使用 3D 高斯进行可微分渲染的灵活技术
摘要
快速、可靠的形状重建是许多计算机视觉应用中的重要组成部分。 神经辐射场证明,逼真的新颖视图合成是可以实现的,但受到快速重建真实场景和物体的性能要求的限制。 最近的几种方法建立在替代形状表示的基础上,特别是 3D 高斯。 我们开发了这些渲染器的扩展,例如集成可微光流、导出防水网格和渲染每光线法线。 此外,我们还展示了两种最近的方法如何彼此互操作。 这些重建快速、稳健,并且可以在 GPU 或 CPU 上轻松执行。 有关代码和可视化示例,请参阅 https://leonidk.github.io/fmb-plus。
1简介
随着计算机视觉系统在社会中得到更广泛的部署,无论是在机器人上还是通过混合现实耳机,用户将希望重建他们的许多日常物体。 虽然可以使用多视图场景重建的经典技术[61],但现代方法力求生成更加真实的场景,例如由神经辐射场(NeRF)创建的方法[48] 以及大量后续工作[64]。 值得注意的是,这些 NeRF 方法可以被视为可微渲染器 [39, 73],其中底层场景表示针对视图合成进行了优化。 然而,NeRF 方法的计算要求很高,即使使用 Instant-NGP [51] 等加速方法也是如此。


最近的两篇论文探讨了快速 NeRF 替代方案的类似方法 - ECCV 2022 中的 Fuzzy Metaballs [34] 和 SIGGRAPH 2023 中的 3D Gaussian Splatting [33]。 两种方法都使用一组经典基元(特别是 3D 高斯[21, 56])来表示几何。 前者构建了3D高斯的可微分光线追踪器,将其连接到元球文献[4],开发了无排序渲染函数,专注于快速CPU运行时间,使用了数十个高斯,并进行了定量实验用于对象重建和姿态估计。 在年份层中,后者设计了一个带有自定义 CUDA 内核的快速光栅器,用于绘制 [46, 54],使用了数百万个高斯,并将他们的系统集中于重建整个场景以接近 NeRF 保真度级别。 我们演示了这两种方法之间的联系和扩展。
本文的重点是扩展 Fuzzy Metaballs 渲染器,使其更简单、更强大,并添加其他功能。 我们证明这些最近的论文是可互操作的并呈现相同的底层表示。 由于大多数成熟的渲染技术都是基于三角形网格构建的,因此我们演示了一种将 3D 高斯表示转换为网格的可靠方法。
我们的贡献总结如下:
-
•
开发模糊元球 [34] 的简化版本,用于高斯形状重建(Section 3.2)。
-
•
展示如何在没有超参数的情况下渲染模糊元球 [34](Section 3.3)。
-
•
展示如何获得每像素、可微的光流及其在重建中的好处(部分 5)。
-
•
演示如何从 3D 高斯定义的形状导出网格(Section 6)。
-
•
证明现有的 3D 高斯渲染方法 [33, 34] 是可互操作的(Section 7)。
-
•
开发一种基于损失的方法,通过拆分组件来重新参数化高斯函数(Section 8)。
这些技术使得这些 3D 高斯形状表示能够更强大、更灵活地用于涉及形状重建的应用。 值得注意的是,这些方法不需要预训练,并且可以直接在感兴趣的场景上进行优化,而不会产生数据集偏差,这使得它们适用于机器人可能与新物体交互的机器人应用,并且受到机载计算的限制。
2相关工作
相关工作的全面概述可以在之前使用 3D 高斯的论文中找到,包括 Fuzzy Metaballs [34]、3D Gaussian Splatting [33] 和 VoGE [66 ]。
一些根据部分观测建立模型的早期方法使用广义圆柱体[2]。 更常见的是,方法建立在三角形网格、点云和面元[57]之上。 已为这些表示构建了可微渲染,最初是针对网格 [30, 39, 40]。 其中包括可实现基于 GPU 的快速结果[36]和高质量结果[53]的自定义后端。 其他作品关注点云[26, 73]。 Pulsar [37] 使用球体作为表示形式,相当于各向同性 3D 高斯。 基于基元的渲染方法对于合成 [74] 和跟踪 [43] 都有好处。
最早在渲染中使用 3D 高斯的工作来自 Blinn [4],最初称为原子、斑点或元球,是隐式曲面的诞生。 这些技术有多种方法[18,23,52,63,67,68,69]。 一些渲染器使用光线,而另一些渲染器使用splatting [1],最近的一些可微渲染构建屏幕空间高斯[50]。 其他人使用高斯作为计算机视觉中的主要表示[9, 10, 11, 16, 17, 22, 44]或通过投影、搜索或其他技术渲染它们[25, 55 ,62]。
高斯可以被视为仅使用一阶 () 和二阶 () 阶矩 [27] 的基本构建块。 点云仅使用。 定向点云添加协方差特征向量[9],高斯混合[11]使用所有信息。 该空间中的连接包括误差指标[15, 45]和物理模拟[49]。
目前正在开展将 NeRF 风格的可微分渲染器连接到网格表示的工作。 MobileNeRF [6] 使用商用硬件的光栅化管道来执行类 NeRF 对象的渲染。 VMesh [19] 构造了体积和网格的混合表示。 NeRFMeshing [58] 学习了有符号曲面近似网络,将 NeRF 表示提炼为网格。
3 光线形状交点
现有的 3D 高斯和射线相交方法通常采用两种形式。 受 NeRF 系列方法 [33, 66] 启发的方法通常会对所有交集进行排序,并使用较近的高斯分布来减弱其他高斯分布的贡献。 Fuzzy Metaballs [34] 引入了一种启发式技术,用于混合不需要排序的交叉点。 Section 3.1 总结了这种技术,Section 3.2提出了一种简化,Section 3.3 提出了一种没有超参数的变体。 所有三个都正确渲染相同的形状,因此其中一个优化的对象可以用另一个复制。
3.1 加权混合
在模糊元球[34]中,每条射线()和每个高斯之间的交点是单独计算的,然后与加权平均值相结合。 每个高斯都被参数化为均值 ()、逆根精度 () 和权重 (),其中 .
多元高斯定义为
| (1) |
每个高斯的非归一化对数距离是
| (2) |
当涉及评估射线的第高斯分布时,我们将其称为(这里我们使用最大似然点,线性方法[34])。
对于每个高斯,其交集 () 和距离 () 用于获取权重 ()。 最终得到的交集为,类似于OIT [12, 47]:
| (3) |
其他属性的每光线估计可以继续使用方程3。 例如,(距相机的距离)可以替换为 (正常)或 (颜色),并且可以重复使用相同的混合函数。 有关正常计算的更多详细信息,请参阅部分 6。 将非标准化高斯密度视为:
| (4) |
原始的模糊元球方法使用 5 个超参数 () 来计算权重和透明度。 还有一个形状比例 () 来考虑不同比例的形状并返回相同的结果。 以下是权重和 (质量/不透明度)函数:
| (5) |
| (6) |
3.2双参数模型
在视频形状重建中,其中 3 个超参数不是必需的,我们开发了一个在重建设置中工作的简化的两参数模型。
首先, 用于对相机后面的交叉点做出一些微小的贡献。 虽然这确实使渲染器更具可微性,但在实践中并没有使用它,因此可以删除 函数,留下我们
| (7) |
由于原始论文 [34] 专注于渲染完整、正确的高斯混合模型(其中 ),因此需要一个归一化因子 来解释如何GMM 应该是非常不透明的。 在重建的情况下,不需要严格的GMM,因此学习可以是非标准化的职责。 此外,GMM 重点建议使用平滑阶跃函数(sigmoid)来计算 ,但形状重建可以将其简化为衰减指数,让我们放弃截距项 。 这使我们能够为 提供一个简单的、也许熟悉的 [48, 65] 表达式:
| (8) |
我们在大多数实验中都使用这个简化的二参数模型。 虽然我们注意到由于失去全局归一化条件而存在一些细微的差异,但它们很小,而且主要是在姿态估计的空间中,这不是我们形状估计实验的重点。
3.3零参数模型
通过上面给出的简化设计,以及其他 3D 高斯论文 [33, 66] 中的 NeRF 风格方法,我们还研究了 Fuzzy Metaball 渲染的 alpha 合成变体,该变体需要对所有交叉点进行排序,然后计算传播。 传输可以被视为权重,并且 Equation 3 可用于计算深度估计(以及法线和颜色估计):
| (9) |
其中 是早期交叉口的累积传输量
| (10) |
这些方程使用元球创建了一个可微分渲染的版本,它是无超参数的,不需要泼溅,并且可以使用与之前的工作[34]相同的深度、法线和颜色计算权重。 正如我们在Table2和Figure7中的实验> 表明,这种方法速度较慢,但性能几乎相同。





4形状重建
系统的输入是视频和单个屏蔽帧。 COLMAP [61] 生成姿势,XMem [7] 传播蒙版,Unimatch [70] 生成流,并优化 3D 高斯以拟合数据。 由于我们使用基于光线的可微渲染器并且能够对包含所有帧中的像素的小批量进行采样,因此形状收敛得很快。
我们的可微渲染代码基于 Fuzzy Metaballs [34],它构建在 JAX [5] 中,并允许在 CPU 和 GPU 上进行重建。 使用 Nvidia GTX 1080,我们可以为大约 的图像序列进行内存处理,而我们的 CPU 实验通常更接近于 。 两组实验通常会在商用硬件上不到一分钟内收敛。 为了便于比较,我们像之前的工作一样使用 40 高斯。
可微渲染为形状重建中的许多损失函数提供了灵活性。 在我们的实验中,我们结合了对象分割掩模的交叉熵损失 () 以及颜色和流量的 损失 (Section 5),由对象蒙版加权。 估计的 alpha 被剪裁为 。 对于 、颜色 () 和光流 (),我们使用以下损失函数:
| (11) | ||||
| (12) | ||||
| (13) | ||||
| (14) |
在实践中,我们使用已将伽玛校正回线性强度的颜色,并使用 sigmoid 从无约束参数化映射到 。 流量以较短图像尺寸的一半的比例来测量。 这让我们可以为所有实验设置 和 。 我们对所有实验都使用相同的设置:初始化来自随机的小高斯球体,并且我们使用学习率、规范重新缩放、批量大小和所有其他已知参数的固定参数。 学习率根据统计标准[34]自动衰减。
我们使用 Adam [35] 优化器,并根据相机姿态距离将所有场景重新缩放为规范尺寸,以平衡使用时发生的均值和精度 [34] 的优化重新调整优化器。 我们从整个序列中随机采样 50,000 条光线的小批量,这导致收敛速度极快,通常在一个时期内就可以得到合理的形状(图 7 )。 为简单起见,我们使用先前工作 [34] 中使用的每高斯简单颜色,但可以扩展球谐函数以获得更高的每高斯 [14, 33] 颜色保真度。
我们的重建示例可以参见图2。 尽管优化只需要几分钟,在相当低分辨率的图像上运行,并且高斯函数相当少,但我们仍然可以看到良好的结果。 深度估计能够捕捉小的几何细节(注意摩托车上的支架和两个镜子)。 尽管初始化是一个小的、不可见的高斯球体,但优化过程能够重建具有丰富几何形状的形状(例如自行车和植物)。 最后,颜色结果看起来相当真实。 尽管必须使用单独的高斯将 2D 平面纹理绘制到表面上,但玩具卡车和滑板重建仍获得了合理的结果。 在玩具卡车中,灰色侧面和车顶板细节出现在重建中。 在滑板中,所绘制的曲线形状也在重建中近似建模,两个轮子也是如此。
我们使用 Section 3.1 和 Section 3.3 获得了类似的良好结果,但图2中的所有结果都使用更快的双参数模型进行优化和生成的视觉效果。
5 光流重建
许多 3D 重建方法仅专注于从给定序列 [33] 重建独立图像,包括所有 3D 高斯方法 [33, 34, 66]。 然而,在实践中,这些图像序列通常是通过手机视频[60]收集的,并且具有很强的时间先验。 受到重建 4D 场景[38,71,72]工作的启发,我们利用光流来生成更精确的静态对象 3D 重建。
光流提供了表面对应的假设,从而规范了形状重建。 对应性在形状估计的经典技术中至关重要[29, 42]。 稀疏粒子视频跟踪器扩展了这一点,并获得长期视频对应[20]。
光流是一个有用的信号,因为它是一个局部估计器,并且对于典型用户在自动曝光下捕获场景时发生的长期光照变化具有鲁棒性[28]。 这使得它可能是比颜色模型更合适的损失术语,因为颜色模型对光照变化敏感。 此外,颜色通常意味着纹理,这意味着难以重建的高频纹理细节[48],而高效的形状估计可能不需要。
流的好处可以从我们的实验中看出,定性见图4,定量见表1。 一个有趣的结果是,即使经典的光流[13]也为形状优化提供了有用的线索,尽管它非常嘈杂(参见图 4 (a))。 更好的是,最先进的流方法(例如 Unimatch [70])速度非常快(在 GPU 硬件上实时),并且即使在无纹理区域也能学到良好的先验知识。 使用这样的学习流图(图 4(b))可以极大地帮助形状估计。 优化后,预测模型流量(图 4(d))与用于监督的网络给定的流量估计非常相似它。 结合流动还可以产生明显更平滑的深度图,如图3所示。




在我们的实验中,光流稍微损害了重建模型的颜色保真度,但提供了更准确的形状重建,如图 3. 添加流动损失项后,表面对应的替代估计有助于解决轮廓和颜色损失项的凹/凸模糊性。 例如,泰迪熊的身体变得光滑,手臂变得轮廓分明。
通过基于光线的 3D 高斯可微分渲染,计算每像素光流相当容易。 它只需要获取从 Equation 3 获得的 3D 坐标,并将其与相邻相机姿态进行变换,然后投影回相机坐标。
在我们的实现中,我们将所有相机姿势传递到渲染函数中,并用单个反焦距参数表示相机(假设图像没有失真,投影位于图像的中心,并且像素是正方形)。 计算给定帧的深度图像后,我们转换点云(向前和向后)并将转换后的坐标投影到图像中。 坐标的变化是直接的每射线光流估计。 在不使用其他源来规范光流的情况下,我们得到了合理的估计,但由于形状不确定性而出现了一些伪影(如 图 4(c) 所示) )。
我们包括对前向流量(姿势到姿势)和后向流量(姿势到姿势)的估计对于每条光线,可微分渲染器。




| Depth Error | Runtime (seconds) | |
|---|---|---|
| No Color or Flow | 0.271 | 17 |
| Color | 0.262 | 15 |
| Color & Classic Flow [13] | 0.237 | 14 |
| Color & Learned Flow [70] | 0.155 | 15 |





6 导出网格
许多成功的可微渲染器意识到快速、高效、鲁棒的可微渲染通常需要平滑、模糊和不确定的表面表示[48,34,33]。 为了优化视频中的形状,具有一定程度的柔软度以帮助梯度流动是有帮助的。
另一方面,大多数桌面和移动 GPU 中的商业光栅化管道通常在三角形网格 [19, 6] 上运行。 此外,形状处理领域通常不仅喜欢网格形式的确定表面,还喜欢防水网格[75, 24]。 可微分网格渲染器通常使用显式空间平滑项 [39, 59] 来弥合这一鸿沟。
相反,3D 高斯、神经表面和其他类似方法都是隐式表面方法,其中对象的属数可以在优化过程中发生变化。 许多现有作品使用行进立方体[41,48,34]导出网格,其中评估体积网格并在穿过特定水平集阈值的边缘处生成三角形。 虽然快速且简单,但可以生成非防水网格。 此外,它可能需要在理想阈值上进行搜索,以找到隐式表面的哪个水平集与显式表面最匹配[34]。
在这项工作中,我们利用底层可微分渲染器使用的表面定义,然后求解适当的泊松方程 [31, 32]。 在泊松曲面重建中,定向点集(法线指示曲面局部切平面的点)用作输入来求解泊松方程:
| (15) |
求解这些方程可以通过条件良好的稀疏线性系统[31]来完成。 定向点云中的每个点提供指示函数的局部梯度的估计(这些点位于对象表面内部)。 泊松曲面求解器的一个很好的特性是,它们的解总是产生防水网格,因为它们求解指示体积,从而产生一个折叠在 中的 流形表面。 这个过程可以通过具有紧凑支持的 B 样条的基本函数集来完成。
为了生成定向点集,我们只需遍历所有训练视图并渲染对象的点云,即可生成点位置 。 每个点的方向可以通过两种不同的方式产生(如图图8所示)。 第一种也是最常见的一种方法是使用光栅化局部性,为每个点 () 取一个水平 () 和一个垂直 () 屏幕空间相邻点,然后求它们的交乘:
| (16) |
该技术适用于在网格上生成图像(因此光栅化)的任何可微渲染器,但在不连续性时产生较差的结果。
3D 高斯的另一种方法是重新使用 Equation 3 来混合法线的所有局部估计 ( 而不是 )进入最终估计。 法线的局部估计由方程1的导数给出。
| (17) |
一般来说,法线的符号和比例是固定的:法线的符号应该面向创建它的相机,以及。 这两种技术都可以在图8中看到。 在实践中,混合定义是首选,因为它不需要邻居。
为了从渲染器生成网格,我们通常使用 Section 3.1 执行更快的优化。 Section 3.3 中的渲染方程可以直接渲染该表示,无需任何更改。 Alpha 合成定义是网格导出的首选,因为它比启发式混合具有更高的视图一致性。 最后,我们可以拒绝任何未达到直接交叉点质量阈值 的交叉点,该阈值通常设置为 0.9。 泊松曲面重构产生曲面插值,因此点样本的稀疏性不是问题。 此外,我们可以导出彩色的、定向的点云,其中颜色可以是重建的颜色,也可以是这些点处图像本身的颜色(参见图 5)。 我们通过求解具有狄利克雷边界约束[32]的方程15来获得对象重建。

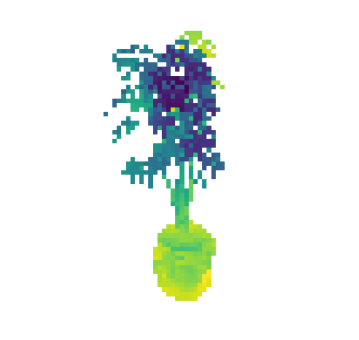
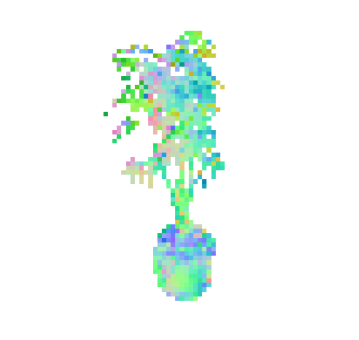


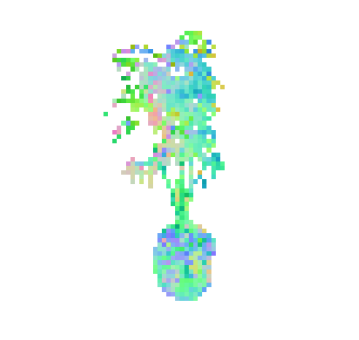


























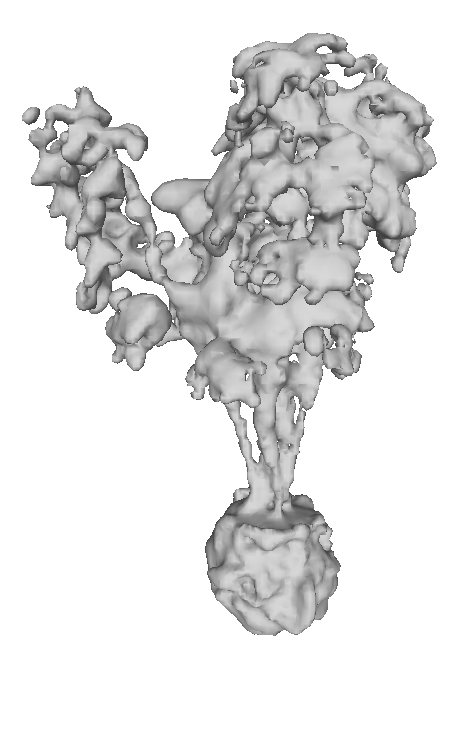



7互操作性
我们描述了模糊元球 [34] 和 3D 高斯分布 [33] 如何共享相似的底层形状表示。 我们通过在 图 6 和 9 中显示结果来证明这一点,其中使用 3D 高斯执行初始形状重建泼纸[33],然后使用Sections3.1和3.3,然后使用 Section2> 63>1> 使用定向点导出。
我们在图7和部分6中进行的实验表明 Sections 3.1 和 3.3 使用相互兼容的形状表示定义。 然而,Gaussian Splatting [33] 工作使用完全不同的代码库,在不同的框架中,优化场景而不是对象,没有对象掩码,使用自定义 CUDA 内核,并且更喜欢 到 估计值。 然而,由于两者都使用 3D 高斯,我们可以用另一个渲染一个。
我们只需几个步骤即可将高斯分布方法转换为与我们的方法兼容。 直接使用均值,将每个转换为,并替换每个高斯的。 为简单起见,我们忽略 并为剩余的 3D 高斯设置 ,我们发现效果相当好111 的反 sigmoid 转换也许与适当的 也是合理的,但我们没有搜索。 . 大约 90% 的高斯模型 不足,在我们的实验中创造了十倍的加速。 对于加权混合实验,我们重复使用了之前实验中的 和 设置。
从图 6中可以看出,两种技术都能够捕获重建榕树植物中的精细茎和叶结构。 加权混合技术表现出更平滑的法线,但网格导出使用alpha堆肥方法,可以获得合理的网格。
在图 9中,我们展示了榕树的泊松曲面重建,其中用于求解方程的定向点云是由我们的渲染器生成的,但是原始重建是通过 3D 高斯喷射进行的。 我们展示了不同树深度的重建,以更精细的尺度显示细节的增加和噪声的增加。 考虑到定向点云的低分辨率,求解器可以恢复相当精细的细节。
这扩展了 3D 高斯泼溅方法的实用性,可以使用我们具有可行的 JAX [5] CPU 和 GPU 后端的快速方法进行渲染。 我们的方法支持每光线深度计算、法线和网格导出(Section 6)。 提供的榕树数据没有颜色,因此我们在图5中显示彩色导出。 网格导出提供了与大多数 3D 创建工具的互连。
| CPU | GPU | |
|---|---|---|
| Weighted Blending | ||
| (Section 3.1) | 4.94 s | 226.6 ns |
| Alpha Compositing | ||
| (Section 3.3) | 12.7 s | 377.6 ns |
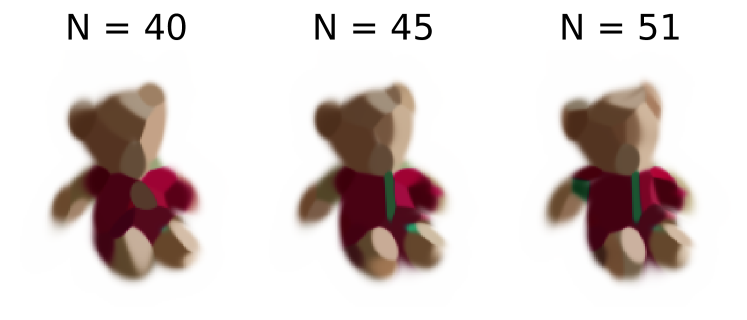
8 分裂高斯
虽然 3D Gaussian Splatting [33] 探索了一些用于合并和分裂高斯的启发式技术,但在这里我们开发了一种替代的确定性方法来修改重建中的高斯数量。
我们在初始模型根据统计标准[34]收敛后分割 3D 高斯。 然后我们重复优化过程。 图10中显示了其中的两个步骤。 分裂和去除过程基于去除对重建贡献最小的高斯和分裂基于所选择的损失被赋予太多重建责任的高斯。
为了计算贡献最小的高斯集,我们计算分配给每个高斯 和 的权重的均值和标准差,并删除满足的高斯
| (18) |
其中 是 z 分数,通常设置为 2。
为了计算分割标准,我们随机选取一批光线(通常约为数据集的 5%)并计算每条光线的损失(例如 Eq. 14但任何重建损失都是可行的)。 每条射线还有一组关联的计算权重 (等式 9 和7)。 在这批 射线中,我们将与每个高斯相关的平均损失估计为 。 我们将这些损失的平均值和标准差计算为 和 并分割满足以下条件的高斯分布:
| (19) |
其中 是 z 分数,通常设置为 1。
高斯分布是通过利用半正态分布[8]的性质形成两个高斯分布来分裂的。 这两个新均值是通过将初始均值 () 按主特征向量 () 的方向向相反方向移动,并通过主特征值 () 的适当因子 (协方差矩阵 () 的 ):
| (20) |
两个新的高斯函数都被赋予相同的协方差矩阵,从初始特征值和特征向量重建,但具有缩放的主导特征值:
| (21) |
缩放因子 和 基于半正态分布的属性。
我们复制新高斯的初始权重 () 和颜色 (),并在其不受约束的参数化空间中添加噪声 (),以避免出现问题进一步优化期间的耦合梯度:
| (22) | ||||
| (23) |
这种分割方法是确定性的,并且允许以迭代方式增加细节,如图10所示。
9讨论
随着视觉系统在日常环境中的部署不断增加,需要灵活、高效且易于计算的形状重建。 逼真可微分渲染的最新发展使虚拟系统准确捕捉虚拟世界中的日常物体的梦想成为现实。 3D 高斯分布或元球是一种简单而强大的形状表示形式,可以轻松重建,如先前的工作[33,34,66]所示。 这些技术扩展并互连了这些方法,并为它们提供了额外的灵活性。
加权混合和阿尔法堆肥方法的等效性提供了更广泛的选择——一种明显更快,另一种则缺乏超参数。 每光线混合法线的计算允许可靠的网格导出,连接到其他 3D 技术和方法,无需为行进立方体选择阈值[41],并通过泊松重建生成防水网格[32]。 我们展示了一种更具确定性、更扎实的方法来执行高斯函数的重新参数化。 最后,光流作为正则化器和表面对应的先验可以轻松可靠地提高形状重建的质量。
10结论
我们扩展了现有的 3D 高斯可微分渲染方法,以提高速度、简单性和灵活性。 这种扩展的灵活性应该允许这些表示形式用于更多的地方、更多的应用程序,并且可能比以前跨越更广泛的计算平台。
致谢: 我们要感谢 Jonathon Luiten,他看似无穷无尽的好奇心、兴趣和提问;事实证明,这对于开发这项工作的某些部分至关重要。 Georgios Kopanas 提供了 3DGS 榕树和有用的对话。 Arkadeep Chaudhury、Jon Barron 和 Adam Harley 提供了额外有益的对话和反馈。
参考
- [1] Bart Adams, Toon Lenaert, and Philip Dutré. Particle splatting: Interactive rendering of particle-based simulation data. Report CW 453, KU Leuven, July 2006.
- [2] Gerald Jacob Agin. Representation and Description of Curved Objects. PhD thesis, Stanford University, CA, USA, 1972.
- [3] Simon Baker, Stefan Roth, Daniel Scharstein, Michael J. Black, J.P. Lewis, and Richard Szeliski. A database and evaluation methodology for optical flow. In International Conference on Computer Vision, pages 1–8, 2007.
- [4] James F. Blinn. A generalization of algebraic surface drawing. ACM Trans. Graph., 1(3):235–256, July 1982.
- [5] James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018.
- [6] Zhiqin Chen, Thomas Funkhouser, Peter Hedman, and Andrea Tagliasacchi. Mobilenerf: Exploiting the polygon rasterization pipeline for efficient neural field rendering on mobile architectures. In The Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
- [7] Ho Kei Cheng and Alexander G. Schwing. XMem: Long-term video object segmentation with an atkinson-shiffrin memory model. In ECCV, 2022.
- [8] Cuthbert Daniel. Use of half-normal plots in interpreting factorial two-level experiments. Technometrics, 1(4):311–341, 1959.
- [9] Ben Eckart, Kihwan Kim, and Jan Kautz. Hgmr: Hierarchical gaussian mixtures for adaptive 3d registration. In ECCV 2018, pages 730–746, 2018.
- [10] Ben Eckart, Kihwan Kim, Alejandro Troccoli, Alonzo Kelly, and Jan Kautz. MLMD: Maximum Likelihood Mixture Decoupling for Fast and Accurate Point Cloud Registration. In 3DV, pages 241–249, 2015.
- [11] Ben Eckart, Kihwan Kim, Alejandro Troccoli, Alonzo Kelly, and Jan Kautz. Accelerated Generative Models for 3D Point Cloud Data. In CVPR, pages 5497–5505, 2016.
- [12] Eric Enderton, Erik Sintorn, Peter Shirley, and David Luebke. Stochastic transparency. In I3D ’10: Proceedings of the 2010 symposium on Interactive 3D graphics and games, pages 157–164, New York, NY, USA, 2010.
- [13] Gunnar Farnebäck. Two-frame motion estimation based on polynomial expansion. In Josef Bigun and Tomas Gustavsson, editors, Image Analysis, pages 363–370, Berlin, Heidelberg, 2003. Springer Berlin Heidelberg.
- [14] Sara Fridovich-Keil, Alex Yu, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. Plenoxels: Radiance fields without neural networks. In CVPR, 2022.
- [15] Michael Garland and Paul S Heckbert. Surface simplification using quadric error metrics. In SIGGRAPH, pages 209–216, 1997.
- [16] Kyle Genova, Forrester Cole, Avneesh Sud, Aaron Sarna, and Thomas Funkhouser. Local deep implicit functions for 3d shape, 2020.
- [17] Kshitij Goel, Nathan Michael, and Wennie Tabib. Probabilistic point cloud modeling via self-organizing gaussian mixture models. IEEE Robotics and Automation Letters, 8(5):2526–2533, 2023.
- [18] Olivier Gourmel, Anthony Pajot, Mathias Paulin, Loic Barthe, and Pierre Poulin. Fitted BVH for Fast Raytracing of Metaballs. Computer Graphics Forum, 3:7 – 288, 2010.
- [19] Yuan-Chen Guo, Yan-Pei Cao, Chen Wang, Yu He, Ying Shan, Xiaohu Qie, and Song-Hai Zhang. Vmesh: Hybrid volume-mesh representation for efficient view synthesis, 2023.
- [20] Adam W. Harley, Zhaoyuan Fang, and Katerina Fragkiadaki. Particle video revisited: Tracking through occlusions using point trajectories. In ECCV, 2022.
- [21] Paul S. Heckbert. Fun with gaussians. SIGGRAPH ’86 Advanced Image Processing seminar notes, 1986.
- [22] Amir Hertz, Rana Hanocka, Raja Giryes, and Daniel Cohen-Or. Pointgmm: a neural gmm network for point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020.
- [23] Robert Horvath. Image-space metaballs using deep learning. Master’s thesis, Faculty of Informatics, TU Wien, July 2019.
- [24] Shi-Min Hu, Zheng-Ning Liu, Meng-Hao Guo, Junxiong Cai, Jiahui Huang, Tai-Jiang Mu, and Ralph R. Martin. Subdivision-based mesh convolution networks. ACM Trans. Graph., 41(3):25:1–25:16, 2022.
- [25] H. Huang, H. Ye, Y. Sun, and M. Liu. Gmmloc: Structure consistent visual localization with gaussian mixture models. IEEE Robotics and Automation Letters, 5(4):5043–5050, 2020.
- [26] Eldar Insafutdinov and Alexey Dosovitskiy. Unsupervised learning of shape and pose with differentiable point clouds, 2018.
- [27] S. Julier, J. Uhlmann, and H.F. Durrant-Whyte. A new method for the nonlinear transformation of means and covariances in filters and estimators. IEEE Transactions on Automatic Control, 45(3):477–482, 2000.
- [28] Kim Jun-Seong, Kim Yu-Ji, Moon Ye-Bin, and Tae-Hyun Oh. Hdr-plenoxels: Self-calibrating high dynamic range radiance fields. In ECCV, 2022.
- [29] Takeo Kanade, Peter Rander, and P.J. Narayanan. Virtualized reality: constructing virtual worlds from real scenes. IEEE MultiMedia, 4(1):34–47, 1997.
- [30] Hiroharu Kato, Yoshitaka Ushiku, and Tatsuya Harada. Neural 3d mesh renderer, 2017.
- [31] Michael Kazhdan, Matthew Bolitho, and Hugues Hoppe. Poisson Surface Reconstruction. In Alla Sheffer and Konrad Polthier, editors, Symposium on Geometry Processing. The Eurographics Association, 2006.
- [32] Michael Kazhdan and Hugues Hoppe. Screened poisson surface reconstruction. ACM Transactions on Graphics (ToG), 32(3):1–13, 2013.
- [33] Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics (ToG), 42(4), July 2023.
- [34] Leonid Keselman and Martial Hebert. Approximate differentiable rendering with algebraic surfaces. In European Conference on Computer Vision (ECCV), Oct 2022.
- [35] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR (Poster), 2015.
- [36] Samuli Laine, Janne Hellsten, Tero Karras, Yeongho Seol, Jaakko Lehtinen, and Timo Aila. Modular primitives for high-performance differentiable rendering. ACM Transactions on Graphics, 39(6), 2020.
- [37] Christoph Lassner and Michael Zollhöfer. Pulsar: Efficient sphere-based neural rendering. arXiv:2004.07484, 2020.
- [38] Zhengqi Li, Simon Niklaus, Noah Snavely, and Oliver Wang. Neural scene flow fields for space-time view synthesis of dynamic scenes. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [39] Shichen Liu, Tianye Li, Weikai Chen, and Hao Li. Soft rasterizer: A differentiable renderer for image-based 3d reasoning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2019.
- [40] Matthew M. Loper and Michael J. Black. Opendr: An approximate differentiable renderer. In David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuytelaars, editors, ECCV, pages 154–169, Cham, 2014.
- [41] William E Lorensen and Harvey E Cline. Marching cubes: A high resolution 3d surface construction algorithm. ACM siggraph computer graphics, 21(4):163–169, 1987.
- [42] David G. Lowe and Thomas O. Binford. Interpretation Of Geometric Structure From Image Boundaries. In James J. Pearson, editor, Techniques and Applications of Image Understanding, volume 0281, pages 224 – 231. International Society for Optics and Photonics, SPIE, 1981.
- [43] Jonathon Luiten, Georgios Kopanas, Bastian Leibe, and Deva Ramanan. Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis. 2023.
- [44] Martin Magnusson. The three-dimensional normal-distributions transform: an efficient representation for registration, surface analysis, and loop detection. PhD thesis, Örebro universitet, 2009.
- [45] Prasanta Chandra Mahalanobis. On the generalized distance in statistics. Proceedings of the National Institute of Sciences (Calcutta), pages 49–55, 1936.
- [46] Petr Man. Generating and real-time rendering of clouds. Central European seminar on computer graphics, 2006.
- [47] Morgan McGuire and Louis Bavoil. Weighted blended order-independent transparency. Journal of Computer Graphics Techniques (JCGT), 2(2):122–141, December 2013.
- [48] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm, editors, Computer Vision – ECCV 2020, pages 405–421, Cham, 2020. Springer International Publishing.
- [49] Brian Mirtich. Fast and accurate computation of polyhedral mass properties. JGT, 1(2):31–50, 1996.
- [50] Jan U. Müller, Michael Weinmann, and Reinhard Klein. Unbiased gradient estimation for differentiable surface splatting via poisson sampling. In European Conference on Computer Vision (ECCV), 2022.
- [51] Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph., 41(4):102:1–102:15, July 2022.
- [52] Shigeru Muraki. Volumetric shape description of range data using “blobby model”. In Proceedings of the 18th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH ’91, page 227–235, New York, NY, USA, 1991. Association for Computing Machinery.
- [53] Merlin Nimier-David, Delio Vicini, Tizian Zeltner, and Wenzel Jakob. Mitsuba 2: A retargetable forward and inverse renderer. ACM Trans. Graph., 38(6), nov 2019.
- [54] Manjushree Nulkar and Klaus Mueller. Splatting with shadows. In Klaus Mueller and Arie E. Kaufman, editors, Volume Graphics 2001, pages 35–49, Vienna, 2001. Springer Vienna.
- [55] C. O’Meadhra, W. Tabib, and N. Michael. Variable resolution occupancy mapping using gaussian mixture models. IEEE Robotics and Automation Letters, 4(2):2015–2022, 2019.
- [56] Karl Pearson. Contributions to the mathematical theory of evolution. Philosophical Transactions of the Royal Society of London. A, 185:71–110, 1894.
- [57] Hanspeter Pfister, Matthias Zwicker, Jeroen van Baar, and Markus Gross. Surfels: Surface elements as rendering primitives. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH ’00, page 335–342, USA, 2000.
- [58] Marie-Julie Rakotosaona, Fabian Manhardt, Diego Martin Arroyo, Michael Niemeyer, Abhijit Kundu, and Federico Tombari. Nerfmeshing: Distilling neural radiance fields into geometrically-accurate 3d meshes, 2023.
- [59] Nikhila Ravi, Jeremy Reizenstein, David Novotny, Taylor Gordon, Wan-Yen Lo, Justin Johnson, and Georgia Gkioxari. Accelerating 3d deep learning with pytorch3d. arXiv:2007.08501, 2020.
- [60] Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. In International Conference on Computer Vision, 2021.
- [61] Johannes Lutz Schönberger, Enliang Zheng, Marc Pollefeys, and Jan-Michael Frahm. Pixelwise view selection for unstructured multi-view stereo. In European Conference on Computer Vision (ECCV), 2016.
- [62] Kumar Shaurya Shankar and Nathan Michael. Mrfmap: Online probabilistic 3d mapping using forward ray sensor models. In Robotics: Science and Systems, 2020.
- [63] László Szécsi and Dávid Illés. Real-time metaball ray casting with fragment lists. In Eurographics, 2012.
- [64] Matthew Tancik, Ethan Weber, Evonne Ng, Ruilong Li, Brent Yi, Terrance Wang, Alexander Kristoffersen, Jake Austin, Kamyar Salahi, Abhik Ahuja, David Mcallister, Justin Kerr, and Angjoo Kanazawa. Nerfstudio: A modular framework for neural radiance field development. In Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Proceedings. ACM, 2023.
- [65] Delio Vicini, Wenzel Jakob, and Anton Kaplanyan. A non-exponential transmittance model for volumetric scene representations. ACM Trans. Graph., 40(4), jul 2021.
- [66] Angtian Wang, Peng Wang, Jian Sun, Adam Kortylewski, and Alan Yuille. VoGE: A differentiable volume renderer using gaussian ellipsoids for analysis-by-synthesis. In The Eleventh International Conference on Learning Representations, 2023.
- [67] Lee Westover. Footprint evaluation for volume rendering. SIGGRAPH Comput. Graph., 24(4):367–376, sep 1990.
- [68] Geoff Wyvill, Craig McPheeters, and Brian Wyvill. Data structure forsoft objects. The Visual Computer, 2(4):227–234, Aug 1986.
- [69] Geoff Wyvill and Andrew Trotman. Ray-tracing soft objects. In Tat-Seng Chua and Tosiyasu L. Kunii, editors, CG International, pages 469–476, Tokyo, 1990. Springer Japan.
- [70] Haofei Xu, Jing Zhang, Jianfei Cai, Hamid Rezatofighi, Fisher Yu, Dacheng Tao, and Andreas Geiger. Unifying flow, stereo and depth estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- [71] Gengshan Yang, Deqing Sun, Varun Jampani, Daniel Vlasic, Forrester Cole, Huiwen Chang, Deva Ramanan, William T Freeman, and Ce Liu. Lasr: Learning articulated shape reconstruction from a monocular video. In CVPR, 2021.
- [72] Gengshan Yang, Deqing Sun, Varun Jampani, Daniel Vlasic, Forrester Cole, Ce Liu, and Deva Ramanan. Viser: Video-specific surface embeddings for articulated 3d shape reconstruction. In NeurIPS, 2021.
- [73] Wang Yifan, Felice Serena, Shihao Wu, Cengiz Öztireli, and Olga Sorkine-Hornung. Differentiable surface splatting for point-based geometry processing. ACM Transactions on Graphics, 38(6):1–14, Nov 2019.
- [74] Xiaoshuai Zhang, Abhijit Kundu, Thomas Funkhouser, Leonidas Guibas, Hao Su, and Kyle Genova. Nerflets: Local radiance fields for efficient structure-aware 3d scene representation from 2d supervision. CVPR, 2023.
- [75] Qingnan Zhou and Alec Jacobson. Thingi10k: A dataset of 10, 000 3d-printing models. CoRR, abs/1605.04797, 2016.