks,” in CVPR, 2022, pp. 2736–2746.
- [9] Z. Tian, C. Shen, and H. Chen, “Conditional convolutions for instance segmentation,” in ECCV. Springer, 2020.
- [10] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,” arXiv preprint arXiv:1704.04861, 2017.
- [11] B. Yang, G. Bender, Q. V. Le, and J. Ngiam, “Condconv: Conditionally parameterized convolutions for efficient inference,” arXiv preprint arXiv:1904.04971, 2019.
- [12] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning spatiotemporal features with 3d convolutional networks,” in ICCV, 2015, pp. 4489–4497.
- [13] D. Tran, H. Wang, L. Torresani, J. Ray, Y. LeCun, and M. Paluri, “A closer look at spatiotemporal convolutions for action recognition,” in CVPR, 2018, pp. 6450–6459.
- [14] Z. Qiu, T. Yao, and T. Mei, “Learning spatio-temporal representation with pseudo-3d residual networks,” in ICCV, 2017, pp. 5533–5541.
- [15] D. L. Ruderman and W. Bialek, “Statistics of natural images: Scaling in the woods,” Physical review letters, vol. 73, no. 6, p. 814, 1994.
- [16] E. P. Simoncelli and B. A. Olshausen, “Natural image statistics and neural representation,” Annual review of neuroscience, vol. 24, no. 1, pp. 1193–1216, 2001.
- [17] J. Zhou, V. Jampani, Z. Pi, Q. Liu, and M.-H. Yang, “Decoupled dynamic filter networks,” in CVPR, 2021, pp. 6647–6656.
- [18] J. Wu, D. Li, Y. Yang, C. Bajaj, and X. Ji, “Dynamic filtering with large sampling field for convnets,” in ECCV, 2018, pp. 185–200.
- [19] C. Feichtenhofer, H. Fan, J. Malik, and K. He, “Slowfast networks for video recognition,” in ICCV, 2019, pp. 6202–6211.
- [20] C. Feichtenhofer, “X3d: Expanding architectures for efficient video recognition,” in CVPR, 2020, pp. 203–213.
- [21] X. Jia, B. De Brabandere, T. Tuytelaars, and L. V. Gool, “Dynamic filter networks,” NeurIPS, vol. 29, pp. 667–675, 2016.
- [22] Y. Chen, X. Dai, M. Liu, D. Chen, L. Yuan, and Z. Liu, “Dynamic convolution: Attention over convolution kernels,” in CVPR, 2020, pp. 11 030–11 039.
- [23] Z. Huang, S. Zhang, L. Pan, Z. Qing, M. Tang, Z. Liu, and M. H. Ang Jr, “TAda! temporally-adaptive convolutions for video understanding,” in ICLR, 2022.
- [24] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” NeurIPS, vol. 30, 2017.
- [25] J. Carreira and A. Zisserman, “Quo vadis, action recognition? a new model and the kinetics dataset,” in CVPR, 2017, pp. 6299–6308.
- [26] D. Tran, H. Wang, L. Torresani, and M. Feiszli, “Video classification with channel-separated convolutional networks,” in ICCV, 2019, pp. 5552–5561.
- [27] K. Simonyan and A. Zisserman, “Two-stream convolutional networks for action recognition in videos,” arXiv preprint arXiv:1406.2199, 2014.
- [28] J. Lin, C. Gan, and S. Han, “Tsm: Temporal shift module for efficient video understanding,” in ICCV, 2019, pp. 7083–7093.
- [29] L. Wang, Z. Tong, B. Ji, and G. Wu, “Tdn: Temporal difference networks for efficient action recognition,” in CVPR, 2021, pp. 1895–1904.
- [30] B. Jiang, M. Wang, W. Gan, W. Wu, and J. Yan, “Stm: Spatiotemporal and motion encoding for action recognition,” in ICCV, 2019, pp. 2000–2009.
- [31] Z. Liu, L. Wang, W. Wu, C. Qian, and T. Lu, “Tam: Temporal adaptive module for video recognition,” ICCV, 2021.
- [32] H. Wang, D. Tran, L. Torresani, and M. Feiszli, “Video modeling with correlation networks,” in CVPR, 2020, pp. 352–361.
- [33] J. Wang, Z. Sun, Y. Qian, D. Gong, X. Sun, M. Lin, M. Pagnucco, and Y. Song, “Maximizing spatio-temporal entropy of deep 3d cnns for efficient video recognition,” in ICLR, 2023.
- [34] X. Li, Y. Wang, Z. Zhou, and Y. Qiao, “Smallbignet: Integrating core and contextual views for video classification,” in CVPR, 2020, pp. 1092–1101.
- [35] Y. Zhou, Z. Huang, X. Yang, M. Ang, and T. K. Ng, “Gcm: Efficient video recognition with glance and combine module,” Pattern Recognition, vol. 133, p. 108970, 2023.
- [36] Z. Liu, H. Mao, C.-Y. Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A convnet for the 2020s,” arXiv preprint arXiv:2201.03545, 2022.
- [37] J. D. M.-W. C. Kenton and L. K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” in Proceedings of NAACL-HLT, 2019, pp. 4171–4186.
- [38] A. Radford, K. Narasimhan, T. Salimans, I. Sutskever et al., “Improving language understanding by generative pre-training,” 2018.
- [39] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [40] H. Fan, B. Xiong, K. Mangalam, Y. Li, Z. Yan, J. Malik, and C. Feichtenhofer, “Multiscale vision transformers,” in ICCV, 2021, pp. 6824–6835.
- [41] T. Meinhardt, A. Kirillov, L. Leal-Taixe, and C. Feichtenhofer, “Trackformer: Multi-object tracking with transformers,” in CVPR, 2022, pp. 8844–8854.
- [42] Z. Cao, Z. Huang, L. Pan, S. Zhang, Z. Liu, and C. Fu, “Tctrack: Temporal contexts for aerial tracking,” in CVPR, 2022, pp. 14 798–14 808.
- [43] H. Bao, L. Dong, S. Piao, and F. Wei, “Beit: Bert pre-training of image transformers,” arXiv preprint arXiv:2106.08254, 2021.
- [44] C. Zhou, Z. Luo, Y. Luo, T. Liu, L. Pan, Z. Cai, H. Zhao, and S. Lu, “Pttr: Relational 3d point cloud object tracking with transformer,” in CVPR, 2022, pp. 8531–8540.
- [45] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image generation with clip latents,” arXiv preprint arXiv:2204.06125, 2022.
- [46] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in ECCV. Springer, 2020, pp. 213–229.
- [47] X. Wang, R. Girshick, A. Gupta, and K. He, “Non-local neural networks,” in CVPR, 2018, pp. 7794–7803.
- [48] Z. Liu, J. Ning, Y. Cao, Y. Wei, Z. Zhang, S. Lin, and H. Hu, “Video swin transformer,” arXiv preprint arXiv:2106.13230, 2021.
- [49] A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lučić, and C. Schmid, “Vivit: A video vision transformer,” in ICCV, 2021, pp. 6836–6846.
- [50] G. Bertasius, H. Wang, and L. Torresani, “Is space-time attention all you need for video understanding,” arXiv preprint arXiv:2102.05095, vol. 2, no. 3, p. 4, 2021.
- [51] X. Liu, Q. Wang, Y. Hu, X. Tang, S. Zhang, S. Bai, and X. Bai, “End-to-end temporal action detection with transformer,” IEEE TIP, vol. 31, pp. 5427–5441, 2022.
- [52] G. Chen, Y.-D. Zheng, J. Wang, J. Xu, Y. Huang, J. Pan, Y. Wang, Y. Wang, Y. Qiao, T. Lu et al., “Videollm: Modeling video sequence with large language models,” arXiv preprint arXiv:2305.13292, 2023.
- [53] M. Patrick, D. Campbell, Y. Asano, I. Misra, F. Metze, C. Feichtenhofer, A. Vedaldi, and J. F. Henriques, “Keeping your eye on the ball: Trajectory attention in video transformers,” Advances in neural information processing systems, vol. 34, pp. 12 493–12 506, 2021.
- [54] X. Chen, S. Xie, and K. He, “An empirical study of training self-supervised vision transformers,” in ICCV, 2021, pp. 9640–9649.
- [55] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” in CVPR, 2022, pp. 16 000–16 009.
- [56] Z. Tong, Y. Song, J. Wang, and L. Wang, “Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training,” arXiv preprint arXiv:2203.12602, 2022.
- [57] C. Feichtenhofer, Y. Li, K. He et al., “Masked autoencoders as spatiotemporal learners,” NeurIPS, vol. 35, pp. 35 946–35 958, 2022.
- [58] Z. Qing, S. Zhang, Z. Huang, Y. Xu, X. Wang, C. Gao, R. Jin, and N. Sang, “Self-supervised learning from untrimmed videos via hierarchical consistency,” PAMI, 2023.
- [59] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in ICML. PMLR, 2021, pp. 8748–8763.
- [60] J. Yu, Z. Wang, V. Vasudevan, L. Yeung, M. Seyedhosseini, and Y. Wu, “Coca: Contrastive captioners are image-text foundation models,” arXiv preprint arXiv:2205.01917, 2022.
- [61] X. Zhai, A. Kolesnikov, N. Houlsby, and L. Beyer, “Scaling vision transformers,” in CVPR, 2022, pp. 12 104–12 113.
- [62] M. Dehghani, J. Djolonga, B. Mustafa, P. Padlewski, J. Heek, J. Gilmer, A. Steiner, M. Caron, R. Geirhos, I. Alabdulmohsin et al., “Scaling vision transformers to 22 billion parameters,” arXiv preprint arXiv:2302.05442, 2023.
- [63] W. Wang, H. Bao, L. Dong, J. Bjorck, Z. Peng, Q. Liu, K. Aggarwal, O. K. Mohammed, S. Singhal, S. Som et al., “Image as a foreign language: Beit pretraining for all vision and vision-language tasks,” arXiv preprint arXiv:2208.10442, 2022.
- [64] L. Wang, B. Huang, Z. Zhao, Z. Tong, Y. He, Y. Wang, Y. Wang, and Y. Qiao, “Videomae v2: Scaling video masked autoencoders with dual masking,” arXiv preprint arXiv:2303.16727, 2023.
- [65] J. Pan, Z. Lin, X. Zhu, J. Shao, and H. Li, “St-adapter: Parameter-efficient image-to-video transfer learning for action recognition,” arXiv preprint arXiv:2206.13559, 2022.
- [66] Y. Li, Y. Chen, X. Dai, D. Chen, Y. Yu, L. Yuan, Z. Liu, M. Chen, N. Vasconcelos et al., “Revisiting dynamic convolution via matrix decomposition,” in ICLR, 2021.
- [67] Y. Li, Y. Chen, X. Dai, D. Chen, M. Liu, L. Yuan, Z. Liu, L. Zhang, and N. Vasconcelos, “Micronet: Towards image recognition with extremely low flops,” arXiv preprint arXiv:2011.12289, 2020.
- [68] Y. Chen, X. Dai, M. Liu, D. Chen, L. Yuan, and Z. Liu, “Dynamic relu,” in ECCV. Springer, 2020, pp. 351–367.
- [69] X. Wang, F. Yu, Z.-Y. Dou, T. Darrell, and J. E. Gonzalez, “Skipnet: Learning dynamic routing in convolutional networks,” in ECCV, 2018, pp. 409–424.
- [70] Y. Li, L. Song, Y. Chen, Z. Li, X. Zhang, X. Wang, and J. Sun, “Learning dynamic routing for semantic segmentation,” in CVPR, 2020, pp. 8553–8562.
- [71] Z. Ye, M. Xia, R. Yi, J. Zhang, Y.-K. Lai, X. Huang, G. Zhang, and Y.-j. Liu, “Audio-driven talking face video generation with dynamic convolution kernels,” IEEE Transactions on Multimedia, 2022.
- [72] Z.-H. Jiang, W. Yu, D. Zhou, Y. Chen, J. Feng, and S. Yan, “Convbert: Improving bert with span-based dynamic convolution,” NeurIPS, vol. 33, pp. 12 837–12 848, 2020.
- [73] Y.-S. Xu, S.-Y. R. Tseng, Y. Tseng, H.-K. Kuo, and Y.-M. Tsai, “Unified dynamic convolutional network for super-resolution with variational degradations,” in CVPR, 2020, pp. 12 496–12 505.
- [74] F. Wu, A. Fan, A. Baevski, Y. N. Dauphin, and M. Auli, “Pay less attention with lightweight and dynamic convolutions,” arXiv preprint arXiv:1901.10430, 2019.
- [75] Y. Meng, R. Panda, C.-C. Lin, P. Sattigeri, L. Karlinsky, K. Saenko, A. Oliva, and R. Feris, “Adafuse: Adaptive temporal fusion network for efficient action recognition,” in ICLR, 2021.
- [76] Z. Wu, C. Xiong, C.-Y. Ma, R. Socher, and L. S. Davis, “Adaframe: Adaptive frame selection for fast video recognition,” in CVPR, 2019, pp. 1278–1287.
- [77] Y. Meng, C.-C. Lin, R. Panda, P. Sattigeri, L. Karlinsky, A. Oliva, K. Saenko, and R. Feris, “Ar-net: Adaptive frame resolution for efficient action recognition,” in ECCV. Springer, 2020, pp. 86–104.
- [78] G. Elsayed, P. Ramachandran, J. Shlens, and S. Kornblith, “Revisiting spatial invariance with low-rank local connectivity,” in ICML. PMLR, 2020, pp. 2868–2879.
- [79] J. Chen, X. Wang, Z. Guo, X. Zhang, and J. Sun, “Dynamic region-aware convolution,” in CVPR, 2021, pp. 8064–8073.
- [80] V. Nair and G. E. Hinton, “Rectified linear units improve restricted boltzmann machines,” in Icml, 2010.
- [81] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in ICML. PMLR, 2015, pp. 448–456.
- [82] J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,” arXiv preprint arXiv:1607.06450, 2016.
- [83] W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijayanarasimhan, F. Viola, T. Green, T. Back, P. Natsev et al., “The kinetics human action video dataset,” arXiv preprint arXiv:1705.06950, 2017.
- [84] R. Goyal, S. E. Kahou, V. Michalski, J. Materzynska, S. Westphal, H. Kim, V. Haenel, I. Fruend, P. Yianilos, M. Mueller-Freitag et al., “The” something something” video database for learning and evaluating visual common sense.” in CVPR, vol. 1, 2017, p. 5.
- [85] D. Damen, H. Doughty, G. M. Farinella, A. Furnari, E. Kazakos, J. Ma, D. Moltisanti, J. Munro, T. Perrett, W. Price et al., “Rescaling egocentric vision,” arXiv preprint arXiv:2006.13256, 2020.
- [86] H. Zhao, A. Torralba, L. Torresani, and Z. Yan, “Hacs: Human action clips and segments dataset for recognition and temporal localization,” in ICCV, 2019, pp. 8668–8678.
- [87] K. Soomro, A. R. Zamir, and M. Shah, “Ucf101: A dataset of 101 human actions classes from videos in the wild,” arXiv preprint arXiv:1212.0402, 2012.
- [88] H. Kuehne, H. Jhuang, E. Garrote, T. Poggio, and T. Serre, “Hmdb: a large video database for human motion recognition,” in ICCV. IEEE, 2011, pp. 2556–2563.
- [89] J. Carreira, E. Noland, A. Banki-Horvath, C. Hillier, and A. Zisserman, “A short note about kinetics-600,” arXiv preprint arXiv:1808.01340, 2018.
- [90] J. Carreira, E. Noland, C. Hillier, and A. Zisserman, “A short note on the kinetics-700 human action dataset,” arXiv preprint arXiv:1907.06987, 2019.
- [91] K. Li, Y. Wang, Y. He, Y. Li, Y. Wang, L. Wang, and Y. Qiao, “Uniformerv2: Spatiotemporal learning by arming image vits with video uniformer,” arXiv preprint arXiv:2211.09552, 2022.
- [92] I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017.
- [93] E. D. Cubuk, B. Zoph, J. Shlens, and Q. V. Le, “Randaugment: Practical automated data augmentation with a reduced search space,” in CVPR Workshops, 2020, pp. 702–703.
- [94] G. Huang, Y. Sun, Z. Liu, D. Sedra, and K. Q. Weinberger, “Deep networks with stochastic depth,” in ECCV. Springer, 2016, pp. 646–661.
- [95] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in CVPR, 2016, pp. 2818–2826.
- [96] H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz, “mixup: Beyond empirical risk minimization,” arXiv preprint arXiv:1710.09412, 2017.
- [97] S. Yun, D. Han, S. J. Oh, S. Chun, J. Choe, and Y. Yoo, “Cutmix: Regularization strategy to train strong classifiers with localizable features,” in ICCV, 2019, pp. 6023–6032.
- [98] B. T. Polyak and A. B. Juditsky, “Acceleration of stochastic approximation by averaging,” SIAM journal on control and optimization, vol. 30, no. 4, pp. 838–855, 1992.
- [99] L. Wang, Y. Xiong, Z. Wang, Y. Qiao, D. Lin, X. Tang, and L. Van Gool, “Temporal segment networks: Towards good practices for deep action recognition,” in ECCV. Springer, 2016, pp. 20–36.
- [100] K. Hara, H. Kataoka, and Y. Satoh, “Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet?” in CVPR, 2018, pp. 6546–6555.
- [101] Y. Li, C.-Y. Wu, H. Fan, K. Mangalam, B. Xiong, J. Malik, and C. Feichtenhofer, “Mvitv2: Improved multiscale vision transformers for classification and detection,” in CVPR, 2022, pp. 4804–4814.
- [102] D. Kondratyuk, L. Yuan, Y. Li, L. Zhang, M. Tan, M. Brown, and B. Gong, “Movinets: Mobile video networks for efficient video recognition,” in CVPR, 2021, pp. 16 020–16 030.
- [103] A. Bulat, J. M. Perez Rua, S. Sudhakaran, B. Martinez, and G. Tzimiropoulos, “Space-time mixing attention for video transformer,” NeurIPS, vol. 34, pp. 19 594–19 607, 2021.
- [104] S. Yan, X. Xiong, A. Arnab, Z. Lu, M. Zhang, C. Sun, and C. Schmid, “Multiview transformers for video recognition,” in CVPR, 2022, pp. 3333–3343.
- [105] Z. Qing, S. Zhang, Z. Huang, X. Wang, Y. Wang, Y. Lv, C. Gao, and N. Sang, “Mar: Masked autoencoders for efficient action recognition,” IEEE Transactions on Multimedia, 2023.
- [106] C. Wei, H. Fan, S. Xie, C.-Y. Wu, A. Yuille, and C. Feichtenhofer, “Masked feature prediction for self-supervised visual pre-training,” in CVPR, 2022, pp. 14 668–14 678.
- [107] B. Zhang, J. Yu, C. Fifty, W. Han, A. M. Dai, R. Pang, and F. Sha, “Co-training transformer with videos and images improves action recognition,” arXiv preprint arXiv:2112.07175, 2021.
- [108] Z. Lin, S. Geng, R. Zhang, P. Gao, G. de Melo, X. Wang, J. Dai, Y. Qiao, and H. Li, “Frozen clip models are efficient video learners,” in ECCV. Springer, 2022, pp. 388–404.
- [109] B. Ni, H. Peng, M. Chen, S. Zhang, G. Meng, J. Fu, S. Xiang, and H. Ling, “Expanding language-image pretrained models for general video recognition,” in ECCV. Springer, 2022, pp. 1–18.
- [110] H. Rasheed, M. U. Khattak, M. Maaz, S. Khan, and F. S. Khan, “Fine-tuned clip models are efficient video learners,” in CVPR, 2023, pp. 6545–6554.
- [111] Y. Li, B. Ji, X. Shi, J. Zhang, B. Kang, and L. Wang, “Tea: Temporal excitation and aggregation for action recognition,” in CVPR, 2020, pp. 909–918.
- [112] B. Zhou, A. Andonian, A. Oliva, and A. Torralba, “Temporal relational reasoning in videos,” in ECCV, 2018, pp. 803–818.
- [113] Z. Huang, Z. Qing, X. Wang, Y. Feng, S. Zhang, J. Jiang, Z. Xia, M. Tang, N. Sang, and M. H. Ang Jr, “Towards training stronger video vision transformers for epic-kitchens-100 action recognition,” arXiv preprint arXiv:2106.05058, 2021.
- [114] C.-Y. Wu, Y. Li, K. Mangalam, H. Fan, B. Xiong, J. Malik, and C. Feichtenhofer, “Memvit: Memory-augmented multiscale vision transformer for efficient long-term video recognition,” in CVPR, 2022, pp. 13 587–13 597.
- [115] X. Xu, T. M. Hospedales, and S. Gong, “Multi-task zero-shot action recognition with prioritised data augmentation,” in ECCV. Springer, 2016, pp. 343–359.
- [116] Q. Wang and K. Chen, “Alternative semantic representations for zero-shot human action recognition,” in Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2017, Skopje, Macedonia, September 18–22, 2017, Proceedings, Part I 10. Springer, 2017, pp. 87–102.
- [117] S. Chen and D. Huang, “Elaborative rehearsal for zero-shot action recognition,” in ICCV, 2021, pp. 13 638–13 647.
- [118] M. Wang, J. Xing, and Y. Liu, “Actionclip: A new paradigm for video action recognition,” arXiv preprint arXiv:2109.08472, 2021.
- [119] C. Ju, T. Han, K. Zheng, Y. Zhang, and W. Xie, “Prompting visual-language models for efficient video understanding,” in ECCV. Springer, 2022, pp. 105–124.
- [120] Y. Zhao, B. Zhang, Z. Wu, S. Yang, L. Zhou, S. Yan, L. Wang, Y. Xiong, D. Lin, Y. Qiao et al., “Cuhk & ethz & siat submission to activitynet challenge 2017,” arXiv preprint arXiv:1710.08011, vol. 8, no. 8, 2017.
- [121] M. Xu, C. Zhao, D. S. Rojas, A. Thabet, and B. Ghanem, “G-tad: Sub-graph localization for temporal action detection,” in CVPR, 2020, pp. 10 156–10 165.
- [122] T. Lin, X. Liu, X. Li, E. Ding, and S. Wen, “Bmn: Boundary-matching network for temporal action proposal generation,” in ICCV, 2019, pp. 3889–3898.
- [123] C.-L. Zhang, J. Wu, and Y. Li, “Actionformer: Localizing moments of actions with transformers,” in ECCV. Springer, 2022, pp. 492–510.
- [124] C. Zhang, L. Sui, A. Majeedi, V. R. Gajjala, and Y. Li, “Detecting egocentric actions with actionformer,” https://epic-kitchens.github.io/Reports/EPIC-KITCHENS-Challenges-2022-Report.pdf.
- [125] Z. Qing, Z. Huang, X. Wang, Y. Feng, S. Zhang, J. Jiang, M. Tang, C. Gao, M. H. Ang Jr, and N. Sang, “A stronger baseline for ego-centric action detection,” arXiv preprint arXiv:2106.06942, 2021.
- [126] Z. Qing, X. Wang, Z. Huang, Y. Feng, S. Zhang, M. Tang, C. Gao, N. Sang et al., “Exploring stronger feature for temporal action localization,” arXiv preprint arXiv:2106.13014, 2021.
- [127] G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov, “Improving neural networks by preventing co-adaptation of feature detectors,” arXiv preprint arXiv:1207.0580, 2012.
- [128] Y. Li, B. Ji, X. Shi, J. Zhang, B. Kang, and L. Wang, “Tea: Temporal excitation and aggregation for action recognition,” in CVPR, 2020, pp. 909–918.
- [129] Z. Qing, H. Su, W. Gan, D. Wang, W. Wu, X. Wang, Y. Qiao, J. Yan, C. Gao, and N. Sang, “Temporal context aggregation network for temporal action proposal refinement,” in CVPR, 2021, pp. 485–494.
附录 A概述
附录B时间卷积的详细分析
在这里,我们提供详细的分析来展示通过时间卷积进行时间建模的基本过程。 正如在第二节中一样。 3.1,为了简单性和广泛的应用,我们使用深度时间卷积。 我们首先分析时间卷积直接放置在空间卷积之后而中间没有非线性激活的情况,然后在分析的第二部分中插入激活函数。
无需激活。 我们首先考虑时间卷积和空间卷积之间没有非线性激活函数的简单情况。 给定一个由 参数化的 311 个深度方向时间卷积,其中 是由 ,第帧的输出特征可以通过以下方式获得:
| (9) |
其中 表示与广播进行元素级乘法, 表示空间维度上的卷积。 在这种情况下,可以与空间卷积权重分组,并且时间和空间卷积的组合可以重写为:
| (10) |
其中 、 和 。 该方程与方程具有相同的形式。手稿中的2。 在这种情况下,时间卷积与空间卷积的结合当然可以看作是时间卷积在聚合之前简单地对空间卷积进行校准,并为不同的时间步分配不同的权重来进行校准。
随着激活。 接下来,我们考虑激活位于时间卷积和空间卷积之间的情况。 输出特征 现在通过以下方式获得:
| (11) |
接下来,我们证明这仍然可以重写为方程的形式。 2。 这里,我们考虑使用 ReLU [80] 作为激活函数的情况,记为 :
| (12) |
因此,术语可以很容易地表示为:
| (13) |
其中是与形状相同的二值映射,表示中对应的元素是否大于0。 那是:
| (14) |
其中 是张量中的位置索引。 因此,通过激活,时间卷积可以表示为:
| (15) |
在这种情况下,我们可以设置、和,其中表示空间位置索引。 在这种情况下,特定时间步的每个过滤器由过滤器和等式1组成。 1 可以重写为等式: 2。 有趣的是,可以观察到,使用 ReLU 激活函数,所有时空位置的卷积权重都是不同的,因为二进制映射 取决于空间卷积的结果。
附录C进一步的实施细节
在这里,我们进一步描述动作分类和动作定位实验的实现细节。 为了公平比较,我们将基线、插件评估以及我们自己的模型的所有训练策略保持相同。
| training config | K710 | K400 (K710) | K400 (ImageNet) | SSV1/SSV2 | EK100 |
| optimizer | AdamW [92] | ||||
| learning rate schedule | cosine decay | ||||
| weight decay | 0.02 | ||||
| optimizer momentum | |||||
| dropout [127] | 0.5 | ||||
| clip grading | None | ||||
| base learning rate | 5e-4 | ||||
| batch size | 512 | ||||
| training epochs | 100 | 30 | 100 | 64 | 50 |
| warmup epochs | 8 | 4 | 8 | 2.5 | 5 |
| randaugment [93] | (9, 0.5) | ||||
| label smoothing [95] | 0.0 | 0.1 | |||
| stochastic depth | 0.2 (T) | 0.2 (T) | 0.2 (T) | 0.3 (T) | 0.3 (T) |
| 0.4 (S) | 0.4 (S) | 0.4 (S) | 0.5 (S) | 0.5 (S) | |
| 0.6 (B) | 0.6 (B) | 0.6 (B) | 0.6 (B) | - | |
C.1 使用 TAdaConvNeXtV2 进行动作分类
| training config | K710 | K400 (K710) | K400 (CLIP) | SSV1/SSV2 | EK100 | |||||
| optimizer | AdamW [92] | |||||||||
| learning rate schedule | cosine decay | |||||||||
| weight decay | 0.05 | |||||||||
| optimizer momentum | ||||||||||
| dropout [127] | 0.5 | |||||||||
| clip grading | None | |||||||||
| EMA [98] | 0.9996 | |||||||||
| Base | Large | Base | Large | Base | Large | Base | Large | Base | Large | |
| base learning rate | 1e-4 | 5e-5 | 1e-5 | 5e-6 | 5e-5 | 2e-5 | 5e-4 | 2.5e-4 | 2.5e-4 | 1e-4 |
| batch size | 512 | 256 | 256 | 128 | 256 | 128 | 256 | 128 | 128 | 64 |
| training epochs | 30 | 24 | 15 | 10 | 30 | 24 | 24 | 24 | 24 | 15 |
| warmup epochs | 5 | 5 | 2.5 | 2 | 5 | 5 | 5 | 5 | 5 | 2.5 |
| layer-wise lr decay [43] | 0.7 | 0.8 | 0.7 | 0.8 | 0.7 | 0.85 | 0.7 | 0.85 | 0.7 | 0.85 |
| randaugment [93] | (9, 0.5) | (9, 0.5) | (9, 0.5) | (9, 0.5) | (9, 0.5) | |||||
| label smoothing [95] | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | |||||
| stochastic depth | - | - | - | - | 0.2 | - | ||||
C.2 动作本地化
我们使用两个大型数据集评估我们的动作定位任务模型。 我们的动作定位评估的整体流程分为微调分类模型、获取动作建议和对建议进行分类。
微调。 在Epic-Kitchens上,我们简单地使用评估的动作分类模型。 在 HACS 训练中,在 [126] 之后,我们使用 Kinetics-400 预训练权重初始化模型,并使用 adamW [92] 初始化模型使用 32 个 GPU 进行 30 个周期(8 次预热)。 小批量大小为每个 GPU 16 个视频。 基本学习率设置为 0.0002,余弦学习率衰减与动力学中一样。 在我们的例子中,只有带有动作标签的片段用于训练。
提案生成。 对于行动建议,边界匹配网络 (BMN) [122] 在两个数据集上提取的特征上进行训练。 在Epic-Kitchens上,我们使用以 60 FPS 统一解码的视频来提取特征。 对于每个剪辑,我们使用 8 帧,间隔为 8,以与微调保持一致,这意味着一个特征大致覆盖了 1 秒的视频剪辑。 用于特征提取的每个剪辑之间的间隔也是 8 帧(即 0.133 秒)。 视频较短一侧的大小调整为 224,我们将整个空间区域输入主干以保留尽可能多的信息。 继[125]之后,我们使用基于滑动窗口的BMN生成提案。 对不同滑动窗口的重叠区域的预测进行简单平均。 在HACS上,视频以 30 FPS 解码,并将剪辑之间的间隔延长为 16(即 0.533 秒),因为 HACS 中的动作持续时间比在 HACS 中长得多史诗般的厨房。 为了高效处理,短边尺寸调整为 128。 对于生成提案的设置,我们主要遵循[126],只不过在我们的例子中时间分辨率调整为100而不是200。
分类。 在 Epic-Kitchens 上,我们使用 6 个剪辑通过微调模型对提案进行分类。 在空间上,为了符合特征提取过程,我们将短边的大小调整为 224,并将整个空间区域输入模型进行分类。 在HACS上,考虑到数据集的特性,一个视频中只能存在一个动作类别,我们通过对视频级别特征进行分类,得到视频级别分类结果,如下[126].
使用 ActionFormer 进行动作本地化。 我们遵循 [124, 123] 中的所有设置,使用 ActionFormer 进行动作本地化实验。
评估。 为了进行评估,我们遵循各自数据集中使用的标准评估协议,即 HACS [86] IoU 阈值 [0.5:0.05:0.95] 的平均平均精度(平均 mAP) ] 和 [0.1:0.1:0.5] 对于 Epic-Kitchens-100 [85]。
附录D模型结构
| Stage | R3D | R(2+1)D | R2D | output sizes |
| Sampling | interval 8, 1 | interval 8, 1 | interval 8, 1 | 8224224 |
| conv1 | 37, 64 | 17, 64 | 17, 64 | 8112112 |
| stride 1, 2 | stride 1, 2 | stride 1, 2 | ||
| res2 | 3 | 3 | 3 | 85656 |
| res3 | 4 | 4 | 4 | 82828 |
| res4 | 6 | 6 | 6 | 81414 |
| res5 | 3 | 3 | 3 | 877 |
| global average pool, fc | 111 | |||
R2D、R(2+1)D 和 R3D 的详细模型结构在表A3中指定。 我们突出显示默认或可选地被 TAdaConv 替换的卷积。 对于我们所有的模型,我们进行了一个小的修改,即我们在第一个卷积之后删除了最大池化层,并将第二阶段的空间步长设置为 2,遵循 [32]。 最近的工作[19,128,30]之后,时间分辨率保持不变。 我们的 R3D 是通过简单地将 R2D 基线在时间维度上扩展三倍来获得的。 我们初始化时权重减少了 3 倍,这意味着原始权重均匀分布在相邻时间步长中。 我们通过在空间卷积之后添加时间卷积操作来构造R(2+1)D。 时间卷积也可以选择用 TAdaConv 替换,如手稿和表 A5 所示。 对于其初始化,时间卷积权重是随机初始化的,而其他权重则使用 ImageNet 上预先训练的权重进行初始化。 对于 SlowFast 模型,我们保持所有模型结构与原始工作[19]相同。
对于 TAdaConvNeXt,我们保留 ConvNeXt [36] 中的大部分模型架构,只是我们使用类似于 [49] 的小管嵌入,大小为 344,步幅为 244。 中心初始化的用法与[49]中一样。 基于此,我们简单地用 TAdaConv 替换深度卷积来构造 TAdaConvNeXt。 对于 TAdaConvNeXtV2,我们另外用 TAdaConv 代替 TAdaConvV2,并引入时间聚合方案。
| Kernel size | Top-1 |
| 1 | 37.5 |
| 3 | 56.5 |
| 5 | 57.3 |
| 7 | 56.5 |
| K2=1 | K2=3 | K2=5 | K2=7 | |
| K1=1 | 36.8 | 57.1 | 57.8 | 57.9 |
| K1=3 | 57.3 | 57.8 | 57.9 | 58.0 |
| K1=5 | 57.6 | 57.9 | 58.2 | 57.9 |
| K1=7 | 57.4 | 57.6 | 58.0 | 57.6 |
| Ratio | Top-1 |
| 1 | 57.79 |
| 2 | 57.83 |
| 4 | 57.78 |
| 8 | 57.66 |
| Top-1 | Top-5 | ||||||||
| Model | Frames | GFLOPs | Params. | Act. | Verb | Noun | Act. | Verb | Noun |
| SlowFast 416 | 4+32 | 36.10 | 34.5M | 38.17 | 63.54 | 48.79 | 58.68 | 89.75 | 73.37 |
| SlowFast 416 + TAdaConv | 4+32 | 36.11 | 37.7M | 39.14 | 64.50 | 49.59 | 59.21 | 89.67 | 73.88 |
| SlowFast 88 | 8+32 | 65.71 | 34.5M | 40.08 | 65.05 | 50.72 | 60.10 | 90.04 | 74.26 |
| SlowFast 88 + TAdaConv | 8+32 | 65.73 | 37.7M | 41.35 | 66.36 | 52.32 | 61.68 | 90.59 | 75.89 |
| R(2+1)D | 8 | 49.55 | 28.1M | 37.45 | 62.92 | 48.27 | 58.02 | 89.75 | 73.60 |
| R(2+1)D + TAdaConv | 8 | 49.57 | 31.3M | 39.72 | 64.48 | 50.26 | 60.22 | 90.01 | 75.06 |
| R(2+1)D + TAdaConv | 8 | 49.58 | 34.4M | 40.10 | 64.77 | 50.28 | 60.45 | 89.99 | 75.55 |
| R3D | 8 | 84.23 | 47.0M | 36.67 | 61.92 | 47.87 | 57.47 | 89.02 | 73.05 |
| R3D + TAdaConv | 8 | 84.24 | 50.1M | 39.30 | 64.03 | 49.94 | 59.67 | 89.84 | 74.56 |
| HACS | Epic-Kitchen-100 | ||||||||||||
| Model | @0.5 | @0.6 | @0.7 | @0.8 | @0.9 | Avg. | Task | @0.1 | @0.2 | @0.3 | @0.4 | @0.5 | Avg. |
| S.F. 88 | 50.0 | 44.1 | 37.7 | 29.6 | 18.4 | 33.7 | Verb | 19.93 | 18.92 | 17.90 | 16.08 | 13.24 | 17.21 |
| Noun | 17.93 | 16.83 | 15.53 | 13.68 | 11.41 | 15.07 | |||||||
| Act. | 14.00 | 13.19 | 12.37 | 11.18 | 9.52 | 12.04 | |||||||
| S.F. 88 + TAdaConv | 51.7 | 45.7 | 39.3 | 31.0 | 19.5 | 35.1 | Verb | 19.96 | 18.71 | 17.65 | 15.41 | 13.35 | 17.01 |
| Noun | 20.17 | 18.90 | 17.58 | 15.83 | 13.18 | 17.13 | |||||||
| Act. | 14.90 | 14.12 | 13.32 | 12.07 | 10.57 | 13.00 | |||||||
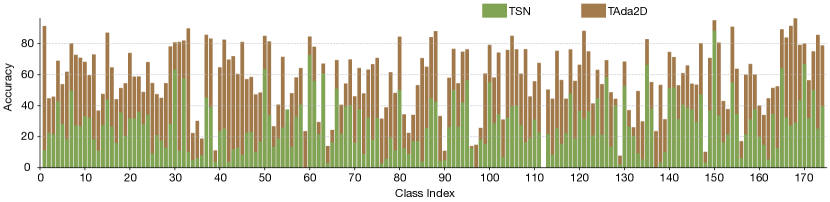
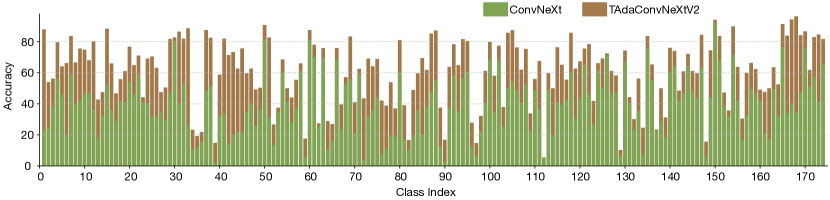
附录ESSV2的每类别改进分析
本节对图A1和图A2中的Something-Something-V2数据集进行按类别的改进分析。 在整体性能方面,我们的 TAda2D 比基线 TSN 提高了 31.7%,而 TAdaConvNeXtV2 比 ConvNeXt 提高了 25.4%。 我们的按类别分析显示,TAda2D 和 TAdaConvNeXtV2 的平均改进分别比所有类别高 30.35% 和 21.36%。 由于 TSN 和 ConvNeXt 都没有时间建模功能,并且我们的方法对基本模型引入了类似的修改,因此每类别准确度的差异模式是相似的。 因此,我们以TAda2D为例进行分析。 最大的改进出现在 0 级(78.5%,用相机接近某物)、32 级(78.4%,用相机远离某物)、30 级(74.3 %,抬起某物的一端而不让它掉落),44(66.2%,将某物移向相机)和 41(66.1%,移动远离相机的东西)。 这些类别中的大多数都包含整个视频中的大动作,其改进受益于全局空间上下文的时间推理。 对于30级来说,大部分动作都会持续很长时间(因为需要确定某件事的结局是否令人失望)。 相对于基线的改进主要受益于权重生成过程中包含的全局时间上下文。
附录F进一步的消融研究
在这里,我们对校准权重生成中的内核大小进行了进一步的消融研究。 如表LABEL:tab:ablationstudieskernelsizelin和表LABEL:tab:ablationstudieskernelsizenonlin所示,只要考虑时间上下文,内核大小对分类影响不大。 此外,表LABEL:tab:ablationstudiesreductionratio显示了对缩减率的敏感性分析,这证明了我们的方法针对不同超参数集的稳健性。
附录G对TAdaConv分类的进一步插件评估
作为对手稿的补充,我们在表 A5 中进一步显示了 Epic-Kitchens-100 数据集上动作分类任务的插件评估。 正如在 Kinetics 和 Something-Something-V2 的插件评估中一样,我们比较了使用和不使用 TAdaConv 的三个基线模型的性能:SlowFast [19]、R(2+1)D [13]和R3D[100]分别代表了三种时间建模技术。 结果与我们在手稿中插件评估中的观察结果一致。 在所有三种时间建模策略中,添加TAdaConv进一步提高了模型的识别精度。
附录 HTAdaConv 动作本地化插件评估
在这里,我们展示了对时间动作定位任务的插件评估。 具体来说,我们使用 SlowFast 作为基准,因为与许多早期骨干网相比,它在 [129] 中的本地化性能表现出优越性。 结果如表A6所示。 使用 TAdaConv,HACS 上的平均 mAP 提高了 1.4%,Epic-Kitchens-100 动作定位的平均 mAP 提高了 1.0%。
附录一训练程序比较
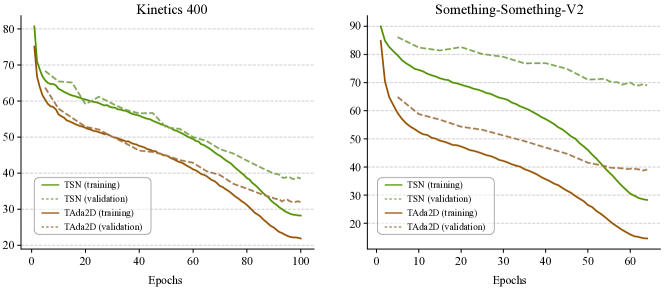
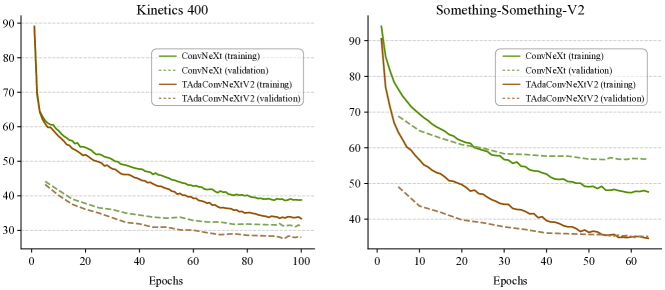
我们比较了图A3中TSN和TAda2D在Kinetics-400和Something-Something-V2上的训练过程,以及图A4中ConvNeXt和TAdaConvNeXtV2的训练过程。 尽管 TAda2D 和 TAdaConvNeXtV2 的初始化与 TSN 和 ConvNeXt 相同,但 TAda2D 和 TAdaConvNeXtV2 在训练集和验证集上都表现出了更强的性能。
| Temporal | Location | Pretrained | ||
| Operations | Weights | Modelling | Adaptive | weights |
| CondConv | Mixture of experts | ✗ | ✗ | ✗ |
| DynamicFilter | Completely generated | ✗ | ✗ | ✗ |
| DDF | Completely generated | ✗ | ✓ | ✗ |
| TAM | Completely generated | ✓ | ✗ | ✗ |
| TAdaConv | Calibrated from a base weight | ✓ | ✓ | ✓ |
| Calibration Generation | Our Init. | Temp. Varying | Generation source | Top-1 |
| DynamicFilter | ✗ | ✗ | 41.7 | |
| DDF-like | ✗ | ✓ | 49.8 | |
| TAM (global branch) | ✗ | ✗ | 39.7 | |
| TAM (local*+global branch) | ✗ | ✓ | 41.3 | |
| DynamicFilter | ✓ | ✗ | 51.2 (+9.5) | |
| DDF-like | ✓ | ✓ | 53.8 (+4.0) | |
| TAM (global branch) | ✓ | ✗ | 52.9 (+13.2) | |
| TAM (local*+global branch) | ✓ | ✓ | 54.3 (+13.0) | |
| TAdaConv w/o global info | ✓ | ✓ | 57.9 | |
| TAdaConv | ✓ | ✓ | both | 59.2 |
| and |
附录J与现有动态滤波器的比较
在本节中,我们从两个角度比较我们的 TAdaConv 和以前的动态滤波器,分别是方法论和性能上的差异。
J.1 方法比较
我们将 TAdaConv 与图像和视频中的几种代表性动态过滤方法进行比较,分别是 CondConv [11]、DynamicFilter [21]、DDF [17] 和谭[31]。
方法论上的第一个区别在于权重的来源,以前的方法通过专家混合或完全依赖于输入的生成来获得权重。 专家混合表示,其中是由函数获得的标量,即 。 完全生成表示权重仅取决于输入,即 ,其中为卷积生成完整的内核。 相比之下,TAdaConv中的权重是通过校准获得的,即, ,其中是矢量校准权重和 ,其中 生成卷积的校准向量。 因此,如何获取卷积权重的这种根本差异使得以前的方法难以利用预训练的权重,而 TAdaConv 可以轻松地在 中加载预训练的权重。 这种能力对于视频模型加速收敛至关重要。
第二个区别在于执行时间建模的能力。 执行时间建模的能力不仅意味着能够根据视频动态滤波器中的整个序列生成权重,而且还要求模型能够针对不同顺序的同一组帧生成不同的权重。 例如,通过对整个视频 进行全局平均池化获得的全局描述符生成的权重不具备时间建模能力,因为如果输入序列中帧的顺序不同,它们无法生成不同的权重被逆转或随机化。 因此,大多数基于全局描述符向量(例如CondConv和DynamicFilter)或基于相邻空间内容(DDF)的基于图像的方法无法实现时间建模。 TAM 基于空间维度 上的全局平均池化获得的时间局部描述符来生成时间卷积的卷积权重,如果序列发生变化,就会产生不同的权重。 因此,从这个意义上说,TAM具有时间建模能力。 相比之下,TAdaConv 利用时间局部和全局描述符来不仅利用局部时间上下文,还利用全局时间上下文。 权重生成过程来源的详细信息也显示在表A8中。
第三个区别在于生成的权重是否为不同位置共享。 对于CondConv、DynamicFilter和TAM,它们生成的权重是所有位置共享的,而对于DDF,权重根据空间位置而变化。 相比之下,TAdaConv 生成时间自适应权重。
J.2 性能水平比较
由于 TAdaConv 在生成校准权重方面与以前的方法有根本的不同,因此很难直接比较视频建模的性能,特别是对于那些不是为视频建模而设计的方法。 然而,由于TAdaConv中的校准权重已经完全生成,即即,我们可以使用其他动态滤波器来生成TAdaConv的校准权重。 由于基于 MoE 的方法(例如 CondConv)本质上是为内存限制较少但计算要求较高的应用程序设计的,因此它不适合视频应用程序,因为它对于视频模型来说内存太大。 因此,我们应用生成完整核权重的方法来生成校准权重并将其与 TAdaConv 进行比较。 性能如表A8所示。
值得注意的是,这些方法最初生成随机初始化的权重。 然而,正如手稿所示,我们的校准权重初始化策略对于产生合理的结果至关重要,我们进一步将初始化应用于这些现有方法,看看它们的生成函数是否比 TAdaConv 中的生成函数更好。 在以下段落中,我们提供了在 TAdaConv 中应用代表性的先前动态滤波器来生成校准权重的详细信息。
对于 DynamicFilter [21],校准权重 是使用全局描述符上的 MLP 生成的,全局描述符是通过对整个输入 执行全局平均池化获得的>,即。 在这种情况下,校准权重在不同的时间步长之间共享。
对于 DDF [17],我们仅使用通道分支,因为手稿中显示最好保持基本内核的空间结构不变。 类似地,DDF 中的权重也是通过在全局描述符上应用 MLP 来生成的,即 。 DDF 和 DynamicFilter 的区别在于,对于不同的时间步,DDF 生成不同的校准权重。
TAM [31] 的原始结构仅使用其全局分支生成内核权重,并使用本地分支生成不同时间步长的注意力图。 在我们的实验中,我们对 TAM 进行了一些修改,并进一步使本地分支也生成内核校准权重。 因此,对于 TAM 的唯一全局版本,校准权重计算如下:,其中 表示空间维度上的全局平均池化, 表示 TAM 中的全局分支。 在这种情况下,所有时间位置共享校准权重。 对于本地+全局版本的TAM,通过结合本地和全局分支的结果来计算校准权重,即 ,其中 表示按元素进行广播的乘法。 这意味着在这种情况下,校准权重是时间自适应的。 请注意,这是我们的 TAM 修改版本。 原始 TAM 无人机没有时间自适应卷积权重。
表A8中的结果表明(a)如果没有我们的初始化策略,以前在初始化时生成随机权重的方法不适合在TAdaConv中生成校准权重; (b) 我们的初始化策略可以方便地改变这一点,并使以前的方法在用于生成校准权重时产生合理的性能; (c) TAdaConv 中的校准权重生成函数结合了局部和全局上下文,优于之前所有的校准方法。
此外,当我们将没有全局信息的 TAdaConv 与 TAM(局部*+全局分支)进行比较时,可以看出,尽管两种方法都从形状为 的帧描述符 生成时间变化的权重>,我们的 TAdaConv 实现了显着更高的性能。 添加全局信息使 TAdaConv 与之前的动态滤波器相比取得了更显着的领先优势。