检索增强生成中大型语言模型的基准测试
摘要
检索增强生成(RAG)是一种很有前途的减轻大语言模型(大语言模型)幻觉的方法。 然而,现有的研究缺乏对检索增强生成对不同大语言模型的影响的严格评估,这使得识别不同大语言模型的 RAG 能力的潜在瓶颈变得具有挑战性。 在本文中,我们系统地研究了检索增强生成对大型语言模型的影响。 我们分析了不同大型语言模型在 RAG 所需的 4 种基本能力方面的性能,包括噪声鲁棒性、负拒绝、信息集成和反事实鲁棒性。 为此,我们建立了检索增强生成基准(RGB),这是一个用于中英文RAG评估的新语料库。 RGB 根据解决案例所需的上述基本能力将基准测试中的实例划分为 4 个独立的测试平台。 然后我们在RGB上评估6个有代表性的大语言模型,以诊断当前大语言模型在应用RAG时面临的挑战。 评估表明,虽然大语言模型表现出一定程度的噪声鲁棒性,但它们在负面拒绝、信息整合和处理虚假信息方面仍然存在很大困难。 上述评估结果表明,将RAG有效地应用于大语言模型还有很长的路要走。
介绍
最近,ChatGPT (OpenAI 2022) 和 ChatGLM (THUDM 2023a) 等大型语言模型(大语言模型)取得了令人瞩目的进展。 尽管这些模型表现出了卓越的综合能力(Bang 等人 2023;Guo 等人 2023),但它们仍然面临着包括事实幻觉在内的严峻挑战(Cao 等人 2020;Raunak、Menezes 和Junczys-Dowmunt 2021;Ji 等人 2023),知识过时(He、Zhang 和 Roth 2022),以及缺乏特定领域的专业知识(Li 等)人 2023c; 沉等人 2023).
通过信息检索结合外部知识,即检索增强生成(RAG),被认为是解决上述挑战的一种有前途的方法。 (Guu 等人 2020; Lewis 等人 2020; Borgeaud 等人 2022; Izacard 等人 2022)。 借助外部知识,大语言模型可以生成更准确、更可靠的响应。 最常见的方法是使用搜索引擎作为检索器,例如 New Bing。 由于互联网上提供的信息量巨大,使用搜索引擎可以提供更多实时信息。
然而,检索增强生成给大语言模型带来的不仅仅是积极的影响(Liu,Zhang,and Liang 2023;Maynez 等人 2020)。 一方面,互联网上的内容中存在大量的噪音信息甚至假新闻,这给搜索引擎准确检索所需知识带来了挑战。 另一方面,大语言模型面临着不可靠生成的挑战。 大语言模型可能会被上下文中包含的错误信息(Bian 等人 2023)所误导,并且在生成过程中也会产生幻觉(Adlakha 等人 2023),导致生成超越外部信息的内容。 这些挑战导致大语言模型无法持续生成可靠且准确的响应。 不幸的是,目前对这些因素如何影响 RAG 以及每个模型如何克服这些缺点并通过信息检索提高其性能缺乏全面的了解。 因此,迫切需要对大语言模型有效利用检索信息的能力以及抵御信息检索中存在的各种缺陷的能力进行综合评估。
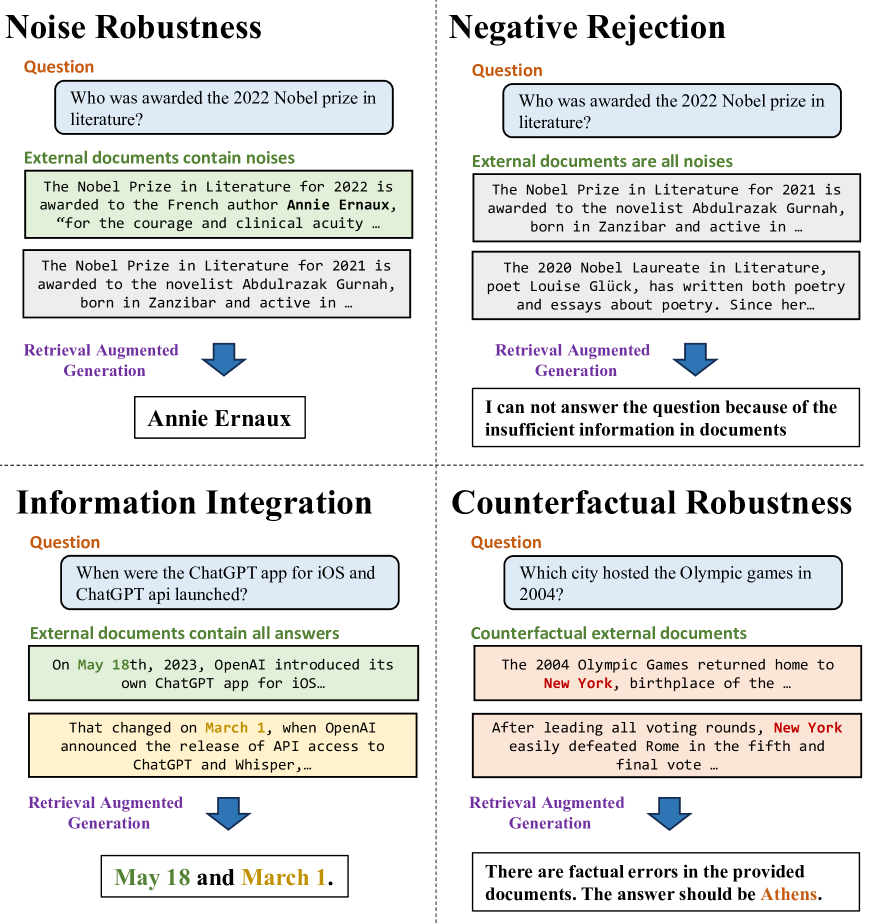
为此,本文对现有大语言模型的RAG进行了综合评价。 具体来说,我们创建了一个新的检索增强生成基准,即 RGB,有英文和中文版本。 为了保证大语言模型的内部知识不会给评估结果引入偏差,RGB选择聚合最新的新闻信息,并根据新闻信息构建查询。 然后,根据这些查询,我们使用搜索 API 来获取相关文档,并从内容中选择最相关的片段作为外部检索文档。 最后,根据查询和文档集对的不同组成,我们扩展语料库并将其分为4个测试床,根据RAG中常见的挑战来评估大语言模型的以下基本能力,如图1:
-
•
噪声鲁棒性,这意味着大语言模型可以从噪声文档中提取有用的信息。 在本文中,我们将噪声文档定义为与问题相关但不包含答案的任何信息的文档。 以图1为例,与“谁获得了2022年诺贝尔文学奖”问题相关的噪声文档包括有关2021年诺贝尔文学奖的报道。 为此,噪声鲁棒性测试台包含外部文档包含基于所需噪声比的一定数量的噪声文档的实例。
-
•
否定拒绝,这意味着当任何检索到的文档中不存在所需的知识时,大语言模型应该拒绝回答问题。 否定拒绝的测试台包含外部文档仅包含噪声文档的实例。 大语言模型预计会指示“信息不足”或其他拒绝信号。
-
•
信息集成,评估大语言模型是否能够回答需要集成多个文档信息的复杂问题。 以图1为例,对于“iOS版ChatGPT应用程序和ChatGPT api何时推出?”的问题,大语言模型预计将提供ChatGPT iOS应用程序的发布日期信息和 ChatGPT API。 信息集成的测试平台包含只能使用多个文档来回答的实例。
-
•
反事实鲁棒性,评估当通过指令向大语言模型发出有关检索信息中潜在风险的警告时,大语言模型是否能够识别检索文档中已知事实错误的风险。 反事实稳健性的测试平台包括大语言模型可以直接回答的实例,但外部文档包含事实错误。
基于RGB,我们对ChatGPT (OpenAI 2022)、ChatGLM-6B (THUDM 2023a)、ChatGLM2-等6种最先进的大型语言模型进行了评估6B (THUDM 2023b)、Vicuna-7b (Chiang 等人 2023)、Qwen-7B-Chat (QwenLM 2023)、BELLE-7B (季云杰2023)。 我们发现,尽管RAG可以提高大语言模型的响应准确性,但它们仍然面临着上述挑战。 具体来说,我们发现,尽管大语言模型表现出一定程度的噪声鲁棒性,但它们往往会混淆相似的信息,并在存在相关信息时经常生成不准确的答案。 例如,当面对关于2022年诺贝尔文学奖的问题时,如果外部文档中有关于2021年诺贝尔文学奖的嘈杂文档,大语言模型可能会变得混乱并提供不准确的答案。 此外,当外部文档不包含相关信息时,大语言模型经常无法拒绝回答并生成错误的答案。 此外,大语言模型缺乏对多个文档进行总结的能力,因此如果需要多个文档来回答一个问题,大语言模型往往无法提供准确的答案。 最后,我们发现,即使大语言模型包含所需的知识,并通过指令对检索到的信息中的潜在风险发出警告,他们仍然倾向于信任检索到的信息,并优先考虑检索到的信息而不是自己现有的知识。 上述实验结果凸显了现有 RAG 方法中重要问题需要进一步解决。 因此,谨慎行事并仔细设计其用法至关重要。
总的来说,本文的贡献是111我们的代码和数据:https://github.com/chen700564/RGB。:
-
•
我们提出评估大语言模型检索增强生成的四种能力,并创建了中英文检索增强生成基准。 据我们所知,这是第一个旨在评估大语言模型检索增强生成的这四种能力的基准。
-
•
我们使用 RGB 评估了现有的大语言模型,发现了它们在四种不同能力上的局限性。
-
•
我们分析了大语言模型在 RGB 中的响应,找出了它们当前的缺陷以及改进的建议方向。
相关工作
检索增强模型
大型语言模型中存储的知识通常是过时的(He,Zhang,and Roth 2022),并且有时还会产生幻觉(Cao等人2020;Raunak,Menezes和Junczys-Dowmunt 2021; Ji 等人 2023) 即,它们可能会生成不相关或事实上不正确的内容。 通过使用外部知识作为指导,检索增强模型可以生成更准确、更可靠的响应(Guu 等人 2020; Lewis 等人 2020; Borgeaud 等人 2022; Izacard 等人 2022; Shi 等人 2023; Ren 等人2023)。 检索增强模型在开放域 QA (Izacard and Grave 2021; Trivedi 等人 2023; Li 等人 2023a)、对话 (Cai 等人 2019a) 等各种任务中取得了显着的成绩, b; Peng 等人 2023),特定领域问答 (Cui 等人 2023) 和代码生成 (Zhou 等人 2023b)。 近年来,随着大型模型的发展,一系列检索增强工具和产品受到广泛关注,如ChatGPT检索插件、Langchain、New Bing等。 然而,在现实场景中,检索到的文本不可避免地包含噪声。 因此,本文对大语言模型中的检索增强生成进行了系统的评估和分析。
大语言模型评价
大语言模型的评估因其卓越的通用能力而受到广泛关注(Chang 等人 2023)。 它使我们能够更深入地了解大语言模型的具体能力和局限性,同时也为未来的研究提供有价值的指导。 过去,GLUE (Wang 等人 2019b) 和 SuperCLUE (Wang 等人 2019a) 等基准测试主要侧重于评估 NLP 任务,特别是自然语言理解方面的任务。 然而,这些评估往往无法充分体现大语言模型的能力。 随后提出了 MMLU (Hendrycks 等人 2021) 来衡量语言模型在预训练时获得的知识。 近年来,随着大语言模型的发展,出现了一系列通用评估基准,例如AGIEval (Zhong 等人 2023)、C-Eval (Huang 等人 2023) t1>、AlpacaEval (Li 等人 2023b)、OpenLLM 排行榜 (Edward Beeching 2023) 等 除了一般能力之外,还有一些具体的基准,重点评估模型的能力。 例如,CValues (Xu 等人 2023a) 侧重于大语言模型的安全性和责任性,M3Exam (Zhang 等人 2023) 侧重于人类考试和 ToolBench (Qin 等人 2023) 评估大语言模型使用外部工具的情况。 最近,Adlakha 等人 (2023) 在现有 QA 数据集中评估了大语言模型的 RAG。 与他们的工作不同,我们关注RAG所需的4个能力,并创建检索增强生成基准来评估大语言模型。
检索增强生成基准
在本节中,我们首先介绍我们旨在评估的具体检索增强生成能力。 接下来,我们概述构建 RAG 评估基准的过程。 最后,我们提出评估指标。
RAG所需能力
外部知识是解决大语言模型的幻觉和知识过时等问题的关键,它可以使大语言模型通过检索增强生成(RAG)产生更准确、更可靠的响应。 然而,大语言模型并不总是能按照RAG的预期做出反应。 一方面,互联网上存在大量不相关的文件和虚假信息。 将这些外部文档纳入大语言模型可能会产生不利影响。 对于另一个人来说,大语言模型面临着不可靠生成的挑战。 大语言模型的生成往往是不可预测的,我们不能保证它们会利用外部文档中包含的有用信息。 此外,大语言模型很容易被文档中不正确的信息误导。 为此,我们构建了检索增强生成基准(RGB)来评估大语言模型的检索增强生成,我们关注4个具体能力:
Noise Robustness是大语言模型在噪声文档中的鲁棒性。 由于检索器并不完美,它们检索的外部知识通常包含大量噪声,即与问题相关但不包含有关答案的任何信息的文档。 为了有效地回答用户问题,大语言模型必须能够从文档中提取必要的信息,尽管文档中有噪音。
否定拒绝是衡量大语言模型在没有上下文提供有用信息时是否可以拒绝回答问题的指标。 在现实情况下,搜索引擎经常无法检索到包含答案的文档。 在这些情况下,模型具有拒绝识别并避免生成误导性内容的能力非常重要。
信息整合是整合多个文档的答案的能力。 在许多情况下,问题的答案可能包含在多个文档中。 例如,对于问题“2022年美国公开赛男女单打冠军是谁?”,这两个冠军可能会在不同的文档中提及。 为了更好地回答复杂的问题,大语言模型需要具备信息整合的能力。
反事实稳健性是指处理外部知识错误的能力。 在现实世界中,互联网上存在大量虚假信息。 请注意,我们仅评估大语言模型通过指令对检索到的信息中的潜在风险进行警告的情况。
在现实场景中,不可能获得具有所有必要外部知识的完美文档。 因此,为了衡量大语言模型的RAG,评估模型的这四种能力就变得至关重要。
数据建设
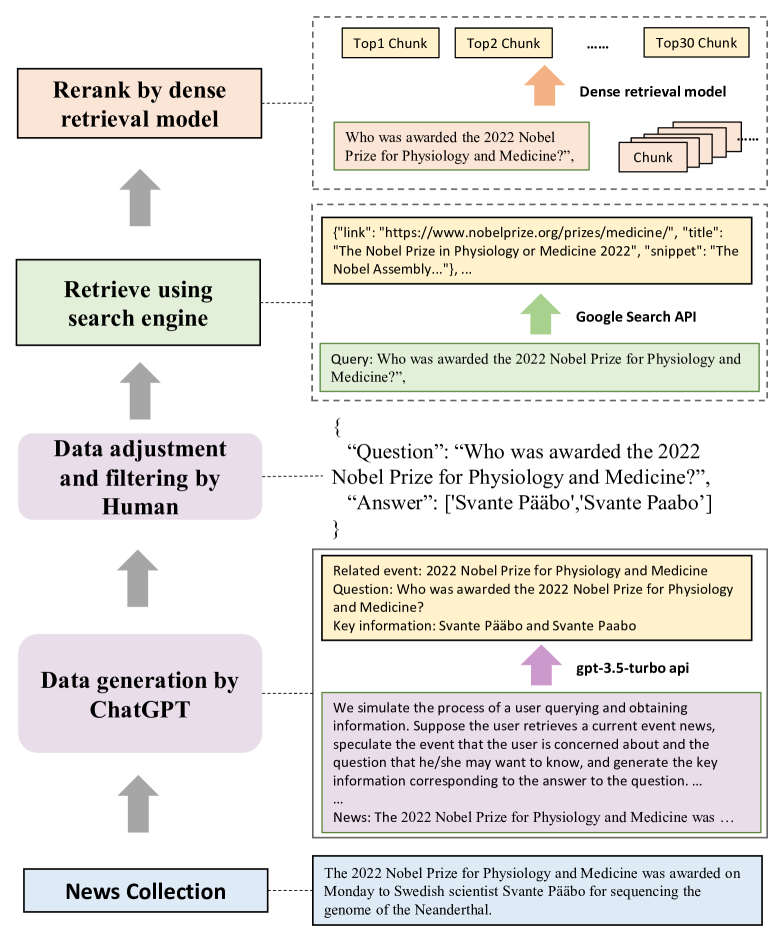
受之前大语言模型基准测试的启发,RGB 采用问答形式进行评估。 我们通过判断大语言模型对问题的检索增强反应来评估大语言模型。 为了模拟现实世界的场景,我们使用实际的新闻文章构建问答数据。 由于大语言模型中包含丰富的知识,在测量前三种能力时可能存在偏差。 为了缓解这种情况,RGB 的实例是由最新的新闻文章构建的。 此外,我们通过搜索引擎从互联网检索外部文档。 最后,我们对语料库进行了扩展,并将其分为4个测试床来评估大语言模型的上述基本能力。 我们数据构建的总体流程如图2所示。
QA 实例生成。 我们首先收集最新的新闻文章,并使用提示让 ChatGPT 为每篇文章生成事件、问题和答案。 例如,如图2所示,对于“2022年诺贝尔奖”的报道,ChatGPT将生成相应的事件、问题并提供回答的关键信息。 通过生成事件,模型能够初步过滤掉不包含任何事件的新闻文章。 生成后,我们手动检查答案并过滤掉难以通过搜索引擎检索到的数据。
使用搜索引擎检索。 对于每个查询,我们使用 Google 的 API 获取 10 个相关网页并从中提取相应的文本片段。 同时,我们读取这些网页并将其文本内容转换为最大长度为 300 个标记的文本块。 使用现有的密集检索模型 222中文:https://huggingface.co/moka-ai/m3e-base;英语:https://huggingface.co/sentence-transformers/all-mpnet-base-v2。,我们选择与查询最有效匹配的前 30 个文本块。 这些检索到的文本块以及搜索 API 提供的片段将作为我们的外部文档。 这些文件将根据是否包含答案分为正面文件和反面文件。
每种能力的测试平台建设。 我们对语料库进行了扩展,将其分为4个测试床来评估大语言模型的上述基本能力。 为了评估噪声鲁棒性,我们根据所需的噪声比率对不同数量的负面文档进行采样。 对于否定拒绝,所有外部文档均从否定文档中抽样。 对于信息整合能力,我们根据上述生成的问题进一步构建数据。 这涉及扩展或重写这些问题,以便它们的答案涵盖多个方面。 例如,问题“谁赢得了 2023 年超级碗 MVP?”可以重写为“谁赢得了 2022 年和 2023 年超级碗 MVP?”。 因此,回答此类问题需要利用各种文档中的信息。 与前三种能力不同,反事实稳健性的数据完全基于模型的内部知识构建。 基于上述生成的问题,我们采用ChatGPT自动生成其已知知识。 具体来说,我们使用提示让模型生成已知的问题和答案。 例如,基于问题“谁获得了2022年诺贝尔生理学和医学奖?”,模型将生成已知问题“谁获得了2021年诺贝尔文学奖?”并回答“Abdulrazak Gurnah”。 然后,我们手动验证生成的答案,并检索相关文档,如上所述。 为了使文档包含事实错误,我们手动修改答案并替换文档中的相应部分。

| English | Chinese | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Noise Ratio | 0 | 0.2 | 0.4 | 0.6 | 0.8 | 0 | 0.2 | 0.4 | 0.6 | 0.8 |
| ChatGPT (OpenAI 2022) | 96.33 | 94.67 | 94.00 | 90.00 | 76.00 | 95.67 | 94.67 | 91.00 | 87.67 | 70.67 |
| ChatGLM-6B (THUDM 2023a) | 93.67 | 90.67 | 89.33 | 84.67 | 70.67 | 94.33 | 90.67 | 89.00 | 82.33 | 69.00 |
| ChatGLM2-6B (THUDM 2023b) | 91.33 | 89.67 | 83.00 | 77.33 | 57.33 | 86.67 | 82.33 | 76.67 | 72.33 | 54.00 |
| Vicuna-7B-v1.3 (Chiang et al. 2023) | 87.67 | 83.33 | 86.00 | 82.33 | 60.33 | 85.67 | 82.67 | 77.00 | 69.33 | 49.67 |
| Qwen-7B-Chat (QwenLM 2023) | 94.33 | 91.67 | 91.00 | 87.67 | 73.67 | 94.00 | 92.33 | 88.00 | 84.33 | 68.67 |
| BELLE-7B-2M (Yunjie Ji 2023) | 83.33 | 81.00 | 79.00 | 71.33 | 64.67 | 92.00 | 88.67 | 85.33 | 78.33 | 67.68 |
| Long-distance information. | Evidence uncertainty. | Concept confusion. | |||||||||||||||||||
| Question | Who did Iga Swiatek defeat to win the Qatar Open 2022? | What is the name of Apple’s headset? | What was Tesla’s revenue in Q1 2022? | ||||||||||||||||||
| Answer | Anett Kontaveit | Vision Pro | 18.76 billion | ||||||||||||||||||
| Documents |
|
|
|
||||||||||||||||||
| Responses |
|
|
|
最后,我们总共收集了 600 个 RGB 基本问题,以及 200 个关于信息整合能力的附加问题和 200 个关于反事实鲁棒性能力的附加问题。 一半实例是英文,另一半是中文。
评估指标
该基准的核心是评估大语言模型是否能够利用提供的外部文档来获取知识并生成合理的答案。 我们对大语言模型的反应进行评估,以衡量他们的上述四种能力。
准确度用于衡量噪声鲁棒性和信息集成度。 我们采用精确匹配方法,如果生成的文本包含与答案完全匹配的内容,则将其视为正确答案。
拒绝率用于衡量负面拒绝。 当只提供嘈杂的文档时,大语言模型应该输出具体内容——“由于文档中的信息不足,我无法回答问题。” (我们使用指令来通知模型。)。 如果模型生成此内容,则表明拒绝成功。
错误检测率衡量模型是否能够检测出文档中的事实错误,以实现反事实的稳健性。 当提供的文档包含事实错误时,模型应输出具体内容——“所提供的文档存在事实错误”。 (我们使用指令来通知模型。)。 如果模型生成此内容,则表明模型检测到文档中的错误信息。
纠错率衡量模型在识别错误后是否能够提供正确的答案,以实现反事实的鲁棒性。 在识别事实错误后,要求模型生成正确的答案。 如果模型生成正确的答案,则表明该模型有能力纠正文档中的错误。
考虑到模型可能不完全遵循指令,对于拒绝率和错误检测率,我们还使用 ChatGPT 对答案进行额外评估。 具体来说,我们通过使用说明和演示来评估模型的响应,以确定它们是否可以反映文档中不存在的信息或识别任何事实错误。
实验
在本节中,我们评估各种大语言模型的性能,并对结果进行分析和讨论,总结现有大语言模型在使用外部知识时遇到的主要挑战。
设置
任务格式。 由于上下文限制,我们为每个问题提供 5 个外部文档。 在我们的噪声鲁棒性实验中,我们评估了噪声比范围为 0 到 0.8 的场景。 为了综合评估整体能力,我们对每种语言采用了统一的指令,如图3所示。 实验使用 NVIDIA GeForce RTX 3090 进行。
模型我们对包括ChatGPT在内的6种最先进的可以生成英语和中文的大型语言模型进行评估(OpenAI 2022)333我们在实验中使用gpt-3.5-turbo api。、ChatGLM-6B (THUDM 2023a)、ChatGLM2-6B (THUDM 2023b)、Vicuna-7b-v1.3 (Chiang 等人 2023)、Qwen-7B-Chat (QwenLM 2023)、BELLE-7B-2M (季云杰 2023)。
噪声鲁棒性结果
我们根据外部文档中不同的噪声比来评估准确性,结果如表1所示。 我们可以看到:
(1)RAG可以有效提高大语言模型的反应能力。 即使存在噪声,大语言模型也表现出很强的性能,这表明 RAG 是大语言模型生成准确可靠响应的一种有前途的方法。
(2) 不断增加的噪声率对大语言模型中的RAG提出了挑战。 具体来说,当噪声比超过80%时,精度在0.05的显着性水平上显着下降。 例如,ChatGPT的性能从96.33%下降到76.00%,而ChatGLM2-6B的性能从91.33%下降到57.33%。
误差分析。
为了更好地理解噪声对模型生成的负面影响,我们检查了错误答案,发现这些错误通常源于三个原因,如表2所示。
(1)远程信息。 当与问题相关的信息与与答案相关的信息相距甚远时,大语言模型常常面临从外部文档中识别正确答案的困难。 这种情况很常见,因为互联网上经常遇到较长的文本。 在这种情况下,问题的信息通常首先出现在文档的开头,然后使用代词来引用。 在表2中,问题信息(“Qatar Open 2022”)仅在开头被提及一次,并且与答案文本“Anett Kontaveit”出现的位置相距甚远。 这种情况可能会导致大语言模型依赖于其他文档的信息并产生错误的印象,即幻觉。
(2)证据的不确定性。 在苹果新产品发布或奥斯卡颁奖典礼等备受期待的事件发生之前,互联网上经常会流传大量的推测信息。 尽管相关文献明确指出其内容为不确定性或推测性内容,但仍会对大语言模型的检索增强生成产生影响。 表2中,当噪声比增大时,错误文档的内容都是一些人对耳机名称(“Apple Reality Pro”)的预测。 即使相关文件中有正确答案(“Vision Pro”),大语言模型仍然可能被不确定的证据所误导。
(3)概念混淆。 外部文档中的概念可能与问题中的概念相似,但也可能不同。 这可能会导致大语言模型混乱并导致大语言模型生成错误的答案。 在表2中,模型答案重点关注文档中的“汽车收入”概念,而不是问题中的“收入”。
基于上述分析,我们发现大语言模型在检索增强生成方面存在一定的局限性。 为了有效处理互联网上存在的大量噪声,需要对模型进行进一步的细节增强,例如长文档建模和精确的概念理解。
阴性拒绝测试台的结果
我们评估了仅提供噪音文件时的拒绝率。 结果如表3所示。 除了通过精确匹配评估拒绝率外(表 3 中的 Rej),我们还利用 ChatGPT 来确定大语言模型的回复是否包含任何拒绝信息(表 3 中的 Rej)。 我们可以看到: 否定拒绝对大语言模型中的RAG提出了挑战。 英语和汉语大语言模型的最高拒绝率分别仅为45%和43.33%。 这表明大语言模型很容易被嘈杂的文档误导,导致错误的答案。
另外,通过比较Rej和Rej,我们发现大语言模型未能严格遵循指令,常常会产生不可预测的响应,这使得很难将它们用作状态触发器(例如识别拒绝)。
| Languages | English | Chinese | ||
|---|---|---|---|---|
| Rej | Rej | Rej | Rej | |
| ChatGPT | 24.67 | 45.00 | 5.33 | 43.33 |
| ChatGLM-6B | 9.00 | 25.00 | 6.33 | 17.00 |
| ChatGLM2-6B | 10.33 | 41.33 | 6.33 | 36.33 |
| Vicuna-7B-v1.3 | 17.00 | 33.33 | 3.37 | 24.67 |
| Qwen-7B-Chat | 31.00 | 35.67 | 8.67 | 25.33 |
| BELLE-7B-2M | 5.67 | 32.33 | 5.33 | 13.67 |
| Question | Answer | Response | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|||||||||
|
Norway |
|
我们在表4中进行了案例研究。 第一个错误是由于证据不确定。 尽管该文件只提到了与“亚当·麦凯”的联系,并没有明确说明他是电影的导演,但模型仍然得出他担任这个角色的结论。 第一个错误是由于概念混淆造成的。 答案中提供的信息涉及“2018 年冬季奥运会”,而不是问题中提到的“2022 年奥运会”。 与直接回答相比,检索增强生成带来了更大的否定拒绝挑战,因为它提供的相关文档可能会误导大语言模型并导致错误的回答。 在未来的发展中,提高问题与文档的准确匹配能力对于大语言模型来说至关重要。
信息集成测试平台的结果
(1)信息集成对大语言模型中的RAG提出了挑战。 即使没有噪声,大语言模型对于英语和汉语的最高准确率也只能分别达到 60% 和 67%。 添加噪声后,最高精度下降至43%和55%。 这些结果表明,大语言模型难以有效地整合信息,并且不太适合直接回答复杂的问题。
(2) 复杂的问题对于带有噪声文档的 RAG 来说更具挑战性。 当噪声比为 0.4 时,性能下降变得显着,但对于简单问题,仅在噪声比为 0.8、显着性水平为 0.05 时才会出现显着下降。 这表明复杂的问题更容易受到噪声的干扰。 我们推测这是因为解决复杂问题需要集成来自多个文档的信息,而这些信息可以被视为彼此的噪音,使得模型更难从文档中提取相关信息。
| English | Chinese | |||||
|---|---|---|---|---|---|---|
| Noise Ratio | 0 | 0.2 | 0.4 | 0 | 0.2 | 0.4 |
| ChatGPT | 55 | 51 | 34 | 63 | 58 | 47 |
| ChatGLM-6B | 45 | 36 | 35 | 60 | 53 | 52 |
| ChatGLM2-6B | 34 | 32 | 21 | 44 | 43 | 32 |
| Vicuna-7B-v1.3 | 60 | 53 | 43 | 43 | 36 | 25 |
| Qwen-7B-Chat | 55 | 50 | 37 | 67 | 56 | 55 |
| BELLE-7B-2M | 40 | 34 | 24 | 49 | 41 | 38 |
| Question | Answer | Response | Errors | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
|||||||||||||
|
|
|
|
|||||||||||||
|
|
|
|
误差分析。
我们对ChatGLM2-6B(噪声比为0)进行了误差分析。 除了噪声鲁棒性实验中发现的类似误差(占总数的38%)外,还存在三种类型的独特误差。 我们在表 6 中介绍了这些案例。
(1)合并错误(占总数的28%)。 该模型有时会合并两个子问题的答案,从而导致错误。 它错误地使用一个问题的答案来解决两个问题。 此时,模型将忽略与一个子问题相关的任何文档。 例如,在表6中,它错误地指出D组是法国和德国的世界杯小组,而实际上德国实际上被分配到E组。
(2)忽略误差(占总数的28%)。 有时,模型可能会忽略其中一个子问题,而只回答另一个子问题。 当模型缺乏对问题的完整理解并且无法认识到它由多个子问题组成时,就会发生此错误。 因此,该模型仅考虑一个子问题的相关文档来生成答案,而忽略另一个子问题提出的问题。 例如,在表6中,模型仅提供了 2022 年超级碗 MVP 的答案,并未考虑 2023 年。
(3)不对中误差(占总数的6%)。 有时,模型会错误地将一个子问题的文档识别为另一子问题的文档,从而导致答案不一致。 例如,在表6中,第三个答案有两个错误:忽略错误和未对齐错误。 首先,模型只提到了2023年(第95届)奥斯卡金像奖最佳影片,完全无视2022年的奖项。 此外,它错误地宣称《CODA》是 2023 年最佳影片,而实际上它被授予了 2022 年最佳影片。
上述错误主要是由于对复杂问题的理解有限,阻碍了有效利用不同子问题信息的能力。 关键在于提高模型的推理能力。 一种可能的解决方案是使用链式思维方法来分解复杂问题(Zhou 等人 2023a; Xu 等人 2023b; Drozdov 等人 2023)。 然而,这些方法降低了推理速度并且不能提供及时的响应。
| Acc | Acc | ED | ED | CR | |
|---|---|---|---|---|---|
| ChatGPT-zh | 91 | 17 | 1 | 3 | 33.33 |
| Qwen-7B-Chat-zh | 77 | 12 | 5 | 4 | 25.00 |
| ChatGPT-en | 89 | 9 | 8 | 7 | 57.14 |
反事实稳健性测试平台的结果
为了确保大语言模型具备相关知识,我们通过直接提问的方式评估他们的表现。 然而,我们发现大多数大语言模型都很难正确回答这些问题。 为了保证评价更加合理,我们只考虑准确率在70%以上的大语言模型,因为这个阈值比较高,包含的大语言模型也比较多。 结果如表7所示。 我们提出以下指标:没有任何文档的准确性、反事实文档的准确性、错误检测率和错误纠正率。 可以看出,大语言模型很难识别并纠正文档中的事实错误。 这表明该模型很容易被包含不正确事实的文档误导。
值得注意的是,检索增强生成并不是为了自动解决给定上下文中的事实错误而设计的,因为这与模型缺乏知识并依赖于检索到的文档来获取附加信息的基本假设相矛盾。 然而,由于互联网上存在大量假新闻,这个问题在实际应用中至关重要。 现有的大语言模型没有保障措施来处理由错误信息引起的不准确响应。 事实上,他们很大程度上依赖于他们检索到的信息。 即使大语言模型包含有关问题的内部知识,他们也经常相信检索到的虚假信息。 这对大语言模型中RAG的未来发展提出了重大挑战。
结论
在本文中,我们评估了大语言模型中检索增强生成的四种能力:噪声鲁棒性、否定拒绝、信息集成和反事实鲁棒性。 为了进行评估,我们构建了检索增强生成基准(RGB)。 RGB 的实例是从最新的新闻文章和从搜索引擎获得的外部文档生成的。 实验结果表明,目前的大语言模型在这4个能力上都存在局限性。 这表明将RAG有效地应用到大语言模型中还需要大量的工作。 为了确保大语言模型的响应准确可靠,RAG 的谨慎设计至关重要。
致谢
该研究工作得到了国家自然科学基金委的资助,批准号为: 62122077、62106251、62306303,中科院青年科学家基础研究项目,批准号:YSBR-040。 韩贤培由CCF-百川-易博科技基金会示范基金资助。
参考
- Adlakha et al. (2023) Adlakha, V.; BehnamGhader, P.; Lu, X. H.; Meade, N.; and Reddy, S. 2023. Evaluating Correctness and Faithfulness of Instruction-Following Models for Question Answering. arXiv:2307.16877.
- Bang et al. (2023) Bang, Y.; Cahyawijaya, S.; Lee, N.; Dai, W.; Su, D.; Wilie, B.; Lovenia, H.; Ji, Z.; Yu, T.; Chung, W.; Do, Q. V.; Xu, Y.; and Fung, P. 2023. A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. arXiv:2302.04023.
- Bian et al. (2023) Bian, N.; Liu, P.; Han, X.; Lin, H.; Lu, Y.; He, B.; and Sun, L. 2023. A Drop of Ink Makes a Million Think: The Spread of False Information in Large Language Models. arXiv:2305.04812.
- Borgeaud et al. (2022) Borgeaud, S.; Mensch, A.; Hoffmann, J.; Cai, T.; Rutherford, E.; Millican, K.; van den Driessche, G.; Lespiau, J.-B.; Damoc, B.; Clark, A.; de Las Casas, D.; Guy, A.; Menick, J.; Ring, R.; Hennigan, T.; Huang, S.; Maggiore, L.; Jones, C.; Cassirer, A.; Brock, A.; Paganini, M.; Irving, G.; Vinyals, O.; Osindero, S.; Simonyan, K.; Rae, J. W.; Elsen, E.; and Sifre, L. 2022. Improving language models by retrieving from trillions of tokens. arXiv:2112.04426.
- Cai et al. (2019a) Cai, D.; Wang, Y.; Bi, W.; Tu, Z.; Liu, X.; Lam, W.; and Shi, S. 2019a. Skeleton-to-Response: Dialogue Generation Guided by Retrieval Memory. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 1219–1228. Minneapolis, Minnesota: Association for Computational Linguistics.
- Cai et al. (2019b) Cai, D.; Wang, Y.; Bi, W.; Tu, Z.; Liu, X.; and Shi, S. 2019b. Retrieval-guided Dialogue Response Generation via a Matching-to-Generation Framework. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 1866–1875. Hong Kong, China: Association for Computational Linguistics.
- Cao et al. (2020) Cao, M.; Dong, Y.; Wu, J.; and Cheung, J. C. K. 2020. Factual Error Correction for Abstractive Summarization Models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 6251–6258. Online: Association for Computational Linguistics.
- Chang et al. (2023) Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; Ye, W.; Zhang, Y.; Chang, Y.; Yu, P. S.; Yang, Q.; and Xie, X. 2023. A Survey on Evaluation of Large Language Models. arXiv:2307.03109.
- Chiang et al. (2023) Chiang, W.-L.; Li, Z.; Lin, Z.; Sheng, Y.; Wu, Z.; Zhang, H.; Zheng, L.; Zhuang, S.; Zhuang, Y.; Gonzalez, J. E.; Stoica, I.; and Xing, E. P. 2023. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality.
- Cui et al. (2023) Cui, J.; Li, Z.; Yan, Y.; Chen, B.; and Yuan, L. 2023. ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases. arXiv:2306.16092.
- Drozdov et al. (2023) Drozdov, A.; Schärli, N.; Akyürek, E.; Scales, N.; Song, X.; Chen, X.; Bousquet, O.; and Zhou, D. 2023. Compositional Semantic Parsing with Large Language Models. In The Eleventh International Conference on Learning Representations.
- Edward Beeching (2023) Edward Beeching, N. H. S. H. N. L. N. R. O. S. L. T. T. W., Clémentine Fourrier. 2023. Open LLM Leaderboard. https://huggingface.co/spaces/HuggingFaceH4/open˙llm˙leaderboard.
- Guo et al. (2023) Guo, B.; Zhang, X.; Wang, Z.; Jiang, M.; Nie, J.; Ding, Y.; Yue, J.; and Wu, Y. 2023. How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection. arXiv:2301.07597.
- Guu et al. (2020) Guu, K.; Lee, K.; Tung, Z.; Pasupat, P.; and Chang, M.-W. 2020. REALM: Retrieval-Augmented Language Model Pre-Training. In Proceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org.
- He, Zhang, and Roth (2022) He, H.; Zhang, H.; and Roth, D. 2022. Rethinking with Retrieval: Faithful Large Language Model Inference. arXiv:2301.00303.
- Hendrycks et al. (2021) Hendrycks, D.; Burns, C.; Basart, S.; Zou, A.; Mazeika, M.; Song, D.; and Steinhardt, J. 2021. Measuring Massive Multitask Language Understanding. In International Conference on Learning Representations.
- Huang et al. (2023) Huang, Y.; Bai, Y.; Zhu, Z.; Zhang, J.; Zhang, J.; Su, T.; Liu, J.; Lv, C.; Zhang, Y.; Lei, J.; Fu, Y.; Sun, M.; and He, J. 2023. C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models. arXiv preprint arXiv:2305.08322.
- Izacard and Grave (2021) Izacard, G.; and Grave, E. 2021. Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, 874–880. Online: Association for Computational Linguistics.
- Izacard et al. (2022) Izacard, G.; Lewis, P.; Lomeli, M.; Hosseini, L.; Petroni, F.; Schick, T.; Dwivedi-Yu, J.; Joulin, A.; Riedel, S.; and Grave, E. 2022. Atlas: Few-shot Learning with Retrieval Augmented Language Models. arXiv:2208.03299.
- Ji et al. (2023) Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y. J.; Madotto, A.; and Fung, P. 2023. Survey of Hallucination in Natural Language Generation. ACM Comput. Surv., 55(12).
- Lewis et al. (2020) Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.-t.; Rocktäschel, T.; Riedel, S.; and Kiela, D. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20. Red Hook, NY, USA: Curran Associates Inc. ISBN 9781713829546.
- Li et al. (2023a) Li, D.; Rawat, A. S.; Zaheer, M.; Wang, X.; Lukasik, M.; Veit, A.; Yu, F.; and Kumar, S. 2023a. Large Language Models with Controllable Working Memory. In Findings of the Association for Computational Linguistics: ACL 2023, 1774–1793. Toronto, Canada: Association for Computational Linguistics.
- Li et al. (2023b) Li, X.; Zhang, T.; Dubois, Y.; Taori, R.; Gulrajani, I.; Guestrin, C.; Liang, P.; and Hashimoto, T. B. 2023b. AlpacaEval: An Automatic Evaluator of Instruction-following Models. https://github.com/tatsu-lab/alpaca˙eval.
- Li et al. (2023c) Li, X.; Zhu, X.; Ma, Z.; Liu, X.; and Shah, S. 2023c. Are ChatGPT and GPT-4 General-Purpose Solvers for Financial Text Analytics? An Examination on Several Typical Tasks. arXiv:2305.05862.
- Liu, Zhang, and Liang (2023) Liu, N. F.; Zhang, T.; and Liang, P. 2023. Evaluating Verifiability in Generative Search Engines. arXiv:2304.09848.
- Maynez et al. (2020) Maynez, J.; Narayan, S.; Bohnet, B.; and McDonald, R. 2020. On Faithfulness and Factuality in Abstractive Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 1906–1919. Online: Association for Computational Linguistics.
- OpenAI (2022) OpenAI. 2022. Chatgpt: Optimizing language models for dialogue. https://openai.com/blog/chatgpt.
- Peng et al. (2023) Peng, B.; Galley, M.; He, P.; Cheng, H.; Xie, Y.; Hu, Y.; Huang, Q.; Liden, L.; Yu, Z.; Chen, W.; and Gao, J. 2023. Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback. arXiv:2302.12813.
- Qin et al. (2023) Qin, Y.; Liang, S.; Ye, Y.; Zhu, K.; Yan, L.; Lu, Y.; Lin, Y.; Cong, X.; Tang, X.; Qian, B.; Zhao, S.; Tian, R.; Xie, R.; Zhou, J.; Gerstein, M.; Li, D.; Liu, Z.; and Sun, M. 2023. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. arXiv:2307.16789.
- QwenLM (2023) QwenLM. 2023. Qwen-7B. https://github.com/QwenLM/Qwen-7B.
- Raunak, Menezes, and Junczys-Dowmunt (2021) Raunak, V.; Menezes, A.; and Junczys-Dowmunt, M. 2021. The Curious Case of Hallucinations in Neural Machine Translation. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 1172–1183. Online: Association for Computational Linguistics.
- Ren et al. (2023) Ren, R.; Wang, Y.; Qu, Y.; Zhao, W. X.; Liu, J.; Tian, H.; Wu, H.; Wen, J.-R.; and Wang, H. 2023. Investigating the Factual Knowledge Boundary of Large Language Models with Retrieval Augmentation. arXiv:2307.11019.
- Shen et al. (2023) Shen, X.; Chen, Z.; Backes, M.; and Zhang, Y. 2023. In ChatGPT We Trust? Measuring and Characterizing the Reliability of ChatGPT. arXiv:2304.08979.
- Shi et al. (2023) Shi, W.; Min, S.; Yasunaga, M.; Seo, M.; James, R.; Lewis, M.; Zettlemoyer, L.; and tau Yih, W. 2023. REPLUG: Retrieval-Augmented Black-Box Language Models. arXiv:2301.12652.
- THUDM (2023a) THUDM. 2023a. ChatGLM-6B. https://github.com/THUDM/ChatGLM-6B.
- THUDM (2023b) THUDM. 2023b. ChatGLM2-6B. https://github.com/THUDM/ChatGLM2-6B.
- Trivedi et al. (2023) Trivedi, H.; Balasubramanian, N.; Khot, T.; and Sabharwal, A. 2023. Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 10014–10037. Toronto, Canada: Association for Computational Linguistics.
- Wang et al. (2019a) Wang, A.; Pruksachatkun, Y.; Nangia, N.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; and Bowman, S. R. 2019a. SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems. Red Hook, NY, USA: Curran Associates Inc.
- Wang et al. (2019b) Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; and Bowman, S. R. 2019b. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In International Conference on Learning Representations.
- Xu et al. (2023a) Xu, G.; Liu, J.; Yan, M.; Xu, H.; Si, J.; Zhou, Z.; Yi, P.; Gao, X.; Sang, J.; Zhang, R.; Zhang, J.; Peng, C.; Huang, F.; and Zhou, J. 2023a. CValues: Measuring the Values of Chinese Large Language Models from Safety to Responsibility. arXiv:2307.09705.
- Xu et al. (2023b) Xu, S.; Pang, L.; Shen, H.; Cheng, X.; and Chua, T.-S. 2023b. Search-in-the-Chain: Towards Accurate, Credible and Traceable Large Language Models for Knowledge-intensive Tasks. arXiv:2304.14732.
- Yunjie Ji (2023) Yunjie Ji, Y. G. Y. P. Q. N. B. M. X. L., Yong Deng. 2023. BELLE: Bloom-Enhanced Large Language model Engine. https://github.com/LianjiaTech/BELLE.
- Zhang et al. (2023) Zhang, W.; Aljunied, S. M.; Gao, C.; Chia, Y. K.; and Bing, L. 2023. M3Exam: A Multilingual, Multimodal, Multilevel Benchmark for Examining Large Language Models.
- Zhong et al. (2023) Zhong, W.; Cui, R.; Guo, Y.; Liang, Y.; Lu, S.; Wang, Y.; Saied, A.; Chen, W.; and Duan, N. 2023. AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models. arXiv:2304.06364.
- Zhou et al. (2023a) Zhou, D.; Schärli, N.; Hou, L.; Wei, J.; Scales, N.; Wang, X.; Schuurmans, D.; Cui, C.; Bousquet, O.; Le, Q. V.; and Chi, E. H. 2023a. Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. In The Eleventh International Conference on Learning Representations.
- Zhou et al. (2023b) Zhou, S.; Alon, U.; Xu, F. F.; Jiang, Z.; and Neubig, G. 2023b. DocPrompting: Generating Code by Retrieving the Docs. In The Eleventh International Conference on Learning Representations.