YaRN:大型语言模型的高效上下文窗口扩展
和EleutherAI
和日内瓦大学
)
摘要
旋转位置嵌入 (RoPE) 已被证明可以在基于 Transformer 的语言模型中有效地编码位置信息。 然而,这些模型无法泛化超过它们训练的序列长度。 我们提出了 YaRN(另一种 RoPE 扩展训练方法),这是一种计算高效的方法,用于扩展此类模型的上下文窗口,与以前的方法相比,需要的 Token 少 10 倍,步骤少 2.5 倍。 使用 YaRN,我们表明 LLaMA 模型可以有效地利用和推断比原始预训练允许的更长的上下文长度,同时也超越了上下文窗口扩展方面的最新技术。 此外,我们还证明 YaRN 具有超越微调数据集的有限上下文进行推断的能力。 我们在 https://github.com/jquesnelle/yarn 上发布了使用具有 64k 和 128k 上下文窗口的 YaRN 微调的 Llama 2 7B/13B 检查点。
1简介
基于 Transformer 的大型语言模型(Vaswani 等人,2017)(大语言模型)已表现出强大的上下文学习(ICL)能力,并已成为近期的- 许多自然语言处理 (NLP) 任务的普遍选择。 Transformer 的自注意力机制使得训练高度可并行化,允许以分布式方式处理长序列。 大语言模型训练的序列长度称为其上下文窗口。
Transformer 的上下文窗口直接决定了可以提供示例的空间量,从而限制了其 ICL 能力。 然而,如果模型的上下文窗口有限,则为模型提供可执行 ICL 的稳健示例的空间就较小。 此外,当模型的上下文窗口特别短时,其他任务(例如摘要)将受到严重阻碍。
根据语言本身的本质,标记的位置对于有效建模至关重要,而自注意力由于其并行性,并不直接编码位置信息。 在 Transformers 的架构中,引入了位置编码来解决这个问题。
最初的 Transformer 架构使用绝对正弦位置编码,后来改进为可学习的绝对位置编码(Gehring 等人,2017)。 此后,相对位置编码方案(Shaw等人,2018)进一步提高了Transformers的性能。 目前最流行的相对位置编码有T5relative Bias (Roberts 等人, 2019)、RoPE (Su 等人, 2022)、XPos (Sun 等人,2022)、ALiBi (Press 等人,2022).
位置编码的一个反复出现的限制是无法泛化训练期间看到的上下文窗口。 虽然 ALiBi 等一些方法只能进行有限的泛化,但没有一种方法能够泛化到明显长于预训练长度的序列(Kazemnejad 等人,2023)。
已经做了一些工作来克服这种限制。 (Chen 等人, 2023) 和同时 (kaiokendev, 2023) 提出通过位置插值 (PI) 稍微修改 RoPE 并在少量数据。 作为替代方案,我们在(bloc97, 2023a)中提出了考虑高频损失的“NTK-aware”插值。 此后,我们提出了“NTK-aware”插值的两项改进,侧重点不同:
-
•
用于预训练模型的“动态 NTK”插值方法,无需微调。
-
•
“NTK-by-part”插值方法在对少量较长上下文数据进行微调时表现最佳。
我们很高兴看到“NTK感知”插值和“动态NTK”插值已经出现在Code Llama等开源模型中(Rozière等人,2023) (使用“NTK 感知”插值)和 Qwen 7B (qwe, )(使用“动态 NTK”)。
在本文中,除了对“NTK-aware”、“动态 NTK”和“NTK-by-part”插值的先前工作进行完整说明之外,我们还提出了 YaRN(另一种 RoPE 扩展方法),一种有效扩展使用 Rotary Position Embeddings (RoPE) 训练的模型上下文窗口的方法,其中包括 LLaMA (Touvron 等人, 2023a)、GPT-NeoX (Black 等人, 2022 ) 和 PaLM (Chowdhery 等人, 2022) 模型系列。 在对原始模型预训练数据的小于 0.1% 大小的代表性样本进行微调后,YaRN 达到了最先进的上下文窗口扩展。
1.1致谢
作者要感谢 Stability AI、Carper AI 和 Eleuther AI 对重要计算资源的慷慨支持,使这些模型的训练和这项研究得以完成。 我们还要直接感谢 Jonathan Tow 和 Dakota Mahan 在就 Stability AI 计算集群的使用提供建议方面提供的帮助。 此外,我们还要感谢 a16z 和 PygmalionAI 提供资源来对模型进行评估和实验。
2 背景及相关工作
2.1 旋转位置嵌入
我们工作的基础是(Su等人,2022)中介绍的旋转位置嵌入(RoPE)。 给定一系列输入标记 ,用 表示它们的嵌入向量,其中 是隐藏状态的维度。 按照 (Su 等人, 2022) 的表示法,注意力层首先将嵌入加上位置索引转换为查询向量和键向量:
| (1) |
其中 是每个头的隐藏尺寸。 之后,注意力分数将计算为
其中 被视为列向量,我们只是计算分子中的欧几里得内积。 在 RoPE 中,我们首先假设 是偶数,并将嵌入空间和隐藏状态识别为复向量空间:
其中内积 成为标准 Hermitian 内积 的实部。 更具体地说,同构交错实部和复数部分
| (2) | |||
| (3) |
为了将嵌入 转换为查询和键向量,我们首先给出 -线性运算符
在复坐标中,函数 由下式给出
| (4) |
其中 和 。 这样做的要点是查询向量和键向量之间的点积仅取决于相对距离,如下所示
| (5) | ||||
| (6) | ||||
| (7) | ||||
| (8) |
在实际坐标中,RoPE可以写成如下:
2.2 位置插值
由于语言模型通常是使用固定的上下文长度进行预训练的,因此很自然地会问如何通过对相对较少的数据量进行微调来扩展上下文长度。 对于使用 RoPE 作为位置嵌入的语言模型,(Chen 等人, 2023),同时 /u/kaiokendev (kaiokendev, 2023) ,提出了位置插值(PI)来将上下文长度扩展到超出预训练限制。 虽然直接外推在 大于预训练限制的序列 上表现不佳,但他们发现在预训练限制内插入位置索引可以很好地使用少量微调的帮助。 具体来说,给定一个带有 RoPE 的预训练语言模型,他们通过以下方式修改 RoPE:
| (9) |
其中 是超出预训练限制的新上下文窗口。 利用原始的预训练模型加上修改后的 RoPE 公式,他们在减少几个数量级的标记((Chen 等人,2023)中的几十亿)上进一步微调语言模型,并成功实现了上下文窗口扩展。
2.3 附加符号
由于我们假设 RoPE 嵌入的插值在 和 域中是对称的,因此我们重写并简化了等式: 9 转换为以下通用形式:
| (10) |
其中 PI 为
| (11) | ||||
| (12) | ||||
| (13) |
值通常也称为上下文长度扩展的比例因子。
在后续章节中,每当我们引入新的插值方法时,我们只需要指定函数和。
此外,我们将 定义为尺寸 处 RoPE 嵌入的波长
| (14) |
对于基数 、维度 和维度总数 。 波长描述了尺寸 处的 RoPE 嵌入执行完整旋转 () 所需的 Token 长度。 它在最低维度处最高,在最高维度处最低。
考虑到一些插值方法(例如 位置插值)不关心尺寸的波长,我们将这些方法称为“盲”插值方法,而其他方法(例如 YaRN),我们将其归类为“有针对性的”插值方法。
2.4相关工作
ReRoPE (Su, 2023) 还旨在扩展使用 RoPE 预训练的现有模型的上下文大小,并声称无需任何微调即可实现“无限”上下文长度。 在 Llama 2 13B 模型上,随着上下文长度增加到 16k,损失单调递减支持了这一说法。 它通过修改注意力机制来实现上下文扩展,因此并不是纯粹的嵌入插值方法。 由于它目前与 Flash Attention 2 (Dao, 2023) 不兼容,并且在推理过程中需要两次注意力传递,因此我们不考虑将其进行比较。
与我们的工作同时,LM-Infinite (Han 等人, 2023) 提出了与 YaRN 类似的想法,但专注于非微调模型的“即时”长度泛化。 由于它们还修改了模型的注意力机制,因此它不是嵌入插值方法,并且不能立即与 Flash Attention 2 兼容。
3方法论
尽管 PI 同等地拉伸了所有 RoPE 维度,但我们发现 PI (Chen 等人, 2023) 描述的理论插值界限不足以预测 RoPE 与大语言模型内部嵌入之间的复杂动态。 在下面的小节中,我们将描述我们单独识别和解决的 PI 的主要问题,以便为读者提供我们协同使用的每种方法的背景、起源和理由,以获得完整的 YaRN 方法。
3.1 高频信息丢失 - “NTK 感知”插值(bloc97,2023a)
如果我们仅从信息编码的角度来看RoPE,(Tancik等人,2020)中表明,使用神经正切核(NTK)理论,深度神经网络在学习高频信息方面存在困难如果输入维度较低并且相应的嵌入缺乏高频分量。 这里我们可以看到相似之处:词符的位置信息是一维的,而RoPE将其扩展为n维复向量嵌入。
RoPE 在许多方面与傅里叶特征(Tancik 等人,2020)非常相似,因为可以将 RoPE 定义为傅里叶特征的特殊一维情况。 不加区别地拉伸 RoPE 嵌入会导致重要的高频细节的丢失,网络需要这些高频细节来解析非常相似且非常接近的标记(描述最小距离的旋转不需要太小,以使网络能够能够检测到)。
我们假设,在 PI (Chen 等人,2023) 中看到的对较大上下文大小进行微调后,较短上下文大小的困惑度略有增加可能与此问题有关。 在理想情况下,对较大上下文大小的微调不会降低较小上下文大小的性能。
为了解决 RoPE 嵌入插值时丢失高频信息的问题,(bloc97,2023a)中提出了“NTK-aware”插值。 我们不是将 RoPE 的每个维度均等地缩放 倍,而是通过减少高频和增加低频来将插值压力分散到多个维度。 可以通过多种方式获得这样的转换,但最简单的是对 的值执行基本更改。
由于我们希望最低频率与线性位置缩放一样多,而最高频率保持不变,因此我们需要找到一个新的基,使得最后一个维度与线性插值的波长相匹配比例因子。由于原始 RoPE 方法会跳过奇数维度以便将 和 组件连接到单个嵌入中,因此最后一个维度 为 .
求解 得到:
| (15) | ||||
| (16) |
按照 2.3 节的表示法,“NTK 感知”插值方案只是应用基本变化公式,如下所示:
| (17) | ||||
| (18) |
在我们的测试(bloc97, 2023a)中,与 PI (Chen 等人, 2023) 相比,该方法在扩展非微调模型的上下文大小方面表现得更好。 然而,这种方法的一个主要缺点是,鉴于它不仅仅是一种插值方案,某些维度会稍微外推到“越界”值,因此可以使用“NTK 感知”插值进行微调(bloc97 , 2023a) 的结果不如 PI (Chen 等人, 2023)。 此外,由于“出界”值,理论比例因子不能准确描述真实的上下文扩展比例。 实际上,比例值 必须设置为高于给定上下文长度扩展的预期比例。
在本文发布前不久,代码 Llama Rozière 等人 (2023) 发布,它通过手动将基数 设置为 1M 来使用“NTK 感知”缩放。
3.2 相对局部距离损失 - “NTK-by-parts”插值(bloc97, 2023b)
RoPE 嵌入的一个有趣的观察是,给定上下文大小 ,有一些维度 ,其中波长比预训练期间看到的最大上下文长度长(),这表明某些维度的嵌入可能在旋转域中分布不均匀。
在 PI 和“NTK 感知”插值的情况下,我们同等对待所有 RoPE 隐藏维度(因为它们对网络具有相同的影响)。 然而,我们通过实验发现网络对某些维度的处理方式与其他维度不同。 如前所述,给定上下文长度,某些维度的波长大于或等于。考虑到当隐藏维度的波长大于或等于时,所有位置对都编码唯一的距离,我们假设绝对位置信息被保留,而当波长较短时,仅保留绝对位置信息相对位置信息可供网络使用。
当我们通过比例 或使用基数变化 拉伸所有 RoPE 维度时,所有标记都会变得彼此更接近,因为两个向量的点积旋转了更小的值。金额较大。 这种缩放严重削弱了大语言模型理解其内部嵌入之间的小型和局部关系的能力。 我们假设这种压缩会导致模型对附近标记的位置顺序感到困惑,从而损害模型的能力。
为了解决这个问题,考虑到我们在这里发现的观察结果,我们选择根本不插值更高的频率维度。 尤其,
-
•
如果波长远小于上下文大小,我们不进行插值;
-
•
如果波长 等于或大于上下文大小 ,我们只想进行插值并避免任何外推(与之前的“NTK-aware”方法不同);
-
•
中间的维度可以同时具有两者,类似于“NTK 感知”插值。
为了在给定特定上下文长度 的完整旋转次数 的情况下找到我们想要的维度 ,我们可以展开等式: 14 例如:
| (19) | ||||
| (20) |
求解 得到:
| (21) |
我们还建议所有维度 其中 是我们通过比例 线性插值的维度(与 PI 完全相同,避免任何外推),并且 根本不进行插值(总是推断)。 定义斜坡函数为
| (22) |
借助斜坡函数,我们将新波长定义为
| (23) |
和 的值应根据具体情况进行调整。 例如,我们通过实验发现,对于 Llama 系列模型, 和 的最佳值为 和 。
将转换为后,方法可以描述为:
| (24) | ||||
| (25) |
使用本节中描述的技术,生成的方法的变体以“NTK-by-parts”插值 (bloc97, 2023b) 的名称发布。 这种改进的方法比之前的 PI (Chen 等人, 2023) 和“NTK-aware”3.1 插值方法表现更好,无论是使用非微调模型还是使用微调模型。 由于该方法避免了外推旋转域中分布不均匀的尺寸,因此它避免了以前方法中的所有微调问题。
3.3 动态缩放 - “动态 NTK”插值 (emozilla,2023)
当使用 RoPE 插值方法扩展上下文大小而不进行微调时,我们希望模型在较长的上下文大小下优雅地降级,而不是在比例 的情况下在整个上下文大小上进行完全降级。设置为高于所需值的值。 回想一下,在 2.3 节中,PI 中的 ,其中 是经过训练的上下文长度, 是新扩展的上下文长度。 在“动态NTK”方法中,我们动态计算尺度如下:
| (26) |
当超过上下文大小时,在推理过程中动态更改比例允许所有模型优雅地降级,而不是在达到训练的上下文限制 时立即中断。
将动态扩展与 kv 缓存结合使用时必须小心(Chen,2022),因为在某些实现中,RoPE 嵌入会被缓存。 正确的实现应该在应用 RoPE 之前缓存 kv 嵌入,因为每个词符的 RoPE 嵌入会随着 的变化而变化。
3.4 长距离平均最小余弦相似度的增加 - YaRN
即使我们解决了3.2节中描述的局部距离问题,也必须在阈值处插值更大的距离,以避免外推。 直观上,这似乎不是问题,因为全局距离不需要高精度就能区分词符位置(即网络只需要大致知道词符是在词符的开头、中间还是结尾)顺序)。 然而,我们发现,因为随着标记数量的增加,平均最小距离变得更近111More precisely, if we select random points uniformly on a line of length , the average minimum distance between any two points follow the equation ,它使注意力softmax分布变得“尖峰”(即减少注意力softmax的平均熵)。 换句话说,随着长距离衰减的影响因插值而减弱,网络“更加关注”更多的 Token 。 这种分布变化导致大语言模型输出的下降,这与之前的问题无关。
由于当我们将 RoPE 嵌入插入到更长的上下文大小时,注意力 Softmax 分布中的熵会减少,因此我们的目标是扭转熵的减少(即增加注意力逻辑的“温度”)。 这可以通过在应用 softmax 之前将中间注意力矩阵乘以温度 来完成,但由于 RoPE 嵌入被编码为旋转矩阵,我们可以简单地按常数因子缩放 RoPE 嵌入的长度。 “长度缩放”技巧使我们能够避免对注意力代码进行任何修改,这显着简化了与现有和推理管道的集成,并且时间复杂度为 。
由于我们的 RoPE 插值方案对 RoPE 尺寸的插值不均匀,因此很难计算相对于尺度 所需的温度尺度 的解析解。幸运的是,我们通过实验发现,通过最小化困惑度,所有 Llama 模型都遵循大致相同的拟合曲线:
| (27) |
上面的方程是通过在 LLaMA 7b、13b、33b 和 65b 模型上拟合 得出的,其中困惑度相对于尺度扩展的因子 最低,无需微调,使用3.2中描述的插值方法。 我们还发现这个方程相当适用于 Llama 2 模型(7b、13b 和 70b),只有细微的差别。 它表明这种增加熵的属性是常见的,并且可以在不同的模型和训练数据中推广。
3.5 外推和迁移学习
在 Code Llama Rozière 等人 (2023) 中,使用了具有 16k 上下文的数据集,比例因子设置为 ,对应于 355k 的上下文大小。 他们表明,网络可以推断出多达 100k 的上下文,而在训练过程中却从未看到这些上下文的大小。 与 3.1 和 Rozière 等人 (2023) 类似,YaRN 也支持比数据集长度更高的比例因子 的训练。 由于计算限制,我们仅通过使用具有 64k 上下文的相同数据集进一步微调 模型 200 个步骤来测试 。
我们在 4.2 中表明, 模型在训练期间仅使用 64k 上下文成功推断出多达 128k 上下文。 与之前的 "盲 "插值方法不同,当尺度 增加时,YaRN 的迁移学习效率要高得多。这展示了从 到 的成功迁移学习,网络无需重新学习插值嵌入,因为尽管只在 上训练了 200 步,但 模型在整个上下文大小中等同于 模型。
4实验
我们证明 YaRN 成功实现了大语言模型的上下文窗口扩展。 此外,这一结果仅用 400 个训练步就实现了,约占模型原始预训练语料库的 0.1%,比 Rozière 等人 (2023) 减少了 10 倍,训练步数减少了 2.5 倍Chen 等人训练 (2023),使其具有很高的计算效率,且无需额外的推理成本。 我们计算长文档的困惑度并在既定基准上进行评分以评估生成的模型,发现它们超越了所有其他上下文窗口扩展方法。
我们大致遵循 Chen 等人 (2023) 中概述的训练和评估程序。
4.1训练
对于训练,我们扩展了 Llama 2 Touvron 等人 (2023b) 7B 和 13B 参数模型。 除了 3.4 以及 和 中描述的嵌入频率的计算之外,LLaMA 模型架构没有进行任何更改。
我们使用 的学习率,没有权重衰减,并使用 AdamW Loshchilov 和 Hutter (2019) 和 。 对于 ,我们使用 PyTorch 对全局批量大小 进行了 400 步的微调 Paszke 等人 (2019) 完全分片数据并行 Zhao 等人 (2023) 和 Flash Attention 2 Dao (2023) 在 PG19 数据集 Rae 等人 (2020) 上分块为 64k 段,并用 BOS 和 EOS 进行记录词符。 对于 ,我们遵循相同的过程,但从完成的 检查点开始,并进行额外 200 个步骤的训练。
4.2评估
4.2.1 长序列语言建模
为了评估长序列语言建模性能,我们使用 GovReport Huang 等人 (2021) 和 Proof-pile Azerbayev 等人 (2022) 数据集,这两个数据集都包含许多长序列样品。 对于所有评估,仅使用两个数据集的测试分割。 所有困惑度评估均使用 Press 等人 (2022) 和 的滑动窗口方法计算。
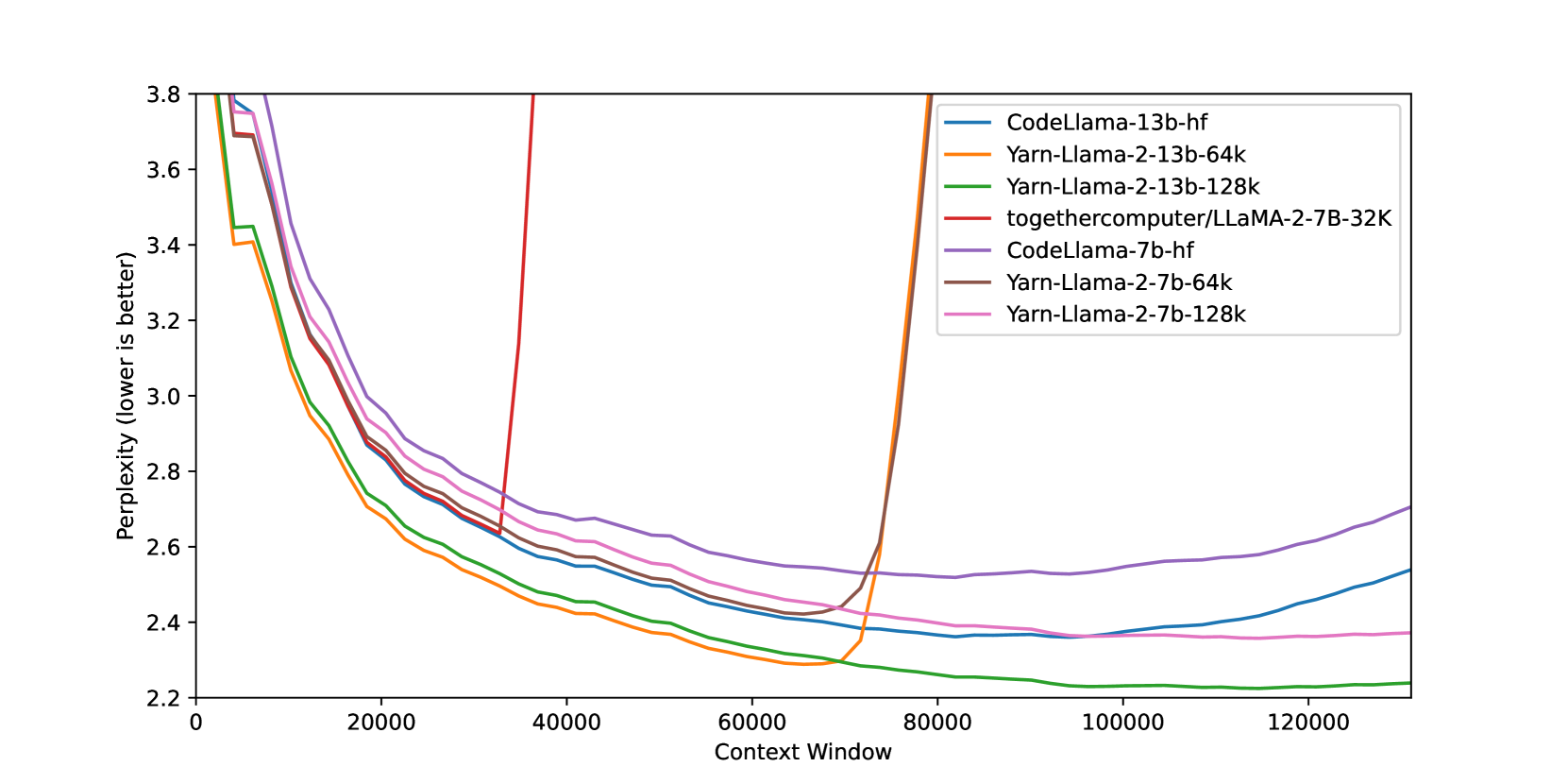
首先,我们评估了模型随着上下文窗口增加的表现。 我们从证明堆中随机选择了 10 个长度至少为 128k 个 Token 的样本,并评估了从 2k 个 Token 到 128k 个 Token 的序列长度以 2k 步截断时每个样本的计算复杂度。 图1显示了与其他上下文窗口扩展方法相比的结果。 特别是,我们与 Together.ai Together.ai (2023) 和“NTK-aware”Code Llama Rozière 等人 (2023)< 中以 32k 训练的公开 PI 模型进行比较/t1>. 这些结果总结在表1中。
| Model | Model | Context | Extension | Evaluation Context Window Size | ||||
| Size | Name | Window | Method | 8192 | 32768 | 65536 | 98304 | 131072 |
| 7B | Together | 32k | PI | 3.50 | 2.64 | |||
| 7B | Code Llama | 100k | NTK | 3.71 | 2.74 | 2.55 | 2.54 | 2.71 |
| 7B | YaRN () | 64k | YaRN | 3.51 | 2.65 | 2.42 | ||
| 7B | YaRN () | 128k | YaRN | 3.56 | 2.70 | 2.45 | 2.36 | 2.37 |
| 13B | Code Llama | 100k | NTK | 3.54 | 2.63 | 2.41 | 2.37 | 2.54 |
| 13B | YaRN () | 64k | YaRN | 3.25 | 2.50 | 2.29 | ||
| 13B | YaRN () | 128k | YaRN | 3.29 | 2.53 | 2.31 | 2.23 | 2.24 |
表 2 显示了在 32k 上下文窗口中评估的 50 个未截断的 GovReport 文档(长度至少为 16k 标记)的最终困惑度。
| Model | Model | Context | Extension | Perplexity |
| Size | Name | Window | Method | |
| 7B | Together | 32k | PI | 3.67 |
| 7B | Code Llama | 100k | NTK | 4.44 |
| 7B | YaRN () | 64k | YaRN | 3.59 |
| 7B | YaRN () | 128k | YaRN | 3.64 |
| 13B | Code Llama | 100k | NTK | 4.22 |
| 13B | YaRN () | 64k | YaRN | 3.35 |
| 13B | YaRN () | 128k | YaRN | 3.39 |
我们观察到该模型在整个上下文窗口中表现出强大的性能,优于所有其他上下文窗口扩展方法。 特别值得注意的是 YaRN () 模型,尽管微调数据的长度限制为 64k 标记,但其复杂度在 128k 范围内持续下降。 这表明该模型能够泛化到未见过的上下文长度。
4.2.2 标准化基准
Hugging Face 开放大语言模型排行榜 Hugging Face (2023) 通过一组标准化的四个公共基准对众多大语言模型进行了比较。 具体来说,25发ARC-Challenge Clark 等人 (2018)、10发 HellaSwag Zellers 等人 (2019)、5发 MMLU Hendrycks 等人(2021) 和 0-shot TruthfulQA Lin 等人 (2022)。
为了测试上下文扩展下模型性能的下降,我们使用该套件评估了我们的模型,并将其与 Llama 2 基线以及公开可用的 PI 和“NTK 感知”模型的既定分数进行比较。 结果总结在表3中。
| Model | Model | Context | Extension | ARC-c | Hellaswag | MMLU | TruthfulQA |
|---|---|---|---|---|---|---|---|
| Size | Name | Window | Method | ||||
| 7B | Llama 2 | 4k | None | 53.1 | 77.8 | 43.8 | 39.0 |
| 7B | Together | 32k | PI | 47.6 | 76.1 | 43.3 | 39.2 |
| 7B | Code Llama | 100k | NTK | 39.9 | 60.8 | 31.1 | 37.8 |
| 7B | YaRN () | 64k | YaRN | 52.3 | 78.8 | 42.5 | 38.2 |
| 7B | YaRN () | 128k | YaRN | 52.1 | 78.4 | 41.7 | 37.3 |
| 13B | Llama 2 | 4k | None | 59.4 | 82.1 | 55.8 | 37.4 |
| 13B | Code Llama | 100k | NTK | 40.9 | 63.4 | 32.8 | 43.8 |
| 13B | YaRN () | 64k | YaRN | 58.1 | 82.3 | 52.8 | 37.8 |
| 13B | YaRN () | 128k | YaRN | 58.0 | 82.2 | 51.9 | 37.3 |
我们观察到,YaRN 模型与其各自的 Llama 2 基线之间的性能下降很小。 我们还观察到,YaRN 和 模型之间的分数平均下降了 0.49%。 由此我们得出结论,从 64k 到 128k 的迭代扩展导致的性能损失可以忽略不计。
5结论
总之,我们已经证明 YaRN 改进了所有现有的 RoPE 插值方法,并且可以作为 PI 的直接替代品,没有任何缺点,并且实现工作量最少。 经过微调的模型在多个基准上保留了其原始能力,同时能够处理非常大的上下文大小。 此外,YaRN 允许在较短的数据集上进行微调并进行有效的外推,并且可以利用迁移学习来实现更快的收敛,这两者在计算受限的情况下都至关重要。 最后,我们展示了使用 YaRN 进行外推的有效性,它能够“训练短,测试长”。
参考
- [1] Introducing Qwen-7B: Open foundation and human-aligned models (of the state-of-the-arts). URL https://github.com/QwenLM/Qwen-7B/blob/main/tech_memo.md.
- Azerbayev et al. [2022] Z. Azerbayev, E. Ayers, , and B. Piotrowski. Proof-pile, 2022. URL https://github.com/zhangir-azerbayev/proof-pile.
- Black et al. [2022] S. Black, S. Biderman, E. Hallahan, Q. Anthony, L. Gao, L. Golding, H. He, C. Leahy, K. McDonell, J. Phang, M. Pieler, U. S. Prashanth, S. Purohit, L. Reynolds, J. Tow, B. Wang, and S. Weinbach. GPT-NeoX-20B: An open-source autoregressive language model, 2022. arXiv: 2204.06745.
- bloc97 [2023a] bloc97. NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation., 2023a. URL https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/.
- bloc97 [2023b] bloc97. Add NTK-Aware interpolation "by parts" correction, 2023b. URL https://github.com/jquesnelle/scaled-rope/pull/1.
- Chen [2022] C. Chen. Transformer Inference Arithmetic, 2022. URL https://kipp.ly/blog/transformer-inference-arithmetic/.
- Chen et al. [2023] S. Chen, S. Wong, L. Chen, and Y. Tian. Extending context window of large language models via positional interpolation, 2023. arXiv: 2306.15595.
- Chowdhery et al. [2022] A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, P. Schuh, K. Shi, S. Tsvyashchenko, J. Maynez, A. Rao, P. Barnes, Y. Tay, N. Shazeer, V. Prabhakaran, E. Reif, N. Du, B. Hutchinson, R. Pope, J. Bradbury, J. Austin, M. Isard, G. Gur-Ari, P. Yin, T. Duke, A. Levskaya, S. Ghemawat, S. Dev, H. Michalewski, X. Garcia, V. Misra, K. Robinson, L. Fedus, D. Zhou, D. Ippolito, D. Luan, H. Lim, B. Zoph, A. Spiridonov, R. Sepassi, D. Dohan, S. Agrawal, M. Omernick, A. M. Dai, T. S. Pillai, M. Pellat, A. Lewkowycz, E. Moreira, R. Child, O. Polozov, K. Lee, Z. Zhou, X. Wang, B. Saeta, M. Diaz, O. Firat, M. Catasta, J. Wei, K. Meier-Hellstern, D. Eck, J. Dean, S. Petrov, and N. Fiedel. PaLM: Scaling language modeling with pathways, 2022. arXiv: 2204.02311.
- Clark et al. [2018] P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord. Think you have solved question answering? try ARC, the AI2 Reasoning Challenge, 2018.
- Dao [2023] T. Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. 2023.
- emozilla [2023] emozilla. Dynamically Scaled RoPE further increases performance of long context LLaMA with zero fine-tuning, 2023. URL https://www.reddit.com/r/LocalLLaMA/comments/14mrgpr/dynamically_scaled_rope_further_increases/.
- Gehring et al. [2017] J. Gehring, M. Auli, D. Grangier, D. Yarats, and Y. N. Dauphin. Convolutional sequence to sequence learning, 2017. arXiv: 1705.03122.
- Han et al. [2023] C. Han, Q. Wang, W. Xiong, Y. Chen, H. Ji, and S. Wang. LM-Infinite: Simple on-the-fly length generalization for large language models, 2023.
- Hendrycks et al. [2021] D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR), 2021.
- Huang et al. [2021] L. Huang, S. Cao, N. Parulian, H. Ji, and L. Wang. Efficient attentions for long document summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1419–1436. Association for Computational Linguistics, June 2021.
- Hugging Face [2023] Hugging Face. Open LLM Leaderboard, 2023. URL https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard.
- kaiokendev [2023] kaiokendev. Things I’m learning while training superhot., 2023. URL https://kaiokendev.github.io/til#extending-context-to-8k.
- Kazemnejad et al. [2023] A. Kazemnejad, I. Padhi, K. N. Ramamurthy, P. Das, and S. Reddy. The impact of positional encoding on length generalization in transformers, 2023. arXiv: 2305.19466.
- Lin et al. [2022] S. Lin, J. Hilton, and O. Evans. TruthfulQA: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214–3252, May 2022.
- Loshchilov and Hutter [2019] I. Loshchilov and F. Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019.
- Paszke et al. [2019] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Köpf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala. PyTorch: An imperative style, high-performance deep learning library. In NeurIPS, pages 8024–8035, 2019.
- Press et al. [2022] O. Press, N. Smith, and M. Lewis. Train Short, Test Long: Attention with linear biases enables input length extrapolation. In International Conference on Learning Representations, 2022.
- Rae et al. [2020] J. W. Rae, A. Potapenko, S. M. Jayakumar, C. Hillier, and T. P. Lillicrap. Compressive transformers for long-range sequence modelling. In International Conference on Learning Representations, 2020.
- Roberts et al. [2019] A. Roberts, C. Raffel, K. Lee, M. Matena, N. Shazeer, P. J. Liu, S. Narang, W. Li, and Y. Zhou. Exploring the limits of transfer learning with a unified text-to-text transformer. Technical report, Google, 2019.
- Rozière et al. [2023] B. Rozière, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y. Adi, J. Liu, T. Remez, J. Rapin, A. Kozhevnikov, I. Evtimov, J. Bitton, M. Bhatt, C. C. Ferrer, A. Grattafiori, W. Xiong, A. Défossez, J. Copet, F. Azhar, H. Touvron, L. Martin, N. Usunier, T. Scialom, and G. Synnaeve. Code Llama: Open foundation models for code, 2023.
- Shaw et al. [2018] P. Shaw, J. Uszkoreit, and A. Vaswani. Self-attention with relative position representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 464–468, New Orleans, Louisiana, June 2018. Association for Computational Linguistics.
- Su [2023] J. Su. Rectified rotary position embeddings. https://github.com/bojone/rerope, 2023.
- Su et al. [2022] J. Su, Y. Lu, S. Pan, A. Murtadha, B. Wen, and Y. Liu. RoFormer: Enhanced transformer with rotary position embedding, 2022. arXiv: 2104.09864.
- Sun et al. [2022] Y. Sun, L. Dong, B. Patra, S. Ma, S. Huang, A. Benhaim, V. Chaudhary, X. Song, and F. Wei. A length-extrapolatable transformer, 2022.
- Tancik et al. [2020] M. Tancik, P. P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ramamoorthi, J. T. Barron, and R. Ng. Fourier features let networks learn high frequency functions in low dimensional domains. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20, Red Hook, NY, USA, 2020. Curran Associates Inc. ISBN 9781713829546.
- Together.ai [2023] Together.ai. LLaMA-2-7B-32K, 2023. URL https://huggingface.co/togethercomputer/LLaMA-2-7B-32K.
- Touvron et al. [2023a] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample. LLaMA: Open and efficient foundation language models, 2023a. arXiv: 2302.13971.
- Touvron et al. [2023b] H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, D. Bikel, L. Blecher, C. C. Ferrer, M. Chen, G. Cucurull, D. Esiobu, J. Fernandes, J. Fu, W. Fu, B. Fuller, C. Gao, V. Goswami, N. Goyal, A. Hartshorn, S. Hosseini, R. Hou, H. Inan, M. Kardas, V. Kerkez, M. Khabsa, I. Kloumann, A. Korenev, P. S. Koura, M.-A. Lachaux, T. Lavril, J. Lee, D. Liskovich, Y. Lu, Y. Mao, X. Martinet, T. Mihaylov, P. Mishra, I. Molybog, Y. Nie, A. Poulton, J. Reizenstein, R. Rungta, K. Saladi, A. Schelten, R. Silva, E. M. Smith, R. Subramanian, X. E. Tan, B. Tang, R. Taylor, A. Williams, J. X. Kuan, P. Xu, Z. Yan, I. Zarov, Y. Zhang, A. Fan, M. Kambadur, S. Narang, A. Rodriguez, R. Stojnic, S. Edunov, and T. Scialom. Llama 2: Open foundation and fine-tuned chat models, 2023b.
- Vaswani et al. [2017] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017.
- Zellers et al. [2019] R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, and Y. Choi. HellaSwag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019.
- Zhao et al. [2023] Y. Zhao, A. Gu, R. Varma, L. Luo, C.-C. Huang, M. Xu, L. Wright, H. Shojanazeri, M. Ott, S. Shleifer, A. Desmaison, C. Balioglu, B. Nguyen, G. Chauhan, Y. Hao, and S. Li. PyTorch FSDP: Experiences on scaling fully sharded data parallel, 2023.