通过知识图谱嵌入推荐类比 API
摘要。
在软件演进过程中,库迁移,即用不同的库替换当前库以保留相同的软件行为,非常普遍。 其中,找到与所需功能类似的 API 是至关重要的。 然而,由于库/API 的数量众多,手动查找此类 API 既耗时又容易出错。 研究人员创建了自动化的类比 API 推荐技术,特别是基于文档的方法。 尽管有潜力,但这些方法存在局限性,例如文档中的语义理解不完整以及可扩展性问题。
在本研究中,我们提出了 KGE4AR,一种新颖的基于文档的方法,使用知识图谱 (KG) 嵌入在库迁移期间推荐类比 API。 KGE4AR 引入了统一的 API KG,以全面地表示文档知识,捕获高级语义。 它进一步将此统一的 API KG 嵌入到向量中,以进行高效且可扩展的相似性计算。 我们在两种情况下(有无目标库)评估了 KGE4AR,使用 35,773 个 Java 库。 KGE4AR 明显优于最先进的技术(例如,MRR 提高了 47.1%-143.0% 和 11.7%-80.6%),展示了随着库数量的增加而扩展的能力。
1. 绪论
第三方库在现代软件开发中至关重要,可以提高质量和生产力 (Lim, 1994; Mohagheghi and Conradi, 2007; Cossette and Walker, 2012; Kula et al., 2018)。 然而,随着软件和库的快速发展,当前的库可能会因可持续性失败 (Coelho 和 Valente,2017;Valiev 等人,2018)、许可证限制 (Germán 和 Penta,2012;van der Burg 等人,2014)、缺乏功能 (He 等人,2021b) 以及安全/性能问题 (He 等人,2021b) 等因素而变得不合适。 这就需要 库迁移,即开发人员用新的库替换当前的库来重新实现相同的软件行为。 这种迁移在软件演化中很常见 (He 等人,2021a);例如,He 等人 (He 等人,2021a) 发现,在 17,426 个开源项目中,有 8.98% ~ 28.72% 的项目经历了至少一次库迁移。
然而,库迁移 (Cossette 和 Walker,2012;Kula 等人,2018;Alrubaye 等人,2019c;Alrubaye 和 Mkaouer,2018;Alrubaye 等人,2019b) 对开发人员来说是一项非常耗时、劳动密集且容易出错的任务。 例如,先前的研究表明,一些开发人员甚至花 42 天的时间来进行库迁移 (Alrubaye 等人,2019b)。 鉴于当前使用的库(称为 源库)和 API(称为 源 API),库迁移中一个重要的部分是找到一个类似的库(称为 目标库)和一个类似的 API(称为 目标 API),它们可以提供与当前库相同的的功能。 然而,手动查找类似的 API 对开发人员来说是一个沉重的负担,因为他们需要阅读冗长的 API 文档和可能类似的 API 的代码片段 (Alrubaye 等人,2019b,a;Alrubaye 和 Mkaouer,2018;Alrubaye 等人,2020),而第三方库和 API 的数量极其庞大且变化迅速(例如,截至 2020 年 1 月,Libraries.io 上有 35,773 个常见的 Java 库,拥有 15,441,057 个 API (lib, 2023))。
为了减少 手动搜索和阅读 API 文档和代码片段以确定库和 API 之间类似关系的努力,已经提出了许多技术来推荐合适的目标库或类似的目标 API。 在这项工作中,我们专注于类似 API 的推荐。 研究人员利用各种资源来促进这种推荐 (Alrubaye 等人,2019a;Alrubaye 和 Mkaouer,2018;Alrubaye 等人,2020,2019b),包括演化历史 (Teyton 等人,2013;Nguyen 等人,2014)、在线问答互动 (Chen 等人,2021) 和 API 文档 (Alrubaye 等人,2020,2019b;Pandita 等人,2015;Chen 等人,2021;Pandita 等人,2017;Lu 等人,2017;Zhang 等人,2020)。 在这些资源中,基于文档的 API 推荐在文献中得到了广泛的研究,因为 API 文档很普遍,收集成本很低,而其他信息可能很费时才能收集到,而且并不总是可用。 对于给定的源 API,现有的基于文档的技术会计算每个候选 API 与源 API 之间的文本相似度(例如,文档中两个 API 功能描述之间的文本相似度),然后推荐相似度最高的候选 API 作为目标 API。
虽然很有希望,但现有的基于文档的 API 推荐技术面临着两个局限性。 首先,它们计算文本相似度的方式在捕获 API 文档中的语义级连接方面存在不足。 这些技术主要基于重叠的符元来计算文本相似度 (Pandita 等人,2017),或者在没有上下文考虑的情况下测量符元的相似度 (Zhang 等人,2020)。 这会导致识别出在 API 描述中共享类似名词短语但动作动词不同的类似语义(例如,“设置 S3 对象内容”与“获取 S3 对象内容长度”)。 此外,这些技术在计算文本相似度时很少考虑领域知识。 例如,JSON 数组、JSON 对象、键和值都是与 JSON 相关的概念,这些概念经常出现在与 JSON 处理相关的 API 中。 在我们的工作中,概念指的是特定于领域的实体或术语,通常用名词短语表示,它捕获 API 领域中的特定元素或想法。 如果不考虑这些概念关系,对两个类比 API 之间语义相似性/相关性的估计可能会被低估。 其次,这些技术通常成对地计算相似度,在大量候选 API 情况下会造成计算挑战。 例如,想象一个像 TestNG (tes, 2023) 这样的库,它包含超过 4,000 个候选 API。 现有技术需要执行超过 4,000 次成对比较,才能计算单个源 API 与所有候选 API 之间的相似度。 这种详尽的计算需要大量的在线成本,并且在涉及多个目标库时变得过于昂贵。
为了解决这个问题,我们提出了 KGE4AR,这是一种新颖的基于文档的方法,它利用 Knowledge Graph Embedding for analogical API Recommendation effectively and scalably。 KGE4AR 从 API 文档构建了一个统一的 API 知识图谱 (KG),利用图嵌入将节点和边表示为数值向量。 它可以从嵌入的 KG 中有效地检索给定源 API 的最相似 API。 与以前的方法相比,KGE4AR 引入了两项技术创新。 首先,它提出了一种新颖的 统一的 API KG,它全面地表示了跨不同库的三种文档知识类型,更好地捕获了 API 文档中的整体语义。 其次,KGE4AR 提出 嵌入统一的 API KG,通过简化类比 API 向量检索(通过向量索引)来提高效率和可扩展性。
为了实现 KGE4AR,我们构建了一个统一的 API KG,它包含 59,155,631 个 API 元素,这些元素来自 35,773 个 Java 库。 这个 KG 包含总共 72,242,099 个实体和 289,122,265 个关系,这些关系连接着这些实体。 我们在两种 API 推荐场景中评估了 KGE4AR:有和没有目标库。 当给出目标库时,KGE4AR 在 MRR 和 Hit@10 方面分别比基线提高了 47.1%-143.0% 和 41.4%-95.4%;而没有给定目标库的情况下,KGE4AR 在 MRR、精度和召回率方面分别比现有的类比 API 推荐技术大幅提高了 11.7%-80.6%、26.2%-72.0% 和 33.2%-116.5%。 我们还评估了 KGE4AR 的可扩展性,发现它随着库数量的增加而很好地扩展。 此外,我们广泛地调查了 KGE4AR 中不同设计选择的的影响。
总之,这项工作做出了以下贡献:
-
•
新颖方法: 我们引入了 KGE4AR,一种基于文档的类比 API 推荐方法,它为众多库构建了一个统一的 API KG,通过 KG 嵌入提供可扩展的推荐。
-
•
彻底评估: 我们通过在两种 API 推荐场景中的有效性比较、跨各种库数量的可扩展性评估以及设计选择影响的分析,对 KGE4AR 进行了彻底的评估。
-
•
公共基准:我们发布了一个基准,用于对多个库进行广泛的类比 API 评估。
2. 背景和相关工作
在本节中,我们将讨论类比 API 推荐和软件工程中的知识图的相关工作。
2.1. 类比 API 推荐
现有的类比 API 推荐技术利用各种来源,如演化历史 (Alrubaye 等人,2019a;Nguyen 等人,2014)、在线帖子 (Liu 等人,2022b) 和 API 文档 (Alrubaye 等人,2020, 2019b;Pandita 等人,2015;Chen 等人,2021;Pandita 等人,2017;Lu 等人,2017;Zhang 等人,2020) 来查找合适的目标 API。 基于演化历史的方法 (Teyton 等人,2013) 使用演化历史 (例如,代码更改) 来挖掘频繁共同出现的 API 对,而基于文档的方法 (Pandita 等人,2017;Alrubaye 等人,2020, 2019b;Pandita 等人,2015;Chen 等人,2021;Lu 等人,2017) 使用与 API 相关的文本 (例如,描述) 计算文本相似度。 由于其普遍性、低数据收集成本和最近的研究重点,我们专注于基于文档的推荐。
现有的基于文档的 API 类比技术主要分为两类,例如,基于监督学习的 (Alrubaye 等人,2020) 和基于无监督学习的 (Pandita 等人,2015, 2017; Alrubaye 等人,2019b; Chen 等人,2021; Lu 等人,2017; Zhang 等人,2020; Chen 等人,2016)。 对于基于监督学习的技术,Alrubaye 等人 (Alrubaye 等人,2020) 提出训练一个机器学习模型 (即 提升决策树) 用于基于从 API 文档中提取的特征的类比 API 推理 (例如,它们的方法描述、返回类型描述、方法名称和类名称的相似性),并利用训练好的模型来预测看不见的 API 对是否为类比的概率。 与需要大量标记数据的监督技术不同,基于无监督学习的技术通常以无监督的方式将 API 向量化,然后根据向量相似性推荐类比 API。 例如,Zhang 等人 (Zhang 等人,2020) 利用 Word2Vec 模型将 API 功能描述、API 参数和 API 返回值向量化,然后基于这些向量计算联合相似性。
尽管现有的基于文档的技术取得了令人鼓舞的有效性,但它们存在两个主要缺点。 首先,它们基于重叠的符元来计算文本相似性 (Pandita 等人,2017) 或测量符元相似性而不考虑整个上下文 (Zhang 等人,2020),因此无法很好地捕获 API 文档中的语义级相似性。 其次,它们以穷举的方式计算所有 API 之间的成对相似性,因此在 API 数量庞大时会遇到可扩展性问题。 为了解决这些问题,我们的工作首次尝试使用新颖的 统一的 API KG 来全面而结构化地表示 API 文档中的知识。 此外,我们进一步利用 KG 嵌入来实现更有效和可扩展的相似性计算。 我们的评估结果也证明了我们对现有基于文档的技术的改进。
2.2. 软件工程中的知识图
在软件工程领域,研究人员已经建立了用于不同目标的知识图,涵盖 API 概念 (Liu 等人,2019; Xing 等人,2021)、API 注意事项 (Li 等人,2018)、API 比较 (Liu 等人,2020a)、API 文档 (Peng 等人,2018; Liu 等人,2020b)、领域术语 (Wang 等人,2019, 2023b, 2023a)、编程任务 (Liu 等人,2022a)、ML/DL 模型 (Liu 等人,2023) 和错误 (Wang 等人,2017b; Su 等人,2021)。 我们的工作将 API 知识图应用于一项与现有工作不同的任务,即类比 API 推荐。 此外,由于针对不同的任务,我们 API 知识图的设计和重点也与现有知识图不同。 例如,为 API 误用检测而构建的现有 API 知识图 (Ren 等人,2020) 主要包括 API 之间的调用顺序和条件检查关系,而我们的 API 知识图侧重于 API 文档中的三种知识 (即 API 结构、API 功能描述和 API 概念关系),这些知识有助于类比 API 推荐。 此外,我们还提出了一种新颖的知识图嵌入,以实现更有效和更可扩展的类比 API 推荐。
2.3. 知识图谱嵌入
知识图谱嵌入 (KGE) 使用低维向量来表示知识图谱中的实体和关系,捕捉实体之间的语义关系 (Wang et al., 2017a). KGE 模型将实体映射到一个向量空间中,其中相似的实体更接近。 它们在问答、推荐和知识图谱补全等应用中表现出色 (Wang et al., 2017a; Du et al., [n. d.]). 常见的 KGE 方法包括 TransE、TransR 和 DistMult (Bordes et al., 2013; Lin et al., 2015; Yang et al., 2015). 这些方法将 KG 三元组 (头实体、关系、尾实体) 编码成连续的向量表示。 例如,TransE 将实体和关系视为向量,将关系定义为从头实体到尾实体的平移 (Bordes et al., 2013). 我们使用 KGE 将统一的 API KG 嵌入到类比 API 推荐中。
3. 方法
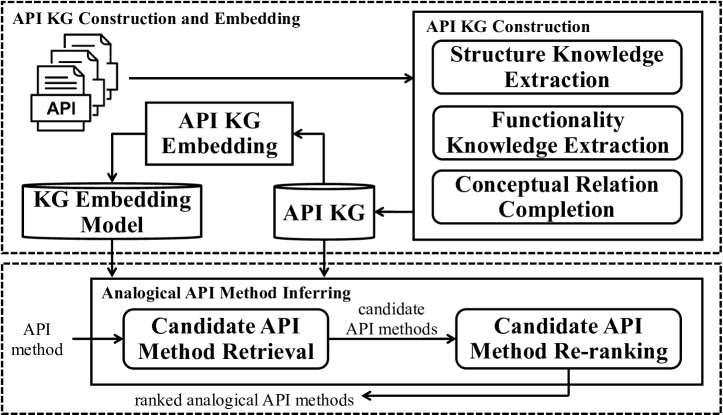
如图 1 所示,KGE4AR 包括三个阶段,即 API KG 建立、API KG 嵌入和类比 API 方法推断。 给定来自大量库的 API 文档作为输入,KGE4AR 首先构建一个统一的 API KG (第 3.1 节),然后训练一个嵌入模型来嵌入构建的 KG (第 3.2 节)。 最后,对于给定的源 API,KGE4AR 根据嵌入的 KG 返回其类比 API (第 3.3 节)。 注意,前两个阶段只需要运行一次。 一旦统一的 KG 被构建和嵌入,KGE4AR 就可以 针对给定的 API 有效地推荐类比 API。 特别是,KGE4AR 主要有两个技术上的新颖之处。
新颖之处 1:为大量库构建统一的 API KG。 我们建议为大量库(例如,在本研究中为 35,773 个 Java 库)构建一个统一的 API KG。 我们的 API KG 包含文档中发现的三种知识类型,这些知识类型通常类似于模拟 API:(1)API 结构(例如,包结构、类定义、方法声明)、(2)API 功能描述(例如,“获取 JSONArray 中元素的数量”)和 (3) API 概念关系(即 API 概念及其关系,例如 “属于”)。 与仅关注作为标记序列呈现的 API 结构或功能描述的现有方法不同,我们统一的 API KG 提供了更广泛的结构化表示,涵盖所有三种知识类型。 这包括一个以前未探索过的新类别——API 概念关系。 图形结构本质上适合多类型数据的结构化统一,因此可以有效地捕捉 API 文档中的高级语义。
新颖之处 2:基于 KG 嵌入的相似性计算。 我们建议嵌入统一的 API KG,将每个 KG API 表示为一个向量。 KG 嵌入提供了两个优势。 首先,它有效地保留了统一 KG 中的结构化和语义数据。 其次,它加速了 KG 中 API 之间的相似性计算。 通过向量索引从数据库中检索类似的 API 向量非常高效。 与现有方法需要对所有 API 对进行详尽的相似性计算不同,我们的 KG 嵌入为相似性计算提供了一种更有效和有效的方法。
3.1. API 知识图谱构建
在此阶段,KGE4AR 基于大量库的 API 文档构建一个统一的 API KG。 API KG 的构建主要包含三个步骤。 (1) 结构知识提取:KGE4AR 首先从文档中提取所有 API 元素 (例如,包、类/接口、方法、字段、参数) 及其关系,以形成 API KG 的基本骨架;(2) 功能知识提取:然后,KGE4AR 从方法的名称和文本描述中提取 API 库的功能知识,即,方法的标准化功能表达式 (包括功能动词、功能类别和短语模式) 以及所涉及的概念;(3) 概念关系补全:KGE4AR 通过分析 API 元素和概念的名称和文本描述来完成 API 元素和概念之间的概念关系。 通过这种方式,来自不同库的 API 元素可以根据共享的类型引用 (例如,方法参数和返回值的类型)、功能表达式和概念相互关联。
3.1.1. 统一 API 知识图谱模式
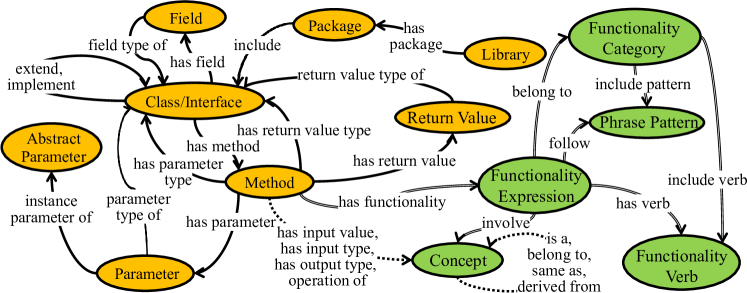

我们的 API KG 捕获了 API 文档中存在的结构和高级信息。 它由表示 API 不同方面的实体 (节点) 和关系 (边) 组成。 这里,我们提供关键实体和关系的定义:
-
•
API 元素。 API 元素 包括库、包、类/接口、字段、方法、返回值、参数和抽象参数等组件,构成 API 的基本构建块。
-
•
结构关系。 结构关系 描述 API 元素之间的关系,包括“扩展”(继承)、“实现”(接口实现)、“包含字段”(类/接口中的字段)、“包含方法”(类/接口中的方法) 和“包含参数”(方法需要的参数),构成 API KG 的基础。
-
•
功能表达式元素 . 功能表达式元素 涉及 API 功能描述的结构化表示。 这包括功能表达式、功能动词、功能类别和短语模式。 它们促进了 API 功能的标准化表示,正如 Xie 等人所定义的。 (Xie 等人,2020)。
-
•
功能表达式 . 一个 功能表达式 为方法的功能描述提供了一个结构化表示,遵循 Xie 等人 (Xie 等人,2020) 定义的标准化形式。 它从方法的描述句中提取出来。
-
•
功能动词 . 一个 功能动词 代表表达功能主要动作的动词,例如,“返回”,“获取”和“获得”。
-
•
功能类别 . 一个 功能类别 根据其语义含义对功能表达式进行分类,它是从具有类似含义的功能动词集中抽象出来的,例如,“返回”,“获取”和“获得”可以归类为同一类别。
-
•
短语模式 . 短语模式 捕获功能表达式中使用的特定语法模式或模板,例如,“V {患者}” 和 “V {患者} 在 {位置}”。 在短语模式 “V {患者} 在 {位置}” 中,占位符“患者”和“位置”代表满足语义角色的名词短语。 “{患者}“对应于功能动词的直接宾语,表示直接受动作影响的实体或对象。 “{位置}”表示与动词相关的空间或时间上下文。
-
•
概念。 API KG 中的概念是特定的语义单元,它们捕获特定于领域的知识或 API 文档中的常见主题。 这些概念通常由名词短语表示。 例如,在与 JSON 处理相关的 API 中,像 JSON 数组、JSON 对象、键和值这样的概念经常出现。 概念可以通过扮演一些语义角色 (例如,宾语、地点) 来参与功能表达。
图 2 展示了我们 API KG 的模式,说明了所涉及的实体和关系类型。 此外,图 3 提供了一个部分 API KG 示例,突出了这些实体和关系的互连性。 完整的模式,包括所有实体和关系类型的定义,可在我们的复制包中获得 (rep, 2023)。 橙色的椭圆形和实线分别表示 API 元素以及它们之间的结构关系。 其中,抽象参数代表具有相同名称和类型不同方法参数的抽象。 例如,所有名为 path 且类型为 java.lang.String 的方法参数都被视为同一个抽象参数的实例。 绿色的椭圆形表示功能表达元素 (即,功能表达、功能动词、功能类别和短语模式) 以及相关的概念,双线表示这些元素和概念之间的关系。 请注意,如果多个方法的功能描述包含相同的函数动词、短语模式、函数类别和概念,则它们可能共享相同的功能表达。 虚线表示概念之间的各种关系 (例如,“是” 和 “属于”) 以及 API 元素和概念之间参与关系 (例如,方法和概念之间的“具有输入类型”)。 为了简洁起见,图 2 中省略了一些关系,例如,类和概念之间的 “概念的实例类” 关系 (参见第 3.1.4 节)。
通过这种方式,来自不同库的 API 元素可以通过结构关系 (例如,共享参数或返回类型)、功能表达 (例如,共享功能类别和涉及的概念) 和概念 (例如,与相关概念相关联) 间接地联系起来。
图 3 展示了与 API 方法 org.json.JSONArray.length() 和 com.google.gson.JsonArray.size() 相关的一些实体和关系。 这两种方法是来自两个库 org.json (org, 2023a) 和 gson (gso, 2023) 的类比 API 方法。 虽然它们有不同的名称 (即 length() 和 size()) 和功能描述 (即 “获取 JSONArray 中元素的数量,包括 null” 和 “返回数组中元素的数量”),但它们在 API KG 中通过不同类型的关系间接相关。 它们具有共同点,例如返回值类型、功能类别以及与“json 数组”和“元素数量”等概念的关联。
3.1.2. 结构知识提取
此步骤从文档中提取结构知识,以便构建 API KG 的基本骨架。 在这项工作中,我们关注 Java 库,因为它很流行,但我们的方法并不局限于特定的编程语言。 我们使用每个库的 JAR 文件中的 Javadoc API 文档,因为它格式整洁且流行,KGE4AR 也能使用来自其他来源的 API 文档 (例如,在线官方文档)。 特别是,KGE4AR 根据图 2 中所示的模式从 API 定义中提取所有 API 元素及其结构关系。 同时,KGE4AR 进一步从 API 元素的 Javadoc 注释中提取文本描述 (即,方法声明之前的注释 (doc, 2023))。 提取的文本描述 可以 用于随后的功能知识提取和概念知识提取。 在我们的实现中,我们利用 JavaParser (jav, 2023) 分析 JAR 文件中包含的 Java 源文件。 通过基于抽象语法树 (AST) 的静态分析,我们提取所有 API 元素,以及它们的结构关系和文本描述。
3.1.3. 功能知识提取
我们通过分析 API 方法的名称和文本描述来提取 API 方法的功能知识。 Xie 等人 (Xie et al., 2020) 提供了一个标准化功能描述数据集,该数据集可在网上获取 (fun, 2023b)。 它包含 10,016 个功能动词、89 个功能类别和 523 个短语模式。 我们将所有这些添加到 API KG 中,作为功能知识提取的基础。 Xie 等人 (Xie et al., 2020) 还提供了一个工具 FuncVerbNet (fun, 2023a),它可以将功能描述解析为标准化的功能表达式。 FuncVerbNet 使用文本分类器将功能描述分类为功能类别,然后基于依赖树解析识别相应的短语模式、功能动词和概念。 例如,它从描述 “返回数组中的元素数量” 中提取以下功能表达式:
功能类别: 获取; 功能动词: 返回; 短语模式: V {患者} 在 {位置}; 概念: [元素数量,数组]; 功能表达式: 返回 | 元素数量 | 数组
对于每个 API 方法,我们以其文本描述的第一句话作为其功能描述(如果存在),遵循先前的工作 (Xie et al., 2020; Liu et al., 2020a)。 接下来,我们利用 FuncVebNet 提取相关的功能表达式。 功能表达式中存在的概念,对应于在短语模式中履行语义角色的名词短语,通过去除停用词和词形还原技术进行提取和细化 (Xie et al., 2020)。 如果提取的功能表达式和关联的概念在 API KG 中不存在,我们会将它们添加为实体,并在它们之间建立 “涉及” 关系。 我们还建立了提取的功能表达式与其他现有元素之间的关系,例如由模式定义的功能动词、短语模式和功能类别(见图 2)。
如果方法没有文本描述,我们从其名称中提取功能表达式。 我们根据驼峰命名法和下划线将名称拆分为一系列符元,然后使用符元序列作为方法的功能描述。 例如,例如,"getInt" 可以从方法 getInt() 的名称中提取为其功能描述。 如果方法名称开头缺少动词,我们会根据以下规则添加默认功能动词。 我们利用 WordNet (Miller, 1995),一个提供词义和分类的词汇数据库,来确定单词的词性 (例如, 形容词,名词)。
-
•
如果方法名称是名词短语,则添加 “获取”,例如,"getLength" 用于 JSONArray.length();
-
•
如果方法名称以“to”开头,则添加 “convert”,例如,JSONArray.toString() 的 “convert to String”;
-
•
如果方法名称是形容词,则添加 “check”,例如,ArrayList.empty() 的 “check empty”。
3.1.4. 概念关系完成
概念关系完成通过分析 API 元素和概念的名称/描述来建立类比 API 之间的概念关系,然后完成方法的概念关系。 API 元素名称/描述分析创建 API 元素和概念之间的关系,并在必要时添加新概念。 概念名称分析创建概念之间的关系。 方法概念关系完成基于现有关系完成 API 方法和概念之间的关系。
API 元素名称分析。 每个 API 元素(方法除外)都可以被视为对应概念的实例,例如 java.io.File 代表概念 file 的实例。 我们根据 API 元素的类型以不同的方式提取相应的概念:
-
•
包、类和接口:通过驼峰式大小写和下划线拆分 API 元素的短名称(即 完全限定名称的最后一个点之后的部分)获得的小写短语,例如,“json array”是org.json.JSONArray的概念;
-
•
返回值:通过骆驼命名法和下划线分割返回值类型的短名称获得的小写短语;
-
•
参数和字段:通过骆驼命名法和下划线分割参数/字段的短名称获得的小写短语,例如 File srcFile 的概念是 “src file”。
对于以这种方式获得的每个概念,我们在 API 元素和概念之间创建“instance of”关系,例如 <org.json.JSONArray, instance class of concept, json array>。
API 元素描述分析。 我们通过以下步骤从 API 元素的描述中提取概念:
-
•
使用 Spacy (spa, 2023) 提取所有名词短语,例如 “A JSONObject” 和 “the value” 是从返回值描述 “A JSONObject which is the value” 中提取的;
-
•
将提取的名词短语小写化并词形还原,例如 “files” 和 “A JSONObject” 分别转换为 “file” 和 “a jsonobject”;
-
•
删除短语开头的停用词,例如从 “a jsonobject” 中删除 “a”。
所有剩余的名词短语都被视为 API 元素描述中提到的概念,并在它们之间创建相应的概念提及关系,例如,<jsonobject, mentioned in return value description, org.json.JSONObject.optJSONObject(java.lang.String).<R>>。
概念名称分析。 概念的名称可能暗示概念之间的一些概念关系,例如,<json array, is, array>。 这些概念关系有助于建立 API 元素之间可能存在的关联,这些元素在概念表达上存在细微差异。 遵循之前的工作 (Liu et al., 2020a),我们使用以下规则来识别 API KG 中两个概念 和 之间的可能概念关系:
-
•
如果 的名称是从 的名称派生的,则添加关系 <C1, derived from, C2>,例如,<builder, derived from, build>。
-
•
如果 的名称比 的名称短且是其前缀,并且没有其他更长的概念满足 的此规则,则添加关系 <C2, facet of, C1>,例如,<character sequence length, facet of, character sequence>;
-
•
如果 的名称比 的名称后缀短,并且没有其他更长的概念满足 的此规则,则添加关系 <C2, is, C1>,例如,<json array, is, array>。
-
•
如果 的名称与 的名称在去除空格后相同,则添加双向关系 <C2, same as, C1> 和 <C1, same as, C2>,例如,<json array, same as, jsonarray> 和 <jsonarray, same as, json array>;
API 方法概念关系补全。 为了更好地反映后续 API KG 嵌入中方法之间的概念关联,我们进一步创建方法和通过多跳关系间接连接的概念之间的直接关系。 我们遵循表 1 中所示的规则来完成这些关系。 通过这种方式,我们基于方法的不同部分,即 对象、输入值、输入类型和输出类型,建立了方法和概念之间的直接关系。
| Existing Multi-hop Relations | Completed Relation |
| <C, has method, M> | <M, operation of, Con> |
| <C, instance class of concept, Con> | |
| <M, has parameter, P> | <M, has input value, Con> |
| <P, instance parameter of concept, Con> | |
| <M, has parameter type, T> | <M, has input type, Con> |
| <T, instance class of concept, Con> | |
| <M, has return value type, T> | <M, has output type, Con> |
| <T, instance class of concept, Con> |
3.2. API 知识图谱嵌入
在此阶段,KGE4AR 训练了一个基于 API KG 所有关系三元组的 KG 嵌入模型。 该模型将 API KG 中的所有实体 (例如,API 元素、功能表达元素、概念) 映射到一个高维向量空间,其中具有相似结构、功能和概念关系的 API 元素彼此靠近。 KG 嵌入的优势包括:(i) 图嵌入可以很好地保留图中的结构和语义信息,以及 (ii) 将 API 映射到向量空间可以加速相似 API 的检索,因为所有 API 向量都存储在向量数据库中,并且向量索引非常高效。
特别地,我们使用 ComplEx 模型 (Trouillon 等人,2016),一种基于张量分解的 KG 嵌入方法,来训练 API KG 嵌入模型。 张量分解将 KG 建模为一个三维张量 (即,一个三维邻接矩阵),它可以分解为低维向量 (即,实体和关系的嵌入 (Trouillon 等人,2016)) 的组合。 ComplEx 使用以下公式计算每个关系三元组 <,,> 的分数:,其中 、 和 分别是头部实体、关系类型和尾部实体,、 和 是它们的嵌入。 分数表示对应关系成立的概率。 模型训练将 KG 中的所有关系三元组作为输入,并产生 KG 中所有实体和关系的嵌入作为输出。 训练期间优化的目标是与损坏的错误三元组 和 相比,为真实三元组 分配更高的分数。 为了支持反对称关系,该模型在复数空间实例中表示 、 和 ,而不是实数空间,例如, 具有实部 和虚部 ,即,。
鉴于 API KG 的庞大规模 (即,包括超过 7200 万个实体和超过 2.89 亿个关系),我们使用 PyTorch-BigGraph (PBG) (Lerer 等人,2019) 及其在 GitHub 上共享的实现 (Big,2023) 来训练 ComplEx 模型。 PyTorch-BigGraph 是 Facebook 实现的一个分布式系统,其目的是支持对大型图上的知识图谱嵌入模型进行训练。 我们还在第 4.3 节中研究了使用其他 KG 嵌入模型 (例如,TransE (Bordes 等人,2013) 和 DistMult (Yang 等人,2015))。
为了促进基于 KG 嵌入的更有效的相似度计算,我们将所有 KG 嵌入存储在向量数据库中,即,Milvus (Wang 等人,2021)。 Milvus 是一个开源向量数据库,支持高效的向量索引和相似度搜索。 基于 Milvus,我们可以有效地获取给定 KG 中实体的 KG 嵌入,或找到给定嵌入的 top- 个相似的实体嵌入。
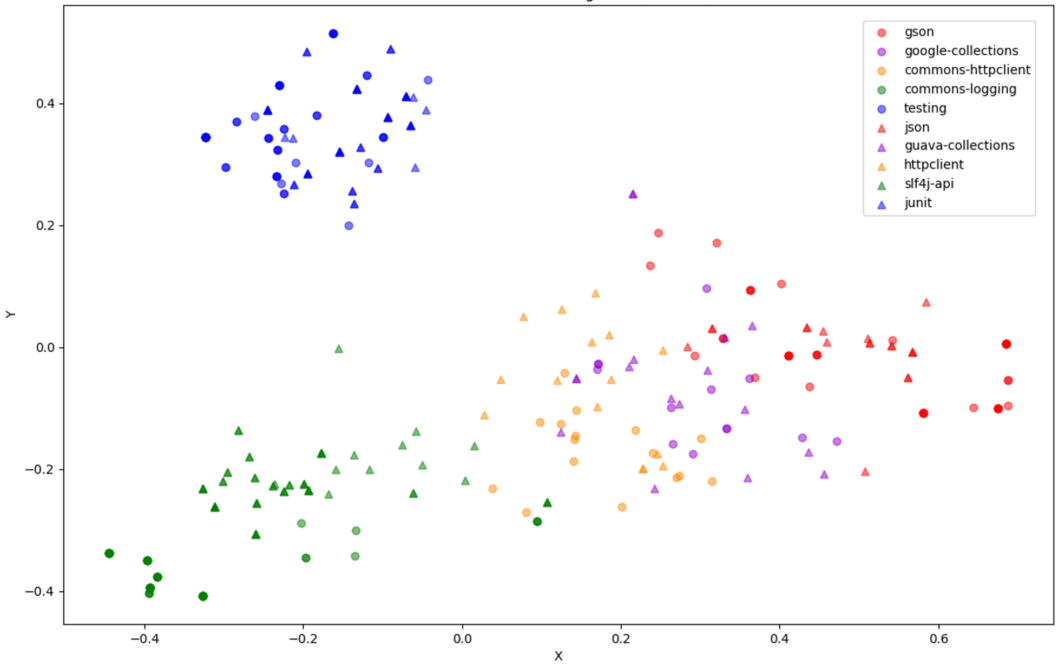
图 4 显示了向量空间中一些 API 方法的 KG 嵌入分布,该分布是在通过 PCA(主成分分析)(Abdi 和 Williams,2010) 降维后生成的。 图 4 中的每个点代表我们基准测试(在第 4.1.1 节中)中的一个 API 方法。 具有相同颜色和形状(即,三角形或圆形)的点代表来自同一库的 API 方法。 两个类比库的 API 方法具有相同的颜色,但形状不同。 我们可以观察到,同一库(例如,org.json)或类比库(例如,org.json 和 gson)中的 API 方法在向量空间中相对靠近,而不同主题的库的 API 方法则相距甚远。 例如,与日志记录相关的库(slf4j (slf,2023) 和 commons-logging (com,2023))的 API 方法,与与测试相关的库(例如,junit (jun,2023) 和 org.testing (org,2023b))的 API 方法相距甚远。
3.3. 类比 API 方法推断
在此阶段,KGE4AR 基于 API KG 和嵌入模型,为给定的源 API 方法返回一个排序的类比 API 方法列表。 首先,KGE4AR 根据候选 API 方法与给定 API 方法的相似性来选择候选 API 方法(第 3.3.1 节中的候选 API 方法检索);然后,KGE4AR 通过考虑给定 API 方法与候选 API 方法的邻居之间的相似性来重新排序候选 API 方法(第 3.3.2 节中的候选 API 方法重新排序)。 第一步中候选 API 方法检索的目的是缩小候选 API 的范围,以便第二步重新排序步骤只需要计算给定 API 与少量候选 API 之间的相似性。
3.3.1. 候选 API 方法检索
对于给定的源 API 方法 ,我们首先通过 查询 Milvus 获取其 KG 嵌入 。 然后我们根据等式 1 计算 与其他库中的方法(称为方法相似度 )之间的 KG 相似度 ,它是它们 KG 嵌入之间的归一化余弦相似度。 我们利用数据库中高效的向量索引选择前 (e.g., 100) 个 API 方法作为候选,在万亿向量数据集上实现了毫秒级的低延迟。
| (1) |
3.3.2. 候选 API 方法重新排序
具有高 KG 嵌入相似度的两个 API 方法不一定是类比 API 方法。 例如,org.json.JSONArray.getJSONObject(int) 和 com.google.gson.JsonArray.remove(int) 具有很高的 KG 嵌入相似度,因为它们属于类比类。 为了解决这个问题,我们进一步计算给定 API 方法 和每个候选 API 方法 的相同类型邻居概念之间的相似度,这反映了 API 方法在不同方面 (e.g., 功能、输入和输出) 的概念相似度。 我们计算的基于邻居的相似度包括功能相似度 、对象相似度 、输入类型相似度 、输入值相似度 、输出类型相似度 和平均邻居相似度 。 为了获得最终的类比得分 ,我们然后根据等式 2 对这些基于邻居的相似度和方法相似度 进行加权求和。
| (2) |
所有候选者都按类比得分排序。 然后我们解释每个相似度如下。
方法相似度 (). 是两种方法之间的 KG 相似度,它已经在检索步骤中计算出来。
功能相似性 (). 功能相似度度量 () 捕获了两种 API 方法提供的功能的相似度。 它依赖于这样的假设:可比较的 API 应该具有相似的功能表达。 我们根据公式 3 计算对应于两种方法的功能表达式的最大相似度,作为它们的功能相似性 。 在公式 3 中, 表示方法 的功能表达式(即,<, 具有功能, >),该表达式从方法名称或功能描述中提取(参见第 3.1.3 节)。 这种度量使我们能够根据 API 方法的预期功能和目的来捕获它们的相似度。
| (3) |
对象相似性 (). 捕获了两个 API 方法的类别之间的概念级相似性。 它基于这样一种直觉,即属于类似类别的类方法很可能表现出类似的行为和使用模式。 是根据公式 4 计算的,其中 表示与方法 的类相对应的概念(即,<, 具有操作, >)。
| (4) |
输入类型相似性 (). 两种方法的 反映了它们的形参类型的概念级相似性。 预计类比 API 将对类似类型的输入数据进行操作。 是根据公式 5 计算的,其中 表示与方法 的一个形参类型相对应的概念(即,<, 具有输入类型, >),而 表示所有 的 KG 嵌入的平均值。
| (5) |
输入值相似性 (). 的目的是捕获两种方法之间形参的概念级相似性,这有助于识别类比 API。 类比 API 通常在其作为输入接受的值方面表现出相似性,而与具体的形参类型无关。 是根据公式 6 计算的,其中 表示与方法 的一个形参相对应的概念(即,<, 具有输入值, >),而 表示所有 的 KG 嵌入的平均值。
| (6) |
输出类型相似度 (). 反映了两种方法的返回值类型在概念层面的相似性。 类比 API 通常在返回值类型方面表现出相似性。 是根据公式 4 计算的,其中 代表对应于方法 的返回值类型的概念 (即, <, 具有输出类型, >)。
| (7) |
平均相邻概念相似度 (). 类比 API 通常不仅在其各个方面表现出相似性,而且在其整体上下文或行为方面也表现出相似性。 通过使用公式 8 和公式 9 计算 ,其中 代表方法及其相邻概念的 KG 嵌入的平均值,我们可以捕获两种方法之间整体相邻概念的相似性。 这种相似性度量提供了方法周围环境的整体视图,使我们能够根据其整体行为的相似性识别类比 API。
| (8) |
| (9) |
请注意,我们不是直接使用两种方法的相邻 API 元素的相似性 (例如, 它们的返回值),而是使用与相邻 API 元素相关的概念,因为 API 元素是库特定的,而概念更有可能在库之间共享。 此外,为了确保返回值 API 的多样性,我们进一步限制了来自同一个库的推荐 API 方法的数量 (即, 3)。
4. 评估
| Type | Number | Type | Number |
| Library | 35,773 | Return Value | 15,451,223 |
| Package | 229,061 | Abstract Parameter | 1,892,120 |
| Class | 3,090,537 | Functionality Expression | 5,200,297 |
| Interface | 281,854 | Functionality Category | 89 |
| Field | 6,232,643 | Functionality Verb | 10,016 |
| Method | 15,441,057 | Phrase Pattern | 523 |
| Parameter | 16,501,363 | Concept | 5,660,553 |
为了实现 KGE4AR,我们从 35,773 个 Java 库构建了一个统一的 API KG。 表 2 展示了生成的 API KG 的实体类型统计信息。 为了收集这些库的 Javadoc 文档, 我们首先根据 Libraries.io 数据集 (lib, 2023)(最后更新于 2020 年 1 月)获取一组 Java 库的元数据(例如,groupId 和 artifactId);然后,我们从 Maven 中央仓库下载最新版本的 JAR 文件(截至 2022 年 8 月 11 日),共计 35,773 个 JAR 文件;最后,我们利用 zipfile (zip, 2023) 和 JavaParser (jav, 2023) 从 JAR 文件中提取与 API 相关的文档,包括 API 定义和 API 功能描述。 通过这种方式,我们构建了一个包含 72,242,099 个实体的 API KG,其中包括 59,155,631 个 API 元素、5,210,925 个功能元素和 5,660,553 个概念。 此外,我们使用 ComplEx 和逻辑损失来训练 KG 嵌入模型。
我们通过回答以下研究问题来评估 KGE4AR。 RQ1 和 RQ2 研究了 KGE4AR 在两种模拟 API 推荐场景中的有效性,即,一种是给定目标库的场景,另一种是不给定目标库的场景。 为了更好地理解 KGE4AR 的能力和特征,RQ3 分析了 KGE4AR 中不同组件的影响,而 RQ4 则进一步研究了当库数量增加时 KGE4AR 的可扩展性。
-
•
RQ1(具有目标库的有效性): 当推荐具有 给定目标库 的模拟 API 方法时,KGE4AR 与现有的基于文档的技术相比如何?
-
•
RQ2(没有目标库的有效性): 当推荐具有 没有给定目标库 的模拟 API 方法时,KGE4AR 与现有的基于文档的技术相比如何?
-
•
RQ3(影响分析):KGE4AR 中的不同组件(即 KG 嵌入模型、知识类型以及相似性类型和权重)如何影响 KGE4AR 的有效性?
-
•
RQ4(可扩展性):随着库数量的增加,KGE4AR 的可扩展性如何?
4.1. RQ1:具有目标库的有效性
在这个 RQ 中,我们评估了 KGE4AR 和最先进的基于文档的模拟 API 推荐技术的有效性,这些技术具有给定的目标库。
4.1.1. 协议
在本节中,我们将介绍用于本研究问题的基准、基线和指标。
基准测试。 存在两个现有的基准测试 (Teyton 等人,2013;Alrubaye 等人,2019b),其中包含手动验证的类比 API 对;我们直接从他们的复制包 (Tey,2023;Alr,2023) 中获取这两个数据集,并将它们合并成一个基准测试。 通过这种方式,我们构建了一个大型基准测试,其中包含来自 16 对类比库的 245 对类比 API 方法,涵盖 JSON 处理、测试、日志记录和网络请求等不同主题。 对于每对模拟 API,任何一个 API 都可以作为源 API 使用,从而产生 490 个源 API(245 对 2)。 在每个查询中,源 API 和目标库中的所有候选 API 都会作为输入提供,输出是候选 API 的排序列表。
基线。 我们包含了两种最先进的基于文档的类比 API 推荐技术(即,RAPIM (Alrubaye 等人,2020) 和 D2APIMap (Zhang 等人,2020))进行比较。 我们选择这两种技术,因为它们分别是无监督学习和监督学习类别中最新的和最有效的技术。
-
•
RAPIM (Alrubaye 等人,2020) 是一种基于监督学习的方法,它训练一个机器学习模型(即,提升决策树),并利用训练后的模型来预测一个看不见的 API 对是类比的概率。 特别地,对于给定的 API 对,RAPIM 计算一组特征,这些特征基于两个 API 之间的描述、返回值描述、方法名称和类名称的词汇相似性。 我们根据论文收集了他们的特征,然后通过网络请求直接使用 RAPIM (asc,2023)。
-
•
D2APIMap (Zhang 等人,2020) 是一种基于无监督学习的方法,它利用 Word2Vec 模型来计算 API 对的功能描述、返回值和参数之间的相似性。 它推荐总相似度最高的 API。 由于源代码不可用,我们根据原始论文重新实现了 D2APIMap。
指标。 遵循先前的研究 (Chen 等人,2021),我们采用常用的评估指标:MRR(平均倒数排名)和 Hit@k ()。 MRR 计算生成的列表中正确类比 API 的平均排名,而 Hit@k 测量正确类比 API 出现在前 k 个位置的查询比例。 考虑到每个库中 API 的数量庞大,我们将分析限制为每个查询中排名列表中的前 100 个候选者。
| Approach | MRR | Hit@1 | Hit@3 | Hit@5 | Hit@10 |
| RAPIM | 0.158 | 0.082 | 0.180 | 0.229 | 0.304 |
| D2APIMap | 0.261 | 0.180 | 0.278 | 0.343 | 0.420 |
| KGE4AR | 0.384 | 0.267 | 0.449 | 0.527 | 0.594 |
4.1.2. 结果
表 3 展示了评估结果,每个指标的最佳值以粗体显示。 KGE4AR 在所有指标上均显著优于基线方法。 特别是,KGE4AR 在 MRR、Hit@1、Hit@3、Hit@5 和 Hit@10 方面分别比基线方法提高了 47.1%-143.0%、48.3%-225.6%、61.5%-149.4%、53.6%-130.1% 和 41.4%-95.4%。
我们进一步研究了结果,发现 KGE4AR 优于基线方法的潜在原因可能是 KGE4AR 以更好的方式分析了 API 功能描述。 例如,当两个 API 共享相同的词组但动词不同时(例如,StorageObject.getContentLength() 和 S3ObjectWrapper.setObjectContent(S3ObjectInputStream)),RAPIM 和 D2APIMap 通常难以区分它们。 RAPIM 采用 TF-IDF 模型来计算相似度相关的特征,由于功能动词在名称和描述中出现的频率很高,因此通常会为它们分配较低的权重;D2APIMap 采用 Word2Vec 模型来计算相似度,由于功能动词的上下文相似,因此通常会用相似的向量表示它们。 然而,KGE4AR 提取了方法的功能知识(例如,功能类别、功能动词),并在重新排序步骤中考虑了方法的功能相似度(参见第 3.3 节),这可以有效地区分方法之间的差异,即使它们共享相同的词组。 因此,在本例中,KGE4AR 成功地将这两个 API 识别为非类比,而基线方法则将它们视为类比。
总之,在推断具有给定目标库的类比 API 方法时,KGE4AR 显著优于最先进的基于文档的技术。
4.2. RQ2:没有目标库的有效性
RQ1 评估了在已知目标库的情况下类比 API 推荐技术的有效性。 然而,在实际应用中,选择正确的目标库具有挑战性,现有的自动目标库推荐方法的有效性有限(Top1 回调率 < 20% (He et al., 2021b))。 因此,在这个研究问题中,我们评估了 KGE4AR 在没有目标库的情况下有效性。
4.2.1. 协议
然后,我们介绍了在这个研究问题中使用的基准、指标和基线。
基准。 RQ1 中的基准只包含候选 API 来自给定目标库的类比 API 对,不适用于没有目标库的类比 API 推荐场景。 因此,在这个研究问题中,我们手动构建了一个新的类比 API 对基准,这些类比 API 对的候选 API 来自广泛的库,而不是来自给定的目标库。 具体来说,基于之前的工作 (Chen et al., 2021)、在线资源,如 Awesome-Java (awe, 2023),以及我们的专业知识,我们首先手动选择了 9 对类比库 (i.e., 18 个库);然后,对于这 18 个库中的每一个,我们随机选择了库中的 15 个 API 方法作为评估的源 API,总共导致 270 个源 API。 所选的库包括流行的库(在 Maven Central (mav, 2023) 中的使用次数 > 500),例如 gson (gso, 2023),以及不太流行的库,例如 dsl-json (dsl, 2023) 和 dom4j (dom, 2023)。 所选的库代表了数据处理和代码分析等不同的领域,确保了我们的方法在现实世界场景中的有效性和普遍性的评估。
真实标签。 我们手动标记了新构建的基准中的 API 对是否为类比。 由于潜在 API 对的数量众多,我们只标记了每个技术在每个查询中返回的 Top-10 API,总共标记了 6,986 个 API 对。 具体来说,六位参与者,每个人都有超过三年的 Java 开发经验,手动评估返回的 API 是否与源 API 相似。 在每个查询中,要求两名参与者阅读源 API 和返回 API 的 API 文档,以判断它们是否具有类比性。 在评估之前,对每个源 API 返回的 API 进行随机排序,并且标注者不知道产生结果的技术。 在两个标注者评估不一致的情况下,会让第三个标注者参与做出判断,最终的标注基于多数协议。 标注者之间的一致性很高,Cohen’s Kappa 系数 (McHugh, 2012) 为 0.666。
指标。 除了在 RQ1 中使用的四个指标(即 MRR、Hit@1、Hit@3、Hit@5 和 Hit@10)之外,我们还在此 RQ 中进一步纳入了精确度和召回率,因为在这种情况下,可能有多个正确答案对应于源 API。 特别地,精确度是指返回结果中类比 API 方法的比例,而召回率是指检索到的类比 API 方法的比例。 总之,我们基于人工标注的真实情况,在所有这些指标上比较了 KGE4AR 与基准。
基准。 现有的基准 (即,RAPIM 和 D2APIMap) 穷举地计算源 API 与所有候选 API 之间的相似性,因此当没有给定目标库并且候选 API 的数量极大时 (例如,当没有指定目标库时,每个源 API 可能存在超过 1500 万个候选 API),直接应用这些技术成本高昂。 因此,在本 RQ 中,我们通过首先缩小其候选 API 的范围来增强基准。 特别地,我们首先利用轻量级信息检索技术 BM25 (Robertson 和 Walker, 1994) 选择文档与源 API 高度相关的 Top-100 候选 API;然后,我们将基准应用于这些候选 API。 我们采用 BM25 因为它具有有效性和效率 (Robertson 和 Walker, 1994)。 此外,我们根据先前的工作 (Zhang 等人,2020) 清理文档 (例如,删除停用词,拆分驼峰式命名,并执行词形还原),以进一步提高 BM25 的有效性。 为了区别,我们将使用 BM25 增强的两个基准 (即,RAPIM 和 D2APIMap) 分别表示为 RAPIM 和 D2APIMap。 我们使用 Elasticsearch (ela, 2023) 实现基于 BM25 的候选选择。
4.2.2. 结果
| Approach | MRR | Hit@1 | Hit@3 | Hit@5 | Hit@10 | Precision | Recall |
| RAPIM | 0.381 | 0.311 | 0.404 | 0.485 | 0.585 | 0.271 | 0.237 |
| D2APIMap | 0.616 | 0.570 | 0.644 | 0.685 | 0.715 | 0.369 | 0.385 |
| KGE4AR | 0.688 | 0.648 | 0.719 | 0.737 | 0.774 | 0.513 | 0.480 |
表 4 展示了评估结果。 总体而言,KGE4AR 在所有指标上都优于基线,在 MRR、Hit@1、Hit@3、Hit@5、Hit@10、精确率和召回率方面分别实现了 11.7%-80.6%、13.7%-108.3%、11.6%-77.9%、7.6%-52.0%、8.3%-32.3%、26.2%-72.0% 和 33.2%-116.5% 的提升。
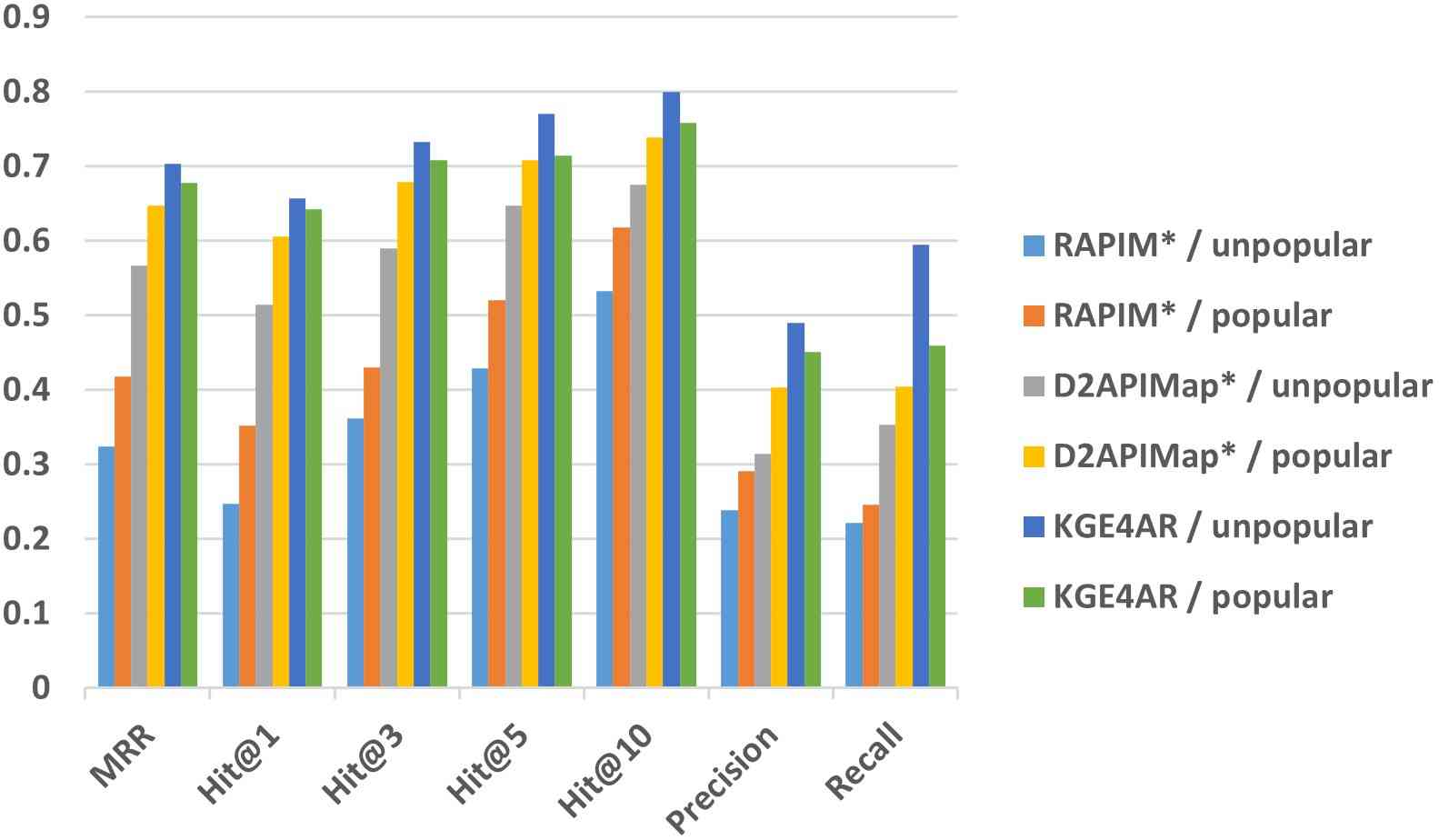
我们进一步研究了 KGE4AR 在不同库中的表现。 图 5 展示了 KGE4AR 和基线在流行库和不流行库上的表现。 我们发现,KGE4AR 在流行库和不流行库中始终优于基线。 有趣的是,KGE4AR 对基线的改进在那些不流行的库上更大。 例如,KGE4AR 在 dsl-json (dsl, 2023) (在 Maven Central 上只有 18 次使用)上的 MRR、精确率和召回率分别为 0.542、0.327 和 0.562;而 D2APIMap 在同一个库上的这些指标分别只有 0.206、0.080 和 0.171。 一个潜在的原因可能是,不流行的库的 API 可能针对相对不常见的功能,其描述可能与类似的 API 存在较大的语义差距。 现有的基线依赖于简单的文本匹配来推荐类似的 API,这无法很好地处理不流行的 API;而 KGE4AR 可以通过知识图谱嵌入将 API 的结构信息和功能描述更好地结合在一起,从而从大量的候选 API 中推断出类似的 API。
总之,KGE4AR 在没有给定目标库的情况下,优于现有的推断类似 API 的技术。
4.3. RQ3:因素影响
在这个 RQ 中,我们进一步分析了 KGE4AR 中各个组件的影响,包括重新排序组件、KG 嵌入模型、知识类型、相似度类型和权重。 鉴于这个 RQ 中比较实验数量众多(即 15 次运行),我们在基于 RQ1 基准的小规模 API KG 上进行实验。
4.3.1. 重新排序组件的影响
为了探究重新排序步骤在 KGE4AR 中的贡献,我们通过移除推断类比 API 中的重新排序步骤,包含了 KGE4AR 的一个变体(表示为 KGE4AR-Ret)。 KGE4AR-Ret 在 MRR、Hit@1、Hit@3、Hit@5 和 Hit@10 中的结果分别为 0.233、0.133、0.253、0.327 和 0.447,远低于默认的 KGE4AR (例如,Hit@1 低 50.2%)。 这些结果表明,重新排序步骤确实有助于提高 KGE4AR 的有效性。
4.3.2. KG 嵌入模型的影响
我们在小型 API KG 上训练了各种 KG 嵌入模型,以探索它们的影响。 我们将 ComplEx 与 TransE (Bordes 等人,2013) 和 DistMult (Yang 等人,2015) 进行比较。 我们使用 KGE4AR-Ret 基线评估 KG 嵌入模型,通过给定目标库推断类比 API 方法(第 4.1 节)。 KGE4AR-Ret 使用 KG 嵌入相似度检索类比 API 方法,反映了模型学习方法语义的程度。 比较基于前 100 个结果(表 5)。 如表所示,ComplEx(KGE4AR 中的默认值)在所有指标上都取得了最佳性能,这意味着它的适用性。
| Method | MRR | Hit@1 | Hit@3 | Hit@5 | Hit@10 |
| TransE | 0.284 | 0.174 | 0.312 | 0.396 | 0.518 |
| DistMult | 0.288 | 0.180 | 0.331 | 0.400 | 0.494 |
| ComplEx | 0.293 | 0.183 | 0.324 | 0.422 | 0.524 |
4.3.3. API 知识图谱中知识类型的影响
为了评估 API KG 中不同类型知识的影响,我们基于小型 API KG 中的一部分关系三元组训练了不同的 KG 嵌入模型。 我们尝试三种情况:仅结构关系三元组(表示为 Structure),所有关系三元组(除了功能相关的关系,表示为 Functionality*),以及所有关系三元组(除了概念相关的关系,表示为 Concept*)。 然后,我们基于 KGE4AR-Ret 和基准评估了不同的 KG 嵌入模型。 结果如表 6 所示。 功能性和概念性都对类比 API 方法推断有积极作用,而概念性知识的影响大于功能性知识。
| Knowledge Type | MRR | Hit@1 | Hit@3 | Hit@5 | Hit@10 |
| Structure | 0.154 | 0.070 | 0.169 | 0.233 | 0.331 |
| Functionality* | 0.282 | 0.185 | 0.309 | 0.385 | 0.489 |
| Concept* | 0.237 | 0.150 | 0.259 | 0.335 | 0.422 |
| All | 0.293 | 0.183 | 0.324 | 0.422 | 0.524 |
4.3.4. 相似类型和相似权重的影响
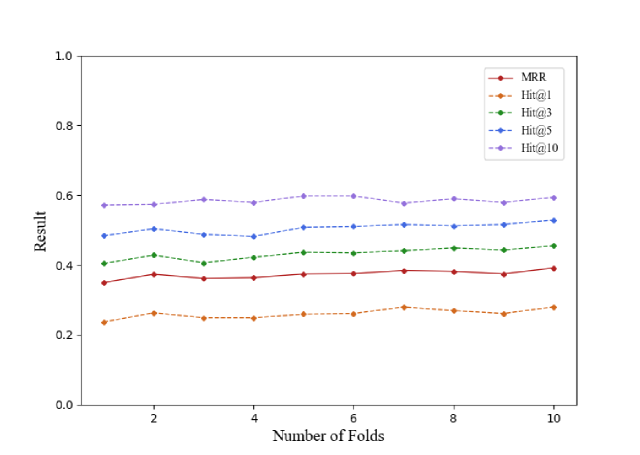
如第 3.3.2 节所述,我们在小型 API KG 上调整相似度的权重(即 、、、、、 和 ),而不是在大型 API KG 上调整,以避免过拟合。 特别地,我们将基准随机地分成 10 折,然后依次使用不同数量的折来调整权重。 我们使用束搜索 (Gao 等人,2020) 一次调整所有权重,步长为 0.05,束数量为 4。 图 6 显示了使用不同折数据调整权重的实验结果。 我们观察到,当使用更多调整数据时,会有细微的改进,表明使用一小部分数据进行调整可能已经足以达到相当的有效性。 请注意,我们的权重调整是在小型 API KG 上进行的,而之前的实验(RQ1 和 RQ2)是在大型 API KG 上进行的。 因此,这进一步表明调整后的权重甚至可以推广到不同的 API KG 上。 此外,我们进一步移除每个相似性(通过将其权重设置为 0),以便调查其对 KGE4AR 有效性的影响。 表 7 展示了评估结果,其中 代表排除了相似性 的 KGE4AR 变体。 我们观察到,当移除每个相似性时,KGE4AR 的性能会下降。 特别是,移除功能相似性 导致 MRR 下降最大,下降了 22.9%。 这表明功能知识对于类比 API 方法推断的重要性。 此外,移除 会增加 MRR 并减少 Hit@10,表明邻居相似性带来了一些噪声,但提高了召回率。
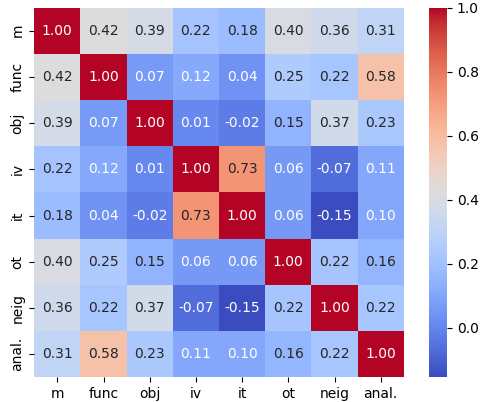
图 7 展示了相关矩阵的热图,显示了不同相似性度量(例如,m、func、obj)与类比关系(即,anal。)之间的关系。 我们执行了广泛使用的皮尔逊相关系数 (Cohen et al., 2009) 和 Welch 的 t 检验 (Welch, 1947) 来评估观察到的相关性的统计显着性。 首先,我们基于 Welch 的 t 检验,观察到所有相似性与类比关系 () 之间存在统计学上正相关性,这意味着包含的相似性或多或少有助于推断类比关系。 其次,每个相似性得分对类比关系表现出不同的相关系数,这意味着它们在推断类比关系中的作用存在不同重要性。 第三,大多数相似性得分与其他相似性得分之间表现出低相关性,只有少数相似性得分之间表现出高相关性(例如,it 与 iv)。 总体而言,统计分析表明不同相似性对类比关系推断的潜在益处;但同时,某些相似性之间可能存在一些冗余信息,表明未来工作的潜在改进方向。
总之,当前的设计选择(即重新排序步骤、KG 嵌入模型、知识类型、相似性类型和权重)都对 KGE4AR 的有效性做出了积极贡献。
| Similarity | MRR | Hit@1 | Hit@3 | Hit@5 | Hit@10 |
| * | 0.382 | 0.263 | 0.449 | 0.522 | 0.590 |
| * | 0.297 | 0.194 | 0.343 | 0.410 | 0.502 |
| * | 0.340 | 0.229 | 0.390 | 0.465 | 0.573 |
| * | 0.383 | 0.271 | 0.447 | 0.520 | 0.592 |
| * | 0.370 | 0.251 | 0.437 | 0.510 | 0.592 |
| * | 0.381 | 0.265 | 0.451 | 0.527 | 0.580 |
| * | 0.385 | 0.273 | 0.447 | 0.527 | 0.578 |
| All | 0.384 | 0.267 | 0.449 | 0.527 | 0.594 |
4.4. RQ4:可扩展性
在此 RQ 中,我们探讨了 KGE4AR 的可扩展性。
在线成本。 在 RQ1 和 RQ2 中,KGE4AR 的在线推理时间对于一个查询而言不到一秒钟。 它包括两个主要步骤:候选 API 方法检索和重新排序。 重新排序步骤的时间与候选数量成正比,并且一旦确定候选,时间就会保持不变。 检索步骤的时间取决于 API KG 的大小和所使用的向量数据库。 为了解决这个问题,我们采用了 Milvus 提供的高效向量索引机制,Milvus 是一个可扩展且高可用的向量数据库。 Milvus 已被证明在万亿向量数据集上实现平均毫秒级的向量搜索和检索延迟 (mil, 2023; wang2021milvus)。 这确保了即使 API KG 的大小增加,KGE4AR 的检索步骤也能有效地执行。
离线成本。 我们主要讨论了不同 KG 规模下 KGE4AR 的离线成本。 表 8 展示了三种 API KG 的构建成本:大规模、中规模和小规模。 成本是在具有 36 核 CPU 和 128GB RAM 的 Linux 服务器上计算的。 列 Input、Construct. 和 Embed. 分别代表下载/准备文档作为输入、API KG 构建和 API KG 嵌入的时间。 尽管实体数量从小型 API KG 增长到大型 API KG 时增加了 2,019 倍,但收集输入、构建 API KG 和嵌入 API KG 所需的时间分别只增加了 386 倍、121 倍和 40 倍。 请注意,KG 的构建和嵌入只执行一次,并且当有新的库时,KG 可以逐步扩展。
| Type | Library | Entity | Relation | Input | Construct. | Embed. |
| Small | 16 | 35K | 2M | 7m | 49m | 1.5h |
| Medium | 899 | 2M | 8M | 1h | 4h | 6h |
| Large | 35,773 | 72M | 289M | 45h | 99h | 60h |
总之,有证据表明 KGE4AR 具有随着库数量增加而有效扩展的潜力。
4.5. 有效性威胁
内部有效性。 我们研究的内部有效性受到 RQ2 中人为标注的主观性的威胁。 为了减轻这种威胁,我们实施了一些措施,例如多位标注者、冲突解决和报告一致性系数。 这些做法被用来最大程度地减少偏差并确保人为标注的可靠性。
外部有效性。 我们研究的局限性在于只关注 Java 库,这可能会限制我们的发现对其他编程语言的普遍性。 然而,我们方法的核心概念,即跨库构建统一的知识图,仍然适用。 虽然我们的知识图设计不局限于 Java,但可以扩展以适应来自其他面向对象语言的库。 然而,需要进行具体的实现调整。 例如,支持像 Python 这样的缺乏强类型化的语言,将需要修改模式。 未来工作将探索更多编程语言,以全面评估我们的方法在不同语言环境中的有效性。
构建效度。 一个常见的威胁是,由于公开不可用的实现,我们在 RQ1 和 RQ2 中使用的基线是由我们自己实现的。 但是,我们仔细地复制和测试了基线,以避免引入错误。 另一个威胁是相似度权重的确定方式。 我们通过 RQ1 中的基准调整了权重,这些权重可能会过度拟合基准。 为了减轻这种威胁,我们在一个小规模的 API KG 上调整了权重,而不是 RQ1 使用的大规模 API KG。 图 6 也表明我们的权重没有过度拟合基准。
5. 结论
本文提出了一种基于文档的新型 API 推荐方法 KGE4AR,该方法利用知识图谱 (KG) 嵌入来推荐库迁移过程中的类似 API。 特别地,KGE4AR 提出了一种新的统一 API KG,以全面且结构化地表示文档中的三种知识类型,从而更好地捕捉高级语义。 此外,KGE4AR 提出对统一 API KG 进行嵌入,这使得更有效且可扩展的相似度计算成为可能。 我们将 KGE4AR 实现为一种全自动技术,为 35,773 个 Java 库构建了统一 API KG。 我们进一步在两种 API 推荐场景(即给出目标库或不给出目标库)中评估 KGE4AR,结果表明,KGE4AR 在所有指标上均显著优于最先进的基于文档的技术。 此外,我们进一步研究了 KGE4AR 的可扩展性,发现 KGE4AR 能够很好地随着库数量的增加而扩展。
6. 数据可用性
所有数据和代码都可以在我们的复制包 (rep, 2023) 中找到。
致谢
本工作由国家自然科学基金资助,项目编号为 61972098.
参考文献
- (1)
- Alr (2023) 2023. Alrubaye et al. Dataset. Retrieved January 20, 2023 from http://migrationlab.net/ds/groundTruth_icpc2019.html
- com (2023) 2023. Apache Commons Logging. Retrieved January 20, 2023 from https://mvnrepository.com/artifact/commons-logging/commons-logging
- awe (2023) 2023. awesome-java. Retrieved January 20, 2023 from https://github.com/akullpp/awesome-java
- gso (2023) 2023. com.google.code.gson:gson. Retrieved January 20, 2023 from https://mvnrepository.com/artifact/com.google.code.gson/gson
- doc (2023) 2023. Doc Comment. Retrieved January 20, 2023 from https://www.oracle.com/technical-resources/articles/java/javadoc-tool.html
- dom (2023) 2023. dom4j. Retrieved January 20, 2023 from https://github.com/dom4j/dom4j
- dsl (2023) 2023. dsl-json. Retrieved January 20, 2023 from https://github.com/ngs-doo/dsl-json
- ela (2023) 2023. Elasticsearch. Retrieved January 20, 2023 from https://github.com/elastic/elasticsearch
- fun (2023a) 2023a. FuncVerbNet. Retrieved January 20, 2023 from https://github.com/FudanSELab/funcverbnet
- jav (2023) 2023. JavaParser. Retrieved January 20, 2023 from https://javaparser.org/
- jun (2023) 2023. junit:junit. Retrieved January 20, 2023 from https://mvnrepository.com/artifact/junit/junit
- lib (2023) 2023. Libaries.io open data. Retrieved January 20, 2023 from https://libraries.io/data
- mav (2023) 2023. Maven Central Repository. Retrieved January 20, 2023 from https://mvnrepository.com
- mil (2023) 2023. milvus. Retrieved January 20, 2023 from https://github.com/milvus-io/milvus
- org (2023a) 2023a. org.json:json. Retrieved January 20, 2023 from https://mvnrepository.com/artifact/org.json/json
- slf (2023) 2023. org.slf4j:slf4j-api. Retrieved January 20, 2023 from https://mvnrepository.com/artifact/org.slf4j/slf4j-api
- org (2023b) 2023b. org.testing:testing. Retrieved January 20, 2023 from https://mvnrepository.com/artifact/org.testng/testng
- Big (2023) 2023. PyTorch-BigGraph. Retrieved January 20, 2023 from https://github.com/facebookresearch/PyTorch-BigGraph
- asc (2023) 2023. RAPIM Service. Retrieved January 20, 2023 from http://migrationlab.net/MigrationWebService.php
- rep (2023) 2023. Replication Package. Retrieved August 20, 2023 from https://github.com/FudanSELab/KGE4AR
- fun (2023b) 2023b. Replication Package of FuncVerbNet. Retrieved January 20, 2023 from https://github.com/FudanSELab/Research-FSE2020-FuncVerb
- spa (2023) 2023. Spacy. Retrieved January 20, 2023 from https://spacy.io/
- tes (2023) 2023. TestNG. Retrieved January 20, 2023 from https://mvnrepository.com/artifact/org.testng/testng
- Tey (2023) 2023. Teyton et al. Dataset. Retrieved January 20, 2023 from http://web.archive.org/web/20160412155706/http://www.labri.fr/perso/cteyton/Matching/lang_commons_guava.html
- zip (2023) 2023. zipfile. Retrieved January 20, 2023 from https://docs.python.org/3/library/zipfile.html
- Abdi and Williams (2010) Hervé Abdi and Lynne J Williams. 2010. Principal component analysis. Wiley interdisciplinary reviews: computational statistics 2, 4 (2010), 433–459.
- Alrubaye and Mkaouer (2018) Hussein Alrubaye and Mohamed Wiem Mkaouer. 2018. Automating the detection of third-party Java library migration at the function level. In Proceedings of the 28th Annual International Conference on Computer Science and Software Engineering, CASCON 2018, Markham, Ontario, Canada, October 29-31, 2018. ACM, 60–71. https://dl.acm.org/citation.cfm?id=3291299
- Alrubaye et al. (2020) Hussein Alrubaye, Mohamed Wiem Mkaouer, Igor Khokhlov, Leon Reznik, Ali Ouni, and Jason Mcgoff. 2020. Learning to recommend third-party library migration opportunities at the API level. Appl. Soft Comput. 90 (2020), 106140. https://doi.org/10.1016/j.asoc.2020.106140
- Alrubaye et al. (2019a) Hussein Alrubaye, Mohamed Wiem Mkaouer, and Ali Ouni. 2019a. MigrationMiner: An Automated Detection Tool of Third-Party Java Library Migration at the Method Level. In 2019 IEEE International Conference on Software Maintenance and Evolution, ICSME 2019, Cleveland, OH, USA, September 29 - October 4, 2019. IEEE, 414–417. https://doi.org/10.1109/ICSME.2019.00072
- Alrubaye et al. (2019b) Hussein Alrubaye, Mohamed Wiem Mkaouer, and Ali Ouni. 2019b. On the use of information retrieval to automate the detection of third-party Java library migration at the method level. In Proceedings of the 27th International Conference on Program Comprehension, ICPC 2019, Montreal, QC, Canada, May 25-31, 2019. IEEE / ACM, 347–357. https://doi.org/10.1109/ICPC.2019.00053
- Alrubaye et al. (2019c) Hussein Alrubaye, Mohamed Wiem Mkaouer, and Anthony Peruma. 2019c. Variability in Library Evolution. In Software Engineering for Variability Intensive Systems - Foundations and Applications. Auerbach Publications / Taylor & Francis, 295–320. https://doi.org/10.1201/9780429022067-13
- Bordes et al. (2013) Antoine Bordes, Nicolas Usunier, Alberto García-Durán, Jason Weston, and Oksana Yakhnenko. 2013. Translating Embeddings for Modeling Multi-relational Data. In Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a meeting held December 5-8, 2013, Lake Tahoe, Nevada, United States. 2787–2795. https://proceedings.neurips.cc/paper/2013/hash/1cecc7a77928ca8133fa24680a88d2f9-Abstract.html
- Chen et al. (2016) Chunyang Chen, Sa Gao, and Zhenchang Xing. 2016. Mining Analogical Libraries in Q&A Discussions - Incorporating Relational and Categorical Knowledge into Word Embedding. In IEEE 23rd International Conference on Software Analysis, Evolution, and Reengineering, SANER 2016, Suita, Osaka, Japan, March 14-18, 2016 - Volume 1. IEEE Computer Society, 338–348. https://doi.org/10.1109/SANER.2016.21
- Chen et al. (2021) Chunyang Chen, Zhenchang Xing, Yang Liu, and Kent Ong Long Xiong. 2021. Mining Likely Analogical APIs Across Third-Party Libraries via Large-Scale Unsupervised API Semantics Embedding. IEEE Trans. Software Eng. 47, 3 (2021), 432–447. https://doi.org/10.1109/TSE.2019.2896123
- Coelho and Valente (2017) Jailton Coelho and Marco Túlio Valente. 2017. Why modern open source projects fail. In Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, ESEC/FSE 2017, Paderborn, Germany, September 4-8, 2017. ACM, 186–196. https://doi.org/10.1145/3106237.3106246
- Cohen et al. (2009) Israel Cohen, Yiteng Huang, Jingdong Chen, Jacob Benesty, Jacob Benesty, Jingdong Chen, Yiteng Huang, and Israel Cohen. 2009. Pearson correlation coefficient. Noise reduction in speech processing (2009), 1–4.
- Cossette and Walker (2012) Bradley Cossette and Robert J. Walker. 2012. Seeking the ground truth: a retroactive study on the evolution and migration of software libraries. In 20th ACM SIGSOFT Symposium on the Foundations of Software Engineering (FSE-20), SIGSOFT/FSE’12, Cary, NC, USA - November 11 - 16, 2012. ACM, 55. https://doi.org/10.1145/2393596.2393661
- Du et al. ([n. d.]) Xueying Du, Mingwei Liu, Liwei Shen, and Xin Peng. [n. d.]. Research on Knowledge Graph Representation Learning Methods for Link Prediction: A Review. Journal of Software ([n. d.]).
- Gao et al. (2020) Zhipeng Gao, Xin Xia, John Grundy, David Lo, and Yuan-Fang Li. 2020. Generating Question Titles for Stack Overflow from Mined Code Snippets. ACM Trans. Softw. Eng. Methodol. 29, 4 (2020), 26:1–26:37. https://doi.org/10.1145/3401026
- Germán and Penta (2012) Daniel M. Germán and Massimiliano Di Penta. 2012. A Method for Open Source License Compliance of Java Applications. IEEE Softw. 29, 3 (2012), 58–63. https://doi.org/10.1109/MS.2012.50
- He et al. (2021a) Hao He, Runzhi He, Haiqiao Gu, and Minghui Zhou. 2021a. A large-scale empirical study on Java library migrations: prevalence, trends, and rationales. In ESEC/FSE ’21: 29th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Athens, Greece, August 23-28, 2021. ACM, 478–490. https://doi.org/10.1145/3468264.3468571
- He et al. (2021b) Hao He, Yulin Xu, Yixiao Ma, Yifei Xu, Guangtai Liang, and Minghui Zhou. 2021b. A Multi-Metric Ranking Approach for Library Migration Recommendations. In 28th IEEE International Conference on Software Analysis, Evolution and Reengineering, SANER 2021, Honolulu, HI, USA, March 9-12, 2021. IEEE, 72–83. https://doi.org/10.1109/SANER50967.2021.00016
- Kula et al. (2018) Raula Gaikovina Kula, Daniel M. Germán, Ali Ouni, Takashi Ishio, and Katsuro Inoue. 2018. Do developers update their library dependencies? - An empirical study on the impact of security advisories on library migration. Empir. Softw. Eng. 23, 1 (2018), 384–417. https://doi.org/10.1007/s10664-017-9521-5
- Lerer et al. (2019) Adam Lerer, Ledell Wu, Jiajun Shen, Timothée Lacroix, Luca Wehrstedt, Abhijit Bose, and Alex Peysakhovich. 2019. Pytorch-BigGraph: A Large Scale Graph Embedding System. In Proceedings of Machine Learning and Systems 2019, MLSys 2019, Stanford, CA, USA, March 31 - April 2, 2019. mlsys.org. https://proceedings.mlsys.org/book/282.pdf
- Li et al. (2018) Hongwei Li, Sirui Li, Jiamou Sun, Zhenchang Xing, Xin Peng, Mingwei Liu, and Xuejiao Zhao. 2018. Improving API Caveats Accessibility by Mining API Caveats Knowledge Graph. In 2018 IEEE International Conference on Software Maintenance and Evolution, ICSME 2018, Madrid, Spain, September 23-29, 2018. IEEE Computer Society, 183–193. https://doi.org/10.1109/ICSME.2018.00028
- Lim (1994) Wayne C. Lim. 1994. Effects of Reuse on Quality, Productivity, and Economics. IEEE Softw. 11, 5 (1994), 23–30. https://doi.org/10.1109/52.311048
- Lin et al. (2015) Yankai Lin, Zhiyuan Liu, Maosong Sun, Yang Liu, and Xuan Zhu. 2015. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, January 25-30, 2015, Austin, Texas, USA. AAAI Press, 2181–2187. http://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/view/9571
- Liu et al. (2022a) Mingwei Liu, Xin Peng, Andrian Marcus, Christoph Treude, Jiazhan Xie, Huanjun Xu, and Yanjun Yang. 2022a. How to formulate specific how-to questions in software development?. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2022, Singapore, Singapore, November 14-18, 2022. ACM, 306–318. https://doi.org/10.1145/3540250.3549160
- Liu et al. (2022b) Mingwei Liu, Xin Peng, Andrian Marcus, Shuangshuang Xing, Christoph Treude, and Chengyuan Zhao. 2022b. API-Related Developer Information Needs in Stack Overflow. IEEE Trans. Software Eng. 48, 11 (2022), 4485–4500. https://doi.org/10.1109/TSE.2021.3120203
- Liu et al. (2019) Mingwei Liu, Xin Peng, Andrian Marcus, Zhenchang Xing, Wenkai Xie, Shuangshuang Xing, and Yang Liu. 2019. Generating query-specific class API summaries. In Proceedings of the ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/SIGSOFT FSE 2019, Tallinn, Estonia, August 26-30, 2019. ACM, 120–130. https://doi.org/10.1145/3338906.3338971
- Liu et al. (2020b) Mingwei Liu, Xin Peng, Xiujie Meng, Huanjun Xu, Shuangshuang Xing, Xin Wang, Yang Liu, and Gang Lv. 2020b. Source Code based On-demand Class Documentation Generation. In IEEE International Conference on Software Maintenance and Evolution, ICSME 2020, Adelaide, Australia, September 28 - October 2, 2020. IEEE, 864–865. https://doi.org/10.1109/ICSME46990.2020.00114
- Liu et al. (2023) Mingwei Liu, Chengyuan Zhao, Xin Peng, Siming Yu, Haofen Wang, and Chaofeng Sha. 2023. Task-Oriented ML/DL Library Recommendation based on a Knowledge Graph. IEEE Transactions on Software Engineering (2023).
- Liu et al. (2020a) Yang Liu, Mingwei Liu, Xin Peng, Christoph Treude, Zhenchang Xing, and Xiaoxin Zhang. 2020a. Generating Concept based API Element Comparison Using a Knowledge Graph. In 35th IEEE/ACM International Conference on Automated Software Engineering, ASE 2020, Melbourne, Australia, September 21-25, 2020. IEEE, 834–845. https://doi.org/10.1145/3324884.3416628
- Lu et al. (2017) Yangyang Lu, Ge Li, Zelong Zhao, Linfeng Wen, and Zhi Jin. 2017. Learning to Infer API Mappings from API Documents. In Knowledge Science, Engineering and Management - 10th International Conference, KSEM 2017, Melbourne, VIC, Australia, August 19-20, 2017, Proceedings (Lecture Notes in Computer Science, Vol. 10412). Springer, 237–248. https://doi.org/10.1007/978-3-319-63558-3_20
- McHugh (2012) Mary L McHugh. 2012. Interrater reliability: the kappa statistic. Biochemia Medica: Biochemia Medica 22, 3 (2012), 276–282.
- Miller (1995) George A. Miller. 1995. WordNet: A Lexical Database for English. Commun. ACM 38, 11 (1995), 39–41. https://doi.org/10.1145/219717.219748
- Mohagheghi and Conradi (2007) Parastoo Mohagheghi and Reidar Conradi. 2007. Quality, productivity and economic benefits of software reuse: a review of industrial studies. Empir. Softw. Eng. 12, 5 (2007), 471–516. https://doi.org/10.1007/s10664-007-9040-x
- Nguyen et al. (2014) Anh Tuan Nguyen, Hoan Anh Nguyen, Tung Thanh Nguyen, and Tien N. Nguyen. 2014. Statistical learning approach for mining API usage mappings for code migration. In ACM/IEEE International Conference on Automated Software Engineering, ASE ’14, Vasteras, Sweden - September 15 - 19, 2014. ACM, 457–468. https://doi.org/10.1145/2642937.2643010
- Pandita et al. (2017) Rahul Pandita, Raoul Jetley, Sithu D. Sudarsan, Tim Menzies, and Laurie A. Williams. 2017. TMAP: Discovering relevant API methods through text mining of API documentation. J. Softw. Evol. Process. 29, 12 (2017). https://doi.org/10.1002/smr.1845
- Pandita et al. (2015) Rahul Pandita, Raoul Praful Jetley, Sithu D. Sudarsan, and Laurie A. Williams. 2015. Discovering likely mappings between APIs using text mining. In 15th IEEE International Working Conference on Source Code Analysis and Manipulation, SCAM 2015, Bremen, Germany, September 27-28, 2015. IEEE Computer Society, 231–240. https://doi.org/10.1109/SCAM.2015.7335419
- Peng et al. (2018) Xin Peng, Yifan Zhao, Mingwei Liu, Fengyi Zhang, Yang Liu, Xin Wang, and Zhenchang Xing. 2018. Automatic Generation of API Documentations for Open-Source Projects. In IEEE Third International Workshop on Dynamic Software Documentation, DySDoc@ICSME 2018, Madrid, Spain, September 25, 2018. IEEE, 7–8. https://doi.org/10.1109/DySDoc3.2018.00010
- Ren et al. (2020) Xiaoxue Ren, Xinyuan Ye, Zhenchang Xing, Xin Xia, Xiwei Xu, Liming Zhu, and Jianling Sun. 2020. API-Misuse Detection Driven by Fine-Grained API-Constraint Knowledge Graph. In 35th IEEE/ACM International Conference on Automated Software Engineering, ASE 2020, Melbourne, Australia, September 21-25, 2020. IEEE, 461–472. https://doi.org/10.1145/3324884.3416551
- Robertson and Walker (1994) Stephen E. Robertson and Steve Walker. 1994. Some Simple Effective Approximations to the 2-Poisson Model for Probabilistic Weighted Retrieval. In Proceedings of the 17th Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval. Dublin, Ireland, 3-6 July 1994 (Special Issue of the SIGIR Forum), W. Bruce Croft and C. J. van Rijsbergen (Eds.). ACM/Springer, 232–241. https://doi.org/10.1007/978-1-4471-2099-5_24
- Su et al. (2021) Yanqi Su, Zhenchang Xing, Xin Peng, Xin Xia, Chong Wang, Xiwei Xu, and Liming Zhu. 2021. Reducing Bug Triaging Confusion by Learning from Mistakes with a Bug Tossing Knowledge Graph. In 36th IEEE/ACM International Conference on Automated Software Engineering, ASE 2021, Melbourne, Australia, November 15-19, 2021. IEEE, 191–202. https://doi.org/10.1109/ASE51524.2021.9678574
- Teyton et al. (2013) Cédric Teyton, Jean-Rémy Falleri, and Xavier Blanc. 2013. Automatic discovery of function mappings between similar libraries. In 20th Working Conference on Reverse Engineering, WCRE 2013, Koblenz, Germany, October 14-17, 2013. IEEE Computer Society, 192–201. https://doi.org/10.1109/WCRE.2013.6671294
- Trouillon et al. (2016) Théo Trouillon, Johannes Welbl, Sebastian Riedel, Éric Gaussier, and Guillaume Bouchard. 2016. Complex Embeddings for Simple Link Prediction. In Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016 (JMLR Workshop and Conference Proceedings, Vol. 48). JMLR.org, 2071–2080. http://proceedings.mlr.press/v48/trouillon16.html
- Valiev et al. (2018) Marat Valiev, Bogdan Vasilescu, and James D. Herbsleb. 2018. Ecosystem-level determinants of sustained activity in open-source projects: a case study of the PyPI ecosystem. In Proceedings of the 2018 ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/SIGSOFT FSE 2018, Lake Buena Vista, FL, USA, November 04-09, 2018. ACM, 644–655. https://doi.org/10.1145/3236024.3236062
- van der Burg et al. (2014) Sander van der Burg, Eelco Dolstra, Shane McIntosh, Julius Davies, Daniel M. Germán, and Armijn Hemel. 2014. Tracing software build processes to uncover license compliance inconsistencies. In ACM/IEEE International Conference on Automated Software Engineering, ASE ’14, Vasteras, Sweden - September 15 - 19, 2014. ACM, 731–742. https://doi.org/10.1145/2642937.2643013
- Wang et al. (2019) Chong Wang, Xin Peng, Mingwei Liu, Zhenchang Xing, Xuefang Bai, Bing Xie, and Tuo Wang. 2019. A learning-based approach for automatic construction of domain glossary from source code and documentation. In Proceedings of the ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/SIGSOFT FSE 2019, Tallinn, Estonia, August 26-30, 2019. ACM, 97–108. https://doi.org/10.1145/3338906.3338963
- Wang et al. (2023a) Chong Wang, Xin Peng, Zhenchang Xing, and Xiujie Meng. 2023a. Beyond Literal Meaning: Uncover and Explain Implicit Knowledge in Code Through Wikipedia-Based Concept Linking. IEEE Trans. Software Eng. 49, 5 (2023), 3226–3240. https://doi.org/10.1109/TSE.2023.3250029
- Wang et al. (2023b) Chong Wang, Xin Peng, Zhenchang Xing, Yue Zhang, Mingwei Liu, Rong Luo, and Xiujie Meng. 2023b. XCoS: Explainable Code Search based on Query Scoping and Knowledge Graph. ACM Transactions on Software Engineering and Methodology (2023).
- Wang et al. (2021) Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xiangyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, Kun Yu, Yuxing Yuan, Yinghao Zou, Jiquan Long, Yudong Cai, Zhenxiang Li, Zhifeng Zhang, Yihua Mo, Jun Gu, Ruiyi Jiang, Yi Wei, and Charles Xie. 2021. Milvus: A Purpose-Built Vector Data Management System. In SIGMOD ’21: International Conference on Management of Data, Virtual Event, China, June 20-25, 2021. ACM, 2614–2627. https://doi.org/10.1145/3448016.3457550
- Wang et al. (2017b) Lu Wang, Xiaobing Sun, Jingwei Wang, Yucong Duan, and Bin Li. 2017b. Construct bug knowledge graph for bug resolution: poster. In Proceedings of the 39th International Conference on Software Engineering, ICSE 2017, Buenos Aires, Argentina, May 20-28, 2017 - Companion Volume. IEEE Computer Society, 189–191. https://doi.org/10.1109/ICSE-C.2017.102
- Wang et al. (2017a) Quan Wang, Zhendong Mao, Bin Wang, and Li Guo. 2017a. Knowledge Graph Embedding: A Survey of Approaches and Applications. IEEE Trans. Knowl. Data Eng. 29, 12 (2017), 2724–2743. https://doi.org/10.1109/TKDE.2017.2754499
- Welch (1947) Bernard L Welch. 1947. The generalization of ‘STUDENT’S’problem when several different population varlances are involved. Biometrika 34, 1-2 (1947), 28–35.
- Xie et al. (2020) Wenkai Xie, Xin Peng, Mingwei Liu, Christoph Treude, Zhenchang Xing, Xiaoxin Zhang, and Wenyun Zhao. 2020. API method recommendation via explicit matching of functionality verb phrases. In 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/SIGSOFT FSE 2020, November 8-13, 2020, Virtual Event, USA. ACM, 1015–1026. https://doi.org/10.1145/3368089.3409731
- Xing et al. (2021) Shuangshuang Xing, Mingwei Liu, and Xin Peng. 2021. Automatic Code Semantic Tag Generation Approach Based on Software Knowledge Graph. Journal of Software 33, 11 (2021), 4027–4045.
- Yang et al. (2015) Bishan Yang, Wen-tau Yih, Xiaodong He, Jianfeng Gao, and Li Deng. 2015. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings. http://arxiv.org/abs/1412.6575
- Zhang et al. (2020) Zejun Zhang, Minxue Pan, Tian Zhang, Xinyu Zhou, and Xuandong Li. 2020. Deep-Diving into Documentation to Develop Improved Java-to-Swift API Mapping. In ICPC ’20: 28th International Conference on Program Comprehension, Seoul, Republic of Korea, July 13-15, 2020. ACM, 106–116. https://doi.org/10.1145/3387904.3389282