从全局到局部:
多尺度分布外检测
摘要
分布外(OOD)检测旨在检测在分布内(ID)训练过程中未看到其标签的“未知”数据。 表示学习的最新进展产生了基于距离的 OOD 检测,该检测根据输入与 ID 类训练数据的相对距离将输入识别为 ID/OOD。 以前的方法仅依赖于全局图像表示来计算成对距离,这可能不是最佳的,因为不可避免的背景混乱和类内变化可能会导致同一 ID 类的图像级表示在给定的表示空间中相距很远。 在这项工作中,我们通过提出多尺度 OOD 检测 (MODE) 克服了这一挑战,这是第一个利用全局视觉信息和图像局部区域细节来最大程度地有利于 OOD 检测的框架。 具体来说,我们首先发现,由于 ID 训练和 OOD 检测过程之间的规模差异,通过现成的交叉熵或对比损失进行预训练的现有模型无法捕获 MODE 有价值的局部表示。 为了缓解这个问题并鼓励 ID 训练中的局部判别表示,我们提出了基于注意力的局部 PropAgation (),这是一个可训练的目标,利用交叉注意力机制来对齐和突出目标的局部区域成对示例的对象。 在测试时 OOD 检测期间,在最具辨别力的多尺度表示上进一步设计了跨尺度决策 () 函数,以更忠实地区分 ID/OOD 数据。 我们在多个基准测试中证明了 MODE 的有效性和灵活性 - 平均而言,MODE 在 FPR 方面比之前最先进的技术高出高达 19.24%,2.77%在奥罗克。 代码可在 –https://github.com/JimZAI/MODE-OOD˝ 获取。
索引术语:
分布外检测、异常值检测、异常检测、多尺度表示。我简介
“没有机器是完美的”,现代机器学习(ML)系统被证明会对“未知”的分布外(OOD)输入产生过度自信且不可信的预测——其标签在分布内(ID)期间没有被看到) 训练过程[1,2,3]。 这最近引发了 OOD 检测的更普遍、更现实的任务,其目标是区分传入的示例是否是 ID/OOD,并允许 ML 系统在部署中采取预防措施[4,5,6,7 ]。 例如,在自动驾驶这一安全关键应用中,驾驶系统在检测到 OOD 数据(例如异常物体、场景)时必须将控制权移交给驾驶员。
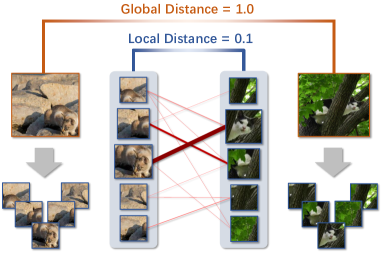
人们已经提出了大量 OOD 检测方案来减轻 OOD 数据的风险,同时正确分类 ID 类别。 许多先前的工作依靠 softmax 评分机制来防范 OOD 示例,其动机是简单地观察到 softmax 置信度分数较低的示例更有可能是 OOD [5, 3]。 尽管如此,性能良好的模型可以为远离训练数据 [8, 9] 的输入产生任意高的 softmax 置信度。 表示学习的最新进展产生了基于距离的训练 OOD 检测,它在适当的表示空间中表示图像数据,并使用距离函数根据测试示例与 ID 类 [10,11,9]。 特别是,Sun 等人提出了 KNN [9],这是第一个探索在全局图像表示上使用 k-最近邻搜索(又名: 用于 OOD 检测的倒数第二层表示。 除了在各种 OOD 基准和网络结构上建立最先进的性能之外,基于 KNN 的 OOD 检测还具有几个引人注目的优势,例如i)易于使用、 ii)模型无关,iii)分布无假设,使其具有良好的实用性和可扩展性。
尽管具有令人鼓舞的优势,但我们观察到不可避免的背景混乱和类内变化可能会导致同一 ID 类的全局图像级表示在给定的表示空间中相距很远,如图 1 因此,仅依靠单尺度全局表示来有效地区分ID-OOD示例变得更加困难。 此外,压倒性的经验证据表明,从多尺度表示中探索更丰富的视觉信息对于理解有区别的局部区域和目标对象的语义类别非常重要[12, 13]. 然而,纵观过去几年 OOD 检测的文献,利用判别性局部表示来实现更好的 ID-OOD 可分离性的效率迄今为止尚未受到任何关注,更不用说利用全局和局部表示来最大程度地有利于 OOD 检测了。 这种限制引出了以下问题:
我们能否利用图像中的全局视觉信息和局部区域细节来更有效地区分 ID/OOD 示例?
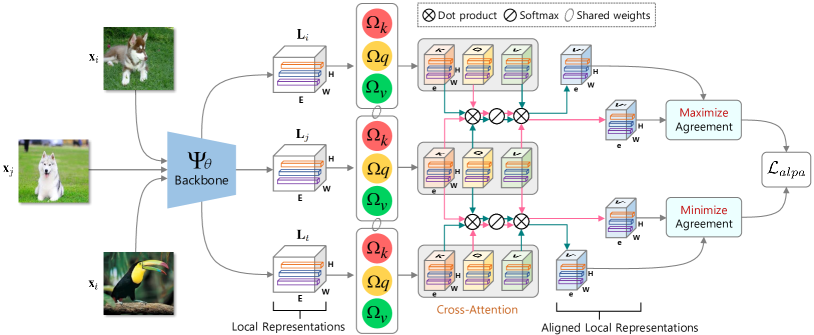
在这项工作中,我们通过提出M多尺度OOD DE保护(MODE)来回答上述问题,第一个利用多尺度(即全局和局部)表示进行 OOD 检测的框架。 具体来说,如图2所示,我们首先发现通过现成的交叉熵(CE)或对比学习(CL)损失预训练的现有模型无法捕获有价值的局部表示MODE,由于 ID 训练和 OOD 检测程序之间的规模差异。 为了解决这个问题,我们提出了基于注意力的局部 PropAgation (),这是一个可训练的目标,鼓励在 ID 训练期间从图像中挖掘局部判别性表示。 如图3所示,利用对比表示学习来促进通用视觉信息,捕获更丰富、更灵活的表示以识别ID/OOD数据。 然而,并没有直接使用全局表示来最大化/最小化成对示例的一致性,而是采用交叉注意机制来对齐和突出每对示例的目标对象的局部区域,使得提取的本地表示更具辨别力。 在测试时 OOD 检测中,为 MODE 进一步设计了跨尺度决策 () 函数,其中探索最具辨别力的多尺度表示以更忠实地区分 ID/OOD 示例,如下所示图4。
灵活性和强大的性能。 所提出的 MODE 与 ID 训练过程以及用不同方式预训练的模型是正交的。 更具体地说,MODE不仅可以将作为插件来规范ID训练损失,还可以直接利用它以端到端的方式微调现有的预训练模型。 我们在应用于各种网络结构的广泛基线方法上证明了 MODE 的有效性和灵活性。 值得注意的是,我们的 MODE 在多个基准测试中建立了新的最先进性能,在 FPR 方面平均优于之前的最佳方案 KNN [9] 高达 19.24% ,以及 AUROC 中的2.77%(参见表I)。 更重要的是,当 MODE 仅基于 5% ID 训练数据进行测试时 OOD 检测时,它仍然表现出比强大竞争对手 KNN(依赖于 100% ID 训练示例),在 FPR 中优于 KNN 6.08%,在 AUROC 中优于 KNN 0.68%(参见表 V)。
贡献。 总而言之,我们的贡献有四重。
-
•
我们提出了 MODE,这是第一个利用多尺度(即全局和局部)表示进行 OOD 检测的框架。
-
•
在 ID 训练期间,我们开发了 ,这是一个端到端、即插即用和基于交叉注意力的学习目标,专为鼓励 MODE 的局部歧视性表示而定制。
-
•
在测试时 OOD 检测期间,我们设计了 ,一个简单、有效、基于多尺度表示的 MODE ID-OOD 决策函数。
-
•
在多个基准数据集上的综合实验结果证明了 MODE 的有效性和灵活性。 值得注意的是,我们的 MODE 比最先进的方法取得了明显更好的性能。
II 相关工作
在本节中,我们简要回顾了与我们的工作密切相关的先前研究,包括分布外(OOD)检测、基于距离的 OOD 检测、OOD 检测的表示学习和基于部分的视觉对应。
分布外检测。 分布外 (OOD) 检测,又名 异常值检测[14, 15],异常检测[16, 17]或新颖性检测[18, 19],旨在识别来自开放世界的未知输入,以防止不可预测的风险。 之前的绝大多数工作都是测试时方法,依赖于预训练模型的输出 softmax 置信度得分来防范 OOD 输入。 这一系列工作背后的见解是,输出 softmax 置信度分数较低的传入示例更有可能来自 OOD [5, 3]。 有效的测试时评分函数包括 OpenMax [20]、MSP [1]、LogitNorm [21]、DICE [22] 、能源[3]、ODIN [5]等 在最近的工作[23]中,提出了一种简单而有效的测试时方法,名为LINE。 通过利用重要的神经元进行事后 OOD 检测,LINE 产生了卓越的测试时 OOD 检测性能。 虽然结果令人印象深刻,但事实证明,性能良好的模型可以为远离训练数据 [8] 的输入产生任意高的 softmax 置信度。 此外,大多数测试时 OOD 方法通常单独考虑有效 OOD 决策函数的开发,我们在这项工作中提出的 MODE 框架同时考虑训练时表示学习和测试时 OOD 检测。
基于距离的 OOD 检测。 基于距离的 OOD 检测的核心概念是计算输入示例和训练数据之间的距离度量。 测试示例被认为是 OOD(分别为 OOD)。 ID)数据,如果它们距离(resp.)相对较远。 接近)ID 类的训练示例。 随着表示学习的最新进展,各种基于距离的 OOD 检测算法已被采用。 其中,基于马氏距离的方法具有显着的性能[2, 24]。 然而,这些方法的成功建立在底层表示空间的强大分布假设之上,而现实中可能并不总是如此。 为了解决这个限制,Sun等人提出了KNN[9],这是第一个研究,探索在倒数第二层表示上使用k-最近邻搜索进行OOD检测的有效性。 与基于马哈拉诺比斯距离的方法相比,KNN[9]不对底层表示空间强加任何分布假设,更加简单、灵活和有效。 在[25]中,提出了一种新颖的表示学习框架(CIDER),用于利用超球形嵌入进行基于距离的 OOD 检测。 最近,利用 CLIP [26] 等大型视觉语言预训练模型进行多模态下游任务取得了显着的成功。 通过将 CLIP 模型中的视觉特征与文本类原型进行匹配,[27]中提出了一种有效的测试时间方法(称为 MCM),用于基于距离的 OOD 检测。 尽管基于距离的 OOD 检测具有令人鼓舞的优势,但我们观察到背景杂乱以及较大的类内变化可能会导致同一 ID 类的图像级表示在给定的表示空间中相距很远。 因此,仅根据从全局图像表示计算出的成对距离来正确区分 ID/OOD 示例变得更加困难。 此外,已经广泛证明,全局平均池化图像表示会破坏图像结构,并导致目标对象[28, 29]的大量判别性局部表示受到损害。 在这项工作中,我们首次利用图像中的全局视觉信息和局部区域细节来计算每对示例之间的距离,以最大程度地有利于基于距离的 OOD 检测。
OOD 检测的表示学习。 很多方法都尝试在 ID 训练阶段提高类内示例的紧凑性,以实现更好的测试时 OOD 检测性能[11,6,30]。 对比表示学习 [31, 32, 33, 34, 35, 36] 的目标是学习判别表示空间,其中正样本对齐,负样本分散,已被证明可以改善 OOD 检测 [10,11,37]。 特别是,Tack等人[11]提出了一种名为对比移位实例(CSI)的方案来学习非常适合新颖性检测的表示。 在[10]中,作者提出了一种基于未标记 ID 数据以及自监督表示学习技术的有效异常值检测器。 最近的研究[38, 39]还表明,提高闭集(即ID)分类精度是进一步提升OOD检测性能的关键。 另一项有前途的工作是通过训练时正则化[3,40,41]来改进 ID 训练。 然而,大多数正则化方法都需要大量的模拟 OOD 数据,而这在实践中可能无法实现。 令人惊讶的是,获得的定量和定性结果表明,仅依靠 ID 训练数据,我们设计的损失函数 可以使不同类别的分布更加紧凑,从而有利于 OOD 检测和 ID 分类任务。
基于注意力的局部特征对齐。 局部特征对齐[42,43,44]已经成为一种强大的范式,通过匹配图像(或图像文本对)的局部特征来实现有意义的表示,并在广泛的领域取得了巨大的成功。任务,如领域适应[45, 46]、图文匹配[47, 48]、少样本学习[28, 49, 50]. 在这些方法中,利用交叉注意力来增强特征对齐的想法已被广泛研究。 特别是,CDTrans [45] 将交叉注意力和自注意力应用于源-目标域对齐,以同时学习有区别的域不变和特定于域的特征。 SCAN [47] 在交叉注意模块中突出显示图像区域和句子中单词的对齐,以学习模态不变特征。 FEAT [49] 使用 set-to-set 函数(即 Transformer [51]),产生区分性和信息性特征。 与那些利用特定于任务的监督来鼓励局部特征之间的交互的作品不同,所设计的 将学习目标制定为对比损失,其中交叉注意模块将 CNN 的输出密集特征视为输入最大化(分别) 最小化)来自同一 ID 类(分别是)的每对样本的一致性。 不同的 ID 类别)。 此外,大多数这些工作的目标是学习一个共享的特征空间来对齐来自不同领域的特征[45](或模态[47]),而我们的ALPA旨在学习一个判别性特征空间,在该空间中可以建立合适的阈值或紧凑的决策边界来准确地区分ID/OOD数据。 据我们所知,这项工作是第一个使用基于注意力的局部特征对齐的思想来促进 OOD 检测中的局部判别表示的工作。
多尺度表示学习。 多尺度表示对于许多视觉任务非常重要,例如分类 [52, 53]、检索 [54, 55] 和检测 [12, 56],显着提高了这些领域的单尺度(即全球)表示所取得的性能。 与使用多尺度表示来识别 ID 类别的领域中的大多数工作不同,在这项工作中,我们首次利用多尺度表示在 OOD 检测中实现更好的 ID-OOD 可分离性,由于以下原因,这更具挑战性。 一方面,仅依赖 ID 类别的训练数据,学习到的多尺度表示可能不足以泛化以识别 OOD 数据的零件、对象及其周围环境。 另一方面,潜在的 OOD 数据的样本空间可能会非常大,甚至与 ID 类别 [40, 57] 的样本空间严重重叠,使得在 OOD 数据上建立决策边界变得困难。在测试时提取 ID 类别和 OOD 数据的多尺度表示。
III 方法论
在本节中,我们将详细介绍我们的 MODE 框架。 在此之前,我们先介绍一些重要的基础知识。
III-A 初步知识
在处理有监督的多类分类时,我们通常将 、 分别表示为输入、输出空间。 令 为 上的分布, 为神经网络,其输入从 中抽取的示例以输出 logit向量,然后用于预测输入示例的标签。 将表示为对于的边际分布,它表示分布内(ID)数据的分布。 在测试时 OOD 检测期间,环境可以呈现 OOD 数据在 上的分布 ,其标签空间 s.t. 。
分布外检测。 本质上,OOD 检测可以被视为二元分类任务,其目标是拒绝“未知”输入以防止任何潜在风险。 更具体地说,为了确定示例是否属于(即),可以通过水平集估计来做出决策函数:
| (1) |
其中输入示例 x 被分类为 ID(分别为 ID)。 OOD)如果其获得的分数 更高(resp. 低于)低于阈值。 实际上,通常选择 以便正确分类大部分 ID 数据(例如 95%)。
基于 KNN 的 OOD 检测。 表示学习的最新进展带来了基于距离的 OOD 检测,它在适当的表示空间中表示图像数据,并利用距离函数根据测试示例与 ID 类的可见示例的相对距离来决定测试示例是否是 ID/OOD。 特别是,Sun 等人提出了 KNN [9],它使用 -最近邻(创造了 -)建立了最先进的性能NN(下文中的 NN)搜索全局图像表示以进行 OOD 检测。
令 为将输入 x 映射到全局平均池表示 的特征主干(由 参数化)。 基于 KNN 的 OOD 检测对距离计算的全局表示 进行归一化。 在测试示例之前,我们首先获取ID训练数据的表示集合,记为。 在测试时 OOD 检测期间,我们计算欧几里德距离 w.r.t. 表示。 将重新排序的 ID 数据表示为 ,基于 KNN 的 OOD 检测的决策函数采用以下形式
| (2) |
其中 表示第 个最近邻居。 阈值不依赖于OOD数据,实际中可以在大部分ID数据(例如95%)被正确分类时选择。
对比表征学习。 我们利用对比表示学习[58]来促进通用视觉信息,捕获更丰富、更灵活的表示,可用于识别 ID/OOD 数据。 具体来说,我们首先将 x、g 的全局表示投影到具有投影头 的低维空间,即 . 令 为投影空间中每对图像的余弦相似度。 我们从 ID 类的训练数据中采样一批 对图像和标签,并增强批次中的每个图像以获得 标记数据点。 因此,有监督对比表示学习的损失函数可以表示为
| (3) |
我们有
| (4) |
其中是指示函数,是具有相同标签的样本数量,是标量温度范围。 上述学习目标引入了标签信息,以避免将同一类的增强视图分开,从而能够挖掘更具辨别力和鲁棒性的表示。
III-B 多尺度 OOD 检测 (MODE)
我们这项工作的目标是利用图像的多尺度(即全局和局部)表示来更有效地区分 ID/OOD 示例。 特别是,局部表示是卷积神经网络(CNN)最终全局平均池化层之前的输出特征图。 对于输入图像x,我们将获得的维局部表示表示为,将全局表示表示为,其中表示特征主干,是附加的平均池化层。 因此,x 的多尺度表示可以表示为 。
直观上,我们可以直接借用现有的预训练 CNN 来生成 MODE 的多尺度表示。 不幸的是,由于 ID 训练和 OOD 检测过程之间存在规模差异,通过现成的交叉熵 (CE) 或对比学习 (CL) 损失学习的模型无法捕获判别性用于识别 OOD 数据的局部表示,如图2所示。 这一观察结果也与大量的经验证据相一致,即平均池化图像表示会破坏图像结构并在训练[59,28,60]期间丢失目标对象的大量辨别性局部表示。 一旦学习了模型,那些丢失的有价值的本地表示就很难恢复。 因此,这一挑战引出了一个重要问题:
我们能否开发一种与模型无关的方法来鼓励 ID 训练中的局部判别表示,从而克服尺度差异问题并在测试期间使 MODE 受益?
基于注意力的局部传播 ()。 我们对上述问题的解决方案是 ,这是一个可训练的损失函数,专为在 ID 训练期间挖掘判别性局部表示而定制。 利用对比表示学习来促进通用视觉信息,捕获更丰富、更灵活的表示以识别 ID/OOD 数据。 然而,而不是像方程式那样利用全局表示(,)。 3,我们使用局部表示(,)来计算每对输入的相似性/不相似性( ,),如图3所示。
具体来说,我们的采用交叉注意机制来对齐和突出每对示例的目标对象的局部区域,从而提取更具辨别力的局部表示。 遵循 Transformers [61] 的设计,首先为 生成键 、值 和查询 L使用三个独立的线性映射:分别是键头、值头、查询头。 请注意,我们设置 是为了更简单的说明。 令 和 分别为两个成对示例 和 的局部表示。 我们的目标是计算 w.r.t 的对齐值。 ,记为。 为此,我们首先使用键和查询来确定注意力权重,由此我们可以获得 :
| (5) |
同样,我们可以通过对齐 的值来计算 。 使用键 和查询 。
因此,对于每对值 和 ,我们可以通过使用确定它们的两个对齐公式,即 和 前面提到的交叉注意力机制。 然后,我们对所有这些值 的每个表示向量 进行 归一化。 和 之间的相似度可以表示为
| (6) |
最后,类似于等式。 3,我们可以如下定义的损失函数:
| (7) |
在哪里
| (8) |
本质上,方程中的目标。 7打破了同一类训练示例的界限,并共同利用它们的局部表示,为每个类提供更丰富、更灵活的表示。 此外,通过利用交叉注意机制来对齐和突出每对示例的目标对象的局部表示,可以显着减轻背景杂乱和类内变化的不利影响。 在这种情况下,学习到的局部表示更具可转移性,并且可以捕获 ID 类之外的更多关键模式。
备注①:作为插件。 在实践中,开发的可以用作插件,通过i)规范ID训练过程来鼓励本地歧视性表示,创造- 或 ii)以端到端的方式直接微调用不同方式预训练的模型,称为 -。 总而言之,-增强型 ID 训练目标可以采用以下形式
| (9) |
其中表示现有ID训练(或表示学习)过程的学习目标,是控制对-。
备注②:ALPA 和 DenseCL 之间的主要区别。 与 ALPA 最密切相关的工作是 DenseCL [60],它通过基于图像的不同视图制定密集特征级对比损失来实现对比表示学习。 我们强调 和 DenseCL 之间的主要区别如下。 一方面,DenseCL 在无监督学习环境中设计了损失函数,而我们的 利用标签信息来避免将同一类的增强视图分开。 另一方面,DenseCL 使用相同的 卷积层作为投影头来为各个示例生成低维密集特征向量,而我们的 利用交叉注意机制来生成低维密集特征向量。突出显示成对示例的对象区域,使学习到的表示更具辨别力和鲁棒性。 尽管如此,DenseCL [60]确实给我们的方法带来了一些启发。
备注③:的时间复杂度。 我们的的时间复杂度是,其中。 因此,我们可以i)减少批量大小,ii)在上应用额外的平均池化步骤(以减少),iii)在注意力头中设置较小的维度以避免实践中过多的计算成本。
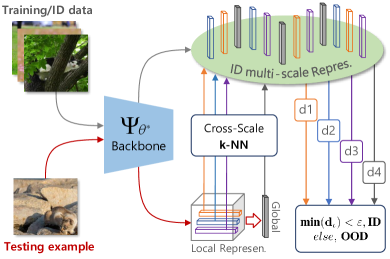
具有跨尺度决策的 OOD 检测 ()。 在 ID 训练过程中,我们提出 ,一种端到端、即插即用和基于交叉注意的损失函数,用于鼓励 MODE 的局部判别表示。 为了最大程度地有利于测试时 OOD 检测,我们开发了一个跨尺度决策 () 函数,依靠最具辨别力的多尺度表示的相对距离,更忠实地区分 ID/OOD 示例。
从数学上讲,让 为 增强的特征骨干。 我们首先应用 和 为训练数据 生成多尺度表示,表示为 ,其中 。 类似地,将第个测试示例的多尺度表示表示为。 对于每个 ,我们搜索 以确定其到归一化表示空间中第 k 个最近邻的距离(如 KNN [9]),记为。 区分ID/OOD数据的决策函数的形式为
| (10) |
其中 和 是计算 中每个表示与其搜索到的第 k 个最近邻之间的欧氏距离。 类似地,当大部分ID数据(例如95%)被正确分类时,可以选择阈值。
| Method | SVHN | Places365 | LSUN | iSUN | Texture | Average | |||||||
| FPR | AUROC | FPR | AUROC | FPR | AUROC | FPR | AUROC | FPR | AUROC | FPR | AUROC | ||
| MSP[1]∗ | 59.66 | 91.25 | 62.46 | 88.64 | 51.93 | 92.73 | 54.57 | 92.12 | 66.45 | 88.50 | 59.01 | 90.65 | |
| Energy[3]∗ | 54.41 | 91.22 | 42.77 | 91.02 | 23.45 | 96.14 | 27.52 | 95.59 | 55.23 | 89.37 | 40.68 | 92.67 | |
| ODIN[5]∗ | 20.93 | 95.55 | 63.04 | 86.57 | 31.92 | 94.82 | 33.17 | 94.65 | 56.40 | 86.21 | 41.09 | 91.56 | |
| GODIN[4]∗ | 15.51 | 96.60 | 62.63 | 87.31 | 32.43 | 95.08 | 34.03 | 94.94 | 46.91 | 89.69 | 38.30 | 92.72 | |
| Mahalanobis[2]∗ | 9.24 | 97.80 | 83.50 | 69.56 | 4.76 | 98.85 | 6.02 | 98.63 | 23.21 | 92.91 | 25.35 | 91.55 | |
| KNN[9]∗ | 24.53 | 95.96 | 25.29 | 95.69 | 25.55 | 95.26 | 27.57 | 94.71 | 50.90 | 89.14 | 30.77 | 94.15 | |
| MODE-T (ours)∗ | 4.33 | 97.67 | 25.01 | 95.45 | 7.79 | 98.46 | 34.08 | 94.87 | 24.14 | 94.74 | 19.07 | 96.24 | |
| MODE-F (ours)∗ | 1.00 | 99.79 | 29.58 | 94.39 | 5.06 | 99.12 | 32.55 | 95.03 | 19.56 | 97.11 | 17.55 | 97.09 | |
| CE+SimCLR[62]† | 6.98 | 99.22 | 54.39 | 86.70 | 64.53 | 85.60 | 59.62 | 86.78 | 16.77 | 96.56 | 40.46 | 90.97 | |
| CSI[11]† | 37.38 | 94.69 | 38.31 | 93.04 | 10.63 | 97.93 | 10.36 | 98.01 | 28.85 | 94.87 | 25.11 | 95.71 | |
| SSD[10]† | 2.47 | 99.51 | 22.05 | 95.57 | 10.56 | 97.83 | 28.44 | 95.67 | 9.27 | 98.35 | 14.56 | 97.38 | |
| ProxyAnchor[63]† | 39.27 | 94.55 | 43.46 | 92.06 | 21.04 | 97.02 | 23.53 | 96.56 | 42.70 | 93.16 | 34.00 | 94.46 | |
| LINE[23]† | 5.46 | 98.37 | 23.98 | 94.71 | 4.49 | 98.43 | 22.11 | 96.72 | 9.12 | 97.86 | 13.03 | 97.21 | |
| CIDER[25]† | 2.89 | 99.72 | 23.88 | 94.09 | 5.45 | 99.01 | 20.61 | 96.64 | 12.33 | 96.85 | 12.95 | 97.26 | |
| KNN[9]† | 2.42 | 99.52 | 23.02 | 95.36 | 1.78 | 99.48 | 20.06 | 96.74 | 8.09 | 98.56 | 11.07 | 97.93 | |
| MODE-T (ours)† | 1.24 | 99.76 | 24.51 | 95.20 | 3.83 | 99.22 | 24.41 | 96.22 | 9.93 | 98.31 | 12.78 | 97.74 | |
| MODE-F (ours)† | 0.65 | 99.86 | 20.13 | 96.44 | 2.15 | 99.31 | 19.87 | 97.59 | 8.46 | 98.22 | 10.05 | 98.42 | |
| (a) CIFAR-10 (ID) with ResNet-18 | |||||||||||||
| Method | SVHN | Places365 | LSUN | iSUN | Texture | Average | |||||||
| FPR | AUROC | FPR | AUROC | FPR | AUROC | FPR | AUROC | FPR | AUROC | FPR | AUROC | ||
| MSP[1]∗ | 78.89 | 79.80 | 84.38 | 74.21 | 83.47 | 75.28 | 84.61 | 74.51 | 86.51 | 72.53 | 83.12 | 75.27 | |
| ODIN[5]∗ | 70.16 | 84.88 | 82.16 | 75.19 | 76.36 | 80.10 | 79.54 | 79.16 | 85.28 | 75.23 | 78.70 | 79.11 | |
| Mahalanobis[2]∗ | 87.09 | 80.62 | 84.63 | 73.89 | 84.15 | 79.43 | 83.18 | 78.83 | 61.72 | 84.87 | 80.15 | 79.53 | |
| Energy[3]∗ | 66.91 | 85.25 | 81.41 | 76.37 | 59.77 | 86.69 | 66.52 | 84.49 | 79.01 | 79.96 | 70.72 | 82.55 | |
| GODIN[4]∗ | 74.64 | 84.03 | 89.13 | 68.96 | 93.33 | 67.22 | 94.25 | 65.26 | 86.52 | 69.39 | 87.57 | 70.97 | |
| LogitNorm[21]∗ | 59.60 | 80.74 | 80.25 | 78.58 | 91.07 | 82.99 | 84.19 | 80.77 | 86.64 | 75.60 | 78.35 | 81.74 | |
| KNN[9]∗ | 29.08 | 93.90 | 87.50 | 72.35 | 87.97 | 74.11 | 91.62 | 80.55 | 47.66 | 87.44 | 66.77 | 81.67 | |
| MODE-T (ours)∗ | 27.50 | 93.94 | 59.63 | 83.14 | 40.67 | 75.68 | 64.35 | 86.20 | 52.71 | 87.59 | 48.97 | 85.31 | |
| MODE-F (ours)∗ | 24.13 | 94.11 | 61.95 | 82.22 | 34.76 | 72.07 | 65.52 | 86.48 | 51.28 | 87.30 | 47.53 | 84.44 | |
| ProxyAnchor[63]† | 87.21 | 82.43 | 70.10 | 79.84 | 37.19 | 91.68 | 70.01 | 84.96 | 65.64 | 84.99 | 66.03 | 84.78 | |
| CE+SimCLR[62]† | 24.82 | 94.45 | 86.63 | 71.48 | 56.40 | 89.00 | 66.52 | 83.82 | 63.74 | 82.01 | 59.62 | 84.15 | |
| CSI[11]† | 44.53 | 92.65 | 79.08 | 76.27 | 75.58 | 83.78 | 76.62 | 84.98 | 61.61 | 86.47 | 67.48 | 84.83 | |
| SSD[10]† | 31.19 | 94.19 | 77.74 | 79.90 | 79.39 | 85.18 | 80.85 | 84.08 | 66.63 | 86.18 | 67.16 | 85.90 | |
| LINE[23]† | 30.45 | 92.21 | 79.54 | 77.67 | 50.70 | 89.01 | 67.84 | 83.64 | 54.60 | 89.37 | 56.62 | 86.38 | |
| CIDER[25]† | 23.09 | 95.16 | 79.63 | 73.43 | 16.16 | 96.33 | 71.68 | 82.98 | 43.87 | 90.42 | 46.89 | 87.67 | |
| KNN[9]† | 39.23 | 92.78 | 80.74 | 77.58 | 48.99 | 89.30 | 74.99 | 82.69 | 57.15 | 88.35 | 60.22 | 86.14 | |
| MODE-T (ours)† | 29.37 | 92.29 | 73.91 | 78.93 | 48.16 | 89.38 | 75.96 | 83.39 | 51.37 | 87.87 | 55.75 | 86.38 | |
| MODE-F (ours)† | 21.18 | 95.19 | 67.88 | 80.24 | 51.67 | 90.22 | 59.61 | 86.92 | 52.32 | 86.94 | 50.53 | 87.90 | |
| (b) CIFAR-100 (ID) with ResNet-34 | |||||||||||||
备注④:加速策略。 在实践中,为了避免过多的时间成本,我们遵循 KNN [9] 到 i)将所有示例的多尺度表示存储在键值映射中,并且ii)使用[64]库来加速-NN搜索过程。 具体而言,我们采用作为欧氏距离的索引方案。 此外,如图 5 所示,我们通过对不同位置上每四个最近的局部表征执行 近邻聚合步骤(即 平均池化步骤),进一步将每幅图像提取的局部表征数量从 减少到 。 IV-E 节介绍了我们设计的 在推理时的计算成本的定量分析。
我们的 MODE 框架的灵活性。 我们提出的 MODE 框架与 ID 训练过程以及使用不同损失进行预训练的模型正交。 在这项工作中,我们根据 如何促进局部判别性表示来考虑 MODE 的两个版本,即 MODE-T = - + ,MODE-F = - + 。 实际中,我们可以根据模型当前的训练阶段,灵活决定采用MODE-T还是MODE-F,即模型尚未开始时采用MODE-T,模型已预训练时采用MODE-F 。

IV 实验。
在本节中,我们在经常使用的 OOD 基准、功能主干和评估指标上广泛测试我们提出的模式。 具体来说,我们首先在常见基准上检查我们的 MODE 的有效性,然后我们进一步在大规模 ImageNet 基准上评估它。 消融研究和可视化结果显示在最后。
评估指标。 我们遵循文献中广泛采用的设置,使用以下评估指标:FPR(又称为 FPR)。 FPR95) [65]:当ID示例的真阳性率达到95%时,OOD示例的误报率。 AUROC [1]:接收器工作特性曲线下的面积。 请注意,FPR 和 AUROC 都用于测试 OOD 检测性能,此外我们不需要在推理时手动调整 FPR 和 AUROC 的阈值 ,因为这两个指标可以确定 根据测试ID样本的分类结果。 为了研究 ID 训练(或表示学习)性能,我们还引入了 ID ACC:ID 示例的分类准确性。
IV-A 通用基准评估
数据集。 遵循OOD检测中的常见基准,我们采用CIFAR-10和CIFAR-100作为分布内(ID)数据集,并且它们通常被溢出以进行ID训练。 在测试时 OOD 检测中,Textures [66]、SVHN [67]、Places365 [68]、LSUN-C [ 69]和iSUN [70]作为OOD数据集进行性能评估。 具体来说,Places365由365个场景类别的图像组成,SVHN和iSUN是包含彩色街道号码和大规模自然场景的数据集。 此外,Textures 由 47 个术语的野外图像组成,LSUN 包含来自 10 个场景和 20 个对象类别的数百万张图像。
| Method | iNaturalist | SUN | Places365 | Texture | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| FPR | AUROC | FPR | AUROC | FPR | AUROC | FPR | AUROC | FPR | AUROC | ||
| MSP[1]∗ | 54.99 | 87.74 | 70.83 | 80.86 | 73.99 | 79.76 | 68.00 | 79.61 | 66.95 | 81.99 | |
| ODIN[5]∗ | 47.66 | 89.66 | 60.15 | 84.59 | 67.89 | 81.78 | 50.23 | 85.62 | 56.48 | 85.41 | |
| Energy[3]∗ | 55.72 | 89.95 | 59.26 | 85.89 | 64.92 | 82.86 | 53.72 | 85.99 | 58.41 | 86.17 | |
| GODIN[4]∗ | 61.91 | 85.40 | 60.83 | 85.60 | 63.70 | 83.81 | 77.85 | 73.27 | 66.07 | 82.02 | |
| Mahalanobis[2]∗ | 97.00 | 52.65 | 98.50 | 42.41 | 98.40 | 41.79 | 55.80 | 85.01 | 87.43 | 55.47 | |
| SSD[10]† | 57.16 | 87.77 | 78.23 | 73.10 | 81.19 | 70.97 | 36.37 | 88.52 | 63.24 | 80.09 | |
| LINE[23]† | 32.31 | 92.51 | 43.37 | 90.50 | 60.73 | 84.81 | 30.24 | 91.97 | 41.66 | 89.95 | |
| KNN[9]† | 30.83 | 94.72 | 48.91 | 88.40 | 60.02 | 84.62 | 16.97 | 94.45 | 39.18 | 90.55 | |
| MODE-F (ours)† | 29.11 | 96.46 | 46.39 | 89.73 | 54.38 | 87.80 | 15.65 | 94.95 | 36.38 | 92.24 | |
实施细节。 在我们的实验中,我们遵循常见的做法,使用 ResNet-18 作为 CIFAR-10 的特征主干,使用 ResNet-34 作为 CIFAR-100 的特征骨干。 我们基于[58]111https://github.com/HobbitLong/SupContrast。 我们使用动量为 0.9 的随机梯度下降来更新网络,权重衰减设置为 0.0001。 特别是,方程中的平衡重量。对于 MODE-T(或 -),9 设置为 1.0。 对于 MODE-F(或 -),初始学习率 设置为 0.1。 注意力头中的维度取值为80。 中的温度为0.1。 -NN 超参数 为 50。 我们发现批量大小在一定范围内对性能的影响可以忽略不计,因此我们设置以避免过多的计算成本。 我们在消融研究中仔细调整关键超参数 、 和 。
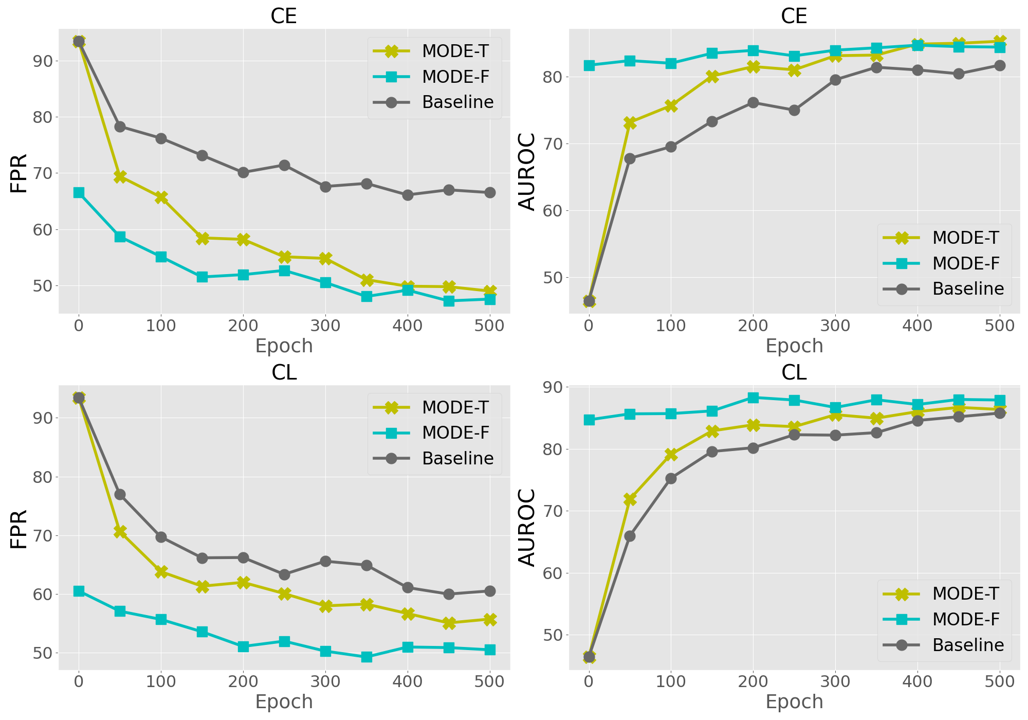
实验结果。 实验结果如表 I 所示,其中比较了各种最先进的 OOD 检测方法。 请访问[9]了解这些方法的更多详细信息。 特别是,我们将这些方法分为两组,具体取决于预训练模型是通过交叉熵(CE)损失还是对比学习(CL)损失来学习的。 根据表中报告的结果,我们强调以下观察结果。 首先,我们提出的 MODE 显着提高了 OOD 检测性能。 平均而言,经过 CE 培训(分别) CL 训练的)模型,我们的方法比强大的竞争对手 KNN [9] 的性能最多领先 19.24%(分别为 19.24%)。 就 FPR 而言,9.69%),以及 2.77%(分别为 1.76%)以 AUROC 计算。 第二,对于两个版本的MODE,MODE-F(即- + )优于MODE-T(即 - + )在绝大多数情况下,表明我们的 -不会引发灾难性的遗忘问题——覆盖之前学到的预训练模型的知识。 图7中描绘的OOD检测性能曲线进一步证实了这一结论——MODE-F不断提高预训练基线模型的OOD检测性能。 第三,我们的 MODE 在 CE 训练方法上的性能改进明显优于 CL 训练方法。 一个可能的原因是,我们设计的 作为 CL 损失的一种变体,能够补充普通的 CE 损失,以挖掘通用视觉信息,捕获更丰富、更灵活的表示来识别 ID/OOD 数据。 该问题的更多定性结果在第 IV-F 节中进行了系统讨论,并在图 10 中进行了演示。 简而言之,表 I 中取得的结果表明,我们的 MODE 框架与 ID 训练损失以及使用不同方式预训练的模型无关。
IV-B 大规模 ImageNet Benchmark 评估
数据集。 我们通过使用 ImageNet [71] 作为 ID 数据集在大规模 OOD 检测任务上进行评估,进一步证明了我们方法的有效性和灵活性。 遵循基于 ImageNet 的 OOD 检测 [72, 9] 中的常见设置,我们对四个 OOD 数据集进行评估,这些数据集具体是纹理 [66]、Places365 [68]、iNaturalist [73] 和 SUN [74],并且没有重叠类别。 图像网。
实施细节。 我们使用 ResNet-50 特征主干对 ID 数据集 ImageNet 进行评估。 在这里,我们没有在 ImageNet 上从头开始精心训练主干网,而是直接从 KNN 的公共存储库借用 CL 训练的 ResNet-50 模型[9]222https://github.com/deeplearning-wisc/knn-ood提高效率。 请注意,我们仅在 CL 训练的模型上测试我们的方法,因为 CE 训练的模型尚未公开。 在 ID 训练期间,我们使用 - 迭代微调预训练模型 300 个 epoch,其中批量大小 和初始学习率 使用余弦调度。 其他超参数设置与第IV-A节相同。 此外,按照 KNN [9],我们从 ImageNet 中采样了一小部分训练数据(),用于我们的方法和 LINE 的测试时 OOD 检测期间的最近邻搜索[23]。
实验结果。 表II报告了四个 OOD 数据集上不同方法所实现的 OOD 检测性能。 从表中,我们有以下发现。 首先,我们的方法 (MODE-F) 在四个 OOD 数据集上显着优于那些强大的竞争对手,并建立了新的最先进的结果。 第二,值得注意的是,SSD [10] 的性能低于 KNN [9] 和我们的方法。 这可能是因为大规模基准测试的数据复杂性增加,使得类条件高斯假设对于有效的 OOD 检测不太可行。 相比之下,KNN 和我们的方法都是无分布假设的,因此不受此限制。 第三,在对预训练模型(即ResNet-50)进行微调后,我们的MODE-F(更具体地说,设计的)随机采样一个微小的比率() 用于 KNN 中最近邻搜索的训练数据。 在这种情况下,我们的方法在所有 OOD 数据集上仍然始终优于其他竞争对手,这表明 增强的多尺度表示更具信息性和可转移性。
IV-C Clean OOD 基准评估
正如 [75] 中所揭示的,大多数广泛使用的 OOD 数据集都是有噪声的:测试 OOD 数据与很大一部分(在某些情况下高达 50%)来自 ImageNet 的 ID 示例混合在一起。 1k。 为了进一步证明我们提出的方法的有效性,我们还在两个 clean OOD 数据集上将我们的方法与强基线 KNN [9] 进行了比较:OpenImage-O [ 76] 和 NINCO [75]。 获得的结果报告在表III中,其中实验设置与第IV-B节中的相同。 从表中的结果来看,我们的方法在两个数据集上始终优于竞争对手 KNN。
| Method | OpenImage-O | NINCO | |||
|---|---|---|---|---|---|
| FPR | AUROC | FPR | AUROC | ||
| KNN[9]† | 80.04 | 69.88 | 66.06 | 84.11 | |
| MODE-F (ours)† | 75.73 | 73.91 | 64.42 | 85.07 | |
| ID Training | ID ACC | + (Testing) | FPR | AUROC |
|---|---|---|---|---|
| CE | 73.23 | ✗ | 66.77 | 81.67 |
| ✔ | 66.52 | 81.63 | ||
| + - | 75.52 | ✗ | 52.31 | 83.94 |
| ✔ | 48.97 | 85.31 | ||
| + - | 75.04 | ✗ | 50.56 | 82.45 |
| ✔ | 47.53 | 84.44 | ||
| CL | 73.65 | ✗ | 60.22 | 86.14 |
| ✔ | 60.54 | 85.79 | ||
| + - | 74.26 | ✗ | 59.02 | 83.74 |
| ✔ | 55.75 | 86.38 | ||
| + - | 75.28 | ✗ | 54.31 | 85.89 |
| ✔ | 50.53 | 87.90 |
IV-D 消融研究
在本节中,我们首先进行烧蚀分析,以验证表 IV 中我们的 MODE 设计组件的有效性。 然后,我们分析i)多尺度表示,ii)平衡权重,iii)学习的效果率和iv)-NN超参数来深入研究我们的模式。
MODE 设计组件的有效性。 在这里,我们试图回答以下两个问题:①我们的训练时间可以在ID训练期间鼓励局部歧视性表征吗? ② 我们的测试时间可以进一步提高测试时间OOD检测吗? 为此,我们在ResNet-34特征主干上进行实验,并使用CIFAR-100作为ID数据集。 平均结果 w.r.t. 表 IV 报告了五个常见 OOD 基准的 ID ACC、FPR 和 AUROC。 我们有以下观察结果。 首先,从“ID ACC”的单元格中,可以明显看出-和-提高了分布内分类性能,这表明设计的有利于学习ID类的判别表示。 这与历史证据一致,即图像内部的局部表示(即密集特征)可以提供有关目标对象的更丰富、更灵活的信息[28,29,60]。 更多定性结果见图 11,并在第 IV-F 节中讨论。其次,从""单元格中,我们可以看到我们的显著改善了通过-和-学习的多尺度表示的测试时间 OOD 检测结果,这表明了我们的函数的功效。 第三、不会对通过现成的交叉熵(CE)或对比学习(CL)损失学习的单尺度图像表示带来显着的性能提升,这证明了解决ID训练和OOD检测之间的尺度差异的必要性,也证实了我们的解决这个问题的有效性。 第四,从“FPR”和“AUROC”的单元格中,可以观察到- + 中的每一个> 和 - + 优于基线方法(即,具有基于 KNN 的 OOD 检测的普通 CE/CL 训练模型[9 ])大幅提高,清楚地证明了设计组件的有效性(即训练时间 和测试时间 ),以及我们的灵活性提出的模式框架。
| Method | Infer. Time (ms/img) | FPR | AUROC |
|---|---|---|---|
| KNN [9] | 0.14 | 60.22 | 86.14 |
| MODE-F () | 0.12 | 54.14 | 86.82 |
| MODE-F () | 0.25 | 53.18 | 87.15 |
| MODE-F () | 0.74 | 52.75 | 87.68 |
| MODE-F () | 1.51 | 50.53 | 87.90 |

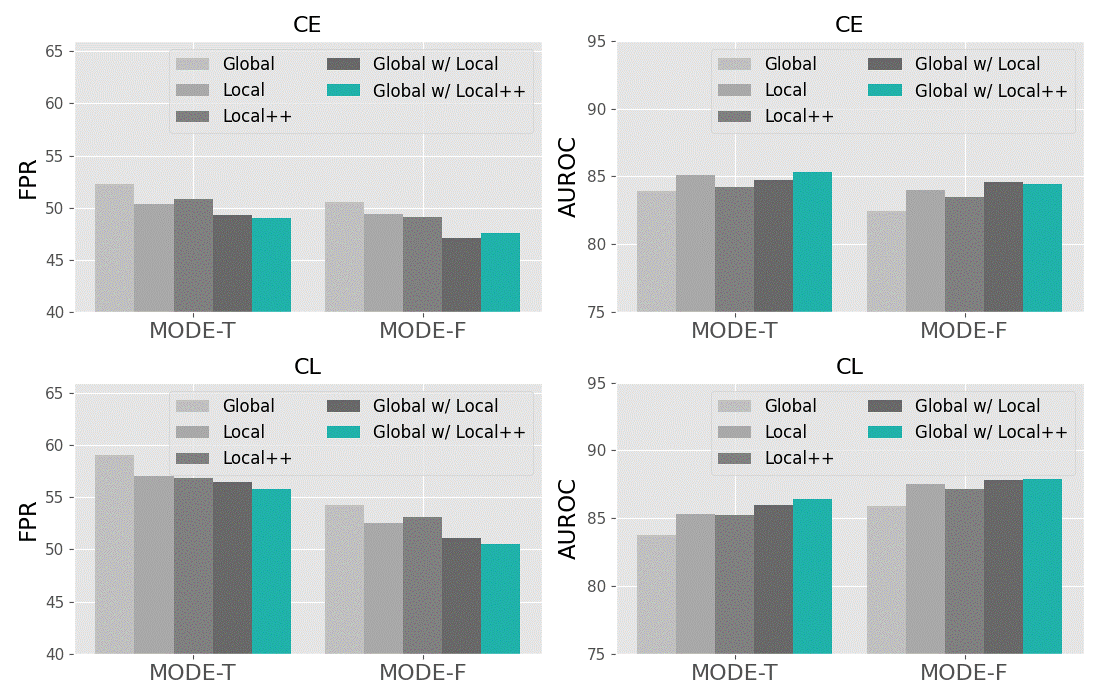
多尺度表示的影响。 在测试时 OOD 检测期间,我们设计的 函数探索最具辨别力的多尺度(即全局和局部)表示,以更忠实地区分 ID/OOD 示例。 每个输入图像x提取的局部表示具体是卷积网络(或特征主干)的最终全局平均池化层之前的输出特征图,表示为。 因此,图像可以映射到局部表示(或分割图像区域),具有相应的区域大小。 这意味着局部表示的数量越多,区域的大小就越小。 正如III-B节中提到的以及图5中所描述的,我们可以将每个图像提取的局部表示的数量从减少到(具体来说,在我们的实验中从到5),通过对不同位置的每四个最近的局部表示执行邻居聚合过程,并获得邻居聚合的局部表示,称为local++交涉。 在图6中,我们研究了这些多尺度(即全局、局部和局部++)表示对 MODE 框架的 OOD 检测性能的影响。 我们从图中得到了几个重要的观察结果。 首先,与增强的全局表示相比,增强的局部表示更有利于提高OOD检测性能,这揭示了以下事实:我们的 支持本地区分表示,捕获更丰富、更灵活的表示来识别 ID/OOD 数据。 其次,利用图像的全局和本地表示可以进一步提升结果。 这符合我们的意图,即利用图像的多尺度表示有助于最大程度地有利于 OOD 检测。 第三,全局和局部++表示的结合在大多数情况下实现了最佳性能。 一个可能的原因是,当图像被划分为大量(即 )局部表示时,每个对应区域的大小会变小,因此,其中一些分割区域无法捕获目标对象。 因此,为了更高的性能和计算效率,在我们的实验中,每个图像的多尺度表示具体包括一个全局表示和五个局部++表示。
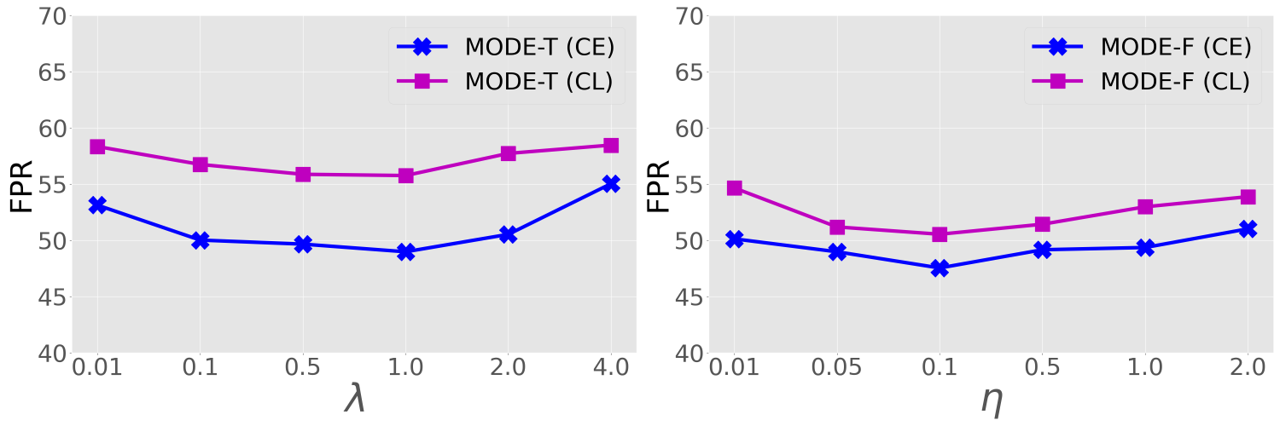
平衡配重 对 MODE-T 的影响。 在ID训练期间,MODE-T(即- + )使用-来通过使用设计的(即等式中的)规范现有的ID训练损失函数来鼓励有区别的局部表示。 9,其中采用超参数来平衡我们的 在本部分中,我们通过将 设置为{0.001、0.1、0.5、1.0、2.0、4.0}来仔细调整 ,并在图 8 中报告了五个常见 OOD 数据集的平均测试结果(左)。 可以看出,我们的MODE-T对在一定范围内(从0.1到2.0)的变化并不敏感。 值得注意的是,当 取值为 1.0 时,我们的 MODE-T 通过 CE 训练和 CL 训练的基线模型建立了最佳的 OOD 检测性能。 因此,我们在实验中为 MODE-T 设置。
学习率 对 MODE-F 的影响。 我们的 MODE-F 最重要的超参数(即 - + )是用于微调的初始学习率 使用开发的 - 通过不同损失学习预训练模型。 为了研究 对性能 MODE-F 的影响,我们通过将其设置为不同的值 {0.001, 0.05, 0.1, 0.5, 1.0, 2.0} 来仔细调整 。 我们在图 8(右)中报告了五个常见 OOD 数据集的平均结果。 可以看出,当 取值在一定范围内(从 0.05 到 0.5)时,我们的 MODE-F 实现了显着且稳定的性能。 特别是,当 我们的 MODE-F 在 CE 训练和 CL 训练的基线上均取得最佳结果时,因此我们在实验中为 MODE-F 设置 。
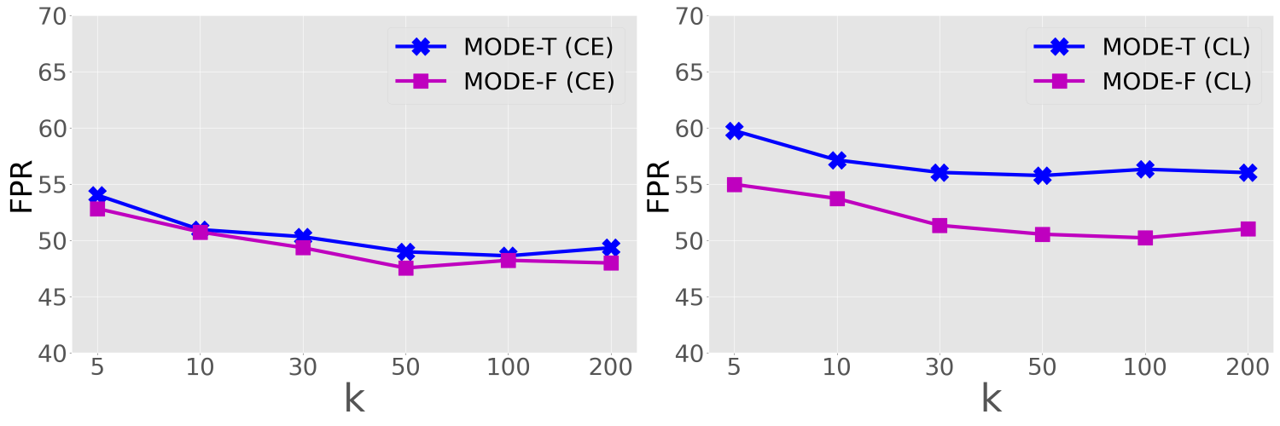
-NN 超参数 的影响。 KNN [9] 和我们的 MODE(更具体地说是 )都需要调整 -NN 超参数 。在图9中,我们分析了对我们的MODE的OOD检测性能的影响。 具体来说,我们通过将 设置为 {5, 10, 30, 50, 100, 200} 的值来仔细调整 ,并报告五个常见 OOD 数据集的平均结果。 从图中可以看出,在达到50之前,随着的增加,OOD检测性能逐渐提高。 这一趋势也与相同设置下KNN[9]中的消融结果一致。 此外,我们还观察到当取值50、100和200时,MODE-T和MODE-F的OOD检测结果保持相似。 因此,在我们的实验中,我们将 设置为 KNN [9] 中的值。
IV-E 计算成本
研究我们提出的 MODE 的计算成本对于实际目的非常重要。 在这一部分中,我们根据每个图像的推理时间(以 毫秒为单位)定量研究我们的 MODE 的测试时间 OOD 检测计算成本(具体来说,由测试时间 带来) )。 特别是,我们从 ID 数据集的每个类别(即具有 50,000 个训练示例的 CIFAR-100)中随机采样 训练数据,用于测试 OOD 数据的 -最近邻搜索。 我们在表 V 中报告了 MODE-F 在不同 值下的每个图像推理时间(而 MODE-T 的结果具有相似的趋势),其中我们在 NVIDIA GeForce RTX 3090 上进行了实验。 需要注意的是,当取{5,10,50,100}的值时,我们将-NN超参数设置为{10 , 20, 30, 50} 分别代表我们的 MODE-F。 我们在表中强调了四个重要的观察结果。 首先,当时,我们方法的每张图像推理时间为1.51毫秒,这个结果在许多现实世界中可能是可以接受的(离线或在线)应用程序。 第二,正如预期的那样,我们方法的推理时间成本随着的减少而逐渐减少。 第三,的骤降并没有严重降低我们方法的OOD检测性能。 第四,当花费与最先进的 KNN [9] 相当的时间消耗时,我们的方法仍然大幅优于 KNN(即 6.08%(FPR)。 所有上述结果表明我们提出的模式具有良好的实用性和可扩展性。
IV-F 可视化分析
到目前为止,我们已经定量证明了我们开发的 OOD 检测 MODE 框架的有效性和灵活性。 在这一部分中,我们提出了一些可视化结果来定性研究我们的模式。
使用 tSNE [77] 进行可视化。 在图 10 中,我们展示了普通 CE 训练的 tSNE 可视化和我们的 增强的全局表示(从特征主干 ResNet-18 的倒数第二层提取) ID 数据集 CIFAR-10 和 OOD 数据 LSUN (OOD) 的结果——普通 CL 训练表示的结果具有相似的趋势。 从图中可以看出,与普通CE训练的全局表示相比,我们每个-或学习到的全局表示- 表现出更好的ID-OOD可分离性。 我们还看到,虽然基线提高了每个 ID 类的紧凑性,但这些 ID 类和 OOD 数据之间存在显着的重叠。 一般来说,结合表IV中的定量ID分类和OOD检测结果,显然我们设计的不仅鼓励ID训练期间的局部判别表示,而且还鼓励使不同 ID/OOD 类别的提取图像表示更加紧凑,以有利于 OOD 检测和多类别分类任务。
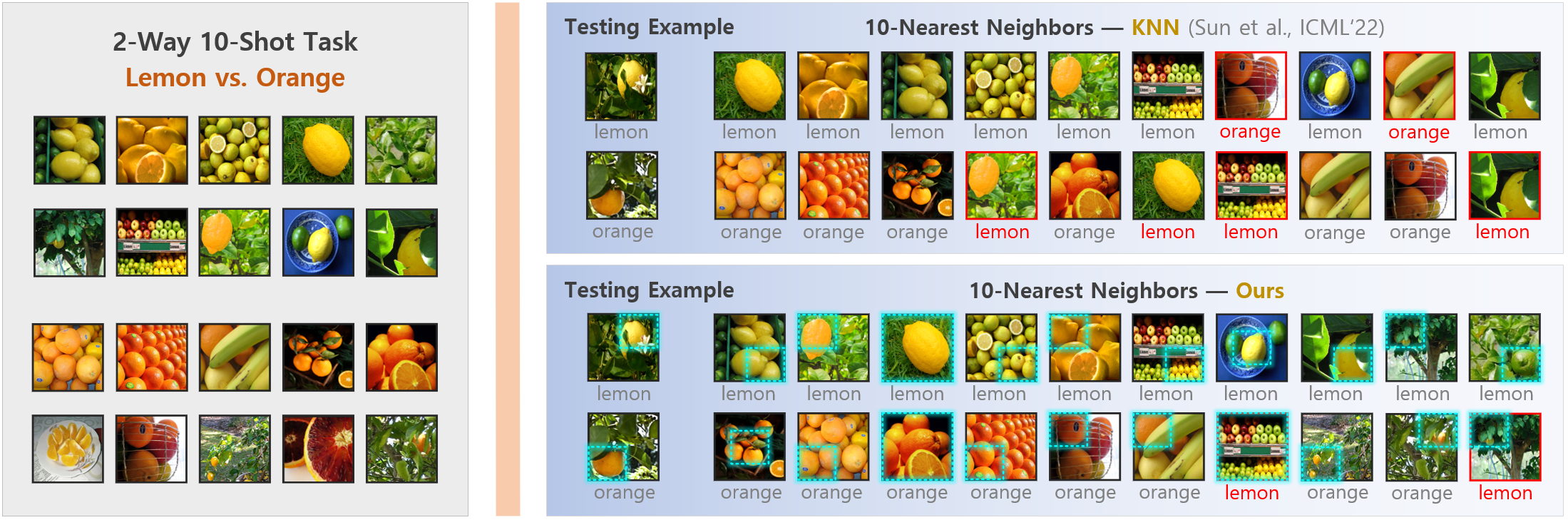
- 最近邻居的可视化。 在图 11 中,我们通过定性比较其搜索的 -最近邻与 KNN [9] 的搜索结果,进一步证明了我们的 MODE 的有效性。测试示例。 在本实验中,利用{“Lemon”与“Orange”}任务进行可视化分析的灵感来自于hard OOD检测这一事实正如 [39, 78] 中所揭示的,由近 ID-OOD 类/示例组成的任务是现有机器学习系统的主要挑战。 在此任务中,当我们将“Lemon”视为 ID 数据时,“Orange”将变为 OOD,反之亦然。 从图中可以看出,我们的方法在绝大多数情况下成功地识别了与目标对象(或对象区域)相对应的最具辨别力的多尺度表示。 值得注意的是,当地代表/地区在成功识别那些背景混乱的困难例子方面发挥着关键作用。 此外,当 时,总共 6 个和 2 个 OOD 示例分别被错误地检测为 KNN [9] 和我们的方法的 ID 数据。 总而言之,受益于在 ID 训练期间突出显示更丰富且更可转移的表示(通过 ),并利用最具辨别力的多尺度表示进行测试时 OOD 检测(通过 ) t1>),我们提出的 MODE 在区分 ID/OOD 数据方面显示出卓越的性能。
V 结论
这项工作首次提出利用图像内部的多尺度表示进行 OOD 检测的 MODE。 具体来说,我们首先观察到,由于 ID 训练和 OOD 检测过程之间的规模差异,通过现成的交叉熵或对比损失预训练的现有模型无法捕获 MODE 的可用局部表示。 为了解决这个问题,我们提出了 ,它通过在 ID 训练期间对齐和突出显示成对示例的局部对象区域来实现局部判别表示。 在测试时 OOD 检测期间,我们在最具辨别力的多尺度表示上设计了一个 函数,以更忠实地区分 ID/OOD 示例。 我们的 MODE 框架与 ID 训练损失和用不同方式预训练的模型正交。 大量的实验结果证明了我们的 MODE 在应用于各种网络结构的各种基线方法上的有效性和灵活性。 我们希望这项工作能为OOD检测以及其他相关领域带来新的启发。 为了方便未来的研究,我们已将代码公开在:–https://github.com/JimZAI/MODE-OOD˝。
参考
- [1] D. Hendrycks and K. Gimpel, “A baseline for detecting misclassified and out-of-distribution examples in neural networks,” ICLR, 2017.
- [2] K. Lee, K. Lee, H. Lee, and J. Shin, “A simple unified framework for detecting out-of-distribution samples and adversarial attacks,” NeurIPS, vol. 31, 2018.
- [3] W. Liu, X. Wang, J. Owens, and Y. Li, “Energy-based out-of-distribution detection,” NeurIPS, vol. 33, pp. 21 464–21 475, 2020.
- [4] Y.-C. Hsu, Y. Shen, H. Jin, and Z. Kira, “Generalized odin: Detecting out-of-distribution image without learning from out-of-distribution data,” in CVPR, 2020, pp. 10 951–10 960.
- [5] S. Liang, Y. Li, and R. Srikant, “Enhancing the reliability of out-of-distribution image detection in neural networks,” ICLR, 2018.
- [6] H. Bai, R. Sun, L. Hong, F. Zhou, N. Ye, H.-J. Ye, S.-H. G. Chan, and Z. Li, “Decaug: Out-of-distribution generalization via decomposed feature representation and semantic augmentation,” in AAAI, vol. 35, no. 8, 2021, pp. 6705–6713.
- [7] M. Salehi, H. Mirzaei, D. Hendrycks, Y. Li, M. H. Rohban, and M. Sabokrou, “A unified survey on anomaly, novelty, open-set, and out of-distribution detection: Solutions and future challenges,” Transactions of Machine Learning Research.
- [8] A. Nguyen, J. Yosinski, and J. Clune, “Deep neural networks are easily fooled: High confidence predictions for unrecognizable images,” in CVPR, 2015, pp. 427–436.
- [9] Y. Sun, Y. Ming, X. Zhu, and Y. Li, “Out-of-distribution detection with deep nearest neighbors,” in ICML, 2022, pp. 20 827–20 840.
- [10] V. Sehwag, M. Chiang, and P. Mittal, “Ssd: A unified framework for self-supervised outlier detection,” in ICLR, 2021.
- [11] J. Tack, S. Mo, J. Jeong, and J. Shin, “Csi: Novelty detection via contrastive learning on distributionally shifted instances,” NeurIPS, vol. 33, pp. 11 839–11 852, 2020.
- [12] S.-H. Gao, M.-M. Cheng, K. Zhao, X.-Y. Zhang, M.-H. Yang, and P. Torr, “Res2net: A new multi-scale backbone architecture,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 2, pp. 652–662, 2019.
- [13] A. Jain and G. Healey, “A multiscale representation including opponent color features for texture recognition,” IEEE Transactions on Image Processing, vol. 7, no. 1, pp. 124–128, 1998.
- [14] W. Lu, Y. Cheng, C. Xiao, S. Chang, S. Huang, B. Liang, and T. Huang, “Unsupervised sequential outlier detection with deep architectures,” IEEE Transactions on Image Processing, vol. 26, no. 9, pp. 4321–4330, 2017.
- [15] H. Zhao, H. Liu, Z. Ding, and Y. Fu, “Consensus regularized multi-view outlier detection,” IEEE Transactions on Image Processing, vol. 27, no. 1, pp. 236–248, 2017.
- [16] P. Wu and J. Liu, “Learning causal temporal relation and feature discrimination for anomaly detection,” IEEE Transactions on Image Processing, vol. 30, pp. 3513–3527, 2021.
- [17] M. Sabokrou, M. Fayyaz, M. Fathy, and R. Klette, “Deep-cascade: Cascading 3d deep neural networks for fast anomaly detection and localization in crowded scenes,” IEEE Transactions on Image Processing, vol. 26, no. 4, pp. 1992–2004, 2017.
- [18] S.-Y. Lo, P. Oza, and V. M. Patel, “Adversarially robust one-class novelty detection,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 4, pp. 4167–4179, 2023.
- [19] W. Hu, T. Hu, Y. Wei, J. Lou, and S. Wang, “Global plus local jointly regularized support vector data description for novelty detection,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–13, 2021.
- [20] A. Bendale and T. Boult, “Towards open world recognition,” in CVPR, 2015, pp. 1893–1902.
- [21] H. Wei, R. Xie, H. Cheng, L. Feng, B. An, and Y. Li, “Mitigating neural network overconfidence with logit normalization,” in ICML, 2022, pp. 23 631–23 644.
- [22] Y. Sun and Y. Li, “Dice: Leveraging sparsification for out-of-distribution detection,” in ECCV, 2022.
- [23] Y. H. Ahn, G.-M. Park, and S. T. Kim, “Line: Out-of-distribution detection by leveraging important neurons,” in CVPR, 2023, pp. 19 852–19 862.
- [24] J. Ren, S. Fort, J. Liu, A. G. Roy, S. Padhy, and B. Lakshminarayanan, “A simple fix to mahalanobis distance for improving near-ood detection,” arXiv preprint arXiv:2106.09022, 2021.
- [25] Y. Ming, Y. Sun, O. Dia, and Y. Li, “How to exploit hyperspherical embeddings for out-of-distribution detection?” ICLR, 2023.
- [26] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in ICML, 2021, pp. 8748–8763.
- [27] Y. Ming, Z. Cai, J. Gu, Y. Sun, W. Li, and Y. Li, “Delving into out-of-distribution detection with vision-language representations,” NeurIPS, vol. 35, pp. 35 087–35 102, 2022.
- [28] W. Li, L. Wang, J. Xu, J. Huo, Y. Gao, and J. Luo, “Revisiting local descriptor based image-to-class measure for few-shot learning,” in CVPR, 2019, pp. 7260–7268.
- [29] C. Zhang, Y. Cai, G. Lin, and C. Shen, “Deepemd: Few-shot image classification with differentiable earth mover’s distance and structured classifiers,” in CVPR, 2020, pp. 12 203–12 213.
- [30] J. Nandy, W. Hsu, and M. L. Lee, “Towards maximizing the representation gap between in-domain & out-of-distribution examples,” NeurIPS, vol. 33, pp. 9239–9250, 2020.
- [31] E. Cole, X. Yang, K. Wilber, O. Mac Aodha, and S. Belongie, “When does contrastive visual representation learning work?” in CVPR, 2022, pp. 14 755–14 764.
- [32] J. Zhang, J. Song, L. Gao, Y. Liu, and H. T. Shen, “Progressive meta-learning with curriculum,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 9, pp. 5916–5930, 2022.
- [33] J. Zhang, J. Song, L. Gao, and H. Shen, “Free-lunch for cross-domain few-shot learning: Style-aware episodic training with robust contrastive learning,” in ACM MM, 2022, pp. 2586–2594.
- [34] Y. Fu, Y. Fu, J. Chen, and Y.-G. Jiang, “Generalized meta-fdmixup: Cross-domain few-shot learning guided by labeled target data,” IEEE Transactions on Image Processing, vol. 31, pp. 7078–7090, 2022.
- [35] Y. Mo, Y. Chen, Y. Lei, L. Peng, X. Shi, C. Yuan, and X. Zhu, “Multiplex graph representation learning via dual correlation reduction,” IEEE Transactions on Knowledge and Data Engineering, pp. 1–14, 2023.
- [36] P. Zeng, H. Zhang, L. Gao, J. Song, and H. T. Shen, “Video question answering with prior knowledge and object-sensitive learning,” IEEE Transactions on Image Processing, vol. 31, pp. 5936–5948, 2022.
- [37] Y. Zhou, P. Liu, and X. Qiu, “Knn-contrastive learning for out-of-domain intent classification,” in ACL, 2022, pp. 5129–5141.
- [38] S. Vaze, K. Han, A. Vedaldi, and A. Zisserman, “Open-set recognition: a good closed-set classifier is all you need?” ICLR, 2022.
- [39] S. Fort, J. Ren, and B. Lakshminarayanan, “Exploring the limits of out-of-distribution detection,” NeurIPS, vol. 34, pp. 7068–7081, 2021.
- [40] Y. Ming, Y. Fan, and Y. Li, “Poem: Out-of-distribution detection with posterior sampling,” in ICML, 2022, pp. 15 650–15 665.
- [41] X. Du, Z. Wang, M. Cai, and S. Li, “Towards unknown-aware learning with virtual outlier synthesis,” ICLR, 2022.
- [42] O. Halimi, O. Litany, E. Rodola, A. M. Bronstein, and R. Kimmel, “Unsupervised learning of dense shape correspondence,” in CVPR, 2019, pp. 4370–4379.
- [43] S. Kim, D. Min, B. Ham, S. Jeon, S. Lin, and K. Sohn, “Fcss: Fully convolutional self-similarity for dense semantic correspondence,” in CVPR, 2017, pp. 6560–6569.
- [44] Y. Lifchitz, Y. Avrithis, S. Picard, and A. Bursuc, “Dense classification and implanting for few-shot learning,” in CVPR, 2019, pp. 9258–9267.
- [45] T. Xu, W. Chen, P. Wang, F. Wang, H. Li, and R. Jin, “Cdtrans: Cross-domain transformer for unsupervised domain adaptation,” ICLR, 2021.
- [46] Y. Zuo, H. Yao, and C. Xu, “Attention-based multi-source domain adaptation,” IEEE Transactions on Image Processing, vol. 30, pp. 3793–3803, 2021.
- [47] K.-H. Lee, X. Chen, G. Hua, H. Hu, and X. He, “Stacked cross attention for image-text matching,” in ECCV, 2018, pp. 201–216.
- [48] K. Zhang, Z. Mao, Q. Wang, and Y. Zhang, “Negative-aware attention framework for image-text matching,” in CVPR, 2022, pp. 15 661–15 670.
- [49] H.-J. Ye, H. Hu, D.-C. Zhan, and F. Sha, “Few-shot learning via embedding adaptation with set-to-set functions,” in CVPR, 2020, pp. 8808–8817.
- [50] J. Zhang, L. Gao, X. Luo, H. Shen, and J. Song, “Deta: Denoised task adaptation for few-shot learning,” arXiv preprint arXiv:2303.06315, 2023.
- [51] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” ICLR, 2020.
- [52] C.-F. R. Chen, Q. Fan, and R. Panda, “Crossvit: Cross-attention multi-scale vision transformer for image classification,” in CVPR, 2021, pp. 357–366.
- [53] L. Jiao, J. Gao, X. Liu, F. Liu, S. Yang, and B. Hou, “Multi-scale representation learning for image classification: A survey,” IEEE Transactions on Artificial Intelligence, 2021.
- [54] Y. Gao, Z. Kuang, G. Li, P. Luo, Y. Chen, L. Lin, and W. Zhang, “Fashion retrieval via graph reasoning networks on a similarity pyramid,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [55] J. Bai, B. Gong, Y. Zhao, F. Lei, C. Yan, and Y. Gao, “Multi-scale representation learning on hypergraph for 3d shape retrieval and recognition,” IEEE Transactions on Image Processing, vol. 30, pp. 5327–5338, 2021.
- [56] Y. Gao, Z. Kuang, G. Li, W. Zhang, and L. Lin, “Hierarchical reasoning network for human-object interaction detection,” IEEE Transactions on Image Processing, vol. 30, pp. 8306–8317, 2021.
- [57] X. Du, Z. Wang, M. Cai, and Y. Li, “Vos: Learning what you don’t know by virtual outlier synthesis,” in ICML, 2022.
- [58] P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y. Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan, “Supervised contrastive learning,” NeurIPS, vol. 33, pp. 18 661–18 673, 2020.
- [59] O. Boiman, E. Shechtman, and M. Irani, “In defense of nearest-neighbor based image classification,” in CVPR. IEEE, 2008, pp. 1–8.
- [60] X. Wang, R. Zhang, C. Shen, T. Kong, and L. Li, “Dense contrastive learning for self-supervised visual pre-training,” in CVPR, 2021, pp. 3024–3033.
- [61] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” NeurIPS, vol. 30, 2017.
- [62] J. Winkens, R. Bunel, A. G. Roy, R. Stanforth, V. Natarajan, J. R. Ledsam, P. MacWilliams, P. Kohli, A. Karthikesalingam, S. Kohl et al., “Contrastive training for improved out-of-distribution detection,” EMNLP, 2021.
- [63] S. Kim, D. Kim, M. Cho, and S. Kwak, “Proxy anchor loss for deep metric learning,” in CVPR, 2020, pp. 3238–3247.
- [64] J. Johnson, M. Douze, and H. Jégou, “Billion-scale similarity search with gpus,” IEEE Transactions on Big Data, vol. 7, no. 3, pp. 535–547, 2019.
- [65] D. Macêdo, T. I. Ren, C. Zanchettin, A. L. Oliveira, and T. Ludermir, “Entropic out-of-distribution detection: Seamless detection of unknown examples,” IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 6, pp. 2350–2364, 2021.
- [66] M. Cimpoi, S. Maji, I. Kokkinos, S. Mohamed, and A. Vedaldi, “Describing textures in the wild,” in CVPR, 2014, pp. 3606–3613.
- [67] Y. Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, and A. Y. Ng, “Reading digits in natural images with unsupervised feature learning,” 2011.
- [68] B. Zhou, A. Lapedriza, A. Khosla, A. Oliva, and A. Torralba, “Places: A 10 million image database for scene recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 6, pp. 1452–1464, 2017.
- [69] F. Yu, A. Seff, Y. Zhang, S. Song, T. Funkhouser, and J. Xiao, “Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop,” arXiv preprint arXiv:1506.03365, 2015.
- [70] P. Xu, K. A. Ehinger, Y. Zhang, A. Finkelstein, S. R. Kulkarni, and J. Xiao, “Turkergaze: Crowdsourcing saliency with webcam based eye tracking,” arXiv preprint arXiv:1504.06755, 2015.
- [71] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in CVPR. IEEE, 2009, pp. 248–255.
- [72] R. Huang and Y. Li, “Mos: Towards scaling out-of-distribution detection for large semantic space,” in CVPR, 2021, pp. 8710–8719.
- [73] G. Van Horn, O. Mac Aodha, Y. Song, Y. Cui, C. Sun, A. Shepard, H. Adam, P. Perona, and S. Belongie, “The inaturalist species classification and detection dataset,” in CVPR, 2018, pp. 8769–8778.
- [74] J. Xiao, J. Hays, K. A. Ehinger, A. Oliva, and A. Torralba, “Sun database: Large-scale scene recognition from abbey to zoo,” in CVPR. IEEE, 2010, pp. 3485–3492.
- [75] J. Bitterwolf, M. Müller, and M. Hein, “In or out? fixing imagenet out-of-distribution detection evaluation,” ICML, 2022.
- [76] H. Wang, Z. Li, L. Feng, and W. Zhang, “Vim: Out-of-distribution with virtual-logit matching,” in CVPR, 2022, pp. 4921–4930.
- [77] L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.” Journal of machine learning research, vol. 9, no. 11, 2008.
- [78] C. S. Sastry and S. Oore, “Detecting out-of-distribution examples with gram matrices,” in ICML. PMLR, 2020, pp. 8491–8501.