EdgeMoE: 基于 MoE 的大型语言模型的快速设备上推理
摘要。
大型语言模型 (LLM) 如 GPT 和 LLaMa 由于其在广泛机器学习任务中的出色能力,引领了机器智能领域的革命。 然而,将 LLM 从数据中心迁移到边缘设备带来了挑战和机遇。 虽然这种转变可以增强隐私和可用性,但它受到这些模型庞大参数尺寸的阻碍,导致运行时成本不切实际。
鉴于这些考虑因素,我们介绍了 EdgeMoE,这是第一个专门针对混合专家 (MoE) LLM 的设备上推理引擎,这是稀疏 LLM 的一种流行变体,其计算复杂度几乎恒定,因为其参数尺寸在扩展。 EdgeMoE 通过战略性地在存储层次结构中对模型进行分区来实现内存和计算效率。 具体来说,非专家权重存储在设备的内存中,而专家权重则保存在外部存储中,只有在激活时才会被提取到内存中。 这种设计基于一个关键见解,即专家权重虽然庞大,但由于稀疏激活模式而很少被访问。 为了进一步减轻与专家 I/O 交换相关的开销,EdgeMoE 结合了两种创新技术: (1) 专家级位宽自适应:该方法以可接受的精度损失来减少专家权重的规模。 (2) 专家管理:它提前预测将被激活的专家并将其预加载到计算 I/O 管道中,从而进一步优化流程。 在对成熟的 MoE LLM 和各种边缘设备进行的实证评估中,EdgeMoE 与竞争基准解决方案相比,展示了显著的内存节省和性能改进。
1. 导言
大型语言模型 (LLM),例如 GPT (radford2018improving, ; radford2019language, ; brown2020language, ; ouyang2022training, ; openai2023gpt4techinicalreport, ; eloundou2023gpts, ) 和 LLaMa (touvron2023llama, ; touvron2023llama2, ),由于其在通用多模态任务、少样本能力和可扩展性方面的卓越性能,正在重塑机器智能。 虽然 LLM 诞生于数据中心仓库,但为了更好地保护数据隐私、提供 AI 功能和实现个性化,它们将逐渐下沉到个人电脑、智能手机,甚至物联网等边缘设备。 在这种趋势下,LLM 不仅与传统神经网络相比极大地提升了边缘 ML 任务的最新性能,而且还催生了许多令人兴奋的新边缘应用 (chatgpt-googleplay, )。 例如,高通已将一个拥有超过 10 亿个参数的文本到图像生成式 LLM 模型完全部署在智能手机上 (qualcommstabledef, ). 华为已将其智能手机中嵌入一个多模态 LLM,以方便进行准确的基于自然语言的内容搜索 (huaweuai, ).
将 LLM 部署到移动设备面临着其参数规模庞大,进而导致运行时成本高昂的关键挑战。 为了缓解这个问题,最近提出了混合专家 (MoE) 架构 (jacobs1991textordfeminineadaptive, ; fedus2022review, ),该架构允许在每个符元解码时仅激活 LLM 的一部分。 直观地说,这种稀疏激活很有意义,因为 LLM 越来越大,并充当各种任务的基础模型,不同的任务或输入数据可能只需要模型的微小部分来工作,就像人脑的工作方式一样 (friston2008hierarchical, ). 在这项工作中,我们针对的是最流行的 MoE 设计形式之一,其中每个 Transformer 块中的单个前馈网络 (FFN) 被许多专家(每个专家都是一个独立的 FFN)所取代。 在推理过程中,每个 Transformer 块中一个可训练的函数(称为 路由器)将输入路由到所有专家中的前 K 个 (K=1 或 2)。 MoE LLM 的更多设计细节将在 2 中介绍。 这种基于 MoE 的 LLM 已被广泛研究 (shazeer2017outrageously, ; lepikhin2020gshard, ; fedus2022switch, ; du2022glam, ; lewis2021base, ; roller2021hash, ; zhou2022mixture, ) 并已在工业中应用 (microsoft-moe, ).
MoE 的优缺点 通过其稀疏性设计,MoE LLM 能够以几乎恒定的计算复杂度扩展其参数大小和能力,使其非常适合存储成本效益和可扩展性远大于计算能力的边缘设备。 根据经验,要保存一个像 GLaM(1.7B/256E) (du2022glam, ) 这样的 105B 参数模型,设备需要 1T(外部)存储,这仅花费不到 100 美元; 然而,要以合理的速度执行它,例如 1 秒/符元,则需要 10 个高端 GPU,这些 GPU 的成本超过 10 万美元。 然而,MoE LLM 太大,无法放入设备内存,如 2.2 中所示。 例如,Switch Transformers(每层有 32 个专家)需要 54GB 的内存进行推理,这在大多数边缘设备上是无法承受的。 简单地缩小专家数量会显著降低性能能力 (fedus2022switch, ); 或者,由于 LLM 的自回归性质,在内存和存储之间频繁交换权重会导致巨大的开销。
边缘教育部 : 一种专为边缘设备设计的专家中心推理引擎。 在这项工作中,我们提出了EdgeMoE,这是第一个能够在内存和时间效率上扩展模型大小(专家数量)的设备级 LLM 推理引擎。 EdgeMoE 的整体设计基于一个独特的观察结果: 大多数计算都存在于一小部分权重(非专家是“热权重”)中,这些权重可以保存在设备内存中; 而大多数权重只贡献很少的计算(专家是“冷权重”)。 这种特性自然适合存储层次结构(更快的 RAM 与更大的磁盘)。 基于这些观察结果,EdgeMoE 区分了专家和非专家在存储层次结构中的位置。 具体来说,它永久地将所有热权重保存在内存中,因为它们用于每个符元推理;而其余的内存预算用作专家缓冲区,用于冷专家权重。
借助专家缓冲区设计,EdgeMoE 只需要按需从存储器加载到内存中激活的专家。 然而,与处理相比,这种 I/O 开销仍然很大,例如,在 Jetson TX2 上高达 4.1 的延迟,这将在 2.1 中展示。 为了解决这个问题,有两种通用的方法: 一种是直接减少 I/O 数据,例如,通过量化; 另一种是将 I/O 与计算流水线化以隐藏其延迟。 这两个方向在之前的 MoE 系统中都没有探索,并且面临着独特的挑战: (1) 复杂的量化算法(zadeh2020gobo, ; aji2020compressing, ; kim2023squeezellm, ) 可以实现更高的压缩率,但会产生大量的预处理时间用于反序列化和解压缩,如3.2 中所述。 另一方面,更简单的量化(han2015deep, ) 无法有效地减少专家 I/O。 (2) 与具有固定执行模式的静态模型不同,MoE 中的专家是动态激活的,系统无法在路由器功能之前获得先验知识。 因此,EdgeMoE 没有空间预加载要激活的专家。 不考虑专家激活的知识,可以简单地缓存更频繁地激活的专家以提高专家命中率; 然而,这种方法带来的益处有限,因为专家之间的激活频率经过专门的训练以保持平衡(fedus2022review, )。
为了解决上述问题,EdgeMoE 具有两种新颖的设计。
专家级位宽自适应。 EdgeMoE 为一种预处理轻量级量化方法(每个通道线性量化(kim2022mixture, ))添加了专家级位宽自适应。 这是基于一个关键的观察结果:在量化之后,不同层甚至同一层的专家对模型精度的影响不同。 因此,EdgeMoE 采用了一种细粒度的专家级位宽自适应方法来充分利用模型冗余。 在离线阶段,EdgeMoE 逐步降低一些对量化最鲁棒的专家的位宽,直到精度下降满足用户指定的容忍阈值。 选择哪些专家进行进一步量化也同时考虑了低位宽量化可以提高推理速度的程度。 最终,EdgeMoE 获得了一个混合精度模型,该模型以最小的模型尺寸(即最快的加载时间)实现了目标精度。
内存专家管理。 为了实现 I/O-计算管道,EdgeMoE 在其路由函数之前预测哪个专家将被激活。 该设计源于一个新颖的观察结果:在实践中,专家激活路径(即每个符元依次激活的专家集)高度不平衡且倾斜。 这表明专家激活之间存在显著的相关性,我们的实验进一步证实了这一点,如 3.3.2 中所示。 因此,在离线阶段,EdgeMoE 建立一个统计模型,根据前几层的激活来估计当前层专家激活的概率。 在线推理中,EdgeMoE 查询该模型并预加载最有可能的专家,以进行 I/O-计算管道。 此外,EdgeMoE 为专家缓冲区设计了一种新颖的缓存逐出策略,利用激活频率及其与当前执行的相对位置。 总的来说,预测然后预加载和逐出技术都是为了最大化专家缓存命中率,当它们被激活时。
结果 我们已经在 PyTorch 之上实现了一个 EdgeMoE 原型,该原型完全实现了上述技术。 然后,我们通过 7 个基于 MoE 的 LLM 和 2 个嵌入式平台(包括 Raspberry Pi 4B(CPU)和 Jetson TX2(GPU))进行了广泛的实验,以评估 EdgeMoE 的性能。 与将整个模型保存在设备内存中相比,EdgeMoE 将内存占用减少了 1.05–1.18; 与内存优化的基线(如动态加载专家和 STI (guo2023sti, ))相比, EdgeMoE 实现了 1.11–2.78 的推理加速。 为了第一次,EdgeMoE 使得在像 Jetson TX2 这样的商用现货边缘设备上对 100 亿规模的 LLM 进行快速推理成为可能。 消融研究进一步表明,EdgeMoE 的每项单独技术都对显著的改进做出了贡献。
贡献 本文做出了以下贡献:
-
•
我们进行了初步实验,以揭开 MoE LLM 在边缘设备上的性能的神秘面纱,并分析了其影响。
-
•
我们提出了 EdgeMoE,一个设备上的 MoE 引擎,它采用了一种关键设计,将内存视为专家缓存,这些专家在未激活时被保存在外部存储中。
-
•
我们进一步整合了两种新技术,即专家级位宽自适应和内存中专家管理,以降低 EdgeMoE 的专家 I/O 负担。
-
•
我们通过大量的实验证明了 EdgeMoE 的有效性。
2. 试点实验和分析
2.1. 关于混合专家 LLM 的入门知识
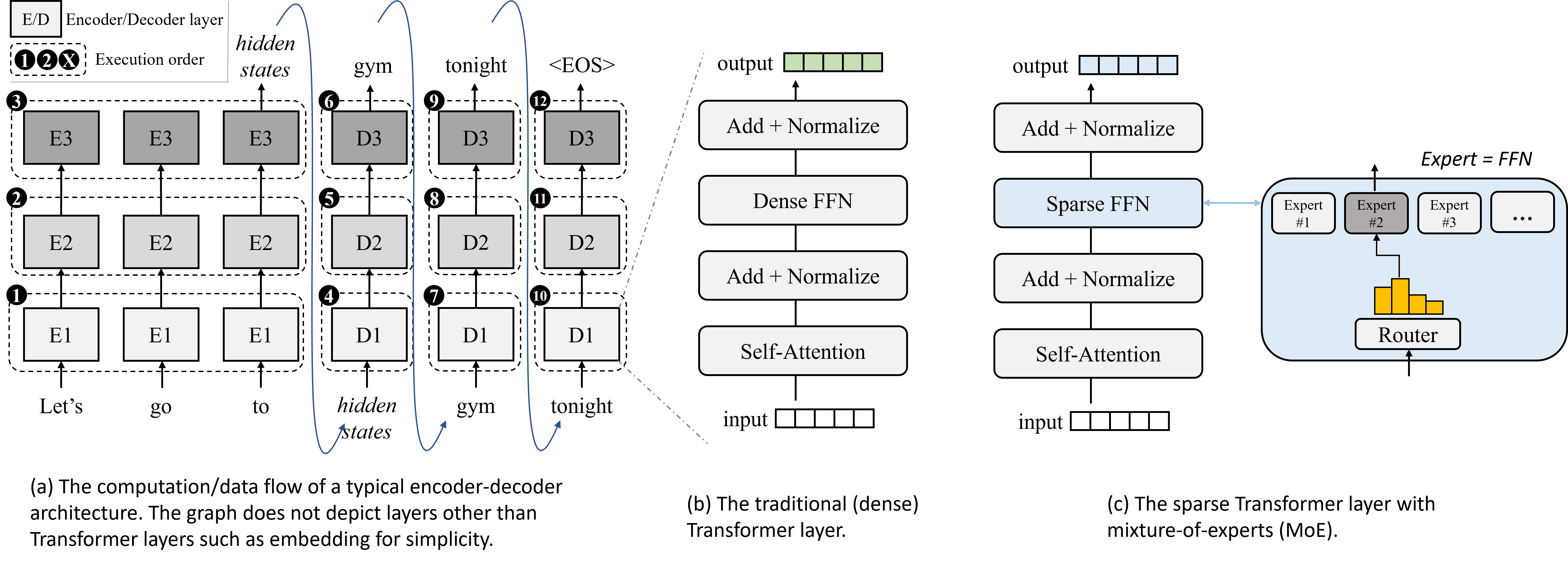
这项工作重点关注编码器-解码器 1 11像 GPTs 这样的解码器专用 LLM (radford2018improving, ; radford2019language, ; brown2020language, ; ouyang2022training, ; openai2023gpt4techinicalreport, ; eloundou2023gpts, ) 可以被视为编码器-解码器的特例,因此也受到我们系统的支持。 ,这是如今最流行的 LLM 架构之一。 编码器处理输入序列并将这些信息压缩成一个连续的中间表示,而解码器接收这种表示并生成(预测)一个输出序列。 解码器的一个独特特征是它以自回归的方式生成符元,即在生成下一个符元时将最后一个输出符元附加到输入序列的末尾(符元级依赖)。 图1(a) 展示了具有三个 Transformer 层的 LLM 推理过程的简化计算和数据流图。 编码器和解码器都以 Transformer 层为基础(vaswani2017attention, ),每个层都包含一组注意力头(用于提取单词对关系)、FFNs(用于处理和增强非线性信息表示)以及其他次要运算符,如图1(b) 所示。
最近的趋势是部署稀疏 FFNs——一组“专家”,这些专家在运行时通过小型、离线训练的“路由器”进行选择,如图1(c) 所示。 结果,MoE 架构能够以亚线性增长的计算复杂度来扩展模型参数大小。 这是因为每个符元只会激活固定数量(通常为 1 或 2)的专家/权重。 例如,GLaM(du2022glam, ),一个基于 MoE 的 LLM,在 NLP 任务上的准确率明显高于 GPT-3,而其计算成本仅为 GPT-3 的一半。 也有传言说 GPT-4(openai2023gpt4techinicalreport, ),最先进的 LLM,也在使用 MoE。 这种参数可扩展性使基于 MoE 的 LLM 成为边缘设备的良好候选者,因为边缘设备的计算能力有限。
2.2. 设备上稀疏 LLM 推理
稀疏性越高,模型规模越大。 稀疏扩展的大语言模型对内存造成压力,而内存是边缘设备的关键资源。 为了更好地了解它们对边缘设备的影响,特别是内存/计算权衡和执行特性,我们对 Switch Transformer (fedus2022switch, )(谷歌最流行的基于 MoE 的稀疏大语言模型之一)在两种商用现货芯片组(COTS SoCs)Jetson TX2 和 Raspberry Pi 4B 上的执行情况进行了分析。 我们得出了以下关键观察结果:
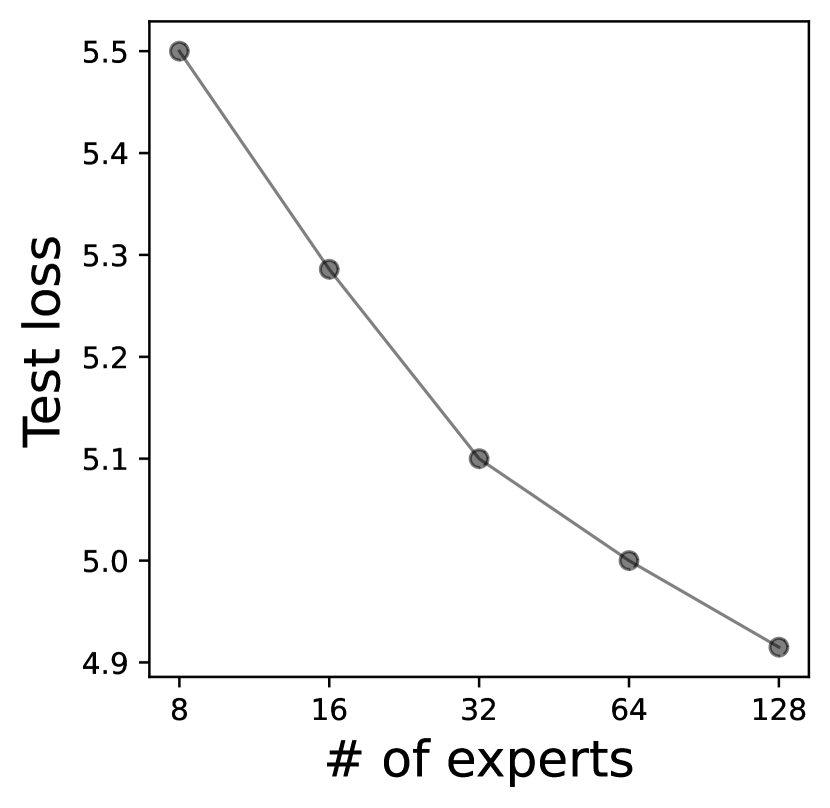
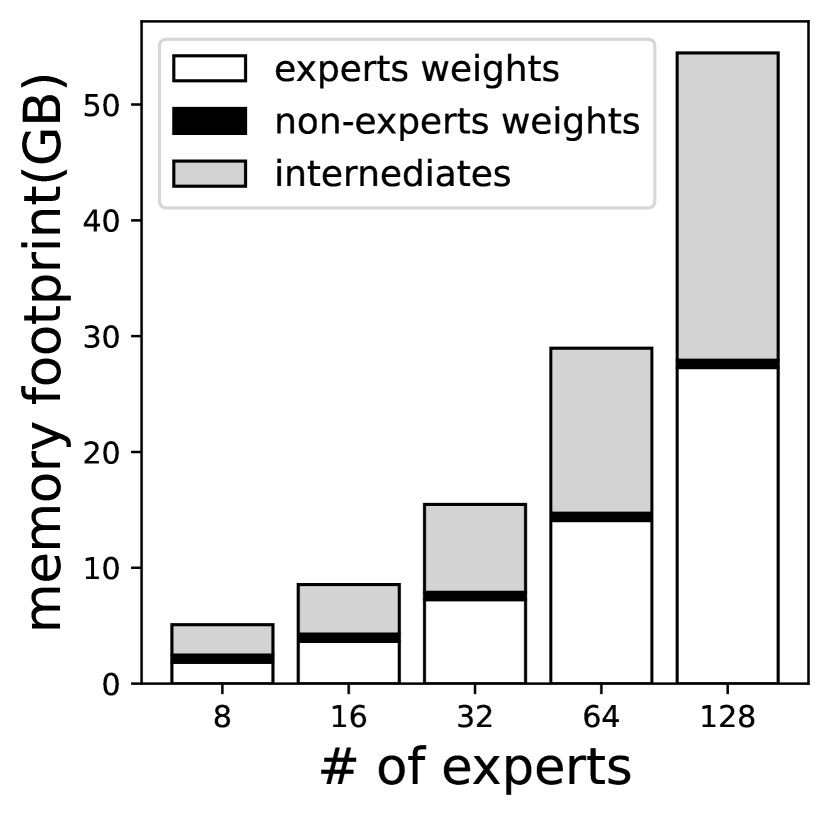
(1) 专家权重会占用设备内存。 尽管提高了模型精度,但随着专家数量的增加,专家权重也会迅速增加模型的大小。 谷歌已经表明,通过将每个前馈网络(FFN)的专家数量从 8 扩展到 256,模型容量可以持续显著提高 (fedus2022switch, )。 但是,如图 2所示,专家数量的增加会导致巨大的峰值内存占用,这是边缘设备无法承受的。 例如,具有 8GB 内存的 Raspberry Pi 4B 只能容纳具有 8 个专家/FFN 的最小的 Switch Transformers 变体。 因此,内存墙严重限制了基于 MoE 的大语言模型的可扩展性,而可扩展性对其成功至关重要。 请注意,即使设备内存足够大(例如,Jetson TX2 配备 8GB 内存)可以容纳整个模型,但大型模型的大小使其极有可能成为操作系统内存管理的受害者。 结果是,模型只能在被回收之前进行几次推断。
可以采用逐层交换策略(guo2023sti, )来处理内存效率低下问题。 但是,由于 LLMs 的自回归性质,解码每个符元都需要加载整个模型权重。 结果,I/O 加载时间可能比计算时间多 30.9 倍,这使得推断速度极其缓慢。
(2) 专家权重庞大但很少使用。 我们发现,在推断过程中,大多数计算都集中在一小部分权重(非专家)中,而大多数权重(专家)只贡献了很小一部分计算。 这是由于专家的稀疏激活性质。 以 ST-base-16 为例,专家贡献了 86.5% 的总内存使用量,但只贡献了 26.4% 的计算量。
直观地说,上述特征自然适合设备存储层次结构(更快的 RAM 与更大的磁盘)。 因此,我们可以使用判别式交换策略,将所有非专家保留在内存中,但仅在内存和磁盘之间交换专家。 具体而言,只有当专家被路由器激活时,才会将其加载到内存中;一旦使用,其内存就会立即释放。 在这种情况下,内存使用量可以少到所有非专家权重的总大小加上一个专家的大小。 同时,I/O 负担被减少到每一层一个专家的权重。
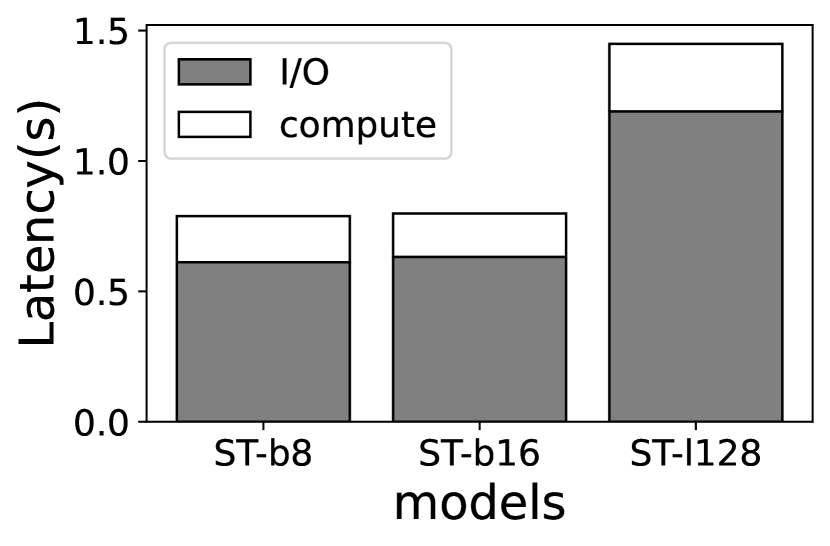
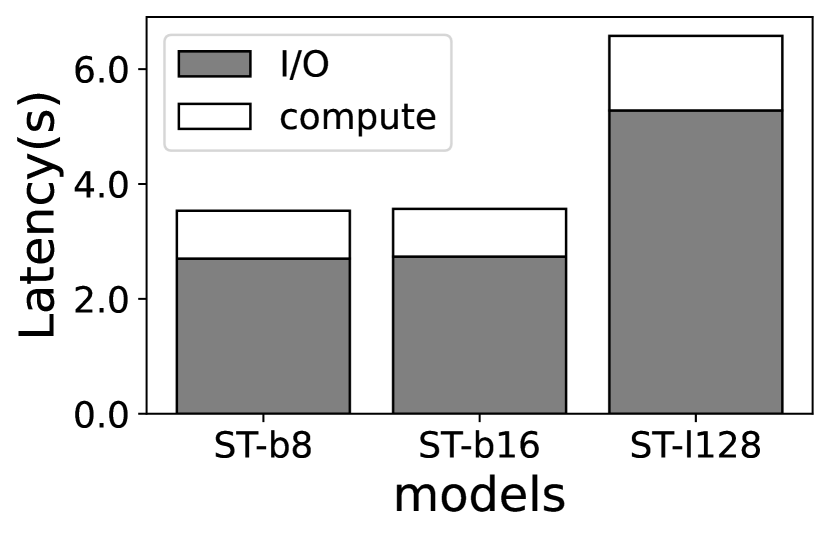
(3) 专家权重计算与 I/O 差异。 不幸的是,即使每层只加载一个专家也会显著降低 MoE 的执行性能。 通过上述判别性交换策略,我们发现 Jetson TX2 上的每个样本推理时间(生成具有多个标记的整个序列)很慢(例如,Jetson TX2 上平均超过 17 秒),并且解码时间占主导地位,因为它的自回归性质。 我们进一步在图 3 中将延迟分解为计算(推断)和 I/O(专家加载),发现后者贡献最大。 与具有无限内存的预言机案例(因此没有专家 I/O)相比,每个 Token 的解码时间增加了 3.2–3.9 和 3.3
(4) 计算/IO 管道不可行。 可以进一步利用计算/IO 并行性,并使专家加载与权重计算重叠,类似于 STI (guo2023sti, )。 但是,我们发现这种方法由于以下原因不可行。
-
•
专家激活依赖性。 与 STI 所针对的标准 Transformer 模型(按顺序预加载层)不同,MoE Transformer 仅在前一层完成计算时决定加载哪些专家。 这种专家级激活依赖性禁止计算/IO 管道。
-
•
专家激活频率。 可以将“热门”专家预加载到内存中,使其更有可能被激活,就像管道一样,即基于频率的缓存策略。 但是,我们发现这种方法并不有利,因为同一层中的专家被激活的可能性相似,如图 8(左)所示。 这种均衡的激活现象并不令人惊讶,因为训练机制设计了它,以在训练时最大限度地利用 GPU (fedus2022switch, )。
3. EdgeMoE 设计
3.1. 概述
系统模型
EdgeMoE 是第一个执行引擎,能够在边缘设备上实现 快速 推理 大型 MoE Transformer 模型(例如,¿8GB)。 它支持用于交互式任务(如文本生成和摘要)的通用 MoE Transformer 模型。
EdgeMoE 作为链接到用户应用程序的运行时库而存在。 除了 EdgeMoE 之外,还将具有 专家压缩到不同位宽 的 MoE LLM 安装在边缘设备上。 它由两个关键参数配置。 首先,一个内存预算 ,由用户或操作系统指定。 该预算范围从 1.5GB 到 3GB,比现有的 MoE LLM 小一个到两个数量级。 灵活的约束适应了不同的设备内存,并适应了系统内存压力。 其次,用户选择的容许精度损失 。 基于所需的精度损失 ,EdgeMoE 为专家调整各个位宽,以构建在运行时执行的模型。 请注意,这是一个软目标,因为现有的 MoE LLM 无法提供精度保证。
在用户调用时,EdgeMoE 首先选择满足精度损失 的模型,并实例化一个专家预加载/计算管道以减少推理延迟: 它按层顺序加载所有非专家权重; 根据先前激活的专家,它有选择地加载 下一 层的专家,与 当前 层的计算重叠。 作为推理的结果,EdgeMoE 生成一组预测的符元(例如,在文本生成任务中)或摘要(例如,在摘要任务中)。
在执行期间,EdgeMoE 维护两个内存缓冲区: 1)一个专家缓冲区,用于管理和缓存专家权重。它与 EdgeMoE 一同驻留在内存中,以支持多轮推理。 2)一个工作缓冲区,用于保存所有中间结果。 它只是临时的,可以在每次推理完成后立即丢弃。
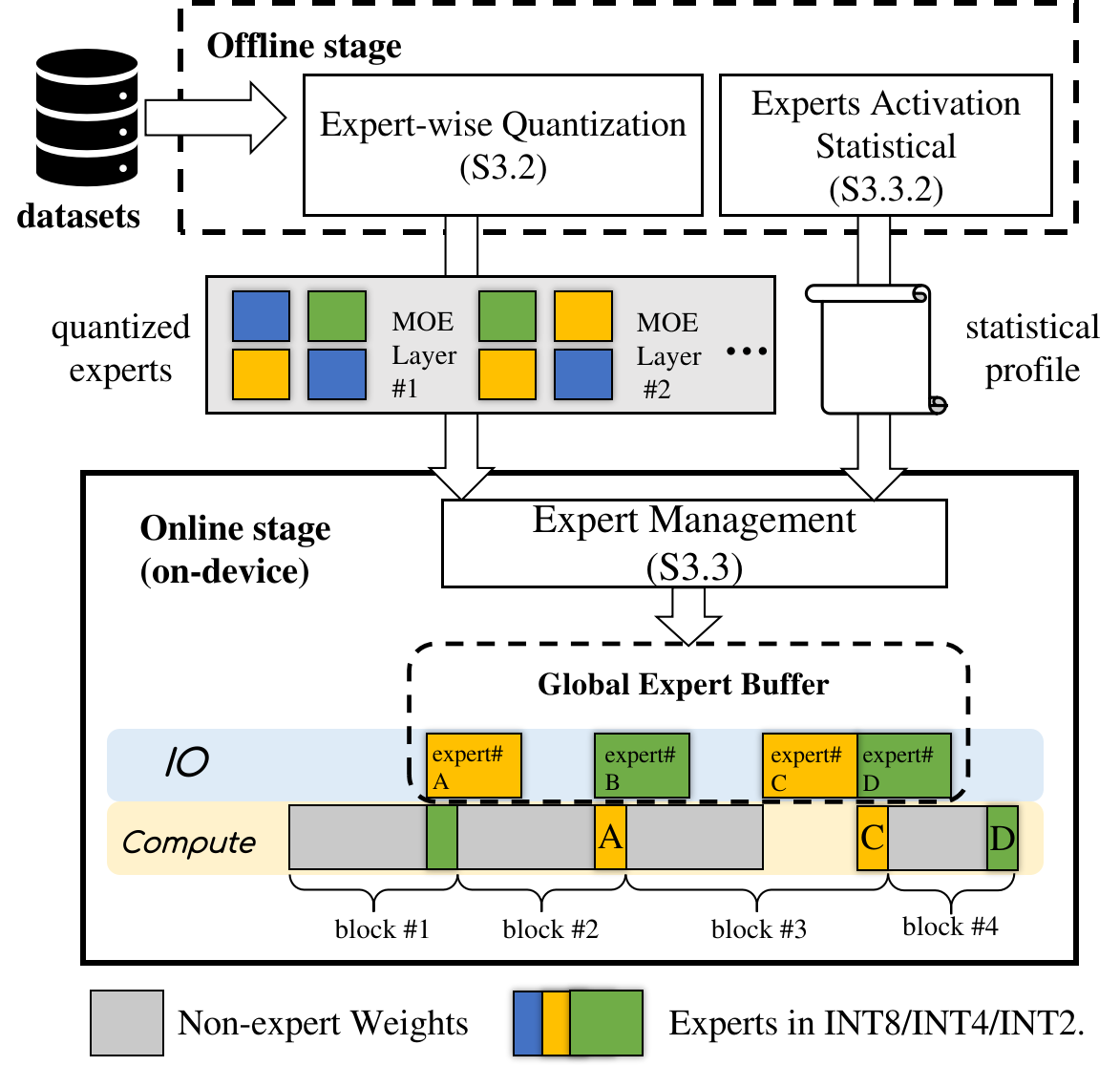
操作
要使用,EdgeMoE 按图 5 所示的两个主要阶段工作。
应用
EdgeMoE 框架是通用的,适用于仅解码器和仅编码器的 Transformer 架构。 它与动态(例如 Switch Transformers (fedus2022switch, ), GLaM (du2022glam, )) 和静态路由(例如 Hash 层 (roller2021hash, ), 专家选择 MoE (zhou2022mixture, )) MoE 层兼容。 值得注意的是,在静态路由层中,专家激活仅取决于原始输入符元,而不依赖于它们的隐藏状态。 对于这些层,EdgeMoE 只是根据管道中的输入符元指示的指令预加载专家,而无需预测。
3.2. 专家量化
为了在设定的内存预算下拟合专家权重,并平衡计算/IO 差异,我们选择了基于词典的量化(han2015deep, ),它与未修改的预训练模型一起使用; 我们不使用量化感知训练 (QAT) (liu2023llm, ) 以避免重新训练 LLM,因为这既繁琐又昂贵。 虽然量化技术是众所周知的,但 EdgeMoE 是第一个将其应用于 单个 专家并利用准确率与位宽权衡的模型。
选择算法。
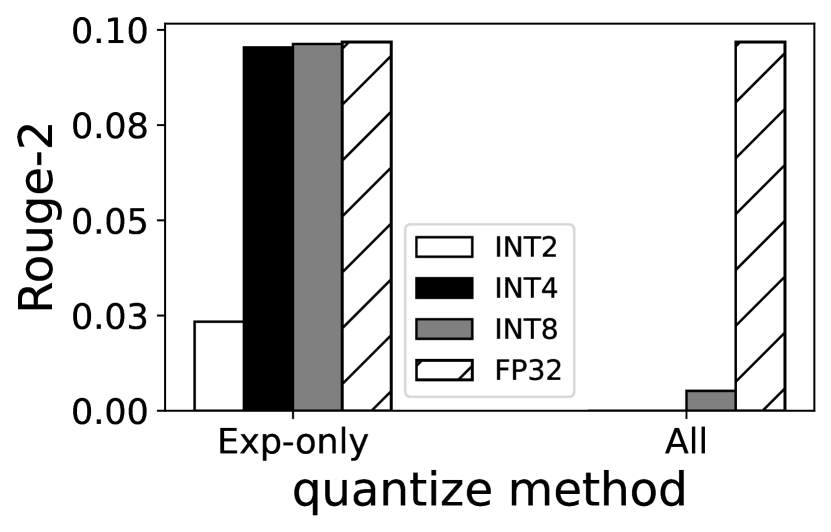
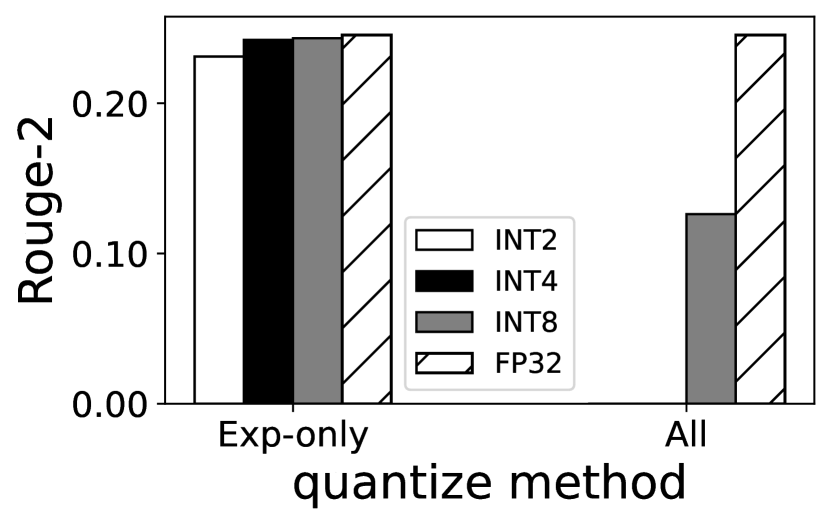
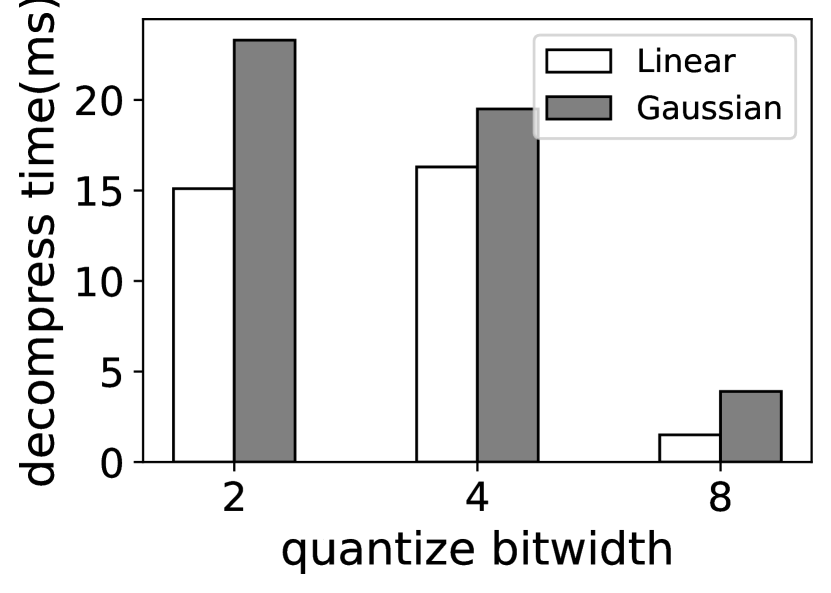
我们调查了各种量化技术(例如高斯异常值感知量化 (zadeh2020gobo, ) 和基于对数的量化 (aji2020compressing, )),并选择了逐通道线性量化 (han2015deep, ),因为它具有良好的准确率和快速的解压缩时间。 如图 6 所示,将所有专家权重量化为 4 位整数 (INT4) 仅导致 1.30%–1.44% 的准确率下降; 在 SAMsum 数据集上,专家可以进一步量化为 2 位整数,仅损失 5.82%,在我们使用中是可以接受的。 如图 7(b) 所示,与其他量化技术(例如高斯异常值感知量化 (zadeh2020gobo, ))相比,逐通道线性量化快 1.1%–25%,这归因于其作为直接线性映射的简化解压缩过程。
逐通道线性量化使用缩放因子将量化整数的值统一映射到原始浮点值。 每个通道的缩放因子由该通道内最大绝对值和位宽所能表达的范围决定。
量化权重不打算按原样使用,这与 QAT (liu2023llm, ) 不同。 在使用之前,我们必须解压缩它们,这是一个压缩过程的镜像。
分析专家重要性。
对于专家,我们将它们量化为不同的位宽,例如 INT2/4/8。 其基本原理是专家对模型准确率表现出不同的重要性;我们希望最重要的专家拥有高位宽,因此对模型准确率的贡献更加积极。
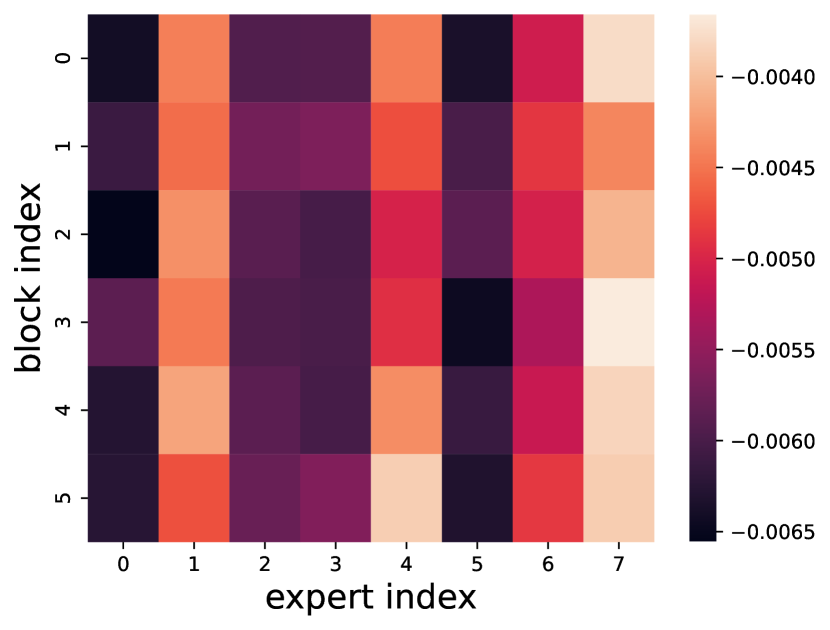
为此,EdgeMoE 枚举所有专家,将每个专家量化为 INT2,并在不同的验证集(例如 ST-base-8)上分析由此产生的精度损失。 结果如图 7(a) 中的热图所示。 例如,将 专家在 Transformer 块量化为 INT2 会导致精度下降 0.44%,而将 专家量化为相同精度会导致精度下降 0.59%。 因此, 专家对量化更敏感,对模型精度更重要。
因此,EdgeMoE 获得了专家重要性列表,该列表按将相应专家量化为 INT2 时模型精度排序。 该列表将用于构建运行时模型,我们将在下面简要介绍。
请注意,EdgeMoE 不会量化非专家权重,因为量化它们会导致模型无法使用,这一点我们在图 6 中所示的早期实验中观察到。 我们的推测是:虽然专家权重很大,但在每次推理过程中,被激活的专家数量很少,因此压缩的权重不会造成太大差异。
选择专家级位宽。
基于用户可容忍的精度损失,EdgeMoE 谨慎地离线选择各个专家的位宽,如下所示。
-
•
首先,EdgeMoE 决定模型 所有 专家的位宽界限,作为 EdgeMoE 进一步调整的基线。 为此,EdgeMoE 枚举所有专家的可用位宽(例如 INT2/4/8 和 FP32),并分别测量模型精度。 EdgeMoE 然后将位宽的下限和上限设置为其精度与可容忍的精度损失非常接近的那些。
-
•
其次,EdgeMoE 基于位宽的下限和上限,单独调整专家的位宽。 它从之前获得的列表中排名前 的专家开始。 由于它们不太重要,EdgeMoE 将它们量化为较低位宽(即 INT2),同时保持其余部分为较高位宽(例如 INT4)。 EdgeMoE 然后测量所得模型的准确性。 如果其准确性损失仍然低于预期目标,这意味着模型可以承受更多低位宽专家,EdgeMoE 按照列表逐步增加参数 ,直到准确性损失达到目标。 否则,EdgeMoE 减少参数 以减少准确性损失,即通过将更多专家提升到更高位宽。
通过上述过程,EdgeMoE 获得了一个混合精度模型,在准确性和存储之间取得平衡。
3.3. 内存中专家管理
3.3.1. 编码器专家重新批处理
在编码器中执行 MoE 层时,专家是逐个符元激活的,其中多个符元可能会选择同一个专家。 在没有系统视图的情况下,在符元调用时简单地拉取专家权重会导致重复加载,从而造成显著的延迟和 I/O 带宽浪费。
为了解决这个问题,EdgeMoE 通过重新批处理来重新组织输入符元。 具体来说,EdgeMoE 重新排序编码器计算,将其从逐个符元的方式转变为逐个专家的方式。 按照专家的顺序,EdgeMoE 加载每个专家的权重,然后将所有选择该专家的符元连接起来进行计算。 此策略确保每个专家的权重只加载一次,从而防止冗余加载。
3.3.2. 预加载和管道
为了将专家加载与权重计算重叠,我们必须预测专家的激活,而不是被动地等待前一个 MoE 层的路由器输出。
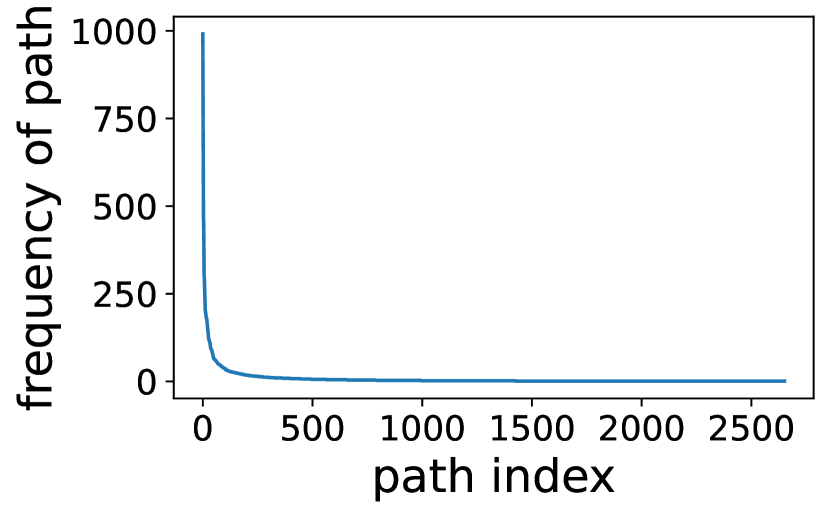
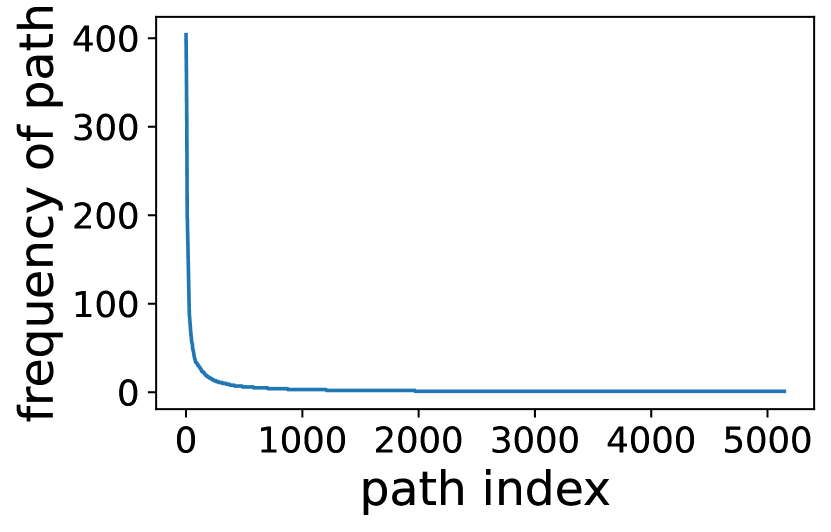
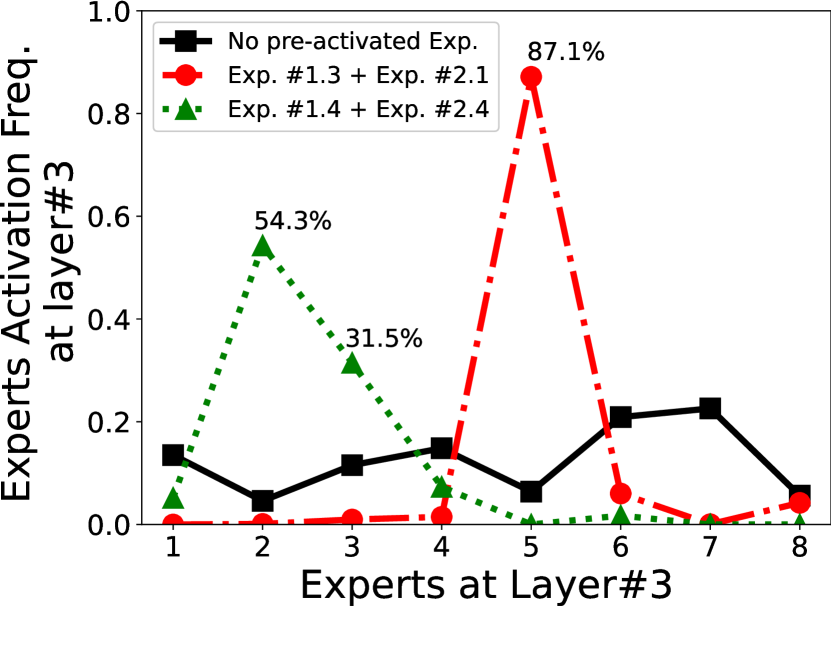
事先估计专家激活。 如何预测专家激活? 我们利用了一个关键观察结果,即顺序层的专家激活在统计学上是相关的。 也就是说,给定层的专家激活的先验知识,我们可以很好地估计每层在层的激活概率,公式为,其中是专家的索引,是层的索引。 为了证明这种相关性,我们分析了在 SAMSum 数据集上运行 ST-base-8 模型的专家激活。 如图 8(左)所示,观察到前两层的激活后,在第 层,第 5 个专家被激活的概率很高(87.1%),即 。 图 8(右)通过统计汇总不同激活路径进一步证实了这一观察结果。
机会预加载。 EdgeMoE 利用之前的观察结果,以机会方式预加载专家权重并按如下方式执行管道。 在离线阶段,基于之前的观察结果 EdgeMoE 在多个数据集上执行模型,以构建专家激活的统计特征。 为此,EdgeMoE 生成一个字典, 其中键表示来自两个连续 MoE 层的专家的激活状态, 而值表示在后续 MoE 层中个别专家被激活的概率。 然后存储统计特征,以便在线推理中使用。
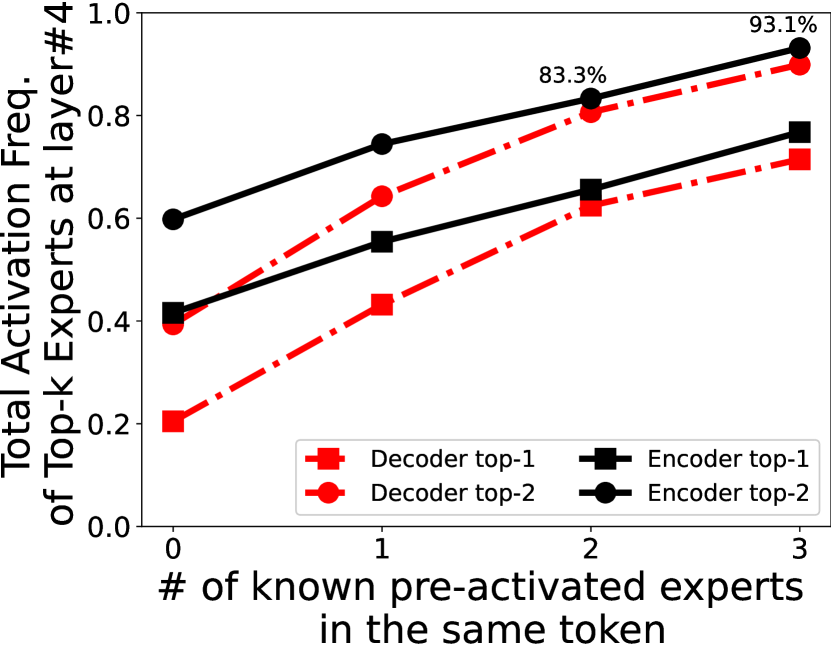
在在线阶段,在每个 MoE 层路由之前,EdgeMoE 使用前一层中专家的激活状态作为键查询统计特征。 然后,它按估计的激活概率的优先级顺序将专家依次预加载到专家缓冲区(如果不存在)。 预加载一直持续到路由器完成,从而确定实际激活的专家。 在实践中,EdgeMoE 能够为管道预加载每层 1-3 个专家,具体取决于计算 I/O 加速差距。
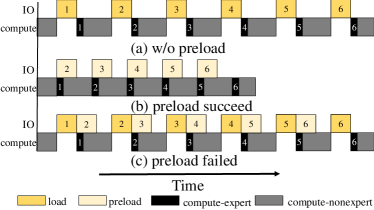
管道调度。 EdgeMoE 实例化了一个预加载/计算管道,以根据统计配置文件做出的预测,同时执行当前 Transformer 块内的计算和后续 Transformer 块的预加载。 图 9 说明了预测成功/失败情况下的管道调度。 当 EdgeMoE 正确预测了下一个 MoE 层的专家激活(这是一种常见情况)时,它会显著减少端到端推理延迟,将加载时间隐藏在计算中。 作为最坏情况(我们从未观察到),当所有预测都失败时,推理时间与按需加载专家一样长。
3.3.3. 缓存清除策略
EdgeMoE 在内存中维护一个专家权重的缓存,其大小由内存预算 决定。 一旦缓存中的专家被激活,权重将直接从缓冲区获取,即缓存命中。 否则,EdgeMoE 需要从磁盘获取专家,并在缓存已满时清除旧的专家。 缓存清除策略——确定要清除哪个专家,对 EdgeMoE 的性能至关重要,因为错误地清除未来将使用的专家会导致重大的 I/O 负担。
FIFO/LRU/LFU 等经典缓存策略是为操作系统设计的,主要基于数据访问历史和频率。 EdgeMoE 利用了专家激活频率,但还包含了另一个独特的优势:由于 LLM 是用顺序堆叠的 Transformer 层构建的,每个专家的激活时间与其位置(即层索引)相关联。 具体来说,如果一个专家位于即将执行的层中,则应赋予它更高的分数,以防止其被清除。
基于此启发式算法,EdgeMoE 的清除策略考虑了专家使用频率和 MoE 层索引。 主要思想是优先清除存储在缓冲区中,使用频率较低且层距离当前块较远的专家。 我们将清除策略表述如下。 对于第 个专家,位于第 个 MoE 层,我们将其清除分数定义为 :
其中 是当前 MoE 层的索引, 是第 个专家在第 个 MoE 层被激活的频率。 并且 表示该模型解码器中 MoE 层的大小。 因此,分数 越高,专家被驱逐的可能性就越大。 对于编码器中的专家,我们将频率 设置为 0。 原因是这些专家在重新批处理后只加载一次,因此应该优先考虑驱逐它们。 初始化专家缓冲区时,我们按顺序加载编码器专家权重。 对于仅编码器模型,专家缓冲区使用使用频率最高的专家进行初始化。
4. 评估
4.1. 实现和方法
| Model | Type | EnM/En | DeM/De | Exp. | Top-k | Params. |
|---|---|---|---|---|---|---|
| ST-b-8 | en-de | 6/12 | 6/12 | 8 | 1 | 0.4B |
| ST-b-16 | en-de | 6/12 | 6/12 | 16 | 1 | 0.9B |
| ST-b-32 | en-de | 6/12 | 6/12 | 32 | 1 | 1.8B |
| ST-b-64 | en-de | 6/12 | 6/12 | 32 | 1 | 3.5B |
| ST-b-128 | en-de | 6/12 | 6/12 | 128 | 1 | 7.1B |
| ST-l-128 | en-de | 12/24 | 12/24 | 128 | 1 | 26B |
| GPTSAN | de | 0/0 | 9/9 | 16 | 2 | 0.6B |
EdgeMoE 原型 我们基于 transformers 全面实现了 EdgeMoE 的一个原型,它包含 1K 行 Python 代码。 我们使用 Pytorch 作为 Transformer 的后端和 CUDA 后端,因为它对不同平台具有更通用的支持。 请注意,EdgeMoE 的技术也与其他 DL 库兼容。
模型 我们使用 7 个流行的基于 MoE 的稀疏 LLM,如表 1 所示,以测试 EdgeMoE 的性能。 这些模型中的大多数基于编码器-解码器结构中的 Switch Transformers (fedus2022switch, ) 架构,具有 top-1 路由,即每层只激活一个专家。 此外,GPTSAN (tanrei-gptsan-jp, ) 具有仅解码器结构,并作为前缀输入符元的移位掩码语言模型工作。 它使用 top-2 路由。 这些模型的预训练权重直接从 Hugging Face (huggingfacehubmodels, ) 下载。
数据集 我们使用三个 NLP 下游数据集评估 EdgeMoE: (1) Xsum 数据集 (huggingface-xsum, ):包含大量 226,711 篇新闻文章,每篇文章都附带简洁的单句摘要。 (2) SAMsum 数据集 (huggingface-samsum, ):该数据集包含大约 16,000 个对话记录,类似于消息传递交换,以及相应的摘要。 (3) Wikipedia-jp 数据集 (huggingface-wikipedia-japanese, ):该大型数据集包含截至 2022 年 8 月 8 日的整个日语维基百科文章语料库。 Xsum 和 SAMsum 数据集专门用于摘要任务,其中目标是生成输入内容的摘要。 我们评估了 Switch Transformers 模型在这些数据集上的性能。 相反,Wikipedia-jp 数据集作为文本生成任务的基础。 我们使用该数据集评估了 GPTSAN 在文本生成任务中的能力。
指标 我们主要报告模型准确率、推理速度(每个符元和序列)、峰值内存占用和 EdgeMoE 和基线的模型大小。 为了评估模型准确率,我们在实验中使用 Rouge-2 指标 (lin2005recall, )。 它包含一组用于评估自动摘要和文本生成任务的指标。 在摘要的背景下,Rouge-2 通过比较自动生成的摘要与一组参考摘要(通常是人工制作的)来量化相似性。
硬件 我们在两个知名的边缘设备上评估 EdgeMoE:Jetson TX2(GPU)和 Raspberry Pi 4B(CPU)。 Jetson TX2 (tx2, ) 和 Raspberry Pi 4B (rpi4b, ) 都运行 Ubuntu 18.04 作为其操作系统。 由于 MoE LLM 很大,我们需要外部存储来保存它们。 对于 Raspberry Pi 4B,我们使用 SD 卡(SanDisk Ultra 128GB (sdcard, )); 对于 Jetson TX2,我们使用两种类型的硬盘驱动器,即 SSD(默认)和 HDD。 SSD 型号是 SAMSUNG 860 EVO (samsungssd, ),其读写速度为 550/520 MB/s。 HDD 型号是 MOVE SPEED YSUTSJ-64G2S (movespeed, ),其读写速度为 50/20 MB/s。 EdgeMoE 的离线阶段(生成量化的 MoE)是在配备 8x NVIDIA A40 的 GPU 服务器上执行的。
基准 我们将 EdgeMoE 与四个基准进行比较。 (1) IO-FREE 假设所有模型权重都保存在内存中,因此不需要交换 I/O。 这是最有效率的计算方法,但由于内存限制,无法扩展。 (2) IO-EXP 将内存视为专家缓存,并在激活时动态加载它们,类似于 EdgeMoE。 (3) IO-QEXP 将上述方法与 MoQE (kim2022mixture, ) 相结合, 将专家权重量化为 INT4 并动态加载它们以进行推理。 与 EdgeMoE 一样,量化的权重需要转换回 FP32 以便在设备处理器上快速推理。 (4) STI 通过模型分片最小化推理精度,并在严格的内存预算下实例化一个 IO/计算管道 (guo2023sti, )。 它没有区分专家和非专家的权重。 为了公平比较,我们调整了预加载分片的缓冲区大小,使 STI 和 EdgeMoE 具有相同的内存占用。
配置 除非另有说明,我们设置 EdgeMoE 的专家缓冲区为 10 个专家;容许的精度损失为 5%。 每个实验都通过多次重复系统地进行,报告的值基于其各自的平均值。
4.2. 端到端结果

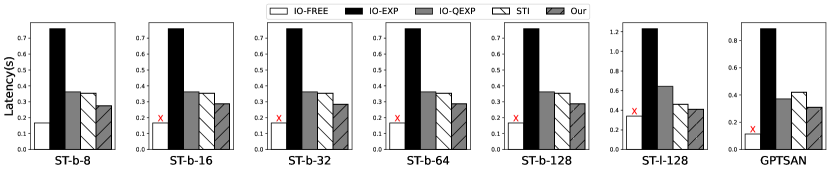
内存占用。 我们在边缘设备上对 EdgeMoE 和基准模型进行了内存占用评估。 结果如 10 所示。 EdgeMoE 在所有模型和平台上都显著优于基准模型,与 IO-FREE 相比,实现了 2.6 到 3.2 的内存节省。 这种改进归功于 EdgeMoE 对非活动专家权重和激活的有效管理。 此外,EdgeMoE 会动态加载和缓存内存中的已激活专家权重,以减少内存占用。
相比之下,EdgeMoE 的内存占用与 IO-EXP 和 IO-QEXP 相似。 由于这两个基准模型不需要缓存先前的专家权重,因此 EdgeMoE 的内存占用略高。 例如,当专家缓冲区设置为 10 专家内存占用时,ST-base 模型比 IO-EXP 和 IO-QEXP 多消耗大约 180MB 内存。 根据4.1 中概述的设置,基线 STI 与EdgeMoE 的内存占用相同。
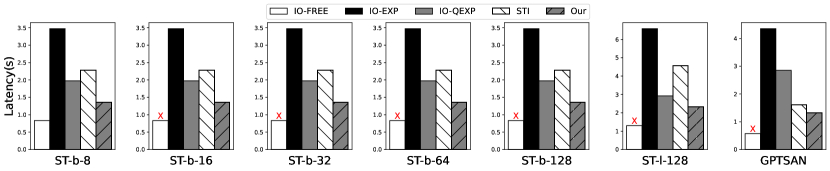
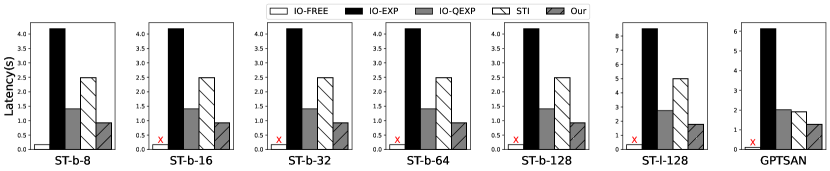
每个符元推理延迟。 图 11 对边缘设备上 EdgeMoE 与基线的每个符元推理延迟进行了全面比较。 结果突出了EdgeMoE 在所有模型和平台上都取得了显著的性能提升。 在 Jetson TX2 上,与 IO-EXP 相比,EdgeMoE 的加速比在 2.63 到 3.01 之间,而在 Raspberry Pi 4B 上,加速比在 4.49 到 5.43 之间。 这种显著的性能提升可以归因于几个关键因素。 首先,EdgeMoE 对专家使用权重量化,有效地减少了加载延迟。 此外,EdgeMoE 采用了一种有效的专家权重预加载策略,巧妙地将此预加载过程与计算重叠,从而有效地掩盖了大部分延迟。 因此,与 IO-QEXP 相比,EdgeMoE 取得了 1.35–1.5 的显著加速,与 STI 相比,推理速度提高了 1.11–2.78 倍。
然而,EdgeMoE 和 IO-FREE 之间仍然存在性能差距,因为EdgeMoE 的预加载阶段并不总是能预测下一层 MoE 要激活哪个专家。 一些专家仍然需要动态加载。
硬盘读取速度的影响。 图 11 还比较了 Jetson TX2 上 SSD 和 HDD 之间的每个符元推理延迟。 值得注意的是,与 SSD 相比,EdgeMoE 在低成本 HDD 上实现了更高的加速率,尤其是在与基线 IO-EXP 相比时。 例如,与 IO-EXP 相比,EdgeMoE 在 HDD 上实现了 4.49 到 4.76 的加速,在 SSD 上实现了 2.63 到 3.01 的加速。 这种差异是由于 HDD 的读取速度相对较慢,导致专家权重加载时间比 SSD 更长。 EdgeMoE 在专家加载方面展现出更显著的改进,导致每个符元推理延迟的提升更加明显。
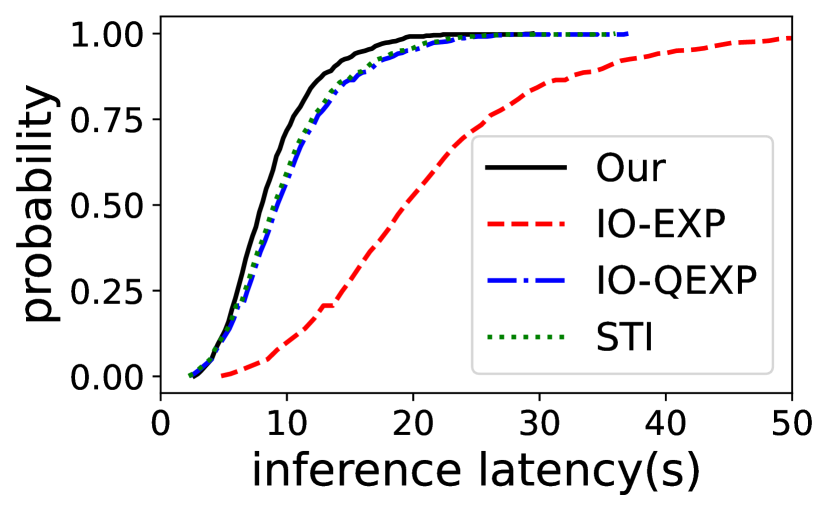
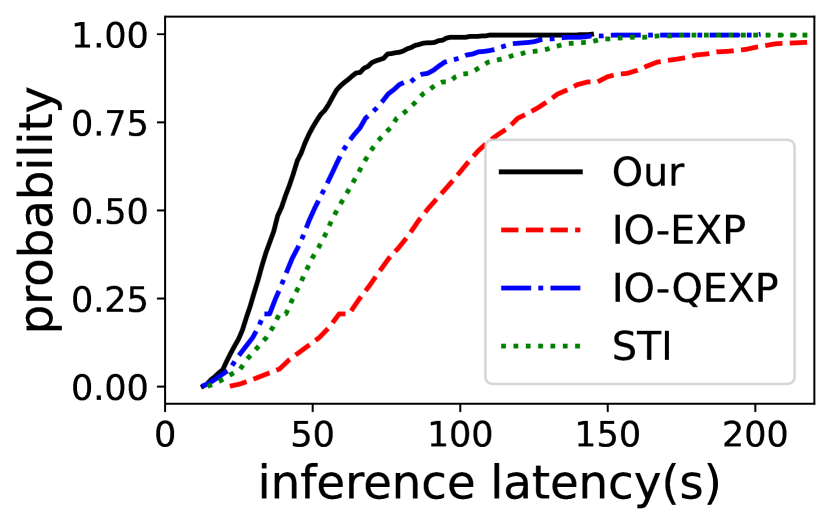
每个样本的推理延迟。 我们还评估了 EdgeMoE 与基线相比在 Jetson TX2 和 Raspberry Pi 4B 上的每个样本推理延迟。 ST-base-8 模型的累积分布函数 (CDF) 如图 12 所示。 结果表明 EdgeMoE 一直优于基线。 例如,在 Raspberry Pi 4B 上,EdgeMoE 处理的 50% 样本的延迟小于 46 秒,而对于 IO-FREE,50% 的样本的延迟小于 106 秒。
| baseline | Storage(GB) | Loss(%) |
|---|---|---|
| IO-FREE | 2.43 | 0.00 |
| IO-EXP | 2.53 | 0.00 |
| IO-QEXP | 0.85 | 2.04 |
| STI | 0.85 | 20.0 |
| Our | 0.81 | 4.89 |
| baseline | Storage(GB) | Loss(%) |
|---|---|---|
| IO-FREE | 4.12 | 0.00 |
| IO-EXP | 4.12 | 0.00 |
| IO-QEXP | 1.03 | 3.15 |
| STI | 1.03 | 25.1 |
| Our | 0.95 | 4.95 |
存储和准确性。 我们还比较了 EdgeMoE 和基线的存储需求,同时测量了它们的准确性损失。 表 2 展示了 ST-base-8 和 ST-base-16 的实验结果。 值得注意的是,EdgeMoE 在存储方面明显优于基线,与 IO-FREE 相比提高了 3.03,与 IO-QEXP 相比提高了 1.11(针对 ST-base-8)。 这种优势源于 EdgeMoE 对专家权重采用混合精度量化方法。
此外,精度损失符合我们的预期。 EdgeMoE 的精度损失与可容忍的 5% 阈值非常接近。 IO-FREE、IO-EXP 和 IO-QEXP 模型也同样表现出与各自位宽配置一致的精度损失。 与其他基线不同,STI 对非专家权重和专家权重都进行了量化,导致精度损失显著。
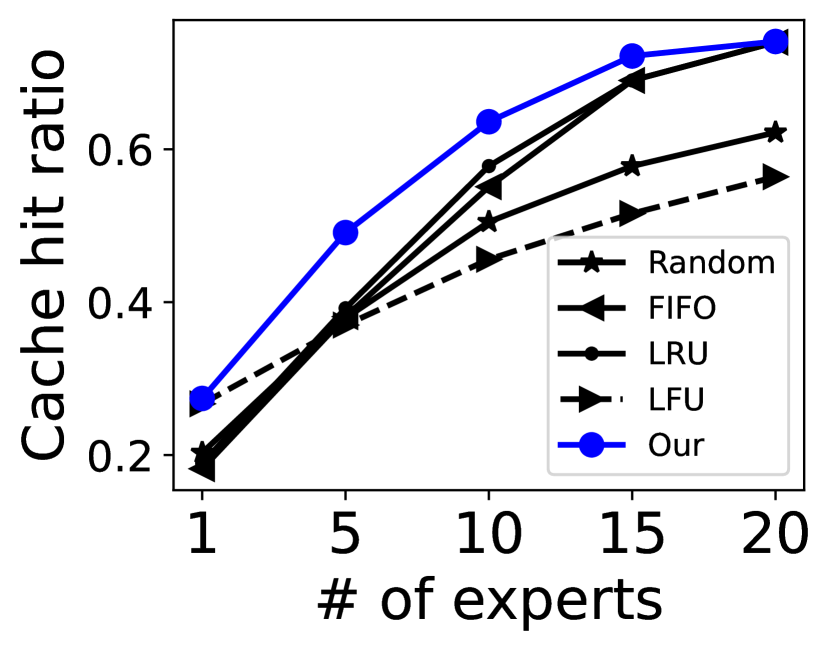
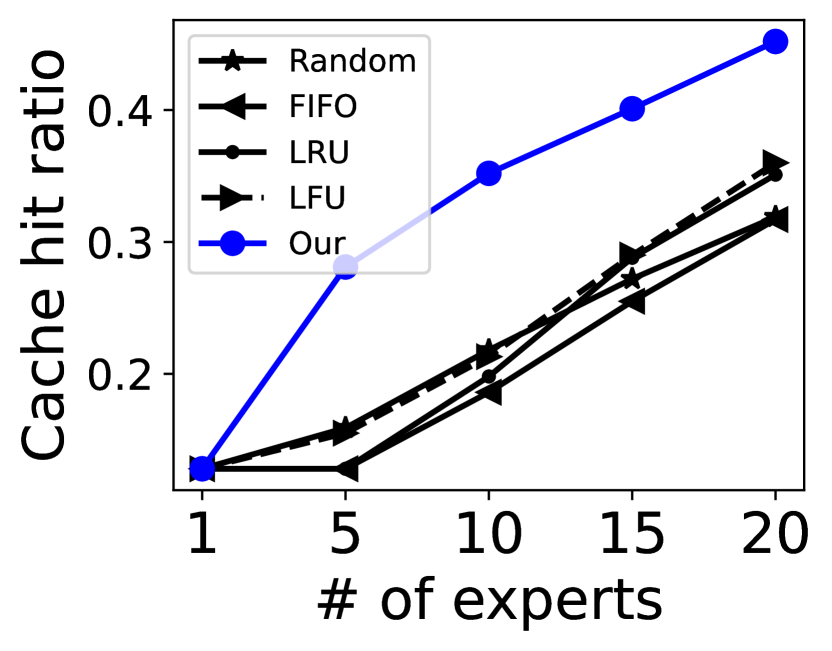
缓存驱逐策略。 我们对我们新颖的缓存驱逐策略和其他具有不同专家缓冲区大小的策略的缓存命中率进行了比较分析。 为了减轻预加载对命中率的影响,我们在这些实验中禁用了预加载功能。 结果如图 13 所示。 我们新颖的驱逐策略比其他几种策略表现出更强的有效性。
4.3. 敏感性分析
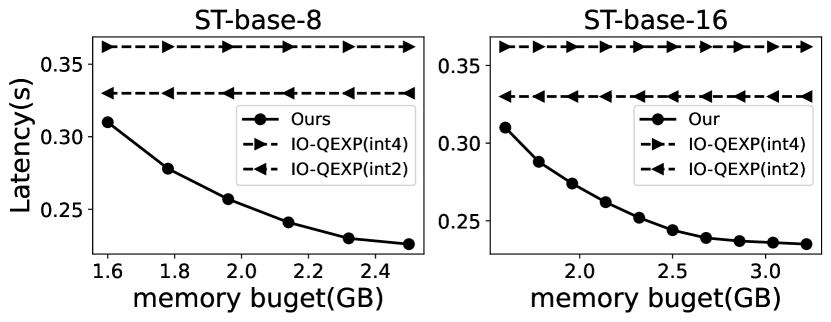
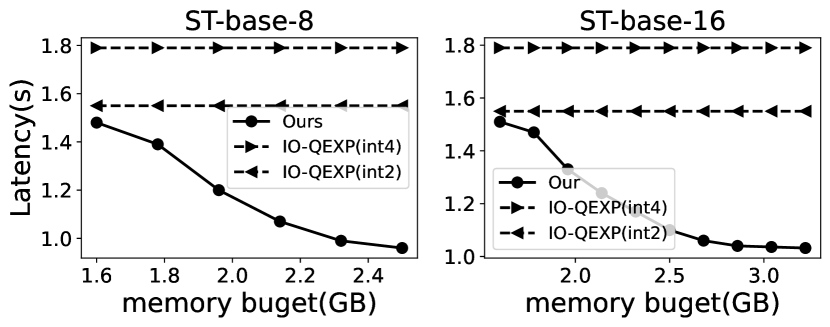
各种内存预算。 EdgeMoE 通过根据内存预算调整专家缓冲区((3.3)),适应了具有不同设备内存大小的各种边缘设备。 在我们的实验中,我们将内存预算配置为 1.6GB 到 3.5GB,反映了现实世界中边缘设备的内存配置。 我们广泛评估了 EdgeMoE 在这些内存预算下与基线模型相比的每个符元推理延迟,结果如图 14 所示。 值得注意的是,随着专家缓冲区大小的增加,推理延迟会降低。 这是因为扩展的专家缓冲区可以保留更多先前激活的专家权重,从而导致更高的缓存命中率并节省权重加载时间。
图 14 在两种设备上比较了 EdgeMoE 和 IO-QEXP。 结果始终表明,与 INT4 和 INT2 版本的 IO-QEXP 相比,EdgeMoE 在所有内存预算配置中都具有更低的推理延迟。
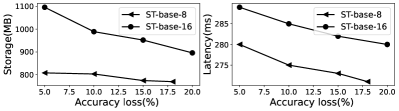
可容忍的精度损失的影响。 图 15 提供了对不同所需精度损失 的比较。 在这些实验中,我们在 Jetson TX2 上评估了 ST-base-8 和 ST-base-16 模型的推理延迟和模型存储,精度损失水平范围从 5% 到 20%。 结果表明,精度损失随模型大小和推理延迟而变化。 它证实 EdgeMoE 通过调整专家的各个位宽,有效地适应了可用资源(存储和延迟)。
4.4. 消融研究
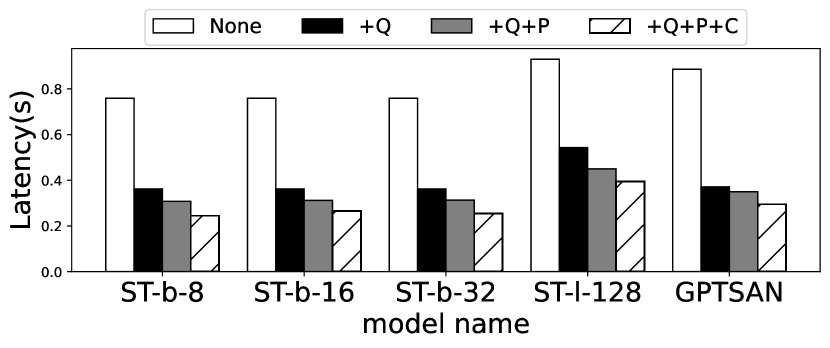
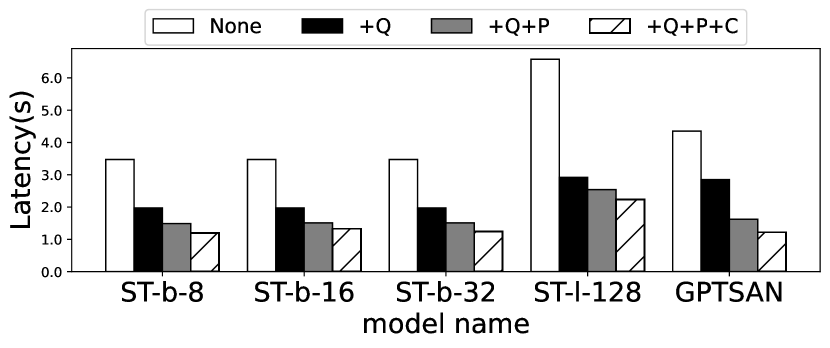
然后,我们分别评估了 EdgeMoE 每项关键技术的优势。 图 16 展示了每个符元推理延迟评估的结果。 我们的主要观察结果是,EdgeMoE 的每项关键技术都对推理加速做出了显著贡献。 例如,使用 ST-base-8 和 Jetson TX2,专家级量化首先将推理延迟从 0.789 秒降低到 0.392 秒。 预加载和流水线进一步将延迟降低到 0.305 秒,而通过使用专家缓冲区,延迟最终降至 0.245 秒。
5. 相关工作
资源高效的 LLM 对资源高效的 LLM 的研究非常流行。 先前的工作使用了诸如知识蒸馏 (wu2023lamini, ; li2023symbolic, ; fu2023specializing, ; tan2023industry, ; yuan2023distilling, ; wang2023scott, )、 网络剪枝 (frantar2023sparsegpt, ; ma2023llm, ; sun2023simple, )、 量化 (frantar2022gptq, ; xiao2023smoothquant, ; lin2023awq, ; yuan2023rptq, ; liu2023llm, ; chee2023quip, )、 架构设计 (liu2023deja, ; miao2023specinfer, ; spector2023accelerating, ; del2023skipdecode, ; ning2023skeleton, ; li2023losparse, ; xu2023tensorgpt, )、 高效结构设计 (dao2022flashattention, ; dao2023flashattention, )、 以及文本压缩 (valmeekam2023llmzip, ; chevalier2023adapting, ; ge2023context, ) 等方法来实现资源高效的 LLM。 然而,这种类型的工作的场景与 EdgeMoE 不同。 一方面,这些工作可以实现 LLM 在云端的有效部署,但它们往往无法适应资源极其有限的边缘设备。 另一方面,这些工作往往不关注基于 MoE 的 LLM。 基于 MoE 的 LLM 已在业界得到广泛应用。 具体来说,EdgeMoE 是为了高效地进行设备上的 MoE LLM 推理而构建的,并且与上述大多数技术正交。
设备上 ML 优化 设备上 DNN 推理优化主要有两类。 一种是在系统层面,例如,通过利用异构处理器 (cao2017mobirnn, ; fu2017crnn, ; huynh2017deepmon, ; lane2016deepx, ),缓存 (mathur2017deepeye, ; xu2018deepcache, ), 生成高性能GPU内核 (liang2022romou, ),或自适应卸载 (laskaridis2020spinn, ; xu2019deepwear, )。 另一种是在模型层面,例如,量化 (joo2011fast, ; liu2018demand, ) 或稀疏化 (bhattacharya2016sparsification, ; niu2020patdnn, )。 它们减少了执行时间和/或从磁盘读取的权重。 这些工作可以优化小型机器学习模型,但它们无法优化运行内存比边缘设备大一百倍的大型语言模型。 EdgeMoE 是为资源高效的基于MoE的稀疏LLM而构建的,并且与它们正交。
DNN内存优化 鉴于内存是移动设备的关键且稀缺资源,内存节省长期以来一直是移动社区关注的研究方向。 DNN内存优化主要有两类。 一种是设备上操作系统的通用内存管理。 现有研究主要集中在应用程序级内存管理上。 另一种是针对DNN的定制内存优化方法。 Split-CNN (jin2019split, ) 提议将单个层的权重拆分为多个子窗口,在这些子窗口上应用内存卸载和预取,以减少激活内存和权重内存。 Melon (wang2022melon, ) 整合了新技术来处理高内存碎片和内存适应,以适应资源受限的移动设备,即重新计算和微批处理。 这些研究大多集中在设备上训练和传统的较小的DNN模型上,而不是LLM。 EdgeMoE 是为了优化LLM的内存占用而构建的,并且与上述技术正交。
非自回归MoE模型优化 一些工作集中在优化设备上的非自回归MoE模型。 Edge-MoE (sarkar2023edge, ) 旨在提高边缘设备上非自回归Transformer模型的性能。 在基于 MoE 的模型情况下,它引入了按专家计算的方式,以最大限度地重用已加载的专家。 然而,必须注意的是,Edge-MoE 主要加速了非自回归的基于 Transformer 的模型,例如 ViT (dosovitskiy2020image, )。 这些工作只能优化近似于设备能力的内存占用。 相反,对于具有解码器的自回归大型语言模型,EdgeMoE 表现出色。 具体而言,EdgeMoE 是为基于自回归 MoE 的 LLM 而构建的,并且与它们正交。
6. 结论
在这项工作中,我们提出了 EdgeMoE,第一个用于混合专家 (MoE) LLM 的设备上推理引擎。 EdgeMoE 整合了两种创新技术:专家特定位宽自适应,在可接受的精度损失下减少专家大小;以及专家预加载,它预测激活的专家并使用计算-I/O 管道预加载它们。 大量实验表明,EdgeMoE 使得 MoE LLM 在边缘 CPU 和 GPU 平台上能够进行实时推理,同时保持可接受的精度损失。
参考文献
- [1] Microsoft translator enhanced with z-code mixture of experts models. https://www.microsoft.com/en-us/research/blog/microsoft-translator-enhanced-with-z-code-mixture-of-experts-models/, 2022.
- [2] Beating google and apple, huawei brings large ai model to mobile voice assistant - huawei central. https://www.huaweicentral.com/beating-google-and-apple-huawei-brings-large-ai-model-to-mobile-voice-assistant/, 2023.
- [3] c4 · datasets at hugging face. https://huggingface.co/datasets/c4, 2023.
- [4] Chatgpt - google play. https://play.google.com/store/apps/details?id=com.openai.chatgpt, 2023.
- [5] Jetson tx2 module — nvidia developer. https://developer.nvidia.com/embedded/jetson-tx2, 2023.
- [6] Model card for tanrei/gptsan-japanese. https://huggingface.co/Tanrei/GPTSAN-japanese, 2023.
- [7] Models - hugging face. https://huggingface.co/models, 2023.
- [8] Move speed usb2.0. http://www.movespeed.com/productinfo/1162939.html, 2023.
- [9] Raspberry pi 4 model b – raspberry pi. https://www.raspberrypi.com/products/raspberry-pi-4-model-b/2, 2023.
- [10] samsum · datasets at hugging face. https://huggingface.co/datasets/samsum, 2023.
- [11] Samsung 860 evo — consumer ssd — specs & features — samsung semiconductor global. https://semiconductor.samsung.com/consumer-storage/internal-ssd/860evo/, 2023.
- [12] Sandisk ultra® microsd, uhs-i card, full hd store — western digital. https://www.westerndigital.com/products/memory-cards/sandisk-ultra-uhs-i-microsd#SDSQUNC-016G-AN6MA, 2023.
- [13] wikipedia-japanese · datasets at hugging face. https://huggingface.co/datasets/inarikami/wikipedia-japanese, 2023.
- [14] World’s 1st on-device stable diffusion on android — qualcomm. https://www.qualcomm.com/news/onq/2023/02/worlds-first-on-device-demonstration-of-stable-diffusion-on-android, 2023.
- [15] xsum · datasets at hugging face. https://huggingface.co/datasets/xsum, 2023.
- [16] Alham Fikri Aji and Kenneth Heafield. Compressing neural machine translation models with 4-bit precision. In Proceedings of the Fourth Workshop on Neural Generation and Translation, pages 35–42, 2020.
- [17] Sourav Bhattacharya and Nicholas D Lane. Sparsification and separation of deep learning layers for constrained resource inference on wearables. In Proceedings of the 14th ACM Conference on Embedded Network Sensor Systems CD-ROM, pages 176–189, 2016.
- [18] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [19] Qingqing Cao, Niranjan Balasubramanian, and Aruna Balasubramanian. Mobirnn: Efficient recurrent neural network execution on mobile gpu. In Proceedings of the 1st International Workshop on Deep Learning for Mobile Systems and Applications, pages 1–6, 2017.
- [20] Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, and Christopher De Sa. Quip: 2-bit quantization of large language models with guarantees. arXiv preprint arXiv:2307.13304, 2023.
- [21] Alexis Chevalier, Alexander Wettig, Anirudh Ajith, and Danqi Chen. Adapting language models to compress contexts. arXiv preprint arXiv:2305.14788, 2023.
- [22] Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691, 2023.
- [23] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
- [24] Luciano Del Corro, Allie Del Giorno, Sahaj Agarwal, Bin Yu, Ahmed Awadallah, and Subhabrata Mukherjee. Skipdecode: Autoregressive skip decoding with batching and caching for efficient llm inference. arXiv preprint arXiv:2307.02628, 2023.
- [25] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- [26] Nan Du, Yanping Huang, Andrew M Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, et al. Glam: Efficient scaling of language models with mixture-of-experts. In International Conference on Machine Learning, pages 5547–5569. PMLR, 2022.
- [27] Tyna Eloundou, Sam Manning, Pamela Mishkin, and Daniel Rock. Gpts are gpts: An early look at the labor market impact potential of large language models. arXiv preprint arXiv:2303.10130, 2023.
- [28] William Fedus, Jeff Dean, and Barret Zoph. A review of sparse expert models in deep learning. arXiv preprint arXiv:2209.01667, 2022.
- [29] William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. The Journal of Machine Learning Research, 23(1):5232–5270, 2022.
- [30] Elias Frantar and Dan Alistarh. Sparsegpt: Massive language models can be accurately pruned in one-shot. 2023.
- [31] Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323, 2022.
- [32] Karl Friston. Hierarchical models in the brain. PLoS computational biology, 4(11):e1000211, 2008.
- [33] Xinyu Fu, Eugene Ch’ng, Uwe Aickelin, and Simon See. Crnn: a joint neural network for redundancy detection. In 2017 IEEE international conference on smart computing (SMARTCOMP), pages 1–8. IEEE, 2017.
- [34] Yao Fu, Hao Peng, Litu Ou, Ashish Sabharwal, and Tushar Khot. Specializing smaller language models towards multi-step reasoning. arXiv preprint arXiv:2301.12726, 2023.
- [35] Tao Ge, Jing Hu, Xun Wang, Si-Qing Chen, and Furu Wei. In-context autoencoder for context compression in a large language model. arXiv preprint arXiv:2307.06945, 2023.
- [36] Liwei Guo, Wonkyo Choe, and Felix Xiaozhu Lin. Sti: Turbocharge nlp inference at the edge via elastic pipelining. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, pages 791–803, 2023.
- [37] Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149, 2015.
- [38] Loc N Huynh, Youngki Lee, and Rajesh Krishna Balan. Deepmon: Mobile gpu-based deep learning framework for continuous vision applications. In Proceedings of the 15th Annual International Conference on Mobile Systems, Applications, and Services, pages 82–95, 2017.
- [39] RA Jacobs, MI Jordan, SJ Nowlan, and GE Hinton. ªadaptive mixtures of local experts, º neural computation, vol. 3. 1991.
- [40] Tian Jin and Seokin Hong. Split-cnn: Splitting window-based operations in convolutional neural networks for memory system optimization. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, pages 835–847, 2019.
- [41] Yongsoo Joo, Junhee Ryu, Sangsoo Park, and Kang G Shin. FAST: Quick application launch on Solid-State drives. In 9th USENIX Conference on File and Storage Technologies (FAST 11), 2011.
- [42] Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W Mahoney, and Kurt Keutzer. Squeezellm: Dense-and-sparse quantization. arXiv preprint arXiv:2306.07629, 2023.
- [43] Young Jin Kim, Raffy Fahim, and Hany Hassan. Mixture of quantized experts (moqe): Complementary effect of low-bit quantization and robustness. 2022.
- [44] Nicholas D Lane, Sourav Bhattacharya, Petko Georgiev, Claudio Forlivesi, Lei Jiao, Lorena Qendro, and Fahim Kawsar. Deepx: A software accelerator for low-power deep learning inference on mobile devices. In 2016 15th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), pages 1–12. IEEE, 2016.
- [45] Stefanos Laskaridis, Stylianos I Venieris, Mario Almeida, Ilias Leontiadis, and Nicholas D Lane. Spinn: synergistic progressive inference of neural networks over device and cloud. In Proceedings of the 26th annual international conference on mobile computing and networking, pages 1–15, 2020.
- [46] Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668, 2020.
- [47] Mike Lewis, Shruti Bhosale, Tim Dettmers, Naman Goyal, and Luke Zettlemoyer. Base layers: Simplifying training of large, sparse models. In International Conference on Machine Learning, pages 6265–6274. PMLR, 2021.
- [48] Liunian Harold Li, Jack Hessel, Youngjae Yu, Xiang Ren, Kai-Wei Chang, and Yejin Choi. Symbolic chain-of-thought distillation: Small models can also” think” step-by-step. arXiv preprint arXiv:2306.14050, 2023.
- [49] Yixiao Li, Yifan Yu, Qingru Zhang, Chen Liang, Pengcheng He, Weizhu Chen, and Tuo Zhao. Losparse: Structured compression of large language models based on low-rank and sparse approximation. arXiv preprint arXiv:2306.11222, 2023.
- [50] Rendong Liang, Ting Cao, Jicheng Wen, Manni Wang, Yang Wang, Jianhua Zou, and Yunxin Liu. Romou: Rapidly generate high-performance tensor kernels for mobile gpus. In Proceedings of the 28th Annual International Conference on Mobile Computing And Networking, pages 487–500, 2022.
- [51] C Lin. Recall-oriented understudy for gisting evaluation (rouge). Retrieved August, 20:2005, 2005.
- [52] Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, and Song Han. Awq: Activation-aware weight quantization for llm compression and acceleration. arXiv preprint arXiv:2306.00978, 2023.
- [53] Sicong Liu, Yingyan Lin, Zimu Zhou, Kaiming Nan, Hui Liu, and Junzhao Du. On-demand deep model compression for mobile devices: A usage-driven model selection framework. In Proceedings of the 16th annual international conference on mobile systems, applications, and services, pages 389–400, 2018.
- [54] Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, and Vikas Chandra. Llm-qat: Data-free quantization aware training for large language models. arXiv preprint arXiv:2305.17888, 2023.
- [55] Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Re, et al. Deja vu: Contextual sparsity for efficient llms at inference time. In International Conference on Machine Learning, pages 22137–22176. PMLR, 2023.
- [56] Xinyin Ma, Gongfan Fang, and Xinchao Wang. Llm-pruner: On the structural pruning of large language models. arXiv preprint arXiv:2305.11627, 2023.
- [57] Akhil Mathur, Nicholas D Lane, Sourav Bhattacharya, Aidan Boran, Claudio Forlivesi, and Fahim Kawsar. Deepeye: Resource efficient local execution of multiple deep vision models using wearable commodity hardware. In Proceedings of the 15th Annual International Conference on Mobile Systems, Applications, and Services, pages 68–81, 2017.
- [58] Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Rae Ying Yee Wong, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. Specinfer: Accelerating generative llm serving with speculative inference and token tree verification. arXiv preprint arXiv:2305.09781, 2023.
- [59] Xuefei Ning, Zinan Lin, Zixuan Zhou, Huazhong Yang, and Yu Wang. Skeleton-of-thought: Large language models can do parallel decoding. arXiv preprint arXiv:2307.15337, 2023.
- [60] Wei Niu, Xiaolong Ma, Sheng Lin, Shihao Wang, Xuehai Qian, Xue Lin, Yanzhi Wang, and Bin Ren. Patdnn: Achieving real-time dnn execution on mobile devices with pattern-based weight pruning. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, pages 907–922, 2020.
- [61] OpenAI. Gpt-4 technical report. arXiv preprint arXiv:2303.08774v2, 2023.
- [62] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- [63] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. 2018.
- [64] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- [65] Stephen Roller, Sainbayar Sukhbaatar, Jason Weston, et al. Hash layers for large sparse models. Advances in Neural Information Processing Systems, 34:17555–17566, 2021.
- [66] Rishov Sarkar, Hanxue Liang, Zhiwen Fan, Zhangyang Wang, and Cong Hao. Edge-moe: Memory-efficient multi-task vision transformer architecture with task-level sparsity via mixture-of-experts. arXiv preprint arXiv:2305.18691, 2023.
- [67] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
- [68] Benjamin Spector and Chris Re. Accelerating llm inference with staged speculative decoding. arXiv preprint arXiv:2308.04623, 2023.
- [69] Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. A simple and effective pruning approach for large language models. arXiv preprint arXiv:2306.11695, 2023.
- [70] Shicheng Tan, Weng Lam Tam, Yuanchun Wang, Wenwen Gong, Shu Zhao, Peng Zhang, and Jie Tang. [industry] gkd: A general knowledge distillation framework for large-scale pre-trained language model. In The 61st Annual Meeting Of The Association For Computational Linguistics, 2023.
- [71] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [72] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [73] Chandra Shekhara Kaushik Valmeekam, Krishna Narayanan, Dileep Kalathil, Jean-Francois Chamberland, and Srinivas Shakkottai. Llmzip: Lossless text compression using large language models. arXiv preprint arXiv:2306.04050, 2023.
- [74] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [75] Peifeng Wang, Zhengyang Wang, Zheng Li, Yifan Gao, Bing Yin, and Xiang Ren. Scott: Self-consistent chain-of-thought distillation. arXiv preprint arXiv:2305.01879, 2023.
- [76] Qipeng Wang, Mengwei Xu, Chao Jin, Xinran Dong, Jinliang Yuan, Xin Jin, Gang Huang, Yunxin Liu, and Xuanzhe Liu. Melon: Breaking the memory wall for resource-efficient on-device machine learning. In Proceedings of the 20th Annual International Conference on Mobile Systems, Applications and Services, pages 450–463, 2022.
- [77] Minghao Wu, Abdul Waheed, Chiyu Zhang, Muhammad Abdul-Mageed, and Alham Fikri Aji. Lamini-lm: A diverse herd of distilled models from large-scale instructions. arXiv preprint arXiv:2304.14402, 2023.
- [78] Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. In International Conference on Machine Learning, pages 38087–38099. PMLR, 2023.
- [79] Mengwei Xu, Feng Qian, Mengze Zhu, Feifan Huang, Saumay Pushp, and Xuanzhe Liu. Deepwear: Adaptive local offloading for on-wearable deep learning. IEEE Transactions on Mobile Computing, 19(2):314–330, 2019.
- [80] Mengwei Xu, Mengze Zhu, Yunxin Liu, Felix Xiaozhu Lin, and Xuanzhe Liu. Deepcache: Principled cache for mobile deep vision. In Proceedings of the 24th annual international conference on mobile computing and networking, pages 129–144, 2018.
- [81] Mingxue Xu, Yao Lei Xu, and Danilo P Mandic. Tensorgpt: Efficient compression of the embedding layer in llms based on the tensor-train decomposition. arXiv preprint arXiv:2307.00526, 2023.
- [82] Siyu Yuan, Jiangjie Chen, Ziquan Fu, Xuyang Ge, Soham Shah, Charles Robert Jankowski, Deqing Yang, and Yanghua Xiao. Distilling script knowledge from large language models for constrained language planning. arXiv preprint arXiv:2305.05252, 2023.
- [83] Zhihang Yuan, Lin Niu, Jiawei Liu, Wenyu Liu, Xinggang Wang, Yuzhang Shang, Guangyu Sun, Qiang Wu, Jiaxiang Wu, and Bingzhe Wu. Rptq: Reorder-based post-training quantization for large language models. arXiv preprint arXiv:2304.01089, 2023.
- [84] Ali Hadi Zadeh, Isak Edo, Omar Mohamed Awad, and Andreas Moshovos. Gobo: Quantizing attention-based nlp models for low latency and energy efficient inference. In 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 811–824. IEEE, 2020.
- [85] Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew M Dai, Quoc V Le, James Laudon, et al. Mixture-of-experts with expert choice routing. Advances in Neural Information Processing Systems, 35:7103–7114, 2022.