弥合差距:利用大型语言模型解读表格数据
摘要
在自然语言处理领域,对表格数据的理解一直是学术研究的重点。 以 ChatGPT 为代表的大型语言模型的出现,引发了一波研究热潮,研究人员试图利用这些模型来完成与表格相关的问答任务。 我们研究的核心是阐明增强大型语言模型在理解表格结构和内容方面能力的方法,最终使其能够对相关查询提供有见地的回答。 为此,我们设计了一个专门用于序列化表格的模块,以便与大型语言模型无缝集成。 此外,我们在模型中建立了一种纠正机制来纠正潜在的错误。 实验结果表明,尽管我们提出的方法落后于 SOTA 约 11.7
1 引言
表格数据是许多行业的基础,从医疗保健和金融到营销和机器学习。 其普遍性突出了有效查询和解释这种结构化信息的重要性。 但是,多维查询的复杂性和涵盖的数据量往往需要大量的人工干预,主要体现在构建和完善 SQL 语句 [RBE+20]。 因此,数据管理领域面临着诸多挑战,使得解释和利用此类数据成为一项艰巨的任务 [NKP+18]。
人工智能的快速发展为这些挑战提供了潜在的解决方案。 更具体地说,大型语言模型的最新进展为将它们的理解和生成能力应用于这一研究领域提供了令人着迷的机会。 这些模型是在多样化且庞大的文本语料库上训练的,它们已经展示了生成类似人类的文本和理解文本中包含的信息的上下文和复杂性的能力 [RSR+20]。
在此背景下,当前的研究对大语言模型 (LLMs) 在解码和查询表格数据方面的应用进行了创新性探索。 我们的工作旨在通过使用 LLM 来破译表格结构、理解所呈现问题的复杂性,并随后制定 SQL 查询,从而减少对人工干预的需要。 与传统方法相比,这种方法为处理大规模、多维数据提供了一种可扩展、高效且稳健的解决方案。
我们的策略扩展了 LLM 的迭代性质,不仅将其用于生成 SQL 查询,还用于从错误中学习并以演进的方式改进。 这种适应性有助于处理不同复杂程度的查询,有效地扩展了可管理的数据查询范围。 因此,这种方法极大地提高了数据管理系统的效率和可访问性,为减少耗时且容易出错的手动 SQL 语句构建过程提供了途径。 此外,我们提出了一种创新的 LLM 部署方式,有效地重新定义了它们在数据分析和管理领域的角色。 这种开创性方法的潜力通过其在各种数据集上的出色表现得到证实,例如其在基准 Spider 数据集上的出色表现。
本文分为几个部分,详细介绍了我们的研究。 我们首先回顾了该领域的相关工作,强调了我们的研究试图填补的空白。 接下来,我们将详细解释我们的方法论以及如何利用 LLM 处理表格数据。 随后的部分详细介绍了我们的实验设置,然后是对结果的深入分析。 最后,我们以对研究结果的影响、局限性和未来工作可能方向的讨论结束。
2 相关工作
当前研究的范围涵盖并贡献了该领域的几个开创性作品和关键领域,即大型语言模型和从自然语言生成 SQL 查询,这些领域不仅是我们研究的基础,而且也是我们创新得以彰显的背景。
2.1 大型语言模型
我们的研究很大程度上基于大型语言模型的进步。 具体而言,OpenAI 等人[Ope23] 关于 GPT-4 的开创性研究,这是一个具有数万亿个自回归参数的语言模型,为这类模型的能力树立了先例。 他们证明,扩大语言模型的规模可显著提高其在各种任务上的性能,包括翻译、问答和完形填空任务等。 我们的工作扩展了这些大型语言模型的能力,特别是 LLaMA-2[TMS+23],使其能够理解和生成来自表结构和问题陈述的 SQL 查询,从而突破了这些模型所能达到的极限。
2.2 从自然语言生成 SQL 查询
SQL 查询生成一直是许多研究人员[RSR+22] 的关注焦点。 Yu 等人[YZY+18] 做出了重大贡献,他们使用 Spider 数据集和 Text-to-SQL 模型显著提高了对复杂跨域 SQL 查询的处理能力。 然而,处理最复杂的查询仍然是一个挑战[KSHL20]。
为了解决这个问题,Pourreza 和 Rafiei[PR23a] 引入了 Din-SQL,通过采用分解的自纠正方法来应用文本到 SQL 的上下文学习。 与此同时,Li 等人[PR23b] 提出了 GraphiX-T5,将预训练的 Transformer 和图感知层结合起来用于文本到 SQL 解析,利用了两种方法的优势。此外,在 2023 年的 AAAI 人工智能大会上,Li、Zhang、Li 等人[LZLC23] 公布了 ResdSQL,它将模式链接和骨架解析分离用于文本到 SQL,展示了完成此任务的新方法。虽然这些工作取得了重大进展,但复杂查询的处理仍然具有挑战性。 我们的工作使用具有大量预训练的大型语言模型来处理复杂的查询,从而促进不同领域之间的泛化。
3 方法
我们的方法利用 LLaMA-2[TMS+23] 作为 LLM,将表结构和问题序列化为模型的输入,然后生成用于在表上查询的 SQL 语句。 在整个过程中,我们采用迭代优化程序和微调技术来确保模型的准确性和效率。
3.1 输入构造
首先,我们设计了一种输入构造机制,该机制包含问题陈述和表模式。 通过连接这些元素,我们为模型生成了一个稳健的指令输入。 此连接并非简单的任意组合,而是经过精心策划的,将数据(表模式)和所需输出(问题陈述)融合在一起。 这样做的原因有两点:模式为模型提供了对数据结构的必要理解,而问题陈述则提供了查询应达成的目标。 整个输入的构建过程如图 1 所示。
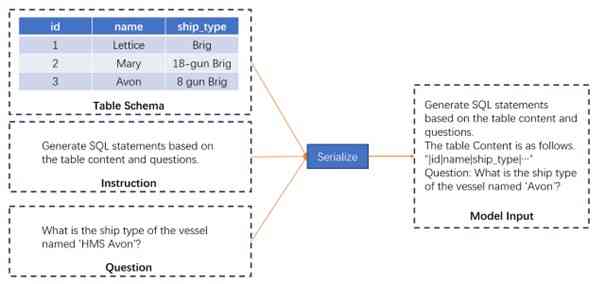
3.2 SQL 生成
构建好输入后,将其用于提示 LLaMA-2 模型 [TMS+23]。 利用其庞大的 700 亿参数结构,该模型的任务是生成 SQL 语句作为输出。 这不仅仅是对输入的简单复述,而是对输入复杂性的主动解读,将其转换为适当的 SQL 查询。 目标是让模型以问题和模式作为输入,生成一个能够准确有效地回答问题的 SQL 语句,同时遵循模式所表示的数据结构。 整个输入的生成过程如图 2 所示。
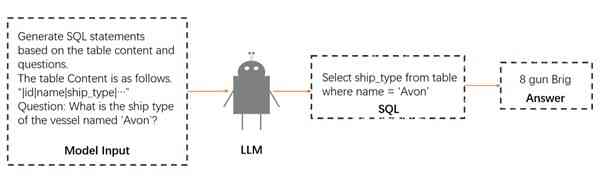
3.3 迭代细化
这种输入-输出关系构成了我们方法的核心。 但是,为了提高 SQL 语句的准确性和效率,我们进一步采用了迭代细化过程。 这涉及到生成的 SQL 语句的准确性评估,模型使用该评估来改进其未来的输出。 这个迭代过程不仅仅是一个循环,而是一个学习周期,其中模型利用过去的经验来改进未来的性能,有效地体现了一种人工进化形式。 整个输入的迭代细化过程如图 3 所示。
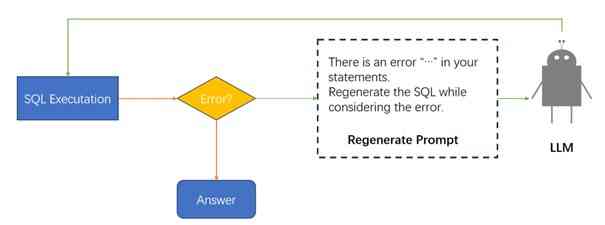
4 实验
4.1 实验设置
为了评估我们的方法,我们使用 Spider 基准数据集进行了实证分析,该数据集为测试和比较提供了丰富且多样化的基础。 该实验在一台强大的硬件配置上运行,该配置配备了四个 A100 80GB GPU,以有效地利用 LLaMA-2 70b 版本提供的计算能力。
4.2 性能指标
我们将我们的工作与 BRIDGE[LZLC23] 和 RESDSQL[LSX20] 进行比较,结果如表 2 所示。 我们模型的性能在 Spider 数据集中使用的两个主要指标上进行评估:执行准确性和精确集匹配[ZYK20]。 结果表明,我们的方法表现出强大的性能,执行准确率为 70.5,同时实现了 59.3 的精确集匹配得分。 我们的方法明显优于 BRIDGE 提出的方法,但略逊于 RESDSQL。
| Methods | Executation Accuracy | Exact Match Score |
|---|---|---|
| BRIDGE | 59.9 | 65.2 |
| RESDQL | 79.9 | 72.0 |
| Ours | 70.5 | 59.3 |
4.3 比较分析
我们根据难度级别将 Spider 数据集分为三个类别:简单、中等和困难,数据比例为 3:2:1。 如 LABEL:tab:2 所示,我们评估了 RESDSQL、BRIDGE 和我们提出的方法在这三种类型的问题上的 EX 和 EM 分数,其中数据格式为 'EX/EM'。 通过分析 LABEL:tab:2 的结果,我们发现我们的方法在简单问题上表现得非常好,但在处理更难的问题时并没有超过当前最佳解决方案。
| Methods | Easy | Medium | Hard |
|---|---|---|---|
| BRIDGE | 72.4/75.7 | 61.3/64.1 | 42.9/43.5 |
| RESDQL | 84.8/87.0 | 81.2/83.5 | 68.1/63.6 |
| Ours | 85.2/76.9 | 74.0/48.9 | 74.0/48.9 |
5 结论
总之,我们的研究强调了大型语言模型的灵活性,强调了它们探索各种解决方案路径的能力,并利用其广泛的参数空间。 尽管有时会导致较低的精确集匹配分数,但这些模型仍然保持较高的执行准确性,这使得它们在现实世界场景中特别有价值,在这些场景中,得出正确答案比遵循预定义路径[DZG+23]更重要。 我们的研究强调了大型模型在准确执行 SQL 查询方面的巨大能力及其在数据集之间的出色泛化能力。 这突出了它们在数据管理任务中发挥变革性作用的潜力。 展望未来,未来的研究方向是增强大型语言模型[ZZL+23]理解表格数据的能力,并提高生成 SQL 查询的准确性。 我们的发现标志着朝着充分利用大型语言模型的潜力迈出了重要的一步。
参考文献
- [DZG+23] Xuemei Dong, Chao Zhang, Yuhang Ge, Yuren Mao, Yunjun Gao, Jinshu Lin, Dongfang Lou, et al. C3: Zero-shot text-to-sql with chatgpt. arXiv preprint arXiv:2307.07306, 2023.
- [KSHL20] Hyeonji Kim, Byeong-Hoon So, Wook-Shin Han, and Hongrae Lee. Natural language to sql: Where are we today? Proceedings of the VLDB Endowment, 13(10):1737–1750, 2020.
- [LSX20] Xi Victoria Lin, Richard Socher, and Caiming Xiong. Bridging textual and tabular data for cross-domain text-to-sql semantic parsing. arXiv preprint arXiv:2012.12627, 2020.
- [LZLC23] Haoyang Li, Jing Zhang, Cuiping Li, and Hong Chen. Resdsql: Decoupling schema linking and skeleton parsing for text-to-sql. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 13067–13075, 2023.
- [NKP+18] Fatemeh Nargesian, Udayan Khurana, Tejaswini Pedapati, Horst Samulowitz, and Deepak Turaga. Dataset evolver: An interactive feature engineering notebook. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018.
- [Ope23] OpenAI. Gpt-4 technical report, 2023.
- [PR23a] Mohammadreza Pourreza and Davood Rafiei. Din-sql: Decomposed in-context learning of text-to-sql with self-correction. arXiv preprint arXiv:2304.11015, 2023.
- [PR23b] Mohammadreza Pourreza and Davood Rafiei. Din-sql: Decomposed in-context learning of text-to-sql with self-correction. arXiv preprint arXiv:2304.11015, 2023.
- [RBE+20] Alexander Ratner, Stephen H Bach, Henry Ehrenberg, Jason Fries, Sen Wu, and Christopher Ré. Snorkel: Rapid training data creation with weak supervision. The VLDB Journal, 29(2-3):709–730, 2020.
- [RSR+20] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
- [RSR+22] TJ Revanth, K Venkat Sai, R Ramya, Renusree Chava, V Sushma, and BS Ramya. Nl2sql: Natural language to sql query translator. In Emerging Research in Computing, Information, Communication and Applications: ERCICA 2020, Volume 2, pages 267–278. Springer, 2022.
- [TMS+23] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [YZY+18] Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, et al. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. arXiv preprint arXiv:1809.08887, 2018.
- [ZYK20] Ruiqi Zhong, Tao Yu, and Dan Klein. Semantic evaluation for text-to-sql with distilled test suites. arXiv preprint arXiv:2010.02840, 2020.
- [ZZL+23] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models. arXiv preprint arXiv:2303.18223, 2023.