用于解决多步回归股票价格预测中的随机性的扩散变分自动编码器
摘要。
长期的多步股价预测对于预测其波动性至关重要,使金融机构能够对衍生品进行定价和对冲,并使银行能够量化其交易账簿中的风险。 此外,大多数金融监管机构还要求机构投资者退出风险资产需要几天的流动性期限,以免对市场价格产生重大影响。 然而,鉴于股票数据的高度随机性,多步股票价格预测的任务具有挑战性。 目前解决这个问题的解决方案大多是为单步、基于分类的预测而设计的,并且仅限于较低的表示表达能力。 随着目标价格序列的引入,问题也变得越来越困难,目标价格序列也包含随机噪声并降低了测试时的普遍性。
为了解决这些问题,我们结合了深层分层变分自动编码器(VAE)和扩散概率技术,通过随机生成过程进行 seq2seq 股票预测。 分层 VAE 允许我们学习用于股票预测的复杂且低水平的潜在变量,而扩散概率模型通过逐步向股票数据添加随机噪声来训练预测器来处理股票价格随机性。 为了处理目标价格序列中的额外随机性,我们还通过耦合扩散过程用噪声增强目标序列。 然后,我们执行去噪过程来“清理”在随机目标序列数据上训练的预测输出,这提高了模型在测试时的通用性。 我们的 Diffusion-VAE (D-Va) 模型在预测精度和方差方面表现优于最先进的解决方案。 通过消融研究,我们还展示了引入的每个组件如何通过减少数据噪声来帮助提高整体预测准确性。 最重要的是,多步输出还可以让我们在预测长度内形成股票投资组合。 我们通过夏普比率指标证明了我们的模型输出在投资组合投资任务中的有效性,并强调了处理不同类型的预测不确定性的重要性。 我们的代码可以通过 https://github.com/koa-fin/dva 访问。
1. 介绍
股票市场是投资者买卖上市公司股票的渠道,2022 年总市值将超过 111 万亿美元111https://www.sifma.org/resources/research/research-quarterly-equities/。 准确的股价预测可以帮助投资者做出明智的投资决策,允许金融机构为衍生品定价,并让监管机构管理金融体系中的风险量。 因此,股市预测任务已成为金融领域日益具有挑战性和重要的任务,引起了学术界和工业界的高度关注(冯等人,2019b;林等人,2021;杨等人,2022)。
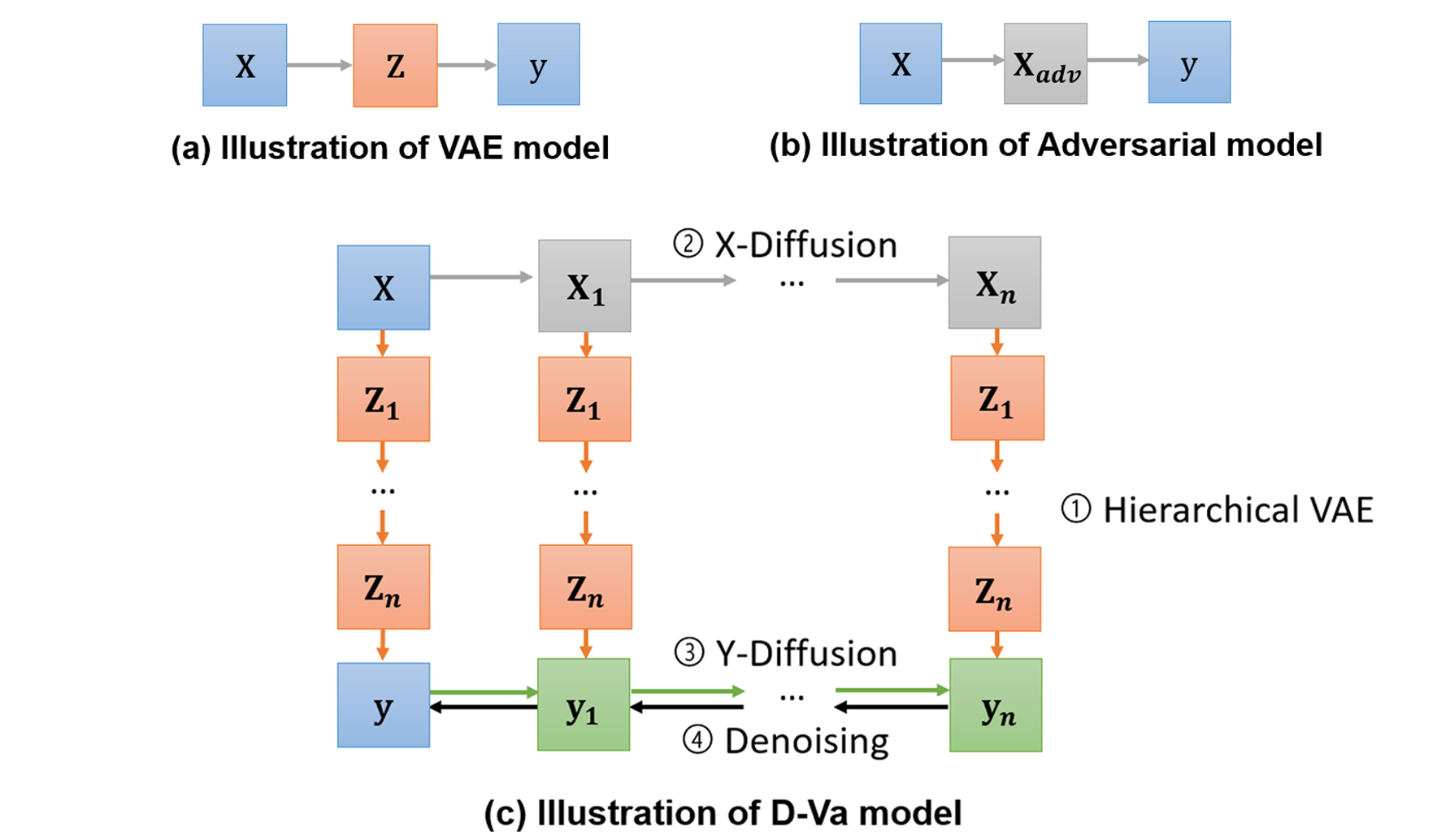
通常,当前大多数股票预测工作都是进行单日预测(胡等人,2018a;陈等人,2018),而不是对接下来的多日进行预测。 直观上,这使他们能够做出是否买入或卖出股票的交易决策,以实现第二天的利润。 然而,长期的股票预测对于预测其波动性也至关重要,这允许金融机构对金融衍生品进行定价和对冲以及量化银行交易账簿中的风险等应用(Raunig,2006). 此外,大多数金融监管机构要求机构投资者退出风险资产的流动性期限至少为 10 天,以免对市场价格产生重大影响222 大多数金融监管机构针对不同资产类别设定了从 {10, 20, 40, 60, 120} 天中选择的监管流动性期限。 一些参考资料可以在以下位置找到: • https://www.mas.gov.sg/publications/consultations/2021/consultation-paper-on-draft-standards-for-market-risk-capital-and-capital-reporting-requirements • https://www.eba.europa.eu/regulation-and-policy/market-risk/draft-technical-standards-on-the-ima-under-the-frtb . 目前,进行多步股价预测的作品还很有限(Dong等人,2013;Liu和Wang,2019)。 我们的工作通过设计一种方法来解决这一任务来填补这一空白。
对于我们的多步骤股票预测任务,确定了两个主要挑战。 首先,在以往的股票预测文献中,众所周知,股票价格具有高度随机性,标准预测模型在处理此类数据时往往不能很好地概括(Xu和Cohen,2018;Feng等人,2019a). 鉴于股票价格是连续的且变化频率很高,用于训练模型的离散股票价格数据本质上是在特定时间步(例如每天上午 12 点或每分钟的 60 秒)提取的随机 "样本",这可能无法完全捕捉股票价格的内在行为。 目前,解决这个问题的现有技术包括(见图1):使用VAE模型(Kingma and Welling,2014)作为学习连续的“潜在”变量用于预测股票走势的新自变量(Xu and Cohen,2018);并在股票训练数据中添加对抗性扰动(Goodfellow 等人, 2020)来模拟股价随机性(Feng 等人, 2019a)。 然而,这些模型是为基于单步分类的股票走势预测而设计的,并且仅限于较低的表示表达能力。 其次,对于多步回归任务,随着目标价格序列的引入,问题变得越来越困难。 目标序列还包含随机噪声,训练模型来直接预测该序列也会降低测试时预测的普遍性。
为了解决上述问题,我们提出了 Diffusion-VAE(D-Va)模型,该模型结合了深层分层 VAE (Sønderby 等人,2016;Klushyn 等人,2019;Vahdat 和 Kautz,2020) 和扩散概率(Sohl-Dickstein 等人,2015;Song 和 Ermon,2019;Ho 等人,2020) 技术进行 seq2seq 股票预测(见图1) 。 首先,深层分层 VAE 增加了近似后验股票价格分布的表达能力,使我们能够学习更复杂和低水平的潜在变量。 同时,扩散概率模型通过逐步向输入股票数据添加随机噪声(图 1 中的 X-Diffusion)来训练预测器处理股票价格随机性。 其次,我们通过耦合扩散过程(图 1 中的 Y 扩散)额外用噪声增强目标序列来处理随机目标价格序列。 然后通过去噪过程“清理”预测的扩散目标(Da Silva and Shi,2019;Ma 等人,2022)以获得广义的“真实”目标序列。 这是通过在训练期间对扩散目标预测与实际目标进行去噪分数匹配,然后在测试时间 应用单步梯度去噪跳跃来完成的(Saremi 和 Hyvärinen,2019;Li 等人,2019; Jolicoeur-Martineau 等人,2021)。 这个过程也可以被视为消除由数据随机性导致的估计任意不确定性(Li等人,2022)。
为了证明 D-Va 的有效性,我们进行了广泛的实验,并表明我们的模型能够在整体预测精度和方差方面优于最先进的模型。 此外,我们还在实际投资环境中测试该模型。 预测股票回报的序列使我们能够使用其均值和协方差信息在预测长度的持续时间内形成股票投资组合。 然后,使用标准马科维茨均值方差优化,我们计算每只股票的投资组合权重,以最大化投资组合的总体预期回报并最小化其波动性(Markowitz,1952)。 我们通过图形套索(Friedman等人,2008)进一步对预测协方差矩阵进行正则化,以减少预测模型不确定性的影响,这可以看作是认知不确定性的一种形式(Hüllermeier 和 Waegeman,2021)。 我们表明,解决数据(任意)和模型(认知)的不确定性使我们能够在指定的范围内实现最佳投资组合绩效(以夏普比率(Sharpe,1994)而言)测试期。
本文的主要贡献总结如下:
-
•
我们研究了多步回归设置下股票预测任务的泛化问题,并处理输入序列和目标序列的随机性。
-
•
我们提出了一种集成了分层 VAE 模型、随机扩散过程和去噪组件的解决方案,并在股票预测的端到端模型中实现它。
-
•
我们对三个不同时间段的公开股票价格数据进行了广泛的实验,结果表明,D-Va 在预测准确性和方差方面比最先进的方法有所改进。 我们进一步证明了该模型在实际股票投资环境中的有效性。
2. 相关作品
股票预测任务很受欢迎,并且有大量关于该主题的文献。 在文献中,我们可以将它们分为各种特定类别,以便定位我们的工作:
技术和基本面分析。 技术分析(TA)方法侧重于根据定量市场数据(例如价格和交易量)来预测股票价格的未来走势。 常见技术包括使用基于注意力的长短期记忆(LSTM)网络(Qin等人,2017)、自回归模型(Li等人,2016)或傅里叶分解(张等人,2017)。 另一方面,基本面分析(FA)从外部数据源寻求信息来预测价格,例如新闻(胡等人,2018a),财报电话会议(杨等人,2022) 或关系知识图谱(冯等人,2019b)。 在我们的工作中,我们专注于 TA 来评估我们处理定量金融数据的技术。
分类和回归。 股票预测任务可以表述为二元分类任务,其目标是预测价格在下一个时间步中是否会上涨或下跌(丁等人,2020)。 这通常被认为是一个更容易实现的任务(叶等人,2020)并且足以帮助散户投资者决定是否购买或出售股票。 另一方面,我们也可以将其制定为回归任务并直接预测股价。 这为投资者提供了更多决策信息,例如能够根据利润对股票进行排名并购买排名靠前的股票(冯等人,2019b;林等人,2021)。 在这项工作中,我们解决回归任务,以便能够权衡投资组合中每只股票的数量。
单步和多步预测。 当前大多数股票预测工作都是对下一个时间步进行单步预测(Tuncer等人,2022),因为它允许人们立即做出第二天的交易决策。 另一方面,关于多步预测的文献很少,其中对接下来的多个时间步进行库存预测。 一个例子可以在(Liu and Wang,2019)中找到,作者通过多步预测来分析一段时间内突发新闻对股价的影响。 对于这项工作,我们将处理多步骤预测任务,其动机是允许较大的机构做出长期的、具有波动性意识的投资决策。 请注意,这与在较长时期内进行单步预测(Feng 等人,2021)不同,后者可以被视为单步预测任务。
3. 方法
在本节中,我们首先制定多步回归股票预测的任务。 然后,我们提出了所提出的 D-Va 模型,如图2所示。 该框架有四个主要组成部分:(1)分层 VAE 来生成序列预测; (2) 扩散过程,逐渐将高斯噪声添加到输入序列中,以模拟股价随机性; (3)对目标序列附加应用耦合扩散过程; (4) 去噪函数,经过训练,通过消除预测序列中的随机性来“清理”预测。 我们将更详细地阐述每个组件。
3.1. 问题表述
对于每只股票 s,给定 交易日 的输入序列,我们的目标是预测其在接下来的 交易日 的收益序列,其中 指的是其在 时间的收益百分比,即 ,而 是收盘价。 输入向量由开盘价、最高价、最低价、交易量、绝对收益和百分比收益组成,即,使其成为单变量输出预测任务的多变量输入。 此外,鉴于我们有兴趣预测百分比回报,开盘价、最高价和最低价均按之前的收盘价标准化,例如,与所做的类似见(Xu和Cohen,2018;Feng等人,2019a)。 绝对回报 也作为输入特征包含在内。
3.2. 深层次VAE
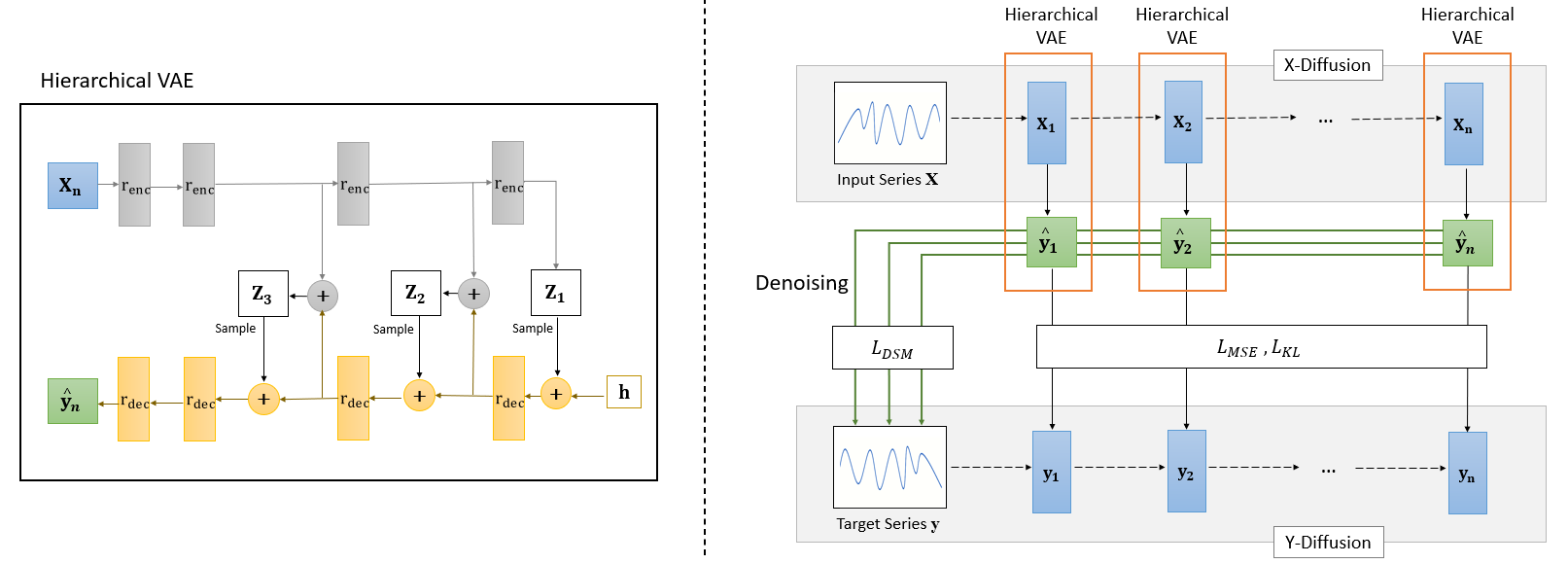
为了提高对影响股票价格的连续潜在因素进行建模的表现力,我们利用深层分层 VAE 来学习更复杂和低级的潜在变量。
对于我们的主干模型,我们使用 Noveau 变分自动编码器 (NVAE)(Vahdat 和 Kautz,2020),它被重新用作 seq2seq 预测模型。 NVAE 是一种最先进的深度分层 VAE 模型,最初是通过使用深度可分离卷积和批量标准化来生成图像的。 框架如图2(左)所示。 在生成网络中,由隐藏层初始化的一系列解码器残差单元被训练以生成条件概率分布。 然后使用它们生成潜在变量。 潜在变量 作为附加输入进一步传递到下一个残差单元,最终生成预测序列 。 同时,在编码器网络中,一系列编码器残差单元用于从输入序列中提取表示,这些表示也被馈送到同一生成网络推断潜在变量。 形式上,我们可以将预测序列的数据密度定义为:
| (1) |
其中表示所有潜在变量的聚合数据密度,是表示聚合解码器网络的参数化函数。 预测序列可以被定义为根据概率分布生成。
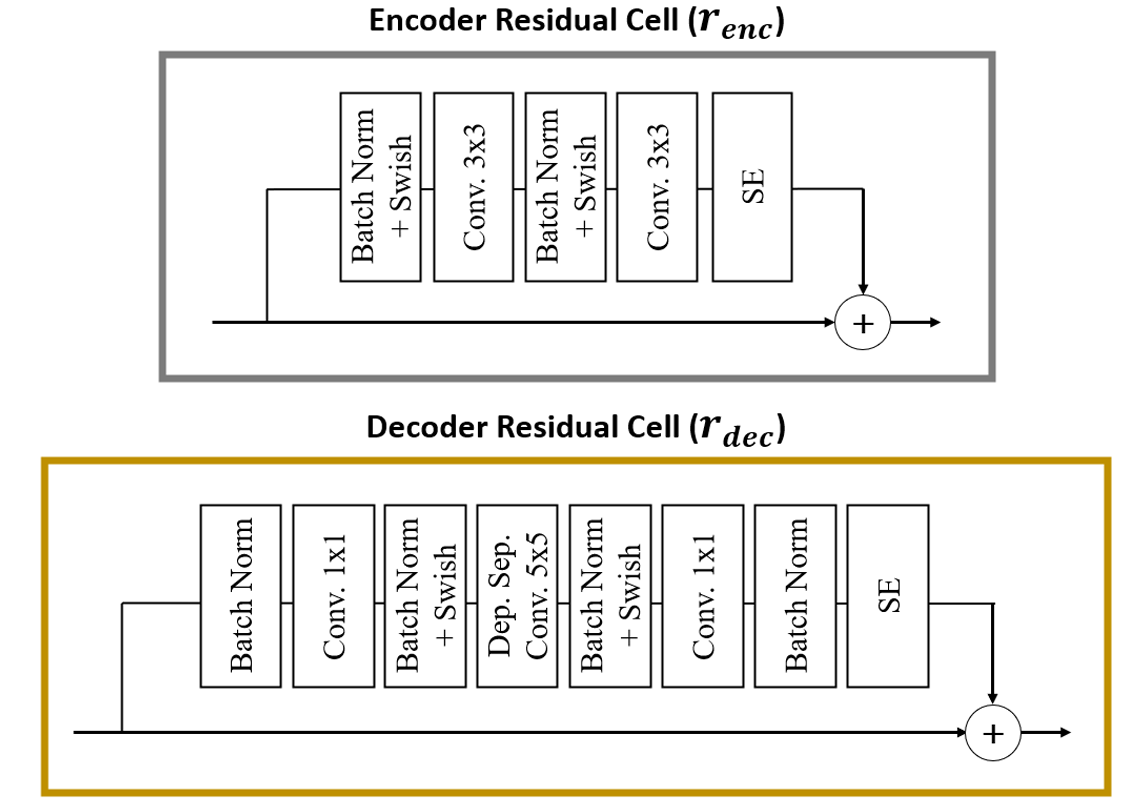
接下来,我们按照(Vahdat and Kautz,2020)中所做的工作来设计两种类型的剩余单元,如图3所示。 编码器残差单元 由两个系列的批量归一化、Swish 激活和卷积层组成,后面是挤压和激励 (SE) 层。 Swish 激活 (Ramachandran 等人, 2017)、 和 SE 层 (Hu 等人, 2018b),一个对卷积通道之间的相互依赖性都经过实验验证,可以提高分层 VAE 的性能。 对于解码器残差单元 ,使用这些单元的不同组合,并添加深度可分离卷积层。 该层通过单独映射输入特征中的所有跨通道相关性(Chollet,2017),有助于增加网络的感受野,同时保持较低的计算复杂性。 这使我们能够捕获每个单元内数据的远程依赖性。
分层 VAE 中的潜在变量堆栈 以及每个残差单元中的深度可分离卷积层使我们能够捕获股票价格数据超出其随机性的复杂、低级依赖性。 这使我们能够更准确地生成目标序列,从而获得更好的预测。
3.3. 输入序列扩散
接下来,为了指导模型从随机股票数据中学习,我们通过使用扩散概率模型逐渐向输入股票价格序列添加随机噪声。
在扩散概率模型中,我们定义了一个扩散步骤的马尔可夫链,它将随机高斯噪声缓慢添加到输入序列中,以获得噪声样本,其中是扩散步骤数。 每一步添加的噪声由方差表 控制。 然后可以通过以下方式获得每个扩散步骤的噪声样本:
| (2) |
在这里,我们没有为每个扩散步骤采样 次,而是使用重新参数化技巧 (Ho 等人, 2020) 来获取样本 在任意步骤中,以便能够以易于处理的封闭形式训练模型。 让。 然后我们有:
| (3) |
从 生成 的过程类似于对输入序列执行逐渐增强,训练模型通过不同级别的噪声生成目标序列。 这会产生更通用、更稳健的预测。
3.4. 目标序列扩散
此外,(Li 等人, 2022)中显示,通过同时向序列和添加扩散噪声并匹配从通过生成模型和扩散过程,可以减少生成模型产生的总体不确定性和数据中固有的随机噪声(即任意不确定性的来源)。 该关系可以表述为:
| (4) |
这里,第一项是加法扩散过程之后的噪声分布与扩散系列生成过程的噪声分布之间的Kullback-Leibler(KL)散度, ,即增强后的不确定性。 第二项是固有数据噪声分布 与生成原始 系列 、 的噪声分布之间的 KL 散度,即增强之前的不确定性。 因此,通过耦合生成过程和扩散过程,可以降低模型的整体预测不确定性。
根据这一观察,我们另外将耦合高斯噪声添加到目标序列中以获得噪声样本。 这里,每一步添加的噪声是 的 ,其中 是缩放超参数。 因此,我们有:
| (5) |
与之前类似,为了允许我们在任意步骤获取样本,我们让和。 然后,我们有:
| (6) |
对于耦合扩散过程,我们最小化 KL 散度:
| (7) |
其中指的是在扩散步骤生成预测序列的分层VAE的后验分布,是来自生成噪声目标序列 的扩散模型的相应分布。
此处,应用于目标序列 以生成 的扩散噪声有助于模拟目标序列中的随机性,类似于对输入序列 所做的操作>。此外,遵循方程中的定理。 4,耦合扩散过程还允许我们生成不确定性较小的预测序列。
3.5. 去噪分数匹配
在 D-Va 中,标准扩散模型 (Ho 等人, 2020) 的逆过程被 的预测器取代,从而无需对扩散样本。 在测试时,我们只需将输入序列 输入到分层 VAE 模型中,该模型将预测目标序列 。 然而,我们注意到我们之前将目标序列定义为随机序列,即,这对于完全恢复来说并不理想。 相反,我们的目标是捕获位于实际数据流形上的“真实”序列。
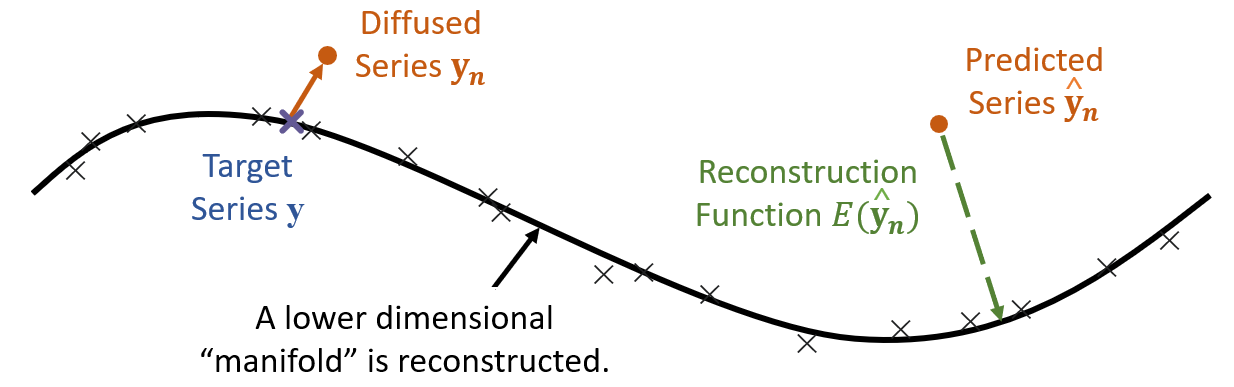
之前的多项工作已经表明,通过在最终样本 上添加额外的去噪步骤,可以获得更接近实际数据流形的样本(Saremi 和 Hyvärinen,2019;Kadkhodaie 和 Simoncelli,2020;Song 和埃尔蒙,2020)。 这类似于帮助消除残留噪声,这可能是由不适当的采样步骤(Jolicoeur-Martineau等人,2021),等引起的。 在我们的例子中,此步骤将用于从生成的目标序列 中去除固有噪声 ,进一步减少序列预测的任意不确定性。 为此,我们首先遵循标准扩散概率模型的去噪得分匹配(DSM)过程(Song and Ermon,2019;Li等人,2019)。 该过程将从噪声预测 到“干净” 的梯度与要学习的能量函数 的梯度进行匹配,按量缩放扩散过程中添加的噪声。 请注意,通过进行基于能量的学习,模型并不是学习精确复制目标 y 序列,而是学习低维流形,它更接近“真实”序列(见图4)。 需要最小化的DSM损失函数如下:
| (8) |
学习到的能量函数的梯度可以看作是一个重建步骤,它能够从任何高斯级别的损坏的序列中恢复噪音。 在测试时,我们就能够执行一步去噪跳跃:
| (9) |
其中 是我们模型的最终预测序列。
此外,这一一步去噪过程也可以被视为消除了由数据随机性引起的估计任意不确定性(Li等人,2022)。 这里, 是生成 VAE 产生的噪声和数据中固有随机噪声之和的估计,我们将其从预测序列中删除。
3.6. 优化与推理
训练过程如下:在训练过程中,我们首先对输入序列和应用耦合扩散过程,生成扩散序列 和。 然后,我们训练分层 VAE 以根据扩散输入序列 生成预测 ,该预测与扩散目标序列 相匹配。 同时,我们还训练了一个去噪能量函数,以从获得“干净”的预测。
在推理过程中,训练后的分层 VAE 模型用于根据输入序列 生成预测 。 通过采取一步去噪跳跃(方程 1)进一步“清理”预测序列。 9)以消除估计的任意不确定性。 这使我们能够获得最终的预测序列。
4. 实验
我们使用两个不同的数据集,在 2014 年至 2022 年三个不同时间段的真实股票数据上广泛评估 D-Va。 我们的工作旨在回答以下三个研究问题:
-
•
RQ1:在多步回归股票预测任务中,D-Va 与最先进的方法相比表现如何?
-
•
RQ2:每个建议的组件(即,分层 VAE、X 扩散、Y 扩散、去噪)如何影响 D-Va 的预测性能?
-
•
RQ3:D-Va 的多步输出如何在实际环境中帮助机构投资者,例如投资组合优化?
4.1. 实验设置
4.1.1. 数据集
使用的第一个数据集是 ACL18 StockNet 数据集(Xu 和 Cohen,2018)。 它包含美国市场88只高交易量股票的历史价格,代表9个主要行业资本规模前8-10名的股票。 数据持续时间范围为 01/01/2014 至 01/01/2017。 该数据集是一个流行的基准,已在许多股票预测作品中使用(Feng 等人,2021;Sawhney 等人,2020;Feng 等人,2019a)。
此外,我们通过收集从 01/01/2017 到 01/01/2023 的更新美国股票数据来扩展此数据集,从 11 个主要行业中选取最新的前 10 只股票(请注意,自上一篇工作以来,行业列表已扩大) ),总共给我们 110 只股票。 数据收集自雅虎财经333https://finance.yahoo.com/,其处理方式与ACL18数据集相同。
对于这项工作,为了在整个实验中保持一致的数据集长度,我们进一步将该数据集分成两个。 这为我们提供了三个数据集,每个数据集为期 3 年,用于评估。 在结果中,每个数据集都将按其最后一年进行标注,这也与测试期的年份相对应,即2016、2019、2022。 我们在表1中总结了三个数据集的统计数据。
对于所有数据集,我们还将所有数据按时间顺序按 7:1:2 的比例分为训练集、验证集和测试集。
| Dataset | Duration | # Stocks | # Trading Days |
|---|---|---|---|
| 2016 | Jan 01 2014 - Dec 31 2016 | 88 | 756 |
| 2019 | Jan 01 2017 - Dec 31 2019 | 110 | 754 |
| 2022 | Jan 01 2020 - Dec 31 2022 | 110 | 756 |
4.1.2. 基线
由于多步股价预测任务尚未得到广泛探索,为了证明 D-Va 的有效性,我们还包括来自通用 seq2seq 任务的基线进行比较。 这包括统计和深度学习方法,这些方法已被证明在时间序列预测中效果良好。
| Model | ARIMA | NBA | VAE | VAE + Adv | Autoformer | D-Va | MSE | SD | |
|---|---|---|---|---|---|---|---|---|---|
| 2016 | 10 | 11.41% | 73.06% | ||||||
| 20 | 7.83% | 76.16% | |||||||
| 40 | 3.04% | 67.56% | |||||||
| 60 | 2.50% | 71.09% | |||||||
| 2019 | 10 | 10.57% | 77.87% | ||||||
| 20 | 9.84% | 79.10% | |||||||
| 40 | 6.58% | 75.40% | |||||||
| 60 | 3.51% | 75.93% | |||||||
| 2022 | 10 | 13.10% | 70.23% | ||||||
| 20 | 10.70% | 78.41% | |||||||
| 40 | 7.83% | 77.12% | |||||||
| 60 | 3.01% | 78.22% | |||||||
-
•
ARIMA (Box 等人, 2015) 自回归综合移动平均 (ARIMA) 是一种传统的统计方法,结合了自回归、差分和移动平均成分来进行时间序列预测。 这是流行的时间序列预测竞赛 M5 准确性竞赛的基线之一(Makridakis 等人,2022)。
-
•
NBA (Liu and Wang,2019):基于数值的注意力(NBA)是解决多步股价预测任务的基线模型。 它利用长短期记忆 (LSTM) 网络(Hochreiter 和 Schmidhuber,1997;Akita 等人,2016)以及额外的注意力组件来捕获股票价格的文本和时间依赖性。 对于此模型,我们删除了文本输入组件以进行等效比较。
-
•
VAE (Kingma 和 Welling,2014;Xu 和 Cohen,2018) 我们采用普通 VAE 模型作为基准来与分层 VAE 进行比较。 在此模型中,编码器有一个密集层,要生成一个潜在变量,采样解码器有一个密集层。 VAE 模型已被证明可以改进单步库存变动分类任务(Xu 和 Cohen,2018)。
-
•
VAE + Adversarial (Goodfellow 等人, 2014; Feng 等人, 2019a):与上述模型类似,但在输入序列中添加了对抗性扰动。 添加的扰动等于模型损失函数的梯度,类似于(Goodfellow等人,2014;Feng等人,2019a)中的做法。
-
•
Autoformer (Wu 等人, 2021):Autoformer 是一种最先进的 seq2seq 预测模型,它聚合序列依赖关系以进行长期预测。 该模型采用标准 Transformer 模型,具有渐进分解能力和自相关机制来查找序列周期性。
4.1.3. 参数设置
为了比较不同范围下的性能,我们评估了一系列序列长度,输入和输出长度 和 均为 10 天、20 天、40 天和 60 天。 所选择的长度是金融监管机构要求的典型流动性范围,这遵循了这项工作的动机。
使用Adam优化器(Kingma and Ba,2014)来优化模型,初始学习率为5e-4。 批量大小为 16,我们分别为每只股票训练 20 个 epoch 的模型,对每只股票进行最佳验证结果的迭代。 对于权衡超参数,我们在范围内执行步骤0.1的网格搜索,并设置和。 所有实验对每只股票重复五次:我们在结果部分报告所有股票的总体平均 MSE 和标准差。 然后,我们根据每个实验设置的最强基线来测量 MSE 的改进百分比和 D-Va 的标准差。
5. 结果
接下来,我们将讨论 D-Va 在解决上一节提出的每个研究问题方面的表现。
5.1. 性能比较(RQ1)
表2报告了多步回归股票预测任务的结果。 从表中,我们观察到以下几点:
-
•
当序列长度较长时,统计模型 ARIMA 往往比其他基线表现更好。 这可以归因于它有足够的信息来捕获序列内的自相关性以进行预测,而不是较短的序列,其中周期性不那么明显,噪声数据比更大。 后来在 Autoformer 中也观察到了这一点,它也从序列自相关中学习。
-
•
当预测不确定性较高时(通过多次运行的标准差来衡量),VAE 模型往往会表现出 MSE 改进。 在比较 NBA 和 VAE 模型的性能时可以观察到这一点。 当 NBA 模型的预测值显示出较高的标准偏差(即超过 0.075)时,VAE 模型的 MSE 有明显改善。 另一方面,当 NBA 的标准差较低时,VAE 模型的表现较差。 在所有情况下,VAE 模型预测的标准偏差都要低得多。 当数据有噪声时,NBA 模型很可能无法很好地学习,从而导致预测结果很差并且变化很大。 然而,在数据噪声较少的时期,NBA 模型的 LSTM + Attention 组件能够比 VAE 模型中编码器/解码器的简单密集层表现更好。
-
•
VAE + Adversarial 模型与 VAE 模型相比并没有显示出太大的改进。 MSE 的差异不具有统计显着性,可能归因于结果的标准偏差。 然而,与纯 VAE 模型相比,额外的对抗性组件似乎在其预测结果的标准偏差方面提供了一些轻微的改进。
-
•
尽管没有变分组件,Autoformer 模型在所有序列长度上都显着优于上述三种深度学习模型,这凸显了该方法的稳健性。 源材料(吴等人,2021)中也提到了这一特性,即使在没有明显周期性的情况下,模型也能够在汇率预测任务上表现良好。 我们的结果能够在股票预测任务上验证这一点。 我们还观察到,随着序列长度的增加,该模型的预测标准差逐渐增加,这与前三个模型的趋势相反。 这可能归因于在用于生成输出序列的捕获的序列周期中累积的噪声。
-
•
我们的 D-Va 模型在 MSE 性能和预测的标准差方面优于所有模型。 平均而言,D-Va 的 MSE 性能比最强基线(表 2 中下划线)提高了 7.49%,标准差提高了 75.01%。 这展示了 D-Va 在处理数据不确定性方面的能力,以改进多步回归股票预测任务中的预测。
-
•
最后,我们注意到 MSE 的改进随着预测长度的增加而减小。 这可能是因为预测范围较长的市场出现意外重大变化的可能性更大,而这是模型无法预见的。 在实际环境中,考虑到较长的时间范围,最好使用较短长度的模型进行滚动预测。
5.2. 模型研究(RQ2)
为了证明 D-Va 中每个附加组件的有效性,我们对模型的不同变体进行了消融研究。 我们为每个变体删除一个附加组件,即没有去噪组件(D-VaDn);无目标系列扩散和去噪分量(D-VaYdDn);并且没有输入序列扩散、目标序列扩散和去噪组件,只剩下骨干分层VAE模型(D-VaXdYdDn)。
5.2.1. 消融研究
| Model |
|
|
|
D-Va | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2016 |
10 |
||||||||||
|
20 |
|||||||||||
|
40 |
|||||||||||
|
60 |
|||||||||||
| 2019 |
10 |
||||||||||
|
20 |
|||||||||||
|
40 |
|||||||||||
|
60 |
|||||||||||
| 2022 |
10 |
||||||||||
|
20 |
|||||||||||
|
40 |
|||||||||||
|
60 |
|||||||||||
表3报告了消融研究的结果。 从表中,我们得出以下观察结果:
-
•
骨干模型D-VaXdYdDn,即仅分层VAE,已经展示了比之前的基线模型强大的MSE改进,即,ARIMA 和 Autoformer,凸显了该方法的优势。 对于股票价格预测任务来说,通过分层 VAE 的潜在变量处理数据随机性可能比从序列自相关中学习更有效。
-
•
对于每个附加扩散组件,即,在 D-VaYdDn 和 D-VaDn 中 模型,我们看到预测的标准偏差可以明显改善。 额外的噪声增强有助于提高预测的稳定性,这也是之前在 VAE + 对抗模型中观察到的。 这也表明我们提出的组件有助于提高模型的稳健性并降低预测的不确定性。
-
•
不同模型的最佳 MSE 性能似乎有所不同。 然而,我们可以看到一个模型的预测不确定性(通过其结果的标准差来衡量)与下一个模型的 MSE 性能之间存在明显的关系。 当标准偏差较低时,即低于 0.050,下一个附加组件似乎几乎没有提供 MSE 改进。 这些组件的工作原理很可能是使模型对数据中的噪声更加鲁棒——然而,对于数据噪声足够低(因此标准差低)的实验设置,预测中没有太多改进。 我们将在下一小节中更详细地探讨这一观察结果。
-
•
有趣的是,我们注意到去噪分量即从D-VaDn到D-Va,也稍微增加预测的标准差。 这可能是因为它被训练为采取单步去噪步骤朝向目标序列(参见方程8),我们之前定义为随机的。
5.2.2. 减少不确定性
对结果分析进行的一个关键观察是,变分分量的 MSE 改进似乎与先前模型的不确定性有关,不确定性是通过结果的标准差来衡量的。 在本节中,我们将更详细地研究这一观察结果。
首先,我们注意到报告的业绩是根据个股结果的平均值计算的,每个股票都有自己的平均 MSE 和超过 5 次运行的标准差。 在所有 12 个实验设置(即3 个测试周期和 4 个序列长度)中得出所有的单个结果后,我们绘制了一个模型的标准偏差与改进变体的 MSE 百分比变化的对比图,其中给定了一个额外的分量。
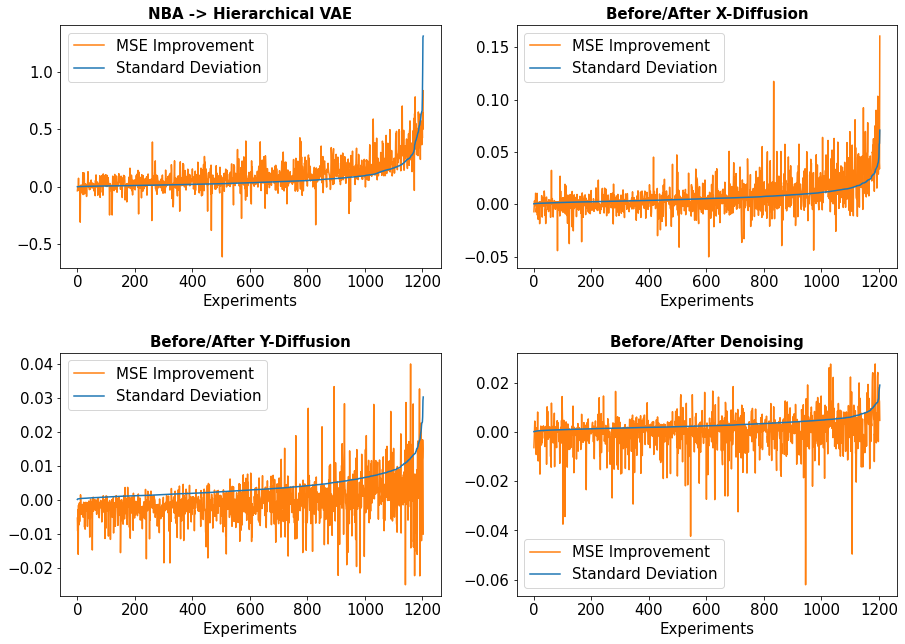
如图5所示,模型的预测不确定性(通过引入每个变分分量之前的预测结果的标准差来衡量)与引入每个变分分量之后得到的 MSE 改进之间存在明显的关系。介绍了每个组件。 当模型对其预测更加不确定时(可能是由于股票数据的随机性),额外的 VAE 和扩散组件会变得更加有效,因为它们具有处理数据噪声和不确定性的能力。 对于每个附加组件,这种关系变得不那么明显,可能是因为其之前的每个组件的不确定性显着减少(请注意图 5 中每个子图的标准差规模的减小)。
这种关系在去噪组件中最不明显。 这可能归因于两个可能的原因:首先,通过VAE和扩散组件,数据噪声已被降低到尽可能小的限度,使得最后一个组件很难产生更多的改进。 其次,去噪组件通过不同的机制工作也是合理的,该机制不太依赖于先前模型的不确定性。 如前所述,模型经过训练,对随机目标序列采取一步去噪步骤,这增加了目标的信息,但降低了其泛化性。 这类似于偏差方差问题(Kohavi 和 Wolpert,1996;von Luxburg 和 Schölkopf,2011),而我们的模型不希望过度拟合目标数据,因为它也包含随机噪声。
5.3. 投资组合优化 (RQ3)
此外,我们还研究了该模型在实际环境中的实用性。 与单日预测不同,多步预测使我们能够了解股票未来几天的回报前景,从而使我们能够形成一个能够最大化回报并最小化其波动性的资产组合。
5.3.1. 均值-方差优化
给定每只股票的回报序列预测,我们首先计算它们在每个单独预测周期的整体均值和协方差:
| (11) |
其中和表示预测期内所有股票收益的均值向量和协方差矩阵,是总收益股票数量。 然后,我们使用马科维茨均值方差优化(Markowitz,1952)形成该时期的股票投资组合:
| (12) |
其中是要学习的投资组合权重向量,其总和为1,代表总资本。 是风险规避参数,可以将其视为超参数,通过最大化验证集上的投资组合结果来调整(Peng 和 Linetsky,2022)。 此外,我们还设置了无卖空约束,即,这已被证明可以降低整体投资组合风险(Jagannathan 和 Ma,2003 年;DeMiguel等人,2009),也经常受到金融机构的限制(Chang 等人,2014;Beber 和 Pagano,2013)。
| 2016 | Sharpe Ratio |
|
2019 | Sharpe Ratio |
|
2022 | Sharpe Ratio |
|
|||||||||||
| NBA | 0.0270 | 0.0691 | Handling aleatoric | NBA | 0.0820 | 0.1767 | Handling aleatoric | NBA | 0.0332 | 0.0404 | Handling aleatoric | ||||||||
| Equal | 0.1089 | Equal | 0.2337 | Equal | 0.0437 | ||||||||||||||
| D-Va | 0.0772 | 0.1174 | D-Va | 0.1197 | 0.2767 | D-Va | 0.0600 | 0.0645 | |||||||||||
| Handling epistemic | Handling epistemic | Handling epistemic | |||||||||||||||||
5.3.2. 图形套索正则化
此外,我们通过应用图形套索(Friedman等人,2008)进一步对协方差矩阵进行正则化。 这是通过最大化惩罚对数似然来完成的:
| (13) |
其中是要学习的正则化的倒置协方差矩阵,是一个超参数,我们在实验中将其设置为0.1。 该方法类似于在机器学习中执行 L1 正则化(Tibshirani,1996),它通过降低预测的维度来提高预测的概括性。 它也类似于在金融领域执行协方差收缩(Ledoit 和 Wolf,2004a,b),其中极值被拉向更中心的值。 然而,图形套索已被证明对于较小样本的协方差效果更好(Belilovsky 等人,2017;Gao 等人,2018),这也在我们的实验中观察到。
L1 正则化也可以被视为减少模型不确定性影响的一种方法,模型不确定性是认知不确定性的一种形式(Hüllermeier 和 Waegeman,2021)。 另一方面,我们基于扩散的预测模型主要处理数据不确定性或任意不确定性(Li等人,2022)。 应用这两种技术,我们探讨了处理每种类型的不确定性对股票投资组合绩效的影响。
5.3.3. 比较法
为了比较投资组合的表现,我们使用夏普比率(Sharpe,1994),它是衡量投资组合回报与其波动性之比的指标。 它被定义为投资组合的总体预期收益(我们将无风险利率设置为0)除以收益的标准差,即: :
对于每个预测周期,我们首先使用方程式形成跨序列长度的投资组合。 12,它允许我们计算其夏普比率。 然后,我们评估测试期内所有 的平均夏普比率,以及 5 次预测运行结果的平均值。 此外,我们还包括等权重投资组合的表现,即。 事实证明,朴素等权重投资组合在前瞻性能方面优于大多数现有投资组合方法(DeMiguel 等人,2009),这使其成为强有力的比较基线。 我们进行三个比较:首先,我们将使用和不使用正则化的情况下 D-Va 的平均 10 天夏普比率与基线模型 NBA 进行比较,以分析处理每种不确定性类型的影响。 接下来,我们比较不同序列长度 的平均 天夏普比率。最后,我们比较正则化后基准多步预测模型的平均日夏普比率。
5.3.4. 投资组合结果
表 4 比较了不同数据集年份的平均 10 天夏普比率。 我们可以看到,使用D-Va作为预测模型并应用正则化都有助于改善夏普比结果,并且结合这两种方法可以让我们获得最佳的夏普比性能。 相对于我们的非正规化模型,等权重投资组合仍然是一个强有力的基准:这可能是由于 D-Va 没有纳入新闻等额外信息源,因此无法预期价格趋势的新变化或冲击。 然而,仅使用历史价格数据,该模型仍然能够为正则化投资组合方法提供足够的信息,使其优于该基准,这对其预测能力来说是一个乐观的信号。
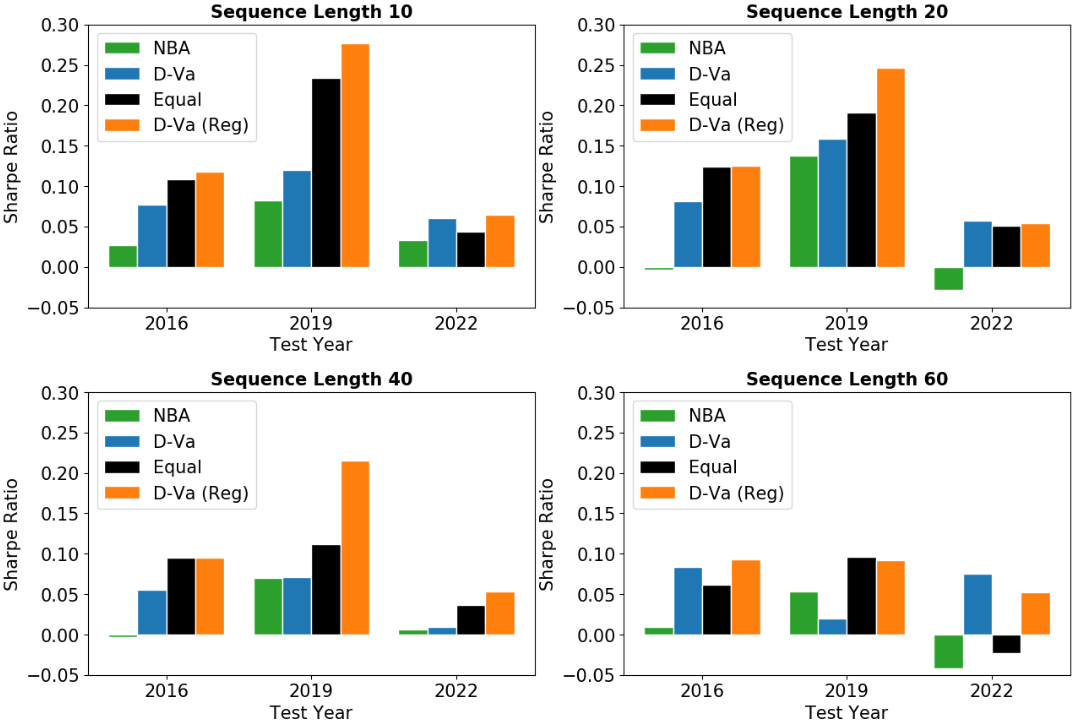
图6比较了不同预测长度的平均日夏普比率。 正如之前所观察到的,使用 D-Va 的预测以及协方差正则化,我们能够形成始终实现最佳夏普比率的投资组合,即使在不同的序列长度 上也是如此。我们注意到,在某些设置中,经过正则化的 D-Va 的表现并不优于等权重投资组合,例如2019 年测试期和。 这可能是由于 D-Va 无法捕获有关未来 天内价格趋势可能受到冲击的任何信息。 然而,对于这种情况,其表现通常接近于等权重投资组合,这表明正则化方法能够在信息有限的情况下很好地分散风险。
最后,表 5 比较了应用图形套索正则化后三个基准模型的平均 天夏普比率。 我们看到,我们的 D-Va 模型能够在夏普比率上获得最佳结果,并且在没有获得夏普比率的情况下,结果接近于等权重投资组合的结果,正如之前观察到的那样。 一个重要的观察结果是,夏普比率结果与表 2 中的预测 MSE 结果并不成正比。 这可能是因为投资组合的形成考虑了预测的波动方向 - 例如,对于 0.0 的真实值,-0.01 和 0.01 的预测将对 MSE 产生相同的影响但在形成投资组合时会导致不同的交易决策。 然而,我们的 D-Va 模型仍然能够在这两个指标上取得最先进的结果。 处理目标序列的随机性可能使模型能够做出“更清晰”的预测,这使得 MSE 能够准确反映其与目标序列的实际接近度,而不是其噪声。
| Model | ARIMA | NBA | Autoformer | Equal | D-Va | |
|---|---|---|---|---|---|---|
| 2016 | 10 | 0.0953 | 0.0691 | 0.1114 | 0.1089 | 0.1174 |
| 20 | 0.0815 | 0.1075 | 0.0921 | 0.1243 | 0.1246 | |
| 40 | 0.0683 | 0.0717 | 0.0438 | 0.0950 | 0.0953 | |
| 60 | 0.0544 | 0.0803 | 0.0235 | 0.0614 | 0.0929 | |
| 2019 | 10 | 0.2736 | 0.1767 | 0.2350 | 0.2337 | 0.2767 |
| 20 | 0.2455 | 0.1443 | 0.1672 | 0.1912 | 0.2467 | |
| 40 | 0.2152 | 0.1252 | 0.1031 | 0.1113 | 0.2152 | |
| 60 | 0.0732 | 0.0826 | 0.0804 | 0.0965 | 0.0914 | |
| 2022 | 10 | 0.0173 | 0.0404 | 0.0544 | 0.0437 | 0.0645 |
| 20 | 0.0408 | 0.0404 | 0.0141 | 0.0505 | 0.0540 | |
| 40 | 0.0287 | -0.0223 | -0.0016 | 0.0365 | 0.0527 | |
| 60 | -0.0329 | -0.0179 | -0.0630 | -0.0230 | 0.0524 | |
6. 结论和未来的工作
在本文中,我们解释了多步回归股票价格预测任务的重要性,这在当前文献中经常被忽视。 对于这项任务,我们强调了两个挑战:现有方法在处理股票价格输入数据中的随机噪声方面的局限性,以及多步骤任务的目标序列中的噪声问题。 为了应对这些挑战,我们提出了一个深度学习框架 D-Va,它集成了分层 VAE 和扩散概率技术来进行多步骤预测。 我们对两个基准数据集进行了广泛的实验,其中一个是我们通过扩展流行的股票预测数据集(Xu and Cohen,2018)收集的。 我们发现我们的 D-Va 模型在预测精度和结果标准差方面都优于最先进的方法。 此外,我们还证明了模型输出在实际投资环境中的有效性。 根据 D-Va 的预测形成的投资组合也能够优于其他基准预测模型形成的投资组合以及等权重投资组合,这是金融文献中已知的强基线(DeMiguel 等人,2009).
这项工作的结果开辟了一些未来可能的研究方向。 在数据增强方面,我们在这项工作中探索了通过损失函数梯度(Feng等人,2019a)和高斯扩散噪声来扰动数据。 其他可能性包括在最高价和最低价范围之间添加噪声,这代表每个时间步长观察到的最大价格变动。 最近的一项工作(Liu等人,2022)也从理论上提出,用强度的噪声增强股票数据是实现最佳夏普比率的最佳选择。 此外,已有大量利用替代数据预测股票走势的研究,例如文本(胡等人,2018a;冯等人,2021)或音频(杨等人, 2022)。 这可以合并到 D-Va 中,目前 D-Va 仅使用历史价格数据。 然而,除了简单地查看预测准确性之外,我们还可以探索附加信息源如何帮助减少预测的不确定性。 这对于预测高度随机数据(例如股票价格)的情况将非常有帮助。 最后,考虑到 D-Va 的序列预测输出,还可以探索其他最先进的投资组合技术,例如分层风险平价 (HRP) 方法(De Prado,2016) ,或最新的部分平等投资组合选择 (PEPS) 技术(Peng 和 Linetsky,2022),来评估我们的模型与不同金融技术的协同作用。
7. 致谢
这项研究得到了国防科学技术局和 NExT 研究中心的支持。
参考
- (1)
- Akita et al. (2016) Ryo Akita, Akira Yoshihara, Takashi Matsubara, and Kuniaki Uehara. 2016. Deep learning for stock prediction using numerical and textual information. In ICIS. IEEE Computer Society, 1–6.
- Beber and Pagano (2013) Alessandro Beber and Marco Pagano. 2013. Short-selling bans around the world: Evidence from the 2007–09 crisis. J. Finance 68, 1 (2013), 343–381.
- Belilovsky et al. (2017) Eugene Belilovsky, Kyle Kastner, Gaël Varoquaux, and Matthew B. Blaschko. 2017. Learning to Discover Sparse Graphical Models. In ICML (Proceedings of Machine Learning Research, Vol. 70). PMLR, 440–448.
- Box et al. (2015) George EP Box, Gwilym M Jenkins, Gregory C Reinsel, and Greta M Ljung. 2015. Time series analysis: forecasting and control. John Wiley & Sons.
- Chang et al. (2014) Eric C Chang, Yan Luo, and Jinjuan Ren. 2014. Short-selling, margin-trading, and price efficiency: Evidence from the Chinese market. J. Bank. Finance 48 (2014), 411–424.
- Chen et al. (2018) Yingmei Chen, Zhongyu Wei, and Xuanjing Huang. 2018. Incorporating Corporation Relationship via Graph Convolutional Neural Networks for Stock Price Prediction. In CIKM. ACM, 1655–1658.
- Chollet (2017) François Chollet. 2017. Xception: Deep Learning with Depthwise Separable Convolutions. In CVPR. IEEE Computer Society, 1800–1807.
- Da Silva and Shi (2019) Brandon Da Silva and Sylvie Shang Shi. 2019. Style transfer with time series: Generating synthetic financial data. arXiv preprint arXiv:1906.03232 (2019).
- De Prado (2016) Marcos Lopez De Prado. 2016. Building diversified portfolios that outperform out of sample. The Journal of Portfolio Management 42, 4 (2016), 59–69.
- DeMiguel et al. (2009) Victor DeMiguel, Lorenzo Garlappi, and Raman Uppal. 2009. Optimal versus naive diversification: How inefficient is the 1/N portfolio strategy? Rev. Financ. Stud. 22, 5 (2009), 1915–1953.
- Ding et al. (2020) Qianggang Ding, Sifan Wu, Hao Sun, Jiadong Guo, and Jian Guo. 2020. Hierarchical Multi-Scale Gaussian Transformer for Stock Movement Prediction. In IJCAI. ijcai.org, 4640–4646.
- Dong et al. (2013) Guanqun Dong, Kamaladdin Fataliyev, and Lipo Wang. 2013. One-step and multi-step ahead stock prediction using backpropagation neural networks. In ICICS. IEEE, 1–5.
- Feng et al. (2019a) Fuli Feng, Huimin Chen, Xiangnan He, Ji Ding, Maosong Sun, and Tat-Seng Chua. 2019a. Enhancing Stock Movement Prediction with Adversarial Training. In IJCAI. ijcai.org, 5843–5849.
- Feng et al. (2019b) Fuli Feng, Xiangnan He, Xiang Wang, Cheng Luo, Yiqun Liu, and Tat-Seng Chua. 2019b. Temporal Relational Ranking for Stock Prediction. ACM TOIS 37, 2 (2019), 27:1–27:30.
- Feng et al. (2021) Fuli Feng, Xiang Wang, Xiangnan He, Ritchie Ng, and Tat-Seng Chua. 2021. Time horizon-aware modeling of financial texts for stock price prediction. In ICAIF. ACM, 51:1–51:8.
- Friedman et al. (2008) Jerome Friedman, Trevor Hastie, and Robert Tibshirani. 2008. Sparse inverse covariance estimation with the graphical lasso. Biostatistics 9, 3 (2008), 432–441.
- Gao et al. (2018) Xu Gao, Weining Shen, Chee-Ming Ting, Steven C Cramer, Ramesh Srinivasan, and Hernando Ombao. 2018. Modeling brain connectivity with graphical models on frequency domain. arXiv preprint arXiv:1810.03279 (2018).
- Goodfellow et al. (2020) Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. 2020. Generative adversarial networks. Commun. ACM 63, 11 (2020), 139–144.
- Goodfellow et al. (2014) Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. 2014. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572 (2014).
- Ho et al. (2020) Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Probabilistic Models. In NeurIPS.
- Hochreiter and Schmidhuber (1997) Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long Short-Term Memory. Neural Comput. 9, 8 (1997), 1735–1780.
- Hu et al. (2018b) Jie Hu, Li Shen, and Gang Sun. 2018b. Squeeze-and-Excitation Networks. In CVPR. Computer Vision Foundation / IEEE Computer Society, 7132–7141.
- Hu et al. (2018a) Ziniu Hu, Weiqing Liu, Jiang Bian, Xuanzhe Liu, and Tie-Yan Liu. 2018a. Listening to Chaotic Whispers: A Deep Learning Framework for News-oriented Stock Trend Prediction. In WSDM. ACM, 261–269.
- Hüllermeier and Waegeman (2021) Eyke Hüllermeier and Willem Waegeman. 2021. Aleatoric and epistemic uncertainty in machine learning: an introduction to concepts and methods. Mach. Learn. 110, 3 (2021), 457–506.
- Jagannathan and Ma (2003) Ravi Jagannathan and Tongshu Ma. 2003. Risk reduction in large portfolios: Why imposing the wrong constraints helps. J. Finance 58, 4 (2003), 1651–1683.
- Jolicoeur-Martineau et al. (2021) Alexia Jolicoeur-Martineau, Rémi Piché-Taillefer, Ioannis Mitliagkas, and Remi Tachet des Combes. 2021. Adversarial score matching and improved sampling for image generation. In ICLR. OpenReview.net.
- Kadkhodaie and Simoncelli (2020) Zahra Kadkhodaie and Eero P Simoncelli. 2020. Solving linear inverse problems using the prior implicit in a denoiser. arXiv preprint arXiv:2007.13640 (2020).
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
- Kingma and Welling (2014) Diederik P. Kingma and Max Welling. 2014. Auto-Encoding Variational Bayes. In ICLR.
- Klushyn et al. (2019) Alexej Klushyn, Nutan Chen, Richard Kurle, Botond Cseke, and Patrick van der Smagt. 2019. Learning Hierarchical Priors in VAEs. In NeurIPS. 2866–2875.
- Kohavi and Wolpert (1996) Ron Kohavi and David H. Wolpert. 1996. Bias Plus Variance Decomposition for Zero-One Loss Functions. In ICML. Morgan Kaufmann, 275–283.
- Ledoit and Wolf (2004a) Olivier Ledoit and Michael Wolf. 2004a. Honey, I shrunk the sample covariance matrix. J. Portf. Manag. 30, 4 (2004), 110–119.
- Ledoit and Wolf (2004b) Olivier Ledoit and Michael Wolf. 2004b. A well-conditioned estimator for large-dimensional covariance matrices. J. Multivar. Anal. 88, 2 (2004), 365–411.
- Li et al. (2016) Lili Li, Shan Leng, Jun Yang, and Mei Yu. 2016. Stock market autoregressive dynamics: a multinational comparative study with quantile regression. Mathematical Problems in Engineering 2016 (2016).
- Li et al. (2022) Yan Li, Xinjiang Lu, Yaqing Wang, and Dejing Dou. 2022. Generative time series forecasting with diffusion, denoise, and disentanglement. In NeurIPS.
- Li et al. (2019) Zengyi Li, Yubei Chen, and Friedrich T Sommer. 2019. Learning energy-based models in high-dimensional spaces with multi-scale denoising score matching. arXiv preprint arXiv:1910.07762 (2019).
- Lin et al. (2021) Hengxu Lin, Dong Zhou, Weiqing Liu, and Jiang Bian. 2021. Learning Multiple Stock Trading Patterns with Temporal Routing Adaptor and Optimal Transport. In KDD. ACM, 1017–1026.
- Liu and Wang (2019) Guang Liu and Xiaojie Wang. 2019. A Numerical-Based Attention Method for Stock Market Prediction With Dual Information. IEEE Access 7 (2019), 7357–7367.
- Liu et al. (2022) Ziyin Liu, Kentaro Minami, and Kentaro Imajo. 2022. Theoretically Motivated Data Augmentation and Regularization for Portfolio Construction. In ICAIF. ACM, 273–281.
- Ma et al. (2022) Yanqing Ma, Carmine Ventre, and Maria Polukarov. 2022. Denoised Labels for Financial Time Series Data via Self-Supervised Learning. In ICAIF. ACM, 471–479.
- Makridakis et al. (2022) Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. 2022. M5 accuracy competition: Results, findings, and conclusions. Int. J. Forecast. 38, 4 (2022), 1346–1364.
- Markowitz (1952) Harry Markowitz. 1952. Portfolio Selection. J. Finance 7, 1 (1952), 77–91.
- Peng and Linetsky (2022) Yiming Peng and Vadim Linetsky. 2022. Portfolio Selection: A Statistical Learning Approach. In ICAIF. ACM, 257–263.
- Qin et al. (2017) Yao Qin, Dongjin Song, Haifeng Chen, Wei Cheng, Guofei Jiang, and Garrison W. Cottrell. 2017. A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction. In IJCAI. ijcai.org, 2627–2633.
- Ramachandran et al. (2017) Prajit Ramachandran, Barret Zoph, and Quoc V Le. 2017. Searching for activation functions. arXiv preprint arXiv:1710.05941 (2017).
- Raunig (2006) Burkhard Raunig. 2006. The longer-horizon predictability of German stock market volatility. Int. J. Forecast. 22, 2 (2006), 363–372.
- Saremi and Hyvärinen (2019) Saeed Saremi and Aapo Hyvärinen. 2019. Neural Empirical Bayes. J. Mach. Learn. Res. 20 (2019), 181:1–181:23.
- Sawhney et al. (2020) Ramit Sawhney, Shivam Agarwal, Arnav Wadhwa, and Rajiv Ratn Shah. 2020. Deep Attentive Learning for Stock Movement Prediction From Social Media Text and Company Correlations. In EMNLP (1). ACL, 8415–8426.
- Sharpe (1994) William F Sharpe. 1994. The sharpe ratio. J. Portf. Manag. 21 (1994), 49–58.
- Sohl-Dickstein et al. (2015) Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. 2015. Deep Unsupervised Learning using Nonequilibrium Thermodynamics. In ICML (JMLR Workshop and Conference Proceedings, Vol. 37). JMLR.org, 2256–2265.
- Sønderby et al. (2016) Casper Kaae Sønderby, Tapani Raiko, Lars Maaløe, Søren Kaae Sønderby, and Ole Winther. 2016. Ladder Variational Autoencoders. In NIPS. 3738–3746.
- Song and Ermon (2019) Yang Song and Stefano Ermon. 2019. Generative Modeling by Estimating Gradients of the Data Distribution. In NeurIPS. 11895–11907.
- Song and Ermon (2020) Yang Song and Stefano Ermon. 2020. Improved Techniques for Training Score-Based Generative Models. In NeurIPS.
- Tibshirani (1996) Robert Tibshirani. 1996. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Methodological) 58, 1 (1996), 267–288.
- Tuncer et al. (2022) Tuna Tuncer, Uygar Kaya, Emre Sefer, Onur Alacam, and Tugcan Hoser. 2022. Asset Price and Direction Prediction via Deep 2D Transformer and Convolutional Neural Networks. In ICAIF. ACM, 79–86.
- Vahdat and Kautz (2020) Arash Vahdat and Jan Kautz. 2020. NVAE: A Deep Hierarchical Variational Autoencoder. In NeurIPS.
- von Luxburg and Schölkopf (2011) Ulrike von Luxburg and Bernhard Schölkopf. 2011. Statistical Learning Theory: Models, Concepts, and Results. In Inductive Logic. Handbook of the History of Logic, Vol. 10. Elsevier, 651–706.
- Wu et al. (2021) Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. 2021. Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting. In NeurIPS. 22419–22430.
- Xu and Cohen (2018) Yumo Xu and Shay B. Cohen. 2018. Stock Movement Prediction from Tweets and Historical Prices. In ACL (1). ACL, 1970–1979.
- Yang et al. (2022) Linyi Yang, Jiazheng Li, Ruihai Dong, Yue Zhang, and Barry Smyth. 2022. NumHTML: Numeric-Oriented Hierarchical Transformer Model for Multi-Task Financial Forecasting. In AAAI. AAAI Press, 11604–11612.
- Ye et al. (2020) Jiexia Ye, Juanjuan Zhao, Kejiang Ye, and Chengzhong Xu. 2020. Multi-Graph Convolutional Network for Relationship-Driven Stock Movement Prediction. In ICPR. IEEE, 6702–6709.
- Zhang et al. (2017) Liheng Zhang, Charu C. Aggarwal, and Guo-Jun Qi. 2017. Stock Price Prediction via Discovering Multi-Frequency Trading Patterns. In KDD. ACM, 2141–2149.